1. Introduction
With the rapid expansion of global data volumes, machine learning has become extensively adopted and serves as a principal tool for data analysis across various sectors such as transportation, computer vision, finance, and security [
1,
2]. However, a widely acknowledged truth is that machine learning models are susceptible to adversarial examples. Attackers can probe machine learning models and maliciously manipulate their inputs to mislead the recognition outcomes [
3,
4]. For instance, a machine learning-powered malware detector ingests features extracted from Portable Executable (PE) files and categorizes a test case as either malware or benign software. Here, an adversary could tamper with a malware input by introducing barely perceptible perturbations, thereby tricking the detector into classifying it as benign software [
5].
Adversarial samples become serious security threats for many machine learning-based systems, e.g., by extracting sufficient knowledge to exploit Google’s phishing pages filter [
6] and PDFRATE system-based attack [
7].
Various countermeasures against evasion attacks have been proposed. Previous research demonstrates that dimensionality reduction can be an effective defense mechanism against evasion attacks [
8]. Another defensive strategy is adversarial training [
9], which incorporates adversarial examples into the training process. Some studies indicate that defensive distillation can be leveraged to enhance the robustness of neural networks against adversarial examples [
10].
Furthermore, ensemble methods have been put forward as defense mechanisms. Intuitively, it is more challenging for an attacker to undermine a group of models than a single one. Strauss et al. [
11] argue that compromising individual classifiers does not necessarily imply that other classifiers within the ensemble will also succumb to the attack. Their experimental findings substantiate that ensemble methods can indeed act as defensive strategies against evasion attacks. Tramèr et al. [
12] propose an ’Ensemble Adversarial Training’ approach, aimed at training a robust classification model that is resilient to such attacks. Previous research has also demonstrated that ensemble SVMs are generally more robust against evasion attacks compared to a single SVM [
13].
However, recent studies have indicated that conventional ensemble learning methods may not necessarily enhance the robustness of learning models. Zhang et al. [
14] and Kantchelian et al. [
15] have demonstrated that tree ensembles can be more prone to evasion attacks than SVM classifiers, whether they are single or an ensemble. Zhang et al. [
16] noted that ensemble SVMs are not necessarily more robust against evasion attacks compared to single SVMs. These studies show that it is still possible for attackers to launch evasion attacks on ensemble models. In 2019, Pang et al. [
17] proposed a novel method, Adaptive Diversity Promoting (ADP), which improves the robustness of deep ensembles by promoting diversity in non-maximal predictive scores while keeping the maximal (most likely) prediction consistent with the true label for members in the ensemble. It reveals that promoting the diversity of ensemble models can improve their robustness against adversarial samples.
The main limitations of Linear and Kernel SVM classifiers lie in the fact that their designs do not inherently account for security aspects, rendering them less robust against evasion attacks. Zhang et al. [
18] proposed an adversarial feature selection approach that incorporates security considerations into the training process, thereby improving the robustness of single SVM classifiers. Despite this improvement, single SVM classifiers generally exhibit lower classification accuracy when compared to ensemble methods. Smutz et al. [
13] advocated for the use of ensemble SVMs to against evasion attacks; however, Zhang et al. [
16] pointed out that ensemble SVMs are not necessarily more robust than single SVMs against evasion attacks in practical settings.
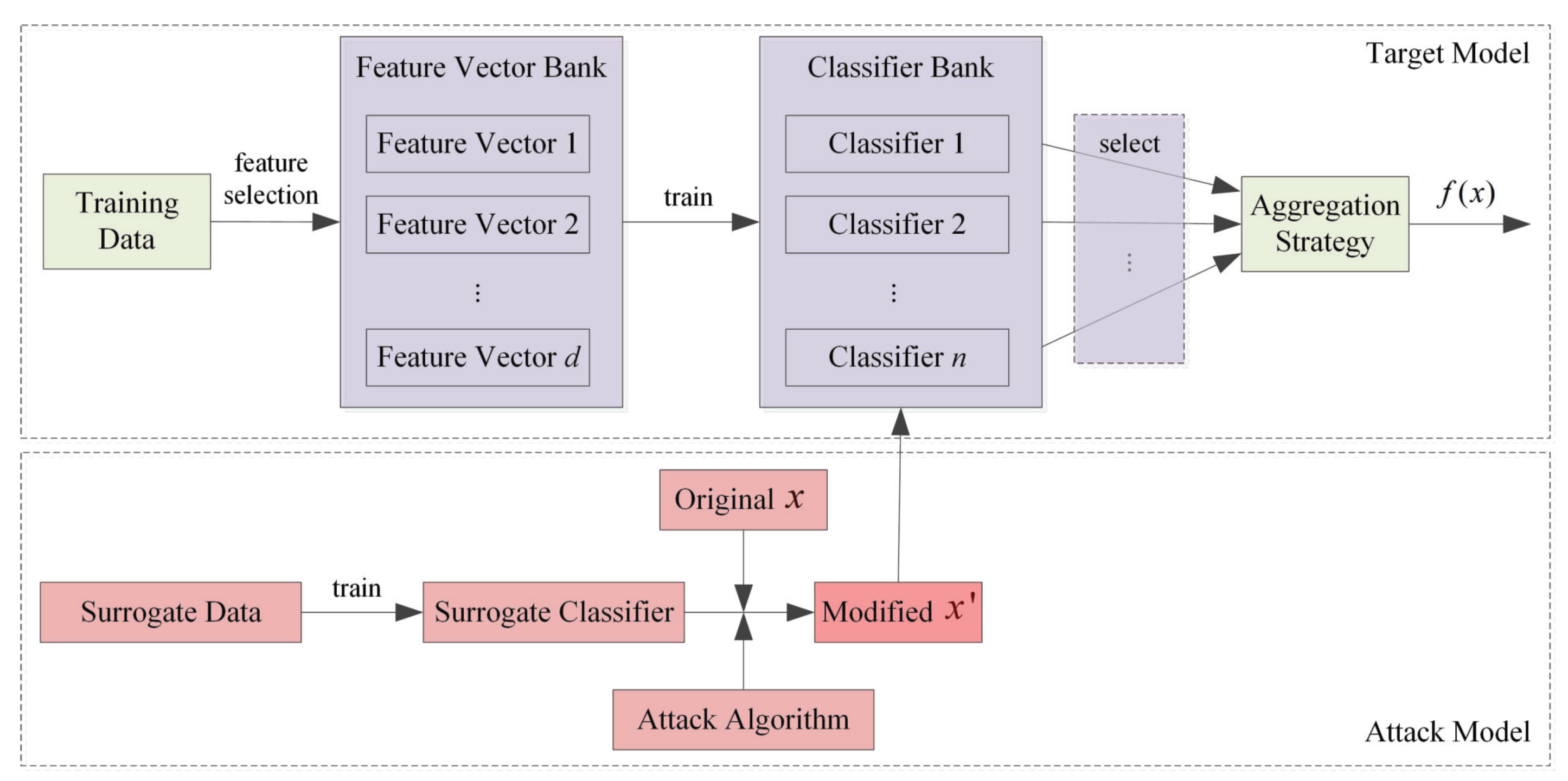
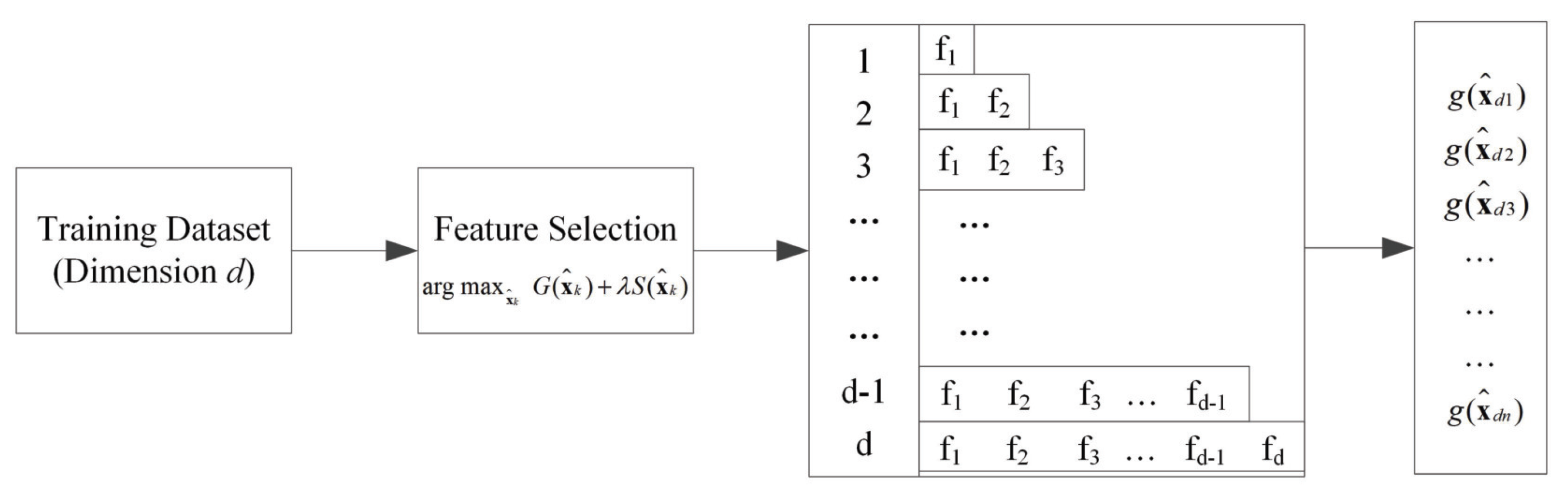
Consequently, we propose to improve the robustness of ensemble classifiers by employing diversified feature selection and stochastic aggregation, thus aiming to create a more resilient solution against adversarial threats. The underlying idea of our approach is to build ensemble classifiers not based on the combination of
weaker classifiers, but the ensemble of classifiers that are robust against adversarial samples. We exploit the adversarial feature selection approach [
18] to train the base classifiers because this method makes a trade-off between the generalization capability and its security against evasion attacks. Experimental results on real-world datasets demonstrate that our approach significantly enhances the classifiers’ robustness against adversarial examples while maintaining comparable accuracy levels even when there is no attack.
The main contributions are summarized as follows:
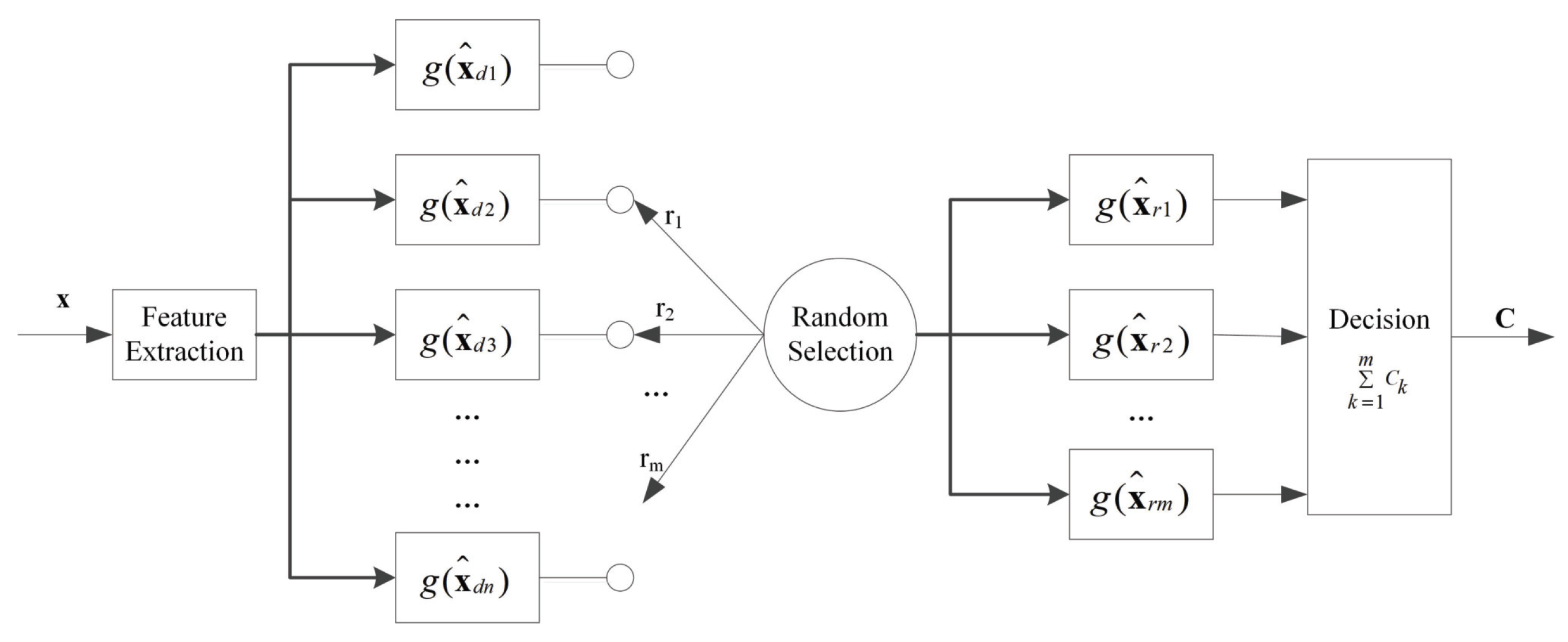
We propose a novel approach to train base classifiers using sequential feature selection, wherein each base classifier encompasses all the features of the preceding trained classifier and subsequently selects an additional new feature.
We introduce stochastic aggregation, in which m classifiers are randomly selected from the base classifier bank to participate in decision-making, which not only improves the classification accuracy, but also improves the robustness against evasion attacks.
We re-investigate the security evaluation problem, and update the gradient correlation measure to extend it to be suitable for any real number feature.
To evaluate the performance of the proposed model, we launched lots of experiments, and the experimental results demonstrate that the proposed ensemble model can improve the robustness against evasion attacks.
5. Classifier Security Evaluation
Following the adversary model presented in [
19,
20,
44], an attacker’s knowledge can be described in four levels: (1) the training data
; (2) the feature set
; (3) the learning algorithm
f, and (4) the targeted model parameters
. Thus, the knowledge can be characterized in terms of
. According to this assumption, the knowledge of an attacker can be divided into two categories:
White-box attacks: An attacker is assumed to know all of the targeted model, namely .
Black-box attacks: In this scenario, an attacker is assumed to possess some level of knowledge about the targeted model. In this paper, we suppose that the attacker knows f and , whereas and remain unknown to the attacker. However, an attacker can estimate the parameters namely trained on a subset of or a surrogate dataset of samples drawn from the resemble distribution of . The surrogate dataset may be collected from an alternate source. Thus, we can define this scenario as .
In this paper, we examine the robustness of SVM classifiers under black-box attack scenarios (while the evaluation under white-box attacks will be given in discussion). With regard to the attacker’s knowledge about the dataset , we consider two distinct attack situations. One is subset scenario which assumes a subset of is able to be collected by an attacker, i.e., . The other is surrogate data scenario which assumes a surrogate dataset drawn from the resemble distribution of can be collected by an attacker.
The gradient descent evasion attack is adopted to solve the optimization problem in Equation (
1), which was shown to be effective against SVM-based classifiers [
16,
20]. The process of the gradient descent evasion attack is detailed in Algorithm 3.
The gradients of single SVMs and ensemble SVMs can be found in [
16]. Here, we give the gradients of the proposed ensemble SVMs used in this paper followed by the updated gradient correlation measure.
| Algorithm 3 Gradient Descent Evasion Attack |
Input: : the initial attack point, : the gradient step size, : the maximum number of iterations. Output: : the final attack point.
- 1:
Make and a matrix - 2:
Rearrange the matrix according to the descending order of - 3:
- 4:
while && do - 5:
- 6:
if && then - 7:
- 8:
else if && then - 9:
- 10:
end if - 11:
end while - 12:
return:
|
5.1. Gradients of the Proposed Ensemble SVMs
Because the classifiers that participate in decision-making are randomly selected from the classifier bank, it is difficult to find the exact gradient. In this section, we give three approaches to find approximate gradients. As discussed above, we assume an attacker knows and f. Here, we further assume that the attacker is aware of the number of classifiers selected in the ensemble, which is parameter m.
Averaging gradient: This means we average each gradient of the classifier from the classifier bank, the gradient function is just like gradients of ensemble SVMs.
Gradient of the minimal features: Since only one feature is added from one feature vector to the next, the shortest feature vector must be contained within all the other vectors, suggesting that these features could be the most significant in the ensemble. Typically, classifiers do not use very few features, such as just one or two. It is worthwhile to investigate the attack efficiency leveraging this gradient.
Gradient of the maximal features: Given the difficulty in determining which specific features contribute significantly to the classification process, it is a prudent choice to employ all available features.
5.2. Updated Gradient Correlation
In [
16], we proposed a gradient correlation measure to evaluate the similarity of gradient between the surrogate and targeted classifiers, which is given by
where
Let denote the original gradient vector of the targeted classifier, is the vector which sorted in descending order, i.e., . is the gradient vector of surrogate classifier with the absolute gradient value of target classifier for the same features between the targeted and surrogate classifiers. n is the amount of features adopted in the targeted classifier.
There are two issues with this metric. First, in
, gradients of all
n features are computed, but not all features need to be modified to launch an attack. Therefore, in the updated gradient correlation (
), only gradients of the modified features are taken into account. The second issue is that the original
only considers binary features. In the updated version of
, we expand it to accommodate any real-valued feature. The updated gradient correlation is given by
where
l represents the number of modified features to let
.
denotes the step size and
, when each feature value is normalized to [0,1]. For binary features,
. The detailed procedure of updated gradient correlation measure is given by Algorithm 4. From Algorithm 4, we can see that
,
and
correspond to the most correlated and the most uncorrelated gradient distribution, respectively.
| Algorithm 4 Updated Gradient Correlation |
Input: , : the original gradient vector of the targeted classifier, : the features adopted in the targeted classifier; , : the original gradient vector of the surrogate classifier, : the features adopted in the surrogate classifier, ; n: the amount of features adopted in the targeted classifier; m: the amount of features adopted in the surrogate classifier; l: the amount of modified features. Output:
- 1:
sort in descending order; - 2:
sort in descending order; - 3:
; - 4:
while do - 5:
find the position of in if exist, otherwise ; - 6:
if then - 7:
- 8:
else - 9:
- 10:
end if - 11:
- 12:
end while - 13:
if
then - 14:
- 15:
end if - 16:
- 17:
return:
|
To illustrate how the updated gradient correlation works, consider the following case with five binary features (see
Figure 4). The top left of
Figure 4 shows the original gradient vector
and the feature vector
from the targeted classifier.
denotes the vector sorted by
in descending order and
is the feature vector sorted with
. The top right of
Figure 4 shows the original gradient vector
and the feature vector
from the surrogate classifier.
denotes the vector sorted by
in descending order and
is the feature vector sorted with
.
is the gradient vector of the surrogate classifier relative to the targeted classifier.
Why use ? From Algorithm 3, one can see that, in a gradient descent attack, an attacker modifies features according to the value of their gradients. In this example, according to the sequence of modifying features obtained by an attacker, the first feature should be modified is , and the gradient change is 3 for the targeted system by modifying . According to the gradient of the targeted system, the feature with the greatest impact is . By modifying , the gradient change is 4. Therefore, in the case of modifying only one feature (), the gradient ratio between the surrogate system and the targeted system is . If two features need to be modified (), an attacker will modify and , the sum of the gradients corresponding to these two features is 4, while for the targeted system, modifying two features can make the gradient change 7, so . In the case, we assume an attacker needs to modify three features to let . Thus, and . It should be noted that we use to represent the updated version of gradient correlation.
6. Experimental Evaluation
In this section, we evaluate the robustness of ARE SVMs, RSE SVMs (Random Subspace Ensemble SVMs [
13,
37]), a conventional SVM and a SVM trained by adversarial feature selection [
18]; we call this approach AFS SVM. However, the authors did not show how to determine the optimal number of selected features. Through the analysis of the results in the paper [
18], we discovered that both classification accuracy and robustness perform satisfactorily when approximately half of the total number of features are selected to train the SVM. Consequently, half the number of features were chosen to train the AFS SVM. Three tasks, namely spam email filtering, malware detection and digit recognition, are considered in the evaluation. In both the subset scenario and the surrogate data scenario, we vary an attacker’s knowledge by portions of data,
.
For RSE SVMs, each ensemble classifier contained 100 independent base classifiers and the feature bagging ratio was set to 50%. For ARE SVMs, we applied five-fold cross-validation to train models. For each Linear-SVM-based classifier, the SVM regularization parameter was set to . For all RBF-SVM-based classifiers, we set the regularization parameter and the kernel parameter .
Both the updated gradient correlation and the hardness of evasion [
18] measures were adopted for security evaluation. For a single SVM, AFS SVM and RSE SVMs, we ran each experiment 30 times and the results were averaged to produce the figures. For ARE SVMs, 30 independent models were built and we ran 30 times on each model. Thus, the results showed in the figures were averaged by 900. All experiments in the paper were implemented using MATLAB. The following shows the experimental results on three real application datasets.
6.1. Feasibility Analysis on Spam Email Filtering
We consider the PU3 dataset in the spam email filtering task [
45,
46]. We apply the experimental setup described in [
16]. There are three subsets split by 4130 emails—one for training, one is used for the surrogate data, and the last one is used for testing.
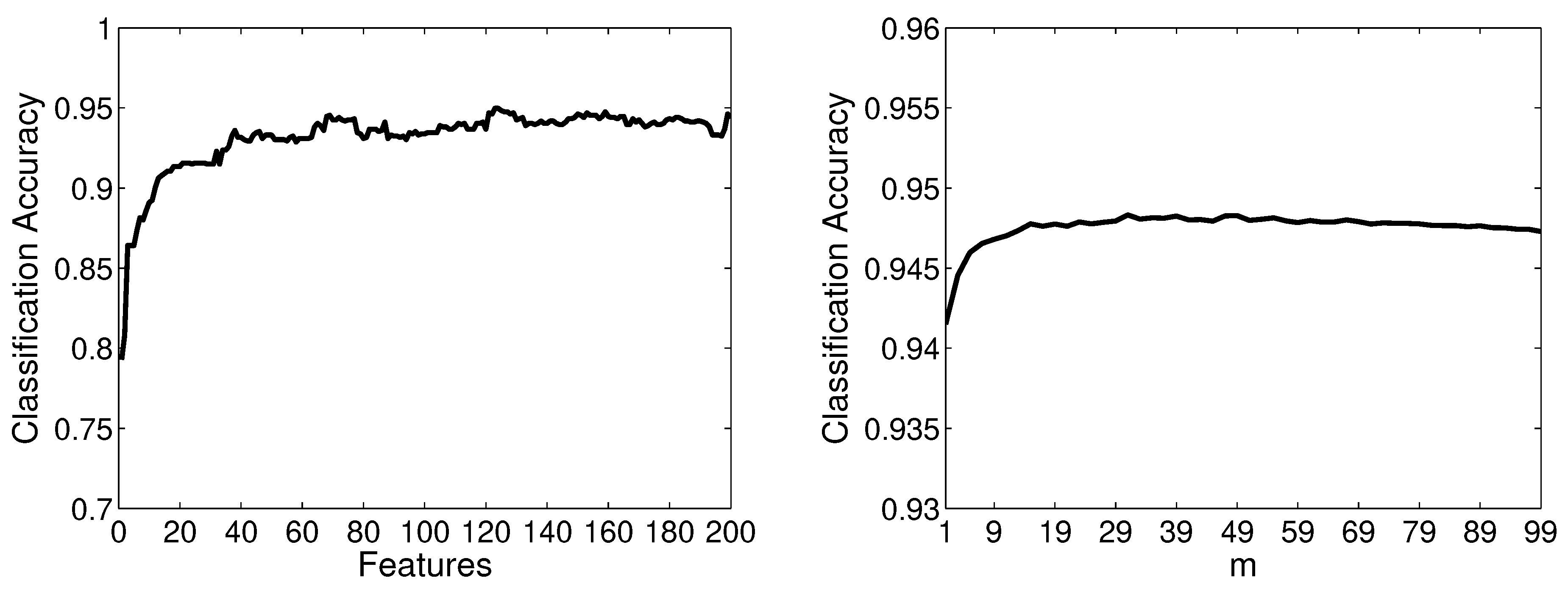
Firstly, we give the results based on Linear-SVM and use the spam email filtering case study to show how to select parameters for ARE SVMs. Then we compare the results with single SVM, AFS SVM and RSE SVMs. The left side of
Figure 5 shows the classification accuracy achieved by ARE Linear-SVMs trained using single feature vectors. We can see that the more features are selected in the vector, the the higher accuracy, when less than 40 features are selected. The accuracy is not much different when more than 40 features are selected in the vector. In order to obtain high and stable classification accuracy, the feature vectors whose feature number is more than half of the original feature space are selected to train the classifiers in the rest of the experiments. The right side of
Figure 5 shows the classification accuracy achieved by ARE Linear-SVMs in which the base classifiers are trained using feature vectors with more than 100 features. It is clear that higher accuracy is achieved with a larger
m. We believe
is a good choice for our evaluation tasks.
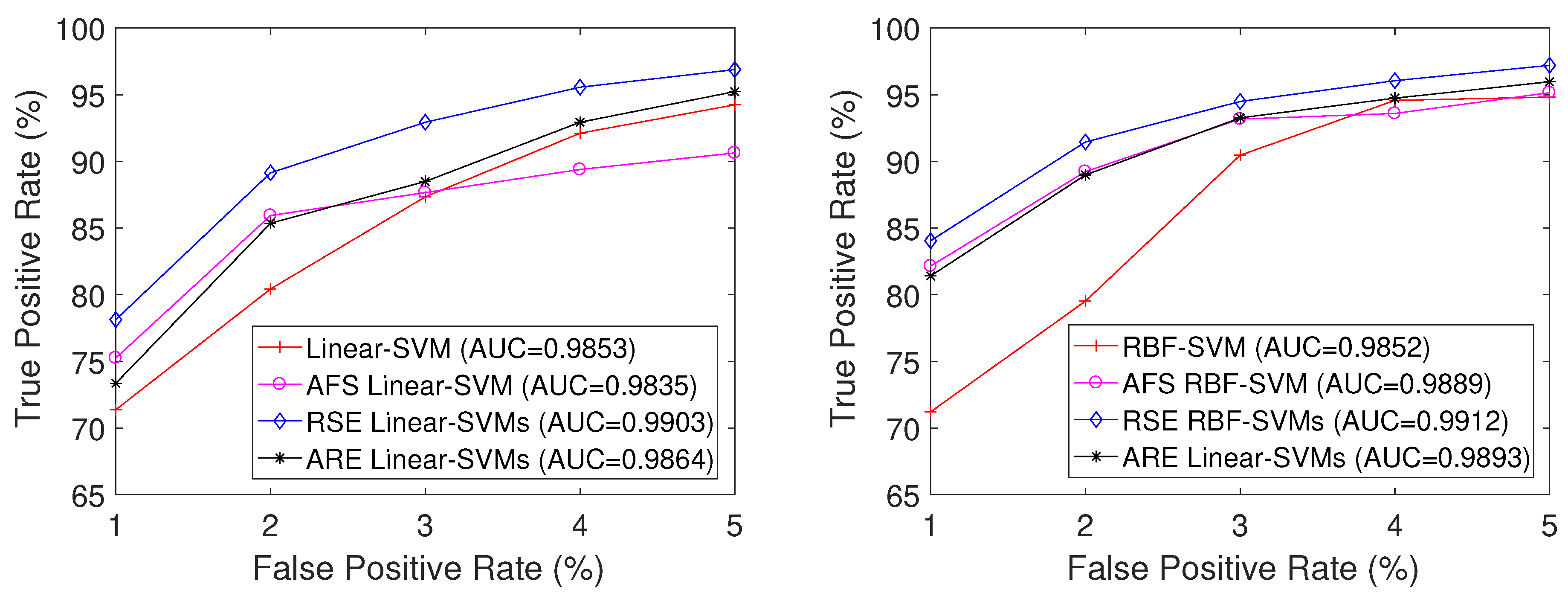
Figure 6 shows the mean ROC curves of the four methods based on Linear-SVM and RBF-SVM, respectively. From the figure, it is evident that ARE SVMs exhibit the second-highest classification performance, with RSE SVMs demonstrating the top performance among them.
As illustrated on the left-hand side of
Figure 7, ARE SVMs consistently demonstrate higher robustness compared to RSE SVMs and single SVMs, regardless of the amount of data accessible to the attacker. Furthermore, this figure highlights that among the three types of gradients in ARE SVMs, the averaging gradient proves to be more effective than the rest. There is not a significant distinction between the gradient of minimal features and the gradient of maximal features.
On the right side of
Figure 7, the gradient correlation measures for the four methodologies are displayed. It can be observed that ARE SVMs consistently exhibit lower
scores than RSE SVMs and single SVMs, corroborating the findings in the left-hand portion of the figure. A higher
score indicates a closer approximation of the gradient estimate between the surrogate and targeted classifiers, rendering the system more susceptible to attacks.
Figure 7 also reveals that, for the ARE approach, the averaging gradient attack is more effective than the other two methods. Thus, we only give results of the averaging gradient attack in the rest of the paper.
Figure 8 shows that, under the surrogate data attack scenario, ARE SVMs are still harder to compromise than RSE SVMs and single SVMs. In this scenario, the amount of surrogate data is not as critical as that in the subset scenario and RSE SVMs are always easier to compromise by modifying fewer words on average. The gradient correlation results shown in the right side of
Figure 8 also support this observation, which is ARE SVMs always have lower gradient correlation scores than RSE SVMs and single SVMs and the scores of RSE SVMs much higher than the others.
The results of RBF-SVM-based classifiers are shown in
Figure 9. The results show the same trend as Linear-SVM-based classifiers. The ARE classifiers always have the highest hardness of evasion scores and lowest gradient correlation scores, which indicates the ARE approach is more robust than RSE SVMs and single SVMs.
6.2. Case Study on Malware Detection in PDF
Malware detection is another real-world task we considered in this paper. Also, the PDF dataset and the experimental setup described in [
16] are applied in these experiments.
In this task, the gap in evasion difficulty between single SVMs and RSE SVMs is quite narrow for both Linear-based and RBF-based SVMs, and AFS SVMs significantly outperform these two methods according to
Figure 10. Notably, ARE SVMs prove to be the most resistant to evasion, requiring almost twice the number of features to be manipulated for successful evasion compared to Linear-SVMs, RBF-SVMs, and RSE SVMs when the attacker possesses identical knowledge about the dataset
.
Figure 11 presents the gradient correlation scores, which further substantiate this observation, showing that ARE SVMs consistently display the lowest scores. This suggests that ARE SVMs exhibit enhanced robustness against gradient descent attacks.
6.3. Case Study on Handwritten Digit Recognition
The third task involves handwritten digit recognition, utilizing the MNIST dataset. In accordance with [
14], we specifically discriminate between the digits “2” and “6”. Thus, we have 11,876 images for training and 1990 images for testing purposes. From the pool of 11,876 images, we randomly select 1000 samples and partition them into two subsets, each containing 500 images, which serve as the training data and the surrogate data, respectively. To assess robustness, we choose 100 instances of the digit “6” from the test data, ensuring that all the considered models accurately recognize these 100 instances. For evaluating the overall classification performance, all 1990 images are employed.
From
Figure 12, it can be discerned that for both Linear-based and RBF-based SVMs, ARE SVMs consistently maintain the second-highest classification performance. However, in the case of Linear-based SVMs, the optimal performance is achieved by RSE Linear-SVMs, while for RBF-based SVMs, the highest degree of performance is attributed to RBF-SVM.
In the digit-recognition task,
Figure 13 confirms that ARE SVMs remain the most robust classifiers. The performances of the other methods are relatively similar. The gradient correlation scores displayed in
Figure 14 further validate this observation, as ARE SVMs consistently exhibit the lowest scores, while the scores of the other three approaches are closely clustered.
8. Conclusions
Machine learning technology was initially designed with the aim of enhancing generalization capabilities. Under this objective, machine learning has thrived and been widely deployed across numerous domains such as image recognition, intrusion detection, among others. However, conventional learning-based algorithms are inherently susceptible to adversarial attacks because their original design did not account for the presence of intelligent adversaries capable of manipulating their behavior to deceive classification algorithms.
In this paper, we propose a method to improve the adversarial robustness of ensemble classifiers through diversified feature selection and stochastic aggregation. Unlike conventional ensemble classifiers that aggregate multiple
weak classifiers, our ensemble is composed of multiple
strong classifiers. The
strong classifiers within AREC are trained by optimizing both their generalization ability and robustness against evasion attacks. For the ensemble integration strategy, the generalization capacity is further bolstered by employing multiple classifier voting. The application of randomly selecting decision classifiers serves to obfuscate the decision boundary of AREC. Additionally, we have updated the gradient correlation measure to ensure it is applicable to any real-number feature. Experimental results across various tasks such as spam email filtering, PDF malware detection, and handwritten digit recognition demonstrate that our proposed approach offers superior robustness compared to conventional single and ensemble classifiers. Furthermore, in contrast to the state-of-the-art algorithm AFS [
18], which trades off generalization capability for security, our method significantly boosts robustness while marginally improving generalization capability.
Our future works involve designing an efficient adversarial feature selection algorithm to mitigate the training costs associated with AREC. Additionally, we aim to extend the proposed gradient correlation metric to explore the security performance of diverse learning-based classifiers beyond the current scope.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}