
Continuous-Time Dynamic Graph Networks Integrated with Knowledge Propagation for Social Media Rumor Detection


Abstract
1. Introduction
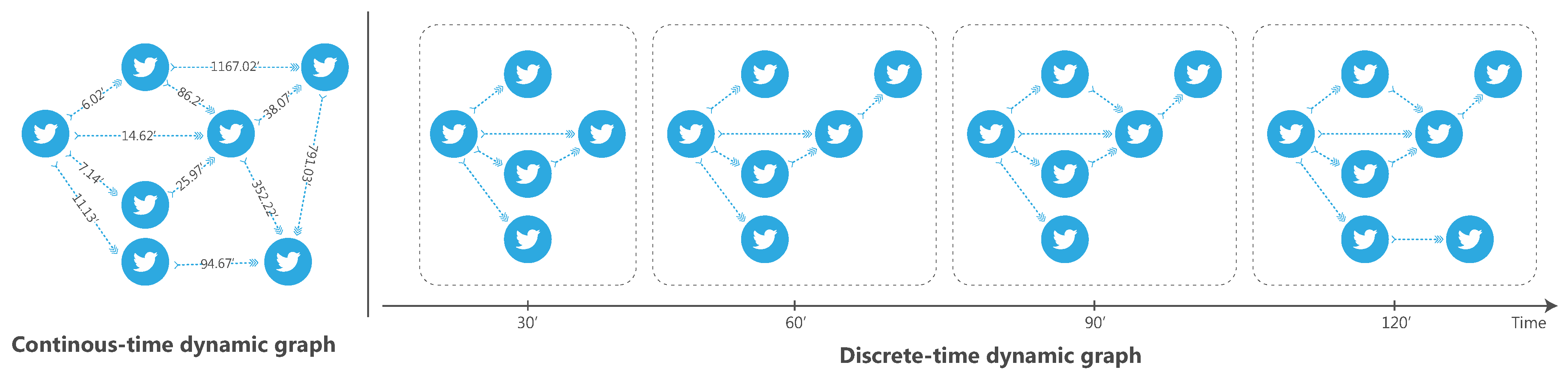
- Joint Spatial and Temporal Structure (L1): We introduce a new continuous-time dynamic encoder to precisely capture the spatio-temporal structural features of rumor propagation.
- Combining Fine-Grained Temporal Features (L2): In contrast to existing methods, CGNKP employs continuous-time dynamic graphs to represent the diffusion process of rumors, utilizing exact temporal information instead of static graph snapshots. This allows for a more refined representation of the temporal diffusion process.
- Dynamic Knowledge Information (L3): CGNKP focuses not only on the diffusion of posts but also on the diffusion of knowledge. Specifically, we construct temporal knowledge graphs that expand over time using external knowledge bases and encode them using the continuous-time dynamic encoder to obtain dynamic knowledge information.
2. Related Work
2.1. Spatial Structure-Based Rumor Detection
2.2. Temporal Structure-Based Rumor Detection
2.3. Knowledge-Enhanced Rumor Detection
2.4. Dynamic Graph Networks
3. Problem Definition
4. Model
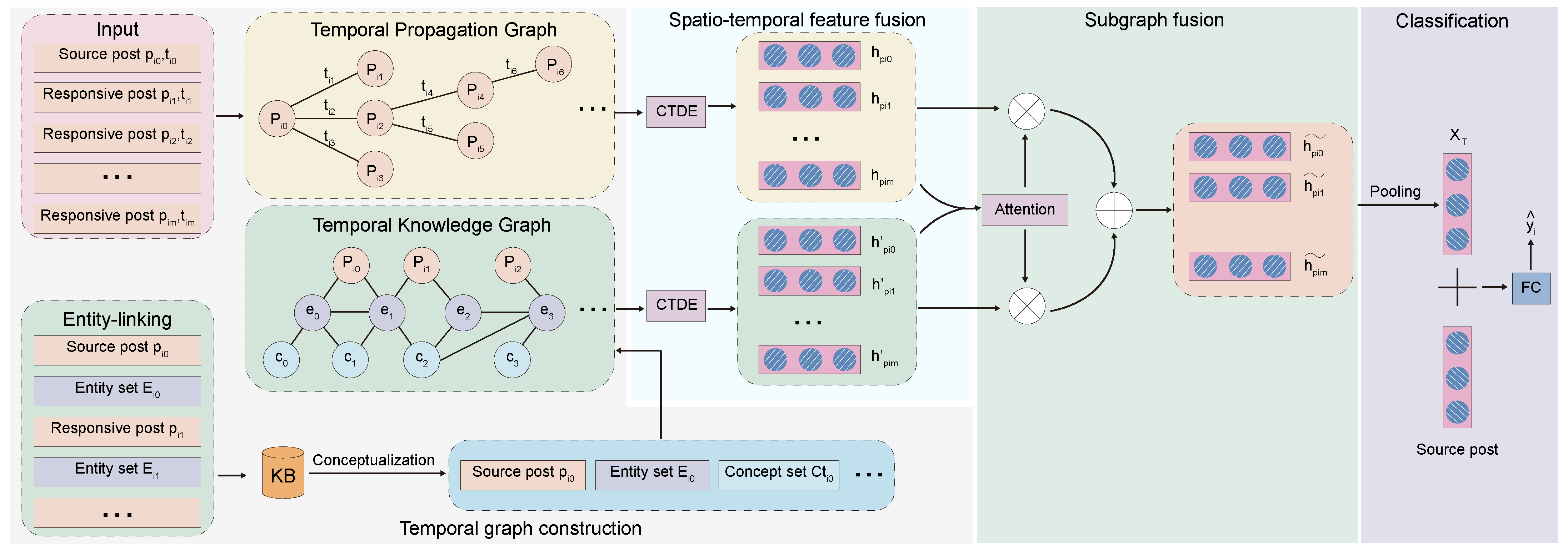
4.1. Model Framework
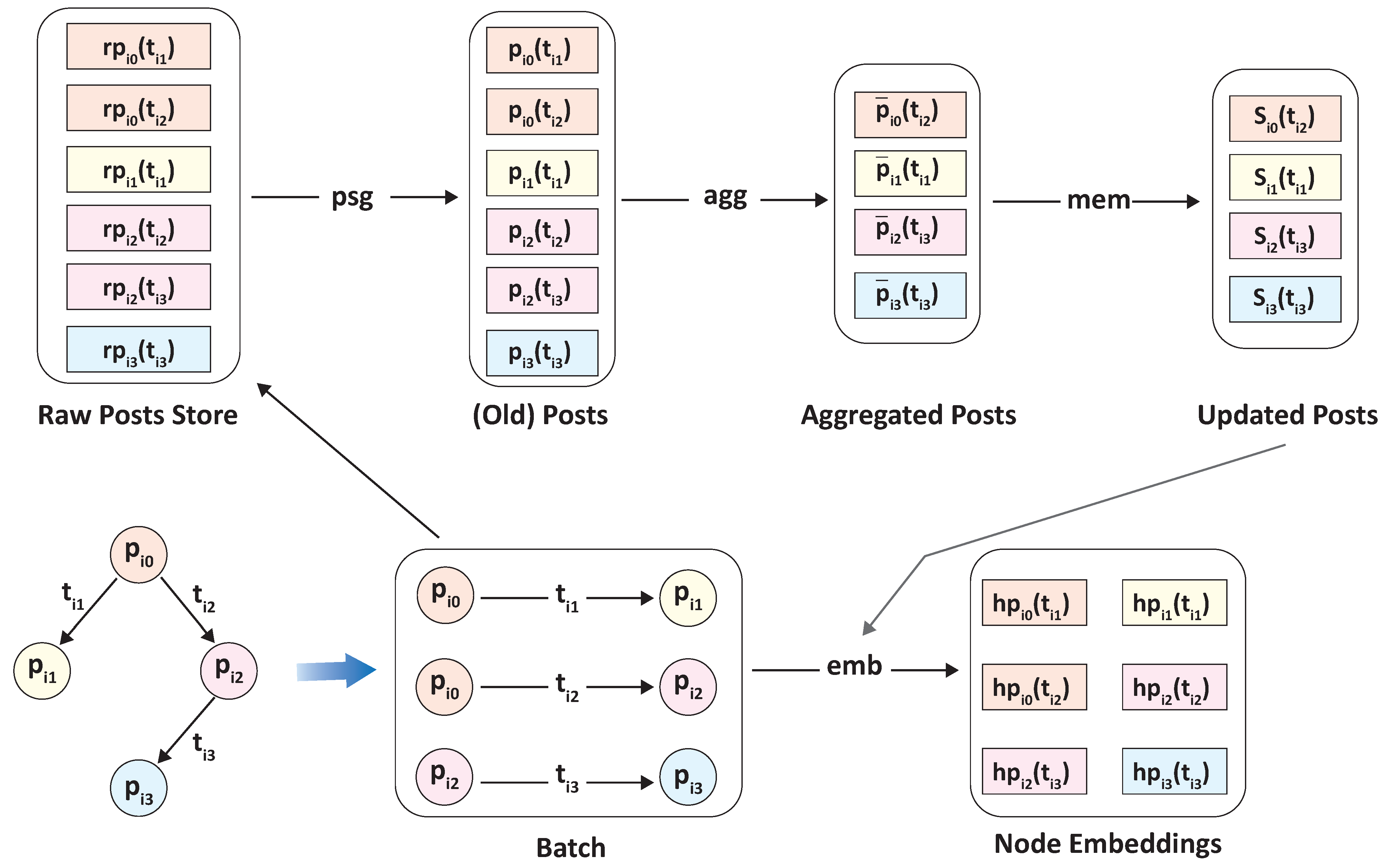
4.2. Temporal Graph Construction Module
4.2.1. Temporal Propagation Graph Construction
4.2.2. Temporal Knowledge Graph Construction
4.3. Spatio-Temporal Feature Fusion Module
4.4. Subgraph Fusion Module
4.5. Classification Module
| Algorithm 1: Training of CGNKP |
 |
5. Experiments
5.1. Experimental Settings
5.1.1. Datasets
5.1.2. Baseline Models
5.1.3. Implementation Setting
5.2. Overall Performance (RQ1)
- Feature-based models such as DTR, DTC, and RFC perform poorly since they use hand-developed features based on the overall statistics of posts. However, these features are too coarse and have low generalizability. RFC performs better than the other two models. This is because RFC uses additional structural features and temporal features.
- Deep learning-based models automatically extract effective features due to the use of neural networks, leading to significantly better performance than feature-based approaches. The performance of GRU-RNN is relatively poor because it only utilizes the content of the posts and ignores other useful information, such as the rumors’ propagation structure and temporal information. BU-RvNN and TD-RvNN perform better than GRU-RNN, indicating that simulating spatial and temporal structures is effective for rumor detection. PLAN performs well on the two datasets, showing that capturing the interaction between posts is effective. STS-NN and Bi-GCN model the propagation structure and temporal information between the source post and comments. Bi-GCN outperforms STS-NN because it can distinguish between spatial and temporal structure patterns. Additionally, Bi-GCN does not incorporate linguistic features but focuses on feature mining of rumor propagation and diffusion. As the number of nodes in the propagation tree decreases, the information that can be provided decreases accordingly, leading to a drop in model performance. The strong performance of GCRES among baseline models demonstrates the effectiveness of leveraging deep residual graph networks to learn content and structure interaction information in network propagation models.
- The RA and LeRuD methods, which are based on LLMs, offer a flexible and interpretative approach to rumor detection. Their use of prompt engineering allows them to guide the model’s focus on specific characteristics, making them adaptable across various scenarios. However, because LLMs are not specifically trained for rumor detection, they may not capture certain nuanced features as effectively as deep learning-based approaches that are fine-tuned for this task, while RA and LeRuD excel in leveraging language understanding and can provide insights through interpretability, they sometimes face challenges in processing complex temporal and contextual information, especially when relying on predefined prompts. In contrast, deep learning models, particularly those using graph neural networks, are adept at extracting dynamic features across time and space, benefiting from specialized training on structured data. This allows them to learn intricate patterns within propagation networks.
- CGNKP achieves the best results on the two datasets. This is for several reasons. First, we use dynamic graphs to adequately model the structural features of rumor propagation and the temporal features, which are crucial for distinguishing rumors. Second, we model the temporal propagation structure as continuous-time dynamic graphs instead of discrete-time dynamic graphs, which can represent the temporal propagation structure in a more fine-grained way with specific temporal information. Finally, we model the dynamic background knowledge information for source posts and comments, which helps CGNKP to achieve the best results (we elaborate on this in Section 5.3). Finally, we use a subgraph-level attention mechanism to dynamically fuse the two subgraphs’ representations instead of simply concatenating them. This allows the model to adjust the proportion of the representation vector occupied by the two types of information.
5.3. Ablation Experiments (RQ2)
- -source: remove source post content enhancement, i.e., use only pooled graph representation as input to the Classification Module.
- -structure: ignore structured features of rumor propagation, but keep content, temporal, and knowledge features.
- -time_GAT: remove temporal information, i.e., keep rumor propagation structure, and aggregate graph structure information with GAT.
- -time_GCN: remove temporal information, i.e., keep the rumor propagation structure, and use vanilla GCN to aggregate the graph structure information.
- -CTDE: Remove the CTDE module and replace CTDE with TGAT [22].
- -Knowledge: remove the dynamic knowledge structure, i.e., keep only the temporal propagation graph.
- -sub_Atten: remove the subgraph-level attention, i.e., concatenate the temporal propagation graph with the temporal knowledge graph representation.
- As the results show, CGNKP outperforms all other variants, and the removal of these components degrades the performance of rumor detection. The content of the source post (-source) remains the most important signal for identifying rumors among the various features. However, relying solely on content-based features is insufficient for effectively identifying rumors.
- -structure suffers a significant decrease, indicating that structured information is crucial for detecting rumors. Both -time_GAT and -time_GCN use a static graph neural network approach, while -time_GCN has poorer performance than -time_GAT, reflecting the negative attention in reducing the weights of noisy nodes. The static graphs approach is much less accurate than the dynamic graphs method (-CTDE), which has much lower accuracy on the two datasets. This indicates that temporal information is a significant feature for detecting rumors. This result also explains why the methods proposed by Bian et al. [11] are not as effective as CGNKP, since the former focuses on simulating temporal information while the latter mainly explores the diffusion process. CGNKP utilizes dynamic graph neural networks, which can fully use temporal information and capture structured features.
- CGNKP has better performance than -knowledge. This indicates that the dynamic diffusion structure of knowledge can also be an important feature for identifying rumors.
- The absence of subgraph-level attention (-sub_Atten) prevents CGNKP from achieving peak performance. Because subgraph-level attention can assign weights to both subgraphs and adaptively adjust the weight size to obtain the best representation.
5.4. Performance on Early Detection (RQ3)
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zheng, P.; Dou, Y.; Yan, Y. Sensing the diversity of rumors: Rumor detection with hierarchical prototype contrastive learning. Inf. Process. Manag. 2024, 61, 103832. [Google Scholar] [CrossRef]
- Rahimi, M.; Roayaei, M. A multi-view rumor detection framework using dynamic propagation structure, interaction network, and content. IEEE Trans. Signal Inf. Process. Netw. 2024, 10, 48–58. [Google Scholar] [CrossRef]
- Yang, Z.; Pang, Y.; Li, X.; Li, Q.; Wei, S.; Wang, R.; Xiao, Y. Topic audiolization: A model for rumor detection inspired by lie detection technology. Inf. Process. Manag. 2024, 61, 103563. [Google Scholar] [CrossRef]
- Sun, M.; Zhang, X.; Ma, J.; Xie, S.; Liu, Y.; Philip, S.Y. Inconsistent Matters: A Knowledge-guided Dual-consistency Network for Multi-modal Rumor Detection. arXiv 2023, arXiv:2306.02137. [Google Scholar] [CrossRef]
- Phan, H.T.; Nguyen, N.T.; Hwang, D. Fake news detection: A survey of graph neural network methods. Appl. Soft Comput. 2023, 139, 110235. [Google Scholar] [CrossRef] [PubMed]
- Lin, H.; Yi, P.; Ma, J.; Jiang, H.; Luo, Z.; Shi, S.; Liu, R. Zero-shot rumor detection with propagation structure via prompt learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 5213–5221. [Google Scholar]
- Shoeibi, A.; Khodatars, M.; Jafari, M.; Ghassemi, N.; Sadeghi, D.; Moridian, P.; Khadem, A.; Alizadehsani, R.; Hussain, S.; Zare, A.; et al. Automated detection and forecasting of COVID-19 using deep learning techniques: A review. Neurocomputing 2024, 577, 127317. [Google Scholar] [CrossRef]
- Zheng, P.; Huang, Z.; Dou, Y.; Yan, Y. Rumor detection on social media through mining the social circles with high homogeneity. Inf. Sci. 2023, 642, 119083. [Google Scholar] [CrossRef]
- Pattanaik, B.; Mandal, S.; Tripathy, R.M. A survey on rumor detection and prevention in social media using deep learning. Knowl. Inf. Syst. 2023, 65, 3839–3880. [Google Scholar] [CrossRef] [PubMed]
- Huang, Q.; Zhou, C.; Wu, J.; Wang, M.; Wang, B. Deep structure learning for rumor detection on twitter. In Proceedings of the 2019 International Joint Conference on Neural Networks, Budapest, Hungary, 14–19 July 2019; pp. 1–8. [Google Scholar]
- Bian, T.; Xiao, X.; Xu, T.; Zhao, P.; Huang, W.; Rong, Y.; Huang, J. Rumor detection on social media with bi-directional graph convolutional networks. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 549–556. [Google Scholar]
- Huang, Q.; Zhou, C.; Wu, J.; Liu, L.; Wang, B. Deep spatial–temporal structure learning for rumor detection on Twitter. Neural Comput. Appl. 2023, 35, 12995–13005. [Google Scholar] [CrossRef]
- Ma, J.; Gao, W.; Mitra, P.; Kwon, S.; Jansen, B.J.; Wong, K.F.; Cha, M. Detecting Rumors from Microblogs with Recurrent Neural Networks. In Proceedings of the 25th International Joint Conference on Artificial Intelligence, New York, NY, USA, 9–15 July 2016; Number 7; pp. 3818–3824. [Google Scholar]
- Sun, M.; Zhang, X.; Zheng, J.; Ma, G. DDGCN: Dual Dynamic Graph Convolutional Networks for Rumor Detection on Social Media. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 22 February–1 March 2022; Volume 36, pp. 4611–4619. [Google Scholar]
- Gao, X.; Wang, X.; Chen, Z.; Zhou, W.; Hoi, S.C. Knowledge enhanced vision and language model for multi-modal fake news detection. IEEE Trans. Multimed. 2024, 26, 8312–8322. [Google Scholar] [CrossRef]
- Wang, Y.; Qian, S.; Hu, J.; Fang, Q.; Xu, C. Fake news detection via knowledge-driven multimodal graph convolutional networks. In Proceedings of the 2020 International Conference on Multimedia Retrieval, Dublin, Ireland, 8–11 June 2020; pp. 540–547. [Google Scholar]
- Dun, Y.; Tu, K.; Chen, C.; Hou, C.; Yuan, X. Kan: Knowledge-aware attention network for fake news detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 2–9 February 2021; Volume 35, pp. 81–89. [Google Scholar]
- Xia, R.; Xuan, K.; Yu, J. A State-independent and Time-evolving Network for Early Rumor Detection in Social Media. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, Online, 16–20 November 2020; pp. 9042–9051. [Google Scholar]
- Yu, L.; Sun, L.; Du, B.; Lv, W. Towards better dynamic graph learning: New architecture and unified library. Adv. Neural Inf. Process. Syst. 2023, 36, 67686–67700. [Google Scholar]
- Chen, J.; Ying, R. Tempme: Towards the explainability of temporal graph neural networks via motif discovery. Adv. Neural Inf. Process. Syst. 2023, 36, 29005–29028. [Google Scholar]
- Chen, C.; Geng, H.; Yang, N.; Yang, X.; Yan, J. Easydgl: Encode, train and interpret for continuous-time dynamic graph learning. arXiv 2024, arXiv:2303.12341. [Google Scholar] [CrossRef] [PubMed]
- Huang, S.; Poursafaei, F.; Danovitch, J.; Fey, M.; Hu, W.; Rossi, E.; Leskovec, J.; Bronstein, M.; Rabusseau, G.; Rabbany, R. Temporal graph benchmark for machine learning on temporal graphs. arXiv 2024, arXiv:2307.01026. [Google Scholar]
- Ma, J.; Gao, W.; Wong, K.F. Detect Rumors in Microblog Posts Using Propagation Structure via Kernel Learning. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017; pp. 708–717. [Google Scholar]
- Wei, L.; Hu, D.; Zhou, W.; Yue, Z.; Hu, S. Towards Propagation Uncertainty: Edge-enhanced Bayesian Graph Convolutional Networks for Rumor Detection. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Virtual, 1–6 August 2021; pp. 3845–3854. [Google Scholar]
- Sankar, A.; Wu, Y.; Gou, L.; Zhang, W.; Yang, H. Dysat: Deep neural representation learning on dynamic graphs via self-attention networks. In Proceedings of the 13th International Conference on Web Search and Data Mining, Virtual, 10–13 July 2020; pp. 519–527. [Google Scholar]
- Pareja, A.; Domeniconi, G.; Chen, J.; Ma, T.; Suzumura, T.; Kanezashi, H.; Kaler, T.; Schardl, T.; Leiserson, C. Evolvegcn: Evolving graph convolutional networks for dynamic graphs. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 5363–5370. [Google Scholar]
- Pellissier Tanon, T.; Weikum, G.; Suchanek, F. Yago 4: A reason-able knowledge base. In Proceedings of the European Semantic Web Conference, Heraklion, Crete, Greece, 31 May–4 June 2020; pp. 583–596. [Google Scholar]
- Ji, L.; Wang, Y.; Shi, B.; Zhang, D.; Wang, Z.; Yan, J. Microsoft Concept Graph: Mining Semantic Concepts for Short Text Understanding. Data Intell. 2019, 1, 238–270. [Google Scholar] [CrossRef]
- Kenton, J.D.M.W.C.; Toutanova, L.K. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the NAACL-HLT, Minneapolis, MN, USA, 2–7 June 2019; Volume 1, p. 2. [Google Scholar]
- Zhao, Z.; Resnick, P.; Mei, Q. Enquiring minds: Early detection of rumors in social media from enquiry posts. In Proceedings of the 24th International Conference on World Wide Web, Florence, Italy, 18–22 May 2015; pp. 1395–1405. [Google Scholar]
- Castillo, C.; Mendoza, M.; Poblete, B. Information credibility on twitter. In Proceedings of the 20th International Conference on World Wide Web, Hyderabad, India, 28 March–1 April 2011; pp. 675–684. [Google Scholar]
- Kwon, S.; Cha, M.; Jung, K.; Chen, W.; Wang, Y. Prominent features of rumor propagation in online social media. In Proceedings of the IEEE 13th International Conference on Data Mining, Dallas, TX, USA, 7–10 December 2013; pp. 1103–1108. [Google Scholar]
- Ma, J.; Gao, W.; Wong, K.F. Rumor Detection on Twitter with Tree-structured Recursive Neural Networks. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Melbourne, Australia, 15–20 July 2018; pp. 1980–1989. [Google Scholar]
- Khoo, L.M.S.; Chieu, H.L.; Qian, Z.; Jiang, J. Interpretable rumor detection in microblogs by attending to user interactions. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 8783–8790. [Google Scholar]
- Ye, N.; Yu, D.; Zhou, Y.; Shang, K.k.; Zhang, S. Graph Convolutional-Based Deep Residual Modeling for Rumor Detection on Social Media. Mathematics 2023, 11, 3393. [Google Scholar] [CrossRef]
- Yue Huang, L.S. FakeGPT: Fake News Generation, Explanation and Detection of Large Language Models. In Proceedings of the ACM Web Conference 2024, Singapore, 13–17 May 2024; p. 1. [Google Scholar]
- Liu, Q.; Tao, X.; Wu, J.; Wu, S.; Wang, L. Can Large Language Models Detect Rumors on Social Media? arXiv 2024, arXiv:2402.03916. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Twitter15 | Twitter16 | |
|---|---|---|
| # of events | 1490 | 818 |
| # of posts | 331,612 | 204,820 |
| # of true-rumors | 374 | 205 |
| # of false-rumors | 370 | 205 |
| # of unverified rumors | 374 | 203 |
| # of non-rumors | 372 | 205 |
| Avg. time length/event(hours) | 1337 | 848 |
| Avg. # of posts/event | 223 | 251 |
| Max # of posts/event | 1768 | 2765 |
| Min # of posts/event | 55 | 81 |
| Model | Twitter15 | Twitter16 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Acc | F1 | Acc | F1 | |||||||
| UR | NR | TR | FR | UR | NR | TR | FR | |||
| DTR | 0.409 | 0.501 | 0.311 | 0.364 | 0.473 | 0.414 | 0.394 | 0.273 | 0.630 | 0.344 |
| DTC | 0.454 | 0.733 | 0.355 | 0.317 | 0.415 | 0.465 | 0.643 | 0.393 | 0.419 | 0.403 |
| RFC | 0.565 | 0.810 | 0.422 | 0.401 | 0.543 | 0.585 | 0.752 | 0.415 | 0.547 | 0.563 |
| GRU-RNN | 0.641 | 0.684 | 0.634 | 0.688 | 0.571 | 0.633 | 0.617 | 0.715 | 0.577 | 0.527 |
| SVM-TK | 0.667 | 0.619 | 0.669 | 0.772 | 0.645 | 0.662 | 0.643 | 0.623 | 0.783 | 0.655 |
| BU-RvNN | 0.708 | 0.695 | 0.728 | 0.759 | 0.653 | 0.718 | 0.723 | 0.712 | 0.779 | 0.659 |
| TD-RvNN | 0.723 | 0.682 | 0.758 | 0.821 | 0.654 | 0.737 | 0.662 | 0.743 | 0.835 | 0.708 |
| PLAN | 0.787 | 0.775 | 0.775 | 0.768 | 0.807 | 0.799 | 0.779 | 0.754 | 0.836 | 0.821 |
| STS-NN | 0.809 | 0.797 | 0.811 | 0.856 | 0.773 | 0.821 | 0.739 | 0.814 | 0.883 | 0.845 |
| Bi-GCN | 0.829 | 0.752 | 0.772 | 0.851 | 0.827 | 0.837 | 0.818 | 0.772 | 0.885 | 0.847 |
| GCRES | 0.842 | 0.811 | 0.801 | 0.852 | 0.839 | 0.882 | 0.857 | 0.765 | 0.904 | 0.832 |
| RA | 0.713 | 0.682 | 0.735 | 0.762 | 0.661 | 0.729 | 0.715 | 0.711 | 0.826 | 0.692 |
| LeRuD | 0.706 | 0.691 | 0.686 | 0.797 | 0.638 | 0.715 | 0.702 | 0.733 | 0.809 | 0.716 |
| CGNKP (ours) | 0.861 | 0.897 | 0.861 | 0.865 | 0.841 | 0.903 | 0.862 | 0.883 | 0.935 | 0.889 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, H.; Jiang, L.; Li, J. Continuous-Time Dynamic Graph Networks Integrated with Knowledge Propagation for Social Media Rumor Detection. Mathematics 2024, 12, 3453. https://doi.org/10.3390/math12223453
Li H, Jiang L, Li J. Continuous-Time Dynamic Graph Networks Integrated with Knowledge Propagation for Social Media Rumor Detection. Mathematics. 2024; 12(22):3453. https://doi.org/10.3390/math12223453
Chicago/Turabian StyleLi, Hui, Lanlan Jiang, and Jun Li. 2024. "Continuous-Time Dynamic Graph Networks Integrated with Knowledge Propagation for Social Media Rumor Detection" Mathematics 12, no. 22: 3453. https://doi.org/10.3390/math12223453
APA StyleLi, H., Jiang, L., & Li, J. (2024). Continuous-Time Dynamic Graph Networks Integrated with Knowledge Propagation for Social Media Rumor Detection. Mathematics, 12(22), 3453. https://doi.org/10.3390/math12223453