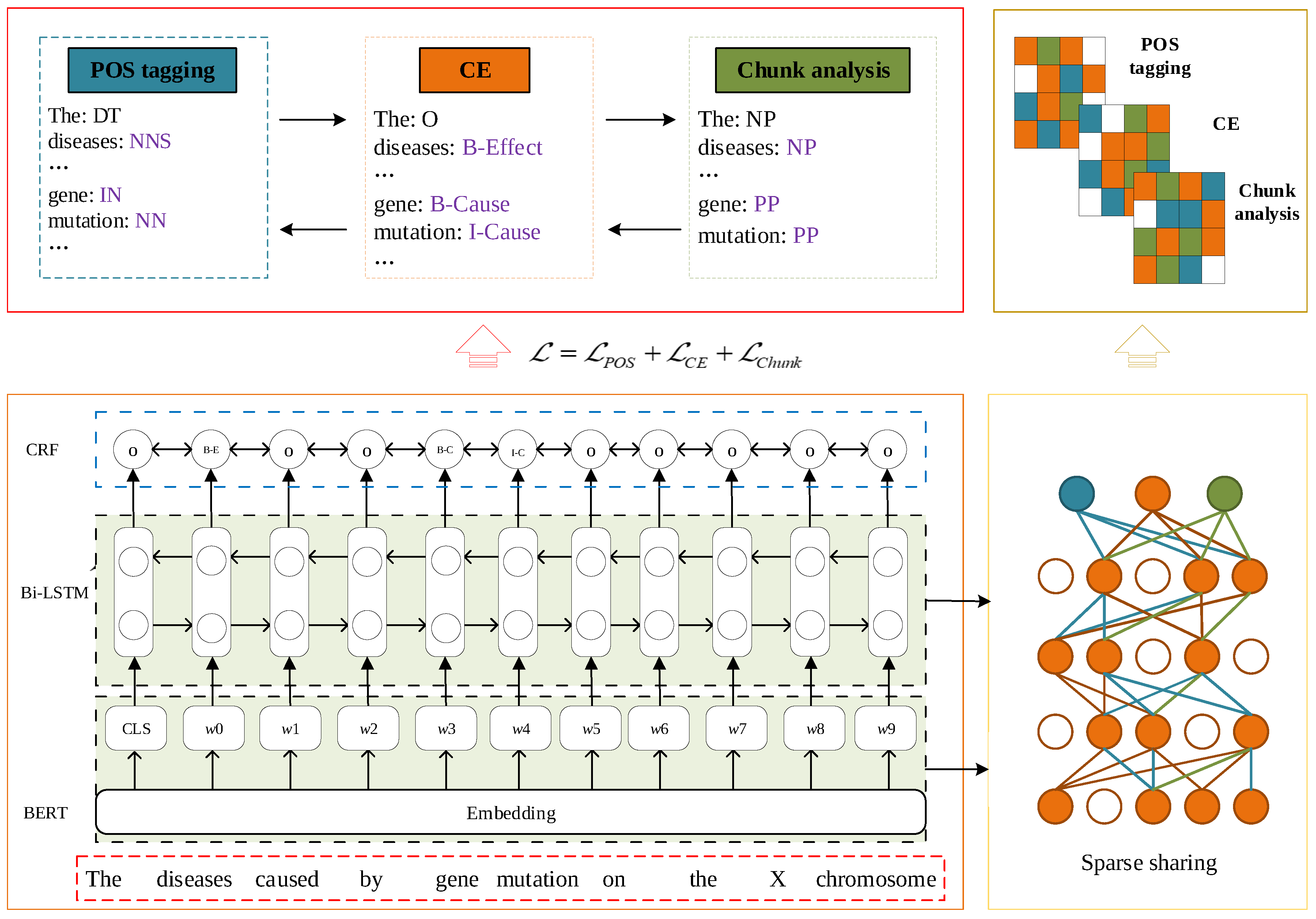
1. Introduction
Causal relation extraction (CE), as a crucial task in natural language processing (NLP), plays an indispensable role in various downstream applications, such as knowledge graphs [
1], event logic graphs [
2], and question-answering systems [
3,
4]. Extracting causal relations is quite challenging since it requires sophisticated models capable of capturing rich semantic information and complex linguistic phenomena [
5]. Prior works utilize the sequence tagging task to complete the CE, while these methods achieve much better performance than traditional methods. Pre-trained language models such as ElMo and BERT are introduced to enhance the understanding capability of the models [
6,
7] hence improving model performance.
However, these methods are all single-task-based and tend to suffer from the problem of noise information [
8]. For instance, certain words in a text, such as adjectives and prepositions, are unlikely to be labeled as “Cause” or “Effect” because they do not point to concrete entities. Yet, such noise information complicates the tagging of cause-and-effect entities. To investigate the impact of noise data, we conducted experiments on the SemEval-2010 Task 8 dataset, Event StoryLine corpus, and Causal TimeBank, with the results shown in
Table 1. We selected four illustrative samples, each labeled by existing models across different datasets. In the first two samples from the SemEval-2010 Task 8 dataset [
9], BERT incorrectly labels “blind” as “B-Cause”, despite it being an adjective. A similar issue occurs in the Causal TimeBank [
10]. Moreover, in the Event StoryLine [
11] sample, the preposition “off” is mistakenly labeled as “B-Cause”. This problem could be mitigated by incorporating parts of speech (POS) and other linguistic information. Therefore, we conclude that conventional single-task learning (STL)-based architectures often make erroneous predictions regarding the positions of cause–effect entities, indiscriminately labeling noisy adjectives and prepositions as “Cause” or “Effect”.
In the field of natural language processing, there are various tasks that can process and analyze text from different perspectives [
12,
13,
14]. At present, the main causal extraction methods are single-task methods, which cannot fully utilize the characteristics of different aspects of text for causal relationship extraction. To address the limitations of single-task learning (STL) strategies, there is an urgent need for models to learn various aspects of information from texts. Inspired by the progress of multi-task learning (MTL), we introduce a framework that can learn much information across related tasks to enhance the performance of the models [
15,
16]. Multi-task learning emerges as a promising approach to enhance model performance by training models on multiple tasks simultaneously, and the inherent advantage of MTL lies in its ability to leverage shared knowledge and complementary information among different but related tasks, thereby alleviating the above problems of the STL-based methods [
17,
18]. Accordingly, we intend to employ the power of MTL to enhance CE performance. We prefer part-of-speech tagging (POS tagging) [
19] and chunk analysis (Chunk) [
20] as the co-training tasks. (1) POS tagging is shown to assign grammatical tags to words in a sentence, and most causes and effects are nouns (“NN” in POS tagging) [
21], as cause and effect entities project to specific objects. Beyond question, this can help the model exclude other labels while locating causes and effects. (2) Chunk involves grouping words in a sentence into meaningful chunks, splitting several spans of distinct semantic components, which is also beneficial for minimizing the scope of cause and effect based on POS results [
20].
To implement multi-task sequence tagging, we adopt a sparse sharing strategy in MTL for more efficient parameter sharing. Parameter sharing in MTL intends to update common parameters during training; typical methods include hard sharing, soft sharing, and hierarchical sharing [
22,
23,
24]. Among them, hard sharing allows all tasks to share the same hidden space, which limits the performance ability of different tasks and makes it difficult to handle loosely related tasks. The soft sharing method does not need to consider the relevance of tasks, but it requires training a model for each task, so the parameters are hyper-parameters. Hierarchical sharing allows each task to only share a portion of the model, and task-specific modules can handle heterogeneous tasks, but designing an effective hierarchical structure is often time-consuming and requires expert experience. Compared to other strategies, sparse sharing can achieve equivalent results compared to other parameter-sharing strategies, while requiring fewer parameters [
25,
26,
27].
Based on the above discussion, we propose a multi-task joint POS tagging and Chunk model for CE named MPC−CE, which can denoise the interference factors in massive semantic components, thus helping the model locate cause–effect entities. However, it raises a new challenge to annotate POS and chunk labels on the basis of existing CE datasets. According to the annotating rule of POS tagging and Chunk, we label a given sentence with three types of labels, as shown in
Table 2. MPC−CE combines the three subnets to optimize each task’s target, respectively. Additionally, we conduct experiments on two distinct datasets, namely the SemEval-2010 Task 8 dataset and MTL-CE dataset, to showcase the efficacy of our proposed MPC−CE. Through these experiments, we aim to demonstrate the superior performance of MPC−CE compared to various baseline models. The empirical results unequivocally highlight the remarkable effectiveness and potential of MPC−CE in pushing the boundaries of CE performance to new heights. In summary, our contribution to this work is four-fold:
We utilize the POS tagging and Chunk task to help capture the attribute of each word, which can alleviate the data noise problem in causal relation extraction.
We propose MPC−CE–a multi-task learning model for causal relation extraction to unify POS tagging and Chunk into a single sequence-labeling task.
We incorporate a sparse sharing mechanism to reduce the scale of training parameters through iterative pruning, which can facilitate efficient pruning of shared layers.
We conduct groups of experiments on both open datasets and our self-merge datasets, and the results demonstrate that MPC−CE gains the most improvement among all baseline models under the cross-domain scenario.
Table 2.
A multi-label data sample from SemEval2010-Task 8 dataset; each word in the input sentence is annotated with three types of labels: POS, Chunk, and CE.
Table 2.
A multi-label data sample from SemEval2010-Task 8 dataset; each word in the input sentence is annotated with three types of labels: POS, Chunk, and CE.
| Sentence | Muscle | fatigue | is | the | number | one | cause | of | arm | muscle | pain | . |
| POS | NNP | NN | VBZ | DT | NN | CD | NN | IN | JJ | NN | NN | . |
| Chunk | O | B-NP | O | B-NP | I-NP | O | B-NP | O | B-NP | I-NP | B-NP | O |
| CE | O | B-Cause | O | O | O | O | O | O | O | O | B-Effect | O |
3. Model
Our proposed framework MPC−CE consists of 3 base modules, which will be illustrated in later parts; it employs a sparse sharing mechanism [
27], including two crucial components: a task-specific layer and a task-sharing layer, as depicted in
Figure 1. Task-specific layers extract features specific to a particular task, while task-sharing layers extract common features used to make predictions for all tasks. By sharing complementary information across these tasks, MPC−CE can learn to denoise irrelevant semantic components amongst interference factors, and hence perform better under complicated CE circumstances efficiently; it can also handle single-source noise data and improve the model’s performance.
As cause entities and effect entities typically manifest as nouns and chunks, POS tagging and Chunk are employed as auxiliary tasks for CE. The shared layer of the model utilizes BERT [
7] and BiLSTM layers. Given the large number of parameters in the pre-trained BERT, we adopt iterative pruning [
48] to minimize the model’s size by pruning parameters that contain “attention” and “lstm”. The 3 tasks generate their subnets individually, and the parameters of each task subnet are partially shared to promote positive transfer learning while mitigating potential over-parameterization issues. Furthermore, each task is equipped with its specific layer, i.e., a linear layer and CRF [
49] layer, to predict and validate the label’s correctness.
3.1. Sharing Layer
3.1.1. BERT Layer
The primary function of BERT is to map each word in the sentence to a contextual information vector dynamically based on the context, due to the polysemy problem of causality sentences in the text. Suppose the input sequence is denoted as
where
m is the number of words in the sentence. Following the BERT model, the output sequence is represented as
This mapping process involves taking into account various factors such as polysemy, the syntactic features of sentences, and so on. To reduce the number of parameters in the model, we prune the parameters containing “attention” in this layer.
3.1.2. BiLSTM Layer
At this layer, we prune the parameter containing “lstm”. For each input sequence of the BiLSTM module, both a forward and a backward LSTM need to encode it into hidden representations, and we concatenate the two directional hidden states to produce a complete sequence, which helps capture the positional information of each word within the sentence. From this, we obtain the output sequence of the forward LSTM hidden state,
as well as the output sequence of the backward LSTM,
These two vectors are combined to obtain the complete output sequence
h of the BiLSTM hidden state as follows:
where
t denotes the position of the word in the sentence,
m denotes the number of words in the sentence, and
n denotes the dimension of the vector.
3.2. Special Layer
3.2.1. Linear Layer
Following the BiLSTM layer, a linear layer is connected, which maps the hidden state vector
h, comprising
n dimensions, to
k dimensions. The linear layer facilitates the extraction of sentence features by employing a matrix, represented as
P, as illustrated in this formula:
where
k is the number of labels, depending on the specific task. For instance, the case of the CE task involves 5 distinct labels, including “B-Cause”, “I-Cause”, “B-Effect”, “I-Effect”, and “O”. The linear layer’s objective is to transform the hidden state vector of
n dimensions to a more compressed vector of
k dimensions, enabling the effective extraction of high-level features. By minimizing information loss during this process, the linear layer facilitates the representation of the sentence in a more informative and meaningful way, thereby improving the performance of all co-training tasks.
3.2.2. CRF
The Conditional Random Field module [
49] aims to tag the label for each word in a given sequence according to an overall maximum probability computation, which can be employed in copious sequence tagging tasks [
49]. For an input sentence
and target tagging sequence
, where
is the
i-th word of
X,
is the tag of
, and
n is the length of both the input and target sequences, we define the score of the whole tagging as follows:
where
compute the score of a given tagged sequence, and
is the emit matrix, which denotes the label vector generated from the BiLSTM layer, representing which label should be the current
map.
is the transfer matrix, storing the score of a transfer from one label to another; the higher the score, the more possible the transfer.
k is the number of labels, and
and
are the start and the end of the sentence. We compute the scores of the tagging result from two directions with the Softmax function to obtain the conditional probability:
where
denotes all possible label sequences. To decrease the cost of computation, we use its logarithm value as follows:
Finally, we can obtain the optimal predicted sequence tagging result through the maximum likelihood estimate (MLE). Then, the model can output a more reasonable labeled sequence with the CRF’s learning ability on dependency among labels, avoiding the unstable issue of tagging orders.
3.3. Sparse Sharing in MPC−CE
Inspaired by [
27], we adopt the sparse sharing strategy. The basic process of multi-task learning training based on a sparse sharing mechanism is as follows: Firstly, iterative magnitude pruning (IMP) is used to induce sparsity in the network, obtaining a subnet for each task. Then, multiple task subnets are trained in parallel, and during the training process, each task only updates the weights of its corresponding subnet. Closely related tasks tend to extract similar subnets, which can use similar weights, while loosely or unrelated tasks tend to extract different subnets. Ref. [
27] demonstrated that using sparse sharing can enable multiple natural language processing tasks to complement each other.
In the process of generating subnetworks for each task, we independently perform iterative pruning on each task to obtain the Mask matrix corresponding to each task, thus obtaining the subnetworks for each task; we choose the subnetwork that performs the best on the validation set [
27,
48], which means the best causal relation extraction results. The underlying network of the model, denoted as
, serves as the base network, with the corresponding model parameters represented by
. The masking matrix, denoted as
, assumes binary values of 0 or 1, where 0 signifies parameter masking and 1 signifies parameter reservation.
During the training process, we iteratively prune the parameters associated with “lstm” and “attention” for each of the three tasks. This allows us to obtain the
matrix specific to each task, as well as the
and
matrices for the base network. The parameters of the subnet corresponding to task
t are then obtained through element-wise multiplication of
and
, resulting in the subnet structure expressed as
To effectively reduce the parameter scale, we employ the iterative order of the magnitude pruning technique. This technique entails iteratively pruning the model parameters associated with “lstm” and “attention” during the training process. Specifically, we perform
n iterations of pruning, executing one pruning operation after each training epoch, and subsequently generating a subnet for the corresponding task. The pruning rate for each iteration is calculated using the following formula:
Here, p represents the pruning rate for each iteration, while signifies the percentage of parameters retained in the final model.
The IMP technique enables the pruning of weight values that fall below a predefined threshold. This process effectively reduces the number of parameters and computational requirements, while concurrently improving the efficiency of neural network training without compromising accuracy. By selectively pruning the network parameters, we obtain a compact representation of the network, facilitating the construction of subnets tailored to specific tasks. This, in turn, enables our model to learn in a more efficient and effective manner, while still maintaining a high level of accuracy on the tasks at hand.
4. Experiment
In this section, we will provide a detailed exposition of the dataset that we utilized for all our experimental evaluations, followed by a comprehensive account of the baseline models. Then, we shall furnish an exhaustive analysis of the results obtained from both the single-task and multi-task learning paradigms. We also conducted ablation studies to scrutinize the efficacy of our proposed methodology, wherein we performed a comprehensive assessment of the impact of individual components on the overall performance of the MPC−CE. Furthermore, we evaluate the CE performance fluctuations under different hyper-parameter settings and the same for co-training tasks. Specifically, we endeavor to address the following research inquiries:
- RQ1:
What is the significance of multi-task for the efficacy of different tasks?
- RQ2:
What is the significance of Pos and Chunk tasks for causal relation extraction?
- RQ3:
What influence does pruning have on the efficacy of different tasks?
- RQ4:
How do different hyper-parameters contribute to the efficacy of different tasks?
4.1. Datasets
As aforementioned, dataset domains affect the models’ final performance a lot. The SemEval-2010 Task 8 dataset [
9] is the most commonly used single-domain CE dataset, and considering the various types of causalities, we intend to combine the Event StoryLine v1.0 [
11] and Causal-TimeBank [
10] into a new CE dataset called MTL-CE, so as to imitate the cross-domain causality scenario. In order to meet the dataset requirements of multi-task learning, we employed the NLTK to annotate POS and chunk labels on all the CE datasets since it can achieve high accuracy on both POS tagging and Chunk. We evaluated our model on the SemEval-2010 Task 8 dataset and MTL-CE datasets. The training set, validation set, and test set were divided according to the ratio of 7:1.5:1.5.
SemEval-2010 Task 8 dataset. The SemEval-2010 Task8 [
9] dataset is used for the multi-way classification of mutually exclusive semantic relations between pairs of nominals, and consists of a total of 10,717 sample data points, and 8000 and 2717 samples for training and testing, respectively. It contains nine directional relations and one other relationship, such as Cause–Effect, and Message–Topic, in which the cause-and-effect entities are annotated, making it a popular dataset for CE. However, the majority of samples are general causal relations from a single source.
MTL-CE dataset. As previously stated, we merged two distinct datasets, namely Causal Timebank [
10] and Event StoryLine, into a newly created one to aggregate more causal data in this new dataset. Causal TimeBank is an annotated dataset on causal relations derived from the original Tempeval-3 TimeBank, whose causal relations are temporal causalities. The Event StoryLine v1.0 dataset [
11] comprises 566 data samples, most of which are causal relations from the news. Therefore, these two datasets are from distinct domains, which is quite suitable for constructing the cross-domain dataset. Finally, our self-made MTL-CE dataset consisted of 3482 data samples, with an equal number of causal and non-causal samples in a 1:1 ratio. The dataset’s statistics are presented in
Table 3.
4.2. Metrics
For the POS tagging task, since part-of-speech tagging aims to tag each word, it does not involve the word boundary problem, so the accuracy is used for evaluation. The accuracy metric (ACC) is a facile and perceptible evaluation technique that assesses the proportion of correct predictions generated by a model. It is straightforward to comprehend and furnishes a swift outline of the model’s performance.
As for Chunk and CE, the annotated boundary involves multiple words, the precision (P), recall (R), and F1 score (F1) were adopted for evaluation metrics. Precision represents the fraction of true positive predictions among all positive predictions, while recall denotes the proportion of true positive predictions among all actual positive instances. F1 serves as the harmonic mean of precision and recall, delivering a balance between the two metrics, and is especially valuable when tackling datasets with a skewed distribution of positive and negative examples.
4.3. Baselines
We investigated many CE models and compared the efficacy of MTL methods in our experiments. In particular, we considered the following baselines:
CNN+BiLSTM: Ref. [
50] presents this multi-task learning method that combines CNN and BiLSTM models to perform multiple NLP tasks simultaneously.
BERT+BiLSTM+MTL: Based on CNN+BiLSTM, we substitute the CNN module with BERT to perform multiple tasks.
BERT+BiLSTM+CRF+MTL: We add CRF after BERT+BiLSTM+MTL in-depth to make the model more complete.
We compare a range of STL-based and MTL-based methods for CE, so we can identify the most effective method for this task and provide insights for future research in this area.
4.4. Implementation
We conducted several experiments on the SemEval-2010 Task 8 and MTL-CE datasets with the following hyper-parameter settings: the iteration pruning rate was set to 10, the final parameter reserve rate was 0.2, the learning rate was 1 × 10−5 on the SemEval-2010 Task 8 and 5 × 10−5 on the MTL-CE, and Adam was chosen as the optimizer. For BiLSTM, we set its hidden size as 256, and the dropout rate was 0.5 to alleviate overfitting. The batch size was 32, the number of iterations was 50, and every epoch was evaluated with the validation set with each epoch carried out.
4.5. Multi-Task Learning Performance (RQ1)
To answer
RQ1, we first conducted experiments to explore the performance of the multi-task learning framework for different tasks. The results are presented in
Table 4 and
Table 5. In this experiment, we conducted 10 prunings to eliminate any redundant ‘lstm’ and ‘attention’ parameters for the MPC−CE. Subsequently, each pruning generates a subnet, and the three tasks select the subnetwork with the optimal performance on the test set as the subnetwork for multi-task training.
Overall, the proposed MPC−CE model achieved the best performance compared with the other multi-task based methods for casual relation extraction (CRE). It obtained the best F1 metrics on the SemEval-2010 Task 8 dataset and MTL-CE dataset. These results demonstrate the efficacy of MPC−CE in boosting the performance of the CRE task. In addition, MPC−CE performs on par with other baselines in POS tagging, while a little worse than other baselines in Chunk. We attribute this minor issue to the errors of NLTK-based chunk labels. In a comparison with the BERT+BiLSTM+CRF model, we can observe that MPC−CE outperforms BERT+BiLSTM+CRF (1.54% and 0.71%) for the CRE task on the SemEval-2010 Task 8 dataset and MTL-CE dataset, respectively. The results demonstrate that the sparse sharing mechanism introduced in our model can help the model improve the CRE performance. By effectively harnessing the benefits of parameter sharing, MPC−CE not only outshines various baseline methods in terms of training speed but also paves the way for streamlined and time-efficient model learning.
In order to verify multi-task learning compared with single-task learning, we also conducted experiments with single-task learning for these baselines aiming at CRE. The results are shown in
Table 6 and
Table 7. The performance improvements of multi-task learning compared to single-task learning are shown in
Table 4 and
Table 5. First, we can observe that BERT+BiLSTM+CRF has the best performance on the two datasets in the case of single-task learning. This observation demonstrates that the BERT+BiLSTM+CRF framework adapted by our model has advantages in the CRE task. Second, we also observed that our proposed model achieves the more significant precision metric, which demonstrates that our model can effectively reduce the possibility of misjudgment, proving the ability of multi-task learning from the perspective of denoising.
We also observed that CNN-based models perform much better on the MTL-CE dataset in terms of performance on the SemEval-2010 Task 8 dataset in the case of single-task learning. On the contrary, BERT-based models performed better on the SemEval-2010 Task 8 dataset. These results may be due to two reasons: (1) The MTL-CE dataset contains cross-domain information; studying cross-domain text semantics can promote the model’s capacity to distinguish various semantics, thus enhancing model performance. Additionally, we noticed that the enhancement in model performance is primarily mirrored in the recall metric, which could possibly be ascribed to the fact that cross-domain information can enhance the model’s fitting ability and further boost its recognition capability for real casual relations. (2) As a pre-trained language model, the BERT architecture exhibits a superior capacity to learn text semantics compared to the CNN approach, resulting in more sufficient performance on two datasets for BERT-based models. Nevertheless, the two variants of BERT-based models in the table demonstrate enhanced efficacy on the SemEval-2010 Task 8 dataset, a phenomenon that may be attributed to the cross-domain information present in the MTL-CE dataset, which induces a disparity in causal distribution between the training and testing sets. When deploying the intricate BERT model, the potential for overfitting emerges, wherein certain noisy data are misidentified as causal relationships, consequently decreasing the model performance for the CRE task.
Although our method did not achieve the best performance for POS and Chunk tasks, this is because our model framework is designed for CRE. For the task of CRE, our model achieves the best performance, which proves that our proposed multi-task framework is effective for the CRE task.
4.6. Task Analysis (RQ2)
To answer
RQ2, we conducted an ablation study to investigate the effect of the Pos and Chunk task for CRE. The results are shown in
Table 8 and
Table 9. It can be observed that the combined learning of two tasks resulted in a slight decrease in performance compared with the combination of three tasks, indicating the need to adopt a joint learning strategy for three tasks. Additionally, we discovered that the performance degradation of BERT-based models was more evident, indicating that the BERT model is more likely to benefit from multi-task learning for capturing semantic information. This is probably due to the multi-task learning technique we adopted leveraging sparse sharing to prune network parameters in the attention mechanism, resulting in a notable effect on the BERT model. The results also show that the CRE task achieves better performance when trained together with the Pos task, in contrast to the Chunk task, highlighting that the Pos task plays a more crucial role for improving the CRE performance. Such an observation could be attributed to the fact that the Pos task mainly focus on discerning the part of speech for a specific word, which provides essential support for the CRE task. Through classifying the parts of speech of words, the noise data can be dealt with at the word level for the CRE task. For example, some parts of speech cannot act as causal entities, the joint learning of Pos and CRE tasks can help the sequence tagging model correctly determine the parts of speech for causal entities, thus maximizing the utility of part-of-speech information to reduce the impact of unrelated words. In addition, we found that the Chunk task is based on the part-of-speech tagging task, which is more elaborate than the Pos task. Therefore, CRE and Chunk are two relatively sophisticated tasks; joint learning for these two tasks will increase the challenge of learning. Also, leveraging part-of-speech tagging outcomes as input in chunk analysis tasks might introduce some incorrect part-of-speech tagging results, consequently producing noisy data and restraining performance optimization during the joint training of Chunk and CRE tasks. Furthermore, we observe that the model exhibits a relatively robust performance on POS tasks with the training of different tasks combinations. This reliability can be ascribed to the elementary aspects of the Pos task, which are less prone to be influenced by noise data and complex semantic information, leading to a stable overall performance. The model’s performance on the Chunk task was also found to be more consistent compared to the CRE task. This might be because the CRE task demands a deeper understanding of textual semantics, thus being more exposed to the effects of noise data. These findings also suggest that multi-task learning is more fitting for the CRE task.
4.7. Ablation Performance (RQ3)
In this study, we introduced sparse sharing into multi-task learning, initially conducted parameter pruning for each task, and estimated the model performance. Then, we obtained the subnet of the sequence tagging model that offers the most optimal performance for multi-task learning. To evaluate the efficacy of the sparse sharing strategy for the CRE performance, we compare the model performance of pre-pruning and post-pruning during multi-task learning, the results of which are shown in
Table 10. These results reveal that the joint learning of the three tasks substantially enhances the model’s overall performance. Notably, the model exhibits a more substantial performance enhancement for the CRE task in comparison to the other two tasks, which demonstrates that the sparse sharing mechanism is more adaptive to the CRE task.
In addition, before the implementation of multi-task learning, the pruning rate that yields the best performance differs across the three tasks. It is crucial to highlight that the pruning rates for the Pos task on two datasets are larger than that for the Chunk task. This phenomenon could potentially be explained through the Pos task being more easily affected by excessive parameters, and the excessive parameters will cause the model to be overfitted due to the simplicity of the task. Our investigation also reveals that on the SemEval2010-Task 8 dataset, the pruning ratios associated with both POS and Chunk tasks are elevated in comparison to their respective rates on the MTL dataset. These results could potentially be ascribed to the incorporation of cross-domain information within the MTL-CE dataset. This dataset is characterized by the concurrent presence of words and sentences exhibiting notable semantic differences. Consequently, the model exhibits a diminished propensity for overfitting on these two tasks when utilizing the MTL dataset, thereby leading to a reduced pruning ratio. The performance accuracy of the CRE task across two datasets remains relatively similar, which is probably attributed to the necessity for the model to capture more profound contextual semantics in causal extraction and to be more easily influenced by the noise data problem. Consequently, even in the MTL datasets encompassing specific cross-domain information, the incidence of overfitting issues remains notably prevalent.
Our findings also suggest that the performance of the model before pruning is worse than that of the model without pruning for single-task learning. This observation could be elucidated by the fact that the model deploys a more substantial number of parameters to comprehensively capture text semantics in the case of single-task learning, which contains more useful parameters than the model with parameter pruning. However, pruning is essential for the CRE task in the scenarios of multi-task learning, which is probably due to the settings for multi-task learning and the neglect of pruning for each task’s redundant parameters, thereby causing mutual interference among different parameters. These results indicate that both pruning and multi-task learning can effectively improve the performance of the model in causal relationship extraction tasks. Moreover, the observation of distinct metrics demonstrates that the model’s performance improvements for the precision metric are more significant after multi-task learning for three tasks, implying that multi-task learning can capably eliminate noisy data and reduce the model’s misjudgment for positive samples during the process of causal extraction. However, multi-task learning may simultaneously remove some useful information, leading to the misidentification of certain positive samples as negative, so that the advancement in the recall metric is not as remarkable as that in the precision metric.
4.8. Parameter Analysis (RQ4)
To answer RQ4, we conducted experiments to evaluate the effectiveness of our model with different types of parameters, including the number of iterative prunings and epochs.
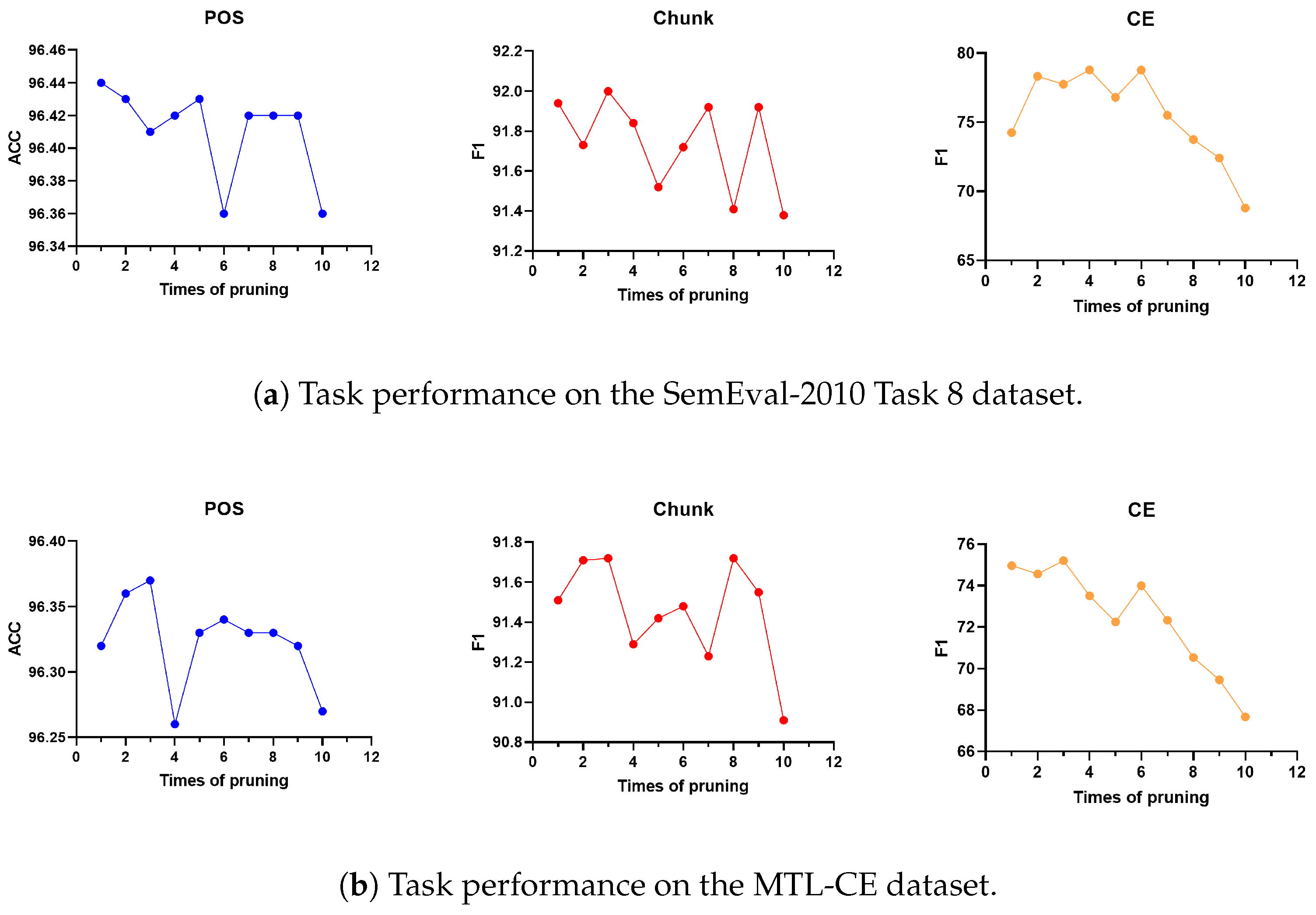
Effect of the number of iterative prunings. Before implementing multi-task learning, we generate several subnets for each task using parameter pruning, followed by the selection of an optimal number of iterative prunings for multi-task training. In an effort to understand the effect of the number of iterative prunings on the model efficacy for different tasks, we conducted an experiment to explore the relation between the number of iterative prunings and the model’s performance on two datasets; the results are shown in
Figure 2. From the results, we can observe the following: (1) On the SemEval-2010 Task 8 dataset, our model achieved the best performance for POS, Chunk, and CRE tasks when the number of iterative prunings was set as 1, 3, and 4 respectively. (2) On the MTL-CE dataset, our model achieved the best performance for POS, Chunk, and CRE tasks when the numbers of iterative prunings were the same as before. The experimental findings indicate that an additional number of iterations might be needed for extensive cross-domain information, thus enhancing the learning of parameters that require pruning.
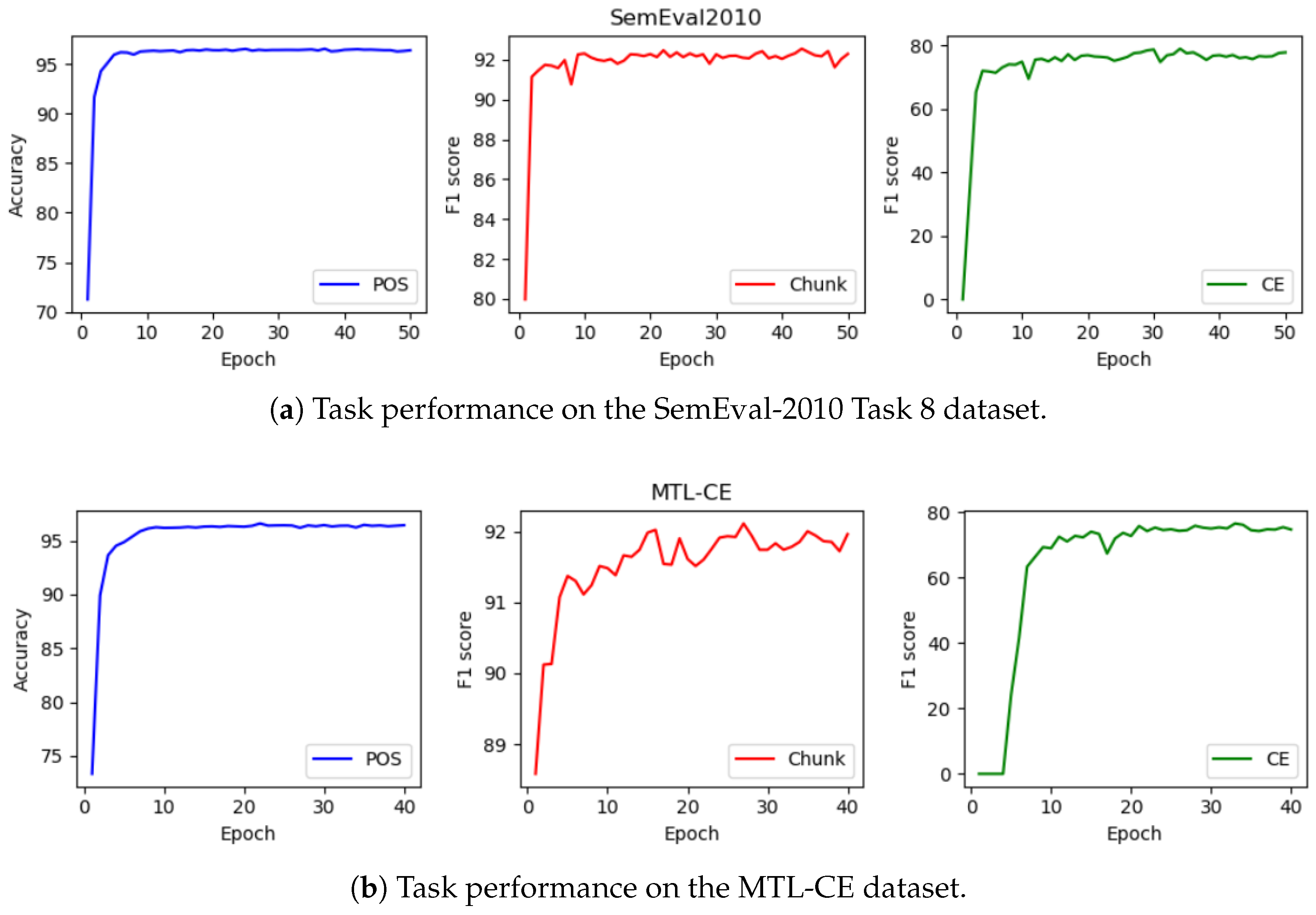
Effect of the number of epochs. We conducted experiments to analyze the convergence for three distinct tasks.
Figure 3 illustrates the performance trend changes with increasing epochs. Firstly, the observations reveal that both the Chunk and CRE tasks converge at approximately 20 epochs on the SemEval-2010 Task 8 dataset, whereas they converge at around 30 epochs on the MTL-CE dataset. In contrast, the Pos task converges in less than 10 epochs on the SemEval-2010 Task 8 dataset, and at bout 10 epochs on the MTL-CE dataset. These findings indicate that all three tasks converge more rapidly on the SemEval-2010 Task 8 dataset compared to the MTL-CE dataset. This difference in convergence rates is probably attributed to the MTL-CE dataset containing more cross-domain information, making the text semantics in this dataset more conpelex; thus, additional epochs for the model are needed to capture the semantic information. Secondly, the convergence trend of the Chunk and CRE tasks exhibits greater variability compared to the Pos task. This trend is possibly due to the Chunk and CRE tasks requiring more stringent demands on semantic analysis, making them more sensitive to the interferences induced by the noisy data.
Analysis of the NLTK. MPC−CE performs on par with other baselines in POS tagging, while a little worse than other baselines in Chunk. We employed the complete NLTK for the CE task and compared it with other baselines; the results are displayed in
Table 11. Given the results of the NLTK and other baselines, we attribute this minor issue to the errors of NLTK-based chunk labels. Note that MPC−CE achieves a lower performance than the NLTK to a limited margin, which illustrates that MPC−CE can perform better if it can be provided with golden labels.



{kind=link}
{kind=link}
{kind=link}