1. Introduction
One common phenomenon in statistics is the presence of excess zeroes only. This phenomenon happens when there are more zero-valued observations than explained by the Poisson distribution. There have been numerous studies conducted in analysing count data with zero-inflation such as zero-inflated models [
1,
2,
3,
4], hurdle models [
4], zero-altered models [
3] and others. Young et al. [
5] has provided a comprehensive review on the use of the zero-inflated models and its associated regression models. The zero-inflated models are commonly used to explain the excess zeroes by introducing an inflation parameter known as zero-inflation parameter.
Recently, the presence of excess zeros and ones in count data have been gaining attraction by researchers as they are also common in statistics. This phenomenon happens when there is an abundance of observed events that are not happening and happening only once. This phenomenon arises quite naturally depending on the questions we would like to answer. Lin and Tsai [
6] have provided a list of questions that will ultimately give the observations inflated at zero and non-zero. For inflation at zero and one, asking questions about a memorable event that happened in one’s life such as the number of marriages [
6] will certainly yield results that have a huge spike at zero and one because it is natural and common across time for mankind to either stay single or get married to one person at a time or in life. The phenomenon of excess zeros and ones can also be found in various fields such as medicine [
6] as well as quantitative criminology [
7,
8].
Introducing two inflation parameters into an existing distribution to describe excess zeros and ones, respectively, is normal and extensively researched [
6,
7,
8,
9,
10]. Although the zero–one-inflated Poisson distribution (
ZOIP) was introduced in the late 20th century by Melkersson and Olsson [
9], its stochastic representations were not explored until 17 years later by Zhang et al. [
10]. The study by Zhang et al. [
10] interrelates the
ZOIP distribution with other known Poisson distributions such as the zero-inflated Poisson, the zero-truncated Poisson and the one-truncated Poisson distributions. Following the idea of Zhang et al. [
10], this paper examines and discusses some notes on the stochastic representations for the zero–one-inflated Poisson Lindley distribution (
ZOIPL) developed by Tajuddin et al. [
8]. Likelihood ratio tests are also developed to investigate whether the presence of one-inflation and fixed parameters is significant.
The probability mass function (pmf) for a random variable
Y following the
ZOIPL distribution [
8] is given as:
where
and
explain the excess zeroes and ones, respectively, and
is the parameter of the Poisson Lindley,
distribution [
11]. The
distribution has been shown to provide a better fit than the Poisson distribution due to its ability to handle overdispersion in the data [
11,
12]. The parameter
in the
distribution plays a crucial role in determining the variation in the distribution. As
increases, the variance and the mean of the
distribution approach to an identical value, a phenomenon known as equidispersion (see [
12], 2009 for further explanation). Similarly, the
distribution has also been shown to provide better model fittings over the
distribution due to its ability to handle extra dispersion, of which cannot be single-handedly described by the inflation parameters in the
distribution [
8].
Note that, if
, the
distribution reduces to a one-inflated Poisson Lindley,
distribution with parameters
and
, which have not been studied yet. Readers are advised to not be confused with a one-inflated-positive Poisson Lindley distribution, which was developed to cater for inflation in one-valued data in positive count data [
13]. If
, the
distribution reduces to the zero-inflated Poisson Lindley distribution (
) with parameters
and
[
14]. If both
, the
distribution reduces to the standard
distribution with parameter
. From the special cases, we can already identify the relationship between these distributions. Based on this idea, the stochastic representations of the
distribution can be studied.
Before proceeding with the stochastic representations, we first adopt the definition of a degenerate distribution from Zhang et al. [
10] to obtain an identical but compact representation for the pmf of the
ZOIPL distribution. Let
be a random variable which follows a degenerate distribution at a single constant point
with
. Let
,
and
be mutually independent. Therefore, the pmf of the
can be written as
where
refers to the indicator function,
,
and
refers to the inflation parameters for excess zeroes and ones, respectively.
The paper is organized as follows:
Section 2 describes various stochastic representations of the
ZOIPL distribution.
Section 3 describes the derivations of
moments based on the different stochastic representations.
Section 4 describes the derivations of conditional distributions for selected stochastic representations.
Section 5 presents several likelihood ratio tests to assess the presence of inflating parameters as well as fixed
θ.
Section 6 examines the performance of the likelihood ratio tests through a simulation study.
Section 7 concludes the study.
2. Stochastic Representation (SR)
Several stochastic representations are discussed to highlight the relationship between the
ZOIPL distribution with the zero-inflated Poisson Lindley (
), the zero-truncated Poisson Lindley (
and the Poisson Lindley,
distributions.
Table 1 provides the probability mass functions for the remaining three distributions.
Before the stochastic representations for the
distribution is discussed, we adapt some notations from Zhang et al. [
10] and present them in
Table 2 to facilitate the understanding of the stochastic representations.
2.1. First Stochastic Representation (SR1)
Let
and
, such that
. The first SR for random variable
is given as
, or equivalently,
Since
with
where
, the pmf of
can be written as:
From the first SR, the pmf is identical as the pmf of the distribution. Therefore, the random variable can be denoted as the mixture of , and distributions.
2.2. Second Stochastic Representation (SR2)
Let
,
and
, such that
. The second SR for random variable
is given as
, or equivalently,
Thus, the pmf of
is given as
Using the reparameterizations and , it can be obtained that and . In other words, the random variable can be denoted as the mixture of and .
2.3. Third Stochastic Representation (SR3)
Let
,
and
, such that
. The third SR for random variable
is given as
, or equivalently,
Thus, the pmf of
is given as
Using the reparameterizations , and , one can obtain that and . In other words, the random variable can be denoted as the mixture of and .
2.4. Fourth Stochastic Representation (SR4)
Let
,
, such that
. The fourth SR for random variable
is given as
, or equivalently,
Thus, the pmf of
is given as
Using the reparameterizations , and , one can obtain that , and . Therefore, can be denoted as the mixture of , and .
6. Simulation Studies
In this section, the hypotheses and its corresponding likelihood ratio tests will be investigated via simulation studies. The simulation studies aim to compare the type I error rates under and the powers under .
6.1. Data Generation
To generate random data which follow the distribution, first, recall the SR1. We independently draw for , where for . We also draw independently. Then, we set for and , where .
6.2. General Algorithm for Hypothesis Testing
Let
be the number of rejecting the
. The type I error rate is obtained by computing
when
is true, whereas the power of the test is obtained by computing
when we fail to reject
. For the type I error and the power of the test, the sample sizes are set to be
. The procedure to determine the type I error rate and the power of the test is repeated
times. The adjusted Wald technique [
17] is used to obtain the 95% confidence interval for the type I error rates. Bradley’s liberal criterion [
18] has outlined that if the type I error rates are in the interval
, the test is robust. In this case,
, so the test is considered robust when type I error rates are between
and
.
6.3. The Presence of One-Inflation
Recall that the
and
. For this simulation study, the value of
is fixed at
, while the value of
varies:
. These different values of
were selected based on previous studies [
8] for the
distribution. These
s are used to study the type I error rates. The results of the simulation studies are shown in
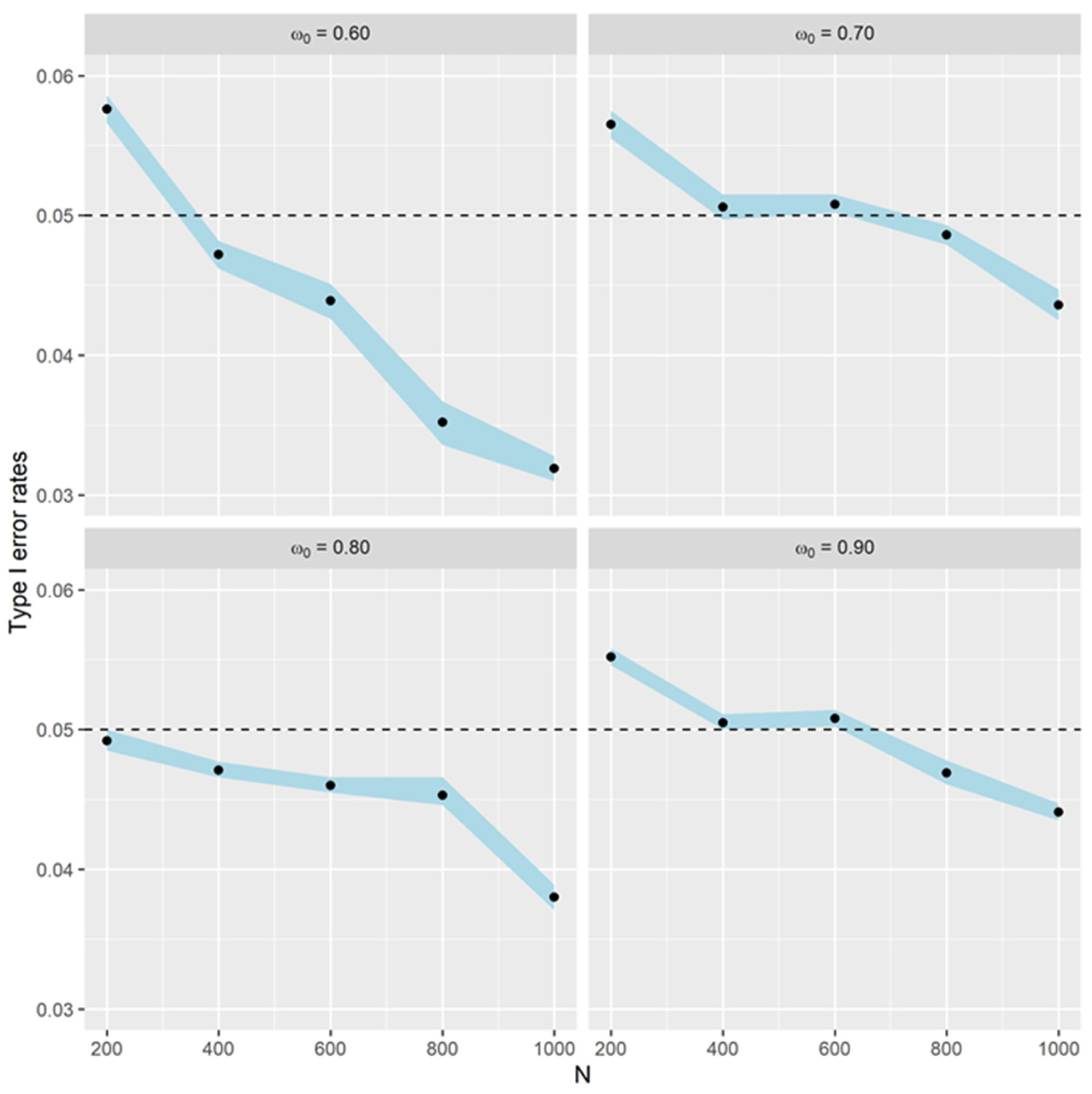
Figure 1.
Figure 1 shows the type I error rate plots for varying
. When
, a sample size of 400 is sufficient to make the type I error rate fall below 0.05. On the other hand, when
, at least a sample size of 800 is needed to make a type I error rate fall below 0.05. Surprisingly, when
, even 200 samples are sufficient. It can be observed that for each value of
, the type I error rates decrease with increasing sample size
and fall below
. Zhang et al. [
10] mentioned that the smaller the type I error rate, the better the performance of the likelihood ratio test in controlling the error rates.
To assess the power of the test, the values of
under
are set at
with
. Let
be the number of rejections of
. The power of the test is obtained by calculating
when
. The results of the simulation studies are shown in
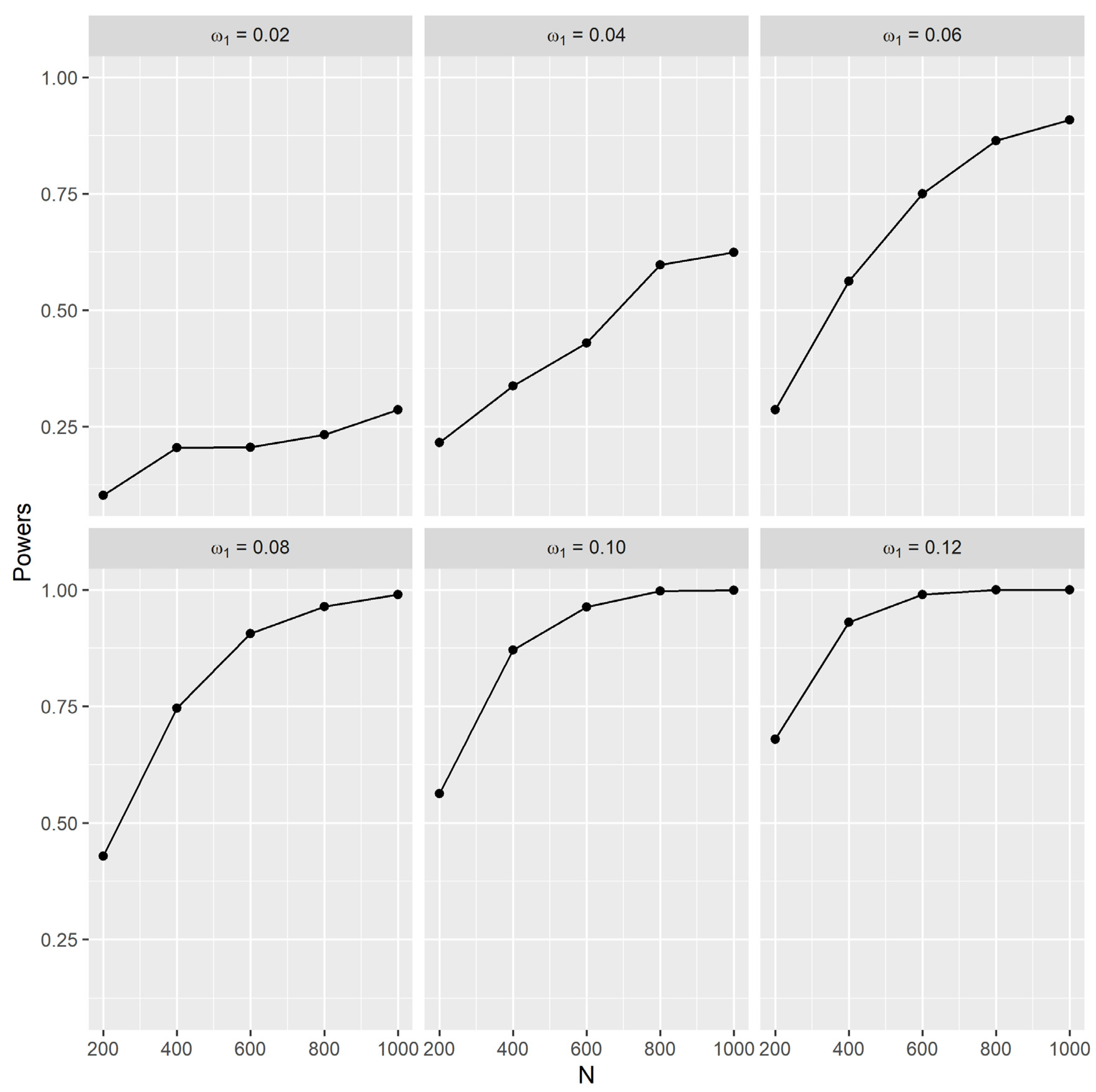
Figure 2.
Figure 2 shows the plots for the power of the test when
varies. It can be observed that the power of the test increases when
and the sample size
increase. Achieving at least 80% power can be carried out for
with at least a sample size of 800. For
, a large sample size is required for the test to obtain 80% power. This means that when
is small and close to zero, the test cannot accurately identify the existence of excess ones in the data. Generally, the larger the value of
, the quicker the power of the test increases as the sample size increases.
6.4. Fixed
Recall that the
and
. For this simulation study, the value of
varies:
for the study of Type I error rates. The values for
and
are fixed.
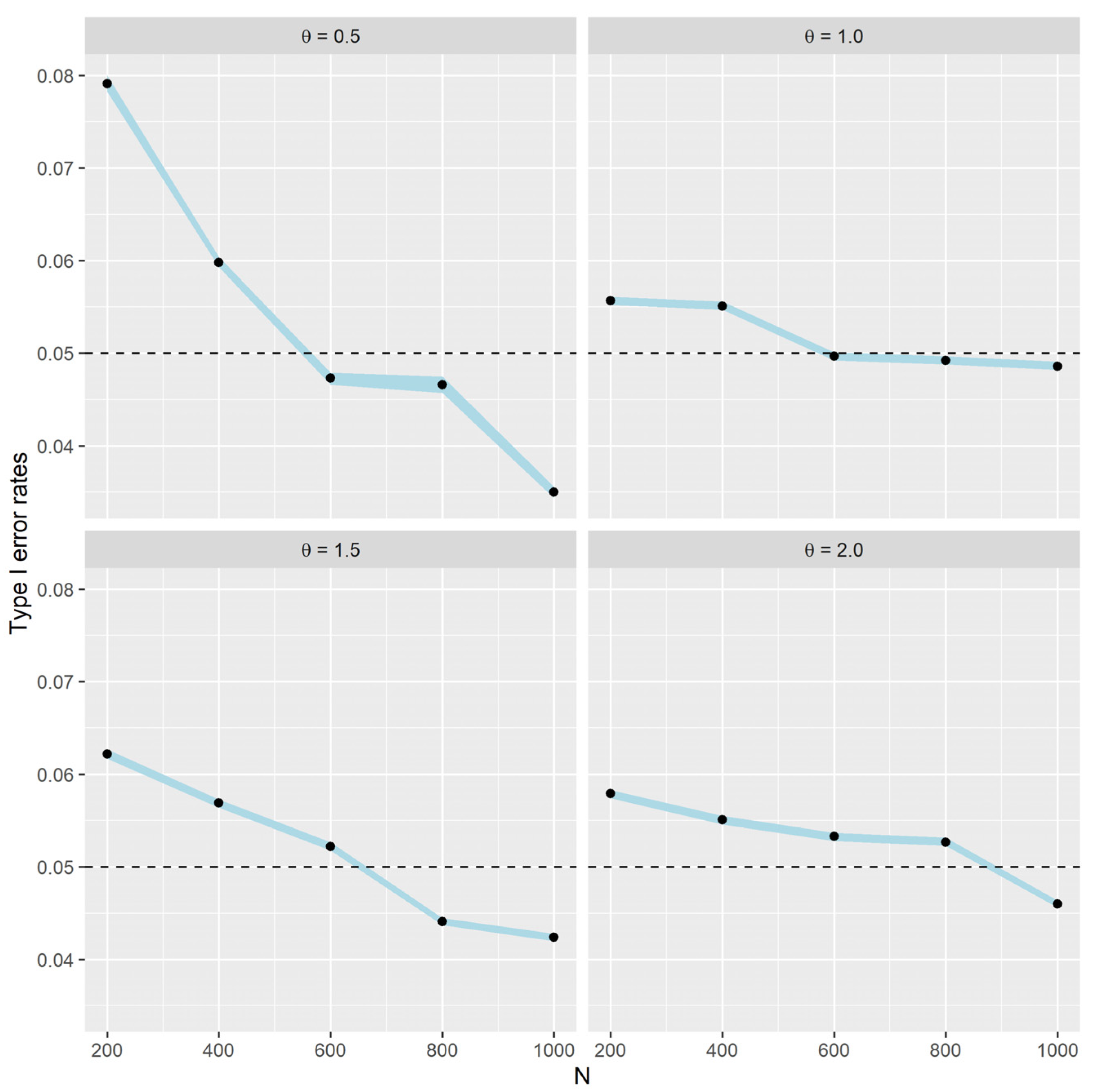
Figure 3 shows the simulation results of the test. From
Figure 3, when
, a sample size of 600 is sufficient to make a type I error rate fall below 0.05. When
, at least a sample size of 800 is needed to make a type I error rate fall below 0.05. Furthermore, a total of 1000 samples are required when
. Generally, the larger the value of
, the larger the sample size required so that the type I error becomes smaller than 0.05.
To investigate the power of the test, data are generated assuming that
, and let
.
Figure 4 shows the simulation results of the test. From
Figure 4, it can be noted that as the sample size increases, the power of the test increases. The further the distance between the assumed
from the true
, the more powerful the test becomes. To achieve 80% power with 1000 samples, the true
must be at least equal to 3.0 when
.
7. Conclusions
In this paper, various stochastic representations for the zero–one-inflated Poisson Lindley distribution have been studied extensively. The stochastic representations allow for us to view the zero–one-inflated Poisson Lindley distribution in different ways by combining several established distributions such as multinomial, degenerate, Poisson Lindley and other distributions. When handling data with excess zeroes and ones, as well as dispersion, these stochastic representations can be exploited. For example, if we are interested in studying positive count data distributions (observed) but we are presented with a full set of data containing both observed and unobserved values, instead of separating the full set of data into both observed and unobserved values, which may incur unnecessary costs, one may use the full set of data and use the fourth stochastic representation to identify the estimated parameter which describes the distribution of the unobserved data.
Besides that, some hypothesis tests have been conducted to investigate the presence of one-inflation in addition to fixed-rate parameters. The extensive simulation studies conducted investigate the ability of the test to handle both type I error and type II error rates in terms of errors as well as powers. All tests, which involve likelihood ratios, are found to be able to handle type I error rates and are found to be powerful as the sample sizes increases; hence, are found to be useful. It is suggested that a sample size of at least 1000 is sufficient for the tests to be useful.





{kind=link}
{kind=link}
{kind=link}
{kind=link}