1. Introduction
Recent advances in artificial intelligence (AI) technology have increased the demand for clearly defined and quantitative assessments of a participant’s nervousness during interviews and audition programs. In particular, AI interview technology is used to evaluate the emotional state of participants by analyzing various nonverbal signals, such as facial expressions, voice signals, and speed of speech.
Dissanayake et al. proposed a machine-learning-based approach using Random Forest models to detect and evaluate changes in the behavioral and personality traits of interviewees based on nonverbal cues [
1]. Among AI techniques, Uparkar et al. used the Deep Face method to perform real-time emotion and sentiment analysis to provide users with insights into their emotional states throughout the interview [
2]. This feedback facilitates improvement in nonverbal communication skills, helping candidates to recognize their emotional tendencies and adjust their interview strategy accordingly. These technologies provide objective and consistent data to better understand emotional states.
It is important to analyze a participant’s level of nervousness in situations such as job interviews or audition programs. It is generally recognized as a psychological and physiological response to a stressful situation, and, while it can be considered a negative emotional state, it can sometimes be a positive factor that promotes motivation. For example, a study by Tod et al. explored the different ways in which athletes transform pre-competition nervousness into a positive stimulus [
3]. It also depends on many factors, such as individual experience, emotional regulation, and context. A study by Roos et al. analyzed emotions such as nervousness and anxiety by observing participants in high-pressure situations such as exams [
4], which can trigger physical reactions such as increased heart rate, voice tremors, and facial expression changes. The emotion of nervousness is complex and influenced by many factors, making it difficult to analyze or define.
Facial expression is one of the most useful sources of information for analyzing emotions such as nervousness. However, the existing AI-based facial expression recognition techniques still have limitations. They typically only classify basic emotional states or approach them with regression models, which makes it difficult to analyze more complex or nuanced emotional states with precision. Nervousness is a complex emotional state that cannot be as easily described as a linear combination of basic emotions such as joy or sadness. If an objective definition and quantitative assessment of nervousness were possible, it could be linked to a variety of services. This study focuses on audition programs, a situation where nervousness is often experienced, and proposes a method to define and evaluate participants’ nervous facial expressions using an emotion model. We collected facial image data from audition programs and used a two-dimensional affective model to identify the distributions and define nervous facial expressions. Based on the defined boundaries, we relabeled the AffectNet dataset into nervous and non-nervous classes and applied knowledge distillation techniques based on the EmoNet model and MobileNetV2 model for training and quantitative evaluation [
5,
6]. We also conducted qualitative evaluation by identifying AU activation patterns in nervous facial expressions through an action unit (AU) relationship modeling method based on multidimensional edge features [
7,
8]. In this paper, we propose a method for the quantitative and qualitative evaluation of ’nervousness’, a complex emotional state, to significantly improve the precision and practicality of emotion recognition.
2. Related Works
2.1. Previous Research on Nervousness Assessment
The existing research on nervousness assessment has primarily focused on analyzing complex emotional states using a variety of methodologies. These studies attempt to quantitatively assess nervousness by utilizing computer vision techniques, biosignal data analysis, and subtle changes in facial expressions. In doing so, they aim to overcome the limitations of the existing emotion recognition systems and provide a more sophisticated assessment of emotional states. Kuipers et al. proposed a method for computer vision to detect nervousness through dynamic facial behavior and analyzed the limitations of humans in interpreting complex emotional states [
9]. The first group of participants in the study generated video data by recreating real-life interview situations and self-assessed their nervousness levels. The second group observed the videos and rated the participants’ nervousness levels. For the video analysis, they used OpenFace to analyze the activation of 17 AUs in the face and proposed a linear regression model to predict nervousness from these data [
10]. The activity of each AU in the face and the underlying emotional expression were converted into statistical features, removing the temporal dimension and selecting features that were highly correlated with th eself-rated nervousness scores. The study found that humans struggled to accurately assess nervousness levels based on facial cues, pointing to the limitations of the human perception system in recognizing complex or subtle emotional expressions. On the other hand, the nervousness scores assessed by the participants and the model were correlated, and the model made more accurate judgments than the observers. Domes et al. analyzed changes in facial emotion recognition and physiological changes, such as cortisol and alpha-amylase levels, based on signal detection theory during acute stress and nervous situations [
11]. Using a virtual reality social stress test, they found that the stressed and nervous group tended to recognize emotions like anger faster and more accurately. A paper by Saraswat et al. proposed a method to measure stress and nervousness levels by analyzing facial expressions, specifically the movement and position changes of the eyebrows [
12]. By analyzing eyebrow contractions and deviations from the average position, they measured stress levels on a scale of 1 to 100 and trained a deep learning model to identify emotional states. The existing studies were conducted by recreating specific situations such as interviews and exams, which may not fully reflect real-life situations. In addition, their regression-model-based inference methods may not fully account for non-linear and complex emotions. In this study, we analyze the complex emotional state of nervousness in a realistic and high-stress situation of an audition program. Rather than relying solely on existing face recognition tools such as OpenFace, we utilize a deep learning model that can understand the valence–arousal distribution to analyze the category and intensity of emotional states in two dimensions. This allows us to more precisely capture subtle differences in emotional states.
2.2. Previous Research on Facial Expression Recognition
In the case of facial expression recognition research, it can be divided into research before and after the advent of deep learning models. Before the advent of deep learning models, various image pattern recognition techniques and machine learning techniques were used, while deep learning refers to learning techniques that apply deep neural network models.
2.2.1. Traditional Facial Expression Recognition Algorithms
The traditional facial expression recognition algorithms, primarily used before the widespread adoption of deep learning technologies, are divided into three main steps: face detection, feature extraction, and facial expression classification. In the traditional approaches, face detection is often performed using algorithms such as cascade classifiers. This process detects key facial components such as the eyes, nose, and mouth within identified facial regions and performs further analysis based on these landmarks. Feature extraction deals with the temporal and spatial features of the face. Geometric feature extraction methods exploit geometric correlations between facial feature locations, and representative techniques include Active Shape Models (ASMs), Active Appearance Models (AAMs), and Scale-Invariant Feature Transform (SIFT) [
13,
14]. Appearance-based methods utilize Local Binary Patterns (LBPs), Gabor wavelets, Histogram of Oriented Gradients (HOG), etc., to capture key information in facial images [
15,
16,
17]. Dimensionality reduction is the process of reducing the volume of data generated during feature extraction while preserving important information. This reduces computational complexity and enables efficient data processing. The main technique is Principal Component Analysis (PCA), which represents images in a lower dimensional space to improve the accuracy and robustness of face detection and recognition [
18]. In the classification phase, the extracted features are used to assign each facial expression to a specific emotion category. Various statistical and machine learning techniques are used in this process, including Decision Trees, K-Nearest Neighbor (KNN), and Support Vector Machines (SVMs) [
19]. These traditional methods played a major role in the early research in facial expression recognition and were widely used until the introduction of complex deep learning techniques.
2.2.2. Deep-Learning-Based Facial Expression Recognition Methods
Deep learning has demonstrated significant advancements in areas such as image recognition, with notable impacts on facial expression recognition. Compared to traditional machine learning methods, deep learning eliminates the need for manual feature engineering by learning directly from raw image data. This enables models to capture complex and subtle patterns of facial expressions more effectively. By leveraging hierarchical representations, deep learning models can accurately identify relationships between complex expressions and train efficiently on large datasets, achieving superior performance. Furthermore, end-to-end training simplifies the pipeline, enabling direct learning from input to output without intermediate preprocessing steps, making the process more efficient and adaptable for real-world applications.
The use of Convolutional Neural Networks (CNNs) marked a major breakthrough in facial expression recognition. CNNs extract features through multiple layers, where each layer progressively learns more abstract features, mimicking the human visual processing system. Pre-trained models such as AlexNet, VGG, and ResNet have been widely utilized for their efficiency in extracting meaningful features from facial images [
20,
21,
22]. Lightweight models like MobileNet and EfficientNet balance accuracy and computational efficiency, making them ideal for resource-constrained environments [
23,
24]. Deep Belief Networks (DBNs) and Autoencoders also contribute significantly, enabling efficient feature extraction, dimensionality reduction, and noise removal, essential for robust facial expression analysis [
25,
26].
Generative Adversarial Networks (GANs) enhance training by generating realistic facial expression datasets, addressing the limitations posed by insufficient labeled data [
27]. Graph neural networks (GNNs), on the other hand, model contextual relationships between facial features, capturing dependencies that are vital for detailed emotional analysis [
28]. Ensemble learning methods, as proposed by Jia et al., further improve generalization by combining outputs from multiple networks such as AlexNet, VGGNet, and ResNet, utilizing an SVM classifier for final predictions [
29].
In addition, action unit (AU) analysis plays a pivotal role in recognizing subtle emotional changes. Luo et al. introduced a graph-based approach to model AU interactions, using multidimensional edge features to better understand the relationships between AUs [
8,
30,
31]. This method incorporates advanced modules like the AU-specific Feature Generator (AFG) and Facial Graph Generator (FGG) to optimize AU relationship modeling. Such approaches have significantly enhanced the ability to analyze complex emotional states, improving both classification and regression performance in facial expression recognition. To further improve the computational efficiency and deployability of deep-learning-based facial expression recognition, especially on edge devices, knowledge distillation has emerged as a promising solution.
2.2.3. Knowledge Distillation
EmoNet represents a significant step forward in emotion recognition, designed to estimate facial landmarks, categorical emotions, and continuous emotions such as valence and arousal [
6]. It incorporates attention mechanisms to focus on regions critical for emotional expression and utilizes knowledge distillation, transferring knowledge from complex teacher models like EmoNet to computationally efficient student models such as MobileNetV2 and EfficientFormer [
32,
33,
34]. The teacher-bounded loss function used in knowledge distillation ensures that the student model achieves comparable accuracy while reducing computational costs.
Transfer learning and knowledge distillation have been widely applied to improve model generalization and efficiency in affective computing. For example, Lee et al. [
32] proposed a fast and accurate facial expression recognition framework using teacher–student knowledge transfer, demonstrating the effectiveness of distillation in emotion recognition. Maiden and Nakisa [
35] introduced a continual learning approach for complex facial expressions by using knowledge distillation from basic emotion representations. Similarly, Zheng et al. [
36] proposed a storage-efficient method called Student–Teacher Oneness (STO) to improve facial expression recognition through integrated teacher–student learning. In a different domain, such as speech recognition, deep transfer learning has also shown improvements in generalization capabilities [
37]. Inspired by these approaches, we leverage EmoNet as a high-capacity teacher model and transfer its learned representations to a lightweight MobileNetV2 model. This strategy allows us to maintain performance while significantly reducing computational costs, which is essential for real-time facial expression recognition tasks.
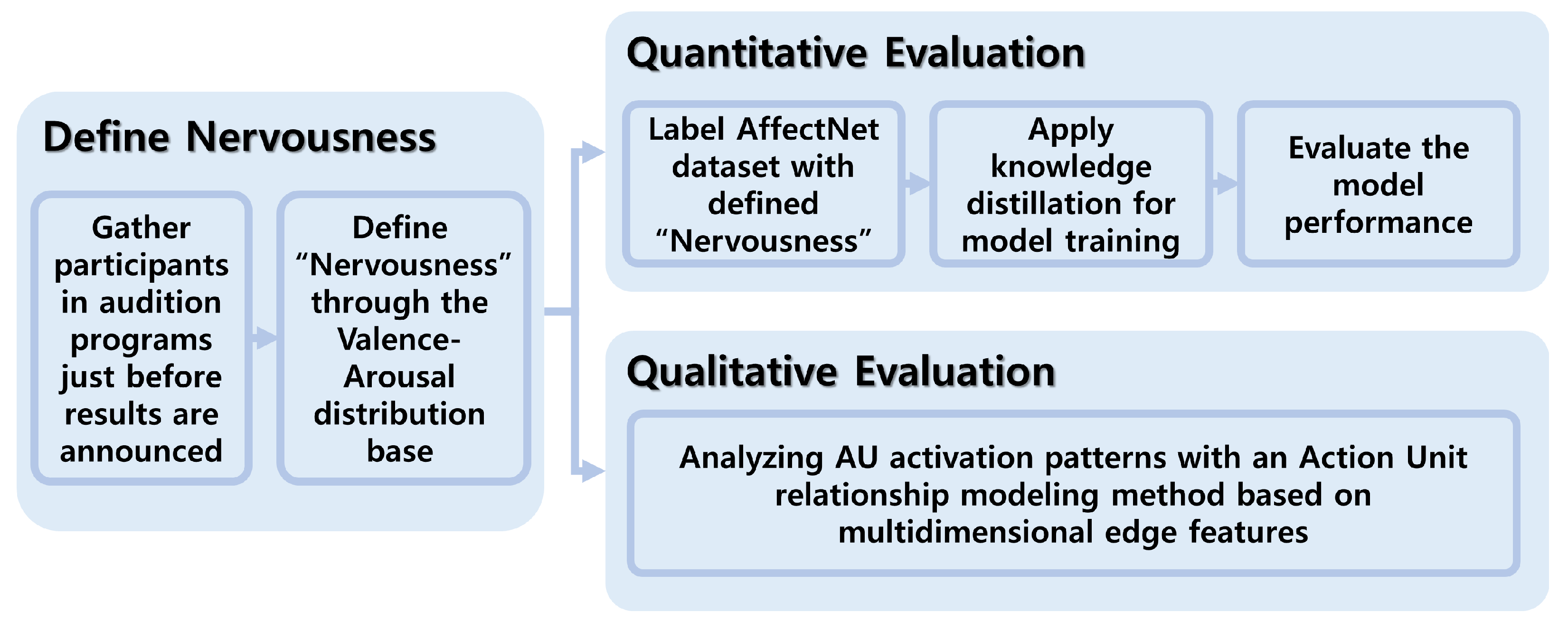
3. Materials and Methods
This study proposes a novel method to accurately define and assess nervousness in real-world audition scenarios, addressing limitations in existing approaches to complex emotional state analysis. An overview of the research methodology is presented in
Figure 1.
3.1. Dataset
To analyze nervousness as a complex state of emotion, we collected facial expression data using broadcast footage from various audition programs in Korea and abroad, which are situations where nervousness is likely to be triggered. The most crucial moment for defining nervous facial expressions was the moment before the announcement of the results, and we selectively collected footage from that moment. In total, we collected facial expression images of 200 participants. These data were important in identifying the characteristics of nervous facial expressions.
3.2. Defining Nervous Facial Expressions
The collected facial expression data were utilized to analyze and visualize the valence and arousal levels of emotional states using the model proposed by Lee et al. in [
32]. To quantify the emotional nature of nervousness in each participant’s facial expression, covariance was estimated using the Minimum Covariance Determinant (MCD). The MCD is a covariance estimation method that minimizes the influence of outliers, and the covariance
S is defined in Equation (
1) [
38].
where
T is the selected subset,
h is the size of the selected
T subset,
represents the relevant data points, and
is the mean of
T. Select an initial subset and calculate the mean and covariance matrix based on it. Compute the Mahalanobis distance of each data point and select the data points with the closest distance to form a new subset, repeating and updating the process. The smaller the sample covariance matrix, the higher the correlation between the data points, and, finally, the subset with the minimum covariance matrix is selected. However, to address the problem of low computational efficiency on large datasets, we use Fast MCD [
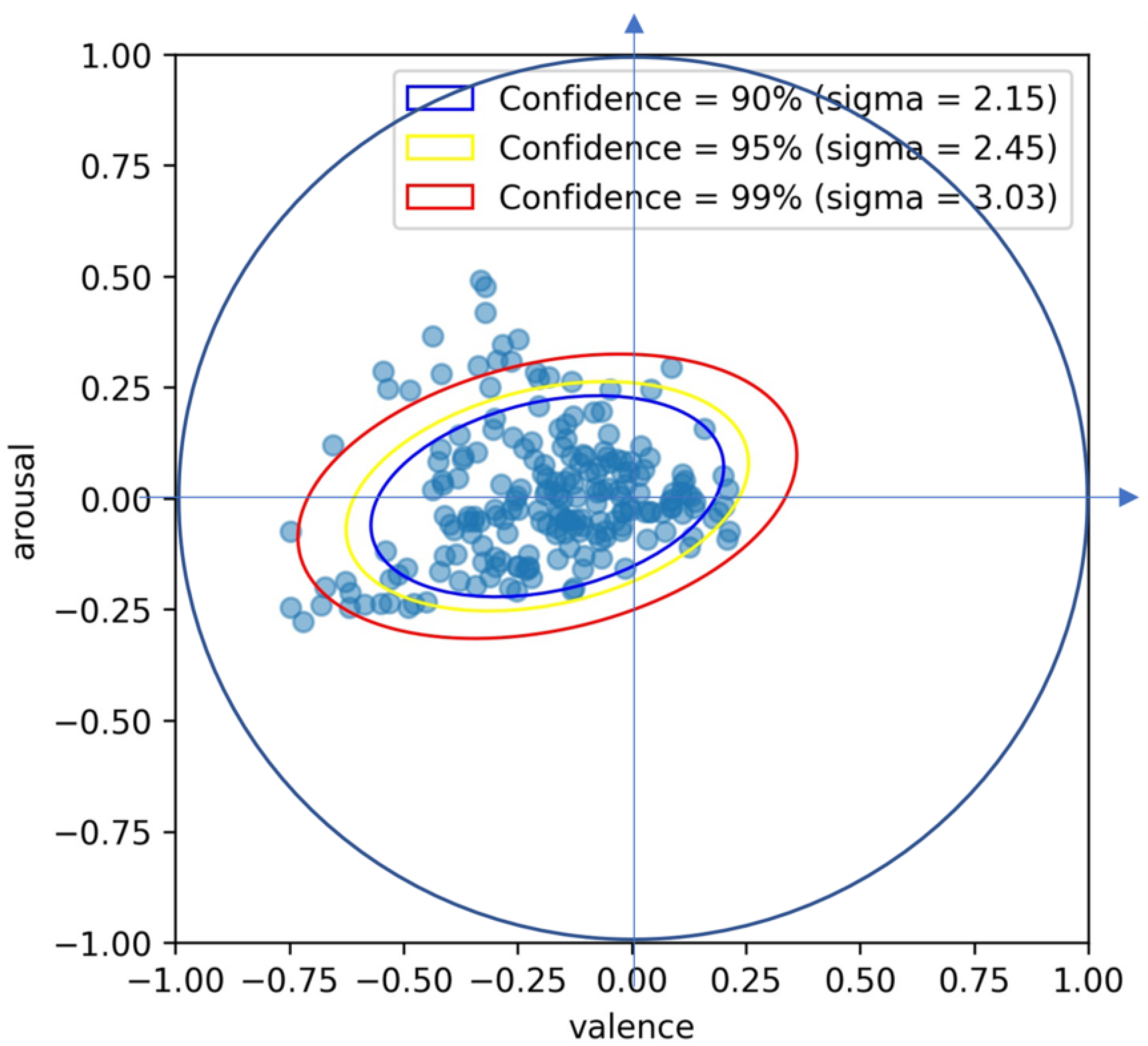
39]. Fast MCD computes the covariance matrix and Mahalanobis distance over multiple randomly selected subsets of the data. The process is repeated for each subset in parallel, and the subset with the smallest covariance matrix determinant is finally selected. This method reduces the impact of outliers in the data while providing a more accurate estimate of the variability in the data. Because of these properties, the confidence ellipses obtained using the MCD estimator provide boundaries that better reflect the true distribution of facial expression data. This process was used to determine the statistical distribution of the data, which led to the creation of 90%, 95%, and 99% confidence ellipses, which can be seen in
Figure 2. Data points that fell within the ellipses were defined as facial expressions that reflected nervousness with a high probability, and this method provided an objective and accurate basis for identifying nervous facial expressions. While traditional models such as those proposed by Lang et al. [
40] place anxiety-related states in the low-valence, high-arousal quadrant, the actual valence–arousal coordinates of these facial expressions tended to exhibit a distribution similar to that of neutral emotions. This discrepancy highlights the complex and context-dependent nature of nervousness.
3.3. Defining Nervousness Using Deep Learning Model
3.3.1. Data Preprocessing
For objective evaluation, we used the AffectNet dataset [
5]. AffectNet is a large dataset of more than one million facial images representing emotions observed in real-world situations. The dataset was created from images found using 1250 emotion-related keywords in combination with terms related to gender, age, or race. Annotations were created that included seven emotion categories and quantification of intensity for valence and arousal. The seven annotated emotions are happiness, sadness, anger, surprise, disgust, fear, and contempt.
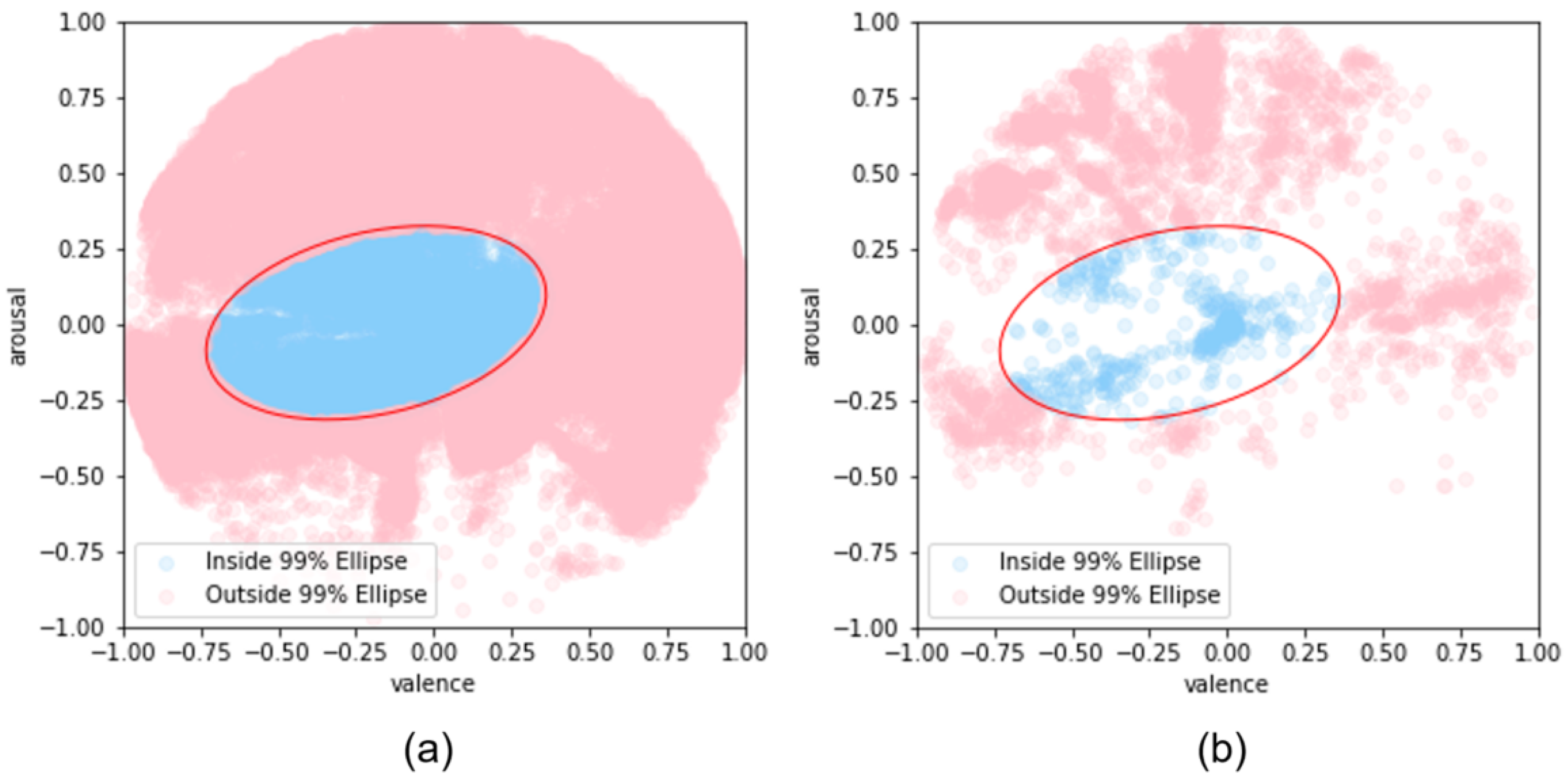
However, for the purposes of this study, we did not use emotion categories to categorize the emotion of tension but instead used the intensity of valence and arousal to determine whether a data point fell inside the confidence ellipse. We chose the 99% confidence ellipse to be the most inclusive of the variability across the data. To mathematically define the relationship between the data points, we calculated the inverse
of the covariance matrix
S, and the squared
of the Mahalanobis distance was calculated using the vector of differences between each data point
x and the mean
in Equation (
2) [
41].
is used as a statistic for the chi-squared distribution, and a data point is defined as being within the confidence ellipse if it is below the threshold for a chi-squared distribution with 2 degrees of freedom and a 99% confidence level. This created a new categorization of annotations as nervous if inside the confidence ellipse and not nervous if outside, and the distribution of the data is shown in
Figure 3.
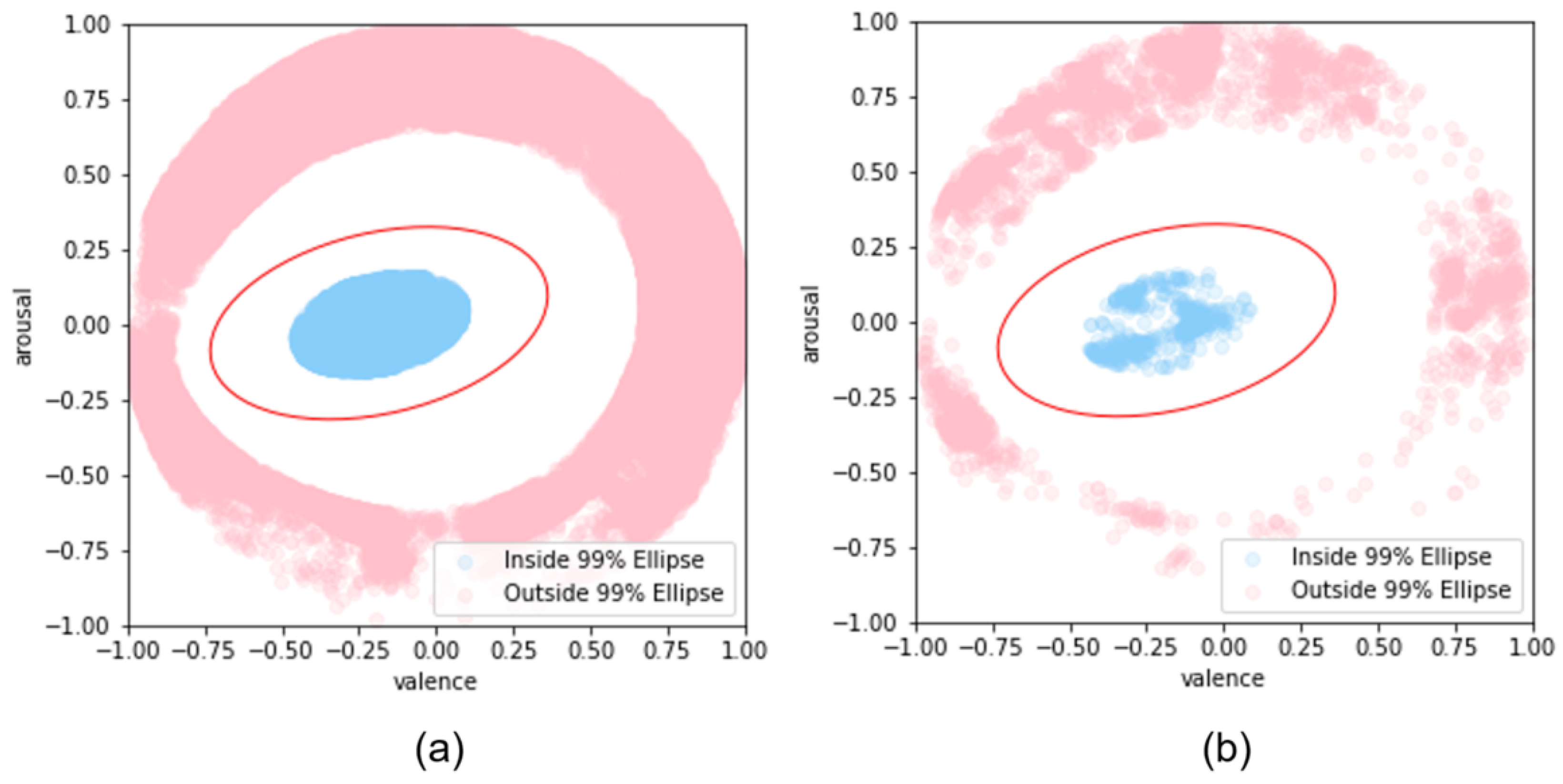
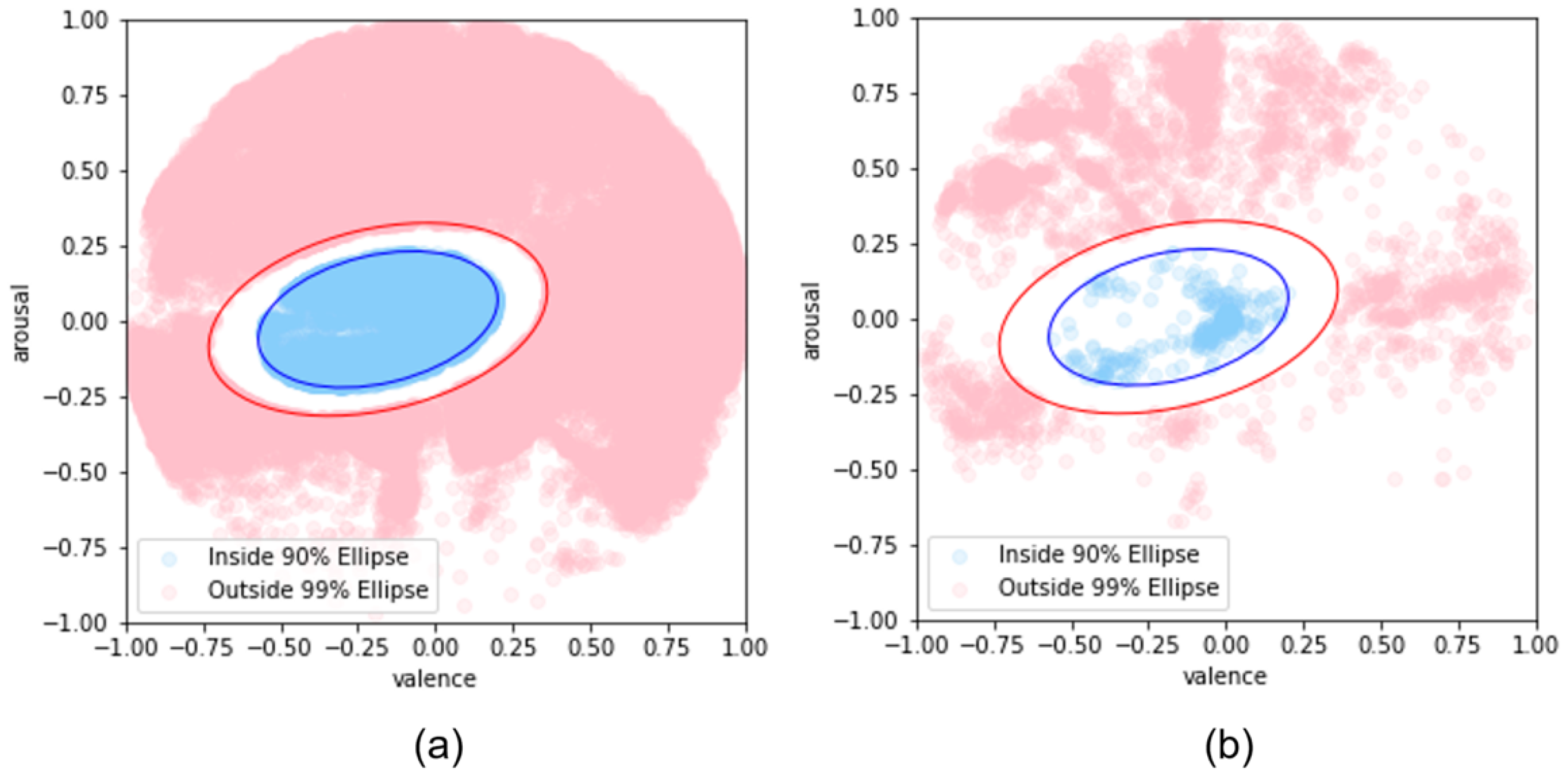
To help the model to better distinguish subtle differences in tension, we created annotations that adjusted the distributions of valence and arousal. For nervous states, the valence and arousal values for each data point were adjusted to be the median of the center of the confidence ellipse and the center of the ellipse so that the data point was closer to the center of the ellipse. In contrast, for non-tension cases, the Euclidean distance between each data point and the circle boundary was calculated and adjusted to the midpoint of the projection points on the boundary of the data point and the circle to move the data point away from the ellipse. The distribution of the newly adjusted data is shown in
Figure 4.
To effectively label the data, we used the following methodology. Data points inside the 90% confidence ellipse were labeled as nervous and data points outside the 99% confidence ellipse were labeled as non-nervous, and the data distribution is shown in
Figure 5. This approach allows for a clear distinction between data points, and a margin was set to effectively exclude uncertain values on the border.
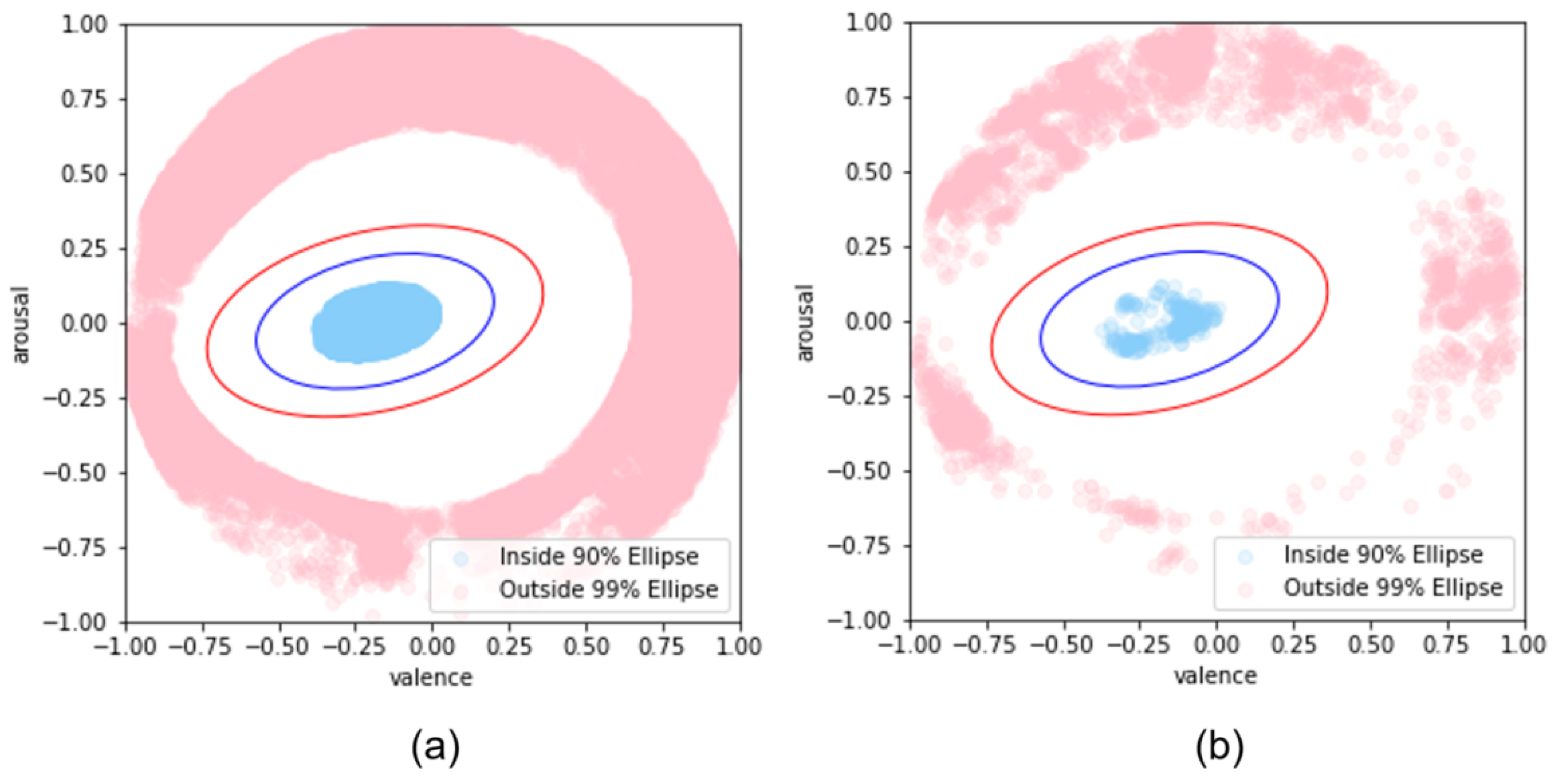
After labeling the data points inside the 90% confidence ellipse and outside the 99% confidence ellipse, we adjusted the values of valence and arousal, as shown in
Figure 4. The resulting distributions can be seen in
Figure 6.
The AffectNet dataset used in this study was first cropped to preserve the proportions of the faces and resized to 256 by 256 to fit the model’s input. The image data were resized and pixel values normalized to produce a form that the model could process. The emotion labels were treated as categorical data using one-hot encoding, while the valence and arousal labels were treated as continuous values.
3.3.2. Model Description and Training Methodology
To recognize tense states, we applied the knowledge distillation technique using EmoNet as the teacher model and MobileNetV2 as the student model, following the method proposed by [
32]. Three new dense layers were added for emotion classification and valence and arousal prediction. The emotion classification layer outputs a probability distribution of whether a person is tense using the softmax activation function, while the valence and arousal prediction layers use the tanh activation function to output continuous values. These layers were connected to the MobileNetV2 output to produce the final tension state predictions. We used the Adam optimizer [
42], which combines the momentum of previous gradients for faster convergence and the adaptive learning rate adjustment of RMSProp for stability. The initial learning rate was set to
Categorical cross-entropy was used for sentiment classification, and Mean Squared Error was employed for valence and arousal prediction [
43]. The training process assigned different loss weights for each task. Sentiment classification, being the primary goal, was assigned a higher weight of 0.4, while valence and arousal were each assigned a weight of 0.3. We calculated the difference between the predicted and actual labels and used this information to update the model’s weights. We also used categorical cross-entropy as the knowledge distillation loss function. This knowledge distillation encourages the student model to learn the soft target distribution, which is the probability distribution predicted by the teacher model, which helps the model to learn more detailed emotional states. The scheduler used Cosine Decay. The initial learning rate was set to
, the learning rate was decreased every 1000 steps, and the final learning rate was controlled at
. A high initial learning rate is used to allow the model to adapt quickly to new data, and the learning rate is gradually reduced as learning progresses to avoid overfitting during optimization and increase learning stability.
The AffectNet dataset exhibits a significant class imbalance, with 75,224 samples in the tense class and 212,427 samples in the non-tense class. To address this, we applied random under-sampling to the non-tense class for balance. Additionally, the Tomek Links algorithm was used to clarify class boundaries by removing noisy data points near the decision boundary [
44]. We used face images with corresponding categorical emotion, valence, and arousal labels as input data. For emotion classification, the model outputs probabilities for each class, while valence and arousal predictions are continuous values between −1 and 1. This improves the recognition of subtle tension differences.
In this study, we applied two learning methods for tension classification using the AffectNet dataset. The first method involved training the proposed model from scratch by relabeling the dataset. The second method utilized a pre-trained model trained on the originally defined seven emotions, which was subsequently fine-tuned on the relabeled data for tension detection. The pre-trained model’s ability to recognize a wide range of emotional states was leveraged to better recognize more granular emotional states, such as nervousness.
3.3.3. Teacher Model (EmoNet)
To provide high-quality supervision for nervousness recognition, we employed EmoNet [
6] as a teacher model. EmoNet is a state-of-the-art deep neural network designed for real-time facial affect analysis in naturalistic settings. It estimates both discrete emotional categories and continuous affective dimensions (valence and arousal) in a single forward pass, integrating facial landmark detection, face alignment, and affect prediction into a unified architecture. Unlike traditional multi-step pipelines that perform face detection, alignment, and emotion recognition separately, EmoNet adopts an end-to-end approach by jointly predicting facial landmarks and affective states. The model builds upon the Face Alignment Network (FAN), using its extracted features and predicted landmarks to guide an attention mechanism. This attention mechanism focuses on regions of the face that are most informative for emotion recognition, such as the eyes, mouth, and brows, improving the robustness of predictions. EmoNet was trained on large-scale datasets, including AffectNet, AFEW-VA, and SEWA, all collected under in-the-wild conditions. By maximizing the concordance correlation coefficient (CCC) for valence and arousal predictions, it achieved superior performance over previous state-of-the-art methods, even surpassing the average inter-annotator agreement on the AffectNet dataset. In our study, we utilized EmoNet as a high-capacity teacher model to guide the learning of a lightweight MobileNetV2 student model through knowledge distillation. The outputs of EmoNet—including soft labels for nervousness and continuous valence–arousal predictions—served as targets for distillation. This strategy allows the student model to inherit the nuanced emotional understanding of EmoNet while remaining computationally efficient enough for real-time inference in edge environments.
3.4. Analyzing Nervousness with Action Unit
3.4.1. Facial Action Coding System and Action Unit
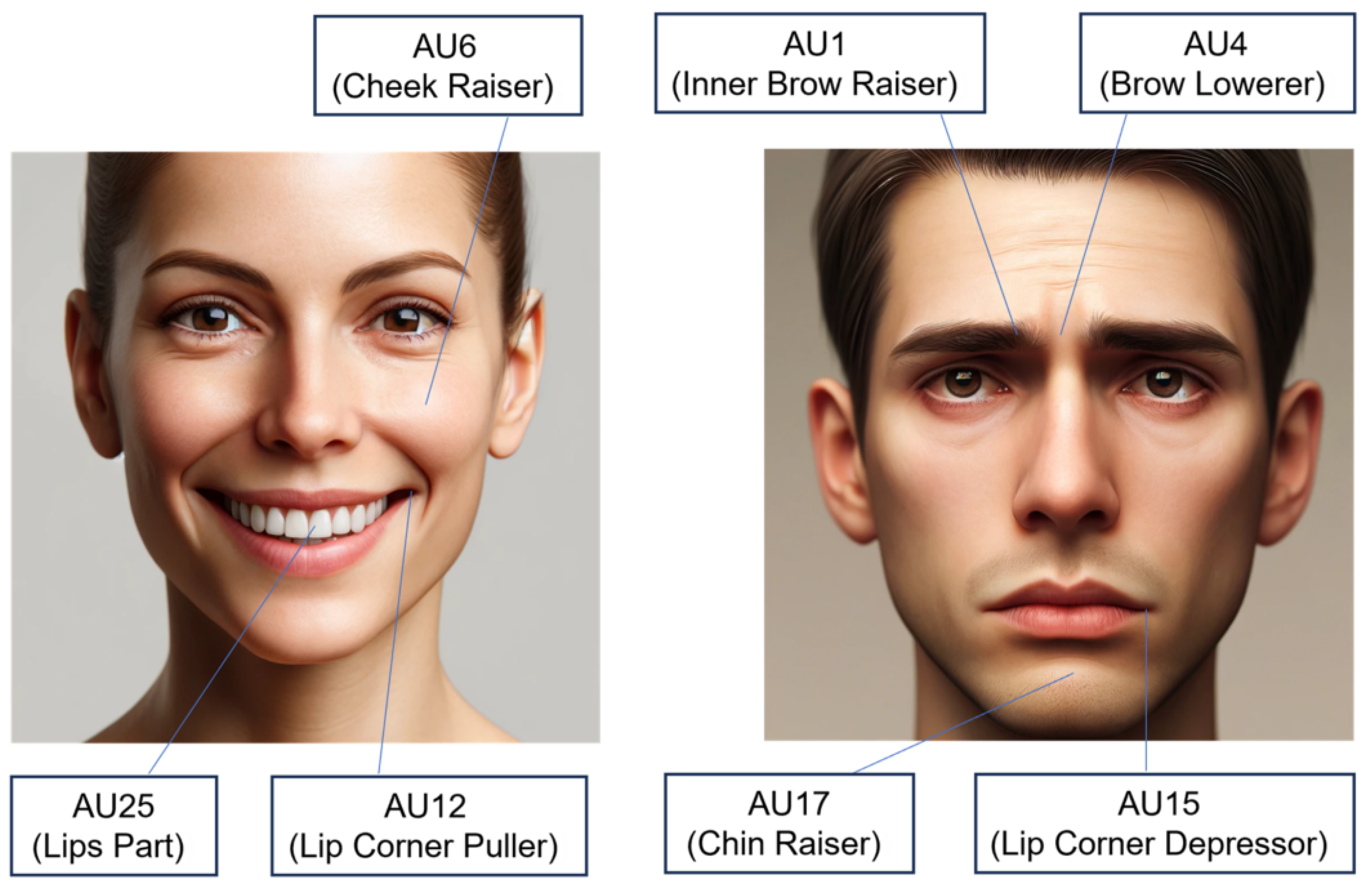
The Facial Action Coding System (FACS) defines 46 AUs that correspond to movements of specific facial muscles [
7]. This system was developed by Ekman et al. and is used to anatomically analyze facial expressions. Each AU represents the movement of an independent facial muscle, which allows subtle changes in emotional expression to be detected. FACS covers different areas of the face; for example, the upper region of the face contains AU1 (inner brow raise) and AU6 (cheek raiser), which represent the movement of the eyebrows and cheeks. On the other hand, in the lower part of the face, AU15 (nose wrinkler) and AU23 (lip tighten) are located to describe the movement of the nose and lips.
According to the FACS, certain combinations of AUs are associated with emotional states. Recent works have advanced this concept by using AU-guided facial regions of interest (ROIs) within graph neural network frameworks to capture the relational structure between AUs. In particular, the Double Dynamic Relationships Graph Convolutional Network (DDRGCN) constructs a facial graph based on AU-informed ROIs and dynamically learns the spatial dependencies among them through a trainable adjacency matrix [
45]. This approach has shown that modeling the interdependence of AU activations improves the recognition of complex emotional expressions. When AU6 (cheek raiser), AU12 (lip corner puller), and AU25 (lip part) were activated simultaneously, they were identified as representing happy emotions. On the other hand, if AU1 (inner brow raiser), AU4 (brow lowerer), AU15 (nose wrinkler), and AU17 (chin raiser) were activated simultaneously, it was analyzed as indicative of sad emotions. An example visualization of this analysis can be seen in
Figure 7. Similarly, the emotion of tension can also be analyzed by looking at the activation patterns of specific AUs.
3.4.2. Model for Analyzing Action Unit
In the facial behavior coding system, the activation of AUs reflects emotional states. However, these AUs influence each other, and their relationships are complex. In this study, we apply the AU relationship modeling method based on multidimensional edge features by Luo et al. to precisely analyze the activation of AUs in human facial expressions under tension [
8]. Using ResNet50 as a backbone and a model pre-trained on a hybrid dataset containing multiple datasets such as BP4D and DISFA, we detected the degree of AU activation in a dataset of audition program participants collected from the audition program and the AffectNet dataset labeled as nervous [
46,
47]. We first extract features associated with each AU from the face image to generate a feature vector and then update the feature vector at each node by graphically modeling the relationship between AUs. The similarity between the updated feature vector and the trained vector is calculated to output the activation probability of individual AUs and the probability of multiple AUs being activated simultaneously. By understanding the influence of each tension-related AU on facial expressions, both individually and interactively, it is possible to more accurately identify and analyze nervous facial expressions.
4. Results
4.1. Quantitative Evaluation of Deep Learning Models
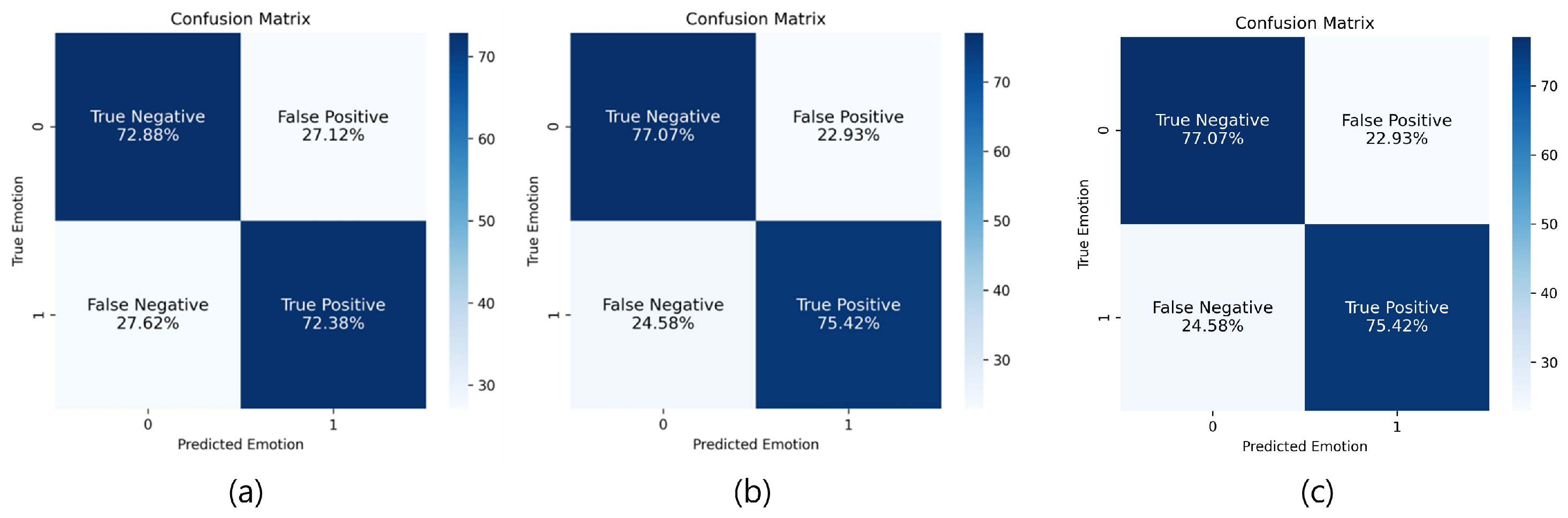
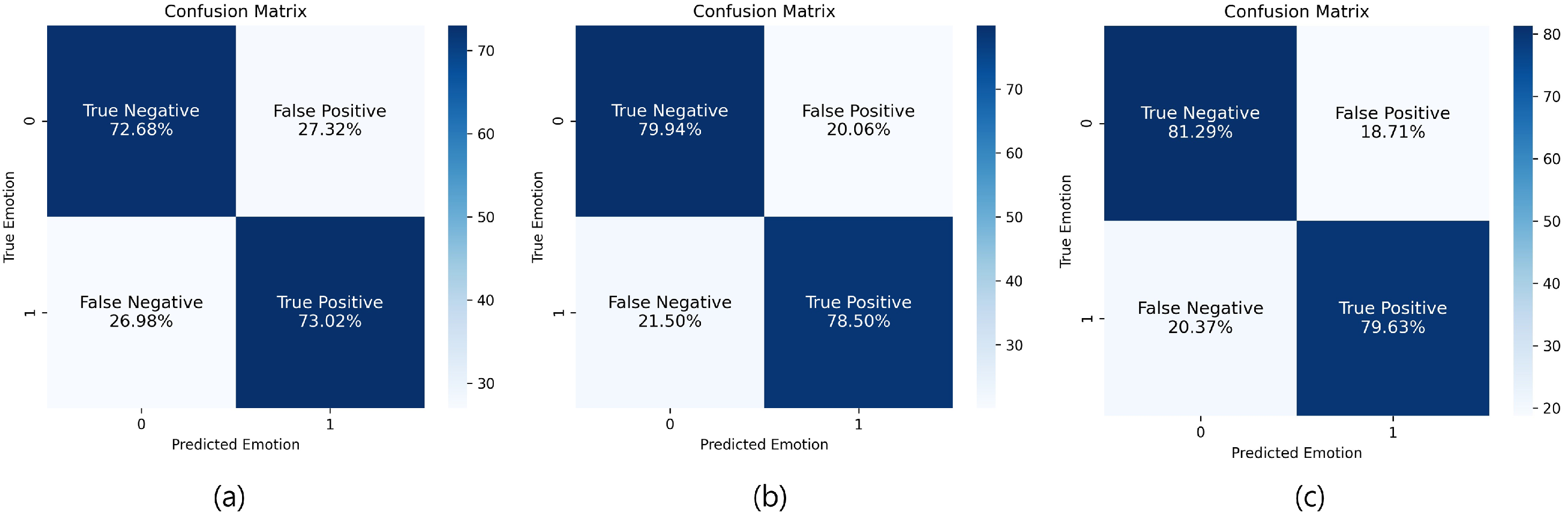
The results of defining facial expressions for nervousness and performing a quantitative evaluation on them are as follows. The knowledge distillation technique was applied using EmoNet as a teacher model and MobileNetV2 as a student model, and the evaluation metrics used were accuracy, precision, recall, and F1-score to classify nervousness. In addition, the root mean square error (RMSE) between the actual and predicted values was calculated to measure the accuracy for valence and arousal intensity. We first applied two training methods using the data labeled based on the 99% confidence ellipse. Method #1 trains a model from scratch, while Method #2 fine-tunes a pre-trained model with default sentiment. The performance evaluation results can be seen in
Table 1 and
Figure 8. Method #3 was also fine-tuned in the same way as Method #2, using the adjusted valence and arousal values, as shown in
Figure 4. The performance evaluation results can be seen in
Table 1 and
Figure 8.
In addition, we applied the two learning methods using only the data inside the 90% confidence ellipse and the data outside the 99% confidence ellipse, and the performance evaluation results are presented in
Table 2 and
Figure 9. Fine-tuning was performed using the adjusted valence and arousal values, as shown in
Figure 6. The performance evaluation results can be seen in
Table 2 and
Figure 9.
4.2. Qualitative Analysis Using Action Units
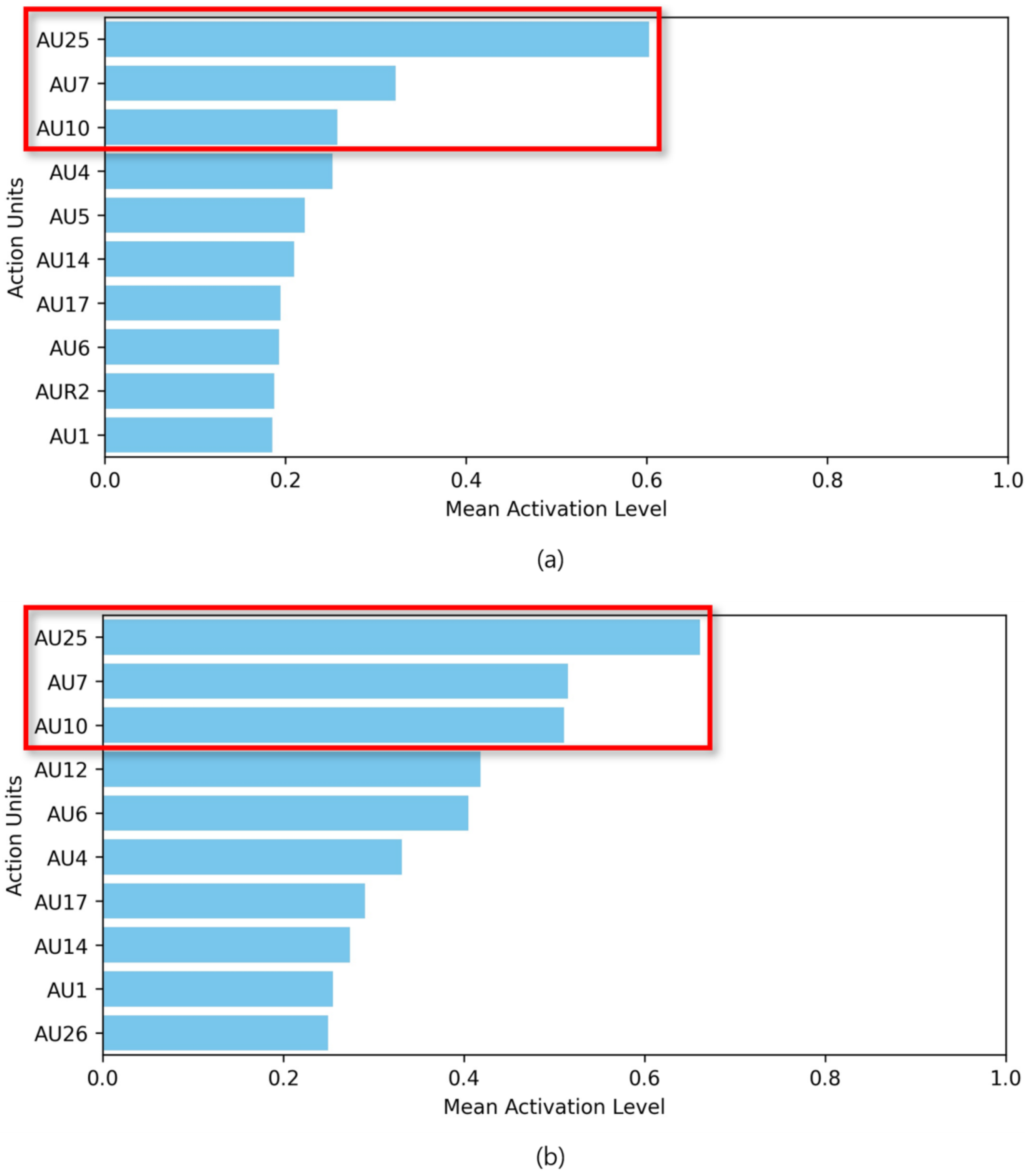
To define nervousness, we analyzed the AU activation patterns from two datasets: facial images collected from audition program participants and the AffectNet dataset labeled as nervous according to the defined confidence ellipses. The average AU activations are shown in
Figure 10.
The most highly activated AU was AU25, which corresponds to natural lip relaxation. Other commonly activated AUs included the following:
AU7: Tensing of the muscles around the eyes.
AU10: Raising of the upper lip.
AU4: Lowering of the eyebrows, forming a crease between them.
AU14: Pulling the corners of the mouth back.
AU6: Raising the under-eye area due to muscle tension.
AU1: Lifting the inner part of the eyebrows.
Each of these AUs reflects an emotional state such as surprise, contempt, displeasure, or anger.
5. Discussion
In this study, we conducted quantitative and qualitative evaluations to define and analyze the nervous facial expressions of participants in an audition program. For the quantitative evaluation, we used two methods: training using only data labeled as nervous, and fine-tuning a pre-trained model using data labeled as default emotions. By using a model that can already recognize a wide range of emotional states, we were able to more accurately capture the nuances needed to recognize complex emotional states such as nervousness. We also found that the best performance was achieved using data that effectively excluded uncertain values on the boundary, and the performance was further improved when we tuned the distribution of valence and arousal used as auxiliary labels to move away from the boundary. However, we can see that the performance is poor despite the binary classification. This result indicates that facial expression classification alone is not sufficient to fully determine the emotional state of nervousness. To analyze the reasons for the results, we performed a qualitative evaluation of the defined nervous facial expressions. Analyzing the activated action units, we found that they reflect several emotional states, such as surprise, contempt, displeasure, or anger. These results suggest the complexity of emotions that participants may experience before the announcement of the audition program results, showing that the uncertainty of the situation and the unpredictability of the outcome may cause participants to feel a variety of emotions simultaneously. Furthermore, with the exception of AU25, the average activation probabilities of the other AUs were generally low. The way people express emotions under pressure can vary between individuals. Some people tend to suppress and internalize their emotions, which may not readily show up as distinct AU activation in facial expressions. Particularly in formal or high-pressure situations, such as auditions or interviews, participants may be more inhibited in their facial expressions due to their will to control their emotions while feeling nervous.
Our findings suggest that nervous facial expressions represent complex emotions and are difficult to define with a basic emotion model. The confidence ellipses we defined were not significantly different from the distribution of neutral facial expressions in the AffectNet dataset, making the classification ambiguous, and our quantitative and qualitative evaluation results show that simple facial expression changes alone do not provide a clear picture of nervousness. To accurately understand nervousness, a new approach is needed that goes beyond the traditional basic emotion models. Composite emotion models can help us to better understand and classify less obvious emotional states such as nervousness. The current facial expression recognition models focus on classifying clear and obvious emotional states. This limits their ability to accurately classify subtle emotional states such as nervousness, and there is a need to develop new models that can encompass complex and diverse emotional states. Furthermore, facial expressions of nervousness can vary across ethnic, cultural, and individual differences. Models that do not account for this diversity are limited in their applicability to real-world situations. In addition to this interpersonal and cultural variability, real-world environments often introduce visual noise such as blur or compression artifacts, which further challenge model performance. To improve the practical robustness of the proposed model, future work will include testing under synthetic noise conditions and real-world distortions. We also plan to apply data augmentation techniques and establish robustness benchmarks to evaluate performance under variable environmental conditions.
6. Conclusions
This study proposed an objective method to define and evaluate nervousness from an emotion model perspective. By collecting facial expression data from audition program participants, we visualized valence and arousal distributions and defined nervousness through confidence ellipses. Using the AffectNet dataset, we labeled data based on these ellipses and introduced adjusted labels to improve classification performance. The knowledge distillation approach, utilizing EmoNet as a teacher model and MobileNetV2 as a student model, demonstrated improved performance when fine-tuned with refined datasets. The best performance (accuracy of 81.08%) was achieved using data that excluded boundary values and adjusted the valence–arousal distributions.
Our results confirm the validity of this method but also reveal limitations. Facial expression analysis alone is insufficient for accurately defining nervousness due to the complexity of emotions and individual variability. Future research should focus on incorporating ethnic and cultural diversity, expanding datasets, and developing models capable of capturing complex emotional states. Multimodal approaches, including biosignals, should be explored to enhance the robustness of nervousness assessment in real-world contexts such as auditions, interviews, and other high-pressure scenarios.
Author Contributions
Conceptualization, H.S., S.K. and E.C.L.; methodology, H.S. and S.K.; software, H.S.; validation, H.S.; formal analysis, H.S.; investigation, H.S.; resources, H.S.; data curation, H.S.; writing—original draft preparation, S.K.; writing—review and editing, S.K.; visualization, S.K.; supervision, E.C.L.; project administration, E.C.L.; funding acquisition, E.C.L. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the NRF (National Research Foundation) of Korea, funded by the Korean government (Ministry of Science and ICT) (Grant No. RS-2024-00340935).
Data Availability Statement
The raw data supporting the conclusions of this article will be made available by the authors on request.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Dissanayake, D.Y.; Amalya, V.; Dissanayaka, R.; Lakshan, L.; Samarasinghe, P.; Nadeeshani, M.; Samarasinghe, P. AI-based Behavioural Analyser for Interviews/Viva. In Proceedings of the 2021 IEEE 16th International Conference on Industrial and Information Systems (ICIIS), Kandy, Sri Lanka, 9–11 December 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 277–282. [Google Scholar]
- Ahmad, M.M.; Srivastava, P.; Bharti, V.; Shamsi, M.F.; Jain, A.; Vishnoi, A. Collaborative Mock Interview Platform. In Proceedings of the 2024 OPJU International Technology Conference (OTCON) on Smart Computing for Innovation and Advancement in Industry 4.0, Raigarh, India, 5–7 June 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 1–5. [Google Scholar]
- Tod, D.; Hardy, J.; Oliver, E. Effects of self-talk: A systematic review. J. Sport Exerc. Psychol. 2011, 33, 666–687. [Google Scholar] [CrossRef]
- Roos, A.L.; Goetz, T.; Voracek, M.; Krannich, M.; Bieg, M.; Jarrell, A.; Pekrun, R. Test anxiety and physiological arousal: A systematic review and meta-analysis. Educ. Psychol. Rev. 2021, 33, 579–618. [Google Scholar] [CrossRef]
- Mollahosseini, A.; Hasani, B.; Mahoor, M.H. Affectnet: A database for facial expression, valence, and arousal computing in the wild. IEEE Trans. Affect. Comput. 2017, 10, 18–31. [Google Scholar] [CrossRef]
- Toisoul, A.; Kossaifi, J.; Bulat, A.; Tzimiropoulos, G.; Pantic, M. Estimation of continuous valence and arousal levels from faces in naturalistic conditions. Nat. Mach. Intell. 2021, 3, 42–50. [Google Scholar] [CrossRef]
- Ekman, P.; Friesen, W.V. Facial action coding system. In Environmental Psychology and Nonverbal Behavior; Springer Science & Business Media: Cham, Swizterland, 1978. [Google Scholar]
- Luo, C.; Song, S.; Xie, W.; Shen, L.; Gunes, H. Learning Multi-dimensional Edge Feature-based AU Relation Graph for Facial Action Unit Recognition. In Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence (IJCAI-22), Vienna, Austria, 23–29 July 2022. [Google Scholar] [CrossRef]
- Kuipers, M.; Kappen, M.; Naber, M. How nervous am I? How computer vision succeeds and humans fail in interpreting state anxiety from dynamic facial behaviour. Cogn. Emot. 2023, 37, 1105–1115. [Google Scholar] [CrossRef]
- Tadas, B.; Amir, Z.; Chong, L.Y.; Philippe, L.M. Openface 2.0: Facial behavior analysis toolkit. In Proceedings of the 13th IEEE International Conference on Automatic Face & Gesture Recognition, Xi’an, China, 15–19 May 2018. [Google Scholar]
- Domes, G.; Zimmer, P. Acute stress enhances the sensitivity for facial emotions: A signal detection approach. Stress 2019, 22, 455–460. [Google Scholar] [CrossRef] [PubMed]
- Saraswat, M.; Kumar, R.; Harbola, J.; Kalkhundiya, D.; Kaur, M.; Goyal, M.K. Stress and Anxiety Detection via Facial Expression Through Deep Learning. In Proceedings of the 2023 3rd International Conference on Technological Advancements in Computational Sciences (ICTACS), Tashkent, Uzbekistan, 1–3 November 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1565–1568. [Google Scholar]
- Iqtait, M.; Mohamad, F.; Mamat, M. Feature extraction for face recognition via active shape model (ASM) and active appearance model (AAM). In Proceedings of the IOP Conference Series: Materials Science and Engineering, Melbourne, Australia, 15–16 September 2018; IOP Publishing: Bristol, UK, 2018; Volume 332, p. 012032. [Google Scholar]
- Zhou, D.; Petrovska-Delacrétaz, D.; Dorizzi, B. Automatic landmark location with a combined active shape model. In Proceedings of the 2009 IEEE 3rd International Conference on Biometrics: Theory, Applications, and Systems, Washington, DC, USA, 28–30 September 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 1–7. [Google Scholar]
- Shan, C.; Gong, S.; McOwan, P.W. Robust facial expression recognition using local binary patterns. In Proceedings of the IEEE International Conference on Image Processing 2005, Genova, Italy, 14 September 2005; IEEE: Piscataway, NJ, USA, 2005; Volume 2, p. II-370. [Google Scholar]
- Oshidari, B.; Araabi, B.N. An effective feature extraction method for facial expression recognition using adaptive Gabor wavelet. In Proceedings of the 2010 IEEE International Conference on Progress in Informatics and Computing, Shanghai, China, 10–12 December 2010; IEEE: Piscataway, NJ, USA, 2010; Volume 2, pp. 776–780. [Google Scholar]
- Eng, S.; Ali, H.; Cheah, A.; Chong, Y. Facial expression recognition in JAFFE and KDEF Datasets using histogram of oriented gradients and support vector machine. In Proceedings of the IOP Conference Series: Materials Science and Engineering, Wuhan, China, 19–20 April 2019; IOP Publishing: Bristol, UK, 2019; Volume 705, p. 012031. [Google Scholar]
- Perlibakas, V. Distance measures for PCA-based face recognition. Pattern Recognit. Lett. 2004, 25, 711–724. [Google Scholar] [CrossRef]
- Jusman, Y.; Nurkholid, M.A.F.; Faiz, M.F.; Puspita, S.; Evellyne, L.O.; Muhammad, K. Caries Level Classification using K-Nearest Neighbor, Support Vector Machine, and Decision Tree using Zernike Moment Invariant Features. In Proceedings of the 2022 International Conference on Data Science and Its Applications (ICoDSA), Bandung, Indonesia, 6–7 July 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 7–11. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Aditya, A.T.; Sigit, R.; Dewantara, B.S.B. Face recognition using deep learning as user login on healthcare Kiosk. In Proceedings of the 2022 14th International Conference on Information Technology and Electrical Engineering (ICITEE), Yogyakarta, Indonesia, 18–19 October 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 292–297. [Google Scholar]
- Anand, R.; Shanthi, T.; Nithish, M.; Lakshman, S. Face recognition and classification using GoogleNET architecture. In Proceedings of the 8th International Conference on Soft Computing for Problem Solving: SocProS, Vellore, India, 17–19 December 2018; Springer: Cham, Swizteland, 2020; Volume 1, pp. 261–269. [Google Scholar]
- Zhang, W. Remote Sensing Scene Classification with Lightweight Model. In Proceedings of the 2022 4th International Conference on Robotics, Intelligent Control and Artificial Intelligence, Dongguan, China, 16–18 December 2022; pp. 680–685. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Li, C.; Wang, Y.; Zhang, X.; Gao, H.; Yang, Y.; Wang, J. Deep belief network for spectral–spatial classification of hyperspectral remote sensor data. Sensors 2019, 19, 204. [Google Scholar] [CrossRef]
- Mohana, M.; Subashini, P. Emotion Recognition using Autoencoders: A Systematic Review. In Proceedings of the 2023 International Conference on Intelligent Systems for Communication, IoT and Security (ICISCoIS), Coimbatore, India, 9–11 February 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 438–443. [Google Scholar]
- Hung, S.K.; Gan, J.Q. Boosting facial emotion recognition by using GANs to augment small facial expression dataset. In Proceedings of the 2022 International Joint Conference on Neural Networks (IJCNN), Padua, Italy, 18–23 July 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–8. [Google Scholar]
- Wu, C.; Chai, L.; Yang, J.; Sheng, Y. Facial expression recognition using convolutional neural network on graphs. In Proceedings of the 2019 Chinese Control Conference (CCC), Guangzhou, China, 27–30 July 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 7572–7576. [Google Scholar]
- Jia, C.; Li, C.L.; Ying, Z. Facial expression recognition based on the ensemble learning of CNNs. In Proceedings of the 2020 IEEE International Conference on Signal Processing, Communications and Computing (ICSPCC), Macau, China, 21–24 August 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–5. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Bresson, X.; Laurent, T. Residual gated graph convnets. arXiv 2017, arXiv:1711.07553. [Google Scholar]
- Lee, K.; Kim, S.; Lee, E.C. Fast and accurate facial expression image classification and regression method based on knowledge distillation. Appl. Sci. 2023, 13, 6409. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Li, Y.; Yuan, G.; Wen, Y.; Hu, J.; Evangelidis, G.; Tulyakov, S.; Wang, Y.; Ren, J. Efficientformer: Vision transformers at mobilenet speed. Adv. Neural Inf. Process. Syst. 2022, 35, 12934–12949. [Google Scholar]
- Maiden, A.; Nakisa, B. Complex facial expression recognition using deep knowledge distillation of basic features. arXiv 2023, arXiv:2308.06197. [Google Scholar]
- Zheng, Z.; Rasmussen, C.; Peng, X. Student-Teacher Oneness: A Storage-efficient approach that improves facial expression recognition. In Proceedings of the IEEE/CVF international Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 4077–4086. [Google Scholar]
- Kheddar, H.; Himeur, Y.; Al-Maadeed, S.; Amira, A.; Bensaali, F. Deep transfer learning for automatic speech recognition: Towards better generalization. Knowl. Based Syst. 2023, 277, 110851. [Google Scholar] [CrossRef]
- Hubert, M.; Debruyne, M. Minimum covariance determinant. Wiley Interdiscip. Rev. Comput. Stat. 2010, 2, 36–43. [Google Scholar] [CrossRef]
- EStimator, D. A Fast Algorithm for the Minimum Covariance. Technometrics 1999, 41, 212. [Google Scholar]
- Lang, P.J.; Bradley, M.M.; Cuthbert, B.N. Emotion, attention, and the startle reflex. Psychol. Rev. 1990, 97, 377. [Google Scholar] [CrossRef]
- De Maesschalck, R.; Jouan-Rimbaud, D.; Massart, D.L. The mahalanobis distance. Chemom. Intell. Lab. Syst. 2000, 50, 1–18. [Google Scholar] [CrossRef]
- Zhang, Z. Improved adam optimizer for deep neural networks. In Proceedings of the 2018 IEEE/ACM 26th International Symposium on Quality of Service (IWQoS), Banff, AB, Canada, 4–6 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–2. [Google Scholar]
- Zhang, Z.; Sabuncu, M. Generalized cross entropy loss for training deep neural networks with noisy labels. In Proceedings of the 32nd Conference on Neural Information Processing Systems (NeurIPS 2018), Montréal, QC, Canada, 3–8 December 2018; Volume 31. [Google Scholar]
- Pereira, R.M.; Costa, Y.M.; Silla Jr, C.N. MLTL: A multi-label approach for the Tomek Link undersampling algorithm. Neurocomputing 2020, 383, 95–105. [Google Scholar] [CrossRef]
- Jin, X.; Lai, Z.; Jin, Z. Learning Dynamic Relationships for Facial Expression Recognition Based on Graph Convolutional Network. IEEE Trans. Image Process. 2021, 30, 7143–7155. [Google Scholar] [CrossRef]
- Zhang, X.; Yin, L.; Cohn, J.F.; Canavan, S.; Reale, M.; Horowitz, A.; Liu, P.; Girard, J.M. Bp4d-spontaneous: A high-resolution spontaneous 3d dynamic facial expression database. Image Vis. Comput. 2014, 32, 692–706. [Google Scholar] [CrossRef]
- Mavadati, S.M.; Mahoor, M.H.; Bartlett, K.; Trinh, P.; Cohn, J.F. Disfa: A spontaneous facial action intensity database. IEEE Trans. Affect. Comput. 2013, 4, 151–160. [Google Scholar] [CrossRef]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}