1. Introduction
Using response functions in a duopoly market model, we develop an empirical model of the market for mobile services in the USA. The wireless telecommunications market is dominated by two providers, AT&T and Verizon, which serve over
of the market. Our empirical strategy relies on the approximation of quarterly data on smartphone subscriptions by continuous functions from the sigmoid family. Guided by our duopoly model, we reformulate this approximation to obtain providers’ response functions. Our model is parsimonious and outperforms the alternative approach of directly estimating the response functions with a polynomial specification. Importantly, our model features unique equilibrium because the empirical response functions satisfy the conditions for semi-cyclic contractions obtained in [
1]. In fact, numerical simulations in the appendix suggest that the model converges to equilibrium from a range of initial conditions significantly wider than their hypotheses.
Market models relying on response functions date as early as [
2], which introduces a model of a market where a few players (known as an oligopoly market) control the price and supply quantity of the goods being traded. In the original model, a few players sequentially respond to each others’ quantities in a rational way, i.e., pursuing profit maximization in their response. The subsequent literature has enriched the response function approach to model market equilibrium by avoiding the rationality assumption [
3,
4]. In another enrichment of the approach by [
5], each company attempts to guess what change in production the other players will make in time
t, while still using data up to period
t.
In a baseline Cournot duopoly model, two producers (firms) are competing for the same consumers and striving to meet the demand with overall production of
, where
,
, is the amount produced by the
firm. The market price is given by
, which is the inverse of the demand function. The (inverse) demand does not change over time and the producers cannot alter it. Their production technologies are reflected in their cost functions
. Both firms act rationally, i.e., each firm chooses quantity
to maximize its profit, with profit (payoff) functions:
Notably, each firm
takes its competitor’s decision as given, formally solving
. Provided that functions
P and
,
, are differentiable, firms’ optimal solutions satisfy the system of equations:
There are various ways to approach (
2). The direct approach of obtaining
and
, called response functions [
6], may encounter technical limitations. Specifically, exact response functions
and their fixed points
, may be difficult or impossible to obtain. Further, if the model is not a stable one, exact or approximate solutions may not be even close to the market equilibrium. Separately to these concerns, one needs to obtain sufficient conditions for a solution
of (
2) to be a solution of (
1) which are either the second-order conditions, i.e.,
for
, or payoff functions
being concave ones [
7,
8,
9]. Finally, this approach assumes that the payoff functions
are differentiable, while in certain settings these may not even be continuous and require different optimization techniques.
In a departure from the direct approach focused on obtaining solutions
and
to (
2), ref. [
10] considers the alternative response functions:
The authors analyze these functions in the context of modeling firms’ responses over time.
We follow this departure from the direct approach of solving maximization (
1). Our main premise is that each firm responds to their and that of their competitor’s past period market results (decisions), i.e., for each ordered pair
, where
is the quantity sold by the first firm and
is the quantity sold by the second firm, they change their output accordingly. There are two functions
and
, which are their responses to the ordered pair of the quantities sold
. Importantly, turning to firms’ response functions substitutes the maximization problem of (
1) with a coupled fixed point problem. This, in turn, renders all assumptions of concavity, differentiability or even continuity unnecessary [
1,
10]. In particular, ref. [
1] shows that in the settings of [
11] it is possible to widen their conditions for ensuring the existence and uniqueness of the market equilibrium beyond the settings of payoff function maximization.
An extensive study on the oligopoly markets can be found in [
7,
8,
9,
12]. Some recent results on oligopoly markets are in [
13,
14,
15,
16,
17] and those of duopoly markets especially are in [
18,
19,
20]. The approach for the investigation of equilibrium in duopoly markets by response functions was introduced in [
10] and further investigated in [
1].
In this paper, we use response functions in a duopoly market to build an empirical model of the USA wireless telecommunications market. We horse race two alternative approaches of obtaining the response functions: a direct approach of fitting polynomial specification with the proposed more conceptually coherent approach combining a time series approximation of the market quantities with a theory of market response in a duopolistic market. This paper concludes with evidence on the statistical superiority of the proposed approach and on the range of starting values guaranteeing convergence to unique long-run equilibrium.
2. Materials and Methods
2.1. Coupled Fixed Points of Semi-Cyclic Maps
Let
A be a nonempty subset of a metric space
. The map
is said to have a fixed point
if
[
21].
Following [
21], there is an enormous number of generalizations. We will use the idea of a coupled fixed point introduced in [
22].
Definition 1 ([
22,
23])
. Let A be a nonempty subset of a metric space , . An ordered pair is said to be a coupled fixed point of F in A if and . A deep result on the connection between fixed points and coupled fixed points is obtained in [
24]. It is proven there that we can consider instead of the map
the map
, defined by
. Then, the ordered pair
is a coupled fixed point for
F if and only if it is a fixed point for
T.
The idea to investigate for the existence and uniqueness of fixed points cyclic maps, i.e.,
and
, instead of self maps was initiated in [
25]. This was further generalized in the context of maps of two variables in [
26].
Definition 2 ([
26])
. Let A and B be nonempty subsets of a metric space . The ordered pair of maps , and is called a cyclic ordered pair of maps. Definition 3 ([
26])
. Let A and B be nonempty subsets of a metric space and be a cyclic ordered pair of maps. An ordered pair is said to be a coupled fixed point of F in A if and . Definition 4 ([
26], Definition 3.4 and Theorem 4.1)
. Let A and B be nonempty subsets of a metric space and be a cyclic ordered pair of maps. We say that the cyclic ordered pair of maps is a cyclic contraction if there exists such thatholds for every and . Theorem 1 ([
26], Theorem 4.1)
. Let A and B be nonempty subsets of a metric space and be a cyclic contraction. Then, F and G have a unique common coupled fixed point , i.e., and . Moreover, it is proven in [
27] that
.
In order to apply the technique of coupled fixed points and a generalization of coupled fixed points, the above-mentioned notion was presented in [
10]. When we investigate duopoly with players’ response functions
F and
G, we see that each player, using the information about their production and the rival’s production, chooses a change in their production, i.e.,
,
. Thus, we reach maps that are not the cyclic type of maps from Definition 2. The authors of [
10] called these new type of maps cyclic again. A more natural name is introduced in [
28], where the authors called them an ordered pair of semi-cyclic maps.
Definition 5 ([
10,
28])
. Let A, B be nonempty subsets of a metric space and , . An ordered pair is called an ordered pair of semi-cyclic maps. Definition 6 ([
10,
28])
. Let A, B be nonempty subsets of a metric space and be an ordered pair of semi-cyclic maps. An ordered pair is called a coupled fixed point of if and . Whenever and , we obtain the notion of coupled fixed points from Definition 1.
There is a sequence of results that guarantees the existence and uniqueness of coupled fixed points for semi-cyclic kinds of maps and thus the existence and uniqueness of market equilibrium in duopoly markets [
1,
10,
28].
We will use a result from [
1].
Theorem 2 (Assumption 1, [
1])
. Let us consider a duopoly market, satisfying the following:- 1.
The two players are producing homogeneous goods that are perfect substitutes.
- 2.
The first player can produce quantities from the set A, and the second one can produce quantities from the set B, where A and B are closed, nonempty subsets of a complete metric space .
- 3.
Let there be a closed subset and maps , such thatfor every are the response functions for players one and two, respectively. - 4.
Let , such that the inequality:holds for all .
Then, there is a unique market equilibrium pair in D, i.e., and .
If in addition the symmetry condition holds, then the market equilibrium pair satisfies .
For any initial start of the market
, we will consider the sequence of iterated productions of the two players
, defined by
. It leads to a more complicated iterated formula,
etc. We will sometimes use the notation
,
.
A similar result to that in Theorem 2 is obtained in [
10], where condition (
3) is replaced by the inequality
for all
(Assumption 1, [
10]).
It is proven in [
1] that both conditions are equivalent.
2.2. Approximation with Sigmoid Functions
Our approach to work with sigmoid functions is motivated by a fundamental result for approximating continuous functions due to [
29]. The author demonstrates that for every continuous function in a closed interval, there exists a finite linear combination of sigmoids that approximates the function with a predetermined accuracy. (Actually, this follows from Stone’s Theorem, which states that every Stone algebra is dense in the space of continuous functions over a compact set. Note that linear combinations of the sigmoids together with constants are trivially such a Stone algebra.) In the following years, the theory of approximating real data with the sigmoids has seen rapid development, e.g., see [
30,
31,
32,
33,
34].
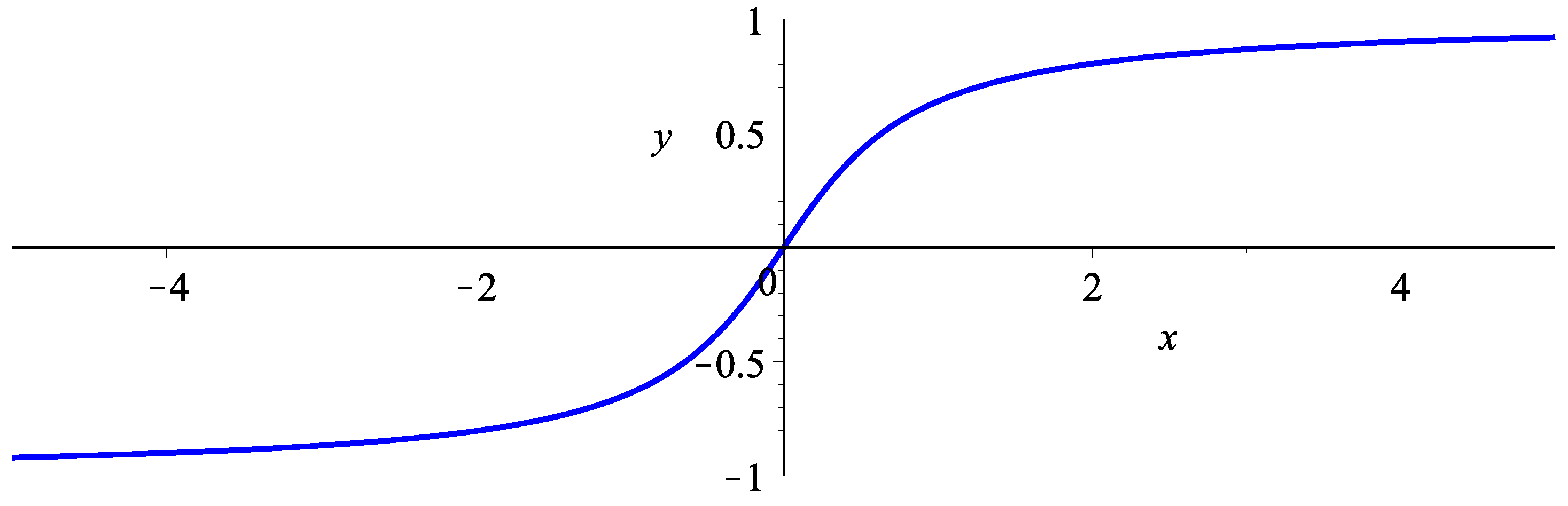
A sigmoid function (also known as an
S-curve) is an increasing function of two horizontal asymptotes
and
(
Figure 1).
Then, approximations of real-world data are sought through a linear combination of a set of sigmoidal curves. Importantly, there is a trade off between the accuracy of the fit and parsimony. To pick a representation, it is common to gauge models’ performance by testing a hypothesis of matching real data with the approximations, e.g., see [
30,
31,
32,
33,
34].
Sigmoid functions have gained popularity with applications ranging from artificial neural networks (as activation functions) to simple classification algorithms. In our model, we use sigmoid functions to better capture the following important characteristics of our settings:
Nonlinearity in an intuitive way with respect to a small number of parameters.
Switching agents’ behavior, e.g., between different suppliers, products, etc.
As a robust technical tool capable of modeling changes in a modular way by scaling these changes down to a predefined range (a to b), thus allowing us to incorporate strategies that are built on incremental changes of output.
In general, one of the main advantages for relying on approximations with sigmoid functions is that these can be applied to both continuous and binary variables (in the latter case, approximation with sigmoids involves the introduction of a threshold).
Related to the trade off above, there are infinitely many continuous curves passing through the data points. Thus, a starting point is the choice of curves of a certain class, i.e., meeting predetermined conditions. For example, consider the class of the logistic curve
, which is a solution to the logistic differential equation
for
and
. Once a class of curves is decided on, the approximation proceeds with some kind of minimization of the deviation between the real and the approximated data by some criterion (e.g., the method of least squares). (Such approximations can be made using modern computer algebra systems. For example, in Wolfram Mathematica, this can be calculated with the “Fit command”).
The main classes of sigmoids are presented in
Figure 2. They have similar behavior but differ on the intervals that double the population. These functions are normed so that the derivative at zero equals 1.
The choice of a particular type of sigmoid is determined by the assumption about the type of impact, e.g., the rate of change, may depend on both the current state and the constraints on the sigmoid (
). The simplest type of such dependence is described by the logistic Equation (
5). Its solution is the logistic curve
where
is the “inflection point” of the curve. A generalization of the logistic equation giving a more general form of sigmoid is
where
g and
h are non-decreasing functions. A particular example is the equation
Sigmoids describe evolutionary processes very well because those are characterized by three stages: slow growth, until reaching a critical region of rapid growth, followed by slow growth. Further, the population size is bounded from above. Indeed, the
S-curves describe such processes well. Following [
35], knowing how long it takes for the population to double suffices for constructing the sigmoid that describes the evolutionary process continuously. This approach is remarkable for the fact that from information about a small interval of time, we can reconstruct the evolutionary behavior over the entire interval.
The model we are looking at is the number of mobile users in the USA. It is well known that this market starts from zero users and its growth is limited (it is possible for one person to use more than one service, not too many in number). This means that sigmoids will describe this process well. We consider linear combinations of sigmoids to obtain a better approximation.
2.3. Testing Model’s Fit
Naturally, there are differences between our continuous model and the discrete real-world data. We interpret these differences as insignificant random deviations. To gauge our model’s performance and the insignificance of these deviations, it is common to perform statistical testing. We use Pearson and the Kolmogorov–Smirnov test. These two tests are most commonly applied in testing non-parametric hypotheses (testing whether a sample has a predetermined distribution or whether two samples have the same distribution).
The Pearson test is an asymptotic one based on the Central Limit Theorem. The test statistic has a distribution that is not actually known but converges asymptotically (very fast, provided that the hypothesis is true) to a Pearson distribution. The Kolmogorov–Smirnov test is more reliable, but more complicated to apply. It is based on a Kolmogorov result for the supremum of the difference between the assumed distribution and the empirical sampling distribution under the “null hypothesis”.
By these tests, we check whether the differences between the empirical and approximated data are insignificant random deviations (acceptance of the null hypothesis) or significant (rejection of the null hypothesis). Wolfram Mathematica calculates the probability of randomness of deviations (p-value). We seek significance with p-value < 0.05 (the limit).
3. Empirical Response Functions
We have data for the number of smartphone subscribers to two companies over a ten-year period, . Formally, , where X and Y are the sets of possible numbers of consumers for each firm. We are searching for an ordered pair of semi-cyclic maps that satisfies the equality , i.e., the response function of each company.
3.1. Data and Empirical Strategy
We use publicly available information on the distribution of mobile operators in the USA for the period 2009–2021, distributed by quarters in percentage of market share from
https://www.statista.com (accessed on 20 March 2022).
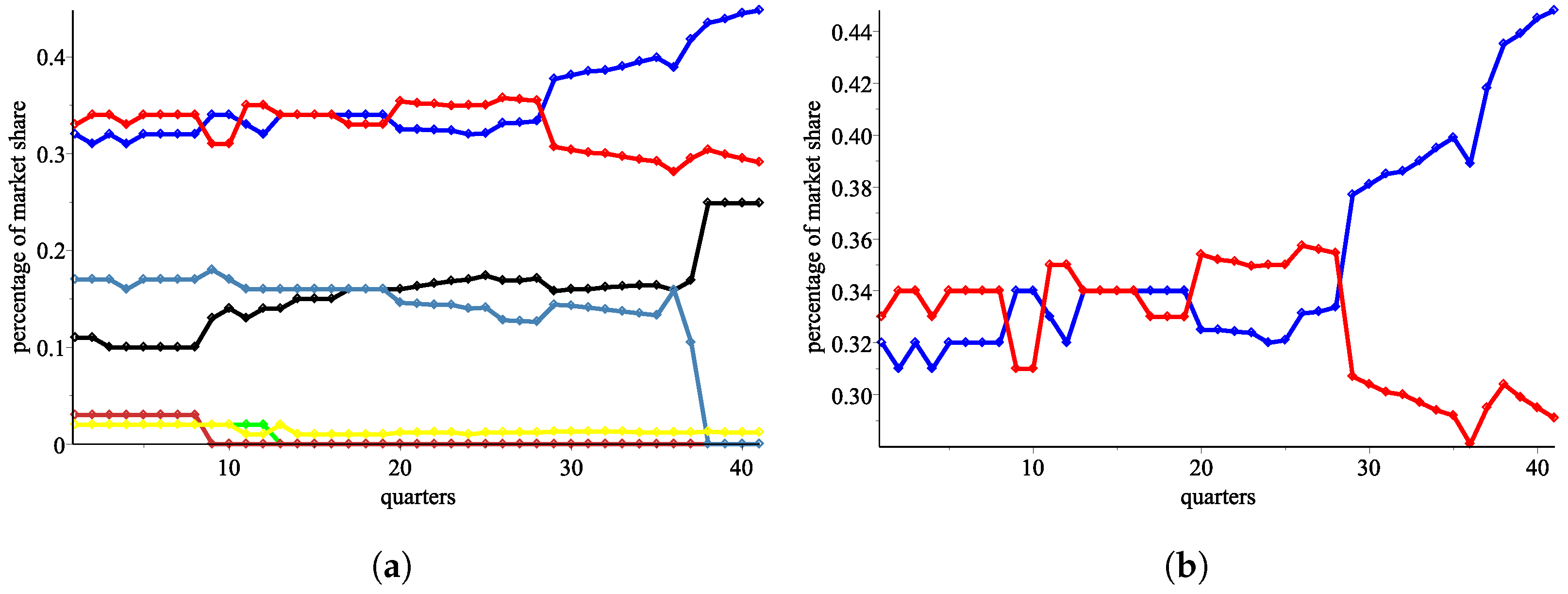
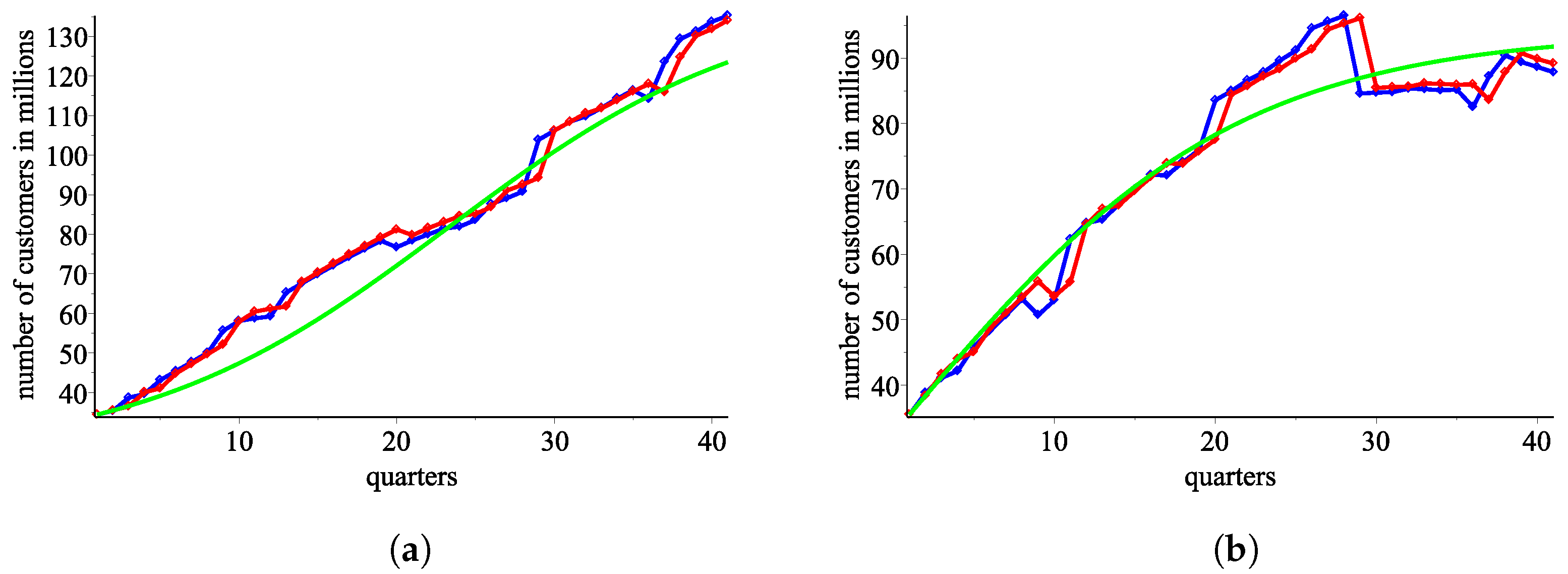
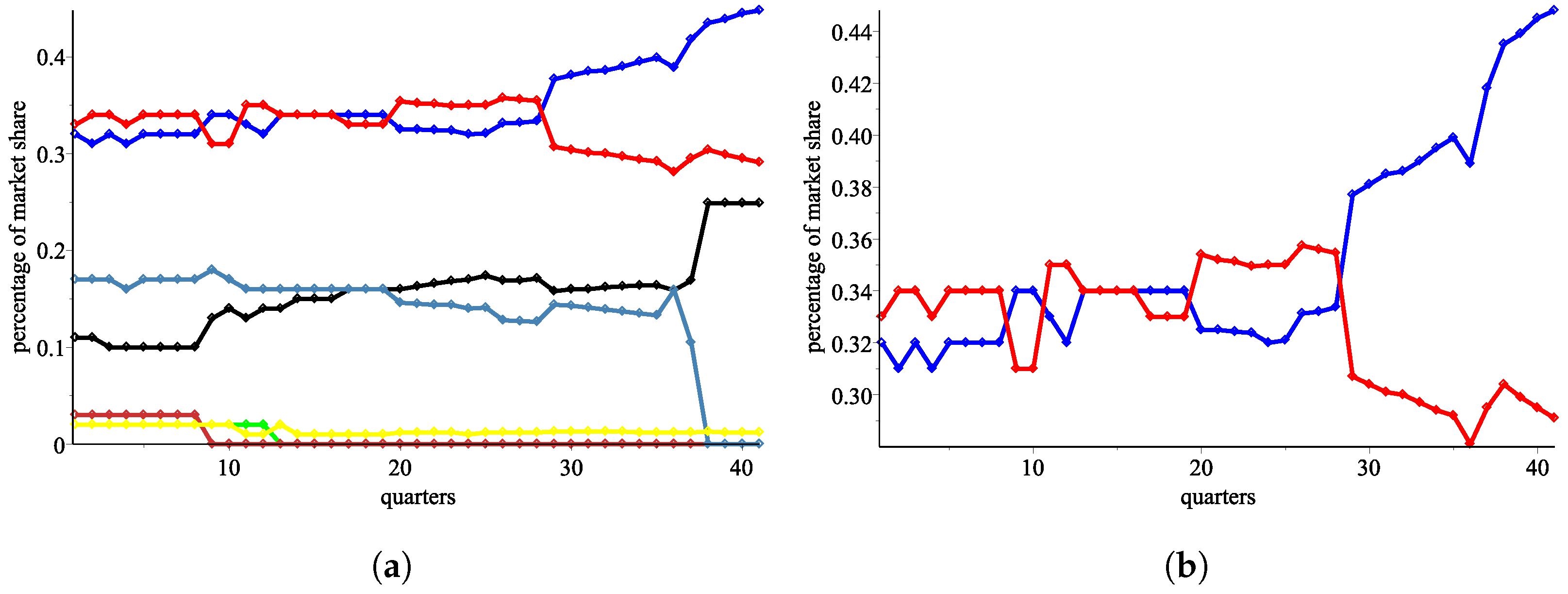
In
Figure 3a, we plot the data in a graphic view.
Our analysis proceeds with the two biggest mobile service providers, AT&T (in blue color) and Verizon (in red color). Specifically, we abstract from all smaller providers, assuming that the two big operators AT&T and Verizon respond only to each other and not to the rest of the market. While we acknowledge that a third operator has a growing share, it is only in the last four quarters, and handling a market with three participants with the proposed methods remains an open question. The lack of long-term data for the third operator and the complexity of modeling motivates us to analyze the market as a duopoly.
We plot in
Figure 3 the percentage shares only for the two biggest mobile providers. We try to model the response functions of the two big providers (
and
) in the form of semi-cyclic maps
and
, where
X and
Y are the sets of consumers for
and
, respectively, rather than the percentage shares in the market. (Formallyspeaking, there is a structural change in the market taking place sometime in the 36th quarter, where something happens and the other big player (
) disappears and its customers are reallocated. Again, handling this structural break is challenging both from the point of insufficient data and from a technical viewpoint. Furthermore, according to data from
www.statista.com (accessed on 15 February 2024) for the third quarter of 2023, AT&T has
and Verizon has
, totaling
, from a market of around 310 million mobile subscribers. With this concentration, we believe that the duopoly model provides a reasonably good description of the market and a probable equilibrium that would last if no changes had occurred, such as new regulations or the entry or exit of operators from the market.)
3.2. Approximation of the Evolution of Smartphone Subscriptions over Time
We need to address a few challenges before we proceed with the construction of empirical response functions.
The real data at our disposal are discrete. We have information at a finite number of moments in time, but we will try to construct continuous response functions. It is well known that an infinite number of functions pass through a finite number of points even when the form of these functions is known to some extent—for example, continuous, differentiable, etc. We will assume that the response functions will be differentiable and that their partial derivatives will be bounded so that no too-big changes of their market shares can appear. In addition, the data are not always accurate enough in practice, i.e., values are known to have some error.
We are searching an approximation of the discrete data of the total number of users of mobile services in the USA by a function
S. Note the assumption that
S is bounded (
), where
b is the upper bound in millions for the possible number of mobile users in the USA, naturally limited. Therefore, a sigmoid kind of function will best fit the data [
29,
36]. The sigmoid functions are monotone and nonlinear, with an
S-type graph and with derivatives that have a bell-formed graph and a pair of horizontal asymptotes.
The choice of the specific type of sigmoid [
29,
36] is determined by the assumption of the type of impact. For the rate of change, we assume that it depends on both the current state and the constraints on the sigmoid
. The simplest type of such dependence is described by the logistic differential Equation (
5), representing a special case of the Bernoulli differential equation, where
S is the unknown sigmoid function, which best fits the data,
a and
b are its lower and upper horizontal asymptotes and
c is a coefficient of the proportionality factor, characterizing the force of impact (usually it is about 1). In our model, we set
.
The meaning of the form of this equation [
29] is that for small values of the variable
y, the rate of change is approximately proportional to the accumulated value
y, and for values close to the maximum value of
y, the rate of change will be close to 0.
The solution of this equation is the so-called logistic curve (
6) [
37], where
is the starting point of the available data.
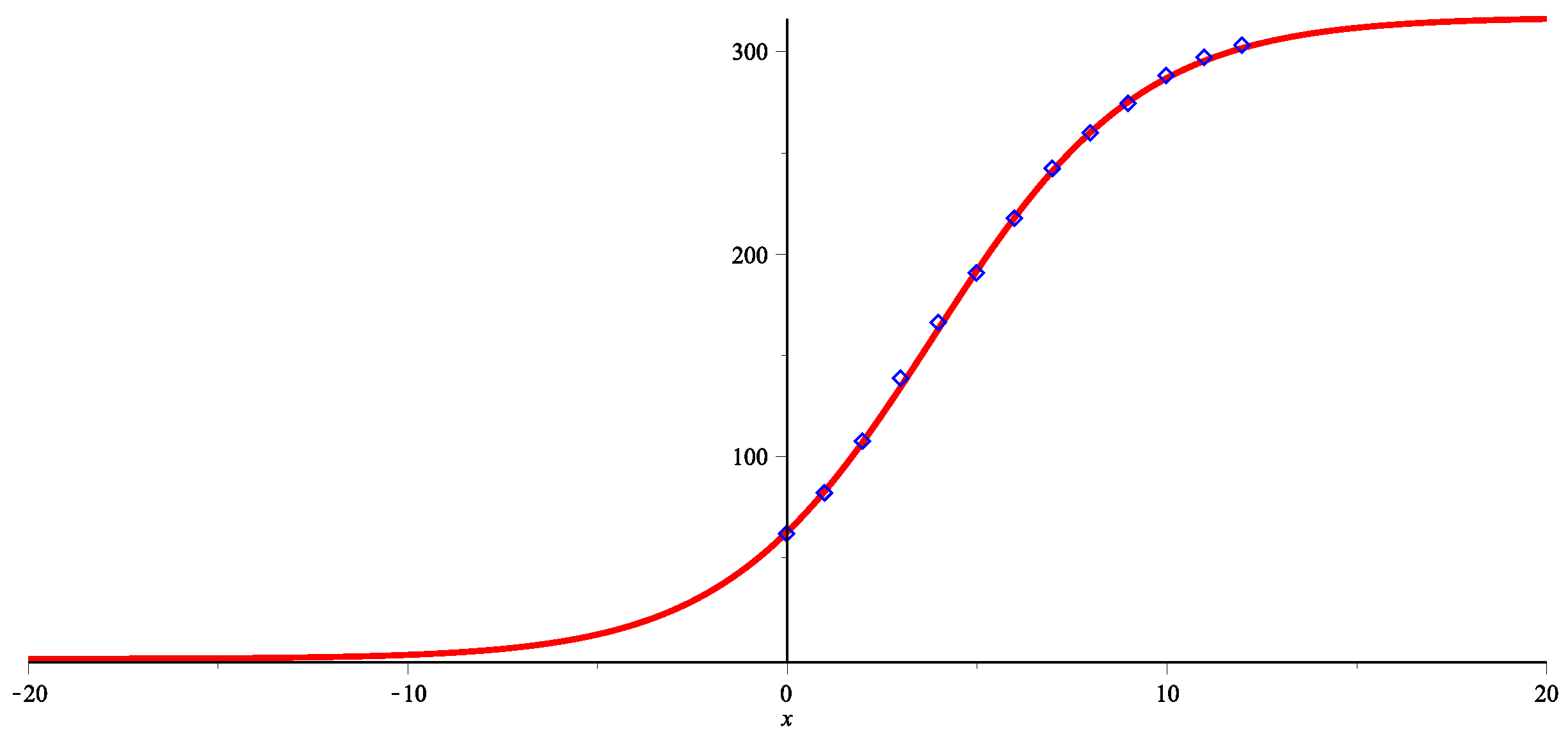
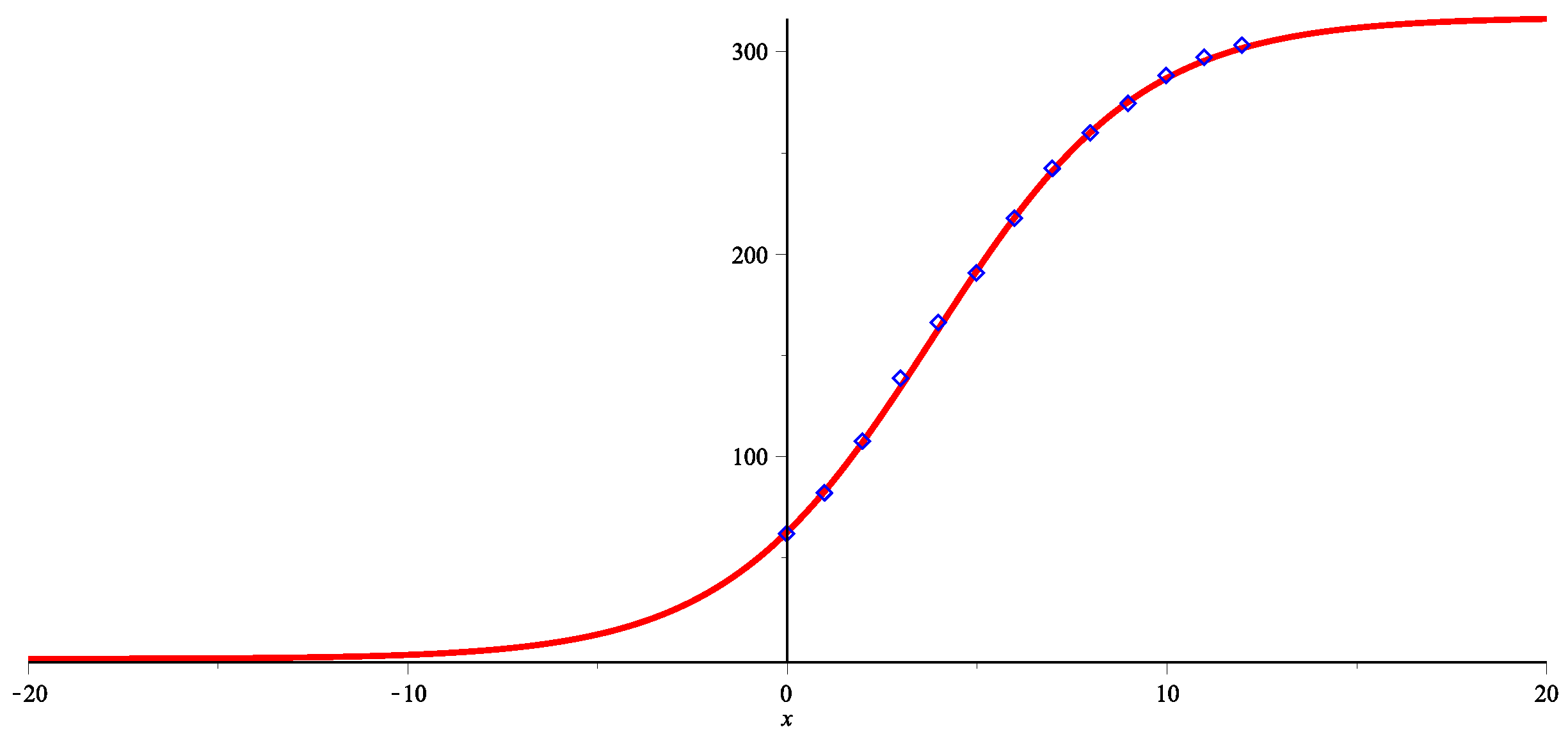
We obtain an approximation curve for the total number of mobile consumers in the USA in the form
where
y is number of years from the starting point
(
Figure 4).
The maximum number of smartphones in the USA in the near future will not exceed million smartphones, which is a realistic estimate given the actual number of smartphones at the time of the study: the number in 2021 is set to be million and in the nearby future the number in 2022 is set to be 302 million.
We see that the function
S fits the data very well (
Figure 4). We see that the start of the process is about 15 years away from the zero one (2009), which is somewhere in the year
. It is actually close to the real beginning of mobile services. Therefore, the sigmoid function
S presents a fair model of the number of mobile users, and we can assume that the total number will not exceed 320 million in the near future.
With the use of the function S, we calculate an approximation of the total number of mobile service users in quarters, rather than years.
3.3. Construction of the Response Function
We prefer to use three different notations for the ordered pairs of response functions to distinguish the three models that we derive from the available empirical data. We denote by the model constructed using least squares, by that obtained with sigmoid functions and by the linear approximation of .
We will use intuition from our duopoly model to reformulate the time series approximation of the total number of consumers and obtain an approximation of the response functions. Specifically, we use the method of least squares for functions of two variables to approximate the response functions of the two biggest mobile operators in the market
and
, where
U and
V are the sets of the possible numbers of consumers. We will minimize
and
, where
is the total number of consumers of AT&T and
is that of Verizon for the quartile
i. We will search the functions
F and
G to be a linear combination of the functions 1,
u,
v,
,
,
,
,
,
and
. Let us set
,
,
,
,
,
,
,
,
and
. Let us denote
and
. We look for
that minimize the problems
As noted above, there is an infinite number of response functions that will fit the data, so we need to make a few regularizations. We assume that the response functions have partial derivatives, which satisfy certain conditions. Intuitively, we assume that the mobile operators cannot increase or decrease their numbers of consumers too fast. Thus, we search for a solution of (
7) satisfying
Wolfram Mathematica delivers two response functions
F and
G for
and
, respectively:
and
where
u is the total number of customers of AT&T and
v is the total number of customers of Verizon.
For each ordered pair , the response functions F and G present the reactions of each of the mobile operators that leads to a change in the number of their consumers, i.e., will be the number of consumers for each of the players after reacting to the market results .
3.4. Alternative Model with Consumer Shares
An alternative approach to modeling these data is in shares as opposed to levels. That is, we can work with functions representing the market share instead of the number of consumers. From the market share, we can recover the real number of subscribers using the total market consumers. As before, we approximate the data from
Figure 3a as time series by sigmoid functions.
Let us denote with and the functions that represent the percentage share of the mobile providers and as a function of time, respectively. Due to the assumption that f and g are percentages, it follows that they are bounded (). This assumption leads us to search for a sigmoid function that will fit best the data, as it was performed for the approximation of the total number of mobile service users. We look for an approximation of the form of a linear combination of logistic curves , , n and m, where and . The functions f and g are of the same class of sigmoidal functions, but with different parameters. One of the functions represents the desire of one operator to increase its users, and the other function is the behavior of its competitor, which leads to a decrease in the users of the first participant. The two functions taken together give the reaction, but over time, not as a reaction to market performance.
This kind of logistic curve describes change in the market share of the operator so that their policy tries to increase its impact and the policy of the other player tries to decrease its impact. The constants A and are, respectively, the lower and upper limits (horizontal asymptote) of the described market share of the considered mobile operator.
Using a series of numerical experiments in the Wolfram Mathematica System, the coefficients A, B and C were calculated for and , best describing the available quarter data on the percentage presence of the market of the two mobile operators and .
The resulting functions for the percentage presence of AT& T and Verizon by quarters over time are the following functions.
The function for AT&T is
and
.
The function for
is
and
.
The functions are plotted in
Figure 3b and
Figure 5a for
and
, respectively, where in black are the real data and in blue is the estimation, obtained.
We specifically note that the graphs are automatically scaled and vertically the curves appear more “stretched” than they would be on a real scale. In fact, the fluctuations of the real data around the approximating curves (in blue) are quite small, and the measurement accuracy is exactly 1 unit (1 percent) vertically, and any further rounding will distort the real data.
3.5. Constructing the Response Functions for the Alternative Model
We construct the response functions of AT&T and Verizon with the help of the sigmoid function in order to apply the technique from [
1]. By repeating the calculation from above, we obtain the functions that present the numbers of mobile customers of each of the two biggest operators as sequences dependent of the time.
recursively, depending only on their values in the previous quarter (3-month period), where
is the total number of consumers for AT& T and
the total number for Verizon.
We search for functions
and
such that
From (
9) and taking into account that
, we obtain
which holds for any
n. Transforming the third and fourth equations, we obtain
Substituting the third and fourth equations into the first and second by all possible combinations, we notice that
Therefore, we arrive at the response functions
and
as a consequence of (
10).
Let
and
be the Taylor series of
and
to power 1 around the point
. Then, we obtain linear response functions for AT&T and Verizon
respectively.
4. Model Fit
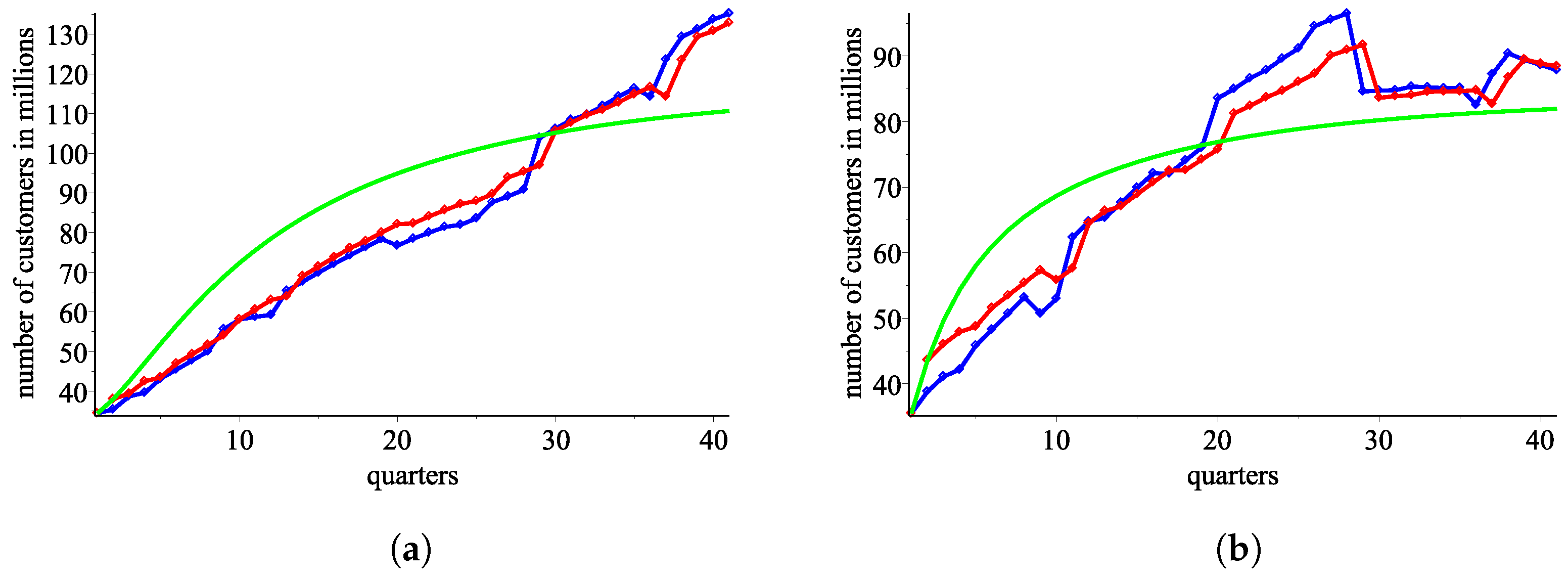
We proceed to statistically examine the model’s fit and to demonstrate that our model, based on the sigmoid approximation, delivers superior results in comparison to the direct estimation of response functions with low-degree polynomials by the least squares method.
4.1. The Least Squares Model
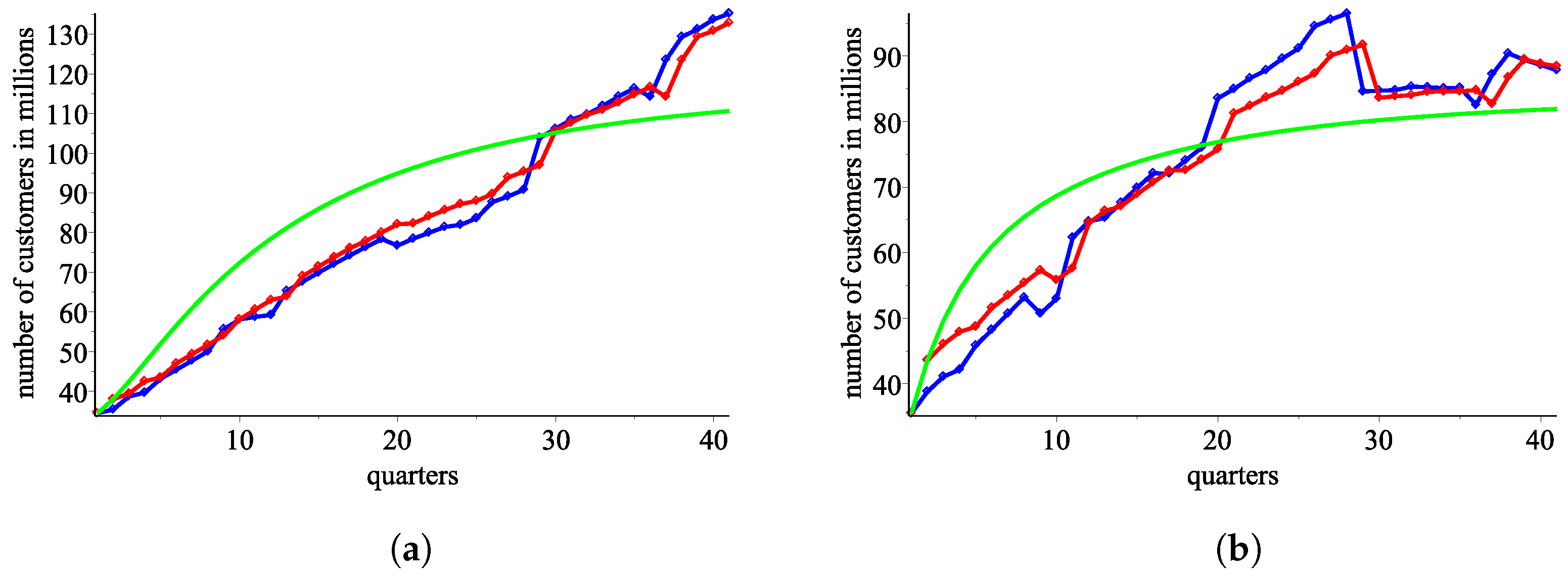
We employ an intuitive process using the obtained ordered pairs of response functions
,
and
. Specifically, we calculate
from
and
(
Figure 6a,b).
According to the Pearson test, sequences and fit to the real data with p-values and , respectively.
According to the Kolmogorov–Smirnov test, and fit to the real data with p-values and , respectively.
According to the Pearson test, sequences and fit to the real data with p-values and , respectively.
According to the Kolmogorov–Smirnov test, and fit to the real data with p-values and , respectively. We can reject the hypothesis that fits the real-world data with the noted p-value, i.e., a high p-value implies good fit.
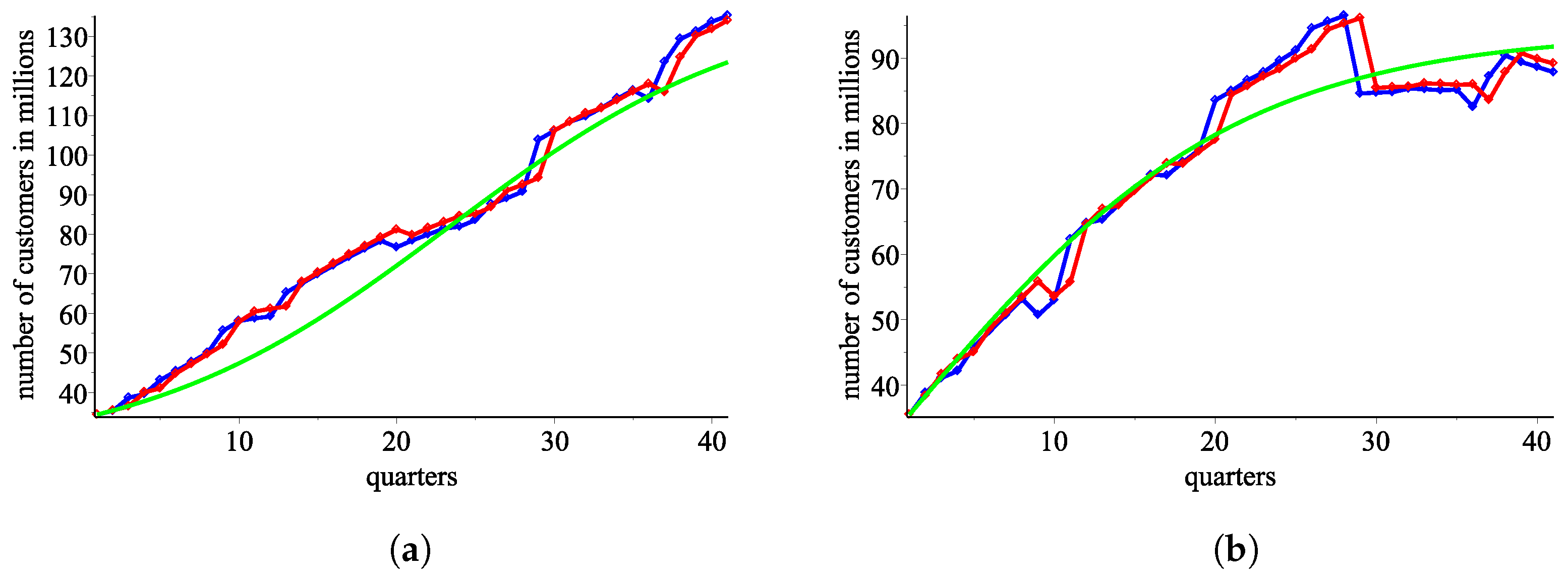
4.2. The Sigmoid Model
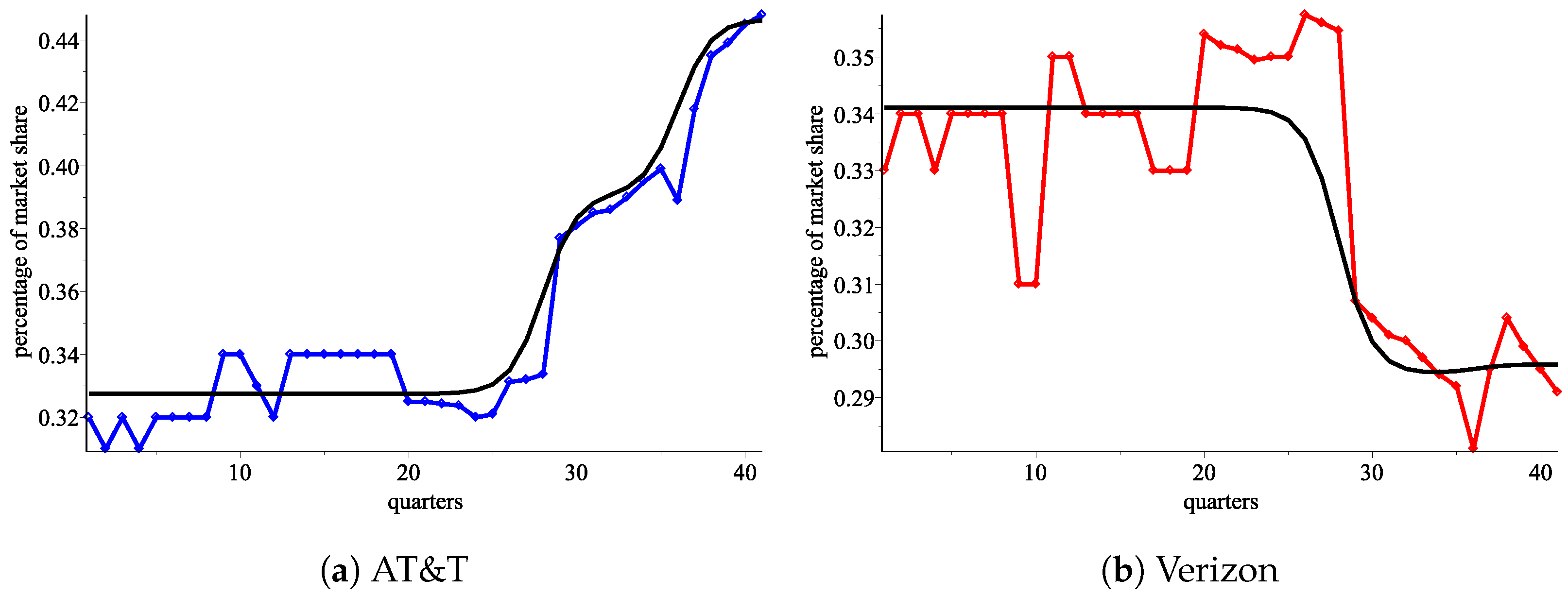
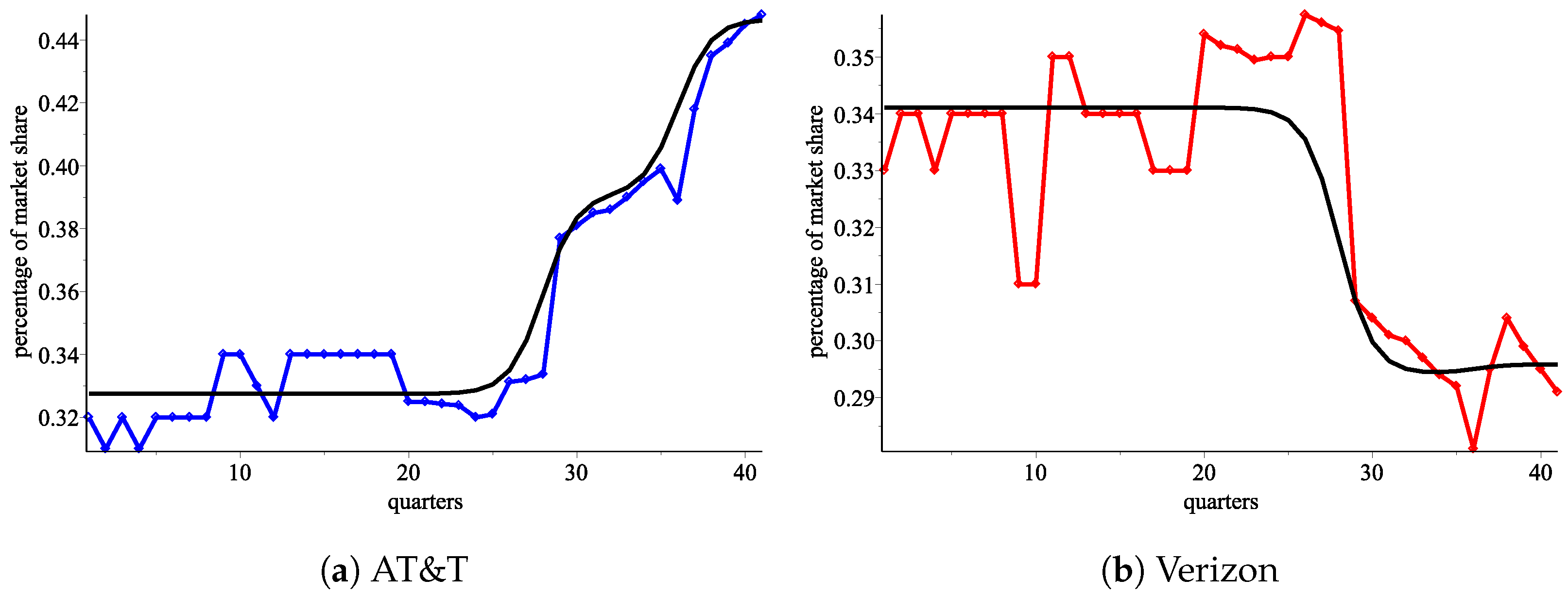
Using the response functions
from the levels model, we plot the number of consumers for AT&T and Verizon, respectively (
Figure 7a,b).
Using the response functions from the alternative model with market shares, we plot the number of consumers for AT&T and Verizon, respectively.
According to the Pearson test, sequences and fit to the real data with p-values and , respectively.
According to the Kolmogorov–Smirnov test, and fit to the real data with p-values and , respectively.
According to the Pearson test, sequences and fit to the real data with p-values and , respectively.
According to the Kolmogorov–Smirnov test, and fit to the real data with p-values and , respectively.
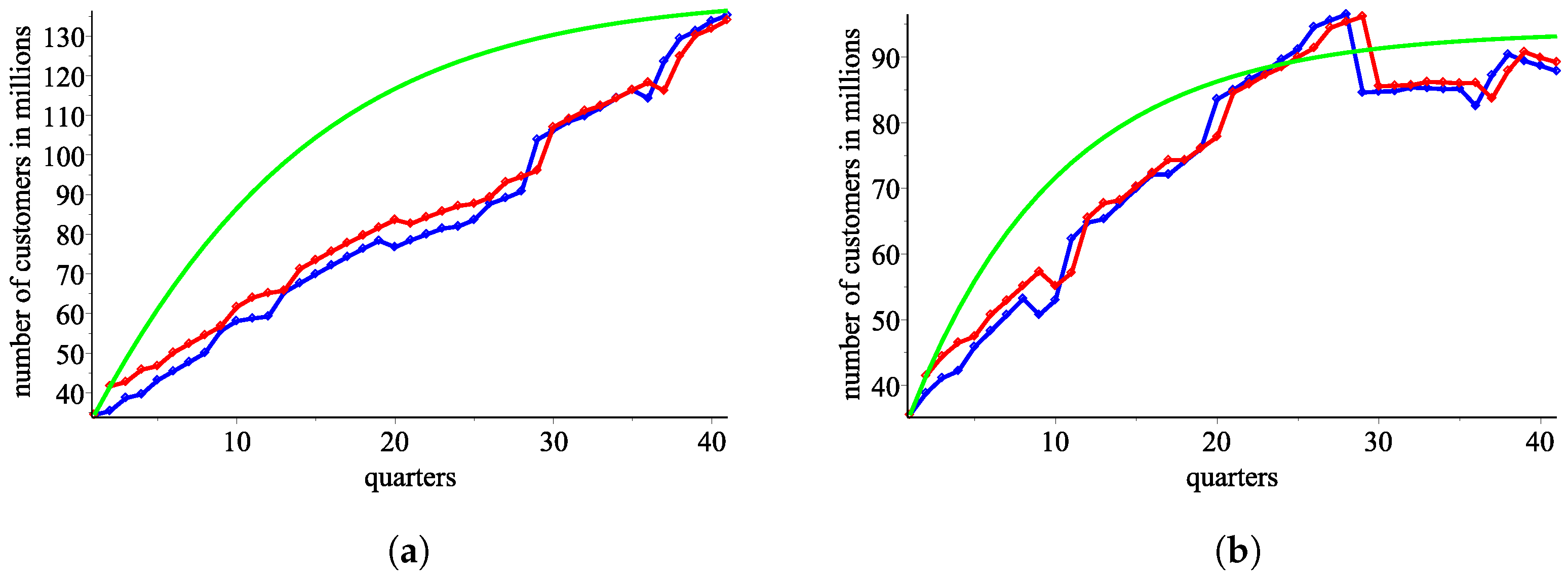
4.3. The Linear Approximation of the Sigmoid Model
Using the response functions
from the levels model, we plot the number of consumers for
and
, respectively (
Figure 8a,b).
According to the Pearson test, sequences and fit to the real data with p-values and , respectively.
According to the Kolmogorov–Smirnov test, and fits to the real data with p-values and , respectively.
According to the Pearson test, sequences and fit to the real data with p-values and , respectively.
According to the Kolmogorov–Smirnov test, and fit to the real data with p-values and , respectively.
Note that only for four recursive sequences our modeling approach based on S-curves presents an approximation with a significant statistical confidence. Recursive approximations sometimes give bad results. The sigmoid approximation gives better fitting to the real data.
It is important to note that the Cournot model and the model of response functions actually are static models, i.e., we assume that there is no change in the external conditions in the market. So, we can conclude that probably there have been some changes in the external conditions (regulations or new technologies) and internal conditions (the market policy of the two players), which have changed the response functions, and thus the least squares method fits well for the quartiles to .
5. Existence, Uniqueness and Stability of Market Equilibrium
We show that our empirical response functions , and satisfy the hypothesis of Theorem 2 so that there exists a long-run equilibrium which is unique and stable. The next proposition is a simplification of the contractive-type condition that we need and is easy to check. Its proof is in the appendix.
Proposition 1. Let X and Y be two intervals in . Let the functions and have continuous partial derivatives in such thatand Then, the ordered pair satisfies (3), i.e., Proof. Let
and
be arbitrary points. Then, we can write for them
Similarly, we obtain that
Adding this to (
11), we can see that
Let us consider
. The functions we integrate are non-negative and the limits of the integrals are the same. Therefore,
From the definition of
, it follows that
for every
and that
. From this and (
13), we obtain
Similarly, we can prove that
Let us substitute this and (
14) in (
12). Then, we obtain that
where
, but from the definitions of
and
, it follows that
and
. Therefore,
, i.e., we obtain that for any
and
we have
where
. □
We will show that the assumptions in Theorem 2 are satisfied by the response functions’ ordered pairs , and .
It is easy to check that
and
After calculating
we obtain that the ordered pair
satisfies Proposition 1. Consequently, there is a unique market equilibrium pair
in
, i.e.,
and
. Moreover, for any market initial conditions
, the sequence of successive responses of productions
and
converge to
, and they hold the error estimates from Theorem 2.
By solving , we obtain the solutions , , , and several solutions with and/or . From the fact that and , it follows that the market equilibrium is attained for productions , .
Let
and
. Then, we can calculate that
and
. Also, we can calculate that
and
From Proposition 1, it follows that the ordered pair satisfies Theorem 2 in with . By solving , we obtain several solutions, but just one of them, , lies in .
Let
and
. Then, we can calculate that
and
. Also, we can calculate that
and
From Proposition 1, it follows that the ordered pair satisfies Theorem 2 in with . By solving , we obtain the solutions , . We see that the linear approximation of the sigmoid functions satisfies Theorem 2 with intervals with greatest length.
Besides the best statistical fitting of the model to the real data, when sigmoid functions are used, the response functions
and
give us more information on the responses of the two players. For example, let us consider player one. With the response function
, it is an increasing and concave function of
u, i.e., any good results
lead to an increase in market results, but as
u becomes bigger and bigger, the increment becomes less and less.
For player two, from we see that a small value of , i.e., the number of consumers of player one, leads to a decrease in the market results for player two.
6. Using the Empirical Response Functions to Simulate Convergence to the Equilibrium
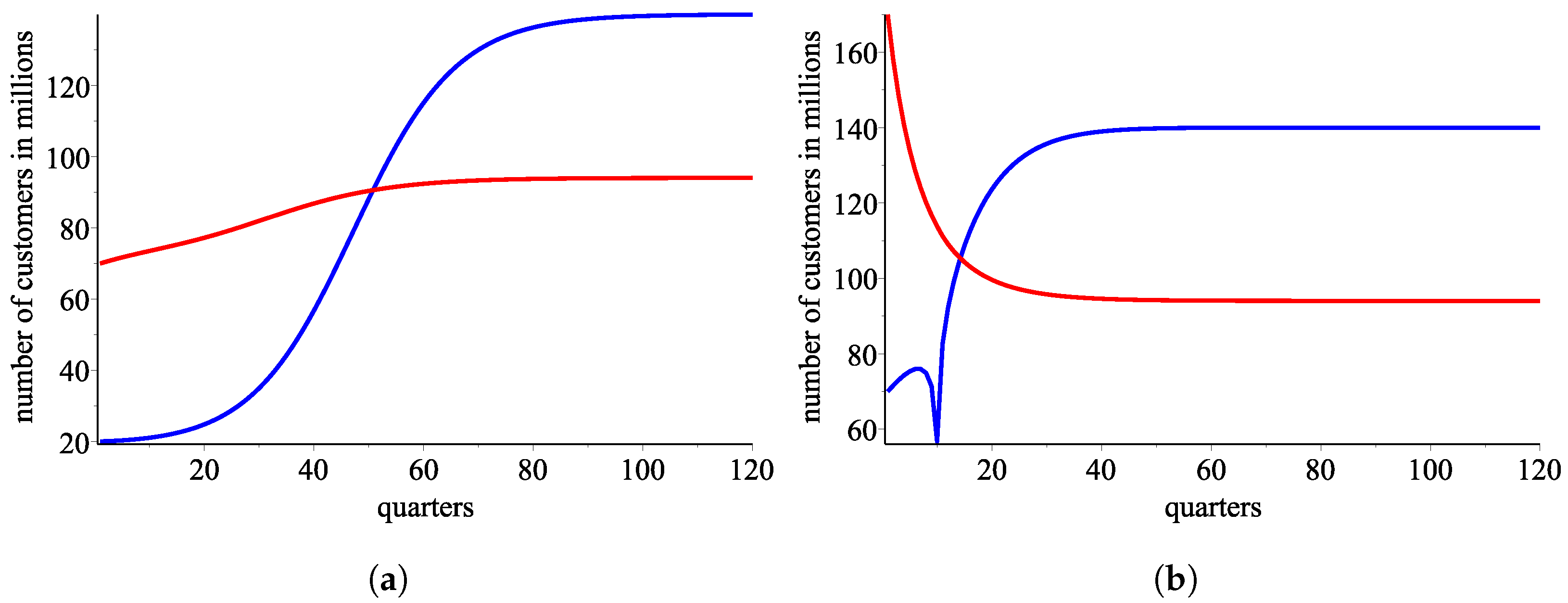
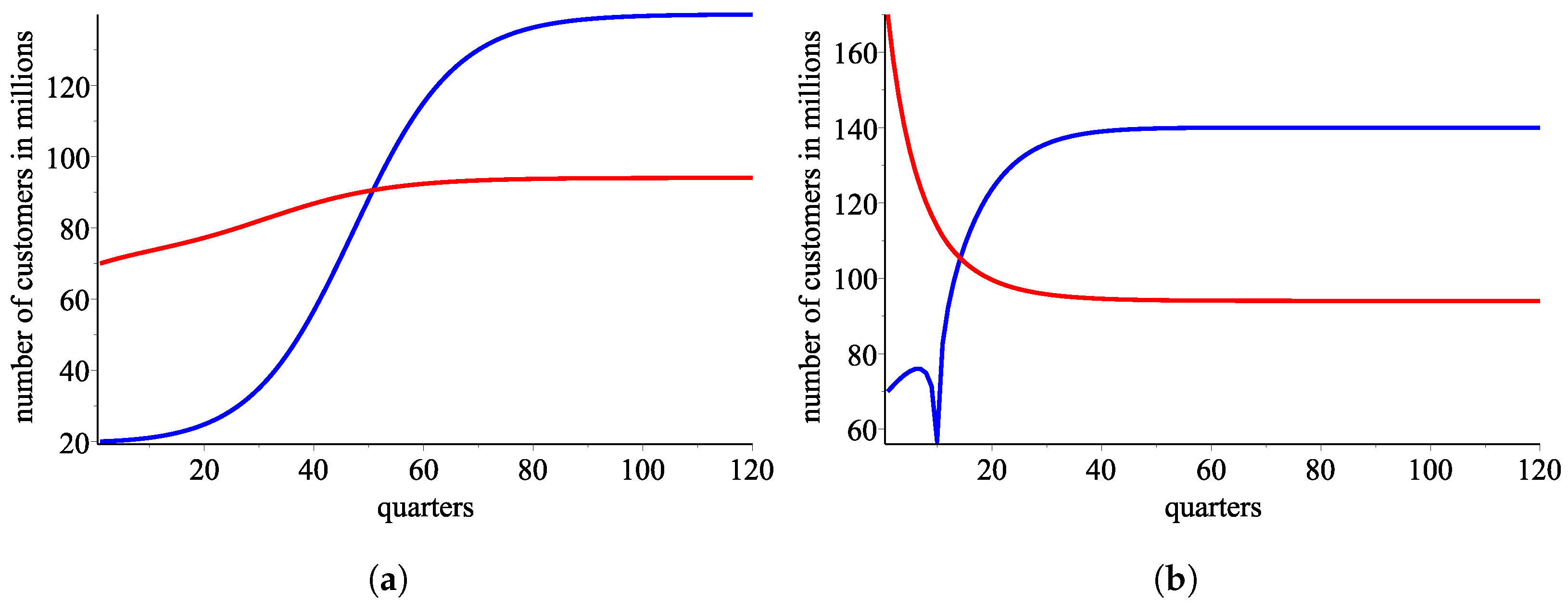
This section illustrates with numerical simulations how our empirical response functions converge to the long-run equilibrium. Specifically, we experiment with initial values that are significantly different from the actual data and that are outside the range where we can invoke Theorem 2, i.e., for which we know with certainty that the responses converge to the long-run equilibrium.
Figure 9a and
Figure 9b plot the sequences of successive market outcomes if the initial start is
and
, respectively, approximated with the sigmoidal response functions
.
Figure 10a and
Figure 10b plot the predicted market path if the initial start is
and
, respectively, approximated with the sigmoidal response functions
.
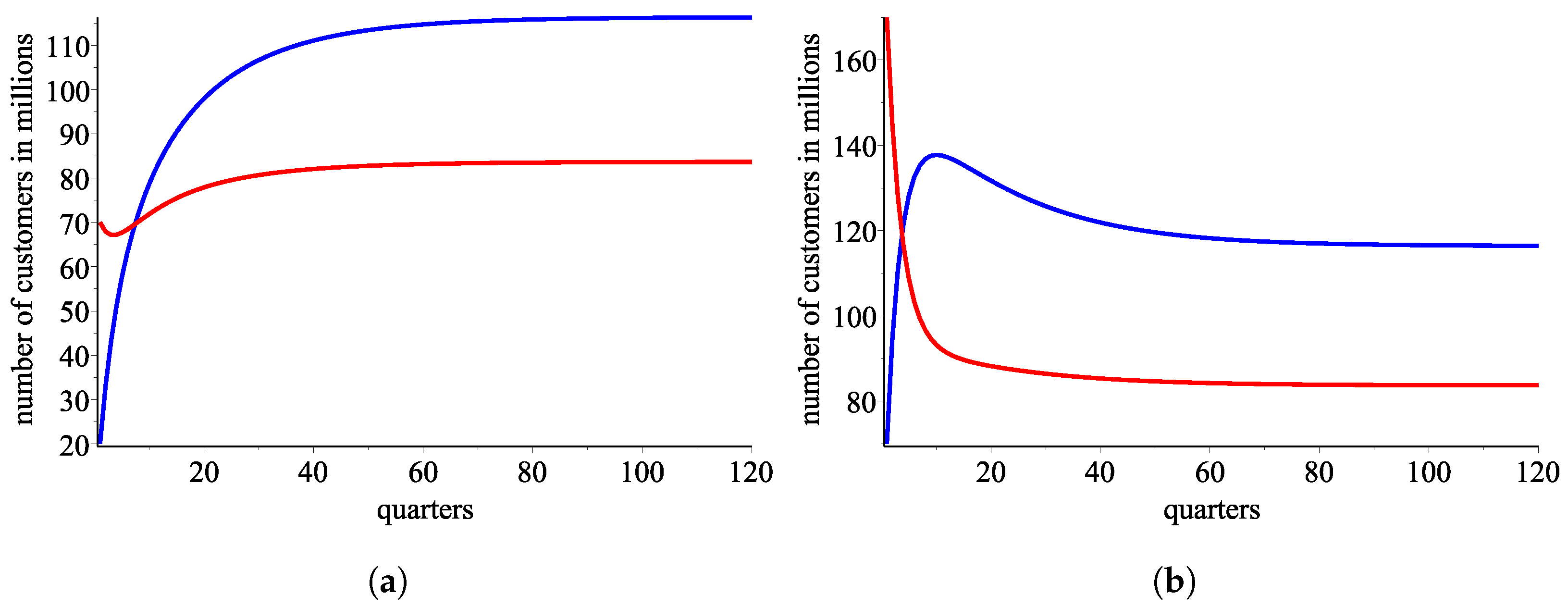
Figure 11a and
Figure 11b illustrate the evolution of the market if the initial start is
and
, respectively, approximated with the sigmoidal response functions
.
Finally, in
Figure 12a and
Figure 12b, the starting values are
and
, respectively, and the market evolution is approximated with the sigmoidal response functions
.
Our numerical analysis demonstrates that the long-run equilibrium is stable even when the initial conditions are not in the set where we can rely on the conclusion of Theorem 2. We note in passing that the response functions generated with the least squares method do not demonstrate stability for this wide range of initial conditions.
7. Conclusions
We empirically study the wireless telecommunication market in the USA using an equilibrium theory based on response functions instead of a payoff maximization problem. In our settings, the approximation technique using sigmoid functions gives slightly better results in comparison to the classical least squares method. It is worth noting that the linear approximation of the sigmoid model approaches the linear part in the function obtained by the method of least squares. All in all, this is an illustration of the framework to model market equilibrium via response functions introduced in [
1,
10],
Numerical simulations from our robustness analysis suggest that the conditions imposed in Theorem 2 are only sufficient. Even with an initial state of the economy, for which we cannot formally guarantee the convergence of the empirical response functions, the market converges to long-run equilibrium. This observation is reaffirming in offering confidence that our approach delivers an adequate description of the evolution of the market.
More generally, our approach is applicable to other settings. If we assume that the participants in the duopoly market behave rationally and we know their cost functions, then from (
2) we can model for the inverse demand function
P. Further, we can model the cost functions of the two participants once we know the demand function.
Our model is simplified on purpose. Indeed, it is possible to look for a functional relationship between several products offered on the market by the two participants, or even to match each product k with an ordered pair of quantity and price , , and examine the presence of equilibrium with the help of response functions , .
Author Contributions
Conceptualization, A.B., S.K., P.K., V.Z. and B.Z.; methodology, A.B., S.K., P.K., V.Z. and B.Z.; investigation, A.B., S.K., P.K., V.Z. and B.Z.; writing—original draft preparation, A.B., S.K., P.K., V.Z. and B.Z.; writing—review and editing, A.B., S.K., P.K., V.Z. and B.Z. The listed authors have contributed equally in the research and are listed in alphabetical order. All authors have read and agreed to the published version of the manuscript.
Funding
The second and the third authors are partially financed by the European Union-NextGenerationEU, through the National Recovery and Resilience Plan of the Republic of Bulgaria, project DUECOS BG-RRP-2.004-0001-C01. The fourth author would like to thank the SP23-FMI-008 project of the Research Fund of the University of Plovdiv Paisii Hilendarski for the partial support.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Acknowledgments
Authors would like to thank anonymous reviewers for the valuable comments and suggestions that have improved the article.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Stanimir, K.; Zhelinski, V.; Zlatanov, B. Coupled Fixed Points for Hardy–Rogers Type of Maps and Their Applications in the Investigations of Market Equilibrium in Duopoly Markets for Non-Differentiable, Nonlinear Response Functions. Symmetry 2022, 14, 605. [Google Scholar] [CrossRef]
- Augustin, C.A. Researches into the Mathematical Principles of the Theory of Wealth, Translation ed.; Macmillan: New York, NY, USA, 1897. [Google Scholar]
- Rubinstein, A. Modeling Bounded Rationality; MIT Press: Cambridge, UK, 2019. [Google Scholar]
- Ueda, M. Effect of information asymmetry in Cournot duopoly game with bounded rationality. Appl. Math. Comput. 2019, 362, 124535. [Google Scholar] [CrossRef]
- Cellini, R.; Lambertini, L. Dynamic oligopoly with sticky prices: Closed-loop, feedback and open-loop solutions. J. Dyn. Control Syst. 2004, 10, 303–314. [Google Scholar] [CrossRef]
- Friedman, J.W. Oligopoly Theory; Cambradge University Press: Cambradge, UK, 2007. [Google Scholar]
- Bischi, G.I.; Chiarella, C.; Kopel, M.; Szidarovszky, F. Nonlinear Oligopolies Stability and Bifurcations; Springer: Berlin/Heidelberg, Germany, 2010. [Google Scholar] [CrossRef]
- Matsumoto, A.; Szidarovszky, F. Dynamic Oligopolies with Time Delays; Springer: Singapore, 2018. [Google Scholar] [CrossRef]
- Okuguchi, K.; Szidarovszky, F. The Theory of Oligopoly with Multi–Product Firms; Springer: Berlin/Heidelberg, Germany, 1990. [Google Scholar] [CrossRef]
- Dzhabarova, Y.; Kabaivanov, S.; Ruseva, M.; Zlatanov, B. Existence, Uniqueness and Stability of Market Equilibrium in Oligopoly Markets. Adm. Sci. 2020, 10, 70. [Google Scholar] [CrossRef]
- Andaluz, J.; Elsadany, A.A.; Jarne, G. Dynamic Cournot oligopoly game based on general isoelastic demand. Nonlinear Dyn. 2020, 99, 1053–1063. [Google Scholar] [CrossRef]
- Okuguchi, K. Expectations and Stability in Oligopoly Models; Springer: Berlin/Heidelberg, Germany, 1976. [Google Scholar] [CrossRef]
- Alavifard, F.; Ivanov, D.; He, J. Optimal divestment time in supply chain redesign under oligopoly: Evidence from shale oil production plants. Int. Trans. Oper. Res. 2020, 27, 2559–2583. [Google Scholar] [CrossRef]
- Geraskin, M. The properties of conjectural variations in the nonlinear stackelberg oligopoly model. Autom. Remote. Control 2020, 81, 1051–1072. [Google Scholar] [CrossRef]
- Siegert, C.; Robert, U. Dynamic oligopoly pricing: Evidence from the airline industry. Int. J. Ind. Organ. 2020, 71, 102639. [Google Scholar] [CrossRef]
- Strandholm, J.C. Promotion of green technology under different environmental policies. Games 2020, 11, 32. [Google Scholar] [CrossRef]
- Xiao, G.; Wang, Z. Empirical study on bikesharing brand selection in china in the post-sharing era. Sustainability 2020, 12, 3125. [Google Scholar] [CrossRef]
- Baik, K.H.; Lee, D. Decisions of duopoly firms on sharing information on their delegation contracts. Rev. Ind. Organ. 2020, 57, 145–165. [Google Scholar] [CrossRef]
- Liu, Y.; Sun, M. Application of duopoly multi-periodical game with bounded rationality in power supply market based on information asymmetry. Appl. Math. Model. 2020, 87, 300–316. [Google Scholar] [CrossRef]
- Xia, W.; Shen, J.; Sheng, Z. Asymmetric model of the quantum Stackelberg duopoly with incomplete information. Phys. Lett. A 2020, 384, 126644. [Google Scholar] [CrossRef]
- Banach, S. Sur les opérations dan les ensembles abstraits et leurs applications aux integrales. Fundam. Math. 1922, 3, 133–181. [Google Scholar] [CrossRef]
- Guo, D.; Lakshmikantham, V. Coupled fixed points of nonlinear operators with applications. Nonlinear Anal. Theory Methods Appl. 1987, 11, 623–632. [Google Scholar] [CrossRef]
- Bhaskar, T.G.; Lakshmikantham, V. Fixed point theorems in partially ordered metric spaces and applications. Nonlinear Anal. 2006, 65, 1379–1393. [Google Scholar] [CrossRef]
- Petruşel, A. Fixed points vs. coupled fixed points. J. Fixed Point Theory Appl. 2018, 20, 150. [Google Scholar] [CrossRef]
- Kirk, W.; Srinivasan, P.; Veeramani, P. Fixed points for mappings satisfying cyclical contractive condition. Fixed Point Theory 2003, 4, 179–189. [Google Scholar]
- Sintunavarat, W.; Kumam, P. Coupled best proximity point theorem in metric spaces. Fixed Point Theory Appl. 2012, 2012, 93. [Google Scholar] [CrossRef]
- Zlatanov, B. Coupled best proximity points for cyclic contractive maps and their applications. Fixed Point Theory 2021, 22, 431–452. [Google Scholar] [CrossRef]
- Ajeti, L.; Ilchev, A.; Zlatanov, B. On Coupled Best Proximity Points in Reflexive Banach Spaces. Mathematics 1992, 10, 1304. [Google Scholar] [CrossRef]
- Cybenko, G. Approximation by superpositions of a sigmoidal function. Math. Control Signals Syst. 1989, 2, 303–314. [Google Scholar] [CrossRef]
- Carr, A.C.; Lykkesfeldt, J. Factors Affecting the Vitamin C Dose-Concentration Relationship: Implications for Global Vitamin C Dietary Recommendations. Nutrients 2023, 15, 1657. [Google Scholar] [CrossRef]
- Eid, E.M.; Keshta, A.; Alrumman, S.; Arshad, M.; Shaltout, K.; Ahmed, M.; Al-Bakre, D.; Alfarhan, A.; Barcelo, D. Modeling Soil Organic Carbon at Coastal Sabkhas with Different Vegetation Covers at the Red Sea Coast of Saudi Arabia. J. Mar. Sci. Eng. 2023, 11, 295. [Google Scholar] [CrossRef]
- Gobin, A.; Sallah, A.-H.M.; Curnel, Y.; Delvoye, C.; Weiss, M.; Wellens, J.; Piccard, I.; Planchon, V.; Tychon, B.; Goffart, J.P.; et al. Crop Phenology Modelling Using Proximal and Satellite Sensor Data. Remote Sens. 2023, 15, 2090. [Google Scholar] [CrossRef]
- Krishnasamy, S.; Alotaibi, M.; Alehaideb, L.; Abbas, Q. Development and Validation of a Cyber-Physical System Leveraging EFDPN for Enhanced WSN-IoT Network Security. Sensors 2023, 23, 9294. [Google Scholar] [CrossRef] [PubMed]
- Martínez Pérez, A.; Pérez Martín, P.S. Logistic regression. Semergen 2024, 80, 102086. [Google Scholar] [CrossRef] [PubMed]
- Debecker, A.; Modis, T. Determination of the Uncertainties in S-Curve Logistic Fits. Technol. Forcasting Soc. Chang. 1994, 46, 153–173. [Google Scholar] [CrossRef]
- Mitchell, T. Machine Learning; McGraw-Hill International Editions Computer Science Series; McGraw-Hill: New York, NY, USA, 1997. [Google Scholar]
- Jan, C. The early origins of the logit model. Stud. Hist. Philos. Sci. Part C Stud. Hist. Philos. Biol. Biomed. Sci. 2004, 35, 613–626. [Google Scholar] [CrossRef]
Figure 1.
A sigmoid function.
Figure 1.
A sigmoid function.
Figure 2.
A few basic sigmoid functions: , , and .
Figure 2.
A few basic sigmoid functions: , , and .
Figure 3.
Percentage shares in the mobile market in the USA. (a) Graphic data for the seven mobile operators in the USA (2009–2020). (b) Graphic data for the two biggest operators, AT&T in blue and Verizon in red (2009–2020).
Figure 3.
Percentage shares in the mobile market in the USA. (a) Graphic data for the seven mobile operators in the USA (2009–2020). (b) Graphic data for the two biggest operators, AT&T in blue and Verizon in red (2009–2020).
Figure 4.
Total number of mobile users (2009–2020) and their approximation by the sigmoid function .
Figure 4.
Total number of mobile users (2009–2020) and their approximation by the sigmoid function .
Figure 5.
A sigmoid approximation of the percentage as a function of the time.
Figure 5.
A sigmoid approximation of the percentage as a function of the time.
Figure 6.
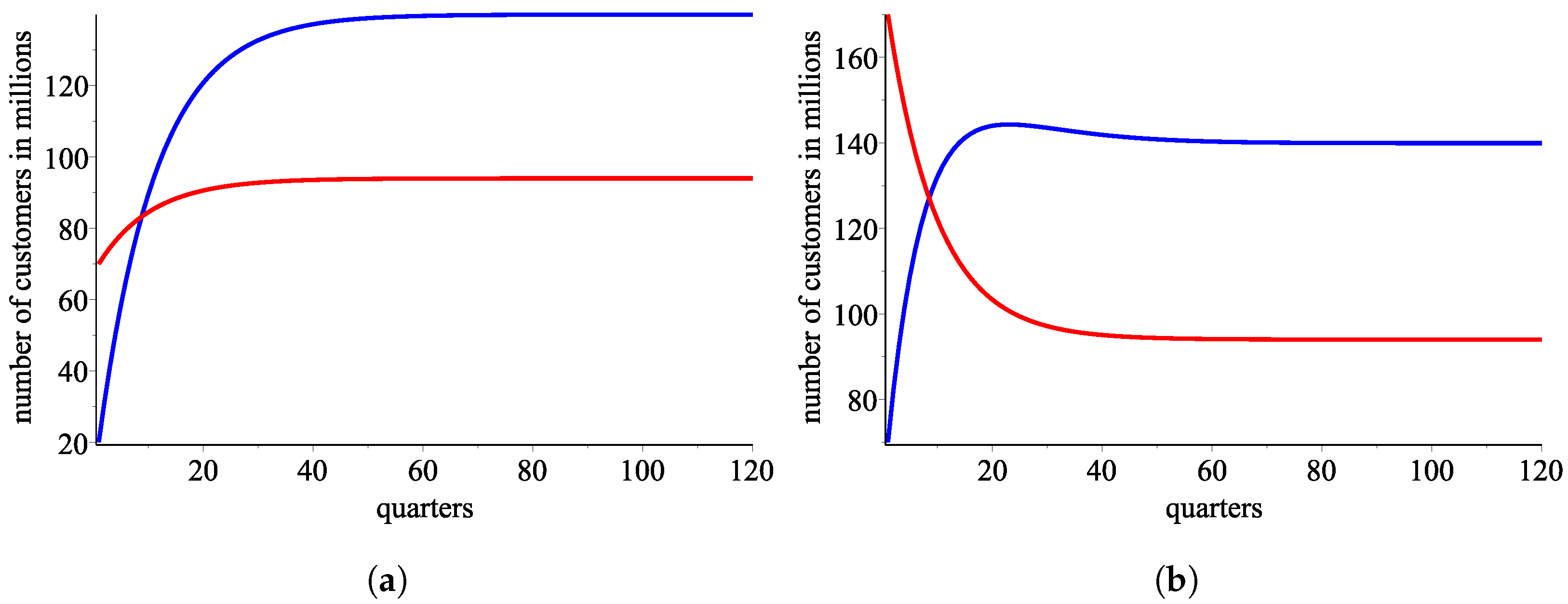
An approximation from using the ordered pair of response functions . (a) AT&T: blue—the real data, red—an approximation using , green—an approximation using . (b) Verizon: blue—the real data, red—an approximation using , green—an approximation using .
Figure 6.
An approximation from using the ordered pair of response functions . (a) AT&T: blue—the real data, red—an approximation using , green—an approximation using . (b) Verizon: blue—the real data, red—an approximation using , green—an approximation using .
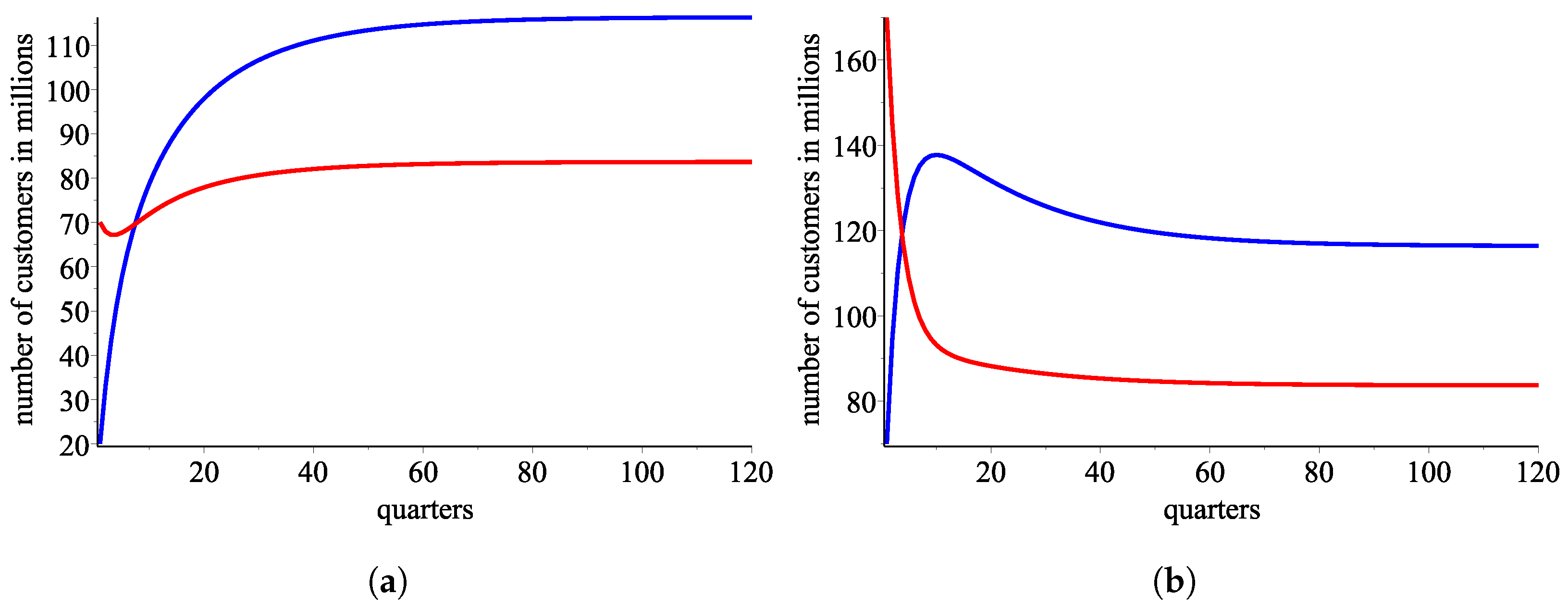
Figure 7.
An approximation from using the ordered pair of response functions . (a) AT&T: blue—the real data, red—an approximation using , green—an approximation using . (b) Verizon: blue—the real data, red—an approximation using , green—an approximation using .
Figure 7.
An approximation from using the ordered pair of response functions . (a) AT&T: blue—the real data, red—an approximation using , green—an approximation using . (b) Verizon: blue—the real data, red—an approximation using , green—an approximation using .
Figure 8.
An approximation from using the ordered pair of response functions . (a) : blue—the real data, red—an approximation using , green—an approximation using . (b) : blue—the real data, red—an approximation using , green—an approximation using .
Figure 8.
An approximation from using the ordered pair of response functions . (a) : blue—the real data, red—an approximation using , green—an approximation using . (b) : blue—the real data, red—an approximation using , green—an approximation using .
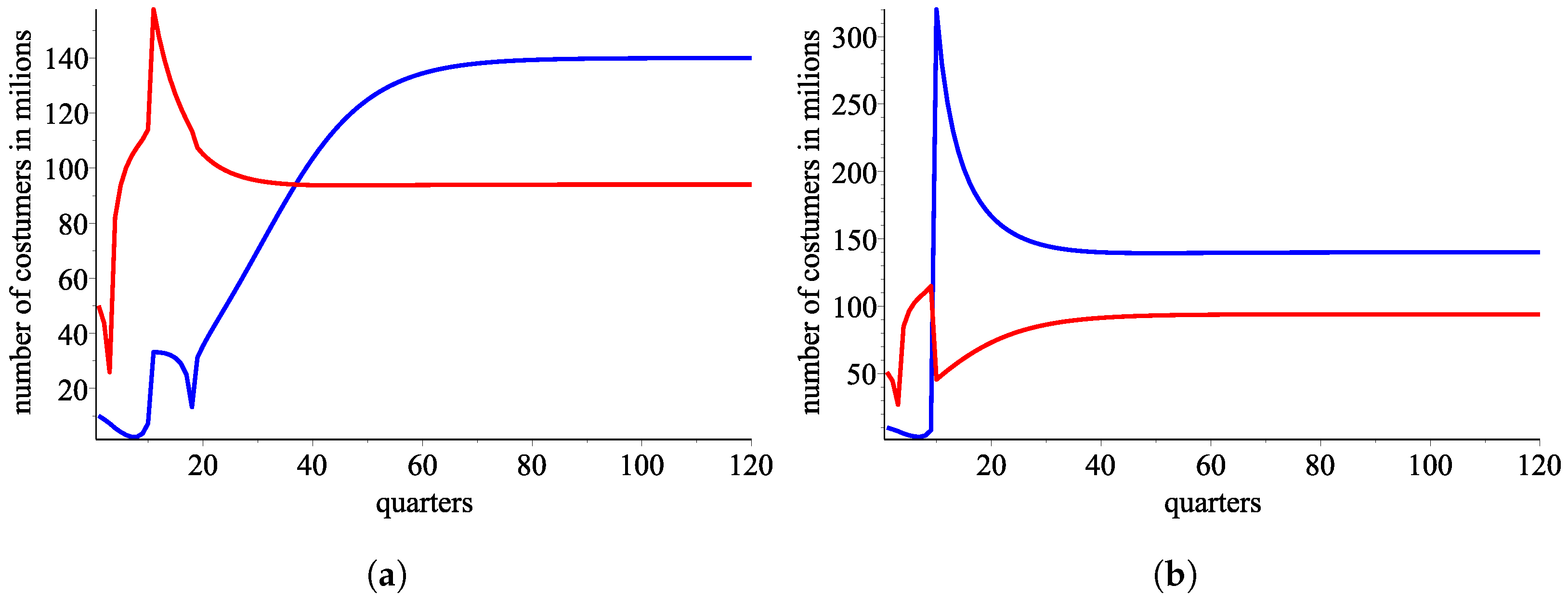
Figure 9.
A simulation with the ordered pair of response functions (blue color for customers of AT&T and red color for Verizone ones) (a) Evolution of the market with the sigmoid model if the initial start is . (b) Evolution of the market with the sigmoid model if the initial start is .
Figure 9.
A simulation with the ordered pair of response functions (blue color for customers of AT&T and red color for Verizone ones) (a) Evolution of the market with the sigmoid model if the initial start is . (b) Evolution of the market with the sigmoid model if the initial start is .
Figure 10.
A simulation with the ordered pair of response functions (blue color for customers of AT&T and red color for Verizone ones) (a) Evolution of the market with the linear approximation of the sigmoid model if the initial start is . (b) Evolution of the market with linear approximation of the sigmoid model if the initial start is .
Figure 10.
A simulation with the ordered pair of response functions (blue color for customers of AT&T and red color for Verizone ones) (a) Evolution of the market with the linear approximation of the sigmoid model if the initial start is . (b) Evolution of the market with linear approximation of the sigmoid model if the initial start is .
Figure 11.
A simulation with the ordered pair of response functions (blue color for customers of AT&T and red color for Verizone ones) (a) Evolution of the market with the least square model if the initial start is . (b) Evolution of the market with the least square model if the initial start is .
Figure 11.
A simulation with the ordered pair of response functions (blue color for customers of AT&T and red color for Verizone ones) (a) Evolution of the market with the least square model if the initial start is . (b) Evolution of the market with the least square model if the initial start is .
Figure 12.
A simulation with the ordered pair of response functions .
Figure 12.
A simulation with the ordered pair of response functions .
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).




{kind=link}
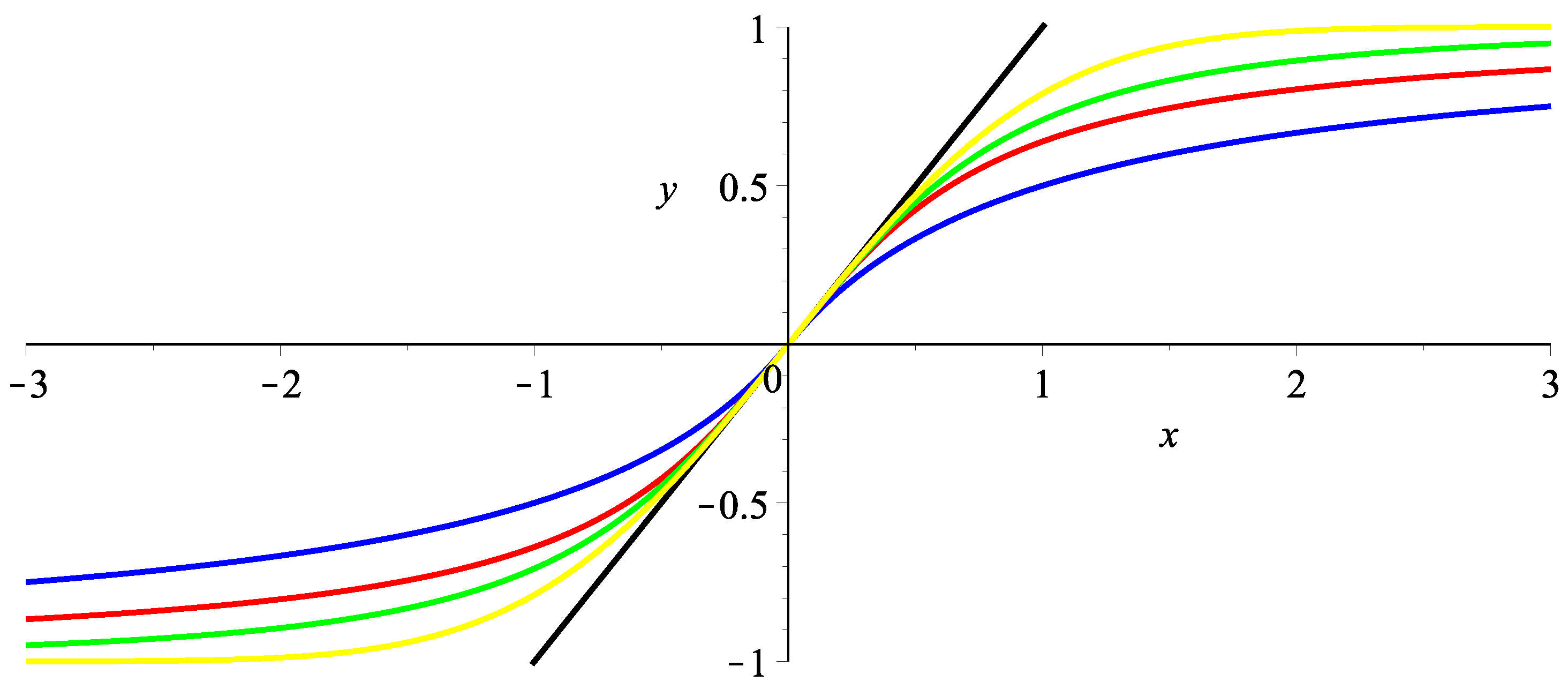{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}