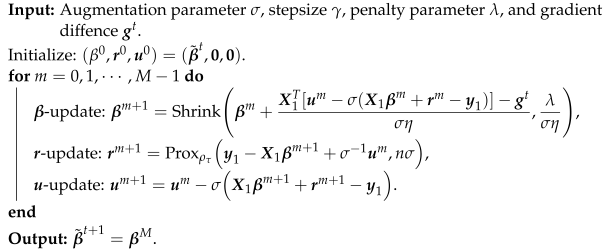1. Introduction
With the rapid development of contemporary networks, science, and technology, large-scale and high-dimensional data have emerged. For a single computer or machine, due to the limitations of memory and computing power, the processing and storage of data have become a great challenge. Therefore, it is necessary to handle data scattered across various machines. Mcdonald et al. [
1] considered a simple divide and conquer, that is, the parameters of interest of the model are learned separately on the local samples of each machine, and then these estimated parameters are averaged on a master machine. The divide and conquer is communication-efficient for large-scale data, but its accuracy of learning is low. Van de Geer et al. [
2] proposed an AVG-debias method, which improves the accuracy under a strong hypothesis but is time-consuming on computation because of the debiasing step. Therefore, it is necessary to develop communication-efficient distributed learning frameworks.
Afterwards, a novel communication-efficient distributed learning algorithm was proposed by [
3,
4]. Wang et al. [
3] developed an Efficient Distributed Sparse Learning (EDSL) algorithm, which optimizes a shifted
regularized
M-estimation problem, and other machines to compute the gradient on local data for the high-dimensional model. Jordan et al. [
4] adopted the same framework of distributed learning, which is called Communication-efficient Surrogate Likelihood (CSL), for solving distributed statistical inference problems in low-dimensional learning, high-dimensional regularized learning, and Bayesian inference. The two algorithms significantly improve the communication efficiency of distributed learning and have been widely used to analyze the big data in medical research, economic development, social security, and other fields. Under the CSL framework, Wang and Lian [
5] investigated a distributed quantile regression; Tong et al. [
6] developed privacy-preserving and communication-efficient distributed learning, which accounts for the heterogeneity caused by a few clinical sites for a distributed electronic health records dataset; and Zhou et al. [
7] developed two types of Byzantine-robust distributed learning with optimal statistical rates for strong convex losses and convex (non-smooth) penalties. It can be seen that the CSL framework plays an important role in distributed learning. In this paper, we will adopt the communication-efficient CSL for our distributed bootstrap simultaneous inference for high-dimensional data. When the data are complex with outliers or heteroscedasticity, the conventional mean regressions are unable to fully capture the information contained in the data. Quantile regression (QR) was proposed by [
8], which not only captures the relationship between features and outcomes but also allows one to characterize the conditional distribution of the outcomes given these features. Compared with the mean regression model, quantile regression can handle heterogeneous data better, especially for these outcomes with heavy tail distribution or outliers. Quantile regression is widely used in many fields [
9,
10,
11]. For quantile regression in high-dimensional sparse models, Belloni and Chernozhukov [
12] considered
-penalized QR and post-penalized QR and showed that under general conditions, the two estimators are consistent at the near-oracle rate uniformly. However, they did not consider large-scale distributed circumstances. Under the distributed framework, quantile regression has also received great attention. For example, Yu et al. [
13] proposed a parallel QPADM algorithm for a large-scale heterogeneous high-dimensional quantile regression model; Chen et al. [
14] proposed a computationally efficient method, which only requires an initial QR estimator on a small batch of data, and proved that the algorithm with only a few rounds of aggregations achieves the same efficiency as the QR estimator obtained on all the data; Chen et al. [
15] developed a distributed learning algorithm that is both computationally and communicationally efficient and showed that distributed learning achieves a near-oracle convergence rate without any restriction on the number of machines; Wang et al. [
5] analyzed the high-dimensional sparse quantile regression under the CSL; and Hu et al. [
16] considered an ADMM distributed quantile regression model for massive heterogeneous data under the CSL. However, the above works mainly focus on the distributed learning to parameters of quantile regression models in circumstances of massive or high-dimensional data and have not yet involved their distributed statistical inference. Volgushev et al. [
17] gave distributed statistical learning on quantile regression processes. So far, the statistical inferences for high-dimensional quantile models are still elusive, especially for distributed bootstrap simultaneous inference on high-dimensional quantile regression.
The bootstrap is a generic method for learning the sampling distribution of a statistic, typically by resampling one’s own data [
18,
19]. The bootstrap method can be used to evaluate the quality of estimators and can effectively solve the problem of statistical inference of high-dimensional parameters [
20,
21]. We refer to the fundamentals of the bootstrap method for high-dimensional data in [
22]. Kleiner et al. [
23] introduced the Bag of Little Bootstraps (BLB) for massive data via incorporating features of both the bootstrap and subsampling, which are suited to modern parallel and distributed computing architectures and maintain the statistical efficiency of the bootstrap. However, the BLB has restrictions on the number of machines in distributed learning. Recently, Yu et al. [
24] proposed K-grad and n+K-1-grad distributed bootstrap algorithms for simultaneous inference for a linear model and a generalized linear model, which do not constrain the number of machines and provably achieve optimal statistical efficiency with minimal communication. Yu et al. [
25] extended the K-grad and n+K-1-grad distributed bootstrap for simultaneous inference to high-dimensional data and adopted the CSL framework of [
4], which not only relaxes the restrictions on the number of machines but also effectively reduces communication costs. In this paper, we will further extend the K-grad and n+K-1-grad distributed bootstrap for simultaneous inference in high-dimensional quantile regression models. This is challenging due to the non-smooth nature of the quantile regression loss function, which cannot directly use the existing methodology.
In this paper, we design a communication-efficient distributed bootstrap simultaneous inference algorithm for high-dimensional quantile regression and provide its theoretical analysis. The algorithm and its statistical theory are the focus of this article, which belongs to the topic of probability and statistics. Its specific sub-field is bootstrap statistical inference. It is a traditional issue in statistics, but it is novel in the context of big data. We consider these methods to fit our model best. First, we adopt a communication-efficient CSL framework for large-scale distributed data, which is a novel distributed learning algorithm proposed by [
3,
4]. Under the master-worker architectures, CSL makes full use of the total information of the data over the master machine while only merging the first-order gradients from all the workers. Especially, a quasi-newton optimization at the master is solved as the final estimator, instead of merely aggregating all the local estimators like one-shot methods [
7]. It has been shown in [
3,
4] that CSL-based distributed learning can preserve sparsity structure and achieve optimal statistical estimation rates for convex problems in finite-step iterations. Second, we consider high-dimensional quantile regression for large-scale heterogeneous data, especially for these outcomes with heavy tail distribution or outliers. Thus, it brings more robust bootstrap inference. Third, we are motivated by communicate-efficient multiplier bootstrap methods K-grad/n+K-1-grad, which are originally proposed in [
24,
25] for mean regression, and propose our K-grad-Q/n+K-1-grad-Q Distributed Bootstrap Simultaneous Inference for high-dimensional quantile regression (Q-DistBoots-SI). Our proposed method relaxes the constraint on the number of machines and can provide more accurate and robust data for large-scale heterogeneous data. To the best of our knowledge, there is no more advanced distributed bootstrap simultaneous inference method available than our Q-DistBoots-SI for high-dimensional quantile regression.
Our main contributions are: (1) we develop a communication-efficient distributed bootstrap for simultaneous inference in high-dimensional quantile regression, under the CSL framework of distributed learning. Meanwhile, the ADMM is embedded for penalized quantile learning with distributed data, which is well suited for distributed convex optimization problems under minimum structural assumption [
26] and can handle the non-smoothness of quantile loss and the Lasso penalty. (2) We theoretically prove the convergence of the algorithm and establish a lower bound on the number of communication rounds
that warrants the statistical accuracy and efficiency. (3) The distributed bootstrap validity and efficiency are corroborated by an extensive simulation study.
The rest of this article is organized as follows. In
Section 2, we present a communication-efficient distributed bootstrap inference algorithm. Some asymptotic properties of bootstrap validity for high-dimensional quantile learning are established in
Section 3. The distributed bootstrap validity and efficiency are corroborated by an extensive simulation study in
Section 4. Finally,
Section 5 contains the conclusion and a discussion. The proof of the main results and additional experimental results is provided in
Appendix A.
Notations
For every integer , denotes a dimensional Euclidean space. The inter product of any two vectors is defined by for and . We denote the -norm () of any vector by , and . The induced q-norm and the max-norm of any matrix are denoted by , and , where the is the i-th row and j-th column element of M. The denotes the largest eigenvalue of a real symmetric matrix. Let and be the conditional density and conditional cumulative distribution function of y given x, respectively. Denote as the index set of nonzero coefficient and as the cardinality of S. denotes the k worker machine. We write for and , for and for , and if .
3. Theoretical Analysis
Recall that the quantile regression model has the conditional quantile
of
Y given the feature
x at quantile level
, that is,
with
. In this section, we establish theoretical results for distributed bootstrap simultaneous inference on high-dimensional quantile regression. We use the following assumptions.
Assumption 1. x is sub-Gaussian, that is,for some absolute constant . Assumption 2. is the unique minimizer of the objective function , and is an inner point in , where is an compact subset.
Assumption 3. is absolutely continuous at y, its conditional density function is bounded and continuously differentiable at y for all x in the support of x, and is uniformly bounded by a constant. In addition, is uniformly bounded away from zero.
Assumption 4. and are sparse for , where with . Especially, , , , , and .
Remark 1. Assumption 1 holds if the covariates are Gaussian. Under Assumption 1, when by Lemma 2.2.2 in [29]. Assumptions 2 and 3 are common in standard quantile regression [9]. Assumption 4 is a sparsity assumption typically adopted in penalized variable selection. In order to state next assumptions, define a restricted set , and is a support of J largest in absolute value components of outside S.
Remark 2. The assumptions of and q come from [12]; they are called restricted eigenvalue conditions and restricted nonlinear impact coefficients, respectively. holds when x are mean zero with diagonal elements of being 1’s by Lemma 1 in [12]. The restricted eigenvalue condition is analogous to the condition in [30]. The q controls the quality of minoration of the quantile regression objective function by a quadratic function over the restricted set, which holds under Design 1 in [12]. First, we give the convergence rates of distributed learning for high-dimensional quantile regression models under the CSL framework.
Theorem 1. Assume that Assumptions 1–5 hold, and . Then, with probability at least , we havewhere . Remark 3. Recall that Lemma A1,where . We can take Thus, Theorem 1 upper bounds the learning error as a function of . So, applying it to the iterative program, we obtain the following learning error bound, which depends on the local -regularized estimation error .
Corollary 1. Suppose the conditions of Theorem 1 are satisfied; takes as (22); and for all t, . Then, with probability at least , we havewhere , and . Remark 4. For initialization estimation, we refer to Theorem 2 in [12], We further explain the bound and see the scaling with respect to n, K, s, and p. When , it is easy to see by takingwe have the following error bounds: Moreover, as long as t is large enough so that , and , thenwhich match the centralized lasso without any additional error term [30] as [3] has done in sparse linear regression distributed learning. Based on the proposed Q-DistBoots-SI algorithm, we define
Theorem 2. (K-gard-Q) Assume that Assumptions 1–5 hold, letfor , and for . Then, if , , and for , wherewe havewhere , in which is the K-grad-Q bootstrap statistics with the same distribution as in (12) and denotes the probability with respect to the randomness from the multipliers. In addition,where is defined in (7). Theorem 2 ensures the effectiveness of constructing simultaneous confidence intervals for quantile regression model parameters using the “K-grad-Q” bootstrap method in Algorithm 1. Moreover, it indicates that bootstrap quantiles can approximate the prior statistics, implying that our proposed bootstrap procedure possesses statistical validity similar to the prior estimation method.
Remark 5. If , , for some constants , , and , then a sufficient condition is , , and Notice that the representation of mentioned above is independent of the dimension p; the direct effect of p only enters through an iterative logarithmic term , which is dominated by .
Theorem 3. (n+K-1-grad-Q) Assume that Assumptions 1–5 hold; take as (24) for and for . Then, if , , and when , wherewe havewhere , in which is the n+K-1-grad-Q bootstrap statistics with the same distribution as in (13), and denotes the probability with respect to the randomness from the multipliers. In addition, (27) also holds. Theorem 3 establishes the statistical validity of the distributed bootstrap method when using “n+K-1-grad-Q”. To gain insight into the difference between “K-grad-Q” and “n+K-1-grad-Q”, we compare the difference between the covariance of the oracle score
A and the conditional covariance of
and
conditioning on the data, and we obtain
and
Remark 6. If , , and for some constants , , and , then a sufficient condition is , , and Notice that the representation of mentioned above is independent of the dimension p; the direct effect of p only enters through an iterative logarithmic term , which is dominated by .
Remark 7. The rates of and in Theorems 3.2 and 3.3 are motivated by Theorem 1 and [2]. Therefore, we fix (e.g., 0.01 in the simulation study) and use the cross-validation method to choose . Remark 8. The total communication cost in our algorithm is of the order because in each iteration we communicate p-dimensional vectors between the master node and K-1 worker nodes, and only grows logarithmically with K when n and p are fixed. Our order matches those in the existing communication-efficient statistical inference literature, e.g., [3,4,25]. 4. Simulation Experiments
In this section, we demonstrate the advantages of our proposed approach through numerical simulation. We consider the problem of parameter estimation for high-dimensional quantile regression models in a distributed environment. In
Section 4.1, we compare our algorithm Q-ADMM-CSL with the oracle estimation (Q-Oracle) and simple divide and conquer (Q-Avg) for high-dimensional quantile regression, evaluating the computational effectiveness of our proposed algorithm. In
Section 4.2, we construct confidence intervals and assess their validity. The data are generated from the following model:
where
by, respectively, taking
and
to demonstrate the benefits of our method for large-scale high-dimensional data with heavy-tailed distribution.
In this section, we consider a high-dimensional quantile regression model with dimension of feature ; fix the total sample size ; and select the numbers of machines , and 20, respectively. Therefore, the sample size on each machine is , that is, 600 for , 300 for and 150 for . Considering the scenario of parameter sparsity, we choose the real coefficient to be p-dimensional, in which s coefficients are non-zero, and the remaining parameters are 0. We consider the two cases: (1) sparsity with , , and the rest of the components are 0; (2) sparsity with , , and the rest are 0. We generate independent and identically distributed covariates from a multivariate normal distribution , where the covariance matrix . Given a quantile level , we consider three levels: 0.25, 0.5, and 0.75.
4.1. Parameter Estimation
In this section, we study the effect of our proposed algorithm. We repeatedly generate 100 datasets of independent data, and we use the - norm to evaluate the quality of parameter estimate. That is, . Meanwhile, we compare the effect of obtained by our proposed algorithm, , obtained by all data estimation and , obtained by naively average data estimation.
For the choice of penalty parameter
, in the oracle estimation, we refer to the method of selecting penalty parameter in [
12]; in the construction of the average estimation, we choose
; in our proposed distributed multi-round communication process,
; and when
we set
. For the parameters
and
in ADMM, we refer to the selection in [
27] to choose
and
.
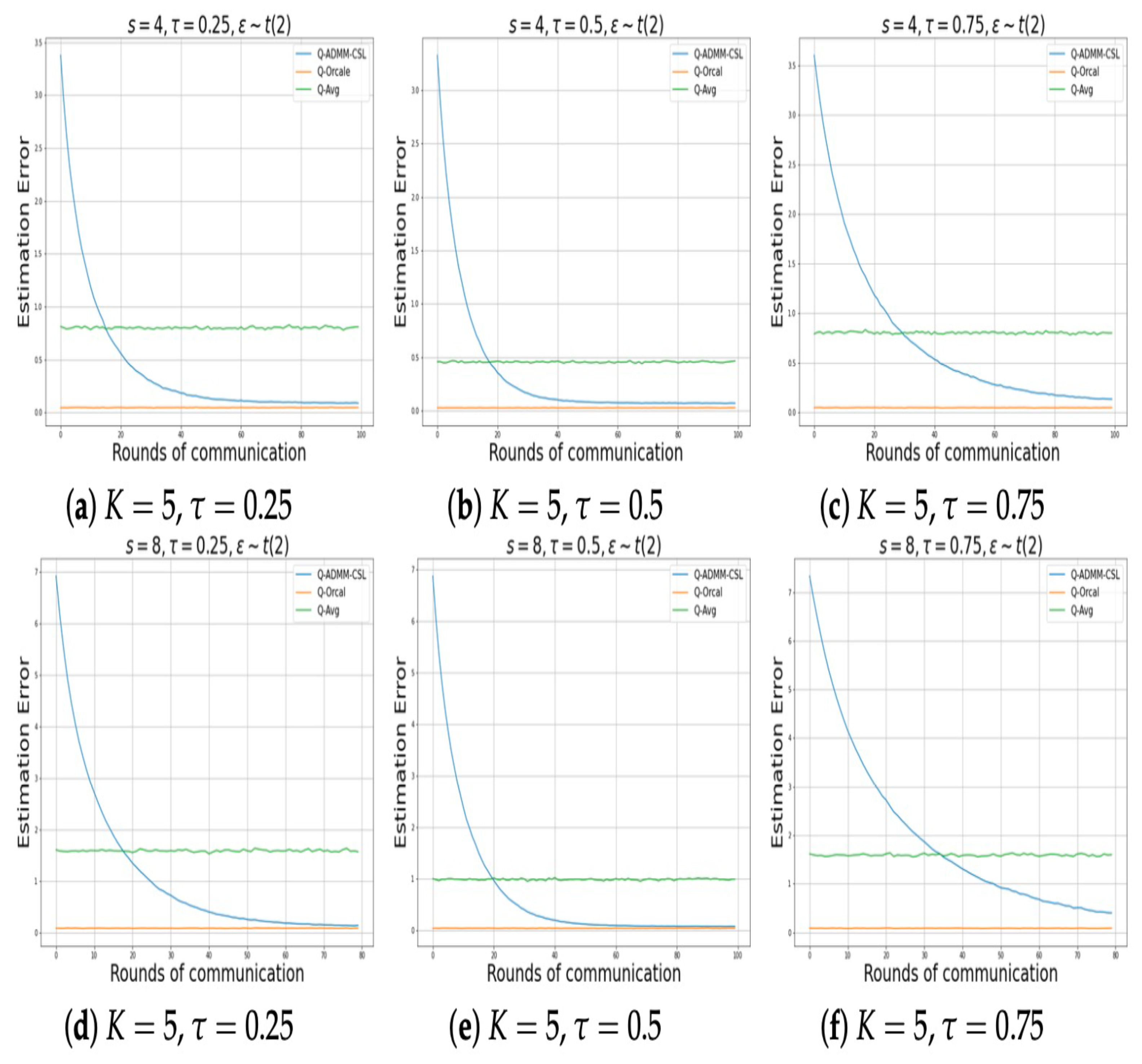
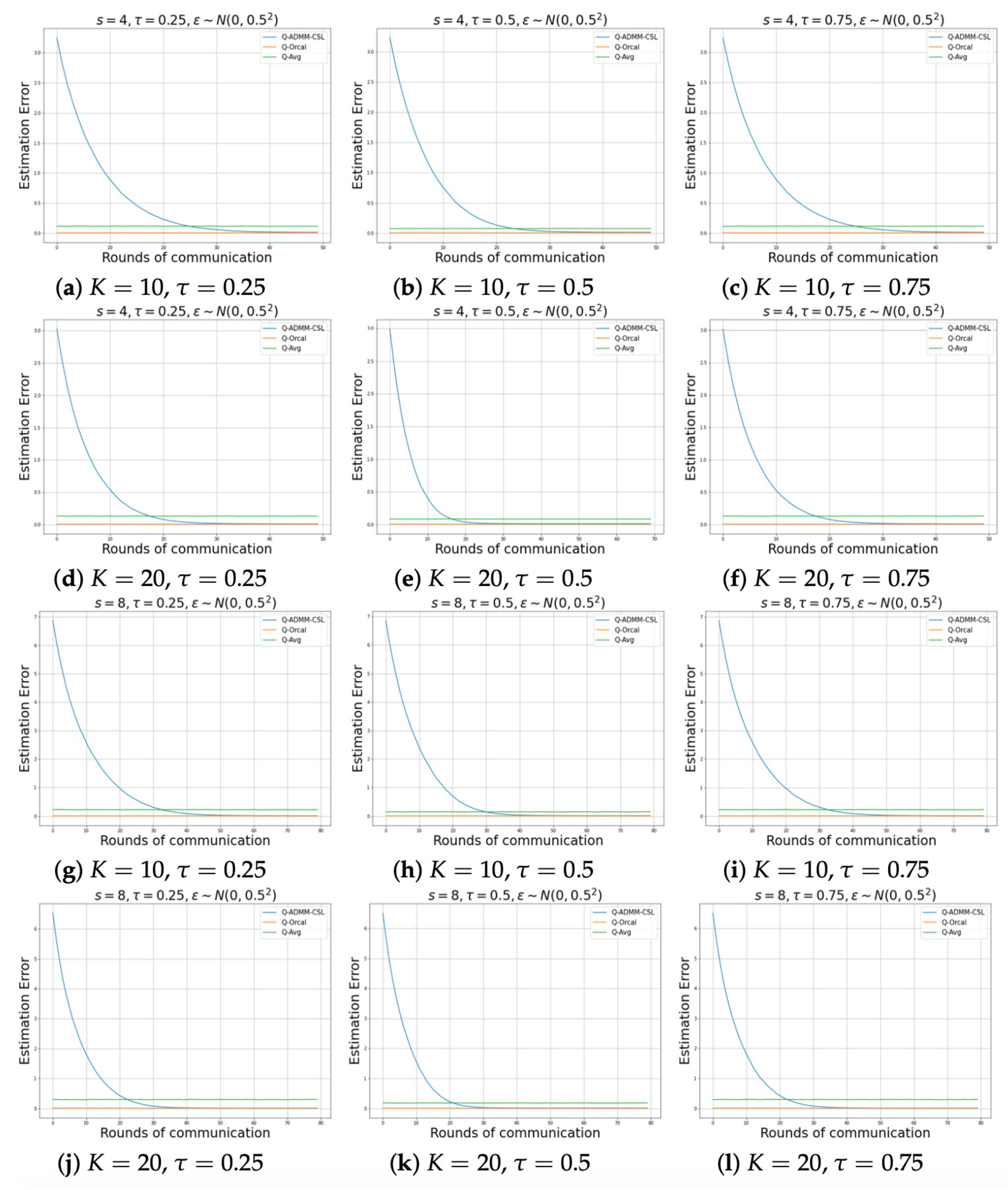
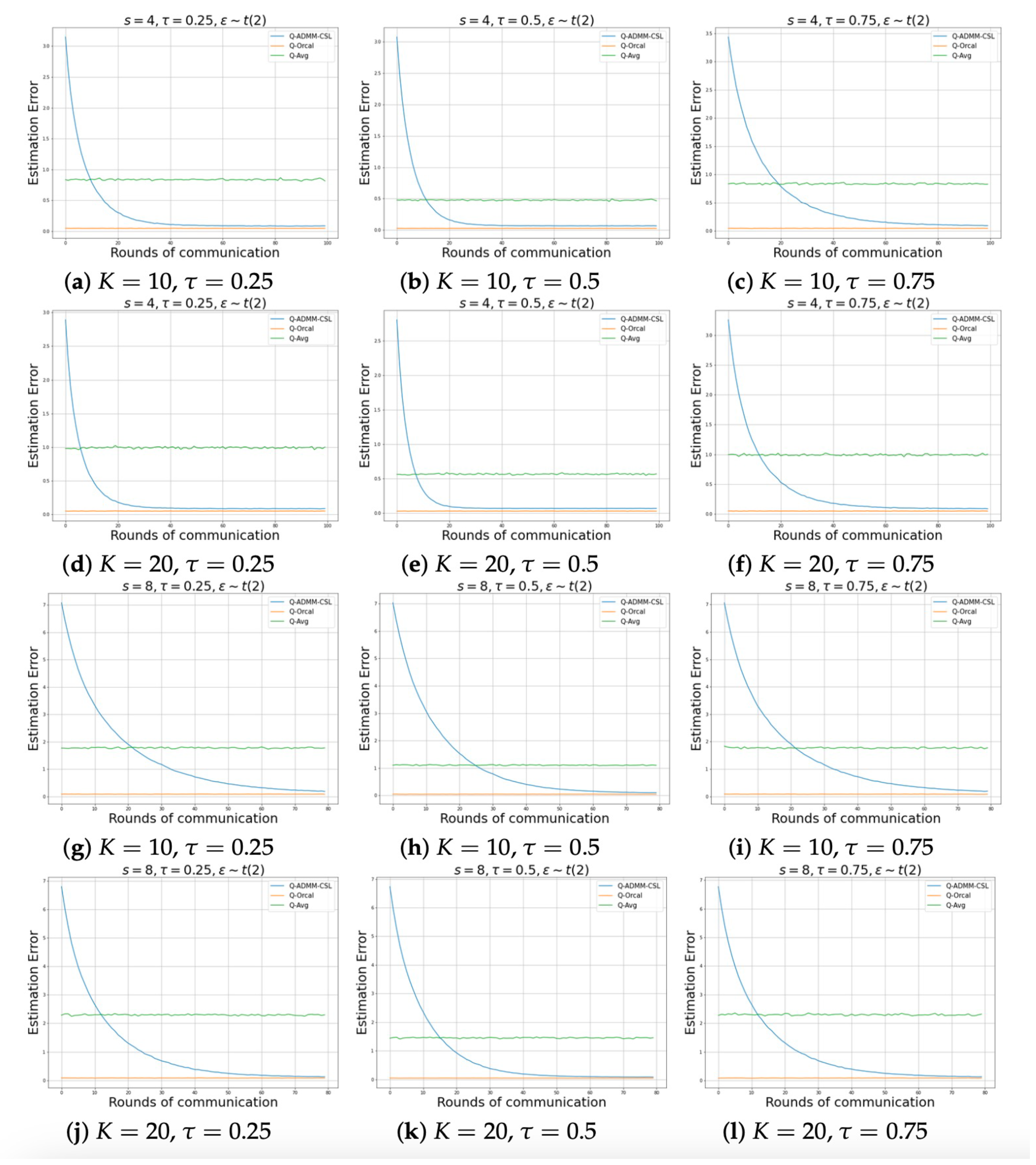
Figure 1 and
Figure 2 show the relationship between the number of communication rounds and the estimation error of parameters, when the noise distributions are normal and
, for the sparsity levels
and
, respectively. We consider various scenarios involving different quantile levels and number of machines. It can be observed that after sufficient communication rounds, our parameter estimation method (Q-ADMM-CSL) can approximate the performance of the Oracle estimation (Q-Oracle), and the performance is significantly better than Q-Avg after a round of communication. In addition, our proposed method converges quickly, and matches the Oracle method after only about 30 rounds of communication.
4.2. Simultaneous Confidence Intervals
In this section, we demonstrate the statistical validity of confidence intervals constructed by our proposed method. For each choice of
s and
K, we run Algorithm 1 with “K-grad“ and “n+K-1-grad” on 100 independently generated datasets and compute the empirical coverage probabilities and the average widths based on the 100 running. At each running, we draw
bootstrap samples and calculate
B bootstrap statistics (
or
) simultaneously. We obtain the
and
empirical quantiles and further obtain the
and
simultaneous confidence intervals. For the selection of the adjustment parameter
in the nodewise algorithm, we refer to the method proposed in [
25].
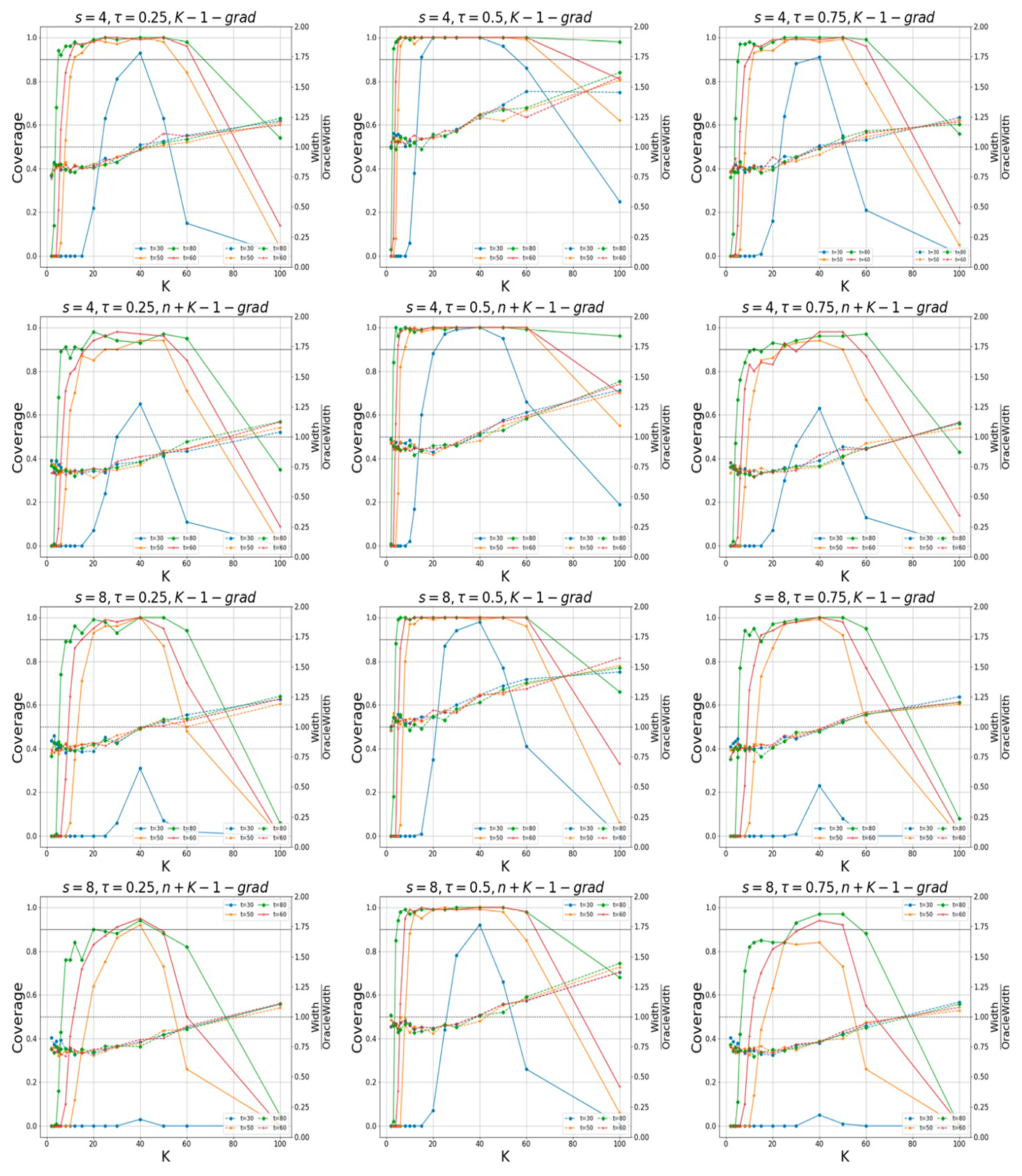
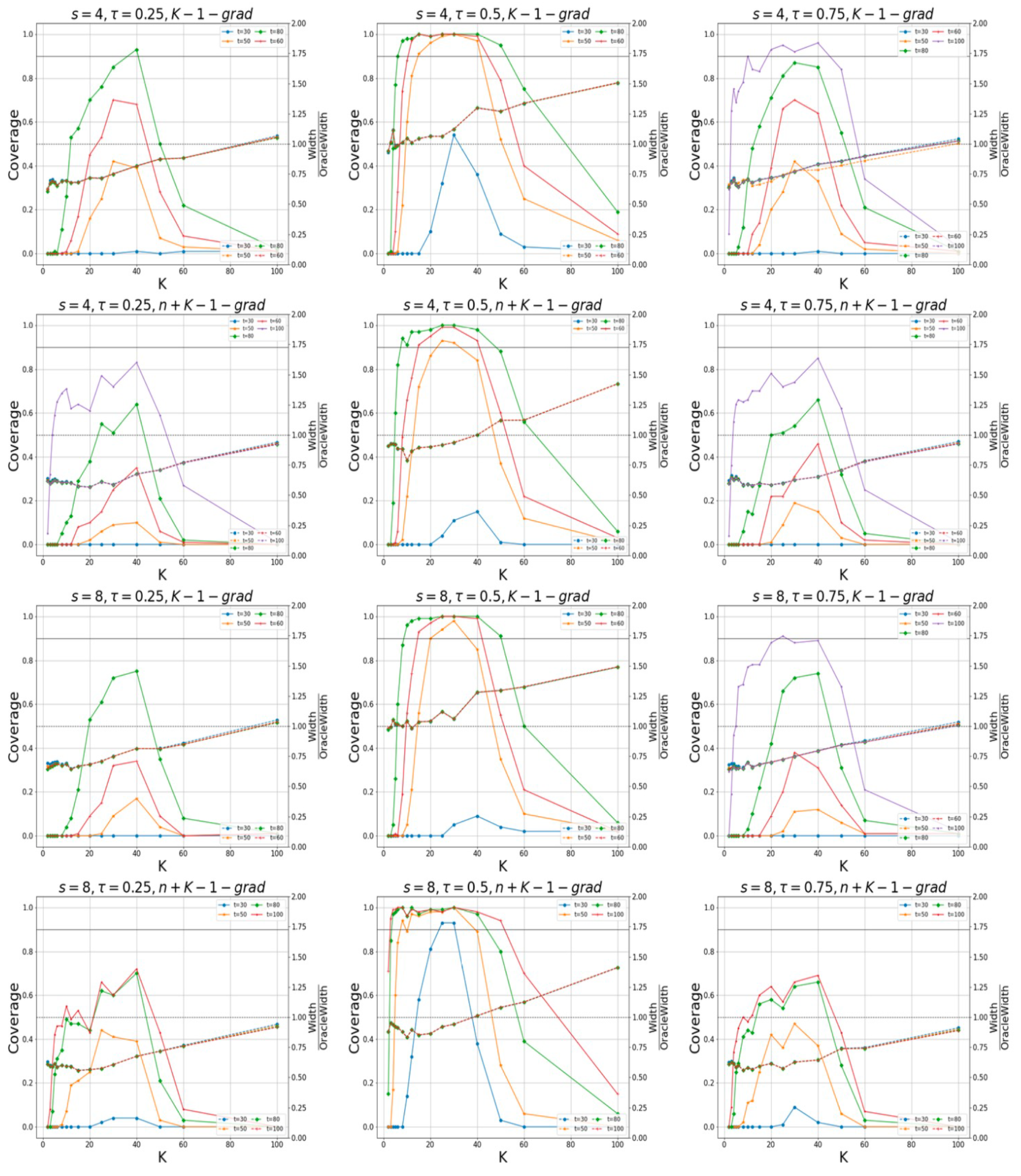
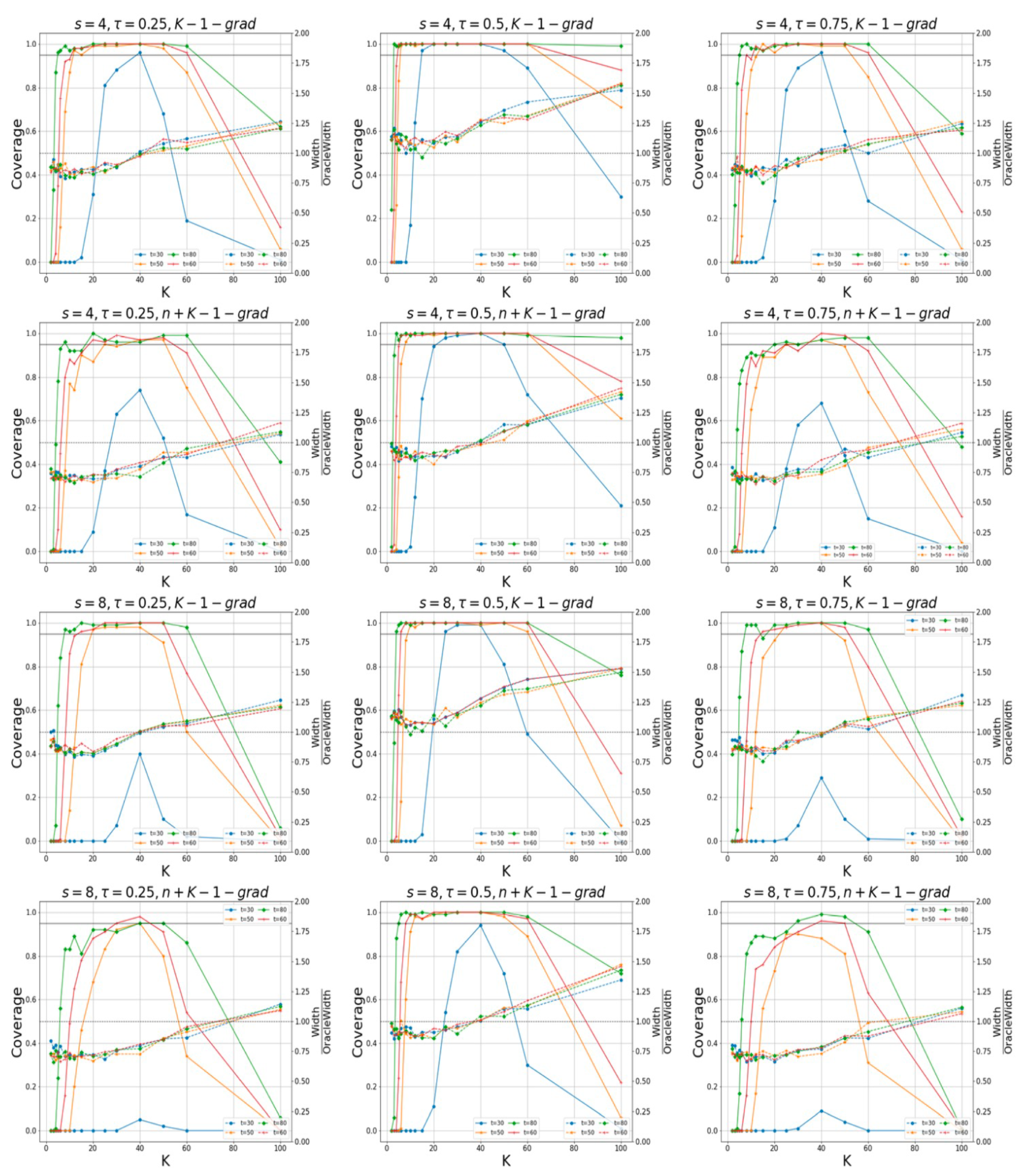
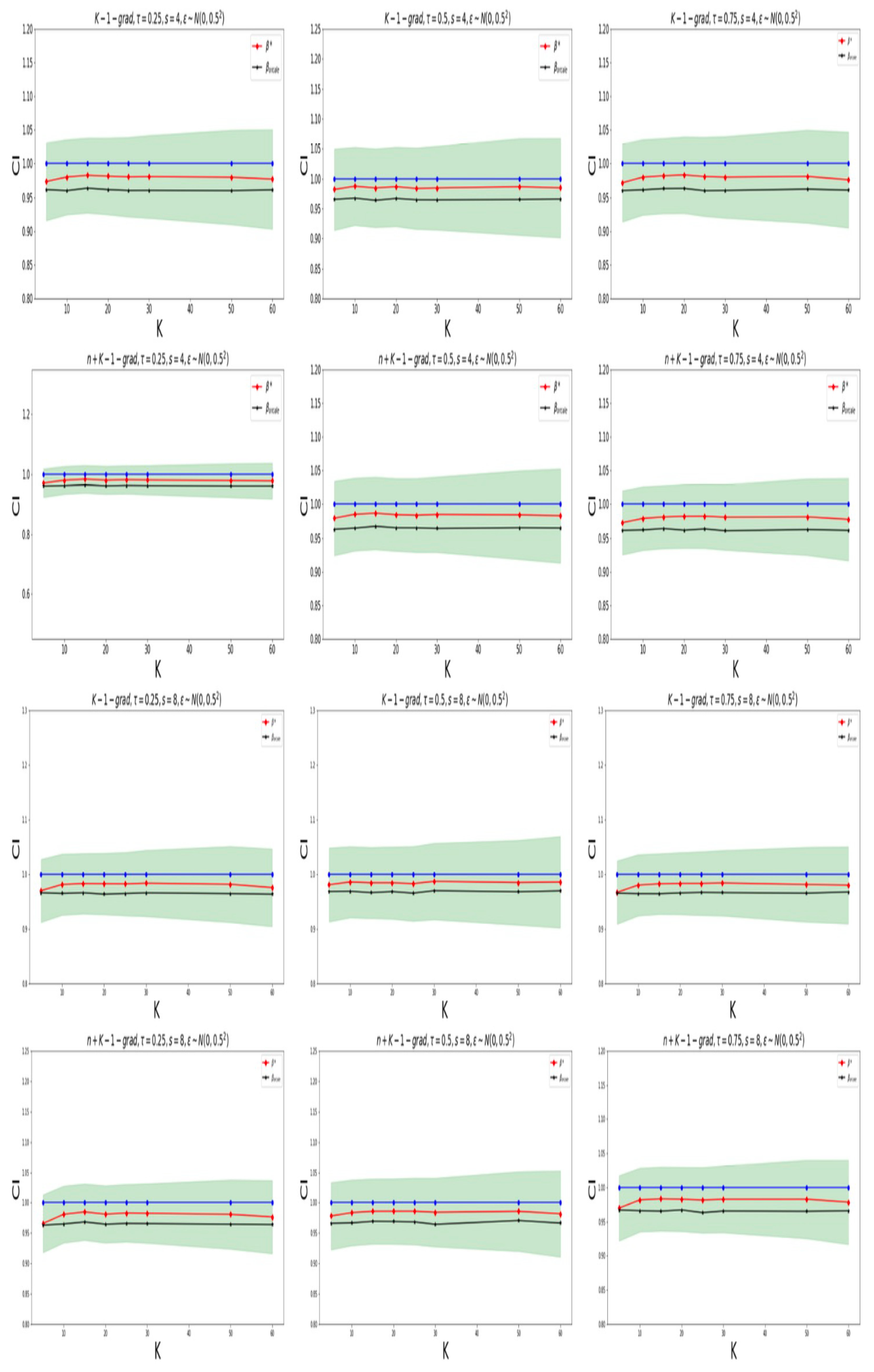
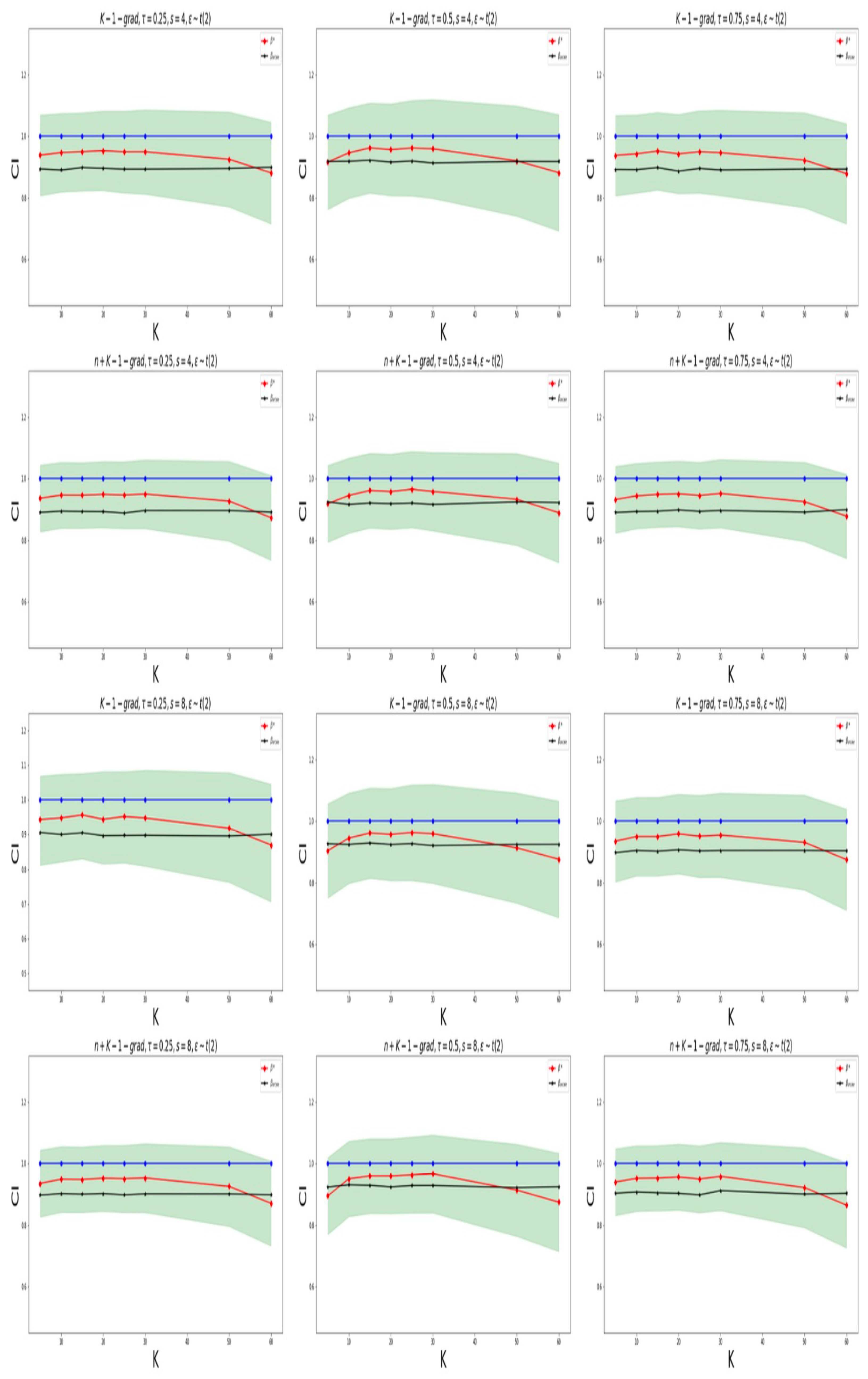
In
Figure 3, for the case of
, and
Figure 4, for the one of
, the coverage probabilities and the ratios of the average widths to the prior widths, calculated using the “K-grad-Q“ and “n+K-1-grad-Q” methods for different quantile levels, are displayed. The confidence levels are 95%. The sparsity levels are
and
. To determine whether the true values of the non-zero elements in the parameter
lie within the intervals constructed by our proposed method, we examine different values for the different number of machines,
K. We observe that the confidence intervals constructed by our method are capable of effectively encompassing the true values of unknown parameters. In
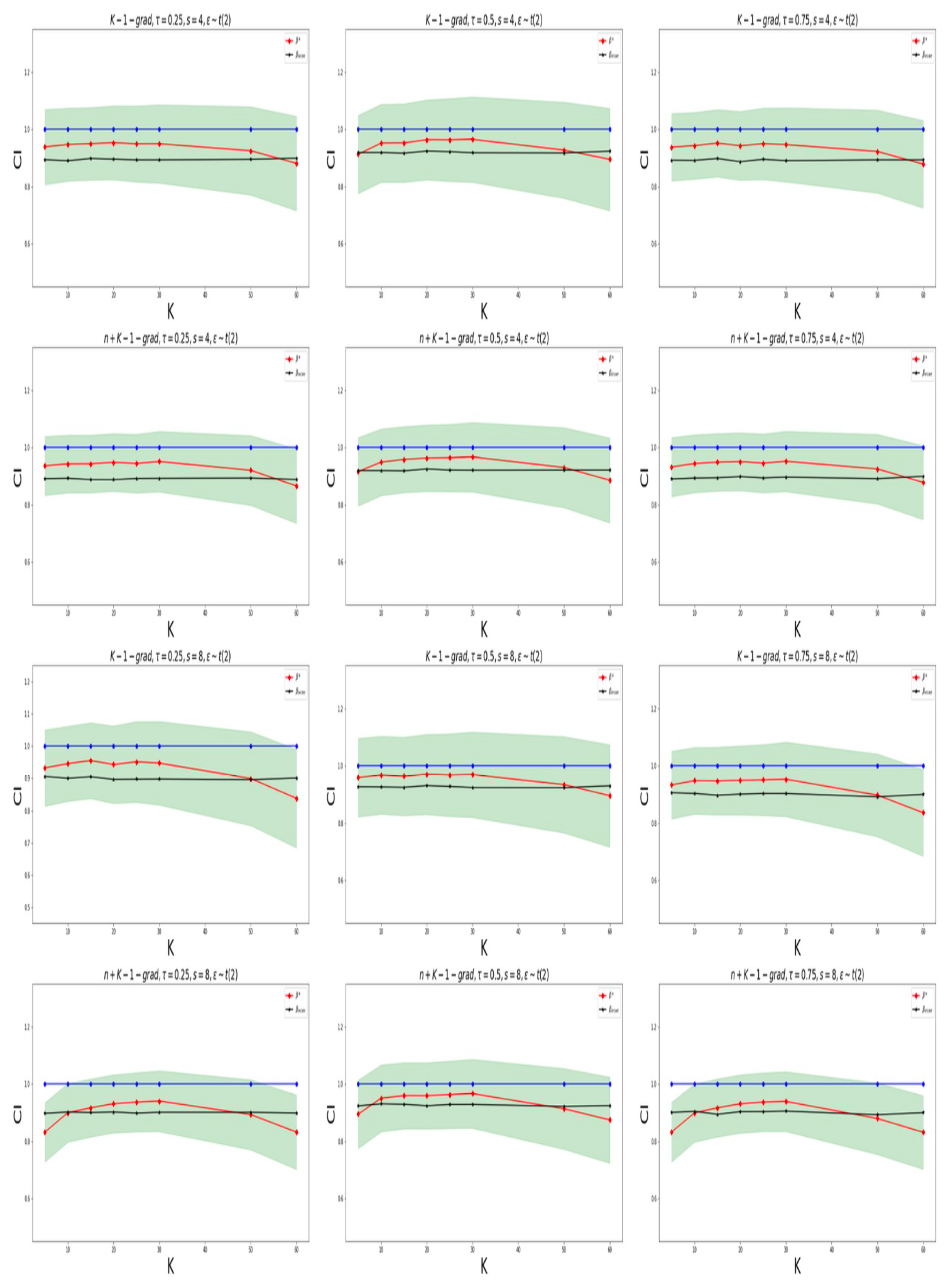
Figure 5 for
and
Figure 6 for
, we construct a 95% confidence interval for the fifth element of the true parameter (
). The case for the confidence level of
is listed in the
Appendix A.
When the round of communication is low, the accuracy of parameter estimation is poor and the coverage probabilities of both methods are low. However, when the round of communication is sufficiently large, the estimation accuracy is relatively high, and the “k-1-grad-Q” method tends to coverage. In addition, the “n+k-1-grad-Q” method is relatively more accurate. The confidence intervals via our method can effectively cover the unknown true parameters. We also find that when the number of machines is too large (with small amounts of data on each machine), the estimation accuracy is low, which also leads to a low coverage probability; when K is too small, both algorithms perform poorly, which is consistent with the results in Remarks 7 and 8.
5. Conclusions and Discussions
Constructing confidence intervals for parameters in high-dimensional sparse quantile regression models is a challenging task. The bootstrap, as a standard inference tool, has been shown useful in handling the issue. However, previous works that extended the bootstrap technique to high-dimensional models focus on non-distributed mean regression [
25] or distributed mean regression [
24]. We extend their “k-1-grad” and “n+k-1-grad” bootstrap techniques to “k-1-grad-Q” and “n+k-1-grad-Q” distributed bootstrap simultaneous inference for high-dimensional quantile regression, which is applicable to large-scale heterogeneous data. Our proposed Q-DistBoots-SI algorithm is based on a communication-efficient distributed learning framework [
3,
4]. Therefore, the Q-DistBoots-SI is a novel communication-efficient distributed bootstrap inference, which relaxes the constraint on the number of machines and is more accurate and robust for the large-scale heterogeneous data. We theoretically prove the convergence of the algorithm and establish a lower bound on the number of communication rounds
that warrants statistical accuracy and efficiency. This also enriches the statistical theory of distributed bootstrap inference and provides a theoretical basis for its widespread application. In addition, our proposed Q-DistBoots-SI algorithm can also be applied to large-scale distributed data in various fields. In fact, the bootstrap method has been applied to statistical inference for a long time. For example, Chattergee and Lahiri [
31] studied the performance of the bootstrapping Lasso estimators on the prostate cancer data and stated that the covariates log(cancer volume), log(prostate weight), seminal vesicle invasion, and Gleason score have a nontrivial effect on log(prostate specific antigen); the rest of the variables (age, log(benign prostatic hyperplasia amount), log(capsular penetration), and percentage Gleason scores 4 or 5) were judged insignificant at level
; Liu et al. [
32] applied their proposed bootstrap lasso + partial ridge method to a data set containing 43,827 gene expression measurements from the Illumina RNA sequencing of 498 neuroblastoma samples and found some significant genes. Yu et al. [
25] tested their distributed bootstrap for simultaneous inference on a semi-synthetic dataset based on the US Airline On-time Performance dataset and successfully selected the relevant variables associated with arrival delay. However, Refs. [
25,
31,
32] mainly focused on bootstrap inference for mean regression. Therefore, they cannot select relevant predictive variables with the responses at the different quantile levels. In contrast, our method can be successfully applied to the US Airline On-time Performance dataset and gene expression dataset to infer predictors with significant effects on the response at each quantile level. This is very important because we may be more interested in the influencing factors of response variables at extreme quantile levels. For example, our approach can be applied to gene expression data to identify genes that have significant effects on predicting a cancer gene’s expression levels in a quantile regression model. Compared with mean regression methods, our method finds genes that should be biologically more reasonable and interpretable because of the characteristics of quantile regression. Future work is needed to investigate the applications of our distributed bootstrap simultaneous inference for quantile regression to large-scale distributed datasets in various fields. Although our Q-DistBoots-SI algorithm is communication-efficient, when the feature dimension of the data is extra-high, the gradient transmitted by each worker machine in the algorithm is still an ultra-high dimensional vector, which also has unbearable communication costs. Thus, we need to develop a more communication-efficient Q-DistBoots-SI algorithm via quantization and sparse techniques (such as Top
k) for large-scale ultra-high-dimensional distributed data. In addition, our Q-DistBoots-SI algorithm cannot cope with Byzantine failure in distributed statistical learning. However, Byzantine failure has recently attracted significant attention [
7] and is becoming more common in distributed learning frameworks because worker machines may exhibit abnormal behavior due to crashes, faulty hardware, and stalled computation or unpredictable communication channels. Byzantine-robust distributed bootstrap inference will also be a topic of our future research. Additionally, in the future, we can also extend our distributed bootstrap inference method into transfer learning and graph models for large-scale high-dimensional data.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}