
Ridge-Type Pretest and Shrinkage Estimation Strategies in Spatial Error Models with an Application to a Real Data Example


Abstract
1. Introduction
2. Spatial Error Model
3. Maximum Likelihood Estimation
4. Materials and Methods: Developing Pretest and Shrinkage Ridge Estimation Strategies
4.1. Full and Reduced Model Ridge Estimators
4.2. Pretest, Shrinkage, and Positive Shrinkage Ridge Estimators
5. Asymptotic Analysis
- (A1)
- , as , where is the ith row of .
- (A2)
- Let . Then, , where is the positive definite matrix.
- (A3)
- LetThen, , where for .
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- E
- 7.
- , where is the cumulative distribution function of a non-central chi-square distribution with q degrees of freedom and the Δ non-centrality parameter.Where , , .
- 1.
- 2.
- 3.
- where
- 1.
- 2.
- 3.
6. Numerical Analysis
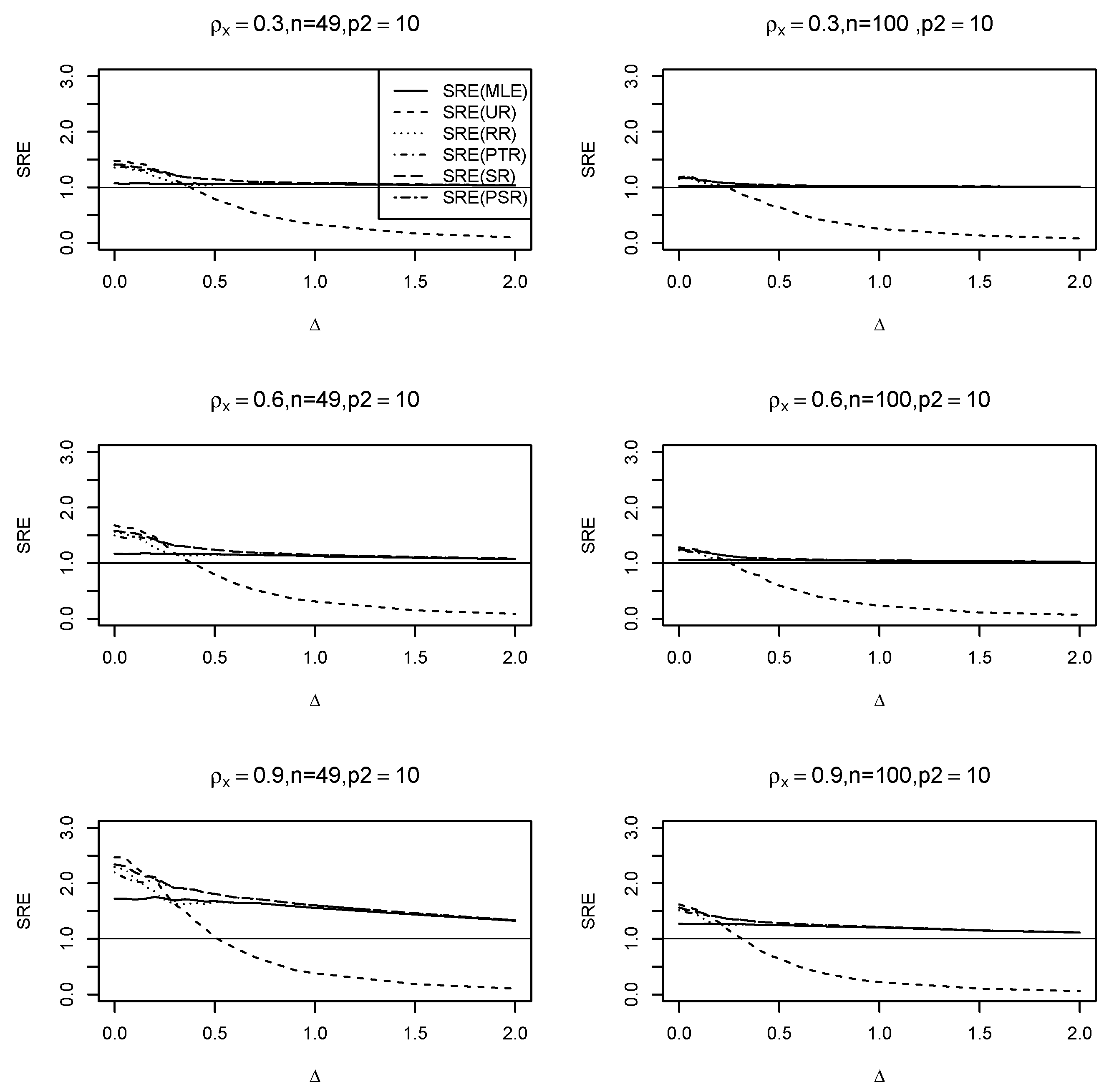
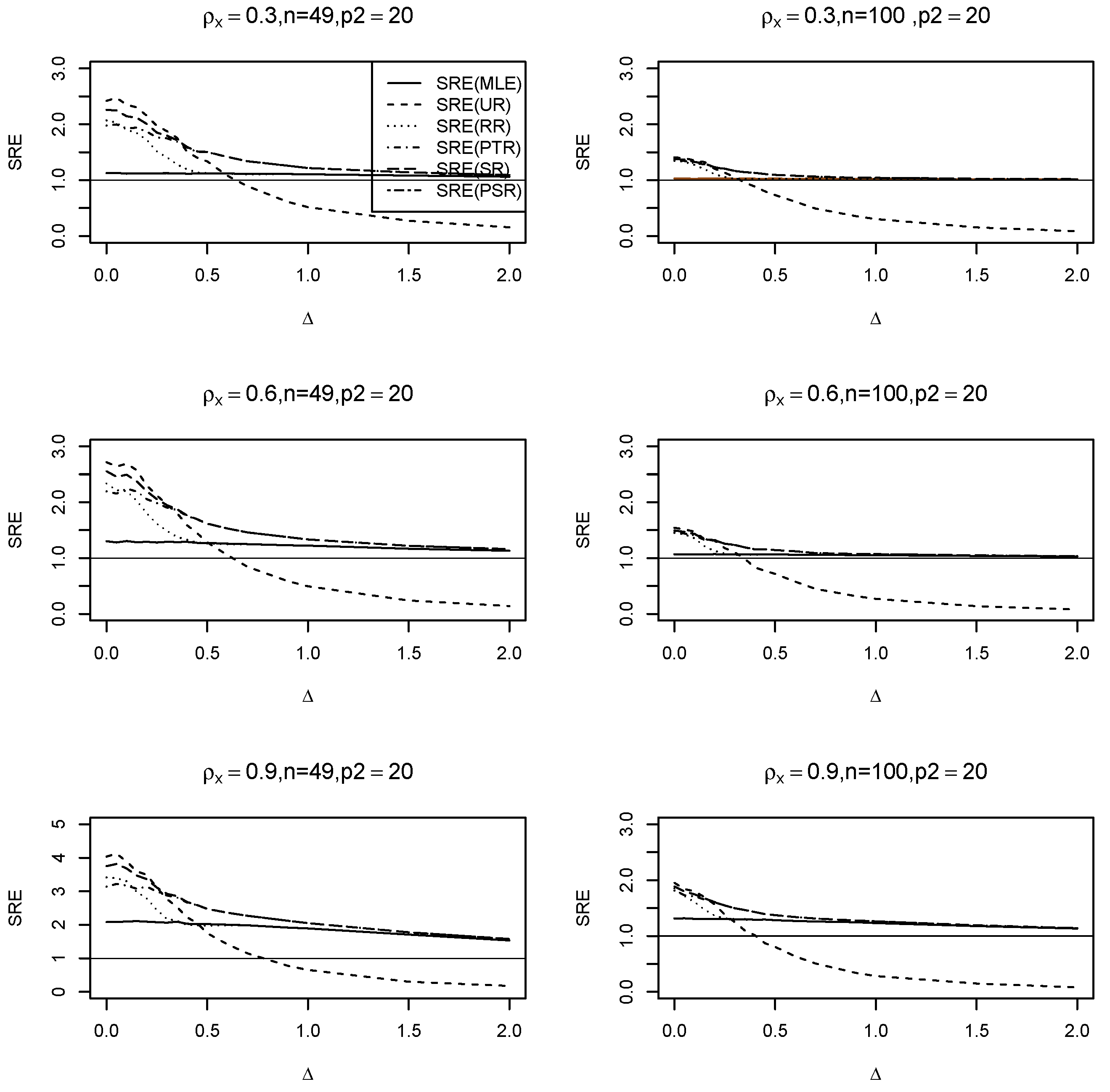
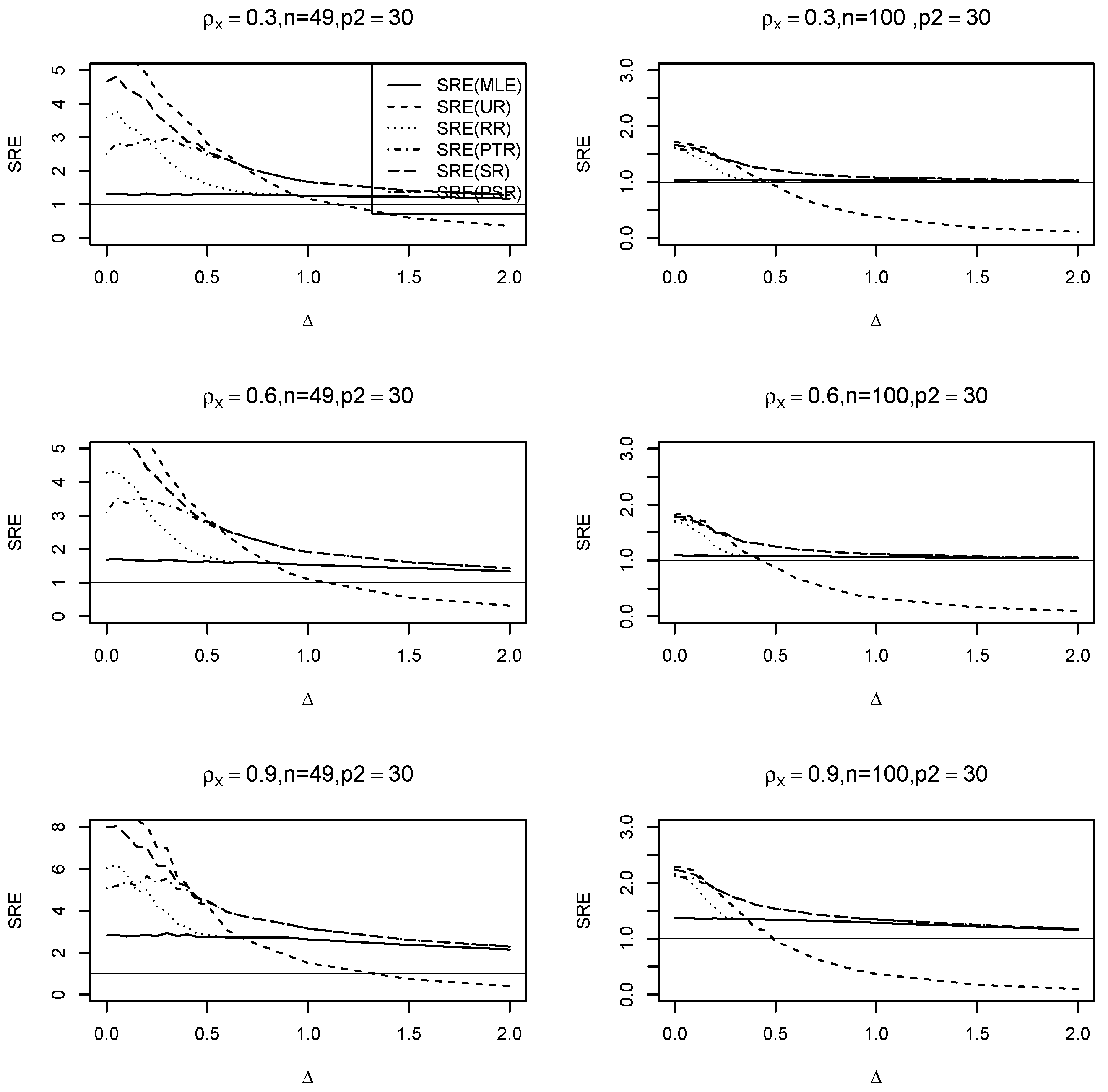
6.1. Simulation Experiments
- (i)
- Across all values, the ridge-type full model estimator consistently outperforms the traditional MLE estimator. Furthermore, as increases, so does its efficiency for fixed values of and . Additionally, when the multicollinearity among the explanatory variables in the design matrix becomes stronger, efficiency increases as expected.
- (ii)
- The ridge-type sub-model estimator outperforms all other estimators when . Since the null hypothesis is correct, it is expected. However, once begins to depart from the null space, the estimator’s SRE drops precipitously and approaches zero, making it less effective than the other estimators.
- (iii)
- The SRE values grow while holding other parameters constant, as the correlation coefficient increases among the explanatory factors.
- (iv)
- As the number of zero coefficients increase =, all SRE estimators also increase.
- (v)
- The ridge-type positive shrinkage estimator uniformly prevails over the competing estimators.
6.2. Data Example
- Fit the SE full and sub-models as they appear in Table 1 using the spautolm function and obtain the MLEs of , , the spatial dependence parameter , and the covariance matrix .
- As the columns of matrices and are not orthogonal, and the sample size is large, we follow [25] to estimate the tuning ridge parameters for the two estimators, and , which are, respectively, given by, and .
- Use the Cholesky decomposition method to express the matrix in a decomposed form as , where is an lower triangular matrix.
- Let , where ; we define the centered residual as , and then select with the replacement a sample of size to obtain .
- Calculate the bootstrapping response value as , and then use it to fit the full and sub-models and obtain bootstrapping estimated values of all estimators.
- Calculate the predicted value of the response variable using each estimator as follows: , where represents any of the estimators in the set .
- For the bootstrapping sample, we calculate the square root of the mean square prediction error (MSPE) aswhere B is the number of bootstrapping samples.
- Calculate the relative efficiency (RE) of any estimator with respect to the MLE as follows:where is any of the ridge-type proposed estimators. We apply the bootstrapping technique times.
- Create a data frame containing the columns of and .
- Divide the data frame into training and testing subsets. The testing data subset is known as the out-of-sample dataset.
- Using the training dataset, we follow the same procedure discussed in Section 3. That is, we divide the training data into two subsets, as , fit the full and sub-models, and obtain the array of estimators, which are denoted by , , , , , .
- Divide the testing data into two subsets, as , and calculate the predicted response values as follows:where is any of the estimators obtained in step (2).
- Compute the average of the MSPE using Equation (24), replacing with , and by .
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Proofs of the Main Results

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Shrinkage Estimator | Function | |
|---|---|---|
References
- Dai, X.; Li, E.; Tian, M. Quantile regression for varying coefficient spatial error models. Commun. Stat.—Theory Methods 2019, 50, 2382–2397. [Google Scholar] [CrossRef]
- Higazi, S.F.; Abdel-Hady, D.H.; Al-Oulfi, S.A. Application of spatial regression models to income poverty ratios in Middle Delta contiguous counties in Egypt. Pak. J. Stat. Oper. Res. 2013, 9, 93. [Google Scholar] [CrossRef]
- Piscitelli, A. Spatial Regression of Juvenile Delinquency: Revisiting Shaw and McKay. Int. J. Crim. Justice Sci. 2019, 14, 132–147. [Google Scholar]
- Liu, R.; Yu, C.; Liu, C.; Jiang, J.; Xu, J. Impacts of haze on housing prices: An empirical analysis based on data from Chengdu (China). Int. J. Environ. Res. Public Health 2018, 15, 1161. [Google Scholar] [CrossRef] [PubMed]
- Yildirim, V.; Mert, K.Y. Robust estimation approach for spatial error model. J. Stat. Comput. Simul. 2020, 90, 1618–1638. [Google Scholar] [CrossRef]
- Cressie, N. Statistics for Spatial Data; John Wiley & Sons: Nashville, TN, USA, 1993. [Google Scholar]
- Cressie, N.; Wikle, C.K. Statistics for Spatio-Temporal Data; Wiley-Blackwell: Chichester, UK, 2011. [Google Scholar]
- Haining, R. Spatial Data Analysis: Theory and Practice; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Al-Momani, M.; Riaz, M.; Saleh, M.F. Pretest and shrinkage estimation of the regression parameter vector of the marginal model with multinomial responses. Stat. Pap. 2022, 64, 2101–2117. [Google Scholar] [CrossRef]
- Lisawadi, S.; Ahmed, S.E.; Reangsephet, O. Post estimation and prediction strategies in negative binomial regression model. Int. J. Model. Simul. 2020, 41, 463–477. [Google Scholar] [CrossRef]
- Nkurunziza, S.; Al-Momani, M.; Lin, E.Y. Shrinkage and lasso strategies in high-dimensional heteroscedastic models. Commun. Stat.—Theory Methods 2016, 45, 4454–4470. [Google Scholar] [CrossRef]
- Hoerl, A.E.; Kennard, R.W. A new Liu-type estimator in linear regression model. Technometrics 1970, 12, 55–67. [Google Scholar] [CrossRef]
- Kejian, L. A new class of biased estimate in linear regression. Commun. Stat.—Theory Methods 1993, 22, 393–402. [Google Scholar] [CrossRef]
- Li, Y.; Yang, H. A new Liu-type estimator in linear regression model. Stat. Pap. 2010, 53, 427–437. [Google Scholar] [CrossRef]
- Arashi, M.; Kibria, B.M.G.; Norouzirad, M.; Nadarajah, S. Improved preliminary test and Stein-rule Liu estimators for the ill-conditioned elliptical linear regression model. J. Multivar. Anal. 2014, 126, 53–74. [Google Scholar] [CrossRef]
- Arashi, M.; Norouzirad, M.; Roozbeh, M.; Khan, N.M. A high-dimensional counterpart for the ridge estimator in multicollinear situations. Mathematics 2021, 9, 3057. [Google Scholar] [CrossRef]
- Al-Momani, M. Liu-type pretest and shrinkage estimation for the conditional autoregressive model. PLoS ONE 2023, 18, e0283339. [Google Scholar] [CrossRef] [PubMed]
- Mardia, K.V.; Marshall, R.J. Maximum likelihood estimation of models for residual covariance in spatial regression. Biometrika 1984, 71, 135–146. [Google Scholar] [CrossRef]
- Al-Momani, M.; Hussein, A.A.; Ahmed, S.E. Penalty and related estimation strategies in the spatial error model. Stat. Neerl. 2016, 71, 4–30. [Google Scholar] [CrossRef]
- Bivand, R. R packages for Analyzing Spatial Data: A comparative case study with Areal Data. Geogr. Anal. 2022, 54, 488–518. [Google Scholar] [CrossRef]
- Harrison, D.; Rubinfeld, D.L. Hedonic housing prices and the demand for Clean Air. J. Environ. Econ. Manag. 1978, 5, 81–102. [Google Scholar] [CrossRef]
- Gilley, O.W.; Pace, R.K. On the Harrison and Rubinfeld data. J. Environ. Econ. Manag. 1996, 31, 403–405. [Google Scholar] [CrossRef]
- Pace, R.K.; Gilley, O.W. Using the Spatial Configuration of the Data to Improve Estimation. J. Real Estate Financ. Econ. 1997, 14, 333–340. [Google Scholar] [CrossRef]
- Solow, A.R. Bootstrapping correlated data. J. Int. Assoc. Math. Geol. 1985, 17, 769–775. [Google Scholar] [CrossRef]
- Boonstra, P.S.; Mukherjee, B.; Taylor, J.M. A small-sample choice of the tuning parameter in ridge regression. Stat. Sin. 2015, 23, 1185. [Google Scholar] [CrossRef] [PubMed]
- Seber, G.A.F. Spatial Data Analysis: Theory and Practice. In A Matrix Handbook for Statisticians; John Wiley & Sons: Hoboken, NJ, USA, 2008. [Google Scholar]
- Lee, L. Best Spatial Two-Stage Least Squares Estimators for a Spatial Autoregressive Model with Autoregressive Disturbances. Econom. Rev. 2003, 22, 307–335. [Google Scholar] [CrossRef]
- Liu, S.F.; Yang, Z. Asymptotic Distribution and Finite Sample Bias Correction of QML Estimators for Spatial Error Dependence Model. Econometrics 2015, 3, 376–411. [Google Scholar] [CrossRef]
- Yuzbasi, B.; Arashi, M.; Ahmed, S.E. Shrinkage estimation strategies in generalized ridge regression models under low/high-dimension regime. Int. Stat. Rev. 2020, 88, 229–251. [Google Scholar] [CrossRef]
- Fu, W.; Knight, K. Asymptotics for lasso-type estimators. Ann. Stat. 2000, 28, 1356–1378. [Google Scholar] [CrossRef]
- Judge, G.G.; Bock, M.E. The Statistical Implications of Pre-Test and Stein-Rule Estimators in Econometrics; North-Holland Pub. Co.: Amsterdam, The Netherlands, 1978. [Google Scholar]

| Selection Criterion | Model |
|---|---|
| Full | log(CMEDV) = log(LSTAT) + I(RM^2) + TAX |
| + B + log(RAD) + CHAS + CRIM + PTRATIO | |
| + AGE + LAT + LON + log(RAD) + I(NOX^2) | |
| + log(DIS) + ZN + INDUS | |
| Sub-model | log(CMEDV) = log(LSTAT) + I(RM^2) + TAX + B + CRIM + PTRATIO |
| Coefficient | |||||
|---|---|---|---|---|---|
| Intercept | 3.8310 | 3.6490 | 3.8310 | 3.7882 | 3.7882 |
| log(LSTAT) | −0.2635 | −0.2872 | −0.2635 | −0.2691 | −0.2691 |
| I(RM^2) | 0.0081 | 0.0077 | 0.0081 | 0.0080 | 0.0080 |
| TAX | −0.0005 | −0.0003 | −0.0005 | −0.0005 | −0.0005 |
| B | 0.0006 | 0.0005 | 0.0006 | 0.0006 | 0.0006 |
| CRIM | −0.0053 | −0.0047 | −0.0053 | −0.0051 | −0.0051 |
| PTRATIO | −0.0168 | −0.0157 | −0.0168 | −0.0165 | −0.0165 |
| Estimator | |||||
|---|---|---|---|---|---|
| 1.0198 | 2.9468 | 2.8624 | 2.3070 | 2.3287 |
| Estimator | |||||
|---|---|---|---|---|---|
| 1.0447 | 5.1399 | 1.2816 | 1.5649 | 1.5649 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Al-Momani, M.; Arashi, M. Ridge-Type Pretest and Shrinkage Estimation Strategies in Spatial Error Models with an Application to a Real Data Example. Mathematics 2024, 12, 390. https://doi.org/10.3390/math12030390
Al-Momani M, Arashi M. Ridge-Type Pretest and Shrinkage Estimation Strategies in Spatial Error Models with an Application to a Real Data Example. Mathematics. 2024; 12(3):390. https://doi.org/10.3390/math12030390
Chicago/Turabian StyleAl-Momani, Marwan, and Mohammad Arashi. 2024. "Ridge-Type Pretest and Shrinkage Estimation Strategies in Spatial Error Models with an Application to a Real Data Example" Mathematics 12, no. 3: 390. https://doi.org/10.3390/math12030390
APA StyleAl-Momani, M., & Arashi, M. (2024). Ridge-Type Pretest and Shrinkage Estimation Strategies in Spatial Error Models with an Application to a Real Data Example. Mathematics, 12(3), 390. https://doi.org/10.3390/math12030390