1. Introduction
Due to the theoretical and technical limitations of hardware equipment, it is often difficult for a single-modality sensor or information obtained by relying solely on a certain shooting scene to fully and accurately describe a complex imaging scene [
1,
2]. Consequently, traditional image processing methodologies are increasingly inadequate to meet the demands for efficient monitoring and intelligent analysis. To address these challenges, multimodal image fusion technology has emerged as a critical solution. This advanced technique integrates complementary data from heterogeneous sensors or imaging devices, synthesizing feature-rich composite images that enhance visual representation. The resultant fused images not only improve feature discriminability but also significantly boost performance in key operational tasks including image segmentation, object detection, and fault diagnosis—providing robust visual intelligence for decision support systems.
In the multimodal image fusion task, there are many complementary images such as infrared images and visible images, infrared images and synthetic aperture radar images, visible images and synthetic aperture radar images, and CT and MRI images in medicine. Infrared images capture the thermal radiation emitted by objects, which can effectively highlight targets such as pedestrians and vehicles while disregarding other objects. This capability makes them immune to environmental interference like smoke, light condition, and rain. However, they also exhibit inherent limitations, including low pixel resolution, poor contrast, and insufficient background texture details. However, IR images typically exhibit limitations in spatial resolution, contrast ratio, and background texture representation. Conversely, visible imaging provides high-resolution textural details but remains susceptible to environmental factors including weather conditions, occlusions, and illumination challenges, often failing to detect targets obscured by darkness or smoke [
3].The complementary nature of these modalities necessitates fusion technology to generate composite images that simultaneously preserve thermal prominence and structural clarity. In addition, experimental results in the field of face recognition show that the face recognition performance of fused images is significantly improved compared with that of single modalities [
4]. At present, infrared and visible image fusion technology has been widely used in military operations, agricultural automation, remote sensing detection, target recognition, detection and tracking, pedestrian recognition, semantic segmentation, etc. [
5,
6,
7].
In recent years, significant progress has been made in the development of fusion algorithms for infrared and visible images, with existing approaches broadly categorized into traditional image fusion approaches and deep-learning-based fusion models. Traditional methodologies primarily encompass transform-domain-based methods [
8,
9], sparse representation (SR)-based methods [
10], subspace-based methods [
11], and hybrid methods [
12], yet they are inherently limited by their reliance on manually designed fusion rules, making the optimization process increasingly complex and challenging. Meanwhile, deep-learning-based methods have gained substantial attention in computer vision (CV) due to their superior feature representation capabilities, leading to their successful adaptation in image fusion tasks. These advanced techniques include encoder–decoder approaches [
13,
14,
15], convolutional neural network (CNN)-based approaches [
16,
17], generative adversarial network (GAN)-inspired approaches [
18,
19,
20], and more recently, Transformer-based approaches [
21,
22,
23], demonstrating remarkable potential in addressing the limitations of traditional fusion strategies.
Furthermore, a critical challenge lies in addressing illumination imbalance [
24], which refers to the significant variation in lighting conditions between daytime and nighttime scenarios. Experimental observations reveal substantial differences in feature representations under these distinct light conditions [
25]: while visible images exhibit superior texture clarity compared to infrared counterparts during daytime, infrared imaging demonstrates enhanced target prominence. Conversely, nighttime conditions present a reversal of these characteristics, with infrared images offering more salient target detection and richer texture representation than visible images. The imbalance of different modal features is also worthy of attention, and different modal features should be fully integrated and represented to achieve balanced modality optimization in training.
To address the aforementioned challenges, this paper proposes a novel infrared and visible image fusion framework: AIF (Ascending–Descending Mechanism and Illumination perception subnetwork guided image Fusion).
First, we design an illumination perception subnetwork to guide the fusion of visible images and infrared images. More specifically, the pre-trained illumination perception subnetwork can calculate the probability of whether the current scene is day- or night-based on a given visible image and assign the contribution weights of the visible image and the infrared image in the fused image according to the above probability. Afterwards, the AdC feature extractor (
Ascending–
descending and
Cross-modal interactive differential feature extractor) containing the CMID module (
Cross-
Modal
Interactive
Differential module) is used to fully extract the complementary and common features in the multimodal images under the action of the Ad feature extraction mechanism(
Ascending–
descending feature extraction mechanism). According to the papers [
26,
27], the mid-way fusion method is conducive to the fusion of complementary information. In addition, the paper [
28] proved through experiments that the model using the mid-way fusion strategy has a significant improvement in detection accuracy, proving the positive impact of this fusion method on network performance. Therefore, this paper uses the mid-way fusion method for fusion. Finally, the image reconstruction module transforms the fused features to the fused image domain.
Guided by the illumination perception subnetwork, our fusion framework can adaptively integrate important information such as discriminative targets and texture details, that is, allocate the contribution ratio of infrared images and visible images in the fused image according to different lighting conditions. This adaptation is automatically achieved based on the information obtained from the illumination perception subnetwork and through the training process of the model through the loss function. In addition, the AdC feature extractor allows our feature extractor to fuse the common and complementary information of each stage and finally obtains a fused image that balances prominent targets and rich texture information.
To summarize, our research provides four main contributions:
We propose an illumination perception subnetwork-guided infrared and visible image fusion approach that can adaptively fuse meaningful information of source images under varying illumination conditions.
According to the characteristics of visible images and infrared images, an AdC feature extractor is designed. The extractor utilizes the ascending–descending feature extraction mechanism and combines it with the cross-modal interactive differential module to more effectively integrate the complementary information and shared information at each stage in a progressive form.
A multi-term loss function enables unsupervised training of the AIF, generating fused images with clear targets and environments without manual fusion strategy design.
Comprehensive experiments conducted on mainstream infrared and visible image fusion datasets, supported by both qualitative and quantitative comparisons with state-of-the-art methods, demonstrate the superior performance of our proposed method. Specifically, the fusion results of AIF can provide clear objects and rich texture details at the same time with high operation efficiency.
This paper is organized as follows:
Section 2 reviews related work in image fusion and illumination-aware vision.
Section 3 details the proposed methodology.
Section 4 presents experimental results and analysis.
Section 5 concludes the study.
3. Method
In this section, we first outline the overall framework of AIF in
Section 3.1. In
Section 3.2, the structure of the AdC feature extractor is described in detail, and the illumination perception subnetwork is elaborated in
Section 3.3. Finally, the loss function designed in this paper is illustrated in
Section 3.4.
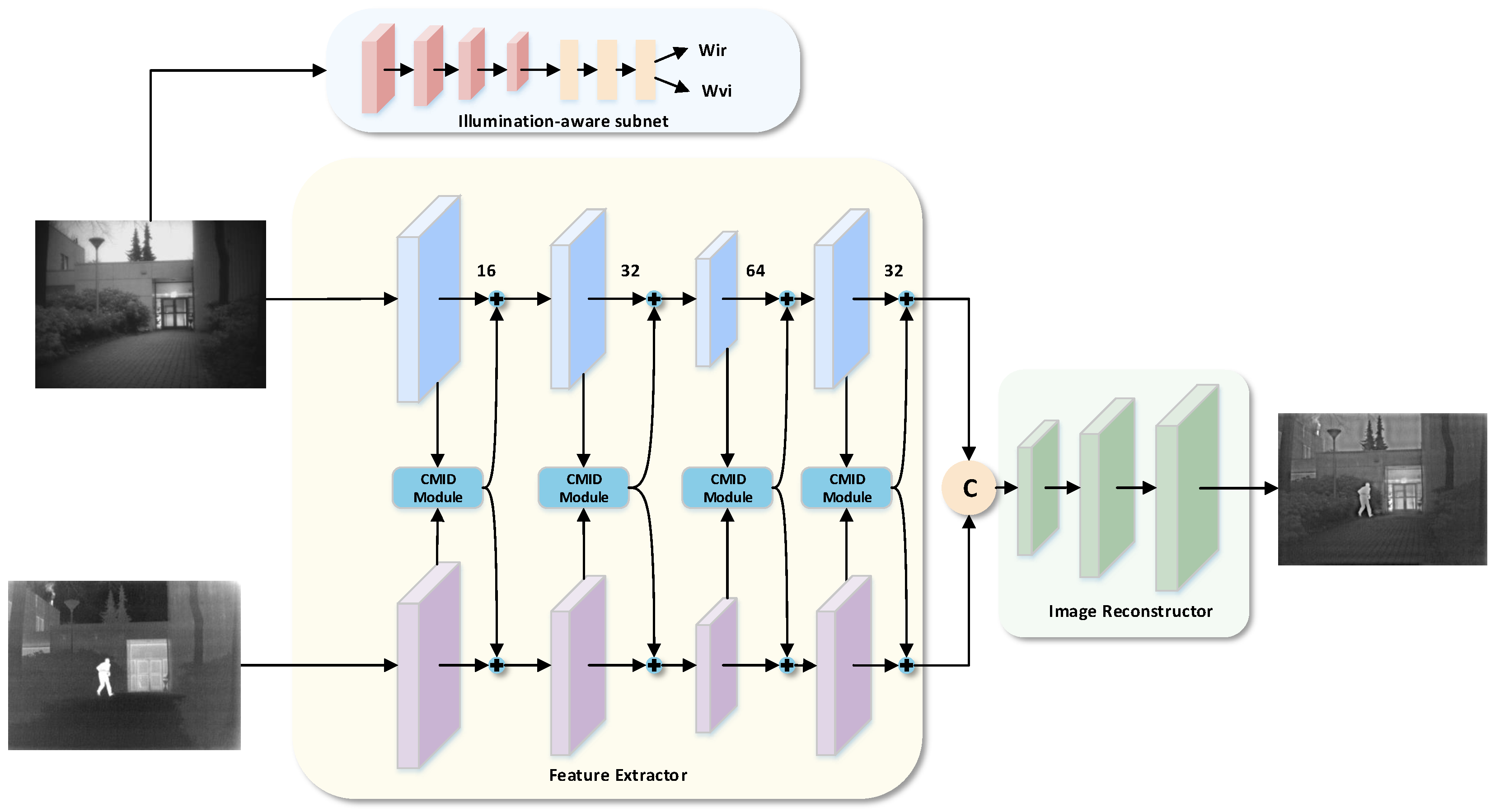
3.1. Fusion Model Architecture
Figure 1 shows the proposed image fusion model of visible images and infrared images. It consists of four parts, namely, the illumination perception subnetwork, the AdC feature extractor, the fusion layer, and the image reconstructor. The illumination perception subnetwork obtains the scene illumination information from the visible image, and based on this information, it can dynamically allocate the contribution of the visible image and the infrared image in the fused image. The AdC feature extractor consists of convolutional blocks and cross-modal interactive differential modules. By using the ascending–descending feature extraction mechanism, it can extract the different features and common features of the visible image and the infrared image faster in multiple stages. This method adopts a mid-way fusion strategy, using independent branches to process the features of each modality separately, and then these features are fused using splicing in the middle layer. The image reconstructor consists of several convolutional layers, which convert the fused features to the image domain to obtain the final fused image.
3.2. The Ascending–Descending and Cross-Modal Feature Extractor
The AdC feature extractor proposed in this paper is shown in
Figure 1. The feature extractor consists of convolutional block and CMID module, organized by the Ad feature extraction mechanism, aiming to extract complementary and common features.
At the initial stage, this paper uses a 1 × 1 convolutional layer. The cleverness of this design is that it can effectively reduce the natural modal differences between infrared and visible images, laying a solid foundation for subsequent feature fusion. Then, a CMID module is embedded after the output of the first convolutional layer. The pipeline begins with a 1 × 1 convolutional layer serving as a modality alignment layer to mitigate inherent distribution discrepancies between infrared and visible images, establishing a unified feature representation for subsequent processing. Following the output of the first convolutional layer, we introduce a cross-modal interactive differential module, which plays a crucial role in facilitating the exchange of complementary information between the features of the two modalities. Its key role is to promote the exchange of complementary information between the two modal image features. It is worth noting that the convolutional layers of image feature extraction share weights. This design not only ensures the consistency of feature extraction but also improves the generalization ability of the model. The model includes three such convolutional layers, enabling the network to progressively integrate complementary information during the feature extraction stage and achieve dynamic feature complementarity at each level of extraction. The size of the convolution kernels is uniformly set to 3 to ensure both the accuracy and efficiency of feature extraction. Additionally, all layers of the feature extractor utilize Leaky ReLU as the activation function. This choice helps prevent the vanishing gradient problem while maintaining neuron activity, ultimately improving the model’s training effectiveness.
In the design of the feature extractor, this study designed the Ad feature extraction mechanism and the CMID module. The design of the Ad feature extraction mechanism is based on the following considerations: from the perspective of feature learning, feature spaces of different dimensions have differentiated representation capabilities: high-dimensional feature spaces are good at encoding abstract semantic information, while low-dimensional spaces are more conducive to capturing specific local features. This characteristic is particularly significant in bimodal image processing—contour detection of visible images often relies on high-dimensional feature representation of deep networks, while the contours of salient targets in infrared images can be effectively extracted through low-dimensional features of shallow networks. Based on this observation, this study proposes a feature dimension adjustment mechanism that first increases and then decreases, which optimizes computational efficiency while ensuring feature expression capabilities. In terms of specific implementation, the design adopts a progressive channel number change strategy: the input image (3 channels) is first expanded to 16 channels through a 1 × 1 convolution kernel and then gradually increased to 32 and 64 channels through two convolution layers with a convolution kernel size of 3 × 3, completing the feature dimension increase process; then a convolution layer with a 3 × 3 convolution kernel is used to compress the number of channels back to 32 dimensions, and finally, feature splicing is performed. This design can achieve efficient and economical image fusion with fewer layers and lower costs while ensuring the fusion effect.
There is an imbalance problem in object detection, which can be categorized into four types: spatial imbalance, object imbalance, class imbalance, and scale imbalance. Spatial imbalance and object imbalance focus on the spatial properties of bounding boxes and multiple loss functions, respectively. Class imbalance arises due to significant inequality between training data of different categories. In addition to the above imbalances, the imbalance of features from different modalities also deserves attention. Since visible images and infrared images have different imaging principles and information characteristics, there are modal differences between the images. Different modal features should be fully integrated and represented, and the most direct method for this is to use a dual-stream architecture for the fusion model, where visible and infrared light learn independently. The features at different levels are concatenated.
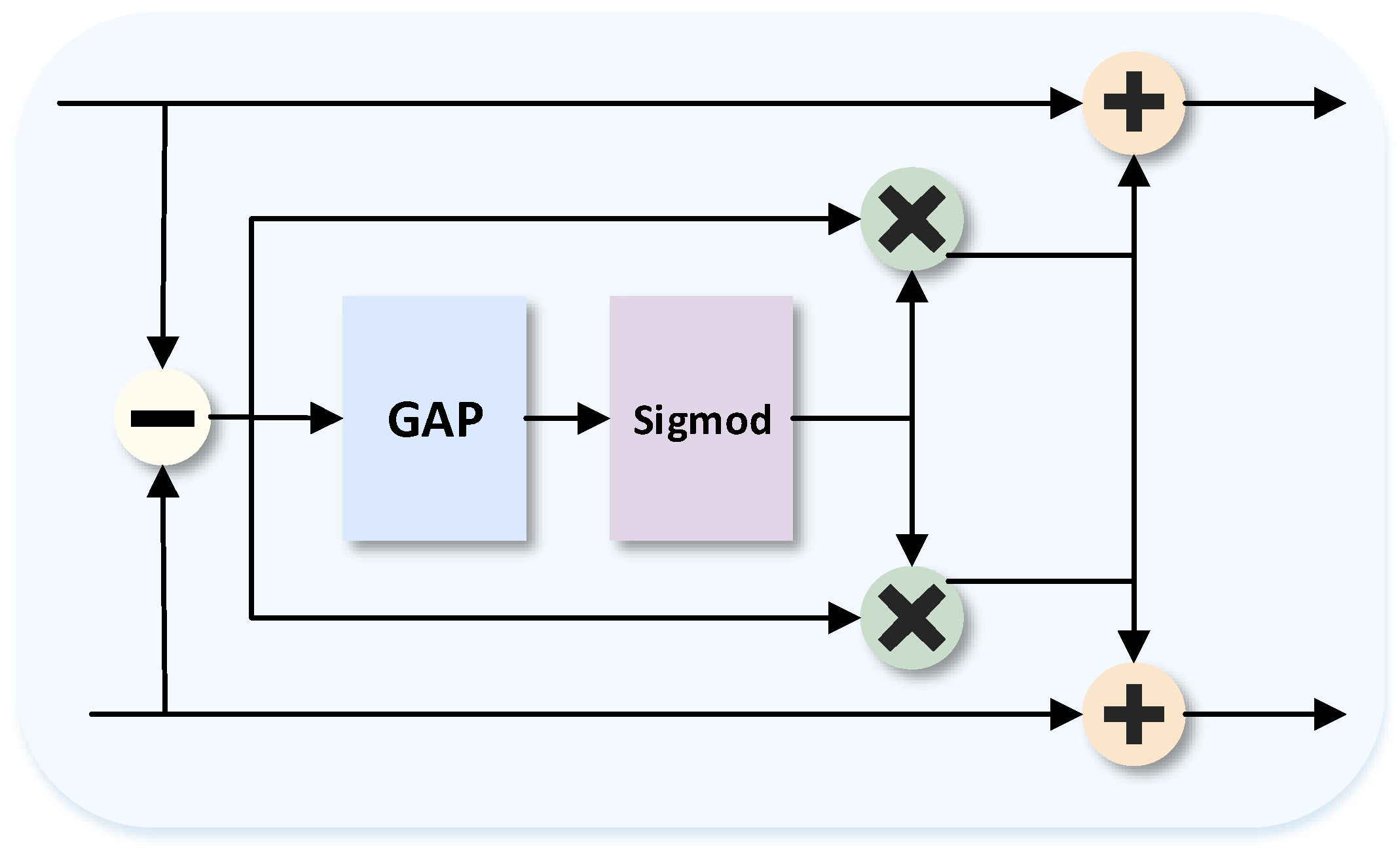
Inspired by differential amplification circuits, where common-mode signals are suppressed and differential-mode signals are amplified, the visible and infrared images are input independently into two 2D convolutional layers to obtain feature maps. Each convolutional layer is followed by a cross-modal interactive differential module that preserves the original features of the images and compensates based on the differential features. The module design is shown in
Figure 2.
Because there are common features between the two modes, such as two images of the same scene having similarities in object outline and layout, sharing the basic scene structure, and the same object has corresponding expressions in both modes (such as the appearance of a vehicle in visible and the heat signal in infrared), infrared images highlight thermal radiation information but are insensitive to material and color. Visible images reflect the color, texture, and geometric details of the object surface but have no perception of temperature information. Therefore, the visible feature map and the infrared feature map can be represented by the common modality part and the differential modality part in each channel, which are defined as follows:
where
and
denote infrared features and visible features.
is the common modal part.
and
are the differential modal parts. The CMID module further defines the features of the processed image based on this. The following formula illustrates the principle of the CMID module:
Among them, and are the feature maps of the infrared image and visible image after the i-th layer is processed by the CMID module, and and are the unprocessed feature maps of the i-th layer of the infrared and visible images, respectively. ⊕ refers to element-wise summation, ⊙ indicates channel-wise multiplication, and denote the sigmoid function and global average pooling, respectively.
The core idea of the CMID module is to obtain complementary features from the other modality through channel-level differential weighting. By explicitly modeling the mutual dependence between modalities, it enhances the learning of complementary features, thereby fully integrating the complementary information between the visible image feature map and the infrared image feature map produced by the convolutional layers.
3.3. Illumination Perception Subnetwork
In practical multimodal datasets, there is a premise assumption: during the day, visible images usually contain a large amount of meaningful information, while at night, infrared images capture more rich detail information. In general, the fusion of infrared and visible images is defined as maintaining the intensity of the infrared image and the texture of the visible image. This assumption is reasonable during the day. However, at night, the fused image should retain more texture details of the infrared image. Therefore, a robust fusion algorithm should adaptively combine meaningful information under the guidance of light condition.
The illumination perception subnetwork can guide the entire model to adaptively fuse source images. That is, the visible image in the image pair is input into the illumination perception subnetwork, and the subnetwork will obtain the probability that the visible image belongs to day or night. Based on this probability value, the illumination perception weight used to represent the contribution of the source image is finally obtained. By introducing the above weight into the loss function, the entire model can control the contribution of the visible image and infrared image in the fused image according to different lighting conditions.
As shown in
Figure 3, the illumination perception subnetwork consists of four convolutional layers, one global pooling layer, and two fully connected layers. The stride of the four 2D convolutional layers is set to 2, and the kernel size is 4 × 4 to compress spatial information and extract lighting information. Leaky ReLU is used as the activation function to enhance the network’s feature learning ability and the stability of gradient propagation. The global average pooling operation performs average pooling over the entire feature map to integrate lighting information. The two fully connected layers compute the probability of the scene belonging to the daytime or nighttime.
3.4. Loss Function
In view of the differences in imaging principles, infrared images and visible images present their own unique image characteristics, and the information differences between them are more significant. Therefore, when designing the loss function, the intrinsic characteristics of the image should be fully considered in order to achieve the optimization of the image fusion effect, i.e., the fused image can not only highlight the target but also contain rich scene information. The loss function is defined in this method as
where
is the light perception loss,
is the intensity loss that constrains the fused image to maintain a similar intensity distribution as the source image, and
is the gradient loss that ensures that the fused image contains rich texture details.
,
, and
are the weighting factors that control the contribution of each.
In order to facilitate the image fusion framework to adaptively fuse meaningful information according to lighting conditions, lighting condition perception weights indicating the contribution of the source image are computed using light probabilities. Specifically, the illumination loss is defined as
where
and
denote the intensity loss of infrared and visible images, respectively, and
and
are the lighting condition perception weights. The intensity loss term is defined as
where H and W are the height and width of the input image, respectively, and
denotes the
norm.
refers to the fused image,
refers to the infrared image, and
refers to the visible image. According to different lighting situations, the intensity distribution of the fused images should be consistent with different source images. Therefore, we use the light perception weights
and
to adjust the intensity constraints of the fused images,
and
, defined as
where
and
are non-negative scalars obtained through the illumination perception subnetwork indicating the probability that the image belongs to day and night.
Intensity loss is the difference between the fused image and the source image measured at the pixel level. In order to ensure that the fused image retains the maximum amount of information and to avoid the loss of critical information, an intensity loss function is introduced, which is defined as follows:
where
denotes the maximum function.
Gradient loss is able to realize the preservation of key information by constraining the gradient information of the source image and the fused image. In order to fuse the edge information and lighting information in the source image into the result as much as possible, the gradient loss is added to guide the network, retaining as much texture detail as possible and ensuring the clarity and structural information of the fused image. Specifically, the gradient loss is defined as follows:
where ▽ denotes the Sobel gradient operator and
denotes the absolute value operator.
As a result, the multimodal image fusion model proposed in this study is able to dynamically retain the optimal intensity distribution by analyzing the scene light condition characteristics in real time according to the lighting information of the scene under the guidance of the illumination loss, intensity loss, and gradient loss, obtaining the information fusion results that can highlight the target and also have rich scene texture details.
4. Experiment
In this section, the experimental setup and implementation details are first described in
Section 4.1. The setup of the comparison experiments is described in
Section 4.1. In
Section 4.3 and
Section 4.4, the superiority of this paper’s algorithm is verified by comparison experiments on two datasets, TNO and RoadScene. The operational efficiency of the different methods is analyzed in
Section 4.5. Finally, some ablation studies are conducted in
Section 4.6 to verify the effectiveness of the specific design of this method.
4.1. Details of Experiments
The experiment uses the MSRS dataset to train the model. The MSRS dataset is a multispectral road scene dataset for infrared and visible image fusion, which comes from the MFNet dataset. The MFNet dataset is an RGB-T dataset, which contains 1569 RGB-T city scene image pairs. It is also the first RGB-T dataset with pixel-level annotations. Each image in the dataset contains four channels, the first three channels are RGB parts, and the fourth channel is the T part. However, many image pairs in the MFNet dataset are not aligned, and the image quality is low. Most infrared images have low signal-to-noise ratio and low contrast. The MSRS dataset is improved on by the basis of the MFNet dataset, and the misaligned image pairs are deleted. The image enhancement algorithm is used to optimize the contrast and signal-to-noise ratio of infrared images. Therefore, the MSRS dataset contains 1444 pairs of high-quality aligned infrared and visible images.
In this paper, the training sets are all from the MSRS dataset, and the test sets are from the TNO dataset and the RoadScene dataset. Since the image fusion task lacks real values, this paper does not divide the val set. The image resolutions of the datasets vary. The image resolution of the MSRS dataset is fixed at 640 × 480. The image resolution of the TNO dataset is between 256 × 256 and 620 × 450, and the main resolution is 620 × 450. The image resolution of the RoadScene dataset is between 371 × 331 and 617 × 290, and the size varies. The training and testing process of the AIF model does not use any pre-processing or post-processing on the image; only the fusion operation is performed.
The batch size is set to 128, and the epochs are set to 10. The model parameters are updated by the Adam optimizer, and the learning is first initialized to 0.001 and then decayed exponentially. For the hyperparameters of the equation, refer to the papers [
26,
53] to set
= 1,
= 10 and
= 100, where the gradient loss weight
is much larger than the other weights, emphasizing the retention of key features, and the weight of the intensity loss
is larger than the weight of the illumination loss
, indicating that while considering the illumination factor, the retention of texture details is emphasized. The experiments were conducted using the PyTorch3.8 framework on an NVIDIA A6000 GPU.
4.2. Compared Methods and Objective Evaluation Metrics
In order to demonstrate the significance of this model, 9 advanced infrared and visible image fusion algorithms are used for performance comparison, including CVT, RP [
54], NSCT [
52], MDLatLrr [
55], Densefuse [
13], DATFuse [
53], PIAFusion [
26], U2Fusion [
40], and AUIF [
39]. Among them, CVT, RP, NSCT, and MDLatLrr are traditional image fusion algorithms. CVT uses curvelet transform for image fusion. RP uses proportional low-pass pyramid for image fusion. NSCT uses non-subsampled contourlet transform for image fusion. MDLatLrr uses a multi-level image decomposition method based on latent low-rank representation (LatLRR) for image fusion. Densefuse, DatFuse, PIAFusion, U2Fusion, and AUIF are image fusion algorithms based on deep learning. Densefuse is an image fusion method based on decoder–encoder, and U2Fusion can solve different fusion problems, including image fusion networks for multi-modal, multi-exposure and multi-focus situations, and can use feature extraction and information measurement to automatically estimate the importance of the corresponding source images and derive adaptive information preservation. AUIF establishes two optimization models to complete two-scale decomposition, that is, separating low-frequency basic information and high-frequency detail information from the source image to achieve image fusion. PIAFusion is a progressive image fusion network based on illumination-aware subnet. DATFuse combines the dual attention residual module and the Transformer module to achieve image fusion.
Mutual information (MI) measures the amount of information transferred from the original image to the fused image. Generally speaking, the larger the value, the more common information the fused image and the original image have, and the greater the amount of information retained. Standard deviation (SD) reflects the information richness of the fused image and is used to measure the change in pixel intensity of the fused image. When the standard deviation of the fused image is larger, the image contrast is higher and the semantic information is richer. Visual information fidelity (VIF) measures the statistical information shared between the fused image and the source image based on natural scene statistics and the human visual system (HVS). Generally speaking, the larger the VIF value, the more consistent the fusion result is with human visual perception. The edge-information-based metric reflects the quality of the visual information obtained from the input image and measures the edge information transferred from the source image to the fused image, and the higher its value, the higher the quality of the visual information obtained from the source image.
4.3. Results in TNO
The TNO dataset is one of the most commonly used datasets for infrared and visible image fusion tasks. The dataset contains 60 pairs of corrected and aligned infrared and visible images with content scenes such as tanks, people, trees, buildings, etc., where the infrared images cover both long-wave infrared and short-wave infrared images.
4.3.1. Qualitative Analysis
In this section, 35 image pairs are selected from TNO to evaluate this method and 9 other methods. Some typical areas are selected in each result and enlarged, and the fusion results are shown in
Figure 4.
In
Figure 4, the fusion result of AIF has better visual effect, contains more infrared thermal radiation information and clearer background details, and has less noise. In the first column of images, observing the upper right part of the image, the image fused by AIF retains the most branch details while the sharpness of the pole outline is higher, and the portrait outline information and the details of the hut behind the portrait are more complete and harmoniously preserved; from the overall image, AIF has less noise than other methods, and the picture is neater and clearer while ensuring the amount of information, achieving an optimal balance between noise reduction and detail preservation. In the second column of images, by comparing the facial detail preservation effect in the upper middle area of the image, it can be seen that AIF retains the most facial information, and the brick wall texture is clearer. In the third column of images, observing the outline of the aircraft head on the right side of the image, AIF obtains the clearest aircraft head, and the background details of the aircraft head are also better than the aircraft head background presented by other methods, and the texture information of the tree area on the right side and upper left side of the picture of AIF is richer than the texture information in the same position of other methods; looking at the entire picture, the picture processed by AIF has fewer ghosting artifacts than the pictures processed by other methods. In the fourth column of images, observe the details of the grass and floor tiles in the lower left part of the image. While retaining the complete outline information of the person and the information inside the building door, AIF retains the most details of the grass and floor tiles compared to other methods. In the fifth column of images, observe the roof in the middle of the image. AIF retains the most roof details, and in the small red box area on the left side of the picture, the image processed by this method has a more significant outline and richer texture. From a global perspective, the image processed by AIF does not have too high contrast and too strong graininess, and the whole picture is smoother.
It should be noted that the 35 pairs of images selected for the experiment have different lighting conditions. Taking the first and fourth columns of images as examples, observing the visible images shows that the illumination of the fourth column image is lower than that of the first column image, but the AIF has completed the fusion task well under different illumination conditions and achieved adaptive fusion that takes into account both significant outline information and rich texture information.
4.3.2. Quantitative Analysis
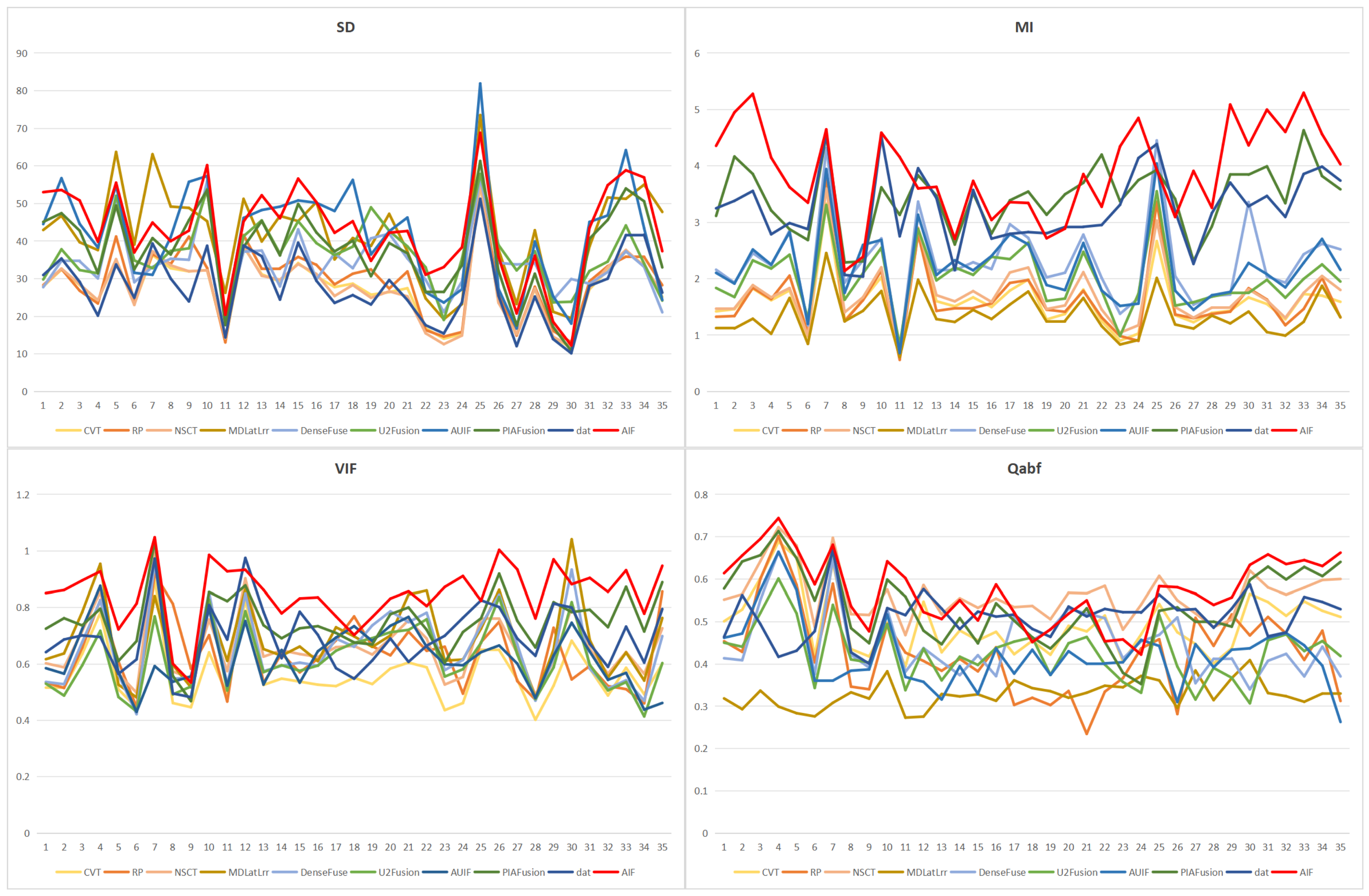
This study conducted a systematic quantitative evaluation on the TNO dataset (covering 35 image pairs of visible and infrared dual modalities) and verified the superiority of the AIF through four core indicators: mutual information (MI), standard deviation (SD), visual information fidelity (VIF), and an edge-information-based indicator ().
Figure 5 shows the quantitative analysis results on the 35 image pairs of the TNO dataset, and AIF is marked in red.
Table 1 compares the performance of the AIF with the other nine methods on the above four indicators, and the best performance has been bolded. The experimental data show that the AIF significantly outperforms the existing comparative methods in all evaluation dimensions; specifically, the AIF has the best performance on MI and ranks first with an average MI value of 3.8885, which is 13.2% higher than the second best method, PIAFusion (△ = 0.4524). This shows that the AIF can retain more meaningful information from the source images than the comparative method. In addition, the AIF also achieved the best SD performance and ranked first with an average SD value of 42.9173, which was 2.9% higher than the second-best method, MDLatLrr (△ = 1.221), indicating that the fused image processed by AIF has higher contrast. AIF ranked first with an average VIF value of 0.8491, which was 13.5% higher than the second-best method, PIAFusion (△ = 0.101), indicating that AIF has a satisfactory visual effect. In addition, the images processed by AIF show the best
, ranking first with an average value of 0.5752, which was 2.2% higher than the second-best method (△ = 0.0124), which means that AIF can retain more edge information.
4.4. Results in RoadScene
In order to comprehensively evaluate the present model, another 30 image pairs were selected in the RoadScene dataset for effect evaluation. The RoadScene dataset is an aligned VIS-IR image dataset constructed on the basis of FLIR videos. This dataset selects image pairs with highly repetitive scenes from the videos to reduce the thermal noise in the original IR images and aligns each image pair to include rich scenes such as roads, vehicles, and pedestrians, which solves the problems of fewer image pairs, low spatial resolution, and lack of detailed information in the IR images in the previous benchmark dataset.
4.4.1. Qualitative Analysis
Figure 6 shows some typical fusion samples of each method on the RoadScene dataset. In the first column, AIF retains richer texture information when processing distant roadside trees, with less noise and clearer edges. When processing small-sized vehicles on the left and right sides of the middle of the picture, AIF obtains clearer vehicle outlines than other methods. The tires, taillights, and spare tires of the vehicles are clearly visible, while other methods have low clarity or artifacts. In addition, when processing larger-sized vehicles in the middle of the right side of the picture, this paper retains more and more effective visible information than other methods. Details such as the rear bumper of the car can be identified, and the entire picture is smooth and harmonious, with stronger noise suppression capabilities.
In the second column, when processing roadside trees on both sides, AIF’s texture detail integrity and edge sharpness are significantly better than the comparison method, and the interlaced structure of branches and leaves is clearly discernible without high-frequency noise interference. When processing smaller trucks, the images processed by AIF have clearer edges and more texture information, making it easy to identify the license plate and wheel parts of the truck, while other methods will be unclear, have less texture information, or have artifacts and ghosting.
In the third column, AIF obtains more abundant visible information when processing the vehicle in the middle of the picture. The taillights, rear bumper, tires, and rearview mirrors of the vehicle have very clear outlines, less noise, and smoother pictures. When processing the windows on the upper right of the picture, the images processed by AIF have clearer outline information and more visible texture information, while the windows obtained by other methods are either unclear or have ghosting artifacts. When processing the person and bicycle on the lower right of the picture, the images processed by AIF have clearer outlines, higher outline sharpness, and richer detail information. The shoulder straps of the backpack on the person and the small bag in front of the person can be identified.
In the fourth column, AIF obtains more detailed information when processing the roadside trees on the right side of the picture. When processing the car on the right side of the picture, the image obtained by AIF has significant outline information. From the perspective of the entire picture, the image processed by AIF not only avoids the texture homogenization caused by over-smoothing but also suppresses the visual abruptness caused by high-frequency noise. The final output result meets the cognitive expectations of the human visual system. In the fifth column of the figure, the fused image processed by AIF has a higher quality of trees with high detail quality, which well takes into account the contour information of the infrared image and the texture information of the visible image, and the whole picture has low noise.
In the sixth column of the figure, the fused image processed by AIF has the characteristic of lower noise and has a more beautiful and harmonious picture as a whole. AIF retains more detail information when processing the roadside trees in the distance. When processing the motorcycle and the child riding a bicycle in the middle of the picture, AIF obtains more significant contour information and more informative texture information. Compared with other methods, each part of the motorcycle in the image obtained by AIF is clearer, the contour is sharper, and it is easier to identify. The seat, tire, front of the motorcycle, and other parts can be identified. Compared with other methods, the child riding a bicycle obtained by AIF has a clearer contour and more visible texture information is retained on the child.
In summary, the advancement of the AIF model is fully demonstrated. The fused image obtained by the AIF model has less noise, more significant contour information, richer texture information, and a more harmonious fusion effect.
In addition, the 30 pairs of images selected for the experiment have different lighting conditions, and the probabilities of belonging to day and night scenes obtained by the illumination perception subnetwork are different. However, the AIF model completes the fusion task well under different lighting conditions, achieving adaptive fusion that takes into account both significant contour information and rich texture information.
4.4.2. Quantitative Analysis
Figure 7 and
Table 2 show the superiority of the AIF in all four indicators. AIF is marked with a red line in
Figure 7, and the highest values of each indicator are bolded in
Table 2. For example, the AIF performs first-class in SD, MI, and VIF indicators, ranking first with an average SD value of 43.9806, an average MI value of 4.4147, and an average VIF value of 0.6901, respectively, and leads the second-best method by 26% (DATFuse, 3.4901), 0.8% (PIAFusion, 43.6065), and 21.2% (NSCT, 0.5692), among which MI is far ahead of all the comparison methods. VIF is also strongly ahead, which shows that the proposed method can transfer more information from the source image to the fused image, which is more in line with human visual perception. At the same time, AIF is also competitive in
, ranking third with an average
value of 0.4809. The two traditional methods are ahead of it. AIF is the highest among the deep learning methods. Although the traditional methods have higher
, the operating efficiency of the traditional methods is very low. The operating efficiency of this method is much higher than these methods (see the next chapter for details).
4.5. Efficiency Comparison
In order to analyze the computational complexity of the comparison methods, this paper compares the average running time of different methods on two datasets and shows the quantitative evaluation and computational efficiency of the AIF and the comparison methods in
Table 3 to show the advantages of the AIF. It can be seen that the traditional fusion method takes more time. In particular, MDLatLRR obtains low-rank representations through multi-scale decomposition, which is extremely time-consuming (78.279 s and 171.462 s). Even the fastest method, RP, among the traditional methods is an order of magnitude different from the method of this paper (0.036 s and 0.083 s). In contrast, thanks to GPU acceleration, data-driven methods have significant advantages in running efficiency. This method is the least time-consuming among all the methods. This method meets the actual engineering deployment requirements with real-time processing capabilities of 0.003 s and 0.004 s, and this efficiency improvement does not sacrifice fusion quality. Even the second-ranked method still takes twice as long as the method of this paper (0.006 s and 0.008 s).
4.6. Ablation Studies
In this section, this paper will remove each module separately for experiments to specifically analyze the effectiveness of each module. The experimental group
stripped the Ad feature extraction mechanism in AIF, the experimental group
stripped the CMID module in AIF, the experimental group
stripped the illumination perception subnetwork in AIF, and
replaced the customized loss function in AIF training with a function that added structural similarity loss. In
Section 4.6.1, this paper will conduct subjective analysis based on the fused images of each experimental group; in
Section 4.6.2, this paper will conduct an objective analysis of SD, MI, VIF, and
indicators based on the fused images of each experimental group.
4.6.1. Qualitative Analysis
Figure 8 shows some typical examples of fused images in ablation experiment groups. This paper selects some typical areas in each result for analysis.
In the upper right corner of the first column of images, it can be observed that AIF retains more branch details than other experimental groups while ensuring the significant outline of the human target. On the left side of the second column of images, the road outline of the experimental group is unrecognizable, while the edge sharpness of the road outline of the AIF model is the highest, and as shown in the details of the upper right corner after enlargement in the red box, the branch information obtained by AIF is richer and has less noise. In the third column of images, only AIF and clearly express the building information in the lower part of the picture, while is not as clear as AIF in the background; and in the red box in the lower left corner of the picture, the enlarged image is located on the right side of the picture, and the AIF model retains more and richer branch information than other experimental groups. In the red boxes on the left and right sides of the fourth column of images, only AIF can retain more branch information while ensuring the significant outline of the aircraft, and other experimental groups generally have blurred details or information loss in these areas.
4.6.2. Quantitative Analysis
As shown in
Table 4, this study systematically evaluated the performance of each variant model through four indicators: SD, MI, VIF, and
. The experimental results show that although the SD indicator of
(removing the illumination perception subnetwork) reaches the highest value in the group (46.5786), MI (3.2373) and VIF (0.2768) are both the lowest values in the five groups, among which VIF drops by 67.1% compared with the AIF baseline (0.8412), indicating the key role of the illumination perception subnetwork in the fidelity of image information. The
index (0.5376) is also lower than the baseline (0.5673), further verifying the positive contribution of this subnetwork to the fusion quality. Although the
index of
(CMID module removed) is slightly better than the baseline (0.5727 and 0.5673), its SD (38.6222), MI (3.6230), and VIF (0.7619) are significantly lower than AIF, indicating that the CMID module is irreplaceable in maintaining structural consistency and information transmission efficiency. The four indicators of
(illumination perception subnetwork removed) are inferior to the baseline in all aspects (SD: 40.5448 vs. 42.2424; MI: 3.5075 vs. 3.7575; VIF: 0.8188 vs. 0.8412;
: 0.5456 vs. 0.5673), confirming the multi-dimensional improvement of the illumination perception subnetwork on the overall performance of the model. Although
(replacement loss function) achieves the best value (3.9719) in the MI index, SD (36.4550) and
(0.5131) are both the lowest in the group, and VIF (0.7556) ranks second to last, indicating that the introduction of structural similarity loss will damage other key performances. AIF is a complete model. It leads significantly in the VIF index with 0.8412, while SD (42.2424), MI (3.7575), and
(0.5673) are all ranked second, proving that its comprehensive performance is the best. The synergy of each module effectively balances the requirements of structure preservation, information transmission, and visual quality.
5. Conclusions
The study proposes an approach for the fusion of infrared and visible images that can be adaptively fused in all weather conditions. The illumination perception subnetwork is used to guide the fusion model to dynamically integrate salient targets and texture details. The AdC feature extractor fully extracts both visible image features and infrared image features with a relatively small number of network layers and fully integrates both the complementary and the differential information between the visible image feature map and the infrared image feature map. Finally, a loss function consisting of illumination loss, gradient loss, and intensity loss is designed to train the proposed fusion model in an unsupervised manner, so that the model can automatically generate the fused images with both salient targets and clear backgrounds. Experimental results on two mainstream datasets, TNO and RoadScene, demonstrate that the proposed network outperforms nine state-of-the-art fusion techniques in terms of object significance, texture richness, and operational efficiency.
In future work, this study aims to advance technological breakthroughs in two key areas: Firstly, we will deepen the theoretical understanding of the ascending–descending feature extraction mechanism, utilizing tools such as multi-modal feature association analysis to uncover its decision-making processes. Secondly, in light of the current limitation of existing image fusion technologies to static scenes, we propose the development of a real-time image fusion approach to address the challenges of image fusion in dynamic scenes, enabling video-like fusion tasks.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}