
TextNeX: Text Network of eXperts for Robust Text Classification—Case Study on Machine-Generated-Text Detection


Abstract
1. Introduction
- We propose TextNeX, a new model that achieves state-of-the-art performance on text classification benchmarks, demonstrating its superiority over traditional ensemble-based models. In addition, it maintains significantly lower computational costs, making it a scalable solution for real-world applications.
- We propose a new ensemble learning approach, which balances high accuracy and computational efficiency by leveraging lightweight transformer-based models.
- We propose a clustering-based selection process, which identifies the most complementary models (experts) from a pool of trained ones for the final ensemble. Unlike traditional methods, which focus solely on validation performance, our approach prioritizes model diversity, reducing the risk of overfitting and improving generalization and robustness.
2. Related Work
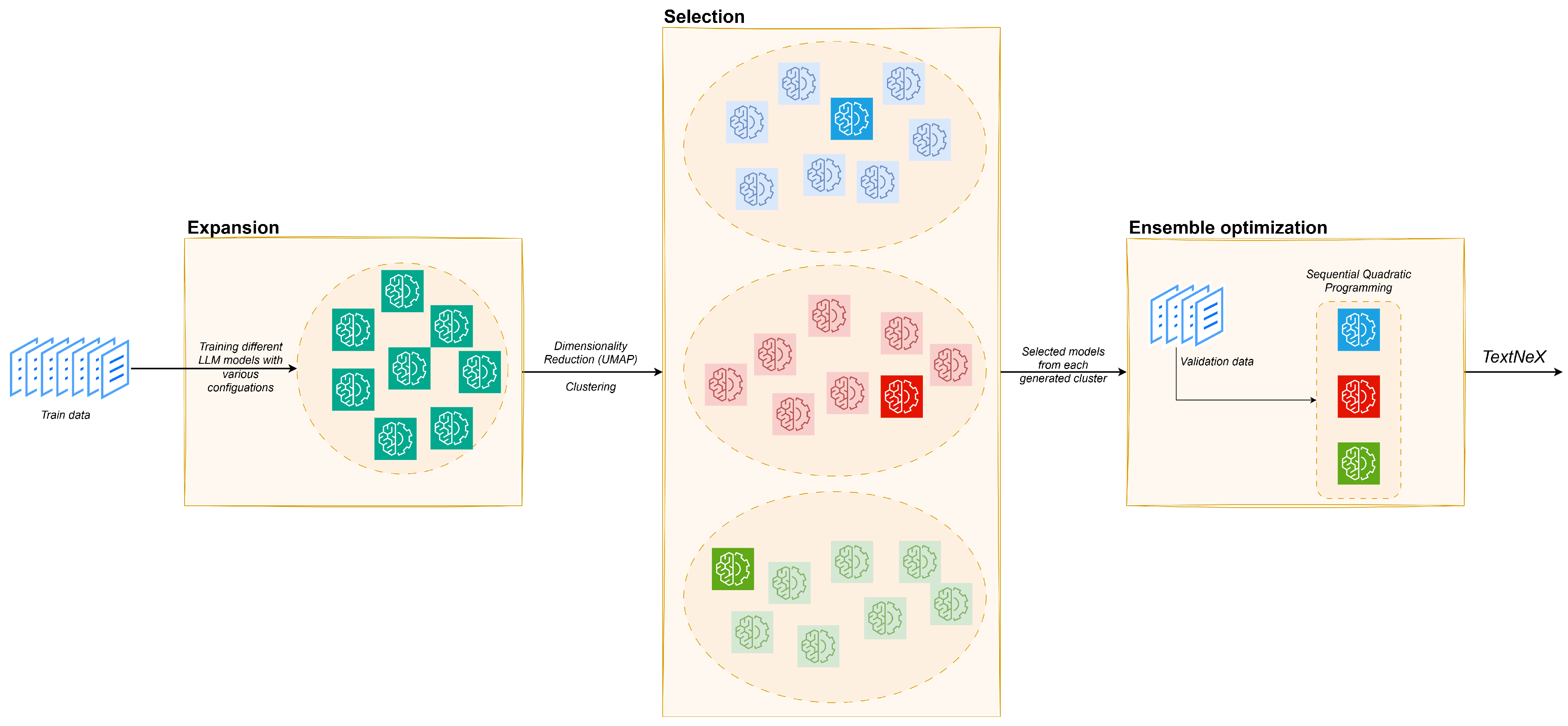
3. TextNeX
3.1. Expansion
| Algorithm 1: Expansion: Generating Diverse Models |
|
- DistilBERT [15]: A distilled version of BERT, retaining 95% of its performance while being 40% smaller and 60% faster.
- MiniLM [16]: A highly efficient transformer model with variants such as MiniLM-L6-H384 (6 layers, 384 hidden units) and MiniLM-L12-H384 (12 layers, 384 hidden units), offering a balance between size and performance.
- MobileBERT [17]: A compact BERT variant optimized for mobile devices, featuring fewer parameters and faster inference.
3.2. Selection
| Algorithm 2: Selection: Selecting Heterogeneous Models |
|
3.3. Ensemble Optimization
| Algorithm 3: Ensemble optimization—Generation of optimal weights |
|
4. Experimental Analysis
4.1. Experimental Setup
- AuTexTification shared task (IberLEF 2023) [11]: This dataset focuses on AI-generated content detection; this dataset includes both human and machine-generated texts encompassing different domains (tweets, legal documents, news articles, among others). The AI-generated texts were generated by six different models, among them BLOOM-7B1 and OpenAI’s text-davinci-003. The dataset is bilingual, available both in English and Spanish and comprises a training set of 33,845 samples (17,046 human/16,799 generated), as well as a test set of 21,832 samples (10,642 human/11,190 generated). Even though the dataset is bilingual, in our experiments only the English version of the dataset was utilized.
- TweepFake—Twitter deep Fake text Dataset [1]: This dataset concerns both human and machine-generated tweets scraped directly from the Twitter API, with the AI-generated content being created by models, such as GPT-2, LSTMs or Markov Chains. It is divided into a training set of 20,712 samples (10,358 human/10,354 generated), a validation set of 2302 samples (1150 human/1152 generated) and a testing set of 2558 samples (1278 human/1280 generated).
- AI Text Detection Pile [25]: This dataset is developed for AI-generated Text Detection tasks and it is mainly constituted by longer texts, such as reviews and essays from sources such as Reddit, OpenAI Webtext, Twitter and HC3. It contains 1,339,000 samples (990,000 human/340,000 generated) while the machine generated texts were generated from OpenAI’s GPT models, i.e., GPT2, GPTJ and ChatGPT (GPT-3.5-Turbo).
- BERT [3]: A transformer-based model widely used for text classification.
- RoBERTa [4]: An optimized variant of BERT with improved performance.
- DeBERTa [5]: A transformer model that improves context understanding with disentangled attention.
- DistilBERT [15]: A smaller, faster and lighter version of BERT, retaining most of its performance.
- XLNet [6]: A generalized autoregressive pretraining method for text classification.
- Majority Voting [9]: An ensemble model which uses RoBERTa, ELECTRA and XLNet as based learners and the final prediction is calculated by majority voting.
- Soft Voting [1]: An ensemble model which uses BLOOM-560m, ErnieM and DeBERTaV3 as based learners and the final prediction is calculated by probability-weighted voting.
- Stacking (SVC) [8]: An ensemble model combining the predictions of BERT, BART, RoBERTa and GPT-2 using a Support Vector Classifier (SVC) as the meta-learner.
- Stacking (Voting) [2]: An ensemble model combining the predictions of BERT, RoBERTa, XLM-RoBERTa and DeBERTa using an ensemble voting classifier (Logistic Regression, Random Forest, Gaussian Naive Bayes and SVC) as the meta-learner.
- Stacking (XGBoost) [11]: An ensemble model, which uses by XLM-RoBERTa, TwHIN-BERT and multilingual BERT as base learners and XGBoost model as a meta-learner.
- TextNeX: The proposed model, which consists of a heterogeneous ensemble of lightweight text models, utilizing a clustering-based selection process to maximize diversity.
4.2. Experimental Results
- Voting-based ensembles (e.g., majority voting, averaging) run models in parallel, meaning the total inference time is determined by the slowest model in the ensemble. However, the trade-off of parallel execution is reduced memory efficiency, as memory usage is computed as the sum of the memory requirements of all base learners in the ensemble.
- Stacking-based ensembles, where outputs from multiple models are passed to a meta-learner sequentially, result in a total inference time equal to the sum of the base learners’ times. However, the advantage of sequential execution lies in its memory efficiency, as memory usage is determined by the model in the ensemble with the highest memory requirement.
4.3. Ablation Study
4.4. Discussion of Research Objectives and Limitations
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Sheykhlan, M.K.; Abdoljabbar, S.K.; Mahmoudabad, M.N. KaramiTeam at IberAuTexTification: Soft Voting Ensemble for Distinguishing AI-Generated Texts. In CEUR Workshop Proceedings, Proceedings of the Iberian Languages Evaluation Forum (IberLEF 2024) Co-Located with the Conference of the Spanish Society for Natural Language Processing (SEPLN 2024), Valladolid, Spain, 24 September 2024; Jiménez-Zafra, S.M., Chiruzzo, L., Rangel, F., Balouchzahi, F., Corrêa, U.B., Bonet-Jover, A., Gómez-Adorno, H., Barba, J.Á.G., Farías, D.I.H., Montejo-Ráez, A., et al., Eds.; CEUR-WS: Aachen, Germany, 2024; Volume 3756. [Google Scholar]
- Abburi, H.; Suesserman, M.; Pudota, N.; Veeramani, B.; Bowen, E.; Bhattacharya, S. Generative AI text classification using ensemble llm approaches. arXiv 2023, arXiv:2309.07755. [Google Scholar]
- Kenton, J.D.M.W.C.; Toutanova, L.K. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the NAACL-HLT, Minneapolis, MN, USA, 2–7 June 2019; Volume 1. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- He, P.; Liu, X.; Gao, J.; Chen, W. DeBERTa: Decoding-enhanced BERT with Disentangled Attention. In Proceedings of the 9th International Conference on Learning Representations, Virtual Event, 3–7 May 2021. [Google Scholar]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.; Le, Q.V. XLNet: Generalized Autoregressive Pretraining for Language Understanding. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Curran Associates, Inc.: New York, NY, USA, 2019; Volume 32, pp. 5754–5764. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the limits of transfer learning with a unified text-to-text transformer. arXiv 2020, arXiv:1910.10683. [Google Scholar]
- Gambini, M.; Fagni, T.; Falchi, F.; Tesconi, M. On pushing deepfake tweet detection capabilities to the limits. In Proceedings of the 14th ACM Web Science Conference 2022, Barcelona, Spain, 26–29 June 2022; pp. 154–163. [Google Scholar]
- Mikros, G.K.; Koursaris, A.; Bilianos, D.; Markopoulos, G. AI-Writing Detection Using an Ensemble of Transformers and Stylometric Features. In Proceedings of the IberLEF@ SEPLN, Andalusia, Spain, 26 September 2023. [Google Scholar]
- Sarmah, U.; Borah, P.; Bhattacharyya, D.K. Ensemble Learning Methods: An Empirical Study. SN Comput. Sci. 2024, 5, 924. [Google Scholar] [CrossRef]
- Preda, A.A.; Cercel, D.C.; Rebedea, T.; Chiru, C.G. UPB at IberLEF-2023 AuTexTification: Detection of Machine-Generated Text using Transformer Ensembles. arXiv 2023, arXiv:2308.01408. [Google Scholar]
- Larson, J.; Menickelly, M.; Wild, S.M. Derivative-free optimization methods. Acta Numer. 2019, 28, 287–404. [Google Scholar] [CrossRef]
- Crothers, E.N.; Japkowicz, N.; Viktor, H.L. Machine-generated text: A comprehensive survey of threat models and detection methods. IEEE Access 2023, 11, 70977–71002. [Google Scholar] [CrossRef]
- Domingo, J.D.; Aparicio, R.M.; Rodrigo, L.M.G. Cross validation voting for improving CNN classification in grocery products. IEEE Access 2022, 10, 20913–20925. [Google Scholar] [CrossRef]
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T. DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter. arXiv 2019, arXiv:1910.01108. [Google Scholar]
- Wang, W.; Wei, F.; Dong, L.; Bao, H.; Yang, N.; Zhou, M. Minilm: Deep self-attention distillation for task-agnostic compression of pre-trained transformers. Adv. Neural Inf. Process. Syst. 2020, 33, 5776–5788. [Google Scholar]
- Sun, Z.; Yu, H.; Song, X.; Liu, R.; Yang, Y.; Zhou, D. Mobilebert: A compact task-agnostic bert for resource-limited devices. arXiv 2020, arXiv:2004.02984. [Google Scholar]
- Healy, J.; McInnes, L. Uniform manifold approximation and projection. Nat. Rev. Methods Prim. 2024, 4, 82. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, M.; Wang, S.; Dai, S.; Luo, L.; Zhu, E.; Xu, H.; Zhu, X.; Yao, C.; Zhou, H. Gaussian mixture model clustering with incomplete data. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2021, 17, 1–14. [Google Scholar] [CrossRef]
- Patel, E.; Kushwaha, D.S. Clustering cloud workloads: k-means vs gaussian mixture model. Procedia Comput. Sci. 2020, 171, 158–167. [Google Scholar] [CrossRef]
- Victoria, A.H.; Maragatham, G. Automatic tuning of hyperparameters using Bayesian optimization. Evol. Syst. 2021, 12, 217–223. [Google Scholar] [CrossRef]
- Livieris, I.E. A novel forecasting strategy for improving the performance of deep learning models. Expert Syst. Appl. 2023, 230, 120632. [Google Scholar] [CrossRef]
- Naidu, G.; Zuva, T.; Sibanda, E.M. A review of evaluation metrics in machine learning algorithms. In Artificial Intelligence Application in Networks and Systems, Proceedings of 12th Computer Science On-line Conference 2023; Springer: Berlin/Heidelberg, Germany, 2023; Volume 3, pp. 15–25. [Google Scholar]
- Ragonneau, T.M.; Zhang, Z. PDFO: A cross-platform package for Powell’s derivative-free optimization solvers. arXiv 2024, arXiv:2302.13246. [Google Scholar] [CrossRef]
- artem9k. AI Text Detection Pile. Available online: https://huggingface.co/datasets/artem9k/ai-text-detection-pile (accessed on 22 January 2024).
- He, X.; Shen, X.; Chen, Z.; Backes, M.; Zhang, Y. Mgtbench: Benchmarking machine-generated text detection. In Proceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security, Salt Lake City, UT, USA, 14–18 October 2024; pp. 2251–2265. [Google Scholar]
- Kingma, D.P. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Smith, L.N. Cyclical learning rates for training neural networks. In Proceedings of the 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 27–29 March 2017; pp. 464–472. [Google Scholar]
- Goodfellow, I. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Hodges, J.L., Jr.; Lehmann, E.L. Rank methods for combination of independent experiments in analysis of variance. In Selected Works of E.L. Lehmann; Springer: Berlin/Heidelberg, Germany, 2011; pp. 403–418. [Google Scholar]
- Juarros-Basterretxea, J.; Aonso-Diego, G.; Postigo, Á.; Montes-Álvarez, P.; Menéndez-Aller, Á.; García-Cueto, E. Post-hoc tests in one-way ANOVA: The case for normal distribution. Methodology 2024, 20, 84–99. [Google Scholar] [CrossRef]
- Kiriakidou, N.; Livieris, I.E.; Pintelas, P. Mutual information-based neighbor selection method for causal effect estimation. Neural Comput. Appl. 2024, 36, 9141–9155. [Google Scholar] [CrossRef]

{kind=link}
| Model | AuTexTification | TweepFake | AI Text Detection Pile | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Acc | AUC | GM | Acc | AUC | GM | Acc | AUC | GM | |
| BERT | 0.652 | 0.741 | 0.645 | 0.891 | 0.905 | 0.884 | 0.865 | 0.901 | 0.798 |
| RoBERTa | 0.675 | 0.765 | 0.670 | 0.896 | 0.912 | 0.890 | 0.877 | 0.909 | 0.812 |
| DeBERTa | 0.690 | 0.780 | 0.685 | 0.902 | 0.918 | 0.898 | 0.879 | 0.914 | 0.818 |
| DistilBERT | 0.731 | 0.805 | 0.725 | 0.887 | 0.899 | 0.876 | 0.851 | 0.892 | 0.780 |
| XLNet | 0.660 | 0.749 | 0.655 | 0.877 | 0.892 | 0.869 | 0.859 | 0.903 | 0.795 |
| Majority Voting | 0.725 | 0.810 | 0.720 | 0.914 | 0.926 | 0.910 | 0.890 | 0.924 | 0.825 |
| Soft Voting | 0.746 | 0.825 | 0.735 | 0.921 | 0.934 | 0.918 | 0.894 | 0.926 | 0.832 |
| Stacking (SVC) | 0.755 | 0.835 | 0.750 | 0.926 | 0.942 | 0.923 | 0.899 | 0.928 | 0.835 |
| Stacking (Voting) | 0.760 | 0.840 | 0.755 | 0.931 | 0.951 | 0.929 | 0.902 | 0.930 | 0.840 |
| Stacking (XGBoost) | 0.735 | 0.815 | 0.733 | 0.929 | 0.943 | 0.926 | 0.896 | 0.924 | 0.828 |
| TextNeX | 0.775 | 0.848 | 0.772 | 0.943 | 0.948 | 0.940 | 0.908 | 0.935 | 0.850 |
| Model | Friedman | Finner Post-Hoc Test | |
|---|---|---|---|
| Ranking | -Value | ||
| TextNeX | 3.67 | − | − |
| Stacking (Voting) | 6.00 | 0.01963 | Rejected |
| Stacking (SVC) | 8.67 | 6.37·10−7 | Rejected |
| Stacking (XGBoost) | 10.67 | 3.2·10−12 | Rejected |
| Soft Voting | 12.00 | 0.0 | Rejected |
| Majority Voting | 18.00 | 0.0 | Rejected |
| DistilBERT | 22.67 | 0.0 | Rejected |
| DeBERTa | 23.33 | 0.0 | Rejected |
| RoBERTa | 25.00 | 0.0 | Rejected |
| BERT | 27.33 | 0.0 | Rejected |
| XLNet | 29.67 | 0.0 | Rejected |
| Model | Friedman | Finner Post-Hoc Test | |
|---|---|---|---|
| Ranking | -Value | ||
| TextNeX | 5.00 | − | − |
| Stacking (Voting) | 5.67 | 0.50499 | Failed to reject |
| Stacking (SVC) | 8.00 | 0.00299 | Rejected |
| Soft Voting | 10.67 | 1.82·10−8 | Rejected |
| Stacking (XGBoost) | 11.17 | 9.96·10−10 | Rejected |
| Majority Voting | 16.83 | 0.0 | Rejected |
| DeBERTa | 22.67 | 0.0 | Rejected |
| DistilBERT | 25.00 | 0.0 | Rejected |
| RoBERTa | 25.33 | 0.0 | Rejected |
| BERT | 28.00 | 0.0 | Rejected |
| XLNet | 28.67 | 0.0 | Rejected |
| Model | Friedman | Finner Post-Hoc Test | |
|---|---|---|---|
| Ranking | -Value | ||
| TextNeX | 3.33 | − | − |
| Stacking (Voting) | 5.33 | 0.04550 | Rejected |
| Stacking (SVC) | 8.67 | 1.07·10−7 | Rejected |
| Soft Voting | 11.33 | 1.67·10−15 | Rejected |
| Stacking (XGBoost) | 11.67 | 0.0 | Rejected |
| Majority Voting | 18.00 | 0.0 | Rejected |
| DeBERTa | 23.00 | 0.0 | Rejected |
| DistilBERT | 24.33 | 0.0 | Rejected |
| RoBERTa | 25.00 | 0.0 | Rejected |
| BERT | 27.33 | 0.0 | Rejected |
| XLNet | 29.00 | 0.0 | Rejected |
| Single Models | Inference Time (ms) | Memory Usage (MB) |
|---|---|---|
| BERT [3] | 12.4 | 444 |
| RoBERTa [4] | 14.1 | 502 |
| DeBERTa [5] | 16.5 | 580 |
| DistilBERT [15] | 7.2 | 280 |
| XLNet [6] | 19.8 | 499 |
| MobileBERT [17] | 5.8 | 111 |
| MiniLM [16] | 4.9 | 142 |
| Majority Voting Ensemble [9] | 19.8 | 1445 |
| Soft Voting Ensemble [1] | 50.0 | 4302 |
| Stacking Ensemble (SVC) [8] | 60.4 | 870 |
| Stacking Ensemble (Voting) [2] | 60.1 | 1086 |
| Stacking (XGBoost) [11] | 17.1 | 2292 |
| TextNeX | 7.2 | 534 |
| Selection Approaches (Algorithm 2) | AuTexTification | TweepFake | AI Text Detection Pile | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Models | Valid | Test | Models | Valid | Test | Models | Valid | Test | |
| Best-Valid-based Selection | 0.858 | 0.782 | 0.953 | 0.938 | 0.910 | 0.818 | |||
| 0.845 | 0.684 | 0.958 | 0.944 | 0.894 | 0.830 | ||||
| 0.832 | 0.729 | 0.956 | 0.902 | 0.880 | 0.835 | ||||
| Ensemble | 0.890 | 0.753 | Ensemble | 0.970 | 0.935 | Ensemble | 0.926 | 0.839 | |
| Centroid-based Selection (proposed) | 0.830 | 0.735 | 0.945 | 0.943 | 0.882 | 0.824 | |||
| 0.828 | 0.748 | 0.944 | 0.929 | 0.890 | 0.835 | ||||
| 0.815 | 0.752 | 0.895 | 0.936 | 0.873 | 0.828 | ||||
| Ensemble | 0.855 | 0.772 | Ensemble | 0.965 | 0.940 | Ensemble | 0.905 | 0.850 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pintelas, E.; Koursaris, A.; Livieris, I.E.; Tampakas, V. TextNeX: Text Network of eXperts for Robust Text Classification—Case Study on Machine-Generated-Text Detection. Mathematics 2025, 13, 1555. https://doi.org/10.3390/math13101555
Pintelas E, Koursaris A, Livieris IE, Tampakas V. TextNeX: Text Network of eXperts for Robust Text Classification—Case Study on Machine-Generated-Text Detection. Mathematics. 2025; 13(10):1555. https://doi.org/10.3390/math13101555
Chicago/Turabian StylePintelas, Emmanuel, Athanasios Koursaris, Ioannis E. Livieris, and Vasilis Tampakas. 2025. "TextNeX: Text Network of eXperts for Robust Text Classification—Case Study on Machine-Generated-Text Detection" Mathematics 13, no. 10: 1555. https://doi.org/10.3390/math13101555
APA StylePintelas, E., Koursaris, A., Livieris, I. E., & Tampakas, V. (2025). TextNeX: Text Network of eXperts for Robust Text Classification—Case Study on Machine-Generated-Text Detection. Mathematics, 13(10), 1555. https://doi.org/10.3390/math13101555