
Machine-Learning-Based Approaches for Multi-Level Sentiment Analysis of Romanian Reviews

 , , , , and
, , , , and
Abstract
1. Introduction
- RQ1
- Is latent semantic indexing (LSI) in conjunction with conventional machine learning classifiers suitable for sentiment analysis of documents written in Romanian?
- RQ2
- Can deep-learned embedding-based approaches improve the performance of document- and/or sentence-level sentiment analysis, as opposed to classical natural language processing (NLP) embedding-based deep learning approaches?
- RQ3
- What is the relevance of different textual representations in the task of sentence polarity classification, and what impact do additional preprocessing steps have in this task?
- RQ4
- In terms of aspect extraction, is it feasible for a clustering methodology relying on learned word embeddings to delineate groups of words capable of serving as aspect categories identified within a given corpus of documents?
- RQ5
- How can the aspect categories discussed within a document be identified, if an aspect category is given through a set of words?
2. Sentiment Analysis
2.1. Document-Level Sentiment Analysis (DLSA)
2.2. Sentence-Level Sentiment Analysis (SLSA)
2.3. Aspect-Based Sentiment Analysis (ABSA)
3. Related Work
3.1. DLSA for Romanian
3.2. SLSA for Romanian
3.3. Aspect Term Extraction (ATE) and Aspect Category Detection (ACD)
4. Methodology
4.1. Case Study
4.1.1. Data Collection
4.1.2. Dataset Description
4.2. Theoretical Models
4.2.1. Document-Level Sentiment Analysis
4.2.2. Sentence-Level Sentiment Analysis
4.2.3. Aspect Term Extraction and Aspect Category Detection
4.3. Data Representation
4.3.1. Preliminaries: Data Preparation and Preprocessing
4.3.2. TF-IDF Representation
4.3.3. LSI Representation
- , where () denotes the value of the i-th feature computed for the document in the documents dataset by using the LSI-based embedding.
4.3.4. Deep-Learned Representation
4.3.5. Word Representations
4.4. Models
4.4.1. Supervised Classification
4.4.2. Unsupervised Analysis
4.5. Evaluation
4.5.1. Methodology
4.5.2. Performance Indicators
5. Results
5.1. Document Level
5.2. Sentence Level
5.3. Aspect Level
5.3.1. Aspect Term Extraction
5.3.2. Aspect Category Detection
6. Discussion
6.1. Comparison to Related Work
6.2. Analysis
6.3. Potential Challenges and Limitations
7. Conclusions and Further Work
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| CNN | Convolution Neural Network |
| DL | Deep Learning |
| DNN | Deep Neural Network |
| DT | Decision Trees |
| GAP | Global Average Pooling |
| GRU | Gated Recurrent Unit |
| kNN | k-Nearest Neighbors |
| LR | Logistic Regression |
| LSI | Latent Semantic Indexing |
| LSTM | Long Short-Term Memory |
| ML | Machine Learning |
| MLP | Multilayer Perceptron |
| NB | Naïve Bayes |
| RF | Random Forest |
| RNN | Recurrent Neural Network |
| SOM | Self-Organizing Maps |
| SVM | Support Vector Machines |
| TF-IDF | Term Frequency–Inverse Document Frequency |
| VP | Voted Perceptron |
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Terms | Assigned Label | NPMI | LCH | |
|---|---|---|---|---|
| culoare, intensitate, intuneric, scenecadră, expunere color, intensity, darkness, scenes/frames, exposure | Display (Image Quality) | −1.000 | 1.441 | |
| mufă, adaptor, cutie, cablu, usb socket, adapter, box, cable, USB | Connectivity | −1.000 | 2.009 | |
| asteptar, pret, produs, leu expectation, price, product, Romanian leu (RON) | Price | −0.384 | 1.000 | |
| săptămână, problemă, achiziție, an, saptaman, lună week, problem, purchase, year, month | Durability | −0.905 | 2.081 | |
| vizibilitate, pixel, ips, visualizare, pixă, unghi, tn visibility, pixel, IPS, visualization, angle, TN | Display (Technology) | −0.382 | 1.493 | |
| imagine, monitor, hd, display, ecran image, monitor, HD, display, screen | Display (Characteristics) | 0.258 | 1.279 | |
| medie, calitate, pro, ok, rest, bun, super average, quality, pro, ok, otherwise, good, great | Quality | −0.648 | 1.417 |
| Review Text | Display (Image Quality) | Connectivity | Price | Durability/ Reliability | Display (Technology) | Display Features | Quality/ General | |
|---|---|---|---|---|---|---|---|---|
| După o luna au apărut dungi pe ecran!!! After a month, stripes appeared on the screen! | 0.059 | 0.010 | 0.011 | 0.672 | 0.064 | 0.157 | 0.027 | |
| Doar conexiune VGA și atât. Bun pentru birou. Only VGA connection, and that’s it. Good for the office | 0.067 | 0.179 | 0.065 | 0.055 | 0.065 | 0.080 | 0.490 | |
| Am monitorul de mai mult de 3 ani si sunt foarte multumit de el. Il folosesc doar pt gaming si se ridica așteptărilor. Cumpărați cu încredere I’ve had the monitor for more than 3 years, and I am very satisfied with it. I use it exclusively for gaming, and it meets expectations. Buy with confidence. | 0 | 0.001 | 0.105 | 0.817 | 0.002 | 0.006 | 0.068 | |
| Are ghosting destul de urat. Is ghosting quite ugly | 0.176 | 0.057 | 0.082 | 0.060 | 0.178 | 0.183 | 0.264 | |
| Pret calitate, DEZAMAGITOR! Price quality, DISAPPOINTING! | 0.005 | 0.003 | 0.147 | 0.037 | 0.020 | 0.017 | 0.771 | |
| Nu am fost atent la detalii si am comandat unul cu port serial in loc de hdmi. Are doar o singura intrare si depinde de model… I wasn’t careful with the details, and I ordered one with a serial port instead of HDMI. It has only one input, and it depends on the model. | 0.006 | 0.839 | 0.003 | 0.003 | 0.113 | 0.027 | 0.009 | |
| Super ok! Se comporta bine! Super ok! It performs well! | 0 | 0 | 0.001 | 0.007 | 0 | 0 | 0.992 | |
| Business as usual de la Dell. Un monitor excelent. ii dau totusi 4 stele pentru ca folosit cu doua deviceuri, dureaza foarte mult functia de autoscan, este mai rapid sa selectez manual input source cand am nevoie sa trec de la un PC la celalalt. E destul de incomod si faptul ca are doar un singur port HDMI si unul singur DisplayPort. USB-urile sunt excelente pentru cei fara docking station. Evident ca cei care au un singur device nu sunt catusi de putin incomodati de micile inconveniente sus mentionate. Business as usual from Dell. An excellent monitor. However, I’m giving it four stars because when used with two devices, the autoscan function takes a long time. It’s faster to manually select the input source when I need to switch from one PC to the other. It’s quite inconvenient that it has only one HDMI port and one DisplayPort. The USB ports are excellent for those without a docking station. Clearly, those with only one device aren’t bothered at all by the minor inconveniences mentioned above. | 0.012 | 0.473 | 0 | 0 | 0.002 | 0 | 0.512 |
References
- Liu, B. Sentiment Analysis and Opinion Mining; Springer Nature: Berlin/Heidelberg, Germany, 2022. [Google Scholar]
- Vernikou, S.; Lyras, A.; Kanavos, A. Multiclass sentiment analysis on COVID-19-related tweets using deep learning models. Neural Comput. Appl. 2022, 34, 19615–19627. [Google Scholar] [CrossRef]
- Hasib, K.M.; Habib, M.A.; Towhid, N.A.; Showrov, M.I.H. A Novel Deep Learning based Sentiment Analysis of Twitter Data for US Airline Service. In Proceedings of the 2021 International Conference on Information and Communication Technology for Sustainable Development (ICICT4SD), Dhaka, Bangladesh, 27–28 February 2021; pp. 450–455. [Google Scholar] [CrossRef]
- Nagamanjula, R.; Pethalakshmi, A. Twitter sentiment analysis using Dempster shafer algorithm based feature selection and one against all multiclass SVM classifier. Int. J. Adv. Res. Eng. Technol. 2020, 11, 163–185. [Google Scholar] [CrossRef]
- Mukta, M.S.H.; Islam, M.A.; Khan, F.A.; Hossain, A.; Razik, S.; Hossain, S.; Mahmud, J. A comprehensive guideline for Bengali sentiment annotation. Trans. Asian Low-Resour. Lang. Inf. Process. 2021, 21, 1–19. [Google Scholar] [CrossRef]
- Elbagir, S.; Yang, J. Twitter sentiment analysis using natural language toolkit and VADER sentiment. In Proceedings of the International Multiconference of Engineers and Computer Scientists, Hong Kong, 13–15 March 2019; Volume 122, p. 16. [Google Scholar]
- Su, J.; Chen, Q.; Wang, Y.; Zhang, L.; Pan, W.; Li, Z. Sentence-level Sentiment Analysis based on Supervised Gradual Machine Learning. Sci. Rep. 2023, 13, 14500. [Google Scholar] [CrossRef] [PubMed]
- Liu, B. Sentiment Analysis: Mining Opinions, Sentiments, and Emotions; Cambridge University Press: Cambridge, UK, 2020. [Google Scholar]
- Chebolu, S.U.S.; Dernoncourt, F.; Lipka, N.; Solorio, T. Survey of Aspect-based Sentiment Analysis Datasets. arXiv 2023, arXiv:cs.CL/2204.05232. [Google Scholar]
- Zhang, W.; Li, X.; Deng, Y.; Bing, L.; Lam, W. A survey on aspect-based sentiment analysis: Tasks, methods, and challenges. IEEE Trans. Knowl. Data Eng. 2023, 35, 11019–11038. [Google Scholar] [CrossRef]
- He, R.; Lee, W.S.; Ng, H.T.; Dahlmeier, D. An Unsupervised Neural Attention Model for Aspect Extraction. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017; Association for Computational Linguistics: Vancouver, BC, Canada, 2017; pp. 388–397. [Google Scholar] [CrossRef]
- Shi, T.; Li, L.; Wang, P.; Reddy, C.K. A simple and effective self-supervised contrastive learning framework for aspect detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 2–9 February 2021; Volume 35, pp. 13815–13824. [Google Scholar]
- Chebolu, S.U.S.; Rosso, P.; Kar, S.; Solorio, T. Survey on aspect category detection. ACM Comput. Surv. 2022, 55, 1–37. [Google Scholar] [CrossRef]
- Luo, L.; Ao, X.; Song, Y.; Li, J.; Yang, X.; He, Q.; Yu, D. Unsupervised Neural Aspect Extraction with Sememes. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence (IJCAI-19), Macao, China, 10–16 August 2019; pp. 5123–5129. [Google Scholar]
- Tulkens, S.; van Cranenburgh, A. Embarrassingly Simple Unsupervised Aspect Extraction. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 3182–3187. [Google Scholar] [CrossRef]
- Dumitrescu, S.D.; Rebeja, P.; Lorincz, B.; Gaman, M.; Avram, A.; Ilie, M.; Pruteanu, A.; Stan, A.; Rosia, L.; Iacobescu, C.; et al. LiRo: Benchmark and leaderboard for Romanian language tasks. In Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks, Online, 6–14 December 2021. [Google Scholar]
- Tache, A.; Gaman, M.; Ionescu, R.T. Clustering Word Embeddings with Self-Organizing Maps. Application on LaRoSeDa—A Large Romanian Sentiment Data Set. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, Association for Computational Linguistics, Online, 19–23 April 2021; pp. 949–956. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Conneau, A.; Khandelwal, K.; Goyal, N.; Chaudhary, V.; Wenzek, G.; Guzmán, F.; Grave, E.; Ott, M.; Zettlemoyer, L.; Stoyanov, V. Unsupervised Cross-lingual Representation Learning at Scale. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 8440–8451. [Google Scholar] [CrossRef]
- Dumitrescu, S.D.; Avram, A.M.; Pyysalo, S. The birth of Romanian BERT. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2020, Online, 16–20 November 2020; pp. 4324–4328. [Google Scholar] [CrossRef]
- Masala, M.; Ruseti, S.; Dascalu, M. RoBERT—A Romanian BERT Model. In Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Spain, 8–13 December 2020; pp. 6626–6637. [Google Scholar] [CrossRef]
- Masala, M.; Iacob, R.C.A.; Uban, A.S.; Cidota, M.; Velicu, H.; Rebedea, T.; Popescu, M. jurBERT: A Romanian BERT Model for Legal Judgement Prediction. In Proceedings of the Natural Legal Language Processing Workshop 2021, Punta Cana, Dominican Republic, 10 November 2021; Association for Computational Linguistics: Punta Cana, Dominican Republic, 2021; pp. 86–94. [Google Scholar] [CrossRef]
- Avram, A.; Catrina, D.; Cercel, D.; Dascalu, M.; Rebedea, T.; Pais, V.F.; Tufis, D. Distilling the Knowledge of Romanian BERTs Using Multiple Teachers. arXiv 2021, arXiv:2112.12650. [Google Scholar]
- Nicolae, D.; Yadav, R.; Tufis, D. A Lite Romanian BERT:ALR-BERT. Computers 2022, 11, 57. [Google Scholar] [CrossRef]
- Joulin, A.; Grave, E.; Bojanowski, P.; Mikolov, T. Bag of Tricks for Efficient Text Classification. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 2, Short Papers, Valencia, Spain, 3–7 April 2017; Association for Computational Linguistics: Valencia, Spain, 2017; pp. 427–431. [Google Scholar]
- Burlăcioiu, C.; Boboc, C.; Mitre, B.; Dragne, I. Text Mining in Business. A Study of Romanian Client’s Perception with Respect to Using Telecommunication and Energy Apps. Econ. Comput. Econ. Cybern. Stud. Res. 2023, 57, 221–234. [Google Scholar]
- Jones, K.S. A statistical interpretation of term specificity and its application in retrieval. J. Doc. 2021, 60, 493–502. [Google Scholar] [CrossRef]
- Russu, R.M.; Dinsoreanu, M.; Vlad, O.L.; Potolea, R. An opinion mining approach for Romanian language. In Proceedings of the 2014 IEEE 10th International Conference on Intelligent Computer Communication and Processing (ICCP), Cluj-Napoca, Romania, 4–6 September 2014; pp. 43–46. [Google Scholar] [CrossRef]
- Esuli, A.; Sebastiani, F. SENTIWORDNET: A Publicly Available Lexical Resource for Opinion Mining. In Proceedings of the International Conference on Language Resources and Evaluation, European Language Resources Association (ELRA), Genoa, Italy, 22–28 May 2006. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed Representations of Words and Phrases and Their Compositionality. Adv. Neural Inf. Process. Syst. 2013, 26, 3111–3119. [Google Scholar]
- Echim, S.V.; Smădu, R.A.; Avram, A.M.; Cercel, D.C.; Pop, F. Adversarial Capsule Networks for Romanian Satire Detection and Sentiment Analysis. In Lecture Notes in Computer Science; Springer Nature: Cham, Switzerland, 2023; Volume 13913, pp. 428–442. [Google Scholar] [CrossRef]
- Neagu, D.C.; Rus, A.B.; Grec, M.; Boroianu, M.A.; Bogdan, N.; Gal, A. Towards Sentiment Analysis for Romanian Twitter Content. Algorithms 2022, 15, 357. [Google Scholar] [CrossRef]
- Istrati, L.; Ciobotaru, A. Automatic Monitoring and Analysis of Brands Using Data Extracted from Twitter in Romanian. In Intelligent Systems and Applications; Springer International Publishing: Berlin/Heidelberg, Germany, 2022; pp. 55–75. [Google Scholar] [CrossRef]
- Coita, I.F.; Cioban, S.; Mare, C. Is Trust a Valid Indicator of Tax Compliance Behaviour? A Study on Taxpayers’ Public Perception Using Sentiment Analysis Tools. In Digitalization and Big Data for Resilience and Economic Intelligence; Springer International Publishing: Berlin/Heidelberg, Germany, 2022; pp. 99–108. [Google Scholar] [CrossRef]
- Buzea, M.C.; Trăuşan-Matu, Ş.; Rebedea, T. A three word-level approach used in machine learning for Romanian sentiment analysis. In Proceedings of the 2019 18th RoEduNet Conference: Networking in Education and Research (RoEduNet), Galați, Romania, 10–12 October 2019; pp. 1–6. [Google Scholar]
- Roșca, C.M.; Ariciu, A.V. Unlocking Customer Sentiment Insights with Azure Sentiment Analysis: A Comprehensive Review and Analysis. Rom. J. Pet. Gas Technol. 2023, 4, 173–182. [Google Scholar] [CrossRef]
- Hu, M.; Liu, B. Mining and summarizing customer reviews. In Proceedings of the Tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Seattle, WA, USA, 22–25 August 2004; pp. 168–177. [Google Scholar] [CrossRef]
- Popescu, A.M.; Etzioni, O. Extracting Product Features and Opinions from Reviews. In Natural Language Processing and Text Mining; Springer: London, UK, 2007; pp. 9–28. [Google Scholar] [CrossRef]
- Wu, Y.; Zhang, Q.; Huang, X.J.; Wu, L. Phrase dependency parsing for opinion mining. In Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing: Volume 3, Singapore, 6–7 August 2009; pp. 1533–1541. [Google Scholar] [CrossRef]
- Hai, Z.; Chang, K.; Kim, J.j. Implicit feature identification via co-occurrence association rule mining. In Computational Linguistics and Intelligent Text Processing; Springer: Berlin/Heidelberg, Germany, 2011; pp. 393–404. [Google Scholar] [CrossRef]
- Schouten, K.; Van Der Weijde, O.; Frasincar, F.; Dekker, R. Supervised and Unsupervised Aspect Category Detection for Sentiment Analysis with Co-occurrence Data. IEEE Trans. Cybern. 2017, 48, 1263–1275. [Google Scholar] [CrossRef] [PubMed]
- Titov, I.; McDonald, R. Modeling Online Reviews with Multi-Grain Topic Models. In Proceedings of the 17th International Conference on World Wide Web, Beijing, China, 21–25 April 2008; Association for Computing Machinery: New York, NY, USA, 2008; pp. 111–120. [Google Scholar] [CrossRef]
- Brody, S.; Elhadad, N. An Unsupervised Aspect-Sentiment Model for Online Reviews. In Proceedings of the Human Language Technologies: The 2010 Annual Conference of the North American Chapter of the Association for Computational Linguistics, Los Angeles, CA, USA, 2–4 June 2010; Association for Computational Linguistics: Los Angeles, CA, USA, 2010; pp. 804–812. [Google Scholar]
- García-Pablos, A.; Cuadros, M.; Rigau, G. W2VLDA: Almost unsupervised system for Aspect Based Sentiment Analysis. Expert Syst. Appl. 2018, 91, 127–137. [Google Scholar] [CrossRef]
- Ghadery, E.; Movahedi, S.; Faili, H.; Shakery, A. An Unsupervised Approach for Aspect Category Detection Using Soft Cosine Similarity Measure. arXiv 2018, arXiv:1812.03361. [Google Scholar]
- Sia, S.; Dalmia, A.; Mielke, S.J. Tired of Topic Models? Clusters of Pretrained Word Embeddings Make for Fast and Good Topics too! In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 1728–1736. [Google Scholar] [CrossRef]
- Viegas, F.; Canuto, S.; Gomes, C.; Luiz, W.; Rosa, T.; Ribas, S.; Rocha, L.; Gonçalves, M.A. CluWords: Exploiting Semantic Word Clustering Representation for Enhanced Topic Modeling. In Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining, Melbourne, Australia, 11–15 February 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 753–761. [Google Scholar] [CrossRef]
- Comito, C.; Forestiero, A.; Pizzuti, C. Word Embedding Based Clustering to Detect Topics in Social Media. In Proceedings of the IEEE/WIC/ACM International Conference on Web Intelligence, Thessaloniki, Greece, 14–17 October 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 192–199. [Google Scholar] [CrossRef]
- Boroș, T.; Dumitrescu, S.D.; Burtica, R. NLP-Cube: End-to-End Raw Text Processing With Neural Networks. In Proceedings of the CoNLL 2018 Shared Task: Multilingual Parsing from Raw Text to Universal Dependencies, Brussels, Belgium, 31 October–1 November 2018; Association for Computational Linguistics: Brussels, Belgium, 2018; pp. 171–179. [Google Scholar] [CrossRef]
- Lupea, M.; Briciu, A. Studying emotions in Romanian words using Formal Concept Analysis. Comput. Speech Lang. 2019, 57, 128–145. [Google Scholar] [CrossRef]
- Deerwester, S.C.; Dumais, S.T.; Landauer, T.K.; Furnas, G.W.; Harshman, R.A. Indexing by Latent Semantic Analysis. J. Am. Soc. Inf. Sci. 1990, 41, 391–407. [Google Scholar] [CrossRef]
- Řehůřek, R.; Sojka, P. Software Framework for Topic Modelling with Large Corpora. In Proceedings of the LREC 2010 Workshop on New Challenges for NLP Frameworks, Valletta, Malta, 22 May 2010; pp. 45–50. [Google Scholar] [CrossRef]
- Nwankpa, C.; Ijomah, W.; Gachagan, A.; Marshall, S. Activation functions: Comparison of trends in practice and research for deep learning. arXiv 2018, arXiv:1811.03378. [Google Scholar]
- Nwankpa, C.E. Advances in optimisation algorithms and techniques for deep learning. Adv. Sci. Technol. Eng. Syst. J. 2020, 5, 563–577. [Google Scholar] [CrossRef]
- Farhadloo, M.; Rolland, E. Multi-class sentiment analysis with clustering and score representation. In Proceedings of the 2013 IEEE 13th International Conference on Data Mining Workshops, Dallas, TX, USA, 7–10 December 2013; pp. 904–912. [Google Scholar]
- Tache, A.M.; Gaman, M.; Ionescu, R.T. Clustering word embeddings with self-organizing maps. application on laroseda—A large romanian sentiment data set. arXiv 2021, arXiv:2101.04197. [Google Scholar]
- Bouma, G. Normalized (Pointwise) Mutual Information in Collocation Extraction. Proc. Bienn. GSCL Conf. 2009, 30, 31–40. [Google Scholar]
- Lau, J.H.; Newman, D.; Baldwin, T. Machine Reading Tea Leaves: Automatically Evaluating Topic Coherence and Topic Model Quality. In Proceedings of the 14th Conference of the European Chapter of the Association for Computational Linguistics, Gothenburg, Sweden, 26–30 April 2014; Association for Computational Linguistics: Gothenburg, Sweden, 2014; pp. 530–539. [Google Scholar] [CrossRef]
- Leacock, C. Combining local context and WordNet similarity for word sense identification. In WordNet: A Lexical Reference System and Its Application; The MIT Press: Cambridge, MA, USA, 1998; pp. 265–283. [Google Scholar]
- Dumitrescu, S.D.; Avram, A.M.; Morogan, L.; Toma, S.A. RoWordNet—A Python API for the Romanian WordNet. In Proceedings of the 2018 10th International Conference on Electronics, Computers and Artificial Intelligence (ECAI), Iasi, Romania, 28–30 June 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Freund, Y.; Schapire, R.E. Large Margin Classification Using the Perceptron Algorithm. In Proceedings of the Eleventh Annual Conference on Computational Learning Theory, Madison, WI, USA, 24–26 July 1998; Association for Computing Machinery: New York, NY, USA, 1998; pp. 209–217. [Google Scholar] [CrossRef]

| Number of Reviews | Number of Sentences | Average Sentence Length | Number of Tokens | Number of Unique Tokens | Number of Unique Lemmas | |
|---|---|---|---|---|---|---|
| 1 star | 1357 | 3574 | 16.51 | 67,188 | 7669 | 5547 |
| 2 stars | 1152 | 3873 | 18.39 | 81,120 | 9152 | 6840 |
| 3 stars | 1280 | 4014 | 18.54 | 84,997 | 9691 | 6984 |
| 4 stars | 1309 | 3621 | 17.43 | 72,305 | 8671 | 6203 |
| 5 stars | 1336 | 2869 | 14.03 | 46,282 | 6123 | 4436 |
| Review Text | Product Category | Number of Stars | Label |
|---|---|---|---|
| Asa cum m-am asteptat…face treaba pt birou As expected…it does the job for the office. | Monitor | 5 | Positive |
| Funcționează bine, mulțumit deocamdată de el It works well, satisfied with it for now. | Smartwatch | 5 | Positive |
| E un router ok It’s an ok router | Router | 4 | Positive |
| NU E ULTRA SUPER CALITATE DAR E BUN It’s not ultra-super quality, but it’s good | Speakers | 4 | Positive |
| Este doar bună pentru jocuri şi desene, pozele ies ca pe telefoanele mai vechi It’s only good for games and drawings; the photos come out like on older phones | Tablet | 3 | Neutral |
| Sunt acceptabile la redarea sunetului, dar la convorbiri nu prea se aude microfonul They are acceptable for sound playback, but the microphone is not very audible during calls | Headphones | 3 | Neutral |
| Mi s-a blocat de nenumărate ori și pierdea des semnalul It has frozen numerous times, and it often lost the signal | Smartphone | 2 | Negative |
| Nu ține deloc bateria, după nici 12 ore de la încărcarea completă (100%)s-a descărcat complet The battery doesn’t hold at all; after not even 12 h from a full (100%) charge, it completely discharged | Fitness bracelet | 1 | Negative |
| Cel mai silențios mouse, dar conexiune prin infraroșu mediocră, se întrerupe non-stop The quietest mouse, but with a mediocre infrared connection, t keeps disconnecting non-stop | Mouse | 1 | Negative |
| Procesor slab rău Terribly weak processor | Laptop | 1 | Negative |
| Product Category | Number of Reviews | Number of Sentences | Average Sentence Length | Total Number of Tokens | Number of Unique Tokens | Number of Unique Lemmas |
|---|---|---|---|---|---|---|
| Headphones | 409 | 984 | 16.54 | 18,480 | 2990 | 2205 |
| Fitness bracelets | 599 | 1578 | 16.45 | 29,500 | 4117 | 2967 |
| Keyboard | 899 | 2522 | 17.71 | 51,160 | 5856 | 4249 |
| Laptop | 404 | 1313 | 16.70 | 25,005 | 4070 | 3038 |
| Monitor | 419 | 971 | 15.98 | 17,852 | 3061 | 2328 |
| Mouse | 395 | 1062 | 16.69 | 20,383 | 3157 | 2298 |
| Router | 300 | 853 | 17.25 | 16,785 | 2919 | 2248 |
| Smartphone | 897 | 2348 | 17.16 | 45,906 | 6432 | 4882 |
| Smartwatch | 577 | 1469 | 17.38 | 29,213 | 4285 | 3109 |
| Speakers | 455 | 1429 | 18.59 | 30,240 | 4325 | 3163 |
| Tablet | 680 | 1753 | 15.59 | 31,445 | 4440 | 3291 |
| Vacuum cleaner | 400 | 1669 | 18.88 | 35,923 | 4842 | 3418 |
| TOTAL | 6434 | 17,951 | 17.08 | 351,892 | 21,430 | 15,311 |
| SVM | RF | LR | VP | |||||
|---|---|---|---|---|---|---|---|---|
| Performance Indicator | Mean | 95% CI | Mean | 95% CI | Mean | 95% CI | Mean | 95% CI |
| Accuracy | 0.878 | 0.001 | 0.880 | 0.001 | 0.893 | 0.001 | 0.891 | 0.001 |
| Precision PPV | 0.924 | 0.001 | 0.903 | 0.002 | 0.911 | 0.001 | 0.897 | 0.002 |
| Precision NPV | 0.838 | 0.001 | 0.858 | 0.001 | 0.876 | 0.001 | 0.885 | 0.003 |
| Average precision | 0.881 | 0.001 | 0.881 | 0.001 | 0.893 | 0.001 | 0.891 | 0.002 |
| Sensitivity/Recall—TPR | 0.830 | 0.001 | 0.859 | 0.001 | 0.878 | 0.001 | 0.890 | 0.003 |
| Specificity—TNR | 0.928 | 0.001 | 0.902 | 0.002 | 0.909 | 0.001 | 0.892 | 0.003 |
| AUC | 0.879 | 0.001 | 0.881 | 0.001 | 0.894 | 0.001 | 0.891 | 0.001 |
| F1-score Positive Class | 0.875 | 0.001 | 0.881 | 0.001 | 0.894 | 0.001 | 0.893 | 0.001 |
| F1-score Negative Class | 0.881 | 0.001 | 0.880 | 0.001 | 0.892 | 0.001 | 0.889 | 0.001 |
| Weighted F1-score | 0.878 | 0.001 | 0.880 | 0.001 | 0.893 | 0.001 | 0.891 | 0.001 |
| SVM | RF | LR | MLP | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Performance Indicator | Mean | 95% CI | Mean | 95% CI | Mean | 95% CI | Mean | 95% CI | |
| Accuracy | Avg | 0.660 | 0.001 | 0.660 | 0.005 | 0.689 | 0.001 | 0.675 | 0.002 |
| Precision | Class 1 Star | 0.599 | 0.001 | 0.644 | 0.002 | 0.656 | 0.002 | 0.660 | 0.014 |
| Class 2 Stars | 0.568 | 0.002 | 0.579 | 0.004 | 0.602 | 0.003 | 0.604 | 0.016 | |
| Class 3 Stars | 0.733 | 0.003 | 0.676 | 0.005 | 0.727 | 0.003 | 0.709 | 0.023 | |
| Class 4 Stars | 0.617 | 0.004 | 0.622 | 0.004 | 0.650 | 0.002 | 0.628 | 0.011 | |
| Class 5 Stars | 0.858 | 0.001 | 0.816 | 0.004 | 0.825 | 0.002 | 0.788 | 0.008 | |
| Recall | Class 1 Star | 0.712 | 0.002 | 0.698 | 0.003 | 0.714 | 0.002 | 0.708 | 0.016 |
| Class 2 Stars | 0.607 | 0.003 | 0.588 | 0.005 | 0.606 | 0.004 | 0.593 | 0.019 | |
| Class 3 Stars | 0.669 | 0.002 | 0.667 | 0.003 | 0.698 | 0.002 | 0.679 | 0.017 | |
| Class 4 Stars | 0.680 | 0.003 | 0.671 | 0.003 | 0.696 | 0.003 | 0.657 | 0.015 | |
| Class 5 Stars | 0.626 | 0.002 | 0.681 | 0.003 | 0.720 | 0.002 | 0.728 | 0.007 | |
| F1 Score | Class 1 Star | 0.650 | 0.001 | 0.670 | 0.001 | 0.684 | 0.001 | 0.682 | 0.005 |
| Class 2 Stars | 0.587 | 0.002 | 0.583 | 0.004 | 0.604 | 0.003 | 0.597 | 0.005 | |
| Class 3 Stars | 0.700 | 0.001 | 0.671 | 0.004 | 0.712 | 0.002 | 0.693 | 0.004 | |
| Class 4 Stars | 0.647 | 0.003 | 0.646 | 0.003 | 0.672 | 0.003 | 0.642 | 0.004 | |
| Class 5 Stars | 0.724 | 0.001 | 0.743 | 0.003 | 0.769 | 0.002 | 0.757 | 0.004 | |
| Precision | Weighted Avg | 0.677 | 0.001 | 0.670 | 0.001 | 0.694 | 0.002 | 0.680 | 0.003 |
| Recall | Weighted Avg | 0.660 | 0.001 | 0.663 | 0.001 | 0.689 | 0.002 | 0.675 | 0.002 |
| F1-Score | Weighted Avg | 0.663 | 0.001 | 0.665 | 0.001 | 0.690 | 0.002 | 0.676 | 0.002 |
| LSTM | GRU | CNN | GAP | |||||
|---|---|---|---|---|---|---|---|---|
| Performance Indicator | Mean | 95% CI | Mean | 95% CI | Mean | 95% CI | Mean | 95% CI |
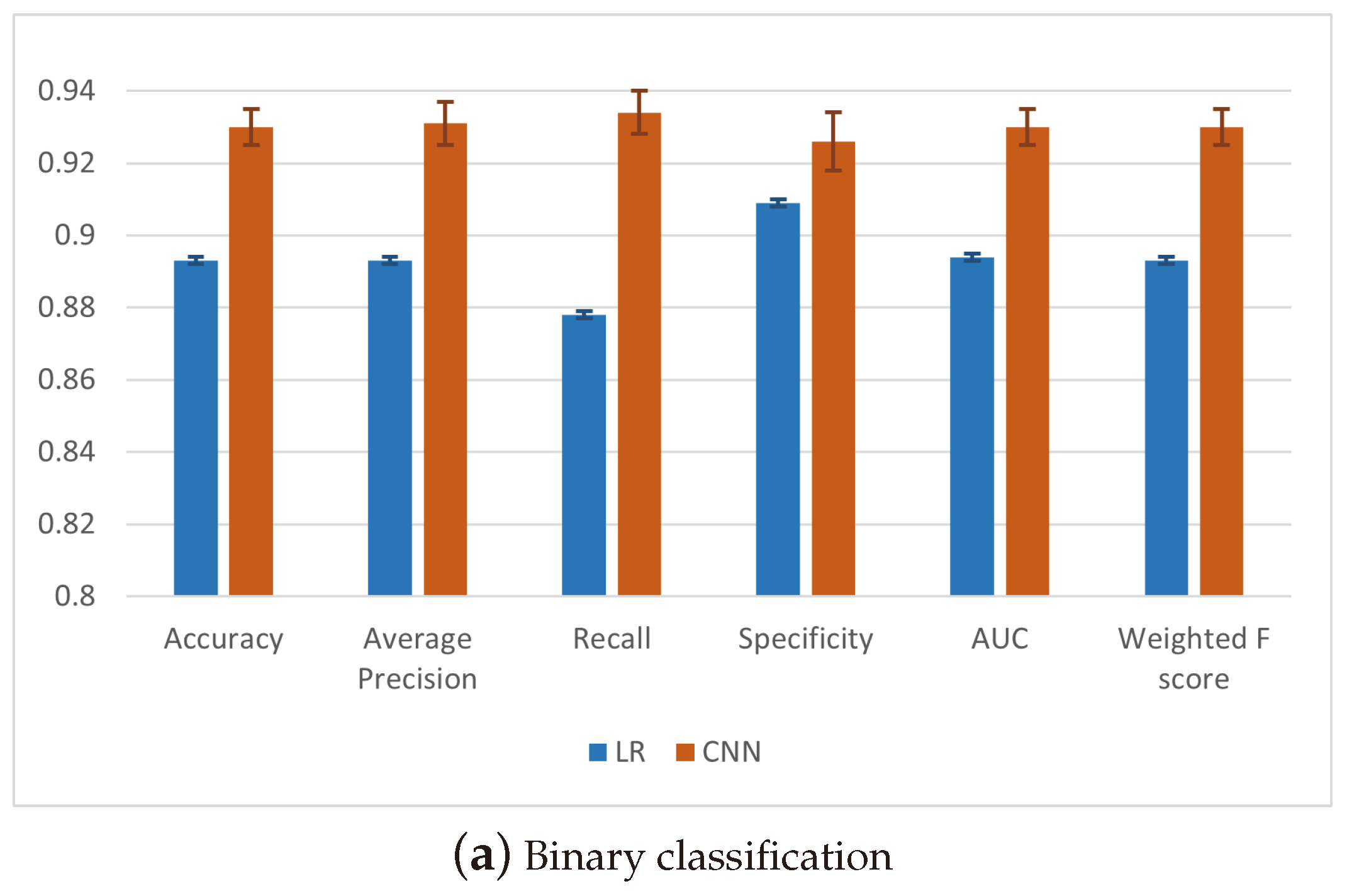
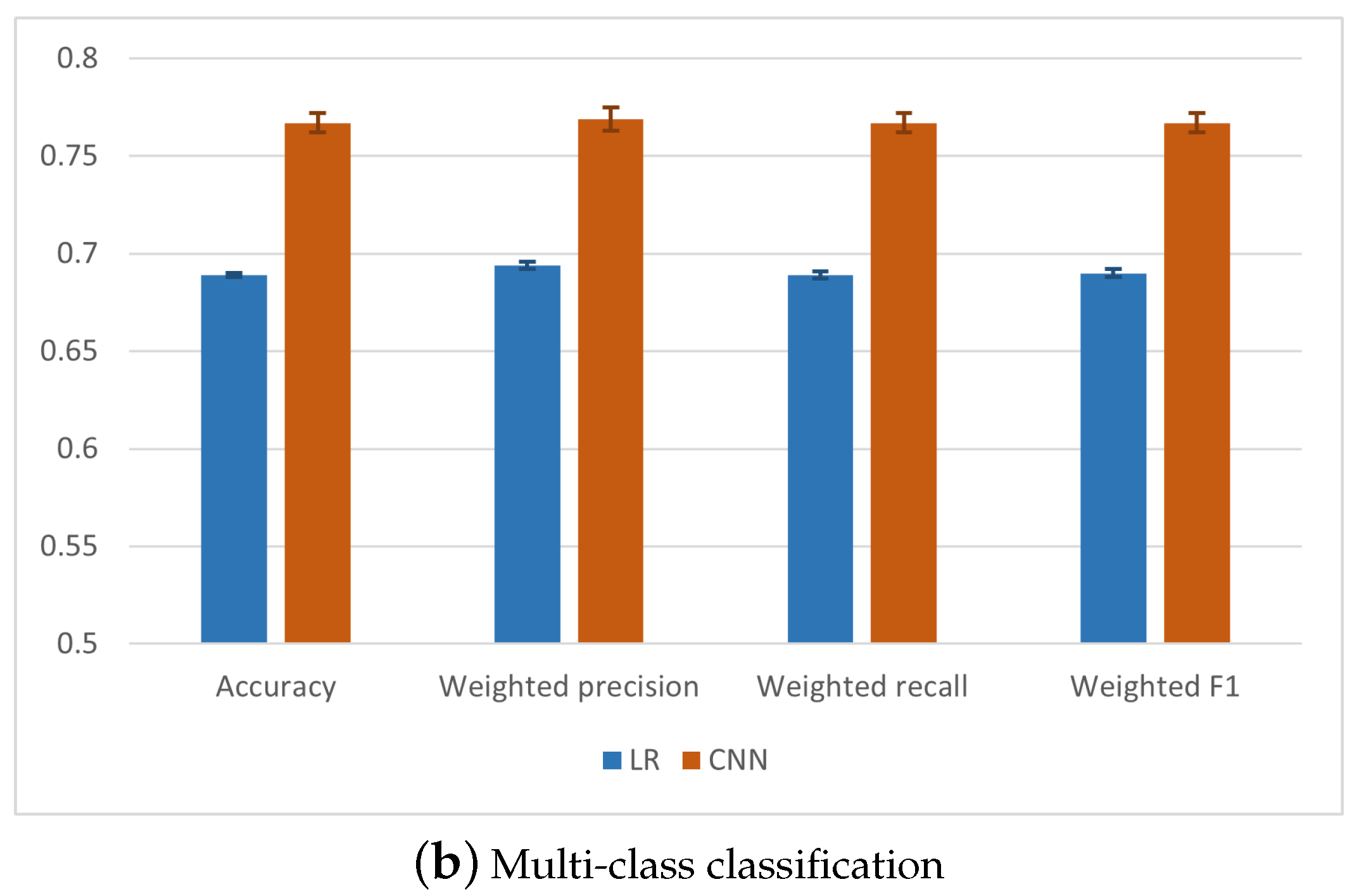
| Accuracy | 0.918 | 0.007 | 0.920 | 0.006 | 0.930 | 0.005 | 0.918 | 0.005 |
| Precision PPV | 0.924 | 0.014 | 0.925 | 0.012 | 0.930 | 0.007 | 0.929 | 0.010 |
| Precision NPV | 0.912 | 0.010 | 0.915 | 0.010 | 0.931 | 0.006 | 0.908 | 0.011 |
| Average precision | 0.918 | 0.012 | 0.920 | 0.011 | 0.931 | 0.006 | 0.918 | 0.011 |
| Sensitivity/Recall—TPR | 0.915 | 0.011 | 0.919 | 0.011 | 0.934 | 0.006 | 0.910 | 0.013 |
| Specificity—TNR | 0.920 | 0.017 | 0.921 | 0.014 | 0.926 | 0.008 | 0.926 | 0.012 |
| AUC | 0.918 | 0.007 | 0.920 | 0.006 | 0.930 | 0.005 | 0.918 | 0.005 |
| AUPRC | 0.920 | 0.006 | 0.922 | 0.006 | 0.932 | 0.004 | 0.920 | 0.005 |
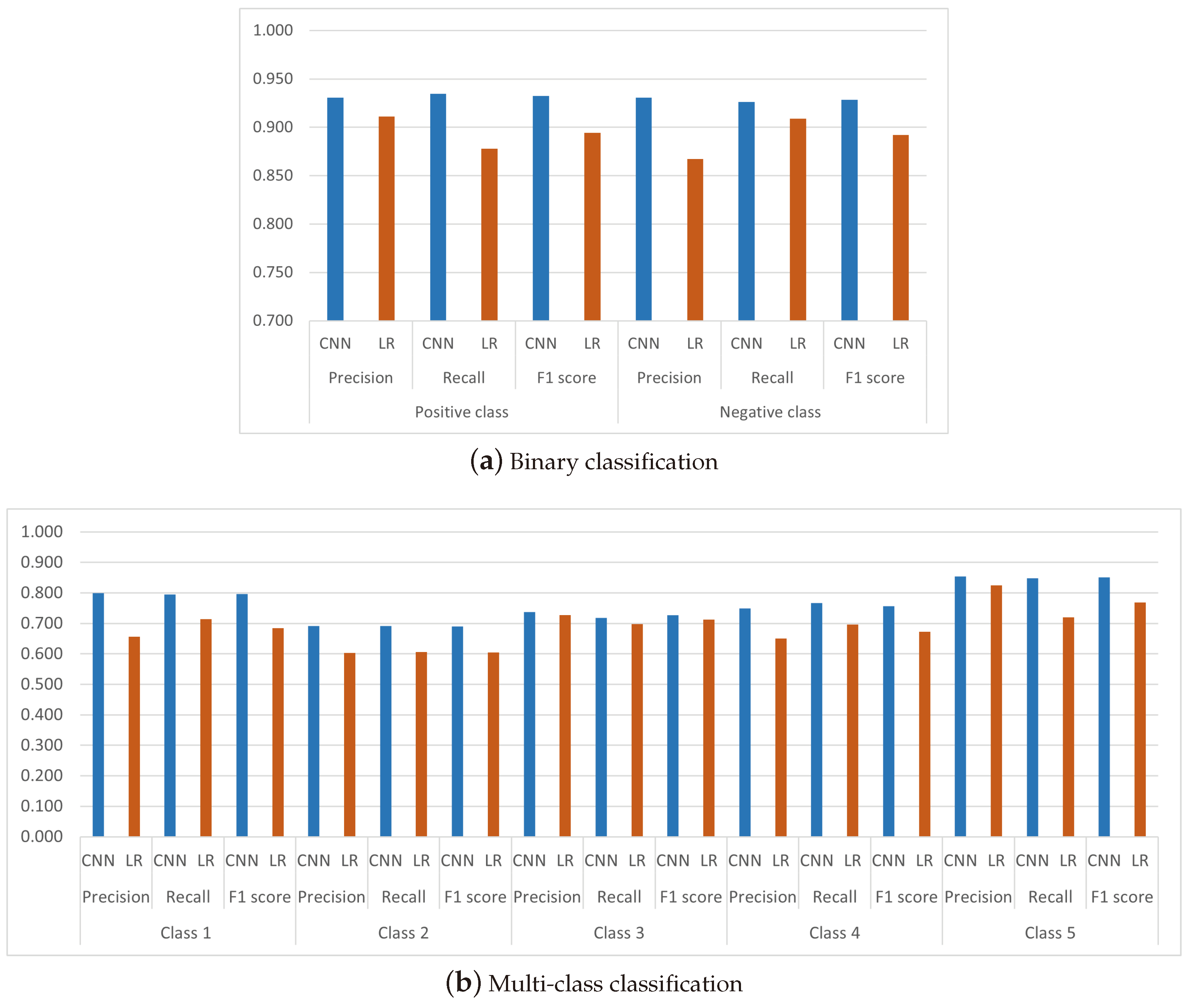
| F1-score Positive Class | 0.919 | 0.006 | 0.921 | 0.006 | 0.932 | 0.004 | 0.919 | 0.005 |
| F1-score Negative Class | 0.916 | 0.007 | 0.918 | 0.007 | 0.928 | 0.005 | 0.917 | 0.005 |
| Average F1-score | 0.918 | 0.007 | 0.920 | 0.006 | 0.930 | 0.005 | 0.918 | 0.005 |
| Weighted F1-score | 0.918 | 0.007 | 0.920 | 0.006 | 0.930 | 0.005 | 0.918 | 0.005 |
| GAP | LSTM | GRU | CNN | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Performance Indicator | Mean | 95% CI | Mean | 95% CI | Mean | 95% CI | Mean | 95% CI | |
| Accuracy | Avg | 0.652 | 0.013 | 0.722 | 0.011 | 0.739 | 0.009 | 0.767 | 0.005 |
| Precision | Class 1 Star | 0.699 | 0.036 | 0.738 | 0.030 | 0.732 | 0.025 | 0.800 | 0.026 |
| Class 2 Stars | 0.527 | 0.039 | 0.626 | 0.027 | 0.645 | 0.026 | 0.692 | 0.023 | |
| Class 3 Stars | 0.624 | 0.039 | 0.698 | 0.033 | 0.726 | 0.022 | 0.738 | 0.021 | |
| Class 4 Stars | 0.637 | 0.026 | 0.727 | 0.024 | 0.751 | 0.022 | 0.750 | 0.019 | |
| Class 5 Stars | 0.805 | 0.040 | 0.833 | 0.022 | 0.846 | 0.022 | 0.854 | 0.014 | |
| Recall | Class 1 Star | 0.714 | 0.040 | 0.713 | 0.042 | 0.722 | 0.031 | 0.796 | 0.023 |
| Class 2 Stars | 0.557 | 0.064 | 0.646 | 0.039 | 0.665 | 0.030 | 0.691 | 0.029 | |
| Class 3 Stars | 0.607 | 0.041 | 0.712 | 0.028 | 0.726 | 0.020 | 0.718 | 0.023 | |
| Class 4 Stars | 0.605 | 0.047 | 0.713 | 0.031 | 0.750 | 0.023 | 0.767 | 0.019 | |
| Class 5 Stars | 0.758 | 0.043 | 0.815 | 0.026 | 0.825 | 0.023 | 0.848 | 0.017 | |
| F1 Score | Class 1 Star | 0.702 | 0.018 | 0.721 | 0.021 | 0.725 | 0.017 | 0.796 | 0.009 |
| Class 2 Stars | 0.533 | 0.032 | 0.633 | 0.022 | 0.653 | 0.021 | 0.690 | 0.012 | |
| Class 3 Stars | 0.610 | 0.021 | 0.702 | 0.012 | 0.725 | 0.010 | 0.726 | 0.008 | |
| Class 4 Stars | 0.617 | 0.025 | 0.718 | 0.015 | 0.750 | 0.014 | 0.757 | 0.009 | |
| Class 5 Stars | 0.776 | 0.016 | 0.822 | 0.012 | 0.834 | 0.014 | 0.851 | 0.009 | |
| Precision | Weighted Avg | 0.663 | 0.014 | 0.727 | 0.010 | 0.743 | 0.009 | 0.769 | 0.006 |
| Recall | Weighted Avg | 0.652 | 0.013 | 0.722 | 0.011 | 0.739 | 0.009 | 0.767 | 0.005 |
| F1-Score | Weighted Avg | 0.652 | 0.014 | 0.722 | 0.011 | 0.740 | 0.009 | 0.767 | 0.005 |
| SVM | LR | RF | NB | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Performance Indicator | Stopwords | Mean | 95% CI | Mean | 95% CI | Mean | 95% CI | Mean | 95% CI | |
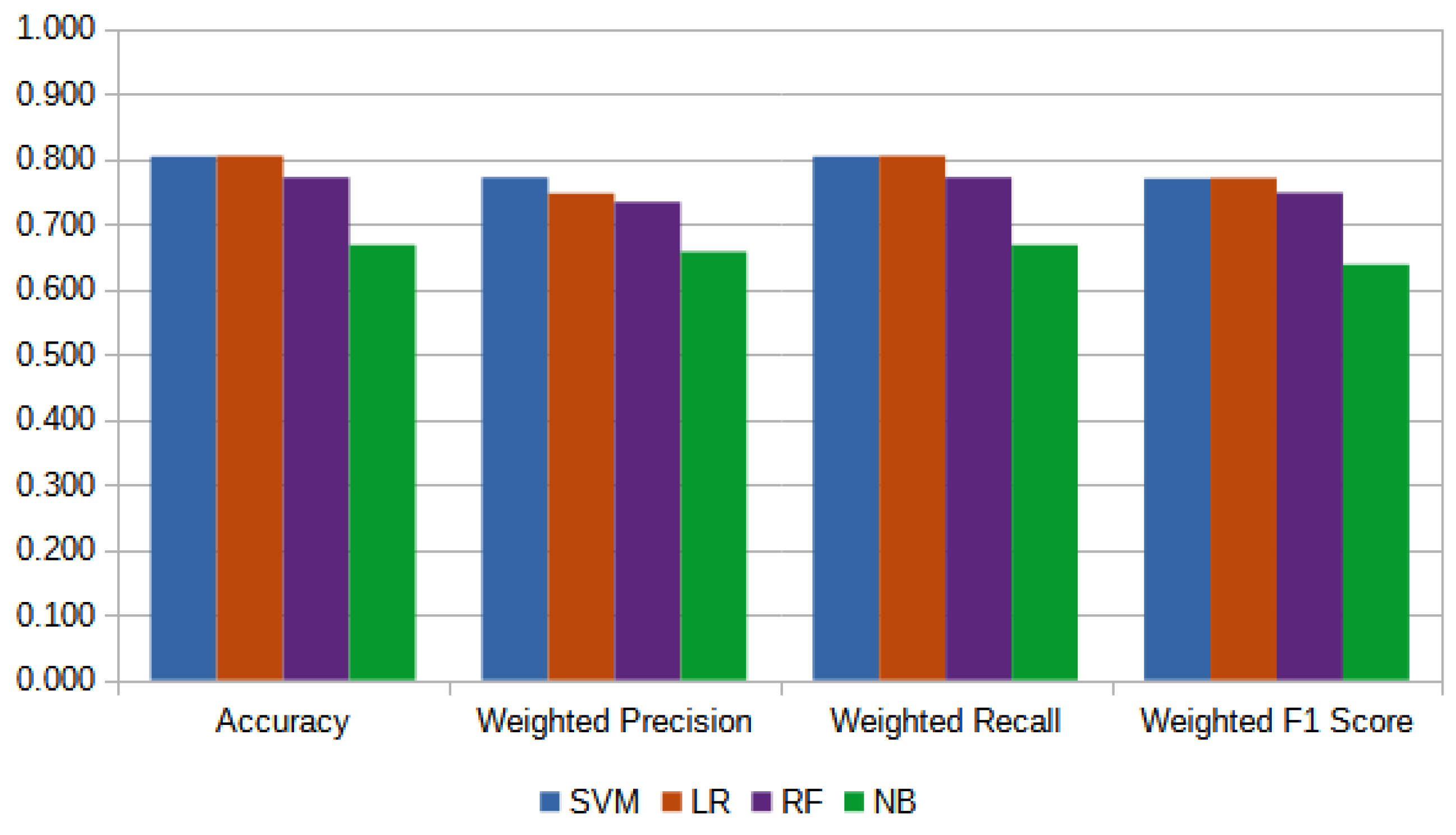
| Accuracy | Avg | Without | 0.774 | 0.012 | 0.778 | 0.012 | 0.751 | 0.017 | 0.663 | 0.015 |
| With | 0.804 | 0.012 | 0.805 | 0.012 | 0.771 | 0.012 | 0.668 | 0.013 | ||
| Precision | Positive | Without | 0.817 | 0.018 | 0.806 | 0.016 | 0.776 | 0.025 | 0.643 | 0.017 |
| With | 0.815 | 0.016 | 0.814 | 0.017 | 0.800 | 0.018 | 0.662 | 0.017 | ||
| Neutral | Without | 0.300 | 0.287 | 0.000 | 0.000 | 0.265 | 0.172 | 0.190 | 0.082 | |
| With | 0.400 | 0.307 | 0.100 | 0.177 | 0.174 | 0.134 | 0.192 | 0.076 | ||
| Negative | Without | 0.722 | 0.022 | 0.741 | 0.025 | 0.753 | 0.030 | 0.782 | 0.030 | |
| With | 0.787 | 0.021 | 0.794 | 0.019 | 0.763 | 0.021 | 0.745 | 0.023 | ||
| Recall | Positive | Without | 0.837 | 0.021 | 0.853 | 0.014 | 0.854 | 0.026 | 0.938 | 0.010 |
| With | 0.899 | 0.014 | 0.907 | 0.013 | 0.868 | 0.016 | 0.905 | 0.013 | ||
| Neutral | Without | 0.008 | 0.008 | 0.000 | 0.000 | 0.056 | 0.035 | 0.045 | 0.022 | |
| With | 0.012 | 0.009 | 0.004 | 0.006 | 0.039 | 0.021 | 0.064 | 0.026 | ||
| Negative | Without | 0.853 | 0.021 | 0.842 | 0.020 | 0.759 | 0.040 | 0.421 | 0.026 | |
| With | 0.842 | 0.018 | 0.836 | 0.019 | 0.796 | 0.019 | 0.475 | 0.022 | ||
| F1-Score | Positive | Without | 0.827 | 0.014 | 0.828 | 0.014 | 0.812 | 0.014 | 0.763 | 0.013 |
| With | 0.855 | 0.011 | 0.858 | 0.012 | 0.832 | 0.011 | 0.764 | 0.011 | ||
| Neutral | Without | 0.017 | 0.016 | 0.000 | 0.000 | 0.080 | 0.045 | 0.070 | 0.033 | |
| With | 0.022 | 0.017 | 0.006 | 0.011 | 0.061 | 0.031 | 0.093 | 0.036 | ||
| Negative | Without | 0.781 | 0.013 | 0.788 | 0.016 | 0.753 | 0.017 | 0.547 | 0.026 | |
| With | 0.813 | 0.015 | 0.814 | 0.014 | 0.778 | 0.013 | 0.579 | 0.019 | ||
| Precision | Weighted Avg | Without | 0.741 | 0.027 | 0.715 | 0.016 | 0.725 | 0.022 | 0.661 | 0.017 |
| With | 0.772 | 0.026 | 0.747 | 0.022 | 0.734 | 0.019 | 0.657 | 0.015 | ||
| Recall | Weighted Avg | Without | 0.774 | 0.012 | 0.778 | 0.012 | 0.751 | 0.017 | 0.663 | 0.015 |
| With | 0.804 | 0.012 | 0.805 | 0.012 | 0.771 | 0.012 | 0.668 | 0.013 | ||
| F1-Score | Weighted Avg | Without | 0.743 | 0.013 | 0.745 | 0.014 | 0.728 | 0.018 | 0.621 | 0.017 |
| With | 0.770 | 0.014 | 0.771 | 0.013 | 0.748 | 0.012 | 0.637 | 0.016 | ||
| SVM | LR | RF | NB | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Performance Indicator | Stopwords | Mean | 95% CI | Mean | 95% CI | Mean | 95% CI | Mean | 95% CI | |
| Accuracy | Avg | Without | 0.663 | 0.014 | 0.660 | 0.010 | 0.699 | 0.012 | 0.609 | 0.013 |
| With | 0.724 | 0.013 | 0.713 | 0.012 | 0.728 | 0.011 | 0.669 | 0.012 | ||
| Precision | Positive | Without | 0.781 | 0.018 | 0.763 | 0.020 | 0.738 | 0.020 | 0.683 | 0.017 |
| With | 0.745 | 0.018 | 0.725 | 0.013 | 0.749 | 0.013 | 0.698 | 0.014 | ||
| Neutral | Without | 0.000 | 0.000 | 0.000 | 0.000 | 0.229 | 0.116 | 0.000 | 0.000 | |
| With | 0.000 | 0.000 | 0.000 | 0.000 | 0.271 | 0.171 | 0.017 | 0.052 | ||
| Negative | Without | 0.574 | 0.019 | 0.577 | 0.016 | 0.662 | 0.019 | 0.537 | 0.020 | |
| With | 0.698 | 0.024 | 0.694 | 0.024 | 0.708 | 0.022 | 0.628 | 0.025 | ||
| Recall | Positive | Without | 0.639 | 0.017 | 0.641 | 0.019 | 0.781 | 0.017 | 0.632 | 0.018 |
| With | 0.821 | 0.019 | 0.833 | 0.017 | 0.829 | 0.017 | 0.780 | 0.019 | ||
| Neutral | Without | 0.000 | 0.000 | 0.000 | 0.000 | 0.034 | 0.018 | 0.000 | 0.000 | |
| With | 0.000 | 0.000 | 0.000 | 0.000 | 0.024 | 0.013 | 0.001 | 0.004 | ||
| Negative | Without | 0.837 | 0.021 | 0.827 | 0.018 | 0.730 | 0.025 | 0.706 | 0.020 | |
| With | 0.749 | 0.024 | 0.701 | 0.020 | 0.743 | 0.020 | 0.659 | 0.020 | ||
| F1-Score | Positive | Without | 0.702 | 0.014 | 0.697 | 0.014 | 0.759 | 0.013 | 0.656 | 0.014 |
| With | 0.781 | 0.012 | 0.775 | 0.010 | 0.786 | 0.010 | 0.736 | 0.010 | ||
| Neutral | Without | 0.000 | 0.000 | 0.000 | 0.000 | 0.057 | 0.029 | 0.000 | 0.000 | |
| With | 0.000 | 0.000 | 0.000 | 0.000 | 0.045 | 0.025 | 0.002 | 0.006 | ||
| Negative | Without | 0.681 | 0.018 | 0.680 | 0.014 | 0.694 | 0.014 | 0.610 | 0.017 | |
| With | 0.722 | 0.016 | 0.697 | 0.016 | 0.724 | 0.014 | 0.642 | 0.016 | ||
| Precision | Weighted Avg | Without | 0.636 | 0.016 | 0.629 | 0.013 | 0.667 | 0.016 | 0.570 | 0.014 |
| With | 0.666 | 0.016 | 0.653 | 0.014 | 0.695 | 0.018 | 0.616 | 0.015 | ||
| Recall | Weighted Avg | Without | 0.663 | 0.014 | 0.660 | 0.010 | 0.699 | 0.012 | 0.609 | 0.013 |
| With | 0.724 | 0.013 | 0.713 | 0.012 | 0.728 | 0.011 | 0.669 | 0.012 | ||
| F1-Score | Weighted Avg | Without | 0.637 | 0.015 | 0.633 | 0.011 | 0.675 | 0.013 | 0.584 | 0.013 |
| With | 0.693 | 0.015 | 0.681 | 0.013 | 0.701 | 0.013 | 0.639 | 0.012 | ||
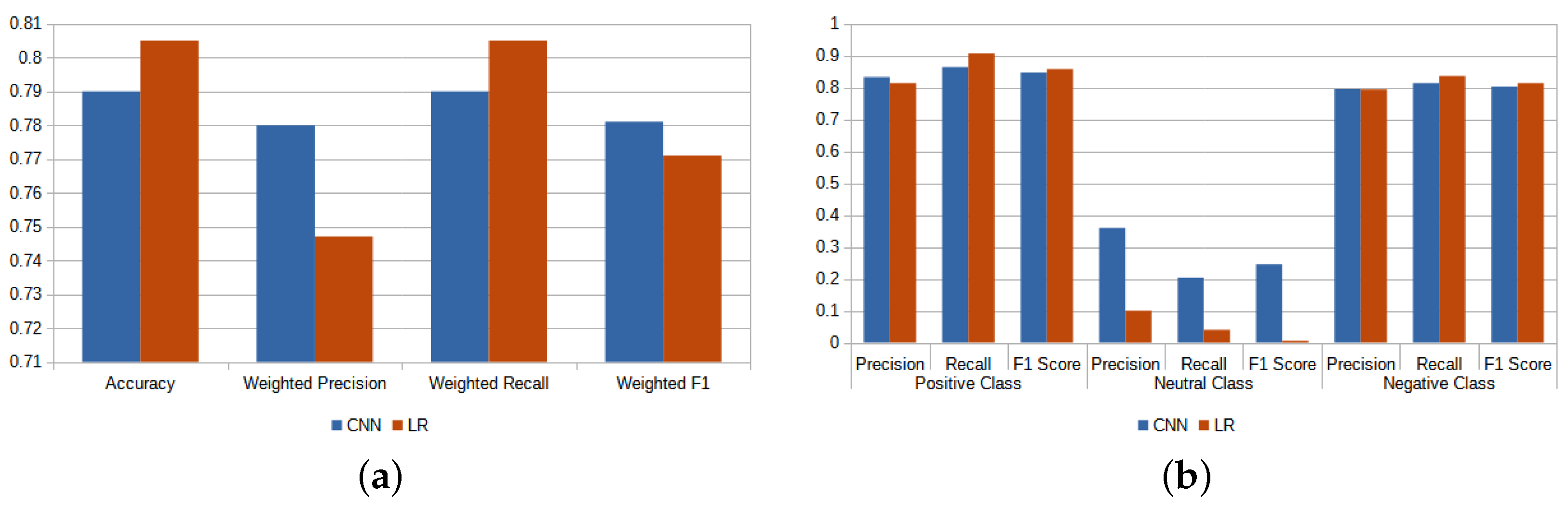
| CNN | |||
|---|---|---|---|
| Performance Indicators | Mean | 95% CI | |
| Accuracy | Avg | 0.790 | 0.011 |
| Precision | Negative | 0.795 | 0.025 |
| Neutral | 0.360 | 0.078 | |
| Positive | 0.833 | 0.017 | |
| Recall | Negative | 0.814 | 0.020 |
| Neutral | 0.203 | 0.050 | |
| Positive | 0.864 | 0.021 | |
| F1-Score | Negative | 0.803 | 0.010 |
| Neutral | 0.246 | 0.045 | |
| Positive | 0.847 | 0.007 | |
| Precision | Weighted Avg | 0.780 | 0.012 |
| Recall | Weighted Avg | 0.790 | 0.012 |
| F1-Score | Weighted Avg | 0.781 | 0.010 |
| SOM | K-Means | |||||||
|---|---|---|---|---|---|---|---|---|
| NPMI | LCH | NPMI | LCH | |||||
| Product Category | Mean | 95% CI | Mean | 95% CI | Mean | 95% CI | Mean | 95% CI |
| Fitness bracelets | −0.698 | 0.017 | 1.412 | 0.031 | −0.697 | 0.028 | 1.390 | 0.023 |
| Headphones | −0.627 | 0.025 | 1.484 | 0.036 | −0.603 | 0.023 | 1.427 | 0.029 |
| Keyboard | −0.660 | 0.024 | 1.421 | 0.022 | −0.666 | 0.023 | 1.432 | 0.024 |
| Laptop | −0.648 | 0.013 | 1.384 | 0.030 | −0.685 | 0.017 | 1.385 | 0.025 |
| Monitor | −0.596 | 0.025 | 1.364 | 0.016 | −0.587 | 0.022 | 1.386 | 0.022 |
| Mouse | −0.636 | 0.011 | 1.626 | 0.043 | −0.654 | 0.019 | 1.526 | 0.026 |
| Router | −0.616 | 0.027 | 1.609 | 0.027 | −0.736 | 0.019 | 1.497 | 0.032 |
| Smartphone | −0.700 | 0.016 | 1.406 | 0.034 | −0.732 | 0.025 | 1.351 | 0.021 |
| Smartwatch | −0.687 | 0.016 | 1.352 | 0.024 | −0.687 | 0.012 | 1.395 | 0.024 |
| Speakers | −0.632 | 0.019 | 1.487 | 0.016 | −0.649 | 0.013 | 1.452 | 0.025 |
| Tablet | −0.735 | 0.013 | 1.352 | 0.024 | −0.753 | 0.017 | 1.347 | 0.031 |
| Vacuum cleaner | −0.604 | 0.011 | 1.421 | 0.022 | −0.642 | 0.016 | 1.448 | 0.019 |
| Terms | Assigned Label | NPMI | LCH | |
|---|---|---|---|---|
| perioadă, timp, pană, problemă, utilizare, inceput, an, lună, folosire period, time, breakdown, problem, usage, start, year, month | Durability | −0.481 | 1.805 | |
| baterie, saptamană, saptaman, figură, oră battery, week, issue, hour | Battery life | −0.445 | 1.595 | |
| așteptare, stea, ron, pret, ban, raport, leu expectation, star, Romanian leu (RON), price, cent/money, ratio | Price | −0.516 | 0.890 | |
| mufă, wireless, pachet, adaptor, laptop, receiver, cutie, usb socket, wireless, package, adapter, laptop, receiver, box, USB | Connectivity | −0.543 | 1.708 | |
| medie, design, slab, calitate, pro, ok, rest, aspect, dorit, material average, design, poor, quality, pro, ok, otherwise, wanted, material | Build quality/ Design | −0.564 | 1.608 | |
| foto, imagine, rezoluție, hd, display, ecran, caracteristică photo, image, resolution, HD (High Definition), display, screen, characteristic | Display | −0.635 | 1.385 | |
| calculator, win, sită, desktop, stick, windows, ubunt computer, win, site, desktop, stick, Windows, Ubuntu | Operating system | −0.407 | 1.779 | |
| modul, proces, driver, instalar, bios, drive, boot, parolă module, process, driver, installation, BIOS, drive, boot, password | Software components | −0.632 | 1.618 |
| Review Text | Durability/ Reliability | Battery Life | Price | Connectivity | Build Quality/ Design | Display | Operating System | Software Components | |
|---|---|---|---|---|---|---|---|---|---|
| Un laptop de buget se poate folosii pentru varsnici sau copii. Pentru banii ceruti este un produs foarte bun. A budget laptop can be used for seniors or children. For the money asked, it’s a very good product. | 0.004 | 0 | 0.792 | 0.001 | 0.203 | 0 | 0 | 0 | |
| Bun ptr bani astia Good for this money | 0.015 | 0.007 | 0.497 | 0.003 | 0.470 | 0.006 | 0.002 | 0 | |
| Instalarea Windows-ului la laptopurile HP cu procesoare Intel de generatie 11 sau 12 necesita drivere speciale pentru fiecare model in parte, altfel masina nu vede hardul. Este un bag de fabricatie. Luati-le mai bine direct pe cele cu Windows-ul preinstalat. Installing Windows on HP laptops with 11th or 12th generation Intel processors requires special drivers for each model; otherwise, the system doesn’t recognize the hard drive. It’s a manufacturing glitch. It’s better to get the ones with pre-installed Windows. | 0 | 0 | 0 | 0 | 0 | 0 | 0.384 | 0.616 | |
| Nu încarcă bateria. Nu recomand decât dacă va doriți un laptop fix, gen PC It doesn’t charge the battery. I only recommend it if you want a desktop-like laptop. | 0.286 | 0.100 | 0.011 | 0.151 | 0.412 | 0.030 | 0.004 | 0 | |
| Fraților, nu vă sfătuiesc să vă zgârciți la câteva sute de lei pentru că acest produs este foarte slab! Îl am de o lună și deja s-a desfăcut toată rama din împrejurul display ului… Foarte slab… Brothers, I advise you not to skimp on a few hundred lei because this product is very weak! I’ve had it for a month, and the frame around the display has already come apart…Very poor… | 0.090 | 0.001 | 0.210 | 0 | 0.695 | 0.003 | 0 | 0 | |
| Nemulțumit. Îl voi returna cât de curând. Se tot actualizează, ba se blochează. Are Windows-ul 10 instalat. Păcat de firma hp și de HDD de 1T. Unsatisfied. I will return it as soon as possible. It keeps updating, and it even freezes. It has Windows 10 installed. It’s a shame for the HP brand and the 1TB HDD. | 0.002 | 0.001 | 0.007 | 0.007 | 0.002 | 0.014 | 0.502 | 0.466 | |
| Dupa a 3 zi nu s-a mai aprins. After 3 days, it didn’t turn on anymore | 0.220 | 0.198 | 0.046 | 0.080 | 0.220 | 0.089 | 0.067 | 0.081 | |
| L. Am luat pentru gaming și deși are rtx 3050 ti in jocuri cu ray tracing nu depășește 25–30 cadre pe full hd, 2k/4k nu mai discutam… I got it for gaming, and even though it has an RTX 3050 Ti, in games with ray tracing, it doesn’t go beyond 25–30 frames per second at full HD. Let’s not even discuss 2K/4K. | 0.001 | 0 | 0.003 | 0 | 0.003 | 0.991 | 0 | 0.002 | |
| Laptopul este performant dar display-ul are probleme… The laptop is performant, but the display has issues… | 0.438 | 0.026 | 0.019 | 0.119 | 0.039 | 0.243 | 0.070 | 0.046 |
| Classifier | Approach | Weighted Precision | Weighted Recall |
|---|---|---|---|
| SVM | LSI-based | 0.794 ± 0.003 | 0.789 ± 0.002 |
| SentiWordnet-based [28] | 0.795 | 0.795 | |
| Search engine-based [28] | 0.729 | 0.705 | |
| RF | LSI-based | 0.784 ± 0.005 | 0.783 ± 0.004 |
| SentiWordnet-based [28] | 0.735 | 0.732 | |
| Search engine-based [28] | 0.723 | 0.703 | |
| kNN | LSI-based | 0.704 ± 0.005 | 0.704 ± 0.005 |
| SentiWordnet-based [28] | 0.671 | 0.646 | |
| Search engine-based [28] | 0.645 | 0.625 | |
| NB | LSI-based | 0.746 ± 0.005 | 0.743 ± 0.005 |
| SentiWordnet-based [28] | 0.818 | 0.818 | |
| Search engine-based [28] | 0.763 | 0.744 | |
| CNN | Dense Embedding | 0.756 | 0.534 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Briciu, A.; Călin, A.-D.; Miholca, D.-L.; Moroz-Dubenco, C.; Petrașcu, V.; Dascălu, G. Machine-Learning-Based Approaches for Multi-Level Sentiment Analysis of Romanian Reviews. Mathematics 2024, 12, 456. https://doi.org/10.3390/math12030456
Briciu A, Călin A-D, Miholca D-L, Moroz-Dubenco C, Petrașcu V, Dascălu G. Machine-Learning-Based Approaches for Multi-Level Sentiment Analysis of Romanian Reviews. Mathematics. 2024; 12(3):456. https://doi.org/10.3390/math12030456
Chicago/Turabian StyleBriciu, Anamaria, Alina-Delia Călin, Diana-Lucia Miholca, Cristiana Moroz-Dubenco, Vladiela Petrașcu, and George Dascălu. 2024. "Machine-Learning-Based Approaches for Multi-Level Sentiment Analysis of Romanian Reviews" Mathematics 12, no. 3: 456. https://doi.org/10.3390/math12030456
APA StyleBriciu, A., Călin, A.-D., Miholca, D.-L., Moroz-Dubenco, C., Petrașcu, V., & Dascălu, G. (2024). Machine-Learning-Based Approaches for Multi-Level Sentiment Analysis of Romanian Reviews. Mathematics, 12(3), 456. https://doi.org/10.3390/math12030456