Abstract
This article presents a high-performance-computing differential-evolution-based hyperparameter optimization automated workflow (AutoDEHypO), which is deployed on a petascale supercomputer and utilizes multiple GPUs to execute a specialized fitness function for machine learning (ML). The workflow is designed for operational analytics of energy efficiency. In this differential evolution (DE) optimization use case, we analyze how energy efficiently the DE algorithm performs with different DE strategies and ML models. The workflow analysis considers key factors such as DE strategies and automated use case configurations, such as an ML model architecture and dataset, while monitoring both the achieved accuracy and the utilization of computing resources, such as the elapsed time and consumed energy. While the efficiency of a chosen DE strategy is assessed based on a multi-label supervised ML accuracy, operational data about the consumption of resources of individual completed jobs obtained from a Slurm database are reported. To demonstrate the impact on energy efficiency, using our analysis workflow, we visualize the obtained operational data and aggregate them with statistical tests that compare and group the energy efficiency of the DE strategies applied in the ML models.
Keywords:
high-performance computing; operational data analytics; energy efficiency; machine learning; AutoML; differential evolution; optimization MSC:
68W50; 68M20; 68T07; 68U10
1. Introduction
High-performance computing (HPC) continues to advance and to provide important infrastructure and a backbone for the scientific community, industry, and beyond, making efficient utilization highly important for both environmental sustainability and cost efficiency [1,2]. Despite the increasing availability of automated ML (AutoML) frameworks, most existing tools prioritize and maximize the performance (accuracy) and neglect other important objectives such as energy efficiency (EE) and resource usage and optimization, which are key factors in large-scale HPC environments and beyond [3,4]. Therefore, the enforcement of sustainable and energy-efficient solutions, including the utilization and optimization of computational resources, now plays a key role in reducing operational financial costs and minimizing environmental impacts [1,3]. Due to the broad accessibility of computational resources for HPC, the scientific community with the myriad of application areas and diverse expertise from different fields, can deploy and run their workflows [5,6]. As their needs, demands, and complexity grow, running data-intensive and parallel workflows involves both different and heterogeneous architectures and the resources of state-of-the-art systems [6,7,8]. Such heterogeneous architectures introduce challenges in workload scheduling, as there are many unknowns and uncertainties [2,9]. However, despite the optimization capabilities and advances, most AutoML frameworks do not incorporate schedulers such as Slurm, nor do they provide support for energy monitoring, as their main focus is on improving ML model performance (accuracy) and ignore constraints such as EE, utilization, and resource allocation [3,4,10]. To address these challenges, adjusted and tailored frameworks that support sustainable and cost-efficient HPC environments are needed. Therefore, this article presents a high-performance-computing (HPC) differential-evolution-based automatic hyperparameter optimization workflow (AutoDEHypO) for energy efficiency and operational data analytics using multiple graphics processing units (GPUs), and this is deployed on the petascale EuroHPC supercomputer Vega [11]. Our proposed method is capable of determining how energy-efficient the differential evolution (DE) algorithm and ML models perform. The proposed AutoDEHypO workflow considers both their achieved accuracy and the utilization of computing resources, such as elapsed time and consumed energy; it collects runtime data through Slurm within the HPC environment, and the job allocation may impact the obtained results. Moreover, resource consumption leads to inefficient workloads, waste of computational resources, the consumption of a project quota, longer queue times, and postponement of scientific research [12]. Since Slurm dynamically schedules jobs to available, unutilized, or idle nodes within the cluster queue, proper adjustments in job submission may lead to faster allocation and faster attainment of the required job results [13]. We aim to develop the ability to operate within the constraints that Slurm users have and determine whether statistical deviations will be significant. Thus, we prepared our environment for the deployment of the AutoDEHypO workflow, where we ensured consistent resource allocation across the submitted job scripts with a Slurm script (SBATCH). Furthermore, this setup includes supervised machine learning (ML) and multi-label classification and allows for applicable optimization for aspects of hyperparameters that could be affected [14]. We chose the recent parallel implementation of the DE algorithm [15], which parallelizes the population operations in an algorithm that was initially introduced by Storn and Price in 1995 [16]. While DE provides a favorable trade-off and balance between accuracy and energy efficiency (EE) in the context of HPC [17], it additionally offers several advantages over other optimization algorithms, such as efficient and faster convergence, suitability and adaptability in a variety of different environments and optimization problems, global optimization, parallelization, scalability, energy optimization, and the possibility for combination and complementarity with different algorithms and techniques due to available implementations and integrations [16,18,19,20,21]. Furthermore, DE is suitable for the given optimization problem, as it can be used for optimizing nonlinearities in data, such as ML-related input/output data within the workflow, and it can be adapted to other use cases and problems [19]. Data are gathered from system scheduling and historical data; resource allocation and job execution times make it difficult to provide prediction and optimization [16,19,20,21]. In the evaluation phase of our experiment, we used basic ML metrics [14]. During the deployment of individual jobs on multiple GPUs in our experiment, we examined the efficiency of a chosen ML model and DE algorithm according to the accuracy [14]. DE functions and strategies show distinct behavior, and this has not yet been extensively measured or optimized within the context of EE and system resource management in HPC environments [20,22,23]. Data on the consumption of resources of individual jobs were obtained from the Slurm database of completed jobs, with energy consumption data being reported for the whole node by Intelligent Platform Management Interface (IPMI) sensors [13,24]. Based on the results of the computations, aggregated statistics were calculated, along with corresponding post hoc procedures and visualizations, to evaluate the efficiency of the combined ML model and the applied DE strategy.
1.1. Problem Statement and Objective
This work addresses the challenge of optimizing machine learning (ML) models in high-performance computing environments by balancing ML accuracy, energy consumption, and resource utilization. To address these challenges, we propose AutoDEHypO, a differential-evolution-based workflow that is specifically designed for energy-monitored hyperparameter optimization. The specific problem stated for this study consists of considering some key limitations, such as inefficient utilization of computational resources during job allocation, extended queue times, and lack of integration with HPC environments and schedulers such as Slurm. The limitations of existing workflows and frameworks are that they mostly focus on a single objective, such as ML performance or integration within HPC environments, and do not necessarily contribute to the sustainability and cost-effectiveness of HPC environments [25,26]. Therefore, we are interested in analysis of the consumption of resources and when the consumed energy and other resources can lead to different ML performance and configurations.
1.2. Main Contributions
The main contributions of this article are as follows:
- We propose AutoDEHypO, a high-performance-computing differential-evolution-based automatic hyperparameter workflow designed to optimize the performance of ML models for energy efficiency and operational data analytics in HPC environments.
- We deploy the AutoDEHypO workflow on the EuroHPC Vega system, utilizing multiple GPUs and Slurm scheduling and submission to execute a specialized fitness function for ML.
- We applied and evaluated this workflow on supervised ML and multi-label classification using the CIFAR10 and CIFAR100 datasets [27].
- We collected runtime data through Slurm within the HPC production environment.
- We evaluated the efficiency of a chosen ML model and DE algorithm strategies according to the ML accuracy and energy efficiency, dependent on ML model architecture, datasets, and resource consumption within the HPC environment.
- We performed aggregated statistical analyses, along with the corresponding post hoc procedures, and validated the collected data using visualizations by evaluating efficiency of combined ML models and applied DE strategies.
- We identified significant differences in key metrics and laid the ground for future work on sustainability and cost-effectiveness using AutoDEHypO.
2. Related Work and Existing Methods
The integration of machine learning (ML) with monitoring and operational data analytics (MODA) is a step towards enhancing operational efficiency, and DE is being utilized to run DE fitness functions and enhance model performance through hyperparameter optimization and other techniques [28]. Furthermore, automated machine learning (AutoML) automates workflows and reduces manual effort [12]; here, the effectiveness of an ML model is evaluated using fundamental ML evaluation metrics, non-parametric tests, post hoc procedures, and visualizations [14]. Despite the improvements, there is still a trade-off between accuracy and energy efficiency [14]. Moreover, checkpoint, restart, and predictive models provide additional robustness and project quotas for allocated computational resources. The following subsections, therefore, describe these topics in the order in which they were mentioned here.
2.1. Machine Learning
Machine learning (ML) is used to discover patterns, make predictions, provide automation, and generate useful knowledge from datasets [29]. Several types of such discoveries have been made, through methods such as classification, regression, segmentation, clustering, error detection, sequence analysis, and others [29]. The design of layers (how they are connected and structured) represents the architecture of a model, while the trained version (system) represents an ML model itself [29]. Furthermore, in the context of learning, there is supervised machine learning and unsupervised machine learning [29]. In ML, patterns are identified within a dataset, and thus the model wants to connect attributes and classes—for example, through classification—with a focus on similarities on the one hand; on the other hand, unsupervised machine learning focuses on identifying underlying structures without a target attribute, such as segmentation [29].
In ML, optimization algorithms are used to improve results—specifically, losses within a selected space [14,30]. With the help of an ML algorithm, hyperparameters can be adjusted and optimized even before the learning phase [14]. The hyperparameters of ML are the configuration variables of ML methods [14]. Some of the most widely used optimization methods are grid search, random search, cross-validation, and Bayesian optimization [30,31]. The execution time of a manual search can be significantly longer due to the complexity of ML models and neural networks within their limits, and as a result, such a search uses significantly more computational resources [8,32].
A convolutional neural network (CNN) is suitable for processing patterns within images, processing video content, performing face recognition, processing medical data, and more. A CNN uses a filter, converts pixels into numerical values in the first layer, and processes or teaches them to recognize and analyze data with the help of subsequent layers [33].
Recurrent neural networks (RNNs) use a mechanism for storing information from previous states and process and interpret it, making them more suitable for processing when the data are structured and in some kind of sequence. They are used in areas such as natural language processing (NLP) and speech and handwriting recognition [34].
The complexity and efficiency of the model may be defined by the architecture design and structure of the NN, the layers, and their connectivity, including the number of layers, the framework, the model size, the optimization that is applied, the input data, and more [8,35]. The efficiency and emergence of smaller ML models, which are also referred to as language models [36], may play a key role, as they are easier to manage and provide flexibility, allowing faster implementation of changes with fewer computational resources [37,38].
Multi-label classification is a type of supervised machine learning that enables each instance to be associated with multiple labels, and it differs from conventional single-label classification, where each instance can be associated with a single label [14,39]. Fine-tuning and other optimization techniques can be applied to hyperparameters, which will have an effect and improve the performance of a model [14,30]. Evaluation of progress and performance is performed using a metric (M). There are some fundamental ML metrics, such as the accuracy, precision, recall, and F-measure; in addition, metrics can be aggregated with possible prediction outcomes, e.g., total (T), true positive (), true negative (), false positive (), and false negative (), as presented in [14].
- Accuracy (A) [14]:
- Precision (P) [14]:
- Recall (R) [14]:
- F-Measure () [14]:
- Metric Aggregation [14]:
2.2. Monitoring and Operational Data Analytics
Monitoring and operational data analytics (MODA) in high-performance computing can be applied to broad standards and practices for the integration, collection, storage, processing, monitoring, visualization, and analysis of system data [28]. MODA is used with the goal of helping end users make informed decisions about information collected on their system through hardware power monitoring and management tools such as IPMI, RAPL, and others [40]. These tools provide information such as sensor data, usage of generic resources, job status, memory, wall time, job and node utilization, power consumption per job, nodes, blades, racks, clusters, data centers, cluster occupancy, billing, and more to be leveraged in many ways [13,28]. Furthermore, MODA can be applied and extended to either an active or a passive setup, which depends on the requirements, potential benefits, and contributions that it may offer [40]. An active setup actively influences the runtime operations, while on the other hand, a passive setup passively monitors, gathers, and collects data without affecting the runtime operations [40]. To enhance the impact of ML and gather insights into data, MODA may be used to monitor energy consumption, improve job efficiency, and improve the ML design for EE by providing real-time feedback mechanisms for adaptive and dynamic changes within ML operations, ML optimization suggestions such as predictions in ML models, or even operational insights to resolve issues by proactively predicting potential trends and patterns within ML operations [9,40,41]. Such an analysis could identify trade-offs and bring the right balance, resulting in potential reductions in the consumption of resources and bringing sustainability and EE into view [28]. Furthermore, MODA offers multiple opportunities and can potentially contribute to EE due to the possibility of monitoring energy and detecting significant differences, preventing potential issues and anomalies, finding potential root causes, detecting security vulnerabilities and malware, and providing improvements in performance, reliability, throughput, and beyond [42]. Using HPC Vega [11], the topics of MODA, including energy monitoring, operational efficiency, and optimization of HPC workloads, were investigated and recently addressed in [43].
2.3. Differential Evolution
The differential evolution (DE) algorithm is a population algorithm and was introduced by Storn and Price in 1995 [44]. DE has been used successfully in the field of optimization of numerical functions and in applications to real problems within different domains [16]. The original DE has a main evolutionary loop through which, with the help of the key and basic operators presented in Figure 1, such as initialization, mutation, crossover, and selection, the final result can be gradually improved soon after each generation by repeating these operators until the end [45]. From its introduction to the present, interest in DE has increased year on year [16,44]. Thus, DE has been developed, improved, and applied to a variety of real-world problems within multidisciplinary domain areas, such as electrical and energy systems, artificial neural networks, manufacturing and pperation research, robotics and advanced systems, pattern recognition, image processing, bioinformatics and biomedicine, electrical engineering, and others, as presented in several articles [16,46,47,48,49]. Those mechanisms can be used to make the selection process easier [50]. DE provides a favorable trade-off and balance between accuracy and energy efficiency within HPC environments and beyond [17]. Additionally, DE offers several advantages over other optimization algorithms, such as efficient and faster convergence and suitability and adaptiveness in a variety of different environments and optimization problems; often, it provides better results than other algorithms [18,51,52,53]. Furthermore, DE can be used for nonlinear, nondifferentiable, and multi-objective problems [16]. It provides robustness in complex and multidimensional spaces, global optimization in complex spaces, parallelization, scalability in high-dimensional problems, and energy optimization and distribution without compromising throughput [16,18]. It can be integrated with penalty functions and other methods to handle constraints, and it can be combined and used to complement different algorithms and techniques due to its easy implementation and integration [16,21]. Last but not least, it is being extensively researched, and constant improvements to the algorithm are being made [16,18,21].
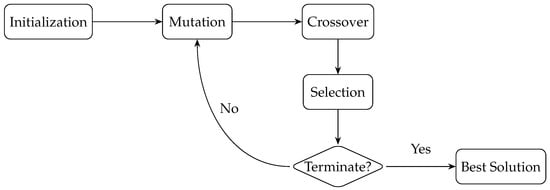
Figure 1.
This figure shows the basic steps of differential evolution, including initialization, crossover, mutation, selection, and condition (loop). Until the stopping condition is met, i.e., max generations or convergence, the mutation, crossover, and selection processes are repeated over generations; then, the best solution that is found is provided [54].
2.3.1. Differential Evolution Operators
In DE [20], the following operators are used as highlighted in Figure 1.
First, the search space is initialized, and all search variables are randomly populated in the search space for a population of vectors defined with a dimension; then, the parameter vectors may change over different iterations [16]. The sequential number of the current generation [16] is denoted by t, the optimization search dimension size is denoted with d, and denotes a population vector index [16].
Within this initialization stage the vector must be composed of the following components within interval limits for minimum and maximum [16]:
During mutation, after the first step is completed, the algorithm selects donor and mutated vectors for each population individual [55]. The following strategies are used most often (interval from 1 to ), where denotes the target vector, denotes the mutant vector, denotes the best individual in the population, denotes random indexes that are mutually different and different from i, F denotes the mutation scaling factor, and t denotes the current generation [16,55,56]
- DE/rand/1: A random vector is chosen as the basis, and a one-sided weighted difference (vector) composed of two other random vectors is added to it.
- DE/best/1: The current best random vector is used as the basis, and an additional random difference (vector) is added to it.
- DE/current-to-best/1: For an individual vector to mutate with the best vector, one random difference (vector) is added.
- DE/rand/2: A random vector is chosen as the basis, and two independent differences (vectors) of four random vectors are added to it.
- DE/best/2: The current best random vector is used as the basis, and two random differences (vectors) of four random vectors are added to it.
In the crossover phase, the donor vector crosses with the targeted vector [16]. The two most commonly used methods of crossing are exponential and binomial [16], and there are a few other combinations of mutation and crossover strategies in the original DE algorithm [20,55], namely, the DE/rand/1/exp, DE/current-to-best/1/exp, DE/best/1/exp, DE/current-to-best/1/bin, DE/rand/2/exp, and DE/best/2/exp strategies. Exponential crossover works by choosing a random number within the size of the dimension {1, 2, …, d}. The target vector is then crossed with the donor vector [16]. The binomial crossover generates a number from interval for each dimension randomly and compares it to crossover value [16], in order to exchange components, or also exchange the component at random index .
In selection, survival to the next generation for both vectors, i.e., the target and the trial vector, is determined [16]. If the condition is met, the target vector is simply replaced according to the strategy chosen for the next generation; otherwise, it remains and is further evolved within the next generation [16].
2.3.2. Improvements to the Differential Evolution Algorithm and Energy Efficiency
Since the introduction and throughout development beyond the original DE algorithm [20], its main foundational concepts were addressed and subsequently extended [57]. Especially from the efficiency perspective, extended versions and improvements have been proposed over the years [16,21]. Numerous improved algorithms have been developed and presented annually at conferences, such as at the Institute of Electrical and Electronics Engineers (IEEE) Congress on Evolutionary Computation (CEC), the Genetic and Evolutionary Computation Conference (GECCO), Parallel Problem Solving From Nature (PPSN), and competitions [58]. DE competitions are organized mainly as part of the CEC [58] and GECCO. After each competition, a review of the algorithms is conducted, and the results are included in a technical report [58]. Therefore, from such efficiency perspective defined at these competitions or other benchmarks, there are newer DE methods with benchmarks, such as L-SHADE [59] and DISH [60] with parameter control benchmarking [61]. Several related works have used DE for energy efficiency (EE), demonstrating applicability within the context of high-performance computing (HPC) and beyond [23,62], including that DE has been utilized in testing benchmarking EE with large dimensions for some CEC functions in [63]. Notably, DE can be used as a tuning platform to utilize and optimize energy-efficient and energy-aware workloads [64].
Other authors have presented a self-adaptive DE method with mutation and crossover operators and its design for NN optimization [65]. Agarwal et al. presented a differential-evolution-based approach to compress and accelerate a convolution neural network model, where the compression of various ML models improved their accuracy on different datasets, including CIFAR10 and CIFAR100 [66]. The compact differential evolution (cDE) algorithm was presented by Mininno et al. for constrained edge environments and provides support in robotics where there are limited computational resources [62]. A memetic DE (MDE) algorithm for EE with a job scheduling mechanism and possibilities for parallelization and scaling was also presented by Xueqi et al. [67]. A differential-evolution-based EE system for minimizing the consumption of resources in unmanned aerial vehicles (UAVs) and IoT devices was recently presented by Abdel-Basset et al. [68]. DE was also applied to autonomous underwater vehicles (AUVs) for underwater glider path planning (UGPP) with the objective of collecting research data within unexplored areas, which presents additional challenges; this provides robustness for such missions by addressing energy optimization for underwater glider vehicles [69,70]. Jannsen et al. also recently presented a comparative study reviewing the potential of the DE algorithm on GPUs due to its advantage of parallelism and more [71].
2.4. Comparison of Hyperparameter Optimization Methods
Differential evolution (DE) can be compared with other hyperparameter optimization methods, such as random search (RS), grid search (GS), and Bayesian optimization (BO) [25,26]. Under constraints of limited time and computational resources, neither GS nor RS proves to be ideal [25,26] and both methods tend to be inefficient, especially in the context of complex ML models [25]. Due to the exhaustive nature of GS, it suffers when dealing with a larger number of dimensions as they increase [25]. As dimensionality increases, GS evaluates a large number of configurations, which leads to the consumption of many computational resources [25]. RS, while simpler and more robust, typically requires a larger set of evaluations to achieve competitive results, regardless of resource constraints [25]. RS selects configurations at random, potentially overlooking promising regions of the search space and resigned to optimal results [25]. BO uses surrogate models, which are very efficient in low-dimensional spaces and black-box problems [25]. Unlike RS and GS, BO does not try every possibility within a given space, insted it uses predictions of outcomes where the acquired knowledge is collected and updated [25,26]. BO is a very useful method for the desire for scalability and with increasing dimensions BO loses performance rapidly with increasing dimensionality [25,26]. Additionally, in connection with DE and other optimization algorithms, a novel deep-learning expansion called Deep-BIAS was introduced and presented by van Stein et al. [72] Furthermore, Explainable AI (XAI) for evolutionary computation (EC) and the current state-of-the-art [73] introducing techniques for global sensitivity analysis in evolutionary optimization with focus on effectiveness is presented [74]. Such comparison strengthens the basis of DE as the optimizer user (within this article), especially in scenarios where the evaluation of ML models is computationally demanding, where parallelism and scalability within robust complex search and multidimensional spaces are required, as well as its implementation in real problems in various fields, including ML as presented in Section 2.3.2.
2.5. Automated Machine Learning
Automated machine learning (AutoML) is the automation of workflows within an ML process and can be applied from the beginning to the end (end-to-end) [12]. The main focus is to avoid unnecessary repeatable steps [75]. The AutoML process itself is multi-step, so we select the data source, select the data, clean and preprocess the data, execute machine learning, algorithm selection, and parameter optimization, and interpret and discover knowledge [29]. This is also reflected in the growth in the number of published works in the last 10 years, e.g., [3,4,26,75,76]. Due to the significant and continuous progress in the field, ML represents a popular branch of computer science and beyond [75]. It has been successfully applied within a myriad of scientific domains [39], including to exploit the potential of infrastructures such as HPC, rids, cloud and edge computing, and beyond [34,77]. Moreover, the complexity and rapid growth in the field have also created a large gap in efforts to transition to more sustainable approaches and strategies [78,79]. Improvements in optimization through Red AI and a proof of concept based on the Scikit-learn library were presented by Castellanos-Nieves et al. [80], with another work presenting an evaluation of various applied and potentially suitable algorithms with a focus on Green AI [81]. Furthermore, Red AI is mostly focused on conventional approaches, such utilizing many computational resources with the relearning of ML models, maximizing the acquired ML accuracy, and neglecting EE [4,10]. However, in recent years, as presented in recent work, advances and evolutions in the fields of ML and AutoML show the necessary contribution of the strategies and concepts of Green AI when considering EE, as well as what the trade-offs of this approach are on the path toward a more sustainable landscape and Green AI [3,4]. Geissler et al. introduced a novel energy-aware hyperparameter optimization approach (Spend More to Save More (SM2)) based on the early rejection of inefficient hyperparameter configurations to save ML training time and resource consumption [78]. While recent studies addressed EE in connection with AutoML, they were not applied to HPC or the cloud, where the utilization of resources is crucial [78]. Evolutionary algorithms have also been applied within or as optimizers as an addition to AutoML, e.g., an improved optimization framework using evolution algorithms such as DE [51], self-adaptive control parameter randomization with DE [82], the application of DE to an energy-aware auto-tuning platform [64], and an auto-selection mechanism with the application of DE [50]. Vakhnin et al. presented a novel multi-objective hybrid evolution-based tuning framework for accurately forecasting power consumption [83], and the application of DE provided better results than those of other algorithms [51,52,53]. Benchmark studies were presented by Gomes et al. [53], in addition to those for other state-of-the-art algorithms [75,84]. These were mostly tailored to specific application domains, and they lacked integration and successful deployment with an HPC or cloud environment, as well as the inclusion of scheduling systems such as Slurm [3]. Therefore, there has been significant advancement in the field of sustainability in multidisciplinary application domains within HPC environments. Researchers and developers have the option of choosing between areas related to their expertise and the task at hand according to their preferences. A collection of AutoML tools and toolkits is available, leveraging a myriad of technologies [85]. Common AutoML tools include AutoKeras [86], Auto-sklearn [87], H20 [88], TPOT [89], TensorFlow [90], Auto-PyTorch [91], and others [12,85]. Furthermore, profiling and benchmark tools are available to evaluate and optimize algorithms in both CPU and GPU architectures, e.g., COCO (COmparing Continuous Optimizers) [92,93], IOH [94,95], jMetal [84,96], irace [97], Optuna [98], BIAS [72], and, last but not least, Ray Tune [99]. Despite their optimization capabilities, none of the listed AutoML frameworks provide native support for energy efficiency [3]. Therefore, external tools such as PyJoules [100], Carbontracker [101], and others can be used for measuring, logging, and tracking energy consumption and emissions during execution [102]. However, Slurm incorporates MODA to gather energy data from hardware interfaces such as RAPL, IPMI, NVML, and others [13]. This data could be used in optimization processes, as part of objective function constraints, or to provide feedback for early stopping when limits are exceeded [9,29]. Taking this into account, AutoML could optimize ML model performance and provide a balance between ML accuracy and energy efficiency, as a step toward sustainability [1].
2.6. Image Datasets
The Canadian Institute for Advanced Research (CIFAR) dataset collection includes publicly available (https://www.cs.toronto.edu/∼kriz/cifar.html, accessed on 19 November 2024) datasets such as CIFAR10 and CIFAR100 [27]. The collection contains 60,000 colored images (32 × 32 × 3 pixels), of which 50,000 are for training and 10,000 are for testing; CIFAR10 contains 10 classes, while CIFAR100 has 100 [27].
The Modified National Institute of Standards and Technology (MNIST) database is a large publicly available (https://yann.lecun.com/exdb/mnist/, accessed on 19 November 2024) database that includes grayscale centered images of handwritten digits [103]. The database contains images of 28 × 28 pixels, comprising 60,000 training images and 10,000 testing images [103]. Furthermore, additional versions have been published, such as Extended MNIST (EMNIST) and Fashion MNISH, which contains 70,000 images (28 × 28 pixels); other customized collections are also available [103].
ImageNet is an image database collection that is publicly available online at address https://www.image-net.org/, accessed on 19 November 2024, and it includes colored images (64 × 64 × 3 pixels) in 1000 object classes, comprising 1,281,167 training images, 50,000 validation images, and 100,000 testing images [104]. In addition, versions with more or fewer images have also been published subsequently.
2.7. Checkpoint and Restart
Checkpoint and Restart (CR) is a mechanism that allows the running workload to be saved [105]. The saved checkpoint may be later restarted, resulting in restoration, a potentially reduced elapsed time, less consumed energy, and the possibility of debugging issues that may appear during the execution of a workload [105,106]. This mechanism provides fault tolerance and resilience to the interruption of hardware, networks, and software, as well as other potential issues [105,107]. CR may be achieved through various technologies on CPU and GPU architectures, including containerized environments [108,109]. Taking EE into account and the additional storage that is needed to store captured checkpoints, if these are properly applied, users may restore their work in the event of a crash, failure, or wall time limitation, saving potential lost time due to redundant computation and power consumption [106,108]. Additionally, users can migrate their workloads to less consuming nodes (additional partitions or constraints), save states before nodes go into sleep or idle mode at higher energy peaks, and restore when necessary, thus saving the state and throttling the CPU/GPU frequencies using dynamic voltage and frequency scaling (DVFS), restoring with lower frequencies, performing cloud bursting, and more [106,108]. While this mechanism is often sufficient, this is not the case for randomized environments and long-running jobs if everything is not captured correctly [105]. Furthermore, this additionally brings increased complexity and potential challenges, resulting in incomplete, inconsistent, and non-deterministic captured states; scaling may introduce overhead (GPUs), divergence from an original state, violations, and misled reproducibility. External systems may behave differently upon restart, in addition to other issues [105,110,111]. We can apply CR inside the basic DE loop presented in Algorithm 1, where we can continue from the last successfully calculated generation [105]. To ensure complete reproducibility, it is necessary to save after a certain number of generation cycles (10) [105]. The checkpoint must contain the current number of generations itself; we also save the current population number, fitness values, and configurations, such as seeds [105].
| Algorithm 1 Differential Evolution for Machine Learning Hyperparameter Optimization |
Require: ML hyperparameter optimization problem fitness function , minimum and maximum of the search space of ML hyperparameters S for function , DE parameters: population size , mutation differential weight F, crossover rate , number of generations G.
|
2.8. Predictive Modeling
Resource allocation in HPC, such as the allocation of time, memory, central processing unit (CPU) cores, GPUs, and other parameters, is submitted through Slurm [13]. Limited knowledge in a research field, optimization, and beyond results in the underestimation of the required resources, which leads to job failure related to wall time or a lack of memory (OOM), resulting in a waste of computational resources, the consumption of the project quota for the allocation of resources, and the postponement of scientific research [2,11,13]. Furthermore, an ML model can be used for the prediction of consumed resources, such as time and energy, based on historical data that can be gathered from the Slurm accounting database through sacct command [2,13]. A prediction model is a step towards energy efficiency, sustainability, and the prevention of job failures; predictions can be based on historical data and fair shares [13]. The job size, age, and failure of some jobs and the consumed resources may cause a fair share score of a user to decrease [13]. Therefore, users with a higher fair share score receive a higher priority in the queue [13]. This results in reduced resources consumption with the lower queue time due to fair share policies [13]. Chu et al. presented the emerging challenges in generic and ML workloads within HPC environments and their correlations with job failures, energy consumption, and other analytics [2,13]. Such solutions based on CPU and GPU workflows have already been presented in other articles [112,113,114].
3. Proposed Methodology: AutoDEHypO
This section presents the proposed methodology and deployment based on AutoDEHypO, a workflow specifically designed for energy efficiency and operational data analytics in HPC environments.
3.1. Experimental Environment
Computing nodes on an HPC Vega partition with graphics accelerators (GPUs) were used [11]. The partition has 60 nodes, each node has 4× NVIDIA Ampere A100, 2× AMD Rome 7H12, 512 GB RAM, 2× HDR dual-port mezzanines, and 1× 1.92TB M.2 SSD [11]. Red Hat Enterprise Linux 8.10 OS, Slurm 24.05.5 Workload Manager, SingularityPRO version 4.1.6, NVIDIA driver 565.57.01, and CUDA 12.7 were installed on the computing nodes [11]. Additionally, a containerized environment based on Pytorch version 2.1.2 and the required libraries [91]. Training and evaluation were conducted on the publicly available CIFAR10 and CIFAR100 datasets [27]. Storage and dataset access were managed through large-capacity storage based on Ceph [11]. Due to the constraints within HPC environments, the execution time of a single run (i.e., 300 times calling the function ) is such that all times together (the total time of all observations) do not exceed the allocated allocation. So far, we have not limited energy consumption but only monitored it. Additional details of the experimental environment can be found in Table 1.

Table 1.
The experimental environment outlines ML model training parameters, and essential configuration to ensure hyperparameter optimization setup and reproducibility of this setup.
3.2. AutoDEHypO
We prepared our environment for the deployment of the AutoDEHypO workflow using supervised machine learning through pre-trained ML models (ResNet18, VGG11, ConvNeXtSmall, and DenseNet121) that are already available within the PyTorch framework; this included building a custom Singularity container for the PyTorch [91] framework with the required libraries. The composed code in the Python programming language takes care of loading a dataset and setting up a Distributed Data Parallel (DDP) that facilitates model parallelization and distribution, while the NVIDIA Collective Communications Library (NCCL) is used in the training phase for faster and more efficient inter-node back-end communication among multiple GPUs, as this ensures and enables efficient scaling among multiple GPUs. A set of methods was used to prepare, develop, and execute AutoDEHypO, including classification, hyperparameter optimization, metric evaluation, resource monitoring, and aggregated statistical analysis of the experimental results.
3.3. Differential-Evolution-Based Hyperparameter Optimization
A basic framework of the DE Algorithm 1 was used from a recent implementation that supports parallelization [15] for the optimization of hyperparameters, as it establishes a basis while minimizing complexity and allows future modifications and improvements as the experiment unfolds [21].
3.4. Job Scheduling, Training, Evaluation, and Visualization
The jobs are submitted through Slurm workload manager, as seen in Figure 2 [11,13]. The input SBATCH contains the required resources within the SBATCH script, the PyTorch container is invoked without modifying the underlying PyTorch code, and the code written in Python is executed. An example of the SBATCH script that can be wrapped in a conditional loop in the command line interface (CLI) or script can be seen in Figure 3.

Figure 2.
Basic workflow of job submission through the Slurm workload manager.

Figure 3.
SBATCH script for job submission.
Furthermore, the workflow is used for training, evaluation, metrics, the storage of data in the appropriate data frame, and graph plotting based on newly acquired data, as presented in Figure 4. Finally, the dataset is loaded, and the basic steps of DE presented in Figure 1 are performed to evaluate and return the most suitable parameters for the training and evaluation phase. When the job is completed, we evaluate the performance metrics, which are saved in a data frame along with visualizations. Thus, we wanted to check the adequacy of the optimization of the hyperparameter space; i.e., we examined the number of epochs and iterations, weights, learning rate (LR), batch size, and optimizers. Given that it has been implemented and deployed, the AutoDEHypO workflow leverages the potential of utilizing multiple GPUs to run DE fitness functions for ML, as presented in Figure 4. In the evaluation phase, basic ML metrics were used (Section 2.1). To obtain, measure, and compare the utilization of computer resources of individual jobs, such as the elapsed time and energy consumption, data from Slurm were used [13].

Figure 4.
Schematic overview of the analytics of the potential efficiency for the AutoDEHypO workflow.
3.5. Checkpoint and Restart, Collected Logs, and Fault Tolerance
Logging of the standard output and standard error output is enabled and generated in the event of an error. Email notifications are also set up to provide information on if a job is queued, started, completed, or failed [13]. This is important for certain cases where anomalies occur during initialization, such as when jobs need to be handled separately. The output files can be taken into account within the AutoDEHypO runtime, which can detect failures in settings, such as issues with NCCL or undetected GPUs within the initialization phase. One can look at these detections, from setting failures to the fact that CR uses feedback mechanisms to check which runs may need to be restarted (Figure 3 line 27). Furthermore, at the beginning of this experiment, we did not know how many resources were needed, and with the CR mechanism, we could accordingly adjust the input Slurm parameters and the need for the computational resource requirements, such as the job state, consumed energy, memory allocation, number of nodes, number of cores, number of cores per node, number of cores per CPU, number of tasks, number of GPUs, number of GPUs per node, and others. The Slurm command requeue allows the resubmission of a failed job when we can avoid and exclude any problematic nodes or, in the opposite case, when we do not want the submission, and a manual check is required after a certain number of—for example, 2—unsuccessful restarts; then, we can use the opposite command: no-requeue. This allows us to detect such errors in certain cases and perform an automatic restart of the job. Manual intervention is still required for cross-checking, and, if necessary, the job is resubmitted to the cluster queue, as shown in Figure 4. Due to the limitations of the experiment, the elapsed time and utilization of computer resources also needed to be taken into account.
4. Experimental Results
The experiments are divided into two phases of benchmarking. Within the first phase, we examine the efficiency of ML models and their parameters. The latter is then used in the second phase as a continuation of the experiments, to which we apply an analysis of the DE mutation strategies presented in Equations (8)–(12). The experiment had to be limited due to resource constraints such as time and the quota of computation resources granted within the development project on the largest Slovenian supercomputer, EuroHPC Vega. The ML models ResNet18, VGG11, ConvNeXtSmall, and DenseNet121 were used with public datasets. For the datasets, we chose CIFAR10 and CIFAR100, as they contain smaller images, thus providing a smaller size than other datasets, allowing them to be included, preprocessed, and trained [27]. The energy consumption is presented in Mega Joules (MJ) [13]. In order to obtain an assessment of the performance of the ML models and algorithms, aggregated statistics were calculated for the obtained results.
Taking into account that resource allocation may impact the obtained results, we ensured that all submitted job scripts had the same resource allocation [2]. Although it would have been possible to restrict our runs to a specific node using an additional Slurm option, this is not the intended use of HPC and was, hence, kept as a constraint. Therefore, jobs and runs were freely distributed across different nodes. During the initiation and execution of the experiment, we faced a few challenges on the software level that we could not avoid encountering, such as the wall time, which was set within the startup script, being too short, as well as a few others. The experiment was also run on the NVIDIA drivers and the Compute Unified Device Architecture (CUDA) Toolkit, which were updated at the beginning of the experiment, as we encountered a set of GPU nodes with incorrect configurations, which were resolved immediately, as well as hardware failures. This necessitated the replacement of DIMM modules and network cards, as well as the cleaning and resetting of network cards, GPUs, and other devices. Hardware problems in which GPUs are not available or are undetected lead to a failure of a large set of submitted jobs in less than 30 s on critical nodes due to failed internal communication through the NCCL back-end. In the event of such an error, a standard error output was generated, and an email notification was successfully received. Furthermore, the deployed CR was included as a common checkpoint for the ML model, therefore demonstrating how we saved important time with AutoDEHypO, with which we enabled resubmission. We received data on failed jobs, such as the time stamp, job state, job name, and job ID, that needed to be resubmitted. An example of the standard error output in the event of a runtime error is given in the following.
- RuntimeError:
- ProcessGroupNCCL is only supported with GPUs, no GPUs found!
The results obtained from the ResNet18, VGG11, ConvNeXtSmall, and DenseNet121 ML models on the CIFAR10 dataset are listed in Table 2, Table 3, Table 4 and Table 5, respectively. These tables present the batch size used and the results obtained, including the maximum achieved accuracy on the test batch, the best learning rate found, the best accuracy achieved, the CPU time consumed, the elapsed time, and the energy consumed in a Slurm job. Figure 5 provides an example of a subset for the ML performance of the ResNet18, VGG11, ConvNeXtSmall, and DenseNet121 ML models on the CIFAR10 dataset, and Figure 6 does so for the CIFAR100 dataset.
Table 2.
Results obtained in 15 epochs using the ResNet18 ML model on CIFAR10.
Table 3.
Results obtained in 15 epochs using the VGG11 ML model on CIFAR10.
Table 4.
Results obtained in 15 epochs using the ConvNeXtSmall ML model on CIFAR10.
Table 5.
Results obtained in 15 epochs using the DenseNet121 ML model on CIFAR10.
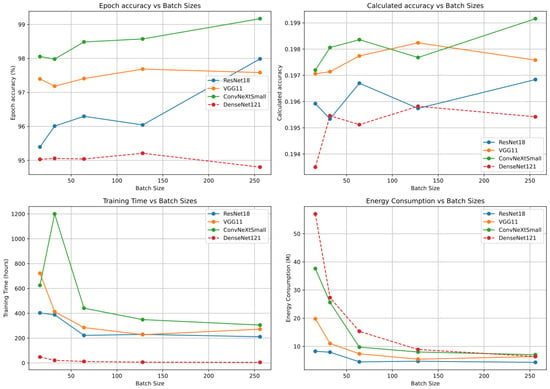
Figure 5.
Plots of the initially obtained results of the ML metrics on the CIFAR10 dataset.

Figure 6.
Plots of the initially obtained results of the ML metrics on the CIFAR100 dataset.
The results obtained from the ML models on the CIFAR100 dataset in the first initial phase are presented in Table 6 for ResNet18, for VGG11 in Table 7, for ConvNeXtSmall in Table 8, and for DenseNet121 in Table 9, respectively.
Table 6.
Results obtained in 15 epochs using the ResNet18 ML model on CIFAR100.
Table 7.
Results obtained in 15 epochs using the VGG11 ML model on CIFAR100.
Table 8.
Results obtained in 15 epochs using the ConvNeXtSmall ML model on CIFAR100.
Table 9.
Results obtained in 15 epochs using the DenseNet121 ML model on CIFAR100.
4.1. Obtained Results
Based on the reported data provided and using our methodology, we observed results in Table 2, Table 3, Table 4 and Table 5 for CIFAR10 and in Table 6, Table 7, Table 8 and Table 9. These tables show a minimum achieved accuracy on test trial and their corresponding impact, highlighting their significance, where the lowest observed accuracy is 62.56%, which corresponds to the calculated ML accuracy of 0.1724. The highest achieved accuracy is 99.17%, with the calculated ML accuracy of 0.19916. Furthermore, for consumed energy metric, we obtained a minimum reported value of 4.43 M (ResNet18) and a maximum value of 59.36 M (DenseNet121). We also observed the elapsed time metric, ranging from the fastest completed job of 03:38:37, to the longest job with wall time 2 d 00:00:17 that exceeded the maximum allowed job execution time within the submitted partition. The results obtained in the first phase of the experiment possibly indicated that using a batch size of 256 in a set of ML models produced the most suitable and efficient results.
We observed that the DenseNet121 model possibly consumed more energy on both datasets than the less complex ML models, such as ResNet18, as presented in Figure 5 and Figure 6. Individual ML models in combination with certain DE strategies possibly performed better and more consistently, while some possibly consumed more energy, e.g., with the exponential DE strategies applied to DenseNet121 or ResNet18, and vice versa, with binomial models possibly consuming more resources in ConvNeXSmall and VGG11. The second phase of the experiment proceeded with a performance comparison of the binomial and exponential DE strategies with each ML model. In this phase, 10 independent runs were executed, as this could more generally determine whether there were significant differences DE-strategy-wise or ML-model-wise, and confirm if there was an impact on key metrics. A mutation was applied randomly with a factor (F) presented in Table 1. The population size (P) and the maximum possible number of generations (G) were appropriately determined due to the project allocation and resource constraints, otherwise we would exceed the current allowable resource consumption within the project allocation. The convergences of metric of accuracy is plotted unified through runtimes in Figure 7 for those runs that obtained median accuracy among each of the 10 independent runs of a DE strategy for a ML model. As observed, the effects of the DE strategies DE/rand/1/bin, DE/best/1/bin, DE/current-to-best/1/bin, DE/rand/2/bin, DE/best/2/bin, as well as the exponential strategies, such as DE/rand/1/exp, DE/best/1/exp, DE/current-to-best/1/exp, DE/rand/2/exp, and DE/best/2/exp [55], possibly varies across different ML model architectures, such as ResNet18, VGG11, ConvNeXtSmall, and DenseNet121, and the CIFAR10 and CIFAR100 datasets [27]. As the results of the tables indicate, is rejected because at least one DE strategy shows a significant difference, and specific DE strategies may even perform better. Therefore, to analyse which and for how much overall when aggregated, we discuss in the next subsection.

Figure 7.
Accuracy convergences through runtime, for the median runs according to accuracy metric.
Figure 8 shows the statistical measure of the mean for each metric in the initial phase, and it is divided into three subplots (a) elapsed time, (b) consumed energy, and (c) accuracy for the DE strategies; these values were measured in 10 runs on the CIFAR10 dataset and are grouped by ML model. Figure 9 shows the same means of the selected DE strategies measured on the CIFAR100 dataset. Moreover, if we have a well-tuned ML model with appropriate weights, and the hyperparameters are poorly tuned, we possibly achieve worse ML performance over key metrics. Furthermore, the results obtained from the ResNet18, VGG11, ConvNeXtSmall, and DenseNet121 ML models with a batch size of 256 on both datasets show that, possibly, more efficient DE strategies consumed fewer resources, as the longer execution time possibly resulted in an increase the consumption of resources, and vice versa. A shorter execution time possibly resulted in lower resource consumption. The results on the CIFAR10 dataset are presented in Table A1, Table A2, Table A3 and Table A4, while the results on the CIFAR100 dataset are presented in Table A5, Table A6, Table A7 and Table A8.

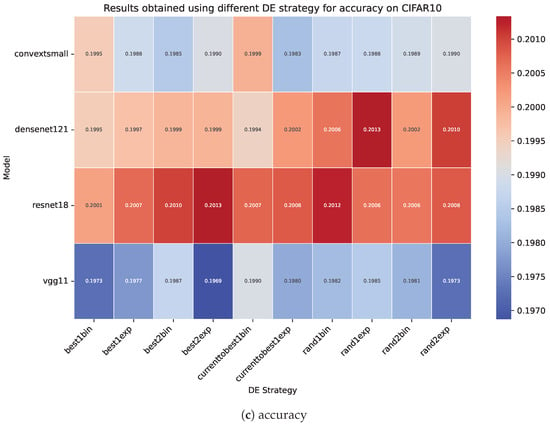
Figure 8.
The statistical measures of the mean for the elapsed time (a), consumed energy (b), and accuracy (c) from the results obtained from 10 runs of 15 epochs of ML models that were hyperoptimized using the different DE strategies presented in Table A1, Table A2, Table A3 and Table A4. The x-axis represents the evaluated DE strategies, while the y-axis shows the ML models used.

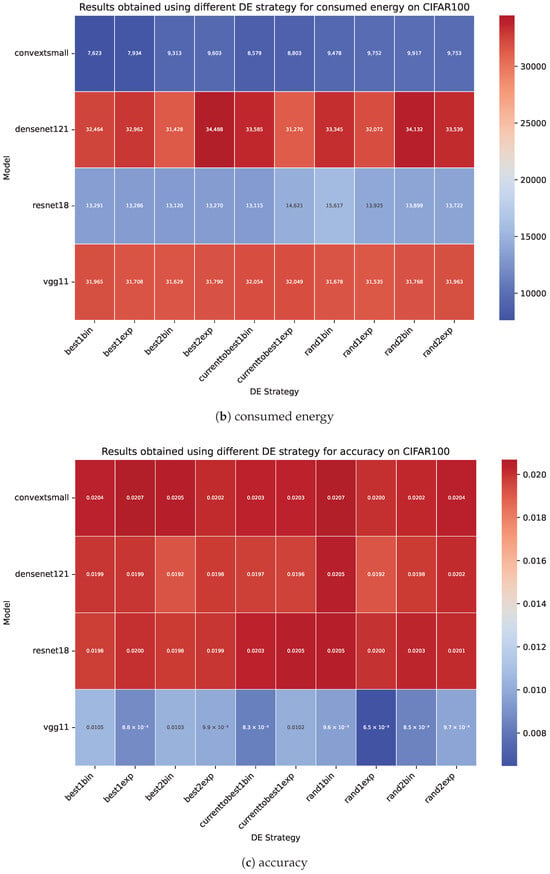
Figure 9.
The statistical measures of the mean for the elapsed time (a), consumed energy (b), and accuracy (c) from the results obtained from 10 runs of 15 epochs of ML models that were hyperoptimized using the different DE strategies presented in Table A5, Table A6, Table A7 and Table A8. The x-axis represents the evaluated DE strategies, while the y-axis shows the ML models used.
4.2. Discussion of the Aggregated Statistics
Aggregate statistical analysis using non-parametric Friedman tests and corresponding procedures for the computational results of the DE strategies was performed on the ResNet18, VGG11, ConvNeXtSmall, and DenseNet121 ML models and on the CIFAR10 and CIFAR100 datasets [27,115]. Control tests were performed on the metrics of elapsed time, consumed energy, and accuracy using custom extraction scripts and publicly available code for statistics [116]. The p-value threshold was set to 0.05, and significant differences were detected and marked (†). This analysis was conducted to determine whether the DE strategies, ML models, and their architectures or a combination thereof had a statistically significant impact and if there were significant differences in key metrics for the computational efficiency. The results of the statistical analysis are presented in Table 10, Table 11, Table 12, Table 13, Table 14, Table 15, Table 16, Table 17 and Table 18.
Table 10.
Statistical analysis of elapsed time in the DE strategies using a non-parametric Friedman test with the maximum rank distribution and corresponding post hoc procedures (rejected, as marked in bold and with † sign, at a statistical value below the threshold of 0.005555555555555556 for Bonferroni–Dunn, 0.05 for Holm and Hommel, 0.025 for Hochberg and Rom, 0.050000000000000044 for Holland and Finner, and 2.9216395384872545 × 10−17 for Li, respectively).
Table 11.
Statistical analysis of energy consumed in the DE strategies using the non-parametric Friedman test with the minimum rank distribution and corresponding post hoc procedures (rejected, as marked in bold and with † sign, at a statistical value below the threshold at 0.005555555555555556 for Bonferroni–Dunn, 0.016666666666666666 for Holm and Hommel, 0.0125 for Hochberg, 0.016952427508441503 for Holland, 0.013109375000000001 for Rom, 0.044570249746389234 for Finner, and 0.011483473500591115 for Li, respectively).
Table 12.
Statistical analysis of the accuracy in the DE strategies using the non-parametric Friedman test with the minimum rank distribution and corresponding post hoc procedures (rejected, as marked in bold and with † sign, at a statistical value below the threshold at 0.005555555555555556 for Bonferroni–Dunn, Holm, and Hommel, 0.005683044988048058 for Holland and Finner, and 7.7532015972022 ×10−4 for Li, respectively).
Table 13.
Statistical analysis of the elapsed time in the DE strategies using the non-parametric Friedman test with the maximum rank distribution and corresponding post hoc procedures (rejected, as marked in bold and with † sign, at a statistical value below the threshold of 0.005555555555555556 for Bonferroni–Dunn, Holm, and Hommel, 0.005683044988048058 for Holland and Finner, and 0.015161939437253264 for Li, respectively).
Table 14.
Statistical analysis of the energy consumed in the DE strategies using the non-parametric Friedman test with the minimum rank distribution and corresponding post hoc procedures (rejected, as marked in bold and with † sign, at a statistical value below the threshold of 0.005555555555555556 for Bonferroni–Dunn, Holm, and Hommel, 0.005683044988048058 for Holland and Finner, and 0.014435245666076669 for Li, respectively).
Table 15.
Statistical analysis of the accuracy in the DE strategies using the non-parametric Friedman test with the minimum rank distribution and corresponding post hoc procedures (rejected, as marked in bold and with † sign, at a statistical value below the threshold of 0.005555555555555556 for Bonferroni–Dunn and Hochberg, 0.00625 for Holm and Hommel, 0.006391150954545011 for Holland, 0.005843911024153359 for Rom, 0.011333792975759982 for Finner, and 0.03180542233195395 for Li, respectively).
Table 16.
Statistical analysis of the elapsed time in the DE strategies using the non-parametric Friedman test with the maximum rank distribution and corresponding post hoc procedures (rejected, as marked in bold and with † sign, at a statistical value below the threshold of 0.005555555555555556 for Bonferroni–Dunn, 0.0125 for Holm and Hommel, 0.01 for Hochberg, 0.012741455098566168 for Holland, 0.010515350115740741 for Rom, 0.039109465610866256 for Finner, and 0.010841964200380961 for Li, respectively).
Table 17.
Statistical analysis of the energy consumed in the DE strategies using the non-parametric Friedman test with the maximum rank distribution and corresponding post hoc procedures (rejected, as marked in bold and with † sign, at a statistical value below the threshold of 0.005555555555555556 for Bonferroni–Dunn, 0.0125 for Hochberg, 0.016666666666666666 for Holm and Hommel, 0.016952427508441503 for Holland, 0.013109375000000001 for Rom, 0.044570249746389234 for Finner, and 0.011898018581242242 for Li, respectively).
Table 18.
Statistical analysis of the accuracy in the DE strategies using the non-parametric Friedman test with the minimum rank distribution and corresponding post hoc procedures (rejected, as marked in bold and with † sign, at a statistical value below the threshold of 0.005555555555555556 for Bonferroni–Dunn, Holm and Hommel, 0.005683044988048058 for Holland, 0.005683044988048058 for Finner, and 0.0010964059917403937 for Li, respectively).
Table 10 presents a statistical analysis of the elapsed time in the DE strategies using a non-parametric Friedman test, where the maximum rank highlights the advantage across the DE strategies, along with the corresponding post hoc procedures. The elapsed time in the DE strategies is significantly better than that of rand2exp on CIFAR10 when using AutoDEHypO according to the post hoc procedures of Holm, Hochberg, Hommel, Holland, and Finner. The Rom procedure shows a significant difference across DE strategies in comparison with rand2exp, with the exception of rand1exp. The Li procedure shows a significant difference across DE strategies in comparison with rand2exp, with the exception of rand2bin. Therefore, AutoDEHypO suggests that on CIFAR10, with the metric of elapsed time, the DE strategies best1bin, best1exp, currenttobest1bin, currenttobest1exp, best2exp, best2bin, rand1bin, rand1exp, and rand2bin are more suitable than rand2exp.
Table 11 presents a statistical analysis of the consumed energy in DE strategies using the non-parametric Friedman test, where the minimum rank highlights the advantage across DE strategies and corresponding post hoc procedures. The consumed energy in the DE strategies rand2bin, rand2exp, best2bin, rand1bin, best2exp, rand1exp, and currenttobest1exp is significantly better than in best1bin on CIFAR10 with AutoDEHypO according to the post hoc procedures of Holm, Hochberg, Hommel, Holland, and Rom. The Finner procedure shows that the DE strategies rand2bin, rand2exp, and best2bin are significantly better than rand2bin. Furthermore, rand1exp is significantly better than rand2bin according to the Holm, Hochberg, Hommel, and Holland procedures. The Li procedure shows significant difference across DE strategies in comparison with best1bin, with the exception of best1exp. Therefore, AutoDEHypO suggests that on CIFAR10, for the metric of consumed energy, the DE strategies rand2bin, rand2exp, best2bin, rand1bin, best2exp, rand1exp, and currenttobest1exp are more suitable than currenttobest1bin, best1exp, and best1bin.
Table 12 presents a statistical analysis of the accuracy in the DE strategies using the non-parametric Friedman test, where the highest rank highlights the advantage across DE strategies and corresponding post hoc procedures. The accuracy in the DE strategy rand1exp is significantly better than that in best1exp on CIFAR10 with AutoDEHypO according to the post hoc procedures of Holm, Holland, and Finner. Therefore, AutoDEHypO suggests that on CIFAR10, for the metric of accuracy, the DE strategy rand1exp is more suitable than best1exp, rand2bin, rand1bin, currenttobest1bin, rand2exp, best2bin, currenttobest1exp, best1bin, and best2exp.
Table 13 presents a statistical analysis of the elapsed time in the DE strategies using the non-parametric Friedman test, where the maximum rank highlights the advantage across DE strategies and corresponding post hoc procedures. The elapsed time in the DE strategy best1exp is significantly better than that in rand2bin on CIFAR100 with AutoDEHypO according to the post hoc procedures of Holm, Holland, and Finner. The Li procedure shows significant differences across DE strategies in comparison with rand2bin, with the exception of rand2exp. Therefore, AutoDEHypO suggests that on CIFAR100, for the metric of elapsed time, the DE strategy best1exp is more suitable than rand2bin, best2bin, best1bin, currenttobest1bin, currenttobest1exp, rand1bin, rand1exp, best2exp, and rand2exp.
Table 14 presents a statistical analysis of the energy consumed in the DE strategies using the non-parametric Friedman test, where the minimum rank highlights the advantage across DE strategies and corresponding post hoc procedures. The energy consumed in the DE strategy rand2bin is significantly better than that in best1bin on CIFAR100 with AutoDEHypO according to the post hoc procedures of Holm, Hommel, Holland, and Finner. The Li procedure shows significant differences across DE strategies in comparison with best1bin, with the exception of best1exp. Therefore, AutoDEHypO suggests that on CIFAR100, for the metric of consumed energy, the DE strategy rand2bin is more suitable than best1bin, rand1bin, rand2exp, best2exp, currenttobest1exp, rand1exp, currenttobest1bin, best2bin, and best1exp.
Table 15 presents a statistical analysis of the accuracy in the DE strategies using the non-parametric Friedman test, where the highest rank highlights the advantage across DE strategies and corresponding post hoc procedures. The accuracy in the DE strategy rand1bin is significantly better than that in rand1exp on CIFAR100 with AutoDEHypO according to the post hoc procedures of Holm, Hommel, Holland, Rom and Finner. The DE strategy best2bin is significantly better than rand1exp according to the procedures of Holm, Hommel, and Holland. The Li procedure shows significant differences across DE strategies in comparison with rand1exp, with the exception of best2bin. Therefore, AutoDEHypO suggests that on CIFAR100, for the metric of accuracy, the DE strategies rand1bin and rand2exp are more suitable than rand1exp, currenttobest1exp, currenttobest1bin, rand2bin, best1bin, best2exp, best1exp, and best2bin.
Table 16 presents a statistical analysis of the elapsed time in the DE strategies using the non-parametric Friedman test, where the maximum rank highlights the advantage across DE strategies and corresponding post hoc procedures. The elapsed time in the DE strategies best1exp and best1bin is significantly better than that in rand2bin on CIFAR10 and CIFAR100 with AutoDEHypO according to the post hoc procedures of Holm, Hochberg, Holland, Rom, and Finner. Additionally, the DE strategies currenttobest1bin, best2bin, and currenttobest1exp are significantly better than rand2bin according to the procedures of Holm, Hochberg, Hommel, Holland, and Rom. best2exp is significantly better than rand2bin according to the procedures of Holm, Hochberg, Hommel, and Holland. The Li procedure shows significant differences across DE strategies in comparison with rand2bin, with the exception of rand2exp. Therefore, AutoDEHypO suggests that on CIFAR10 and CIFAR100, for the metric of elapsed time, the DE strategies best1exp, best1bin, currenttobest1bin, best2bin, currenttobest1exp, and best2exp are more suitable than rand1bin, rand1exp, and rand2exp.
Table 17 presents a statistical analysis of the energy consumed in the DE strategies using the non-parametric Friedman test, where the maximum rank highlights the advantage across DE strategies and corresponding post hoc procedures. The energy consumed in the DE strategies best1bin, best1exp, currenttobest1bin, currenttobest1exp, best2bin, rand1exp, and best2exp is significantly better than that in rand2bin on CIFAR10 and CIFAR100 with AutoDEHypO according to the post hoc procedures of Holm, Hochberg, Hommel, Holland, and Rom. According to Finner’s post hoc procedure, the DE strategies best1bin, best1exp, and currenttobest1bin are significantly better than rand2bin. The Li procedure shows significant differences across DE strategies in comparison with rand2bin, with the exception of rand2exp. Therefore, AutoDEHypO suggests that on CIFAR10 and CIFAR100, for the metric of consumed energy, the DE strategies best1bin, best1exp, currenttobest1bin, currenttobest1exp, best2bin, rand1exp, and best2exp are more suitable than rand2bin, rand1bin, and rand2exp.
Table 18 presents a statistical analysis of the accuracy in the DE strategies using the non-parametric Friedman test, where the highest rank highlights the advantage across DE strategies and corresponding post hoc procedures. The accuracy in the DE strategy rand1bin is significantly better than that in best1exp on CIFAR10 and CIFAR100 with AutoDEHypO according to the post hoc procedures of Holm, Hommel, Holland, and Finner. The Li procedure shows significant differences across DE strategies in comparison with best1exp, with the exception of best2exp. Therefore, AutoDEHypO suggests that on CIFAR10 and CIFAR100, for the metric of accuracy, the DE strategy rand1bin is more suitable than best1exp, currenttobest1bin, rand2exp, rand2bin, currenttobest1exp, rand1exp, best1bin, best2bin, and best2exp.
As shown in Table 10, Table 11 and Table 12, according to Holm, Hochberg, Hommel, Holland, and Finner, on CIFAR10, several DE strategies perform significantly better than rand2exp, with additional confirmation from the Rom and Li procedures, except for rand2bin. The DE strategy best1exp runs significantly better than rand2bin, with confirmation from Li (with the exception of rand2exp). Furthermore, the energy consumption in the DE strategies rand2bin, rand2exp, best2bin, rand1bin, best2exp, rand1exp, and currenttobest1exp is significantly better than that in best1bin, with confirmation from Li, except for rand2exp. Table 16, Table 17 and Table 18 present results on both CIFAR10 and CIFAR100, where best1bin, best1exp, currenttobest1bin, currenttobest1exp, best2bin, rand1exp, and best2exp perform significantly better than rand2bin in terms of metrics according to the Li procedure, with exception of rand2exp. In terms of accuracy, best1exp outperforms rand1exp on CIFAR10. As shown in Table 13, Table 14 and Table 15, on CIFAR100, rand1bin achieves significantly better accuracy than that of rand1exp, with confirmation from Li, with the exception of best2bin. Across both datasets, rand1bin also demonstrates significantly better accuracy than that of best1exp, except for best2exp, according to the Li procedure.
Table 19 presents an overview of the outcomes of the statistical analysis and the aggregated number (counts) of confirmed out of 450, 184 (40.8%) significant differences in the DE strategies counting each post hoc procedure across the tree key metrics. These outcomes show and confirm significant differences in elapsed time, energy efficiency, and accuracy across the DE strategies. In addition to the elapsed time and accuracy, our operational data analytics also confirm the impact on energy efficiency when selecting DE strategies.
Table 19.
Overview of the outcomes of the statistical analysis for the metrics of elapsed time, energy efficiency, and accuracy in the DE strategies using the non-parametric Friedman test on both the CIFAR10 and CIFAR00 datasets.
As ML models depend on the input data characteristics and on the computational complexity of ML architecture designs, it is expected that some ML models are more suitable. To check this, we tested the suitability of some ML models by detecting differences in elapsed time, consumed energy, and accuracy. The aggregated test outcomes are seen in Table 20, where, for all three key metrics (elapsed time, consumed energy, and accuracy), it is evident from the Friedman rankings that the ResNet18 and ConvNextSmall ML models are ranked higher than the other two ML models, DenseNet121 and VGG11. These ranks are significantly different for the accuracy metric in the case of VGG11. For the metrics of elapsed time and consumed energy, in the case of VGG11, this is also significant. Moreover, significant differences from ML model DenseNet121 are also detected, i.e., these two (DenseNet121 and VGG11) require significantly more energy and time than ResNet18 and ConvNextSmall.
Table 20.
Friedman rankings detected differences in elapsed time, consumed energy, and accuracy aggregated across ML models. The individual rankings demonstrate significant differences using the Holm/Hochberg/Hommel, Holland, Rom, Finner, and Li procedures, with a few exceptions for the post hoc procedures (the Rom and Li procedures for time and energy detect these differences only when comparing VGG11 and DenseNet121 against ResNet18 and ConvNextSmall, i.e., for 41 (91.1%) out of 45 rankings in the post hoc procedures, we successfully detected significant differences).
Furthermore, significant differences between four ML models for 10 DE strategies (denoted as k) evaluations per each run result in 20 combinations (denoted as N), with critical value of from the the two-tailed Bonferroni-Dunn test for k is studentized range statistic at the significance level threshold of on their Friedman average ranks. To compare their ranks we calculated critical difference (CD) [117] of approximately . Additionally, we calculated confidence intervals (CI) based on CD, which detected significant difference in 11 (61.11%) out of 18 pairwise comparisons. The results are presented in Table 21.
Table 21.
Ranks and confidence intervals for key metrics elapsed time, consumed energy, and accuracy across ML Models ResNet18, ConvNextSmall, DenseNet121, and VGG11 on CIFAR10 and CIFAR100 datasets.
5. Conclusions and Future Work
In this article, we presented the deployment of a high-performance differential-evolution-based hyperparameter optimization workflow (AutoDEHypO) for energy efficiency and operational data analytics on multiple GPUs, where a DE algorithm with different DE strategies is demonstrated and applied in hyperparameter optimization while considering key factors such as the ML model, dataset, and DE strategy. The challenge of the optimization of ML models in HPC environments was addressed by balancing the ML accuracy, energy consumption, and resource utilization. Practical limitations such as project time constraints and the computational resources allocated to this project on a part of the national share of HPC Vega may have influenced the experiment through aspects such as node availability, high cluster utilization, shared node scheduling, elapsed time and partition (wall time) limitations, network congestion, job failures, undetected GPUs, and limited granularity in energy measurement at the node level. The utilization of computing resources had to be carefully considered, and the evaluation metrics and their scope must be taken into account. AutoDEHypO detected significant differences in the utilization of HPC resources in terms of elapsed time, energy efficiency, and ML accuracy across DE strategies. Furthermore, AutoDEHypO overcomes several limitations of existing workflows, which mostly focus on ML performance, inefficient utilization of computational resources during job allocation, and extended queue times; therefore, there is a lack of integration with HPC environments and schedulers such as Slurm and limited support for sustainability and cost-effectiveness. In addition to tracking the elapsed time and accuracy, our AutoDEHypO uses operational data analytics to determine how energy efficiently DE algorithms and DE strategies perform and confirms the impact on energy efficiency when selecting DE strategies. The analytics of DE strategies influenced the consumption of resources and indicated when the consumption of energy and other resources led to different ML performance and configurations. Furthermore, the statistical analysis of the key metrics of elapsed time, consumed energy, and accuracy demonstrated significant differences in DE strategies and ML models by using the non-parametric Friedman test and corresponding post hoc procedures for CIFAR10 and CIFAR100 datasets.
Specifically, in 10 independent runs, the DE binomial mutation strategies were applied and out of 450 comparisons, 184 (40.8%) detected significant differences between strategies. The effect of used DE strategies DE/rand/1/bin, DE/best/1/bin, DE/current-to-best/1/bin, DE/rand/2/bin, DE/best/2/bin, and exponential such as DE/rand/1/exp, DE/best/1/exp, DE/current-to-best/1/exp, DE/rand/2/exp, and DE/best/2/exp varied across differentent ML model architectures such as ResNet18, VGG11, ConvNeXtSmall and DenseNet121, on datasets CIFAR10 and CIFAR100.
Additionally, as an important outcome, the ML model comparisons show that there are 41 (91.1%) out of 45 rankings in the post hoc procedures, where AutoDEHypO successfully detected significant differences in all three key metrics in the case of the VGG11 ML model; for the metrics of elapsed time and consumed energy, there were further significant differences detected in the DenseNet121 and VGG11 models when compared with the better ML models of ConvNextSmall and ResNet18. Furthermore, the calculated confidence intervals based on critical difference of approximately , detected significant differences in 11 (61.11%) out of 18 pairwise comparisons.
Despite the insights and contributions provided by this article, there are a few limitations to acknowledge. This workflow is designed and optimized for deployment on a single cluster. Generalizing this workflow to another HPC environment may be challenging due to differences in architecture, scheduling policies, and energy monitoring solutions. Furthermore, within the proposed workflow, we used a basic DE algorithm implementation and limited this research to a few ML models, two datasets (CIFAR10 and CIFAR100), a single DE algorithm, 10 DE strategies, and limited runs of each epoch. While this setup was sufficient for initial exploration and experimentation, further research can be conducted. Moreover, this workflow can be adopted for other ML models, such as neural networks with adjustments in their architectures, different DE algorithms and DE strategies, population sizes, and different datasets, such as ImageNet, MNIST, and others; last but not least, more computational resources can be used. Possibilities have emerged for the evaluation and validation of other algorithms and AutoML frameworks to provide a baseline comparison with state-of-the-art AutoML frameworks and beyond. The necessary validation and comparison for a different environment could take place within an additional experiment; this could include a comparison of the final results. System malfunctions may also be resolved through fault-tolerance mechanisms such as Checkpoint and Restart (CR) without affecting the obtained results, allowing one to continue after unexpected interruptions. Additionally, we can apply CR inside the DE loop, where we can continue from the last successfully saved and calculated generation. Furthermore, a real-time feedback mechanism for adaptive and dynamic changes within ML operations has not yet been implemented and may contribute to the workflow; this may be researched in the future. The prediction model and decision making based on historical data can contribute to ML performance, optimization, and energy efficiency. These improvements will not only strengthen the practical applicability of this workflow but also contribute to sustainability, and a reduction in the environmental footprint.
Author Contributions
Conceptualization, T.P. and A.Z.; methodology, T.P. and A.Z.; software, T.P. and A.Z.; validation, T.P. and A.Z.; formal analysis, T.P. and A.Z.; investigation, T.P. and A.Z.; resources, T.P. and A.Z.; data curation, T.P. and A.Z.; writing—original draft preparation, T.P. and A.Z.; writing—review and editing, T.P. and A.Z.; visualization, T.P. and A.Z.; supervision, T.P. and A.Z.; project administration, T.P. and A.Z.; funding acquisition, T.P. and A.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded and conducted within the Individual Research Work 3 Unit of the doctoral program for Computer Science and Informatics at the University of Maribor. The fee for study enrollment was financed by IZUM—Institute of Information Science (17-2141-2023/01-ab and 17-2375-2024/01-ab).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The original data are included within this paper. Further inquiries may be addressed to the corresponding author.
Acknowledgments
The authors acknowledge the EuroHPC JU, HPC RIVR and SLING consortium for allocating computing resources on the national share of HPC Vega within the Development Project (S24R08-01) hosted at the Institute of Information Science (IZUM). Authors also acknowledge the project DAPHNE (Integrated Data Analysis Pipelines for Large-Scale Data Management, HPC, and Machine Learning) funded by the European Union’s Horizon 2020 research and innovation program under grant agreement No 957407. We also acknowledge COST (European Cooperation in Science and Technology) support from COST Actions: CA22137 “Randomised Optimisation Algorithms Research Network (ROAR-NET)”. Authors acknowledge the MDPI Institutional Open Access Program (IOAP) for University of Maribor and thank editors and reviewers of this paper.
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A
Table A1.
Results obtained from 10 runs of 15 epochs of a hyperoptimized ResNet18 using a different DE strategy on CIFAR10.
Table A1.
Results obtained from 10 runs of 15 epochs of a hyperoptimized ResNet18 using a different DE strategy on CIFAR10.
| Run | Strategy | Max Accuracy (%) | Best LR | Best Accuracy | CPU Time | Elapsed Time | Consumed Energy |
|---|---|---|---|---|---|---|---|
| Run 1 | rand1bin | 100% | 0.0001716955308133066 | 0.20128 | 07:17:56 | 01:49:29 | 2.39 MJ |
| Run 2 | rand1bin | 99.976% | 0.0001716955308133066 | 0.20176 | 08:02:20 | 02:00:35 | 2.63 MJ |
| Run 3 | rand1bin | 100% | 0.0001716955308133066 | 0.20128 | 06:35:40 | 01:38:55 | 2.11 MJ |
| Run 4 | rand1bin | 100% | 0.0001716955308133066 | 0.20176 | 09:58:56 | 02:29:44 | 3.12 MJ |
| Run 5 | rand1bin | 99.96% | 0.0001716955308133066 | 0.198 | 09:54:12 | 02:28:33 | 3.11 MJ |
| Run 6 | rand1bin | 100% | 0.0001716955308133066 | 0.20176 | 06:41:04 | 01:40:16 | 2.14 MJ |
| Run 7 | rand1bin | 100% | 0.0001716955308133066 | 0.20128 | 10:13:04 | 02:33:16 | 3.27 MJ |
| Run 8 | rand1bin | 99.984% | 0.0001716955308133066 | 0.20176 | 07:53:16 | 01:58:19 | 2.52 MJ |
| Run 9 | rand1bin | 100% | 0.0001716955308133066 | 0.20176 | 07:58:52 | 01:59:43 | 2.62 MJ |
| Run 10 | rand1bin | 100% | 0.0001716955308133066 | 0.20176 | 07:13:28 | 01:48:22 | 2.32 MJ |
| Run 1 | best1bin | 99.968% | 0.00013244795866876926 | 0.198 | 08:38:48 | 02:09:42 | 2.82 MJ |
| Run 2 | best1bin | 100% | 0.00013244795866876926 | 0.20128 | 09:53:04 | 02:28:16 | 3.20 MJ |
| Run 3 | best1bin | 99.96% | 0.00024077230180039115 | 0.19896 | 06:58:32 | 01:44:38 | 2.37 MJ |
| Run 4 | best1bin | 99.992% | 0.00013244795866876926 | 0.20176 | 09:38:28 | 02:24:37 | 3.18 MJ |
| Run 5 | best1bin | 100% | 0.00024077230180039115 | 0.198 | 05:56:00 | 01:29:00 | 1.95 MJ |
| Run 6 | best1bin | 100% | 0.0002162424541476714 | 0.19896 | 08:18:20 | 02:04:35 | 2.86 MJ |
| Run 7 | best1bin | 99.968% | 0.00024077230180039115 | 0.20176 | 07:53:16 | 01:58:19 | 2.52 MJ |
| Run 8 | best1bin | 99.992% | 0.00024077230180039115 | 0.19896 | 10:41:56 | 02:40:29 | 3.30 MJ |
| Run 9 | best1bin | 99.704% | 0.00024077230180039115 | 0.20176 | 10:49:16 | 02:42:19 | 3.47 MJ |
| Run 10 | best1bin | 99.936% | 0.00024077230180039115 | 0.20176 | 07:17:32 | 01:49:23 | 2.29 MJ |
| Run 1 | currenttobest1bin | 99.952% | 0.00024077230180039115 | 0.20176 | 11:21:40 | 02:50:25 | 3.58 MJ |
| Run 2 | currenttobest1bin | 99.984% | 0.00024077230180039115 | 0.20176 | 09:25:32 | 02:21:23 | 3.05 MJ |
| Run 3 | currenttobest1bin | 100% | 0.0002162424541476714 | 0.19896 | 09:46:36 | 02:26:39 | 3.14 MJ |
| Run 4 | currenttobest1bin | 100% | 0.00024077230180039115 | 0.20176 | 13:04:00 | 03:16:00 | 4.27 MJ |
| Run 5 | currenttobest1bin | 99.984% | 0.00013244795866876926 | 0.20176 | 08:57:32 | 02:14:23 | 2.84 MJ |
| Run 6 | currenttobest1bin | 100% | 0.00024077230180039115 | 0.19896 | 09:10:16 | 02:17:34 | 3.00 MJ |
| Run 7 | currenttobest1bin | 100% | 0.00024077230180039115 | 0.20128 | 09:13:24 | 02:18:21 | 2.95 MJ |
| Run 8 | currenttobest1bin | 99.952% | 0.00013244795866876926 | 0.20176 | 09:28:36 | 02:22:09 | 3.06 MJ |
| Run 9 | currenttobest1bin | 99.976% | 0.0002162424541476714 | 0.198 | 11:38:12 | 02:54:33 | 3.93 MJ |
| Run 10 | currenttobest1bin | 99.264% | 0.00024077230180039115 | 0.20128 | 11:49:40 | 02:57:25 | 3.82 MJ |
| Run 1 | rand2bin | 99.624% | 0.00024077230180039115 | 0.20176 | 12:54:56 | 03:13:44 | 4.40 MJ |
| Run 2 | rand2bin | 100% | 0.00024077230180039115 | 0.20176 | 11:32:48 | 02:53:12 | 3.73 MJ |
| Run 3 | rand2bin | 99.992% | 0.0002162424541476714 | 0.20176 | 10:10:04 | 02:32:31 | 3.30 MJ |
| Run 4 | rand2bin | 99.928% | 0.00024077230180039115 | 0.20128 | 09:53:00 | 02:28:15 | 3.21 MJ |
| Run 5 | rand2bin | 99.992% | 0.0002486243259268821 | 0.198 | 12:27:56 | 03:06:59 | 4.02 MJ |
| Run 6 | rand2bin | 100% | 0.0002162424541476714 | 0.198 | 16:39:40 | 04:09:55 | 5.48 MJ |
| Run 7 | rand2bin | 99.944% | 0.00024077230180039115 | 0.20176 | 12:32:40 | 03:08:10 | 4.09 MJ |
| Run 8 | rand2bin | 100% | 0.00024077230180039115 | 0.198 | 12:17:04 | 03:04:16 | 3.95 MJ |
| Run 9 | rand2bin | 100% | 0.00024077230180039115 | 0.20176 | 08:38:56 | 02:09:44 | 2.82 MJ |
| Run 10 | rand2bin | 100% | 0.00028135858111119703 | 0.20176 | 12:44:44 | 03:11:11 | 3.99 MJ |
| Run 1 | best2bin | 99.144% | 0.0002021582861747835 | 0.19896 | 14:49:44 | 03:42:26 | 4.75 MJ |
| Run 2 | best2bin | 100% | 0.0002021582861747835 | 0.20128 | 10:21:20 | 02:35:20 | 3.30 MJ |
| Run 3 | best2bin | 100% | 0.00024077230180039115 | 0.20176 | 11:26:32 | 02:51:38 | 3.62 MJ |
| Run 4 | best2bin | 100% | 0.0002021582861747835 | 0.20176 | 10:09:48 | 02:32:27 | 3.29 MJ |
| Run 5 | best2bin | 99.896% | 0.0001447530265703141 | 0.20128 | 10:46:08 | 02:41:32 | 3.54 MJ |
| Run 6 | best2bin | 100% | 0.0002021582861747835 | 0.20176 | 08:46:40 | 02:11:40 | 2.79 MJ |
| Run 7 | best2bin | 100% | 0.00024077230180039115 | 0.20128 | 07:18:08 | 01:49:32 | 2.39 MJ |
| Run 8 | best2bin | 100% | 0.00028135858111119703 | 0.20128 | 11:21:12 | 02:50:18 | 3.83 MJ |
| Run 9 | best2bin | 99.936% | 0.00024077230180039115 | 0.19896 | 08:07:20 | 02:01:50 | 2.60 MJ |
| Run 10 | best2bin | 100% | 0.00012393180074355006 | 0.20176 | 14:49:32 | 03:42:23 | 4.69 MJ |
| Run 1 | rand1exp | 99.976% | 0.0001716955308133066 | 0.20176 | 07:19:36 | 01:49:54 | 2.39 MJ |
| Run 2 | rand1exp | 100% | 0.0001716955308133066 | 0.20128 | 07:20:20 | 01:50:05 | 2.37 MJ |
| Run 3 | rand1exp | 99.984% | 0.0001716955308133066 | 0.198 | 10:16:08 | 02:34:02 | 3.24 MJ |
| Run 4 | rand1exp | 99.992% | 0.0001716955308133066 | 0.20176 | 08:01:56 | 02:00:29 | 2.59 MJ |
| Run 5 | rand1exp | 99.992% | 0.0001716955308133066 | 0.20128 | 07:12:32 | 01:48:08 | 2.33 MJ |
| Run 6 | rand1exp | 100% | 0.0001716955308133066 | 0.20176 | 08:33:16 | 02:08:19 | 2.79 MJ |
| Run 7 | rand1exp | 99.992% | 0.0001716955308133066 | 0.19896 | 07:16:08 | 01:49:02 | 2.31 MJ |
| Run 8 | rand1exp | 100% | 0.0001716955308133066 | 0.20176 | 08:34:56 | 02:08:44 | 2.76 MJ |
| Run 9 | rand1exp | 100% | 0.0001716955308133066 | 0.20176 | 08:35:56 | 02:08:59 | 2.80 MJ |
| Run 10 | rand1exp | 99.984% | 0.0001716955308133066 | 0.198 | 10:37:28 | 02:39:22 | 3.45 MJ |
| Run 1 | rand2exp | 99.92% | 0.00024077230180039115 | 0.20176 | 11:20:12 | 02:50:03 | 3.81 MJ |
| Run 2 | rand2exp | 99.968% | 0.00024077230180039115 | 0.20176 | 12:48:44 | 03:12:11 | 4.04 MJ |
| Run 3 | rand2exp | 99.92% | 0.00024077230180039115 | 0.20176 | 14:57:20 | 03:44:20 | 4.86 MJ |
| Run 4 | rand2exp | 99.976% | 0.00024077230180039115 | 0.20176 | 13:53:52 | 03:28:28 | 4.52 MJ |
| Run 5 | rand2exp | 100% | 0.0002162424541476714 | 0.19896 | 11:56:04 | 02:59:01 | 3.76 MJ |
| Run 6 | rand2exp | 99.808% | 0.00024077230180039115 | 0.198 | 14:34:24 | 03:38:36 | 4.54 MJ |
| Run 7 | rand2exp | 99.88% | 0.00024077230180039115 | 0.20176 | 14:13:36 | 03:33:24 | 4.48 MJ |
| Run 8 | rand2exp | 100% | 0.00024077230180039115 | 0.20176 | 10:30:48 | 02:37:42 | 3.39 MJ |
| Run 9 | rand2exp | 100% | 0.0002162424541476714 | 0.19896 | 09:19:56 | 02:19:59 | 2.99 MJ |
| Run 10 | rand2exp | 99.96% | 0.0002162424541476714 | 0.20176 | 19:39:00 | 04:54:45 | 6.27 MJ |
| Run 1 | best1exp | 99.976% | 0.00013244795866876926 | 0.20176 | 06:38:40 | 01:39:40 | 2.15 MJ |
| Run 2 | best1exp | 99.984% | 0.00013244795866876926 | 0.20128 | 12:34:44 | 03:08:41 | 4.02 MJ |
| Run 3 | best1exp | 99.712% | 0.0002162424541476714 | 0.19896 | 11:19:16 | 02:49:49 | 3.67 MJ |
| Run 4 | best1exp | 100% | 0.00013244795866876926 | 0.20176 | 11:52:36 | 02:58:09 | 3.74 MJ |
| Run 5 | best1exp | 100% | 0.00024077230180039115 | 0.19896 | 11:31:00 | 02:52:45 | 3.68 MJ |
| Run 6 | best1exp | 99.96% | 0.00013244795866876926 | 0.20176 | 10:16:44 | 02:34:11 | 3.23 MJ |
| Run 7 | best1exp | 99.928% | 0.00013244795866876926 | 0.20128 | 10:52:20 | 02:43:05 | 3.45 MJ |
| Run 8 | best1exp | 99.952% | 0.00013244795866876926 | 0.198 | 11:16:32 | 02:49:08 | 3.66 MJ |
| Run 9 | best1exp | 100% | 0.00024077230180039115 | 0.20176 | 09:32:08 | 02:23:02 | 3.11 MJ |
| Run 10 | best1exp | 99.968% | 0.0002162424541476714 | 0.20128 | 08:45:16 | 02:11:19 | 2.76 MJ |
| Run 1 | best2exp | 100% | 0.00024077230180039115 | 0.20176 | 12:03:28 | 03:00:52 | 3.84 MJ |
| Run 2 | best2exp | 100% | 0.0002021582861747835 | 0.20176 | 09:13:40 | 02:18:25 | 3.20 MJ |
| Run 3 | best2exp | 100% | 0.0002021582861747835 | 0.20176 | 10:47:16 | 02:41:49 | 3.43 MJ |
| Run 4 | best2exp | 99.928% | 0.00021097950456378797 | 0.19896 | 13:38:24 | 03:24:36 | 4.24 MJ |
| Run 5 | best2exp | 99.584% | 0.00012393180074355006 | 0.20128 | 12:44:44 | 03:11:11 | 4.13 MJ |
| Run 6 | best2exp | 100% | 0.00012393180074355006 | 0.20176 | 08:33:20 | 02:08:20 | 2.71 MJ |
| Run 7 | best2exp | 99.968% | 0.00024077230180039115 | 0.20128 | 07:16:28 | 01:49:07 | 2.33 MJ |
| Run 8 | best2exp | 100% | 0.0002021582861747835 | 0.20176 | 09:07:56 | 02:16:59 | 2.90 MJ |
| Run 9 | best2exp | 100% | 0.0002162424541476714 | 0.20128 | 13:31:32 | 03:22:53 | 4.39 MJ |
| Run 10 | best2exp | 100% | 0.00024077230180039115 | 0.20176 | 08:55:28 | 02:13:52 | 2.87 MJ |
| Run 1 | currenttobest1exp | 100% | 0.00024077230180039115 | 0.19896 | 10:41:24 | 02:40:21 | 3.33 MJ |
| Run 2 | currenttobest1exp | 99.984% | 0.00013244795866876926 | 0.20176 | 12:47:04 | 03:11:46 | 4.01 MJ |
| Run 3 | currenttobest1exp | 99.872% | 0.00013244795866876926 | 0.19896 | 09:16:40 | 02:19:10 | 2.98 MJ |
| Run 4 | currenttobest1exp | 100% | 0.0002162424541476714 | 0.20176 | 06:52:04 | 01:43:01 | 2.24 MJ |
| Run 5 | currenttobest1exp | 100% | 0.0002162424541476714 | 0.20176 | 06:27:28 | 01:36:52 | 2.06 MJ |
| Run 6 | currenttobest1exp | 99.992% | 0.00013244795866876926 | 0.20176 | 11:03:32 | 02:45:53 | 3.73 MJ |
| Run 7 | currenttobest1exp | 99.968% | 0.00024077230180039115 | 0.20176 | 07:45:12 | 01:56:18 | 2.55 MJ |
| Run 8 | currenttobest1exp | 100% | 0.00013244795866876926 | 0.20176 | 07:15:28 | 01:48:52 | 2.36 MJ |
| Run 9 | currenttobest1exp | 99.976% | 0.00024077230180039115 | 0.198 | 09:52:00 | 02:28:00 | 3.08 MJ |
| Run 10 | currenttobest1exp | 99.968% | 0.00013244795866876926 | 0.20176 | 07:17:28 | 01:49:22 | 2.28 MJ |
Table A2.
Results obtained from 10 runs of 15 epochs of a hyperoptimized VGG11 using a different DE strategy on CIFAR10.
Table A2.
Results obtained from 10 runs of 15 epochs of a hyperoptimized VGG11 using a different DE strategy on CIFAR10.
| Run | Strategy | Max Accuracy (%) | Best LR | Best Accuracy | CPU Time | Elapsed Time | Consumed Energy |
|---|---|---|---|---|---|---|---|
| Run 1 | rand1bin | 91.136% | 0.0002850492178633215 | 0.19464 | 1 d 06:51:08 | 07:42:47 | 10.92 MJ |
| Run 2 | rand1bin | 89.84% | 0.00014533476190324503 | 0.1996 | 1 d 15:46:04 | 09:56:31 | 13.54 MJ |
| Run 3 | rand1bin | 88.904% | 0.00016212406890736 | 0.20008 | 2 d 08:05:20 | 14:01:20 | 19.72 MJ |
| Run 4 | rand1bin | 88.096% | 0.00017447715387706086 | 0.19648 | 2 d 14:03:44 | 15:30:56 | 21.79 MJ |
| Run 5 | rand1bin | 78.848% | 0.00013277606163792152 | 0.20008 | 1 d 17:55:48 | 10:28:57 | 14.62 MJ |
| Run 6 | rand1bin | 84.84% | 0.00040217263101021024 | 0.19552 | 1 d 16:39:36 | 10:09:54 | 14.22 MJ |
| Run 7 | rand1bin | 86.832% | 0.00013772520953436778 | 0.1996 | 1 d 13:27:44 | 09:21:56 | 14.32 MJ |
| Run 8 | rand1bin | 91.024% | 0.00024113078304294758 | 0.19984 | 1 d 20:35:00 | 11:08:45 | 15.61 MJ |
| Run 9 | rand1bin | 77.488% | 0.00013959268979809545 | 0.19848 | 2 d 07:07:04 | 13:46:46 | 19.14 MJ |
| Run 10 | rand1bin | 90.2% | 0.00018376849081430186 | 0.196 | 2 d 02:35:04 | 12:38:46 | 18.53 MJ |
| Run 1 | best1bin | 88.888% | 0.00017084651054119834 | 0.19576 | 1 d 05:08:32 | 07:17:08 | 10.27 MJ |
| Run 2 | best1bin | 82.096% | 0.00014986999150705122 | 0.19864 | 1 d 07:07:08 | 07:46:47 | 10.74 MJ |
| Run 3 | best1bin | 54.912% | 0.0003282363808605963 | 0.19712 | 1 d 16:01:36 | 10:00:24 | 14.08 MJ |
| Run 4 | best1bin | 87.728% | 0.0002538875999605611 | 0.19096 | 1 d 06:27:00 | 07:36:45 | 10.75 MJ |
| Run 5 | best1bin | 86.24% | 0.00013244795866876926 | 0.19928 | 1 d 14:55:52 | 09:43:58 | 13.72 MJ |
| Run 6 | best1bin | 87.232% | 0.00018772599078406988 | 0.19544 | 1 d 10:27:20 | 08:36:50 | 11.88 MJ |
| Run 7 | best1bin | 91.024% | 0.0001979983310832409 | 0.19728 | 1 d 11:50:16 | 08:57:34 | 12.46 MJ |
| Run 8 | best1bin | 87.048% | 0.00020452079357047135 | 0.19912 | 1 d 22:41:00 | 11:40:15 | 16.45 MJ |
| Run 9 | best1bin | 86.744% | 0.00011697855792024446 | 0.19976 | 1 d 16:49:24 | 10:12:21 | 14.36 MJ |
| Run 10 | best1bin | 87.848% | 0.00011878144416773795 | 0.19928 | 2 d 01:29:08 | 12:22:17 | 17.48 MJ |
| Run 1 | currenttobest1bin | 94.408% | 0.0001777101347875973 | 0.19848 | 1 d 12:49:12 | 09:12:18 | 12.76 MJ |
| Run 2 | currenttobest1bin | 91.664% | 0.0001676775123940838 | 0.1968 | 1 d 21:12:36 | 11:18:09 | 15.98 MJ |
| Run 3 | currenttobest1bin | 87.704% | 0.00024927427039484336 | 0.19968 | 1 d 17:18:08 | 10:19:32 | 14.53 MJ |
| Run 4 | currenttobest1bin | 93.104% | 0.00012525167316710355 | 0.19864 | 1 d 10:23:44 | 08:35:56 | 12.22 MJ |
| Run 5 | currenttobest1bin | 76.968% | 0.00011271926575249369 | 0.2008 | 1 d 15:54:48 | 09:58:42 | 13.94 MJ |
| Run 6 | currenttobest1bin | 92.656% | 0.00024077230180039115 | 0.19864 | 1 d 15:43:36 | 09:55:54 | 14.74 MJ |
| Run 7 | currenttobest1bin | 83.928% | 0.00018005627173263677 | 0.20008 | 2 d 04:49:00 | 13:12:15 | 18.52 MJ |
| Run 8 | currenttobest1bin | 89.832% | 0.00018005627173263677 | 0.19728 | 1 d 14:02:00 | 09:30:30 | 13.37 MJ |
| Run 9 | currenttobest1bin | 79.304% | 0.00014160970939553836 | 0.20024 | 1 d 18:51:16 | 10:42:49 | 14.97 MJ |
| Run 10 | currenttobest1bin | 92.944% | 0.0001709971131053357 | 0.19952 | 1 d 08:37:12 | 08:09:18 | 11.34 MJ |
| Run 1 | rand2bin | 87.672% | 0.00014043719752531607 | 0.19864 | 2 d 09:31:28 | 14:22:52 | 20.78 MJ |
| Run 2 | rand2bin | 89.04% | 0.00011225716411114573 | 0.19888 | 2 d 10:33:28 | 14:38:22 | 20.83 MJ |
| Run 3 | rand2bin | 94.512% | 0.0002133501243124707 | 0.19624 | 2 d 02:37:08 | 12:39:17 | 17.67 MJ |
| Run 4 | rand2bin | 83.176% | 0.00014653941889018144 | 0.1964 | 2 d 09:09:08 | 14:17:17 | 19.81 MJ |
| Run 5 | rand2bin | 87.024% | 0.00011953364165374843 | 0.19728 | 2 d 05:57:24 | 13:29:21 | 18.39 MJ |
| Run 6 | rand2bin | 84.768% | 0.00023553289350598778 | 0.19968 | 2 d 04:24:04 | 13:06:01 | 17.81 MJ |
| Run 7 | rand2bin | 87.648% | 0.0002237592246513461 | 0.19936 | 1 d 17:36:36 | 10:24:09 | 14.43 MJ |
| Run 8 | rand2bin | 88.624% | 0.00028450076835501793 | 0.19784 | 2 d 14:21:28 | 15:35:22 | 21.70 MJ |
| Run 9 | rand2bin | 87.976% | 0.0001381408910283419 | 0.20008 | 2 d 01:54:12 | 12:28:33 | 17.34 MJ |
| Run 10 | rand2bin | 88.936% | 0.0003745529083655216 | 0.19664 | 2 d 02:32:40 | 12:38:10 | 17.96 MJ |
| Run 1 | best2bin | 87.808% | 0.00019802425459684555 | 0.19792 | 1 d 14:59:48 | 09:44:57 | 13.70 MJ |
| Run 2 | best2bin | 92.296% | 0.0001251396171027152 | 0.19944 | 1 d 12:31:36 | 09:07:54 | 12.92 MJ |
| Run 3 | best2bin | 90.4% | 0.0001904270337836623 | 0.1964 | 1 d 17:50:44 | 10:27:41 | 14.68 MJ |
| Run 4 | best2bin | 81.952% | 0.0001099476225437391 | 0.19888 | 2 d 01:55:36 | 12:28:54 | 17.65 MJ |
| Run 5 | best2bin | 75.464% | 0.00020291861982300505 | 0.19672 | 1 d 20:22:48 | 11:05:42 | 15.79 MJ |
| Run 6 | best2bin | 86.48% | 0.00010060982197001325 | 0.2004 | 2 d 10:13:32 | 14:33:23 | 20.22 MJ |
| Run 7 | best2bin | 88.752% | 0.00016491971624181951 | 0.19968 | 1 d 13:26:40 | 09:21:40 | 12.71 MJ |
| Run 8 | best2bin | 93.512% | 0.00024077230180039115 | 0.19824 | 1 d 21:12:12 | 11:18:03 | 16.09 MJ |
| Run 9 | best2bin | 89.448% | 0.0001714790474648441 | 0.20008 | 1 d 19:37:00 | 10:54:15 | 15.19 MJ |
| Run 10 | best2bin | 84.432% | 0.00014487507677276147 | 0.19928 | 2 d 13:24:04 | 15:21:01 | 21.30 MJ |
| Run 1 | rand1exp | 81.736% | 0.00020572836461939112 | 0.19768 | 1 d 12:40:00 | 09:10:00 | 12.93 MJ |
| Run 2 | rand1exp | 90.736% | 0.0001223335365317393 | 0.20024 | 1 d 13:13:20 | 09:18:20 | 12.97 MJ |
| Run 3 | rand1exp | 81.24% | 0.00028135858111119703 | 0.19888 | 2 d 03:22:28 | 12:50:37 | 18.10 MJ |
| Run 4 | rand1exp | 88.952% | 0.0001716955308133066 | 0.1988 | 2 d 01:32:44 | 12:23:11 | 17.78 MJ |
| Run 5 | rand1exp | 84.584% | 0.00011738980332550895 | 0.19824 | 1 d 20:13:08 | 11:03:17 | 15.40 MJ |
| Run 6 | rand1exp | 88.16% | 0.0001716955308133066 | 0.19688 | 2 d 12:53:48 | 15:13:27 | 21.12 MJ |
| Run 7 | rand1exp | 79.792% | 0.0003402733735045603 | 0.19656 | 1 d 12:26:08 | 09:06:32 | 12.72 MJ |
| Run 8 | rand1exp | 90.84% | 0.0001870614498054844 | 0.19968 | 1 d 22:59:52 | 11:44:58 | 16.24 MJ |
| Run 9 | rand1exp | 85.648% | 0.00031983860861568045 | 0.19824 | 1 d 19:27:24 | 10:51:51 | 15.32 MJ |
| Run 10 | rand1exp | 92.024% | 0.00018074543621654791 | 0.19968 | 1 d 22:00:36 | 11:30:09 | 15.91 MJ |
| Run 1 | rand2exp | 77.792% | 0.0003611529289675765 | 0.19576 | 2 d 13:49:20 | 15:27:20 | 21.95 MJ |
| Run 2 | rand2exp | 88.48% | 0.00017837840176632527 | 0.1988 | 2 d 03:06:40 | 12:46:40 | 17.93 MJ |
| Run 3 | rand2exp | 89.08% | 0.0002653847058764622 | 0.19568 | 1 d 19:58:40 | 10:59:40 | 14.96 MJ |
| Run 4 | rand2exp | 93.68% | 0.00012525167316710355 | 0.19568 | 2 d 09:39:20 | 14:24:50 | 21.03 MJ |
| Run 5 | rand2exp | 79.16% | 0.00011407140713999342 | 0.19768 | 1 d 18:18:16 | 10:34:34 | 14.92 MJ |
| Run 6 | rand2exp | 83.536% | 0.00017301348280091672 | 0.19856 | 2 d 02:53:24 | 12:43:21 | 17.94 MJ |
| Run 7 | rand2exp | 88.992% | 0.0002842880760057267 | 0.19664 | 1 d 19:29:40 | 10:52:25 | 15.56 MJ |
| Run 8 | rand2exp | 87.232% | 0.0003750159877137128 | 0.19952 | 2 d 15:49:40 | 15:57:25 | 22.13 MJ |
| Run 9 | rand2exp | 83.456% | 0.00015812824020433673 | 0.19816 | 1 d 21:09:08 | 11:17:17 | 16.10 MJ |
| Run 10 | rand2exp | 91.888% | 0.00017793388252216702 | 0.19624 | 1 d 22:20:52 | 11:35:13 | 16.15 MJ |
| Run 1 | best1exp | 88.696% | 0.00014033836854647334 | 0.19736 | 1 d 02:15:36 | 06:33:54 | 9.31 MJ |
| Run 2 | best1exp | 86.968% | 0.0002162424541476714 | 0.19768 | 1 d 15:12:56 | 09:48:14 | 14.52 MJ |
| Run 3 | best1exp | 92.84% | 0.00023638094901782316 | 0.19736 | 1 d 07:52:08 | 07:58:02 | 11.21 MJ |
| Run 4 | best1exp | 86.672% | 0.00010427195475288474 | 0.194 | 1 d 10:19:28 | 08:34:52 | 12.09 MJ |
| Run 5 | best1exp | 80.672% | 0.00019427705638157093 | 0.19888 | 1 d 15:29:56 | 09:52:29 | 13.53 MJ |
| Run 6 | best1exp | 77.904% | 0.00015164326800967044 | 0.19792 | 1 d 10:28:24 | 08:37:06 | 12.13 MJ |
| Run 7 | best1exp | 88.776% | 0.00012525167316710355 | 0.19952 | 1 d 11:42:52 | 08:55:43 | 12.57 MJ |
| Run 8 | best1exp | 86.32% | 0.00010635183372531933 | 0.19792 | 1 d 05:52:40 | 07:28:10 | 10.53 MJ |
| Run 9 | best1exp | 90.912% | 0.00016403359809686588 | 0.19832 | 1 d 13:23:48 | 09:20:57 | 12.89 MJ |
| Run 10 | best1exp | 86.616% | 0.00017251878232963605 | 0.19832 | 1 d 13:11:04 | 09:17:46 | 13.27 MJ |
| Run 1 | best2exp | 84.392% | 0.00017548419506410967 | 0.19736 | 1 d 13:47:56 | 09:26:59 | 13.40 MJ |
| Run 2 | best2exp | 85.904% | 0.00021438513173642015 | 0.19648 | 2 d 02:36:56 | 12:39:14 | 17.28 MJ |
| Run 3 | best2exp | 80.952% | 0.00010615086490952649 | 0.19864 | 1 d 15:33:16 | 09:53:19 | 13.77 MJ |
| Run 4 | best2exp | 91.496% | 0.0002586226136233186 | 0.19576 | 1 d 18:41:24 | 10:40:21 | 14.70 MJ |
| Run 5 | best2exp | 80.376% | 0.00017880463506925198 | 0.19584 | 2 d 00:10:20 | 12:02:35 | 16.64 MJ |
| Run 6 | best2exp | 75.912% | 0.00010719837238676701 | 0.19888 | 2 d 10:04:16 | 14:31:04 | 20.64 MJ |
| Run 7 | best2exp | 89.456% | 0.00018524895070882503 | 0.19928 | 1 d 23:31:00 | 11:52:45 | 16.85 MJ |
| Run 8 | best2exp | 87.856% | 0.00015637847083356613 | 0.19592 | 2 d 03:50:20 | 12:57:35 | 19.63 MJ |
| Run 9 | best2exp | 83.952% | 0.0002894986036949542 | 0.19528 | 1 d 12:47:00 | 09:11:45 | 13.00 MJ |
| Run 10 | best2exp | 90.384% | 0.00021267203704380358 | 0.19528 | 1 d 23:50:36 | 11:57:39 | 16.27 MJ |
| Run 1 | currenttobest1exp | 86.328% | 0.00016110168325251075 | 0.19984 | 1 d 15:00:12 | 09:45:03 | 13.84 MJ |
| Run 2 | currenttobest1exp | 83.032% | 0.0001741558151819849 | 0.1992 | 1 d 12:21:16 | 09:05:19 | 12.90 MJ |
| Run 3 | currenttobest1exp | 74.632% | 0.0001900681595332386 | 0.19712 | 1 d 15:17:16 | 09:49:19 | 14.05 MJ |
| Run 4 | currenttobest1exp | 94.304% | 0.0001737849051304597 | 0.19632 | 1 d 07:09:24 | 07:47:21 | 10.74 MJ |
| Run 5 | currenttobest1exp | 87.336% | 0.00033922214947209337 | 0.19384 | 1 d 12:41:56 | 09:10:29 | 13.80 MJ |
| Run 6 | currenttobest1exp | 81.44% | 0.00016020731429975277 | 0.19896 | 2 d 13:42:48 | 15:25:42 | 21.54 MJ |
| Run 7 | currenttobest1exp | 89.128% | 0.00015818566275308356 | 0.19768 | 2 d 02:56:52 | 12:44:13 | 18.15 MJ |
| Run 8 | currenttobest1exp | 88.272% | 0.0002178707118915058 | 0.19824 | 1 d 13:46:40 | 09:26:40 | 12.99 MJ |
| Run 9 | currenttobest1exp | 84.672% | 0.00017059161098273808 | 0.1992 | 2 d 06:39:44 | 13:39:56 | 18.98 MJ |
| Run 10 | currenttobest1exp | 77.736% | 0.00021096296316773999 | 0.19936 | 2 d 00:41:40 | 12:10:25 | 16.82 MJ |
Table A3.
Results obtained from 10 runs of 15 epochs of a hyperoptimized ConvNeXtSmall using a different DE strategy on CIFAR10.
Table A3.
Results obtained from 10 runs of 15 epochs of a hyperoptimized ConvNeXtSmall using a different DE strategy on CIFAR10.
| Run | Strategy | Max Accuracy (%) | Best LR | Best Accuracy | CPU Time | Elapsed Time | Consumed Energy |
|---|---|---|---|---|---|---|---|
| Run 1 | rand1bin | 95.976% | 0.0006654030079491737 | 0.2012 | 16:28:40 | 04:07:10 | 5.76 MJ |
| Run 2 | rand1bin | 98.152% | 0.0005503782814261585 | 0.20064 | 13:47:44 | 03:26:56 | 4.93 MJ |
| Run 3 | rand1bin | 98.12% | 0.0002672795926582179 | 0.19744 | 18:00:04 | 04:30:01 | 6.28 MJ |
| Run 4 | rand1bin | 97.648% | 0.0005503782814261585 | 0.19992 | 17:16:40 | 04:19:10 | 6.12 MJ |
| Run 5 | rand1bin | 98.104% | 0.0002162424541476714 | 0.19728 | 15:15:16 | 03:48:49 | 5.21 MJ |
| Run 6 | rand1bin | 98.112% | 0.0005473609425533086 | 0.19712 | 19:51:44 | 04:57:56 | 7.05 MJ |
| Run 7 | rand1bin | 98.832% | 0.0006082014966333853 | 0.19992 | 18:50:00 | 04:42:30 | 6.60 MJ |
| Run 8 | rand1bin | 97.464% | 0.00034871425456294697 | 0.19976 | 20:47:36 | 05:11:54 | 7.69 MJ |
| Run 9 | rand1bin | 96.952% | 0.0005355373902815665 | 0.19704 | 19:18:52 | 04:49:43 | 7.12 MJ |
| Run 10 | rand1bin | 97.312% | 0.0005712439495039969 | 0.19712 | 15:20:44 | 03:50:11 | 5.34 MJ |
| Run 1 | best1bin | 98.184% | 0.0007927504106257327 | 0.19736 | 17:57:28 | 04:29:22 | 6.28 MJ |
| Run 2 | best1bin | 97.912% | 0.0007927504106257327 | 0.20056 | 12:20:32 | 03:05:08 | 4.39 MJ |
| Run 3 | best1bin | 97.752% | 0.0008678928687917702 | 0.1972 | 16:14:16 | 04:03:34 | 5.78 MJ |
| Run 4 | best1bin | 97.384% | 0.0008678928687917702 | 0.19984 | 18:27:04 | 04:36:46 | 6.55 MJ |
| Run 5 | best1bin | 97.656% | 0.0006654030079491737 | 0.2 | 15:18:44 | 03:49:41 | 5.40 MJ |
| Run 6 | best1bin | 98.496% | 0.0006654030079491737 | 0.20088 | 15:22:52 | 03:50:43 | 5.35 MJ |
| Run 7 | best1bin | 95.768% | 0.00033879562805403946 | 0.20072 | 17:17:56 | 04:19:29 | 6.06 MJ |
| Run 8 | best1bin | 97.44% | 0.0008678928687917702 | 0.19968 | 16:44:52 | 04:11:13 | 5.80 MJ |
| Run 9 | best1bin | 97.592% | 0.0006654030079491737 | 0.20088 | 16:20:48 | 04:05:12 | 5.62 MJ |
| Run 10 | best1bin | 98.184% | 0.0005503782814261585 | 0.19832 | 18:05:00 | 04:31:15 | 6.62 MJ |
| Run 1 | currenttobest1bin | 98.576% | 0.0007734768031311363 | 0.20072 | 15:54:32 | 03:58:38 | 5.87 MJ |
| Run 2 | currenttobest1bin | 97.408% | 0.0005739712323314084 | 0.19936 | 16:11:08 | 04:02:47 | 5.49 MJ |
| Run 3 | currenttobest1bin | 98.264% | 0.0007901080473489402 | 0.20088 | 20:10:40 | 05:02:40 | 7.23 MJ |
| Run 4 | currenttobest1bin | 97.288% | 0.00028135858111119703 | 0.20016 | 16:00:52 | 04:00:13 | 5.54 MJ |
| Run 5 | currenttobest1bin | 97.72% | 0.00034871425456294697 | 0.19776 | 15:13:04 | 03:48:16 | 5.21 MJ |
| Run 6 | currenttobest1bin | 98.824% | 0.0005503782814261585 | 0.19752 | 13:17:36 | 03:19:24 | 4.75 MJ |
| Run 7 | currenttobest1bin | 98.544% | 0.0003862608341030343 | 0.2012 | 13:04:48 | 03:16:12 | 4.70 MJ |
| Run 8 | currenttobest1bin | 97.24% | 0.0003906300656803601 | 0.19976 | 15:54:08 | 03:58:32 | 5.59 MJ |
| Run 9 | currenttobest1bin | 98.752% | 0.0008925326625563701 | 0.20088 | 14:28:52 | 03:37:13 | 5.24 MJ |
| Run 10 | currenttobest1bin | 97.344% | 0.0007901080473489402 | 0.20104 | 14:14:00 | 03:33:30 | 4.25 MJ |
| Run 1 | rand2bin | 97.64% | 0.00028135858111119703 | 0.20112 | 16:13:36 | 04:03:24 | 5.71 MJ |
| Run 2 | rand2bin | 97.456% | 0.0007901080473489402 | 0.19704 | 19:27:44 | 04:51:56 | 6.88 MJ |
| Run 3 | rand2bin | 98.112% | 0.0007901080473489402 | 0.19728 | 16:18:44 | 04:04:41 | 5.68 MJ |
| Run 4 | rand2bin | 98.568% | 0.0007525478022450478 | 0.1992 | 16:20:12 | 04:05:03 | 5.71 MJ |
| Run 5 | rand2bin | 98.84% | 0.0009 | 0.20128 | 13:02:12 | 03:15:33 | 4.58 MJ |
| Run 6 | rand2bin | 98.032% | 0.0002162424541476714 | 0.20024 | 17:50:16 | 04:27:34 | 6.38 MJ |
| Run 7 | rand2bin | 97.904% | 0.0006654030079491737 | 0.1968 | 14:55:04 | 03:43:46 | 5.28 MJ |
| Run 8 | rand2bin | 97.688% | 0.0002162424541476714 | 0.1976 | 17:33:12 | 04:23:18 | 6.12 MJ |
| Run 9 | rand2bin | 98.6% | 0.0003958488676549701 | 0.2012 | 19:04:12 | 04:46:03 | 6.78 MJ |
| Run 10 | rand2bin | 98.672% | 0.0005503782814261585 | 0.19744 | 18:23:00 | 04:35:45 | 6.55 MJ |
| Run 1 | best2bin | 97.984% | 0.0007886925738553567 | 0.20112 | 14:59:12 | 03:44:48 | 5.36 MJ |
| Run 2 | best2bin | 98.008% | 0.0008678928687917702 | 0.20112 | 16:20:20 | 04:05:05 | 5.76 MJ |
| Run 3 | best2bin | 98.576% | 0.0007901080473489402 | 0.19648 | 15:18:52 | 03:49:43 | 5.37 MJ |
| Run 4 | best2bin | 97.688% | 0.0006654030079491737 | 0.19792 | 15:37:12 | 03:54:18 | 5.47 MJ |
| Run 5 | best2bin | 98.2% | 0.0004894533183428303 | 0.19696 | 14:56:44 | 03:44:11 | 5.24 MJ |
| Run 6 | best2bin | 97.272% | 0.00034871425456294697 | 0.19808 | 22:47:20 | 05:41:50 | 8.26 MJ |
| Run 7 | best2bin | 97.664% | 0.0004894533183428303 | 0.20064 | 13:16:40 | 03:19:10 | 4.91 MJ |
| Run 8 | best2bin | 96.464% | 0.0008721269190922968 | 0.19736 | 16:35:20 | 04:08:50 | 6.26 MJ |
| Run 9 | best2bin | 97.6% | 0.0004894533183428303 | 0.19696 | 16:07:00 | 04:01:45 | 5.74 MJ |
| Run 10 | best2bin | 96.928% | 0.0007901080473489402 | 0.198 | 14:11:08 | 03:32:47 | 4.97 MJ |
| Run 1 | rand1exp | 98.672% | 0.00028135858111119703 | 0.20008 | 17:44:28 | 04:26:07 | 6.06 MJ |
| Run 2 | rand1exp | 95.208% | 0.0006654030079491737 | 0.19952 | 20:37:28 | 05:09:22 | 7.23 MJ |
| Run 3 | rand1exp | 98.544% | 0.0005503782814261585 | 0.19744 | 15:33:00 | 03:53:15 | 5.52 MJ |
| Run 4 | rand1exp | 98.424% | 0.00028135858111119703 | 0.19976 | 17:59:16 | 04:29:49 | 6.30 MJ |
| Run 5 | rand1exp | 98.6% | 0.00024077230180039115 | 0.19952 | 17:27:32 | 04:21:53 | 6.11 MJ |
| Run 6 | rand1exp | 97.984% | 0.00028135858111119703 | 0.19992 | 12:34:04 | 03:08:31 | 4.45 MJ |
| Run 7 | rand1exp | 98.4% | 0.0005503782814261585 | 0.19688 | 20:49:48 | 05:12:27 | 7.56 MJ |
| Run 8 | rand1exp | 98.184% | 0.0006175667336409383 | 0.2 | 19:21:28 | 04:50:22 | 6.77 MJ |
| Run 9 | rand1exp | 98.224% | 0.0006082014966333853 | 0.19792 | 15:44:04 | 03:56:01 | 5.47 MJ |
| Run 10 | rand1exp | 98.288% | 0.0005472994801986106 | 0.19696 | 17:46:52 | 04:26:43 | 6.27 MJ |
| Run 1 | rand2exp | 98.928% | 0.0009 | 0.20064 | 13:29:28 | 03:22:22 | 4.74 MJ |
| Run 2 | rand2exp | 97.432% | 0.0007901080473489402 | 0.19992 | 15:01:40 | 03:45:25 | 5.18 MJ |
| Run 3 | rand2exp | 97.512% | 0.0005503782814261585 | 0.19752 | 16:30:44 | 04:07:41 | 5.77 MJ |
| Run 4 | rand2exp | 97.648% | 0.0007830609600370624 | 0.1968 | 14:53:44 | 03:43:26 | 5.07 MJ |
| Run 5 | rand2exp | 98.512% | 0.0008678928687917702 | 0.20112 | 16:14:44 | 04:03:41 | 5.74 MJ |
| Run 6 | rand2exp | 97.48% | 0.0005503782814261585 | 0.1968 | 14:13:24 | 03:33:21 | 4.98 MJ |
| Run 7 | rand2exp | 98.56% | 0.00024077230180039115 | 0.19744 | 20:20:04 | 05:05:01 | 7.29 MJ |
| Run 8 | rand2exp | 98.28% | 0.0003690036337254874 | 0.20064 | 17:17:52 | 04:19:28 | 6.07 MJ |
| Run 9 | rand2exp | 96.912% | 0.00028135858111119703 | 0.20128 | 20:23:28 | 05:05:52 | 7.83 MJ |
| Run 10 | rand2exp | 97.904% | 0.0006998089423710386 | 0.198 | 15:21:20 | 03:50:20 | 5.42 MJ |
| Run 1 | best1exp | 98.336% | 0.0007901080473489402 | 0.20024 | 16:19:36 | 04:04:54 | 6.11 MJ |
| Run 2 | best1exp | 98.168% | 0.0005503782814261585 | 0.19736 | 17:31:16 | 04:22:49 | 6.67 MJ |
| Run 3 | best1exp | 97.912% | 0.0004894533183428303 | 0.20112 | 15:44:28 | 03:56:07 | 5.51 MJ |
| Run 4 | best1exp | 98% | 0.0006082014966333853 | 0.1972 | 15:38:28 | 03:54:37 | 5.59 MJ |
| Run 5 | best1exp | 96.976% | 0.0007901080473489402 | 0.20008 | 14:57:48 | 03:44:27 | 5.29 MJ |
| Run 6 | best1exp | 98.688% | 0.0004894533183428303 | 0.19768 | 16:05:32 | 04:01:23 | 5.80 MJ |
| Run 7 | best1exp | 98.184% | 0.0008678928687917702 | 0.19664 | 14:58:40 | 03:44:40 | 5.23 MJ |
| Run 8 | best1exp | 98.248% | 0.00034871425456294697 | 0.20088 | 15:40:44 | 03:55:11 | 5.54 MJ |
| Run 9 | best1exp | 98.224% | 0.0006654030079491737 | 0.1976 | 17:06:24 | 04:16:36 | 6.13 MJ |
| Run 10 | best1exp | 98.44% | 0.000607815328369001 | 0.19968 | 15:13:48 | 03:48:27 | 5.38 MJ |
| Run 1 | best2exp | 98.072% | 0.0005498722582829092 | 0.19712 | 20:04:36 | 05:01:09 | 7.13 MJ |
| Run 2 | best2exp | 98.168% | 0.0008710360124656422 | 0.19744 | 18:09:28 | 04:32:22 | 6.40 MJ |
| Run 3 | best2exp | 98.416% | 0.0007092619923939011 | 0.19752 | 14:38:44 | 03:39:41 | 5.13 MJ |
| Run 4 | best2exp | 98.56% | 0.00034871425456294697 | 0.20096 | 17:38:56 | 04:24:44 | 6.26 MJ |
| Run 5 | best2exp | 98.952% | 0.0008678928687917702 | 0.19792 | 13:22:08 | 03:20:32 | 4.77 MJ |
| Run 6 | best2exp | 97.632% | 0.0008678928687917702 | 0.19784 | 14:26:16 | 03:36:34 | 5.07 MJ |
| Run 7 | best2exp | 96.784% | 0.00024095502886257157 | 0.1996 | 16:36:12 | 04:09:03 | 5.79 MJ |
| Run 8 | best2exp | 98.008% | 0.00028135858111119703 | 0.20096 | 14:44:00 | 03:41:00 | 5.32 MJ |
| Run 9 | best2exp | 98.112% | 0.0003690036337254874 | 0.20112 | 18:54:08 | 04:43:32 | 6.61 MJ |
| Run 10 | best2exp | 97.88% | 0.0005503782814261585 | 0.19992 | 16:35:04 | 04:08:46 | 5.82 MJ |
| Run 1 | currenttobest1exp | 97.44% | 0.0005355373902815665 | 0.19704 | 17:23:00 | 04:20:45 | 6.06 MJ |
| Run 2 | currenttobest1exp | 98.736% | 0.0005481461251974725 | 0.1976 | 13:52:32 | 03:28:08 | 4.79 MJ |
| Run 3 | currenttobest1exp | 98.104% | 0.000364520908205892 | 0.2004 | 19:24:44 | 04:51:11 | 6.78 MJ |
| Run 4 | currenttobest1exp | 97.152% | 0.0004894533183428303 | 0.19672 | 16:59:32 | 04:14:53 | 5.96 MJ |
| Run 5 | currenttobest1exp | 98.104% | 0.00034809976312238206 | 0.19984 | 17:24:12 | 04:21:03 | 6.12 MJ |
| Run 6 | currenttobest1exp | 97.104% | 0.0004894533183428303 | 0.20016 | 16:53:24 | 04:13:21 | 5.91 MJ |
| Run 7 | currenttobest1exp | 98.248% | 0.0006757524345484006 | 0.19992 | 13:20:08 | 03:20:02 | 4.73 MJ |
| Run 8 | currenttobest1exp | 98.032% | 0.0005503782814261585 | 0.1972 | 17:52:36 | 04:28:09 | 6.45 MJ |
| Run 9 | currenttobest1exp | 97.144% | 0.0006082014966333853 | 0.19704 | 15:00:40 | 03:45:10 | 5.23 MJ |
| Run 10 | currenttobest1exp | 97.888% | 0.0006082014966333853 | 0.19688 | 16:37:08 | 04:09:17 | 5.74 MJ |
Table A4.
Results obtained from 10 runs of 15 epochs of a hyperoptimized DenseNet121 using a different DE strategy on CIFAR10.
Table A4.
Results obtained from 10 runs of 15 epochs of a hyperoptimized DenseNet121 using a different DE strategy on CIFAR10.
| Run | Strategy | Max Accuracy (%) | Best LR | Best Accuracy | CPU Time | Elapsed Time | Consumed Energy |
|---|---|---|---|---|---|---|---|
| Run 1 | rand1bin | 91.136% | 0.0002850492178633215 | 0.19464 | 1 d 06:51:08 | 07:42:47 | 10.92 MJ |
| Run 2 | rand1bin | 89.84% | 0.00014533476190324503 | 0.1996 | 1 d 15:46:04 | 09:56:31 | 13.54 MJ |
| Run 3 | rand1bin | 88.904% | 0.00016212406890736 | 0.20008 | 2 d 08:05:20 | 14:01:20 | 19.72 MJ |
| Run 4 | rand1bin | 88.096% | 0.00017447715387706086 | 0.19648 | 2 d 14:03:44 | 15:30:56 | 21.79 MJ |
| Run 5 | rand1bin | 78.848% | 0.00013277606163792152 | 0.20008 | 1 d 17:55:48 | 10:28:57 | 14.62 MJ |
| Run 6 | rand1bin | 84.84% | 0.00040217263101021024 | 0.19552 | 1 d 16:39:36 | 10:09:54 | 14.22 MJ |
| Run 7 | rand1bin | 86.832% | 0.00013772520953436778 | 0.1996 | 1 d 13:27:44 | 09:21:56 | 14.32 MJ |
| Run 8 | rand1bin | 91.024% | 0.00024113078304294758 | 0.19984 | 1 d 20:35:00 | 11:08:45 | 15.61 MJ |
| Run 9 | rand1bin | 77.488% | 0.00013959268979809545 | 0.19848 | 2 d 07:07:04 | 13:46:46 | 19.14 MJ |
| Run 10 | rand1bin | 90.2% | 0.00018376849081430186 | 0.196 | 2 d 02:35:04 | 12:38:46 | 18.53 MJ |
| Run 1 | best1bin | 88.888% | 0.00017084651054119834 | 0.19576 | 1 d 05:08:32 | 07:17:08 | 10.27 MJ |
| Run 2 | best1bin | 82.096% | 0.00014986999150705122 | 0.19864 | 1 d 07:07:08 | 07:46:47 | 10.74 MJ |
| Run 3 | best1bin | 54.912% | 0.0003282363808605963 | 0.19712 | 1 d 16:01:36 | 10:00:24 | 14.08 MJ |
| Run 4 | best1bin | 87.728% | 0.0002538875999605611 | 0.19096 | 1 d 06:27:00 | 07:36:45 | 10.75 MJ |
| Run 5 | best1bin | 86.24% | 0.00013244795866876926 | 0.19928 | 1 d 14:55:52 | 09:43:58 | 13.72 MJ |
| Run 6 | best1bin | 87.232% | 0.00018772599078406988 | 0.19544 | 1 d 10:27:20 | 08:36:50 | 11.88 MJ |
| Run 7 | best1bin | 91.024% | 0.0001979983310832409 | 0.19728 | 1 d 11:50:16 | 08:57:34 | 12.46 MJ |
| Run 8 | best1bin | 87.048% | 0.00020452079357047135 | 0.19912 | 1 d 22:41:00 | 11:40:15 | 16.45 MJ |
| Run 9 | best1bin | 86.744% | 0.00011697855792024446 | 0.19976 | 1 d 16:49:24 | 10:12:21 | 14.36 MJ |
| Run 10 | best1bin | 87.848% | 0.00011878144416773795 | 0.19928 | 2 d 01:29:08 | 12:22:17 | 17.48 MJ |
| Run 1 | currenttobest1bin | 94.408% | 0.0001777101347875973 | 0.19848 | 1 d 12:49:12 | 09:12:18 | 12.76 MJ |
| Run 2 | currenttobest1bin | 91.664% | 0.0001676775123940838 | 0.1968 | 1 d 21:12:36 | 11:18:09 | 15.98 MJ |
| Run 3 | currenttobest1bin | 87.704% | 0.00024927427039484336 | 0.19968 | 1 d 17:18:08 | 10:19:32 | 14.53 MJ |
| Run 4 | currenttobest1bin | 93.104% | 0.00012525167316710355 | 0.19864 | 1 d 10:23:44 | 08:35:56 | 12.22 MJ |
| Run 5 | currenttobest1bin | 76.968% | 0.00011271926575249369 | 0.2008 | 1 d 15:54:48 | 09:58:42 | 13.94 MJ |
| Run 6 | currenttobest1bin | 92.656% | 0.00024077230180039115 | 0.19864 | 1 d 15:43:36 | 09:55:54 | 14.74 MJ |
| Run 7 | currenttobest1bin | 83.928% | 0.00018005627173263677 | 0.20008 | 2 d 04:49:00 | 13:12:15 | 18.52 MJ |
| Run 8 | currenttobest1bin | 89.832% | 0.00018005627173263677 | 0.19728 | 1 d 14:02:00 | 09:30:30 | 13.37 MJ |
| Run 9 | currenttobest1bin | 79.304% | 0.00014160970939553836 | 0.20024 | 1 d 18:51:16 | 10:42:49 | 14.97 MJ |
| Run 10 | currenttobest1bin | 92.944% | 0.0001709971131053357 | 0.19952 | 1 d 08:37:12 | 08:09:18 | 11.34 MJ |
| Run 1 | rand2bin | 87.672% | 0.00014043719752531607 | 0.19864 | 2 d 09:31:28 | 14:22:52 | 20.78 MJ |
| Run 2 | rand2bin | 89.04% | 0.00011225716411114573 | 0.19888 | 2 d 10:33:28 | 14:38:22 | 20.83 MJ |
| Run 3 | rand2bin | 94.512% | 0.0002133501243124707 | 0.19624 | 2 d 02:37:08 | 12:39:17 | 17.67 MJ |
| Run 4 | rand2bin | 83.176% | 0.00014653941889018144 | 0.1964 | 2 d 09:09:08 | 14:17:17 | 19.81 MJ |
| Run 5 | rand2bin | 87.024% | 0.00011953364165374843 | 0.19728 | 2 d 05:57:24 | 13:29:21 | 18.39 MJ |
| Run 6 | rand2bin | 84.768% | 0.00023553289350598778 | 0.19968 | 2 d 04:24:04 | 13:06:01 | 17.81 MJ |
| Run 7 | rand2bin | 87.648% | 0.0002237592246513461 | 0.19936 | 1 d 17:36:36 | 10:24:09 | 14.43 MJ |
| Run 8 | rand2bin | 88.624% | 0.00028450076835501793 | 0.19784 | 2 d 14:21:28 | 15:35:22 | 21.70 MJ |
| Run 9 | rand2bin | 87.976% | 0.0001381408910283419 | 0.20008 | 2 d 01:54:12 | 12:28:33 | 17.34 MJ |
| Run 10 | rand2bin | 88.936% | 0.0003745529083655216 | 0.19664 | 2 d 02:32:40 | 12:38:10 | 17.96 MJ |
| Run 1 | best2bin | 87.808% | 0.00019802425459684555 | 0.19792 | 1 d 14:59:48 | 09:44:57 | 13.70 MJ |
| Run 2 | best2bin | 92.296% | 0.0001251396171027152 | 0.19944 | 1 d 12:31:36 | 09:07:54 | 12.92 MJ |
| Run 3 | best2bin | 90.4% | 0.0001904270337836623 | 0.1964 | 1 d 17:50:44 | 10:27:41 | 14.68 MJ |
| Run 4 | best2bin | 81.952% | 0.0001099476225437391 | 0.19888 | 2 d 01:55:36 | 12:28:54 | 17.65 MJ |
| Run 5 | best2bin | 75.464% | 0.00020291861982300505 | 0.19672 | 1 d 20:22:48 | 11:05:42 | 15.79 MJ |
| Run 6 | best2bin | 86.48% | 0.00010060982197001325 | 0.2004 | 2 d 10:13:32 | 14:33:23 | 20.22 MJ |
| Run 7 | best2bin | 88.752% | 0.00016491971624181951 | 0.19968 | 1 d 13:26:40 | 09:21:40 | 12.71 MJ |
| Run 8 | best2bin | 93.512% | 0.00024077230180039115 | 0.19824 | 1 d 21:12:12 | 11:18:03 | 16.09 MJ |
| Run 9 | best2bin | 89.448% | 0.0001714790474648441 | 0.20008 | 1 d 19:37:00 | 10:54:15 | 15.19 MJ |
| Run 10 | best2bin | 84.432% | 0.00014487507677276147 | 0.19928 | 2 d 13:24:04 | 15:21:01 | 21.30 MJ |
| Run 1 | rand1exp | 81.736% | 0.00020572836461939112 | 0.19768 | 1 d 12:40:00 | 09:10:00 | 12.93 MJ |
| Run 2 | rand1exp | 90.736% | 0.0001223335365317393 | 0.20024 | 1 d 13:13:20 | 09:18:20 | 12.97 MJ |
| Run 3 | rand1exp | 81.24% | 0.00028135858111119703 | 0.19888 | 2 d 03:22:28 | 12:50:37 | 18.10 MJ |
| Run 4 | rand1exp | 88.952% | 0.0001716955308133066 | 0.1988 | 2 d 01:32:44 | 12:23:11 | 17.78 MJ |
| Run 5 | rand1exp | 84.584% | 0.00011738980332550895 | 0.19824 | 1 d 20:13:08 | 11:03:17 | 15.40 MJ |
| Run 6 | rand1exp | 88.16% | 0.0001716955308133066 | 0.19688 | 2 d 12:53:48 | 15:13:27 | 21.12 MJ |
| Run 7 | rand1exp | 79.792% | 0.0003402733735045603 | 0.19656 | 1 d 12:26:08 | 09:06:32 | 12.72 MJ |
| Run 8 | rand1exp | 90.84% | 0.0001870614498054844 | 0.19968 | 1 d 22:59:52 | 11:44:58 | 16.24 MJ |
| Run 9 | rand1exp | 85.648% | 0.00031983860861568045 | 0.19824 | 1 d 19:27:24 | 10:51:51 | 15.32 MJ |
| Run 10 | rand1exp | 92.024% | 0.00018074543621654791 | 0.19968 | 1 d 22:00:36 | 11:30:09 | 15.91 MJ |
| Run 1 | rand2exp | 77.792% | 0.0003611529289675765 | 0.19576 | 2 d 13:49:20 | 15:27:20 | 21.95 MJ |
| Run 2 | rand2exp | 88.48% | 0.00017837840176632527 | 0.1988 | 2 d 03:06:40 | 12:46:40 | 17.93 MJ |
| Run 3 | rand2exp | 89.08% | 0.0002653847058764622 | 0.19568 | 1 d 19:58:40 | 10:59:40 | 14.96 MJ |
| Run 4 | rand2exp | 93.68% | 0.00012525167316710355 | 0.19568 | 2 d 09:39:20 | 14:24:50 | 21.03 MJ |
| Run 5 | rand2exp | 79.16% | 0.00011407140713999342 | 0.19768 | 1 d 18:18:16 | 10:34:34 | 14.92 MJ |
| Run 6 | rand2exp | 83.536% | 0.00017301348280091672 | 0.19856 | 2 d 02:53:24 | 12:43:21 | 17.94 MJ |
| Run 7 | rand2exp | 88.992% | 0.0002842880760057267 | 0.19664 | 1 d 19:29:40 | 10:52:25 | 15.56 MJ |
| Run 8 | rand2exp | 87.232% | 0.0003750159877137128 | 0.19952 | 2 d 15:49:40 | 15:57:25 | 22.13 MJ |
| Run 9 | rand2exp | 83.456% | 0.00015812824020433673 | 0.19816 | 1 d 21:09:08 | 11:17:17 | 16.10 MJ |
| Run 10 | rand2exp | 91.888% | 0.00017793388252216702 | 0.19624 | 1 d 22:20:52 | 11:35:13 | 16.15 MJ |
| Run 1 | best1exp | 88.696% | 0.00014033836854647334 | 0.19736 | 1 d 02:15:36 | 06:33:54 | 9.31 MJ |
| Run 2 | best1exp | 86.968% | 0.0002162424541476714 | 0.19768 | 1 d 15:12:56 | 09:48:14 | 14.52 MJ |
| Run 3 | best1exp | 92.84% | 0.00023638094901782316 | 0.19736 | 1 d 07:52:08 | 07:58:02 | 11.21 MJ |
| Run 4 | best1exp | 86.672% | 0.00010427195475288474 | 0.194 | 1 d 10:19:28 | 08:34:52 | 12.09 MJ |
| Run 5 | best1exp | 80.672% | 0.00019427705638157093 | 0.19888 | 1 d 15:29:56 | 09:52:29 | 13.53 MJ |
| Run 6 | best1exp | 77.904% | 0.00015164326800967044 | 0.19792 | 1 d 10:28:24 | 08:37:06 | 12.13 MJ |
| Run 7 | best1exp | 88.776% | 0.00012525167316710355 | 0.19952 | 1 d 11:42:52 | 08:55:43 | 12.57 MJ |
| Run 8 | best1exp | 86.32% | 0.00010635183372531933 | 0.19792 | 1 d 05:52:40 | 07:28:10 | 10.53 MJ |
| Run 9 | best1exp | 90.912% | 0.00016403359809686588 | 0.19832 | 1 d 13:23:48 | 09:20:57 | 12.89 MJ |
| Run 10 | best1exp | 86.616% | 0.00017251878232963605 | 0.19832 | 1 d 13:11:04 | 09:17:46 | 13.27 MJ |
| Run 1 | best2exp | 84.392% | 0.00017548419506410967 | 0.19736 | 1 d 13:47:56 | 09:26:59 | 13.40 MJ |
| Run 2 | best2exp | 85.904% | 0.00021438513173642015 | 0.19648 | 2 d 02:36:56 | 12:39:14 | 17.28 MJ |
| Run 3 | best2exp | 80.952% | 0.00010615086490952649 | 0.19864 | 1 d 15:33:16 | 09:53:19 | 13.77 MJ |
| Run 4 | best2exp | 91.496% | 0.0002586226136233186 | 0.19576 | 1 d 18:41:24 | 10:40:21 | 14.70 MJ |
| Run 5 | best2exp | 80.376% | 0.00017880463506925198 | 0.19584 | 2 d 00:10:20 | 12:02:35 | 16.64 MJ |
| Run 6 | best2exp | 75.912% | 0.00010719837238676701 | 0.19888 | 2 d 10:04:16 | 14:31:04 | 20.64 MJ |
| Run 7 | best2exp | 89.456% | 0.00018524895070882503 | 0.19928 | 1 d 23:31:00 | 11:52:45 | 16.85 MJ |
| Run 8 | best2exp | 87.856% | 0.00015637847083356613 | 0.19592 | 2 d 03:50:20 | 12:57:35 | 19.63 MJ |
| Run 9 | best2exp | 83.952% | 0.0002894986036949542 | 0.19528 | 1 d 12:47:00 | 09:11:45 | 13.00 MJ |
| Run 10 | best2exp | 90.384% | 0.00021267203704380358 | 0.19528 | 1 d 23:50:36 | 11:57:39 | 16.27 MJ |
| Run 1 | currenttobest1exp | 86.328% | 0.00016110168325251075 | 0.19984 | 1 d 15:00:12 | 09:45:03 | 13.84 MJ |
| Run 2 | currenttobest1exp | 83.032% | 0.0001741558151819849 | 0.1992 | 1 d 12:21:16 | 09:05:19 | 12.90 MJ |
| Run 3 | currenttobest1exp | 74.632% | 0.0001900681595332386 | 0.19712 | 1 d 15:17:16 | 09:49:19 | 14.05 MJ |
| Run 4 | currenttobest1exp | 94.304% | 0.0001737849051304597 | 0.19632 | 1 d 07:09:24 | 07:47:21 | 10.74 MJ |
| Run 5 | currenttobest1exp | 87.336% | 0.00033922214947209337 | 0.19384 | 1 d 12:41:56 | 09:10:29 | 13.80 MJ |
| Run 6 | currenttobest1exp | 81.44% | 0.00016020731429975277 | 0.19896 | 2 d 13:42:48 | 15:25:42 | 21.54 MJ |
| Run 7 | currenttobest1exp | 89.128% | 0.00015818566275308356 | 0.19768 | 2 d 02:56:52 | 12:44:13 | 18.15 MJ |
| Run 8 | currenttobest1exp | 88.272% | 0.0002178707118915058 | 0.19824 | 1 d 13:46:40 | 09:26:40 | 12.99 MJ |
| Run 9 | currenttobest1exp | 84.672% | 0.00017059161098273808 | 0.1992 | 2 d 06:39:44 | 13:39:56 | 18.98 MJ |
| Run 10 | currenttobest1exp | 77.736% | 0.00021096296316773999 | 0.19936 | 2 d 00:41:40 | 12:10:25 | 16.82 MJ |
Table A5.
Results obtained from 10 runs of 15 epochs of a hyperoptimized ResNet18 using a different DE strategy on CIFAR100.
Table A5.
Results obtained from 10 runs of 15 epochs of a hyperoptimized ResNet18 using a different DE strategy on CIFAR100.
| Run | Strategy | Max Accuracy (%) | Best LR | Best Accuracy | CPU Time | Elapsed Time | Consumed Energy |
|---|---|---|---|---|---|---|---|
| Run 1 | rand1bin | 86.208% | 0.0006898492093877413 | 0.0208 | 1 d 18:49:56 | 10:42:29 | 14.01 MJ |
| Run 2 | rand1bin | 86.912% | 0.0006288162385445066 | 0.0208 | 1 d 19:05:16 | 10:46:19 | 14.15 MJ |
| Run 3 | rand1bin | 88.992% | 0.0006483502360866756 | 0.02072 | 2 d 02:11:48 | 12:32:57 | 16.05 MJ |
| Run 4 | rand1bin | 89.6% | 0.0006959478723656961 | 0.02064 | 1 d 21:23:48 | 11:20:57 | 14.19 MJ |
| Run 5 | rand1bin | 84.64% | 0.000326904766534731 | 0.02088 | 2 d 07:04:16 | 13:46:04 | 17.39 MJ |
| Run 6 | rand1bin | 92.368% | 0.0005630059148061578 | 0.01952 | 2 d 02:48:00 | 12:42:00 | 16.57 MJ |
| Run 7 | rand1bin | 86.184% | 0.0005503782814261585 | 0.02072 | 1 d 17:27:24 | 10:21:51 | 12.85 MJ |
| Run 8 | rand1bin | 92.056% | 0.00028135858111119703 | 0.02072 | 2 d 04:50:28 | 13:12:37 | 16.78 MJ |
| Run 9 | rand1bin | 85.8% | 0.0006648693450992239 | 0.0196 | 2 d 05:45:12 | 13:26:18 | 16.98 MJ |
| Run 10 | rand1bin | 86.008% | 0.00034871425456294697 | 0.02088 | 2 d 06:00:08 | 13:30:02 | 17.20 MJ |
| Run 1 | best1bin | 85.728% | 0.0005163082557605252 | 0.01912 | 1 d 16:27:08 | 10:06:47 | 13.08 MJ |
| Run 2 | best1bin | 92.064% | 0.0004670748833529715 | 0.01936 | 1 d 23:05:04 | 11:46:16 | 15.44 MJ |
| Run 3 | best1bin | 87.264% | 0.0006221503699548439 | 0.01912 | 1 d 08:42:52 | 08:10:43 | 10.45 MJ |
| Run 4 | best1bin | 92.472% | 0.0005562307211625986 | 0.01928 | 2 d 01:43:08 | 12:25:47 | 16.01 MJ |
| Run 5 | best1bin | 87.312% | 0.00043021019243692554 | 0.0196 | 1 d 08:56:52 | 08:14:13 | 10.45 MJ |
| Run 6 | best1bin | 91.048% | 0.0008620171163876546 | 0.0196 | 2 d 08:03:24 | 14:00:51 | 17.56 MJ |
| Run 7 | best1bin | 89.144% | 0.0005771545954761216 | 0.02064 | 1 d 07:14:32 | 07:48:38 | 9.91 MJ |
| Run 8 | best1bin | 88.952% | 0.0006351275253172771 | 0.02072 | 1 d 16:52:00 | 10:13:00 | 13.30 MJ |
| Run 9 | best1bin | 89.512% | 0.0005090810436596196 | 0.01928 | 1 d 15:08:32 | 09:47:08 | 13.28 MJ |
| Run 10 | best1bin | 88.976% | 0.00056150086412815 | 0.02088 | 1 d 17:22:08 | 10:20:32 | 13.43 MJ |
| Run 1 | currenttobest1bin | 87.6% | 0.00027984706770922403 | 0.02072 | ¸1-11:50:04 | 08:57:31 | 11.53 MJ |
| Run 2 | currenttobest1bin | 92.32% | 0.0007272597820887875 | 0.02072 | 1 d 16:04:40 | 10:01:10 | 12.72 MJ |
| Run 3 | currenttobest1bin | 89.832% | 0.0005856894554353199 | 0.01944 | 1 d 18:41:52 | 10:40:28 | 13.40 MJ |
| Run 4 | currenttobest1bin | 91.152% | 0.00035727426149585967 | 0.02072 | 1 d 06:32:04 | 07:38:01 | 9.78 MJ |
| Run 5 | currenttobest1bin | 87.176% | 0.0005665614364174747 | 0.02056 | 1 d 06:41:24 | 07:40:21 | 9.99 MJ |
| Run 6 | currenttobest1bin | 84.704% | 0.0004177038014207181 | 0.02064 | 1 d 23:06:44 | 11:46:41 | 15.39 MJ |
| Run 7 | currenttobest1bin | 84.368% | 0.0005230841039713556 | 0.02088 | 1 d 20:33:48 | 11:08:27 | 14.57 MJ |
| Run 8 | currenttobest1bin | 90.44% | 0.00033751071001580414 | 0.0196 | 1 d 15:52:28 | 09:58:07 | 13.47 MJ |
| Run 9 | currenttobest1bin | 90.448% | 0.0006533110680923715 | 0.0192 | 2 d 05:18:24 | 13:19:36 | 17.36 MJ |
| Run 10 | currenttobest1bin | 83.344% | 0.0005997052554795654 | 0.02064 | 1 d 15:49:32 | 09:57:23 | 12.94 MJ |
| Run 1 | rand2bin | 91.8% | 0.00045961835771137746 | 0.02064 | 1 d 21:38:00 | 11:24:30 | 14.84 MJ |
| Run 2 | rand2bin | 85.976% | 0.0008678928687917702 | 0.0192 | 1 d 21:09:52 | 11:17:28 | 14.38 MJ |
| Run 3 | rand2bin | 89.632% | 0.0005148477807337315 | 0.02072 | 2 d 00:54:24 | 12:13:36 | 15.97 MJ |
| Run 4 | rand2bin | 90.064% | 0.0005650098673563139 | 0.01912 | 1 d 14:39:56 | 09:39:59 | 12.22 MJ |
| Run 5 | rand2bin | 93.344% | 0.0004267791506738104 | 0.02056 | 2 d 05:05:24 | 13:16:21 | 17.06 MJ |
| Run 6 | rand2bin | 87.56% | 0.0005477842532692508 | 0.02072 | 1 d 08:54:00 | 08:13:30 | 10.46 MJ |
| Run 7 | rand2bin | 91.312% | 0.0006928286607639406 | 0.02088 | 1 d 15:54:20 | 09:58:35 | 13.12 MJ |
| Run 8 | rand2bin | 90.288% | 0.000545421981502821 | 0.0208 | 2 d 00:31:48 | 12:07:57 | 15.45 MJ |
| Run 9 | rand2bin | 86.84% | 0.0005502949547294259 | 0.02048 | 2 d 00:12:48 | 12:03:12 | 15.34 MJ |
| Run 10 | rand2bin | 88.464% | 0.0007410591842543507 | 0.01944 | 1 d 08:31:12 | 08:07:48 | 10.15 MJ |
| Run 1 | best2bin | 84.672% | 0.0004761816434291391 | 0.01912 | 2 d 01:09:28 | 12:17:22 | 15.34 MJ |
| Run 2 | best2bin | 87.872% | 0.0006654030079491737 | 0.0208 | 1 d 21:00:52 | 11:15:13 | 14.19 MJ |
| Run 3 | best2bin | 90.928% | 0.0007928241652003503 | 0.02064 | 1 d 12:51:44 | 09:12:56 | 12.57 MJ |
| Run 4 | best2bin | 92.216% | 0.0008678928687917702 | 0.0204 | 1 d 15:06:52 | 09:46:43 | 12.68 MJ |
| Run 5 | best2bin | 87.256% | 0.0008907358893952029 | 0.01944 | 1 d 10:50:32 | 08:42:38 | 10.86 MJ |
| Run 6 | best2bin | 91.592% | 0.00048186653263607886 | 0.01968 | 2 d 03:55:24 | 12:58:51 | 16.20 MJ |
| Run 7 | best2bin | 90.336% | 0.0005503782814261585 | 0.01888 | 1 d 08:30:12 | 08:07:33 | 10.23 MJ |
| Run 8 | best2bin | 89.12% | 0.00029693532449463636 | 0.01944 | 1 d 10:44:08 | 08:41:02 | 10.95 MJ |
| Run 9 | best2bin | 90.456% | 0.0004894533183428303 | 0.01912 | 1 d 10:40:44 | 08:40:11 | 11.33 MJ |
| Run 10 | best2bin | 91.448% | 0.00042551815420156525 | 0.0208 | 2 d 03:48:24 | 12:57:06 | 16.85 MJ |
| Run 1 | rand1exp | 86.608% | 0.0005473609425533086 | 0.01912 | 1 d 19:23:32 | 10:50:53 | 13.95 MJ |
| Run 2 | rand1exp | 89.832% | 0.000786296559836572 | 0.02072 | 2 d 01:47:12 | 12:26:48 | 15.72 MJ |
| Run 3 | rand1exp | 85.256% | 0.00034871425456294697 | 0.01944 | 1 d 02:00:52 | 06:30:13 | 8.21 MJ |
| Run 4 | rand1exp | 88.92% | 0.0006082014966333853 | 0.02064 | 1 d 20:51:32 | 11:12:53 | 14.37 MJ |
| Run 5 | rand1exp | 88.168% | 0.00047811603912254033 | 0.02072 | 1 d 21:33:28 | 11:23:22 | 14.69 MJ |
| Run 6 | rand1exp | 84.736% | 0.0008893519038559766 | 0.02072 | 2 d 00:20:44 | 12:05:11 | 15.44 MJ |
| Run 7 | rand1exp | 92.112% | 0.0007901080473489402 | 0.01912 | 1 d 09:10:36 | 08:17:39 | 10.51 MJ |
| Run 8 | rand1exp | 91.304% | 0.0005438169990203926 | 0.01912 | 1 d 11:56:56 | 08:59:14 | 11.46 MJ |
| Run 9 | rand1exp | 90.808% | 0.0007679084792402333 | 0.02088 | 2 d 06:16:56 | 13:34:14 | 17.70 MJ |
| Run 10 | rand1exp | 87.128% | 0.0006002695549843218 | 0.0196 | 2 d 06:08:56 | 13:32:14 | 17.20 MJ |
| Run 1 | rand2exp | 85.656% | 0.0003127600179395311 | 0.02064 | 1 d 17:26:00 | 10:21:30 | 12.91 MJ |
| Run 2 | rand2exp | 90.152% | 0.00048186653263607886 | 0.02072 | 1 d 22:14:12 | 11:33:33 | 14.81 MJ |
| Run 3 | rand2exp | 88.856% | 0.0005323176852089923 | 0.0196 | 1 d 11:39:48 | 08:54:57 | 11.54 MJ |
| Run 4 | rand2exp | 88.592% | 0.0003405499303596778 | 0.0192 | 1 d 14:34:52 | 09:38:43 | 11.98 MJ |
| Run 5 | rand2exp | 92.376% | 0.0005862625485870474 | 0.01896 | 2 d 01:45:28 | 12:26:22 | 17.13 MJ |
| Run 6 | rand2exp | 90.496% | 0.0006451815193168959 | 0.0208 | 1 d 13:49:20 | 09:27:20 | 12.45 MJ |
| Run 7 | rand2exp | 91.048% | 0.00048108878499610323 | 0.02088 | 2 d 04:12:24 | 13:03:06 | 16.81 MJ |
| Run 8 | rand2exp | 83.296% | 0.0004894533183428303 | 0.02072 | 1 d 05:34:56 | 07:23:44 | 9.28 MJ |
| Run 9 | rand2exp | 85.08% | 0.00028135858111119703 | 0.02072 | 2 d 04:23:36 | 13:05:54 | 17.13 MJ |
| Run 10 | rand2exp | 84.264% | 0.000365490467163625 | 0.0192 | 1 d 17:33:20 | 10:23:20 | 13.18 MJ |
| Run 1 | best1exp | 93.064% | 0.0005433789960932856 | 0.01912 | 1 d 13:59:44 | 09:29:56 | 12.15 MJ |
| Run 2 | best1exp | 87.8% | 0.0005472544967914471 | 0.02064 | 1 d 21:07:48 | 11:16:57 | 14.13 MJ |
| Run 3 | best1exp | 90.168% | 0.0005472544967914471 | 0.02064 | 1 d 18:50:20 | 10:42:35 | 13.72 MJ |
| Run 4 | best1exp | 89.512% | 0.0004906326786790181 | 0.0196 | 1 d 20:49:44 | 11:12:26 | 14.60 MJ |
| Run 5 | best1exp | 89.624% | 0.000699942960102872 | 0.01912 | 1 d 10:07:24 | 08:31:51 | 10.92 MJ |
| Run 6 | best1exp | 87.144% | 0.0005969144833575155 | 0.01968 | 1 d 19:11:56 | 10:47:59 | 14.06 MJ |
| Run 7 | best1exp | 89.528% | 0.000564013851333992 | 0.0208 | 2 d 01:29:44 | 12:22:26 | 15.76 MJ |
| Run 8 | best1exp | 78.872% | 0.0004902443310631703 | 0.01912 | 1 d 15:10:12 | 09:47:33 | 13.32 MJ |
| Run 9 | best1exp | 82.184% | 0.0006654030079491737 | 0.02064 | 1 d 08:45:40 | 08:11:25 | 10.76 MJ |
| Run 10 | best1exp | 90.832% | 0.0006654030079491737 | 0.0208 | 1 d 19:13:00 | 10:48:15 | 13.44 MJ |
| Run 1 | best2exp | 88.608% | 0.00040434269297750776 | 0.01912 | 1 d 18:05:08 | 10:31:17 | 13.43 MJ |
| Run 2 | best2exp | 91.648% | 0.000425369222658114 | 0.01944 | 2 d 04:18:36 | 13:04:39 | 17.01 MJ |
| Run 3 | best2exp | 93.136% | 0.0005355373902815665 | 0.0208 | 1 d 23:33:48 | 11:53:27 | 15.06 MJ |
| Run 4 | best2exp | 88.712% | 0.0005503782814261585 | 0.01888 | 1 d 15:01:16 | 09:45:19 | 12.12 MJ |
| Run 5 | best2exp | 89.272% | 0.0007901080473489402 | 0.02072 | 1 d 14:47:04 | 09:41:46 | 12.18 MJ |
| Run 6 | best2exp | 84.12% | 0.0005730828877445376 | 0.0196 | 1 d 19:36:20 | 10:54:05 | 13.81 MJ |
| Run 7 | best2exp | 88.176% | 0.0003690036337254874 | 0.0208 | 1 d 11:44:00 | 08:56:00 | 11.46 MJ |
| Run 8 | best2exp | 88.624% | 0.00043974693346348514 | 0.0196 | 1 d 16:58:44 | 10:14:41 | 13.09 MJ |
| Run 9 | best2exp | 88.912% | 0.0008332518117024622 | 0.01936 | 1 d 07:06:12 | 07:46:33 | 10.04 MJ |
| Run 10 | best2exp | 85.536% | 0.00042551815420156525 | 0.02072 | 1 d 21:11:12 | 11:17:48 | 14.50 MJ |
| Run 1 | currenttobest1exp | 87.472% | 0.0008678928687917702 | 0.02096 | 1 d 23:35:16 | 11:53:49 | 14.96 MJ |
| Run 2 | currenttobest1exp | 85.928% | 0.0005104975572802508 | 0.01968 | 1 d 19:12:12 | 10:48:03 | 13.85 MJ |
| Run 3 | currenttobest1exp | 86.992% | 0.0006967732791334938 | 0.0208 | 1 d 22:33:08 | 11:38:17 | 15.21 MJ |
| Run 4 | currenttobest1exp | 88.152% | 0.0005115646370382424 | 0.02088 | 2 d 09:01:56 | 14:15:29 | 18.32 MJ |
| Run 5 | currenttobest1exp | 81.56% | 0.0003992713190217374 | 0.0188 | 1 d 08:30:52 | 08:07:43 | 10.46 MJ |
| Run 6 | currenttobest1exp | 91.048% | 0.0008432099878544876 | 0.02072 | 1 d 20:49:16 | 11:12:19 | 14.58 MJ |
| Run 7 | currenttobest1exp | 86.016% | 0.0004894533183428303 | 0.02088 | 1 d 06:42:04 | 07:40:31 | 9.97 MJ |
| Run 8 | currenttobest1exp | 89.528% | 0.0006390182997286093 | 0.02096 | 1 d 20:04:16 | 11:01:04 | 13.92 MJ |
| Run 9 | currenttobest1exp | 93.392% | 0.0006779766206922889 | 0.02064 | 2 d 07:44:16 | 13:56:04 | 17.74 MJ |
| Run 10 | currenttobest1exp | 86.768% | 0.00028135858111119703 | 0.0208 | 2 d 06:11:20 | 13:32:50 | 17.20 MJ |
Table A6.
Results obtained from 10 runs of 15 epochs of a hyperoptimized VGG11 using a different DE strategy on CIFAR100.
Table A6.
Results obtained from 10 runs of 15 epochs of a hyperoptimized VGG11 using a different DE strategy on CIFAR100.
| Run | Strategy | Max Accuracy (%) | Best LR | Best Accuracy | CPU Time | Elapsed Time | Consumed Energy |
|---|---|---|---|---|---|---|---|
| Run 1 | rand1bin | 12.28% | 0.0004758440842318624 | 0.01184 | 3 d 16:49:04 | 22:12:16 | 31.68 MJ |
| Run 2 | rand1bin | 3.136% | 0.00028198177902085796 | 0.00856 | 3 d 18:30:20 | 22:37:35 | 31.84 MJ |
| Run 3 | rand1bin | 7.8% | 0.000423680887632644 | 0.00752 | 3 d 17:03:16 | 22:15:49 | 30.87 MJ |
| Run 4 | rand1bin | 8.232% | 0.0002135600102883045 | 0.00744 | 3 d 18:26:08 | 22:36:32 | 31.36 MJ |
| Run 5 | rand1bin | 4.248% | 0.0002612096849320728 | 0.00752 | 3 d 18:13:28 | 22:33:22 | 31.14 MJ |
| Run 6 | rand1bin | 8.496% | 0.0001948423383643041 | 0.01016 | 3 d 20:05:36 | 23:01:24 | 32.09 MJ |
| Run 7 | rand1bin | 12.176% | 0.00027093494246908825 | 0.01288 | 3 d 19:56:52 | 22:59:13 | 32.37 MJ |
| Run 8 | rand1bin | 9.056% | 0.0002804668217405539 | 0.0128 | 3 d 19:09:16 | 22:47:19 | 32.17 MJ |
| Run 9 | rand1bin | 11.696% | 0.00010634429367092576 | 0.00896 | 3 d 16:50:24 | 22:12:36 | 31.03 MJ |
| Run 10 | rand1bin | 11.744% | 0.0002167074546496962 | 0.00792 | 3 d 20:46:40 | 23:11:40 | 32.23 MJ |
| Run 1 | best1bin | 2.48% | 0.0003172322326393795 | 0.0076 | 3 d 18:38:40 | 22:39:40 | 31.27 MJ |
| Run 2 | best1bin | 3.616% | 0.0005807374261780628 | 0.00808 | 3 d 16:38:12 | 22:09:33 | 31.24 MJ |
| Run 3 | best1bin | 4.576% | 0.00026301063254584913 | 0.01208 | 3 d 18:53:48 | 22:43:27 | 32.50 MJ |
| Run 4 | best1bin | 8.296% | 0.00028539835409513285 | 0.00808 | 3 d 22:39:40 | 23:39:55 | 33.27 MJ |
| Run 5 | best1bin | 6.304% | 0.00015481075283293468 | 0.01272 | 3 d 21:24:32 | 23:21:08 | 32.89 MJ |
| Run 6 | best1bin | 11.888% | 0.00033471506346695876 | 0.00832 | 3 d 16:45:36 | 22:11:24 | 30.62 MJ |
| Run 7 | best1bin | 10.416% | 0.0005499402033940177 | 0.01264 | 3 d 18:37:12 | 22:39:18 | 31.22 MJ |
| Run 8 | best1bin | 12.752% | 0.0004243900849161208 | 0.01256 | 3 d 19:31:28 | 22:52:52 | 31.19 MJ |
| Run 9 | best1bin | 6.832% | 0.00025781904627593686 | 0.01264 | 3 d 19:30:56 | 22:52:44 | 32.49 MJ |
| Run 10 | best1bin | 4.792% | 0.0001946738068552768 | 0.01056 | 3 d 20:33:24 | 23:08:21 | 32.96 MJ |
| Run 1 | currenttobest1bin | 11.456% | 0.0005631487308943299 | 0.01232 | 3 d 21:13:28 | 23:18:22 | 32.47 MJ |
| Run 2 | currenttobest1bin | 10.064% | 0.00015089334163755292 | 0.00928 | 3 d 20:25:56 | 23:06:29 | 32.70 MJ |
| Run 3 | currenttobest1bin | 14.8% | 0.0002860525956062903 | 0.00808 | 3 d 20:16:40 | 23:04:10 | 32.45 MJ |
| Run 4 | currenttobest1bin | 8.448% | 0.00012517510179303477 | 0.00928 | 3 d 21:55:40 | 23:28:55 | 32.90 MJ |
| Run 5 | currenttobest1bin | 8.352% | 0.00018690680230060093 | 0.00832 | 3 d 21:26:48 | 23:21:42 | 33.46 MJ |
| Run 6 | currenttobest1bin | 10.168% | 0.00018857903833168356 | 0.01264 | 3 d 18:19:36 | 22:34:54 | 31.69 MJ |
| Run 7 | currenttobest1bin | 12.568% | 0.00049620070890269 | 0.012 | 3 d 14:53:12 | 21:43:18 | 30.73 MJ |
| Run 8 | currenttobest1bin | 8.728% | 0.00022051121985955288 | 0.01328 | 3 d 17:43:08 | 22:25:47 | 31.10 MJ |
| Run 9 | currenttobest1bin | 5.608% | 0.00032645793042611023 | 0.00792 | 3 d 18:37:12 | 22:39:18 | 31.60 MJ |
| Run 10 | currenttobest1bin | 6.488% | 0.00025815632809305706 | 0.008 | 3 d 19:09:52 | 22:47:28 | 31.44 MJ |
| Run 1 | rand2bin | 1.08% | 0.0006003062784437555 | 0.01224 | 3 d 16:14:24 | 22:03:36 | 30.24 MJ |
| Run 2 | rand2bin | 9.376% | 0.00011776502032561731 | 0.0084 | 3 d 18:53:48 | 22:43:27 | 33.35 MJ |
| Run 3 | rand2bin | 9.952% | 0.00016914995299162984 | 0.00864 | 3 d 21:59:24 | 23:29:51 | 32.14 MJ |
| Run 4 | rand2bin | 11.336% | 0.000720189407482924 | 0.012 | 3 d 15:40:36 | 21:55:09 | 30.06 MJ |
| Run 5 | rand2bin | 4.76% | 0.00015913542344085668 | 0.01336 | 3 d 20:21:16 | 23:05:19 | 32.07 MJ |
| Run 6 | rand2bin | 12.36% | 0.00017388615860504657 | 0.00816 | 3 d 18:23:32 | 22:35:53 | 31.91 MJ |
| Run 7 | rand2bin | 3.416% | 0.0001876385671549055 | 0.0084 | 3 d 18:58:52 | 22:44:43 | 32.16 MJ |
| Run 8 | rand2bin | 3.752% | 0.0006056778045111888 | 0.00808 | 3 d 17:12:40 | 22:18:10 | 31.03 MJ |
| Run 9 | rand2bin | 1.104% | 0.00029903040059517453 | 0.00792 | 3 d 19:36:56 | 22:54:14 | 32.24 MJ |
| Run 10 | rand2bin | 9.472% | 0.00055288865025198 | 0.00832 | 3 d 16:42:28 | 22:10:37 | 32.48 MJ |
| Run 1 | best2bin | 3.536% | 0.00031516116382460075 | 0.00824 | 3 d 17:27:04 | 22:21:46 | 31.42 MJ |
| Run 2 | best2bin | 1.104% | 0.00047945358603187127 | 0.00816 | 3 d 17:03:20 | 22:15:50 | 31.38 MJ |
| Run 3 | best2bin | 7.808% | 0.00047069820985687696 | 0.012 | 3 d 18:12:24 | 22:33:06 | 31.44 MJ |
| Run 4 | best2bin | 10.816% | 0.00048034952396599237 | 0.01192 | 3 d 20:37:12 | 23:09:18 | 31.99 MJ |
| Run 5 | best2bin | 8.384% | 0.0002073530253546591 | 0.01304 | 3 d 19:33:44 | 22:53:26 | 33.49 MJ |
| Run 6 | best2bin | 9.128% | 0.00022210847523862416 | 0.01312 | 3 d 15:46:08 | 21:56:32 | 30.58 MJ |
| Run 7 | best2bin | 10.336% | 0.00023812048965750771 | 0.00824 | 3 d 18:12:32 | 22:33:08 | 33.00 MJ |
| Run 8 | best2bin | 9.632% | 0.00044376146033904166 | 0.01256 | 3 d 17:34:12 | 22:23:33 | 31.00 MJ |
| Run 9 | best2bin | 7.96% | 0.00011955722907107348 | 0.00768 | 3 d 18:27:52 | 22:36:58 | 31.57 MJ |
| Run 10 | best2bin | 9.464% | 0.00041128106586232817 | 0.00744 | 3 d 15:48:32 | 21:57:08 | 30.42 MJ |
| Run 1 | rand1exp | 3.744% | 0.00017785144953584564 | 0.0084 | 3 d 17:36:44 | 22:24:11 | 31.61 MJ |
| Run 2 | rand1exp | 6.32% | 0.00023122861952963884 | 0.00768 | 3 d 18:25:44 | 22:36:26 | 31.52 MJ |
| Run 3 | rand1exp | 10.728% | 0.00025930895432845055 | 0.00824 | 3 d 18:17:12 | 22:34:18 | 31.46 MJ |
| Run 4 | rand1exp | 7.568% | 0.0003338349379970329 | 0.00768 | 3 d 19:57:28 | 22:59:22 | 31.56 MJ |
| Run 5 | rand1exp | 14.32% | 0.0003017895220101695 | 0.00784 | 3 d 19:44:20 | 22:56:05 | 31.35 MJ |
| Run 6 | rand1exp | 10.576% | 0.0004401082955140203 | 0.008 | 3 d 16:56:32 | 22:14:08 | 30.49 MJ |
| Run 7 | rand1exp | 7.424% | 0.00016894407653567827 | 0.00856 | 3 d 18:07:56 | 22:31:59 | 31.75 MJ |
| Run 8 | rand1exp | 2.072% | 0.00028582383118045074 | 0.00688 | 3 d 18:17:04 | 22:34:16 | 30.64 MJ |
| Run 9 | rand1exp | 10.528% | 0.00022873983152868184 | 0.00744 | 3 d 18:55:36 | 22:43:54 | 32.56 MJ |
| Run 10 | rand1exp | 9.416% | 0.00022362696961414423 | 0.012 | 3 d 19:33:36 | 22:53:24 | 32.41 MJ |
| Run 1 | rand2exp | 11.736% | 0.0006199789406184711 | 0.014 | 3 d 17:02:24 | 22:15:36 | 31.43 MJ |
| Run 2 | rand2exp | 9.872% | 0.0004279177077527727 | 0.00768 | 3 d 17:46:00 | 22:26:30 | 31.44 MJ |
| Run 3 | rand2exp | 8.336% | 0.00017631974141915944 | 0.00768 | 3 d 18:45:12 | 22:41:18 | 31.49 MJ |
| Run 4 | rand2exp | 7.512% | 0.0005678937041351777 | 0.01168 | 3 d 23:10:40 | 23:47:40 | 33.71 MJ |
| Run 5 | rand2exp | 13.488% | 0.000570132408104643 | 0.01344 | 3 d 15:35:20 | 21:53:50 | 30.36 MJ |
| Run 6 | rand2exp | 6.992% | 0.0005123690073092089 | 0.01296 | 3 d 18:45:56 | 22:41:29 | 32.21 MJ |
| Run 7 | rand2exp | 11.96% | 0.00010449537090628753 | 0.00904 | 3 d 21:32:08 | 23:23:02 | 33.40 MJ |
| Run 8 | rand2exp | 8.992% | 0.0007376484761629621 | 0.01192 | 3 d 19:52:52 | 22:58:13 | 31.66 MJ |
| Run 9 | rand2exp | 9.68% | 0.00020687898172008128 | 0.00696 | 3 d 18:52:08 | 22:43:02 | 31.40 MJ |
| Run 10 | rand2exp | 6.912% | 0.00017552466146082978 | 0.01472 | 3 d 19:54:00 | 22:58:30 | 32.53 MJ |
| Run 1 | best1exp | 9.488% | 0.00023131294853765756 | 0.00752 | 3 d 20:08:28 | 23:02:07 | 32.57 MJ |
| Run 2 | best1exp | 5.376% | 0.0003467824856387895 | 0.00736 | 3 d 20:37:52 | 23:09:28 | 32.15 MJ |
| Run 3 | best1exp | 4.656% | 0.0005472544967914471 | 0.01208 | 3 d 16:19:16 | 22:04:49 | 32.43 MJ |
| Run 4 | best1exp | 9.088% | 0.0002195071360625721 | 0.0132 | 3 d 19:25:12 | 22:51:18 | 31.09 MJ |
| Run 5 | best1exp | 10.32% | 0.0007070396261164571 | 0.01192 | 3 d 17:19:00 | 22:19:45 | 31.00 MJ |
| Run 6 | best1exp | 8.968% | 0.00040001364440978113 | 0.00776 | 3 d 17:12:00 | 22:18:00 | 31.42 MJ |
| Run 7 | best1exp | 9.352% | 0.0006085674993746426 | 0.01176 | 3 d 18:15:20 | 22:33:50 | 31.41 MJ |
| Run 8 | best1exp | 5.912% | 0.0002333466258855149 | 0.00736 | 3 d 19:12:28 | 22:48:07 | 31.99 MJ |
| Run 9 | best1exp | 5.496% | 0.0004786371674660226 | 0.00808 | 3 d 17:39:00 | 22:24:45 | 31.38 MJ |
| Run 10 | best1exp | 12.632% | 0.00021593342404912472 | 0.008 | 3 d 18:00:28 | 22:30:07 | 31.64 MJ |
| Run 1 | best2exp | 13.896% | 0.0006167135308129644 | 0.01264 | 3 d 17:46:28 | 22:26:37 | 30.52 MJ |
| Run 2 | best2exp | 4.352% | 0.00017632288556868205 | 0.00744 | 3 d 17:51:52 | 22:27:58 | 31.16 MJ |
| Run 3 | best2exp | 11.44% | 0.0005211581986643281 | 0.01328 | 3 d 17:56:28 | 22:29:07 | 31.05 MJ |
| Run 4 | best2exp | 10.936% | 0.00011551338510091164 | 0.00888 | 3 d 20:16:36 | 23:04:09 | 31.66 MJ |
| Run 5 | best2exp | 11.936% | 0.0002579550274880725 | 0.00736 | 3 d 21:41:04 | 23:25:16 | 32.77 MJ |
| Run 6 | best2exp | 14.464% | 0.00020308846468167224 | 0.01216 | 3 d 21:53:48 | 23:28:27 | 32.60 MJ |
| Run 7 | best2exp | 7.72% | 0.000247896213090593 | 0.01256 | 3 d 17:55:48 | 22:28:57 | 32.04 MJ |
| Run 8 | best2exp | 7.544% | 0.00014886380231794087 | 0.00848 | 3 d 21:18:40 | 23:19:40 | 32.27 MJ |
| Run 9 | best2exp | 9.896% | 0.00025405591553419765 | 0.00808 | 3 d 19:19:08 | 22:49:47 | 33.55 MJ |
| Run 10 | best2exp | 7.424% | 0.0005553197851163659 | 0.0084 | 3 d 15:02:44 | 21:45:41 | 30.28 MJ |
| Run 1 | currenttobest1exp | 12.896% | 0.00041364689657383735 | 0.01248 | 3 d 19:28:20 | 22:52:05 | 32.15 MJ |
| Run 2 | currenttobest1exp | 9.288% | 0.0005264679390351683 | 0.01248 | 3 d 15:57:36 | 21:59:24 | 30.83 MJ |
| Run 3 | currenttobest1exp | 7.104% | 0.00019117767808024858 | 0.01208 | 3 d 20:12:16 | 23:03:04 | 31.82 MJ |
| Run 4 | currenttobest1exp | 3.24% | 0.0001510797914778076 | 0.00824 | 3 d 19:59:28 | 22:59:52 | 31.85 MJ |
| Run 5 | currenttobest1exp | 8.952% | 0.00048267406041127396 | 0.01232 | 3 d 22:45:16 | 23:41:19 | 33.33 MJ |
| Run 6 | currenttobest1exp | 6.56% | 0.00019670530113206582 | 0.00808 | 3 d 16:54:08 | 22:13:32 | 30.96 MJ |
| Run 7 | currenttobest1exp | 8.856% | 0.00020656584365016256 | 0.008 | 3 d 20:54:44 | 23:13:41 | 32.03 MJ |
| Run 8 | currenttobest1exp | 6.824% | 0.0005982859399029891 | 0.01216 | 3 d 19:25:04 | 22:51:16 | 32.40 MJ |
| Run 9 | currenttobest1exp | 11.28% | 0.00025674744573364155 | 0.0148 | 3 d 19:32:16 | 22:53:04 | 33.62 MJ |
| Run 10 | currenttobest1exp | 4.776% | 0.00021676993339812383 | 0.00824 | 3 d 19:14:48 | 22:48:42 | 31.50 MJ |
Table A7.
Results obtained from 10 runs of 15 epochs of a hyperoptimized ConvNeXtSmall using a different DE strategy on CIFAR100.
Table A7.
Results obtained from 10 runs of 15 epochs of a hyperoptimized ConvNeXtSmall using a different DE strategy on CIFAR100.
| Run | Strategy | Max Accuracy (%) | Best LR | Best Accuracy | CPU Time | Elapsed Time | Consumed Energy |
|---|---|---|---|---|---|---|---|
| Run 1 | rand1bin | 96.856% | 0.0007901080473489402 | 0.02096 | 1 d 08:40:24 | 08:10:06 | 11.65 MJ |
| Run 2 | rand1bin | 95.152% | 0.0006889420612678595 | 0.02096 | 23:50:36 | 05:57:39 | 8.54 MJ |
| Run 3 | rand1bin | 95.912% | 0.0004894533183428303 | 0.02088 | 1 d 03:21:36 | 06:50:24 | 10.06 MJ |
| Run 4 | rand1bin | 96.96% | 0.0007901080473489402 | 0.01968 | 1 d 03:52:36 | 06:58:09 | 10.06 MJ |
| Run 5 | rand1bin | 95.168% | 0.0007724669579759172 | 0.02096 | 1 d 13:22:32 | 09:20:38 | 13.23 MJ |
| Run 6 | rand1bin | 97.6% | 0.0006821091229623088 | 0.02096 | 1 d 03:10:08 | 06:47:32 | 9.21 MJ |
| Run 7 | rand1bin | 96.544% | 0.0005843108361629204 | 0.02096 | 22:45:32 | 05:41:23 | 8.04 MJ |
| Run 8 | rand1bin | 94.272% | 0.0007724669579759172 | 0.0196 | 17:44:40 | 04:26:10 | 6.23 MJ |
| Run 9 | rand1bin | 96.624% | 0.0007901080473489402 | 0.02096 | 1 d 02:34:32 | 06:38:38 | 9.60 MJ |
| Run 10 | rand1bin | 94.296% | 0.0007901080473489402 | 0.02088 | 22:40:04 | 05:40:01 | 8.16 MJ |
| Run 1 | best1bin | 96.768% | 0.0006654030079491737 | 0.02096 | 18:06:16 | 04:31:34 | 6.50 MJ |
| Run 2 | best1bin | 98.4% | 0.0007525478022450478 | 0.02096 | 1 d 01:08:04 | 06:17:01 | 8.86 MJ |
| Run 3 | best1bin | 97.84% | 0.0007294670352147221 | 0.01968 | 1 d 02:39:40 | 06:39:55 | 9.31 MJ |
| Run 4 | best1bin | 97.184% | 0.0007228400548920162 | 0.01968 | 19:41:56 | 04:55:29 | 6.83 MJ |
| Run 5 | best1bin | 98.24% | 0.0006082014966333853 | 0.02096 | 19:04:24 | 04:46:06 | 6.84 MJ |
| Run 6 | best1bin | 95.816% | 0.0005503782814261585 | 0.02096 | 18:34:04 | 04:38:31 | 6.92 MJ |
| Run 7 | best1bin | 94.456% | 0.0008721269190922968 | 0.02096 | 1 d 01:10:52 | 06:17:43 | 8.88 MJ |
| Run 8 | best1bin | 97.152% | 0.0006959478723656961 | 0.0196 | 22:53:32 | 05:43:23 | 7.94 MJ |
| Run 9 | best1bin | 97.592% | 0.0006976934222919324 | 0.01928 | 16:39:08 | 04:09:47 | 5.83 MJ |
| Run 10 | best1bin | 96.296% | 0.0006001143469740924 | 0.02088 | 23:14:36 | 05:48:39 | 8.32 MJ |
| Run 1 | currenttobest1bin | 97.448% | 0.0007901080473489402 | 0.01968 | 20:32:32 | 05:08:08 | 7.84 MJ |
| Run 2 | currenttobest1bin | 96.792% | 0.0006082014966333853 | 0.02096 | 1 d 02:38:32 | 06:39:38 | 9.94 MJ |
| Run 3 | currenttobest1bin | 98.48% | 0.0006260315644530029 | 0.0196 | 21:25:04 | 05:21:16 | 7.69 MJ |
| Run 4 | currenttobest1bin | 85.752% | 0.0005285031237901842 | 0.02096 | 1 d 01:10:48 | 06:17:42 | 9.12 MJ |
| Run 5 | currenttobest1bin | 98.36% | 0.0006654030079491737 | 0.01968 | 18:50:56 | 04:42:44 | 6.71 MJ |
| Run 6 | currenttobest1bin | 98.208% | 0.0007538518067250492 | 0.02096 | 22:32:08 | 05:38:02 | 8.64 MJ |
| Run 7 | currenttobest1bin | 98.312% | 0.0005739712323314084 | 0.02096 | 1 d 02:36:48 | 06:39:12 | 9.61 MJ |
| Run 8 | currenttobest1bin | 97.296% | 0.0006654030079491737 | 0.01968 | 1 d 01:29:24 | 06:22:21 | 9.14 MJ |
| Run 9 | currenttobest1bin | 89.992% | 0.0006053438969846567 | 0.02096 | 19:02:48 | 04:45:42 | 6.71 MJ |
| Run 10 | currenttobest1bin | 98.448% | 0.0008678928687917702 | 0.01968 | 1 d 05:51:12 | 07:27:48 | 10.39 MJ |
| Run 1 | rand2bin | 98.624% | 0.0006025519794752405 | 0.01968 | 1 d 07:56:28 | 07:59:07 | 11.09 MJ |
| Run 2 | rand2bin | 98.032% | 0.0006082014966333853 | 0.02096 | 1 d 00:00:20 | 06:00:05 | 8.28 MJ |
| Run 3 | rand2bin | 95.968% | 0.0006082014966333853 | 0.01968 | 21:12:48 | 05:18:12 | 7.49 MJ |
| Run 4 | rand2bin | 94.856% | 0.0005867294920739194 | 0.01968 | 1 d 07:18:04 | 07:49:31 | 10.94 MJ |
| Run 5 | rand2bin | 98.888% | 0.000518783386256142 | 0.02096 | 1 d 06:55:56 | 07:43:59 | 11.38 MJ |
| Run 6 | rand2bin | 95.056% | 0.0006654030079491737 | 0.0196 | 23:30:08 | 05:52:32 | 8.33 MJ |
| Run 7 | rand2bin | 93.936% | 0.000716417524233165 | 0.01968 | 1 d 08:31:40 | 08:07:55 | 11.33 MJ |
| Run 8 | rand2bin | 96.896% | 0.0007074116266477621 | 0.01968 | 22:51:08 | 05:42:47 | 8.10 MJ |
| Run 9 | rand2bin | 97.248% | 0.0005018975833192116 | 0.02096 | 1 d 14:38:40 | 09:39:40 | 13.91 MJ |
| Run 10 | rand2bin | 96.256% | 0.0007107141212986745 | 0.02096 | 23:21:16 | 05:50:19 | 8.32 MJ |
| Run 1 | best2bin | 94.432% | 0.0007901080473489402 | 0.02096 | 22:57:44 | 05:44:26 | 8.12 MJ |
| Run 2 | best2bin | 93.88% | 0.0006082014966333853 | 0.0196 | 1 d 10:21:56 | 08:35:29 | 12.41 MJ |
| Run 3 | best2bin | 96.88% | 0.0007730846229734456 | 0.01968 | 1 d 06:32:52 | 07:38:13 | 10.71 MJ |
| Run 4 | best2bin | 99.024% | 0.0008432099878544876 | 0.02096 | 22:23:52 | 05:35:58 | 7.84 MJ |
| Run 5 | best2bin | 92.024% | 0.0004894533183428303 | 0.02096 | 1 d 10:07:48 | 08:31:57 | 12.03 MJ |
| Run 6 | best2bin | 95.936% | 0.0006980972232017339 | 0.02096 | 21:42:16 | 05:25:34 | 7.68 MJ |
| Run 7 | best2bin | 97.44% | 0.0006654030079491737 | 0.02096 | 1 d 01:37:48 | 06:24:27 | 9.08 MJ |
| Run 8 | best2bin | 97.008% | 0.0008710360124656422 | 0.02096 | 1 d 00:09:16 | 06:02:19 | 8.28 MJ |
| Run 9 | best2bin | 96.92% | 0.0006654030079491737 | 0.01928 | 23:56:08 | 05:59:02 | 8.24 MJ |
| Run 10 | best2bin | 97.76% | 0.0006975880985105572 | 0.02096 | 1 d 00:20:36 | 06:05:09 | 8.74 MJ |
| Run 1 | rand1exp | 97.584% | 0.0006204154396845862 | 0.02096 | 1 d 12:53:20 | 09:13:20 | 13.00 MJ |
| Run 2 | rand1exp | 97.904% | 0.0007901080473489402 | 0.02096 | 23:29:40 | 05:52:25 | 8.39 MJ |
| Run 3 | rand1exp | 96.616% | 0.0007901080473489402 | 0.0196 | 1 d 03:11:24 | 06:47:51 | 9.43 MJ |
| Run 4 | rand1exp | 96.984% | 0.0007186427786502296 | 0.02096 | 1 d 03:09:44 | 06:47:26 | 9.52 MJ |
| Run 5 | rand1exp | 93.584% | 0.0006654030079491737 | 0.01968 | 1 d 04:23:12 | 07:05:48 | 10.24 MJ |
| Run 6 | rand1exp | 97.376% | 0.0005843108361629204 | 0.01968 | 22:00:04 | 05:30:01 | 7.74 MJ |
| Run 7 | rand1exp | 97.616% | 0.0005952230222502635 | 0.01968 | 1 d 01:26:56 | 06:21:44 | 8.82 MJ |
| Run 8 | rand1exp | 96.904% | 0.0005503782814261585 | 0.0196 | 1 d 08:47:16 | 08:11:49 | 11.58 MJ |
| Run 9 | rand1exp | 97.16% | 0.0006082014966333853 | 0.01968 | 1 d 05:34:48 | 07:23:42 | 10.62 MJ |
| Run 10 | rand1exp | 95.544% | 0.0006654030079491737 | 0.01968 | 23:23:36 | 05:50:54 | 8.18 MJ |
| Run 1 | rand2exp | 90.96% | 0.0007107141212986745 | 0.0196 | 1 d 03:47:16 | 06:56:49 | 9.98 MJ |
| Run 2 | rand2exp | 95.184% | 0.0007901080473489402 | 0.0196 | 21:52:44 | 05:28:11 | 8.15 MJ |
| Run 3 | rand2exp | 94.6% | 0.0008678928687917702 | 0.02096 | 23:46:20 | 05:56:35 | 8.43 MJ |
| Run 4 | rand2exp | 96.08% | 0.0004894533183428303 | 0.02088 | 1 d 02:51:36 | 06:42:54 | 9.64 MJ |
| Run 5 | rand2exp | 94.264% | 0.0007901080473489402 | 0.0196 | 1 d 01:25:08 | 06:21:17 | 8.80 MJ |
| Run 6 | rand2exp | 97.808% | 0.0006981023602417849 | 0.01968 | 22:51:08 | 05:42:47 | 8.02 MJ |
| Run 7 | rand2exp | 95.88% | 0.0006396423253417437 | 0.02096 | 1 d 12:57:44 | 09:14:26 | 12.77 MJ |
| Run 8 | rand2exp | 94.184% | 0.0006654030079491737 | 0.02096 | 1 d 06:18:28 | 07:34:37 | 10.81 MJ |
| Run 9 | rand2exp | 92.704% | 0.0006015937509008642 | 0.02096 | 1 d 00:18:12 | 06:04:33 | 9.11 MJ |
| Run 10 | rand2exp | 95.224% | 0.0007525478022450478 | 0.02096 | 1 d 09:31:12 | 08:22:48 | 11.82 MJ |
| Run 1 | best1exp | 97.856% | 0.0006854628207936492 | 0.02096 | 20:46:16 | 05:11:34 | 7.74 MJ |
| Run 2 | best1exp | 96.96% | 0.0007927504106257327 | 0.02096 | 1 d 01:59:36 | 06:29:54 | 9.21 MJ |
| Run 3 | best1exp | 97.592% | 0.0007189822463493425 | 0.02096 | 1 d 00:07:36 | 06:01:54 | 8.46 MJ |
| Run 4 | best1exp | 97.6% | 0.0008864446965370434 | 0.01928 | 20:34:44 | 05:08:41 | 7.31 MJ |
| Run 5 | best1exp | 98.088% | 0.0005503782814261585 | 0.02096 | 22:47:12 | 05:41:48 | 8.20 MJ |
| Run 6 | best1exp | 95.664% | 0.0006654030079491737 | 0.02096 | 23:48:16 | 05:57:04 | 8.81 MJ |
| Run 7 | best1exp | 96.312% | 0.0007189822463493425 | 0.02096 | 21:01:48 | 05:15:27 | 7.23 MJ |
| Run 8 | best1exp | 96.536% | 0.0004592908741909575 | 0.02096 | 20:25:40 | 05:06:25 | 7.11 MJ |
| Run 9 | best1exp | 97.88% | 0.0008678928687917702 | 0.02096 | 19:37:24 | 04:54:21 | 6.93 MJ |
| Run 10 | best1exp | 97.952% | 0.0005817525102614234 | 0.01968 | 22:56:48 | 05:44:12 | 8.34 MJ |
| Run 1 | best2exp | 79.408% | 0.0007901080473489402 | 0.02096 | 1 d 10:02:44 | 08:30:41 | 11.73 MJ |
| Run 2 | best2exp | 96.832% | 0.0006999346845686593 | 0.0196 | 1 d 16:31:24 | 10:07:51 | 14.08 MJ |
| Run 3 | best2exp | 93.768% | 0.0007901080473489402 | 0.02096 | 19:07:16 | 04:46:49 | 6.67 MJ |
| Run 4 | best2exp | 97.744% | 0.0005720037520182216 | 0.0196 | 1 d 08:50:28 | 08:12:37 | 11.38 MJ |
| Run 5 | best2exp | 92.44% | 0.0007410591842543507 | 0.01968 | 1 d 01:40:08 | 06:25:02 | 8.87 MJ |
| Run 6 | best2exp | 98.048% | 0.0007901080473489402 | 0.01968 | 23:16:52 | 05:49:13 | 8.29 MJ |
| Run 7 | best2exp | 95.672% | 0.0008678928687917702 | 0.02096 | 1 d 02:20:32 | 06:35:08 | 9.34 MJ |
| Run 8 | best2exp | 95.016% | 0.0007901080473489402 | 0.02096 | 18:33:28 | 04:38:22 | 6.65 MJ |
| Run 9 | best2exp | 98.256% | 0.000609450316148117 | 0.01968 | 1 d 05:41:48 | 07:25:27 | 10.45 MJ |
| Run 10 | best2exp | 94.192% | 0.0005748075218202315 | 0.01968 | 23:10:24 | 05:47:36 | 8.57 MJ |
| Run 1 | currenttobest1exp | 98.488% | 0.0007901080473489402 | 0.01968 | 1 d 00:31:16 | 06:07:49 | 8.57 MJ |
| Run 2 | currenttobest1exp | 86.744% | 0.0006519191589097266 | 0.01968 | 1 d 01:54:44 | 06:28:41 | 9.06 MJ |
| Run 3 | currenttobest1exp | 98.408% | 0.000747574786423565 | 0.02096 | 20:26:00 | 05:06:30 | 7.22 MJ |
| Run 4 | currenttobest1exp | 97.512% | 0.0006654030079491737 | 0.0196 | 1 d 04:42:44 | 07:10:41 | 10.71 MJ |
| Run 5 | currenttobest1exp | 97.88% | 0.0006082014966333853 | 0.02096 | 22:45:52 | 05:41:28 | 8.12 MJ |
| Run 6 | currenttobest1exp | 98.288% | 0.0005631057606785751 | 0.0196 | 20:57:44 | 05:14:26 | 7.52 MJ |
| Run 7 | currenttobest1exp | 95.728% | 0.0006411974249065124 | 0.0196 | 1 d 06:36:20 | 07:39:05 | 10.78 MJ |
| Run 8 | currenttobest1exp | 97.032% | 0.0007901080473489402 | 0.02096 | 1 d 01:05:24 | 06:16:21 | 8.77 MJ |
| Run 9 | currenttobest1exp | 98.24% | 0.0006082014966333853 | 0.02096 | 23:59:00 | 05:59:45 | 8.62 MJ |
| Run 10 | currenttobest1exp | 96.096% | 0.0006379725003334835 | 0.02096 | 1 d 00:45:40 | 06:11:25 | 8.66 MJ |
Table A8.
Results obtained from 10 runs of 15 epochs of a hyperoptimized DenseNet121 using a different DE strategy on CIFAR100.
Table A8.
Results obtained from 10 runs of 15 epochs of a hyperoptimized DenseNet121 using a different DE strategy on CIFAR100.
| Run | Strategy | Max Accuracy (%) | Best LR | Best Accuracy | CPU Time | Elapsed Time | Consumed Energy |
|---|---|---|---|---|---|---|---|
| Run 1 | rand1bin | 82.92% | 0.0006654030079491737 | 0.02056 | 3 d 15:07:36 | 21:46:54 | 29.99 MJ |
| Run 2 | rand1bin | 82.888% | 0.0006202047668125793 | 0.02064 | 4 d 22:05:44 | 1 d 05:31:26 | 40.69 MJ |
| Run 3 | rand1bin | 76.512% | 0.00048564505518037464 | 0.02064 | 4 d 10:00:44 | 1 d 02:30:11 | 36.86 MJ |
| Run 4 | rand1bin | 78.048% | 0.0008053856824962536 | 0.02048 | 4 d 02:18:40 | 1 d 00:34:40 | 33.63 MJ |
| Run 5 | rand1bin | 79.576% | 0.000675975688771568 | 0.02016 | 3 d 17:07:48 | 22:16:57 | 31.05 MJ |
| Run 6 | rand1bin | 78.408% | 0.0008767364540890501 | 0.0204 | 4 d 15:57:36 | 1 d 03:59:24 | 41.03 MJ |
| Run 7 | rand1bin | 76.92% | 0.00060540286447946 | 0.02048 | 3 d 17:13:40 | 22:18:25 | 29.91 MJ |
| Run 8 | rand1bin | 82.168% | 0.0008721269190922968 | 0.02048 | 4 d 14:04:20 | 1 d 03:31:05 | 37.22 MJ |
| Run 9 | rand1bin | 81.704% | 0.000829737184952023 | 0.02048 | 3 d 03:12:24 | 18:48:06 | 26.43 MJ |
| Run 10 | rand1bin | 84.112% | 0.0005476379869519423 | 0.02032 | 3 d 05:33:04 | 19:23:16 | 26.64 MJ |
| Run 1 | best1bin | 76.288% | 0.0007423530742001329 | 0.0204 | 3 d 18:22:12 | 22:35:33 | 32.99 MJ |
| Run 2 | best1bin | 76.696% | 0.0005326948380079542 | 0.02048 | 3 d 22:52:12 | 23:43:03 | 34.44 MJ |
| Run 3 | best1bin | 78.616% | 0.0005797679228218648 | 0.02008 | 3 d 15:27:40 | 21:51:55 | 29.34 MJ |
| Run 4 | best1bin | 77.696% | 0.0006200823353455683 | 0.02048 | 2 d 22:40:48 | 17:40:12 | 24.30 MJ |
| Run 5 | best1bin | 75.056% | 0.0007564207094200043 | 0.02064 | 4 d 06:46:44 | 1 d 01:41:41 | 35.42 MJ |
| Run 6 | best1bin | 77.44% | 0.0003997420427603187 | 0.0188 | 4 d 14:41:48 | 1 d 03:40:27 | 38.67 MJ |
| Run 7 | best1bin | 79.648% | 0.0004894533183428303 | 0.02024 | 3 d 02:49:00 | 18:42:15 | 26.21 MJ |
| Run 8 | best1bin | 78.52% | 0.0006120682152581484 | 0.01896 | 4 d 16:57:12 | 1 d 04:14:18 | 39.48 MJ |
| Run 9 | best1bin | 77.112% | 0.0007901080473489402 | 0.01864 | 3 d 07:10:32 | 19:47:38 | 27.21 MJ |
| Run 10 | best1bin | 78.352% | 0.0005549515933290077 | 0.02056 | 4 d 10:42:16 | 1 d 02:40:34 | 36.58 MJ |
| Run 1 | currenttobest1bin | 76.92% | 0.0007132299248766175 | 0.02008 | 3 d 22:39:52 | 23:39:58 | 31.86 MJ |
| Run 2 | currenttobest1bin | 78.784% | 0.0006362783276563835 | 0.0204 | 3 d 21:18:48 | 23:19:42 | 32.47 MJ |
| Run 3 | currenttobest1bin | 78.712% | 0.000654213208490852 | 0.01872 | 3 d 20:55:28 | 23:13:52 | 31.95 MJ |
| Run 4 | currenttobest1bin | 76.224% | 0.000787288991867034 | 0.01896 | 3 d 17:49:12 | 22:27:18 | 30.72 MJ |
| Run 5 | currenttobest1bin | 81.304% | 0.0007980896882381098 | 0.02048 | 4 d 03:24:00 | 1 d 00:51:00 | 34.48 MJ |
| Run 6 | currenttobest1bin | 80.384% | 0.0005753402905043697 | 0.01848 | 3 d 17:36:28 | 22:24:07 | 32.39 MJ |
| Run 7 | currenttobest1bin | 81% | 0.0005047913723943186 | 0.02048 | 4 d 05:25:16 | 1 d 01:21:19 | 35.28 MJ |
| Run 8 | currenttobest1bin | 77.168% | 0.0005959635265044236 | 0.02064 | 4 d 15:42:16 | 1 d 03:55:34 | 38.33 MJ |
| Run 9 | currenttobest1bin | 81.336% | 0.00031425557171528703 | 0.01848 | 3 d 18:30:40 | 22:37:40 | 30.91 MJ |
| Run 10 | currenttobest1bin | 75.976% | 0.000503502803921123 | 0.02048 | 4 d 13:53:36 | 1 d 03:28:24 | 37.46 MJ |
| Run 1 | rand2bin | 73.424% | 0.0007901080473489402 | 0.02016 | 3 d 23:45:56 | 23:56:29 | 33.48 MJ |
| Run 2 | rand2bin | 78.408% | 0.0008030331165076808 | 0.02064 | 4 d 01:54:08 | 1 d 00:28:32 | 33.22 MJ |
| Run 3 | rand2bin | 83.08% | 0.0005345789371013722 | 0.01808 | 4 d 07:17:32 | 1 d 01:49:23 | 35.99 MJ |
| Run 4 | rand2bin | 78.44% | 0.00048418893037675234 | 0.02048 | 4 d 09:39:20 | 1 d 02:24:50 | 36.11 MJ |
| Run 5 | rand2bin | 86.144% | 0.0005655821182281734 | 0.02048 | 4 d 07:49:48 | 1 d 01:57:27 | 34.62 MJ |
| Run 6 | rand2bin | 77.312% | 0.0008116289204223694 | 0.0204 | 4 d 00:45:56 | 1 d 00:11:29 | 32.78 MJ |
| Run 7 | rand2bin | 78.096% | 0.0004778887850150283 | 0.01856 | 4 d 19:37:04 | 1 d 04:54:16 | 38.72 MJ |
| Run 8 | rand2bin | 76.072% | 0.0007519131968394462 | 0.01832 | 2 d 22:25:20 | 17:36:20 | 23.72 MJ |
| Run 9 | rand2bin | 80.48% | 0.0004894533183428303 | 0.02048 | 3 d 18:42:20 | 22:40:35 | 32.70 MJ |
| Run 10 | rand2bin | 80.96% | 0.0007645743780018519 | 0.02064 | 4 d 18:18:56 | 1 d 04:34:44 | 39.98 MJ |
| Run 1 | best2bin | 77.208% | 0.0004894533183428303 | 0.01784 | 3 d 02:05:12 | 18:31:18 | 26.87 MJ |
| Run 2 | best2bin | 78.64% | 0.0008315636058555897 | 0.02024 | 3 d 15:54:24 | 21:58:36 | 31.75 MJ |
| Run 3 | best2bin | 80.008% | 0.0005427390544160421 | 0.02016 | 3 d 20:26:32 | 23:06:38 | 31.05 MJ |
| Run 4 | best2bin | 75.048% | 0.0008678928687917702 | 0.01872 | 3 d 19:25:44 | 22:51:26 | 31.88 MJ |
| Run 5 | best2bin | 80.344% | 0.0007581394482273197 | 0.0208 | 4 d 11:40:16 | 1 d 02:55:04 | 36.48 MJ |
| Run 6 | best2bin | 82.904% | 0.0008437911646318687 | 0.02056 | 4 d 06:43:52 | 1 d 01:40:58 | 35.18 MJ |
| Run 7 | best2bin | 73.2% | 0.0007579677831387739 | 0.0184 | 3 d 12:22:56 | 21:05:44 | 29.16 MJ |
| Run 8 | best2bin | 80.864% | 0.0007761478617407693 | 0.01832 | 3 d 05:22:56 | 19:20:44 | 27.09 MJ |
| Run 9 | best2bin | 74.16% | 0.0006462340878852519 | 0.01824 | 3 d 02:33:20 | 18:38:20 | 26.26 MJ |
| Run 10 | best2bin | 74.952% | 0.00045501261509388324 | 0.01896 | 4 d 16:01:08 | 1 d 04:00:17 | 38.56 MJ |
| Run 1 | rand1exp | 74.304% | 0.00052474483955106 | 0.01816 | 3 d 09:37:44 | 20:24:26 | 28.64 MJ |
| Run 2 | rand1exp | 79.888% | 0.0007242696328327767 | 0.01832 | 3 d 08:40:56 | 20:10:14 | 27.85 MJ |
| Run 3 | rand1exp | 77.248% | 0.0007631536352134615 | 0.01832 | 4 d 04:16:12 | 1 d 01:04:03 | 33.67 MJ |
| Run 4 | rand1exp | 78.12% | 0.00043477145698976377 | 0.01784 | 3 d 16:44:12 | 22:11:03 | 30.92 MJ |
| Run 5 | rand1exp | 79.208% | 0.0002907698069310832 | 0.01848 | 4 d 03:13:56 | 1 d 00:48:29 | 33.39 MJ |
| Run 6 | rand1exp | 80.296% | 0.0004994166766487448 | 0.02032 | 2 d 21:39:12 | 17:24:48 | 24.08 MJ |
| Run 7 | rand1exp | 74.568% | 0.00047467542214666 | 0.02064 | 4 d 09:19:48 | 1 d 02:19:57 | 36.24 MJ |
| Run 8 | rand1exp | 78.84% | 0.0007901080473489402 | 0.02048 | 4 d 15:27:24 | 1 d 03:51:51 | 38.04 MJ |
| Run 9 | rand1exp | 80.848% | 0.0004280783087662982 | 0.02056 | 4 d 04:37:52 | 1 d 01:09:28 | 34.79 MJ |
| Run 10 | rand1exp | 80.992% | 0.0002610188130293907 | 0.0184 | 3 d 18:43:04 | 22:40:46 | 32.89 MJ |
| Run 1 | rand2exp | 80.432% | 0.0006410507329638893 | 0.02056 | 3 d 21:45:24 | 23:26:21 | 32.88 MJ |
| Run 2 | rand2exp | 77.736% | 0.0008678928687917702 | 0.0204 | 3 d 15:47:52 | 21:56:58 | 29.60 MJ |
| Run 3 | rand2exp | 80.592% | 0.000568841061839567 | 0.01848 | 2 d 04:15:16 | 13:03:49 | 17.99 MJ |
| Run 4 | rand2exp | 82.136% | 0.0005546137158676577 | 0.02048 | 4 d 04:48:24 | 1 d 01:12:06 | 34.47 MJ |
| Run 5 | rand2exp | 80.24% | 0.0007622868258816035 | 0.02064 | 5 d 00:22:08 | 1 d 06:05:32 | 41.39 MJ |
| Run 6 | rand2exp | 81.224% | 0.0006795795662093253 | 0.02056 | 4 d 04:52:24 | 1 d 01:13:06 | 34.98 MJ |
| Run 7 | rand2exp | 76.784% | 0.0008774537774736814 | 0.02072 | 4 d 14:45:20 | 1 d 03:41:20 | 38.24 MJ |
| Run 8 | rand2exp | 76.92% | 0.0006445884529124566 | 0.02032 | 3 d 22:29:40 | 23:37:25 | 32.78 MJ |
| Run 9 | rand2exp | 77.456% | 0.0007938674387322841 | 0.02056 | 4 d 00:46:08 | 1 d 00:11:32 | 33.52 MJ |
| Run 10 | rand2exp | 78.968% | 0.0004011233408739289 | 0.01888 | 4 d 21:11:28 | 1 d 05:17:52 | 39.54 MJ |
| Run 1 | best1exp | 80.536% | 0.0005432668918096289 | 0.02032 | 3 d 21:49:12 | 23:27:18 | 32.91 MJ |
| Run 2 | best1exp | 85.944% | 0.0005566507896839094 | 0.02032 | 3 d 19:58:28 | 22:59:37 | 32.15 MJ |
| Run 3 | best1exp | 78.376% | 0.0007394698323265238 | 0.02056 | 3 d 19:14:48 | 22:48:42 | 31.12 MJ |
| Run 4 | best1exp | 83.952% | 0.0007203754240154368 | 0.0204 | 3 d 20:47:08 | 23:11:47 | 32.29 MJ |
| Run 5 | best1exp | 82.152% | 0.0004935776147080955 | 0.02024 | 2 d 16:46:40 | 16:11:40 | 22.34 MJ |
| Run 6 | best1exp | 77.032% | 0.0004946461854106993 | 0.01864 | 4 d 20:30:04 | 1 d 05:07:31 | 39.24 MJ |
| Run 7 | best1exp | 78.256% | 0.0008678928687917702 | 0.01864 | 3 d 18:09:08 | 22:32:17 | 31.15 MJ |
| Run 8 | best1exp | 76.568% | 0.0005038676427045084 | 0.02064 | 3 d 21:53:40 | 23:28:25 | 31.41 MJ |
| Run 9 | best1exp | 81.928% | 0.0007620443874603759 | 0.0188 | 4 d 21:55:48 | 1 d 05:28:57 | 40.68 MJ |
| Run 10 | best1exp | 78.616% | 0.0008417298503340027 | 0.02048 | 4 d 10:01:00 | 1 d 02:30:15 | 36.33 MJ |
| Run 1 | best2exp | 78.04% | 0.0005730828877445376 | 0.01856 | 3 d 19:48:52 | 22:57:13 | 32.05 MJ |
| Run 2 | best2exp | 75.856% | 0.0007566147283715602 | 0.01864 | 3 d 09:51:12 | 20:27:48 | 27.85 MJ |
| Run 3 | best2exp | 82.192% | 0.0007262587775800464 | 0.02056 | 4 d 09:36:44 | 1 d 02:24:11 | 36.30 MJ |
| Run 4 | best2exp | 81.816% | 0.0006654030079491737 | 0.02064 | 3 d 17:06:36 | 22:16:39 | 31.09 MJ |
| Run 5 | best2exp | 78.92% | 0.0005806109984995696 | 0.02072 | 4 d 07:19:44 | 1 d 01:49:56 | 36.15 MJ |
| Run 6 | best2exp | 77.376% | 0.0007130271055142935 | 0.0208 | 4 d 22:08:16 | 1 d 05:32:04 | 40.67 MJ |
| Run 7 | best2exp | 78.928% | 0.0007729998130371389 | 0.0188 | 4 d 06:41:32 | 1 d 01:40:23 | 34.85 MJ |
| Run 8 | best2exp | 80.176% | 0.00040053540213785767 | 0.01856 | 3 d 19:25:32 | 22:51:23 | 30.82 MJ |
| Run 9 | best2exp | 74.688% | 0.0005503782814261585 | 0.02032 | 4 d 07:27:08 | 1 d 01:51:47 | 37.24 MJ |
| Run 10 | best2exp | 76.312% | 0.0005355373902815665 | 0.02048 | 4 d 07:18:36 | 1 d 01:49:39 | 37.86 MJ |
| Run 1 | currenttobest1exp | 80.632% | 0.0002672795926582179 | 0.01848 | 2 d 19:45:28 | 16:56:22 | 24.09 MJ |
| Run 2 | currenttobest1exp | 81.752% | 0.0005504565700063033 | 0.02024 | 3 d 13:43:36 | 21:25:54 | 29.50 MJ |
| Run 3 | currenttobest1exp | 79.408% | 0.0008964423615283914 | 0.02048 | 3 d 21:17:40 | 23:19:25 | 32.76 MJ |
| Run 4 | currenttobest1exp | 81.68% | 0.0004931955339084103 | 0.02056 | 3 d 13:29:24 | 21:22:21 | 30.02 MJ |
| Run 5 | currenttobest1exp | 78.368% | 0.0004997356816806906 | 0.01832 | 3 d 23:39:08 | 23:54:47 | 33.75 MJ |
| Run 6 | currenttobest1exp | 78.448% | 0.0006150346912197598 | 0.0188 | 4 d 02:30:56 | 1 d 00:37:44 | 33.19 MJ |
| Run 7 | currenttobest1exp | 77.392% | 0.00039163235149273454 | 0.01872 | 4 d 03:53:24 | 1 d 00:58:21 | 33.63 MJ |
| Run 8 | currenttobest1exp | 75.92% | 0.0004894533183428303 | 0.02024 | 3 d 08:05:00 | 20:01:15 | 28.98 MJ |
| Run 9 | currenttobest1exp | 76.944% | 0.0007513891251893841 | 0.02024 | 4 d 02:20:20 | 1 d 00:35:05 | 33.09 MJ |
| Run 10 | currenttobest1exp | 77.424% | 0.0005445221831417415 | 0.02032 | 4 d 01:16:28 | 1 d 00:19:07 | 33.69 MJ |
References
- Silva, C.; Vilaça, R.; Pereira, A.; Bessa, R. A review on the decarbonization of high-performance computing centers. Renew. Sustain. Energy Rev. 2024, 189, 114019. [Google Scholar] [CrossRef]
- Chu, X.; Hofstätter, D.; Ilager, S.; Talluri, S.; Kampert, D.; Podareanu, D.; Duplyakin, D.; Brandic, I.; Iosup, A. Generic and ML Workloads in an HPC Datacenter: Node Energy, Job Failures, and Node-Job Analysis. arXiv 2024, arXiv:2409.08949. [Google Scholar] [CrossRef]
- Baratchi, M.; Wang, C.; Limmer, S.; van Rijn, J.N.; Hoos, H.; Bäck, T.; Olhofer, M. Automated machine learning: Past, present and future. Artif. Intell. Rev. 2024, 57, 122. [Google Scholar] [CrossRef]
- Bolón-Canedo, V.; Morán-Fernández, L.; Cancela, B.; Alonso-Betanzos, A. A review of green artificial intelligence: Towards a more sustainable future. Neurocomputing 2024, 599, 128096. [Google Scholar] [CrossRef]
- TOP500 Methodology. 2025. Available online: https://www.top500.org/static/media/uploads/methodology-2.0rc1.pdf (accessed on 19 January 2025).
- Miller, J.; Trümper, L.; Terboven, C.; Müller, M.S. A Theoretical Model for Global Optimization of Parallel Algorithms. Mathematics 2021, 9, 1685. [Google Scholar] [CrossRef]
- Damme, P.; Birkenbach, M.; Bitsakos, C.; Boehm, M.; Bonnet, P.; Ciorba, F.; Dokter, M.; Dowgiallo, P.; Eleliemy, A.; Faerber, C.; et al. DAPHNE: An Open and Extensible System Infrastructure for Integrated Data Analysis Pipelines. In Proceedings of the Conference on Innovative Data Systems Research, Chaminade, CA, USA, 9–12 January 2022. [Google Scholar]
- Alangari, N.; El Bachir Menai, M.; Mathkour, H.; Almosallam, I. Exploring Evaluation Methods for Interpretable Machine Learning: A Survey. Information 2023, 14, 469. [Google Scholar] [CrossRef]
- Jakobsche, T.; Lachiche, N.; Ciorba, F.M. Investigating HPC Job Resource Requests and Job Efficiency Reporting. In Proceedings of the 2023 22nd International Symposium on Parallel and Distributed Computing (ISPDC), Bucharest, Romania, 10–12 July 2023; pp. 61–68. [Google Scholar] [CrossRef]
- Yarally, T.; Cruz, L.; Feitosa, D.; Sallou, J.; van Deursen, A. Uncovering Energy-Efficient Practices in Deep Learning Training: Preliminary Steps Towards Green AI. In Proceedings of the 2023 IEEE/ACM 2nd International Conference on AI Engineering—Software Engineering for AI (CAIN), Melbourne, Australia, 15–16 May 2023; pp. 25–36. [Google Scholar] [CrossRef]
- Prica, T. Development and supporting activities on EuroHPC Vega. In Proceedings of the Austrian-Slovenian HPC Meeting 2024—ASHPC24, Grundlsee, Austria, 10–13 June 2024; p. 14. [Google Scholar]
- Oliveira, S.d.; Topsakal, O.; Toker, O. Benchmarking Automated Machine Learning (AutoML) Frameworks for Object Detection. Information 2024, 15, 63. [Google Scholar] [CrossRef]
- Yoo, A.B.; Jette, M.A.; Grondona, M. SLURM: Simple Linux Utility for Resource Management. In Proceedings of the 9th International Workshop on Job Scheduling Strategies for Parallel Processing (JSSPP), Seattle, WA, USA, 24 June 2003. [Google Scholar] [CrossRef]
- Han, M.; Wu, H.; Chen, Z.; Li, M.; Zhang, X. A survey of multi-label classification based on supervised and semi-supervised learning. Int. J. Mach. Learn. Cybern. 2023, 14, 697–724. [Google Scholar] [CrossRef]
- Virtanen, P.; Gommers, R.; Oliphant, T.E.; Haberland, M.; Reddy, T.; Cournapeau, D.; Burovski, E.; Peterson, P.; Weckesser, W.; Bright, J.; et al. SciPy 1.0: Fundamental algorithms for scientific computing in Python. Nat. Methods 2020, 17, 261–272. [Google Scholar] [CrossRef]
- Das, S.; Mullick, S.S.; Suganthan, P.N. Recent Advances in Differential Evolution—An Updated Survey. Swarm Evol. Comput. 2016, 27, 1–30. [Google Scholar] [CrossRef]
- Li, J.Y.; Zhan, Z.H.; Zhang, J. Evolutionary Computation for Expensive Optimization: A Survey. Mach. Intell. Res. 2022, 19, 3–23. [Google Scholar] [CrossRef]
- Qin, X.; Luo, Y.; Chen, S.; Chen, Y.; Han, Y. Investigation of Energy-Saving Strategy for Parallel Variable Frequency Pump System Based on Improved Differential Evolution Algorithm. Energies 2022, 15, 5360. [Google Scholar] [CrossRef]
- Dragoi, E.N.; Dafinescu, V. Parameter control and hybridization techniques in differential evolution: A survey. Artif. Intell. Rev. 2015, 45, 447–470. [Google Scholar] [CrossRef]
- Storn, R.; Price, K. Differential Evolution–A Simple and Efficient Heuristic for global Optimization over Continuous Spaces. J. Glob. Optim. 1997, 11, 341–359. [Google Scholar] [CrossRef]
- Eltaeib, T.; Mahmood, A. Differential Evolution: A Survey and Analysis. Appl. Sci. 2018, 8, 1945. [Google Scholar] [CrossRef]
- Nanthapodej, R.; Liu, C.H.; Nitisiri, K.; Pattanapairoj, S. Hybrid Differential Evolution Algorithm and Adaptive Large Neighborhood Search to Solve Parallel Machine Scheduling to Minimize Energy Consumption in Consideration of Machine-Load Balance Problems. Sustainability 2021, 13, 5470. [Google Scholar] [CrossRef]
- Chhabra, A.; Sahana, S.K.; Sani, N.S.; Mohammadzadeh, A.; Omar, H.A. Energy-Aware Bag-of-Tasks Scheduling in the Cloud Computing System Using Hybrid Oppositional Differential Evolution-Enabled Whale Optimization Algorithm. Energies 2022, 15, 4571. [Google Scholar] [CrossRef]
- IAM Working Group. IPMI Specification. 2006. Available online: https://openipmi.sourceforge.io/IPMI.pdf (accessed on 25 October 2024).
- Bischl, B.; Binder, M.; Lang, M.; Pielok, T.; Richter, J.; Coors, S.; Thomas, J.; Ullmann, T.; Becker, M.; Boulesteix, A.L.; et al. Hyperparameter optimization: Foundations, algorithms, best practices, and open challenges. WIREs Data Min. Knowl. Discov. 2023, 13, e1484. [Google Scholar] [CrossRef]
- Morales-Hernández, A.; Van Nieuwenhuyse, I.; Rojas Gonzalez, S. A survey on multi-objective hyperparameter optimization algorithms for machine learning. Artif. Intell. Rev. 2022, 56, 8043–8093. [Google Scholar] [CrossRef]
- Dataset CIFAR10 and CIFAR100. Available online: https://www.cs.toronto.edu/~kriz/cifar.html (accessed on 19 November 2024).
- Boito, F.; Brandt, J.; Cardellini, V.; Carns, P.; Ciorba, F.M.; Egan, H. Autonomy Loops for Monitoring, Operational Data Analytics, Feedback, and Response in HPC Operations. In Proceedings of the 2023 IEEE International Conference on Cluster Computing Workshops (CLUSTER Workshops), Santa Fe, NM, USA, 31 October 2023; pp. 37–43. [Google Scholar] [CrossRef]
- El Naqa, I.; Murphy, M.J. What Is Machine Learning? In Machine Learning in Radiation Oncology: Theory and Applications; Springer International Publishing: Cham, Switzerland, 2015; pp. 3–11. [Google Scholar] [CrossRef]
- Zhang, X.; Guo, F.; Chen, T.; Pan, L.; Beliakov, G.; Wu, J. A Brief Survey of Machine Learning and Deep Learning Techniques for E-Commerce Research. J. Theor. Appl. Electron. Commer. Res. 2023, 18, 2188–2216. [Google Scholar] [CrossRef]
- Bergstra, J.; Bardenet, R.; Bengio, Y.; Kégl, B. Algorithms for hyper-parameter optimization. In Proceedings of the 25th International Conference on Neural Information Processing Systems, NIPS’11, Granada, Spain, 12–15 December 2011; Curran Associates Inc.: Red Hook, NY, USA, 2011; pp. 2546–2554. Available online: https://dl.acm.org/doi/10.5555/2986459.2986743 (accessed on 7 April 2025).
- Zamuda, A.; Daniel Hernández Sosa, J.; Adler, L. Improving constrained glider trajectories for ocean eddy border sampling within extended mission planning time. In Proceedings of the 2016 IEEE Congress on Evolutionary Computation (CEC), Vancouver, BC, Canada, 24–29 July 2016; pp. 1727–1734. [Google Scholar] [CrossRef]
- Zhu, K.; Wu, J. Residual attention: A simple but effective method for multi-label recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 184–193. [Google Scholar] [CrossRef]
- Zhou, Z.H. Machine Learning; Springer Nature: Berlin/Heidelberg, Germany, 2021. [Google Scholar]
- Hu, X.; Chu, L.; Pei, J.; Liu, W.; Bian, J. Model Complexity of Deep Learning: A Survey. arXiv 2021, arXiv:2103.05127. [Google Scholar] [CrossRef]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training; OpenAI: San Francisco, CA, USA, 2018. [Google Scholar]
- Menik, S.; Ramaswamy, L. Towards Modular Machine Learning Solution Development: Benefits and Trade-offs. arXiv 2023, arXiv:2301.09753. [Google Scholar] [CrossRef]
- Shen, Y.; Zhang, Z.; Cao, T.; Tan, S.; Chen, Z.; Gan, C. ModuleFormer: Modularity Emerges from Mixture-of-Experts. arXiv 2023, arXiv:2306.04640. [Google Scholar] [CrossRef]
- Barandas, M.; Famiglini, L.; Campagner, A.; Folgado, D.; Simão, R.; Cabitza, F.; Gamboa, H. Evaluation of uncertainty quantification methods in multi-label classification: A case study with automatic diagnosis of electrocardiogram. Inf. Fusion 2024, 101, 101978. [Google Scholar] [CrossRef]
- Maloney, S.; Suarez, E.; Eicker, N.; Guimarães, F.; Frings, W. Analyzing HPC Monitoring Data With a View Towards Efficient Resource Utilization. In Proceedings of the 2024 IEEE 36th International Symposium on Computer Architecture and High Performance Computing (SBAC-PAD), Hilo, HI, USA, 13–15 November 2024; pp. 170–181. [Google Scholar]
- Vontzalidis, A.; Psomadakis, S.; Bitsakos, C.; Dokter, M.; Innerebner, K.; Damme, P.; Boehm, M.; Ciorba, F.; Eleliemy, A.; Karakostas, V.; et al. DAPHNE Runtime: Harnessing Parallelism for‚ Integrated Data Analysis Pipelines. In Proceedings of the Euro-Par 2023: Parallel Processing Workshops, Limassol, Cyprus, 28 August–1 September 2023; pp. 242–246. [Google Scholar]
- Jakobsche, T.; Lachiche, N.; Ciorba, F.M. Challenges and Opportunities of Machine Learning for Monitoring and Operational Data Analytics in Quantitative Codesign of Supercomputers. arXiv 2022, arXiv:2209.07164. [Google Scholar] [CrossRef]
- Prica, T.; Zamuda, A. Monitoring Energy Consumption of Workloads on HPC Vega. In Proceedings of the 6th ISC HPC International Workshop on “Monitoring & Operational Data Analytics”, Hamburg, Germany, 9 March–13 June 2025. [Google Scholar]
- Chakraborty, U.K. Advances in Differential Evolution; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2008; Volume 143. [Google Scholar]
- Ahmad, M.F.; Isa, N.A.M.; Lim, W.H.; Ang, K.M. Differential evolution: A recent review based on state-of-the-art works. Alex. Eng. J. 2022, 61, 3831–3872. [Google Scholar] [CrossRef]
- Glotić, A.; Zamuda, A. Short-term combined economic and emission hydrothermal optimization by surrogate differential evolution. Appl. Energy 2015, 141, 42–56. [Google Scholar] [CrossRef]
- Zamuda, A.; Sosa, J.D.H.; Adler, L. Constrained differential evolution optimization for underwater glider path planning in sub-mesoscale eddy sampling. Appl. Soft Comput. 2016, 42, 93–118. [Google Scholar] [CrossRef]
- Lucas, C.; Hernández-Sosa, D.; Greiner, D.; Zamuda, A.; Caldeira, R. An approach to multi-objective path planning optimization for underwater gliders. Sensors 2019, 19, 5506. [Google Scholar] [CrossRef]
- Brest, J.; Greiner, S.; Boskovic, B.; Mernik, M.; Zumer, V. Self-Adapting Control Parameters in Differential Evolution: A Comparative Study on Numerical Benchmark Problems. IEEE Trans. Evol. Comput. 2006, 10, 646–657. [Google Scholar] [CrossRef]
- Fan, Q.; Yan, X.; Zhang, Y. Auto-selection mechanism of differential evolution algorithm variants and its application. Eur. J. Oper. Res. 2018, 270, 636–653. [Google Scholar] [CrossRef]
- Vincent, A.M.; Jidesh, P. An improved hyperparameter optimization framework for AutoML systems using evolutionary algorithms. Sci. Rep. 2023, 13, 4737. [Google Scholar] [CrossRef]
- Sen, A.; Gupta, V.; Tang, C. Differential Evolution Algorithm Based Hyperparameter Selection of Gated Recurrent Unit for Electrical Load Forecasting. arXiv 2023, arXiv:2309.13019. [Google Scholar] [CrossRef]
- Gomes, E.; Pereira, L.; Esteves, A.; Morais, H. Metaheuristic Optimization Methods in Energy Community Scheduling: A Benchmark Study. Energies 2024, 17, 2968. [Google Scholar] [CrossRef]
- Main Stages of the DE Algorithm. Available online: https://www.researchgate.net/figure/Main-stages-of-the-DE-algorithm_fig1_336225430 (accessed on 19 November 2024).
- Opara, K.; Arabas, J. Comparison of mutation strategies in Differential Evolution—A probabilistic perspective. Swarm Evol. Comput. 2018, 39, 53–69. [Google Scholar] [CrossRef]
- Wu, T.; Li, X.; Zhou, D.; Li, N.; Shi, J. Differential Evolution Based Layer-Wise Weight Pruning for Compressing Deep Neural Networks. Sensors 2021, 21, 880. [Google Scholar] [CrossRef]
- Zamuda, A. Foundational Concepts and Real-World Applications of Self-Adaptive Differential Evolution and Success History. In Swarm Intelligence—Foundational Concepts and Real-World Applications; Chibante, R., Miranda, P., Palade, V., Eds.; Artificial Intelligence; IntechOpen: London, UK, 2025; Chapter 1; pp. 1–20. Available online: https://www.intechopen.com/online-first/1222844 (accessed on 7 April 2025).
- Qiao, K.; Wen, X.; Ban, X.; Chen, P.; Price, K.; Suganthan, P.; Liang, J.; Wu, G.; Yue, C. Evaluation Criteria for CEC 2024 Competition and Special Session on Numerical Optimization Considering Accuarcy and Speed; Technical Report; Zhengzhou University: Zhengzhou, China; Central South University: Changsha, China; Henan Institute of Technology: Xinxiang, China; Qatar University: Doha, Qatar, 2023. [Google Scholar]
- Tanabe, R.; Fukunaga, A.S. Improving the search performance of SHADE using linear population size reduction. In Proceedings of the 2014 IEEE Congress on Evolutionary Computation, Beijing, China, 6–11 July 2014; pp. 1658–1665. [Google Scholar]
- Viktorin, A.; Senkerik, R.; Pluhacek, M.; Kadavy, T.; Zamuda, A. Distance based parameter adaptation for Success-History based Differential Evolution. Swarm Evol. Comput. 2019, 50, 100462. [Google Scholar] [CrossRef]
- Tanabe, R.; Fukunaga, A. Reviewing and Benchmarking Parameter Control Methods in Differential Evolution. IEEE Trans. Cybern. 2020, 50, 1170–1184. [Google Scholar] [CrossRef]
- Mininno, E.; Neri, F.; Cupertino, F.; Naso, D. Compact Differential Evolution. IEEE Trans. Evol. Comput. 2011, 15, 32–54. [Google Scholar] [CrossRef]
- Zamuda, A.; Dokter, M. Deploying DAPHNE Computational Intelligence on EuroHPC Vega for Benchmarking Randomised Optimisation Algorithms. In Proceedings of the International Conference on Broadband Communications for Next Generation Networks and Multimedia Applications (CoBCom), Graz, Austria, 9–11 July 2024; pp. 1–8. [Google Scholar]
- Jiang, Y.; Qi, X.; Liu, C. Energy-Aware Automatic Tuning on Many-Core Platform via Differential Evolution. In Proceedings of the 2016 45th International Conference on Parallel Processing Workshops (ICPPW), Philadelphia, PA, USA, 16–19 August 2016; pp. 258–265. [Google Scholar] [CrossRef]
- Baioletti, M.; Di Bari, G.; Milani, A.; Poggioni, V. Differential Evolution for Neural Networks Optimization. Mathematics 2020, 8, 69. [Google Scholar] [CrossRef]
- Agarwal, M.; Gupta, S.K.; Biswas, K.K. DECACNN: Differential evolution-based approach to compress and accelerate the convolution neural network model. Neural Comput. Appl. 2023, 36, 2665–2681. [Google Scholar] [CrossRef]
- Wu, X.; Che, A. A memetic differential evolution algorithm for energy-efficient parallel machine scheduling. Omega 2019, 82, 155–165. [Google Scholar] [CrossRef]
- Abdel-Basset, M.; Mohamed, R.; Alrashdi, I.; Sallam, K.M.; Hameed, I.A. Evolution-based energy-efficient data collection system for UAV-supported IoT: Differential evolution with population size optimization mechanism. Expert Syst. Appl. 2024, 245, 123082. [Google Scholar] [CrossRef]
- Zamuda, A.; Hernández Sosa, J.D. Differential evolution and underwater glider path planning applied to the short-term opportunistic sampling of dynamic mesoscale ocean structures. Appl. Soft Comput. 2014, 24, 95–108. [Google Scholar] [CrossRef]
- Zamuda, A.; Sosa, J.D.H. Success history applied to expert system for underwater glider path planning using differential evolution. Expert Syst. Appl. 2019, 119, 155–170. [Google Scholar] [CrossRef]
- Janssen, D.; Pullan, W.; Liew, A.W.C. GPU Based Differential Evolution: New Insights and Comparative Study. arXiv 2024, arXiv:2405.16551. [Google Scholar] [CrossRef]
- Van Stein, B.; Vermetten, D.; Caraffini, F.; Kononova, A.V. Deep BIAS: Detecting Structural Bias using Explainable AI. In Proceedings of the GECCO ’23 Companion: Proceedings of the Companion Conference on Genetic and Evolutionary Computation, Lisbon, Portugal, 15–19 July 2023; pp. 455–458. [Google Scholar]
- van Stein, N.; Kononova, A.V. (Eds.) Explainable AI for Evolutionary Computation; Springer Nature: Singapore, 2025. [Google Scholar] [CrossRef]
- Raponi, E.; Rodriguez, I.O.; van Stein, N. Global Sensitivity Analysis Is Not Always Beneficial for Evolutionary Computation: A Study in Engineering Design. In Explainable AI for Evolutionary Computation; Springer Nature: Singapore, 2025; pp. 13–40. [Google Scholar] [CrossRef]
- Barbudo, R.; Ventura, S.; Romero, J.R. Eight years of AutoML: Categorisation, review and trends. Knowl. Inf. Syst. 2023, 65, 5097–5149. [Google Scholar] [CrossRef]
- Salehin, I.; Islam, M.S.; Saha, P.; Noman, S.; Tuni, A.; Hasan, M.M.; Baten, M.A. AutoML: A systematic review on automated machine learning with neural architecture search. J. Inf. Intell. 2024, 2, 52–81. [Google Scholar] [CrossRef]
- Chatzilygeroudis, K.; Hatzilygeroudis, I.; Perikos, I. Machine Learning Basics. In Intelligent Computing for Interactive System Design: Statistics, Digital Signal Processing, and Machine Learning in Practice, 1st ed.; Association for Computing Machinery: New York, NY, USA, 2021; pp. 143–193. [Google Scholar] [CrossRef]
- Geissler, D.; Zhou, B.; Suh, S.; Lukowicz, P. Spend More to Save More (SM2): An Energy-Aware Implementation of Successive Halving for Sustainable Hyperparameter Optimization. arXiv 2024, arXiv:2412.08526. [Google Scholar] [CrossRef]
- Ferro, M.; Silva, G.D.; de Paula, F.B.; Vieira, V.; Schulze, B. Towards a sustainable artificial intelligence: A case study of energy efficiency in decision tree algorithms. Concurr. Comput. Pract. Exp. 2021, 35, e6815. [Google Scholar] [CrossRef]
- Castellanos-Nieves, D.; García-Forte, L. Improving Automated Machine-Learning Systems Through Green AI. Appl. Sci. 2023, 13, 11583. [Google Scholar] [CrossRef]
- Castellanos-Nieves, D.; García-Forte, L. Strategies of Automated Machine Learning for Energy Sustainability in Green Artificial Intelligence. Appl. Sci. 2024, 14, 6196. [Google Scholar] [CrossRef]
- Zamuda, A.; Brest, J. Self-adaptive control parameters’ randomization frequency and propagations in differential evolution. Swarm Evol. Comput. 2015, 25, 72–99. [Google Scholar] [CrossRef]
- Vakhnin, A.; Ryzhikov, I.; Niska, H.; Kolehmainen, M. A Novel Multi-Objective Hybrid Evolutionary-Based Approach for Tuning Machine Learning Models in Short-Term Power Consumption Forecasting. AI 2024, 5, 2461–2496. [Google Scholar] [CrossRef]
- Pătrăușanu, A.; Florea, A.; Neghină, M.; Dicoiu, A.; Chiș, R. A Systematic Review of Multi-Objective Evolutionary Algorithms Optimization Frameworks. Processes 2024, 12, 869. [Google Scholar] [CrossRef]
- Liuliakov, A.; Hermes, L.; Hammer, B. AutoML technologies for the identification of sparse classification and outlier detection models. Appl. Soft Comput. 2023, 133, 109942. [Google Scholar] [CrossRef]
- Jin, H.; Chollet, F.; Song, Q.; Hu, X. AutoKeras: An AutoML Library for Deep Learning. J. Mach. Learn. Res. 2023, 24, 1–6. [Google Scholar]
- Shi, M.; Shen, W. Automatic Modeling for Concrete Compressive Strength Prediction Using Auto-Sklearn. Buildings 2022, 12, 1406. [Google Scholar] [CrossRef]
- Omar, I.; Khan, M.; Starr, A.; Abou Rok Ba, K. Automated Prediction of Crack Propagation Using H2O AutoML. Sensors 2023, 23, 8419. [Google Scholar] [CrossRef]
- Olson, R.S.; Moore, J.H. TPOT: A Tree-based Pipeline Optimization Tool for Automating Machine Learning. In PMLR, Proceedings of the Workshop on Automatic Machine Learning, New York, NY, USA, 24 June 2016; Hutter, F., Kotthoff, L., Vanschoren, J., Eds.; Springer: Cham, Switzerland, 2016; Volume 64, pp. 66–74. [Google Scholar]
- TensorFlow. Available online: https://www.tensorflow.org/ (accessed on 28 November 2024).
- PyTorch. Available online: https://pytorch.org/ (accessed on 19 November 2024).
- Hansen, N.; Auger, A.; Ros, R.; Mersmann, O.; Tušar, T.; Brockhoff, D. COCO: A platform for comparing continuous optimizers in a black-box setting. Optim. Methods Softw. 2020, 36, 114–144. [Google Scholar] [CrossRef]
- Varelas, K.; El Hara, O.A.; Brockhoff, D.; Hansen, N.; Nguyen, D.M.; Tušar, T.; Auger, A. Benchmarking large-scale continuous optimizers: The bbob-largescale testbed, a COCO software guide and beyond. Appl. Soft Comput. 2020, 97, 106737. [Google Scholar] [CrossRef]
- Doerr, C.; Wang, H.; Ye, F.; van Rijn, S.; Bäck, T. IOHprofiler: A Benchmarking and Profiling Tool for Iterative Optimization Heuristics. arXiv 2018, arXiv:1810.05281. [Google Scholar] [CrossRef]
- Doerr, C.; Ye, F.; Horesh, N.; Wang, H.; Shir, O.M.; Bäck, T. Benchmarking discrete optimization heuristics with IOHprofiler. Appl. Soft Comput. 2020, 88, 106027. [Google Scholar] [CrossRef]
- Durillo, J.J.; Nebro, A.J. jMetal: A Java framework for multi-objective optimization. Adv. Eng. Softw. 2011, 42, 760–771. [Google Scholar] [CrossRef]
- López-Ibáñez, M.; Dubois-Lacoste, J.; Pérez Cáceres, L.; Birattari, M.; Stützle, T. The irace package: Iterated racing for automatic algorithm configuration. Oper. Res. Perspect. 2016, 3, 43–58. [Google Scholar] [CrossRef]
- Akiba, T.; Sano, S.; Yanase, T.; Ohta, T.; Koyama, M. Optuna: A Next-generation Hyperparameter Optimization Framework. In Proceedings of the KDD ’19: 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 2623–2631. [Google Scholar] [CrossRef]
- Liaw, R.; Liang, E.; Nishihara, R.; Moritz, P.; Gonzalez, J.E.; Stoica, I. Tune: A Research Platform for Distributed Model Selection and Training. arXiv 2018, arXiv:1807.05118. [Google Scholar] [CrossRef]
- Spirals Research Group. PyJoules: A Python Library to Capture the Energy Consumption of Code Snippets; University of Lille and Inria: Lille, France, 2021. [Google Scholar]
- Anthony, L.F.W.; Kanding, B.; Selvan, R. Carbontracker: Tracking and Predicting the Carbon Footprint of Training Deep Learning Models. arXiv 2020, arXiv:2007.03051. [Google Scholar] [CrossRef]
- Ramduny, J.; Garcia, M.; Kelly, C. Establishing a reproducible and sustainable analysis workflow. In Methods for Analyzing Large Neuroimaging Datasets; Springer: New York, NY, USA, 2024; pp. 39–60. [Google Scholar]
- Deng, L. The mnist database of handwritten digit images for machine learning research. IEEE Signal Process. Mag. 2012, 29, 141–142. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Egwutuoha, I.P.; Levy, D.; Selic, B.; Chen, S. A survey of fault tolerance mechanisms and checkpoint/restart implementations for high performance computing systems. J. Supercomput. 2013, 65, 1302–1326. [Google Scholar] [CrossRef]
- Moran, M.; Balladini, J.; Rexachs, D.; Luque, E. Checkpoint and Restart: An Energy Consumption Characterization in Clusters. arXiv 2024, arXiv:2409.02214. [Google Scholar] [CrossRef]
- Kumar, M.; Gupta, S.; Patel, T.; Wilder, M.; Shi, W.; Fu, S.; Engelmann, C.; Tiwari, D. Study of interconnect errors, network congestion, and applications characteristics for throttle prediction on a large scale HPC system. J. Parallel Distrib. Comput. 2021, 153, 29–43. [Google Scholar] [CrossRef]
- Jiao, Y.; Lin, H.; Balaji, P.; Feng, W. Power and Performance Characterization of Computational Kernels on the GPU. In Proceedings of the 2010 IEEE/ACM Int’l Conference on Green Computing and Communications & Int’l Conference on Cyber, Physical and Social Computing, Hangzhou, China, 18–20 December 2010; pp. 221–228. [Google Scholar]
- Timalsina, M.; Gerhardt, L.; Tyler, N.; Blaschke, J.P.; Arndt, W. Optimizing Checkpoint-Restart Mechanisms for HPC with DMTCP in Containers at NERSC. arXiv 2024, arXiv:2407.19117. [Google Scholar] [CrossRef]
- Assogba, K.; Nicolae, B.; Van Dam, H.; Rafique, M.M. Asynchronous Multi-Level Checkpointing: An Enabler of Reproducibility using Checkpoint History Analytics. In Proceedings of the SC-W ’23: SC ’23 Workshops of the International Conference on High Performance Computing, Network, Storage, and Analysis, Denver, CO, USA, 12–17 November 2023; Association for Computing Machinery: New York, NY, USA, 2023; pp. 1748–1756. [Google Scholar] [CrossRef]
- Rojas, E.; Kahira, A.N.; Meneses, E.; Gomez, L.B.; Badia, R.M. A Study of Checkpointing in Large Scale Training of Deep Neural Networks. arXiv 2021, arXiv:2012.00825. [Google Scholar] [CrossRef]
- Gu, R.; Chen, Y.; Liu, S.; Dai, H.; Chen, G.; Zhang, K.; Che, Y.; Huang, Y. Liquid: Intelligent Resource Estimation and Network-Efficient Scheduling for Deep Learning Jobs on Distributed GPU Clusters. IEEE Trans. Parallel Distrib. Syst. 2022, 33, 2808–2820. [Google Scholar] [CrossRef]
- Daradkeh, T.; Roper, G.; Alarcon Meza, C.; Mokhov, S.A. HPC Jobs Classification and Resource Prediction to Minimize Job Failures. In Proceedings of the CompSysTech ’24: International Conference on Computer Systems and Technologies 2024, Ruse, Bulgaria, 14–15 June 2024; ACM: New York, NY, USA, 2024; pp. 95–101. [Google Scholar] [CrossRef]
- Tanash, M.; Yang, H.; Andresen, D.; Hsu, W. Ensemble Prediction of Job Resources to Improve System Performance for Slurm-Based HPC Systems. In Proceedings of the PEARC ’21: Practice and Experience in Advanced Research Computing, Boston, MA, USA, 18–22 July 2021; ACM: New York, NY, USA, 2021; pp. 1–8. [Google Scholar] [CrossRef]
- Friedman, M. The Use of Ranks to Avoid the Assumption of Normality Implicit in the Analysis of Variance. J. Am. Stat. Assoc. 1937, 32, 675–701. [Google Scholar] [CrossRef]
- Soft Computing and Intelligent Information Systems. 2025. Available online: https://sci2s.ugr.es/sicidm (accessed on 14 January 2025).
- Demšar, J. Statistical Comparisons of Classifiers over Multiple Data Sets. J. Mach. Learn. Res. 2006, 7, 1–30. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).