1. Introduction
Credit, as defined by financial institutions such as banks and lending companies [
1], represents a vital loan certificate issued to individuals or businesses. This certification mechanism plays a pivotal role in ensuring the smooth functioning of the financial sector, contingent upon comprehensive evaluations of creditworthiness. The evaluation process inherently gives rise to concerns regarding credit risk, encompassing the potential default risk associated with borrowers. Assessing credit risk entails the utilization of credit scoring, a method aimed at distinguishing between “good” and “bad” customers [
2]. This process is often referred to as credit risk prediction in numerous studies [
3,
4,
5,
6,
7]. Presently, the predominant approaches to classifying credit risk involve traditional statistical models and machine learning models, typically addressing binary or multiple classification problems.
Credit data often exhibit a high number of negative samples and a scarcity of positive samples (default samples), a phenomenon known as the class imbalance (CI) problem [
8]. Failure to address this issue may result in significant classifier bias [
9], diminished accuracy and recall [
10], and weak predictive capabilities, ultimately leading to financial institutions experiencing losses due to customer defaults [
11]. For instance, in a dataset comprising 1000 observations labeled as normal customers and only 10 labeled as default customers, a classifier could achieve 99% accuracy without correctly identifying any defaults. Clearly, such a classifier lacks the robustness required. To mitigate the CI problem, various balancing techniques are employed, either at the dataset level or algorithmically. Dataset-level approaches include random oversampling (ROS), random undersampling (RUS), and the synthetic minority oversampling technique (SMOTE) [
12], while algorithmic methods mainly involve cost-sensitive algorithms. Additionally, ensemble algorithms [
13] and deep learning techniques, such as generative adversarial networks (GANs) [
14], are gradually gaining traction for addressing CI issues.
Indeed, there is no one-size-fits-all solution to the CI problem that universally applies to all credit risk prediction models [
15,
16,
17]. On the one hand, the efficacy of approaches is constrained by various dataset characteristics such as size, feature dimensions, user profiles, and imbalance ratio (IR). Notably, higher IR and feature dimensions often correlate with poorer classification performance [
18]. On the other hand, existing balancing techniques exhibit their own limitations. For instance, the widely used oversampling technique, SMOTE, has faced criticism for its failure to consider data distribution comprehensively. It solely generates new minority samples along the path from the nearest minority class to the boundary. Conversely, some undersampling methods are deemed outdated as they discard a substantial number of majority class samples, potentially leading to inadequately trained models due to small datasets. Additionally, cost-sensitive learning hinges on class weight adjustment, which lacks interpretability and scalability [
11].
In this study, we address the dataset size and IR considerations, and evaluate the performance of oversampling, undersampling, and combined sampling methods across various machine learning classifiers. Notably, we include CatBoost [
19], a novel classifier that has been under-represented in prior comparisons. Furthermore, we introduce a novel hybrid resampling framework, strategic hybrid SMOTE with double edited nearest neighbors (SH-SENN), which demonstrates superior performance in handling extremely imbalanced datasets and substantially enhances the predictive capabilities of ensemble learning classifiers.
The contributions made in this paper can be summarized as follows: First, most credit risk prediction studies within the CI context utilize the widely adopted benchmark credit dataset, which lacks real data representation. Real data tend to be noisier and more complex. This study integrates benchmark and real private datasets, enhancing the practical relevance of our proposed NEW framework. It is likely to practically create value for financial institutions. Second, although advanced ensemble classifiers such as LightGBM [
20] and CatBoost, which have emerged in recent years, are gradually being adopted in credit risk prediction due to their advantages of speed and ability to handle categorical variables more effectively, they still fail to provide new solutions to the CI problem. Moreover, there are few studies assessing their adaptability to traditional balancing methods. Our study confirms that SH-SENN significantly enhances the performance of such new classifiers, especially on real datasets with severe CI issues. We contribute to the real-world applicability of these new classifiers. Third, the fundamental concept of SH-SENN in dealing with extreme IR datasets is to improve data quality by oversampling to delineate clearer decision boundaries and by undersampling multiple times to address boundary noise and overlapping samples of categories, thereby enhancing the classifier’s predictive power. The sampling strategy is tailored to IR considerations rather than blindly striving for category balance. Hence, SH-SENN is suitable for large, extremely unbalanced credit datasets with numerous features. For instance, credit data from large financial institutions often comprise millions of entries and hundreds of features, posing challenges beyond binary classification. SH-SENN effectively enhances dataset quality to tackle such complex real-world problems.
In
Section 2, we provide a comprehensive review of different resampling techniques (RTs), highlighting their effectiveness, advantages, and disadvantages in addressing credit risk prediction problems. Following this, in
Section 3, we employ various RTs on four distinct datasets, comparing and analyzing their performances across (1) different machine learning classifiers and (2) datasets varying in size and IR. Concurrently, we introduce and demonstrate the effectiveness of a novel approach, SH-SENN. Lastly, the research findings are summarized in the concluding section.
2. Background and Related Works
In the domain of credit risk prediction, accurately identifying potential defaulting users holds paramount importance [
21]. Banks meticulously gather user characteristics and devise scoring systems to scrutinize customers and allocate loan amounts judiciously. Upon identifying potential risks, they may either reduce the loan quota or decline lending altogether. This dynamic is evident in the data, where positive samples (minority class) bear greater significance than negative samples (majority class). This poses a dilemma, as the classifier requires substantial information about the minority class to effectively identify positive samples, yet it inevitably tends to be more influenced by the majority class [
22]. Consequently, oversampling and cost-sensitive algorithms have been favored in addressing credit risk prediction scenarios. The former directly enhances the proportion of samples in the minority class, while the latter factors in that misclassifying negatives is less detrimental than misclassifying positives [
23].
To mitigate the risk of underfitting arising from the potential omission of vital information by undersampling techniques, algorithms such as EasyEnsemble and BalanceCascade [
24] have been developed. These algorithms aim to minimize the probability of discarding crucial information during the undersampling process. EasyEnsemble combines the anti-underfitting capacity of boosting with the anti-overfitting capability of bagging. Conversely, to alleviate the risk of overfitting associated with oversampling, distance-based k-neighborhood methods for resampling are considered more effective. Notably, the synthetic minority oversampling technique (SMOTE) has garnered attention in recent years, particularly in credit scenarios characterized by an imbalance between “good and bad customers”.
In the realm of loan default prediction, researchers have utilized the SMOTE algorithm in various ways, emphasizing the criticality of information within the minority class. Studies suggest that SMOTE, or more boundary-point-oriented adaptive oversampling techniques like adaptive integrated oversampling, can yield superior results when modeling with such data [
25]. Moreover, combining oversampling techniques with integrated learning has been proposed to mitigate overfitting risks. For instance, sampling combined with boosting methods and support vector machines, as well as a combination of adaptive integrated oversampling with support vector machines and boosting, have demonstrated promising results in empirical analyses [
26].
Nonetheless, subsequent studies caution against excessively tightening criteria due to potential default risks, as rejecting numerous creditworthy users can significantly diminish bank earnings, sometimes surpassing losses incurred from a single defaulting user [
11]. Over-reliance on oversampling techniques could exacerbate this inverse risk. However, this does not imply superiority of undersampling techniques, which exhibit distinct drawbacks, notably information loss from the majority class, particularly with clustering-based undersampling methods [
27,
28]. To harness the full potential of minority class samples while retaining information from majority class samples, comprehensive techniques combining oversampling and undersampling have emerged. Examples include SMOTE with Tomek links and SMOTE with edited nearest neighbors (ENNs), both of which have demonstrated enhancements in dataset quality and classifier performance [
15]. In a comprehensive study conducted as early as 2012, ref. [
29] designed a detailed examination of RTs. The study evaluated four undersampling, three oversampling, and one composite resampling technique across five datasets to ascertain the potential benefits for intelligent classifiers such as the multilayer perceptron (MLP) when using these techniques. The comparative analysis revealed that there is no one-size-fits-all solution with respect to the effectiveness of sampling techniques across all classifiers. However, it was observed that undersampling methods like neighborhood clean rule (NCL) and oversampling techniques like SMOTE and SMOTE + ENN consistently demonstrated stable performance. Notably, oversampling imparted a significant performance enhancement, particularly benefiting higher-performing intelligent classifiers.
On the other hand, prevailing class balancing experiments often strive to equalize the proportions of majority and minority classes, yet few studies have delved into addressing datasets exhibiting extreme imbalances. The IR, denoting the ratio of majority to minority samples, serves as a gauge for assessing the extent of class imbalance. Commonly used benchmark credit datasets typically exhibit IRs ranging from 2 to 10, such as the German credit dataset (IR: 2.33) and the Australia credit dataset (IR: 1.24), while certain private datasets may escalate to IRs of 10 to 30 [
30]. Typically, larger sample sizes correlate with higher IRs. However, there exists no standardized criterion for defining extreme imbalance. An IR above 5 implies that merely 16.6% of positive samples are available, posing a considerable challenge for classifiers. Ref. [
31] advocated for the use of gradient boosting and random forest algorithms to effectively handle datasets with extreme imbalance. Through experimentation with oversampling techniques, it was observed that an optimal class distribution should encompass 50% to 90% of the minority classes. In other words, it suffices to moderate the extreme imbalances to achieve a mild imbalance without necessitating an IR of 1. Conversely, ref. [
18] employed simulation datasets to simulate varying IRs and found that higher IRs do not consistently lead to poorer classifier performance; rather, performance is significantly influenced by the feature dimensions of the dataset. Indeed, IR serves as one of the statistical features of the dataset, alongside feature dimension, dataset size, feature type, and resampling method, collectively impacting the final prediction outcome [
30]. However, high IR alone does not inherently account for prediction difficulty; rather, it is the indistinct decision boundary stemming from too few minority class samples, overlapping due to resampling, and excessive noise that pose the primary challenges [
15]. Thus, the primary objective of balancing techniques should focus on clarifying classification boundaries rather than merely striving for dataset balance. Ref. [
15] echoes the sentiments of the aforementioned study, emphasizing the collective influence of IR on the efficacy of various RTs. Following a comparative analysis involving methods such as Tomek-link removal (Tomek), ENN, BorderlineSMOTE, adaptive integrated oversampling (ADASYN), and SMOTE + ENN, it was concluded that the complexity of RTs does not necessarily correlate with their ability to address datasets with higher IR. Importantly, it was observed that no single RT emerged as universally effective across all classification and CI problems.
RTs proactively address the CI problem during the data preprocessing stage. While numerous studies propose resolving the CI problem through adjustments within machine learning classifiers or by integrating balancing strategies directly into ensemble models, recent advancements in algorithms such as eXtreme Gradient Boosting (XGBoost) [
32], LightGBM, and CatBoost offer hyperparameters capable of fine-tuning the weights of positive samples. Even amidst imbalanced datasets, these algorithms enable the objective function to prioritize information gleaned from minority class samples. Furthermore, incorporating resampling techniques within ensemble learning to balance each training subset yields models with heightened robustness compared with classifiers solely adjusting sample weights. For instance, bagging classifiers and random forests can be augmented with balancing techniques to ensure a portion of minority class samples in each training subset [
33]. To compare the effectivenesses of various classifiers, ref. [
31] conducted experiments across five datasets, incorporating various IRs. The study evaluated the performances of classifiers such as logistic regression, decision tree (C4.5), neural network, gradient boosting, k-nearest neighbors, support vector machines, and random forest, considering positive sample proportions ranging from 1% to 30%. Results from the experiments revealed that gradient boosting and random forest exhibited exceptional performance, particularly when handling datasets with extreme IR. Conversely, support vector machines, k-nearest neighbors, and decision tree (C4.5) struggled to effectively manage the CI problem. In conclusion, the study suggests that ensemble learning methods, specifically boosting and bagging, outperform individual classifiers when addressing imbalanced credit datasets, highlighting their efficacy in handling CI challenges.
However, the effectiveness of solely relying on model weights to address the CI problem diminishes if RTs are not applied to the dataset beforehand [
34]. Moreover, the embedding of resampling techniques within ensemble models significantly escalates computational costs, rendering it less efficient and more constrained when handling large datasets [
4]. To address this issue, ref. [
30] conducted a comprehensive comparison between various pairs of classifiers and RTs. Their objective was to identify dependable combinations of advanced RTs and classifiers capable of handling datasets with differing IR levels effectively. By conducting paired experiments involving nine RTs and nine classifiers, their findings revealed that the combination of RUS and random subspace consistently achieved satisfactory performance across most cases. Following closely behind was the combination of SMOTE + ENN and logistic regression. Interestingly, these results deviate from previous studies that tended to favor ensemble classifiers. Ref. [
30] argue that even simple classifiers can achieve commendable performance, provided that suitable RTs are employed.
2.1. Oversampling
The synthetic minority oversampling technique (SMOTE) [
12] is a distance-based method utilized to create synthetic samples within the minority class. Its fundamental principle revolves around the concept that samples sharing the same label within the feature space are considered neighbors. Leveraging the original positions of minority class samples, SMOTE establishes connections between these samples and their neighboring data points, subsequently generating new minority class samples along the connecting lines:
where
x is an arbitrary minority class sample,
is the nearest neighbor found according to a set sampling ratio n, and
is a random factor to prevent repeated adoption.
Adaptive integrated oversampling (ADASYN) [
35]. It is similar to SMOTE in that new samples are synthesized through nearest neighbors. The weights of a few classes of samples are added to it. The method is as follows:
BorderlineSMOTE [
36] represents an enhancement over the conventional SMOTE technique, addressing its limitation of synthesizing minority class samples without regard for data distribution [
11]. Specifically, BorderlineSMOTE selects only those minority class samples situated on the decision boundary for synthesis. If the set of boundary points of class
p samples is DANGER, and the sample points are
, for each
, its s nearest neighbors are calculated, and
is the gap from
to its nearest neighbor. Therefore, the new synthesis formula is as follows:
SVMSMOTE [
37]. It uses SVM in boundary point decision making for BorderlineSMOTE and is an improved strategy for BorderlineSMOTE. Its synthesis formula is as follows:
where
is the newly synthesized positive sample,
is the set of sample support vectors,
is the random number in the range
,
is an array containing k positive nearest neighbors, and
is the
positive nearest neighbor of
.
2.2. Undersampling
Cluster centroid [
38]. It is a class of undersampling techniques based on the k-means clustering algorithm. Clustering centers
are generated by continuous iteration, where
is the newly generated center after deleting a portion of the majority class samples closest to the center of
, and so on, until the number of positive and negative samples reaches equilibrium. It is not difficult to find that this method requires the majority class samples to be concentrated enough; otherwise, the sampling effect will become worse.
Edited nearest neighbors (ENN) [
39]. It is based on the modified
k-nearest neighbors rule, which finds the
k-nearest neighbors of a certain majority class sample
, which are
, find the sample points related to it from these nearest neighbors, and remove the misclassified ones, which is an undersampling method. It can achieve the effect of removing the majority class and the minority class samples that are close to each other.
2.3. Combined Resampling
SMOTETomek [
40]. It is a combination of SMOTE oversampling and Tomek links [
41] of an integrated sampling technique. Tomek links can be formulated in a binary classification task as follows:
and
denote a majority class and a minority class sample, respectively, and
denotes the distance between them. If there is no observation
y, which is any
or
such that
or
, then
is called a Tomek link. Oversampling using SMOTE first and then deleting all the Tomek links can make the decision boundary clearer.
SMOTEENN [
42]. It is an integrated sampling technique that combines SMOTE oversampling and ENN undersampling. It resembles SMOTETomek in its approach, both prioritizing the synthesis of minority class samples initially. However, unlike SMOTETomek, it opts not to delete samples in pairs; instead, it selectively removes majority class samples encircled by minority class instances. Due to the requirement for computing neighbors, SMOTEENN carries higher computational costs.
4. Results
4.1. Overall Comparison of RTs
Overall, RTs are significantly different when predicting credit risk, as shown in
Table 3.
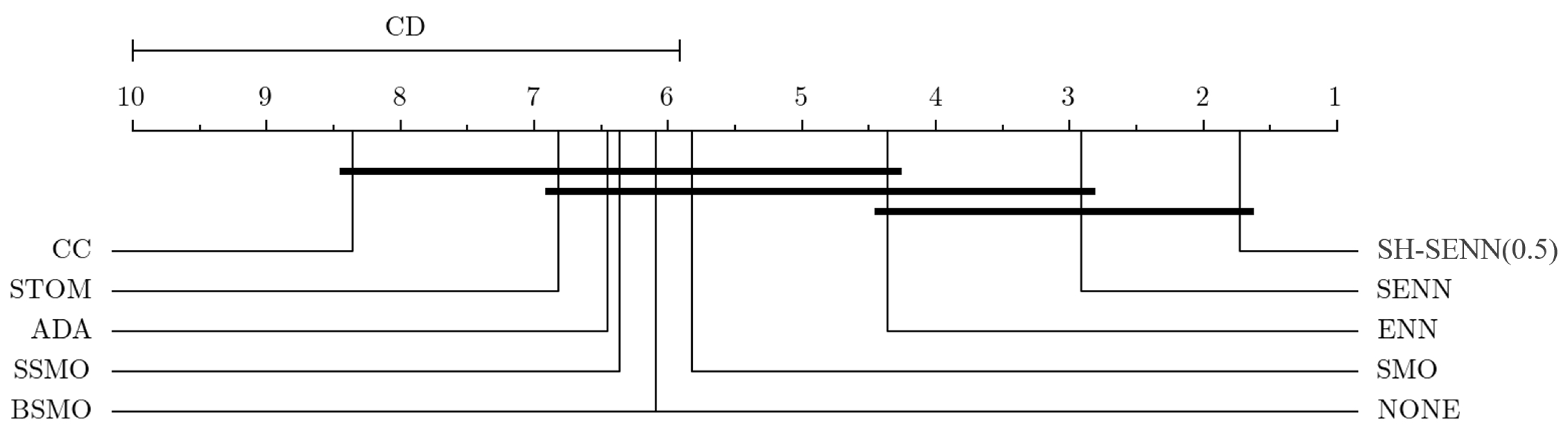
Table 4 shows the pairs’ comparison among RTs with the biggest difference. SENN and ENN emerge as the most effective among all RTs, as shown in
Figure 3. Comparatively, when not utilizing any RTs, SENN showcases notable enhancements, boosting AUC, recall, F1-score, and G-mean by up to 20%, 20%, 30%, and 40%, respectively. For instance, in the LC dataset, the G-mean without RTs stands at 0.1168, while after SENN utilization, the G-mean escalates to 0.5715. This demonstrates a notable improvement in both accuracy and recall rates, leading to a more balanced state.
4.2. Comparison of Resampling Techniques in Terms of Different Datasets
In the results for the German dataset (
Table 5), it is evident that all RTs, along with the ensemble balanced classifiers BBC and BRF, significantly contribute to the enhancement of the recall score. This indicates a notable improvement in the classifiers’ ability to identify defaulting customers. Particularly noteworthy is the combined effect of CC, which emerges as the top-ranking approach. This can be attributed to the fact that, with an IR of 2.33, the training set still retains 240 minority class samples after undersampling. Consequently, it is sufficiently equipped to handle the test set comprising only 60 minority class samples, thus resulting in a relatively low prediction difficulty. However, according to the Friedman test, no significant difference is observed between several resampling methods. Furthermore, there is no discernible disparity with the NONE dataset.
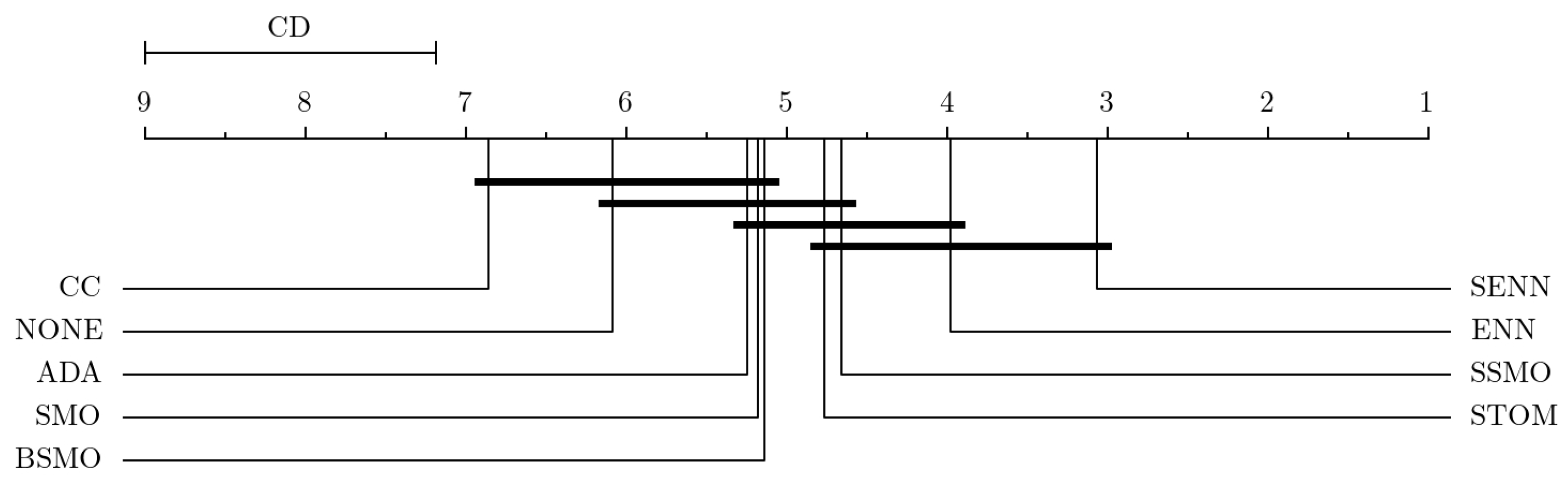
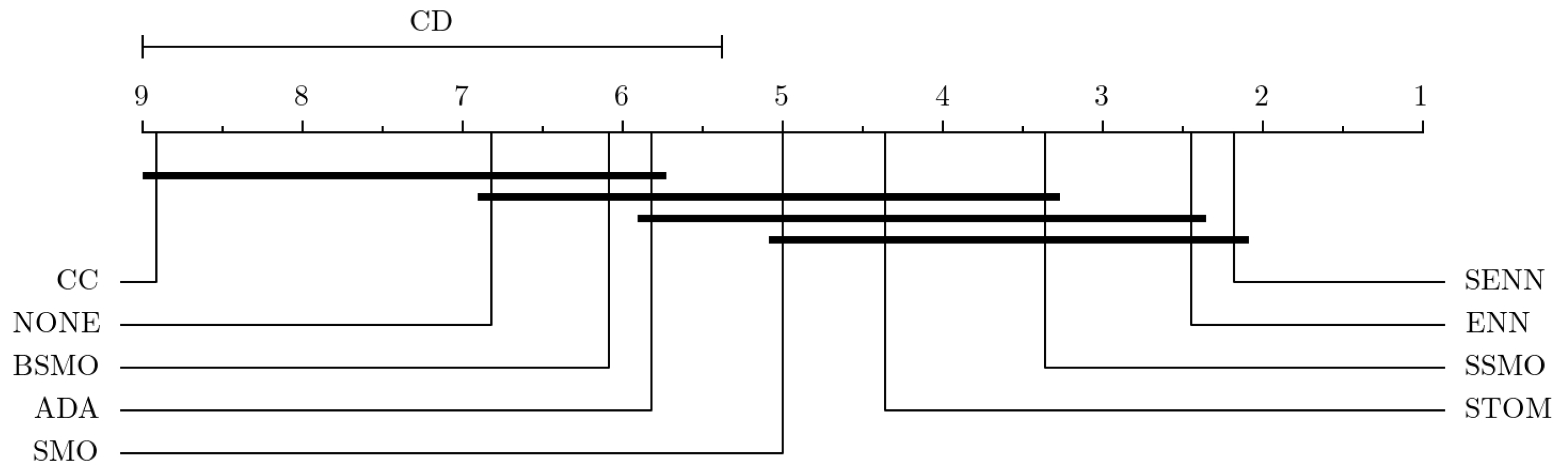
The outcomes obtained from Taiwan (
Table 6) and Prosper (
Table 7) underscore a considerable degree of variability among the different RTs. Through Nemenyi’s post hoc tests, we confirm that SENN and ENN emerge as the most effective resampling methods, as
Figure 4 and
Figure 5 demonstrate. While their efficacy may vary across different classifiers, there is no doubt regarding their applicability across all classifiers. Conversely, CC, which demonstrates dominance in small datasets, ranks last in medium and large datasets. Surprisingly, leaving the dataset untouched (NONE) outperforms the mass removal of most class samples with CC.
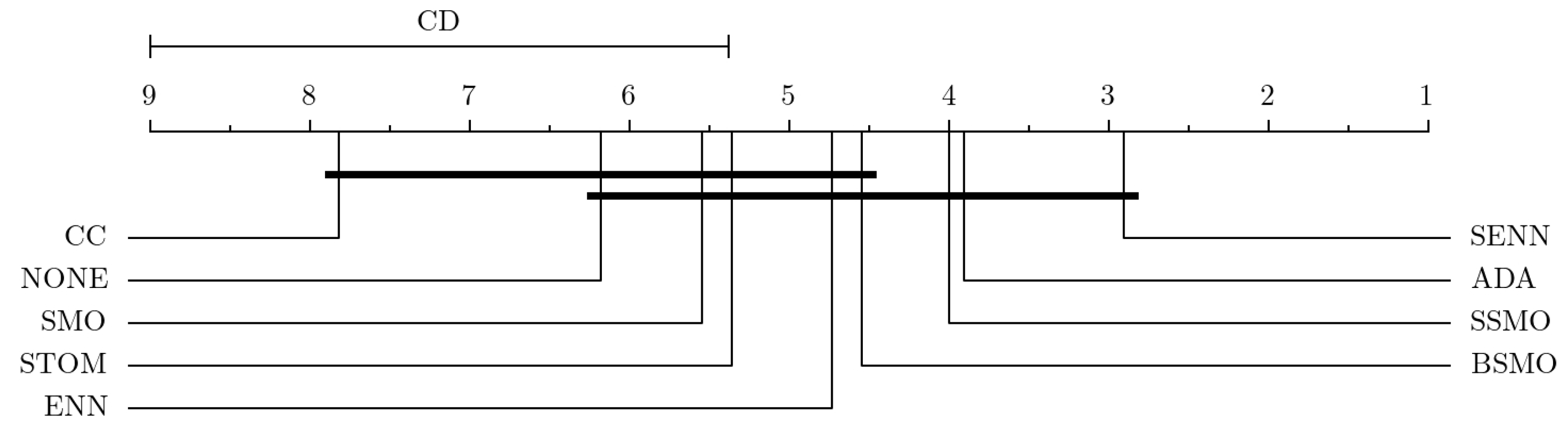
In LC datasets characterized by high IR, there is substantial variability among different resampling methods (
Table 8). Notably, CC, SMOTE, ADA, and SSMO are found to be ineffective, failing to surpass the performance of NONE (
Figure 6). This is particularly evident in terms of F1-score, highlighting the inability of these techniques to enhance model stability and achieve a balanced trade-off between recall and precision. Only SENN emerges as a reliable technique under such circumstances.
Further examination of the relationship between different RTs and datasets can be conducted through the Kruskal–Wallis test (
Table 9). The hypothesis posits that all techniques exhibit significant differences attributable to variations in datasets. For instance, in the case of SENN, its application yields significantly different effects across all subgroups, except for the absence of a significant difference between the German and LC datasets (
Table 10). Moreover, the disparity between Prosper and Taiwan at the 1% significance level suggests that SENN’s efficacy varies depending on the dataset size, while the significant difference between Prosper and LC at the 1% level indicates that SENN’s effectiveness is influenced by the IR of the dataset.
4.3. Comparison of Resampling Techniques in Terms of Different Classifiers
We categorized all classifiers into three groups: individual classifiers, ensemble classifiers, and balanced classifiers. The Kruskal–Wallis test reveals no significant difference between the different types of classifiers except for NONE (
Table 11). This suggests that the utilization of RTs can effectively bridge the performance gap between individual and ensemble classifiers, significantly enhancing the effectiveness of weaker classifiers. However, the extent of enhancement provided by different RTs does not exhibit a significant difference.
According to the results of the two independent samples Mann–Whitney U test on grouped variables, the
p-value of single classifiers and balanced classifiers on NONE is 0.025 **, indicating statistical significance at the 5% level (
Table 12). This signifies a significant difference between single classifiers and balanced classifiers when no RTs are utilized. The magnitude of the difference, as indicated by a Cohen’s d value of 0.692, falls within the medium range. Conversely, ensemble classifiers and balanced classifiers exhibit a smaller magnitude of difference. This implies that balanced classifiers can effectively address CI problems in the absence of RTs, making them a valuable balancing technique to consider.
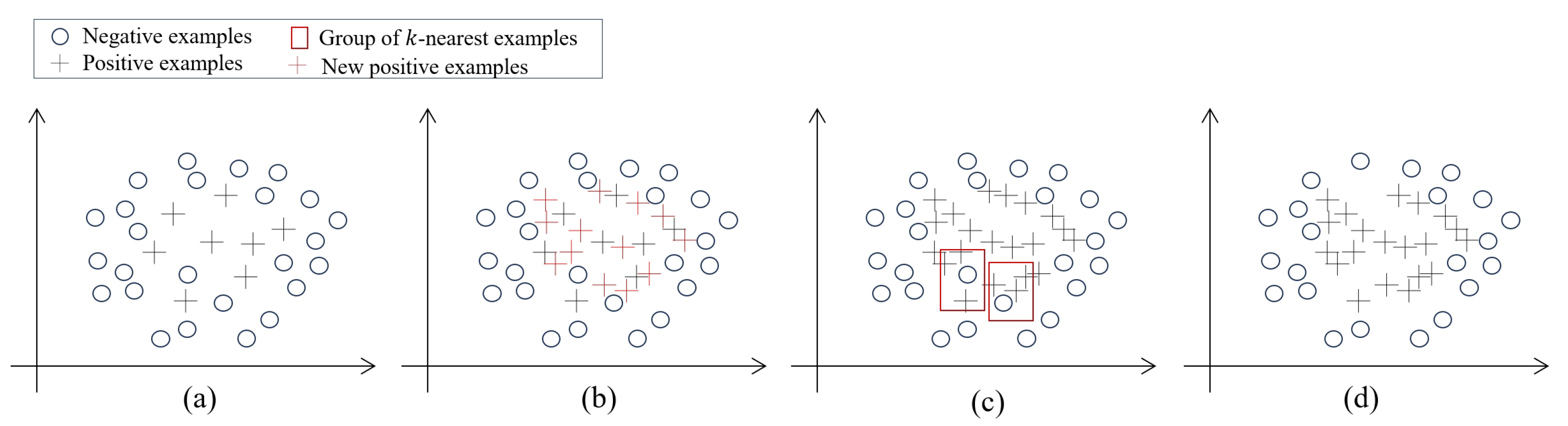
4.4. Experiments with SH-SENN
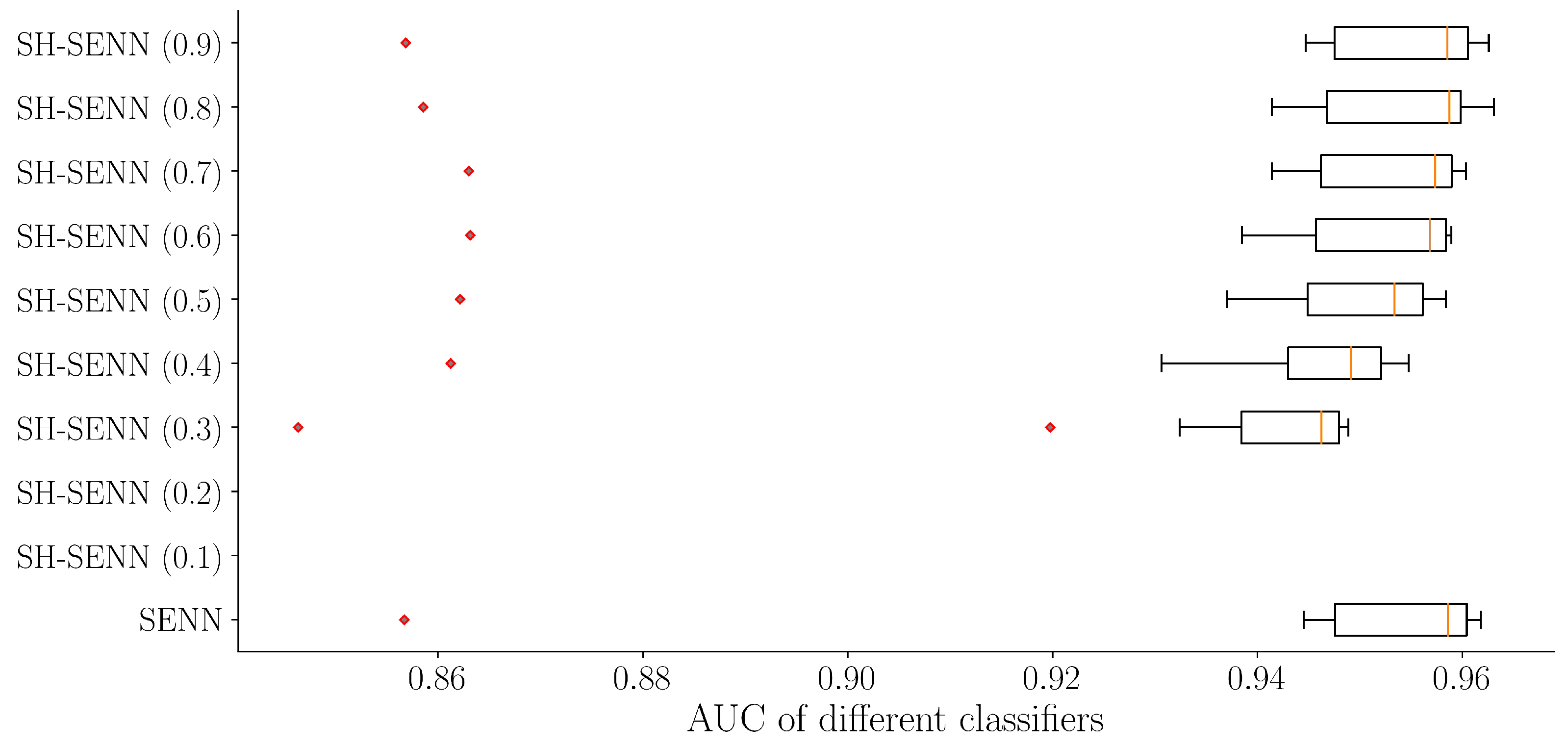
Significant outcomes were observed with SH-SENN on datasets characterized by high IR (
Table 13). Irrespective of the strategy ratio
employed, SH-SENN consistently enhances the prediction performance of ensemble classifiers and balanced classifiers. This enhancement reaches its peak when
approaches 0.5, followed by a diminishing trend. However, for individual classifiers, SH-SENN proves to be less effective than SENN when
is below 0.4. Notably, SH-SENN outperforms SENN when
falls between 0.4 and 0.7. Overall, the results highlight SH-SENN (0.5) as the most advantageous and effective new RT, as shown in
Figure 7.
The Friedman test results reveal that SH-SENN exhibits varying degrees of significant differences and advantages over NONE, ADA, SMO, BSMO, SSMO, CC, and STOM (
Table 14). Notably, the AUC can reach a maximum of 0.784. Post hoc tests confirm that although there is no significant difference between SH-SENN (0.5) and the previous champion SENN (
Figure 8), it still secures the top rank among all RTs with a substantial advantage.
Under various IR conditions, we included the Prosper dataset in the experiment to compare the performance of SH-SENN. This dataset shares the same size as the LC dataset and has an IR of 4.97, representing a normal imbalanced dataset. With positive samples comprising more than 20% of negative samples in the Prosper dataset’s training set, the strategy ratio for this round ranged from 0.3 to 0.9 (if was less than 0.2, undersampling will be conducted initially; however, SMOTE as the first step for SH-SENN is an oversampling method).
Results were compared with SENN, which ranked first on the Prosper dataset in a previous result. The findings reveal that (
Table 15), under the interference of SH-SENN, all classifiers except LR and RF achieved higher AUC values. This suggests that SH-SENN can outperform SENN even in normal IR datasets, albeit with a smaller improvement compared with extreme IR datasets.
A significant difference from the results in the LC dataset was that the SH-SENN (0.9) strategy yielded the best results, contrary to the previous SH-SENN (0.5) strategy. The average AUC of SH-SENN (0.9) across all classifiers reached 0.9465, slightly higher than SENN’s average AUC of 0.9464 (
Figure 9). This discrepancy arises because minority samples in normally imbalanced datasets contain more information than extremely imbalanced minority samples, and there is less noise when oversampling to 90% of the majority sample. Experiments demonstrate that the strategy ratio of SH-SENN should decrease with an increasing IR to achieve better results.
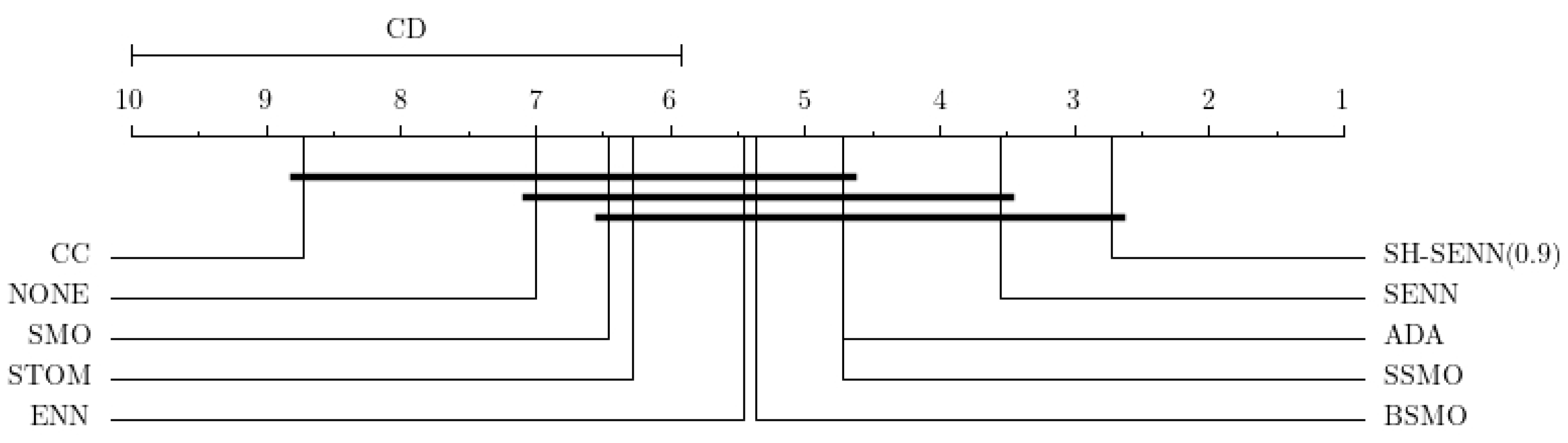
Similarly, the Friedman test results indicate significant differences between SH-SENN (0.9) and NONE, ADA, SMO, BSMO, SSMO, CC, and STOM in the Prosper dataset. Subsequent post hoc tests revealed that SH-SENN (0.9) surpassed all other RTs by a considerable margin (
Figure 10). These two sets of experiments collectively demonstrate that SH-SENN can achieve comparable effectiveness to other RTs across various IR datasets, albeit requiring different strategy ratios (
Table 16). Moreover, the impact of SH-SENN on classifier enhancement is more pronounced in high IR datasets compared with those with common IR levels.
4.5. Discussion and Limitation
Overall, the experimental results align with our discussion in
Section 2. We contend that the CI problem does not directly impact the classifier’s predictive ability but rather obscures the decision boundary, thereby weakening its performance. Certain RTs, such as SMOTE, ADASYN, and cluster centroids, address the CI problem by either oversampling or undersampling to bring the classes closer to equilibrium. However, they merely generate new minority class samples or remove majority class samples without specifically optimizing the decision boundary or addressing the issue of overlapping samples from different classes. Consequently, these techniques prove ineffective across various datasets. SVMSMOTE and BorderlineSMOTE achieve superior results because they focus on generating minority class samples along the border, thereby enhancing the clarity of the decision boundary. Moreover, in SMOTEENN, the ENN method supplements the limitations of the SMOTE-only oversampling approach, which tends to marginalize data distribution. Unlike SMOTETomek, which combines oversampling and undersampling but removes entire pairs, SMOTEENN selectively eliminates examples that do not align with neighboring categorizations. As a result, ENN preserves more information than Tomek link, rendering SMOTEENN more stable and effective across diverse datasets. While SMOTETomek excels in datasets with a pronounced class overlap, it may yield better results in credit datasets characterized by higher feature dimensions and greater diversity in types.
From the dataset perspective, small datasets characterized by limited sample sizes, data structures, and small training sets exhibit no significant disparities among different resampling RTs. Even with oversampling, the potential for expanding the dataset’s information content remains limited. Conversely, medium and large datasets demonstrate similarities in their RT selection. This can be attributed to the classifiers’ capacity to learn sufficient predictive information when the training set is relatively ample. However, further improvement in prediction ability necessitates optimizing decision boundaries in addition to resampling, making combined sampling more effective. On the contrary, large datasets with a high IR demand cautious treatment. These datasets feature high-dimensional features, complex data structures, and sparse minority class samples. Consequently, classifiers may struggle to recognize positive samples unseen during training, resulting in low recall scores. Oversampling the minority class to excessively high proportions, such as with a SMOTE ratio of 1:1 or 1:0.9, may lead to an accumulation of minority class samples without clarifying the decision boundary, potentially generating new noise. In such scenarios, random oversampling may outperform SMOTE [
30]. To address extreme CI, it is advisable to employ a smaller ratio oversampling strategy to prevent an abundance of minority class samples from becoming noise. Emphasizing the handling of boundary points and class overlapping is crucial. SH-SENN stands out as a superior technique due to its strategic oversampling approach and dual handling of boundary points, which contribute to achieving better results compared with other RTs.
From the classifier’s standpoint, ensemble classifiers tend to benefit more from RTs compared with individual classifiers due to their enhanced learning capabilities. This is particularly evident in the boosting family of classifiers, such as XGBoost. When employing oversampling or integrated sampling RTs, the ensemble classifier can capitalize on the increased effective information within the dataset, thereby maximizing its predictive performance. Conversely, when using RTs like cluster centroids, which drastically reduce the amount of information, the ensemble classifier’s performance remains robust, and even regular individual classifiers can achieve satisfactory results. While ensemble classifiers offer hyperparameters to adjust category weights, predicting these weights for a few sample categories in real-world scenarios is impractical. Furthermore, presetting these weights is not feasible, considering the test set’s consistent IR with the training set in this study to ensure comparable effects of different RTs and avoid inconsistent prediction difficulty in the test set. For instance, suppose a bank encounters 10 defaulting credit customers monthly, with the bank approving 10 applicants daily. These defaulters may be distributed over 30 days or concentrated on a single day. Processing the training set beforehand allows for the construction of a robust classifier prior to model fitting.
Lastly, concerning the credit risk prediction problem, real credit data often exhibit high feature dimensions and diverse data types. Existing studies frequently concentrate solely on comparing balancing methods and integrating them with classification models, overlooking the practical significance of aiding credit institutions in addressing the CI problem. Their findings tend to be purely theoretical and algorithmic, failing to address the core issue. For instance, clustering-based undersampling may perform well only with specific datasets and models. If a credit institution modifies user profiles, incorporates new features, or includes audio and video features, the original sampling approach may no longer be suitable for the updated dataset. Thus, applicability becomes a concern. The SH-SENN sampling technique proposed in this study is not a rigid algorithm but rather a versatile framework. The undersampling technique within this framework is ENN, but it can be substituted with other undersampling methods to create new algorithms while remaining within the framework’s conceptual scope. Additionally, SH-SENN employs the more representative Lending Club dataset for experimentation and achieves promising results. This illustrates the framework’s potential for extension to analogous credit datasets and its applicability to classification tasks facing CI challenges. For instance, food safety regulation represents a critical concern in Africa, where establishing an early warning system to oversee food quality is imperative. Given the high stakes involved in safeguarding human life, the testing of positive samples becomes more exacting, necessitating robust and balanced datasets for constructing monitoring models. Even a marginal enhancement in model performance achieved by methods like SH-SENN could potentially safeguard the health of numerous individuals. Similar applications can also be extrapolated to medical disease detection and the machinery industry.
SH-SENN also possesses potential limitations. In comparison with other RTs, SH-SENN requires a longer time for resampling due to its utilization of double ENN. This extended duration arises from the necessity for both SMOTE and ENN to formulate their neighbors to facilitate distance-based computations. Consequently, this process consumes more time, particularly in large datasets with high-dimensional features. Moreover, our experiments did not explore the compatibility of SH-SENN with deep learning algorithms such as artificial neural networks. As previously mentioned, deep learning algorithms currently do not offer significant advantages in credit risk prediction but will be questioned by stakeholders because of its black-box property. Nonetheless, deep learning undoubtedly represents a crucial avenue for future research. We expect that combining SH-SENN with deep learning algorithms will yield superior results.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}