
Distributed Sparse Precision Matrix Estimation via Alternating Block-Based Gradient Descent


Abstract
1. Introduction
2. Distributed Sparse Precision Matrix Estimation
2.1. Model Setups
2.2. Block-Gradient Descent Algorithm
| Algorithm 1 Distributed sparse precision matrix estimation via Bgd |
|
3. Theoretical Properties
- (A1)
- (Sparse matrix class) Suppose that with
- (A2)
- (Irrepresentability condition) Let be the set of all non-zero entries of 0, and be the complement of , for some , the covariance matrix satisfies
- (A3)
- (Bounded condition) There exists a constant such that , where and denote the smallest and largest eigenvalues of matrix , respectively.
- (A4)
- (Restricted strong convexity for negative loglikelihood) There exists a positive constant and such thatfor any satisfying .
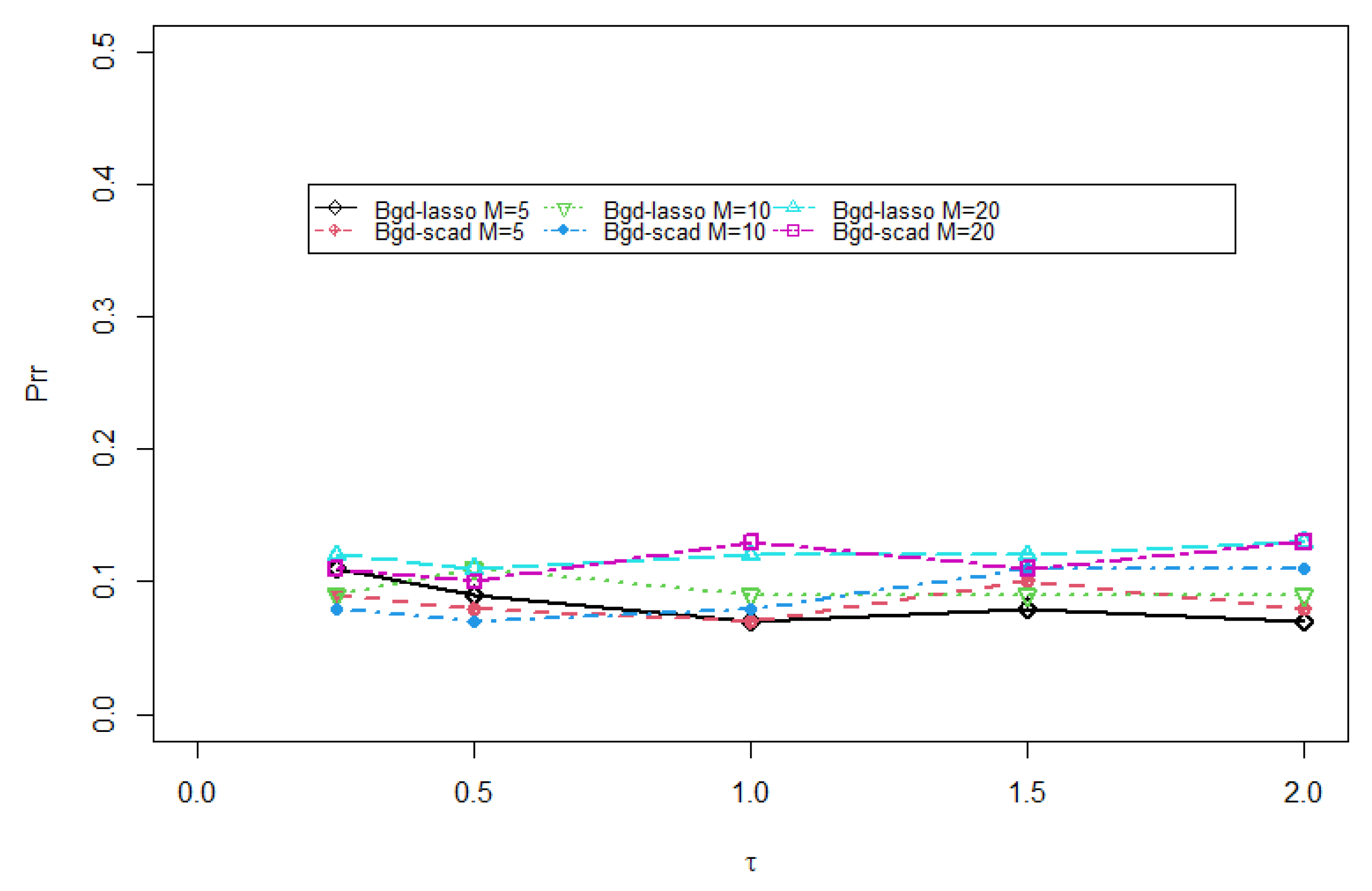
4. Numerical Studies
Real Data Analysis
5. Discussion
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
Appendix A.1. Tables and Figures

{kind=link}
{kind=link}
| Setup | Meth | FN | FP | Time | FN | FP | Time | FN | FP | Time | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Naive | 5.36 | 0.77 | 0 | 0.01 | 7.18 | 7.03 | 0.81 | 0.01 | 0.03 | 5.42 | 8.86 | 1.34 | 0.08 | 0.01 | 3.10 | |
| Dtrace | 3.22 | 0.70 | 0 | 0 | 322 | 5.14 | 0.80 | 0.01 | 0 | 207 | 5.43 | 1.35 | 0.03 | 0 | 214 | |
| S1 (type1) | Dglasso | 3.76 | 0.72 | 0.01 | 0 | 9.44 | 4.97 | 0.97 | 0.05 | 0 | 7.74 | 5.96 | 1.26 | 0.26 | 0 | 3.66 |
| Bgd-lasso | 3.22 | 0.70 | 0.01 | 0 | 32.1 | 4.25 | 0.74 | 0.01 | 0 | 15.9 | 4.26 | 0.75 | 0.02 | 0 | 13.8 | |
| Bgd-scad | 3.20 | 0.68 | 0.01 | 0 | 45.1 | 3.82 | 0.73 | 0.01 | 0 | 33.8 | 3.90 | 0.74 | 0.02 | 0 | 29.2 | |
| Global | 2.80 | 0.68 | 0 | 0 | 62.6 | |||||||||||
| Naive | 9.30 | 0.77 | 0 | 0.03 | 81.8 | 12.1 | 0.96 | 0.01 | 0.01 | 75.2 | 14.5 | 1.30 | 0.90 | 0 | 22.8 | |
| Dtrace | 7.56 | 0.90 | 0.04 | 0 | 923 | 8.15 | 0.84 | 0.02 | 0 | 872 | 9.03 | 1.68 | 0.03 | 0 | 864 | |
| S1 (type2) | Dglasso | 6.04 | 0.85 | 0.05 | 0 | 108 | 7.75 | 0.90 | 0.18 | 0 | 115 | 10.2 | 1.39 | 0.38 | 0 | 122 |
| Bgd-lasso | 6.05 | 0.74 | 0.02 | 0 | 447 | 6.50 | 0.75 | 0.02 | 0 | 301 | 6.40 | 0.74 | 0.02 | 0 | 144 | |
| Bgd-scad | 6.00 | 0.82 | 0.01 | 0 | 448 | 5.95 | 0.77 | 0.01 | 0 | 308 | 6.03 | 0.82 | 0.01 | 0 | 225 | |
| Global | 5.89 | 0.82 | 0 | 0 | 984 | |||||||||||
| Naive | 12.1 | 1.21 | 0.01 | 0.06 | 12.8 | 13.5 | 1.29 | 1.00 | 0 | 15.2 | 13.5 | 1.84 | 1 | 0 | 22.2 | |
| Dtrace | 9.96 | 1.15 | 0.01 | 0.01 | 457 | 10.4 | 1.08 | 0.04 | 0 | 446 | 10.9 | 1.92 | 0.27 | 0 | 438 | |
| S2 (type1) | Dglasso | 8.37 | 1.09 | 0.08 | 0 | 18.8 | 8.41 | 1.06 | 0.19 | 0 | 20.1 | 10.7 | 2.02 | 0.35 | 0 | 24.7 |
| Bgd-lasso | 8.07 | 0.96 | 0.01 | 0.01 | 73.8 | 8.15 | 0.97 | 0.01 | 0.01 | 37.6 | 8.20 | 0.98 | 0.01 | 0.01 | 25.5 | |
| Bgd-scad | 7.78 | 0.97 | 0.01 | 0 | 90.3 | 7.87 | 0.99 | 0.01 | 0.01 | 39.3 | 8.00 | 1.02 | 0.01 | 0.01 | 62.8 | |
| Global | 7.89 | 1.01 | 0.04 | 0 | 210 | |||||||||||
| Naive | 11.9 | 1.12 | 0.19 | 0.04 | 9.79 | 12.5 | 1.24 | 0.17 | 0.04 | 10.4 | 16.2 | 4.28 | 1 | 0 | 12.6 | |
| Dtrace | 11.2 | 1.35 | 0.02 | 0.02 | 592 | 10.8 | 1.16 | 0.24 | 0 | 624 | 14.8 | 3.71 | 0.99 | 0 | 657 | |
| S2 (type2) | Dglasso | 9.02 | 1.24 | 0.10 | 0 | 20.2 | 9.09 | 1.25 | 0.30 | 0 | 26.7 | 14.5 | 4.32 | 0.58 | 0 | 32.8 |
| Bgd-lasso | 8.86 | 1.15 | 0.02 | 0.02 | 80.6 | 8.95 | 1.15 | 0.03 | 0.02 | 40.9 | 12.2 | 1.28 | 0.04 | 0.06 | 25.4 | |
| Bgd-scad | 8.74 | 1.13 | 0.02 | 0.02 | 92.9 | 8.89 | 1.15 | 0.03 | 0.02 | 98.5 | 9.29 | 1.44 | 0.04 | 0.03 | 81.7 | |
| Global | 8.68 | 1.12 | 0.03 | 0 | 208 | |||||||||||
| Naive | 15.2 | 2.02 | 0.40 | 0 | 18.2 | 16.5 | 2.42 | 0.79 | 0.01 | 19.1 | 17.0 | 2.64 | 0.92 | 0 | 25.9 | |
| Dtrace | 9.45 | 1.36 | 0.20 | 0 | 805 | 12.1 | 1.80 | 0.25 | 0.01 | 834 | 16.7 | 2.49 | 0.95 | 0 | 845 | |
| S3 (type1) | Dglasso | 10.6 | 2.35 | 0.26 | 0 | 20.8 | 14.5 | 2.79 | 0.06 | 0.01 | 28.1 | 15.4 | 4.16 | 0.83 | 0 | 30.4 |
| Bgd-lasso | 8.15 | 1.18 | 0.02 | 0.02 | 416 | 10.2 | 1.59 | 0.01 | 0 | 328 | 10.8 | 1.64 | 0 | 0.02 | 232 | |
| Bgd-scad | 6.32 | 0.85 | 0.02 | 0 | 428 | 6.39 | 0.86 | 0.04 | 0 | 388 | 6.74 | 0.91 | 0.06 | 0 | 280 | |
| Global | 5.54 | 0.95 | 0.04 | 0 | 239 | |||||||||||
| Naive | 24.1 | 3.32 | 0.63 | 0 | 11.3 | 25.0 | 3.58 | 0.83 | 0 | 15.5 | 25.1 | 3.80 | 0.96 | 0 | 22.7 | |
| Dtrace | 16.1 | 2.15 | 0.30 | 0 | 874 | 16.2 | 2.26 | 0.36 | 0 | 892 | 21.9 | 2.79 | 0.80 | 0 | 924 | |
| S3 (type2) | Dglasso | 16.4 | 2.40 | 0.01 | 0.06 | 11.7 | 17.8 | 3.60 | 0.18 | 0.09 | 25.8 | 22.4 | 4.01 | 0.88 | 0 | 32.1 |
| Bgd-lasso | 10.6 | 1.42 | 0 | 0.05 | 394 | 10.6 | 1.39 | 0 | 0.05 | 313 | 11.9 | 1.58 | 0.01 | 0.05 | 223 | |
| Bgd-scad | 9.40 | 1.18 | 0 | 0.04 | 408 | 9.43 | 1.19 | 0 | 0.05 | 352 | 11.1 | 1.28 | 0.03 | 0.03 | 261 | |
| Global | 10.1 | 1.49 | 0.09 | 0 | 524 |
| Meth. | Prr | Sen | Spe | Prr | Sen | Spe | Prr | Sen | Spe | |
|---|---|---|---|---|---|---|---|---|---|---|
| Naive | 0.13 | 0.89 | 0.86 | 0.14 | 0.89 | 0.84 | 0.17 | 0.87 | 0.78 | |
| Dtrace | 0.11 | 0.88 | 0.89 | 0.12 | 0.89 | 0.87 | 0.15 | 0.87 | 0.84 | |
| Dglasso | 0.15 | 0.89 | 0.81 | 0.15 | 0.89 | 0.81 | 0.18 | 0.86 | 0.77 | |
| Bgd-lasso | 0.08 | 0.91 | 0.91 | 0.11 | 0.89 | 0.89 | 0.13 | 0.88 | 0.86 | |
| Bgd-scad | 0.10 | 0.89 | 0.90 | 0.11 | 0.88 | 0.89 | 0.14 | 0.86 | 0.86 | |
| Global | 0.06 | 0.92 | 0.95 | |||||||
| Naive | 0.14 | 0.87 | 0.83 | 0.15 | 0.88 | 0.84 | 0.17 | 0.87 | 0.78 | |
| Dtrace | 0.11 | 0.88 | 0.89 | 0.12 | 0.89 | 0.87 | 0.15 | 0.87 | 0.84 | |
| Dglasso | 0.14 | 0.88 | 0.82 | 0.15 | 0.89 | 0.80 | 0.17 | 0.87 | 0.78 | |
| Bgd-lasso | 0.07 | 0.90 | 0.94 | 0.09 | 0.90 | 0.91 | 0.12 | 0.88 | 0.89 | |
| Bgd-scad | 0.07 | 0.90 | 0.94 | 0.08 | 0.89 | 0.95 | 0.13 | 0.87 | 0.87 | |
| Global | 0.04 | 0.96 | 0.97 | |||||||

Appendix A.2. Proof of the Main Results
References
- Hao, B.; Sun, W.W.; Liu, Y.; Cheng, G. Simultaneous clustering and estimation of heterogeneous graphical models. J. Mach. Learn. Res. 2017, 18, 7981–8038. [Google Scholar]
- Ren, M.; Zhang, S.; Zhang, Q.; Ma, S. Gaussian graphical model based heterogeneity analysis via penalized fusion. Biometrics 2022, 78, 524–535. [Google Scholar] [CrossRef]
- Jiang, B.; Wang, X.; Leng, C. Quda: A direct approach for sparse quadratic discriminant analysis. J. Mach. Learn. Res. 2018, 19, 1098–1134. [Google Scholar]
- Friedman, J.; Hastie, T.; Tibshirani, R. Sparse inverse covariance estimation with the graphical lasso. Biostatistics 2008, 9, 432–441. [Google Scholar] [CrossRef]
- Cai, T.T.; Liu, W.D.; Luo, X. A constrained l1 minimization approach to sparse precision matrix estimation. J. Am. Stat. Assoc. 2011, 104, 594–607. [Google Scholar] [CrossRef]
- Liu, W.; Luo, X. Fast and adaptive sparse precision matrix estimation in high dimensions. J. Multivar. Anal. 2015, 135, 153–162. [Google Scholar] [CrossRef]
- Zhang, T.; Zou, H. Sparse precision matrix estimation via lasso penalized D-trace loss. Biometrika 2014, 101, 103–120. [Google Scholar] [CrossRef]
- Cai, T.T.; Liu, W.D.; Zhou, H.H. Estimating sparse precision matrix: Optimal rates of convergence and adaptive estimation. Ann. Stat. 2016, 44, 455–488. [Google Scholar] [CrossRef]
- Fan, J.Q.; Yuan, L.; Han, L. An overview of the estimation of large covariance and precision matrices. Econom. J. 2016, 19, C1–C32. [Google Scholar] [CrossRef]
- Lee, J.D.; Liu, Q.; Sun, Y.; Taylor, J.E. Communication-efficient sparse regression. J. Mach. Learn. Res. 2017, 18, 115–144. [Google Scholar]
- Jordan, M.; Lee, J.; Yang, Y. Communication-efficient distributed statistical inference. J. Am. Stat. Assoc. 2018. [Google Scholar] [CrossRef]
- Fan, J.Q.; Guo, Y.Y.; Wang, K.Z. Communication-efficient accurate statistical estimation. J. Am. Stat. Assoc. 2023, 118, 1000–1010. [Google Scholar] [CrossRef] [PubMed]
- Gao, Y.; Liu, W.D.; Wang, H.S.; Wang, X.Z.; Yan, Y.B.; Zhang, R.Q. A review of distributed statistical inference. Stat. Theory Relat. Fields 2022, 6, 89–99. [Google Scholar] [CrossRef]
- Li, X.X.; Xu, C. Feature screening with conditional rank utility for big-data classification. J. Am. Stat. Assoc. 2023, 1–22. [Google Scholar] [CrossRef]
- Arroyo, J.; Hou, E. Efficient distributed estimation of inverse covariance matrices . In Proceedings of the 2016 IEEE Statistical Signal Processing Workshop (SSP), Mallorca, Spain, 26–29 June 2016; pp. 1–5. [Google Scholar] [CrossRef]
- Wang, G.P.; Cui, H.J. Efficient distributed estimation of high-dimensional sparse precision matrix for transelliptical graphical models. Acta Math. Sin. Engl. Ser. 2021, 37, 689–706. [Google Scholar] [CrossRef]
- Dong, W.; Li, X.X.; Xu, C.; Tang, N.S. Hybrid hard-soft screening for high-dimensional latent class analysis. Stat. Sin. 2023, 33, 1319–1341. [Google Scholar] [CrossRef]
- Zhang, C. Nearly unbiased variable selection under minimax concave penalty. Ann. Stat. 2010, 38, 894–942. [Google Scholar] [CrossRef]
- Ma, S.; Huang, J. A concave pairwise fusion approach to subgroup analysis. J. Am. Stat. Assoc. 2017, 112, 410–423. [Google Scholar] [CrossRef]
- Fan, J.Q.; Li, R.Z. Variable selection via nonconcave penalized likelihood and its oracle properties. J. Am. Stat. Assoc. 2001, 96, 1348–1360. [Google Scholar] [CrossRef]
- Cai, T.T.; Li, H.Z.; Liu, W.D.; Xie, J. Joint estimation of multiple high-dimensional precision matrices. Stat. Sin. 2016, 26, 445–464. [Google Scholar] [CrossRef]
- Ravikumar, P.; Wainwright, M.J.; Raskutti, G.; Yu, B. High-dimensional covariance estimation by minimizing l1-penalized log-determinant divergence. Electron. J. Stat. 2011, 5, 935–980. [Google Scholar] [CrossRef]
- Wang, C.; Jiang, B. An efficient ADMM algorithm for high dimensional precision matrix estimation via penalized quadratic loss. Comput. Data Anal. 2020, 142, 106812. [Google Scholar] [CrossRef]
- Xie, J.H.; Lin, Y.Y.; Yan, X.D.; Tang, N.S. Category-adaptive variable screening for ultra-high dimensional heterogeneous categorical data. J. Am. Stat. Assoc. 2019, 747–760. [Google Scholar] [CrossRef]
- Uçar, M.K.; Nour, M.; Sindi, H.; Polat, K. The effect of training and testing process on machine learning in biomedical datasets. Math. Probl. Eng. 2020, 2020, 2836236. [Google Scholar] [CrossRef]
- Xu, P.; Tian, L.; Gu, Q.Q. Communication-efficient distributed estimation and inference for transelliptical graphical models. arXiv 2016, arXiv:1612.09297. [Google Scholar]
- Beck, A.; Teboulle, M. A fast iterative shrinkage-thresholding algorithm for linear inverse problems. SIAM J. Imaging Sci. 2009, 2, 183–202. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dong, W.; Liu, H. Distributed Sparse Precision Matrix Estimation via Alternating Block-Based Gradient Descent. Mathematics 2024, 12, 646. https://doi.org/10.3390/math12050646
Dong W, Liu H. Distributed Sparse Precision Matrix Estimation via Alternating Block-Based Gradient Descent. Mathematics. 2024; 12(5):646. https://doi.org/10.3390/math12050646
Chicago/Turabian StyleDong, Wei, and Hongzhen Liu. 2024. "Distributed Sparse Precision Matrix Estimation via Alternating Block-Based Gradient Descent" Mathematics 12, no. 5: 646. https://doi.org/10.3390/math12050646
APA StyleDong, W., & Liu, H. (2024). Distributed Sparse Precision Matrix Estimation via Alternating Block-Based Gradient Descent. Mathematics, 12(5), 646. https://doi.org/10.3390/math12050646