1. Introduction
In the past decade, the Omega ratio, proposed by [
1], has received increasing attention both from academics and practitioners as an alternative to the classical Sharpe ratio [
2,
3,
4] when measuring the performance of different investment opportunities; see [
5,
6,
7,
8]. The Omega ratio can be interpreted as a return–risk ratio. The return is measured as the expected gain above a given threshold whereas risk is measured as the expected loss below the same threshold. Since only adverse deviations from the threshold contribute to the risk component of the Omega ratio, this measure is particularly attractive for situations where the return distribution is strongly asymmetric. The Omega ratio is deemed a better performance measurement than the Sharpe ratio which measures risk by the standard deviation since this measure effectively distinguishes between upward and downward deviations from the benchmark. Furthermore, in contrast to the Sharpe ratio which only considers the portfolio return’s first- and second-order moments, it accounts for higher-order information contained in returns.
However, as pointed out by [
9,
10], the optimization problem based on the Omega ratio is ill-posed. Therefore, Lin et al. [
10] modify the Omega ratio to include a reward function for over-performance and a penalty function for under-performance in the definition of the performance ratio. They investigate the optimization problem of maximizing the extended Omega ratio. Based on the fractional programming method, they analyze the non-linear fractional optimization problem by solving a family of related non-fractional optimization problems, where the objective functions are the numerator of the original problem minus the denominator multiplied by a penalty parameter. Since they work in a complete financial market, there exists a unique pricing kernel and therefore the martingale method can be directly used to solve the optimization problem, which involves solving a terminal static optimization problem first to obtain the optimal terminal wealth and then identifying the portfolio strategy that replicates the optimal terminal wealth; see [
11,
12,
13,
14]. From a risk management point of view, the under-performance should be controlled by incorporating a risk constraint. Therefore, Guan et al. [
15] extend [
10] to include a value-at-risk (VaR) constraint.
In [
10,
15], the benchmark is set to be a constant, which is equivalent to a money account. Actually, the choice of the benchmark which measures over-performance and under-performance plays an important role in the performance measure optimization problem. Typically, a benchmark represents a general indicator of market sentiment. A specific choice for the benchmark falls into three usual categories: a portfolio, an index, or any economic indicator. Ng and Nguyen [
16] investigate an optimization problem with a stochastic benchmark based on a different performance measure, in which the performance measure is defined as the Omega ratio of the utility of the portfolio with respect to the utility of the benchmark, which quantifies utility gain over utility loss of the portfolio performance relative to the benchmark. Ng and Nguyen [
16] derive the optimal solution in a complete market setting, when the benchmark is set to be a non-increasing function of the market price density. However, for an incomplete market model setting with infinitely many pricing kernels, the method adopted by [
16] loses effectiveness. Tang et al. [
17] generalize [
10] to a performance measure optimization problem with a stochastic benchmark faced by a fund manager. For a general stochastic benchmark, it is difficult to derive the closed-form solution for the performance measure maximization problem. When the reward and penalty functions are both power functions, Tang et al. [
17] derive the explicit investment strategy of a performance measure optimization problem with a stochastic benchmark, which is set to be a value-weighted portfolio with a fixed proportion invested in the risky asset. However, for other choices of reward and penalty functions, the stochastic benchmark considered in [
17] does not allow to explicitly derive the optimal solution. We consider a stochastic benchmark which allows for closed-form solutions to a performance measure optimization problem for general reward and penalty functions. As suggested in [
15], in order to improve the performance of the fund under downside risk, a risk constraint should be incorporated into the optimization model. The portfolio insurance (PI) constraint requires the manager to keep the terminal wealth above a minimum guarantee, which is essential for the welfare of the investors. Risk management using PI constraint has been investigated in a lot of works; see [
18,
19,
20]. In this paper, we investigate the optimal investment problem of a fund manager based on performance measure under PI and position constraints.
However, there may be some position constraints on the investment possibilities in the real world by financial regulations. In the case of control constraints, the martingale method may lose its effectiveness as the financial market is not complete and explicit solutions have been obtained for only a few special cases. The martingale approach has been generalized by a number of researchers using stochastic duality theory to explicitly solve the optimization problems when the portfolio shares are restricted to lie in a closed convex cone, including prohibiting from investing in or no-short-selling some risky assets. For a concave utility maximization problem, He and Zhou [
21] show that there exists a unique pricing kernel, called the minimal pricing kernel, in the presence of closed convex cone control constraints. So, one may solve the position-constrained problem in the same way as in the complete market case. Dong and Zheng [
22] use the dual control method to find the unique pricing kernel and then solve the non-concave utility maximization problem with closed convex cone control constraints. In this paper, we incorporate position constraints into the performance measure maximization problem.
This paper is related to [
17], where the authors study the performance measure optimization with a stochastic benchmark. However, our paper is different from theirs at least in two aspects. First, we propose a different stochastic benchmark, which allows to explicitly solve the optimization problem for general reward and penalty functions. Furthermore, the stochastic benchmark in [
17], which is a value-weighted portfolio with a fixed proportion invested in the risky asset, can be deemed to be exogenously given. Therefore, the manager’s risk-taking choices are highly influenced by the referenced portfolio. As shown in [
17], there is a tendency for the manager to gambling with excess risk-taking when the benchmark allocates a higher proportion of wealth in the risky asset. Different from [
17], the stochastic benchmark in this paper is updated according to the development of the wealth process, which implies that the benchmark is mainly driven by preferences of the investor. Second, due to the concern about a downside protection and regulations on the investment possibilities, we introduce minimum performance and position constraints, which are not considered in their paper. These constraints lead our model to be more complicated than theirs and help us to learn more of the characteristics of the fund manager’s investment behavior.
The main contribution of this paper is that motivated by [
10,
18,
22]. We investigate the optimal allocation problem based on performance measure with a stochastic benchmark under PI and position constraints. The present paper not only contributes to the literature on the optimal portfolio selection based on performance measure, but also explores the connection between the S-shaped utility maximization problem with the performance measure optimization problem.
The rest of the paper is organized as follows. In
Section 2, we formulate an optimal allocation problem by maximizing a performance measure with a stochastic benchmark under PI and position constraints. In
Section 3, we apply the linearization method, the martingale method, and the concavification technique to derive the optimal solution. In
Section 4, we numerically investigate the impacts of some model parameters on the optimal terminal wealth and the optimal investment strategy.
Section 5 concludes the paper.
Appendix A contains related proofs.
2. The Model
We consider a finite investment time horizon with and a continuous-time financial market without transaction costs. We let be a filtered complete probability space, in which the filtration is P-augmented filtration induced by an n-dimensional standard Brownian motion where are mutually independent and is the transpose of
We consider a financial market with n risky assets, denoted by , and a risk-free security , which accrues interest continuously at the risk-free rate .
It is assumed that under the real-world probability measure
the price process of the risk-free security evolves as
The price processes of the
n risky assets are modeled by
where
,
is an
matrix with diagonal elements
and all other elements 0,
is a constant vector representing the stock growth rate with
and
is an
nonsingular constant matrix representing the volatility and correlation information of
Suppose that the initial wealth of the fund account is
The fund manager invests the wealth in a risk-free asset and
n risky assets. We let
be the proportion of wealth invested in the
ith risky asset at time
t for
The remaining proportion
of wealth is invested in the risk-free security. We let
With the trading strategy
the wealth process
, denoted by
, evolves according to the following stochastic differential equation (SDE):
where
and
denotes the
n-dimensional column vector with each element equal to 1. It is natural to assume that the trading strategy
is
-progressively measurable and satisfies
almost surely so that there exists a unique strong solution
to (
3) where
denotes the
-norm.
Definition 1. We let K be a closed convex cone. A portfolio strategy is said to be admissible if it is a progressively measurable, -adapted process which satisfies , almost surely and there exists a unique strong solution to (3). The set of all admissible portfolio strategies is denoted by . The literature on portfolio performance evaluation starts with the Sharpe ratio (see [
3]). Alternative performance measures are reward-to-risk ratios representing a fraction where a measure of reward is divided by a measure of risk. Examples of such reward-to-risk ratios include the Omega ratio (see, e.g., [
1]) and the extended Omega ratio (see, e.g., [
10]). Based on [
1,
10], we first formally define the performance measure in this paper and next aim at finding the optimal portfolios that have maximum performance measure.
The Omega ratio for a random payoff
with respect to the benchmark
is defined as
where
The Omega ratio is better than the Sharpe ratio since it measures the ratio between the upper tail heaviness (from
onwards) and the corresponding lower tail heaviness (below the level
). However, as shown in [
9,
10], the maximization problem of the Omega ratio is ill-posed due to the linear growth of its numerator. To make the optimization problem bounded, Lin et al. [
10] propose a “utility-transformed” Omega ratio by introducing two weighting functions. We follow the framework in [
10] and introduce a reward function
over gains and a penalty function
over losses for the manager, respectively. Therefore, the performance measure in our paper is defined by
where
U and
D are two monotonically increasing measurable functions. The performance measure defined in (
5) distinguishes the gains and losses by the benchmark
and shows that the manager has different attitudes towards gains and losses. In general, the reward function
U is strictly concave since the decision-makers are usually risk-averse towards gains. However, as discussed in [
23], the decision-makers may have two different attitudes towards the losses: risk aversion and loss aversion. When the penalty function
D is convex, the manager is risk-averse towards the losses. When the penalty function is concave, the manager is loss-averse, which is first proposed by [
24] within the framework of prospect theory. Berkelaar et al. [
23] analyze the optimal investment strategy for loss-averse investors. In what follows, we assume that
U is a strictly concave function, and
D is either concave or convex.
Lin et al. [
10] derive the optimal solution under the assumption that the investor has a constant benchmark for distinguishing losses and gains and there are no constraints on the terminal wealth and trading positions. It seems more plausible that an investor dynamically updates their benchmark according to the development of his wealth. We assume that at initial time the investor is assumed to have an initial reference point
; then, the investor adjusts their initial reference point
with the constant risk-free interest rate
r weighted by
, and with the change in their wealth
weighted by
, where
is a constant. As a result, the stochastic reference point evolves dynamically according to the process as follows:
We formulate the manager’s portfolio selection problem as
The numerator measures the benefit from exceeding the benchmark wealth , while the denominator penalizes shortfalls.
Note that Equation (
6) gives
Hence,
where
We assume that
and
such that
Remark 1. Equation (8) shows that the performance measure optimization problem related to the terminal wealth with a stochastic benchmark given by (6) is identical to the performance measure optimization problem related to the terminal wealth with a constant benchmark. Hence, the performance measure optimization problem with the stochastic benchmark we consider in this paper can be explicitly solved under general penalty and reward functions by using combining the linearization method, the Lagrangian method, and the concavification technique. However, the performance measure optimization problem over the terminal wealth with a stochastic benchmark investigated in [17] cannot be transformed into the performance measure optimization problem over the terminal wealth with a constant benchmark. When the penalty and reward functions are both set to be power functions with the same exponent γ, they use the change in measure method to relate the original optimization problem over the terminal wealth with a stochastic benchmark to the performance measure optimization problem over the relative terminal performance (i.e., the ratio of the terminal wealth and the stochastic benchmark) with a constant benchmark. For general reward and penalty functions, the method adopted by [17] losses its effectiveness. By using (
8), (
7) can be rewritten as
When there are no constraints on the investment strategies, the market has a unique pricing kernel as follows:
However, in the case of control constraints, the market is no longer complete and there are many pricing kernels. Therefore, the traditional martingale method cannot be used to solve the optimization problem with control constraints. According to [
22], there exists a unique pricing kernel in the presence of closed convex cone control constraints given by
where
with
being the positive cone of
From [
7], once the pricing kernel is found, the optimization problem (
9) can be transformed into an equivalent one with respect to the terminal wealth
:
where
denotes the set of non-negative
-measurable random variables. We denote the feasible set of the above problem by
:
The following result states that we can first solve the terminal static optimization problem (
11) over the random variable
and then find the optimal portfolio
by the martingale representation theorem.
Theorem 1. We assume that is the optimal solution to Problem (11). Then, there exists a strategy such that , almost surely. Theorem 1 shows that in order to solve Problem (
7), we only need to investigate Problem (
11) first.
Since the optimal payoff problem (
11) involves a non-linear objective function, it is difficult to solve directly. In order to reformulate it into a tractable problem, we set up the following family of linearized problems parameterized by
:
Remark 2. Similar to the proof of Theorem 1, it is easy to verify that when Problem (12) attains the optimal value, the budget constraint is binding, that is,where We establish the relationship between linearized Problems (
11) and (
12).
Note that for a constrained optimization problem, the optimal solution may not exist for a relatively low value of initial wealth
To guarantee that optimization Problem (
11) is feasible, we assume that
Theorem 2. We assume . For each , we let be a solution to Problem (12) and suppose there exists a constant such that Then, solves Problem (11) and is the optimal value. Remark 3. Prospect theory, introduced by [24,25], is also concerned with gains and losses of a portfolio. Tversky and Kahneman [25] demonstrate the loss aversion and risk seeking behaviour by an asymmetric S-shaped utility function, convex in the domain of losses and concave in the domain of gains. In (12), if λ = 1, U and D are two concave functions, then (12) becomes an S-shaped utility maximization problem studied in [19]. Therefore, different from an S-shaped utility maximization problem, for a performance ratio optimization problem, D may be concave or convex and the optimal multiplier should be determined by (14). Within the framework of prospect theory, the power utilities are widely used to capture the preferences over gains and losses; see [
22,
25,
26,
27]. For simplicity, we follow [
25] to consider
U and
D to be power utilities. However, the following theoretical analysis can also be applied for other choices of reward and penalty functions.
It is easy to check that U is strictly concave. For the weighting function D, we consider two cases: and . Note that D is concave for and convex for respectively.
It remains to show the existence and uniqueness of To this end, we need the following results.
Lemma 1. We assume . We define and . Then, and .
The following proposition presents some relevant properties of the value function
v defined in (
12).
Proposition 1. We suppose that . Then, the function has the following properties:
- (a)
- (b)
v is non-increasing in
- (c)
- (d)
is Lipschitz continuous.
- (e)
Proof. The proof is referred to in Proposition 2.4 in [
10]. □
Similar to [
17], we have the following result:
Proposition 2. There exists a unique such that (14) holds. Proof. The proof is similar to that of Theorem 2.3 in [
17], so we refer the details to [
17]. □
Next, we only need to first solve linearized Problem (
12), and then find the optimal multiplier
by using (
14).
3. Optimal Trading Strategy
In this section, we use a Lagrangian duality approach and the concavification technique to solve linearized optimal Problem (
12).
For each
we first solve the following Lagrangian maximization problem:
where
Problem (
15) can be viewed as a static optimization problem. The related non-randomized version of Problem (
15) is as follows: for each
and
,
The following result reveals the relationship between the optimal solutions to Problems (
12) and (
17).
Lemma 2. For all and , we have the following properties:
- (a)
We let be a Borel measurable function such that is an optimal solution to Problem (17) for each and . Then, solves Problem (15). - (b)
We assume that, given , there exists a constant such that solves Problem (15) with . Then, solves Problem (11).
Proof. See Lemmas 3.1 and 3.2 in [
27]. □
It remains to solve Problem (
17). Since
is not concave, we use the concavification technique as in [
22,
28] to solve Problem (
17). We denote the concave envelope of a given function
f with a domain G by
.
Thus, the concavified version of (
17) is
To simplify the formulation, we denote
to be the slopes of the tangent line to the curve
at point
and
, respectively.
The following two results are useful in deriving the concave envelope of .
Lemma 3. For , , there exists a unique root to the following equation: Lemma 4. We let be given by (21). For , , if , then there exists a unique pair with satisfying Proposition 3. We let be determined by Equation (21). Then, the concave envelope of and the optimal solution to Problem (19) are given as follows: - (a)
For ,and - (b)
For ,
- (b1)
if , then the concave envelope of and the optimal solution to Problem (19) are given by (23) and (24), respectively; - (b2)
if , then the concave envelope of is given byandwhere the pair is determined by (22).
It remains to prove that there exists a positive constant satisfying the budget constraint
Proposition 4. We suppose that . For each , there exists a unique constant such that satisfies , where is given in (24) and (26). As such, based on Theorems 1 and 2, Proposition 2, Lemma 2, and Proposition 4, we can obtain the optimal solution to the original optimization Problem (
7) by the following procedures:
Algorithm for finding the optimal terminal wealth to Problem (
7) and Lagrange multipliers.
In what follows, we follow the above steps to derive the optimal solution. For each
, set
where
is given by (
24) and (
26),
is determined by Eq.
To derive
from (
14), we define
and
Based on Proposition 3, we can obtain the explicit expressions for and as follows:
To simplify notations and avoid repetitions, for any
we define
where
and
denote the standard normal distribution function and its density function, respectively.
Proposition 5. For , Proposition 6. For , we have
- (b1)
if , then and are given by (31); - (b2)
if , then
Once the closed-form expressions for
and
are derived, we can determine the optimal Lagrange multiplier
satisfying
Given , we present the optimal solution for the portfolio optimization Problem (8) in the following results.
Proposition 7. We assume that . Then, for , the optimal terminal wealth, the optimal portfolio value at time , and the optimal trading strategy are given as follows:
The optimal terminal wealth iswhere is determined by (33) with and given by (31), is defined by (20), is the solution to Equation (21) with . The optimal portfolio value at time is given by The optimal portfolio invested in the risky asset at time is as follows: Proposition 8. We assume that . For ,
- (b1)
if then the optimal terminal wealth, the optimal portfolio value at time , and the optimal trading strategy are given by (34), (35) and (36), respectively; - (b2)
if then the optimal terminal wealth, the optimal portfolio value at time , and the optimal trading strategy are as follows:
The optimal terminal wealth is given bywhere is determined by (33) with and given by (32), is defined in (20). The optimal portfolio value at time is as follows: The optimal portfolio invested in the risky asset at time is given by Proof. Since the proof is similar to that of Proposition 7, we omit the proof here. □
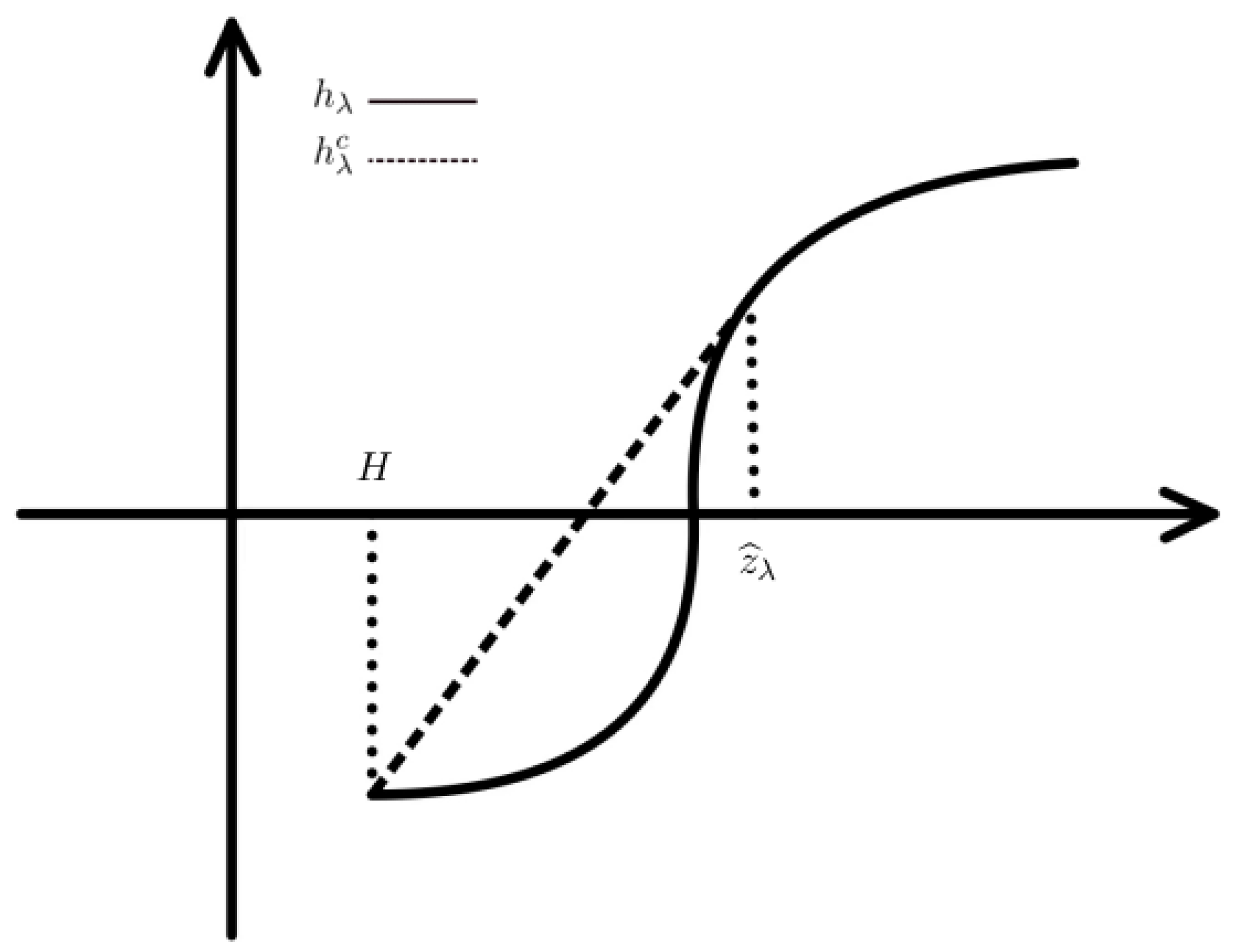
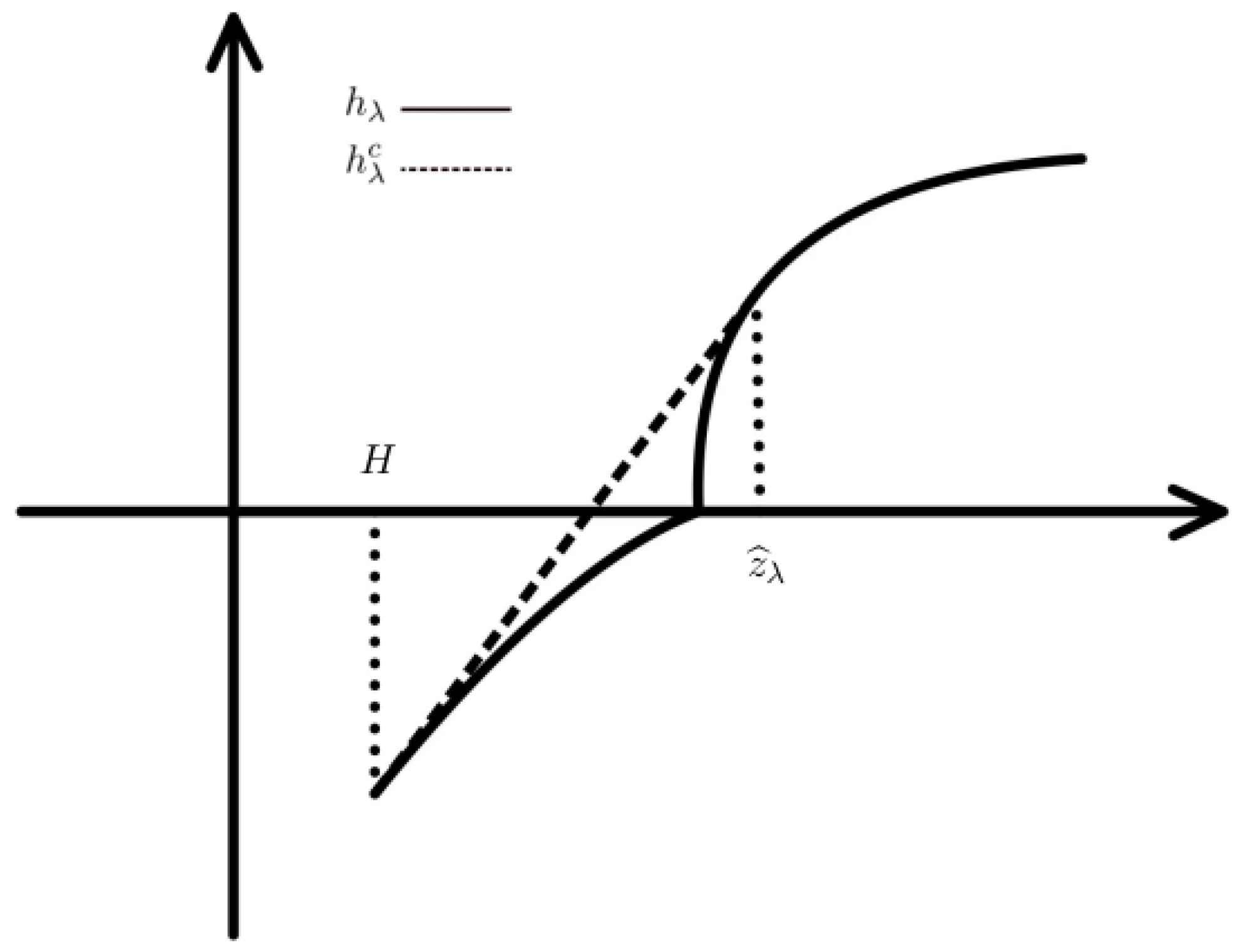
Remark 4. From Proposition 7, we can see that for the manager is loss averse towards losses and the optimal terminal wealth takes a two-region form. When the state price density is relatively low, is similar to the smooth utility; when increases above a critical value of the price density, drops to H since the loss aversion states a risk-seeking preference in the loss domain.
From Proposition 8, we can observe that for the manager is risk-averse towards losses and the optimal terminal wealth takes a two- or three-region form. Comparing with the case that risk aversion towards losses may lead to an increase in the optimal terminal wealth for by letting in the region if
For each case, the the optimal terminal wealth ends with the protection level which implies the PI constraint can protect the investor’s benefits by keeping above the protection level H.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}