1. Introduction
In the design of control systems, various matrix equations are widely used [
1,
2,
3,
4,
5,
6]. Specifically, some coupled matrix equations are important tools for studying the stability of Markov jump linear systems [
7]. It can be seen in [
8] that the mean square stability of an Itô system can be characterized by the corresponding Lyapunov-type matrix equation. Markov jump systems are useful tools that have been instrumental in modeling certain real-world systems susceptible to random factors. This concept, which is highlighted by reference [
9], has garnered significant interest among researchers within this discipline. By employing Markov jumps, scientists and engineers can gain insight into how various components of these complex systems might behave under conditions of uncertainty or change, providing valuable tools for predicting outcomes and making informed decisions. In [
10], the notation of exact detectability is presented for linear systems with state-multiplicative noise. Based on critical stability and exact detectability, some useful properties are derived in [
10] for Itô Lyapunov matrix equations. Uniform definitions are given for the notions of observable and detectable properties in the realm of continuous-time stochastic systems reported in [
11], where the so-called stochastic Lyapunov matrix equations are reviewed. In [
12], some stochastic stability properties are presented for the Markov jump linear system owing to the existence of the solution of coupled Lyapunov matrix equations (CLMEs). In the study referenced in [
13], an approach is developed to design a suboptimal controller, denoted as
/
, specifically for continuous-time linear Itô stochastic systems with Markov jumps (MJIS systems). The extended concept of exact detectability in the literature [
14] has been incorporated into the linear MJIS systems, making it more convenient to analyze the properties of control systems. Research has suggested that under exact detectability conditions, the mean square stability of a linear MJIS system depends on whether the corresponding Lyapunov matrix equations have positive semi-definite solutions. Two iterative algorithms are established for both continuous-time and discrete-time MJIS systems in [
15]. And their convergence are studied using linear positive operators. According to the characteristic of the solution of corresponding Lyapunov equations, a necessary and sufficient condition for the mean square stability of detectable systems of this type is developed in [
16]. In fact, the CLMEs, characterized by their intricate coupling dynamics and appearance in MJIS systems, can indeed be considered as a peculiar example of generalized ones.
For the above case, ref. [
17] proposes a novel implicit iterative approach specifically tailored to the solution of the CLMEs in discrete-time situations. Ref. [
18] proposes a method to tackle the complex challenge of solving coupled equations, through minimizing a quadratic function embedded within the iterative process. In addition, ref. [
19] provides a direct method for the coupled matrix equations, which is less effective for large-scale systems. In recent years, various kinds of iterative methods have been put forward by different researchers. Ref. [
20] presents a new method of least-square iteration to deal with equations of this kind, in which a hierarchical identification principle is employed. In [
21], a full-rank gradient-based algorithm, as well as a reduced-rank one, is constructed. In fact, due to the similarity of coupled and general Lyapunov matrix equations, both can be solved by applying the iterative algorithms. Moreover, all of the above algorithms use the latest estimated value generated by the last iteration process.
In 2016, an implicit iterative algorithm [
22] was put forward to solve continuous CLMEs by using some adjustable parameters. The successive over relaxation (SOR) technique is known to be a classic way to increase the convergence rate of Jacobi iterations in [
23]. Due to this advantage, it was used to solve the discrete periodic Lyapunov matrix equations [
24]. In [
25], a novel iterative algorithm is proposed to deal with coupled Lyapunov equations arising in continuous-time Itô stochastic systems with Markov jumps, in which two adjustment parameters are introduced. And it combines both the latest and the former step information to estimate the unknown matrices. Ref. [
26] establishes a new iterative method for solving the CLMEs associated with continuous-time Markov jump linear systems by the SOR technique. A relaxation parameter is included, which can be selected appropriately to improve the convergence performance.
Inspired by the aforementioned facts, an SOR implicit iterative algorithm is established in this paper for solving continuous stochastic Lyapunov equations. And three tunable parameters are included to improve the convergence speed of the algorithm. Subsequently, the monotonicity and boundedness of the proposed algorithm are analyzed, and the convergence condition is further investigated. With the up-to-date knowledge of the iteration value, this approach exhibits better convergence than others by choosing the tuning parameters appropriately.
In this paper, we use to represent the set of all the -dimensional real matrices. denotes the mathematical expectation. And , represent the transpose and inverse matrices of A, respectively. is written as the spectral radius of A. The notation denotes a discrete finite set , in which both a and b are integers and . The vectorization of a matrix is defined as . means the Kronecker product of matrices M and W. If P is a positive definite matrix, we record it as . Similarly, indicates that in this sequence, . is used to represent Frobenius norm.
2. Problem Formulation and Preliminaries
There exists a continuous-time Itô stochastic system with Markov jumps:
where
is the system state;
,
are both the coefficient matrices;
are real random processes, which are defined on a complete probability space
with
and
.
is a continuous-time discrete-state Markov process. The transition rate matrix is
, while
for
, and
,
. The initial values are set to be
and
. Next, the definition of asymptotically mean square stability (AMSS) is introduced for system (
1).
Definition 1 ([15]). System (1) has AMSS if for any and , there exists The corresponding continuous stochastic Lyapunov equation of system (
1) can be written as follows:
In this equation,
are unknown solutions of Lyapunov Equation (
2) and
,
, are known matrices. This equation is usually used to analyze the stability of system (
1). Regarding the asymptotically mean square stability of (
1), the following result is obtained.
Lemma 1 ([15]). System (1) has AMSS if and only if there is a unique solution of the corresponding Lyapunov Equation (2), for any given . Thus, the stability of the system (
1) is equivalent to finding a unique solution of Equation (
2). While Lyapunov Equation (
2) can be changed into the following format:
with
Through Lemma 1 and the associated theories of stability, we can obtain the following conclusions:
Lemma 2 ([25]). Any matrix , is Hurwitz-stable if system (1) has AMSS. An iterative algorithm in the implicit form is proposed in [
25] to deal with the coupled Lyapunov Equation (
2). It is summarized as follows:
Theorem 1 ([25]). Assume the Markov jump system (1) has AMSS. If the following algorithm (5) satisfies , , and the tuning parameters , then the sequence , generated by the algorithm (5) with zero initial conditions , converges to the unique positive definite solution of the continuous coupled Lyapunov matrix Equation (2). The following is the designed iteration form: 3. Main Result
Enlightened by the idea of SOR technique, in what follows, we plan to find a new algorithm to obtain the solution of Equation (
2). Since we have
and
is a tunable parameter. From the preceding section, we rewrite Equation (
2) as (
3) by substituting the first term on the right-hand side of (
6) with the right-hand item of (
3); we obtain the following relation:
Utilizing the latest updated estimation, we bring up an implicit iterative algorithm below to solve Equation (
2):
Remark 1. If the parameter , then the proposed algorithm (8) is reduced to algorithm (5). Remark 2. For every iteration step of algorithm (8), N standard continuous Lyapunov matrix equations need to be solved. The algorithm proposed in this paper is an implicit form. Remark 3. It can be seen that the algorithm (8) proposed in this article is very similar to the SOR iteration method in ordinary linear equations. Therefore, in the following text, algorithm (8) is abbreviated as the SOR implicit iterative algorithm. First, the following lemma illustrates that the sequence generated by (
8) is bounded.
Lemma 3. Assume system (1) has AMSS, and , . If , and the tuning parameters , then on the condition of zero initial values, there is an upper bound of the sequence generated by algorithm (8) when . In other words, for any integer , we have Proof. According to Lemmas 1 and 2, since the matrices
,
are Hurwitz-stable and Equation (
2) has a unique solution
, we can subtract (
8) from (
7) to obtain
and
In the following text, the proof of this theorem is mainly based on mathematical induction. Because of the zero initial value condition of the algorithm mentioned before, apparently, (
9) holds for
. Now, we suppose when
and
, (
9) holds. This means
Let
,
in relation (
11); we can obtain
Due to the assumptions set by mathematical induction above and
, we can obtain
. Therefore, from (
10), we know that
is Hurwitz-stable, so we can obtain the following inequality from Theorem 3.1 in [
27]:
That is,
Since
from assumption (
12), we have
Using mathematical induction again, we now assume that
Let
,
in Equations (
10) and (
11); we can obtain
and
For
; from assumptions (
12) and (
16), we can obtain
. That is,
Due to the Hurwitz stability of
, the following inequality holds:
It means that
According to assumption (
12), we have the conclusion
. Combine it with relation (
16), by knowledge of mathematical induction, we know that
Eventually, with (
17) and assumption (
12), it could be summarized that for any integer
, (
9) holds. Thus, we complete this proof. □
Second, it is found that the sequence generated by (
8) is monotonically increasing.
Lemma 4. Assume that system (1) has AMSS, and , . If , , and the tuning parameters , then on the condition of zero initial values, the sequence produced by algorithm (8) is strictly monotonically incremental. In other words, for any integer , we have Proof. The matrices
,
are Hurwitz-stable and Equation (
2) has the only solution
according to Lemmas 1 and 2. Let
and
in (
8); subtract the former from the latter to obtain
where
Subsequently, mathematical induction is utilized to help prove the above lemma. Since
, it is easily known that (
18) holds for
. Now, we suppose when
(
18) holds, which means
Let
in (
20); we can obtain
For
, according to assumption (
21), it can be easily found that
. Therefore, from (
19), we can obtain the following inequality:
For the Hurwitz stability of
, we have the following inequality from Theorem 3.1 in [
27]:
Equivalently,
From assumption (
21) that
, we have
Using mathematical induction repeatedly, we now assume that
For relation (
20), let
; we can obtain
Since
, if induction assumptions (
21) and (
25) hold, we can obtain
. For relation (
19) with
, we have that
is Hurwitz-stable; hence,
This is equivalent to
In terms of assumption (
21), we have
. Based on this and relation (
25), the following is evident from mathematical induction:
Consequently, with (
27) and assumption (
21), it is proven that for any integer
, (
18) holds. Thus, the proof is finished. □
Combining Lemmas 3 and 4, the following convergence property of algorithm (
8) can be deduced.
Theorem 2. Assume system (1) has AMSS, and , . If , , and the tuning parameters , then on the condition of zero initial values , , the sequence produced by algorithm (8) monotonically converges to the unique solution of Equation (2). Proof. From Lemmas 3 and 4 and the conditions of Theorem 2, the sequence
produced by the SOR implicit algorithm (
8) increases monotonically and has an upper bound, which is the solution of (
2). It means that
Thus, the sequence
is convergent. Take the limit on
, and denote
By simultaneously taking limits on both sides of algorithm (
8), we can easily obtain
This is equivalent to
so
Dividing both sides by
simultaneously, we obtain
which can be equivalently written as follows:
Compared with matrix Equation (
2), we find that the sequence
is exactly the same solution of the coupled Lyapunov matrix Equation (
2). □
It has been demonstrated that algorithm (
8) can operate under a zero initial condition. However, this condition is too harsh. Consequently, a sufficient condition is provided for the convergence of algorithm (
8) under an arbitrary initial value.
Theorem 3. Assume that system (1) has AMSS, and , . Matrices M and W are expressed from Equation (29) as follows:whereAndwhere If the tuning parameters and , and the relaxation parameter γ, satisfy , then the sequence produced by the SOR implicit algorithm (8), and with any initial condition , will converge to the solution of Equation (2). Proof. We define the vectors
and
q as
Next, algorithm (
8) can be rewritten in the form of Kronecker product:
The definitions of matrices
M and
W are based on the above equation. Combining the vector
,
q, and matrices
M and
W defined earlier, we can further obtain
By multiplying the inverse matrix of
M from the left, we have
According to the relationship between the previous and subsequent vectors
, we can deduce repeatedly and obtain
If
, then when
m approaches infinity,
approaches a zero matrix; hence,
Since the matrix Equation (
2) could be rewritten as
, the sequence
generated by the SOR algorithm (
8) converges to the unique solution of Equation (
2). □
4. Illustrative Example
Consider Equation (
2), in which
,
.
,
are both fourth-order identity matrices. The system matrices and probability transition rate matrix
are defined as follows:
This example is used in [
25]. The iterative error at step
k is defined as
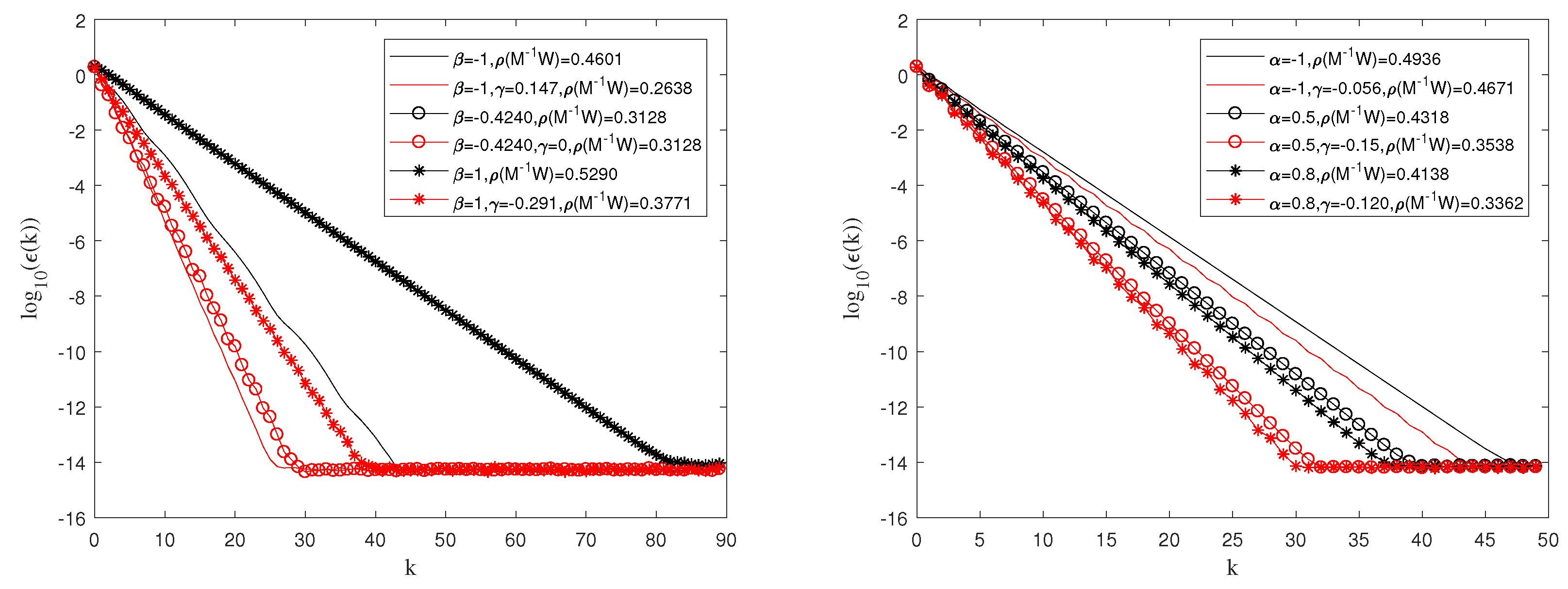
First, we investigated the convergence of algorithm (8) when
and
. The value of
was chosen to be the same as that in [
25]. In order to make the Figure looks concise, in
Figure 1, we only selected three sets of different tuning parameter values from [
25] and compared the convergence performance after selecting a proper parameter
with the Matlab function. We found that by adjusting the value of parameter
, a smaller spectral radius
and fewer iteration steps
k could be obtained. The convergence curves are shown in
Figure 1. It should be mentioned that when
takes the value of 0, algorithm (
8) degenerates to algorithm (
5), which is proposed in [
25], so the two algorithms show the same convergence curves. The red convergence curve represents the convergence situation of algorithm (
8), while the black curve represents that of algorithm (
5). So, it is evident that when the values of
and
remained constant, selecting the appropriate parameter
achieved better convergence results. In [
25], the minimum spectral radius
was gained when
and
. By using the Matlab function, we found that under this condition, it converged fast only when
took the value of 0. But when
and
, we obtained a smaller
by choosing
. It is obvious that when the values of
and
were chosen to be the same as the algorithm (
5) proposed in [
25], we achieved a faster convergence rate by selecting different values of parameter
with the help of Matlab (version R2017a).
Figure 1 shows the algorithm’s convergence after selecting appropriate relaxation parameters. The left figure displays the case when
, and the right figure displays the case when
. The value of
was chosen to be the same as the algorithm in [
25]. By adjusting the appropriate parameter
, we still acquired a smaller spectral radius
and fewer iteration numbers. Obviously, when the values of
and
were the same as in algorithm (
5) proposed in [
25], a better convergence performance was obtained by choosing the appropriate parameter
with the Matlab function.
Figure 1 indicates that all the three parameters
,
, and
simultaneously influence the convergence rate of the algorithm. And through extensive calculations, we found that the fastest convergence rate is approximately achieved when the spectral radius is around 0.3.
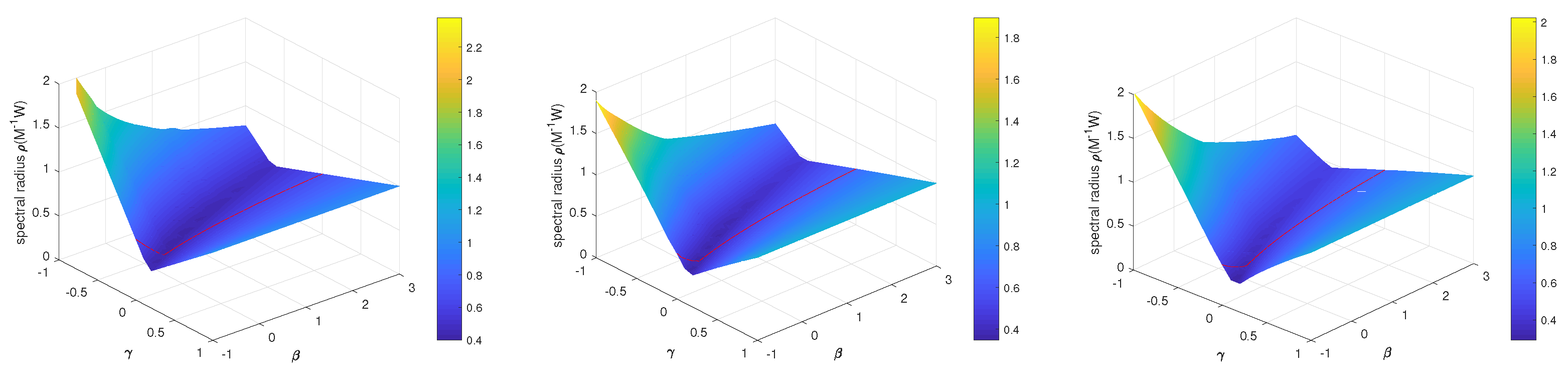
In algorithm (
8), by employing a Matlab function, spectral radius
with different
and
were calculated, with the value of
fixed. Through calculation verification, we found that if
, no matter what value
took, it was always possible to obtain a spectral radius smaller than that of algorithm (
5) under the same values of
and
by selecting the appropriate
. For an iterative algorithm, a smaller spectral radius means a faster convergence speed and a better convergence performance. Since this study had three tuning parameters, it was necessary to first fix the value of one tuning parameter before analyzing the convergence effect of the algorithm. In
Figure 2, due to space limitations, we only selected three representative
values as
,
, and
, since in the previous text we have
.
Figure 2 displays the spectral radius
when
,
take different values and
1, respectively. The red line represents
, which is the spectral radius of algorithm (
5). In
Figure 3, the lowest valley of the surface, which has the smallest spectral radius, is significantly lower than the red curve. This means that when the values of
and
are the same as those of algorithm (
5), through selecting the appropriate relaxation parameter
, algorithm (
8) always yields a smaller spectral radius.
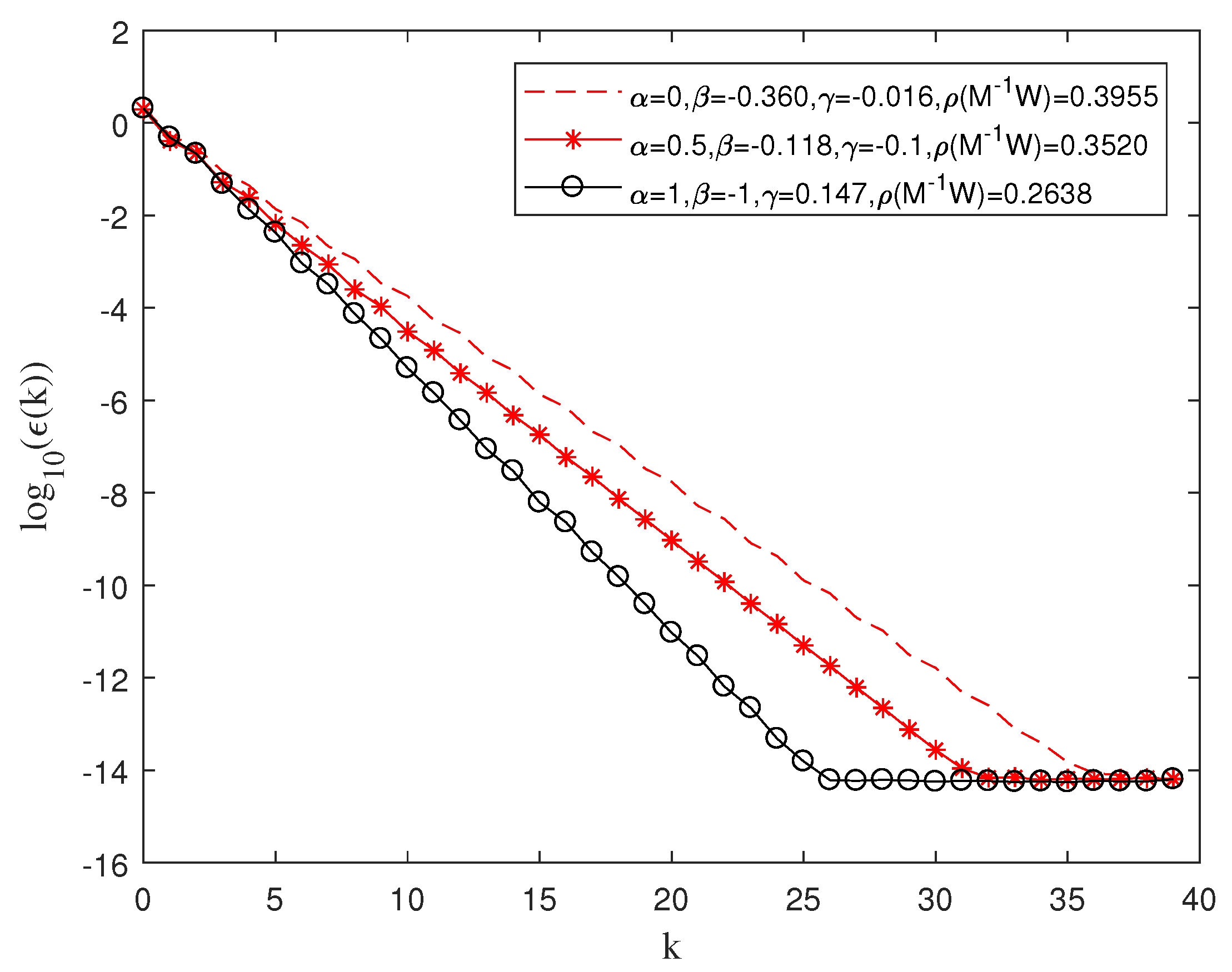
We found the optimal parameters of
and
in
Figure 2, when
and 1, respectively, and presented the convergence curves for these three sets of parameters in
Figure 3. It is worth mentioning that when the value of
was fixed to 1, by adjusting the value of the parameter
, we obtained many spectral radii around 0.26. Algorithm (
5) proposed in [
25] obtained the minimum spectral radius around approximately 0.31. Obviously, as the parameters changed, algorithm (
8) could achieve a better convergence performance.


{kind=link}
{kind=link}
{kind=link}