Abstract
The issue of counting independent sets of a graph, G, represented as , is a significant challenge within combinatorial mathematics. This problem finds practical applications across various fields, including mathematics, computer science, physics, and chemistry. In chemistry, is recognized as the Merrifield–Simmons (M-S) index for molecular graphs, which is one of the most relevant topological indices related to the boiling point in chemical compounds. This article introduces an innovative algorithm designed for tallying independent sets within grid-like structures. The proposed algorithm is based on the ‘branch-and-bound’ technique and is applied to compute for a square grid formed by m rows and n columns. The proposed approach incorporates the widely recognized vertex reduction rule as the basis for splitting the current subgraph. The methodology involves breaking down the initial grid iteratively until outerplanar graphs are achieved, serving as the ’basic cases’ linked to the leaf nodes of the computation tree or when no neighborhood is incident to a minimum of five rectangular internal faces. The time complexity of the branch-and-bound algorithm speeds up the computation of compared to traditional methods, like the transfer matrix method. Furthermore, the scope of the proposed algorithm is more general than the algorithms focused on grids since it could be applied to process general mesh graphs.
MSC:
05C85; 05A15; 68Q25
1. Introduction
While combinatorics has a rich history of addressing counting problems, complexity theory has yielded fewer results in this line in comparison to decision problems. Currently, there exist a limited number of graph counting problems that can be resolved within polynomial time. The realm of combinatorial mathematics and complexity theory has seen the rise of counting problems as a significant area of investigation. Counting algorithms have proven instrumental in addressing real-world challenges across various disciplines such as mathematics, physics, chemistry, and engineering.
There are several counting problems related to count structures in a grid graph, e.g., perfect matching, spanning trees, k-coloring, Hamiltonian circuits, independent sets, acyclic orientations, and so on. For example, one line of research has been the study of the asymptotic Laplacian-energy-like invariant on square lattices. In [1], the authors show that the asymptotic Laplacian-energy-like invariant for square lattices G is independent of the three boundary conditions, which are the free, the cylindrical, and the toroidal boundary conditions. Moreover, they present that the Laplacian-energy-like invariant per vertex of lattices is independent of the boundary conditions.
Determining the number of independent sets on a graph, G, represented as , is acknowledged as a challenging problem, even though specialized algorithms have been developed to efficiently address this issue for certain graph topologies. In the context of challenging counting problems, the calculation of for a graph, G, has played a crucial role in delineating the boundary between the counting methods that are efficient and those that are deemed intractable.
The computation of the number of independent sets in mesh structures is applied in various contexts, for example, when a square grid graph, (representing an initial square grid with m rows and n columns), is considered. For instance, within the realm of statistical physics, determining has proven valuable when examining the dynamics of gas particles in a space represented by a grid structure. The calculation of has been applied in the “hard square model” as a resource to derive the hard quadratic entropy constant [2]. The “hard square model” is also utilized for enumerating configurations of q particles in the Widow–Rowlinson system, extending to cases where [3,4].
Various researchers have explored the challenge of design methods for counting the number of independent sets on square grid graphs. Notably, researchers such as Calkin [5] and Euler [6] have proposed a matrix-based technique for counting independent sets of a grid, and this method is known as the “transfer matrix method”. This method has been extended to compute on mesh structures [7].
However, it is believed that most counting problems related to square grids are intractable, since they rely on the two-dimensional character of the grids as a set of unbounded treewidth. Additionally, the author in [8] considers that counting matchings in square grids, counting Hamiltonian cycles in square grids, and counting Clar sets in fullerene graphs are all hard for the complexity class #.
A graph invariant is a function applied to a graph, independent of the vertex labeling. A topological index, on the other hand, is a numerical value linked to either the chemical structure or physical attributes of a molecular graph. In general, a topological index is linked to chemical constitution, aiming to establish connections between chemical structure and diverse physical properties, biological activities, or chemical reactivities. Since the ground breaking contributions of Merrifield and Simmons [9], the connection between the number of independent sets of a graph, G (denoted as and representing a chemical compound), and the boiling point of the corresponding compound has been acknowledged. Subsequent to the initial study mentioned earlier, extensive research has been conducted in computational chemistry concerning the calculation of while exploring various topologies for molecular graphs.
The branch and bound paradigm is a widely utilized approach for addressing problems characterized by intrinsic combinatorial exponential complexity. This method involves branching the input problem into analogous subproblems with a reduced dimension (size) concerning the original problem. The branching process leads to the formation of an enumerative tree, with leaves representing base cases of the problem that can be solved efficiently. This structured approach facilitates the efficient resolution of those base instances.
Different exponential algorithms have been designed to compute the M-S index on square grids , starting with the super-exponential algorithm based on the transfer matrix method [5,6]. More recently, De Ita et al. [10] propose an exponential-time algorithm based on the use of computing threads for computing . Meanwhile, in this work, a branch-and-bound algorithm is introduced, whose time complexity is of order , where represents a function with a polynomial-time complexity, and m and n are the dimensions of the grid graph.
Notice that all the above algorithms are of exponential order, and the last two algorithms have a different way of measuring the hard exponential complexity of counting independent sets on square grids, since the algorithm in [10] has an exponential growth based on the number of squares by row (or by columns) in the grid. However, for the algorithm presented here, the exponential growth depends on the number of applications of the ramification vertex rule until achieving basic case subgrids. This algorithmic proposal is more general than the algorithms specifically designed to compute the Merrifield–Simmons index in grid graphs since it can process more general topologies such as polygonal mesh graphs due to the ramification vertex rule, which has a widespread application on all types of graphs.
For example, the proposed algorithm offers an exact solution applicable to grids of various types, including regular grids and those with an irregular number of faces by rows. Notably, the time complexity function obtained in this work for calculating exhibits significantly slower growth compared to the complexity function associated with the classical transfer matrix method. This underscores the efficiency and versatility of the proposed algorithm across different grid configurations.
This paper is structured as follows: Section 1 provides a general introduction. Section 2 introduces the preliminaries and the notation that will be employed. In Section 3, the main technique used for designing counting algorithms on grids is presented. Section 4 introduces three counting rules facilitating the processing of various basic cases in the enumerative tree. Section 5 presents the enumerative tree constructed by the proposed algorithm. The final section offers conclusions drawn from this work.
2. Preliminaries
Let be an undirected simple graph, where V is the set of vertices and E is the set of edges. It is assumed that G does not have loops or parallel edges. The edge connecting the vertices u and v is denoted by , and sometimes is used to denote an edge .
The neighborhood of is the set . Meanwhile, denotes the closed neighborhood of x. The degree of a vertex x in the graph G, denoted by , is . The degree of the graph G is . Let be the cardinality of the set A.
A subset of vertices in a graph, G, is termed an “independent set” if for every pair of vertices u and v in S, the edge is not present in . The notation is employed to represent the collection of all independent sets in the graph G.
To specifically denote the independent sets in G containing the vertex v, the notation is used. Conversely, represents the independent sets in G where the vertex v is absent.
On the other hand, to denote the number of independent sets in the graph G, the notation is used. Specifically, in this context, corresponds to the cardinality of the set . An independent set is deemed a “maximal independent set” if it is not a subset of any other independent set within G. Furthermore, if the length of set S is the maximum among all elements in , then S qualifies as a “maximum independent set” (MIS of G).
The computation of is a #P-complete problem for graphs G, where [3,11,12,13]. Calculating continues #P-complete, even under the constraint of three regular graphs [12]. Nevertheless, for certain graph topologies, G, there exist some polynomial methods to determine under the condition that [14,15,16].
Planar graphs hold significance in both graph theory and the realm of graph drawing. A graph, G, is termed a planar graph when it can be represented as an embedding in the plane. The regions enclosed by the vertices and edges are recognized as the internal faces of the graph. Simultaneously, the unbounded face is identified as the outer face or external face of the graph. An outerplanar graph is defined as a planar graph that can be depicted in a manner where all its vertices are incident to the outer face. In the context of an embedding of a planar graph, G, external vertices as those incident to the outer face are distinguished, while the remaining vertices are considered internal vertices of G.
denotes the collection of non-intersecting internal faces, or simply faces, of the planar graph G. Every face is defined by the set of edges that form its boundary and encloses its interior. It is important to note that the outer face of the graph is excluded from the set . In the context of adjacency among faces in G, two distinct faces are considered adjacent if they share common edges. Conversely, when there are no common edges, the relationship between two faces is described as that of independent faces. Consequently, two independent faces may share common vertices but do not have any edges in common.
A particular type of planar graph is referred to as a grid graph, and it is denoted as and it is a grid graph of size ; then, the vertex set is , and the edge set is . In this scenario, denotes a square grid graph with m rows and n columns. And let , which represents the number of internal faces (tilings) of .
Some studies on structures embedded within a grid graph have been conducted, including Hamiltonian cycles, spanning trees, acyclic orientations, k-coloring, and independent sets [5,6,17,18]. The enumeration of mathematics objects on grids extends to various applications, such as tiling and the development of efficient coding schemes for data storage [19].
A primary approach for counting independent sets on grid graphs involves the use of the transfer matrix method [5,6]. However, when applied to compute , this method exhibits a super-exponential time complexity with respect to the dimensions m and n of the grid. Additionally, when extended to more general mesh structures, the resulting algorithms experience a highly exponential increase in complexity over the computation time [7,20].
3. Algorithm Proposal
A branch-and-bound algorithm involves two main phases. The first phase is the branching process, which involves breaking down the graph into two subgraphs through an iterative process, forming an enumeration tree. The second phase is the bound process. This process begins by recognizing that the graph linked with the present node of the enumeration tree acts as a base case for the counting process.
The proposed algorithm for counting independent sets requires a base case graph that is a subgraph of a grid. To qualify as a base case, the subgraph must meet the condition that the closed neighborhood of any vertex is not incident to at least five different internal faces of .
It is possible to process any graph associated with a base case in polynomial time with respect to the size of the current graph. The first step in counting the number of independent sets of the graph from a base case is to create a Hamiltonian path (Hp) on the graph. Simultaneously with the execution of the Hamiltonian path, one of the three fundamental rules specifically designed to maintain a partial count on the independent sets is applied. This count is influenced by the vertices and edges already visited during the tour.
In order to explain the counting process on graphs associated with the base cases, the first step is to illustrate how the Hp is performed on the subgraphs that meet the cut-off condition.
One of the most common ways for traversing a graph is to apply a depth-first search (dfs). Let us consider that G has cycles. A depth-first search will be applied over G. denotes to the graph resulting from the application of a dfs on G, and let T be the spanning tree formed during the application of the dfs. The edges in T are called tree edges. An edge is called a frond edge (or a back edge when it is related to the depth-first search).
Let be a frond edge. The union of the path in T between the endpoints of e with the edge e itself forms a simple cycle ; such a cycle is called a basic cycle of G with respect to T.
The approach involves constructing a Hamiltonian path (Hp) for any subgrid formed by decomposition of the input grid while simultaneously computing the number of independent sets of the graph’s components in an incremental manner. The Hp will visit every vertex only once. Meanwhile, each edge in the subgrid is recognized as a tree edge or a frond edge.
Except for the first and last vertices visited by the Hamiltonian path, the two edges of the vertices of degree 2 are considered tree edges, and they will be processed by the Fibonacci rule. Additionally, for vertices with a degree of 3, two of their edges are traversed as tree edges, while the third edge is identified as a frond edge that is processed by the subtracted rule. On the other hand, the vertices of degree 4 have two of its edges as tree edges, and the remaining two edges are frond edges.
Although the problem of finding a Hamiltonian cycle for any graph is a classic NP-Complete problem [21], in this case, the problem relaxes its constraints by considering paths instead of cycles, which does not force a return to the same starting point of the path. The most significant simplification occurs when considering grid graphs, as the challenge of finding a Hamiltonian path transforms into a problem with linear time complexity. This is because none of the vertices in grid graphs have a degree greater than 4.
For example, the Hp can be constructed using a traversing by columns (or by rows) approach. It is important to ensure that each vertex is visited only once and that each edge is identified as either a tree edge or a frond edge. In a traversing by columns, the direction of the search in the Hp can be from bottom to top for the odd columns and from top to bottom for the even columns. It is common for the last vertex visited in the Hp to have one of its edges as a frond edge.
Two graphical symbols are introduced into a Hamiltonian path of a subgraph of G. The symbol ↦ indicates the beginning of a Hamiltonian path. Meanwhile, the symbol indicates the end of the Hamiltonian path.
4. Counting Rules for Processing Grid Base Cases
Each node is associated with a pair , called the charge of the vertex v, and where and . The charge of a vertex will be computed at the time that v is visited during a traversing on G. Thus, the charge of v is an auxiliary temporal pair used for computing the number of independent sets of G and such that if is the last visited vertex during the traversing on G, then .
There are several methods for computing when G belongs to a reduced set of simple graph topologies [14,15,16,22]. In this proposal, the main element is to compute the charge for each vertex v in the graph during a Hamiltonian walk on G. Different counting rules could be applied to compute the charge of a vertex v, mainly depending on the topology of the subgraph , when v is visited during the Hamiltonian walking on G.
Three main counting rules to process any subgrid will be considered.
- Fibonacci rule: used to process tree edges.
- Subtracted rule: applied to process frond edges.
- Product rule: used to converge different search lines.
4.1. The Fibonacci Rule
Let us consider the first simple basic topology of a graph. Let G be a path of size n,and then . In this case all edges of can be denoted as , where . Let us contemplate the family where each represents the induced graph of G created solely from the first i vertices of G.
Notice that given that the induced subgraph , . If the values for for any are known, when the subsequent induced subgraph is constructed from by adding the vertex and the edge , it becomes apparent that the pair is derived from through the following recurrence relation:
The series (,), i=1, …,n, built from recurrence (1), leads to , . Then, the computation of relies on the step-by-step calculation of . The application of recurrence (1) is denoted as → between the pairs and . The application of the previous recurrence will be called a Fibonacci rule recurrence, since when they are applied on a path, , the following identity is obtained, where is the Fibonacci number.
For example, the computation of is given as: . The series (formed during the computation of ) is called a computing thread (or just a thread). Notice that each temporal charge can be stored in a structure associated with each vertex .
4.2. The Subtracted Rule
Another helpful basic counting rule during a Hamiltonian walk on the grid is applied when visiting a frond edge. In this method, frond edges are processed in two phases. Let be a frond edge of a graph, G.
In the first phase of this counting rule, when the vertex v of the frond edge is visited, it is necessary to duplicate the number of active threads. Assuming that is the pair associated with the active thread at the time of visiting the vertex v, a new thread is created. This thread is subordinated to the master thread and has an initial associated pair . For every active thread where , a new thread is created. The label from is then used as a pointer to its master thread .
The second phase in the processing of the frond edge occurs when the search visits the vertex w, while v has already been marked as a visited vertex. At this point, the control of the search is kept on the vertex w, which helps avoid visiting any vertex of the graph more than once.
Given the charges and for the vertex w in the master thread and subordinated thread , respectively, the subtracted counting rule can be used to update the charge of w in .
After applying the subtracted rule for the frond edge , all subordinated threads are closed, leading to a decrease in the number of active threads. When illustrating a Hamiltonian path on a subgrid, ⊣ will symbolize the beginning of the path and the end of the path; the processing of a tree edge is symbolized by a dashed line or by , and the processing of a frond edge, , is symbolized by a curved arrow between the vertices v and w. Those previous counting rules are applied while G is traversed by a Hamiltonian path.
Additionally, the Fibonacci and subtracted rules are enough to process any row of tiles in a grid. For example, the following figures illustrate how the Fibonacci and subtracted rules can be applied to process the number of independent sets on subgrids.
In the following tables of the computation of the charges of the vertices of the illustrated graphs, the subindex x after the pair of charges indicates that those computing threads are closed. Meanwhile, the symbol = at the beginning of a charge indicates that the subtracted rule was applied to the two previous pairs.
The order of the Hamiltonian path is presented by the order of the columns in Table 1, Table 2 and Table 3. Moreover, each row describes the current charge for the vertex of its corresponding column. The first value in each row is the label describing the name of the corresponding computing thread. The last charge in the row corresponding to will give you the total value for for the graphs shown in Figure 1 and Figure 2. For the example in Figure 1, . Meanwhile, for Figure 2, .

Table 1.
Counting independent sets from Figure 1 (first part).
Table 2.
Counting independent sets from Figure 1 (second part).
Table 3.
Counting independent sets from Figure 2.
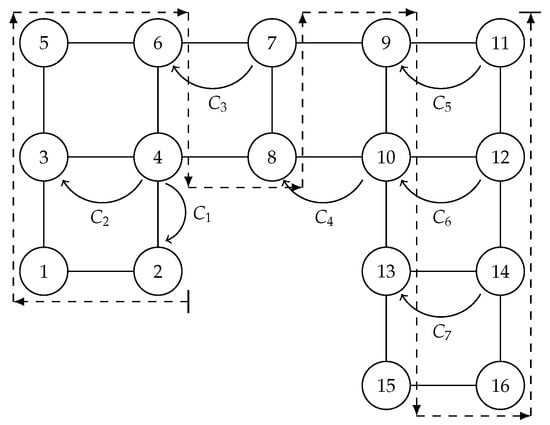
Figure 1.
Proccesing an outerplanar subgrid.
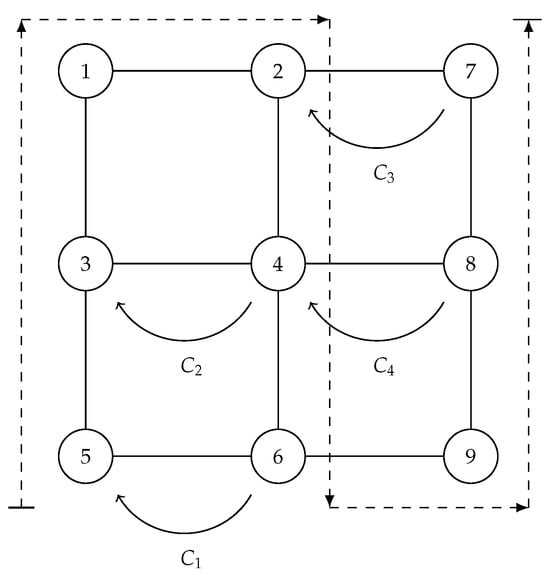
Figure 2.
A basic case of 4 tiles.
De Ita et al. [10] show how calculating the number of independent sets of a grid is possible by taking the Hamiltonian path as a guide while the two counting rules, the Fibonacci rule and the subtracted rule, are applied. Nevertheless, the time complexity of the aforementioned process is exponentially proportional to the maximum number of frond edges in any row of the grid. This is attributed to the necessity of keeping a substantial number of computing lines active during the processing of open cycles in each row of the grid.
In this proposal, a basic case is a subgrid, , where each vertex satisfies the condition that is not part of more than five grid faces, and then the computation of can be performed of polynomial order over the size of ; this is of order , where poly is a polynomial function.
However, the previous rules, the Fibonacci and subtracted rules, are not enough to compute when G is a subgrid, as is illustrated in Figure 3. For this case, a new rule called the product rule is introduced.
4.3. The Product Rule
When multiple path searches converge at a meeting vertex, the product rule is used to calculate the interaction between each pair of active threads on one path line and all pairs of active threads on the second path line.
For example, let us consider that there are two computing threads and which have associated the charges and , respectively. Furthermore, the edges and , with common vertex u, are the next ones to be visited by the Hamiltonian path. In this case, the following multiplicative rule is applied in order to compute the charge for the vertex u.
The product rule can be generalized for the Hp that has more than two line searches. Suppose there are child nodes of v, and all these child nodes have already been visited. In this case, each pair for associated with these child nodes have been previously explored. Therefore, each pair has been established using recurrence (Equation (1)). Then, the charge for v can be computed as: and . The symbol ⊙ will be used to denote when a product rule is applied on the active threads.
The Fibonacci, subtracted, and product rules are enough to compute for any subgrid that is recognized as an outerplanar graph. Moreover, these rules can also be applied to compute for some subgrids G where G is not outerplanar, but it is planar. The product rule is a useful tool that allows us to establish varying starting points for the Hp. This leads to the convergence of some of the search lines at meeting vertices, resulting in the walking reaching a single end point at the end of the Hp.
Let us illustrate how those previous rules are applied to compute for the following subgrid G.
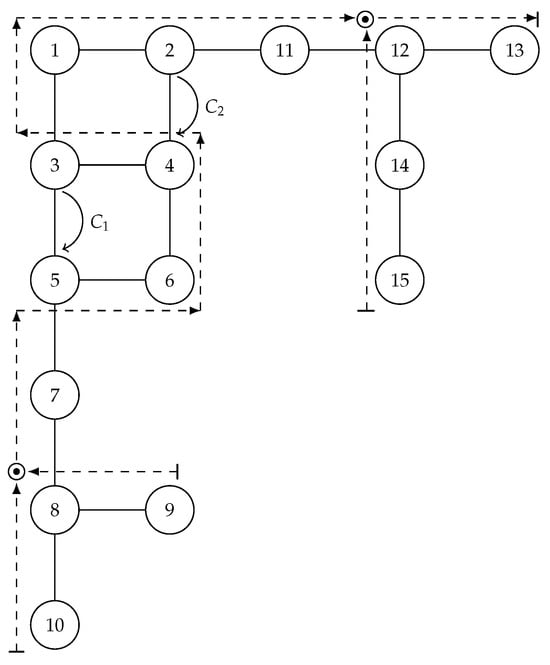
Figure 3.
Applying the product rule.
In Table 4, the order of the Hamiltonian path is determined by the order of the columns. However, it is important to note that this Hp has different start points that are expressed by the number of the vertex in the corresponding row of the table. Additionally, the first value in each row serves as a label that describes the name of the corresponding computing thread. Whenever you see the symbols “–” and “=” in the table, the subtracted rule is applied. On the other hand, when you see the symbols “*” and “=”, this expresses that the product rule is being applied between two charges.
Table 4.
Counting independent sets from Figure 3.
5. Building the Enumerative Tree
Two prevalent rules govern the counting of combinatorial objects on graphs, enabling us to break down the graph either by the selection of a vertex or by the selection of an edge.
- The counting rule based on a vertex—the vertex division: let ,
- The counting rule based on an edge—the edge division: let ,
An alternative rule for decomposing the counting of independent sets is to treat each connected component of the graph independently. For example, let us consider that are the connected components of G, and then . In this case, the overall time complexity for calculating is , where is a connected component of . Thus, it is common to consider the connected components of the graph as its first decomposition.
In this work, a standard branch-and-bound algorithm was developed, denoted as the BB Algorithm 1, for counting the number of independent sets in a grid graph. The BB algorithm constructs a computation tree, and during the branching processes, it focuses on two key aspects: the criteria for selecting a vertex v (when employing the vertex division rule) and a stopping criterion to cease branching at any node within the computation tree. According to the pseudo-code shown, the proposed algorithm can be implemented in any high-level language that allows recursive processes.
| Algorithm 1 BB algorithm | |
| Input: Output: 1: procedure (G) 2: 3: for do | |
| 4: | ▹x is a vertex from G |
| 5: if then 6: return x 7: end if 8: end for 9: return 0 10: end procedure 11: procedure (G) 12: 13: if then 14: 15: else | |
| 16: | ▹ vertex v is removed from G |
| 17: | ▹ the neighborhood (N[v]) is removed from G |
| 18: end if 19: end procedure | |
The selected vertex v from the current subgraph, chosen for the application of the vertex division rule, meets the following criteria:
- The neighborhood of v has to be incident with at least five internal faces.
- One of the internal faces incident to either possesses the maximum size within the current subgraph, or it shares edges with the outer face.
Applying the vertex division rule to v results in the creation of two new child nodes for the enumerative tree, and , which branch out from the current node. The subgraph linked to is defined as . Meanwhile, the subgraph linked to is defined as .
At this point, a comparable problem to the original problem for each subgraph is built, akin to the issue faced with the original grid G. If the problem is solved recursively and its solution denoted as , then the overall solution for is given by . The described process establishes an enumerative tree, where the leaves represent base subgraph instances.
This branching process continues until a subgraph associated with a child-node-based instance is obtained. A primary feature of any base instance is the absence of a vertex that is incident to four internal faces, except in the case where the subgraph is made up of exactly four adjacent tiles. In this scenario, the current subgraphs are recognized as a base case that will be associated with a child node of the enumerative tree. In Figure 4, the enumerative tree built by the BB algorithm when it is applied to the grid is illustrated.
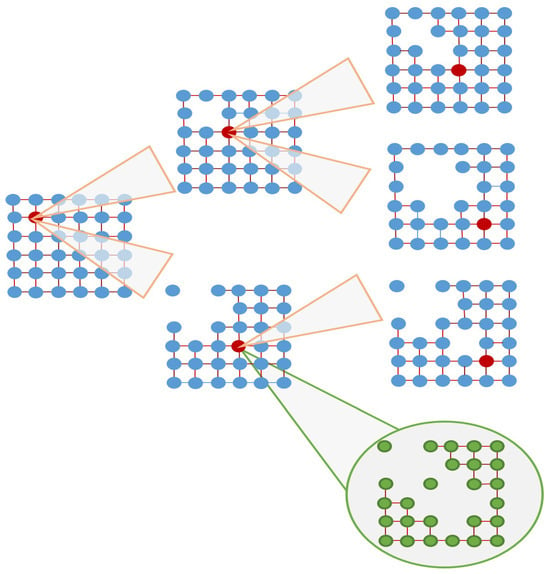
Figure 4.
Processing the grid .
In the previous section, it has been shown how the computation of for the fundamental prime graph can be achieved in linear time with respect to its number of edges. This is possible because these fundamental prime graphs can be considered as outerplanar graphs, as mentioned in [22,23]. Let be the number of internal square faces of the input grid , and let represent the graph linked to a leaf node in the enumerative tree.}. After has been built, the following value is computed: .
Since the computation for each can be carried out in linear time, the overall time complexity of is contingent upon the number of nodes in the enumerative tree. The time complexity of the branch-and-bound procedure results from the number of nodes formed by the recurrence . The branching rule encompasses different scenarios depending on the number of internal faces incident to the vertices in . In the best-case scenario, may be incident to eight tiling faces. In such cases, the decomposition rule, determined by the number of rectangles being decomposed, follows the recurrence: .
Nevertheless, in the worst-case scenario, if G does not align with an optimal case, then must be incident to at least five internal faces. In such situations, the vertex division rule, as expressed by the number of rectangles being decomposed, is defined by the following recurrence:
The aim is to find a solution in the form of . Upon substituting this expression into the preceding recurrence relation (4), the characteristic polynomial is obtained. The five roots of this polynomial correspond to solutions in the form of .
Given the focus is on the asymptotic behavior of the recurrence , the real root is exclusively considered with the condition . In this scenario, the maximum real root is approximately . Consequently, a worst-case upper bound of is derived, where the expression is a polynomial function accounting for the time processing of the basic case in the proposal. Therefore, the total time complexity for the branch-and-bound approach has an upper bound of .
On the other hand, the classic transfer matrix approach involves constructing an initial matrix with dimensions of rows and columns, where denotes the -th Fibonacci number. The rows and columns are labeled with -vectors consisting of zeros and ones. Let S be an independent set of an input grid of m rows and n columns , and let be the set of all vectors v of zeroes and ones, in which two consecutive ones are prohibited, and where a one indicates that its corresponding vertex is in S, and a zero indicates that the vertex is not in S. The cardinality of the set of these vectors is , where corresponds with the -th Fibonacci number.
Consider as a symmetric matrix with dimensions , comprising elements of zeroes and ones. The indexing of both rows and columns of are based on the vectors from .
The requirement for vectors u and v within to constitute a potential consecutive pair of columns in an independent set of is precisely defined by the absence of shared positions containing the value 1. In other words, it is necessary that the dot product of u and v equals 0, employing the conventional dot product of vectors over the real numbers. Then, the entry of in position (u, v) is 1, if ; otherwise, it is 0. is called the transfer matrix of . Then, has inputs with values of zeroes and ones.
The number of independent sets of the grid graph is the result of the sum of all entries of the n-th power matrix , i.e., , where 1 is the vector whose entries are all ones.
Analyzing the complexity time of the computation of , the generation of the initial matrix exclusively entails an order of dot products involving -vectors across the real number domain. Afterward, the computation of request of an order of multiplications among integers, and if the asymptotic behavior of the Fibonacci numbers is considered, the previous upper bound is rewritten as multiplications among integers, considering and approximation to the golden ratio of (1.618). The aforementioned upper bound complexity can be diminished to integer multiplications through the utilization of the Strassen matrix-multiplication algorithm. In any case, the application of the transfer matrix method for computing results in an exponential upper bound on both dimensions m and n of the grid.
When contrasting the upper bound of the time complexity derived from both approaches, the transfer matrix method and the branch-and-bound method, it is evident that the branch-and-bound method has significantly enhanced the time complexity in computing the M-S index on grid graphs. This improvement is attributed to the reduction in the base value as well as the exponentiated function’s superscript values being notably reduced compared to those associated with the transfer matrix method.
While the branch-and-bound method is applicable to any graph, its application specifically to square grid graphs results in an accelerated computational time for computing the M-S index of the input graph. This is achieved by judiciously selecting the vertex in the grid to implement the vertex division rule. Furthermore, the computational time analysis presented here focuses on input instances comprising only grid graphs as input to the branch and bound algorithm.
Indeed, the branch-and-bound method can operate seamlessly on irregular grids or variations of grids, such as the Aztec diamond graphs [7], which is a graph with vertices incident to more than three internal faces. However, while the proposal still exhibits an exponential time complexity, it lacks the explosive combinatorial nature associated with the classic transfer matrix method, a method that was specially designed to compute the number of independent sets in grid graphs.
6. Conclusions
A branch-and-bound algorithm to calculate for grid graphs where m represents the number of rows and n represents the number of columns has been designed. The selected branching rule is widely recognized as the vertex reduction rule. The vertex v chosen for the reduction rule within the current subgraph of must meet the criterion of having incident to a minimum of five internal faces. This strategy entails decomposing the initial grid until reaching the basic cases of the original problem. These basic cases may be either outerplanar subgraphs or subgrids where no neighborhood is incident to a minimum of five internal faces.
Three fundamental counting rules that enable the counting of independent sets in polynomial time for basic graph topologies have been established. These rules work as long as the basic graph is traversed by a Hamiltonian path. Indeed, these counting rules can be applied to compute the number of independent sets for more general topologies than grid graphs. The time complexity of the resulting algorithm for computing the Merrifield–Simmons index in grid graphs is significantly lower compared to the traditional transfer matrix method, which is specifically tailored for computing the number of independent sets in such graphs.
Furthermore, the proposed algorithm exhibits more widespread applicability than those algorithms designed exclusively for calculating the Merrifield–Simmons index in grid graphs, such as the transfer matrix method or more recent thread-based proposals. Indeed, the algorithmic approach developed in this work can be extended to various grid-like graph classes, including irregular grids, general polygonal face grids, and Aztec diamond graphs, or to processing benzenoid systems. This versatility is attributed to the general application of the ramification vertex rule across all classes of graphs.
Author Contributions
G.D.I.L. contributed to the conceptualization, methodology and writing—review and editing of this article; P.B.L. contributed to the validation, programming and writing—review and editing of the proposal; R.M.-R. contributed to the validation, the formal analysis and writing—review and editing the article. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
No new data were created or analyzed in this study.
Acknowledgments
The authors acknowledge and thank the SNII-CONAHCYT for the grants to support their work. The authors would like to thank the anonymous reviewers for their contributions to this paper.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Liu, J.-B.; Pan, X.-F.; Hu, F.-T.; Hu, F.-F. Asymptotic Laplacian-energy-like invariant of lattices. Appl. Math. Comput. 2015, 253, 205–214. [Google Scholar] [CrossRef]
- Baxter, R.J. Planar lattice gases with nearest-neighbor exclusion. Ann. Comb. 1999, 3, 191–203. [Google Scholar] [CrossRef]
- Vadhan, S.P. The Complexity of Counting in Sparse, Regular, and Planar Graphs. SIAM J. Comput. 2001, 31, 398–427. [Google Scholar] [CrossRef]
- Dyer, M.E.; Greenhill, C.S. Corrigendum: The complexity of counting graph homomorphisms. Random Struct. Algorithms 2004, 25, 346–352. [Google Scholar] [CrossRef]
- Calkin, N.J.; Wilf, H.S. The Number of Independent Sets in a Grid Graph. SIAM J. Discret. Math. 1998, 11, 54–60. [Google Scholar] [CrossRef]
- Euler, R. The Fibonacci number of a grid graph and a new class of integer sequences. J. Integer Seq. 2005, 8, 1–16. [Google Scholar]
- Zhang, Z. Merrifield-Simmons index of generalized Aztec diamond and related graphs. MATCH Commun. Math. Comput. Chem. 2006, 56, 625–636. [Google Scholar]
- Montoya, J.A. On the Counting Complexity of Mathematical Nanosciences. MATCH Commun. Math. Comput. Chem. 2021, 86, 453–488. [Google Scholar]
- Merrifield, R.E.; Simmons, H.E. Topological Methods in Chemistry; Wiley: New York, NY, USA, 1989. [Google Scholar]
- De Ita, G.; Tovar, M.; Bernabé, B. A Novel Method for Counting Independent Sets in a Grid Graph. Int. J. Comb. Optim. Probl. Inform. 2023, 14, 11–18. [Google Scholar]
- Valiant, L.G. The complexity of computing the permanent. Theor. Comput. Sci. 1979, 8, 189–201. [Google Scholar] [CrossRef]
- Greenhill, C.S. The complexity of counting colourings and independent sets in sparse graphs and hypergraphs. Comput. Complex. 2000, 9, 52–72. [Google Scholar] [CrossRef]
- Luby, M.; Vigoda, E. Approximately Counting up to Four (Extended Abstract). In Proceedings of the Twenty-Ninth Annual ACM Symposium on Theory of Computing: STOC ’97, El Paso, TX, USA, 4–6 May 1997; pp. 682–687. [Google Scholar] [CrossRef]
- Bubley, R. Randomized Algorithms: Approximation, Generation, and Counting; Springer: Berlin/Heidelberg, Germany, 2001. [Google Scholar]
- Dahllöf, V.; Jonsson, P. An Algorithm for Counting Maximum Weighted Independent Sets and Its Applications. In Proceedings of the Thirteenth Annual ACM-SIAM Symposium on Discrete Algorithms: SODA ’02, San Francisco, CA, USA, 6–8 January 2002; pp. 292–298. [Google Scholar]
- Roth, D. On the hardness of approximate reasoning. Artif. Intell. 1996, 82, 273–302. [Google Scholar] [CrossRef]
- Golin, M.J.; Leung, Y.; Wang, Y.; Yong, X. Counting Structures in Grid Graphs, Cylinders and Tori Using Transfer Matrices: Survey and New Results. In Proceedings of the Seventh Workshop on Algorithm Engineering and Experiments and the Second Workshop on Analytic Algorithmics and Combinatorics, ALENEX/ANALCO 2005, Vancouver, BC, Canada, 22 January 2005; pp. 250–258. [Google Scholar]
- Guillen, C.; Lopez, A.L.; DeIta, G. Computing #2-SAT of Grids, Grid-Cylinders and Grid-Tori Boolean Formulas. In Proceedings of the 15th RCRA Workshop on Experimental Evaluation of Algorithms for Solving Problems with Combinatorial Explosion, Udine, Italy, 12–13 December 2008; CEUR-WS.org. Volume 451, pp. 152–167. [Google Scholar]
- Roth, R.; Siegel, P.; Wolf, J. Efficient coding schemes for the hard-square model. IEEE Trans. Inf. Theory 2001, 47, 1166–1176. [Google Scholar] [CrossRef]
- Zhang, Z. Merrifield-Simmons index and its entropy of the 4-8-8 lattice. J. Stat. Phys. 2014, 154, 1113–1123. [Google Scholar] [CrossRef]
- Karp, R.M. Reducibility Among Combinatorial Problems. In Complexity of Computer Computations; Miller, R.E., Thatcher, J.W., Bohlinger, J.D., Eds.; Plenum: New York, NY, USA, 1972; pp. 85–103. ISBN 978-1-4684-2003-6. [Google Scholar] [CrossRef]
- De Ita, G.; Rodríguez, M.; Bello, P.; Contreras, M. Basic Pattern Graphs for the Efficient Computation of Its Number of Independent Sets. In Proceedings of the Pattern Recognition—12th Mexican Conference, MCPR 2020, Morelia, Mexico, 24–27 June 2020; Volume 12088, pp. 57–66. [Google Scholar] [CrossRef]
- Medina, M.A.L.; Marcial-Romero, J.R.; Luna, G.D.I.; Moyao, Y. A Linear Time Algorithm for Computing #2SAT for Outerplanar 2-CNF Formulas. In Proceedings of the Pattern Recognition—10th Mexican Conference, MCPR 2018, Puebla, Mexico, 27–30 June 2018; Volume 10880, pp. 72–81. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).