Abstract
This paper defines blind spots in continuous optimization problems as global optima that are inherently difficult to locate due to deceptive, misleading, or barren regions in the fitness landscape. Such regions can mislead the search process, trap metaheuristic algorithms (MAs) in local optima, or hide global optima in isolated regions, making effective exploration particularly challenging. To address the issue of premature convergence caused by blind spots, we propose LTMA+ (Long-Term Memory Assistance Plus), a novel meta-approach that enhances the search capabilities of MAs. LTMA+ extends the original Long-Term Memory Assistance (LTMA) by introducing strategies for handling duplicate evaluations, shifting the search away from over-exploited regions and dynamically toward unexplored areas and thereby improving global search efficiency and robustness. We introduce the Blind Spot benchmark, a specialized test suite designed to expose weaknesses in exploration by embedding global optima within deceptive fitness landscapes. To validate LTMA+, we benchmark it against a diverse set of MAs selected from the EARS framework, chosen for their different exploration mechanisms and relevance to continuous optimization problems. The tested MAs include ABC, LSHADE, jDElscop, and the more recent GAOA and MRFO. The experimental results show that LTMA+ improves the success rates for all the tested MAs on the Blind Spot benchmark statistically significantly, enhances solution accuracy, and accelerates convergence to the global optima compared to standard MAs with and without LTMA. Furthermore, evaluations on standard benchmarks without blind spots, such as CEC’15 and the soil model problem, confirm that LTMA+ maintains strong optimization performance without introducing significant computational overhead.
Keywords:
optimization; metaheuristics algorithm; algorithmic performance; duplicate solutions; non-revisited solutions; LTMA; blind spots MSC:
68W50
1. Introduction
Computer optimization is a key area of computational science that focuses on finding optimal solutions in complex problem spaces. Its applications span disciplines such as computer science, engineering, economics, and biology, supporting advancements in system design, resource allocation, and predictive modeling. Metaheuristic algorithms (MAs), a class of techniques inspired by natural processes, are central to this field due to their stochastic nature, which enables the exploration of diverse solutions to find near-optimal outcomes [1]. The comparison of different MAs is verified through experiments on different benchmarks and problems [2]. Although the benchmarks are adapted to measure the efficiency and robustness of the algorithms and are updated regularly, this can lead to the overfitting of the MAs’ development to the problems used for the comparison of the algorithms [3]. The unpredictability of various computational models and the human inclination toward certainty, as described by Nassim Nicholas Taleb in his books The Black Swan: The Impact of the Highly Improbable [4] and Antifragile [5], highlight the limitations of traditional predictive approaches. From stock market crashes and the collapse of empires to smaller anomalies—such as the triple flooding of a stream within 20 years, despite its bed being designed for 400-year flood events—these events underscore the antifragility of systems [6]. This perspective motivated us to explore the robustness of MAs, particularly for optimization problems with deceptive regions in their fitness landscapes. The bare minimum baseline for any optimization algorithm’s average performance on most problems (excluding highly stochastic or noisy problems) should surpass that of the random search (RS) algorithm. If it does not, the algorithm is either ineffective or fundamentally flawed. What we truly seek is the algorithm’s ability to thrive under stress, uncertainty, and challenges, improving its performance over time. A prime example in optimization is the use of self-adaptive control parameters, which enable the algorithm to adjust and enhance its behavior dynamically in response to the problem’s complexity [7,8,9]. By applying the LTMA meta-level approach to detect duplicate solutions and quantify population diversity [10], we introduce a novel diversity-guided adaptation mechanism with a memory-based archive of unique non-revisited solutions, enabling dynamic adjustment of MAs’ exploration mechanisms based on the frequency of duplicates and enhancing robustness against premature convergence in local optima.
The main contributions of this paper are as follows:
- The development of Blind Spot, a novel benchmark problem crafted to expose vulnerabilities in existing algorithms.
- The introduction of LTMA+, a meta-approach integrating diverse strategies to improve the robustness of MAs.
- An empirical evaluation validating LTMA+’s effectiveness in enhancing algorithmic robustness across optimization tasks.
Section 2 provides a brief overview of the concepts of exploration and exploitation. In Section 3, we introduce a benchmark problem called blind spot, and we present unexpected cases where RS outperformed MAs. This outcome serves as a clear indication that the selected algorithms lacked robustness on the Blind Spot benchmark. In Section 4, we propose a novel meta-approach, LTMA+, designed to enhance the robustness of optimization algorithms. In Section 5, we present the experimental results, while, in Section 6 and Section 7, we provide a detailed discussion and conclude the paper, respectively. The paper includes an Appendix composed of seven sections, providing additional results, experiments, and analyses to support the study.
2. Related Work
MAs are a class of optimization algorithms inspired by the process of natural evolution, whose primary goal is the survival of the fittest [11,12,13]. They typically incorporate elements such as randomness, a population of candidate solutions, and mechanisms to search around promising solution candidates. The optimization process is generally iterative and continues until a stopping criterion is met, such as a time limit, a maximum number of evaluations, or another predefined condition [14,15]. The main objective of MAs is to find the optimal solution to a given problem by evolving a population of candidate solutions iteratively. This process relies on two fundamental components: exploration and exploitation of the search space [16]. Exploration refers to the search for new solutions across the unexplored regions, while exploitation focuses on refining and improving the previously visited solutions. Striking the right balance between exploration and exploitation is critical to the success of MAs [17,18,19]. Within the broader category, MAs represent high-level strategies that guide the search process [20]. Recent studies have highlighted their effectiveness in areas like real-world engineering design [21], unrelated-parallel-machine scheduling [22], multi-objective-optimization problems [23], and emerging fields such as swarm intelligence and bio-inspired computing [16,24]. More recently, MAs have advanced through hybridization techniques and applications in dynamic and uncertain environments [25,26]. Modern MAs are designed to be flexible and adaptable, making them suitable for a wide range of optimization problems. However, most MAs require the tuning of control parameters, which can influence their efficiency and effectiveness significantly.
To evaluate the general performance of MAs, researchers use benchmark problems designed to assess algorithm capabilities across diverse optimization challenges. These benchmarks include unimodal, multimodal, and composite functions, each presenting unique difficulties such as deceptive optima and high dimensionality [2]. The most popular benchmarks are the CEC Benchmark Suites [27], Black-Box Optimization Benchmarking (BBOB) [28], International Student Competition in Structural Optimization (ISCSO) [29], and a collection of Classical Benchmark Functions, including Sphere, Ackley, and Schwefel, which are often integrated into the aforementioned suites. These benchmarks are used widely in the research community to compare the performance of different MAs and to identify their strengths and weaknesses. However, it is important to note that the choice of benchmark problems can influence the perceived performance of an algorithm significantly. This has led to concerns about overfitting, where the algorithms are tailored to perform well on specific benchmarks but may not generalize effectively to other problem types [3].
The term “blind spot problem” in the optimization community often describes specific challenges, such as positioning radar antennas or cameras to maximize coverage [30,31,32]. In the paper “Breeding Machine Translations”, blind spots refer to weaknesses in automated evaluation metrics [33]. Similarly, in “Evolutionary-Algorithm-Based Strategy for Computer-Assisted Structure Elucidation”, blind spots are regions in the solution space where the correct structure might be overlooked [34]. With an approach closer to our usage, some authors define blind spots as regions in the search space that an algorithm may skip due to linear steps during exploitation [35]. In reinforcement learning, the term describes mismatches between a simulator’s state representation and real-world conditions, leading to blind spots [36]. In this paper, for continuous optimization problems, we define blind spots as optima that are inherently difficult to locate. The challenge stems from the problem’s fitness landscape, which can influence the search process directly by creating local optima that trap algorithms or guide them toward the global optimum through gradually changing local optima, as seen in the Ackley function. Certain landscapes can also be misleading or deceptive, directing search processes toward suboptimal regions [37,38]. Another difficulty arises in barren plateaus, where gradients vanish exponentially with the problem size, hindering progress [39,40,41]. It becomes particularly challenging when the global optimum lies in a region independent of its surroundings. Such a region represents a blind spot, a part of the search space where the objective function contains an optimum that is especially hard to identify. Defining the blind spot problem is crucial for understanding exploration challenges in algorithm optimization. One might ask the following: why not use established problems like Easom or Foxholes? These problems are insufficiently deceptive for our purposes (Appendix A) [14].
As computational power has advanced rapidly, we have observed an underutilization of memory during optimization processes. This issue has often been overlooked, from the early days of 640 KB memory to today’s 64 GB systems. In 2019, we introduced a meta-approach titled “Long-Term Memory Assistance for Evolutionary Algorithms” [10], which leverages memory during optimization to avoid redundant evaluations of previously explored solutions, known as duplicates. This is particularly significant, as solution evaluation is often the most computationally expensive part of optimization. The study [10] revealed a prevalence of duplicate solutions generated around the best-known solutions—a phenomenon often referred to as stagnation. Duplicates are identified when the genotypes and satisfy for all , where n is the problem dimension. In Java-based experiments, double-value precision (Pr) was limited to three, six, or nine decimal places for real-world optimization problems. LTMA achieved a ≥10% speedup on low computational cost problems, and a ≥59% speedup in a soil model optimization problem where the Artificial Bee Colony (ABC) algorithm generated 35% duplicates, mitigating stagnation around the known optima [10].
Our experiments aimed to explore blind spots, such as underexplored regions, in the optimization process of MAs, rather than compare their superiority. Selecting appropriate metaheuristic algorithms is crucial, as over 500 distinct algorithms had been documented by 2023 [42]. State-of-the-art metaheuristic algorithms are typically adaptive or self-adaptive, making them versatile for diverse optimization challenges. We chose metaheuristic algorithms for our experiments based on their adaptability, implementation within the EARS framework (which includes over 60 algorithms) [43], and recent advancements in the field. To ensure a focused study, we limited our selection to five algorithms. These algorithms or their variants have consistently demonstrated strong performance across diverse benchmark problems [44,45,46].
For the experiments, we selected adaptive, self-adaptive, and more recent MAs from the EARS framework [43], including Artificial Bee Colony (ABC), self-adaptive Differential Evolution (jDElscop) with dynamically encoded parameters and strategies [47], Linear Population Size Reduction Success-History Based Adaptive Differential Evolution (LSHADE) for balanced exploration and exploitation [48], the Gazelle Optimization Algorithm (GAOA) [49], and the Manta Ray Foraging Optimization (MRFO) [50]. A simple RS was included as a separate algorithm that samples solutions randomly in the search space without any specific optimization strategy. It serves as a reference point to evaluate the performance of the other algorithms.
3. The Blind Spot Benchmark
To analyze blind spots’ impact systematically, we define the blind spot problem for three classical optimization problems of increasing difficulty, serving as benchmarks to illustrate their effect on the selected MAs. For each problem, we will define the size of the blind spot.
The blind spot size we define as the percentage of the search space in a single dimension occupied by the blind spot. For example, if the search space is and the blind spot spans , it covers of the search space.
This definition seems intuitive for any number of dimensions. However, the blind spot’s size relative to the entire search space decreases exponentially as the dimensionality increases. To illustrate this, consider a search space where the blind spot’s probability remains constant across all dimensions (see Figure 1). Humans often struggle to visualize how small the blind spot becomes in higher dimensions.
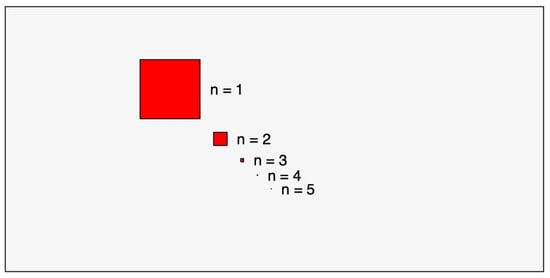
Figure 1.
Search space where the blind spot’s area decreases exponentially for .
The probability of finding the blind spot is , where n is the problem’s dimension. Since its location is independent of the fitness landscape, the likelihood of an MA discovering it is extremely low. In our experiments, we used a blind spot size of per dimension, with n ranging from 2 to 5. To assess algorithm robustness in higher dimensions, we recommend increasing the blind spot size or the number of blind spots.
3.1. Sphere Blind Spot Problem (Easy)
The basic Sphere function is unimodal with a single basin of attraction, making it a simple global optimization problem without local optima [51]. Introducing a blind spot covering of the search interval (denoted as SphereBS) transforms the global optimum into a local one, misleading the search process (see Figure 2).
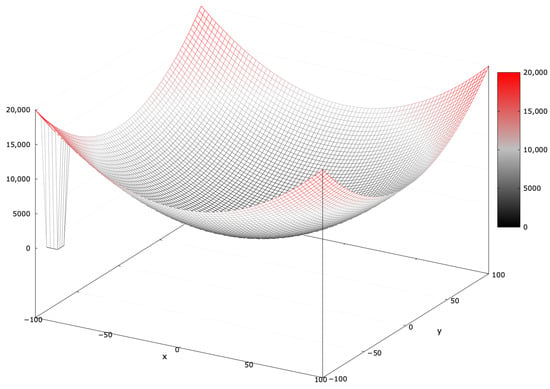
Figure 2.
Fitness landscape of the SphereBS problem for .
Equation (1) defines the SphereBS minimization problem:
The global optimum has a fitness value of . The SphereBS function provides insight into an algorithm’s basic exploitation behavior.
Every MA navigates the search space differently, with success hinging on balancing exploration and exploitation. Visualizing the 2D search space—representing each evaluated solution as a point—helps clarify these mechanics. Greater coverage typically indicates more diverse exploration.
To understand blind spots better and identify regions for improvement, we analyzed the search space explored with the MAs. For a single run of each selected algorithm, we used a population size of , and a stopping criterion of (maximum function evaluations). The results are shown in Figure 3, Figure 4, Figure 5, Figure 6, Figure 7, Figure 8 and Figure 9, with the blind spot highlighted with a gray rectangle.
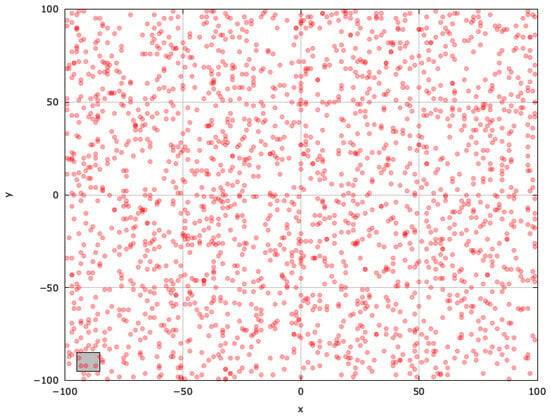
Figure 3.
Search space explored with RS for the SphereBS problem (gray box represents the blind spot).
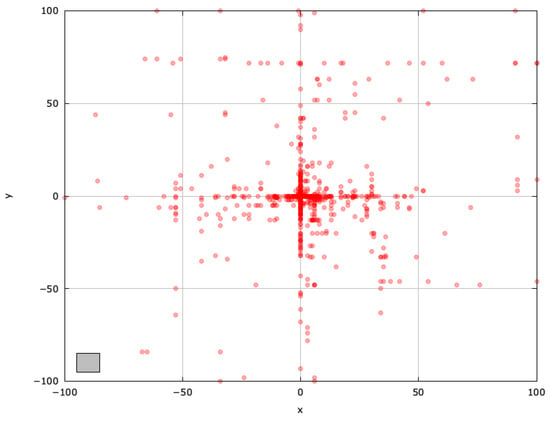
Figure 4.
Search space explored with ABC for the SphereBS problem (gray box represents the blind spot).
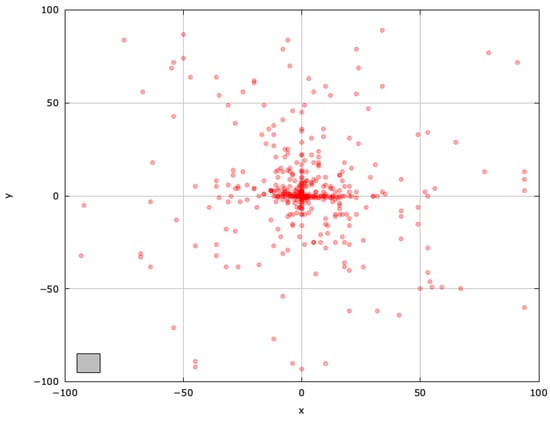
Figure 5.
Search space explored with LSHADE for the SphereBS problem (gray box represents the blind spot).
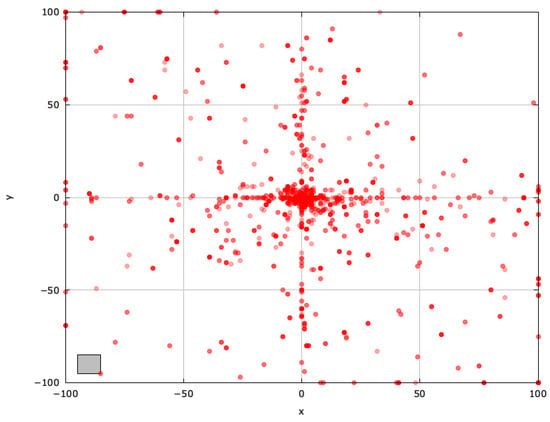
Figure 6.
Search space explored by GAOA for the SphereBS problem (gray box represents the blind spot).
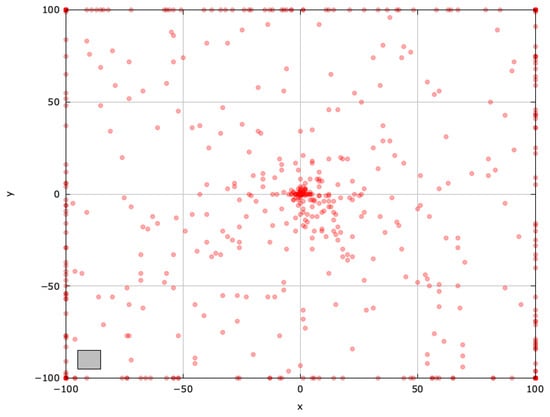
Figure 7.
Search space explored by MRFO for the SphereBS problem (gray box represents the blind spot).
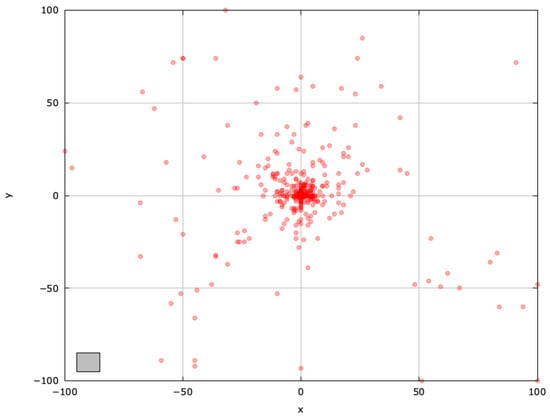
Figure 8.
Search space explored with jDElscop for the SphereBS problem (gray box represents the blind spot).
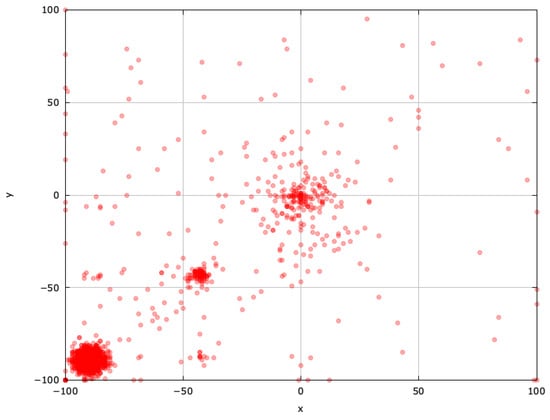
Figure 9.
Search space explored during a successful run of jDElscop for the SphereBS problem.
The ABC algorithm employs probability-based selection and a limit parameter to balance exploration and exploitation. Its search-space exploration shows vertical and horizontal patterns around influential solutions, attributable to scout bees sharing genotypic information probabilistically (Figure 4).
LSHADE’s success-history-based adaptation and population size reduction enable more diverse exploration, outperforming ABC (Figure 5).
GAOA’s big, unpredictable movements enhance exploration, nearly locating the blind spot (Figure 6).
MRFO’s chain foraging promotes highly effective exploration with diverse solutions (Figure 7). Note that a good balance between exploration and exploitation is needed for an efficient search.
The self-adaptive jDElscop excels in exploration, but it can be hindered by intense pressure toward the local optima (Figure 8). A successful run, however, shows it searching around both optima thoroughly, highlighting strong exploitation (Figure 9).
LTMA Experiment Results for the SphereBS Problem
For each problem, we applied the original LTMA approach [10] with and memory precisions (Pr) of 3 and 6 (decimals in the solution space) and the stopping criterion . Since duplicates do not count as evaluations, we added a secondary stopping criterion, , to prevent infinite loops. The results are averaged over 100 runs.
Table 1, Table 2 and Table 3 report the fitness evaluations used (), total duplicates (), the fitness value (), and the success rate () for detecting blind spots. The best results for every n are formatted in bold. For and , RS outperformed the others on SphereBS (Table 1). Some algorithms underutilized the fitness evaluations (e.g., MRFO used 2086 of 8000 for , or 26%, while generating 16,000 duplicates), suggesting premature convergence or success.

Table 1.
LTMA performance statistics for the selected MAs with the SphereBS problem.
Table 2.
LTMA performance statistics for the selected MAs with the AckleyBS problem.
Table 3.
LTMA performance statistics for the selected MAs with the SchwefelBS 2.26 problem.
3.2. Ackley Blind Spot Problem (Medium)
The Ackley function features many local optima with small basins and a global optimum with a large basin [52]. MAs typically find the global optimum easily due to its gradual gradient. Adding a blind spot covering of the search interval (AckleyBS) increases the difficulty (Figure 10). The global optimum fitness is .
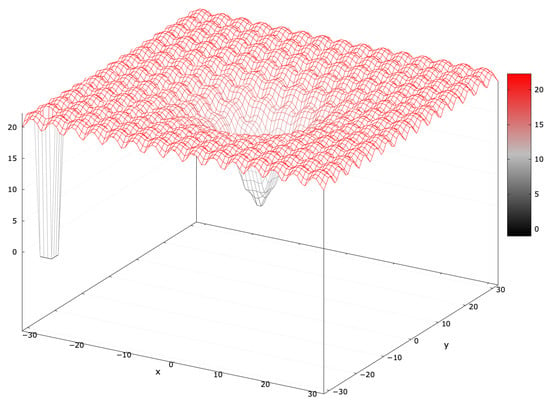
Figure 10.
Fitness landscape of the AckleyBS problem for .
LTMA Experiment Results for the AckleyBS Problem
Classified as medium difficulty, AckleyBS produced fewer duplicates than SphereBS, as confirmed by the results (Table 2). RS’s success rate in detecting blind spots remained consistent.
Figures presenting the search space exploration via MAs for the AckleyBS problem are provided in Appendix B.1.
3.3. Schwefel 2.26 Blind Spot Problem (Hard)
The Schwefel 2.26 function includes a complex landscape with numerous local optima, and its global optimum is distant [53]. MAs often struggle due to its deceptive nature. Adding a blind spot covering of the search interval (SchwefelBS 2.26) heightens the challenge (Figure 11).
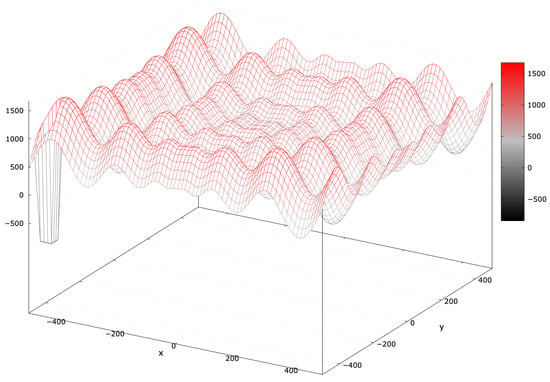
Figure 11.
Fitness landscape of the SchwefelBS 2.26 problem for .
Equation (3) defines the minimization problem:
LTMA Experiment Results for the SchwefelBS 2.26 Problem
The SchwefelBS 2.26 problem proved challenging, with RS achieving a 100% success rate for and (Table 3). Most MAs used all the fitness evaluations, except LSHADE, which used 2733 of 8000 for with , indicating entrapment in the local optima.
Figures presenting the search space exploration with MAs for the SchwefelBS 2.26 problem are provided in Appendix B.2. A further convergence analysis of the selected MAs’ runs with benchmark problems is detailed in Appendix C.
3.4. Blind Spot Problem Benchmark
We created a benchmark including SphereBS, AckleyBS, and SchwefelBS 2.26 for , totaling 12 problems with set to 2000, 6000, 8000, and 10,000. For LTMA, the precision was set to 3.
For statistical analysis, we employed the EARS framework with the Chess Rating System for Evolutionary Algorithms (CRS4EAs), based on the Glicko-2 system [54,55]. CRS4EAs assigns ratings via pairwise comparisons (win, draw, or loss), defining a draw when the fitness values differ by less than 0.001, mitigating bias from the averaging fitness values affected by blind spots. Each MA, initially assigned a rating of 1500 and a rating deviation of 250, undergoes 30 independent optimization runs per benchmark problem in a tournament [43]. Pairwise comparisons, based on fitness values, update ratings using the Glicko-2 system, with the process repeated across 30 tournaments to assess performance robustness [10]. For the calculated ratings and confidence intervals, overlapping intervals indicate no significant difference. For , RS outperformed MAs statistically significantly in detecting blind spots, as shown in Figure 12, suggesting limitations in MAs’ exploration of complex landscapes. The RS excelled at detecting blind spots (Figure 12), raising concerns about MAs.
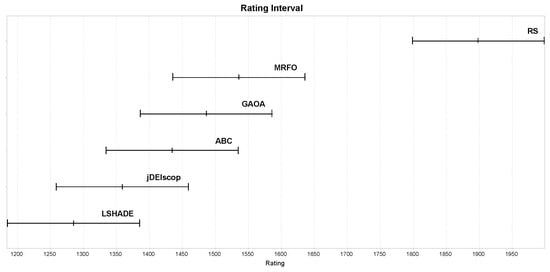
Figure 12.
MAs ratings on the limited Blind Spot benchmark using LTMA for .
Benchmark results with blind spots revealed that only the ABC algorithm outperformed the RS baseline statistically significantly in terms of ratings, as shown in Figure 13, indicating that the selected MAs struggled to explore complex landscapes effectively [43]. To provide context, we repeated the experiments with identical settings on standard benchmark problems without blind spots. These results confirmed the expected superiority of MAs, with higher ratings across all the algorithms, as illustrated in Figure 14 [10].
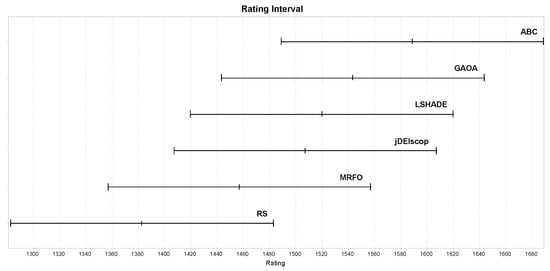
Figure 13.
MAs; ratings on the Blind Spot benchmark using LTMA for .
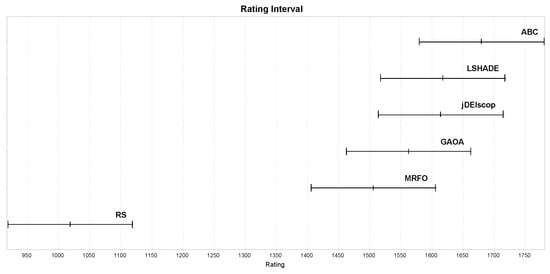
Figure 14.
MAs’ ratings on a benchmark without blind spots using LTMA for .
4. LTMA+
LTMA+ is a novel approach based on LTMA [10] that enhances the exploration mechanics of MAs by leveraging duplicate detection. This mechanism operates independently of the MAs, ensuring a fair algorithm comparison. LTMA+ functions as a meta-operator applicable to any metaheuristic, improving success rates without altering the algorithms themselves.
LTMA [10] is extended with a duplicate replacement strategy: when a duplicate solution is detected, the solution, x, is replaced with a newly generated solution, , (Figure 15). This approach aims to avoid local optima and enhance search-space exploration. However, it raises concerns about its impact on the core mechanics of optimization algorithms, as it may alter exploration procedures and disrupt the exploitation phase significantly. We conducted a detailed analysis in which duplicate solutions were created to address these concerns (Appendix E).
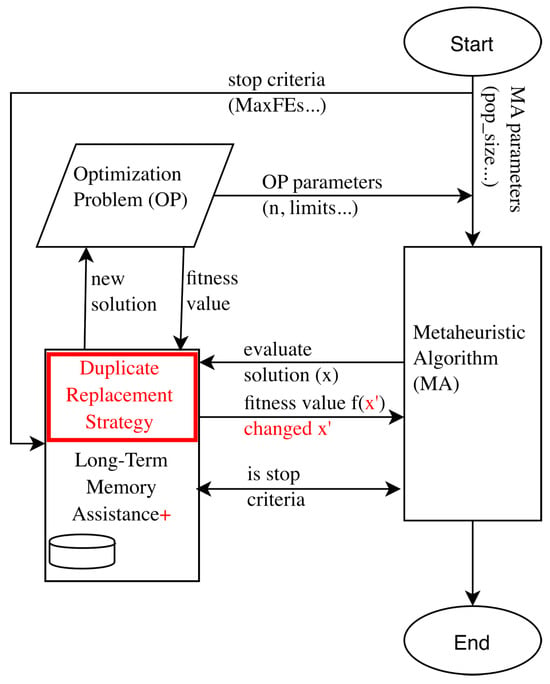
Figure 15.
Schematic of LTMA+ implementation, with key differences from LTMA highlighted in red.
The frequency of duplicates, , is observable in Table 1, Table 2 and Table 3. The percentage of duplicates varies by problem, dimension, population size, and algorithm. However, these data alone do not reveal how often a solution is duplicated or the frequency of such duplicates (LTMA access hits). For instance, if a solution, , is duplicated 1000 times (), it might indicate a local optimum trap. The key distinction is whether a single solution generates many duplicates or multiple solutions are duplicated. This information can be used to trigger a forced exploration of new search-space regions.
A detailed analysis of the LTMA access hits showed that most solutions had low hit counts, while a few had high ones (Figure A19, Figure A20 and Figure A21). This suggests effective search-space exploration. However, the graph’s tail (rare high-hit individuals) indicates a few solutions with very high hit counts, where the total sum of hits is concentrated, potentially signaling entrapment in the local optima. To clarify this, we generated a running sum of hits graph for duplicate creation (Appendix D). The analysis of duplicate creation timing is also crucial for understanding the behavior of LTMA+ and its impact on optimization algorithms. By examining the timing of duplicate creation, we can identify when the algorithm is likely to become trapped in local optima (Appendix E).
Our analysis identified two key parameters to guide the exploration:
- Number of hits (Hit): if a solution is generated x times, a new, non-revised solution replaces it.
- Timing of duplicates: new solutions are created after x sum of memory hits ().
These parameters defined the LTMA+ strategies that preserve MAs’ internal exploration and exploitation dynamics, avoiding premature convergence.
4.1. Generating New Candidate Solutions
Mimicking RS, we could generate random solutions for additional exploration, but this would ignore the prior search information. From Figure 4, Figure 5, Figure 6, Figure 7 and Figure 8, we observed that blind spots near the current solutions are more likely to be found during exploitation. Thus, we propose generating solutions using three random generation variants: basic random, random farther from the duplicate, and random farther from the current best.
We use a triangular probability distribution to generate a solution randomly, likely far from a selected position (Appendix F). For each dimension , we generate a random position from the current position to the search space boundary, deciding to move left or right randomly:
where and are search-space bounds, and generates a number with , , and mode .
4.2. Strategies
Using exploration triggers and random generation methods, we define the following strategies:
- Ignore duplicates (i): ignores duplicates, simulating LTMA.
- Random (r): generates a basic random solution for duplicates, simulating RS.
- Random from current (c): generates a random solution farther from the duplicate.
- Random from best (b): generates a random solution farther from the current best solution.
- Random from best extended (be): generates random solutions farther from the current best for the next 100 evaluations.
Strategies may include a parameter, replacing duplicates only after a specified hit count, or a parameter for the number of prior duplicate evaluations to initiate replacement.
5. Experiments
Having defined various LTMA+ strategies, we now evaluate them empirically through experiments. We compared LTMA+ strategies with the original LTMA and MAs from Section 2 on the Blind Spot benchmark from Section 3.4.
In our experiments, we reported the success rate () and fitness value () for LTMA+ with precision Pr = 3, averaged over 100 runs. We also analyzed the influence of the Hit parameter as a trigger, testing values 1, 2, and 5. We include results for basic LTMA and RS for comparison.
5.1.
The r strategy generates a random individual when the LTMA+ duplicate hit trigger (Hit) is reached, tested for (, , ). The results show a significantly higher number of discovered blind spots with the r strategy (Table 4). The success rates for and were similar, but they were lower for . Notably, GAOA for and performed better without LTMA+ (), an issue addressed in the next section.
Table 4.
MAs’ success using the LTMA+ strategy r for the AckleyBS Problem.
5.2.
The c strategy generates a random individual farther from the current one when the Hit trigger is reached, tested for (, , ). We expected c to outperform r due to its generation of solutions farther from the current one. The results in Table 5 confirm this, with the best performance at .
Table 5.
MAs’ success using the LTMA+ strategy c for the AckleyBS Problem.
5.3.
The b strategy generates a random individual farther from the current best solution when the Hit trigger is reached, tested for (, , ). Since duplicates often cluster around the current best, we that anticipated b would perform similarly to c. Table 6 confirms this expectation.
Table 6.
MAs’ success using the LTMA+ strategy b for the AckleyBS Problem.
5.4.
The strategy includes an parameter, defining how many evaluations generate random individuals from the best solution after the Hit trigger. With , it mirrors b. We set to 0.1% of (e.g., 8 for ), generating random individuals for the next eight evaluations. The results are presented in Table 7.
Table 7.
MAs’ success using the LTMA+ strategy for the AckleyBS Problem.
No significant success rate improvement was observed, though we expect to be more effective in runs with fewer duplicates. We suggest lower values.
5.5. Evaluating of LTMA+ Strategies on the Blind Spot Benchmark
Similar experiments to those described in Section 3.4 were conducted, but with selected MAs wrapped with various LTMA+ strategies to enhance the exploration of blind spots in benchmark problems. We compared standard MAs against those wrapped with LTMA+ strategies, such as (), on the Blind Spot benchmark problems, with the Glicko-2 rating results presented in Figure 16. The MAs wrapped with LTMA+ strategies outperformed the MAs on the Blind Spot benchmark problems statistically significantly, with , employing solution-based randomization from the best solution, achieving the highest Glicko-2 ratings, followed by , as shown in Figure 16.
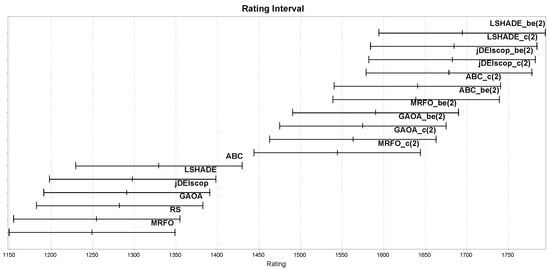
Figure 16.
MAs ratings on the Blind Spot benchmark using LTMA+.
Injecting random individuals helps escape the local optima, but it may degrade performance on problems without blind spots. Testing on a no-blind-spot benchmark (Figure 17) showed that LTMA+ strategies still outperformed baselines, with no significant difference between the problem types.
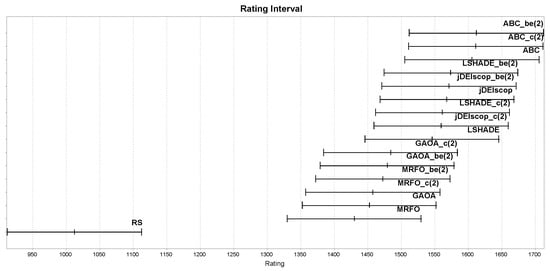
Figure 17.
MAs’ ratings on a benchmark without blind spots using LTMA+.
5.6. Evaluation of LTMA+ Strategies on Benchmarks Without Blind Spots
With the modifications introduced in LTMA+, it is essential to evaluate their impact compared to the original LTMA approach on problems without blind spots. Since these strategies primarily manage generated duplicates, we expect minimal performance differences between LTMA+ and LTMA on such problems. However, replacing duplicates with randomly generated individuals might disrupt the exploitation phase, potentially leading to solutions with reduced precision.
For a thorough comparison with the original LTMA method, we selected two test cases from the original LTMA paper: the CEC’15 benchmark problem (Experiment 2) and the real-world soil problem (Experiment 3) [10]. We set the Hit parameter to 12, using benchmark problems with and MaxFEs = 10,000.
As anticipated, the results for the CEC’15 benchmark problem revealed no significant performance differences between LTMA+ and LTMA. For LSHADE, ABC, and MRFO, LTMA+ outperformed the original LTMA slightly (Figure A29). For the soil problem, we optimized three instances (TE1, TE2, and TE3), yielding similar outcomes with no notable differences between LTMA+ and LTMA (Figure A32). Interestingly, the rating rankings varied by instance: jDElscop excelled in TE1, while ABC led in TE2 and TE3 (Figure A30, Figure A31 and Figure A32).
More information on the experiments is available in Appendix G.5.
6. Discussion
The proposed LTMA+ approach offers advantages, disadvantages, and considerations. To begin the discussion, we first highlight its positive aspects.
6.1. The Good
LTMA+ enhances the robustness of MAs by facilitating a transition from duplicate creation to exploration, often preventing algorithm stagnation. This is particularly effective when the total number of evaluations is unknown. Even RS can outperform MAs when an algorithm is trapped in a local optimum. By leveraging prior evaluations, such as the current duplicate or best solution, LTMA+ generates smarter random individuals positioned farther from the current search space, promoting exploration.
Experiments on the Blind Spot benchmark demonstrated LTMA+’s benefits, with its strategies outperforming LTMA [10] and RS statistically significantly. The top performer, , generated random individuals farther from the current best solution and extended the number of such evaluations. The second-best, , targeted individuals farther from the current duplicate. These results underscore LTMA+’s ability to escape the local optima and enhance search diversity.
Designed as a meta-approach, LTMA+ applies to diverse optimization problems—discrete, continuous, and multi-objective within the EARS framework, where over 60 MAs can be adopted seamlessly. This versatility ensures broad applicability, limited only by inherent search-space constraints, including those that do not sort solutions at the end of the optimization process. Although state-of-the-art MAs are often self-adaptive, dynamically adjusting their control parameters during optimization, our results demonstrate that they can be further enhanced with LTMA+. However, if an MA already incorporates mechanisms similar to LTMA+, significant improvements are not expected.
Moreover, LTMA+ reduces reliance on the algorithm control parameters by enabling self-adaptation to the problem. This is advantageous when the optimal parameters are unknown, minimizing manual tuning and boosting robustness. For instance, if the population size is too small, causing duplicates, LTMA+ generates additional random solutions. While not eliminating parameter tuning entirely, this enhances algorithm robustness.
6.2. The Bad
LTMA+ is an adaptive solution for optimization challenges, including blind spot detection, but its effectiveness diminishes for smaller blind spots or higher problem dimensions. While LTMA+ enhanced MAs’ performance significantly on the Blind Spot benchmark problems, its ability to detect blind spots weakened as the dimensionality increased. At , LTMA+-wrapped MAs identified blind spots inconsistently across the runs.
A second concern, especially for experienced users, is the additional computational cost and resources required. LTMA+ demands extra memory to store and manage long-term optimization data, a burden that grows in large-scale problems with many evaluations. While duplicate evaluations do not count toward stopping criteria, searching memory incurs computational time. Solution comparisons are discretized by decimal places, introducing a parameter (Pr) that is primarily problem-dependent (i.e., how much precision makes sense for a solution), but can also be used to tune the optimization process. Edge-case problems are those that require a very high level of precision. In such cases, the LTMA+ approach may be less effective, as the generation of duplicate solutions is less likely, and more memory is required to store potential duplicates.
An efficient LTMA+ implementation achieves near-linear time complexity for duplicate detection and memory operations, enabling optimization speedups for MAs on benchmark problems with blind spots, such as the blind spot suite. The time complexity and resulting speedups of LTMA-wrapped MAs were discussed in detail in the original LTMA study [10], where we showed that the LTMA computation cost was marginal and non-significant. An edge case for computational efficiency includes methods that rarely generate duplicate solutions; an extreme example of this is the RS algorithm. Another partial edge case involves problems where fitness evaluation is very computationally efficient—comparable to a memory lookup in LTMA+. In such cases, the LTMA+ optimization process is slower than running without LTMA+, but it can offer greater robustness, as the detection of duplicate solutions triggers additional exploration.
Furthermore, LTMA+ introduces the parameters Hit and strategy selection, which require careful tuning. Small values yielded improvements in our experiments, but their effectiveness varied with the MAs, control parameters, and problem nature, emphasizing the need for parameter sensitivity and adaptability.
6.3. The Ugly
LTMA+ requires integration with a metaheuristic, achieved here via the EARS framework, which relies on object-oriented programming. Many EA researchers, not being software development experts, may struggle to implement or use such meta-approaches. However, these implementations standardize the structure, easing comparison and evolution.
From a results perspective, long runs with many duplicates risk over-exploration, potentially reducing effectiveness.
7. Conclusions
This paper has introduced LTMA+, a novel approach to addressing the blind spot problem in MAs, where the optimization process becomes trapped in the local optima, failing to locate specific global optima. This challenge impairs MAs’ effectiveness in optimization tasks significantly. By leveraging LTMA+ strategies, MAs mitigate stagnation by dynamically enhancing exploration when duplicate solutions indicate optimization stagnation. LTMA+ redirects its focus to underexplored search-space regions, promoting continuous improvement and robustness in problems with blind spots, such as the Blind Spot benchmark problems.
Despite LTMA+’s universal applicability across optimization challenges, its effectiveness diminishes for smaller blind spots or higher-dimensional problems. To advance LTMA+ research, several key directions warrant exploration. First, evaluating LTMA+ on comprehensive benchmarks, with diverse blind spot configurations and dimensions beyond , will assess its scalability and robustness. Specifically, testing adaptive LTMA+ strategies, such as , on multimodal and constrained problems could optimize blind spot detection. Second, integrating LTMA+ with hybrid MAs or deep learning techniques may enhance exploration in discrete, continuous, and multi-objective domains, addressing real-world applications like scheduling or neural architecture search. Third, investigating LTMA+’s performance under varying evaluation budgets, from real-time constraints (e.g., autonomous navigation) to extended periods (e.g., structural optimization), will clarify its efficacy in time-sensitive scenarios. Finally, developing new adaptive LTMA+ strategies to guide exploration toward underexplored regions would enhance blind spot detection robustness in high-dimensional benchmark problems. These directions, deferred for brevity, highlight LTMA+’s significant promise. We believe LTMA+ holds substantial potential to enhance the robustness of MA in optimization tasks.
Author Contributions
Conceptualization, M.Č., M.M. and M.R.; investigation, M.Č., M.M. and M.R.; methodology, M.Č.; software, M.Č. and L.M.; validation, M.Č., M.M., L.M. and M.R.; writing, original draft, M.Č., M.M. and M.R.; writing, review and editing, M.Č., M.M., L.M. and M.R. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Slovenian Research Agency Grant Number P2-0041 (B) and P2-0114.
Data Availability Statement
Publicly available datasets were analyzed in this study. This data can be found here: https://github.com/UM-LPM/EARS, accessed on 8 May 2025.
Acknowledgments
AI-assisted tools were used to improve the English language in this paper.
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A. Easom and Foxholes Experiment
Appendix A.1. Easom Problem
The Equation (A1) defines the minimization problem:
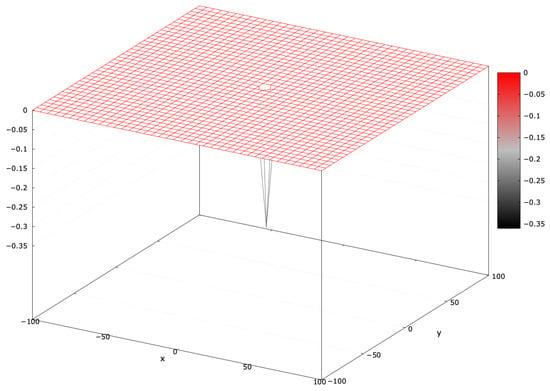
Figure A1.
Fitness landscape of an Easom problem for .
Appendix A.2. Foxholes Problem (Shekel’s Foxholes Function)
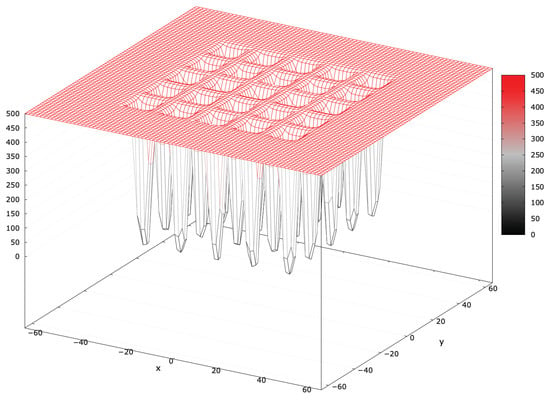
Figure A2.
Fitness landscape of a foxholes problem for .
Appendix A.3. Experiment on Easom and Foxholes
We ran a tournament of selected MAs from Section 2, both with and without LTMA (denoted with the suffix _i, e.g., ABC_i for LTMA+-enhanced ABC), on the Easom and Foxholes problems with , using a stopping criterion of .
The ratings are shown in Figure A3. Further details on this experiment and the interpretation of its results are provided in Section 3.4.
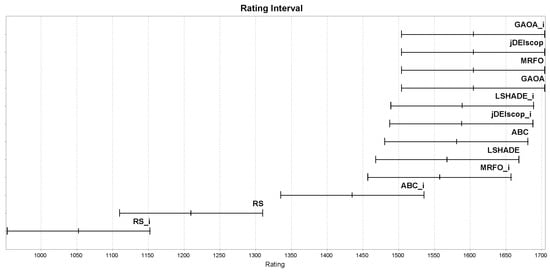
Figure A3.
MAs’ ratings on the Easom and Foxholes benchmark with and without LTMA.
The results demonstrate that classical optimization problems, such as Easom and Foxholes for , are relatively easy to solve using the selected MAs (Figure A3). However, these problems cannot be compared directly to the blind spot problems, for which random search outperformed the selected MAs for .
Appendix B. Search-Space Exploration Problem
Appendix B.1. AckleyBS Problem
To gain deeper insights into blind spots and pinpoint regions for improvement, we examined the search space explored by the selected MAs on the AckleyBS problem () (Figure A4, Figure A5, Figure A6, Figure A7, Figure A8 and Figure A9).
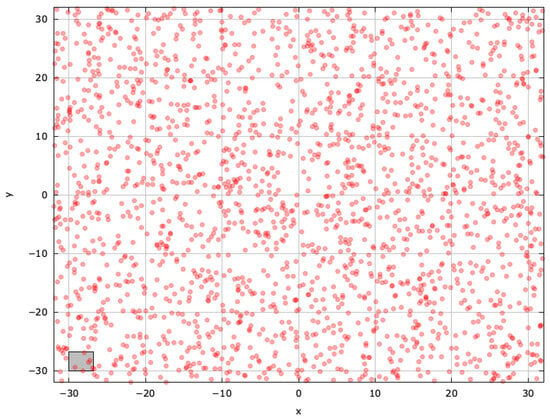
Figure A4.
Search space explored with RS for the AckleyBS problem (gray box represents the blind spot).
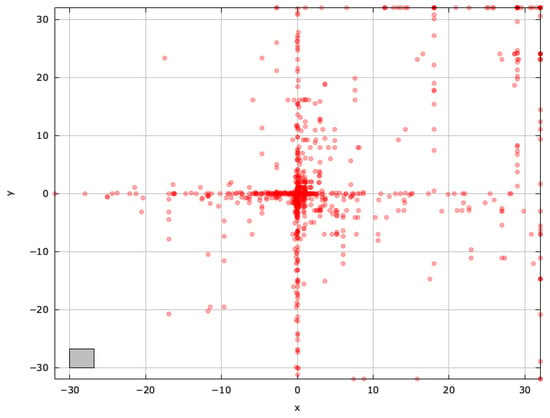
Figure A5.
Search space explored with ABC for the AckleyBS problem (gray box represents the blind spot).
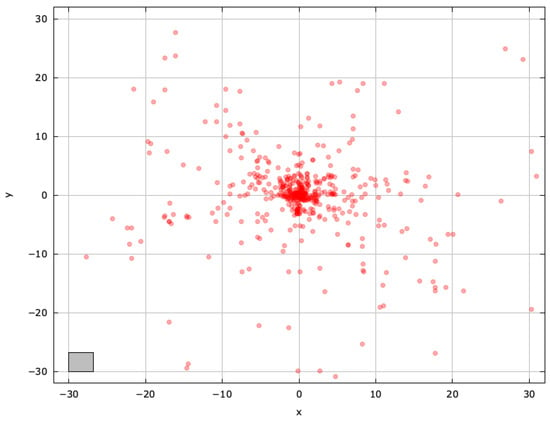
Figure A6.
Search space explored with LSHADE for the AckleyBS problem (gray box represents the blind spot).
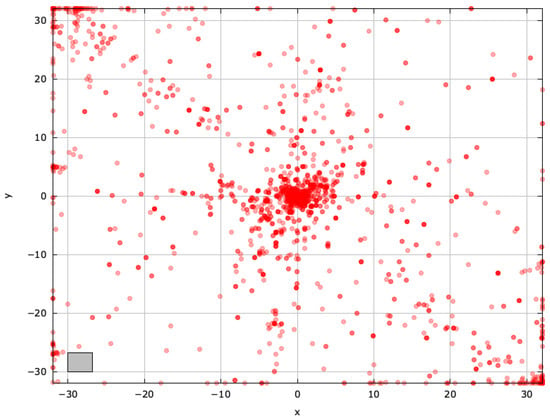
Figure A7.
Search space explored with GAOA for the AckleyBS problem (gray box represents the blind spot).

Figure A8.
Search space explored with MRFO for the AckleyBS problem (gray box represents the blind spot).
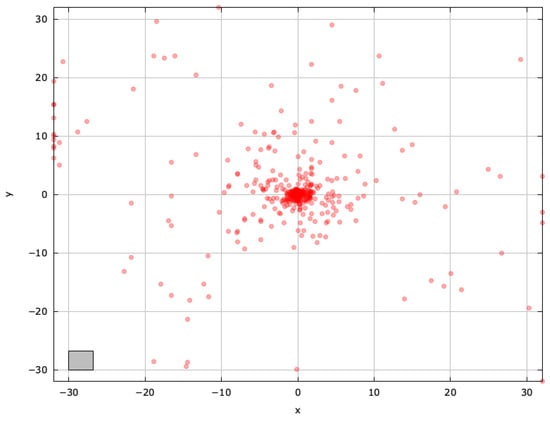
Figure A9.
Search space explored with jDElscop for the AckleyBS problem (gray box represents the blind spot).
Appendix B.2. SchwefelBS 2.26 Problem
To gain deeper insights into blind spots and pinpoint regions for improvement, we examined the search space explored with the selected MAs on the SchwefelBS 2.26 problem () (Figure A10, Figure A11, Figure A12, Figure A13, Figure A14 and Figure A15).
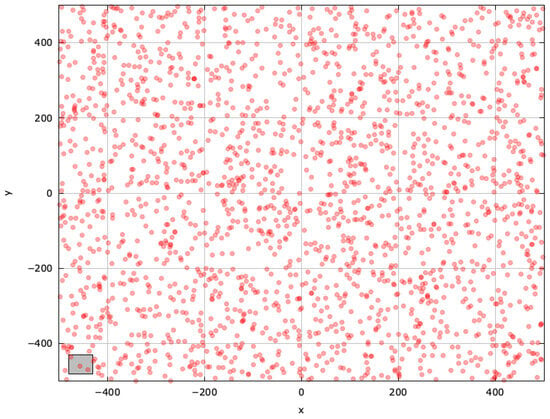
Figure A10.
Search space explored with RS for the SchwefelBS 2.26 problem (gray box represents the blind spot).
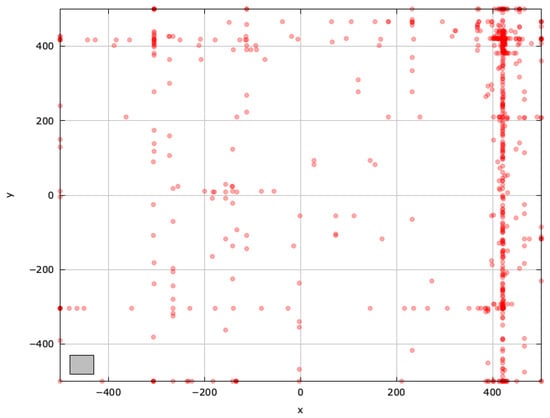
Figure A11.
Search space explored with ABC for the SchwefelBS 2.26 problem (gray box represents the blind spot).
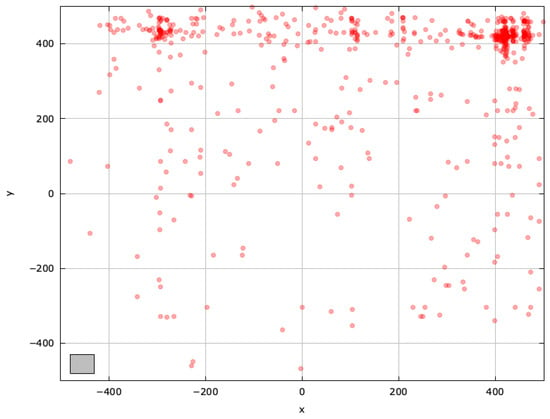
Figure A12.
Search space explored with LSHADE for the SchwefelBS 2.26 problem (gray box represents the blind spot).
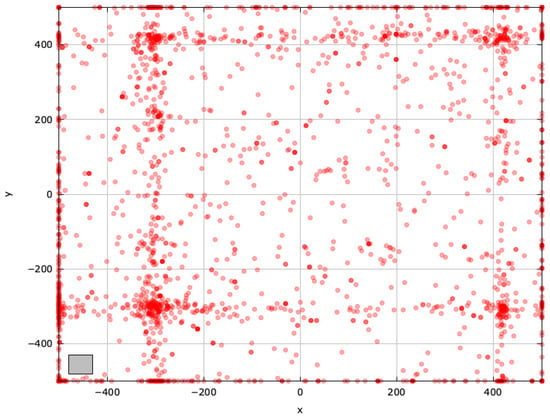
Figure A13.
Search space explored with GAOA for the SchwefelBS 2.26 problem (gray box represents the blind spot).
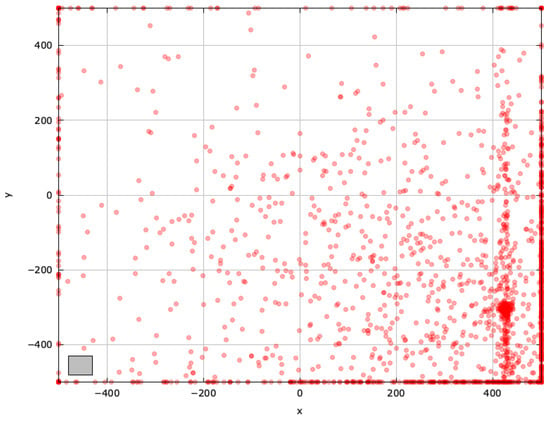
Figure A14.
Search space explored with MRFO for the SchwefelBS 2.26 problem (gray box represents the blind spot).
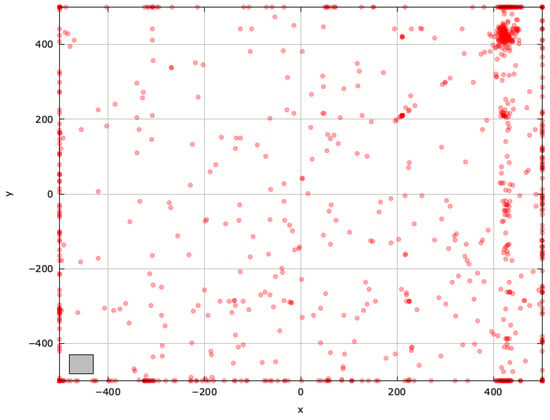
Figure A15.
Search space explored with jDElscop for the SchwefelBS 2.26 problem (gray box represents the blind spot).
The search-space exploration patterns of selected MAs with the SphereBS benchmark problem are presented in Section 3.1.
Appendix C. Analysis of Convergence and Exploration on Blind Spot Benchmark Problems
The typical single-run convergence of selected MAs with LTMA+ on the SphereBS, AckleyBS, and SchwefelBS problems for is shown in Figure A16, Figure A17 and Figure A18. The convergence graphs illustrate the optimization process over time, with the y-axis representing the fitness values and the x-axis indicating the number of evaluations. These graphs demonstrate that extended the convergence and solution quality significantly compared to standard MAs.
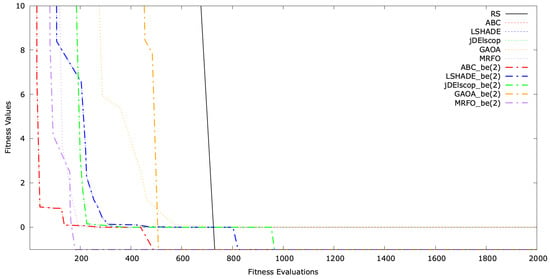
Figure A16.
Convergence graph for SphereBS .
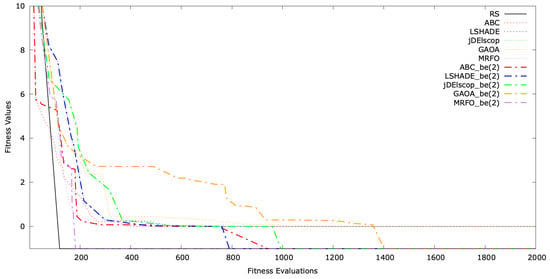
Figure A17.
Convergence graph for AckleyBS .
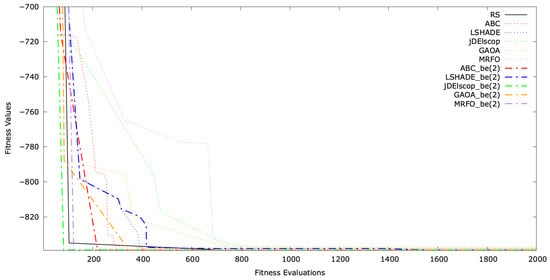
Figure A18.
Convergence graph for SchwefelBS .
Appendix D. Duplicate Hits Analysis
For each problem and algorithm, we generated histograms based on 100 optimization runs, presented as graphs. The y-axis represents frequency (the number of distinct solutions with the same number of memory hits), and the x-axis shows the hit count. For the SphereBS problem with and , Figure A19 displays the histogram for the first 21 duplicate hits, with the frequency truncated at 1000 for clarity due to the high number of unique duplicates at hits 1 and 2. For example, GAOA produced 17,028 unique solutions with , LSHADE had 4287, ABC had 6981, MRFO had 1043, and jDElscop had 485.
The graph reveals that most solutions have low hit counts, while few have high hits (Figure A19). This might suggest effective search space exploration. However, the unshown tail of the graph (rare high-hit individuals) indicates a few solutions with very high hit counts, for which the total sum of hits is concentrated, potentially signaling entrapment in the local optima. To clarify this, we generated a running sum of hits graph for duplicate creation (Figure A22).
Similar patterns emerged for the AckleyBS and problems (Figure A20 and Figure A21).
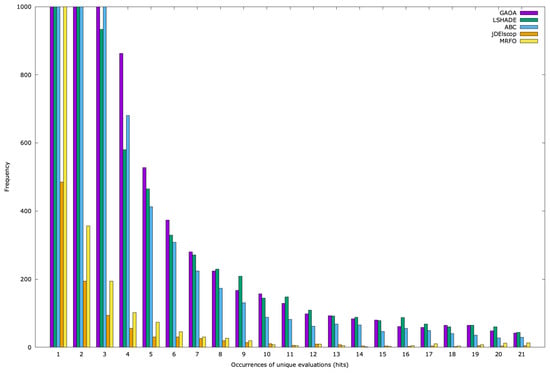
Figure A19.
SphereBS histogram for with hits 1–21.
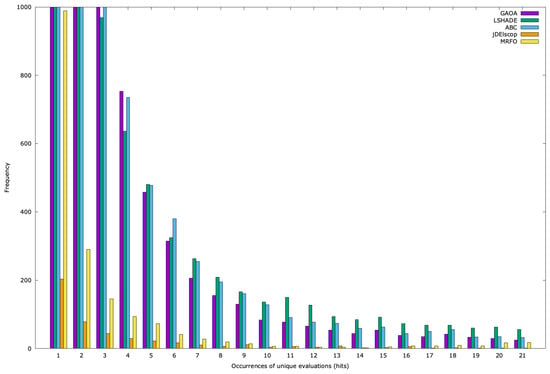
Figure A20.
Ackley histogram pr = 3 for hits 1–21.
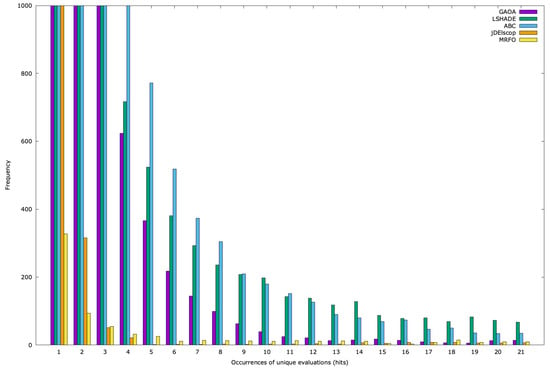
Figure A21.
Schwefel 2.26 histogram pr = 3 for hits 1–21.
Appendix E. Time Analysis of Duplicate Creation
Beyond hit frequency (Hit), the timing of duplicate creation—whether early, mid, or late in the optimization process—is critical. We simulated this by calculating the running sum of duplicates (). This timing indicator can trigger a forced exploration phase.
Visualizing this, we added indicators (the triangle symbol ▲) on the graph to mark fitness improvements at corresponding evaluations (Figure A22, Figure A23 and Figure A24). Significant gaps between these markers may indicate stagnation.
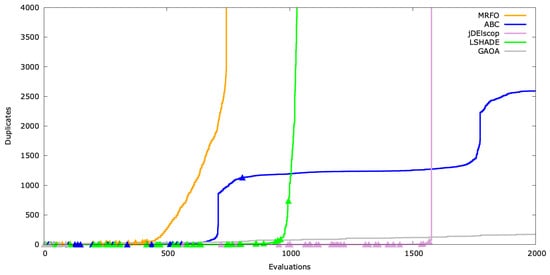
Figure A22.
Duplicates’ timeline for SphereBS .
In Figure A22, ABC and GAOA consumed all the available evaluations, while MRFO, LSHADE, and jDElscop stagnated, reaching the secondary stopping criterion . ABC exhibited two exploration spikes, likely due to the scout bee limit parameter re-engaging exploration. For MRFO, LSHADE, and jDElscop, the vertical lines mark where duplicates dominated, with no new solutions generated thereafter.
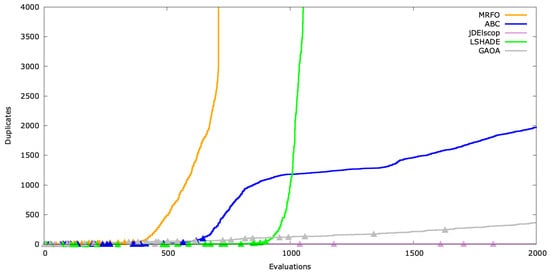
Figure A23.
Duplicates’ timeline for AckleyBS .
For AckleyBS, jDElscop generated many duplicates rarely, suggesting an incomplete or unsuccessful exploitation phase (Figure A23).
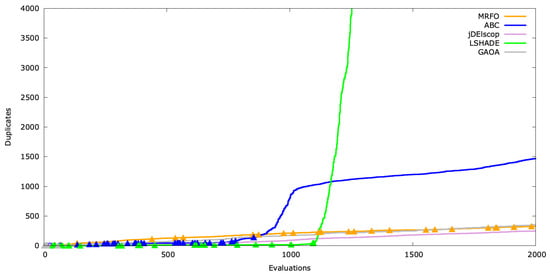
Figure A24.
Duplicates’ timeline for SchwefelBS .
In Figure A24, only LSHADE entered a high-duplicate phase, indicating that it reached exploitation but became trapped in a local optimum.
Duplicate creation varies with problem complexity, such as higher dimensions. Results for are shown in Figure A25, Figure A26 and Figure A27.
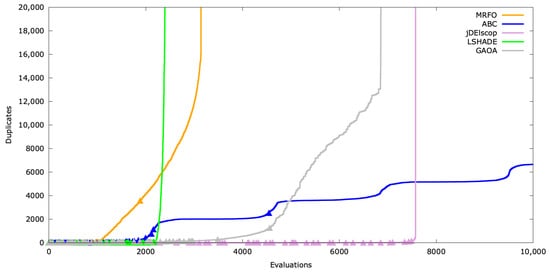
Figure A25.
Duplicates’ timeline for SphereBS .
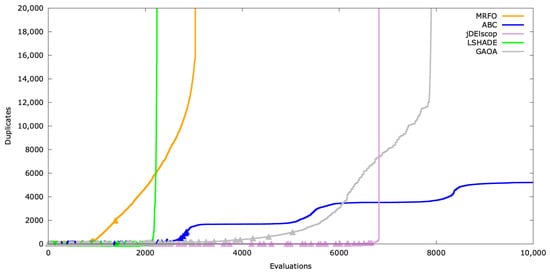
Figure A26.
Duplicates’ timeline for AckleyBS .
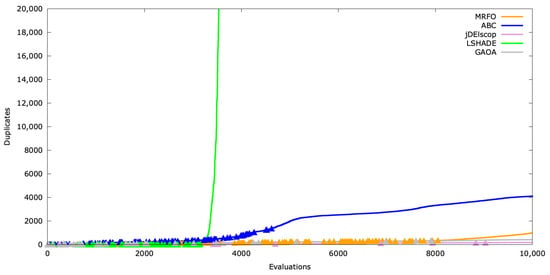
Figure A27.
Duplicates’ timeline for SchwefelBS .
Appendix F. The Triangular Distribution
Triangular distribution is defined by the probability density function (PDF). Equation (A3) gives the CDF for the triangular distribution.
For example, suppose we search for a random solution within the interval . In that case, we define the parameters as follows: the lower bound , the upper bound , and the mode , which shapes the probability distribution (Figure A28).
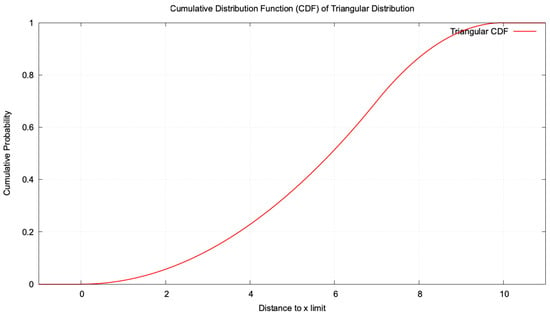
Figure A28.
The triangular distribution generates a random individual farther away from the selected solution.
Appendix G. Experiment
Appendix G.1. LTMA+r
Table A1.
MAs; success using the LTMA+ strategy r for the SphereBS problem.
Table A1.
MAs; success using the LTMA+ strategy r for the SphereBS problem.
| Algorithm | n | MaxFEs | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| RS | 2 | 2000 | 99 | 99 | 99 | 99 | ||||
| ABC | 2 | 2000 | 6 | 91 | 92 | 88 | ||||
| GAOA | 2 | 2000 | 9 | 76 | 41 | 42 | ||||
| MRFO | 2 | 2000 | 18 | 99 | 95 | 96 | ||||
| LSHADE | 2 | 2000 | 7 | 89 | 90 | 93 | ||||
| jDElscop | 2 | 2000 | 37 | 78 | 45 | 48 | ||||
| RS | 3 | 6000 | 37 | 57 | 52 | 47 | ||||
| ABC | 3 | 6000 | 0 | 32 | 18 | 21 | ||||
| GAOA | 3 | 6000 | 5 | 24 | 29 | 32 | ||||
| MRFO | 3 | 6000 | 4 | 46 | 47 | 40 | ||||
| LSHADE | 3 | 6000 | 0 | 39 | 46 | 44 | ||||
| jDElscop | 3 | 6000 | 1 | 23 | 24 | 18 | ||||
| RS | 4 | 8000 | 3 | 8 | 5 | 1 | ||||
| ABC | 4 | 8000 | 0 | 1 | 0 | 0 | ||||
| GAOA | 4 | 8000 | 12 | 0 | 4 | 1 | ||||
| MRFO | 4 | 8000 | 0 | 6 | 6 | 2 | ||||
| LSHADE | 4 | 8000 | 0 | 5 | 3 | 3 | ||||
| jDElscop | 4 | 8000 | 0 | 1 | 3 | 1 | ||||
| RS | 5 | 10,000 | 1 | 0 | 2 | 2 | ||||
| ABC | 5 | 10,000 | 0 | 0 | 1 | 0 | ||||
| GAOA | 5 | 10,000 | 19 | 0 | 1 | 0 | ||||
| MRFO | 5 | 10,000 | 0 | 0 | 0 | 0 | ||||
| LSHADE | 5 | 10,000 | 0 | 0 | 0 | 2 | ||||
| jDElscop | 5 | 10,000 | 0 | 0 | 0 | 0 | ||||
Table A2.
MAs’ success using the LTMA+ strategy r for the SchwefelBS 2.26 problem.
Table A2.
MAs’ success using the LTMA+ strategy r for the SchwefelBS 2.26 problem.
| Algorithm | n | MaxFEs | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| RS | 2 | 2000 | 99 | 99 | 99 | 99 | ||||
| ABC | 2 | 2000 | 5 | 80 | 76 | 67 | ||||
| GAOA | 2 | 2000 | 60 | 71 | 62 | 64 | ||||
| MRFO | 2 | 2000 | 33 | 67 | 69 | 67 | ||||
| LSHADE | 2 | 2000 | 9 | 79 | 79 | 78 | ||||
| jDElscop | 2 | 2000 | 53 | 56 | 73 | 71 | ||||
| RS | 3 | 6000 | 55 | 58 | 48 | 50 | ||||
| ABC | 3 | 6000 | 0 | 20 | 23 | 23 | ||||
| GAOA | 3 | 6000 | 3 | 11 | 6 | 8 | ||||
| MRFO | 3 | 6000 | 8 | 13 | 13 | 16 | ||||
| LSHADE | 3 | 6000 | 0 | 39 | 23 | 40 | ||||
| jDElscop | 3 | 6000 | 1 | 15 | 2 | 6 | ||||
| RS | 4 | 8000 | 2 | 4 | 0 | 8 | ||||
| ABC | 4 | 8000 | 0 | 2 | 0 | 1 | ||||
| GAOA | 4 | 8000 | 1 | 0 | 2 | 1 | ||||
| MRFO | 4 | 8000 | 0 | 1 | 3 | 0 | ||||
| LSHADE | 4 | 8000 | 0 | 5 | 1 | 5 | ||||
| jDElscop | 4 | 8000 | 0 | 1 | 0 | 0 | ||||
| RS | 5 | 10,000 | 0 | 0 | 1 | 0 | ||||
| ABC | 5 | 10,000 | 0 | 0 | 0 | 0 | ||||
| GAOA | 5 | 10,000 | 0 | 0 | 0 | 0 | ||||
| MRFO | 5 | 10,000 | 0 | 0 | 0 | 0 | ||||
| LSHADE | 5 | 10,000 | 0 | 0 | 0 | 1 | ||||
| jDElscop | 5 | 10,000 | 0 | 0 | 0 | 0 | ||||
Appendix G.2. LTMA+c
Table A3.
MAs’ success using the LTMA+ strategy c for the SphereBS Problem.
Table A3.
MAs’ success using the LTMA+ strategy c for the SphereBS Problem.
| Algorithm | n | MaxFEs | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| RS | 2 | 2000 | 99 | 99 | 100 | 99 | ||||
| ABC | 2 | 2000 | 6 | 100 | 100 | 100 | ||||
| GAOA | 2 | 2000 | 9 | 100 | 98 | 90 | ||||
| MRFO | 2 | 2000 | 18 | 100 | 100 | 100 | ||||
| LSHADE | 2 | 2000 | 7 | 100 | 100 | 100 | ||||
| jDElscop | 2 | 2000 | 37 | 100 | 77 | 69 | ||||
| RS | 3 | 6000 | 37 | 47 | 47 | 48 | ||||
| ABC | 3 | 6000 | 0 | 99 | 100 | 100 | ||||
| GAOA | 3 | 6000 | 5 | 100 | 100 | 99 | ||||
| MRFO | 3 | 6000 | 4 | 100 | 100 | 100 | ||||
| LSHADE | 3 | 6000 | 0 | 100 | 100 | 100 | ||||
| jDElscop | 3 | 6000 | 1 | 100 | 94 | 91 | ||||
| RS | 4 | 8000 | 3 | 8 | 7 | 6 | ||||
| ABC | 4 | 8000 | 0 | 67 | 67 | 66 | ||||
| GAOA | 4 | 8000 | 12 | 75 | 79 | 77 | ||||
| MRFO | 4 | 8000 | 0 | 93 | 93 | 93 | ||||
| LSHADE | 4 | 8000 | 0 | 95 | 92 | 91 | ||||
| jDElscop | 4 | 8000 | 0 | 73 | 66 | 65 | ||||
| RS | 5 | 10,000 | 1 | 1 | 1 | 1 | ||||
| ABC | 5 | 10,000 | 0 | 15 | 16 | 15 | ||||
| GAOA | 5 | 10,000 | 19 | 20 | 26 | 23 | ||||
| MRFO | 5 | 10,000 | 0 | 35 | 36 | 38 | ||||
| LSHADE | 5 | 10,000 | 0 | 35 | 37 | 38 | ||||
| jDElscop | 5 | 10,000 | 0 | 22 | 17 | 16 | ||||
Table A4.
MAs’ success using the LTMA+ strategy c for the SchwefelBS 2.26 problem.
Table A4.
MAs’ success using the LTMA+ strategy c for the SchwefelBS 2.26 problem.
| Algorithm | n | MaxFEs | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| RS | 2 | 2000 | 99 | 99 | 99 | 99 | ||||
| ABC | 2 | 2000 | 5 | 100 | 99 | 99 | ||||
| GAOA | 2 | 2000 | 60 | 96 | 90 | 61 | ||||
| MRFO | 2 | 2000 | 33 | 80 | 76 | 79 | ||||
| LSHADE | 2 | 2000 | 9 | 100 | 100 | 100 | ||||
| jDElscop | 2 | 2000 | 53 | 81 | 79 | 83 | ||||
| RS | 3 | 6000 | 55 | 59 | 64 | 58 | ||||
| ABC | 3 | 6000 | 0 | 95 | 97 | 84 | ||||
| GAOA | 3 | 6000 | 3 | 53 | 46 | 18 | ||||
| MRFO | 3 | 6000 | 8 | 45 | 31 | 28 | ||||
| LSHADE | 3 | 6000 | 0 | 100 | 100 | 100 | ||||
| jDElscop | 3 | 6000 | 1 | 88 | 8 | 4 | ||||
| RS | 4 | 8000 | 2 | 6 | 7 | 4 | ||||
| ABC | 4 | 8000 | 0 | 34 | 37 | 28 | ||||
| GAOA | 4 | 8000 | 1 | 12 | 10 | 3 | ||||
| MRFO | 4 | 8000 | 0 | 7 | 7 | 3 | ||||
| LSHADE | 4 | 8000 | 0 | 68 | 65 | 68 | ||||
| jDElscop | 4 | 8000 | 0 | 23 | 0 | 0 | ||||
| RS | 5 | 10,000 | 0 | 0 | 1 | 0 | ||||
| ABC | 5 | 10,000 | 0 | 5 | 10 | 3 | ||||
| GAOA | 5 | 10,000 | 0 | 0 | 1 | 0 | ||||
| MRFO | 5 | 10,000 | 0 | 5 | 1 | 0 | ||||
| LSHADE | 5 | 10,000 | 0 | 19 | 14 | 17 | ||||
| jDElscop | 5 | 10,000 | 0 | 3 | 0 | 0 | ||||
Appendix G.3. LTMA+b
Table A5.
MAs’ success using the LTMA+ strategy b for the SphereBS problem.
Table A5.
MAs’ success using the LTMA+ strategy b for the SphereBS problem.
| Algorithm | n | MaxFEs | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| RS | 2 | 2000 | 99 | 99 | 99 | 99 | ||||
| ABC | 2 | 2000 | 6 | 100 | 100 | 100 | ||||
| GAOA | 2 | 2000 | 9 | 100 | 90 | 70 | ||||
| MRFO | 2 | 2000 | 18 | 100 | 100 | 100 | ||||
| LSHADE | 2 | 2000 | 7 | 100 | 100 | 100 | ||||
| jDElscop | 2 | 2000 | 37 | 100 | 49 | 50 | ||||
| RS | 3 | 6000 | 37 | 51 | 56 | 54 | ||||
| ABC | 3 | 6000 | 0 | 100 | 99 | 100 | ||||
| GAOA | 3 | 6000 | 5 | 100 | 99 | 97 | ||||
| MRFO | 3 | 6000 | 4 | 100 | 100 | 100 | ||||
| LSHADE | 3 | 6000 | 0 | 100 | 100 | 100 | ||||
| jDElscop | 3 | 6000 | 1 | 100 | 88 | 86 | ||||
| RS | 4 | 8000 | 3 | 6 | 5 | 6 | ||||
| ABC | 4 | 8000 | 0 | 72 | 68 | 61 | ||||
| GAOA | 4 | 8000 | 12 | 77 | 71 | 79 | ||||
| MRFO | 4 | 8000 | 0 | 94 | 95 | 89 | ||||
| LSHADE | 4 | 8000 | 0 | 96 | 92 | 89 | ||||
| jDElscop | 4 | 8000 | 0 | 82 | 61 | 58 | ||||
| RS | 5 | 10,000 | 1 | 1 | 0 | 0 | ||||
| ABC | 5 | 10,000 | 0 | 15 | 19 | 16 | ||||
| GAOA | 5 | 10,000 | 19 | 25 | 25 | 20 | ||||
| MRFO | 5 | 10,000 | 0 | 36 | 34 | 29 | ||||
| LSHADE | 5 | 10,000 | 0 | 34 | 34 | 37 | ||||
| jDElscop | 5 | 10,000 | 0 | 20 | 16 | 18 | ||||
Table A6.
MAs’ success using the LTMA+ strategy b for the SchwefelBS 2.26 problem.
Table A6.
MAs’ success using the LTMA+ strategy b for the SchwefelBS 2.26 problem.
| Algorithm | n | MaxFEs | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| RS | 2 | 2000 | 99 | 99 | 99 | 99 | ||||
| ABC | 2 | 2000 | 5 | 100 | 100 | 99 | ||||
| GAOA | 2 | 2000 | 60 | 99 | 98 | 92 | ||||
| MRFO | 2 | 2000 | 33 | 98 | 100 | 100 | ||||
| LSHADE | 2 | 2000 | 9 | 100 | 100 | 100 | ||||
| jDElscop | 2 | 2000 | 53 | 92 | 93 | 89 | ||||
| RS | 3 | 6000 | 55 | 49 | 47 | 50 | ||||
| ABC | 3 | 6000 | 0 | 97 | 88 | 84 | ||||
| GAOA | 3 | 6000 | 3 | 65 | 40 | 25 | ||||
| MRFO | 3 | 6000 | 8 | 65 | 62 | 73 | ||||
| LSHADE | 3 | 6000 | 0 | 99 | 100 | 100 | ||||
| jDElscop | 3 | 6000 | 1 | 83 | 24 | 21 | ||||
| RS | 4 | 8000 | 2 | 6 | 6 | 10 | ||||
| ABC | 4 | 8000 | 0 | 41 | 32 | 18 | ||||
| GAOA | 4 | 8000 | 1 | 14 | 12 | 1 | ||||
| MRFO | 4 | 8000 | 0 | 18 | 11 | 12 | ||||
| LSHADE | 4 | 8000 | 0 | 71 | 66 | 59 | ||||
| jDElscop | 4 | 8000 | 0 | 20 | 4 | 0 | ||||
| RS | 5 | 10,000 | 0 | 0 | 1 | 0 | ||||
| ABC | 5 | 10,000 | 0 | 5 | 6 | 7 | ||||
| GAOA | 5 | 10,000 | 0 | 1 | 1 | 0 | ||||
| MRFO | 5 | 10,000 | 0 | 1 | 0 | 3 | ||||
| LSHADE | 5 | 10,000 | 0 | 15 | 18 | 14 | ||||
| jDElscop | 5 | 10,000 | 0 | 0 | 0 | 0 | ||||
Appendix G.4. LTMA+be
Table A7.
MAs’ success using the LTMA+ strategy for the SphereBS problem.
Table A7.
MAs’ success using the LTMA+ strategy for the SphereBS problem.
| Algorithm | n | MaxFEs | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| RS | 2 | 2000 | 99 | 99 | 100 | 100 | ||||
| ABC | 2 | 2000 | 10 | 100 | 100 | 100 | ||||
| GWO | 2 | 2000 | 3 | 99 | 100 | 99 | ||||
| GAOA | 2 | 2000 | 20 | 99 | 95 | 90 | ||||
| MRFO | 2 | 2000 | 35 | 100 | 100 | 100 | ||||
| LSHADE | 2 | 2000 | 10 | 100 | 100 | 100 | ||||
| jDElscop | 2 | 2000 | 38 | 100 | 75 | 70 | ||||
| RS | 3 | 6000 | 42 | 57 | 55 | 54 | ||||
| ABC | 3 | 6000 | 0 | 100 | 100 | 100 | ||||
| GWO | 3 | 6000 | 0 | 81 | 71 | 67 | ||||
| GAOA | 3 | 6000 | 5 | 100 | 100 | 100 | ||||
| MRFO | 3 | 6000 | 2 | 100 | 100 | 100 | ||||
| LSHADE | 3 | 6000 | 2 | 100 | 100 | 100 | ||||
| jDElscop | 3 | 6000 | 3 | 100 | 96 | 94 | ||||
| RS | 4 | 8000 | 9 | 5 | 7 | 6 | ||||
| ABC | 4 | 8000 | 0 | 84 | 84 | 80 | ||||
| GWO | 4 | 8000 | 0 | 18 | 20 | 18 | ||||
| GAOA | 4 | 8000 | 14 | 82 | 80 | 77 | ||||
| MRFO | 4 | 8000 | 0 | 98 | 95 | 94 | ||||
| LSHADE | 4 | 8000 | 0 | 91 | 95 | 95 | ||||
| jDElscop | 4 | 8000 | 0 | 76 | 69 | 67 | ||||
| RS | 5 | 10,000 | 2 | 0 | 0 | 0 | ||||
| ABC | 5 | 10,000 | 0 | 33 | 33 | 28 | ||||
| GWO | 5 | 10,000 | 0 | 5 | 3 | 3 | ||||
| GAOA | 5 | 10,000 | 19 | 32 | 32 | 30 | ||||
| MRFO | 5 | 10,000 | 0 | 40 | 43 | 45 | ||||
| LSHADE | 5 | 10,000 | 0 | 34 | 34 | 37 | ||||
| jDElscop | 5 | 10,000 | 0 | 19 | 20 | 18 | ||||
Table A8.
MAs’ success using the LTMA+ strategy for the SchwefelBS 2.26 problem.
Table A8.
MAs’ success using the LTMA+ strategy for the SchwefelBS 2.26 problem.
| Algorithm | n | MaxFEs | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| RS | 2 | 2000 | 100 | 99 | 99 | 99 | ||||
| ABC | 2 | 2000 | 9 | 100 | 100 | 99 | ||||
| GWO | 2 | 2000 | 21 | 44 | 42 | 41 | ||||
| GAOA | 2 | 2000 | 54 | 99 | 98 | 95 | ||||
| MRFO | 2 | 2000 | 30 | 100 | 100 | 100 | ||||
| LSHADE | 2 | 2000 | 7 | 100 | 100 | 100 | ||||
| jDElscop | 2 | 2000 | 61 | 90 | 92 | 91 | ||||
| RS | 3 | 6000 | 39 | 61 | 54 | 52 | ||||
| ABC | 3 | 6000 | 0 | 100 | 100 | 99 | ||||
| GWO | 3 | 6000 | 2 | 4 | 5 | 5 | ||||
| GAOA | 3 | 6000 | 4 | 93 | 89 | 82 | ||||
| MRFO | 3 | 6000 | 5 | 89 | 89 | 91 | ||||
| LSHADE | 3 | 6000 | 1 | 100 | 100 | 99 | ||||
| jDElscop | 3 | 6000 | 7 | 93 | 76 | 69 | ||||
| RS | 4 | 8000 | 2 | 5 | 5 | 4 | ||||
| ABC | 4 | 8000 | 0 | 67 | 59 | 52 | ||||
| GWO | 4 | 8000 | 0 | 0 | 0 | 0 | ||||
| GAOA | 4 | 8000 | 0 | 27 | 27 | 21 | ||||
| MRFO | 4 | 8000 | 2 | 30 | 27 | 29 | ||||
| LSHADE | 4 | 8000 | 0 | 73 | 70 | 69 | ||||
| jDElscop | 4 | 8000 | 0 | 18 | 12 | 8 | ||||
| RS | 5 | 10,000 | 1 | 1 | 1 | 1 | ||||
| ABC | 5 | 10,000 | 0 | 13 | 14 | 12 | ||||
| GWO | 5 | 10,000 | 0 | 0 | 0 | 0 | ||||
| GAOA | 5 | 10,000 | 0 | 10 | 7 | 7 | ||||
| MRFO | 5 | 10,000 | 0 | 3 | 3 | 3 | ||||
| LSHADE | 5 | 10,000 | 0 | 18 | 17 | 17 | ||||
| jDElscop | 5 | 10,000 | 0 | 2 | 2 | 1 | ||||
Appendix G.5. Evaluating LTMA+ on Benchmarks Without Blind Spots
For a thorough comparison with the original LTMA method, we selected two test cases from the original LTMA paper: the CEC’15 benchmark problem (Experiment 2) and the real-world soil problem (Experiment 3) [10]. We set the Hit parameter to 12, using benchmark problems with and . The LTMA memory precision (Pr) was set to 9.
As the LTMA+ strategies are intended to improve performance primarily in scenarios with blind spots, no substantial differences were expected on these benchmark problems. Nonetheless, it was important to verify that the LTMA+ strategies do not impact the performance of the original LTMA method negatively.
We employed the CRS4EAs rating system for statistical analysis, as described in Section 3.4 [54,55]. To simulate LTMA, we used the following strategy variants: , , and .
CEC’15 Benchmark
The CEC’15 benchmark comprises a widely recognized collection of test functions designed to assess optimization algorithm performance [27]. For our evaluation, we used a problem dimensionality of and a maximum of function evaluations. These benchmark functions include unimodal functions to test convergence speed, multimodal functions with multiple local optima to challenge exploration, rotated functions to assess the handling of non-separable variables, and composite functions combining multiple properties for complex optimization scenarios.
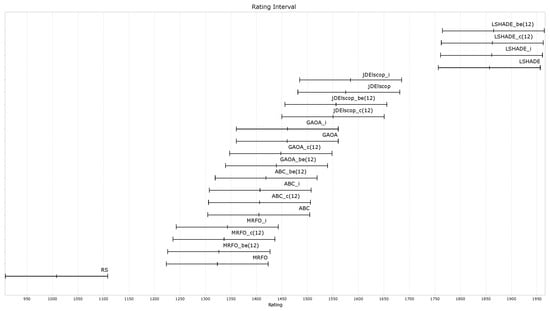
Figure A29.
MAs’ algorithm ratings on the CEC’15 benchmark.
Figure A29 demonstrates that the LTMA+ strategies did not exhibit significant differences in performance compared to the original LTMA.
Appendix G.6. Soil Model Optimization Problems
The real-world optimization task involves estimating the parameters of a three-layer soil model, specifically the thicknesses (, ) and resistivities (, , ) of the layers [56,57]. These parameters are essential for the accurate dimensioning of grounding systems using the finite element method (FEM), which ensures safety during electrical faults or lightning strikes.
To determine these parameters, resistivity measurements were conducted using the Wenner four-electrode method [58], where the apparent resistivity is computed based on electrode spacing and measured voltage/current. The optimization goal is to minimize the error between the measured and model-computed apparent resistivities. The fitness function is defined as the mean relative error over all the measurement points (Equation (A4)).
Three data sets (TE1, TE2, and TE3) were used as separate problem instances. The analytical solution for apparent resistivity is based on Bessel function integrals, approximated via numerical integration with a cutoff at . More details about the problem and the data sets can be found in [10,57].
Figure A30, Figure A31 and Figure A32 demonstrate that the LTMA+ strategies did not exhibit significant differences in performance compared to the original LTMA on benchmarks without blind spots.
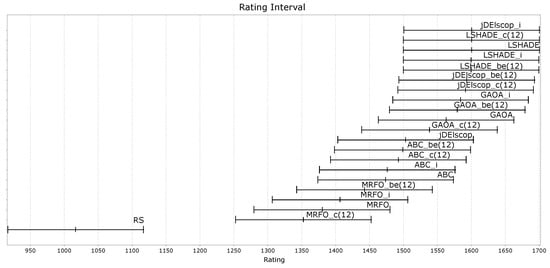
Figure A30.
MAs’ ratings on the soil problem—TE1 Data Set.
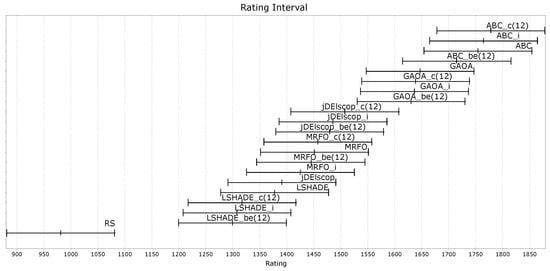
Figure A31.
MAs’ ratings on the soil problem—TE2 Data Set.
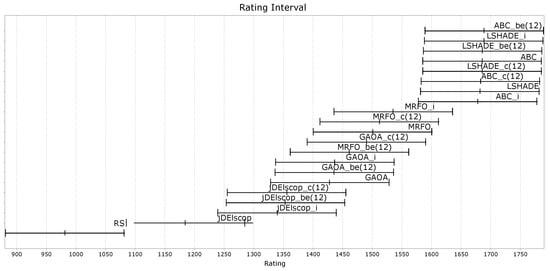
Figure A32.
MAs’ ratings on the soil problem—TE3 Data Set.
References
- Tsai, C.; Chiang, M. Handbook of Metaheuristic Algorithms: From Fundamental Theories to Advanced Applications; Elsevier: Amsterdam, The Netherlands, 2023. [Google Scholar]
- Črepinšek, M.; Liu, S.H.; Mernik, M. Replication and comparison of computational experiments in applied evolutionary computing: Common pitfalls and guidelines to avoid them. Appl. Soft Comput. 2014, 19, 161–170. [Google Scholar] [CrossRef]
- Deng, L.; Liu, S. Metaheuristics exposed: Unmasking the design pitfalls of arithmetic optimization algorithm in benchmarking. Swarm Evol. Comput. 2024, 86, 101535. [Google Scholar] [CrossRef]
- Taleb, N.N. The Black Swan: The Impact of the Highly Improbable; Random House: New York, NY, USA, 2007. [Google Scholar]
- Taleb, N. Antifragile: Things That Gain from Disorder; Incerto; Random House Publishing Group: Westminster, MD, USA, 2012. [Google Scholar]
- Taleb, N.N. Skin in the Game: Hidden Asymmetries in Daily Life; Random House: New York, NY, USA, 2018. [Google Scholar]
- Hansen, N.; Ostermeier, A. Completely derandomized self-adaptation in evolution strategies. Evol. Comput. 2001, 9, 159–195. [Google Scholar] [CrossRef]
- Hsieh, F.S. A Self-Adaptive Meta-Heuristic Algorithm Based on Success Rate and Differential Evolution for Improving the Performance of Ridesharing Systems with a Discount Guarantee. Algorithms 2024, 17, 9. [Google Scholar] [CrossRef]
- Piotrowski, A.P. Review of Differential Evolution population size. Swarm Evol. Comput. 2017, 32, 1–24. [Google Scholar] [CrossRef]
- Črepinšek, M.; Liu, S.H.; Mernik, M.; Ravber, M. Long Term Memory Assistance for Evolutionary Algorithms. Mathematics 2019, 7, 1129. [Google Scholar] [CrossRef]
- Holland, J.H. Adaptation in Natural and Artificial Systems; University of Michigan Press: Ann Arbor, MI, USA, 1975; Reprinted by MIT Press: Cambridge, MA, USA, 1992. [Google Scholar]
- Eiben, A.E.; Smith, J.E. Introduction to Evolutionary Computing; Natural Computing Series; Springer: Berlin/Heidelberg, Germany, 2003. [Google Scholar]
- Zhan, Z.H.; Shi, L.; Tan, K.C.; Zhang, J. A survey on evolutionary computation for complex continuous optimization. Artif. Intell. Rev. 2022, 55, 59–110. [Google Scholar] [CrossRef]
- Jerebic, J.; Mernik, M.; Liu, S.H.; Ravber, M.; Baketarić, M.; Mernik, L.; Črepinšek, M. A novel direct measure of exploration and exploitation based on attraction basins. Expert Syst. Appl. 2021, 167, 114353. [Google Scholar] [CrossRef]
- Piotrowski, A.P.; Napiorkowski, J.J.; Piotrowska, A.E. To what extent evolutionary algorithms can benefit from a longer search? Inf. Sci. 2024, 654, 119766. [Google Scholar] [CrossRef]
- Črepinšek, M.; Liu, S.H.; Mernik, M. Exploration and Exploitation in Evolutionary Algorithms: A Survey. ACM Comput. Surv. 2013, 45, 35. [Google Scholar] [CrossRef]
- Li, G.; Zhang, W.; Yue, C.; Wang, Y. Balancing exploration and exploitation in dynamic constrained multimodal multi-objective co-evolutionary algorithm. Swarm Evol. Comput. 2024, 89, 101652. [Google Scholar] [CrossRef]
- Yu, J.; Zhang, Y.; Sun, C. Balance of exploration and exploitation: Non-cooperative game-driven evolutionary reinforcement learning. Swarm Evol. Comput. 2024, 91, 101759. [Google Scholar] [CrossRef]
- Xia, H.; Li, C.; Tan, Q.; Zeng, S.; Yang, S. Learning to search promising regions by space partitioning for evolutionary methods. Swarm Evol. Comput. 2024, 91, 101726. [Google Scholar] [CrossRef]
- Stork, J.; Eiben, A.E.; Bartz-Beielstein, T. A new taxonomy of global optimization algorithms. Nat. Comput. Int. J. 2022, 21, 219–242. [Google Scholar] [CrossRef]
- Gupta, A.; Zhou, L.; Ong, Y.S.; Chen, Z.; Hou, Y. Half a Dozen Real-World Applications of Evolutionary Multitasking, and More. arXiv 2021, arXiv:2109.13101. [Google Scholar] [CrossRef]
- Jouhari, H.; Lei, D.; A. A. Al-qaness, M.; Abd Elaziz, M.; Ewees, A.A.; Farouk, O. Sine-Cosine Algorithm to Enhance Simulated Annealing for Unrelated Parallel Machine Scheduling with Setup Times. Mathematics 2019, 7, 1120. [Google Scholar] [CrossRef]
- Zhao, S.; Jia, H.; Li, Y.; Shi, Q. A Constrained Multi-Objective Optimization Algorithm with a Population State Discrimination Model. Mathematics 2025, 13, 688. [Google Scholar] [CrossRef]
- Cervantes, L.; Castillo, O.; Soria, J. Hierarchical aggregation of multiple fuzzy controllers for global complex control problems. Appl. Soft Comput. 2016, 38, 851–859. [Google Scholar] [CrossRef]
- Liu, J.; Chen, Y.; Liu, X.; Zuo, F.; Zhou, H. An efficient manta ray foraging optimization algorithm with individual information interaction and fractional derivative mutation for solving complex function extremum and engineering design problems. Appl. Soft Comput. 2024, 150, 111042. [Google Scholar] [CrossRef]
- Yao, X.; Feng, Z.; Zhang, L.; Niu, W.; Yang, T.; Xiao, Y.; Tang, H. Multi-objective cooperation search algorithm based on decomposition for complex engineering optimization and reservoir operation problems. Appl. Soft Comput. 2024, 167, 112442. [Google Scholar] [CrossRef]
- Qu, B.; Liang, J.; Wang, Z.; Chen, Q.; Suganthan, P. Novel benchmark functions for continuous multimodal optimization with comparative results. Swarm Evol. Comput. 2016, 26, 23–34. [Google Scholar] [CrossRef]
- Hansen, N.; Finck, S.; Ros, R.; Auger, A. Real-Parameter Black-Box Optimization Benchmarking 2009: Noiseless Functions Definitions; Technical Report RR-6829; INRIA: Orsay, France, 2009. [Google Scholar]
- Azad, S.K.; Hasançebi, O. Structural Optimization Problems of the ISCSO 2011-2015: A Test Set. Iran Univ. Sci. Technol. 2016, 6, 629–638. [Google Scholar]
- Saxena, V.; Shukla, R.; Khandelwal, S. Stochastic Optimization of Sensor’s Deployment Location over Terrain to Maximize Viewshed Coverage Area for a Fixed Number of Sensors Scenario. In Proceedings of the 2022 9th International Conference on Computing for Sustainable Global Development (INDIACom), New Delhi, India, 23–25 March 2022; pp. 370–376. [Google Scholar] [CrossRef]
- Yao, S.; Zhou, J.; Chieng, D.; Kwong, C.F.; Lee, B.G.; Li, J.; Chen, Y. Investigation of traffic radar coverage efficiency under different placement strategies. In Proceedings of the International Conference on Internet of Things 2024 (ICIoT 2024), Bangkok, Thailand, 16–19 November 2024; Volume 2024, pp. 27–33. [Google Scholar] [CrossRef]
- Majd, A.; Troubitsyna, E. Data-driven approach to ensuring fault tolerance and efficiency of swarm systems. In Proceedings of the 2017 IEEE International Conference on Big Data (Big Data), Boston, MA, USA, 11–14 December 2017; pp. 4792–4794. [Google Scholar] [CrossRef]
- Jon, J.; Bojar, O. Breeding Machine Translations: Evolutionary approach to survive and thrive in the world of automated evaluation. arXiv 2023, arXiv:2305.19330. [Google Scholar]
- Hosea, N.A.; Bolton, E.W.; Gasteiger, W. Evolutionary-Algorithm-Based Strategy for Computer-Assisted Structure Elucidation. J. Chem. Inf. Comput. Sci. 2004, 44, 1713–1721. [Google Scholar] [CrossRef]
- Luo, J.; He, F.; Li, H.; Zeng, X.T.; Liang, Y. A novel whale optimisation algorithm with filtering disturbance and nonlinear step. Int. J. Bio-Inspired Comput. 2022, 20, 71–81. [Google Scholar] [CrossRef]
- Ramakrishnan, R.; Kamar, E.; Dey, D.; Shah, J.A.; Horvitz, E. Discovering Blind Spots in Reinforcement Learning. arXiv 2018, arXiv:1805.08966. [Google Scholar]
- Zou, F.; Chen, D.; Liu, H.; Cao, S.; Ji, X.; Zhang, Y. A survey of fitness landscape analysis for optimization. Neurocomputing 2022, 503, 129–139. [Google Scholar] [CrossRef]
- Malan, K.M.; Engelbrecht, A.P. A survey of techniques for characterising fitness landscapes and some possible ways forward. Inf. Sci. 2013, 241, 148–163. [Google Scholar] [CrossRef]
- Liu, X.; Liu, G.; Zhang, H.K.; Huang, J.; Wang, X. Mitigating barren plateaus of variational quantum eigensolvers. IEEE Trans. Quantum Eng. 2024, 5, 3103719. [Google Scholar] [CrossRef]
- Arrasmith, A.; Cerezo, M.; Czarnik, P.; Cincio, L.; Coles, P.J. Effect of barren plateaus on gradient-free optimization. Quantum 2021, 5, 558. [Google Scholar] [CrossRef]
- Cerezo, M.; Sone, A.; Volkoff, T.; Cincio, L.; Coles, P.J. Cost function dependent barren plateaus in shallow parametrized quantum circuits. Nat. Commun. 2021, 12, 1791. [Google Scholar] [CrossRef]
- Rajwar, K.; Deep, K.; Das, S. An exhaustive review of the metaheuristic algorithms for search and optimization: Taxonomy, applications, and open challenges. Artif. Intell. Rev. 2023, 56, 13187–13257. [Google Scholar] [CrossRef]
- EARS—Evolutionary Algorithms Rating System (Github). 2016. Available online: https://github.com/UM-LPM/EARS (accessed on 8 April 2025).
- Chauhan, D.; Trivedi, A.; Shivani. A Multi-operator Ensemble LSHADE with Restart and Local Search Mechanisms for Single-objective Optimization. arXiv 2024, arXiv:2409.15994. [Google Scholar]
- Tao, S.; Zhao, R.; Wang, K.; Gao, S. An Efficient Reconstructed Differential Evolution Variant by Some of the Current State-of-the-art Strategies for Solving Single Objective Bound Constrained Problems. arXiv 2024, arXiv:2404.16280. [Google Scholar]
- Ravber, M.; Mernik, M.; Liu, S.H.; Šmid, M.; Črepinšek, M. Confidence Bands Based on Rating Demonstrated on the CEC 2021 Competition Results. In Proceedings of the 2024 IEEE Congress on Evolutionary Computation (CEC), Yokohama, Japan, 30 June–5 July 2024; pp. 1–8. [Google Scholar]
- Brest, J.; Maučec, M.S. Self-adaptive differential evolution algorithm using population size reduction and three strategies. Soft Comput. 2011, 15, 2157–2174. [Google Scholar] [CrossRef]
- Tanabe, R.; Fukunaga, A.S. Improving the search performance of SHADE using linear population size reduction. In Proceedings of the 2014 IEEE Congress on Evolutionary Computation (CEC), Beijing, China, 6–11 July 2014; pp. 1658–1665. [Google Scholar]
- Agushaka, J.O.; Ezugwu, A.E.; Abualigah, L. Gazelle optimization algorithm: A novel nature-inspired metaheuristic optimizer. Neural Comput. Appl. 2023, 35, 4099–4131. [Google Scholar] [CrossRef]
- Zhao, W.; Zhang, Z.; Wang, L. Manta ray foraging optimization: An effective bio-inspired optimizer for engineering applications. Eng. Appl. Artif. Intell. 2020, 87, 103300. [Google Scholar] [CrossRef]
- Dixon, L.; Szegö, G. The global optimization problem: An introduction. Towards Glob. Optim. 1978, 2, 1–15. [Google Scholar]
- Ackley, D.H. A Connectionist Machine for Genetic Hillclimbing; The Kluwer International Series in Engineering and Computer Science; Springer: Berlin/Heidelberg, Germany, 1987; Volume 28. [Google Scholar] [CrossRef]
- Schwefel, H.P. Numerical Optimization of Computer Models; John Wiley & Sons: Hoboken, NJ, USA, 1981. [Google Scholar]
- Veček, N.; Mernik, M.; Črepinšek, M. A chess rating system for evolutionary algorithms: A new method for the comparison and ranking of evolutionary algorithms. Inf. Sci. 2014, 277, 656–679. [Google Scholar] [CrossRef]
- Veček, N.; Mernik, M.; Filipič, B.; Črepinšek, M. Parameter tuning with Chess Rating System (CRS-Tuning) for meta-heuristic algorithms. Inf. Sci. 2016, 372, 446–469. [Google Scholar] [CrossRef]
- Gonos, I.F.; Stathopulos, I.A. Estimation of multilayer soil parameters using genetic algorithms. IEEE Trans. Power Deliv. 2005, 20, 100–106. [Google Scholar] [CrossRef]
- Jesenik, M.; Mernik, M.; Črepinšek, M.; Ravber, M.; Trlep, M. Searching for soil models’ parameters using metaheuristics. Appl. Soft Comput. 2018, 69, 131–148. [Google Scholar] [CrossRef]
- Southey, R.D.; Siahrang, M.; Fortin, S.; Dawalibi, F.P. Using fall-of-potential measurements to improve deep soil resistivity estimates. IEEE Trans. Ind. Appl. 2015, 51, 5023–5029. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).