1. Introduction
In this paper, we mainly consider the following saddle-point problem:
where
is a convex and lower semi-continuous (l.s.c.) function that is a finite average of
n convex, smooth and l.s.c. functions
,
,
d is the dimension of the feature,
is the Fenchel conjugate of a convex (but possibly non-smooth) function
, and
is a nonempty closed and convex set. Such a problem is to find a trade-off between minimizing the objective function for primal variable
x and maximizing it for the dual variable
y. Many modern machine learning problems can be formulated as such a problem, such as total variation denoising [
1,
2,
3],
-norm regularization problems [
4], and image reconstruction [
5].
The saddle-point problem mentioned above can be solved equivalently by its primal problem. According to the definition of the conjugate function
, its primal problem can be written as
, which often appears in the machine learning community, such as graph Lasso (i.e.,
) and low-rank matrix recovery (i.e.,
, where
is the nuclear norm of a matrix). By introducing an auxiliary variable
, the primal problem can be formulated an equality-constrained problem. Alternating direction methods of multipliers (ADMMs) [
6,
7,
8,
9] are common algorithms for solving such an equality-constrained problem and have shown excellent advantages. For example, for solving large-scale equality-constrained problems (
n is very large), Online and Stochastic Alternating Direction Methods of Multipliers (OADMM [
8] and SADMM [
10]) have been proposed, though they only have suboptimal convergence rates. Thus, some acceleration techniques such as those in works [
11,
12,
13,
14,
15,
16] have been developed to successfully address the obstacle of the high variance of stochastic gradient estimators. Among them, the stochastic variance reduced gradient (SVRG) methods such as those in the works [
16,
17] can obtain a linear convergence rate for strongly convex (SC) problems. Katyusha [
18], MIG [
16], and ASVRG [
19] have further improved the convergence rates for non-strongly convex (non-SC) problems by designing different momentum tricks. Recently, some researchers have introduced these techniques into SADMM and proposed some stochastic variants with faster convergence rates. SAG-ADMM [
20] can attain linear convergence for SC problems, but it requires
to store the past gradients. Similarly, SDCA-ADMM [
21] inherits the drawbacks of SDCA [
22], which calls for
extra storage. In contrast, stochastic variance reduced gradient ADMM (SVRG-ADMM) [
23] does not require extra storage while ensuring linear convergence for SC problems and
convergence rate for non-SC problems. And ASVRG-ADMM [
24] further achieves the convergence rate of
for non-SC problems. However, as indirect methods for solving saddle-point problems, ADMM-type methods usually require that the proximal mapping of regular function
G is easily computed, and need to update at least three vector variables in each iteration. Thus, when
G is complex [
25] or when solving large-scale structural regularization problems, ADMM-type methods may not be the first choice, and the primal–dual algorithms [
4,
26] are more efficient.
As another effective tool, the primal–dual algorithms are prevalent in solving the saddle-point problem directly, such as Stochastic Primal–Dual Coordinate (SPDC) [
26,
27,
28,
29] and primal–dual hybrid gradient (PDHG) [
25,
30,
31,
32,
33]. Indeed, these methods alternate between maximizing the dual variable
y and minimizing the primal variable
x. Thus, these primal–dual algorithms update at least one less vector variable than ADMMs for solving the saddle-point problem, resulting in a lower per-iteration complexity. Due to such properties, primal–dual algorithms have been widely used in various machine learning applications [
34,
35,
36,
37,
38,
39].
Many SPDC algorithms have obtained excellent performance when
d is very large. The work [
26] proposed the SPDC method with a linear convergence rate when the loss function is smooth and SC. In order to further reduce its per-iteration complexity, the work [
27] proposed a stochastic primal–dual method, called SPD1, with
per-iteration complexity as opposed to
. By incorporating the variance reduction technique [
13], SPD1-VR obtains linear convergence for SC problems. More generally, for empirical composition optimization problems, SVRPDA-I and SVRPDA-II in the work [
28] both achieve linear convergence under the condition of smooth component functions and the SC regularization term.
In contrast, when
n is very large, the stochastic PDHG methods as an alternative become more competitive for solving the saddle-point problem. For solving such a large-scale optimization problem, the deterministic PDHG algorithm [
25] incurs the extremely expensive iteration cost (i.e.,
), and thus its stochastic version (SPDHG) [
4] was developed. SPDHG only selects one sample for updating the primal variable at each iteration, which has accomplished the best possible one regarding the sample complexity. However, SPDHG can only obtain the convergence rates of
and
for the SC and non-SC problems (
1), respectively. Another work [
40] proposed a stochastic accelerated primal–dual (APD) algorithm for solving bilinear saddle-point problems in the online setting, which achieves the convergence rate of
and matches the lower bound based on the primal–dual gap, i.e.,
for the point
. The works [
41,
42] further focused on the finite-sum setting and analyzed primal–dual algorithms for solving the non-smooth case. For example, Song et al. [
42] considered the non-smooth saddle-point problem by using the convex conjugate of the data fidelity term, but it is limited to solving the primal problem with simple regular functions. On the contrary, our algorithms can solve more general structural regularity problems. Thus, their algorithms are orthogonal to our methods. Recently, several faster versions of stochastic primal–dual methods have been proposed. The work [
43] can achieve a linear convergence rate for the problem with strong convexity of
instead of
F. The algorithms proposed by [
44] further achieved the complexity matching the lower bound when
F and
are both SC. However, the non-SC setting is not taken into consideration by these two works. To bridge this gap, Zhao et al. [
45] proposed a restart scheme, which focuses on the general convex–concave saddle-point problems rather than just the bilinear structure but they focused on solving the more general saddle-point problem. Very recently, SVRG-PDFP [
46] integrated the variance reduction technique and the primal–dual fixed point method to solve the graph-guide logistic regression model and CT image reconstruction, and achieved an
convergence rate for non-SC finite-sum problems. But there remains a gap in the convergence rates between it and the lower bound
[
47]. Thus, it is essential to take advantage of the relative simplicity of primal–dual methods to design faster algorithms for solving the finite-sum problem (
1).
1.1. Our Motivations
In this paper, we focus on the large sample regime (i.e., n is large). To solve the large-scale saddle-point problem more effectively, we mainly consider the following factors:
Computational cost per iteration: Although stochastic ADMMs can be used to solve the large-scale saddle-point problem, their per-iteration cost is still high. That is, the stochastic ADMMs usually use positive semi-definite matrix Q and update at least three variables per iteration, which increases the computational cost.
Theoretical properties: SPDHG only employs a decaying step size to reduce the variance of the stochastic gradient estimator, which leads to a suboptimal convergence rate. Thus, there still exists a gap in the convergence rate between SPDHG and state-of-the-art stochastic methods. Recently, SVRG-PDFP has improved the convergence rate from to for non-SC objectives, which only closes this gap in some sense.
Applications: SVRG-PDFP requires both F and to be SC functions in order to obtain a linear convergence rate, which limits its application. SPDC can also reduce the number of updated variables and achieve a linear convergence rate for SC problems as mentioned above. However, these proposals require that regularized functions must be SC. For common regularized problems (e.g., -norm regularization), such a condition is not satisfied.
These facts motivate us to design a more efficient primal–dual algorithm for solving the large-scale saddle-point problem (
1).
1.2. Our Contributions
We address the above tricky issues by proposing efficient stochastic variance reduced primal–dual hybrid gradient methods, which have the following advantages:
Accelerated primal–dual algorithms: We propose novel primal–dual hybrid gradient methods (SVR-PDHG and ASVR-PDHG) to solve SC and non-SC objectives by integrating variance reduction and acceleration techniques. In our ASVR-PDHG algorithm, we design a new momentum acceleration step and a linear extrapolation step to further improve our theoretical and practical convergence speeds.
Better convergence rates: For non-SC problems, we rigorously prove that SVR-PDHG achieves the convergence rate and ASVR-PDHG attains the convergence rate based on the convergence criterion . Moreover, our algorithms enjoy linear convergence rates for SC problems. As by-products, we also analyze their gradient complexity results.
Lower computation cost: Our SVR-PDHG and ASVR-PDHG have simpler structures than SVRG-ADMM and ASVRG-ADMM, respectively. Our algorithms update one less vector variable than stochastic ADMMs, which reduces the per-iteration cost. That is why our algorithms perform better than them in practice.
More general applications: Our algorithms require fewer assumptions, which significantly extends the applicability of our algorithms. Firstly, the boundedness assumptions (i.e., assume
and
, where
and
are the convex compact sets with diameters
and
) are removed. Secondly, unlike SVRPDA [
28], our algorithms are also applicable for non-SC regularization (e.g.,
-regularization). Thirdly, our algorithms only require the strong convexity of
F to achieve a linear convergence rate for SC problems, while SVRG-PDFP and LPD [
44] algorithms call for the strong convexity of
.
Asynchronous Parallel Algorithms: We extend our SVR-PDHG and ASVR-PDHG algorithms to the asynchronous parallel setting. To the best of our knowledge, this is the first asynchronous parallel primal–dual algorithm. Our experiments show that the speedup of our SVR-PDHG and ASVR-PDHG is proportional to the number of threads.
Superior empirical behavior: We conduct various experiments for solving non-SC graph-guided fused Lasso problems, SC graph-guided logistic regression, and multi-task learning problems in the machine learning community. Compared with SPDHG, our algorithms achieve much better performance for both SC and non-SC problems. Due to the low per-iteration cost and acceleration techniques, to speedup can be obtained by our ASVR-PDHG compared with SVRG-PDFP, SVRG-ADMM, and ASVRG-ADMM.
3. Our Stochastic Primal–Dual Hybrid Gradient Algorithms
In this section, we integrate variance reduction and momentum acceleration techniques into SPDHG and propose two stochastic variance reduced primal–dual hybrid gradient methods, called SVR-PDHG and ASVR-PDHG, where we design key linear extrapolation and momentum acceleration steps to improve the convergence rate. Moreover, we design asynchronous parallel versions for the proposed algorithms to further accelerate solving non-SC problems.
3.1. Our SVR-PDHG Algorithm
We first propose a stochastic variance reduced primal–dual hybrid gradient (SVR-PDHG) method for solving SC and non-SC objectives as shown in Algorithms 1 and 2. Our algorithms are divided into
S epochs, and each epoch includes
T updates, where
T is usually set to
as in the works [
13,
23,
24]. More specifically, SVR-PDHG mainly includes the following three steps:
▸
Update Dual Variable. We specially design a term
to ensure the next iterate close to the current iterate
. Specifically, the first-order surrogate function of the dual variable
y is defined as follows:
where
is updated by a linear extrapolation step in (
8) below.
is a conjugate function of
, which is usually easy to solve. For example, for graph-guided fused Lasso problems,
.
▸
Update Primal Variable. Analogous to the sub-problem of
y, we also add
to the sub-problem of
x. Thus,
is updated as follows:
where
is the variance reduced gradient estimator (
4). Note that a constant step size
is used instead of just decaying the step size as in the work [
4].
▸
Linear Extrapolation Step. In order to further improve the theoretical convergence rate, we design the key update rule of
as follows:
where
. When we choose
, there will be an extra inner product term in our proofs, which results in the convergence rate
within a certain error range like the Arrow–Hurwicz method [
25]. While we choose
, this linear extrapolation step can eliminate the extra inner product term, which ensures the
convergence rate for non-SC problems.
| Algorithm 1 SVR-PDHG for SC Objectives. |
- Input:
T, , , , . - Initialize:
, .
- 1:
for
do - 2:
, ; ; - 3:
for do - 4:
Choose of size b, uniformly at random; - 5:
; - 6:
; - 7:
; ; - 8:
end for - 9:
, ; - 10:
end for
- Output:
, .
|
| Algorithm 2 SVR-PDHG for non-SC objectives. |
- Input:
T, , , , . - Initialize:
, .
- 1:
for
do - 2:
, , ; - 3:
for do - 4:
Choose of size b, uniformly at random; - 5:
; - 6:
; - 7:
;; - 8:
end for - 9:
, ; - 10:
end for
- Output:
, .
|
The other detailed update rules of our SVR-PDHG algorithms for SC and non-SC objectives are outlined in Algorithms 1 and 2, respectively (note that the outputs of our algorithms are all denoted by and ). The main differences of SVR-PDHG for solving SC and non-SC problems are listed as follows. The initial dual variable at each epoch is set to , which contributes to attaining a linear convergence rate for SC objectives. For comparison, the initial variables in non-SC problems are set to and . Furthermore, the outputs of SVR-PDHG for SC problems are and in a non-ergodic sense (note that a convergence rate is ergodic if it measures the optimality at (, ), while the convergence rate of an algorithm is non-ergodic if it considers the optimality at the point (,) directly), and by contrast, the outputs of SVR-PDHG for non-SC problems are and .
3.2. Our ASVR-PDHG Algorithm
In this part, we design an accelerated stochastic variance reduced primal–dual hybrid gradient (ASVR-PDHG) method for solving SC and non-SC problems as shown in Algorithms 3 and 4, respectively. In particular, to eliminate the boundedness assumption for the non-SC case, we design a new adaptive epoch length strategy. More specifically, ASVR-PDHG mainly includes three steps:
▸
Update Dual Variable. The optimization sub-problem of
y has a similar term,
, to ensure the next iterate close to the current iterate
. Different from existing works, the quadratic term is preceded by an acceleration factor
(when solving SC problems,
for all
s). Thus, our first-order surrogate function becomes
where
is updated by a linear extrapolation step in (
12) below.
▸Update Primal Variable. We introduce an auxiliary variable to accelerate the primal variable, which mainly includes the following two steps.
Gradient descent: We first update
with
. In particular,
is obtained by solving the following sub-problem with a step size
,
Momentum acceleration: We design a momentum acceleration step to accelerate our algorithms by using the snapshot point of the previous epoch, i.e.,
. In particular,
where
is a momentum parameter. For non-SC objectives, it can be seen from the outer loop that
is monotonically decreasing and satisfies the condition
for all
s, where
b is the size of the mini-batch, and
.
▸
Linear Extrapolation Step. We also design a key linear extrapolation step for
in Algorithms 3 and 4. This step can also eliminate an extra inner product term by setting
, which is also a reason to ensure an
convergence rate of our ASVR-PDHG algorithm for solving non-SC problems. Specifically,
is updated by
| Algorithm 3 ASVR-PDHG for SC objectives. |
- Input:
T, , , , . - Initialize:
, , .
- 1:
for
do - 2:
, , , ; - 3:
for do - 4:
Choose of size b, uniformly at random; - 5:
; - 6:
; - 7:
; - 8:
; ; - 9:
end for - 10:
, ; - 11:
end for
- Output:
, .
|
| Algorithm 4 ASVR-PDHG for non-SC objectives. |
- Input:
, , , . - Initialize:
, , , .
- 1:
for
do - 2:
, , , ; - 3:
for do - 4:
Choose of size b, uniformly at random; - 5:
; - 6:
; - 7:
; - 8:
; ; - 9:
end for - 10:
, ; - 11:
, ; - 12:
end for
- Output:
, .
|
Moreover, we set (for SC problems, , for all s) to further accelerate our algorithms, where is the number of inner loops at the s-th outer-loop. The key differences between ASVR-PDHG for SC and non-SC problems are as follows.
ASVR-PDHG for SC problems: The initial dual variable at each epoch is set to , which contribute to attaining a linear convergence for SC objectives. The momentum parameter and the length of inner-loop are set to the constants and T, respectively.
ASVR-PDHG for non-SC problems: The initial variables are set to
and
. Following ASVRG-ADMM [
24], the sequence
is monotonically decreasing, satisfying
. Different from ASVRG-ADMM, a new adaptive strategy for the epoch length
is designed as follows:
with an initial
, which is the reason to eliminate the boundedness assumption. Since
is decreasing, the coefficient of
is greater than 1 and decreases gradually, while a constant 2 is used in SVRG++ [
49].
3.3. Our Asynchronous Parallel Algorithms
In this subsection, we extend our SVR-PDHG and ASVR-PDHG algorithms to the sparse and asynchronous parallel setting to further accelerate the convergence speed for large-scale sparse and high-dimensional non-SC problems. To the best of our knowledge, this is the first asynchronous parallel stochastic primal–dual algorithm. Our parallel ASVR-PDHG algorithm is shown in Algorithm 5 and the parallel SVR-PDHG algorithm is shown in Algorithm A1 in the
Appendix A. Specifically, we consider
and batch size
to facilitate parallelism. Taking Algorithm 5 as an example, there are three main differences compared with Algorithm 4.
| Algorithm 5 ASVR-PDHG for non-SC objectives in sparse and asynchronous parallel setting. |
- Input:
, , , . - Initialize:
, , , , p threads.
- 1:
for
do - 2:
Read current value of from the shared memory and all threads parallelly compute the full gradient , , , ; - 3:
; //inner loop counter - 4:
while in parallel do - 5:
; //atomic increase counter - 6:
Choose uniformly at random from ; - 7:
support of sample ; - 8:
Inconsistent read of ; - 9:
; - 10:
; - 11:
; - 12:
; - 13:
; - 14:
end while - 15:
, ; - 16:
, ; - 17:
end for
- Output:
, .
|
▸ The full gradient in Algorithm 5 is computed in parallel, while the full gradient in Algorithm 4 is computed serially.
▸ We adopt a sparse approximation technique [
50] to decrease the chances of conflicts between multiple cores, which makes the SVRG estimator (
4) change as follows:
where
is used to construct sparse iterates. The choice of
needs to ensure
. Under such a condition, the sparse approximated estimator (
14) is still an unbiased estimator of
.
▸ The proposed asynchronous parallel algorithm just updates the coordinates of variables, i.e., the support set of chosen random samples, rather than the entire dense vector; see lines 9–10 of Algorithm 5. As long as these dimensions are different, Algorithm 5 can effectively avoid write conflicts. Thus, our parallel ASVR-PDHG can take advantage of the power of multi-core processor architectures and further accelerate Algorithm 4 on sparse datasets.
4. Theoretical Analysis
This section provides the convergence analysis for SVR-PDHG and ASVR-PDHG (i.e., Algorithms 1–4) in SC and non-SC cases, respectively. We first introduce the convergence criterion and then give the key technical results (i.e., Lemmas 1 and 2) for SVR-PDHG and ASVR-PDHG, respectively. Finally, we prove the convergence rate of our algorithms as shown by the following Theorems 1–4.
4.1. Convergence Criterion
In Problem (
1),
is convex for each
and
is concave for each
. Under such conditions, Sion et al. [
51] proved that
. In other words, there exists at least one saddle point
such that
That is,
. Therefore, this setting will contribute to establishing the convergence criterion for our algorithms. Following the work [
4], we first introduce the function
as a convergence criterion. As an illustration, the criterion function
has the following properties.
Property 1. For , if contains a saddle point , then and it vanishes only if is itself a saddle point.
Property 2. According to the definition of , for and , the following inequality holds: .
There are commonly other convergence criteria such as the primal–dual gap, i.e.,
for point
. For example, Chen et al. [
40] used the primal–dual gap as the measurement and achieved the complexity matching the lower bound for solving online bilinear saddle-point problems. Zhao et al. [
41] proposed the OTPDHG algorithm, which still uses the primal–dual gap as the measurement, and achieved the optimal convergence rate for online bilinear saddle-point problems even when
A is unknown a priori. Zhao et al. [
45] further considered the beyond-bilinear setting. Based on the primal–dual gap, they still obtained the optimal convergence rate of online saddle-point problems. It is worth noting that the works mentioned above focus on the online setting, while we focus on analyzing the finite-sum setting. The lower bound for the online setting is usually higher than the lower bound for the finite-sum setting such as [
52,
53]. Although Song et al. [
42] also analyzed the convergence results based on the primal–dual gap in the finite-sum setting, they focused on solving non-smooth problems, while our algorithms focus on improving the convergence rates for solving smooth problems. Thus, these analyses are orthogonal to ours. Thekumparampil et al. [
44] considered the finite-sum setting, but their convergence rates are based on
and require SC
. In this paper, we prove faster convergence rates based on
in the non-SC finite-sum setting.
By the convergence criterion
, we analyze our SVR-PDHG and ASVR-PDHG algorithms in the next two subsections. The detailed proofs of all the theoretical results are provided in the
Appendix A. Here, we give a simple proof sketch: Our main proofs start from one-epoch analysis, i.e., Lemmas 1 and 2 below. Then, in
Section 4.2, we prove the convergence results of SVR-PDHG by Theorems 1 and 2, which rely on the one-epoch inequality in Lemma 1, and the gradient complexity results are also given as a by-product. In
Section 4.3, we prove the convergence rate and gradient complexity results of our ASVR-PDHG by Theorems 3 and 4, which depend on the one-epoch upper bound in Lemma 2.
4.2. Convergence Analysis of SVR-PDHG
This subsection provides the convergence analysis for SVR-PDHG (i.e., Algorithms 1 and 2). Lemma 1 provides a one-epoch analysis for SVR-PDHG.
Key technical challenges for SVR-PDHG. Line 5 in our SVR-PDHG algorithm eases the computational burden but simultaneously increases the difficulty of convergence analysis due to introducing a tricky inner product term in the bound in terms of y. To address this challenge, we use the linear extrapolation step and propose to establish the upper bound on in terms of and to eliminate this inner product term in Lemma 1.
Lemma 1 (One-Epoch Analysis for SVR-PDHG).
Suppose Assumption 1 holds. Consider the sequence generated by Algorithms 1 or 2 in one epoch, and as an optimal solution of Problem (1). If and , then the following inequality holds for all :where , γ satisfies that , and . Lemma 1 provides the upper bound of ’s expectation in one epoch of our SVR-PDHG. Based on this lemma, we are now ready to combine the analysis across epochs, and derive our final Theorems 1 and 2 for SC and non-SC objectives, respectively. Lemma 1 also inspires us to analyze ASVR-PDHG.
Theorem 1 (SVR-PDHG for SC Objectives).
Let be the output of Algorithm 1. Suppose Assumptions 1–3 hold and A has full row rank. If and , and we set such that holds strictly, thenIn other words, choosing , the gradient complexity of SVR-PDHG to achieve an ϵ-additive error (i.e., ) is .
Theorem 1 shows that SVR-PDHG obtains a linear convergence rate for SC objectives. Unlike SVRG-PDFP, SVR-PDHG does not require the strong convexity of
. Our SVR-PDHG algorithm achieves the same coefficient
as in the inexact Uzawa method [
48] for solving SC objectives.
Theorem 2 (SVR-PDHG for Non-SC Objective).
Suppose Assumptions 1 and 3 hold, and let be the output of Algorithm 2. If and , then we havewhere and . That is, if an output satisfies , the gradient complexity of SVR-PDHG is . From Theorem 2, it can be found that it removes the boundedness assumption in SPDHG and only depends on the constants and , and SVR-PDHG achieves the convergence rate for non-SC objectives. In addition, SVR-PDHG has simpler iteration rules than SVRG-ADMM. Thus, despite the consistent convergence rate of SVR-PDHG and SVRG-ADMM, the former is faster in practice.
4.3. Convergence Analysis of ASVR-PDHG
This subsection provides the convergence analysis for ASVR-PDHG (i.e., Algorithms 3 and 4). Similarly, we first provide a one-epoch upper bound for our ASVR-PDHG.
Key technical challenges for ASVR-PDHG. In addition to the same technical challenges in the analysis of SVR-PDHG, the momentum acceleration step further increases the difficulty of analyzing faster convergence rates for our ASVR-PDHG. Clarifying the behavior of momentum acceleration is a key step. To address this challenge, we use the improved variance upper bound [
24], and design
to help to clarify the behavior of momentum acceleration steps while bounding a new and tricky inner product term
in Lemma 2. Fixed
T also hinders achieving the convergence rate of
and makes the convergence rate result still dependent on the boundedness assumption, thereby hindering extending the applicability of our algorithms. Our new adaptive strategy for the epoch length
can address these issues.
Lemma 2 (One-Epoch Analysis for ASVR-PDHG).
The sequence is generated by Algorithm 3 or 4 with Assumption 1 holding, and denote an optimal solution of Problem (1). If and , then the following inequality holds for all s,where , , and γ satisfies that . From Lemma 2, we can obtain the relationship between two consecutive epochs for our ASVR-PDHG algorithm. Based on this, we provide the convergence properties of ASVR-PDHG for both SC and non-SC objectives.
Theorem 3 (ASVR-PDHG for SC Objectives).
Suppose Assumptions 1–3 hold, A has a full row rank, and . Let be the output generated by Algorithm 3, and . If we set and and choose such that , we obtainAnalogous to SVR-PDHG, choosing , the gradient complexity of ASVR-PDHG to achieve an ϵ-additive error (i.e., ) is also .
Theorem 3 indicates that ASVR-PDHG achieves a linear convergence rate for SC objectives. Note that is more concise than , and ASVR-PDHG actually converges faster than SVR-PDHG for SC problems as shown in our experiments, which implies the superiority of momentum acceleration.
Theorem 4 (ASVR-PDHG for Non-SC Objectives).
Suppose Assumptions 1 and 3 hold and be the output of Algorithm 4. If we set , , and , ASVR-PDHG has the following convergence result for non-SC objectives:where , . That is, if an output satisfies , the gradient complexity of ASVR-PDHG is . In light of Theorem 4, ASVR-PDHG achieves an convergence rate with and . Note that ASVR-PDHG removes the extra boundedness assumption in SPDHG and only depends on the constants and . That is, ASVR-PDHG improves the convergence rate of variance reduction algorithms (e.g., SVRG-ADMM, SVRG-PDFP, and SVR-PDHG) from to by an adaptive epoch length strategy, linear extrapolation step, and the momentum acceleration technology.
Remark 1. In order to further highlight the advantages of our algorithms, we compare their gradient complexity with those of other algorithms. When solving non-SC problems, the gradient complexity of SPDHG [4] is only , which is analogous to those of SGD [54] and SADMM [10]. Although SVR-PDHG has the same gradient complexity (i.e., ) as SVRG-ADMM, SVR-PDHG has better practical performance. Theorem 4 implies that our ASVR-PDHG can effectively reduce gradient complexity and does not require additional assumptions. We summarize the gradient complexity of some stochastic primal–dual methods and stochastic ADMMs for non-SC problems as shown in Table 1. Note that we use the notation to hide , , and other constants. 5. Experimental Results
This section evaluates the performance of our SVR-PDHG and ASVR-PDHG methods, and several state-of-the-art algorithms for solving non-SC graph-guided fused Lasso problems, SC graph-guided logistic regression, and non-SC multi-task learning problems. Our source codes are available at
https://github.com/Weixin-An/ASVR-PDHG, accessed on 10 November 2021. The compared algorithms include SPDHG [
55], SVRG-PDFP [
46], SVRG-ADMM [
23] and ASVRG-ADMM [
24]. To alleviate statistical variability, the experiment in each case is carried out repeatedly 10 times, and shadow figures are plotted. The shadow represents the standard deviation, and the solid line in the middle represents the mean value. All the experiments are carried out on Intel Core i7-7700 3.6GHz CPU (Intel Corporation, Santa Clara, CA, USA) and 32GB RAM.
Hyper-parameter Selection. Based on the small-scale synthetic dataset mentioned in
Section 5.1, we perform hyper-parameter selection. We use the grid search method to choose relatively good step sizes
for our algorithms in all the cases unless otherwise specified. We choose
in all experiments due to the same setting in our theoretical analysis. We choose
for our SVR-PDHG solving both SC and non-SC problems, where
is the number of training samples. For ASVR-PDHG solving SC problems, we choose the common momentum parameter
and choose the same number of inner loops
. For ASVR-PDHG solving non-SC problems, we choose the initial value of the momentum parameter
and apply the adaptive strategy for the epoch length
during the first 10 epochs. As for the compared algorithms, we choose the same hyper-parameters as in the work [
56] for ASVRG-ADMM, we tune the parameters as in the work [
20] for SVRG-ADMM, and we also adopt the grid search method and choose the optimal step sizes
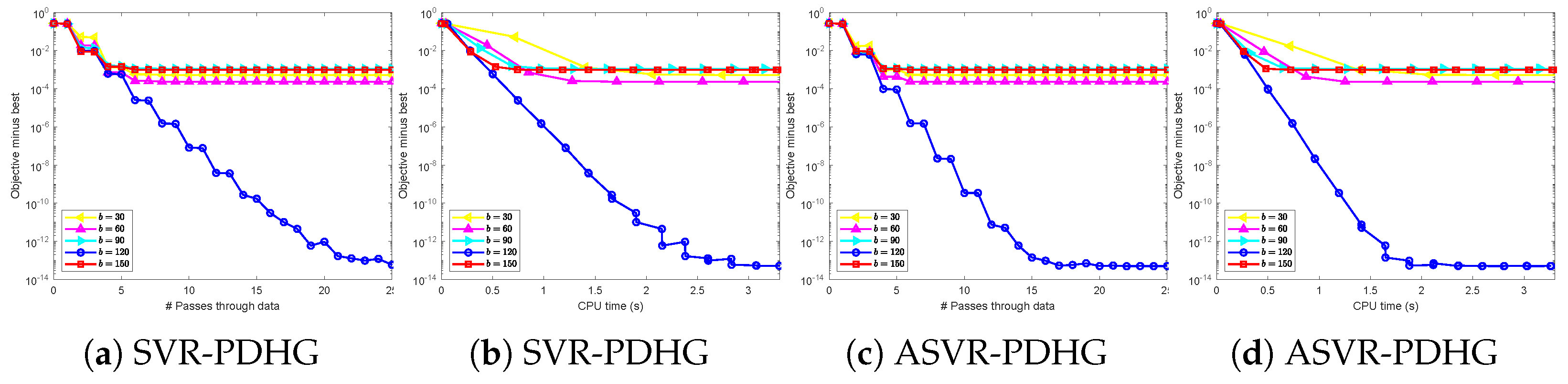
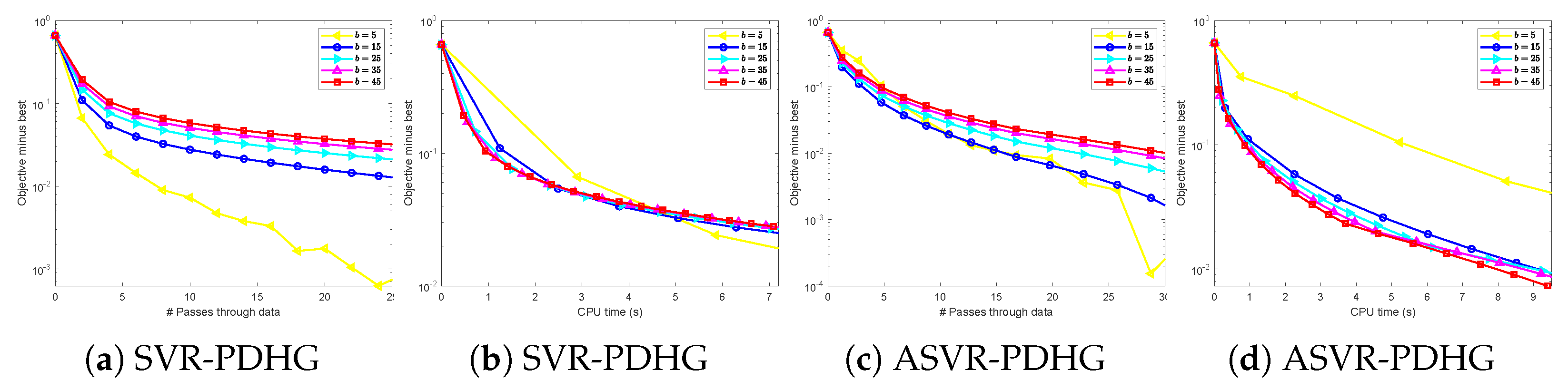
for SVRG-PDFP. About mini-batch sizes, we choose them guided by theory and considering the trade-off between time consumption and reasonably good performance. Specifically, we test the performance of our algorithms under different mini-batch sizes, and the results are shown in
Figure A1 and
Figure A2 in
Appendix B. According to
Figure A1 and
Figure A2, considering the trade-off between time cost and loss, we determine the mini-batch sizes
for SC problems and
for non-SC problems.
We first solve the following non-SC graph-guided fused Lasso problem and SC graph-guided logistic regression problem in
Section 5.1,
Section 5.2,
Section 5.3 and
Section 5.4:
where each
is the logistic loss on the feature–label pair
,
and
are two regularization parameters. And here, we set
A as described in the work [
57]. The
-norm regularized minimization can be converted into Problem (
1) by setting
, where
is the maximum norm of a vector. Thus, Problem (
22) can be converted into the following saddle-point problems, respectively:
Here, the conjugate function
. Then, we consider the general case
in
Section 5.5. Lastly, we solve the non-SC multi-task learning problem in
Section 5.6.
5.1. Comparison of PDHG-Type Algorithms on Synthetic Datasets
In this subsection, to verify the advantages of our algorithms compared with PDHG-type algorithms, we first conduct experiments for solving Problems (
23) and (
24) on synthetic datasets. The method of generating a synthetic dataset is described below. Each sample
is generated from i.i.d. standard Gaussian random variables and normalized according to
, and the corresponding label is obtained by
, where the vector
is generated from the
d-dimensional standard normal distribution. The noise
also comes from the normal distribution with mean 0 and standard deviation 0.01. For Problem (
23), we set
, and for Problem (
24), we set
and
.
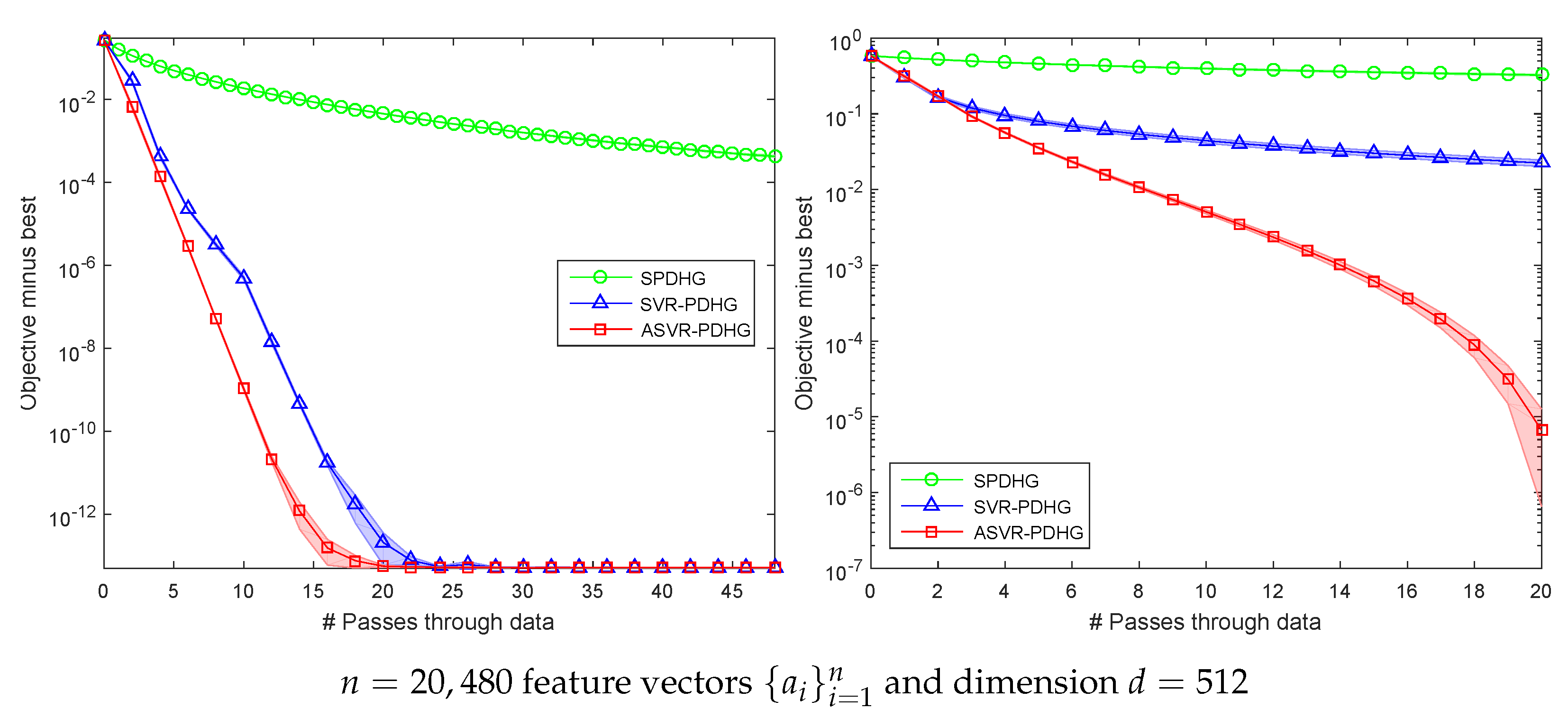
Figure 1 shows the comparison between our algorithms and SPDHG for solving SC and non-SC problems on a small-scale synthetic dataset. The experimental results imply that variance reduction methods including SVR-PDHG and ASVR-PDHG converge obviously faster than SPDHG, which verifies our algorithms improving the theoretical convergence rate. ASVR-PDHG converges much faster than SVR-PDHG in the non-SC setting, which verifies that the momentum acceleration step can significantly improve the convergence speed for solving non-SC problems. ASVR-PDHG performs better than SVR-PDHG in the SC setting, which demonstrates the superiority of momentum acceleration for solving SC problems.
5.2. Comparison of PDHG-Type Algorithms on Real-World Datasets
Due to similar experimental phenomena on the five real-world datasets in
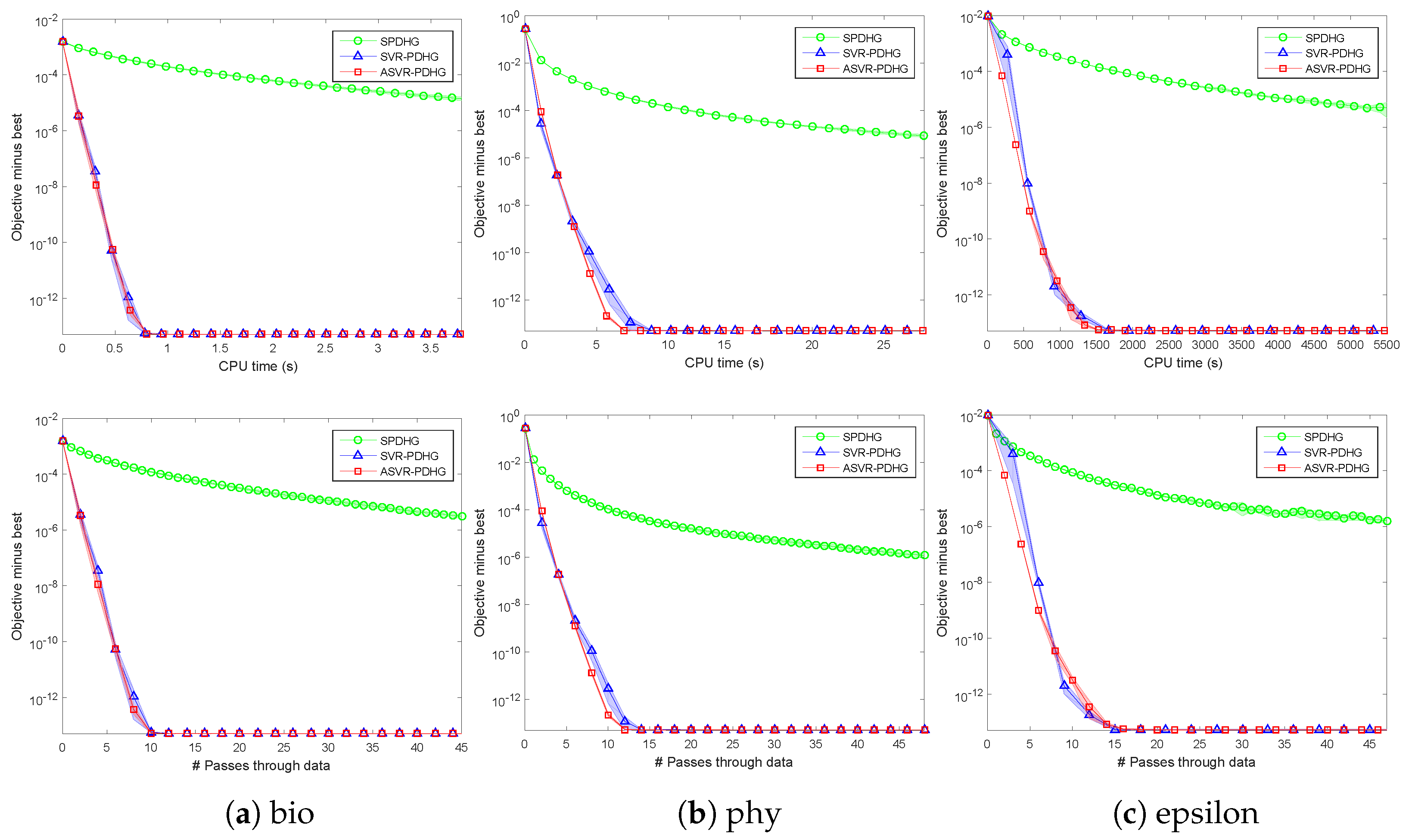
Table 2, we only report the results on the bio, phy, and epsilon datasets in this subsection.
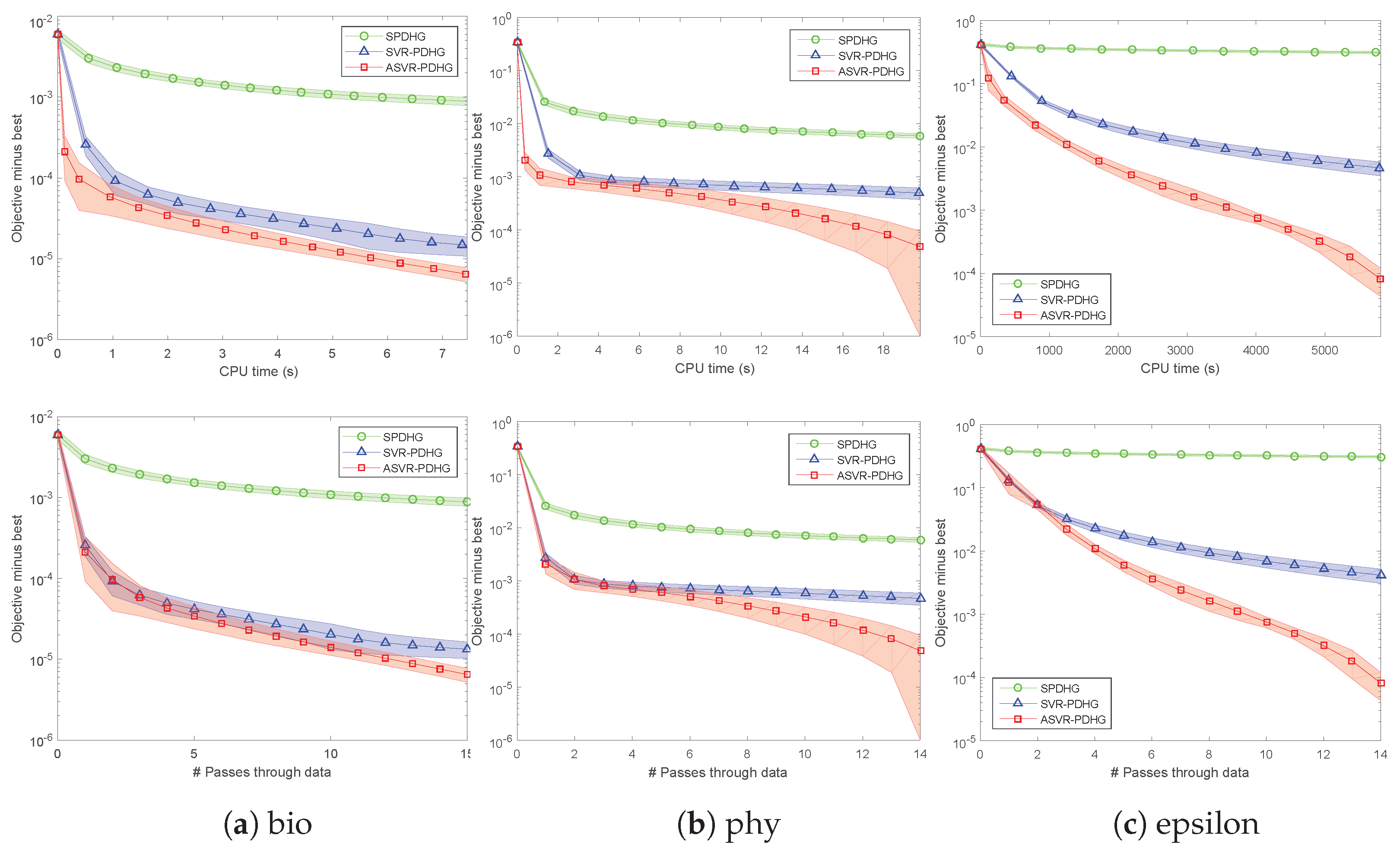
Figure 2 shows the experimental results of Algorithms 2 and 4 to solve the non-SC problem (
23) with
. All the experimental results show that our SVR-PDHG and ASVR-PDHG perform obviously better than their baseline, SPDHG. Moreover, our ASVR-PDHG consistently converges much faster than both SVR-PDHG and SPDHG in all the cases, which verifies the effectiveness of our momentum trick to accelerate the variance reduced stochastic PDHG algorithm.
As for SC objectives,
Figure 3 shows the experimental results of SVR-PDHG and ASVR-PDHG on the three real-world datasets, where
, and
. It can be observed that SVR-PDHG and ASVR-PDHG are superior to the baseline, SPDHG, by a significant margin, in terms of their number of passes through data and CPU time, which also verifies our theoretical convergence results, i.e., linear convergence rate. Note that the standard deviation of the results of our methods is relatively small, which implies that our algorithms are relatively stable.
5.3. Sparse and Asynchronous Parallel Setting
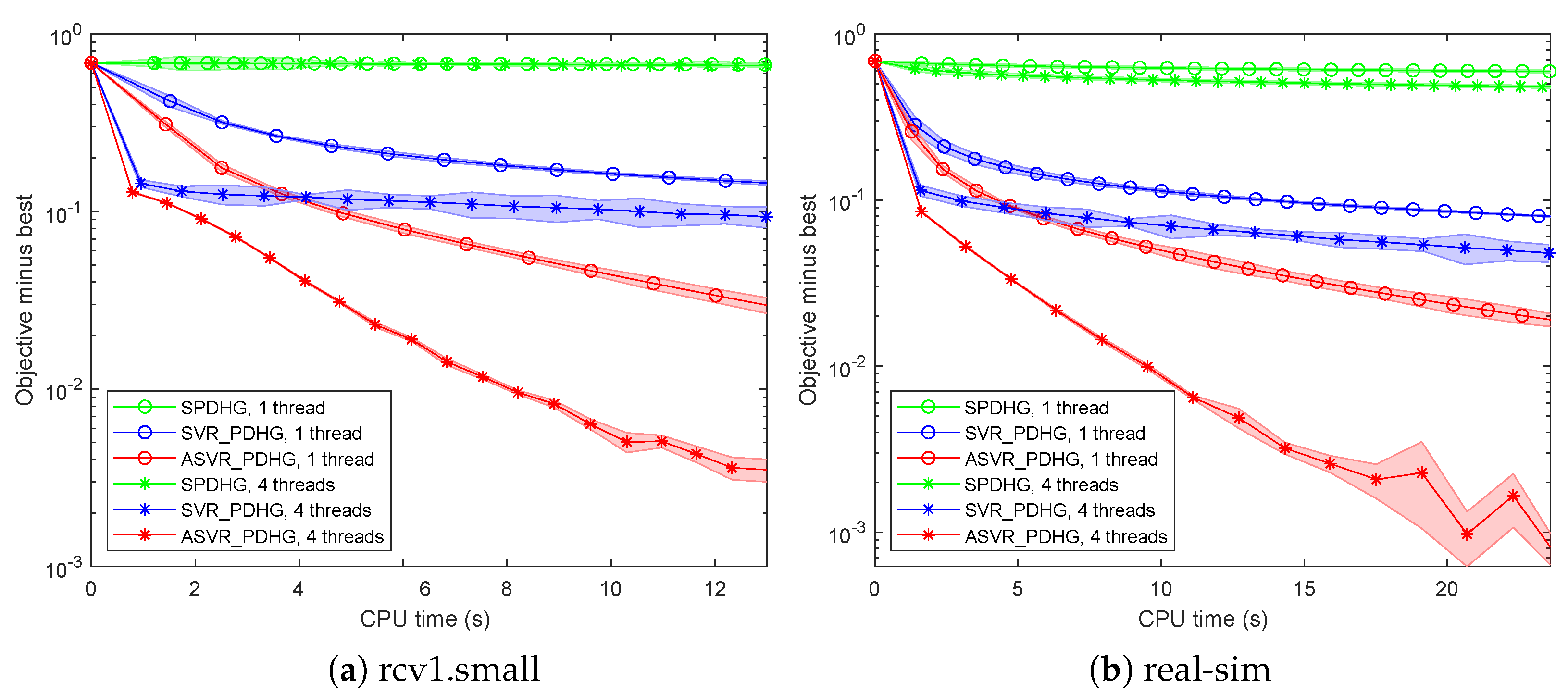
We also conduct our algorithms in the sparse and asynchronous parallel settings. We consider
in the non-SC Problem (
23) to facilitate parallelism and select the regularization parameter
. The sparse datasets rcv1.small and real-sim are used to test our algorithms, and we choose
as in the work [
50]. We choose the single-thread algorithm as the baseline and compare the performance of all the methods in terms of the running time. The parallel SPDHG is achieved by updating the support sets of vectors
and
in a parallel fashion by ourselves. All the algorithms under asynchronous parallel setting are implemented in C++ with a Matlab interface, and the experimental results are shown in
Figure 4.
All the experimental results in
Figure 4 show that our SVR-PDHG and ASVR-PDHG significantly outperform SPDHG in terms of running time on both one thread and four threads. Our ASVR-PDHG method achieves more than
and
speedup over our SVR-PDHG on one thread and four threads, respectively, which benefits from our momentum acceleration and adaptive epoch length strategy. Moreover, SVR-PDHG and ASVR-PDHG with four threads achieve more than
speedup than those with one thread, respectively. These phenomena indicate that the linear extrapolation step, momentum acceleration trick, and adaptive epoch length strategy are also suitable for large-scale machine learning problems in the sparse and asynchronous parallel setting, and our asynchronous parallel algorithms achieve a speedup proportional to the number of threads.
5.4. Compared with State-of-the-Art Stochastic Methods
To illustrate the advantages of our methods over SOTA methods, we further conduct some experiments on a large-scale synthetic dataset and real-world datasets. And we also set and for SC and non-SC problems, respectively.
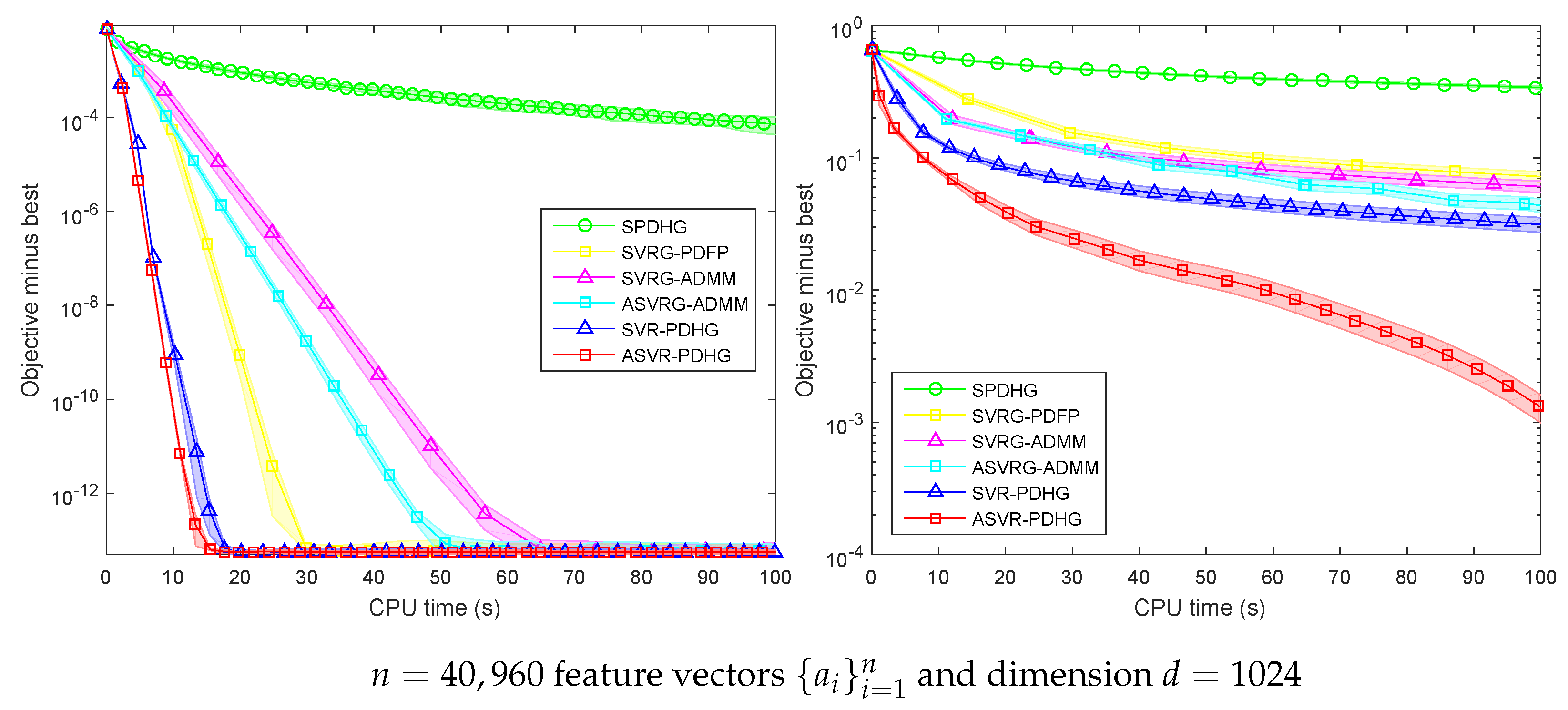
Figure 5 shows the experimental results of SPDHG, SVR-PDHG, ASVR-PDHG, SVRG-ADMM, and ASVRG-ADMM on a larger synthetic dataset. It can be found that our algorithms (SVR-PDHG and ASVR-PDHG) converge significantly faster than SPDHG. For SC problems, SVR-PDHG and ASVR-PDHG achieve an average speedup of
over SVRG-ADMM and ASVRG-ADMM, and
over SVRG-PDFP. For non-SC problems, ASVR-PDHG achieves an average speedup of at least
compared with other algorithms, which benefits from fewer variables, without
Q, and the momentum acceleration technology.
Due to limited space and similar experimental phenomenon on the five real-world datasets in
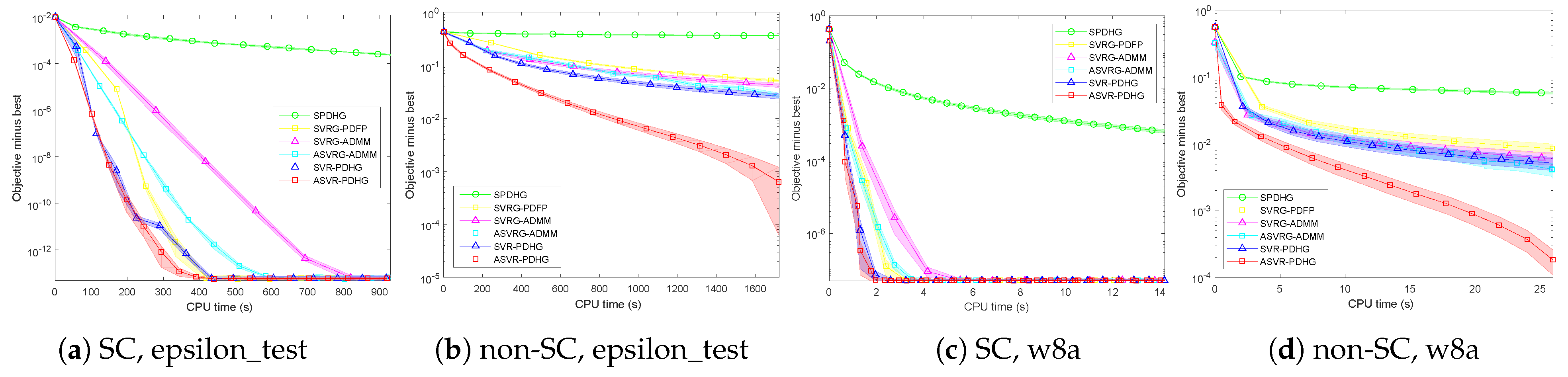
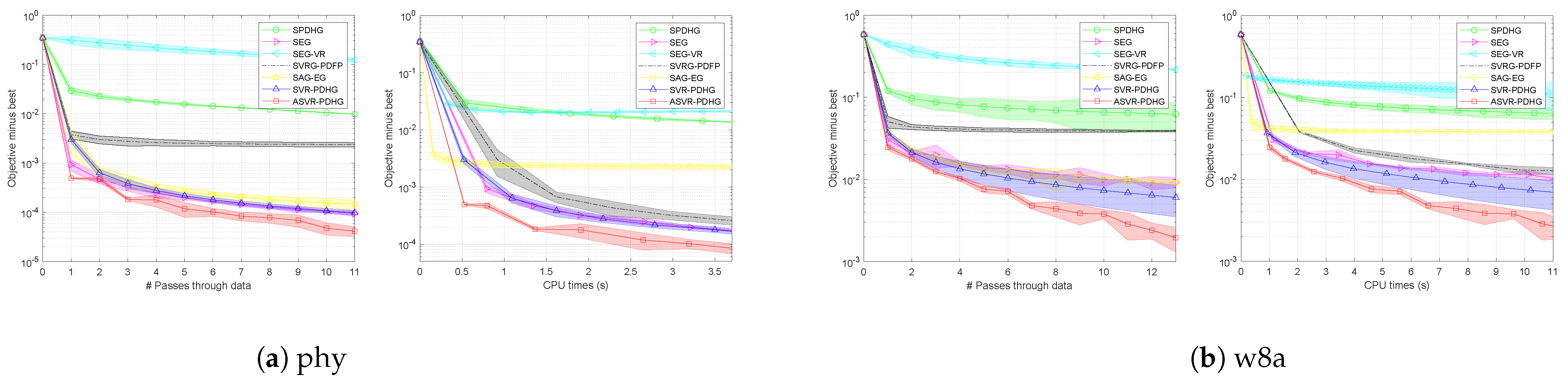
Table 2, we only report the results on the epsilon_test and w8a datasets.
Figure 6 shows the compared results. It can be seen that our ASVR-PDHG almost always converges much faster than the stochastic ADMMs in all the settings. For SC problems, although the linear convergence rate can be obtained by all the algorithms, our algorithms achieve an average speedup of
over SVRG-ADMM and ASVRG-ADMM because we do not require
Q of ADMM-type methods. Moreover, compared with SVRG-PDFP, our algorithms also converge significantly faster. For non-SC problems, our ASVR-PDHG achieves at least
speedup over other stochastic algorithms.
We also compare our methods with the famous extragradient (EG) methods such as stochastic EG [
58] (SEG), stochastic AG-EG [
59] (SAG-EG), and stochastic variance reduction EG [
60] (SEG-VR) methods. We set the same initialization and choose the batch size and step sizes guided by theory, considering the trade-off between time consumption and accuracy, while observing reasonably good performance. The experimental results on the phy, w8a, and epsilon datasets are shown in
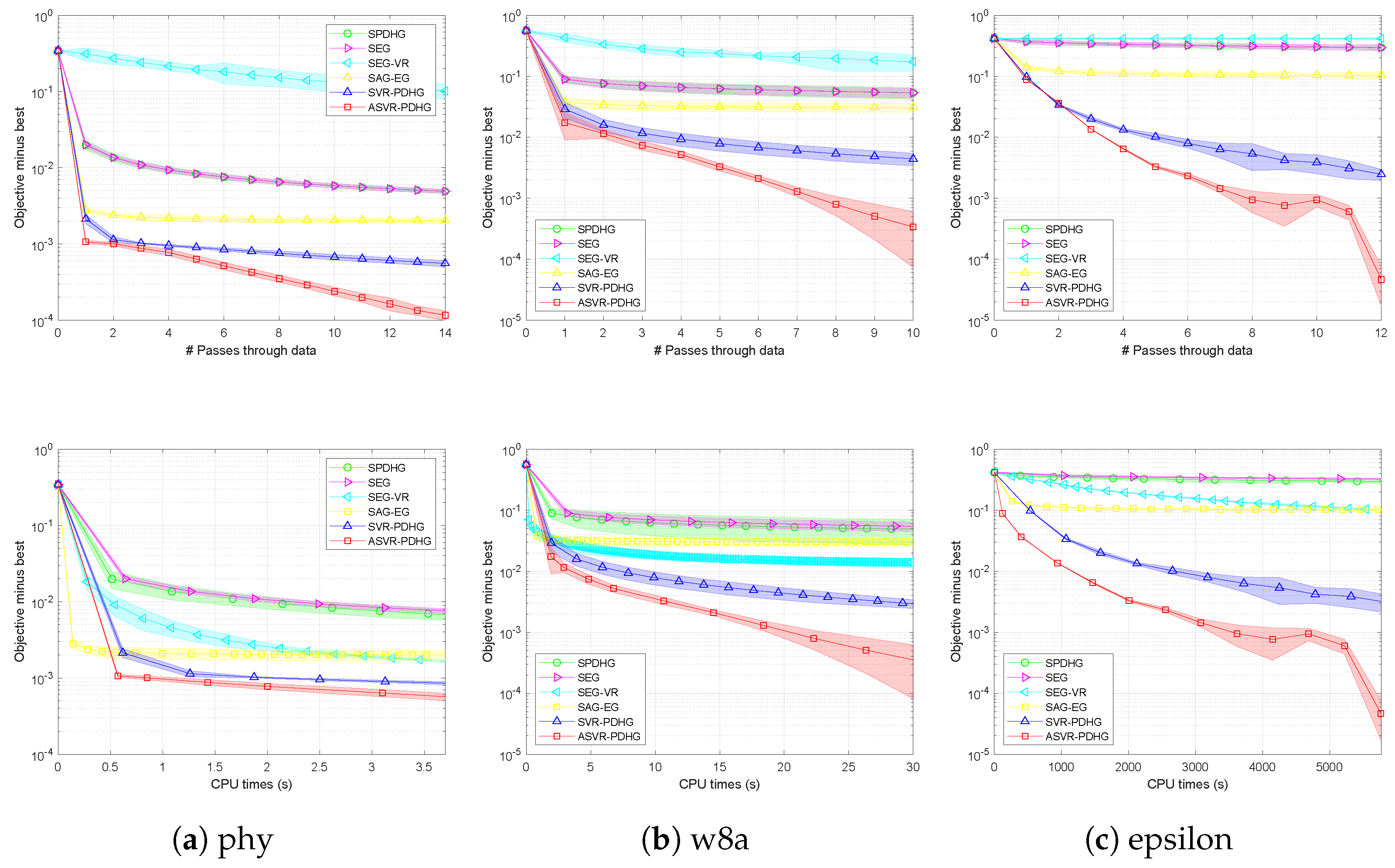
Figure 7. From
Figure 7, we can observe that our proposed methods still converge faster than EG-type methods. Especially for non-SC problems, our SVR-PDHG and ASVR-PDHG algorithms can achieve at least 6× and 7× speedup compared to EG-type methods, respectively, which benefit from the variance reduction and our momentum acceleration technology.
5.5. Comparisons of Primal–Dual Algorithms When
We further conduct our algorithms to solve the general setting, i.e.,
. We compare our methods and other primal–dual algorithms such as SEG [
58], SAG-EG [
59], SEG-VR [
60], and SVRG-PDFP [
46] methods when solving the logistic regression problem with
regularization:
Its primal–dual formulation is
where
and
is a regularization parameter. We set the same initialization
and batch size to compare all the methods. The convergence results are shown in
Figure 8.
From
Figure 8, it can be found that the experimental phenomenon is similar to the case of
. Specifically, our SVR-PDHG algorithm performs sightly better than SEG and SVRG-PDFP methods and achieves a speedup of at least
compared to other comparison methods. Our ASVR-PDHG algorithm further improves the convergence speed of our SVR-PDHG algorithm, which again verifies the effectiveness of our momentum acceleration technology.
5.6. Multi-Task Learning
In this subsection, in order to verify the advantages of our algorithms for solving the matrix nuclear norm regularized problem, we conduct the following multi-task learning experiments. Here, the multi-task learning model can be described as follows:
where
,
N is the number of tasks,
is the logistic loss on the
i-th task, and
is the nuclear norm.
An auxiliary variable
Y is introduced to solve the above model, and the original model can be transformed into the equality constrained problem
, s.t.
, which can be solved by stochastic ADMMs. In order to apply the primal–dual technique to solve this problem, the nuclear norm needs to be rewritten as
, where
is the spectral norm of a matrix. In this way, the multi-task learning model can be formulated into a saddle-point problem as follows:
Here, the conjugate function . This problem can be also solved by SPDHG, SVRG-PDFP, SVRG-ADMM, ASVRG-ADMM, and our algorithms.
We compare the stochastic ADMMs, SVRG-PDFP, and our algorithms on a dataset, 20newsgroups (available at
https://github.com/jiayuzhou/MALSAR/tree/master/data, accessed on 5 November 2021), and set
and the mini-batch size
for each task. The training loss (i.e., the training objective value minus the minimum value) and test error are shown in
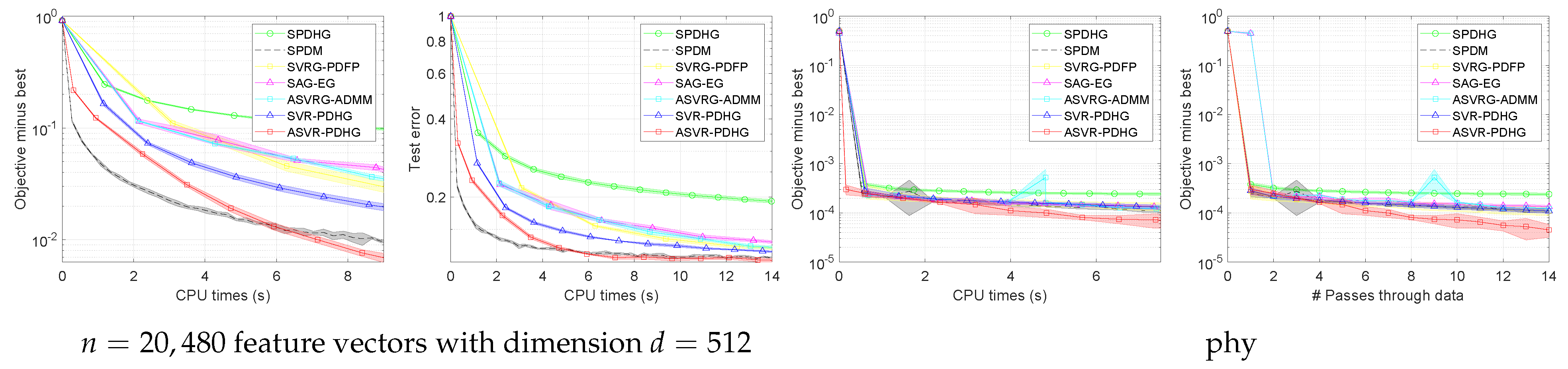
Figure 9. It can be observed that ASVR-PDHG significantly outperforms other algorithms in terms of convergence speed and test error.
5.7. Non-Convex Support Vector Machines
We also compare the related methods on the Support Vector Machine (SVM) problem. Given a training set
, the non-convex
-norm penalized SVMs minimize the following penalized hinge loss function:
In the same way, the SVMs can be formulated into a saddle-point problem:
We compare the ASVRG-ADMM, SVRG-PDFP, SAG-EG [
59], and SPDM [
61] algorithms on a synthetic dataset and the phy dataset, and set
and the mini-batch size
. Regarding other hyper-parameters, we choose them guided by theory and considering the trade-off between time consumption and reasonably good performance. The experimental results are shown in
Figure 10. It can be found that when solving non-convex problems, our ASVR-PDHG algorithm can still maintain a certain advantage.
Limitations. Our algorithms can be proved to achieve an advanced convergence rate under the convex assumption. For the non-convex problems, although our algorithms have unknown convergence properties, they achieve better experimental performance than some state-of-the-art methods as shown in
Figure 10. As for solving complex non-convex problems such as training deep networks, the gradient calculation and acceleration steps may increase computational cost, but since the batch size can be chosen to be
and only vector addition operations are performed, the computational cost will not increase too much and will still be smaller than the ADMM-type algorithms. We will study the convergence properties of non-convex primal–dual problems in future work.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}