
SwinInsSeg: An Improved SOLOv2 Model Using the Swin Transformer and a Multi-Kernel Attention Module for Ship Instance Segmentation


Abstract
1. Introduction
- Satellite Remote Sensing Images: At a microscopic level, these images cover large areas. Their quality and clarity might be poor, leading to misjudgment.
- Synthetic Aperture Radar (SAR) Images: Although accurate, SAR-based object identification algorithms may not always be reliable. Low-frequency spectrum information may not be compatible with the human visual system.
- Infrared Images: Certain scenarios may benefit from infrared images. Low resolution, significant noise, and a lack of color and texture information make them difficult to interpret.
- Visible-Light Images: Compared to other categories, visible-light images are clearer, more detailed, more precise, and better at defining texture. They look nicer and are used in more applications.
- SwinInsSeg significantly improves the accuracy of segmentation, providing precise segmentation of ships of various sizes.
- Our novel MKA module uses attention techniques with different kernel sizes to dynamically extract multiscale features, resulting in feature enhancement. This method enables the model to refine and capture different objects more accurately.
2. Related Works
2.1. Instance Segmentation Techniques
2.2. Transformer-Based Techniques
2.3. Maritime Surveillance and Applications
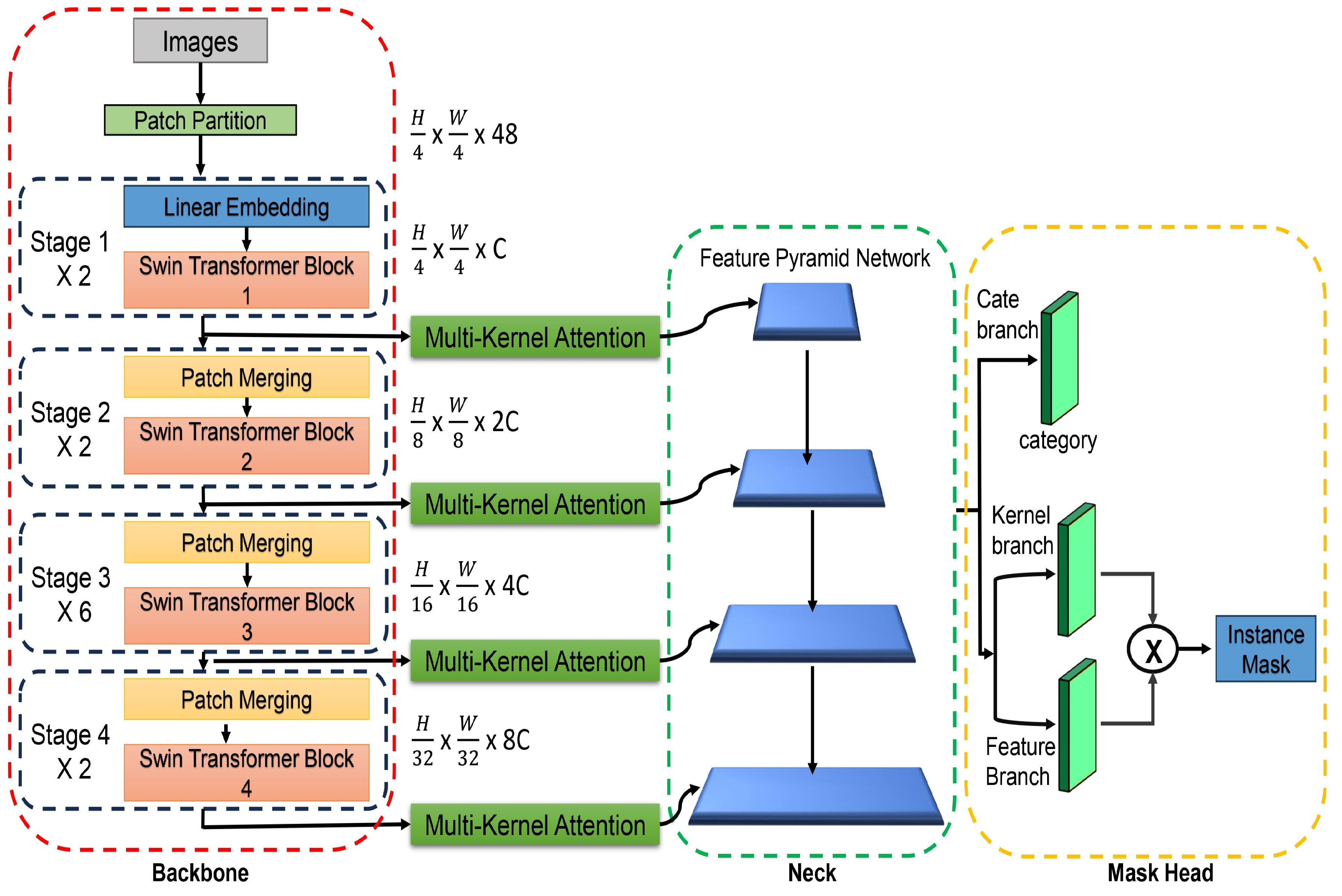
3. Proposed Method
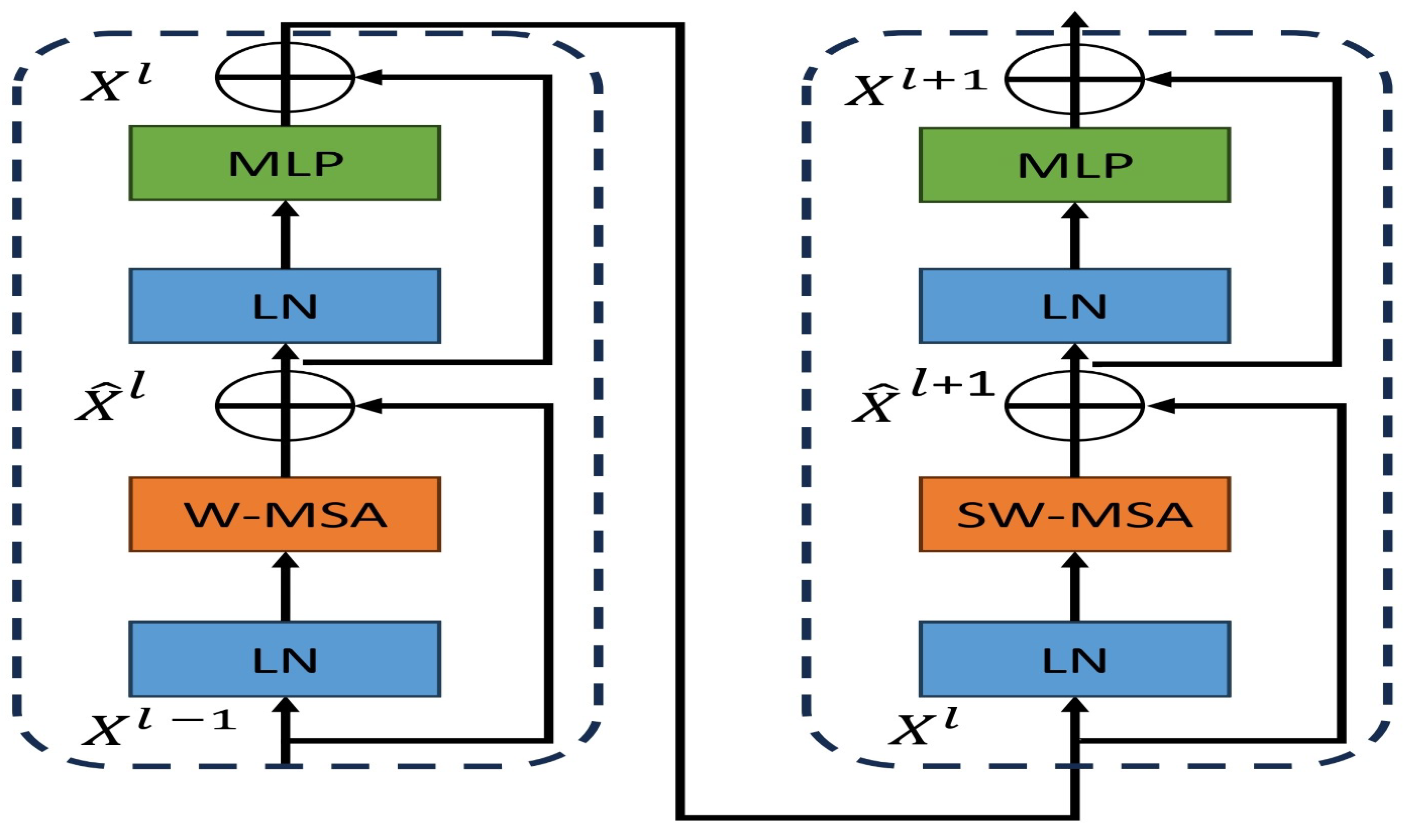
3.1. Overall Architecture
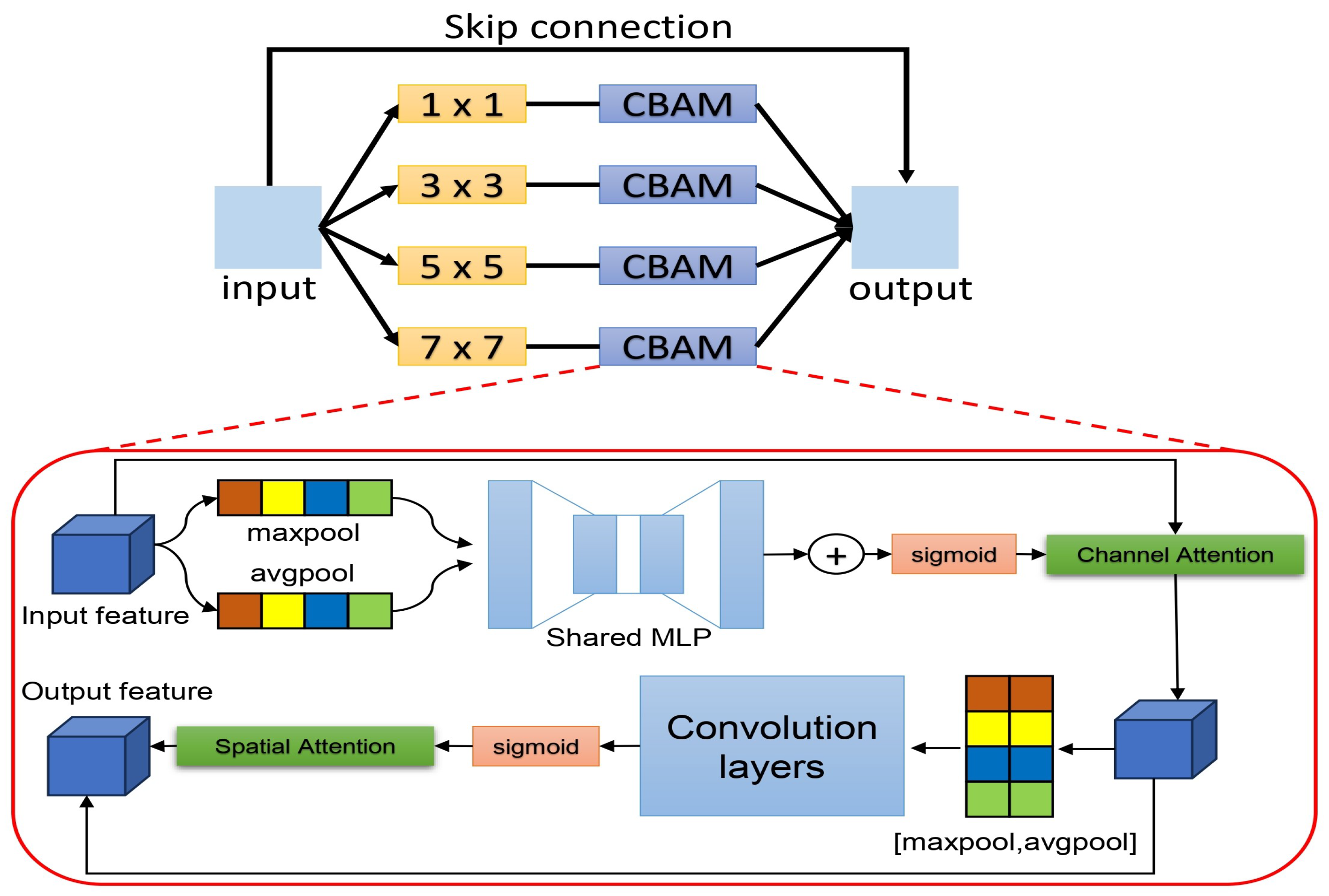
3.2. Multi-Kernel Attention Module
3.3. Loss Function
4. Experiments
4.1. Datasets and Metrics
4.2. Experimental Details
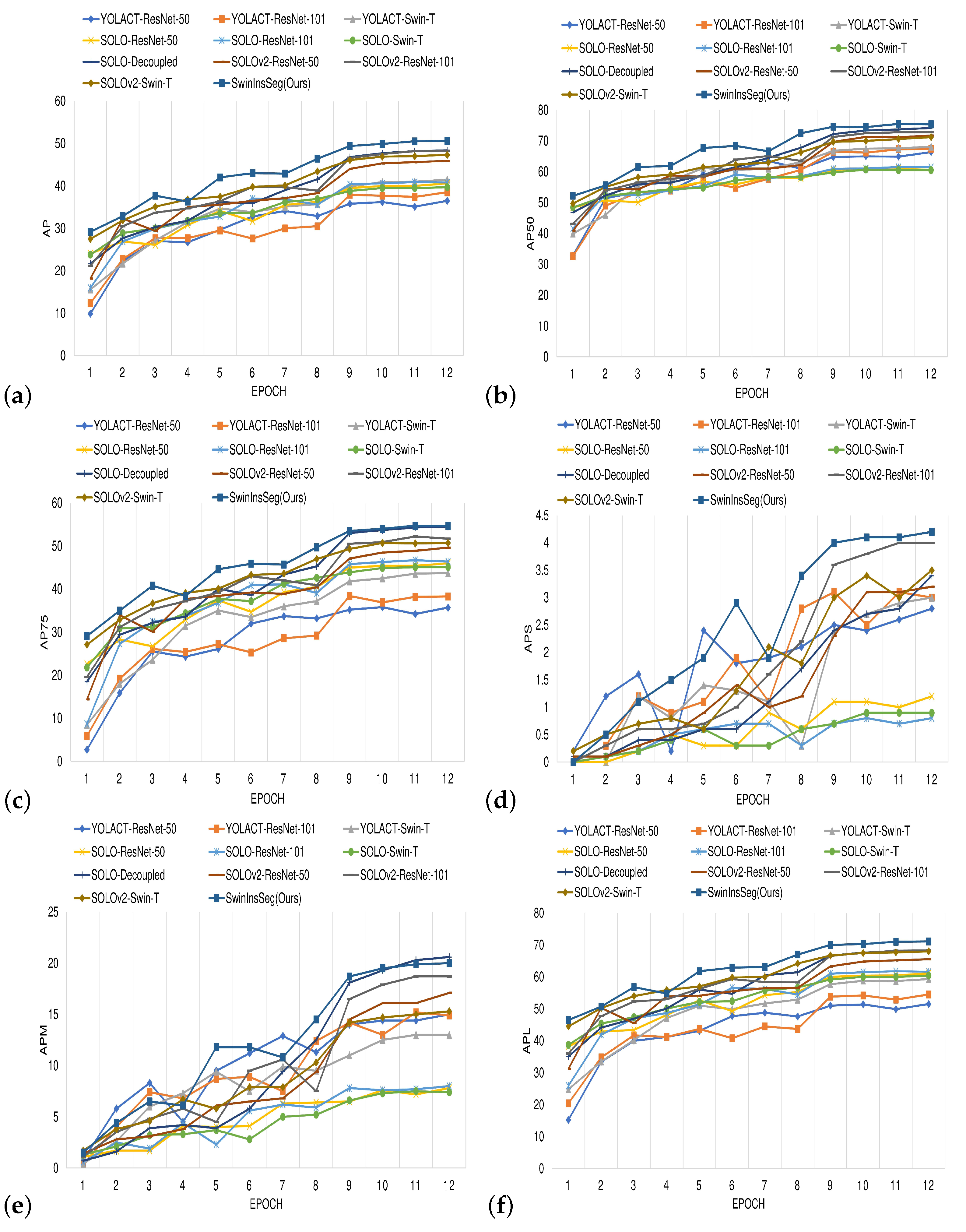
4.3. Main Results
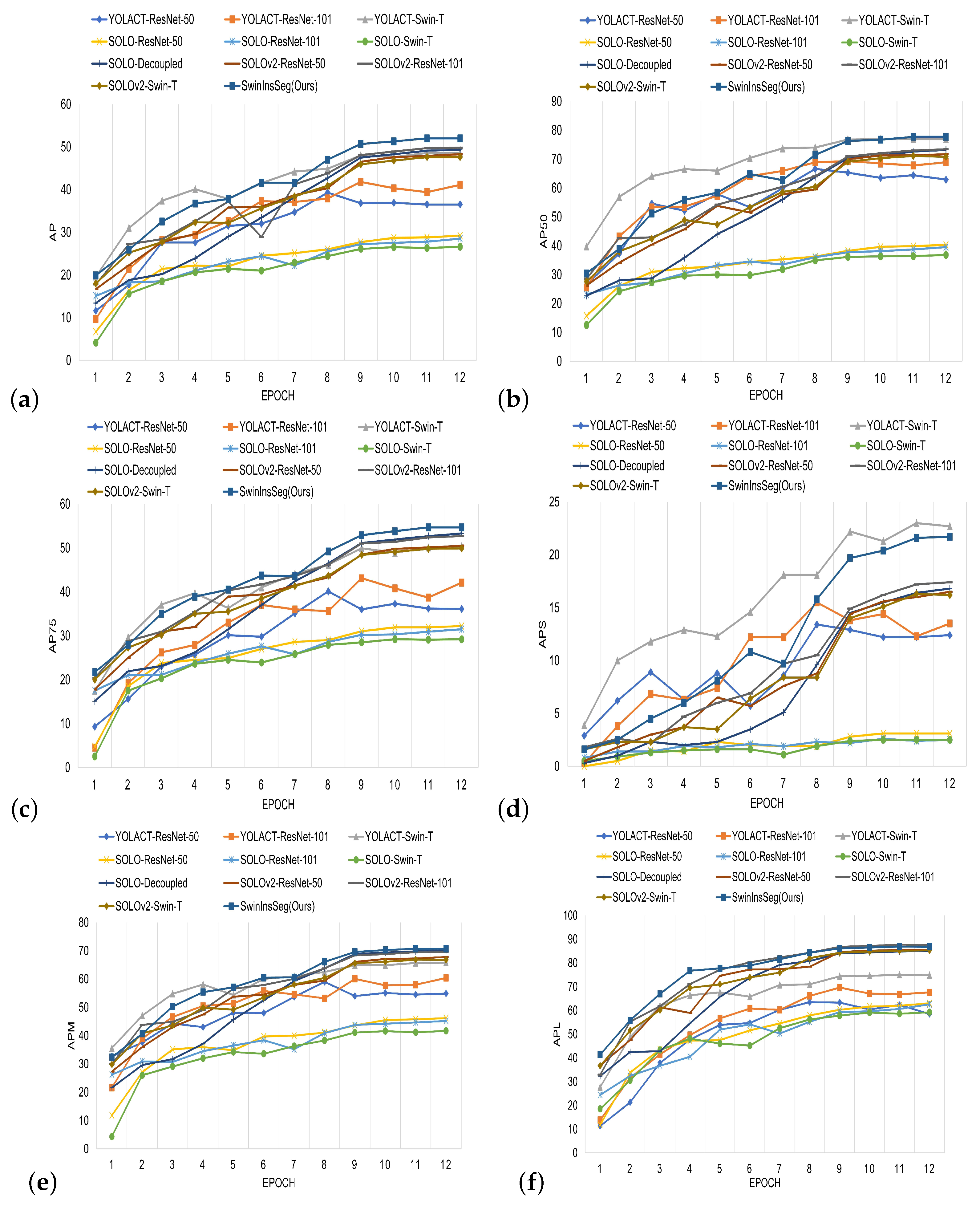
4.3.1. Performance Evaluation
Results on MariBoats Dataset
Results on ShipInsSeg Dataset
4.4. Ablation Experiments
4.5. Qualitative Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Shao, Z.; Wu, W.; Wang, Z.; Du, W.; Li, C. Seaships: A large-scale precisely annotated dataset for ship detection. IEEE Trans. Multimed. 2018, 20, 2593–2604. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, Q.Z.; Zang, F.N. Ship detection for visual maritime surveillance from non-stationary platforms. Ocean. Eng. 2017, 141, 53–63. [Google Scholar] [CrossRef]
- Zhang, W.; He, X.; Li, W.; Zhang, Z.; Luo, Y.; Su, L.; Wang, P. An integrated ship segmentation method based on discriminator and extractor. Image Vis. Comput. 2020, 93, 103824. [Google Scholar] [CrossRef]
- Sun, Y.; Su, L.; Luo, Y.; Meng, H.; Li, W.; Zhang, Z.; Wang, P.; Zhang, W. Global Mask R-CNN for marine ship instance segmentation. Neurocomputing 2022, 480, 257–270. [Google Scholar] [CrossRef]
- Sun, Z.; Meng, C.; Huang, T.; Zhang, Z.; Chang, S. Marine ship instance segmentation by deep neural networks using a global and local attention (GALA) mechanism. PLoS ONE 2023, 18, e0279248. [Google Scholar] [CrossRef]
- Nalamati, M.; Sharma, N.; Saqib, M.; Blumenstein, M. Automated monitoring in maritime video surveillance system. In Proceedings of the 2020 35th International Conference on Image and Vision Computing New Zealand (IVCNZ), Wellington, New Zealand, 25–27 November 2020; pp. 1–6. [Google Scholar]
- Nalamati, M.; Saqib, M.; Sharma, N.; Blumenstein, M. Exploring Transformers for Intruder Detection in Complex Maritime Environment. In Proceedings of the Australasian Joint Conference on Artificial Intelligence, Sydney, NSW, Australia, 2–4 February 2022; pp. 428–439. [Google Scholar]
- Park, H.; Ham, S.H.; Kim, T.; An, D. Object recognition and tracking in moving videos for maritime autonomous surface ships. J. Mar. Sci. Eng. 2022, 10, 841. [Google Scholar] [CrossRef]
- Xing, Z.; Ren, J.; Fan, X.; Zhang, Y. S-DETR: A Transformer Model for Real-Time Detection of Marine Ships. J. Mar. Sci. Eng. 2023, 11, 696. [Google Scholar] [CrossRef]
- Xu, J.; Sun, X.; Zhang, D.; Fu, K. Automatic detection of inshore ships in high-resolution remote sensing images using robust invariant generalized Hough transform. IEEE Geosci. Remote Sens. Lett. 2014, 11, 2070–2074. [Google Scholar]
- Zhang, S.; Wu, R.; Xu, K.; Wang, J.; Sun, W. R-CNN-based ship detection from high resolution remote sensing imagery. Remote Sens. 2019, 11, 631. [Google Scholar] [CrossRef]
- Yao, Y.; Jiang, Z.; Zhang, H.; Zhao, D.; Cai, B. Ship detection in optical remote sensing images based on deep convolutional neural networks. J. Appl. Remote Sens. 2017, 11, 042611. [Google Scholar] [CrossRef]
- Huang, G.; Wan, Z.; Liu, X.; Hui, J.; Wang, Z.; Zhang, Z. Ship detection based on squeeze excitation skip-connection path networks for optical remote sensing images. Neurocomputing 2019, 332, 215–223. [Google Scholar] [CrossRef]
- Huang, L.; Liu, B.; Li, B.; Guo, W.; Yu, W.; Zhang, Z.; Yu, W. OpenSARShip: A dataset dedicated to Sentinel-1 ship interpretation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 11, 195–208. [Google Scholar] [CrossRef]
- Liu, Z.; Yuan, L.; Weng, L.; Yang, Y. A high resolution optical satellite image dataset for ship recognition and some new baselines. In Proceedings of the International Conference on Pattern Recognition Applications and Methods, Porto, Portugal, 24–26 February 2017; Volume 2, pp. 324–331. [Google Scholar]
- Ouchi, K.; Tamaki, S.; Yaguchi, H.; Iehara, M. Ship detection based on coherence images derived from cross correlation of multilook SAR images. IEEE Geosci. Remote Sens. Lett. 2004, 1, 184–187. [Google Scholar] [CrossRef]
- Han, J.; Liang, K.; Zhou, B.; Zhu, X.; Zhao, J.; Zhao, L. Infrared small target detection utilizing the multiscale relative local contrast measure. IEEE Geosci. Remote Sens. Lett. 2018, 15, 612–616. [Google Scholar] [CrossRef]
- Bai, X.; Liu, M.; Wang, T.; Chen, Z.; Wang, P.; Zhang, Y. Feature based fuzzy inference system for segmentation of low-contrast infrared ship images. Appl. Soft Comput. 2016, 46, 128–142. [Google Scholar] [CrossRef]
- Shaodan, L.; Chen, F.; Zhide, C. A ship target location and mask generation algorithms base on Mask RCNN. Int. J. Comput. Intell. Syst. 2019, 12, 1134–1143. [Google Scholar] [CrossRef]
- Chen, X.; Chen, H.; Wu, H.; Huang, Y.; Yang, Y.; Zhang, W.; Xiong, P. Robust visual ship tracking with an ensemble framework via multi-view learning and wavelet filter. Sensors 2020, 20, 932. [Google Scholar] [CrossRef]
- Sharma, R.; Saqib, M.; Lin, C.; Blumenstein, M. MASSNet: Multiscale Attention for Single-Stage Ship Instance Segmentation. Neurocomputing 2024, 594, 127830. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Zhang, R.; Kong, T.; Li, L.; Shen, C. Solov2: Dynamic and fast instance segmentation. Adv. Neural Inf. Process. Syst. 2020, 33, 17721–17732. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Newell, A.; Huang, Z.; Deng, J. Associative embedding: End-to-end learning for joint detection and grouping. Adv. Neural Inf. Process. Syst. 2017. [Google Scholar] [CrossRef]
- De Brabandere, B.; Neven, D.; Van Gool, L. Semantic instance segmentation with a discriminative loss function. arXiv 2017, arXiv:1708.02551. [Google Scholar]
- Liu, S.; Jia, J.; Fidler, S.; Urtasun, R. Sgn: Sequential grouping networks for instance segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3496–3504. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Law, H.; Deng, J. Cornernet: Detecting objects as paired keypoints. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 734–750. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. Centernet: Keypoint triplets for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6569–6578. [Google Scholar]
- Bolya, D.; Zhou, C.; Xiao, F.; Lee, Y.J. Yolact: Real-time instance segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9157–9166. [Google Scholar]
- Wang, X.; Kong, T.; Shen, C.; Jiang, Y.; Li, L. Solo: Segmenting objects by locations. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XVIII 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 649–665. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision; pp. 568–578.
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Cheng, B.; Misra, I.; Schwing, A.G.; Kirillov, A.; Girdhar, R. Masked-attention mask transformer for universal image segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 1290–1299. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision; pp. 10012–10022.
- Schwehr, K. Vessel tracking using the automatic identification system (AIS) during emergency response: Lessons from the Deepwater Horizon incident. Cent. Coast. Ocean. Mapping/Joint Hydrogr. Cent. 2011. [Google Scholar]
- Nikolió, D.; Popovic, Z.; Borenovió, M.; Stojkovió, N.; Orlić, V.; Dzvonkovskaya, A.; Todorovic, B.M. Multi-radar multi-target tracking algorithm for maritime surveillance at OTH distances. In Proceedings of the 2016 17th International Radar Symposium (IRS); pp. 1–6.
- Sharma, N.; Scully-Power, P.; Blumenstein, M. Shark detection from aerial imagery using region-based CNN, a study. In Proceedings of the AI 2018: Advances in Artificial Intelligence: 31st Australasian Joint Conference, Wellington, New Zealand, 11–14 December 2018; Proceedings 31. Springer: Berlin/Heidelberg, Germany, 2018; pp. 224–236. [Google Scholar]
- Saqib, M.; Khan, S.D.; Sharma, N.; Scully-Power, P.; Butcher, P.; Colefax, A.; Blumenstein, M. Real-time drone surveillance and population estimation of marine animals from aerial imagery. In Proceedings of the 2018 International Conference on Image and Vision Computing New Zealand (IVCNZ); pp. 1–6.
- Nalamati, M.; Kapoor, A.; Saqib, M.; Sharma, N.; Blumenstein, M. Drone detection in long-range surveillance videos. In Proceedings of the 2019 16th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Taipei, Taiwan, 18–21 September 2019; pp. 1–6. [Google Scholar]
- Zou, Y.; Zhao, L.; Qin, S.; Pan, M.; Li, Z. Ship target detection and identification based on SSD_MobilenetV2. In Proceedings of the 2020 IEEE 5th Information Technology and Mechatronics Engineering Conference (ITOEC), Chongqing, China, 12–14 June 2020; pp. 1676–1680. [Google Scholar]
- Sun, Y.; Su, L.; Cui, H.; Chen, Y.; Yuan, S. Ship instance segmentation in foggy scene. In Proceedings of the 2021 40th Chinese Control Conference (CCC), Shanghai, China, 26–28 July 2021; pp. 8340–8345. [Google Scholar]
- Sun, Y.; Su, L.; Luo, Y.; Meng, H.; Zhang, Z.; Zhang, W.; Yuan, S. Irdclnet: Instance segmentation of ship images based on interference reduction and dynamic contour learning in foggy scenes. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 6029–6043. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV); pp. 3–19.
- Sharma, R.; Saqib, M.; Lin, C.; Blumenstein, M. Maritime Surveillance Using Instance Segmentation Techniques. In Proceedings of the International Conference on Data Science and Communication; Springer: Berlin/Heidelberg, Germany, 2023; pp. 31–47. [Google Scholar]
- Russell, B.C.; Torralba, A.; Murphy, K.P.; Freeman, W.T. LabelMe: A database and web-based tool for image annotation. Int. J. Comput. Vis. 2008, 77, 157–173. [Google Scholar] [CrossRef]
- Chen, K.; Wang, J.; Pang, J.; Cao, Y.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Xu, J.; et al. MMDetection: Open mmlab detection toolbox and benchmark. arXiv 2019, arXiv:1906.07155. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Configuration Settings | Version |
|---|---|
| Operating System | Ubuntu 18.04.6 LTS |
| GPU | NVIDIA Quadro P6000 |
| Memory | 24 GB |
| Deep Learning Framework | PyTorch 1.7 |
| MMCV | 1.7.1 |
| CUDA | 10.2 |
| MMDETECTION | 2.27.0 |
| Symbol | Description | Object Size |
|---|---|---|
| AP | IOU at 0.5; 0.95; 0.05 | - |
| AP50 | IOU at 0.5 | - |
| AP75 | IOU at 0.75 | - |
| APS | Small objects | |
| APM | Medium objects | |
| APL | Large objects |
| Method | Backbone | AP | AP50 | AP75 | APS | APM | APL | AR | ARS | ARM | ARL | Params (M) | FPS |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| YOLACT [32] | ResNet-50 | 36.5 | 66.4 | 35.7 | 2.8 | 15.0 | 51.5 | 46.0 | 11.0 | 27.0 | 61.6 | 34.73 | 19.429 |
| YOLACT [32] | ResNet-101 | 38.5 | 67.4 | 38.3 | 3.0 | 14.9 | 54.5 | 47.3 | 10.4 | 27.6 | 63.8 | 53.72 | 16.287 |
| YOLACT [32] | Swin-T | 41.5 | 68.1 | 43.7 | 3.0 | 13.0 | 59.3 | 49.3 | 11.0 | 27.8 | 66.9 | 70.32 | 9.96 |
| SOLO [33] | ResNet-50 | 40.6 | 61.5 | 46.0 | 1.2 | 7.8 | 61.1 | 45.3 | 2.3 | 15.8 | 66.9 | 35.89 | 14.563 |
| SOLO [33] | ResNet-101 | 40.8 | 61.8 | 46.4 | 0.8 | 8.0 | 61.6 | 46.0 | 2.0 | 15.7 | 68.0 | 54.89 | 12.699 |
| SOLO [33] | Swin-T | 39.7 | 60.5 | 45.1 | 0.9 | 7.4 | 60.4 | 44.7 | 1.8 | 13.7 | 66.7 | 71.45 | 10.67 |
| SOLO-Decoupled [33] | ResNet-50 | 48.4 | 74.2 | 54.5 | 3.4 | 20.6 | 68.1 | 55.0 | 7.4 | 33.3 | 74.9 | 39.62 | 14.057 |
| SOLOv2 [24] | ResNet-50 | 45.9 | 71.7 | 49.6 | 3.2 | 17.1 | 65.5 | 54.1 | 8.0 | 31.6 | 76.0 | 46.0 | 17.722 |
| SOLOv2 [24] | ResNet-101 | 48.3 | 72.8 | 51.7 | 4.0 | 18.7 | 68.3 | 55.7 | 9.4 | 31.6 | 76.0 | 65.59 | 13.457 |
| SOLOv2 [24] | Swin-T | 47.3 | 71.2 | 50.7 | 3.5 | 15.3 | 68.0 | 53.9 | 9.2 | 28.5 | 74.3 | 80.5 | 12.486 |
| SwinInsSeg (ours) | Swin-T | 50.6 | 75.4 | 54.7 | 4.2 | 20.0 | 71.1 | 57.5 | 11.5 | 35.3 | 77.6 | 90.5 | 11.55 |
| Method | Backbone | AP | AP50 | AP75 | APS | APM | APL | AR | ARS | ARM | ARL | Params (M) | FPS |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| YOLACT [32] | ResNet-50 | 36.5 | 62.9 | 36.1 | 12.4 | 54.9 | 58.5 | 44.7 | 20.8 | 61.5 | 72.7 | 34.73 | 13.617 |
| YOLACT [32] | ResNet-101 | 41.1 | 68.9 | 42.1 | 13.5 | 60.4 | 67.6 | 48.3 | 23.9 | 65.8 | 75.8 | 53.72 | 10.76 |
| YOLACT [32] | Swin-T | 48.6 | 77.0 | 50.4 | 22.7 | 65.8 | 74.9 | 55.2 | 32.9 | 70.9 | 80.9 | 70.40 | 8.17 |
| SOLO [33] | ResNet-50 | 29.2 | 40.3 | 32.2 | 3.1 | 46.2 | 63.0 | 33.0 | 4.4 | 51.6 | 70.6 | 35.89 | 8.217 |
| SOLO [33] | ResNet-101 | 28.5 | 39.5 | 31.5 | 2.5 | 45.2 | 62.6 | 32.9 | 4.1 | 51.3 | 71.6 | 54.89 | 7.061 |
| SOLO [33] | Swin-T | 26.6 | 36.8 | 29.2 | 2.5 | 41.7 | 59.2 | 30.4 | 3.5 | 47.0 | 68.1 | 71.52 | 6.80 |
| SOLO-Decoupled [33] | ResNet-50 | 49.3 | 73.2 | 53.3 | 16.8 | 70.1 | 85.1 | 53.5 | 23.7 | 74.4 | 88.5 | 39.62 | 8.194 |
| SOLOv2 [24] | ResNet-50 | 48.3 | 71.7 | 50.5 | 16.5 | 67.8 | 85.6 | 52.3 | 23.1 | 71.9 | 88.5 | 46.0 | 11.510 |
| SOLOv2 [24] | ResNet-101 | 49.8 | 73.4 | 52.7 | 17.4 | 69.6 | 87.6 | 53.4 | 23.8 | 73.9 | 90.1 | 65.59 | 8.59 |
| SOLOv2 [24] | Swin-T | 47.6 | 70.8 | 49.9 | 16.2 | 66.8 | 85.8 | 51.4 | 22.3 | 70.9 | 88.2 | 82.34 | 7.34 |
| SwinInsSeg (ours) | Swin-T | 52.0 | 77.7 | 54.7 | 21.7 | 70.7 | 86.8 | 56.2 | 33.0 | 74.9 | 90.3 | 91.55 | 7.05 |
| Method | AP | AP50 | AP75 | APS | APM | APL |
|---|---|---|---|---|---|---|
| Swin-T | 47.3 | 71.2 | 50.7 | 3.5 | 15.3 | 68.0 |
| Swin-T + MKA at stage 1 | 47.9 | 72.0 | 51.5 | 3.65 | 16.09 | 68.55 |
| Swin-T + MKA at stages 1 and 2 | 48.5 | 72.9 | 53.1 | 3.78 | 18.55 | 70.05 |
| Swin-T + MKA at stages 1, 2, and 3 | 49.7 | 73.5 | 53.6 | 3.99 | 19.35 | 70.6 |
| Swin-T + MKA at all stages | 50.6 | 75.4 | 54.7 | 4.2 | 20.0 | 71.1 |
| Method | AP | AP50 | AP75 | APS | APM | APL |
|---|---|---|---|---|---|---|
| Swin-T | 47.6 | 70.8 | 49.9 | 16.2 | 66.8 | 85.8 |
| Swin-T + MKA at stage 1 | 49.15 | 72.77 | 50.8 | 17.55 | 67.9 | 85.96 |
| Swin-T + MKA at stages 1 and 2 | 49.87 | 74.03 | 52.5 | 18.90 | 68.5 | 86.09 |
| Swin-T + MKA at stages 1, 2, and 3 | 51.35 | 75.95 | 53.4 | 20.10 | 68.98 | 86.6 |
| Swin-T + MKA at all stages | 52.0 | 77.7 | 54.7 | 21.7 | 70.7 | 86.8 |
| Backbone | AP | AP50 | AP75 | APS | APM | APL |
|---|---|---|---|---|---|---|
| ResNet-50 + MKA at all stages | 46.7 | 72.5 | 50.9 | 3.8 | 17.5 | 68.9 |
| ResNet-101 + MKA at all stages | 49.1 | 73.4 | 52.4 | 4.1 | 19.2 | 69.9 |
| Swin-T + MKA at all stages | 50.6 | 75.4 | 54.7 | 4.2 | 20.0 | 71.1 |
| Backbone | AP | AP50 | AP75 | APS | APM | APL |
|---|---|---|---|---|---|---|
| ResNet-50 + MKA at all stages | 49.6 | 72.3 | 52.2 | 18.1 | 68.5 | 85.9 |
| ResNet-101 + MKA at all stages | 50.8 | 75.8 | 53.4 | 19.9 | 70.1 | 87.8 |
| Swin-T + MKA at all stages | 52.0 | 77.7 | 54.7 | 21.7 | 70.7 | 86.8 |
| Method | AP | AP50 | AP75 | APS | APM | APL |
|---|---|---|---|---|---|---|
| Baseline Model | 47.3 | 71.2 | 50.7 | 3.5 | 15.3 | 68.0 |
| 1 × 1 with CBAM | 47.8 | 71.8 | 51.2 | 3.65 | 16.5 | 68.5 |
| 3 × 3 with CBAM | 48.4 | 72.5 | 52.0 | 3.83 | 17.7 | 69.2 |
| 5 × 5 with CBAM | 48.1 | 73.6 | 52.9 | 3.98 | 18.5 | 70.1 |
| 7 × 7 with CBAM | 49.2 | 74.5 | 53.8 | 4.05 | 19.4 | 70.95 |
| Full MKA with skip connections | 50.6 | 75.4 | 54.7 | 4.2 | 20.0 | 71.1 |
| Method | AP | AP50 | AP75 | APS | APM | APL |
|---|---|---|---|---|---|---|
| Baseline Model | 47.6 | 70.8 | 49.9 | 16.2 | 66.8 | 85.8 |
| 1 × 1 with CBAM | 48.5 | 72.3 | 50.7 | 17.7 | 68.1 | 85.4 |
| 3 × 3 with CBAM | 49.2 | 73.9 | 51.6 | 19.1 | 68.95 | 85.9 |
| 5 × 5 with CBAM | 50.4 | 75.1 | 52.88 | 19.9 | 69.6 | 86.2 |
| 7 × 7 with CBAM | 51.2 | 76.5 | 54.05 | 20.9 | 70.1 | 86.5 |
| Full MKA with skip connections | 52.0 | 77.7 | 54.7 | 21.7 | 70.7 | 86.8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sharma, R.; Saqib, M.; Lin, C.-T.; Blumenstein, M. SwinInsSeg: An Improved SOLOv2 Model Using the Swin Transformer and a Multi-Kernel Attention Module for Ship Instance Segmentation. Mathematics 2025, 13, 165. https://doi.org/10.3390/math13010165
Sharma R, Saqib M, Lin C-T, Blumenstein M. SwinInsSeg: An Improved SOLOv2 Model Using the Swin Transformer and a Multi-Kernel Attention Module for Ship Instance Segmentation. Mathematics. 2025; 13(1):165. https://doi.org/10.3390/math13010165
Chicago/Turabian StyleSharma, Rabi, Muhammad Saqib, Chin-Teng Lin, and Michael Blumenstein. 2025. "SwinInsSeg: An Improved SOLOv2 Model Using the Swin Transformer and a Multi-Kernel Attention Module for Ship Instance Segmentation" Mathematics 13, no. 1: 165. https://doi.org/10.3390/math13010165
APA StyleSharma, R., Saqib, M., Lin, C.-T., & Blumenstein, M. (2025). SwinInsSeg: An Improved SOLOv2 Model Using the Swin Transformer and a Multi-Kernel Attention Module for Ship Instance Segmentation. Mathematics, 13(1), 165. https://doi.org/10.3390/math13010165