1. Introduction
Many complex systems in reality can be represented as network structures [
1], such as social networks, protein interaction networks, the computer internet, and biological disease transmission networks [
2]. Network nodes symbolize entities, whereas linked edges symbolize the relationships between these things. The network structure of complex systems has an associative nature, meaning that the entire network comprises several community structures that are highly interconnected within each community and sparsely interconnected between communities. Nevertheless, the relevance of a community in terms of its physical implications is mostly determined by the specific field of application with which the network is associated. For example, in social networks, communities are defined as groups with common interests or preferences [
3]. Functional units in metabolic networks are represented by communities.
The accurate identification of community structure in networks has significant theoretical importance and practical utility for analyzing the component structure of complex systems, understanding the internal mechanisms of system interactions, revealing the patterns of system evolution, and predicting the behavior of complex systems [
4,
5,
6]. Over the last several years, numerous techniques for community detection have been suggested [
7], such as spectral clustering-based approaches [
7], modularity-based approaches [
8], NMF-based approaches [
9], and others. Ye et al. [
9] developed a deep non-negative matrix factorization (NMF) autoencoder to uncover the community structure in complex networks by using both hierarchical and structural information. Their approach was influenced by the deep self-encoder and aimed to learn hierarchical features with hidden information. Li et al. [
8] observed that many existing community detection algorithms mostly rely on the original network topology and overlook the underlying community structure information. In their study, they utilized the node attribute matrix and the community structure to address this limitation. The attribute community identification issue may be represented as a non-negative matrix optimization problem, where the embedding matrix is used to identify all the communities in the attribute graph.
Nevertheless, the majority of current community detection algorithms, such as those based on NMF, struggle to accurately identify community structures in vast and sparse networks. In the realm of community detection research, several strategies have been presented in recent years to tackle the issue of network sparsity. Amini et al. [
4] introduced a semi-supervised approach for identifying communities in social networks by integrating deep learning techniques with the topological characteristics of the networks. Santo et al. [
4] addressed the challenges of dimensionality and sparsity by enhancing the conventional CNN convolution layer. They proposed an optimized convolution layer specifically designed for efficient convolutional computation on large, high-dimensional sparse matrices. This approach focuses on non-zero values, effectively reducing memory usage while performing sparse matrix computations. Sperli et al. [
3] introduced a method that combines deep learning and the topological characteristics of social networks to automatically identify communities. This method utilizes a specialized convolutional neural network to collect and depict common user interactions in online social networks. Xie et al. [
1] examined four distinct network representations in order to determine the most optimal representation for inputting into a deep sparse filtering network. The objective was to produce a mapping of the community attributes that are represented at each node. Sparse filtering is a straightforward two-layer learning model capable of processing high-dimensional graph data and representing very sparse inputs as low-dimensional feature vectors. The utilization of deep learning techniques as the foundation for the sparse network community detection approach also proves effective in addressing the issue of network sparsity. The complexity of the algorithm needs to be further reduced only during the parametric learning of the model and feature engineering. Furthermore, there is a need to find adaptive techniques to estimate the number of possible communities. Thus, due to the sparsity constraint, the development of an efficient community detection method remains a difficult undertaking.
Presently, community detection methods based on NMF are evaluated based on two primary perspectives. One aspect to consider is the parameterization of the method, which often includes setting values for various parameters used in NMF-based algorithms [
9,
10,
11]. These parameters often have reasonable default values. This includes the identification of prospective variables, particularly for the issue of community detection, i.e., the determination of the number of communities. However, this pertains to the creation of the data matrix, which is also referred to as the feature matrix [
12,
13]. This matrix is the one that will undergo decomposition in the NMF model.
In order to address the above issues, given the limited number of connections in the network, we propose a community detection technique called CDNMF, which is based on non-negative matrix factorization. The CDNMF technique addresses the problem of localizing the eigenvectors of data matrices caused by sparsity or noise. It improves the accuracy and practicality of the NMF community-finding approach. The main contributions of this study are as follows:
We propose a matrix regularization procedure to enhance the representation of the overall topological characteristics of the network, addressing the issue of localizing the eigenvectors of the data matrix while dealing with sparse networks.
We have designed a method for discovering sparse network communities by decomposing a non-negative matrix. This method utilizes regularization transformations and incorporates the spectral analysis of non-backtracking matrices. It effectively determines the number of community divisions without adding computational complexity and enhances the algorithm’s performance.
The experimental findings obtained from many datasets demonstrate that our proposed CDNMF algorithm achieves superior accuracy in community segmentation for sparse networks, surpassing existing state-of-the-art NMF-based techniques.
This paper is organized in the following manner. The text presents a demonstration of the equality between the goal functions of symmetric non-negative matrix factorization (NMF) and spectral clustering. Based on this premise, a CDNMF technique is presented for community finding in sparse networks by utilizing a regularization transform. Furthermore, the efficacy of the suggested approach in addressing community detection in networks with a low density is also assessed by experimentation on both actual and artificially made sparse networks. Ultimately, the approach is condensed and examined, and potential avenues for expansion in the future are suggested.
3. Equivalence Proof
The spectral clustering approach shows promising application potential and continues to be a highly researched data clustering method, especially when the data can be represented in matrix form. The objective functions for spectral clustering can be categorized into three types: ratio cuts, normalized cuts, and maximum–minimum cuts. To establish the similarity between the objective function for symmetric non-negative matrix decomposition and the objective function for spectral clustering, this section specifically examines the clustering objective function expressed as a ratio cut.
Let us consider a weighted undirected graph, denoted by G = (V,E), where V represents the set of nodes and E represents the set of edges. The graph G has a weighted adjacency matrix indicated by . The elements of the set are denoted by , where i and j range from 1 to n. All element values are greater than or equal to zero. The value of is 0. The absence of an edge between nodes and is denoted by , whereas a non-negative weight is denoted by for the connecting edges between nodes and . The total of the weights for node in the set V is represented by , which is equal to the summation of all weights for j ranging from 1 to n.
A matrix
U is a diagonal matrix with diagonal elements represented by
. The ratio cut technique may be mathematically represented by Equations (1) and (2) for a certain number of subsets, denoted by
K, which are labeled as
.
where the subset of the node set is indicated by
(
), and its complement is denoted by
. The function
is defined as the sum of the weights
for all pairs of elements
i in
and
j in
. The symbol
represents the cardinality of the subset
, which is the number of nodes it contains.
To define
K indication nodes, denoted by
,
j = 1, 2, …,
K, for a given
K subsets of
, refer to Equation (3).
The nodes indicated by
K are utilized as column vectors to create a new matrix represented by
. The column nodes in the matrix
H are mutually perpendicular, ensuring the validity of Equation (4).
Combining the traces of the matrix, Equation (5) can be obtained.
where the matrix
L represents the non-normalized Laplace matrix, which is represented by the equation
L =
U −
W. In addition, the objective function of the ratio cut clustering can be simplified to Equation (6) when
K takes any value.
Assuming that
tr denotes the trace of the matrix, the minimization ratio cut problem can be expressed as shown in Equation (7).
where
. By allowing the values of the elements of the matrix
H to be any real value, the relaxed optimization case of the problem can be obtained, as shown in Equation (8).
As a result of this transformation, the trace minimization problem has been transformed into its standard form. The spectral clustering solution, denoted by the symbol
H, can be considered the corresponding spectral clustering result for
K-mean clustering. This is due to the fact that the theoretical frameworks of spectral clustering and
K-mean clustering have a unified structure. In the case of a set of n data points, which are represented by the equation
, the objective function of
K-mean clustering can be stated as Equation (9).
where
is the center of clustering among the
points of the cluster
.
K non-negative indicator vectors are defined as solutions to the clustering, which can be expressed as
and
.
The solution of the
K-means clustering, denoted by the matrix
Y, and the solution of the ratio cut clustering, denoted by the matrix
H, are almost identical. Consequently, it can then be expressed as Equation (9).
Therefore, Equation (9) may be rewritten as Equation (11) due to the fact that the first component is a constant.
The solution representation is the only difference between the two methods. In the data representation, the ratio cut uses a Laplace matrix, denoted by
L, whereas the
K-mean method uses the matrix
. To summarize, the weighted adjacency matrix
W may be regarded as a versatile data representation. The proof of equivalence between the spectral clustering objective function and the symmetric NMF objective function can be demonstrated using Equation (12).
In order to finish the proof that was presented before, it is possible to loosen the restriction that . After the research described above, it was found that spectral clustering is directly related to K-mean clustering. The K-mean clustering algorithm is somewhat similar to the NMF algorithm. Therefore, in a simple way, NMF and spectral clustering are compatible with each other.
4. Proposed Model
Before outlining the basics of NMF-based community detection techniques, we will first give a brief introduction to the definition of classical community detection methods and their mathematical constructions. The goal of community detection is to divide the set of nodes of a graph
G = (
V,
E) into a number of unique subsets in such a way that the solution satisfies the fundamental characteristics of the community structure. The partitioning result of the network is then represented by the partitioning matrix
P, as shown in Equation (13). This is based on the assumption that
n represents the total number of nodes and that the community solution with
c subsets has been provided in advance.
The size of the k-th community may be represented as the sum of for i ranging from 1 to n. In addition, when considering a community, we make the assumption that each value of k satisfies the constraint . These divisions are referred to as hard divisions because they create partitions where each node is assigned to a certain community.
Evidently, nodes that share similarities are found within the same community. Consequently, we can establish the similarity function as a means of assessing the similarity between nodes. If nodes and are identical, then the similarity score is equal to 1. If nodes and are entirely different, then the similarity score is equal to 0. We find the value of , which is between 0 and 1. The function is continuously differentiable for every .
The aforementioned similarity function is denoted by
. When evaluating the similarity between nodes, one might make acceptable assumptions based on existing knowledge. For instance, a connection between nodes
and
signifies their similarity, but the absence of a connection suggests their dissimilarity. We can evaluate a given partition by calculating the proximity of the actual similarity value to the required similarity value, as shown in Equation (14).
In order to represent this concept using matrices, we define the matrices
and
. In general, we regard the adjacency matrix
A of a given graph as a reasonable choice for capturing a priori similarity. Therefore, the matrix
is equal to the matrix
. Given that, the adjacency matrix fulfills the similarity assumption, meaning that it is equal to 1 for pairs of nodes that are connected by edges. For pairs of nodes that are not connected by edges, their similarity is equal to 0. This is demonstrated by implementing the provided similarity function and satisfying the above requirement.
The similarity of a node to another node belonging to the same partition must be one for the idea described above to hold; otherwise, it must be zero. If it is represented in matrix form, it can simply be written as
To minimize the function
E(
P), we create an NMF problem and acquire a partition matrix
P that is suitable for this purpose. The formal statement of this problem is given by Equation (17).
The user provides the desired similarity matrix and the number of communities as input to the adjacency matrix A. The number of communities is determined by setting the potential factor k.
4.1. Algorithm Principles
The spectral technique outperforms general spectral clustering on sparse networks by using the regularization matrix derived from local feature vectors as an alternative matrix representation of the network. Thus, we incorporate regularization matrices into the community detection process based on non-negative matrix factorization (NMF).
Localization characterizes the local arrangement of the network system, while delocalization expands the scope of these localized vectors, resulting in feature vectors that capture the broader global structural information with higher eigenvalues. The Inverse Participation Ratio (IPR) is a metric employed in spectral clustering to quantify the level of localization of feature vectors. It is defined as the sum of the fourth power of each element in the feature vector, represented as . Greater IPR values suggest that the vectors exhibit a higher level of localized structure. The values of I(l) vary between and 1. These values correspond to two sets of vectors: and , respectively.
The proposed technique involves creating a regularized matrix, denoted as a Z-Laplacian (), that has a comparable structure to that of the adjacency matrix (A). The regularization matrix, indicated by , is defined as the sum of A and Z, where A represents the data matrix or a variation of it. The regularization learning procedure yields Z.
The regularization matrix
Z mentioned above is a diagonal matrix. Each diagonal element of this matrix is learned incrementally from the most localized vectors. The learning process involves applying penalties to the localized eigenvectors to suppress the corresponding eigenvalues. The learning process concludes after all
g primary characteristic vectors have been disentangled from their specific locations. The resultant
Z-Laplacian matrix is believed to be a simple representation of the overall structure of the matrix
A, excluding its individual nodes. The steps of the CDNMF algorithm are illustrated in Algorithm 1.
| Algorithm 1 Learning process of the CDNMF model |
- Require :
Regularization matrix , number of communities k - Ensure :
Community detection results - 1:
Use non-backtracking matrices to estimate appropriate values for the number of communities k - 2:
Compute symmetric non-negative matrix factorization - 3:
The update rule is - 4:
- 5:
- 6:
After the objective function, i.e., Equation (19), converges, the partition matrix can be obtained
|
For every row vector for the matrix P, it is necessary to normalize in such a way that the cumulative sum of all elements in is equal to one, which is denoted by the expression . The element in the normalized P reflects the strength of the affiliation of node i to community j. Furthermore, the community that has the highest degree of attachment is the one that is allocated node i.
4.2. Parameter Learning
In this part, we select a straightforward and speedy approach to estimate the number of communities k for community detection methods that are founded on non-negative matrix decompositions. The spectral qualities of particular graph operators, such as non-backtracking matrices, serve as the foundation and basis for this.
In the context of a complex network, the adjacency matrix A represents the connections between nodes in the network. The degree of a certain node k may be calculated by summing the values in the k-th row of the matrix A. Below is the definition of the non-backtracking matrix, which is utilized to estimate the number of communities.
In an undirected complex network, the variable
m represents the number of edges, while
B represents the associated non-backtracking matrix. When generating the matrix B, two directed edges are used to represent the connection between nodes
i and
j. One path travels from node
i to node
j, while the other path travels from node
j to node
i. The matrix
B has dimensions of 2
m × 2
m and can be represented by Equation (
18).
The spectrum of the matrix
B is demonstrated to have two components, namely, ±1, along with the eigenvalues of the 2
n × 2
n matrix, as given in Equation (
19).
where
is a matrix of size
n ×
n, with all elements being zero. The symbol
I represents the identity matrix of size
n ×
n, and
U is a diagonal matrix of size
n ×
n with diagonal elements
. If the network is divided into
k communities, the first
k greatest eigenvalues of the matrix
are real. Specifically, they are distinct from the areas where the remaining eigenvalues are concentrated. The regions where the remaining eigenvalues are grouped are enclosed by a circle with a radius equal to the square root of the norm of the matrix
. The eigenvalues of the
matrix that contain information are denoted by the symbol
k. Equation (
20) provides an approximation of the spectral characteristics of the non-retrospective matrix.
The non-backtracking matrix information eigenvalues are real and separated from the other eigenvalues in a circle with the radius . To obtain an idea of the k value, we count the number of eigenvalues that are not in this circle. Experiments also show that the parameter learning process performs well, especially when communities of complex networks are known to have similar sizes and edge densities.
The number of true out-of-circle eigenvalues seems to be a natural indication of the number of clusters present in the network when it comes to networks formed using the random block model. In some networks, true eigenvalues with high out-of-circle distributions may correlate with tiny clusters on the network graph. This is something that can be taken into account in actual network segmentation procedures.
5. Experiments
This research performed a comparative analysis using numerous approaches that are considered to be the state of the art on both synthetic and actual networks. The purpose of this analysis was to validate the efficacy of CDNMF. The experimental hardware platform consists of an Intel Core i7-9700 CPU operating at 2.4 GHz, 32 gigabytes of random-access memory (RAM), and Windows 10 as the operating system. Python 3.7 was used to implement each of the compared methods.
5.1. Compared Methods
We chose a number of algorithms that are considered to be the state of the art in order to provide a comparison with the approach that is given in this work.
DCSBM [
28]: This strategy separates the row labels from the column labels in the probability function to achieve fast alternation maximization. This novel technique has great computational efficiency, is suitable for both small and large networks, and includes guarantees of convergence that can be demonstrated.
NMF [
11]: This method uses the basic NMF model to directly decompose the adjacency matrix
A to obtain the matrices
U and V,
, where
U serves as the community membership representation matrix.
SNMF [
12]: This technique is founded on the symmetrical non-negative matrix decomposition model, whereby
and
H may directly reflect the degree of affiliation that a community member has with the community.
M-NMF [
13]: The non-negative matrix decomposition and modularity-based community detection approaches are simultaneously optimized by this modularity-based NMF community detection model. This model incorporates the community structure of the network into the network embedding and takes into account the modularity of the network.
ONMF [
29]: The approach is founded on the orthogonal non-negative matrix factorization model. The main concept involves imposing orthogonal constraints on the matrix
W within the framework of the NMF model
, resulting in the condition
.
HPNMF [
30]: The graph regularization NMF model serves as the foundation for this technique. This model has the capability to use both the topology of the network and the homogeneity information of the nodes in order to establish community detection.
NSED [
24]: In addition to being based on the joint NMF model, the approach includes both an encoder and a decoder, both of which are capable of being utilized in order to obtain the community membership representation matrix.
5.2. Datasets
Both synthetic and real networks were included in the datasets used for the studies, which are described below.
Artificial Synthetic Networks: We utilized the LFR benchmark network synthesis program [
31] to create artificial networks with actual community labels. This tool offers several configurable settings, as shown in
Table 1. Various distinct sets of artificial networks are created by manipulating the parameters. To begin with, a collection of five networks is created by keeping the variables
n,
k,
maxk,
minc, and
maxc constant. The value of
mu ranges from 0.1 to 0.3, with an increment of 0.05 for each iteration. By manipulating the variables
k,
maxk,
minc,
maxc, and
mu, the number of nodes
n is incremented from 1000 to 5000. This process is repeated five times, with each iteration increasing
n by 1000, resulting in the generation of five distinct networks. The precise parameter configurations of the two sets of networks are shown in
Table 2.
Real Networks: We selected four datasets consisting of actual networks, namely, WebKB, Cora, Citeseer, and Pubmed [
32]. The precise characteristics of these datasets are provided in
Table 3. The aforementioned datasets may be downloaded from the following URL:
https://linqs.org/datasets/ (accessed on 14 January 2024).
5.3. Experimental Setup
In order to assess the effectiveness of community discovery outcomes, we employ four widely accepted assessment metrics: normalized mutual information (NMI), the adjusted Rand index (ARI), accuracy (ACC), and modularity (Q). When evaluating the results of synthetic networks, we utilize all four of these metrics. In the case of actual networks, when there is no specific labeling for community segmentation, we employ the modularity Q as a means of evaluating the results. Greater values for all rating categories indicate superior performance, whereas smaller values indicate the opposite.
In order to ensure that the comparisons made in the experiment are accurate, the parameters of all of the compared techniques are based on the default values that were found in the original text. For the M-NMF algorithm, the regularization parameters equals 1 and equals 5. The value of the regularization parameter is equal to 1 for HPNMF. In addition, the tests were carried out ten times according to each approach, and the average of each evaluation indicator was taken into consideration for the assessment.
5.4. Synthetic Networks
An examination of the similarities and differences between the two synthetic network datasets, shown in
Table 2, was carried out, and the results of the experiments carried out on the first network are shown in
Table 4.
The data shown in
Table 4 demonstrate that when the confusion factor increases, the community structure of the network becomes less transparent, and it becomes more challenging to locate existing communities. The approach that is discussed in this work, CDNMF, performs better on all of the methods, despite the fact that the performance of each method decreases more significantly as a consequence of this. As an illustration, when the value of
mu is equal to 0.1, CDNMF exhibits significant improvements in ACC, NMI, ARI, and modularity Q of 7.7%, 3.1%, 8.2%, and 2.4%, respectively, in comparison to SNMF, which is the most effective community detection algorithm based on NMF. In addition, CDNMF demonstrates varying degrees of improvement across the four assessment measures when applied to several distinct datasets. The results of the experiments carried out on the second set of synthetic networks are shown in
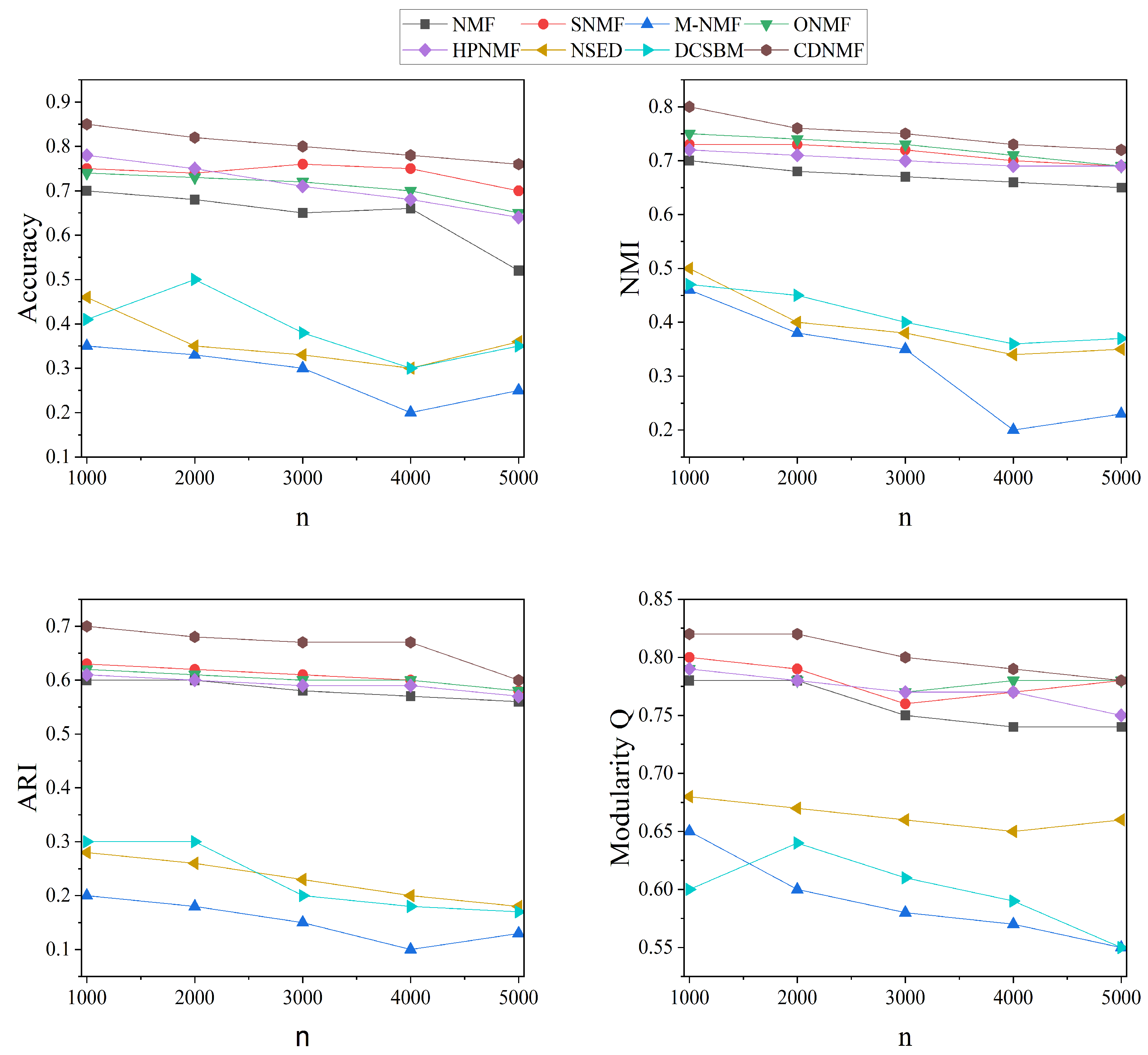
Figure 1. In this figure, it is also possible to observe that CDNMF achieves the highest level of performance across all networks, regardless of the number of nodes present.
The aforementioned experimental results on synthetic networks show that CDNMF outperforms current NMF-based community detection techniques.
5.5. Real Networks
In order to provide more evidence that CDNMF is successful, comparative studies were carried out on four actual networks. The results of these experiments are presented in
Table 5 and
Table 6. The results of CDNMF on each real network are found to be superior to the results obtained by the comparative techniques, as can be observed. After comparing the modularity of CDNMF to that of HPNMF, the best-performing NMF-based approach, the modularity of CDNMF is increased by 5.4%, 1.5%, 9.3%, and 1.3%, respectively, on WebKB, Cora, Citeseer, and Pubmed. The complexity of real networks is often higher, and they typically include a greater number of nonlinear node properties than synthetic networks. On synthetic networks, the SNMF model performs better than average, but on the three real datasets, its performance is average. On the other hand, CDNMF is a nonlinear community detection model that performs better than the other models in both real and synthetic networks. It is particularly effective in the former. The results reported above demonstrate that CDNMF has the potential to enhance the manner in which the nonlinear characteristics of networks are represented, which, in turn, improves the performance of NMF community detection.
5.6. Time Complexity
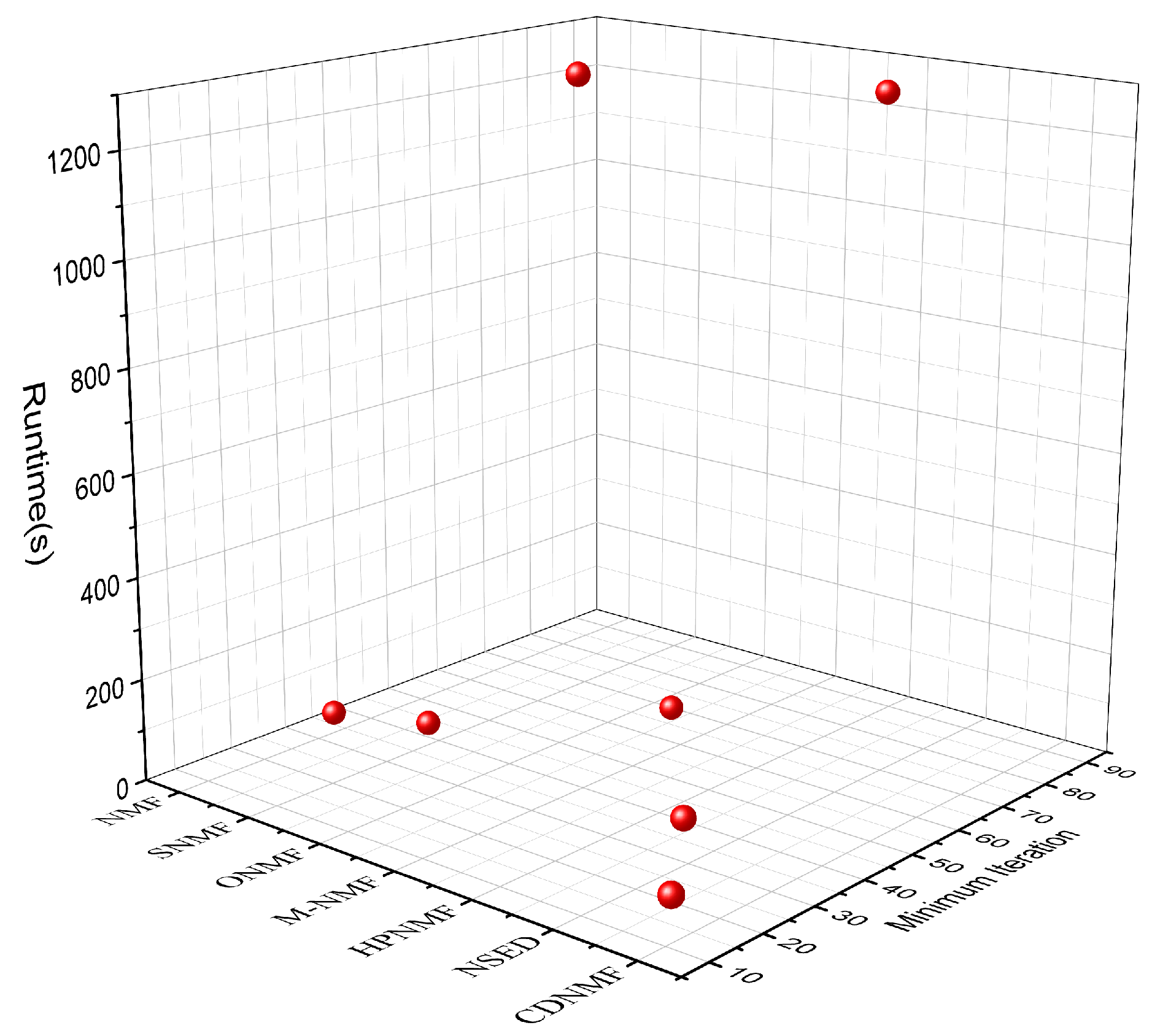
In the analysis described in this section, the real network Pubmed was chosen as the experimental data, and the NMF-based community detection methods NMF, SNMF, M-NMF, ONMF, HPNMF, and NSED were chosen for comparison. The purpose of this experiment was to investigate the minimum number of iterations required for CDNMF to achieve the best community delineation results. The minimum number of iterations, denoted by , and the time required for each approach to achieve the best possible results in terms of community delineation were evaluated and documented.
The experimental results are shown in
Figure 2, which shows that, in terms of running time, NMF and SNMF take less time to obtain the best neighborhood delineation result due to the simplicity of the models and their higher running efficiency, while ONMF takes the longest time, which is mainly due to the high complexity of the orthogonality constraint computation, and HPNMF takes only the second-longest time due to the high complexity of the model in calculating the similarity matrix and the corresponding larger value of
. Consequently, it takes the second-longest amount of time, behind only ONMF. With a
of 11, the CDNMF model is able to obtain community segmentation results that are optimal with a reduced number of iterations compared to the other models. When compared to ONMF and HPNMF, CDNMF has a far more glaring advantage in terms of the amount of time it takes to operate.




{kind=link}
{kind=link}