

A Conceptual Framework for Quantifying the Robustness of a Regression-Based Causal Inference in Observational Study


{kind=link}
{kind=link}
Abstract
1. Introduction
2. Research Setting and Definitions
2.1. Research Setting
2.2. Definitions
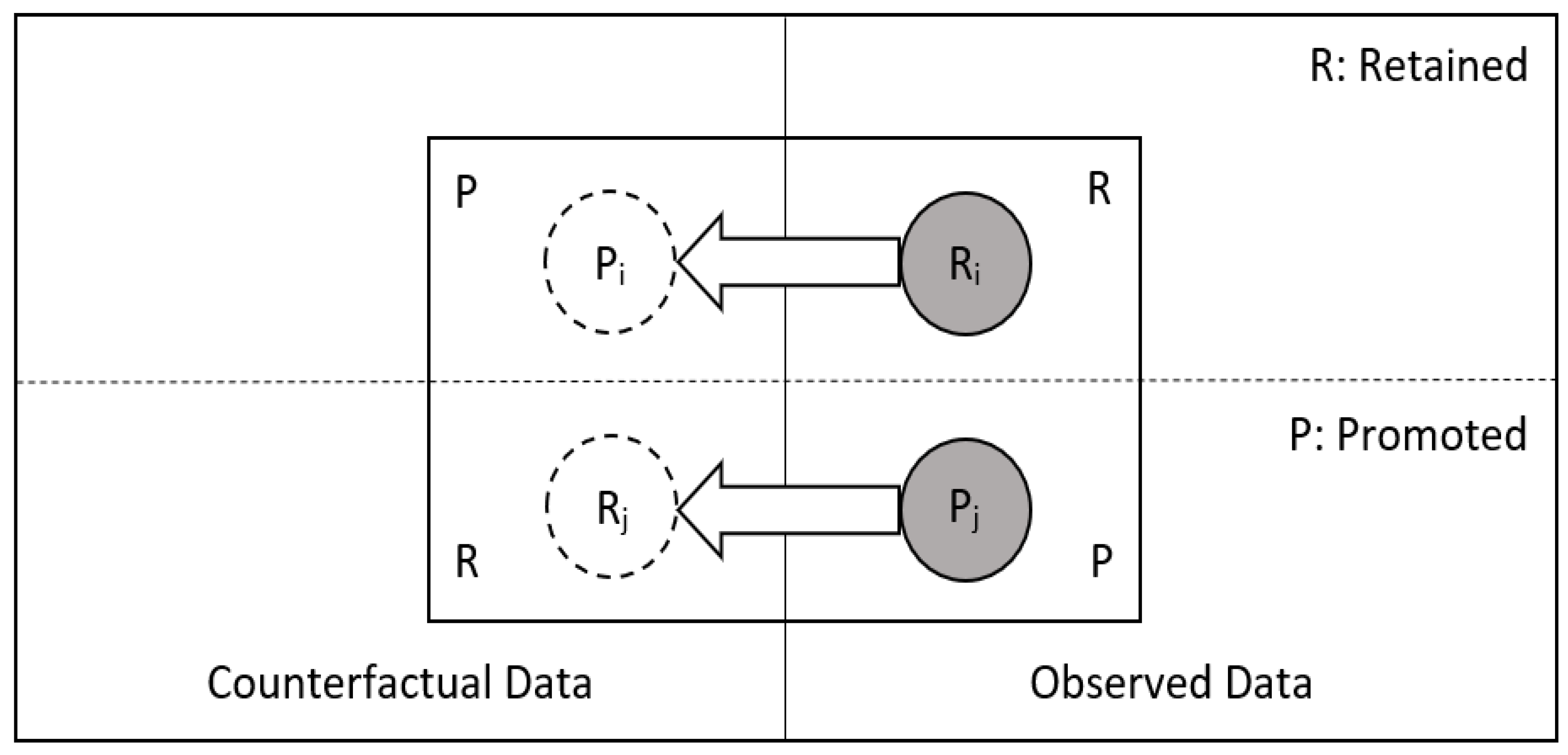
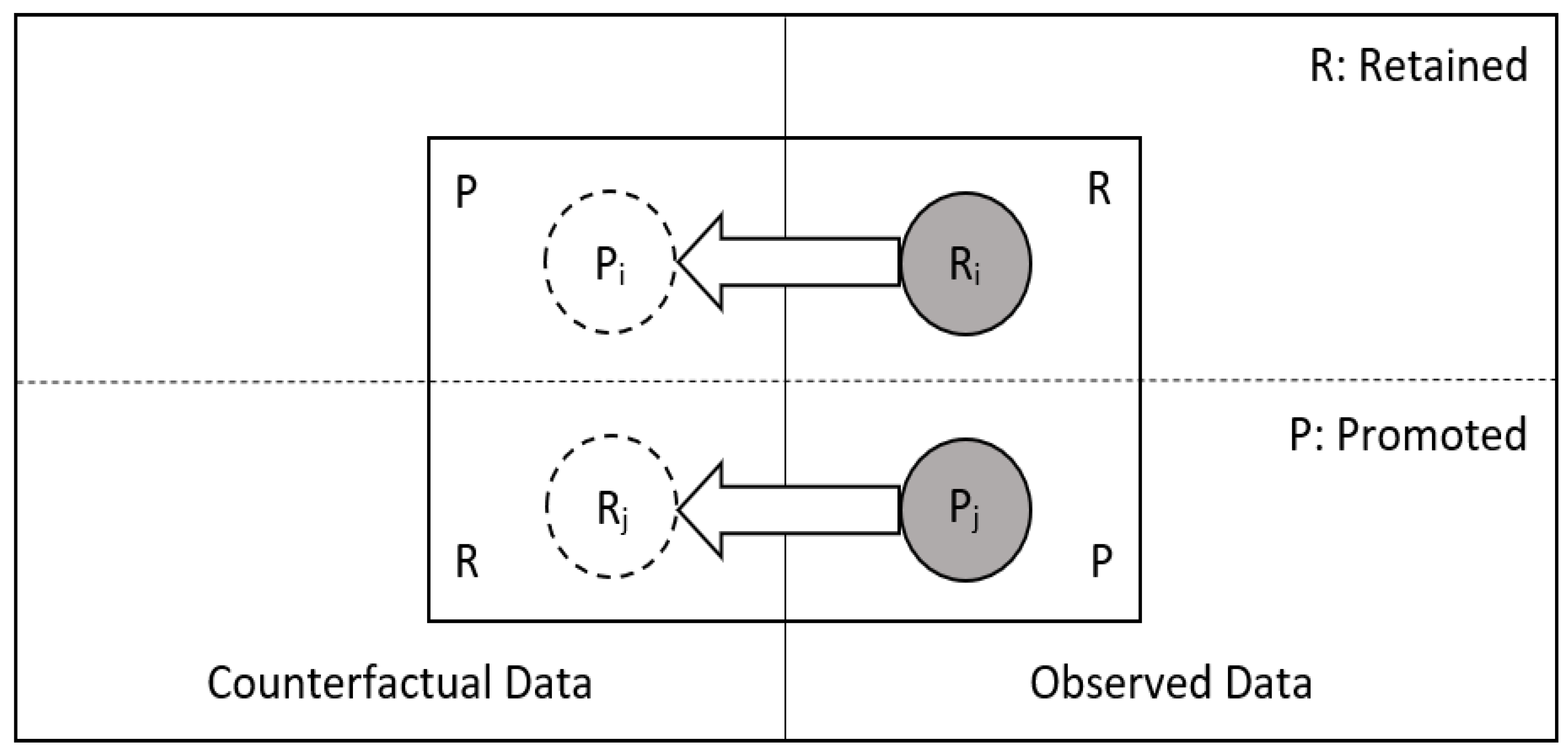
3. The Probability of a Robust Inference for Internal Validity in Regression
4. The Relationship between the PIVR and the Counterfactual Outcomes
5. Example: The Effect of Kindergarten Retention on Reading Achievement
5.1. Overview
5.2. Quantifying the Robustness of the Inference of Hong and Raudenbush (2005) [25]
- (i)
- Obtain the required sample statistics: The required observed sample statistics , are obtained as follows: [20].
- (ii)
- Choose critical value C: Given that [25] reported that kindergarten retention had a significant negative effect on reading achievement, we decided to choose C as −1.96 which means the level of significance is 0.05 for rejecting the null hypothesis .
- (iii)
- Obtain the relationship between the PIVR and the mean counterfactual outcomes: Plugging the observed sample statistics and the critical value above into (5), the PIVR is the probit function of the mean counterfactual reading score for the retained students had they been promoted instead (i.e., ) and the mean counterfactual reading score for the promoted students had they been retained instead (i.e.,) as follows:
- (iv)
- Specify a joint distribution about the mean counterfactual outcomes: This step requires one to form a joint distribution about the two mean counterfactual outcomes. In general, the distributional belief about the mean counterfactual outcomes should be based on counterfactual thought experiments with explicit justifications. It is recommended that one choose the ranges of the mean counterfactual outcomes based on domain knowledge and literature, and that those ranges should only include the unfavorable scenarios, i.e., the values of mean counterfactual outcomes that would make the observed results less significant. As a rule of thumb, one can then form uniform distributions based on the ranges of the mean counterfactual outcomes.
- (v)
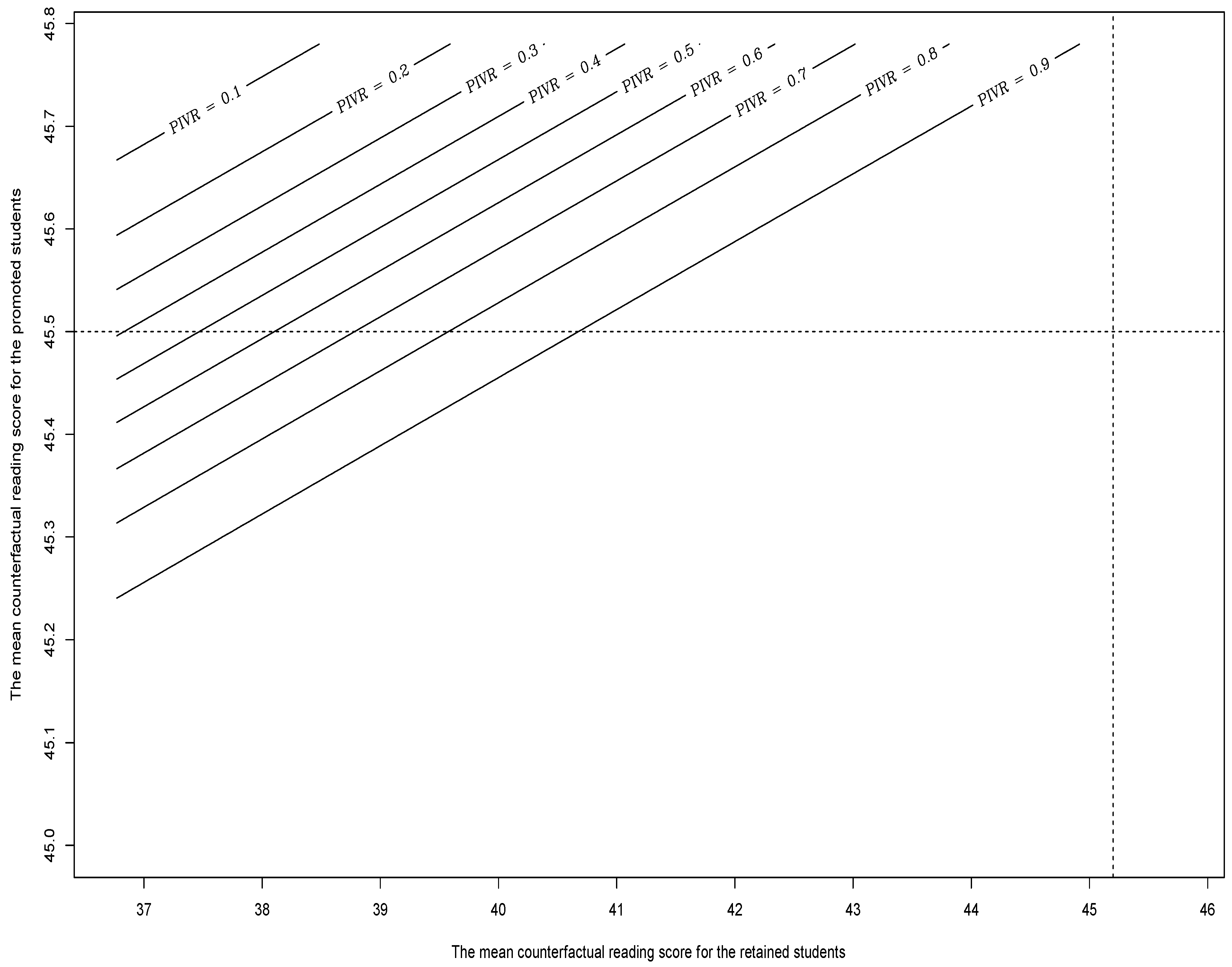
- Calculate the expected value and confidence interval for the PIVR: Figure 2 illustrates the levels of the PIVR for [25] based on the first joint distribution of and . The distribution of the PIVR is approximated by the following process: 1—repeatedly draw random values from the first joint distribution; 2—obtain the corresponding normal distribution for (specifically, the mean of such normal distribution); 3—compute the PIVR which is based on the normal distribution obtained in the second step. We can then derive the expected value of the PIVR as 0.86 and its 95% confidence interval as [0.14, 1.00], for the first joint distribution. This means the chance that the inference of [25] is robust for internal validity is expected to be 86% based on the first joint distribution. For the second joint distribution of and , we derive the expected value of the PIVR as 0.96 and its 95% confidence interval as [0.66, 1.00] by a similar fashion. This suggests the chance that Hong and Raudenbush’s inference is robust for internal validity is expected to be 96% based on the second joint distribution, and we have higher confidence about the robustness of Hong and Raudenbush’s inference compared to the results obtained based on the first joint distribution.
- (vi)
- Evaluate the robustness based on the expected value of the PIVR: Given the PIVR can be interpreted as the statistical power of retesting the null hypothesis based on the ideal sample, we use PIVR = 0.8 as the threshold which is often used for strong statistical power [37,38]. Consequently, we conclude that the inference of [25] is expected to be robust given the first joint distribution of and , as the expected value 0.86 exceeds the threshold 0.8. We conclude again that the inference of [25] is expected to be robust given the second joint distribution of and , as the expected value 0.96 exceeds the threshold 0.8. We caution readers that the above conclusions might not hold if a different joint distribution and and/or a different threshold for strong statistical power is chosen for PIVR analysis.
6. Discussion
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Gelman, A.; Hill, J. Data Analysis Using Regression and Multilevel/Hierarchical Models; Cambridge University Press: New York, NY, USA, 2006. [Google Scholar]
- Imbens, G.W.; Rubin, D.B. Causal Inference for Statistics, Social, and Biomedical Sciences: An Introduction; Cambridge University Press: New York, NY, USA, 2015. [Google Scholar] [CrossRef]
- Morgan, S.L.; Winship, C. Counterfactuals and Causal Inference; Cambridge University Press: New York, NY, USA, 2015. [Google Scholar]
- Murnane, R.J.; Willett, J.B. Methods Matter: Improving Causal Inference in Educational and Social Science Research; Oxford University Press: New York, NY, USA, 2011. [Google Scholar]
- Shadish, W.R.; Cook, T.D.; Campbell, D.T. Experimental and Quasi-Experimental Designs for Generalized Causal Inference; Houghton Mifflin: New York, NY, USA, 2002. [Google Scholar]
- Imai, K.; King, G.; Stuart, E.A. Misunderstandings between experimentalists and observationalists about causal inference. J. R. Stat. Soc. Ser. A Stat. Soc. 2008, 171, 481–502. [Google Scholar] [CrossRef]
- Rosenbaum, P.R. Observational Studies; Springer: New York, NY, USA, 2002. [Google Scholar]
- Rosenbaum, P.R.; Rubin, D.B. Assessing sensitivity to an unobserved binary covariate in an observational study with binary outcome. J. R. Stat. Soc. Ser. B Methodol. 1983, 45, 212–218. [Google Scholar] [CrossRef]
- Rubin, D.B. Neyman (1923) and causal inference in experiments and observational studies. Stat. Sci. 1990, 5, 472–480. [Google Scholar] [CrossRef]
- Holland, P.W. Statistics and causal inference. J. Am. Stat. Assoc. 1986, 81, 945–960. [Google Scholar] [CrossRef]
- Rubin, D.B. For objective causal inference, design trumps analysis. Ann. Appl. Stat. 2008, 2, 808–840. [Google Scholar] [CrossRef]
- Rubin, D.B. The design versus the analysis of observational studies for causal effects: Parallels with the design of randomized trials. Stat. Med. 2007, 26, 20–36. [Google Scholar] [CrossRef] [PubMed]
- Schafer, J.L.; Kang, J. Average causal effects from nonrandomized studies: A practical guide and simulated example. Psychol. Methods 2008, 13, 279. [Google Scholar] [CrossRef]
- Imbens, G.W. Nonparametric estimation of average treatment effects under exogeneity: A review. Rev. Econ. Stat. 2004, 86, 4–29. [Google Scholar] [CrossRef]
- Rosenbaum, P.R.; Rubin, D.B. The central role of the propensity score in observational studies for causal effects. Biometrika 1983, 70, 41–55. [Google Scholar] [CrossRef]
- Heckman, J.J. The scientific model of causality. Sociol. Methodol. 2005, 35, 1–97. [Google Scholar] [CrossRef]
- Rosenbaum, P.R. Sensitivity analysis for certain permutation inferences in matched observational studies. Biometrika 1987, 74, 13–26. [Google Scholar] [CrossRef]
- Frank, K.A. Impact of a confounding variable on a regression coefficient. Sociol. Methods Res. 2000, 29, 147–194. [Google Scholar] [CrossRef]
- Frank, K.; Min, K.S. Indices of Robustness for Sample Representation. Sociol. Methodol. 2007, 37, 349–392. [Google Scholar] [CrossRef]
- Frank, K.A.; Maroulis, S.J.; Duong, M.Q.; Kelcey, B.M. What would it take to change an inference? Using Rubin’s causal model to interpret the robustness of causal inferences. Educ. Eval. Policy Anal. 2013, 35, 437–460. [Google Scholar] [CrossRef]
- Li, T.; Frank, K.A. The probability of a robust inference for internal validity. Sociol. Methods Res. 2022, 51, 1947–1968. [Google Scholar] [CrossRef]
- Rubin, D.B. Teaching statistical inference for causal effects in experiments and observational studies. J. Educ. Behav. Stat. 2004, 29, 343–367. [Google Scholar] [CrossRef]
- Rubin, D.B. Causal inference using potential outcomes: Design, modeling, decisions. J. Am. Stat. Assoc. 2005, 100, 322–331. [Google Scholar] [CrossRef]
- Sobel, M.E. An introduction to causal inference. Sociol. Methods Res. 1996, 24, 353–379. [Google Scholar] [CrossRef]
- Hong, G.; Raudenbush, S.W. Effects of kindergarten retention policy on children’s cognitive growth in reading and mathematics. Educ. Eval. Policy Anal. 2005, 27, 205–224. [Google Scholar] [CrossRef]
- Allen, C.S.; Chen, Q.; Willson, V.L.; Hughes, J.N. Quality of research design moderates effects of grade retention on achievement: A meta-analytic, multilevel analysis. Educ. Eval. Policy Anal. 2009, 31, 480–499. [Google Scholar] [CrossRef]
- Hong, G. Marginal mean weighting through stratification: Adjustment for selection bias in multilevel data. J. Educ. Behav. Stat. 2010, 35, 499–531. [Google Scholar] [CrossRef]
- Hoff, P.D. A First Course in BAYESIAN Statistical Methods; Springer Science & Business Media: New York, NY, USA, 2009. [Google Scholar]
- Li, T. The Bayesian Paradigm of Robustness Indices of Causal Inferences. Doctoral Dissertation, Michigan State University, East Lansing, MI, USA, 2018. Unpublished. [Google Scholar]
- Alexander, K.L.; Entwisle, D.L.; Dauber, S.L. On the Success of Failure: A Reassessment of the Effects of Retention in the Primary School Grades; Cambridge University Press: New York, NY, USA, 2003. [Google Scholar]
- Tingle, L.R.; Schoeneberger, J.; Algozzine, B. Does grade retention make a difference? Clear. House A J. Educ. Strateg. Issues Ideas 2012, 85, 179–185. [Google Scholar] [CrossRef]
- Burkam, D.T.; LoGerfo, L.; Ready, D.; Lee, V.E. The differential effects of repeating kindergarten. J. Educ. Stud. Placed Risk 2007, 12, 103–136. [Google Scholar] [CrossRef]
- Jimerson, S. Meta-analysis of grade retention research: Implications for practice in the 21st century. Sch. Psychol. Rev. 2001, 30, 420–437. [Google Scholar] [CrossRef]
- Lorence, J.; Dworkin, G.; Toenjes, L.; Hill, A. Grade retention and social promotion in Texas 1994–1999: Academic achievement among elementary school students. In Brookings Papers on Education Policy; Ravitch, D., Ed.; Brookings Institution Press: Washington, DC, USA, 2002; pp. 13–67. [Google Scholar]
- Manski, C.F. Nonparametric bounds on treatment effects. Am. Econ. Rev. 1990, 80, 319. [Google Scholar]
- Manski, C.F. Identification Problems in the Social Sciences; Harvard University Press: Cambridge, MA, USA, 1995. [Google Scholar]
- Cohen, J. Statistical Power Analysis for the Behavioral Sciences; Lawrence Earlbaum Associates: Hillsdale, NJ, USA, 1988. [Google Scholar]
- Cohen, J. A power primer. Psychol. Bull. 1992, 112, 155. [Google Scholar] [CrossRef] [PubMed]
- Rosenbaum, P.R. Dropping out of high school in the United States: An observational study. J. Educ. Stat. 1986, 11, 207–224. [Google Scholar] [CrossRef]
- Rosenbaum, P.R. Sensitivity analysis for matched case-control studies. Biometrics 1991, 47, 87–100. [Google Scholar] [CrossRef]
- Rosenbaum, P.R. Design of Observational Studies; Springer: New York, NY, USA, 2010. [Google Scholar]
- Copas, J.B.; Li, H.G. Inference for non-random samples. J. R. Stat. Soc. Series B Stat. Methodol. 1997, 59, 55–95. [Google Scholar] [CrossRef]
- Hosman, C.A.; Hansen, B.B.; Holland, P.W. The sensitivity of linear regression coefficients’ confidence limits to the omission of a confounder. Ann. Appl. Stat. 2010, 4, 849–870. [Google Scholar] [CrossRef]
- Lin, D.Y.; Psaty, B.M.; Kronmal, R.A. Assessing the sensitivity of regression results to unmeasured confounders in observational studies. Biometrics 1998, 54, 948–963. [Google Scholar] [CrossRef] [PubMed]
- Masten, M.A.; Poirier, A. Identification of treatment effects under conditional partial independence. Econometrica 2018, 86, 317–351. [Google Scholar] [CrossRef]
- Robins, J.M.; Rotnitzky, A.; Scharfstein, D.O. Sensitivity analysis for selection bias and unmeasured confounding in missing data and causal inference models. In Statistical Models in Epidemiology, the Environment, and Clinical Trials; Springer: New York, NY, USA, 2000; pp. 1–94. [Google Scholar]
- VanderWeele, T.J. Sensitivity analysis: Distributional assumptions and confounding assumptions. Biometrics 2008, 64, 645–649. [Google Scholar] [CrossRef] [PubMed]
- Contreras-Reyes, J.E.; Quintero, F.O.L.; Wiff, R. Bayesian modeling of individual growth variability using back-calculation: Application to pink cusk-eel (Genypterus blacodes) off Chile. Ecol. Model. 2018, 385, 145–153. [Google Scholar] [CrossRef]
- McCandless, L.C.; Gustafson, P.; Levy, A. Bayesian sensitivity analysis for unmeasured confounding in observational studies. Stat. Med. 2007, 26, 2331–2347. [Google Scholar] [CrossRef]
- McCandless, L.C.; Gustafson, P.; Levy, A.R.; Richardson, S. Hierarchical priors for bias parameters in Bayesian sensitivity analysis for unmeasured confounding. Stat. Med. 2012, 31, 383–396. [Google Scholar] [CrossRef] [PubMed]
- McCandless, L.C.; Gustafson, P. A comparison of Bayesian and Monte Carlo sensitivity analysis for unmeasured confounding. Stat. Med. 2017, 36, 2887–2901. [Google Scholar] [CrossRef]
- Busenbark, J.R.; Yoon, H.; Gamache, D.L.; Withers, M.C. Omitted variable bias: Examining management research with the impact threshold of a confounding variable (ITCV). J. Manag. 2022, 48, 17–48. [Google Scholar] [CrossRef]
- Altonji, J.G.; Elder, T.E.; Taber, C.R. An evaluation of instrumental variable strategies for estimating the effects of catholic schooling. J. Hum. Resour. 2005, 40, 791–821. [Google Scholar] [CrossRef]
- Manski, C.F.; Nagin, D.S. Bounding disagreements about treatment effects: A case study of sentencing and recidivism. Sociol. Methodol. 1998, 28, 99–137. [Google Scholar] [CrossRef]
- Boos, D.D.; Stefanski, L.A. P-value precision and reproducibility. Am. Stat. 2011, 65, 213–221. [Google Scholar] [CrossRef] [PubMed]
- Greenwald, A.; Gonzalez, R.; Harris, R.J.; Guthrie, D. Effect sizes and p values: What should be reported and what should be replicated? Psychophysiology 1996, 33, 175–183. [Google Scholar] [CrossRef] [PubMed]
- Killeen, P.R. An alternative to null-hypothesis significance tests. Psychol. Sci. 2005, 16, 345–353. [Google Scholar] [CrossRef] [PubMed]
- Posavac, E.J. Using p values to estimate the probability of a statistically significant replication. Underst. Stat. Stat. Issues Psychol. Educ. Soc. Sci. 2002, 1, 101–112. [Google Scholar] [CrossRef]
- Shao, J.; Chow, S.C. Reproducibility probability in clinical trials. Stat. Med. 2002, 21, 1727–1742. [Google Scholar] [CrossRef] [PubMed]
- Camerer, C.F.; Dreber, A.; Forsell, E.; Ho, T.-H.; Huber, J.; Johannesson, M.; Kirchler, M.; Almenberg, J.; Altmejd, A.; Chan, T.; et al. Evaluating replicability of laboratory experiments in economics. Science 2016, 351, 1433–1436. [Google Scholar] [CrossRef] [PubMed]
- Open Science Collaboration. Estimating the reproducibility of psychological science. Science 2015, 349, aac4716. [Google Scholar] [CrossRef]
- Iverson, G.J.; Wagenmakers, E.J.; Lee, M.D. A model-averaging approach to replication: The case of prep. Psychol. Methods 2010, 15, 172. [Google Scholar] [CrossRef]
- Doros, G.; Geier, A.B. Probability of replication revisited: Comment on “An alternative to null-hypothesis significance tests”. Psychol. Sci. 2005, 16, 1005–1006. [Google Scholar] [CrossRef]
- Li, T.; Lawson, J. A generalized bootstrap procedure of the standard error and confidence interval estimation for inverse probability of treatment weighting. Multivar. Behav. Res. 2023, 2023, 2254541. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, T.; Frank, K.A.; Chen, M. A Conceptual Framework for Quantifying the Robustness of a Regression-Based Causal Inference in Observational Study. Mathematics 2024, 12, 388. https://doi.org/10.3390/math12030388
Li T, Frank KA, Chen M. A Conceptual Framework for Quantifying the Robustness of a Regression-Based Causal Inference in Observational Study. Mathematics. 2024; 12(3):388. https://doi.org/10.3390/math12030388
Chicago/Turabian StyleLi, Tenglong, Kenneth A. Frank, and Mingming Chen. 2024. "A Conceptual Framework for Quantifying the Robustness of a Regression-Based Causal Inference in Observational Study" Mathematics 12, no. 3: 388. https://doi.org/10.3390/math12030388
APA StyleLi, T., Frank, K. A., & Chen, M. (2024). A Conceptual Framework for Quantifying the Robustness of a Regression-Based Causal Inference in Observational Study. Mathematics, 12(3), 388. https://doi.org/10.3390/math12030388