1. Introduction
Autoregressive (AR) models constitute a pivotal class within the realm of time series analysis and have found extensive applications across various domains, including economics, finance, industry, and meteorology. The traditional AR model, with fixed autoregressive coefficients, has seen rapid advancements. However, in the process of solving practical problems, observational data are often characterized as nonlinear and dynamic, which cannot be explained by traditional AR models. By introducing random coefficients, the parameters of the model are allowed to change over time. This makes the models better adapt to the characteristics and changes in complex data, thereby enhancing the model’s fitting and predictive capabilities. This research has attracted wide interest among statisticians and scholars in related fields. The references to nonlinear time series are burgeoning. Notably, a well-known class of nonlinear AR models is random coefficient AR (RCAR) models. A study by Nicholls and Quinn (1982) [
1] contained a detailed study of RCAR models, including statistical properties of the model, estimation methods, and hypothesis testing. Based on this foundation, Aue et al. (2006) [
2] proposed the quasi-maximum likelihood method for estimating the parameters of an RCAR(1) process. Zhao et al. (2015) [
3] investigated the parameter estimation of the RCAR model and its limiting properties under a sequence of martingale errors. This work was subsequently expanded by Horváth and Trapani (2016) [
4] to encompass panel data, broadening the applicability of the theory. Most recently, Proia and Soltane (2018) [
5] introduced an RCAR process in which the coefficients are correlated. Regis (2022) [
6] presented a structured overview of the literature on RCAR models. The autoregressive coefficient discussed in Regis (2022) [
6] incorporates a stochastic process, which is a characteristic also shared by our model. However, a key distinction lies in the time-varying nature of the random coefficient’s variance in our model. Furthermore, the existing structure in Regis (2022) [
6] to which our model relates is the Dynamic Factor Model (DFM) mentioned in Section 6.2 of Regis (2022) [
6]. The DFM consists of three equations relating to an observation, an unobservable latent process, and a time-varying parameter. Similarly, both models incorporate a state variable evolving as a random walk. The difference is that in the DFM the latent process has a linear time-varying autoregressive (TV-AR) structure, whereas in our model it is the observed process that has a nonlinear TV-AR structure. In this regard, the proposed model is at a higher level than the existing structures. This research introduces a novel model aimed at addressing gaps in the existing literature, with an enhanced ability to handle non-stationarity and non-linearity. By leveraging the strengths of multiple approaches, the proposed model offers a more robust framework for capturing the inherent complexity of the data. Moreover, the conventional nonparametric autoregressive models were discussed by Härdle et al. (1998) [
7], Kreiss and Neumann (1998) [
8], and Vogt (2012) [
9], where the nonparametric component is typically related to past observational variables. It is important to note that, despite their nonlinear nature, these models are fundamentally based on stationary processes.
Differing from the aforementioned, this paper presents a nonlinear, non-stationary AR model. There has been some work on non-stationary RCAR models. For instance, Berkes et al. (2009) [
10] considered a non-stationary RCAR(1) model by controlling the log expectation of the random coefficients. They demonstrated that, under such conditions, the variance of the error term cannot be estimated via the quasi-maximum-likelihood method, while proving the asymptotic normality of the quasi-maximum-likelihood estimators for the other parameters. Subsequently, Aue and Horváth (2011) [
11] proposed a unified quasi-likelihood estimation procedure for both the stationary and non-stationary cases of the model. By contrast, our model features an autoregressive coefficient represented as a potentially nonlinear unknown function. Additionally, its argument at each time-point is defined by a non-stationary unobservable state equation. While the estimation process becomes more intricate, it significantly broadens the model’s applicability. Our model is also regarded as a novel random coefficient autoregressive model, incorporating a time-varying state equation.
Time-varying parameter models are recognized for their superior predictive capabilities and adaptability to data, especially in economic contexts. One of the characteristics of time-varying parameter models is that their parameters change over time, also known as time-varying parameters. The class of TV-AR time series models has been extensively studied. Ito et al. (2022, 2014, 2016) [
12,
13,
14] studied the estimation of TV-AR and time-varying vector autoregressive (TV-VAR) models and applied them to stock prices and exchange rates. Dahlhaus et al. (1999) [
15] delved into nonparametric estimation for TV-AR processes. The autoregressive coefficient in our model is an unknown function that depends on an unobservable state variable. This state variable is time-varying. Compared with the traditional TV-AR model, our model is more suitable for handling nonlinear time series data and dynamic data.
Another important feature of our model is its non-stationarity. The combination of time-varying elements and non-stationary traits is particularly significant. The non-stationarity is primarily reflected through its state equation, which allows for the model to be interpreted within the framework of state-space models. These models were initially introduced for predicting rocket trajectories in the field of engineering control, as described by Kalman (1960) [
16]. A key advantage of state-space models is their capacity to incorporate unobservable state variables into an observable model, thereby enabling the derivation of estimation results. The integration of “state-space” concepts with time series analysis has emerged as a significant trend in statistics and economics, offering effective solutions to a variety of time series analysis problems. Theil and Wage (1964) [
17] discussed the model that decomposes time series into a trend term and a seasonal term from the perspective of adaptive forecasting. The model was based on an autoregressive integrated moving average (ARIMA) process. Gardner (1985) [
18] discussed the ARIMA(0,1,1) process from the perspective of exponential smoothing and demonstrated the rationality of the exponential smoothing method through a state-space model. State-space models offer a flexible way to decompose time series into observation and state equations. This flexibility enables better modeling of various components, including level, trend, and seasonality. Durbin and Koopman (2012) [
19] provided a comprehensive overview of the application of state-space methods to time series, encompassing linear and nonlinear models, estimation methods, statistical properties, and simulation studies. In recent years, there have been some advancements in applying state-space models to autoregressive time series. Kreuzer and Czado (2020) [
20] presented a Gibbs sampling approach for general nonlinear state-space models with an autoregressive state equation. Azman et al. (2022) [
21] implemented the state-space model framework for volatility incorporating the Kalman filter and directly forecasted cryptocurrency prices. Additionally, Giacomo (2023) [
22] proposed a novel state-space method by integrating a random walk with drift and autoregressive components for time series forecasting.
Existing RCAR and state-space models primarily analyze stationary processes. However, in practical applications like financial markets and macroeconomic data, time series often exhibit non-stationarity. And in time series, the effect of the previous moment on the current moment may not be fixed and is likely to change over time. To address these challenges, this paper introduces a novel model designed to accommodate such dynamic changes in time series. The autoregressive coefficient of our model is an unknown function of an unobservable state variable that is controlled by a non-stationary autoregressive state equation. The combination of nonlinearity, state-space formulation, and non-stationarity is novel and more suitable to explain real phenomena. Our model is applicable to a wide range of data types without presupposing the data distribution. Moreover, it offers an enhanced portrayal of data volatility, particularly for the non-stationary data with the trends and seasonality. Given the non-linear and non-stationary nature of our model, it is well suited to capture the complexities of time-varying financial and economic data. The accuracy of model fitting and prediction is improved because it takes into account the characteristics and variations of the data in a more comprehensive way.
Regarding the estimation methods, the existing methods are mainly based on the least squares and maximum likelihood classes of methods. These traditional methods usually require many conditions, such as the error terms being independent identically distributed (i.i.d.) or normally distributed. The introduction of the state equation enables estimation using the Kalman-smoothing method.This method eliminates the need for error terms to be i.i.d. or Gaussian, making it better suited for nonlinear and non-stationary scenarios while enhancing computational efficiency. This provides another efficient approach, especially when the model is extended to more complicated cases. A brief description of the methods used in this paper follows. The unknown function is initially estimated by using the local linear method. The ordinary least squares (OLS) and Kalman-smoothing methods are used to estimate the unobservable state variable. The variances of the errors are estimated using the OLS residuals. The theoretical underpinnings and development of these methods can be referred to in many studies in the literature. Fan and Gijbels (1996) [
23] and Fan (1993) [
24] presented the theory and utilization of local linear regression techniques. The OLS method, noted for its flexibility and broad applicability, is further elaborated by Balestra (1970) [
25] and Young and Basawa (1993) [
26]. For non-stationary stochastic processes, the Kalman-smoothing estimation method is particularly suitable, as discussed by Durbin and Koopman (2012) [
19]. Given the nonlinearity of our model, the ideology of extended Kalman filtering (EKF) (Durbin and Koopman (2012) [
19]) is used in this paper. Under the detectability condition that the filtering error tends to zero, Picard (1991) [
27] proved the EKF is a suboptimal filter, while the smoothing problem is also investigated. Pascual (2019) [
28] has also contributed to the understanding of EKF for the simultaneous estimation of state and parameters in a generalized autoregressive conditional heteroscedastic (GARCH) process. Some traditional understanding of Kalman filtering can also be found in Craig and Robert (1985) [
29], Durbin and Koopman (2012) [
19], Yan et al. (2019) [
30], Hamilton (1994) [
31].
The rest of this paper is organized as follows.
Section 2 introduces the random coefficient autoregressive model driven by an unobservable state variable.
Section 3 details the estimation methods and their corresponding algorithms.
Section 4 presents the results of numerical simulations. The model is applied to a real stock indices dataset for trend forecasting in
Section 5. Finally,
Section 6 concludes the paper.
2. Model Definition
In this section, a new random coefficient autoregressive model is introduced. It differs from traditional random coefficients, which usually consist of a constant and a function of time. This aspect of the model presents one of the methodological challenges discussed in this paper.
The random coefficient autoregressive model driven by an unobservable state variable is defined as
for
, where:
- (i)
is an observable variable and is an unobservable state variable;
- (ii)
and are two independent sequences of i.i.d. random variables. is independent of , and is independent of . The residual variances, and , are assumed to be constant;
- (iii)
The unknown function is bounded. It has bounded and continuously differentiable up to order 2;
- (iv)
For the initial value of and , we assume and
Remark 1. For the setting of initial values, the more general conditions can also be considered. The use of ’burn-in’ period would yield a more appropriate representation of a time series for . And could be assumed to follow a normal distribution with known mean and variance, i.e., . This may increase the volatility of the model. As our model is already non-stationary, these assumptions would not affect subsequent studies.
The first equation of (
1) is known as the observation equation, while the second is referred to as the state equation. The non-stationarity in our model stems from the cumulative nature of the state equation. The recursive formulation of the state equation,
, represents a random walk process. In particular, when
is the identity, the model coincides with the TV-AR model of Ito et al. (2022) [
12].
The subsequent proposition establishes the conditional mean, second-order conditional origin moment, and conditional variance of the model, which plays an important role in the study of the process properties and parameter estimation.
Proposition 1. Suppose is a process defined by (1), and is a σ-field generated by . Then, when , we have - (1)
- (2)
- (3)
Proof. According to (
1), we have
- (1)
- (2)
- (3)
□
4. Simulation
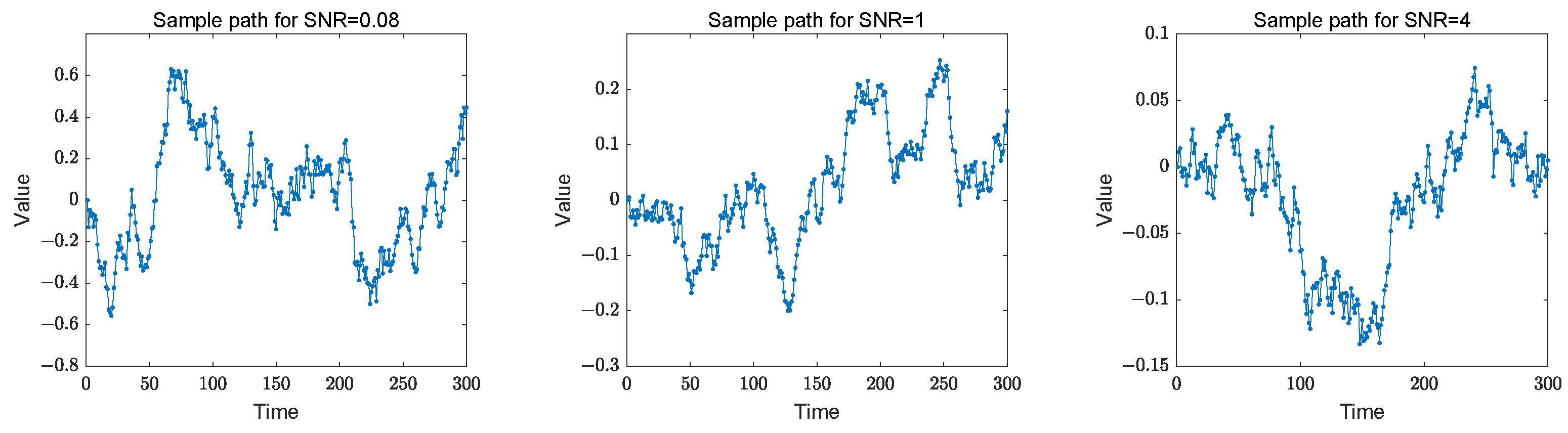
In this section, the numerical simulations of the two proposed methods are utilized to assess the effectiveness of parameter estimation under identical conditions. We select sample of sizes
with
replications for each parameter configuration. Given the non-stationarity of our model, the Gaussian kernel function is applied throughout the simulation, defined as
. Compared to other kernel functions, the Gaussian kernel is widely used for its smoothing and good mathematical properties, especially when dealing with data with different variances and distributions, which helps to reduce the variance of the estimates and provide stable estimates. Since the Gaussian kernel function is used for kernel density estimation, we employ Silverman’s (1986) [
32] “rule of thumb” to select the bandwidth, which is given by
, where
is the standard deviation of the dependent variable. This is a common practice in the field. In the data generation process, experimental data are generated according to model (
1), with
. The selection of these parameters is relevant to the results of the real data example. Meanwhile, the signal-to-noise ratio (SNR) serves as a guide, calculated as the variance of
relative to
(Ito et al. (2022) [
12]). Consequently, three representative SNR values, {0.08, 1, 4}, are considered by adjusting the variance of the error term in the observation equation. These three sample paths of our model are plotted in
Figure 1. We can see that the sample paths are non-stationary and that variation in the parameter combinations results in a change in the sample dispersion of the samples.
The performance of the parameter estimates derived from the two methods is assessed using the mean absolute deviation (MAD) and the mean squared error (MSE). Let
represent the true values and
represent the corresponding estimates. The sample means and the evaluation criteria are defined as:
The MAD compares each element of
and can be interpreted as the median distance between the estimate and the true process, reflecting the level of similarity between
and
. The non-stationary nature of the data generation process can sometimes lead to the occurrence of outliers. In our analysis, we focus on the means of the estimated parameters. The simulated results are summarized in
Table 1 and
Table 2. The estimators of
and
, derived from Equation (
9), are formulated as follows:
where
represents the observation at time
t, generated by each repetition. The simulation results are given in
Table 3. As the sample size increases, the variance estimates asymptotically approach the true values, reflecting the consistency of the estimators.
Table 1 and
Table 2 display some important statistical metrics for the estimators obtained by 1000 replications across various sample sizes. First, note that the order of magnitude of the MAD is much larger compared to the order of magnitude of
. As shown in (
14), the comparison between
and
is the mean of all the true and estimated values. Since the expectation of
is 0, the overall means of the sample are all very close to 0. In contrast, the MAD compares each element of the true and estimated values at the corresponding time point. Also, the values of
can be both positive and negative. As a result, they may cancel each other out when absolute values are not used. This, combined with the variability of
, explains why MAD exhibits a relatively large magnitude. Observing the trend, both the MAD and MSE decrease with an increase in sample size. This trend indicates that the precision of the OLS and Kalman-smoothing estimations improves as the sample size grows. Specifically, for smaller sample sizes (e.g.,
), the estimation error is relatively large. However, as the sample size increases to
, the error metrics for both methods decrease significantly, indicating that larger sample sizes reduce estimation error and improve the predictive performance. Additionally, while varying parameter selections have a minimal impact on the estimation outcomes, it is evident that the impact on the two methods is different. OLS performs better at lower SNR values, as indicated by the smaller MAD and MSE in
Table 1 for
. The Kalman-smoothing works relatively well when the SNR approaches 1. Furthermore, in the assessment of performance for nine different parameter settings, including various SNR and sample sizes
T, based on the comparison of the 18 MAD and MSE values in
Table 1 and
Table 2, the OLS estimation performs better for 4 values, while the Kalman-smoothing estimation performs better for the remaining 14 values. But their differences are very small. In practice, the Kalman-smoothing estimation is observed to be more computationally efficient. Therefore, for models of this nature, the Kalman-smoothing estimation may be deemed more appropriate.
Table 3 shows the behavior of the OLS residuals. As the sample size increases, the residuals get closer to the true values. This is an expected result since larger sample sizes typically have higher accuracy.
We calculate the mean of the estimation measures to focus on the overall performance of the methods. However, this approach does not allow us to verify the proximity of each estimated value
to the true
across the sample period. Moreover, as the sample size increases, the number of parameters to be estimated also grows, potentially introducing a significant bias in fitting the function
. To address this, we fit the curves of
by substituting the true
into the estimator
from Equation (
4). Due to the fact that there are as many estimators as observations
T and the non-stationarity of the model, the asymptotic theories are not involved in the previous section. However, the asymptotic nature of
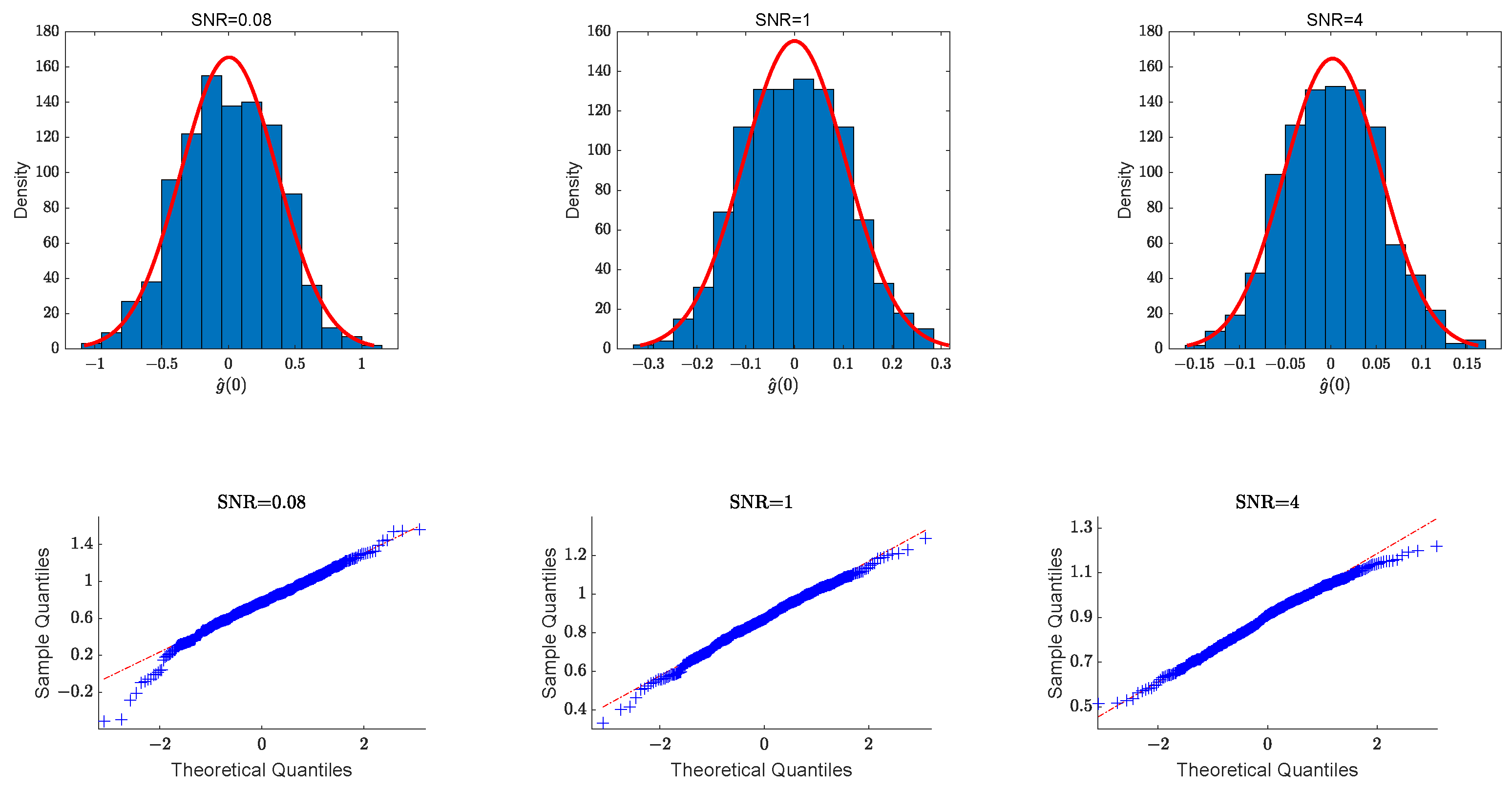
is verified using histograms and Q-Q plots. Since the values of
are near 0,
Figure 2 shows the histograms and Q-Q plots of
at point 0 for three parameter selections when the sample size is
. We can see that the vertical bars and distribution curves in the histograms and the scatter and straight lines in the Q-Q plots are very close to each other, meaning that empirically the estimates of the unknown function are asymptotically normal.
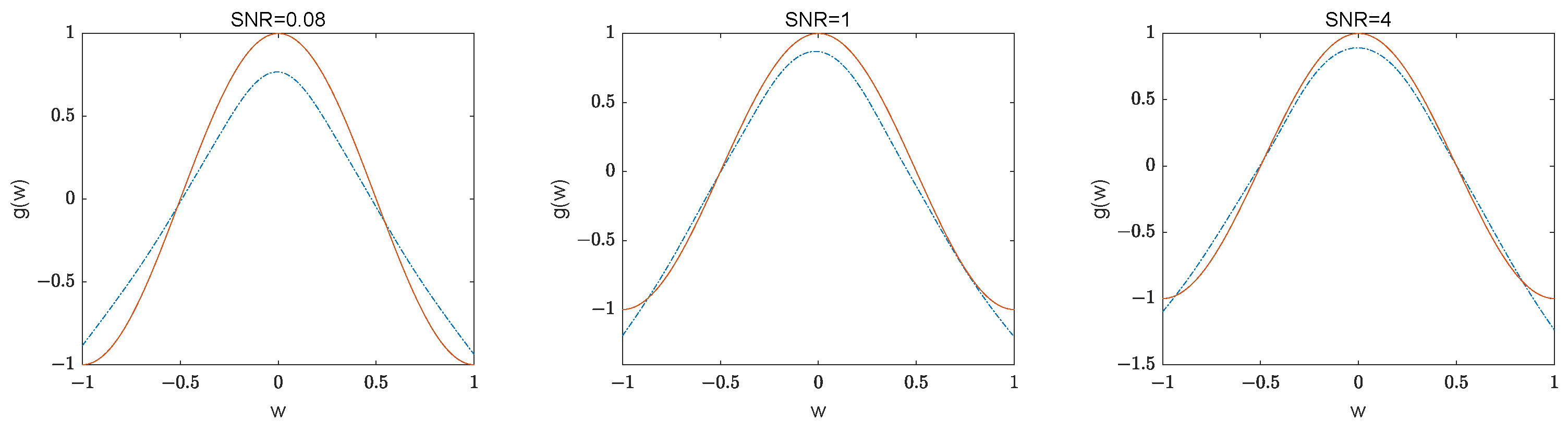
Figure 3 presents the fitted curves of the function for SNR = {0.08, 1, 4} with sample size
. It is evident that the fitted curves are close to the real curves. The estimators for the unknown function
are assessed using the root mean squared error (RMSE), defined as RMSE =
, where
represent the regular grid points.
Table 4 indicates that the RMSE values for
are small and decrease as the sample size increases.
In summary, the simulation results substantiate the validity and effectiveness of the estimation methods used in this paper.
5. Real Data Example
This section utilized the closing points of the S&P/HKEX Large Cap Index (SPHKL) to demonstrate an application of our model and estimation methods. The dataset, spanning from 6 September 2020 to 28 January 2024, is accessible online at the website (
https://cn.investing.com/indices/s-p-hkex-lc-chart, accessed on 11 February 2024). A stock index encapsulates the overall trend and volatility of stock prices in the market, making it a complex financial time series with characteristics such as time dependence, nonlinearity, and non-stationarity. Given these attributes, forecasting stock indices holds substantial practical importance for both investors and regulatory bodies. The dataset comprises 178 weekly observations, and
Figure 4 illustrates their closing points along with the Partial Autocorrelation Function (PACF) plots. It is intuitively obvious from the sample path that the dataset is non-stationary.
We have also performed the Augmented Dickey–Fuller (ADF) test to examine the stationarity of the data. The results indicate the presence of unit root, with the
p-value of 0.2172, suggesting that the dataset exhibits non-stationary behavior with a stochastic trend. The PACF plot corroborates this by revealing first-order autocorrelation, validating the suitability of our model for this dataset. The descriptive statistics for the data are displayed in
Table 5. Its large variance implies that the data exhibit higher volatility and randomness, and the complexity of data interpretation also increases accordingly.
For the analysis, the dataset is divided into a training set, encompassing 168 data points from 6 September 2020 to 19 November 2023 and a test set, comprising 10 data points from 26 November 2023 to 28 January 2024. The training set is used to fit the model and estimate the parameters, while the test set serves to evaluate the predictive ability of the model. The OLS method is used to estimate the parameters. The local linear regression method, as defined by
in Equation (
4), is used to estimate the function. The estimator of function
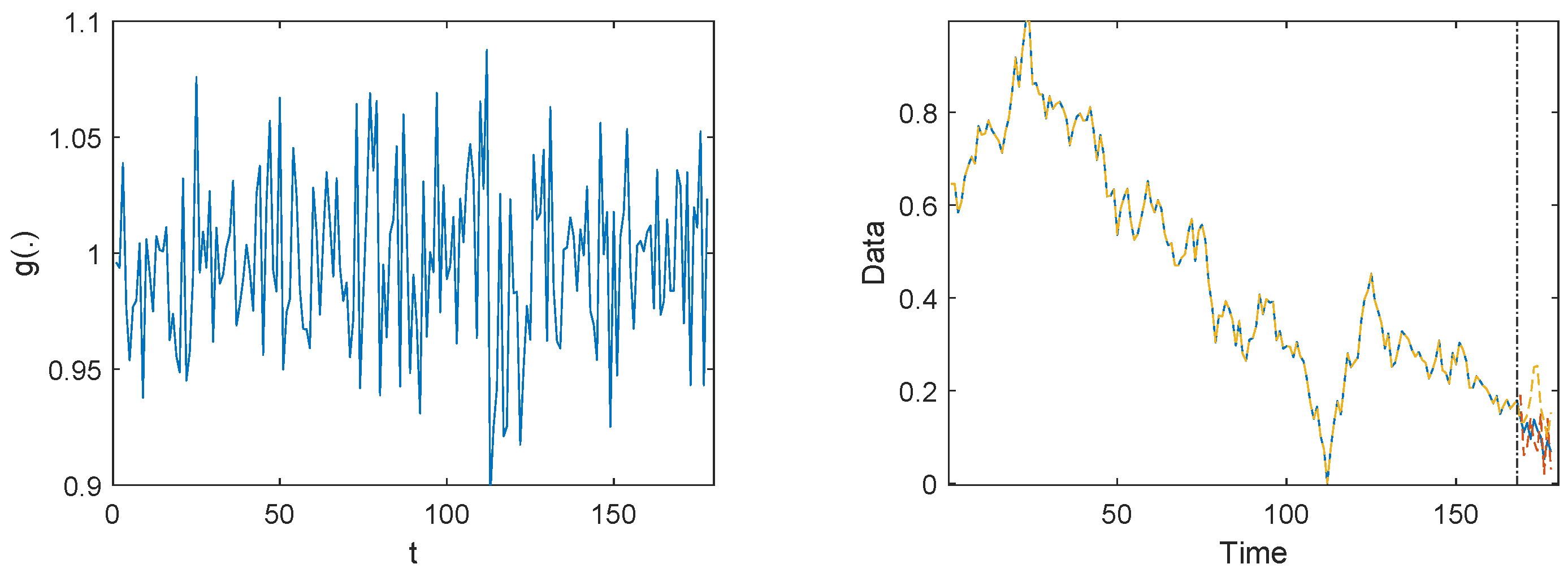
is presented in
Figure 5. From the figure, we can see that there is a clear unsteady volatility. This volatility suggests that the model captures the dynamics in the time series data and that the autoregressive coefficient is not constant but varies over time. The estimated value of
is 0.0016, while the variances are estimated as
and
.
The h-step-ahead predictive values of the stock index data are formulated as follows:
The training set expands as more observations become available because
changes with
t. That is, for each additional prediction step, a further
must be estimated. Because of the large order of magnitude of the sample data, the data are Min-Max Normalized
to eliminate the impact of the order of magnitude, allowing the data to be analyzed at the same scale. The descriptive statistics for the transformed data are displayed in
Table 6. The sample path of the normalized data and the forecast data are presented in
Figure 5. It is shown that the prediction on the test set seems to overestimate variability. This may be due to the complexity of our model, which could lead to overfitting. This overfitting may result in the model capturing noise in the training data rather than the underlying data-generating process, thereby inflating the estimated variability.
The mean absolute deviation (MAD) and the root mean square error (RMSE) between the real stock index data and the predicted data are used to evaluate the predictive effectiveness of the model.
Table 7 presents the results, comparing our model’s predictive performance with the RCA(1) model proposed by Nicholls and Quinn (1982) [
1], which is defined as
, where
is a constant parameter,
is a random term with mean zero and variance
. The parameter estimates we obtained using the least squares method are
= 0.99207 and
= 0.05494. The data predicted by the RCA(1) model are also shown in
Figure 5. A comparison of the prediction curves demonstrates that our model outperforms the RCA(1) model in predicting non-stationary data.
The results verify the performance of our model and method. To verify the adequacy of the model, we analyze the standardized Pearson residuals.
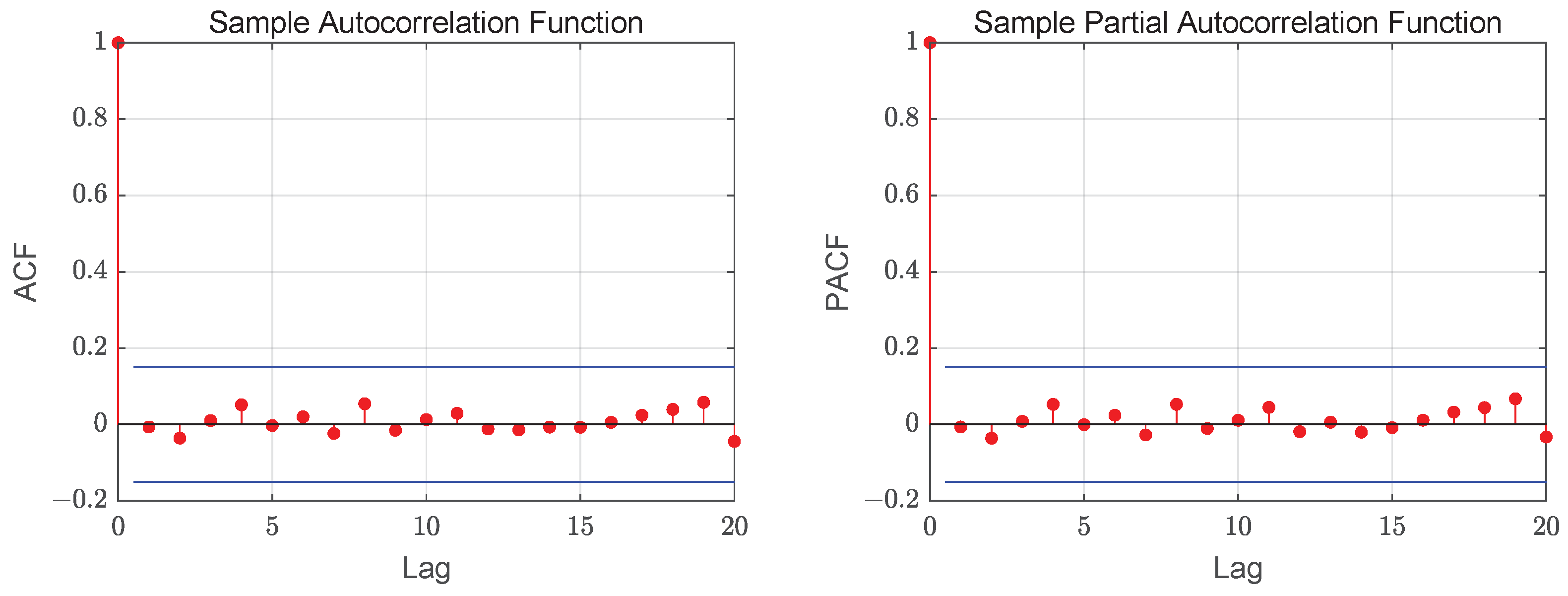
Figure 6 exhibits the ACF and PACF plots of the residuals, which indicate the absence of correlation among the residuals. For our model, the mean and variance of the Pearson residuals are 0.0685 and 1.0003, respectively. As discussed in Aleksandrov and Wei (2019) [
33], for an adequately chosen model, the variance of the residuals should take a value approximating 1. Accordingly, the proposed model is deemed to fit the data satisfactorily.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}