
Regression of Likelihood Probability for Time-Varying MIMO Systems with One-Bit ADCs


Abstract
1. Introduction
1.1. Contributions
- Two probabilities influenced by time-varying channels are derived. Channel-based likelihood probability, which tracks the change in the likelihood probability based on the channel model, is simplified to reduce computational complexity compared to [38]. In addition, a sample-based likelihood probability is introduced to exploit the received data that contain the likelihood information. Unlike the conventional sample-based likelihood probability in [37] which relies on a detected symbol, the proposed approach leverages the output of the decoder. These two probabilities are then used to estimate the true probability.
- An optimization problem is formulated to minimize the MSE between the true and estimated likelihood probabilities derived from the channel- and sample-based likelihood probabilities. Unlike previous work [19], which requires complex algorithms such as RL algorithms, the proposed method solves this problem using a regression model, eliminating the need for such intensive computation. Instead of heavy computation, the proposed method exploits the precomputed optimal weights stored in memory to calculate the regression-based likelihood probability efficiently. To further optimize the calculation, LASSO regression is introduced, allowing the model to adapt to gradual channel changes under the assumption of slow time-varying channels.
- Simulations demonstrate that the proposed method outperforms conventional methods on both slow and fast time-varying channels. This improvement results from the optimal weights, which enhance the reliability of the channel- and sample-based likelihood probabilities by fully utilizing the channel statistics and output of the decoder.
1.2. Related Works
- The proposed method learns the likelihood probability in time-varying channels. The original approach of learning likelihood probability, initially introduced in [37], efficiently exploited input–output samples from the data detector using reinforcement learning. However, the approach in [37] was designed for time-invariant channels and faces limitations in scalability when applied to time-varying channels. To address this limitation, a channel-based likelihood probability is derived following the methodology outlined in [38]. Additionally, unlike [37], this study introduces a sample-based likelihood leveraging the decoder’s output to enhance scalability further.
- The proposed method reduces detection complexity, making it more applicable to practical systems. While a learning method that updates likelihood probability was proposed in [38] based on the on the time-varying channel model, the complexity remains a significant barrier to practical implementation. This study proposes a reduced-complexity algorithm to efficiently update the likelihood probability in time-varying channels. To achieve this, an offline learning method inspired by [39] is developed for time-varying channels. Especially, a regression-based approach is proposed to efficiently integrate channel- and sample-based likelihood probabilities.
1.3. Organization
1.4. Notation
2. System Model
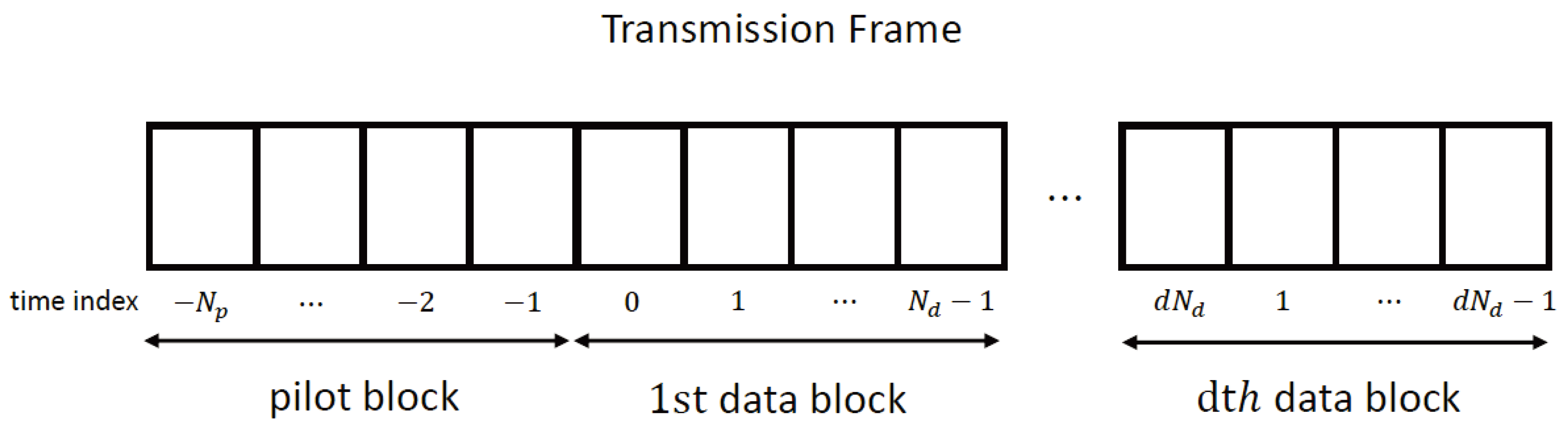
2.1. Transmitter
2.2. Receiver
2.3. ML Detection
3. Proposed Problem
3.1. Channel-Based Likelihood Probability
3.2. Sample-Based Likelihood Probability
3.3. Optimization Problem
4. Proposed Solution
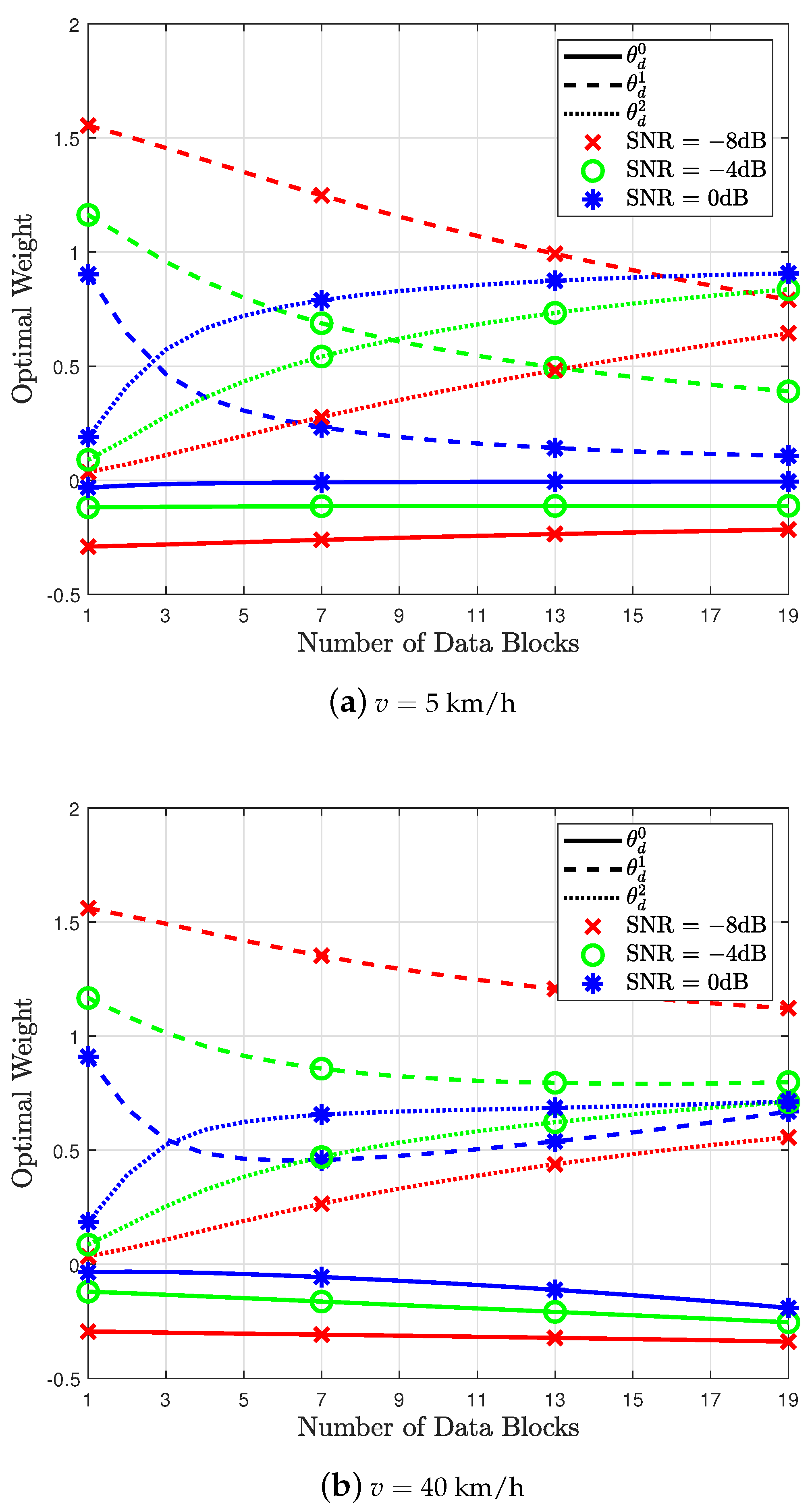
4.1. Linear Regression
4.2. Regularization
4.3. Proposed Receiver
| Algorithm 1: Procedure of the Proposed Receiver |
| 1 Pilot Block |
| 2 Obtain initial channel estimate . |
| 3 Calculate the initial channel-based likelihood probability , from . |
| 4 Set the proposed likelihood probability , . |
| 5 Data Block |
| 6 for to D do |
| 7 for to do |
| 8 Compute LLR in (24) based on the proposed likelihood probability . |
| 9 Obtain decoded data from the channel decoder. |
| 10 end |
| 11 Bring the optimal weight in memory trained using (21). |
| 12 Update channel-based likelihood probability from (12) and . |
| 13 The sample-based likelihood probabilities are updated from the decoding output in (16). |
| 14 Calculate the proposed likelihood probability using (22). |
| 15 end |
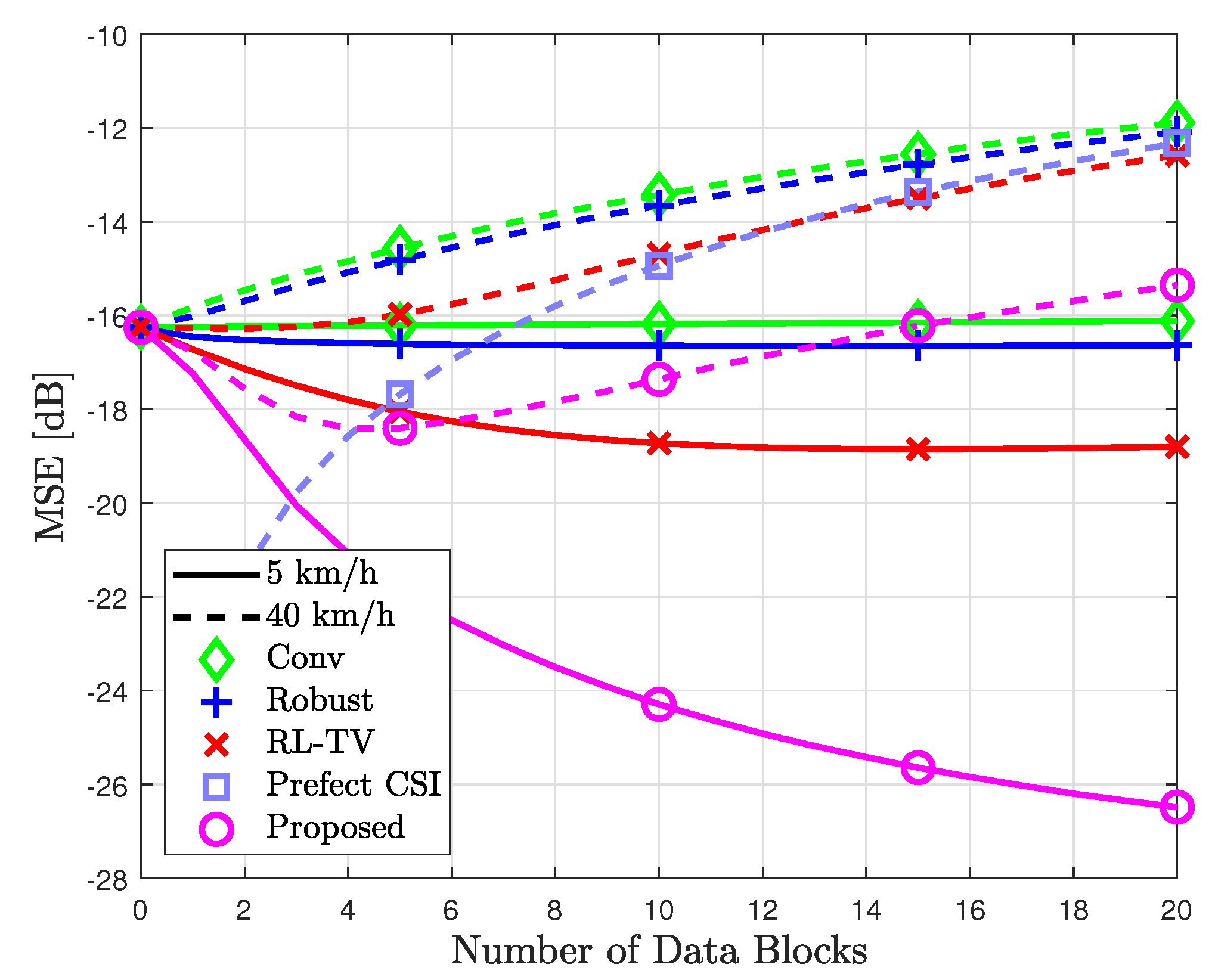
5. Simulation Results
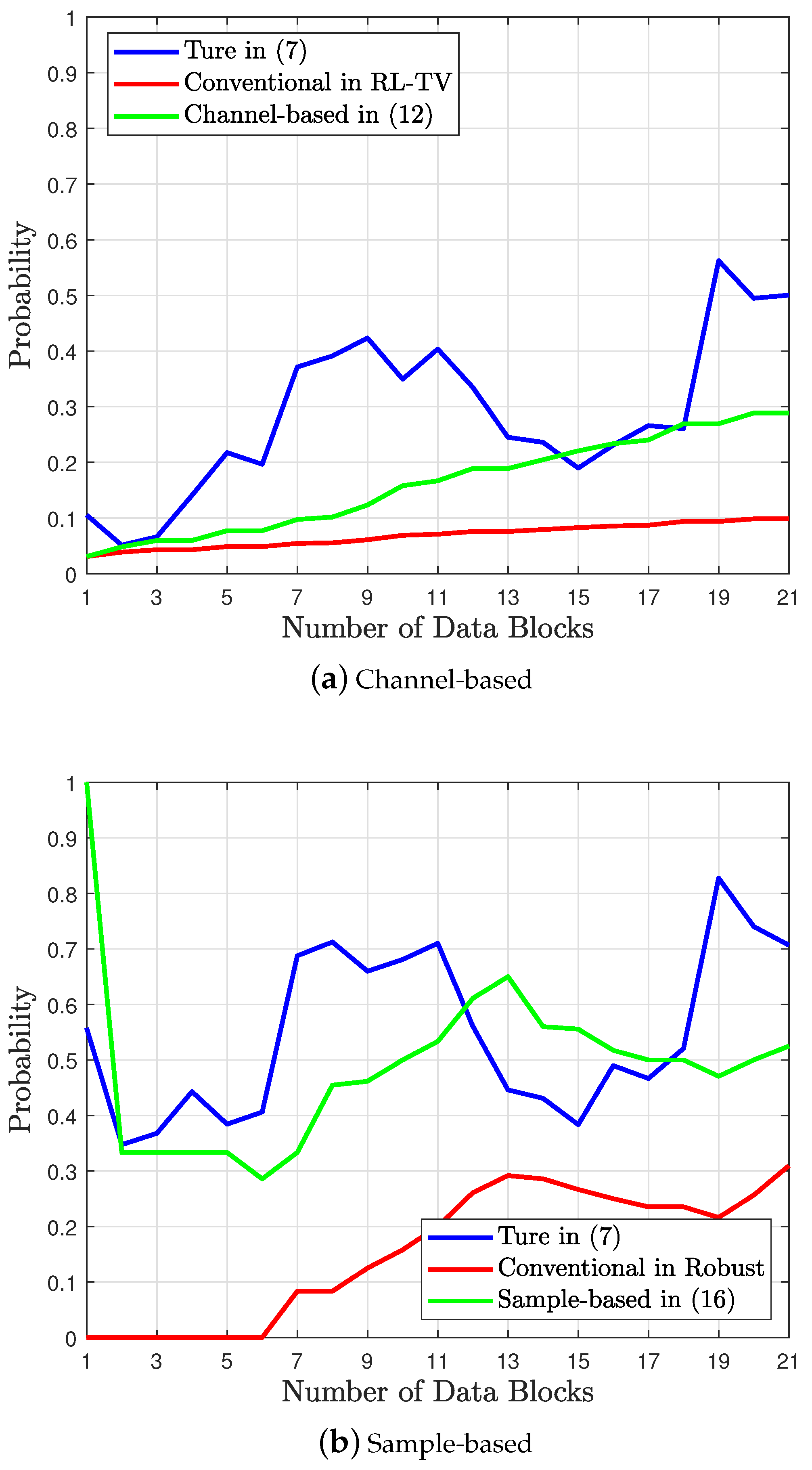
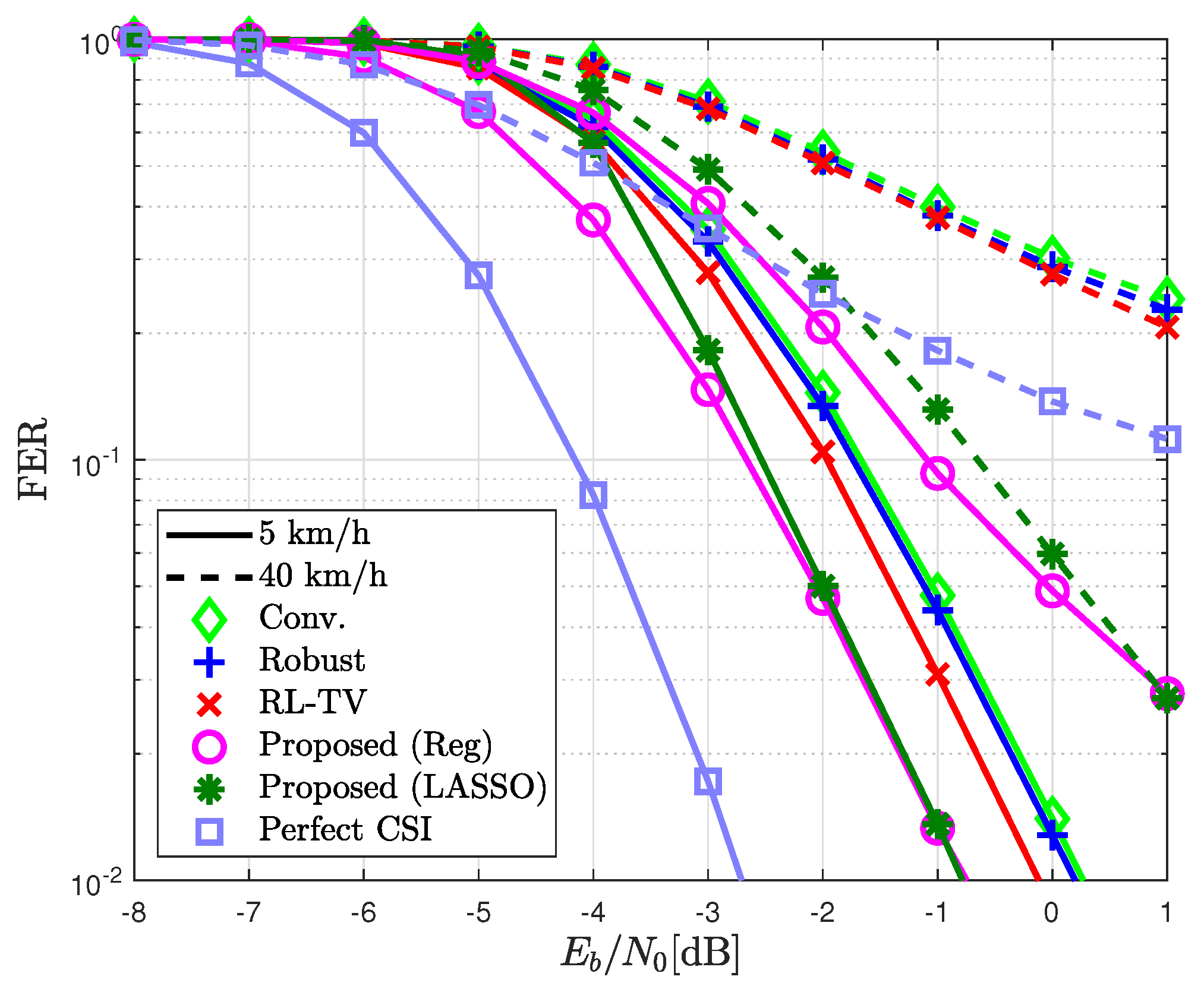
- Perfect CSI: This represents the optimal case in time-invariant channels, where the likelihood probability is obtained using perfect channel state information (CSI) of . Note that the resulting likelihood probability remains constant over time, and thus is not optimal in time-varying channels.
- Conv.: This conventional method calculates the probability based on channel estimates obtained during pilot transmission. In this method, the likelihood probability remains fixed during data transmission.
- Robust: Developed in [37] for time-invariant MIMO channels. This method calculates the likelihood probability using an RL algorithm, where the initial likelihood probability is optimally combined with the empirical-based likelihood probability obtained from the detected symbol.
- RL-TV: Introduced in [38] for time-varying MIMO channels, this method calculates the likelihood probability using an RL algorithm, where the model-based likelihood probability and the quantized received signal are optimally combined. Notably, the sample refinement scheme is not used in this study where all input–output samples are used to update the likelihood probability when the cyclic redundancy check (CRC) is correct. This exclusion is intended to ensure a fair comparison with other methods.
- Proposed: The proposed method exploits the likelihood probability from (22), where both the channel- and the sample-based likelihood probabilities are learned via linear regression. The proposed (Reg) denotes the case when the optimization problem in (19) is applied, while the proposed (LASSO) refers to when the regularization technique in (23) is applied. The precise definitions for the channel- and sample-based likelihood probabilities differ from those in [37] and [38], respectively.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Swindlehurst, A.L.; Ayanoglu, E.; Heydari, P.; Capolino, F. Millimeter-Wave Massive MIMO: The Next Wireless Revolution? IEEE Commun. Mag. 2014, 52, 56–62. [Google Scholar] [CrossRef]
- Rangan, S.; Rappaport, T.S.; Erkip, E. Millimeter-Wave Cellular Wireless Networks: Potentials and Challenges. Proc. IEEE 2014, 102, 366–385. [Google Scholar] [CrossRef]
- Busari, S.A.; Huq, K.M.S.; Mumtaz, S.; Dai, L.; Rodriguez, J. Millimeter-Wave Massive MIMO Communication for Future Wireless Systems: A survey. IEEE Commun. Surv. Tutor. 2017, 20, 836–869. [Google Scholar] [CrossRef]
- Wang, X.; Kong, L.; Kong, F.; Qiu, F.; Xia, M.; Arnon, S.; Chen, G.; Rodriguez, J. Millimeter Wave Communication: A Comprehensive Survey. IEEE Commun. Surv. Tutor. 2018, 20, 1616–1653. [Google Scholar] [CrossRef]
- Uwaechia, A.N.; Mahyuddin, N.M. A Comprehensive Survey on Millimeter Wave Communications for Fifth-Generation Wireless Networks: Feasibility and Challenges. IEEE Access 2020, 8, 62367–62414. [Google Scholar] [CrossRef]
- Bang, J.; Chung, H.; Hong, J.; Seo, H.; Choi, J.; Kim, S. Millimeter-Wave Communications: Recent Developments and Challenges of Hardware and Beam Management Algorithms. IEEE Commun. Mag. 2021, 59, 86–92. [Google Scholar] [CrossRef]
- Walden, R.H. Analog-to-Digital Converter Survey and Analysis. IEEE J. Sel. Areas Commun. 1999, 17, 539–550. [Google Scholar] [CrossRef]
- Murmann, B. ADC Performance Survey 1997–2024. [Online]. Available online: https://github.com/bmurmann/ADC-survey (accessed on 13 November 2024).
- Fan, L.; Jin, S.; Wen, C.K.; Zhang, H. Uplink Achievable Rate for Massive MIMO Systems With Low-Resolution ADC. IEEE Commun. Lett. 2015, 19, 2186–2189. [Google Scholar] [CrossRef]
- Roth, K.; Nossek, J.A. Achievable Rate and Energy Efficiency of Hybrid and Digital Beamforming Receivers With Low Resolution ADC. IEEE J. Sel. Areas Commun. 2017, 35, 2056–2068. [Google Scholar] [CrossRef]
- He, H.; Wen, C.K.; Jin, S. Bayesian Optimal Data Detector for Hybrid mmWave MIMO-OFDM Systems with Low-Resolution ADCs. IEEE J. Sel. Signal Process. 2018, 12, 469–483. [Google Scholar] [CrossRef]
- Zhang, J.; Dai, L.; Li, X.; Liu, Y.; Hanzo, L. On Low-Resolution ADCs in Practical 5G Millimeter-Wave Massive MIMO Systems. IEEE Commun. Mag. 2018, 56, 205–211. [Google Scholar] [CrossRef]
- Wang, H.; Shih, W.T.; Wen, C.K.; Jin, S. Reliable OFDM Receiver with Ultra-Low Resolution ADC. IEEE Trans. Commun. 2019, 67, 3566–3579. [Google Scholar] [CrossRef]
- Liu, J.; Luo, Z.; Xiong, X. Low-Resolution ADCs for Wireless Communication: A Comprehensive Survey. IEEE Access 2019, 7, 91291–91324. [Google Scholar] [CrossRef]
- Khalili, A.; Shirani, F.; Erkip, E.; Eldar, Y.C. MIMO Networks with One-Bit ADCs: Receiver Design and Communication Strategies. IEEE Trans. Commun. 2021, 70, 1580–1594. [Google Scholar] [CrossRef]
- Nguyen, L.V.; Swindlehurst, A.L.; Nguyen, D.H. Linear and Deep Neural Network-based Receivers for Massive MIMO Systems with One-Bit ADCs. IEEE Trans. Wirel. Commun. 2021, 20, 7333–7345. [Google Scholar] [CrossRef]
- Choi, J.; Love, D.J.; Brown, D.R.; Boutin, M. Quantized Distributed Reception for MIMO Wireless Systems Using Spatial Multiplexing. IEEE Trans. Signal Process. 2015, 63, 3537–3548. [Google Scholar] [CrossRef]
- Choi, J.; Mo, J.; Heath, R.W. Near Maximum-Likelihood Detector and Channel Estimator for Uplink Multiuser Massive MIMO Systems with One-Bit ADCs. IEEE Trans. Commun. 2016, 64, 2005–2018. [Google Scholar] [CrossRef]
- Jeon, Y.S.; Lee, N.; Hong, S.N.; Heath, R.W. One-Bit Sphere Decoding for Uplink Massive MIMO Systems with One-Bit ADCs. IEEE Trans. Wirel. Commun. 2018, 17, 4509–4521. [Google Scholar] [CrossRef]
- Hong, S.N.; Lee, N. Soft-Output Detector for Uplink MU-MIMO Systems with One-Bit ADCs. IEEE Commun. Lett. 2018, 22, 930–933. [Google Scholar] [CrossRef]
- Sant, A.; Rao, B.D. Insights Into Maximum Likelihood Detection for 1-bit Massive MIMO Communications. IEEE Trans. Wirel. Commun. 2024, 23, 16275–16289. [Google Scholar] [CrossRef]
- Wang, F.; Fang, J.; Li, H.; Chen, Z.; Li, S. One-Bit Quantization Design and Channel Estimation for Massive MIMO Systems. IEEE Trans. Veh. Technol. 2018, 67, 10921–10934. [Google Scholar] [CrossRef]
- Nguyen, L.V.; Swindlehurt, A.L.; Nguyen, D.H.N. SVM-Based Channel Estimation and Data Detection for One-Bit Massive MIMO Systems. IEEE Trans. Signal Process. 2021, 69, 2086–2099. [Google Scholar] [CrossRef]
- Wang, S.; Li, Y.; Wang, J. Multiuser Detection in Massive Spatial Modulation MIMO with Low-Resolution ADCs. IEEE Trans. Wirel. Commun. 2015, 14, 2156–2168. [Google Scholar] [CrossRef]
- Mollen, C.; Choi, J.; Larsson, E.G.; Heath, R.W. Uplink Performance of Wideband Massive MIMO with One-Bit ADCs. IEEE Trans. Wirel. Commun. 2017, 16, 87–100. [Google Scholar] [CrossRef]
- Li, Y.; Tao, C.; Seco-Granados, G.; Mezghani, A.; Swindlehurst, A.L.; Liu, L. Channel Estimation and Performance Analysis of One-Bit Massive MIMO Systems. IEEE Trans. Signal Process. 2017, 65, 4075–4089. [Google Scholar] [CrossRef]
- Mo, J.; Schniter, P.; Gonzalez-Prelcic, N.; Heath, R.W. Channel Estimation in Millimeter Wave MIMO Systems with One-Bit Quantization. In Proceedings of the 48th Asilomar Conference on Signals, Systems and Computers, Pacific Grove, CA, USA, 2–5 November 2014; pp. 957–961. [Google Scholar]
- Wen, C.K.; Wang, C.J.; Jin, S.; Wong, K.K.; Ting, P. Bayes-Optimal Joint Channel-and-Data Estimation for Massive MIMO with Low-Precision ADCs. IEEE Trans. Signal Process. 2016, 64, 2541–2556. [Google Scholar] [CrossRef]
- Wang, H.; Memon, F.H.; Wang, X.; Li, X.; Zhao, N.; Dev, K. Machine Learning-enabled MIMO-FBMC Communication Channel Parameter Estimation in IIoT: A Distributed CS Approach. Digit. Commun. Netw. 2023, 9, 306–312. [Google Scholar] [CrossRef]
- Fesl, B.; Turan, N.; Bock, B.; Utschick, W. Channel Estimation for Quantized Systems based on Conditionally Gaussian Latent Models. IEEE Trans. Signal Process. 2024, 72, 1475–1490. [Google Scholar] [CrossRef]
- Rahman, M.H.; Sejan, M.A.S.; Aziz, M.A.; Tabassum, R.; Baik, J.I.; Song, H.K. Deep Learning Based One Bit-ADCs Efficient Channel Estimation Using Fewer Pilots Overhead for Massive MIMO System. IEEE Access 2024, 12, 64823–64836. [Google Scholar] [CrossRef]
- Jeon, Y.S.; Kim, D.; Hong, S.N.; Lee, N.; Heath, R.W. Artificial Intelligence for Physical-Layer Design of MIMO Communications with One-Bit ADCs. IEEE Commun. Mag. 2022, 60, 76–81. [Google Scholar] [CrossRef]
- Kim, T.K.; Jeon, Y.S.; Min, M. Low-Complexity MIMO Detection Based on Reinforcement Learning with One-Bit ADCs. IEEE Trans. Veh. Technol. 2021, 70, 9022–9035. [Google Scholar] [CrossRef]
- Choi, J.; Cho, Y.; Evans, B.L.; Gatherer, A. Robust Learning-based ML Detection for Massive MIMO Systems with One-Bit Quantized Signals. In Proceedings of the 2019 IEEE Global Communications Conference (GLOBECOM), Big Island, HI, USA, 9–13 December 2019. [Google Scholar]
- Jeon, Y.S.; Hong, S.N.; Lee, N. Supervised-Learning-Aided Communication Framework for MIMO Systems with Low-Resolution ADCs. IEEE Trans. Veh. Technol. 2018, 67, 7299–7313. [Google Scholar] [CrossRef]
- Kim, S.; Hong, S.N. A Supervised-Learning Detector for Multihop Distributed Reception Systems. IEEE Trans. Veh. Technol. 2019, 68, 1958–1962. [Google Scholar] [CrossRef]
- Jeon, Y.S.; Lee, N.; Poor, H.V. Robust Data Detection for MIMO Systems with One-Bit ADCs: A Reinforcement Learning Approach. IEEE Trans. Wirel. Commun. 2020, 19, 1663–1676. [Google Scholar] [CrossRef]
- Jeon, Y.S.; Lee, N.; Poor, H.V. Reinforcement-Learning-Aided Detector for Time-Varying MIMO Systems with One-Bit ADCs. In Proceedings of the 2019 IEEE Global Communications Conference (GLOBECOM), Big Island, HI, USA, 9–13 December 2019. [Google Scholar]
- Kim, T.K. Improved Likelihood Probability in MIMO systems Using One-Bit ADCs. Sensors 2023, 23, 5542. [Google Scholar] [CrossRef] [PubMed]
- 3GPP TS 38.104; 3rd Generation Partnership Project; Technical Specification Group Radio Access Network; NR; Base Station (BS) Radio Transmission and Reception (Release 15), V1.0.0. 2017. Available online: https://portal.3gpp.org/desktopmodules/Specifications/SpecificationDetails.aspx?specificationId=3202 (accessed on 13 November 2024).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notations | Descriptions |
|---|---|
| conjugate transpose | |
| transpose | |
| set of real number | |
| set of complex numbers | |
| real component of the complex number | |
| imaginary component of the complex number | |
| function whose output is 1 for and −1 otherwise | |
| cumulative distribution of the standard normal random variable | |
| standard Q-function | |
| cardinality of the set | |
| one if the event is true; otherwise, it is 0 | |
| probability operation | |
| expectation operation | |
| the 0-th order Bessel function of the first kind |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, T.-K.; Min, M. Regression of Likelihood Probability for Time-Varying MIMO Systems with One-Bit ADCs. Mathematics 2024, 12, 3957. https://doi.org/10.3390/math12243957
Kim T-K, Min M. Regression of Likelihood Probability for Time-Varying MIMO Systems with One-Bit ADCs. Mathematics. 2024; 12(24):3957. https://doi.org/10.3390/math12243957
Chicago/Turabian StyleKim, Tae-Kyoung, and Moonsik Min. 2024. "Regression of Likelihood Probability for Time-Varying MIMO Systems with One-Bit ADCs" Mathematics 12, no. 24: 3957. https://doi.org/10.3390/math12243957
APA StyleKim, T.-K., & Min, M. (2024). Regression of Likelihood Probability for Time-Varying MIMO Systems with One-Bit ADCs. Mathematics, 12(24), 3957. https://doi.org/10.3390/math12243957