1. Introduction
Metaheuristic algorithms (MAs) nowadays represent the standard approach to complex engineering optimization problems. The popularity of these algorithms is demonstrated by the wide variety of applications of MAs to various fields of science, engineering and technology. For example, some areas that can be mentioned include static and dynamic structural optimization [
1,
2], mechanical characterization of materials and structural identification (also including damage identification) [
3,
4,
5], vehicle routing optimization [
6], optimization of solar devices [
7], forest fire mapping [
8], urban water demand [
9], 3D printing process optimization [
10], identification of COVID-19 infection and cancer classification [
11,
12] image processing including feature extraction/selection [
13].
Unlike gradient-based optimizers, MAs are stochastic algorithms that do not use gradient information to perturb design variables. In metaheuristic optimization, new trial solutions are randomly generated according to the inspiring principle of the selected algorithm. The trial solutions generated in each iteration attempt to improve the best record obtained so far. Exploration and exploitation are the two typical phases of metaheuristic search. In exploration, optimization variables are perturbed to a great extent to try to quickly identify the best regions of the design space, while exploitation performs local searches in a set of selected neighborhoods of the most promising solutions. Exploration governs the optimization search in the early iterations, while exploitation dominates as soon as the optimizer converges toward the global optimum.
Several classifications of MAs have been proposed in the literature. The first distinction is between single-solution algorithms where the optimizer updates the position of only one search agent and population-based algorithms where the optimizer operates on a population of candidate designs or search agents. However, the single-point search is limited to a few classical algorithms, such as simulated annealing and tabu search. Hence, the vast majority of MAs are population-based optimizers and their classification relies on the inspiring principle that drives the metaheuristic search. In this regard, MAs can be roughly divided into four categories: (i) evolutionary algorithms; (ii) science-based algorithms; (iii) human-based algorithms; (iv) swarm intelligence-based algorithms.
Evolutionary algorithms imitate evolution theory and evolutionary processes. Genetic algorithms (GAs) [
14,
15], differential evolution (DE) [
16,
17], evolutionary programming (EP) [
18], evolution strategies (ES) [
19], biogeography-based optimization (BBO) [
20] and black widow optimization (BWO) [
21] fall in this category. GAs and DE algorithms certainly are the most popular evolutionary algorithms. Their success is demonstrated by the about 7000 citations gathered by Refs. [
14,
15] and the 23,030 citations gathered by Ref. [
16] in the Scopus database over about 35 years (a total of about 860 citations/year up to October 2024). GAs are based on Darwin’s concepts of natural selection. Selection, crossover and mutation operators are used for creating a new generation of designs starting from the parent designs stored in the previous iteration. DE includes four basic steps: random initialization of the population, mutation, recombination and selection. GAs and DE mainly differ in the selection process for generating the next generation of designs that will be stored in the population.
Science-based MAs mimic the laws of physics, chemistry, astronomy, astrophysics and mathematics. Simulated annealing (SA) [
22,
23], charged system search (CSS) [
24], magnetic charged system search (MCSS) [
25], ray optimization (RO) [
26], colliding bodies optimization (CBO) [
27], water evaporation optimization (WAO) [
28], thermal exchange optimization (TEO) [
29], equilibrium optimizer (EO) [
30] and light spectrum optimizer (LSO) [
31] are examples of physics-based MAs. Generally speaking, the above-mentioned methods tend to reach the equilibrium condition of mechanical, electro-magnetic or thermal systems under external perturbations. Optics-based methods such as RO and LSO utilize the concepts of refraction and dispersion of the light to set directions for exploring the search space. SA certainly is the most popular science-based metaheuristic algorithm considering the about 33,940 citations gathered by Ref. [
22] in the Scopus database over 42 years (about 810 citations/year up to October 2024). SA mimics the annealing process in liquid or solid materials that reach the lowest energy level (a globally stable condition) as temperature decreases. The SA search strategy is rather simple: (i) a new trial solution replaces the current best record if it improves it; (ii) otherwise, a probabilistic criterion indicates if solution may improve the current best record in the next iteration. The “temperature” parameter is used in SA for computing probability and is progressively updated as the optimization progresses. SA has an inherent hill-climbing capacity given by search strategy (ii) that allows local minima to be eventually bypassed in the next iterations.
The artificial chemical reaction optimization algorithm (ACROA) [
32], gas Brownian motion optimization (GBMO) [
33] and Henry gas solubility optimization (HGSO) [
34] are examples of chemistry-based MAs that also rely on important physics concepts such as Brownian motion and Henry’s law. ACROA simulates interactions between chemical reactants: the positions of search agents correspond to concentrations and potentials of reactants and they are no longer perturbed when no more reactions can take place. GBMO utilizes the law of motion, the Brownian motion of gasses and turbulent rotational motion to search for an optimal solution; search agents correspond to molecules and their performance is measured by their positions. HGSO mimics the state of equilibrium of a gas mixture in a liquid; search agents correspond to gasses and their optimal positions correspond to the equilibrium distribution of gasses in the mixture. HSGO is the most popular algorithm in this sub-category considering the about 780 citations (up to October 2024) gathered by Ref. [
34] five years after its release.
Big bang–big crunch optimization (BB-BC) [
35], the gravitational search algorithm (GSA) [
36], galaxy-based search algorithm (GBSA) [
37], black hole algorithm [
38], astrophysics-inspired grey wolf algorithm [
39] and supernova optimizer [
40] are examples of MAs that mimic astronomical or astrophysical phenomena, such as the expansion (big bang)–contraction (big crunch) cycles that lead to the formation of new star–planetary systems, the spreading of stellar material following supernovae explosions, gravitational interactions between masses, interactions between black holes and starsand the movement of spiral galaxy arms, which also introduces the concept of elliptical orbit in the hunting process of wolves. GSA and BB-BC are the most popular algorithms in this sub-category, considering the about 6030 and 1280 citations, respectively, gathered by Refs. [
35,
36] in the Scopus database over almost two decades (a total of about 415 citations per year).
The sine cosine algorithm (SCA) [
41], the Runge–Kutta optimizer (RUN) [
42] and the arithmetic optimization algorithm (AOA) [
43] are inspired by mathematics. In the SCA, candidate solutions fluctuate outwards or towards the best solution using a mathematical model based on sine and cosine functions. RUN combines a slope calculation scheme based on the Runge–Kutta method with an enhanced solution quality mechanism to increase the quality of trial designs. The AOA uses the four basic arithmetic operators (i.e., addition, subtraction, multiplication, division) to perturb the design variables of the current best record: in particular, multiplication and division drive the exploration phase, while addition and subtraction drive the exploitation phase. The AOA and RUN, respectively, were associated with about 1830 and 705 citations in Scopus after only 3 years from their release (a total of 845 citations/year). The SCA also achieved a considerable number of citations, about 4040 over 8 years with an average of about 505 citations/year up to October 2024.
Human-based MAs mimic human activities (e.g., talking, walking, playing, exploring new places/situations), behaviors (e.g., natural tendency to look for the best and avoid the worst, parental cares, teaching–learning, decision processes) and social sciences (including politics). Tabu search (TS) [
44,
45] was the first human-based MA and was developed about 40 years ago. TS is inspired by the ancestral concept that sacred things cannot be touched: hence, in the optimization process, local search is performed in the neighborhood of candidate solutions and solutions that do not improve the design are stored in a database so that the optimizer will not explore them and their neighborhoods further. Harmony search optimization (HS), which simulates the music improvisation process of jazz players [
46,
47], teaching–learning-based optimization (TLBO) [
48], which simulates the teaching–learning mechanisms in a classroom and JAYA [
49] using just one single equation to perturb the optimization variables to approach the current best record and escape from the worst candidate solution, are the most popular human-based MAs according to the number of citations reported in the Scopus database. In particular, TLBO achieved the highest average number of citations/year (about 300) and was cited in about 3920 papers since its release in 2011 as of October 2024. TLBO is followed by JAYA (about 250 citations/year for about 2000 citations gathered over 8 years and a huge number of variants and hybrid schemes) and HS (about 235 citations/year for 5450 citations over 23 years).
The learning process is an important source of inspiration in human-based MAs. This is demonstrated by the group teaching optimization algorithm (GTOA) [
50], another teaching–learning-based algorithm where students (i.e., candidate solutions) are divided into groups according to defined rules; the teacher (current best record) adopts specific teaching methods to improve the knowledge of each group. The mother optimization algorithm (MOA) [
51] mimics the human interaction between a mother and her children, simulating the mother’s care of her children in education, advice and upbringing. The preschool education optimization algorithm (PEOA) [
52] simulates the phases of children’s preschool education, including (i) the gradual growth of the preschool teacher’s educational influence, (ii) individual knowledge development guided by the teacher and (iii) individual increases in knowledge and self-awareness. The learning cooking algorithm (LCA) [
53] mimics the cooking learning activity of humans: children learn from their mothers, and children and mothers learn from a chef. The decision making behavior of humans is instead simulated by the collective decision optimization algorithm (CDOA) [
54]: candidate solutions are generated by operators reproducing the different phases of the decision process that can be experience-based, others-based, group thinking-based, leader-based and innovation-based.
The imperialist competitive algorithm (ICA) [
55] and the political optimizer (PO) [
56] are based on politics, another important human activity. The ICA simulates the international relationships between countries: search agents represent countries that are categorized into colonies and imperialist states; powerful empires take possession of the former colonies of weak empires. Imperialistic competitions direct the search process toward the powerful imperialist or the optimum points. PO simulates all the major phases of politics (i.e., constituency allocation, party switching, election campaign, inter-party election and parliamentary affairs); the population is divided into political parties and constituencies, thus facilitating each candidate to update its position with respect to the party leader and the constituency winner. Learning behaviors of the politicians from the previous election are also accounted for in the optimization process.
Swarm intelligence-based algorithms reproduce the social/individual behavior of animals (insects, terrestrial animals, birds, and aquatic animals) in reproduction, food search, hunting, migration, etc. Most of the newly published MAs belong to this category. Particle swarm optimization (PSO) [
57,
58,
59], developed in 1995, is the most popular MA overall: in particular, the seminal studies [
57,
58] gathered about 73,550 citations over 29 years in the Scopus database; the average citation rate is about 2535 articles/year, more than three times higher than for SA. PSO simulates interactions between individuals of bird/fish swarms. If one leading individual or a group of leaders see a desirable path to go through (for food, protection, etc.), the rest of swarm quickly follows the leader(s), even in the absence of direct connections. In the optimization process, a population of candidate designs (the particles) is generated. Particles move through the search space and their positions and velocities are updated based on the position of the leader(s) and the best positions of individual particles in each iteration until the optimum solution is reached.
Insect behavior has also inspired MA experts to a great extent. Ant system and colony optimization (AS, ACO) [
60,
61,
62], which mimic the cooperative search technique in the foraging behavior of real-life ant colonies, artificial bee colony (ABC) [
63], which simulates the nectar search carried out by bees, the firefly algorithm (FFA) [
64,
65], which simulates the social behavior of fireflies and their bioluminescent communication, and ant lion optimizer (ALO) [
66], which simulates the hunting mechanism of ant lions, fall in this sub-category. The interest of the optimization community in insect-based MAs is confirmed by the high number of citations achieved by the algorithms mentioned above: about 11,320 for AS, ACO (i.e., 405 citations/year since 1996), 6335 for ABC (i.e., 370 citations/year since 2007), 2720 for ALO (i.e., about 300 citations/year since 2015) and 2895 for FFA (i.e., 207 citations/year since 2010) up to October 2024.
The grey wolf optimizer (GWO) [
67], coyote optimization algorithm (COA) [
68], snake optimizer (SO) [
69] and snow leopard optimization algorithm (SLOA) [
70] are MAs simulating the behavior of terrestrial animals. GWO and COA, respectively, mimic the hunting behavior of grey wolves and coyotes; SO mimics the mating behavior of snakes. SLOA is somehow more general than GWO, COA and SO as it perturbs optimization variables by means of operators simulating a wide variety of behaviors of a snow leopard, including travel routes and movement, hunting, reproduction and mortality. GWO is one of the most popular MAs considering the about 13,700 citations reported in Scopus since its release in 2014 up to October 2024: the average number of citations per year is about 1370, the second best amongst all MAs after PSO.
Cuckoo search (CS) [
71,
72], the crow search algorithm (CSA) [
73], starling murmuration optimizer (SMO) [
74] and bat algorithm (BA) [
75,
76] are MAs that mimic the behavior of birds and bats. While BA updates the population of candidate designs simulating the echolocation behavior of bats, CS reproduces the parasitic behavior of some cuckoo species that mix their eggs with those of other birds to guarantee the survival of their chicks. CSA simulates crows’ behavior concerning how they hide their excess food and retrieve it when the food is needed. SMO explores the search space by reproducing the flying behavior of starlings: exploration is carried out by means of the separating and diving search strategies while exploitation relies on the whirling strategy. CS is the most popular MA in this sub-category: the Scopus database reports about 8570 citations for Refs. [
71,
72] over 15 years with about 570 citations/year up to October 2024. CS is followed by BA (about 6030 citations for Refs. [
75,
76] since 2010 with about 430 citations/year) and CSA (about 1765 citations since 2016 with about 220 citations/year).
Among MAs inspired by aquatic animals, the following methods have to be mentioned. The dolphin echolocation algorithm (DE) [
77] simulates the hunting strategy of dolphins based on the echolocation of prey. The whale optimization algorithm (WOA) [
78] mimics the social behavior of humpback whales and, in particular, their bubble-net hunting strategy. The salp swarm algorithm (SSA) [
79] simulates swarming and foraging behaviors of ocean salps. The marine predators algorithm (MPA) [
80] updates design variables by simulating random walk movements (essentially Brownian motion and Lévy flight) of ocean predators. The giant trevally optimizer (GTO) [
81] mimics hunting strategies of giant trevally marine fish, including Lévy flight movement. WOA is the most popular algorithm in this sub-category: the Scopus database reports about 9790 citations since 2016 with an average rate of about 1225 citations/year. WOA is followed by SSA, which gathered about 3920 citations since 2017 with about 560 citations/year, and by MPA, which gathered about 1600 citations since 2020 with about 400 citations/year up to October 2024.
A large number of improved/enhanced variants for existing MAs, hybrid algorithms combining MAs with gradient-based optimizers, and hybrid algorithms combining two or more MAs have been developed by optimization experts (see, for example, Refs. [
82,
83,
84,
85,
86,
87,
88,
89,
90,
91,
92,
93,
94,
95,
96,
97,
98,
99,
100,
101,
102], published in the last two decades). High-performance MAs were often selected as component algorithms in developing hybrid formulations. The common denominator of all those studies was to find the best balance between exploration and exploitation phases that hopefully resulted in the following: (i) the optimizer’s ability to avoid local minima (i.e., hill-climbing capability, especially for algorithms including SA-based operators), keeping the diversity in the population, and avoiding stagnation and premature convergence to false optima; (ii) a reduction in the number of function evaluations (structural analyses, analyses) required in the optimization process; (iii) high robustness in terms of low dispersion on optimized cost function values; (iv) a reduction in the number of internal parameters as well as in the level of heuristics entailed by the search process. In general, these tasks were accomplished by (i) combining highly explorative methods with highly exploitative methods; (ii) forcing the optimizer to switch again to exploration if the exploitation phase started prematurely or the design did not improve for a certain number of iterations in the exploitation phase; (iii) introducing new perturbation strategies (for example, chaotic perturbation of the design; mutation operators to avoid stagnation and increase the diversity of the population; Lévy flight/movements in swarm-based methods, etc.) for optimization variables tailored to the specific MA under consideration.
Continuous increases in computing power have greatly favored the development of new metaheuristic algorithms (including enhanced variants and hybrid formulations). However, some aspects should carefully be considered in metaheuristic optimization: (i) according to the No Free Lunch theorem [
103,
104], no metaheuristic algorithm can always outperform all other MAs in all optimization problems; (ii) MAs often require a very large number of function evaluations (analyses) for completing the optimization process, even 1–2 orders of magnitude higher than their classical gradient-based optimizer counterparts; (iii) the easiness of implementation, which is typically underlined as a definite strength point of Mas, is very often nullified by the complexity of algorithmic variants or hybrid algorithms combining multiple methods; and (iv) sophisticated MA formulations often include many internal parameters that may be difficult to tune.
It should be noted that newly developed MAs often add very little to the optimization field and their appeal quickly vanishes just a few years after their release. This is confirmed by the literature survey presented in this introduction. The “classical” MAs developed prior to 2014, such as GA, DE, SA, PSO, ACO, CS, BA, HS, GSA, BBBC and GWO, gathered a much higher number of citations/year (up to 2535 until October 2024) than the MAs developed in 2015-2024, except for WOA, SCA, AOA/RUN, SSA, MPA, ALO, JAYA and CSA (up to 1225 citations/year). For this reason, the present study focused on improving available MAs rather than formulating a new MA from scratch. The main goal was to prove that a very efficient hybrid metaheuristic algorithm can be built by simply combining the basic formulations of two well-established MAs without complicating the formulation of the hybrid optimizer both in terms of number of strategies/operators used for perturbing the design variables and number of internal parameters (including parameters that regulate the switching from one optimizer to another).
In view of the arguments above, a very simple hybrid metaheuristic algorithm (SHGWJA, where the acronym stands for Simple Hybrid Grey Wolf JAYA) able to solve engineering optimization problems with less computational effort than the other currently available MAs was developed by combining two classical population-based MAs, namely the Grey Wolf Optimizer (GWO) and the Jaya Algorithm (JAYA). GWO and JAYA were selected in this study as the component algorithms of the new optimizer SHGWJA because of their simple formulations without internal parameters, and in view of the high interest of metaheuristic optimization experts in these two methods, proven by the various applications and many algorithmic variants documented in the literature. These motivations are detailed as follows.
- (1)
GWO, originally developed by Mirjalili et al. [
67] in 2014, is the second most cited metaheuristic algorithm after PSO in terms of citations/year. However, GWO has a much simpler formulation than PSO and, unlike PSO, does not require any setting of internal parameters. GWO mimics the hierarchy of leadership and group hunting of the grey wolves in nature: the optimization search is driven by the three best individuals that catch the prey and attract the rest of the hunters. Applications of GWO to various fields of science, engineering and technology are reviewed in Refs. [
105,
106].
- (2)
JAYA, originally developed by Rao [
49] in 2016, is one of the most cited MAs released in the last decade. It utilizes the most straightforward search scheme ever presented in the metaheuristic optimization literature for a population-based MA: to approach the population’s best solution and move away from the worst solution, thus achieving significant convergence capability. Hence, optimization variables are perturbed by JAYA using only one equation, thus minimizing the computational complexity of the search process. In spite of its inherent simplicity, JAYA is a powerful metaheuristic algorithm that has been proven able to efficiently solve a wide variety of optimization problems (see, for example, the reviews presented in [
107,
108]). An interesting argument made in [
107] may explain JAYA’s versatility. JAYA combines the basic features of evolutionary algorithms, in terms of the fittest individual’s survivability (such a feature is, however, common to all population-based MAs), and swarm-based algorithms where the swarm normally follow the leader during the search for an optimal solution. This hybrid nature, in addition to the inherent algorithmic simplicity, makes JAYA an ideal candidate to be selected as a component of new hybrid metaheuristic algorithms.
- (3)
Both GWO and JAYA do not have internal parameters that have to be set by the user, except the parameters common to all population-based MAs, such as population size and the limit on the number of optimization iterations.
- (4)
Both algorithms have good exploration capabilities but have weaknesses in the exploitation phase. The challenge is to combine their exploration capabilities to directly approach the global optimum. Elitist strategies may facilitate the exploitation phase, which only has to focus on a limited number of potentially optimal solutions to be refined.
Here, GWO and JAYA were simply merged, and the JAYA perturbation strategy was applied to improve the positions of the leading wolves, thus avoiding the search stagnation that may occur in GWO if the three best individuals of the population remain the same for many iterations. The original formulations of GWO and JAYA combined into the hybrid SHGWJA algorithm were slightly modified to maximize the search capability of the new algorithm and reduce the number of function evaluations required by the GWO and JAYA engines. However, while algorithmic variants of GWO and JAYA (including hybrid optimizers) usually include specific operators/schemes to increase the diversity of the population or/and improve the exploitation capability (this, however, increases the computational complexity of the optimizer) [
105,
106,
107,
108], SHGWJA adopts a very straightforward elitist approach. In fact, SHGWJA always attempts to improve the current best design of the population regardless of having generated new trial solutions in the exploration phase or exploitation phase. Trial solutions that are unlikely to improve the current best record stored in the population are directly rejected without evaluating constraints. This allows SHGWJA to reduce the computational cost of the optimization process by always directing the search process towards the best regions of the search space, and eliminating any unnecessary exploitation of trial solutions that cannot improve the current best record.
The proposed SHGWJA was successfully tested in seven “real-world” engineering problems selected from civil engineering, mechanical engineering and robotics. The selected test problems, including up to 14 optimization variables and 721 nonlinear constraints, regarded: (i) shape optimization of a concrete gravity dam (volume minimization); (ii) optimal design of a tension/compression spring (weight minimization); (iii) optimal design of a welded beam (minimization of fabrication cost); (iv) optimal design of a pressure vessel (minimization of forming, material, and welding costs); (v) optimal design of an industrial refrigeration system; (vi) 2D path planning (minimization of trajectory length); (vii) mechanical characterization of a flat composite panel under axial compression (by matching experimental data and finite element simulations). Test problems (ii) through (v) were included in the CEC 2020 (IEEE Congress on Evolutionary Computing) test suite for constrained mechanical engineering problems. Example (vii) is a typical highly nonlinear inverse problem in the fields of aeronautical engineering and mechanics of materials. Besides the seven “real-world” engineering problems listed above, two classical mathematical optimization problems (i.e., Rosenbrock’s banana function and Rastrigin’s function) with up to 1000 variables were solved in this study to evaluate the scalability of the proposed algorithm.
For all test cases, the optimization results obtained by SHGWJA were compared with those quoted in the literature for the best-performing algorithms. SHGWJA was compared with at least 10 other MAs, each of which had been reported in the literature to have outperformed in turn up to 35 other MAs. Comparisons with high performance algorithms and CEC competitions winners such as LSHADE and IMODE variants as well as with other MAs that were reported to outperform CEC winners (i.e., MPA and GTO among others) also are presented in the article.
The rest of the article is structured as follows.
Section 2 recalls formulations of GWO and JAYA, while
Section 3 describes the new hybrid optimization algorithm SHGWJA developed in this research. Test problems and implementation details are presented in
Section 4, while optimization results are presented and discussed in
Section 5. In the last section, the main findings are summarized, and directions of future research are outlined.
3. The SHGJA Algorithm
The simple hybrid metaheuristic algorithm SHGWJA developed in this research combined the GWO and JAYA methods to improve search by means of elitist strategies. The new algorithm is very simple and efficiently explores the search space. This allows for limiting the number of function evaluations. The new algorithm is now described in detail. A population of
NPOP candidate designs (i.e., wolves) is randomly generated as follows:
where NDV is the number of optimization variables;
and
, respectively, are the lower and upper bounds of jth variable;
is a random number extracted in the interval (0, 1).
Considering the classical statement of the optimization problem where the goal is to minimize the function
W(
) of NDV variables (stored in the design vector
), subjected to
NCON inequality/equality constraint functions of the form G
k(
) ≤ 0, the penalized cost function
Wp(
) is defined as follows:
where
p is the penalty coefficient. The penalty function
is defined as follows:
The penalized cost function Wp() obviously coincides with the cost function W() if the trial solution is feasible. Candidate solutions are sorted with respect to penalized cost function values: the current best record corresponds to the lowest value of .
The best three search agents achieving the lowest penalized cost values are set as the wolves α, β and δ. Let , and be the corresponding design vectors. It obviously holds that Wp() < Wp() < Wp(). The α wolf is also set as the current best record and the corresponding penalized cost function Wp() is set as Wp,opt.
Each individual
of the population is provisionally updated with the classical GWO Equations (1) through (7). As in [
67], the components of the
vector linearly decrease from 2 to 0 as the optimization goes by in SHGWJA. Let
denote the new trial solution obtained by perturbing the generic individual
stored in the population in the previous iteration.
Each new trial design generated in Step 1 via classical GWO with Equations (1) through (7) is evaluated by SHGWJA using two new operators. In GWO implementations, each new design is compared with its counterpart solution previously stored in the population. If the new design is better than the old design it is stored in the updated population in the current iteration, replacing the old design. However, this task requires a new evaluation of the constraint functions for each new .
In order to reduce the computational cost, SHGWJA implements an elitist strategy, retaining only the trial solutions that are likely to improve the current best record. Hence, SHGWJA initially compares only the cost function W() of the new trial solution with 1.1 times the cost function W() of the current best record. If the new trial design does not improve the current best record—i.e., if W() > 1.1W() holds— it is not necessary to process it further and the old design is provisionally maintained also in the new population.
The 1.1
W(
) threshold has proven to be effective in all test problems solved in this study. Such a behavior may be explained in the following way. In the exploration phase, the optimizer assigns large movements to design variables and the probability to improve design is high: hence, the
W(
) > 1.1
W(
) scenario will not be likely to occur. In the exploitation phase, the optimizer should bypass local minima to find the global optimum: like SA, the optimizer may accept candidate solutions slightly worse than
. Looking at the probabilistic acceptance/rejection criterion used by advanced SA formulations [
84,
93], it can be seen that the threshold level of acceptance probability is 0.9 if the γ ratio between the cost function increment recorded for the trial solution
with respect to the current best record
and the annealing temperature
T is 0.1; hence, the probability of provisionally accepting some design worse than
and improving it in the next iterations is 90%. Since the initial value of the
T temperature set in SA corresponds to the expected optimum cost (or the cost value of the current best record), it may be reasonably assumed that trial solutions up to 10% worse than
would become better than
in the next iterations.
However, the new design
is generated by classical GWO to try to approach the position of the best three individuals, the wolves
α,
β and
δ. To avoid stagnation, the
design is perturbed using a JAYA-based scheme if the classical GWO generation was unsuccessful and the trial solution
did not satisfy the condition
W(
) ≤ 1.1
W(
). That is, the following holds:
If the classical GWO generation was successful and trial design
satisfied the condition
W(
) ≤ 1.1
W(
), the JAYA scheme is applied directly to
as follows:
In Equations (12) and (13), and are two vectors including NDV random numbers in the interval [0, 1]. The absolute values of optimization variables (like the values in Equation (8)) are taken for each component Xj,i or Xj,i,tr of vectors or , respectively.
The cost function W(()′) is evaluated also for the new trial design defined by Equations (12) or (13). W(()′) is compared with 1.1W(). The modified trial design ()′ is always directly rejected if it certainly does not improve the current best record, that is, if the condition W(()′) > 1.1W() is satisfied. If W(()′) ≤ 1.1W() and W() ≤ 1.1W(), W(()′) and W() are compared. ()′ is used to update the population if W(()′) ≤ 1.1W() or is used if W(()′) > W().
Equation (12) is related to exploration. In fact, it tries to involve the whole population in the formation of the new trial design ()′ because the α, β and δ wolves could not move the other search agents (i.e., ) to better positions of search space near the prey (i.e., ) with respect to the previous iteration. Since the main goal of the population renewal task is to improve each individual , SHGWJA tries searching on descent direction with respect to (the cost function certainly improves, moving from a generic individual towards the current best record) and escapes from the worst individual of population , which certainly may not improve .
Equation (13) is instead related to exploitation because it operates on a good trial solution dictated by wolves α, β and δ. This design is very likely to be close to or even to improve it. The δ wolf is temporarily selected as the worst individual of the population. This forces SHGWJA to locally search in a region of design space containing high-quality solutions like the three best individuals of the population.
When all have been updated by SHGWJA via the classical GWO scheme based on Equations (1) through (7) or the JAYA-based schemes of Equations (12) and (13), and their quality has been evaluated using the elitist strategy W() ≤ 1.1W(), the population is re-sorted and the NPOP individuals are ranked with respect to penalty function values. Should Wp() or Wp(()′) be greater than Wp(), all new trial solutions generated/refined for are rejected and the old design is retained in the population.
SHGWJA sets the best three individuals of the new population as wolves α, β and δ with , and design vectors, respectively. The best and worst solutions are set as and , respectively.
The present algorithm attempts to avoid stagnation by checking the ranking of wolves
α,
β and
δ with an elitist criterion. This is achieved each time that the wolves’ positions are not updated in the current iteration. The elitist criterion adopted by SHGWJA relies on the concept of descent direction.
and
are obviously descent directions with respect to the positions
and
of wolves
β and
δ. Hence, SHGWJA perturbs
and
along the descent directions
and
. The positions of
β and
δ wolves are “mirrored” with respect to
as follows:
In Equation (14), the random numbers ηmirr,β and ηmirr,δ are extracted in the (0, 1) interval. They limit step sizes to reduce the probability of generating infeasible positions. The best three positions amongst , , , and are set as the α, β and δ wolves in the next iteration. The two worst positions are compared with the rest of the population to see if they can replace and the second worst design of old population. The latter check also covers the scenario where and could not improve any of the α, β and δ wolves.
Figure 1 illustrates the rationale of the mirroring strategy adopted by SHGWJA. The figure shows the following: (i) the original positions of the
α,
β and
δ wolves (respectively, points P
opt≡P
α, P
β and P
δ of the search space); (ii) the positions of mirror wolves
βmirr and
δmirr (respectively, points P
β,mirr and P
δ,mirr of search space); (iii) the cost function gradient vector
evaluated at
, that is, wolf
α. The “mirror” wolves
βmirr and
δmirr— i.e.,
and
— defined by Equation (14) lie on descent directions and may even improve
(i.e., the position of wolf α). In fact, the conditions
and
hold, where “
” denotes the scalar product between two vectors. Since
is in all likelihood a steeper descent direction than
, the
δ wolf may have a higher probability than wolf
β of replacing wolf
α even though wolf
β occupies a better position than wolf
δ in the search space. The consequence of this elitist approach is that SHGWJA must perform a new exploration of the search space instead of attempting to exploit trial solutions that did not improve the design in the last iteration. Furthermore, the replacement of the two worst designs of population improves the average quality of search agents and increases the probability of defining higher-quality trial solutions in the next iteration.
The standard deviations of design variables and cost function values of search agents decrease as the search approaches the global optimum. Therefore, SHGWJA normalizes standard deviations with respect to the average design
and the average cost function
. The convergence criterion used by SHGWJA is the following:
where the convergence limit
is equal to 10
−7. Equation (15) is based on the following rationale. The classical convergence criteria of optimization algorithms compare the cost function values with
as well as the best solutions set as
obtained in the last iterations, and stop the search process if both these quantities do not change more than the fixed convergence limit. Accounting for variation in the best solution
allows for avoiding local minima if the optimizer enters a large region of the design space containing many competitive solutions with the same cost function values. However, this approach may not be effective in population-based algorithms where all candidate designs stored in the population should cooperate in searching for the optimum. For example, it may occur that the optimizer updates only sub-optimal solutions and leaves
unchanged over many iterations. Should this occur, the optimizer would stop the search process while there is still a significant level of diversity in the population, which is a typical scenario of the exploration phase dominating the early stage of the optimization process. Equation (15) assumes instead that all individuals are in the best region of the search space which hosts the global optimum and cooperate in the exploitation phase: hence, diversity must decrease and search agents must aggregate in the neighborhood of
. For this reason, in Equation (15), the standard deviation of search agents’ positions with respect to the average solution is normalized to the average solution to quantify population diversity. As all solutions come very close to
, they coincide with their average and the search process finally converges. The standard deviation of solutions is hence normalized with respect to the average solution, thus having a dimensionless convergence parameter. The same approach is followed for cost function values by normalizing their standard deviation with respect to the average cost: competitive solutions almost coincide with the optimum only when are effectively close to it, that is, when the search process is near its end.
Steps 1 through 3 are repeated until SHGWJA converges to the global optimum.
SHGWJA terminates the optimization process and writes output data in the results file.
Algorithm 1 presents the SHGWJA pseudo-code.
Figure 2 shows the flow chart of the proposed hybrid optimizer.
| Algorithm 1 Pseudo-code of SHGWJA |
| START SHGWJA. |
Set population size NPOP and generate randomly a population of NPOP candidate designs (i = 1,…,NPOP) using Equation (9). For i = 1,…,NPOP Compute cost function and constraints of the given optimization problem for each candidate design . Compute penalized cost function for each candidate design using Equations (10) and (11). end for Sort population by values in ascending order. Set the best three individuals with the lowest values as wolves α, β and δ. Let , and the design vectors for wolves α, β and δ, respectively. Set the α wolf as current best record ≡ with penalized cost Wp,opt = Wp(). For i = 1,…,NPOP Step 1. Use classical GWO Equations (1)–(7) to provisionally update each individual of the population to Step 2. Evaluate trial design and/or additional/new trial design If W() ≤ 1.1W() Keep trial design and define additional trial design using the JAYA strategy of Equation (13). else Reject trial design and define the new trial design using the JAYA strategy of Equation (12). end if If > 1.1W() & W() > 1.1W() Reject also and keep individual in the new population. end if If ≤ 1.1W() & W() ≤ 1.1W() & < W() Use trial design to update the population. end if If ≤ 1.1W() & W() ≤ 1.1W() & > W() Use trial design to update the population. end if If Wp() or < Wp() Keep or in the updated population. else Discharge or and keep also in the updated population. end if end for Step 3. Re-sort population, define new wolves α, β and δ, update and Sort the updated population by the values of in ascending order Update the positions , and of wolves α, β and δ, respectively. Use the elitist mirror strategy of Equation (14) to avoid the stagnation of wolves α, β and δ. Update, if necessary, positions , and or at least the worst two individuals of the population. Set the α wolf as the current best record ≡ with penalized cost Wp,opt = Wp(). Step 4. Check for convergence If the convergence criterion stated by Equation (15) is satisfied Terminate the optimization process. Output the optimal design and optimal cost value W(). else Continue the optimization process. Go to line 6. end if
|
| END SHGWJA. |
In summary, SHGWJA is a grey wolf-based optimizer, which updates the population by checking whether the α, β, δ wolves may effectively improve the current best record. The JAYA operators (indicated in red on the flowchart) and the elitist strategies included in SHGWJA enhance the exploration and exploitation phases, forcing the algorithm to increase the population diversity and select high-quality trial solutions without performing too many function evaluations. The classical GWO algorithmic structure is modified by the elitist strategy W() ≤ 1.1W(), by the JAYA-based strategies stated in Equations (12) and (13) to generate high-quality trial designs, and by the mirroring strategy stated in Equation (14) to increase the population diversity over the whole optimization search. These four operators introduced in the GWO formulation can be defined “simple modifications” because they are very easy to implement.
It should be noted that since classical GWO and JAYA formulations do not include any specific operator taking care of the exploitation phase, they may suffer from a limited exploitation capability. Conversely, SHGWJA performs exploration or exploitation based on the current trend in the optimization history, and, in particular, on the quality of the currently generated trial solution. If a trial solution does not improve the current best record, SHGWJA performs exploration to search for higher-quality trial solutions over the whole search space (JAYA strategy of Equation (12)). If a trial solution is good, SHGWJA performs exploitation to further improve the current best record (JAYA strategy of Equation (13)). These phases alternate over the whole optimization history and, hence, are dynamically balanced. Furthermore, SHGWJA continuously explores the search space to avoid stagnation of the α, β and δ wolves.
Since JAYA operators modify the trial solutions generated by GWO, the proposed algorithm is a “high-level” hybrid optimizer where both components concur to form the new design. Interestingly, SHGWJA does not require any new internal parameters with respect to classical GWO and JAYA. This feature is not very common in metaheuristic optimization because hybrid algorithms usually utilize new heuristic internal parameters to switch the search process from one component optimizer to another.
Another interesting issue is the selection of the population size NPOP. Increasing the population size in metaheuristic optimization may lead to performing too many function evaluations. This occurs because the total number of evaluations is usually determined as the product of population size NPOP with the limit number of iterations. Using a larger population size may improve the exploration capability but computational cost may significantly increase. However, a large population is not necessary if the optimizer can always generate high-quality designs that continuously improve the current best record or the currently perturbed search agents. Furthermore, grey wolves hunt in nature in groups including at most 10–20 individuals (a family pack is typically formed by 5–11 animals; however, the pack can be composed by up to 2–3 families). For this reason, all SHGWJA optimizations carried out here for engineering design problems were performed with a population of 10 individuals. Sensitivity analysis confirmed the validity of this setting also for mathematical optimization where the population size was increased to 30 or 50, consistent with the referenced studies on other MAs.
The last issue is the computational (i.e., time) complexity of the proposed SHGWJA method. In general, this parameter is obtained by summing over the complexity of different algorithm steps, such as the search agent initialization, optimization variables perturbation and population sorting. The computational complexity of classical GWO over
Niter iterations performed is O(
NPOP ×
NDV +
Niter ×
NPOP × (
NDV + log
NPOP)). For each optimization iteration of SHGWJA, the following occurs: (i) the elitist strategy
W(
) ≤ 1.1
W(
) introduces
NPOP new operations; (ii) each JAYA-based strategy (Equations (12) and (13)) introduces
NPOP ×
NDV new operations; (iii) the mirroring strategy of Equation (14) introduces 2
NDV new operations. In summary, SHGWJA performs in each iteration
NPOP + (
NPOP + 2) ×
NDV more operations than classical GWO. For example, for the largest test problem solved in this study with
NDV = 14 and
NPOP = 10, SHGWJA performed in each iteration at most 10 + (12 × 14) = 178 more operations than classical GWO. In the worst-case scenario where all operators are used for all agents, the computational complexity of SHGWJA increases to O(140 +
Niter × 328) from only O(140 +
Niter × 150) for classical GWO. The levels of computational complexity reported in the literature for very efficient GWO/JAYA variants such as GGWO [
105] and EHRJAYA [
98] are O(140 +
Niter × 150) and O(
Niter × 160), respectively, significantly lower than for SHGWJA. However, the higher number of operations performed by SHGWJA in each iteration are always finalized to generate high-quality trial designs, thus allowing the present algorithm to better explore/exploit the search space than its competitors.
5. Results and Discussion
5.1. Mathematical Optimization
Table 1 compares the optimization results obtained by SHGWJA and the other 31 MAs for the Rosenbrock problem. For each selected combination (
NDV;
NPOP), the table lists (when available) the best, average and worst optimized values, the corresponding standard deviation on the optimized cost (always indicated as ST Dev in all result tables), and the required function evaluations (NFE) for all optimizers. The limit number of function evaluations for SHGWJA was set equal to 15,000, which is the smallest number of function evaluations indicated in the literature for practically all SHGWJA’s competitors.
It can be seen from the table that SHGWJA always converged to the lowest values of the cost function, ranging from 1.000·10−15 for the parameter settings (NDV = 30; NPOP = 30) and (NDV = 30; NPOP = 50) commonly used in the literature to 5.179·10−13 for (NDV = 10; NPOP = 10). Remarkably, SHGWJA’s performance was practically insensitive to the selected combination of problem dimensionality and population size. In particular, the present algorithm always converged to a best solution very close to the target optimum cost of 0 within 15,000 function evaluations: the optimized cost obtained in the best runs of all (NDV;NPOP) settings never exceeded 5.179·10−13, while the standard deviation on the optimized cost never exceeded 2.669·10−12. Interestingly, for all (NDV;NPOP) settings, the average optimized cost and standard deviation on the optimized cost obtained by HSGWJA dropped to 10−28 when the convergence limit in Equation (14) was reduced to 10−15 and the computational budget was increased to 30,000 function evaluations, the same as for LCA and much less than for MOA (50,000), to obtain their reported null standard deviations.
The above results indicate that SHGWJA was the best optimizer overall. In fact, only the mother optimization algorithm (MOA) [
51] and the learning cooking algorithm (LCA) [
53] reached the 0 target solution in all optimization runs, but this required, respectively, 50,000 and 30,000 function evaluations. However, for the (
NDV = 30;
NPOP = 30) setting used by LCA, the best/average/worst optimized costs and standard deviation reached by SHGWJA within at most 15,000 function evaluations ranged between 1.001·10
−15 and 7.545·10
−14, very close numerically to the 0 target value. Furthermore, for
NPOP = 50 set in MOA optimizations, SHGWJA obtained its best values: 10
−15 for
NDV = 30 and 100 with corresponding averages between 1.1·10
−15 and 1.1·10
−14, again very close to 0. The convergence curves provided in [
51] for MOA and in [
53] for LCA have low resolution and cannot be compared directly with those recorded for the present algorithm. However, SHGWJA’s intermediate solutions reached the cost of 10
−7 within only 1000–1500 function evaluations in all optimization runs. Such behavior was fully consistent with the trends shown in [
51,
53].
The performance of SHGWJA was comparable to the hybrid harmony search (hybrid HS), hybrid big bang–big crunch (hybrid BBBC) and hybrid fast simulated annealing (HFSA) algorithms developed in [
93]. In fact, the average optimized cost resulting from
Table 1 for SHGWJA is 1.1·10
−12, while the average optimized costs of hybrid HS/BBBC/SA were always above 1.197·10
−11. The standard deviation on the optimized cost was on average 1.478·10
−12 vs. the 7.4·10
−12 average deviation of hybrid HS/BBBC/SA. However, the algorithms of Ref. [
93] were run with a convergence limit
of 10
−15. The inspection of convergence curves reveals that hybrid HS/BBBC/SA actually stopped to improve the cost function already at about 80% of the search process in spite of their tighter convergence limit. This was due to the use of gradient information in the generation of new trial solutions. Conversely, SHGWJA kept reducing the cost function until the very last iterations of its search process.
SHGWJA also outperformed the two particle swarm optimization variants based on global best (GPSO) or including the presence of an aging leader with challengers (ALC-PSO) [
114]. In fact, these PSO variants completed their best optimization runs within less than 6500 function evaluations but their best optimized cost was at most 3.7·10
−7 vs. 1.001·10
−15 to 4.789·10
−13 obtained by SHGWJA for the same number of optimization variables (30) and similar population sizes (10 and 30). Furthermore, the average optimized cost and standard deviation of PSO variants, respectively, ranged between 7.6 and 11.7, and 6.7 and 15 vs. only 2.832·10
−12 obtained by SHGWJA in the worst case.
Limiting our analysis to the classical setting (
NDV = 30;
NPOP = 30 ± 10) used in the metaheuristic optimization of unimodal functions and the very small computational budget of 15,000 function evaluations, the algorithms ranked as follows in terms of average optimized cost: SHGWJA, mEO, ALCO-PSO, GPSO, hSM-SA, AOA, EO, IAOA and LSHADE-SPACMA. When the computational budget increased to 30,000 function evaluations with (
NDV;
NPOP) ≤ 50, the ranking changed as follows: SHGWJA, MOA and LCA, SAMP-JAYA, GTO, IMPA, PEOA, mEO, ALC-PSO, EGTO, GPSO, hSM-SA, MGWO-III, SLOA, RUN, AOA, EO, MPA, CMA-ES, IAOA, LSHADE-SPACMA, LSHADE and LSHADE-CnEpSin. Increasing the population size to 70 and the number of function evaluations to 80,000 allowed the hybrid CJAYA-SQP algorithm (combining chaotic perturbation in JAYA’s exploration and sequential quadratic programming for exploitation) [
95] to rank ninth between mEO and ALC-PSO; the hybrid NDWPSO algorithm (combining PSO, differential evolution and whale optimization) [
115] ranked right before the high-performance algorithm LSHADE [
117]. Interestingly, all JAYA variants except the steady-state JAYA (SJAYA) [
110]) ranked in the top 10 algorithms, while high-performance algorithms like the LSHADE variants [
117,
118,
119] and the basic formulation of the marine predators algorithm (MPA) [
80] were not very efficient in the Rosenbrock problem. This confirms the advantage in selecting JAYA as a component algorithm for hybrid metaheuristic optimizers.
As mentioned before, SHGWJA was insensitive to parameter settings while all other algorithms showed a marked decay in performance as the number of optimization variables increased. For example, fixing the population size at 30 and varying the problem dimension from 30 to 1000, the average optimized cost went up to almost 1000 except for the giant trevally optimizer (GTO) [
81] and equilibrium optimizer with a mutation strategy (mEO) [
92] that limited this increase to 3.57·10
−6 for
NDV = 1000 and 6.2 for
NDV = 500, respectively. For
NDV = 1000, SHGWJA ranked first followed by hybrid HS/BBBC/SA and GTO with at most 2.53·10
−8 average optimized costs; mEO had an average optimized cost still below 0.5; CJAYA-SQP, MGWO-III [
39] (an astrophysics-based GWO variant), EO, leopard snow optimizer (LSO) [
91] and SaDN [
94] (hybridized differential evolution naked mole-rat) obtained average optimized costs between 13 and 99.
Table 2 presents the optimization results obtained by SHGWJA and its 29 MA competitors in the Rastrigin problem. The data arrangement is the same as for
Table 1. The limit number of function evaluations for SHGWJA was also set to 15,000 for this multimodal problem. SHGWJA’s performance was again insensitive to the setting of
NDV and
NPOP. SHGWJA’s competitors were also much less sensitive to parameter settings than in the case of Rosenbrock’s problem. Such a behavior was somehow expected considering that the convergence of Rastrigin’s function to the global optimum becomes “easier” as the problem dimensionality increases.
It can be seen from
Table 2 that most of the algorithms (including the astrophysics-based GWO variant MGWO-III [
39], giant trevally optimizer (GTO) [
81], improved marine predators algorithm (IMPA) [
101], and improved arithmetic optimization algorithm (IOAO) [
96]) converged to the target global optimum of 0 with a null average and standard deviation already for the lowest number of optimization variables. SHGWJA performed very well also in this multimodal optimization problem, converging to the best cost of 1.776·10
−15 in eight cases, 2.842·10
−14 in one case, and from 1.492·10
−13 to 2.934·10
−13 in the remaining two cases, always very close to the 0 target value. Furthermore, SHGWJA achieved a 0 standard deviation in three cases with all independent optimization runs converging to 1.776·10
−15, and practically null standard deviation values ranging between 5.13·10
−16 and 9.175·10
−16 in the other five cases where the best value was 1.776·10
−15. The average optimized cost and average standard deviation on the optimized cost obtained by SHGWJA for all (
NDV;
NPOP) combinations, respectively, were 3.171·10
−13 and 6.606·10
−13, hence, 1–2 orders of magnitude smaller than their counterpart values recorded for hybrid HS/BBBC/SA. Again, the hybrid HS/BBBC/SA algorithms of Ref. [
93] stopped to significantly improve the cost function well before the end of the optimization iterations.
Interestingly, SHGWJA obtained cost function values and corresponding standard deviation values on the order of 10−28 by setting the convergence limit in Equation (14) to 10−15 and increasing the computational budget to 25,000 function evaluations, that is, (i) the same as for MPA, EGTO, SaDN and MSCA, (ii) less than for MGWO-III, LCA and GTO (30,000), (iii) much less than for LSO, MOA, PEOA, SLOA and IMPA (50,000), and CJAYA-SQP (80,000) to obtain their reported null standard deviations.
SHGWJA always required on average less than 14,000 function evaluations (i.e., the computational cost of NDWPSO, the fastest algorithm to reach the 0 target solution with a 0 standard deviation) to successfully complete the optimization process when the problem dimensionality was at most 100. The fastest optimization runs of SHGWJA converging to 1.776·10
−15 were always completed within 12,877 function evaluations, less than the 14,000 evaluations required by NDWPSO for the single setting (
NDV = 50;
NPOP = 70); a more detailed inspection of convergence curves revealed that SHGWJA’s intermediate solutions always reached the cost of 10
−7 within about 1000 function evaluations, practically the same behavior observed for NDWPSO. The I-JAYA algorithm (augmenting classical JAYA with fuzzy clustering competitive learning, experience learning and Cauchy mutation) rapidly reduced within only 15,700 function evaluations the cost function value to the 10
−10 target value set in [
113]. ALC-PSO also performed well in terms of optimized cost, which was reduced to 7.105·10
−15 but required almost five times more function evaluations than SHGWJA (i.e., 74,206 vs. at most 15,000).
Since SHGWJA practically converged to the target optimum cost of 0 with a null or nearly null average optimized cost and standard deviation on the optimized cost within the lowest number of function evaluations in all cases, it should be considered the best optimizer also for Rastrigin’s problem. The MAs listed in
Table 2 that failed to reach 0 average cost and 0 standard deviation by more than 10
−7 obviously occupy the worst seven positions in the algorithm ranking as follows: AOA, MPA, LSHADE, LSHADE-SPACMA, SAMP-JAYA, LSHADE-cnEpSin and CMA-ES. All of these MAs were executed with
NDV = 30 except LSHADE-SPACMA, which was run with
NDV = 50.
5.2. Shape Optimization of Concrete Gravity Dam
Table 3 presents the optimization results for the concrete gravity dam design problem. The table also reports the average number of function evaluations
NFE (structural analyses), the corresponding standard deviation, and the number of function evaluations required by the fastest optimization run for SHGWJA and some of its competitors.
The multi-level cross entropy optimizer (MCEO) [
120] and the flying squirrel optimizer (FSO) [
121] reduced the concrete volume per unit width of 10,502.1 m
3 of the real structure to only 7448.774 m
3. The hybrid harmony search, big bang–big crunch and simulated annealing algorithms developed in [
93] found a similar solution to the improved JA [
93] (a JAYA variant including line search to reduce the number of function evaluations entailed by the optimization) and significantly reduced the dam’s concrete volume to about 6831 m
3. However, hybrid HS/BBBC/SA completed the optimization process within less function evaluations and converged to practically feasible designs while JAYA’s solution violated constraints by 4.06%. The 32% constraint violation reported for MCEO and FSO solutions refers to the fact that the constraint on the dam’s height
X2 +
X4 +
X6 = 150 m (see
Section 4.2) was not considered in [
120,
121].
It can be seen from
Table 3 that the simple hybrid algorithm SHGWJA proposed in this study was the best optimizer overall. In fact, it could reduce the dam’s concrete volume by 2.68% with respect to the best solutions quoted in [
93], reaching the optimal volume of 6647.874 m
3. This optimal solution practically satisfied the design constraints, achieving a very low violation of 1.284·10
−3%. The number of function evaluations performed in the SHGWJA optimizations was on average 50% lower than for the metaheuristic algorithms of Ref. [
93] (i.e., only 10,388 analyses vs. 14,560 to 16,200 analyses) and 70% for MCEO [
120], which required 35,000 function evaluations. FSO was reported in [
121] to be considerably faster than particle swarm optimization and genetic algorithms, thus achieving a similar converge speed to MCEO.
Standard JAYA converged to the same optimal solution as SHGWJA, 6647.874 m3, but required 2.5 times the average number of function evaluations of SHGWJA (i.e., the JAYA’s computational budget was set to 25,000 function evaluations while SHGWJA converged within only 10,388 evaluations) and almost four times the function evaluations of the fastest SHGWJA’s optimization run (i.e., 25,000 vs. only 6584). Standard GWO obtained a slightly worse solution than SHGWJA and standard JAYA in terms of concrete dam volume (6654.927 m3 vs. 6647.874 m3). The GWO’s solution was also practically feasible but constraint violation increased to 7.209·10−3 vs. only 1.284·10−3% recorded for SHGWJA and standard JAYA. Furthermore, the computational cost of GWO was about five times higher than for SHGWJA (i.e., 50,000 analyses vs. only 10,388 analyses). This confirms the validity of the hybrid search scheme used by SHGWJA.
The modified sinusoidal differential evolution (MsinDE) (derived from [
124]), the modified big bang–big crunch with upper bound strategy (mBBBC–UBS) (derived from [
123]), and modified harmony search optimization with adaptive parameter updating (mAHS) (derived from [
122]), respectively, ranked third, fifth and sixth in terms of optimized volumes that were very close to the global optimum found by SHGWJA and standard JAYA, ranging from 6652.513 to 6658.024 m
3 vs. only 6647.874 m
3. It should be noted that the SHGWJA’s elitist strategy
W(
) ≤ 1.1
W(
) implemented also in mAHS, mBBBC–UBS and MsinDE was very effective because it allowed these algorithms to improve the best solution quoted in the literature and to significantly reduce the gap with respect to the best optimizer. In particular, the optimized volumes by mAHS, mBBBC–UBS and MsinDE were at most 0.15% larger than the SHGWJA’s optimum volume (i.e., only 10.150 m
3 gap vs. 6647.874 m
3) vs. the 0.89% seen for the original algorithms with respect to hybrid BBBC, the best optimizer in Ref. [
93]. Furthermore, the optimized designs obtained by mAHS, mBBBC–UBS and MsinDE in their best runs were always practically feasible: in fact, constraint violation was, respectively, 1.311·10
−3%, 3.376·10
−3% and 3.653·10
−3% vs. 1.437·10
−3%, 6.733·10
−3% and 6.598·10
−3%, as reported in [
93]. The computational cost of the best optimization runs was reduced compared to [
93], saving about 10,000 function evaluations in the case of mAHS. However, mBBBC–UBS, mAHS and MsinDE still required on average more than three times the function evaluations required by SHGWJA (i.e., from 31,690 to 35,208 analyses vs. only 10,388 analyses) and their best optimization runs required 4.9 to 5.7 times more function evaluations than the present algorithm (i.e., from 32,004 to 37,545 analyses vs. only 6584 analyses).
Remarkably, SHGWJA achieved a 100% rate of success converging to the same optimal solution of 6647.874 m
3 in all independent optimization runs with a null standard deviation on the optimized cost. None of the other algorithms referred to in
Table 3 could obtain in all of their optimization runs better designs than the best volume of 6830.235 m
3 quoted in [
93] for hybrid BBBC. The standard deviation on the number of function evaluations required by SHGWJA was about 35% of the average number of function evaluations. These results prove the robustness of SHGWJA.
Further information on SHGWJA’s convergence behavior and robustness can be gathered from
Figure 9, which compares the optimization history of the proposed algorithm and its competitors. The curves relative to best and average optimization runs of SHGWJA are shown in the figure. Since SHGWJA always converged to the global optimum of 6647.874 m
3 in all optimization runs, its best run also corresponds to the fastest one. For the sake of clarity, the plot is limited to the first 18,000 function evaluations. The initial cost function value for the best individual of all algorithms ranged from 13,265.397 m
3 to 17,351.728 m
3, well above the global optimum of 6647.874 m
3. The better convergence behavior of SHGWJA with respect to its competitors is clear from the very beginning of the search process. In fact, the optimized cost found on average by SHGWJA for a feasible intermediate design generated within the 6584 function evaluations of the best optimization run was only 0.933% larger than the target global optimum. Interestingly, in its best run, SHGWJA could generate a feasible intermediate design just 1% worse than the global optimum at approximately 69% of the optimization process. The mBBBC-UBS algorithm was the only optimizer close enough to SHGWJA in terms of convergence speed for the first 630 function evaluations and for 5400 to 6600 function evaluations.
Table 4 lists the optimized designs obtained by SHGWJA and its main competitors. SHGWJA and standard JAYA designs coincided as these algorithms converged to the same optimal solution and were just slightly different from the optimized designs of standard GWO and MsinDE. The new optimal solution yielding 6647.874 m
3 concrete volume was very similar to the optimal solutions of the algorithms of Ref. [
93]: all variables changed by at most 5% except X
3, which was fixed to its lower bound by SHGWJA or close to the lower bound by GWO and MsinDE.
Figure 10 compares the dam’s optimized shapes (coordinates are expressed in meters) as found by SHGWJA and MsinDE, with the dam configurations reported in [
93,
120,
121]. Since standard JAYA found the same optimum design as SHGWJA, while standard GWO, mAHS, mBBBC–UBS and MsinDE obtained very similar configurations to SHGWJA, only the plot referred to MsinDE (the best optimizer after SHGWJA and standard JAYA) is shown in the figure for the sake of clarity.
Remarkably, the dam safety factors against sliding and overturning corresponding to the SHGWJA’s optimal solution became 6.318 and 3.515, respectively, vs. their counterpart values of 6.213 and 3.453 indicated in [
93]. Hence, reducing the concrete volume of the dam from 6831 m
3 to 6647.874 m
3 not only resulted in a more convenient design but also allowed a higher level of structural safety to be achieved. This proves the suitability of the proposed SHGWJA algorithm for civil engineering design problems.
5.3. Optimal Design of Tension/Compression Spring
Table 5 presents the optimization results obtained by SHGWJA and its competitors in the spring design problem. Statistical data on the optimization runs (i.e., best cost, average cost, worst cost and standard deviation optimized cost for the independent optimization runs), number of function evaluations
NFE and optimal design are listed in the table for all the algorithms compared in this study. The values of the standard deviation on optimized cost listed in the table for the referenced algorithms are exactly those reported in the literature.
It can be seen that the SHGWJA algorithm proposed in this study performed very well: its best solution, 0.0126665, practically coincided with the optimized costs of MGWO-III —the astrophysics-based GWO variant of Ref. [
39] (0.0126662) -, the preschool education optimization algorithm (PEOA) [
52] (0.012667), and the modified sine cosine algorithm (MSCA) [
99] (0.012668). SHGWJA’s optimized cost was only 0.0121% larger than the 0.012665 global optimum obtained by the JAYA variants EHRJAYA [
98], SAMP-JAYA [
111] and EJAYA [
112], the mother optimization algorithm (MOA) [
51], the marine predators algorithm (MPA) [
80], the hybridized differential evolution naked mole-rat algorithm (SaDN) [
94] and improved multi-operator differential evolution (IMODE) [
125]. The gaze cues learning-based grey wolf optimizer (GGWO) ([
105], the currently known best GWO variant), light spectrum optimizer (LSO) [
31], starling murmuration optimizer (SMO) [
74], hybrid EGTO algorithm combining marine predators and gorilla troops optimizer [
102] and queuing search algorithm (QSA, which mimics the human activities in queuing and was the best amongst the nine MAs compared in [
127]) converged to 0.0126652, the same as for EHRJAYA, MOA, MPA, SaDN and IMODE up to the fifth significant digit. The high-performance algorithm success history-based adaptive differential evolution with gradient-based repair (En(L)SHADE) was reported in [
126] to obtain an optimized cost of 1.27·10
−2, corresponding to the round up of the 0.0126652 cost.
The arithmetic optimization algorithm (AOA) [
43] and its improved variant IAOA [
96] found the smallest optimized costs, respectively, of 0.012124 and 0.012018, but the corresponding optimal designs were infeasible, violating the second constraint equation—g
2(
) in Equation (19)—by 8.05% and 10.8%. All other algorithms compared in
Table 3 obtained practically feasible solutions, violating constraints by less than 0.143%. The learning cooking algorithm (LCA) was reported in [
53] to converge within 30,000 function evaluations to the optimized cost of 0.0125 for the corresponding solution
(0.05566; 0.4591; 7.194). However, the actual value of cost function computed by giving in input
to Equation (19) is 0.013107, much higher than the 0.012665 optimum quoted in
Table 5.
The rate of success of SHGWJA was 100% also for this test problem: in fact, the present algorithm found very close designs to the global optimum in all independent optimization runs. SHGWJA obtained the seventh-lowest standard deviation on optimized cost out of the 29 MAs compared in this study (21 listed in
Table 3 and the other 8 from Ref. [
127], while no information was available for LSO and its 31 competitors, compared in [
31]), thus ranking in the first quartile. The standard deviation on optimized cost was only 0.0876% of the best design found by SHGWJA. Furthermore, the average optimized cost and worst optimized cost by SHGWJA, respectively, were at most 0.134% and 0.213% larger than the 0.012665 target value. Statistical dispersion on the optimized cost was very similar in its counterparts, that is, in MGWO-III, EHRJAYA and PEOA. However, EHRJAYA exhibited a larger average optimal cost than SHGWJA, while the worst solutions of MGWO-III and PEOA achieved a larger cost than that of SHGWJA.
As far computational cost is concerned, SHGWJA was on average the third fastest optimizer overall after EHRJAYA and LSO. However, the fastest optimization run of SHGWJA converging to the best solution of 0.0126665 was completed within only 2247 function evaluations, practically the same as for EHRJAYA, while the LSO’s convergence curve indicated in [
31] for the best optimization run covered 5000 function evaluations. Among other JAYA variants, SAMP-JAYA was just slightly slower than SHGWJA (6861 function evaluations vs. only 6347). Furthermore, the present algorithm was on average about (i) 4.7 times faster than MGWO-III, LCA, PEOA, SO, SMO and IMODE, (ii) 4 times faster than MPA, EGTO and MSCA, (iii) 3.6 times faster than GGWO, (iv) 2.8 times faster than QSA and the other algorithms of Ref. [
127], and (v) 2.4 times faster than EJAYA, EO, AOA, IAOA, SaDN and hSM-SA. It should be noted that
Table 5 compares the average number of function evaluations required by SHGWJA either with the fixed computational budget of all optimization runs or the computational cost of the best optimization run. Furthermore, SHGWJA was robust enough in terms of computational cost: the standard deviation on the number of function evaluations was about 35.4% of the average number of evaluations.
Figure 11 shows a more detailed comparison of the optimization history of SHGWJA with those of EGTO [
102] and QSA [
127]. For the sake of clarity, the plot is limited to the first 3000 function evaluations. It can be seen that the convergence curves of the best and average optimization runs recorded for the present algorithm practically coincided after only 700 function evaluations, that is, at about 31% of the optimization history of the best run. Interestingly, EGTO started its optimization search from a much better initial design than those of SHGWJA and EGTO: the initial cost evaluated for its best individual was only 0.016 vs. 0.06 for QSA, 0.1 for the best SHGWJA run and 0.1528 for the average SHGWJA run. In spite of this, the present algorithm recovered the gap with respect to EGTO already in the early optimization cycles and the convergence curves of EGTO and the best SHGWJA’s run crossed each other after 650 function evaluations. Furthermore, SHGWJA generated on average better feasible intermediate designs than QSA after only 135 function evaluations, keeping this ability over the first 750 function evaluations. After about 2500 function evaluations, the cost function values of 0.012673 and 0.012697, respectively, achieved by EGTO and QSA in their best optimization runs were still higher than the best cost of 0.0126665, finally reached by SHGWJA after only 2250 function evaluations.
The data presented in this section demonstrate without a shadow of a doubt the computational efficiency of SHGWJA. In fact, the present algorithm generated very competitive results as compared to the 21 state-of-the art MAs, each of which was in turn proven in the literature to outperform 5 to 34 other metaheuristic algorithms and their variants.
5.4. Optimal Design of Welded Beam
Table 6 presents the optimization results for the welded beam design problem. The values of the standard deviation on optimized cost listed in the table for the referenced algorithms are exactly those reported in the literature. It can be seen that the proposed SHGWJA method was the best optimizer overall. In fact, the optimum cost of 1.724852 corresponds to the target solution of the classical formulation (see
Section 4.4) and practically coincided with the optimized cost values obtained by all SHGWJA competitors except for the hybrid JAYA variant EHRJAYA [
98], arithmetic optimization algorithm (AOA) [
43], hybridized differential evolution naked mole-rat algorithm (SaDN) [
94], improved multi-operator differential evolution (IMODE) [
125], and Taguchi method integrated harmony search algorithm (TIHHSA) [
132]. In particular, IMODE and SaDN converged to the largest costs, respectively, about 63.8% and 14.6% higher than the optimum cost of 1.72485. The Taguchi method integrated harmony search algorithm (TIHHSA) [
132] converged to an optimized cost of 1.74026, close enough to the global optimum reached by SHGWJA.
The arithmetic optimization algorithm (AOA) [
43] converged to an optimized solution yielding a slightly lower cost than SHGWJA: 1.7164 vs. 1.72485. However, this solution violates the shear stress constraint of the classical problem formulation—g
1(
) in Equation (20)—by 25.3%. All other algorithms of
Table 6 solving the classical problem formulation converged to feasible designs.
SHGWJA found the target optimum cost of 1.6702 in all optimization runs (zero standard deviation), as well as in problem variant 3 of the CEC 2020 library, including J = 2
, beam tip displacement
, and critical load
. The high-performance algorithms En(L)SHADE [
126], LSHADE-SPACMA [
119,
129] and SASS [
130,
131] also converged to the same target optimal solution with 0 or near-0 standard deviations. However, SHGWJA required on average less than 4450 function evaluations vs. between 20,000 and 100,000 evaluations required by SASS, LSHADE-SPACMA and En(L)SHADE, thus confirming the computational efficiency of the proposed algorithm.
The rate of success of SHGWJA was again 100%: in fact, it converged to the global optima of the three problem variants (i.e., 1.72485; 1.69725; 1.6702) in all independent optimization runs. The zero or “practically zero” dispersion on optimized cost was achieved only by (i) SHGWJA, GGWO, SAMP-JAYA, EJAYA, MOA, EGTO and QSA in the classical problem variant 1; (ii) SHGWJA and NDWPSO in problem variant 2; and (iii) SHGWJA, En(L)SHADE, LSHADE-SPACMA and SASS in problem variant 3. These data confirm the robustness of the present algorithm.
SHGWJA was robust also in terms of computational cost. In fact, the values of the ratio between the standard deviations on the number of function evaluations and the corresponding average value were only 11.9%, 9.7% and 9.6% for problem variants 1, 2 and 3, respectively. In problem variant 1 (classical formulation), the present algorithm was the fastest optimizer together with SAMP-JAYA, completing its best optimization run within only 3670 function evaluations, 37.5% less than in the case of the third fastest optimizer LSO, which required 5000 function evaluations. Furthermore, SHGWJA was on average 3.3 times faster than GGWO and 7 times faster than MGWO-III. The EO, AOA, SaDN and hSM-SA algorithms ranked fifth because they were slightly slower than GGWO; however, AOA converged to an infeasible solution while SaDN missed the global optimum. All other MAs listed in
Table 6 were 4.2 to 7 times slower than SHGWJA, requiring between 18,000 (e.g., QSA and all other MAs of [
127]) and 30,000 (i.e., the high performance algorithm IMODE) function evaluations.
In problem variant 2, SHGWJA was on average slightly faster than FSO (i.e., 4201 vs. 4500 function evaluations) but also about six times faster than MSCA and about five times faster than NDWPSO. Its fastest optimization run required only 3635 function evaluations, close enough to the 2000 function evaluations required by EHRJAYA. The other JAYA variants of Ref. [
98] were also slower than SHGWJA, as their optimization runs required between 4000 and 5000 function evaluations. Finally, in problem variant 3, SHGWJA required on average only 4438 function evaluations vs. the fixed computational budgets of 20,000, 40,000 and 100,000 evaluations, respectively, set in [
119,
126,
129,
130,
131] for the high-performance algorithms SASS, LSHADE-SPACMA and En(L)SHADE.
Figure 12 presents a detailed comparison of the convergence curves of SHGWJA, LSO [
31], EGTO [
102], FSO [
121] and QSA [
127] in the three problem variants. As in the dam case, the best optimization runs of SHGWJA correspond also to the fastest runs, as the present algorithm achieved 0 standard deviation on the optimized cost in all problem variants. For the sake of clarity, the plot is limited to the first 4500 function evaluations. All algorithms except LSO started from very large costs compared to the target optima: (i) between 2.6 and 6.273 vs. only 1.72485 for problem variant 1; (ii) between 3.144 and 4.675 vs. only 1.69525 for problem variant 2; (iii) between 3.465 and 4.5 vs. only 1.6702 for problem variant 3. The analysis of convergence curves plotted in
Figure 12 and its insert confirms the superiority of SHGWJA over its competitors also for this test problem. In fact, the best and average optimization runs’ convergence curves of SHGWJA practically coincided after only 2000 (i.e., 54.5% of the best run’s optimization history), 2100 (i.e., 57.8% of the best run’s optimization history) and 1700 (i.e., 44.8% of the best run’s optimization history) function evaluations, respectively, for problem variants 1, 2 and 3.
In problem variant 1, LSO started from the cost function value of 1.745, which is just 1.168% larger than the target optimum cost of 1.72485, while SHGWJA started from 6.273. However, SHGWJA recovered such a large gap in cost function with respect to LSO at 60% of its optimization history and then reduced the cost function to a slightly lower value than LSO (i.e., 1.724852 vs. 1.724866). EGTO started its best run from the cost of 2.6, about 58.5% lower than SHGWJA’s initial cost. The present algorithm recovered the gap before completing 68% of its optimization history also in this case. QSA’s best run started from a lower cost than SHGWJA (i.e., 4 vs. 6.273) but the present algorithm generated better feasible intermediate designs right after the first optimization iteration and for the first 400 function evaluations. The convergence curves of QSA and SHGWJA then crossed each other, with the former algorithm generating better intermediate designs until about 2000 function evaluations: in particular, SHGWJA reached the cost of 1.72507 after 1968 function evaluations while QSA’s cost was 1.725 after 2000 function evaluations. However, SHGWJA returned better than QSA from that point to the end of the search process, further reducing the cost function to the target cost of 1.72485 over the remaining 1692 function evaluations while QSA completed such a task over further 5000 function evaluations.
In problem variant 2, SHGWJA and FSO practically started from the same cost (4.237 vs. 4.675) but the present algorithm approached the target solution of 1.69525 long before FSO. In particular, SHGWJA generated in its best optimization run a feasible intermediate design only 0.6% higher in cost than the target minimum (i.e., 1.70526 vs. 1.69525) already at 46% of its optimization history (i.e., after only 1674 function evaluations) while FSO’s cost still was 2.26653. The optimization histories coincided after 2200 function evaluations with both algorithms practically converging to the target cost of 1.69525.
The data presented in this section clearly prove the computational efficiency of SHGWJA in this additional test problem. In fact, the present algorithm generated very competitive results compared to 24 state-of-the art MAs, each of which was in turn proven in the literature to outperform 5 to 32 other metaheuristic algorithms and their variants.
5.5. Optimal Design of Pressure Vessel
Table 7 presents the optimization results for the pressure vessel design problem. The values of the standard deviation on optimized cost listed in the table for the referenced algorithms are exactly those reported in the literature. In the continuous version of the problem, the SHGWJA approach developed in this study and the hybrid algorithm EGTO combining the marine predators algorithm and gorilla troops optimizer [
102] found the lowest cost overall of 5885.331 in all of their independent optimization runs (zero standard deviation). This fully feasible solution was practically the same as those obtained by the gaze cues learning-based grey wolf optimizer (GGWO [
105], the so-far known best GWO variant, 5885.3328), starling murmuration optimizer (SMO, 5885.3329) [
74], EJAYA [
112] (5885.333 for this JAYA variant utilizing a larger sets of solutions than classical JAYA to form new trial solutions), marine predators algorithm (MPA, 5885.3353) [
80], and equilibrium optimizer (EO) [
31] (5585.329, with just 0.000042% violation on constraint g
3(
) in Equation (21)).
The light spectrum optimizer (LSO) [
31], learning cooking algorithm (LCA) [
53], hybrid slime mould simulated annealing (hSM-SA) algorithm [
100], snake optimizer (SO) [
69], giant trevally optimizer (GTO) [
81] and NDWPSO [
115] (combining PSO, differential evolution and whale optimization) ranked right after SHGWJA and the other top MAs in this example, as they found optimized cost values ranging from 5585.434 to 5890. The modified sine cosine algorithm (MSCA) [
99], Taguchi method integrated harmony search algorithm (TIHHSA) [
132], and arithmetic optimization algorithm (AOA) [
43] converged to significantly larger optimized costs than SHGWJA and EGTO: from 5917.5 to 6059.7 vs. only 5885.331. Interestingly, LSO missed the global optimum of the continuous problem, although it was superior over the other 18 MAs (see Ref. [
31] for details).
The optimized designs reported in
Table 7 for the continuous version of the pressure vessel problem were all feasible except for those algorithms that converged to lower costs than SHGWJA and EGTO: (i-ii) the mother optimization algorithm (MOA) [
52] and preschool education optimization algorithm (PEOA) [
53] (i.e., 5882.901 with 0.040% violation on constraint g
3(
) in Equation (21)); (iii) the astrophysics based GWO variant MGWO-III [
39] (5884.0616 with 0.039% violation on constraint g
3(
) in Equation (21)); (iv) the hybrid JAYA variant EHRJAYA [
98] (5734.9132 with 3.57% violation on constraint g
1(
) in Equation (21)); and (v) the improved arithmetic optimization algorithm (IAOA) [
96] (5813.551 with 3.85% violation on constraint g
1(
) in Equation (21)). SAMP-JAYA [
111], the JAYA variant using subpopulations to optimize the balance between exploration and exploitation, converged to an unfeasible design of cost 5872.213, practically within the same number of function evaluations as the SHGWJA’s fastest optimization run (i.e., 6513 vs. 6732).
SHGWJA was the fastest optimizer overall, up to one order of magnitude faster than the giant trevally optimizer (GTO) [
81], which even missed the target optimum cost of 5885.331 and exhibited the third worst standard deviation on optimized cost. In particular, SHGWJA required on average the following: (i) 25% fewer function evaluations than GGWO; (ii) about 1.5 times fewer function evaluations than EJAYA, EO and hSM-SA; (iii) about 2 times fewer function evaluations than MPA, EGTO and MSCA; (iv) about 2.5 times fewer function evaluations than MPA and EGTO; and (v) about 3 times fewer function evaluations than MGWO-III, PEOA, LCA, SO, SMO and IMODE. It should be noted that the fastest optimization run of SHGWJA was completed within only 6732 function evaluations, very close to the following: (i) the 4000 function evaluations required by EHRJAYA [
100] to prematurely converge to an infeasible solution (the other JAYA variants analyzed in [
100] required between 8000 and 10,000 function evaluations), and (ii) the 5000 function evaluations covered by the LSO’s convergence curve indicated in [
31]. However, in its fastest optimization run, SHGWJA generated a feasible intermediate design better than the optimized cost of LSO (only 5585.431 vs. 5585.434) within only 4880 function evaluations.
In the mixed variable version of the pressure vessel problem, SHGWJA and its competitors all converged to the target optimum cost of 6059.714. However, the zero or “almost 0” standard deviation on optimized cost was achieved only by SHGWJA and self-adaptive spherical search (SASS) [
130,
131], not even by the high-performance algorithm En(L)SHADE [
126]. This occurred in spite of the fact that the present algorithm was on average (i) one order of magnitude faster than En(L)SHADE; (ii) about 54% faster than EO [
30], its improved version mEO [
92] and the hybridized differential evolution naked mole-rat algorithm (SaDN) [
94]; (iii) about 2 times faster than SASS; and (iv) about 2.6 times faster than the queuing search algorithm (QSA, the best amongst the nine MAs compared in [
127]). The fastest optimization run of SHGWJA required 7604 function evaluations, practically the same as the flying squirrel optimizer (FSO) [
121]. It should be noted that SHGWJA did not implement any specific strategy for handling discrete variables x
1 and x
2 but rounding the continuous values generated for these variables to their nearest multiples of 0.0625.
SHGWJA was robust enough also with respect to computational cost because the ratio between the standard deviation of the number of function evaluations and the corresponding average value was, respectively, 26.2% and 28.1% for the continuous and mixed variables problem versions. The excellent convergence behavior of SHGWJA was confirmed by the optimization histories shown in
Figure 13 for the best and average optimization runs recorded for the two problem variants with continuous variables or mixed variables. Again, the best SHGWJA runs correspond to the fastest ones since the present algorithms achieved a null standard deviation on optimized cost in both problem variants. The plot is limited to 7500 function evaluations for the sake of clarity. It can be seen that the best and average optimization runs’ convergence curves of SHGWJA practically coincided after only 4500 (i.e., 66.8% of best run’s optimization history) and 4000 (i.e., 52.6% of best run’s optimization history) function evaluations, respectively, for problem variants 1 and 2. Such a behavior is highlighted in detail by the insert in
Figure 13.
The optimization histories of SHGWJA, LSO [
31] and EGTO [
102] recorded for problem variant 1 are compared in
Figure 13. LSO and EGTO started their optimizations from 10,128.57 and 22,233.47, respectively, while SGHJA started its search process from the much larger cost of 526,765. In spite of such a large gap, FSO generated worse intermediate designs than the present algorithm over the whole optimization history and converged to a higher optimized cost than the target solution reached by SHGWJA (i.e., 5884.434 vs. 5885.331). Furthermore, the optimization histories of SHGWJA and EGTO practically coincided for the first 100 function evaluations and then EGTO reduced the cost function to 6359.256 at 150 function evaluations while SHGWJA obtained a similar cost function value at 200 function evaluations. However, the present algorithm kept reducing the cost while EGTO exhibited a large step in the cost function up to 2200 function evaluations: at this NFE, SHGWJA had already reduced the cost to about 5887.3 (just 0.034% more than the 5885.331 target optimum) while the cost function values of EGTO’s intermediate designs remained fixed at 6359.256.
The optimization histories recorded for SHGWJA, FSO [
121] and QSA [
127] in problem variant 2 again started from significantly larger costs than the 6059.714 target: 263,805.7, 35,000 and 19,097.22, respectively (see
Figure 13). FSO was much slower than the present algorithm and recorded a cost of 14,179 after about 5780 function evaluations, that is, when SHGWJA’s intermediate designs had already reduced the cost function to 6061.85, just 0.035% higher than the target optimum. SHGWJA recovered the initial gap with respect to QSA already within the first 60 function evaluations and the optimization histories of the two algorithms practically coincided after 3500 function evaluations.
The data presented in this section demonstrate without a shadow of a doubt the computational efficiency of SHGWJA in this further test problem. In fact, the present algorithm performed very competitively compared to 27 state-of-the art MAs, each of which was in turn proven in the literature to outperform 5 to 31 other metaheuristic algorithms and their variants.
5.6. Optimal Design of Industrial Refrigeration System
Table 8 presents the optimization results for the industrial refrigeration system design problem. The values of the standard deviation on optimized cost listed in the table for the referenced algorithms are exactly those reported in the literature. All algorithms listed in the table converged to fully feasible solutions. The new algorithm SHGWJA was very competitive with the other optimizers selected for comparison. In fact, it reached the global optimum cost of 0.032213 (and the target design P
OPT[0.001;0.001;0.001;0.001;0.001;0.001;1.524;1.524;5;2;0.001;0.001;0.0072934;0.087556]) along with the standard JAYA and improved JAYA [
93] variants, starling murmuration optimizer (SMO) [
74], hybrid fast simulated annealing (HFSA) algorithm [
93], success history-based adaptive differential evolution with gradient-based repair En(L)SHADE [
118], self-adaptive spherical search (SASS) algorithm [
130,
131], and improved cuckoo search (CS-DP1) [
134]. The hybrid HS and hybrid BBBC algorithms developed in [
93], mBBBC–UBS (derived from [
123]) and MsinDE (derived from [
124]) ranked right after the best algorithms, achieving best optimized costs of 0.032214, 0.032215, 0.032218 and 0.032220, respectively. The mAHS algorithm (derived from [
122]) captured the target optimum only up to the third significant digit (i.e., 0.032239 vs. 0.032213). As in the gravity dam design problem, the elitist strategy involving the condition
W(
) ≤ 1.1
W(
) implemented in SHGWJA was effective also for mBBBC–UBS, mAHS and MsinDE in that it improved their optimized solutions with respect to the original formulations but not enough to outperform SHGWJA. The hybrid Split–Detect–Discard–Shrink–Sophisticated Artificial Bee Colony algorithm (SDDS-SABC) [
131] and standard grey wolf optimizer (GWO) found the worst solutions overall, with a maximum cost of 0.033740.
The rate of success of SHGWJA was above 80% considering only the solutions yielding optimized costs between the global minimum of 0.032213 and the average cost 0.032215, hence within only 0.00621% penalty with respect to global minimum. Overall, SHGWJA was sufficiently competitive compared to all the other algorithms in terms of robustness. In fact, the average optimized cost coincided with its counterpart for the other algorithms up to the fourth significant digit (i.e., 0.03221). For SHGWJA, the ratio of standard deviation on optimized cost to average optimized cost was only 0.0114%. Standard GWO and CS-DP1 exhibited the largest dispersions on optimized cost. The high-performance algorithms En(L)SHADE [
126] and SASS [
130,
131] achieved zero standard deviation on optimized cost but their computational budgets were, respectively, 100,000 (fixed in the CEC 2020 benchmark) and 20,000 function evaluations vs. only 8517 function evaluations required on average by SHGWJA. Interestingly, SHGWJA completed on average within 10,000 function evaluations all optimization runs thus converging to the target global optimum of 0.032213 with null standard deviation when the convergence limit
in Equation (14) was reduced to 10
−10.
It can be seen from
Table 8 that SHGWJA required a considerably lower number of function evaluations than standard GWO and JAYA to complete the optimization process. The convergence rate increased by about 2.4 times with respect to standard JAYA and by a factor 6 with respect to standard GWO. Hence, the hybrid GWO-JAYA scheme implemented by SHGWJA was very effective in increasing the diversity of trial solutions from the
α,
β and
δ wolves in the exploration phase and enhancing the exploitation phase through the generation of very high-quality designs.
SHGWJA was robust enough in terms of computational cost, limiting the ratio between the standard deviation of the number of function evaluations to the corresponding average value to 27.8%. SHGWJA required on average 1.6 times more function evaluations than the hybrid HS/BBBC/SA algorithms of Ref. [
93], about 4% more function evaluations than mAHS, mBBBC–UBS and MsinDE, and slightly fewer function evaluations than the improved JAYA. However, the fastest optimization run of SHGWJA converging to the global optimum of 0.32213 was completed within only 5165 function evaluations, practically at the same convergence rate of the fastest algorithms reported in the literature. This confirms the high computational efficiency of the present algorithm.
The superior convergence behavior of SHGWJA with respect to its competitors is confirmed by
Figure 14, which compares the optimization histories of the best runs for the algorithms listed in
Table 8. The average convergence curve of SHGWJA is also shown in the figure. The plot is limited to 9000 function evaluations for the sake of clarity. It can be seen that the best and average optimization runs’ convergence curves of SHGWJA practically coincided after only 2700 function evaluations, that is, at 52.3% of the best run’s optimization history. All algorithms started their optimization runs from much larger initial costs than the target optimum: from 50 to 235.562 vs. only 0.032213. SHGWJA rapidly approached the target design, reducing the cost function to 0.0325 (less than 1% larger than the target cost) within only 900 function evaluations vs. the 3000 function evaluations performed by hybrid fast simulated annealing (HFSA) [
93], the fastest competitor to achieve the same intermediate solution of 0.0325.
The mAHS algorithm (derived from [
122]) was faster than the present algorithm over the first 170 function evaluations but then exhibited two large steps, respectively, lasting about 2950 function evaluations where the cost function decreased from 0.0612 to 0.04 and 3050 function evaluations where the cost function decreased from 0.04 to 0.034. The elitist strategy
W(
) ≤ 1.1
W(
) of SHGWJA allowed for significantly improving the convergence speed in the early optimization iterations for mBBBC–UBS (derived from [
123]) and MsinDE (derived from [
124]) as well. In particular, the average optimization history of SHGWJA and the best optimization run of mBBBC–UBS practically coincided between 320 and 1200 function evaluations, while the best optimization runs of SHGWJA and MsinDE overlapped for the first 120 function evaluations. However, similar to what was reported above for mAHS, the optimization histories of mBBBC–UBS and MsinDE presented large steps, yielding very little improvement in the cost function. In summary, the
W(
) ≤ 1.1
W(
) strategy is very effective when the cost function has to be rapidly reduced but it should be complemented by other elitist strategies such those implemented in SHGWJA.
5.7. Two-Dimensional Path Planning
Table 9 presents the optimization results for the sixth engineering design problem solved in this study, the 2-D path planning. All data listed in the table correspond to feasible solutions. The new algorithm SHGWJA was the best optimizer overall and designed the shortest path of 41.057 mm. The component algorithms of SHGWJA, the standard grey wolf optimizer (GWO) and standard JAYA, were less efficient than the hybrid algorithm developed here: they designed longer trajectories than SHGWJA (41.116 mm and 41.083 mm vs. only 41.057 mm, respectively).
The other algorithms compared with SHGWJA ranked as follows: hybrid BBBC [
93], improved JAYA [
93], mBBBC–UBS (derived from [
123]), mAHS (derived from [
122]), hybrid harmony search (hybrid HS) [
93], hybrid fast simulated annealing (HFSA) [
93], MsinDE (derived from [
124]) and dynamic differential annealed optimization (DDAO) [
136]. Optimized trajectory lengths ranged from 41.083 mm to 41.104 mm, except for DDAO, which designed the very long trajectory of 42.653 mm. Remarkably, the simple formulation of SHGWJA was able to solve a highly nonlinear optimization problem such as 2-D path planning in a more efficient way than algorithms including approximate line search and gradient information. This happened because SHGWJA is inherently able to balance exploration and exploitation phases: the JAYA operator enhances the exploration capability of the
α,
β and
δ wolves and forces the optimizer to search for very high-quality solutions in the exploitation phase. As in the industrial refrigeration system design problem, the high nonlinearity of the 2-D path planning problem was handled better by SHGWJA than by other HS/BBBC/SA hybrid algorithms that included line search and gradient information. The approximate line searches and gradient information are introduced in the optimization formulation to try to minimize the number of function evaluations. However, this may limit the quality of the approximation and, hence, the ability of the optimizer to generate trial solutions that are effectively located in regions of the search space where the current best record can be improved. As in the gravity dam and refrigeration system design problems, the elitist strategy
W(
) ≤ 1.1
W(
) implemented in SHGWJA was effective also for mBBBC–UBS, mAHS and MsinDE and improved their optimized solutions with respect to the original BBBC–UBS, SAHS and sinDE algorithms. However, the overall rank BBBC-JAYA-HS-SA-GWO-DE of the base algorithms after SHGWJA was substantially confirmed.
The rate of success of SHGWJA was 100% considering that the solutions of all independent optimization runs corresponded to shorter trajectories than the best solutions obtained by its competitors. The present algorithm was very competitive with all other optimizers in terms of robustness. In fact, it achieved the best average optimized path length of only 41.066 mm, followed by 41.093 mm of improved JAYA and 41.095 mm of standard JAYA and hybrid BBBC. The standard deviation of the optimized path length was only 0.0181% of the shortest path length designed by SHGWJA. Amongst the top five algorithms that designed the shortest trajectories (i.e., SHGWJA, standard JAYA, hybrid BBBC, improved JAYA, and mBBBC-UBS), SHGWJA presents the lowest ratio between the worst and best solutions. Interestingly, mBBBC–UBS ranked third in terms of the best solution together with improved JAYA but only seventh in terms of its average optimized path length, 41.103 mm. Standard GWO again exhibited the largest dispersion on optimized cost considering that only 10 independent optimization runs were executed for DDAO in [
136] vs. the 20 runs carried out for standard GWO.
SHGWJA was computationally efficient also for this test problem. In this regard,
Table 9 shows that the proposed SHGWJA algorithm required on average far fewer function evaluations than standard GWO and JAYA to converge to the optimal solution. In fact, SHGWJA was about 4.3 and 14.1 times faster than standard JAYA and standard GWO, respectively. The computational speed of SHGWJA was practically the same as for the HS/BBBC/SA hybrid algorithms and improved JAYA. The fastest optimization run of SHGWJA that converged to the global optimum path length of 41.057 mm required 3416 function evaluations, which falls in the middle of the 3122 to 3615 interval recorded for the function evaluations of the fastest algorithms reported in the literature. The mBBBC–UBS algorithm ranked sixth overall (right after HFSA, and on average about 11% slower than SHGWJA), while MsinDE and DDAO were the slowest optimizers, requiring about 50% more function evaluations than SHGWJA. The present algorithm was very robust also with respect to computational cost: just 7.6% dispersion on the number of function evaluations, followed by hybrid fast simulated annealing with 9.6%.
The excellent convergence behavior of SHGWJA is confirmed by
Figure 15, which compares the optimization histories of the best runs for the algorithms listed in
Table 9. The average convergence curve of SHGWJA is also shown in the figure. The plot is limited to 4200 function evaluations for the sake of clarity. The best and average optimization runs’ convergence curves of SHGWJA practically coincided after only 1450 function evaluations, that is, at 42.5% of the best run’s optimization history. The best optimization run of SHGWJA started from the very large cost of 254.713 mm (i.e., about 6.2 times the globally optimum length of 41.017 mm found by the present algorithm), while the initial cost for all other optimizers ranged between 50.01 and 59.62 mm (i.e., at most 45.2% longer than the shortest trajectory designed by SHGWJA). As in the other test problems discussed in this section, the present algorithm immediately recovered the initial gap in the cost function with respect to its competitors. The hybrid simulated annealing (HFSA) and hybrid big bang–big crunch algorithms of Ref. [
93] were the only algorithms to compete in convergence speed with SHGWJA, respectively, for the first 230 and 450 function evaluations.
The optimized trajectories obtained in the best optimization runs of SHGWJA and its competitors are compared in
Figure 16. SHGWJA, hybrid HS/BBBC/SA, mBBBC–UBS and improved JAYA substantially reduced the path length between the obstacles O
1 and O
7 with respect to the solution of DDAO. Furthermore, the present code reduced the curvature of the central part of the designed trajectory with respect to hybrid HS/BBBC/SA, improved JAYA and mBBBC–UBS (trajectories referred to mAHS and MsinDE are not shown in the figure because are very similar to the one plotted for mBBBC–UBS), thus shortening the path length. This is confirmed by comparing the optimal solution of SHGWJA with that of hybrid BBBC, the second best solution overall. The optimal positions of base points found by SHGWJA were (10.001;5.778), (17.183;16.589) and (19.696;20.495) mm, while they were (12.362;8.940), (15.060;13.460) and (18.198;18.446) mm for hybrid BBBC, which obtained the best solution quoted in the literature so far [
93]. The base points of SHGWJA may be fitted in the XY plane by a linear regression with R
2 = 1, while for the base points of hybrid BBBC, the correlation coefficient is only R
2 = 0.999.
5.8. Mechanical Characterization of Flat Composite Panel Under Axial Compression
Table 10 presents the results obtained in the last engineering problem solved in this study. The values of the material properties and ply orientations of the axially compressed flat composite panel identified by SHGWJA and its competitors in their best optimization runs are listed in the table. The average and maximum errors on the identified parameters and the panel’s fundamental buckling mode shape for the best optimization runs of all the algorithms also are listed in the table, along with the number of finite element (FEM) analyses required in the identification process.
It can be seen that SHGWJA identified the panel’s properties more accurately than its competitors. In fact, the average error on material/layup parameters recorded for SHGWJA was only 0.03888%, while the corresponding errors for the other algorithms ranged between 0.197 (hybrid fast simulated annealing, HFSA, of Ref. [
3]) and 5.214 (improved JAYA variant of Ref. [
3]). The largest error on the parameters for the present algorithm was only 0.07080% (on the longitudinal modulus
EL), while the other algorithms could not reduce this error below 0.389% (the best SHGWJA competitor again was HFSA). The superiority of SHGWJA over its competitors emerges clearly from the analysis of the identified parameters. In particular, SHGWJA identified the 0° ply angle at the fourth digit while the other algorithms could at most identify it up to the third digit. Furthermore, the errors in the 90° and ±45° ply directions were only 0.01222% and 0.008889%, respectively.
The maximum residual error on the panel’s buckling mode shape evaluated for the SHGWJA solution was only 1.035% vs. 2.281% of HFSA, while the other algorithms obtained error values ranging from 2.504% (hybrid fast harmony search optimization, HFHS, of Ref. [
3]) to 4.421% (standard GWO). The average error on buckling mode shape for the present algorithm was only 0.674 vs. at least 1.554% for its competitors. The largest errors on
w-displacements were localized in correspondence with the regions near points A and B of the vertical control path sketched in
Figure 8c, that is, where the panel is fixed to the testing machine and displacements should be close to zero. The selected mesh size allowed for avoiding numerical noise in the finite element analyses performed in the optimization search. Interestingly, SHGWJA minimized the error functional Ω of Equation (25), considering 170 control points, while the hybrid fast HS/BBBC/SA algorithms used in Ref. [
3] considered only the 86 control points lying on the AB path parallel to the loading direction. In spite of this, SHGWJA significantly reduced the error on the buckling pattern with respect to the optimizers of Ref. [
3].
SHGWJA outperformed its component algorithms, standard GWO and JAYA, which failed in identifying the target value of the shear modulus
GLT (respectively, 4317 and 4308 MPa with 4.275% and 4.058% error on this elastic property). Furthermore, the present algorithm required only 366 finite element analyses vs. 5000 and 2000 analyses required, respectively, by standard GWO and JAYA. The improved JAYA variant used in [
3] required 975 analyses but prematurely converged to the worst solution overall with 20.749% error for the shear modulus. The hybrid GWO–JAYA formulation implemented by SHGWJA was thus very effective also in this highly nonlinear optimization problem.
As in the gravity dam design, refrigeration system design and 2D path planning problems, the elitist strategy
W(
) ≤ 1.1
W(
) implemented in SHGWJA was effective also for mAHS (derived from [
122]) and mBBBC–UBS (derived from [
123]). In fact, mAHS and mBBBC–UBS significantly improved their performance with respect to the original AHS and BBBC–UBS algorithms used in Ref. [
3]. In particular, mAHS reduced the identification errors on the transverse elastic modulus
ET and Poisson’s ratio ν
LT from 2.470% to only 0.282% and from 1.589% to only 0.199%, respectively. Ply angles were also identified much more accurately than in [
3]: errors on 90° and ±45° orientations decreased from 2.631% to 0.771% and from 1.796% to 0.620%, respectively. The 0° ply angle was identified up to the third digit, reducing its value by more than one order of magnitude with respect to [
3]: 0.007373° vs. 0.08884°. Furthermore, mAHS completed its search process within only 1044 finite element analyses, while the original AHS algorithm used in [
3] required 1650 analyses.
The mBBBC–UBS algorithm reduced the identification errors on the transverse elastic modulus
ET, shear modulus
GLT and Poisson’s ratio ν
LT from 1.503% to only 0.175%, from 3.478% to 0.773%, and from 1.987% to 0.861%, respectively. Ply angles were also identified much more accurately than in [
3]: errors on 90° and ±45° orientations decreased from 1.652% to 0.638% and from 2.227% to 0.698%, respectively. The 0° ply angle was identified up to the third digit, reducing its value by almost 48% from 0.03891° vs. 0.008162°. Furthermore, mBBBC–UBS completed the identification process within only 819 finite element analyses while the original BBBC–UBS algorithm required 1250 analyses in [
3].
The MsinDE algorithm (derived from [
124]) augmented by SHGWJA’s
W(
) ≤ 1.1
W(
) elitist strategy also performed well, ranking fifth overall in terms of accuracy in panel’s property identification and buckling pattern reconstruction after SHGWJA and hybrid fast HS/BBBC/SA. MsinDE ranked sixth overall in terms of computational cost after SHGWJA, hybrid fast HS/BBBC/SA and mBBBC–UBS, completing the identification process within 968 finite element analyses.
Statistical dispersion on the identified panel properties and residual error for the buckling pattern evaluated over the 20 independent runs remained below 0.75%, thus confirming the robustness of SHGWJA. In the worst optimization run, SHGWJA was still able to limit maximum errors on panel properties and the buckling mode to 0.08% and 1.0625%, respectively, while its best competitor, HFSA, recorded 0.389% and 2.281% for the same quantities. The present algorithm was also very robust in terms of computational cost: in fact, the standard deviation of the number of finite element analyses required by SHGWJA in the identification process for the different runs was only 10.2% of the corresponding average number of analyses. The present algorithm was on average 35.6%, 19.7% and 10.9% faster than hybrid fast SA, hybrid fast HS and hybrid fast BBBC, respectively, and 2.1 to 2.7 times faster than mBBBC–UBS, MsinDE and mAHS.
More information on the convergence behavior of SHGWJA and its competitors is available from
Figure 17, which compares convergence curves relative to the best optimization runs of the algorithms listed in
Table 10. The average convergence curve of SHGWJA is also shown in the figure. The plot is limited to 1050 function evaluations for the sake of clarity. It can be seen from the figure that SHGWJA generated better intermediate designs than its competitors over the whole search process. The best and average optimization runs’ convergence curves of SHGWJA practically coincided after 275 function evaluations, that is, at 75.1% of the best run’s optimization history. The convergence curve recorded for the best optimization run of the hybrid fast harmony search (HFHS) algorithm was close enough to the average convergence curve of SHGWJA for the first 40 finite element analyses and from 150 to 210 analyses. HFHS and HFBBBC (hybrid fast big bang–big crunch) were the only algorithms able to reduce the error functional value below 10
−4 within 350–360 structural analyses, that is, when SHGWJA concluded its optimization process with the final cost function value Ω
OPT = 1.97·10
−6. Since SHGWJA started its best run from an initial population including individuals with at least Ω = 2.049 while the best optimization runs of HFHS and HFBBBC started from populations with at least Ω = 0.891, the present algorithm proved once again its inherent ability to quickly approach the global optimum solution.
In order to check whether residual errors on the panel buckling pattern evaluated for each optimization run were caused by some inherent limitation of SHGWJA formulation, the identification problem stated by Equation (25) was solved in silico. For that purpose, the target buckling pattern of the panel was computed by ANSYS for the target panel’s properties. SHGWJA performed the optimizations to reconstruct the target displacement field generated via FEM. Remarkably, the present algorithm always converged to target properties reproducing the panel displacement field with 0 residual error in all independent optimization runs. The 0.08% maximum errors on the buckling pattern mentioned above for the 20 SHGWJA optimization runs were thus caused by the uncertainties usually entailed by the hybrid characterization process, a very complicated task matching experimental data and FEM results. Optically measured displacements certainly are a good target to select because the double projection moiré method is a highly sensitive full-field measurement technique. However, in this study, control points were located at critical locations where even small changes in measured quantities may affect the success of the identification process to a great extent. Hence, the present results are very satisfactory.
5.9. Statistical Analysis of Results of Engineering Optimization Problems
Besides the classical statistical analysis carried out for the above engineering optimization problems, which relied on the best, average and worst solutions and the corresponding standard deviations of optimized cost over the independent optimization runs, the optimized designs obtained by SHGWJA and its competing algorithms—standard GWO, standard JAYA, improved JAYA [
93], hybrid HS/BBBC/SA [
93], hybrid fast HS/BBBC/SA (specifically developed for inverse problems) [
3], mAHS (derived from [
122]), mBBBC–UBS (derived from [
123]) and MsinDE (derived from [
124])—in the independent runs were also analyzed by performing a Wilcoxon test with a level of significance of 0.05. Interestingly,
p-values determined for each pair of algorithms’ solutions were always smaller than 0.05, thus confirming the superiority of SHGWJA over its competitors.
In this second part of statistical analysis, SHGWJA and its competitors are ranked with respect to five performance criteria: (i) best optimized cost (BEST); (ii) average optimized cost (AVERAGE); (iii) worst optimized cost (WORST); (iv) standard deviation on optimized cost (STD); and (v) number of function evaluations (or finite element analyses) (NFE).
Table 11 lists the corresponding ranks achieved by SHGWJA in each engineering optimization problem. The table actually includes 10 entries for each ranking criterion because the welded beam and pressure vessel design problems have three and two variants, respectively. For each test problem, the total score (TOTSCO) assigned to SHGWJA (also reported in
Table 11) was determined by summing over the ranks achieved for the different criteria: TOTSCO = 5 may be obtained only if the optimizer ranks first with respect to all the performance criteria.
It can be seen that SHGWJA ranked 1st overall, respectively, 9 times out of 10 for best cost optimized cost, 8 times out of 10 for average and worst optimized cost, 7 times out of 10 for standard deviation on optimized cost, 6 times out of 10 for number of function evaluations. The low rankings obtained by SHGWJA in the tension/compression spring design problem for best optimized cost (14th among the 22 MAs compared here), average optimized cost (8th), worst optimized cost (6th) and standard deviation on optimized cost (7th) do not represent a major issue if one considers that SHGWJA’s best solution was 0.0126665, practically the same as the target value 0.012665; moreover, the average and worst optimized costs were also very close to 0.012665. The same arguments applied to the refrigeration system design problem where SHGWJA ranked fifth and seventh (among the 15 MAs compared here) with respect to the average/worst optimized cost and standard deviation on optimized cost. In fact, the average and worst optimized costs found by SHGWJA were, respectively, 0.032215 and 0.032219, practically the same as the target optimum of 0.032213. Furthermore, two algorithms that obtained standard deviations on optimized cost lower than SHGWJA could never converge to the 0.032213 target value in their independent runs. In the 2D path planning problem, SHGWJA ranked fourth (among the 11 MAs compared here) with respect to standard deviation on optimized cost; indeed, since SHGWJA’s worst solution was better than the best solutions obtained by all its competitors, SHGWJA’s actual rank should be first.
Table 11 shows that SHGWJA obtained a very large value of TOTSCO (i.e., 37) in only the tension/compression spring design problem and quite a large total score (i.e., 20) in the industrial refrigeration system problem. In view of this, SHGWJA’s competitors that obtained lower cost function values than 0.0126665 were analyzed with respect to all performance criteria and total score: the corresponding results are listed in
Table 12. It can be seen that SHGWJA practically reached the same overall performance of GGWO and EHRJYA, the most advanced GWO and JAYA variants considered for this test problem: 37 vs. 31 and 36 total score values. While GGWO and EHRJYA converged to the target optimum, they were less efficient than SHGWJA with respect to three out of the other four performance indicators. Interestingly, SHGWJA would be the fifth best algorithm overall if the contribution of the best convergence run were removed from the total score (see the last column of the table), thus recovering from the small gaps with GGWO and EHRJYA and reducing its original 22-point gap from the top-ranked algorithms MPA and En(L)SHADE to only 9 points.
The same analysis of
Table 12 was then carried out for the welded beam and the pressure vessel design problems, limiting the set of SHGWJA’s competitors to GGWO, EHRJAYA, EJAYA, MPA, EGTO, SaDN, En(L)SHADE and QSA. These algorithms were selected because (i) all the necessary data for determining performance indicators were available from the literature for at least one test problem, and (ii) they had achieved better total score values than SHGWJA in the tension/compression spring problem.
Table 13 compares the performance indicators and the total score values obtained by SHGWJA and its competitors in the welded beam and pressure vessel problems. The first entries of each row in the table refer to the welded beam problem results. Since some algorithms were run for only one of the welded beam problem or pressure vessel problem variants, the values of the performance indicators and total score reported for SHGWJA represent the average of the corresponding values listed in
Table 12.
It can be seen from
Table 13 that SHGWJA significantly improved its rank with respect to the other algorithms. En(L)SHADE remained the best algorithm over the spring/welded beam/vessel problem but SHGWJA reduced the gap to only 7.3 points (47.3 vs. 40), equaling almost the 2
nd rank position of GGWO (47.3 vs. 45). SHGWJA actually ranks above both MPA, which reached a total score of 44 for only the tension/compression spring and welded beam problems, and EHRJAYA that converged to an infeasible solution in the pressure vessel problem obtaining a total score of 45 for only the tension/compression spring and welded beam problems: even adding only 5 points (best case scenario) the total score would raise to 49 for MPA and 50 for EHRJYA, above the 47.3 score of SHGWJA.
Interestingly, SHGWA and En(L)SHADE can also be compared in the industrial refrigeration system design problem, while no data are available for the other algorithms. The ranks of En(L)SHADE were 〈1, 1, 1, 1, 14〉 for a total score of 18, less than the score of 20 obtained by SHGWA (see
Table 11). However, the En(L)SHADE results were collected for a computational budget of 100,000 function evaluations, while the present algorithm always required on average only 8517 function evaluations to complete its optimization runs. As mentioned in
Section 5.6, SHGWJA completed on average within only 10,000 function evaluations (one whole order of magnitude less than En(L)SHADE) all optimization runs always converging to the target global optimum of 0.032213 with a null standard deviation when the convergence limit
in Equation (14) was reduced to 10
−10. Hence, the total score of SHGWJA in the industrial refrigeration system problem would be five. Consequently, the total score of SHGWJA in the four CEC2020 test problems (i.e., tension/compression spring, welded beam, pressure vessel, industrial refrigeration system) would be only 37 + 5.3 + 5 + 5 = 52.3, better than the total score 15 + 8 + 17 + 18 = 58 of En(L)SHADE. This confirms the high efficiency of the present algorithm.
The last part of statistical analysis regards the trajectory of optimization variables during the search process. However, it should be noted that analyzing the trajectory of only a few (very often just one or two) optimization variables of one individual of the population, as is usually done in the literature, may provide only partial information on the convergence behavior and robustness of an optimization algorithm if the selected variables do not drive the search process. For example, some optimization variables may fluctuate to a large extent over the whole search process, while other variables may converge to their target values within just a few iterations. The former may occur if the optimizer becomes stuck in a region of the search space which hosts many competitive solutions that are weakly dependent on the fluctuating variable(s). In order to overcome this limitation, the worst-case scenario was considered in this study by monitoring the evolution of the largest percent variation experienced by the optimization variables of the whole population as the search progressed. If the optimizer truly converges to the optimal solution, the design variables should not fluctuate. The selected representation is a sort of normalized trajectory of the variables that cycle by cycle have the highest difficulty to converge. The normalized trajectory is hence formed by the trajectories of many different variables. The maximum variation in optimization variables over the whole population also gives information about the population diversity, which will tend to zero as the global optimum is reached.
Figure 18 shows the plots for the best runs of SHGWJA for the engineering optimization problems solved in this study. In order to evaluate the overall behavior of SHGWJA, normalized trajectories were plotted with respect to the percent fraction of the best run’s convergence history: (i)
Figure 18a presents the data obtained for the tension/compression spring, welded beam and pressure vessel test problems; and (ii)
Figure 18b shows the data obtained for the concrete dam, industrial refrigeration system, 2D path planning and composite panel characterization test problems. For the sake of clarity, the scale of the vertical axes of the plot was limited to 45%.
It can be seen from
Figure 18 that the largest variation in optimization variables became smaller than 1–2% at about half of the optimization history. Such behavior was observed for all the engineering design test problems solved in this study. Oscillations in the normalized trajectory (with peaks up to 45%) were relevant over the first 10% of the optimization history for the spring/beam/vessel problems, while they lasted until 25–30% of the optimization history for the dam/refrigeration system/2D path planning/composite panel problems. This was expected in view of the larger number of optimization variables and higher complexity of the latter group of test problems. In all cases, the oscillations were smoothed as the optimization search progressed. For example, in variant 2 of the pressure vessel problem, the largest percent variation in the variables was 45% at 3% of the search, 25% at 6%, 15% at 9%, and only 2% at 17% of the search. In the composite panel identification problem, the largest percent variation in the variables was 42% at 4% of the search, 20% at 14%, 8% at 20%, 5% at 25% and only 2.5% at 30% of the search.
6. Conclusions and Future Work
This paper described a novel hybrid metaheuristic optimization algorithm, SHGWJA, combining grey wolf optimizer (GWO) and JAYA. The new algorithm developed in this study utilizes an elitist approach and JAYA operators to minimize the number of function evaluations and optimize the balance between exploration and exploitation. The rationale of this study was to develop an efficient hybrid algorithm for carrying out engineering optimizations without overly complicating the formulation of the new optimizer.
SHGWJA was successfully tested in two classical mathematical optimization problems (the Rosenbrock and Rastrigin functions) with up to 1000 variables, and in seven “real-world” engineering optimization problems (four of those problems were taken from the CEC 2020 test suite), covering very different fields such as civil engineering (shape optimization of a concrete gravity dam), mechanical engineering (tension/compression spring, welded beam, pressure vessel, refrigeration system), aeronautical engineering (mechanical characterization of a flat composite panel under axial compression) and robotics (2-D path planning). The seven engineering problems included up to 14 optimization variables and 721 nonlinear constraints.
SHGWJA was extensively compared with the metaheuristic optimization literature: in particular, with 31, 29, 11, 21, 24, 27, 14, 10 and 10 state-of-the art optimizers (each of which in turn had been proven in the literature to outperform up to 34 other MAs), respectively, including the algorithms that provide the best solutions in the literature for each problem, high-performance algorithms and CEC competitions winners. The comparison carried out in this article was very indicative considering that most of the selected competitors were (i) improved variants of the most commonly used MAs, (ii) recently developed methods that are very competitive with high-performance algorithms and CEC winners, and (iii) hybrid algorithms that use approximate line searches and gradient information to generate new trial designs.
The present algorithm always converged to the global optima quoted in the literature or to very close solutions to the global optima. In particular, in the mathematical optimization problems with 0 target optima, SHGWJA’s best costs were about 10−15 with average standard deviation values on the order of 10−13 to 10−12. In the “real-world” problems, a very small deviation (only 0.0121% of the target global optimum cost) was only observed for the spring design problem. SHWGJA always ranked first or second in terms of optimized cost.
The computational cost of SHGWJA was always lower than those of the standard GWO and JAYA formulations, as well as of the advanced GWO and JAYA variants. Such behavior confirmed the validity of the proposed hybrid formulation, which allowed the performance of the GWO and JAYA components to be significantly improved. Remarkably, the present algorithm always ranked first or second overall with respect to the average computational speed and its fastest optimization runs were better or highly competitive with those of the best MAs.
SHGWJA was very robust, achieving a very high rate of success in all the test problems. A null or near-to-0 standard deviation optimized cost was obtained in most cases. Furthermore, the standard deviation of the number of function evaluations required in the optimization process never exceeded 35% of the average number of function evaluations.
The results presented in this paper fully supported the conclusion that SHGWJA is a very efficient tool for optimizations related to engineering design problems. The proposed algorithm does not present major theoretical limitations that could affect its search ability and robustness. However, the selected engineering test problems, despite covering many different fields, included at most only 14 optimization variables. For this reason, further research is currently being carried out in order to maximize the convergence speed of SHGWJA in constrained optimization problems with a larger number of design variables. This may be achieved by introducing additional JAYA operators into the definitions of wolves α, β and δ. For example, preliminary results obtained in the weight minimization of a planar 200 bar truss structure optimized with 29 sizing variables (the structure must carry three independent loading conditions and the optimization problem includes 1200 nonlinear constraints on bar stresses; sizing variables correspond to the cross-sectional areas of the elements that belong to each group) confirm the validity of the above-mentioned approach: in fact, SHGWJA converged to the target optimum weight of 11,542.4 kg. Furthermore, numerical tests carried out on the whole CEC2020 test suite of mechanical engineering benchmark problems, which includes 19 test cases also covering discrete optimization, equality constraints and topology optimization (with up to 30 design variables and 86 nonlinear inequality/equality constraints), indicate that the present algorithm can converge to the target optima within a significantly smaller number of function evaluations than the computational budget allowed in CEC competitions.
An interesting issue is the scalability of the SHGWJA. While mathematical functions (e.g., Rosenbrock and Rastrigin) may easily be scaled because the analytical formulation of the optimization problem does not change with the problem dimension, the same is not in general true for engineering optimization problems. In this regard, other preliminary investigations are currently being conducted for a classical large-scale structural optimization problem: the weight minimization of a planar 200 bar truss structure subject to five independent loading conditions, with 3500 nonlinear constraints on nodal displacements and element stresses. Because of the symmetry of the structure, the bars can be grouped in 96, 105 or 200 groups: hence, the optimization problem may be solved with 96, 105 or 200 sizing variables. The lowest weights reported in the literature [
143] for the 96-, 105- and 200-variable problem variants are 12,823.808 kg, 13,062.339 kg and 13,054.841 kg, respectively. However, these designs are not consistent with the amount of design freedom included in the optimization. Interestingly, this problem can be solved by SHGWJA, which obtains optimized structural weights of 12,822.902 kg, 12,821.543 kg and 12,820.289 kg for the 96-, 105- and 200-variable problem variants, respectively.
SHGWJA was applied in this study to single-objective optimization problems. However, since both of its component algorithms, GWO and JAYA, have already been successfully used in multi-objective optimization problems (see, for example, Refs. [
108,
144]), and our hybrid SHGWJA formulation does not entail any theoretical limitations in this regard, further studies will focus on developing a suitable version of the proposed algorithm for multi-objective optimization problems. For example, multiple populations could be used for independently solving each single-objective problem, and a “good” solution weighted over the single-objective solutions could be generated for the multi-objective optimization problem.







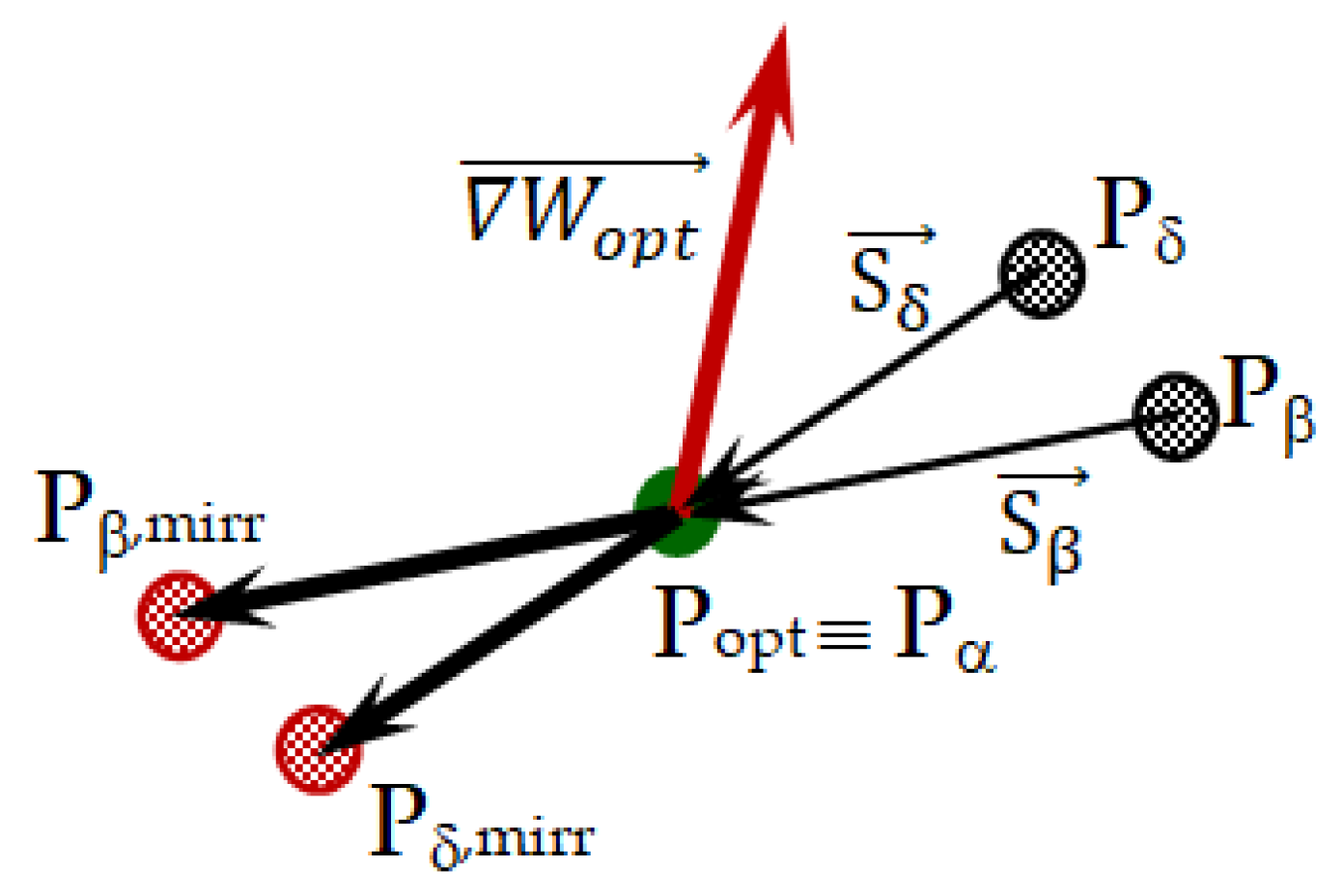

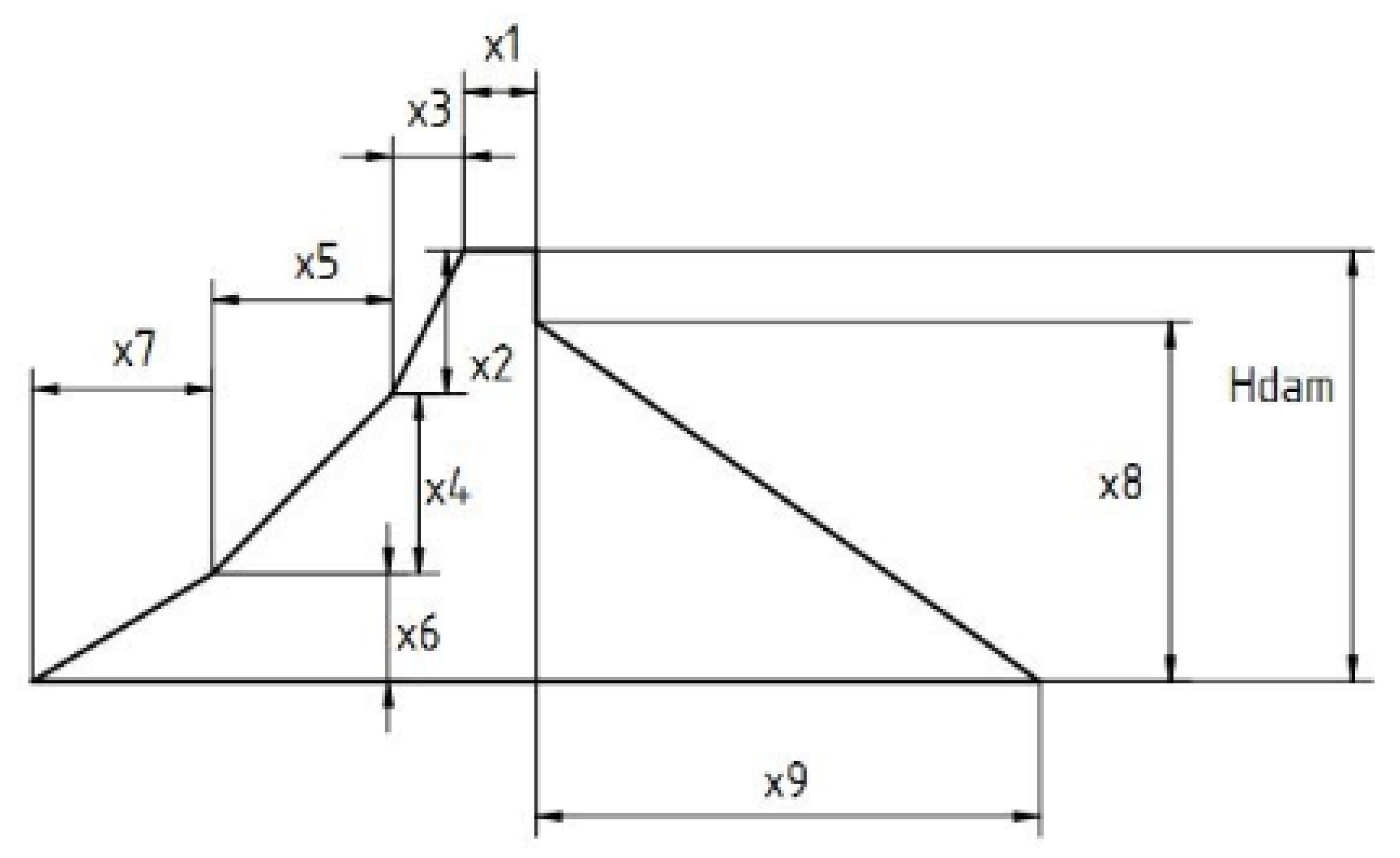

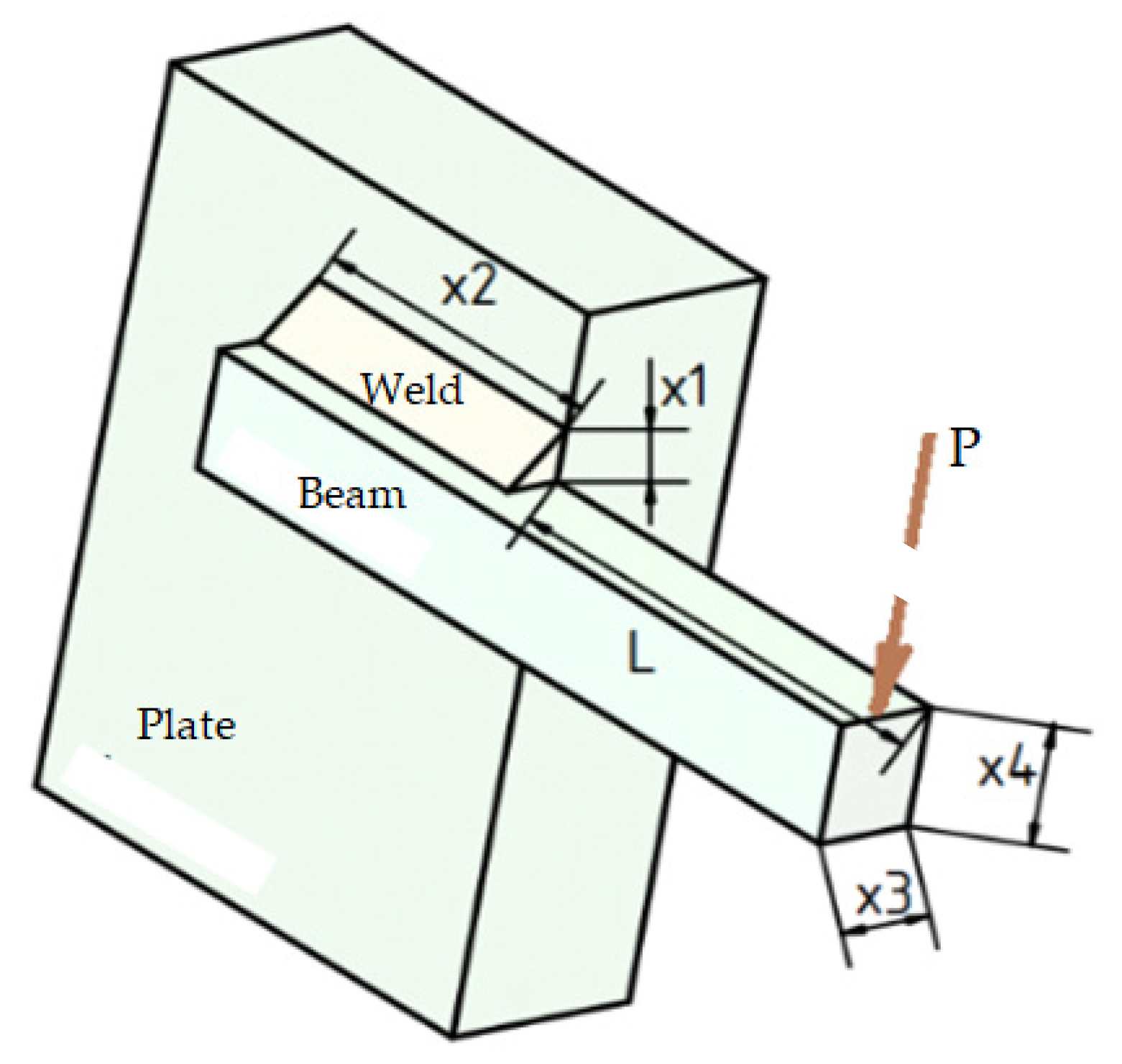


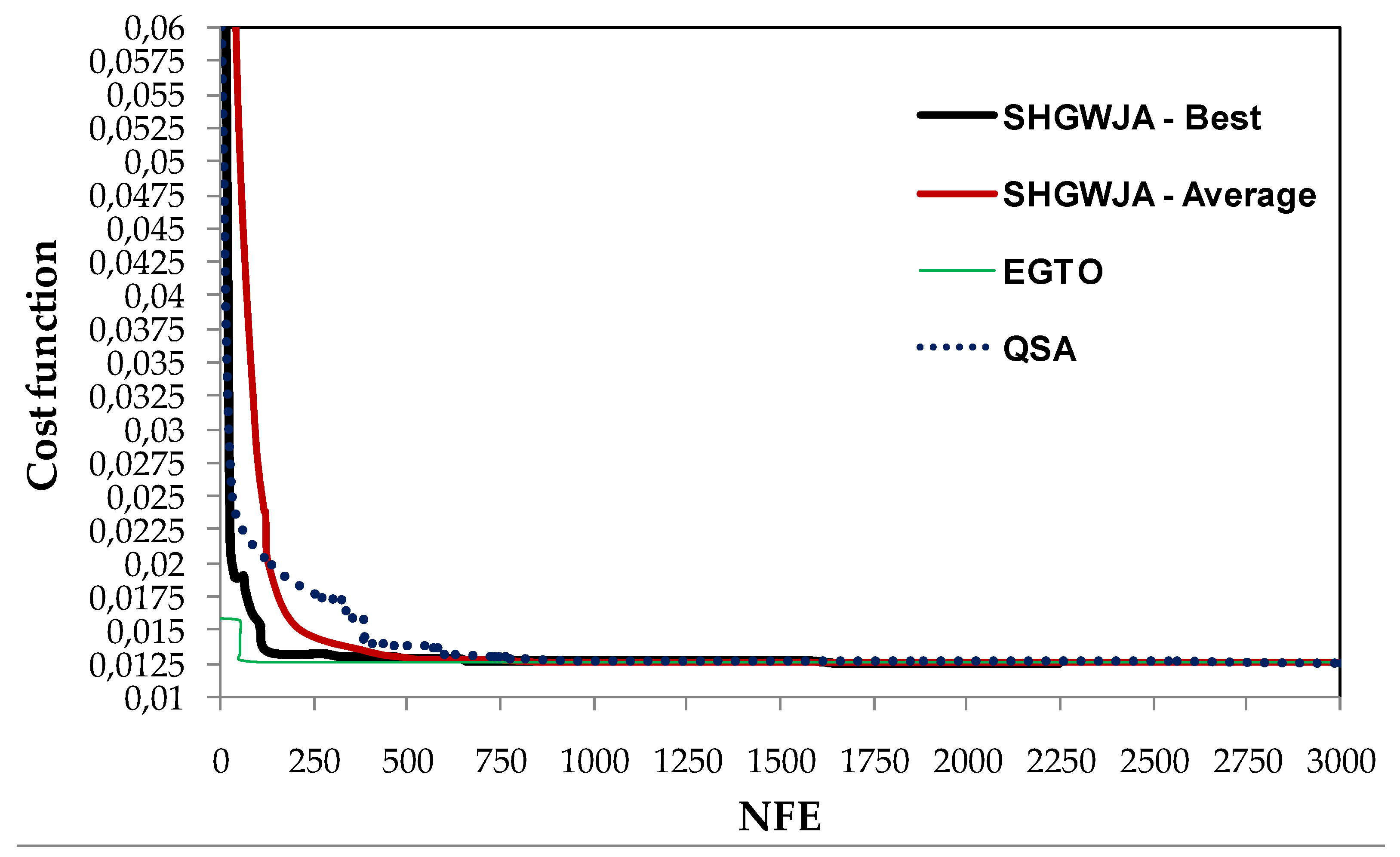
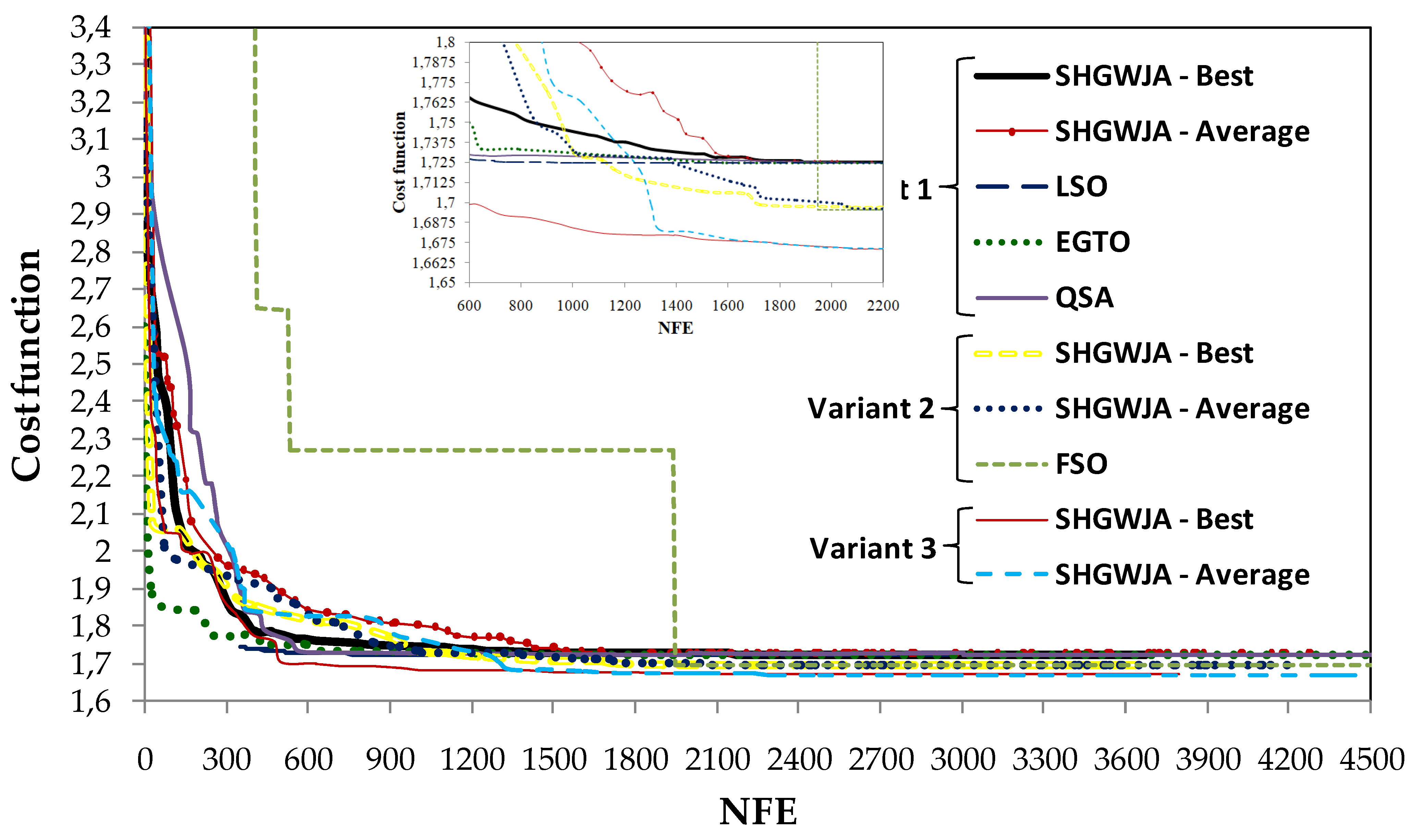


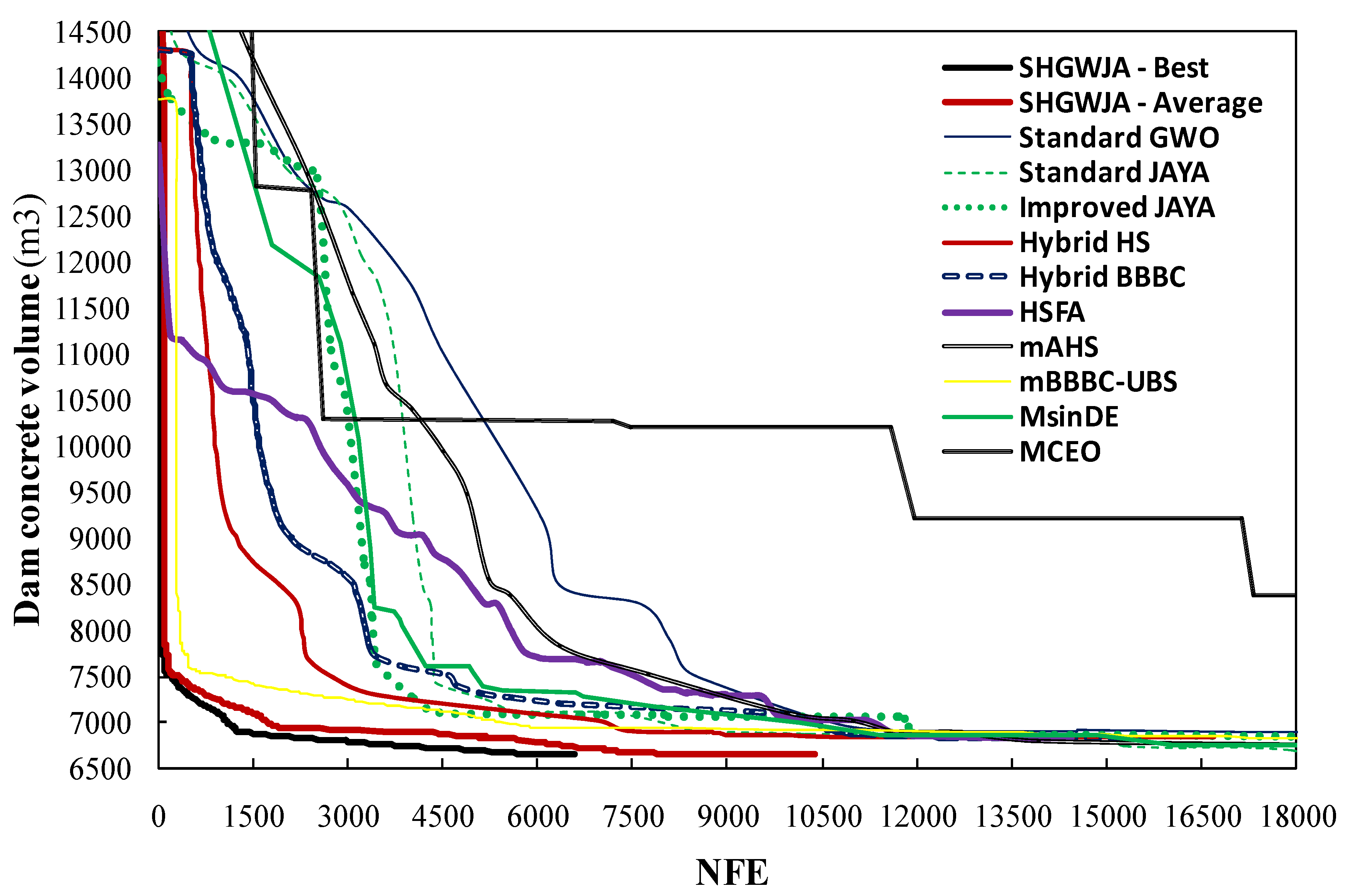



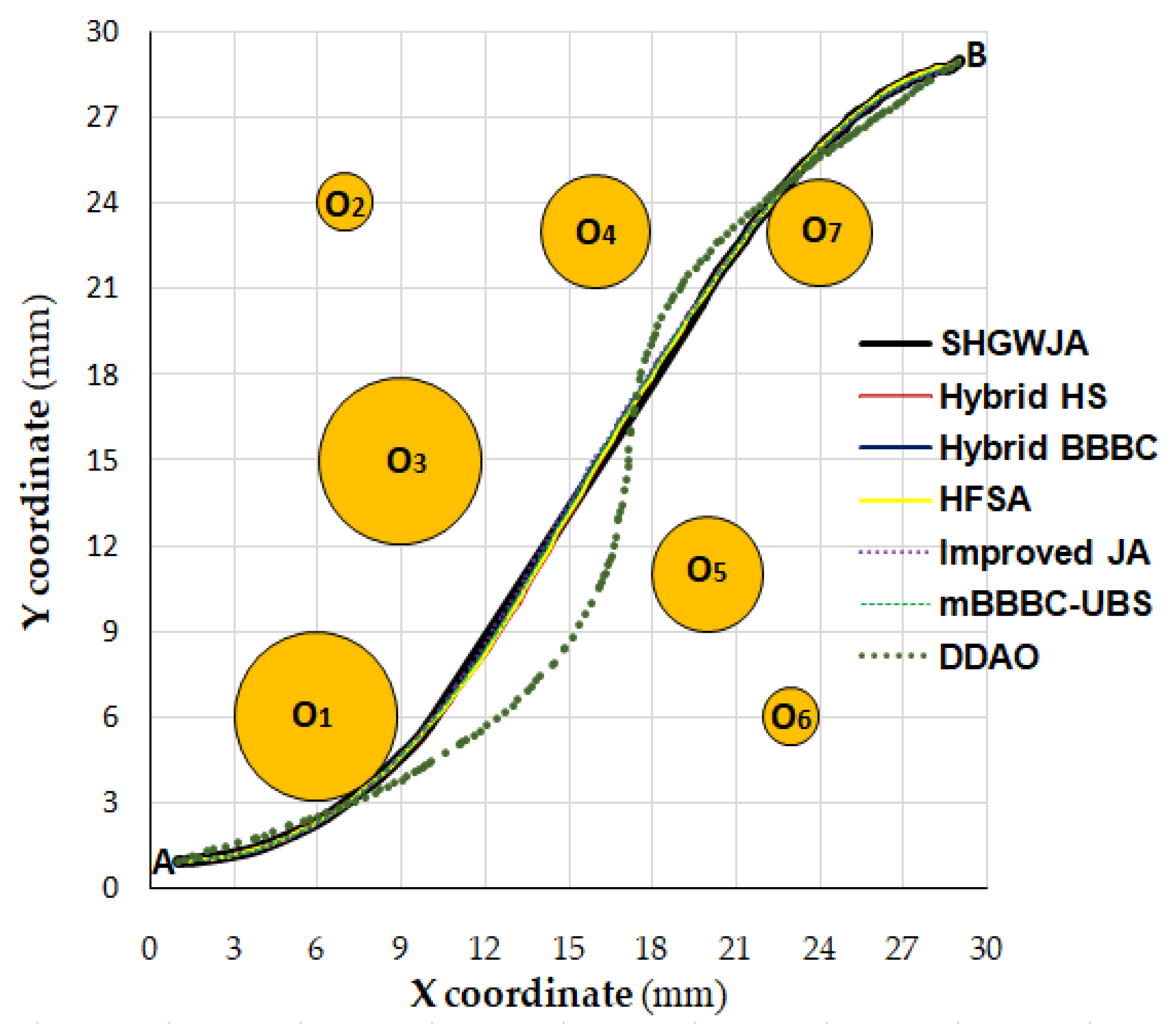


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}