1. Introduction
Covariance matrix estimation is essential in statistics [
1], econometrics [
2], finance [
3], genomic studies [
4], and other related fields. This matrix quantifies the pairwise interdependencies between variables in a dataset, and each element signifies the covariance between two variables. The accuracy of this estimation is critical for statistical and data analyses. As the size of the matrix increases, the efficiency of the estimation process often decreases. Therefore, the development of efficient methods for this estimation remains a significant research challenge. Various approaches concentrate on assuming specific features in the matrix. Initial methods include principal component analysis (PCA) [
5] and factor models [
6]. Other prevalent techniques encompass the constant correlation approach [
7], maximum likelihood estimation (MLE) [
8], shrinkage methods [
9,
10], and so on [
11]. Notably, shrinkage methods have demonstrated exceptional efficacy in financial portfolio allocation.
For the estimation of sparse or approximately sparse covariance matrices, various element-wise thresholding techniques for the sample covariance matrix have emerged. These include hard thresholding [
12,
13], soft thresholding with extensions [
14], and adaptive thresholding [
15,
16]. Generally, these methods offer low computational demands and high consistency. However, the resulting matrix might not always be semi-positive definite. To address this, more sophisticated methods have been introduced to ensure the estimators are semi-positive definite [
17,
18].
While the sparsity condition is often assumed in [
6,
19], it is not universally applicable. For instance, in financial studies, variables such as stock returns often share common factors, making the sparsity assumption less appropriate. Instead, a more common pattern in the covariance matrix of financial data is the clustering of entries. This occurs because stocks within the same industry sector are often similarly correlated with stocks from other sectors [
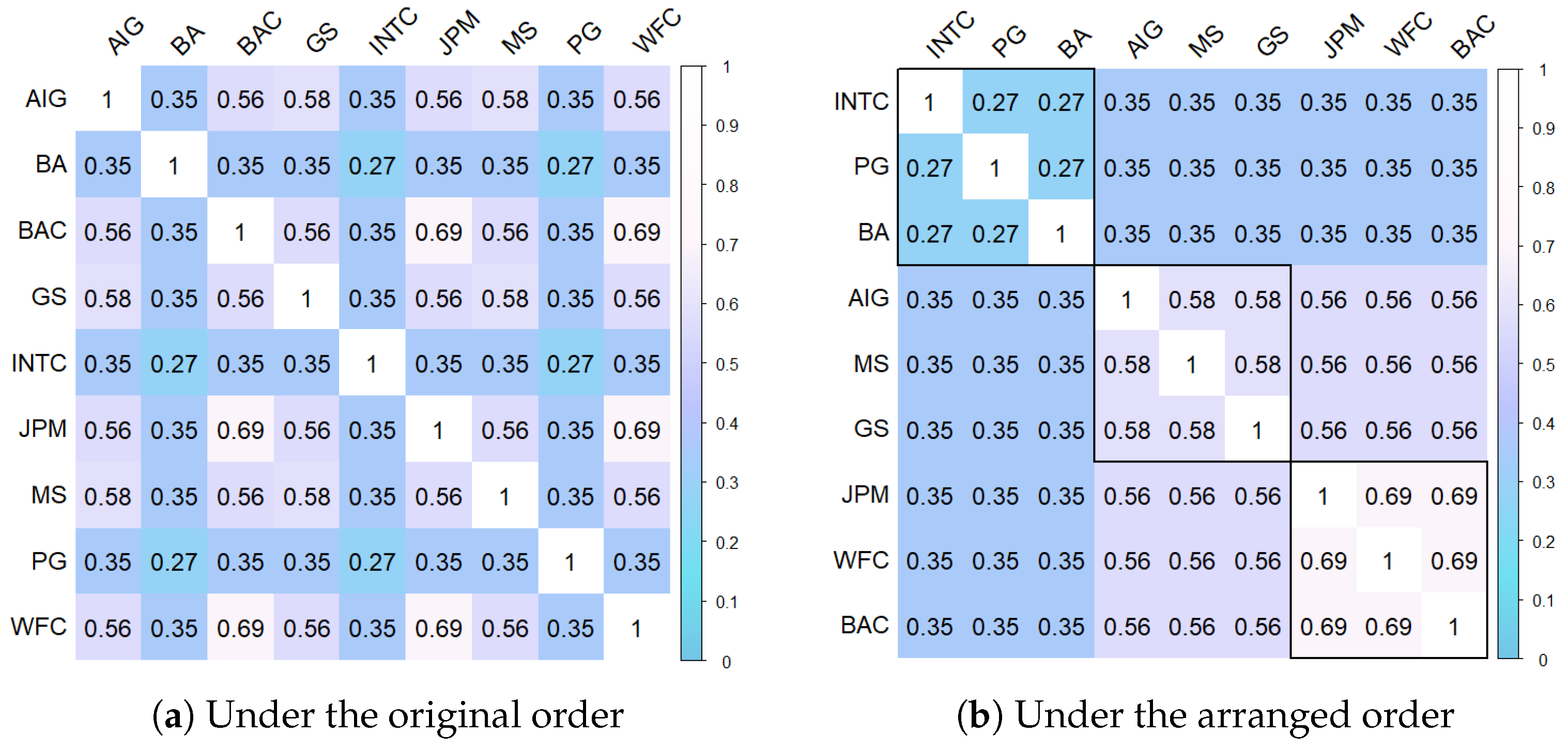
20]. An illustrative example is provided by [
21,
22], who analyzed the daily returns of nine companies on the New York Stock Exchange (NYSE) market based on 2515 observations from 2000 to 2009. Their analysis revealed a matrix of correlation coefficients without zero entries, with many coefficients sharing identical values. Using statistical hypothesis testing, the correlation coefficients were grouped into five distinct values
, shown in
Figure 1a. A similar observation was made by [
23]. When stocks are arranged in a particular order, the correlation coefficient matrix manifests itself as a block-symmetric matrix, as depicted in
Figure 1b, which can be written as
where ⊗ is the Kronecker product. We will demonstrate later that this uncomplicated framework is highly effective for estimating the covariance matrix in Corollary 3.
The proposed estimation method in this paper derives from the correlation matrix structure mentioned earlier. This structure is widespread in numerous financial research situations, encompassing sparse covariance matrices, the formerly noted block-wise covariance matrices, and all correlation coefficients in a global constant [
24]. However, many existing methods are unsuitable for estimating covariance matrices under this structure. To broaden our scope, we delve into the estimation of covariance matrices with clustered entries. To achieve this, we propose an element-aggregation method that is tailored towards covariance matrix estimation. Moreover, we examine the theoretical properties of our method and confirm its effectiveness through extensive numerical simulations and real-world data analysis.
The rest of this paper is organized as follows. In
Section 2, we propose the element-aggregation method for covariance matrix estimation while also elucidating its implementation.
Section 3 assesses the theoretical consistency of the estimation errors and exhibits corresponding convergence rates. All theoretical proofs are in
Appendix A,
Appendix B,
Appendix C,
Appendix D,
Appendix E and
Appendix F. Numerical simulation analyses and real data analysis with portfolio allocation are presented in
Section 4 and
Section 5, respectively. Conclusions are provided in
Section 6.
2. Estimation and Implementation for Covariance Matrix
Suppose the multiple random variable
has the covariance matrix
, and samples
,
are generated from
X. The sample covariance matrix is defined as
. For
,
where
and
for
.
Motivated by the structure of the correlation matrix discussed in the introduction and aiming to analyze the covariance matrices with clustered entries, we consider the following specification for the covariance matrix. Let
denote the collection of off-diagonal elements in the covariance matrix
, and let the set of distinct elements in
be represented by
where
K is the cardinality of set
ℵ, and
K changes with
p. In other words,
for all
. For
, the index set of covariance matrix elements that are equal to
is defined as
In brief,
stands for the category of
. Similarly, for
, the index set of covariance matrix elements that are equal to
is defined as
Then, for
, we have
.
If the sets
are known, i.e., the indices for same elements in
are known, then we can estimate
by averaging the sample covariance elements
as follows for all
,
where
is the cardinality of set
. Thus, the covariance matrix
can be estimated by
Element-Aggregation Estimation Method (ELA)
We hereby introduce the element-aggregation (ELA) estimation method for estimation purposes. As
is unknown, we estimate
, i.e., the category of each
, as follows,
where
is a sample estimate of
and
c is a tuning parameter. Regarding the choice of this tuning parameter
c, Cai and Liu [
15] show that a good choice of the tuning parameter
c does not affect the rate of convergence but it does affect the numerical performance of the estimators. The tuning parameter
c can be taken as fixed at
, as suggested in [
15], or it can be chosen empirically by cross-validation, such as via the five-fold cross-validation method used in [
12,
15]. The tuning parameter
c operates akin to a significance level in statistical testing, and the 2-
rule is widely endorsed for normally distributed data, wherein approximately
of observations are encapsulated within the interval of the mean plus or minus two standard deviations, denoted as
. In our simulations, we also discover that employing
as the tuning parameter for the proposed ELA algorithm yields commendable performance in high-dimensional cases, and does not differ significantly from the parameter optimization obtained by cross-validation. Consequently, we adopt
as the tuning parameter for our subsequent analysis.
Analogous to (
1), we estimate the covariance matrix element
by
and
by
. This is the element-aggregation (ELA) estimator of the covariance matrix.
In terms of computational complexity, the ELA process requires time, where accounts for the binary search computation of in . In comparison, element-wise thresholding has a computational complexity of . Therefore, the ELA estimation calculation is only slightly more complex than the element-wise thresholding approach.
3. Theoretical Properties
In this section, we provide the theoretical justification for the element-aggregation estimation under the assumption of a normal distribution of X. The results can be proven under more general conditions using more complicated techniques. Let denote the operator norm, i.e., , where is the square root of the largest eigenvalue of .
Lemma 1. Let K be the number of different values of the off-diagonal elements in the covariance matrix . Let be the numbers of elements that are equal to in the i-th row of Σ, i.e., . If for some constant andwhere and is the estimate in (1), then the covariance matrix estimator in (2) has the following estimation error An important characteristic is that the effect of dimension on the estimation error is regulated by a slowly varying function, . Lemma 1 could also be extended to the case that is unknown. In such cases, we need to identify the corresponding category . To simplify the explanation, we will use here, since if .
Lemma 2. Suppose X is normally distributed with for some constant . Ifthen the identification by (3) is consistent, i.e., for any , Theorem 1. With the above notation, if the conditions in Lemmas 1 and 2 are satisfied, then Below, we give some special cases of Theorem 1, and show the convergence rates in Corollaries 1–3.
Corollary 1. Suppose is sparse with a number of non-zero elements in each row of , i.e., , where . If the conditions in Theorem 1 hold, then This result is a special case in [
12]. It could be extended to more general cases.
Corollary 2. Suppose follows normal distribution with If for some , then Finally, we consider a simple block covariance matrix with the matrix in
Figure 1b as a special case.
Corollary 3. Suppose where is a identity matrix, is a diagonal matrix, is a matrix with all elements 1, and is an symmetric matrix. If M is fixed as , then we have Remark 1. Since the dimension M of the matrix and the diagonal matrix assumed in Corollary 3 are fixed (), the different values for their matrix elements are at most and M, respectively, so Σ also has at most different values, which is fixed at . By Lemma 2, the estimates and satisfy the rate of , i.e., for any , a subset of the probability space can be found, such thatwhere Using the eigenvalue and Kronecker product properties, we show in the Appendix A, Appendix B, Appendix C, Appendix D, Appendix E and Appendix F that the covariance matrix estimate also has the same rate . That is, since the number of selectable elements of the covariance matrix is determined by a fixed M, which is not dependent on p, the rate of convergence for the covariance matrix estimate is also independent of p. Our ELA method efficiently estimates the covariance matrix with the above structure, demonstrating both efficiency and dimensional independence. Mathematically, this block-wise structure is straightforward. Furthermore, we hypothesize that these conclusions can be extended to more general block-wise matrices, such as the Khatri–Rao product or the Tracy–Singh product [
25].
4. Numerical Simulation
Our study presents the ELA method to estimate the covariance matrix using an element-aggregation idea. The ELA method is designed for simplicity and clarity, making it easy to implement. The steps for implementing the method were thoroughly detailed in the preceding section. This section focuses on comparing the algorithmic performance of the proposed method with several estimation methods for high-dimensional sparse and non-sparse covariance matrices. We compare our ELA estimation method with multiple established methods: (1) the adaptive thresholding method [
15], (2) the POET
k method [
19] with
factors, and (3) the Rothman method [
18].
The numerical simulation focuses on the relative matrix errors when estimating the covariance matrix and the correlation coefficient matrix. To estimate the covariance matrix, first standardize each variable. Then, multiply the elements of the correlation coefficient matrix by the sample standard deviations of each random variable. This effectively transforms the estimation of the covariance matrix into the estimation of the corresponding correlation coefficient matrix. Thus, the ELA method’s efficiency and accuracy in capturing the underlying data structure can be comprehensively assessed through the dual focus on both covariance and correlation coefficient matrix estimations.
The metric employed to compare the estimation efficiency between these estimation methods is the average matrix loss over 500 replications. The matrix losses are measured by the spectral norm of the correlation coefficient matrix and the covariance matrix, similar to that performed in [
18]. To aid visualization, we define the relative estimation errors between the estimated matrix and the actual matrix for both the correlation coefficient matrix
R and the covariance matrix
as follows:
where
denote the operator norm. The next simulation compares the relative matrix estimation errors for various matrix types and algorithms, but also shows how the matrix estimation error changes as the matrix dimension
p increases, in order to demonstrate more clearly the superiority of the proposed estimation algorithm.
The following three covariance matrices are considered.
Example 1. with .
Example 2. where for and are IID uniform on [0, 1]. A similar example was used in [16]. Example 3. Constant block matrixwhere , is a matrix with all elements 1, and is the identity matrix of size . Remark 2. Due to the assumption of sparse covariance matrices in the adaptive thresholding method, the POET0 method, and the Rothman estimation method [6,15,18], the covariance matrix is estimated as a sparse matrix, where most of the matrix elements are estimated to be zero. This is significantly different from the non-sparse covariance matrix in Example 3. The relative estimation error of the covariance matrix estimated by these methods is relatively large compared to the sample covariance estimation method. Therefore, the adaptive thresholding method, the POET0 method, and the Rothman method cannot be used directly for Example 3. Note that Σ can be written aswhere is a sparse matrix and and are the first two largest eigenvalues of Σ, with and as the corresponding eigenvectors, respectively. By this decomposition, the POETk method with factors in [19] can be used, i.e., POET2 is applicable to the estimation for Example 3. Random samples are generated from
with sample sizes
and
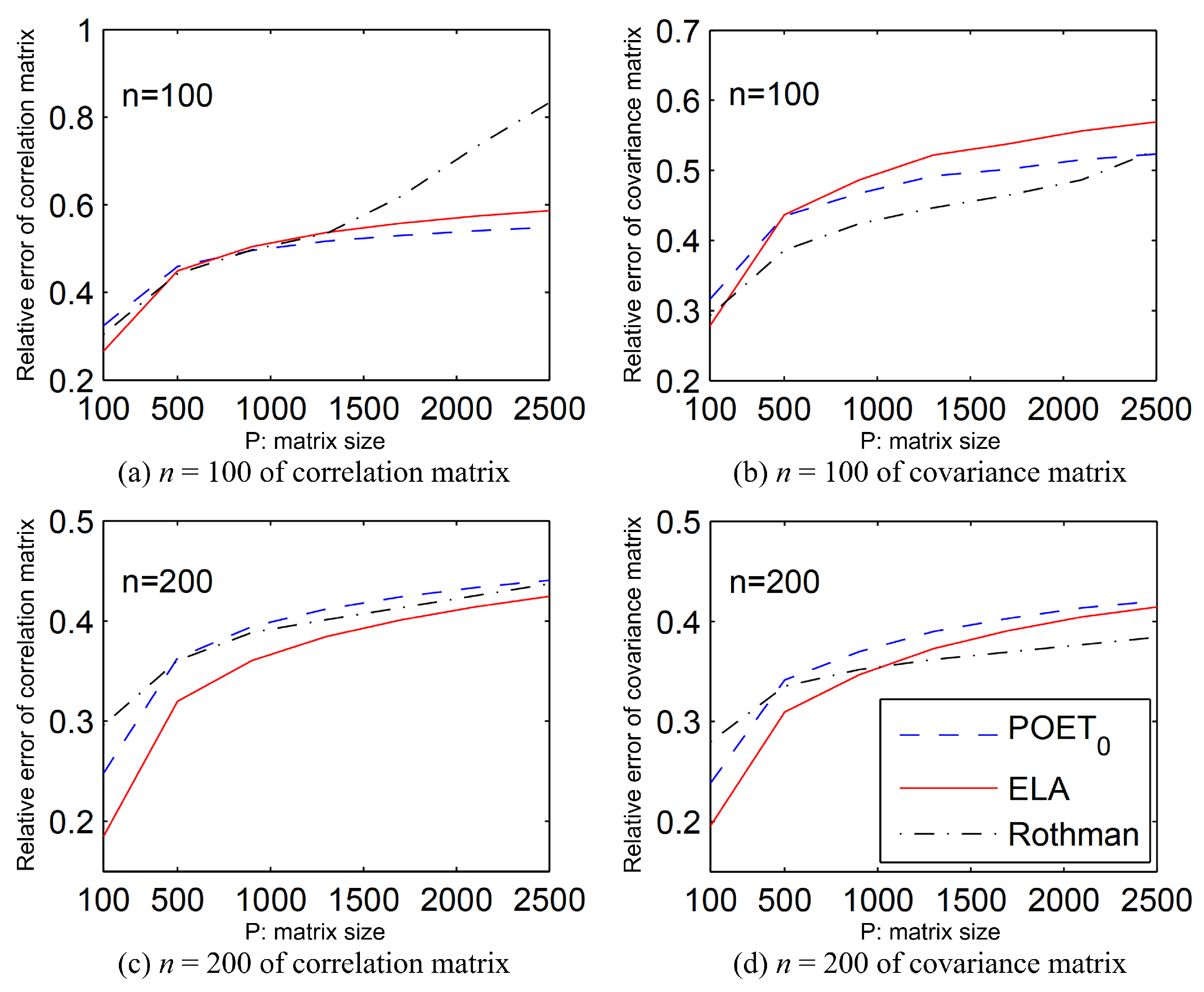
. The averages of the relative estimation errors, based on 500 replications, are depicted in
Figure 2,
Figure 3 and
Figure 4. The ELA method is represented by a solid red line. Only methods with a performance comparable to the best one are displayed in each panel.
In
Figure 2 for Example 1 with
, our ELA estimator for the correlation coefficient matrix
R is slightly inferior to POET
0 but exceeds Rothman. For the covariance matrix
, our method slightly lags behind both POET
0 and Rothman. However, with
, the ELA method outperforms them in both the correlation coefficient matrix and the covariance matrix with
, ranking first for the correlation coefficient matrix and second for the covariance matrix with
. In general, the ELA method is comparable to both POET and Rothman for Example 1.
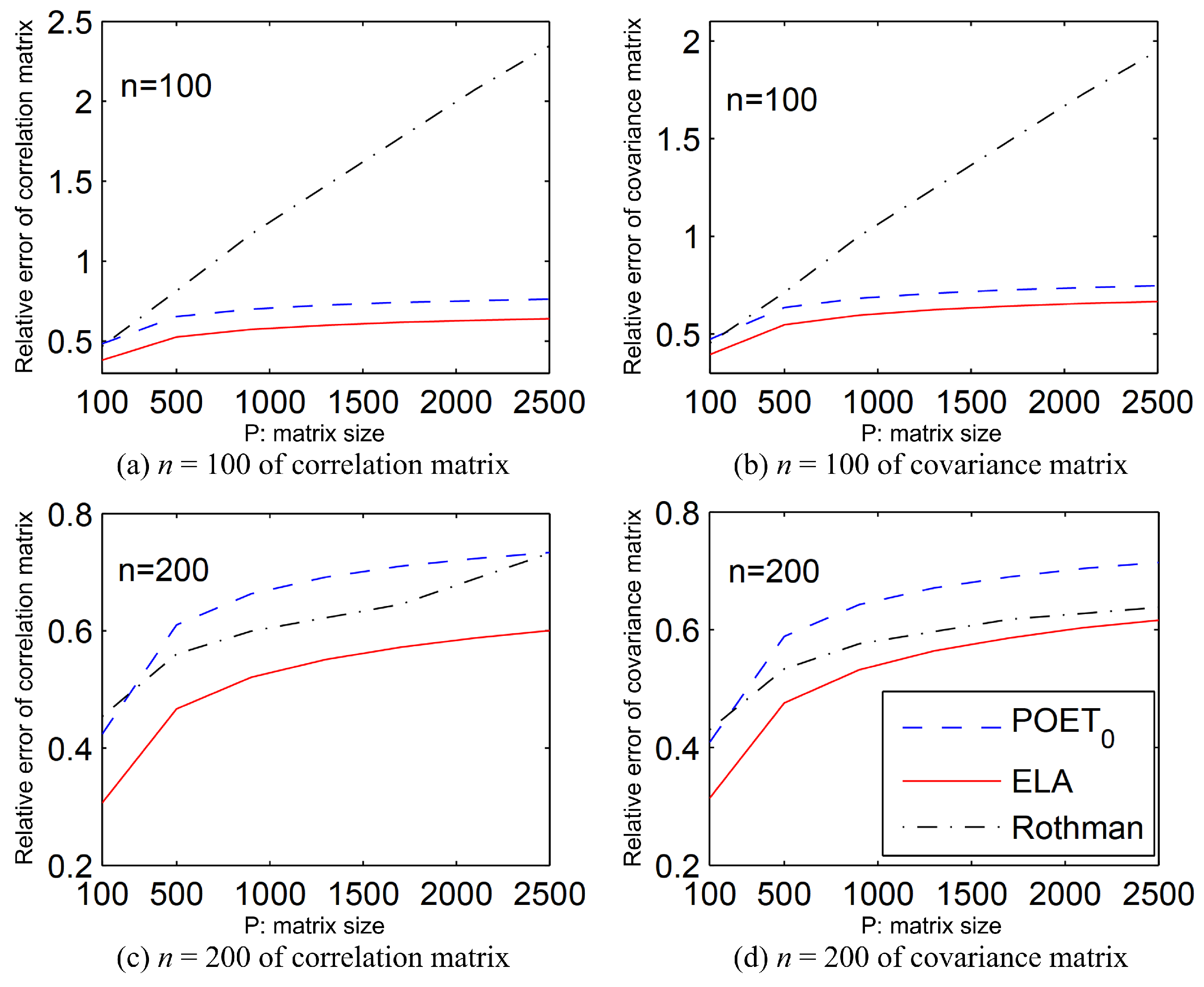
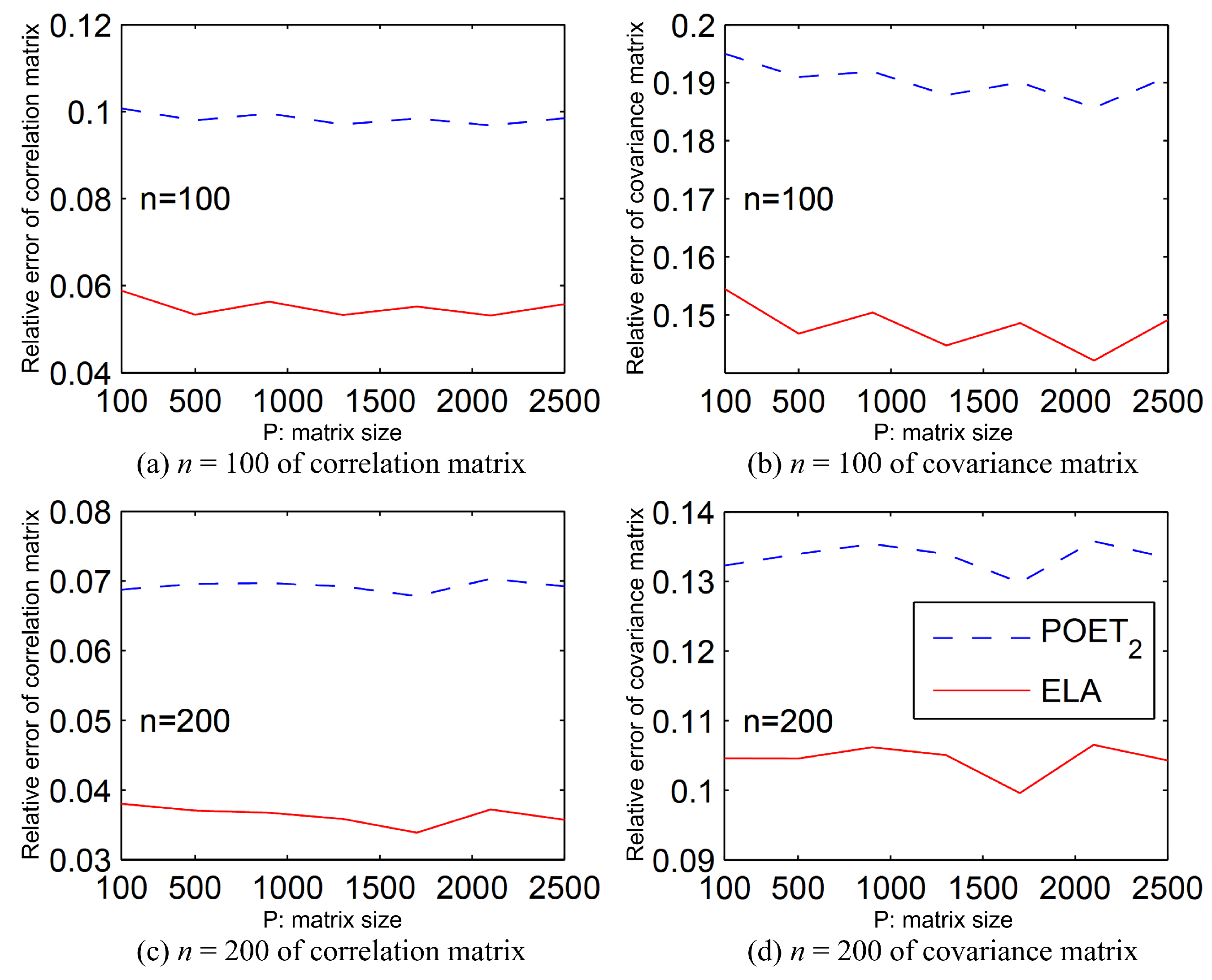
In
Figure 3 for Example 2, the ELA estimator consistently outperforms both POET and Rothman for both matrices when
. Although Remark 2 suggests that POET
2 is suitable for Example 3,
Figure 4 for Example 3 demonstrates the superior efficiency of the ELA method over POET
2 for both matrices with
. In summary, the ELA method significantly outperforms both POET and Rothman for Examples 2 and 3.
Furthermore, we conducted a comprehensive analysis comparing the average computational time across 500 replications for our ELA method alongside the adaptive thresholding method [
15], the POET method [
19], and the Rothman method [
18]. These comparisons are detailed in
Table 1. The random samples are still generated from
with
following Example 1, sample sizes
, and covariance matrix dimensions
. Notably, due to the POET
k methods exhibiting computational times that are broadly analogous for different values of
k, we present only the results for POET
1.
Upon examination of
Table 1, it is evident that, for lower dimensions of
, the ELA method has a higher computational cost compared to the adaptive thresholding and Rothman methods but outperforms the POET method. For
, the ELA method is slightly slower than adaptive thresholding but remains superior to both the POET and Rothman methods. When dealing with higher dimensions of
, the ELA method demonstrates a significant computational advantage over its counterparts. This suggests that the ELA method scales more efficiently with increasing dimensionality, which is a desirable attribute for high-dimensional data analysis.
Our simulation studies have yielded the following conclusions: The ELA method outperforms both POET and Rothman for Examples 2 and 3 in both the correlation coefficient matrix and the covariance matrix with and . For Example 1, it performs comparably to them. These results emphasize the efficiency of the ELA method for estimating covariance matrices. Our proposed ELA technique is not just computationally efficient but also markedly lowers the relative estimation error, i.e., with minimal loss of spectral norm for the correlation coefficient and the covariance matrix.
5. Real Data Analysis and Portfolio Allocation
The component stocks of the SP500 index were analyzed using historical daily prices sourced from Yahoo Finance through the R package ‘tidyquant’. We selected 430 stocks from SP500 with daily prices spanning over 3000 days, from 1 January 2008 to 31 December 2019, to ensure a sufficiently large sample size. This allowed for a larger window,
, to be selected when we use the rolling window method later. Our emphasis is on the correlation coefficient matrix and covariance matrix for daily returns. Although the covariance matrix, in particular the individual stock variances, is known to fluctuate over time, the correlation coefficient matrix remains relatively stable. This stability underscores the significance of evaluating estimation methods based on the correlation coefficient matrix [
26]. The constant conditional correlation multivariate GARCH model [
26] is defined as
where
,
is the constant correlation coefficient matrix, and
is the conditional volatility modeled by GARH(1,1) for
i-th stock based on its past daily returns. See [
27] for more discussion about the performance of GARCH(1,1). Let
be the return of the
k-th stock on day
t, where
. We begin by standardizing the returns using
In order to evaluate the estimation performance of the covariance matrix, we assume that the covariance matrix of
remains constant over time or changes very slowly.
Rooted in modern portfolio theory (MPT), portfolio allocation advocates strategically distributing investments across diverse asset classes to optimize the trade-off between risk and return. The MPT theory highlights the significance of not only choosing individual stocks but also the proportional weighting of these stocks in a portfolio [
28,
29]. Therefore, we investigate the optimal allocation for minimum risk portfolios of stocks, utilizing the estimated covariance matrix of various methods.
To evaluate various methods, we apply their estimators to construct minimum risk portfolios. For any rolling window of time
, we utilize data from one window to estimate the covariance matrix via different methods, including (1) our ELA method, (2) the POET
k method [
19] with
factors, (3) the shrinkage method [
9], denoted by Shrink
Market, and (4) the simple sample covariance matrix, denoted by Sample. The simple sample estimate of the covariance matrix
for a given time
t is defined as
with
.
For an estimated covariance matrix
, the minimum risk portfolio
for time
t is defined as
The portfolio for time
t is then
. To determine the portfolio with the lowest risk, we calculate the standard deviation of the portfolio returns
. Estimators yielding a smaller standard deviation are deemed superior in portfolio allocation.
To understand how risk varies with the number of stocks, we alphabetically order the stocks by their symbols on the New York Stock Exchange and analyze growing subsets of stocks with
,
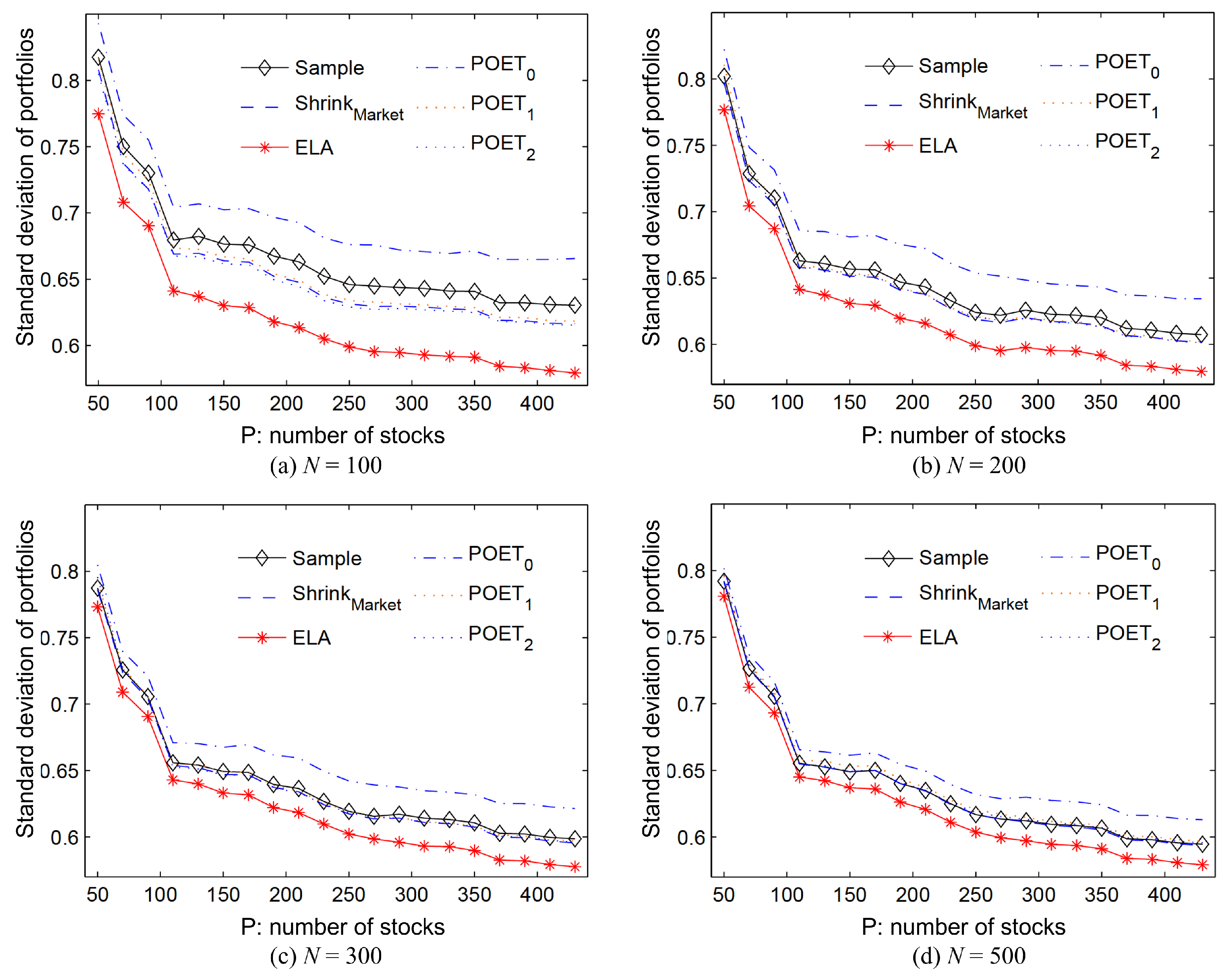
. The risks associated with portfolios based on different methods are illustrated in
Figure 5, with the ELA method highlighted by a red solid line. As the sample size
N in the rolling window increases from 100 to 500 across the panels, the performance gap between the different estimation methods narrows, illustrating the homogeneity of the correlation matrix.
Figure 5 shows that portfolios crafted using the ELA method consistently have the lowest risk compared to the POET
k methods, the shrinkage method, and the sample covariance matrix method, especially with smaller sample sizes of
and
. Therefore, the ELA method is superior in constructing portfolios that minimize risk, is an effective tool for reducing portfolio risk, and is suitable for a wide range of sample sizes.
6. Conclusions
In this paper, we introduce a novel method called element-aggregation (ELA) estimation for the estimation of covariance matrices. The ELA method stands out due to its simplicity, low computational complexity, and applicability to both sparse and non-sparse matrices. Our theoretical analysis shows that the ELA method offers strong consistency while maintaining computational efficiency and dimensional independence, especially concerning block-wise covariance matrices.
In our numerical simulation study, we highlight the exceptional effectiveness of the ELA method in estimating correlation coefficient matrices and covariance matrices using diverse random samples. In comparison to established methods like POET and Rothman, the ELA method consistently either outperforms or equals them. The computational efficiency of our ELA method is complemented by a significant reduction in the relative estimation error for both correlation coefficients and covariance matrices.
In the real data analysis of the SP500 index stocks, the ELA method consistently generates portfolios with the lowest risk in comparison to other listed methods. This outcome is particularly pronounced in scenarios with smaller sample sizes, underscoring the potent ability of the ELA method to construct risk-minimized portfolios.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}