We start with the definition of logical distance based on the uninorm and absorbing norm, and then present the suggested algorithm. In the last subsection we consider numerical simulations and compare the suggested algorithm with the known method.
3.1. Logical Distance Based on the Uninorm and Absorbing Norm
Let
be two truth values. Given neutral element
and absorbing element
, fuzzy logical dissimilarity of the values
and
is defined as follows:
where the value
is a fuzzy logical similarity of the values
and
.
If , we will write instead of and instead of .
Lemma 1. If , then the function is a semi-metric in the algebra .
Proof. To prove the lemma, we need to check the three following properties:
.
By the commutativity and identity properties of the uninorm holds
Then, by the property of absorbing element holds
and
if .
If
, then either
or
.
It follows directly from the commutativity of the absorbing norm.
Using the dissimilarity function, we define a fuzzy logical distance
between the values
as follows (
):
Lemma 2. If , then the function is a semi-metric in the algebra of real numbers on the interval .
Proof. Since, for any
and any
both
,
and
, and by the properties a and b of semi-metric, holds
If
, then and
If , then . So and
Symmetry
follows directly from the symmetry of the dissimilarity
. □
An example of the fuzzy logic distance
between the values
with
is shown in
Figure 1a. For comparison,
Figure 1b shows the Euclidean distance between the values
.
It is seen that the fuzzy logical distance better separates the close values and is less sensitive to the far values than Euclidean distance.
Now, let us extend the introduced fuzzy logical distance to multidimensional variables.
Let
be
-dimensional vectors such that each vector
,
, is a point in a
-dimensional space.
The fuzzy logical dissimilarity of the points
and
,
, is defined as follows:
where, as above, the value
is the fuzzy logical similarity of the points
and
.
Let
. Then, as above, the fuzzy logical distance between the points
and
,
, is
Lemma 3. If , then the function is a semi-metric in the algebra , .
Proof. This statement is a direct consequence of Lemma 1 and the properties of the uninorm.
.
If
, then for each
if .
If
, then for each
.
It follows directly from the symmetry of dissimilarity for each and the commutativity of the uninorm. □
Lemma 4. If , then the function is a semi-metric on the hypercube , .
Proof. The proof is literally the same as the proof of Lemma 2. □
The suggested algorithm uses the introduced function as a distance measure between the instances of the data.
3.2. The c-Means Algorithm with Fuzzy Logical Distance
The suggested algorithm considers the instances of data as truth values and uses Algorithm 1 with fuzzy logical distance on these values.
As above, assume that the raw data are represented by
-dimensional vectors
where
,
,
,
, is a data instance.
Since function
requires the values from the hypercube
,
, vector
must be normalized
and the algorithm should be applied to the normalized data vector
. After the definition of the cluster centers
, the inverse normalization must be applied to the vector
Normalization can be conducted by several methods; in
Appendix A, we present a simple Algorithm A1 of normalization by linear transformation also called the min–max scaling. The inverse transformation provided by Algorithm A2 is also presented in
Appendix A. These transformations are the simplest ones for the normalization of the raw data. Note that with respect to the task, other normalization methods can be applied.
In general, the suggested Algorithm 2 follows the Bezdek fuzzy
c-means Algorithm 1, but differs in the distance function and in initialization of cluster centers
,
, and, consequently, in the definition of the number of clusters.
| Algorithm 2. Fuzzy c-means algorithm with fuzzy logical distance measure |
Input: -dimensional data vectors , , ,
termination criterion ,
weighting exponent ,
precision ,
distance function with the parameters .
Output: vector , , of cluster centers,
matrix , , , of membership degrees.
Calculate normalized data vectors and the values , using Algorithm A1. Initialize vector of cluster centers as a -dimensional grid with the step in the hypercube . The number of clusters is defined as a number of nodes in this grid. Initialize the membership degrees , , , Do Save membership degrees , , , Calculate cluster centers Calculate membership degrees where is the fuzzy logical distance between the instance and the cluster center , While . Calculate renormalized vector from the vector using Algorithm A2. Return and .
|
The main difference between the suggested Algorithm 2 and the original Bezdek fuzzy
c-means Algorithm 1 [
13,
14] and the known Gustafson–Kessel [
16] and Gath–Geva [
17] is the use of the fuzzy logical distance
. The use of this distance requires the normalization and renormalization of the data.
Another difference is in the need to initialize the cluster centers as a grid in the algorithm’s domain. Such initialization is required because of the quick convergence of the algorithm; thus, the regular distribution of initial cluster centers avoids missing clusters. A simple Algorithm A3 for creating a grid in the square
is outlined in
Appendix A.
Let us consider the two main properties of the suggested algorithm.
Theorem 1. Algorithm 2 converges.
Proof. The convergence of Algorithm 2 follows directly from the fact that is a semi-metric (see Lemma 4).
In fact, in the lines 3 and 7 of the algorithm holds
and the algorithm converges. □
Theorem 2. The time complexity of Algorithm 2 is , where is the dimensionality of the data, is the number of clusters, is the number of instances in the data, and is the number of iterations.
Proof. At first, consider the calculation of the fuzzy logical distances , , . The complexity of this operation is for each dimension ; thus, the calculation of the distances has a complexity .
Now, let us consider the lines of the algorithm. The normalization of the data vector (line 1) requires
steps and the initialization of the cluster centers (line 2) requires
steps (see Algorithm A1 in
Appendix A).
Initialization of the membership degrees (line 3) requires steps for each dimension that gives .
In the do-while loop, saving membership degrees (line 5) requires , the calculation of the cluster centers given the membership degrees (line 6) requires steps, and the calculation of membership degrees (line 7) requires, as above, steps for each dimension that gives .
Finally, the renormalization of the vector of the cluster centers (line 9) requires steps.
Thus, initial (lines 1–3) and final (9) operations of the algorithm require
steps and each iteration requires
Then, for
iterations, it is required that
steps. □
For experimental validation of the running time, the suggested Algorithm 2 was implemented using MATLAB® R2024b and was trialed on the PC HP with the processor Intel® Core™ i7-1255U 1.70 GHz and RAM 16.0 GB operated by OS Microsoft Windows 11.
In the trials, we checked the dependence of the runtime
on the number
of clusters for the datasets of different sizes
. The results of the trials are summarized in
Table 1.
As was expected (see Theorem 2), the runtime of the algorithm increases with the number of instances and the number of clusters, and it is easy to verify that the increase is linear.
Finally, note that, in the considerations above, we assumed that which supported the semi-metric properties of the function . Along with that, in practice, these parameters can differ, and despite the absence of formal proofs, the use of the function with while can provide better clustering. In the numerical simulations we used the values and , and since the data are normalized before clustering, these values do not depend on the range of the raw data.
The other parameter used in the suggested algorithm is precision , which defines the step of the grid, and consequently—an initial number of clusters. In practice, the value should result in which is greater than or equal to the expected number of clusters. If an expected number of clusters is unknown, then should have a value such that the initial number of clusters is greater than or equal to the number of instances in the dataset. Note that the smaller and consequently larger lead to a longer computation time. The dependence of the results of the algorithm on the value is illustrated below.
3.3. Numerical Simulations
In the first series of simulations, we will demonstrate that the suggested Algorithm 2 with fuzzy logical distance results in more precise centers of the clusters than the original Algorithm 1 with the Euclidean distance.
For this purpose, in the simulations, we generate a single cluster, as normally distributed instances with the known center, and apply Algorithms 1 and 2 to these data. As a measure of the quality of the algorithms, we use the mean squared error (MSE) in finding the center of the cluster center and the means of the standard deviations of the calculated clusters centers.
To avoid the influence of the instance values, in the simulations, we considered the normalized data. An example of the data (white circles) and the results of the algorithms (gray diamonds for Algorithm 1 and black pentagrams for Algorithm 2) are shown in
Figure 2.
The simulations were conducted with different numbers of clusters by the series of trials. The results were tested and compared by the one-sample and two-sample Student’s -tests.
In the simulations, we assumed that the algorithm, which for a single cluster provides less dispersed cluster centers, is more precise in the calculation of the cluster centers. In other words, the algorithm, which results in the clusters centers concentrated near the actual cluster center, is better than the algorithm, which results in more dispersed cluster centers.
The results of the simulations are summarized in
Table 2. In the table, we present the results of clustering of two-dimensional data distributed around the mean
.
It is seen that both algorithms result in cluster centers close to the actual cluster center and the errors in calculating the centers are extremely small. Additional statistical testing by the Student’s -test demonstrated that the differences between the obtained clusters centers are not significant with .
This conclusion was additionally verified using the silhouette criterion [
26] with the Euclidean distance measure, which was applied to the cluster centers obtained by Algorithms 1 and 2 with respect to the real cluster centers. The results of the validation with different numbers
of instances and different numbers
of clusters are summarized in
Table 3.
It is seen that both algorithms result in very close means of the silhouette criterion and the difference between the values of this criterion are not significant. Hence, both algorithms result in cluster centers close to the real cluster centers with the same precision.
Along with that, from
Table 2, it follows that the suggested Algorithm 2 results in a smaller standard deviation than the Algorithm 1 and this difference is significant with
. Hence, the suggested Algorithm 2 results in more precise cluster centers than Algorithm 1.
These results are supported by the values of the Dann partition coefficient [
27,
28], which represents the degree of fuzziness of the clustering. The graph of the Dann coefficient with respect to the initial number of clusters is shown in
Figure 3.
In the figure, the dataset includes ten real clusters. The algorithms started with a single cluster () and continued up to clusters (precision ). For each initial number of clusters, the trial included ten runs, and the plotted value is an average of the coefficients obtained in ten runs.
As expected, for the suggested Algorithm 2, the Dann coefficient is much lower than it is for Algorithm 1, except in the case of a single initial cluster center, for which these values are close. The reason for such behavior from the algorithms is the following: Algorithm 1 distributes the clusters centers over the instances, while the suggested Algorithm 2 concentrates the clusters centers close to the real centers of the clusters.
To illustrate these results, let us consider simulations of the algorithms on the data with several predefined clusters.
Consider the application of Algorithms 1 and 2 to the data with two predefined clusters with the centers in the points
and
. The resulting cluster centers with
and
clusters are shown in
Figure 4. The notation in the figure is the same as in
Figure 2.
It is seen that the clusters centers obtained by Algorithm 2 (black pentagrams) are concentrated closer to the actual cluster centers than the cluster centers obtained by Algorithm 1 (gray diamonds). Moreover, some of the cluster centers obtained by Algorithm 2 are located in the same points, while all cluster centers obtained by Algorithm 1 are located in different points.
More clearly, the effect is observed on the data with several clusters.
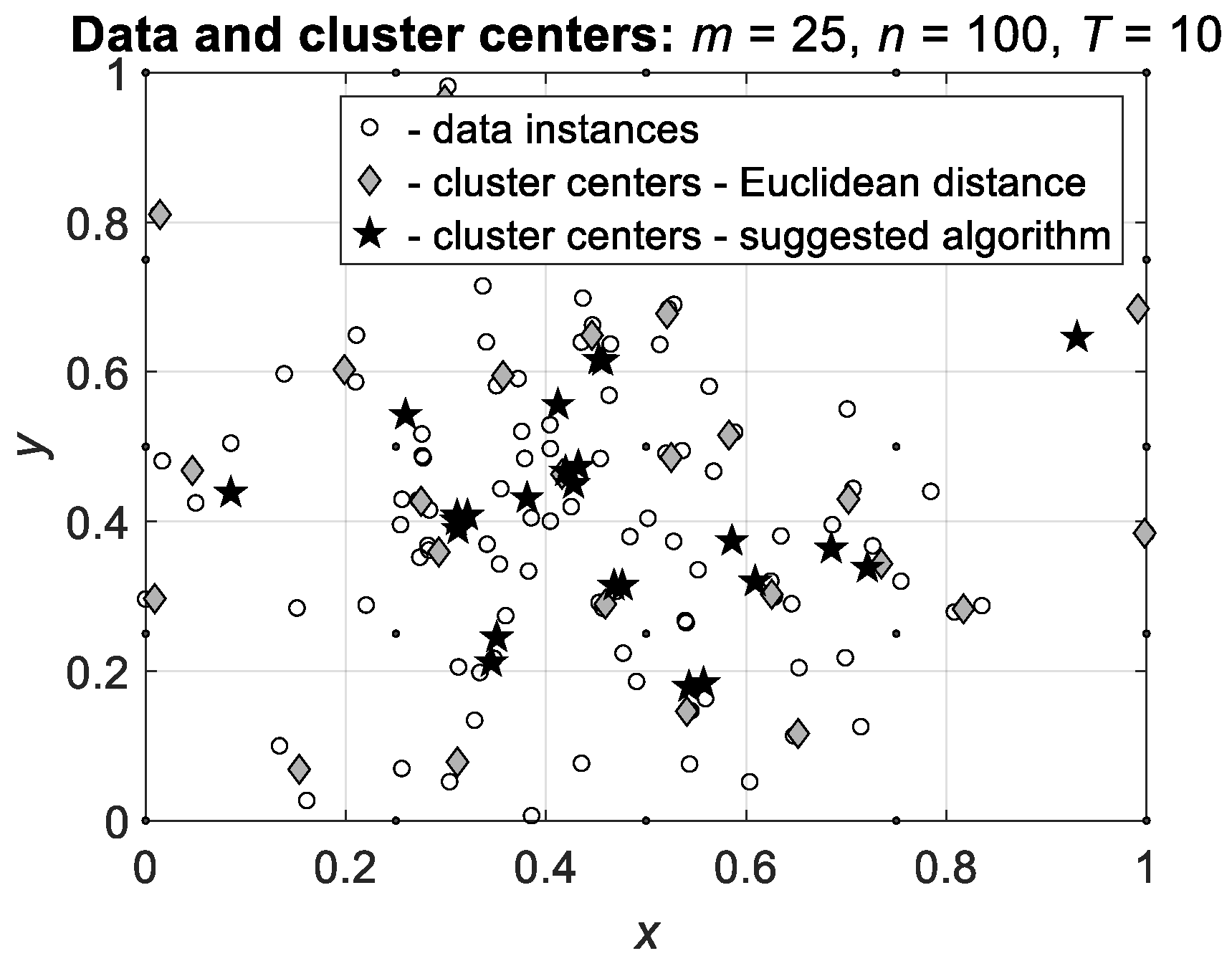
Figure 5 shows the results of Algorithms 1 and 2 applied to the data with
predefined clusters.
It is seen that the cluster centers calculated by Algorithm 2 are concentrated at the real centers of the clusters and, as above, several centers are located at the same points. Hence, the suggested Algorithm 2 allows the more correct definition of the cluster centers and consequently, more correct clustering.
Now, let us apply Algorithms 1 and 2 to the well-known Iris dataset [
29,
30]. The dataset describes three types of Iris flowers using
instances (
for each type), and each instance includes four attributes—sepal length, sepal width, petal length, and petal width.
In the trials, we applied the algorithms to four pairs of attributes: sepal length and petal length, sepal length and petal width, sepal width and petal length, and sepal width and petal width. Results of Algorithms 1 and 2 are shown in
Figure 6.
Similarly to the previous trials, the cluster centers found by the suggested Algorithm 2 are less dispersed than the cluster centers found by Algorithm 1. For large numbers of iterations (in the trials, we used
), the suggested Algorithm 2, in contrast to Algorithm 1, recognizes the cluster centers in hardly separable data, but does not always result in unambiguous cluster centers. In
Figure 6b,c, where one cluster is separate and two are hardly separable, Algorithm 2 correctly defined three clusters, and in
Figure 6a,d, where also one cluster is separate and two are non-separable, in two non-separable clusters, the algorithm defined four centers.
Finally, let us illustrate the dependence of the results of the suggested algorithm on the precision
and, consequently, on the initial number
of the clusters. The results of algorithms 1 and 2 with
,
and
,
, are shown in
Figure 7a and
Figure 7b, respectively. Note that, in
Figure 7a, the number of cluster centers is four times smaller than the number of instances,
, and in
Figure 7b the number of cluster centers is equal to the number of instances,
.
It is seen that the cluster centers defined by Algorithm 2 with the precision and are concentrated in the same regions. The further increase in the precision provides the same results but requires a longer computation time.
To illustrate the usefulness of the suggested algorithm in recognition of the number of clusters and the analysis of the data structure, let us compare the results of the algorithm with the results obtained by the MATLAB
® fcm function [
15] with three possible distance measures: Euclidean distance, Mahalanobis distance [
16], and exponential distance [
17]. These algorithms were applied to
data instances distributed around
centers; the obtained results are shown in
Figure 8.
It is seen that the suggested algorithm (
Figure 8a) correctly recognizes the real centers of the clusters and locates the cluster centers close to these real centers. In contrast, the known algorithms implemented in MATLAB
® do not recognize the real centers of the clusters, and consequently, do not define correct number of the clusters and locations of their centers. The function
fcm with Euclidean and Mahalanobis distance measures (
Figure 8b and
Figure 8c) results in two cluster centers and the function
fcm with exponential distance (
Figure 8d) results in three cluster centers. Note that the use of the Euclidean and Mahalanobis distance measures leads to very similar results.
Thus, the recognition of real cluster centers can be conducted in two stages. At first, the cluster centers are defined by the application of the suggested algorithm to raw data, and secondly, the cluster centers are defined by the application of k-means to cluster centers found at the first stage. The resulting cluster centers indicate the real cluster centers.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}