3.1. Refining UAP in Frequency Domain via Learnable Filters
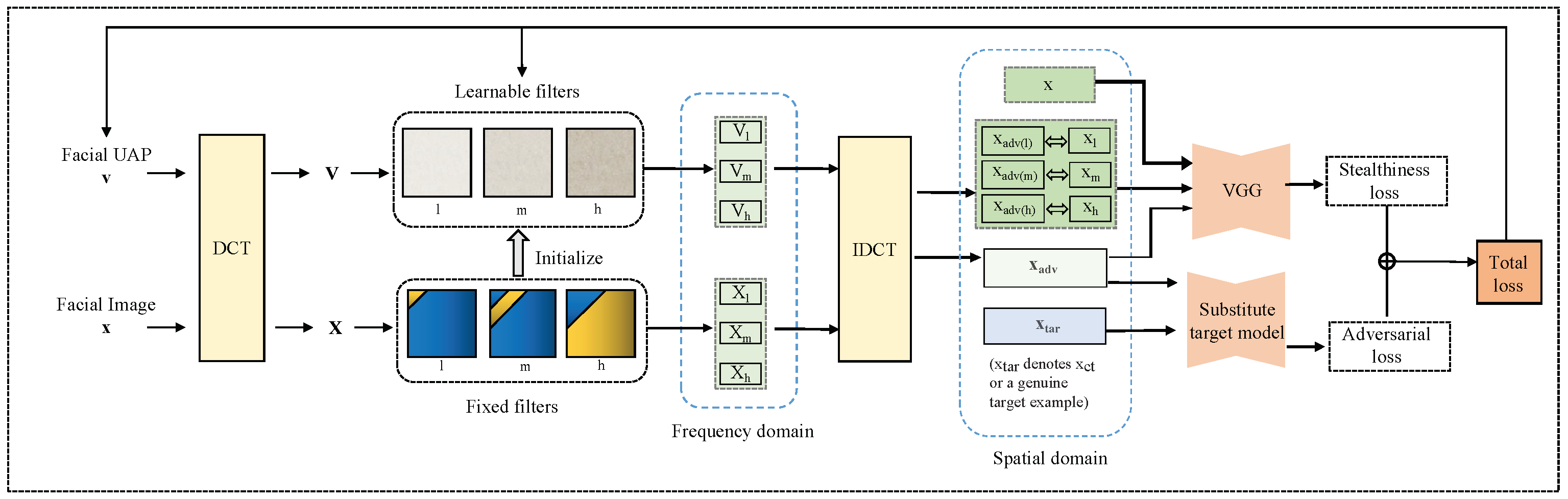
For a general understanding of our idea, we here outline the general procedure of FaUAP-FBF, as shown in
Figure 1. The lowercase letters and capital letters denote examples in the spatial domain and frequency domain, respectively. The two domains are mutually converted by using discrete cosine transform (DCT) and inverse discrete cosine transform (IDCT). For the images, DCT is used to transform an image block from the spatial domain to the frequency domain, and IDCT is used to reconstruct an image block from the frequency domain to the spatial domain. Suppose there is a matrix
, where
represents the element at position
; after DCT transformation, we obtain the transformed matrix
, where the element
at position
can be expressed as:
where
for
and
otherwise.
can be reconstructed from
by using IDCT, i.e.,
For an 8 × 8 spatial block, DCT encapsulates 64 distinct frequency components. We employ the widely used Type-II DCT for both DCT and IDCT.
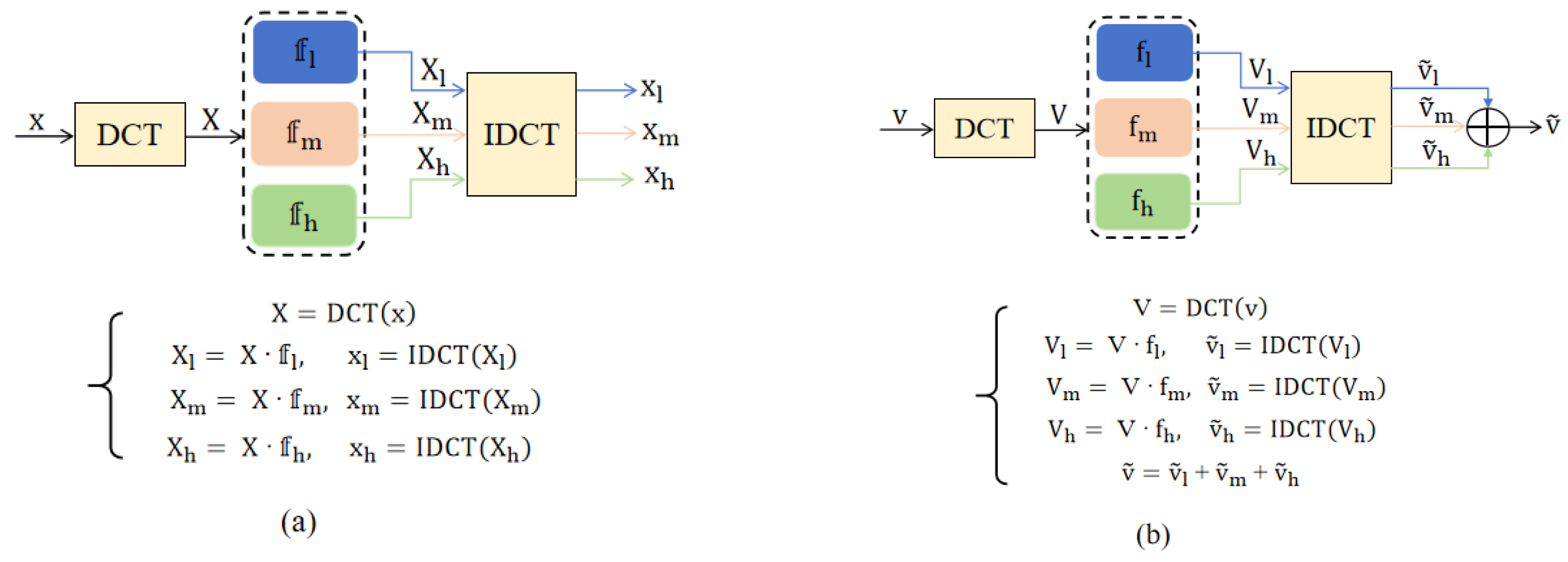
The filters used in FaUAP-FBF consist of fixed filters and learnable filters in high, middle, and low frequency bands, in which the fixed filters are used to separate the legitimate example into non-overlapped three frequency regions, and learnable filters are used to refine the perturbation using three band filters. Details for frequency domain filtering using fixed filters and learnable filters are shown in
Figure 2a,b. {
,
,
} and {
,
,
} denote the fixed filters and learnable filters, respectively. For the fixed filters, the low-, middle-, and high-frequency bands account for hard separated regions in the entire spectrum, respectively, where each band region is sketched by a yellow color, and the values in the corresponding spectrum are set to 1, or 0 for the fixed filters. Further, they are used to initialize the learnable filters, and the ultimate values in the learnable filters are located in between 0 and 1. The fixed filters and learnable filters are shown in
Figure 1 and
Figure 2.
First, both UAP and legitimate images in a training set are converted to the frequency domain through DCT, in which UAP in the spatial domain is initialized with Gaussian noise and the three learnable band filters are initialized with fixed filters. To calculate loss, both image and perturbation need to be converted back into the spatial domain through IDCT. During learning, both UAP in the spatial domain and the learnable filters are alternately and repeatedly updated in terms of a weighted combination of adversarial loss and stealthiness loss, and UAP in the spatial domain is also constrained by
-norm. The iteration continues until a certain criterion is satisfied. The target function is formulated as follows:
where
and
denote the adversarial loss and stealthiness loss, respectively, and
controls the balance between them.
and
denote the optimal UAP and filters.
may be the customized target example or a genuine target example, and
is a parameter controlling the strength of the perturbation.
and
denote the legitimate training example and the corresponding adversarial example, and they are related with Equation (2). From
Figure 1, it can be seen that, in addition to the whole example in the spatial domain, respective bands of the example in the spatial domain are also needed to calculate stealthiness loss. The respective bands of the example in the spatial domain are obtained using Equation (3). The calculations of
and
are shown in
Figure 2b.
Once
and
are obtained, they can be utilized to yield an adversarial example for a legitimate test example, as explained in Equation (4):
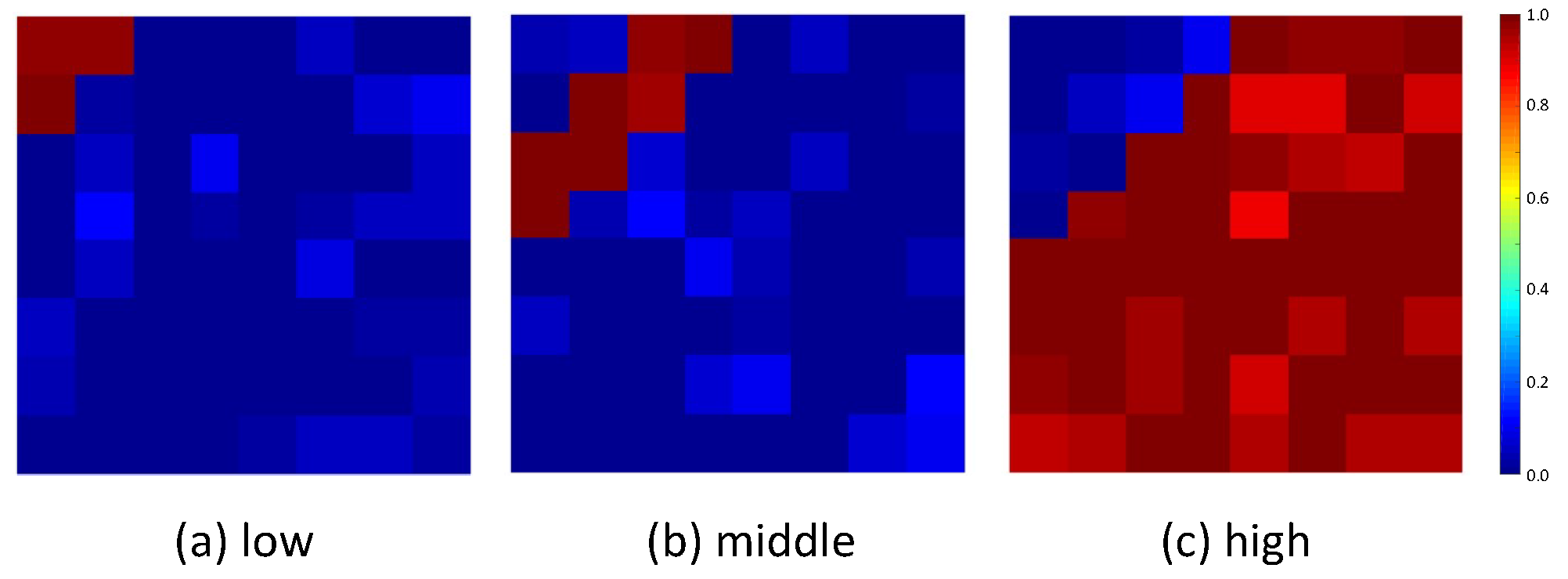
We apply the frequency domain as an additional dimension to iteratively optimize universal adversarial perturbations, allowing the optimizer to continually refine the perturbation to achieve the objective of fooling face recognition systems. The use of learnable filters ensures that the extracted frequency segment is not solely confined to the predefined high, middle-, and low-frequency ranges. Incorporating these adjustable filters facilitates the capture of subtle yet valuable information within each frequency segment. Consequently, this approach aligns the generated perturbation more closely with the frequency-divided facial image. The visualization of ultimately learned filters
are shown in
Figure 3. The pipeline of FaUAP-FBF is provided in Algorithm 1, and the definitions of the notations used in this paper are listed in
Table 1.
| Algorithm 1 The procedure of FaUAP-FBF |
Input: Training set , (customized target example or a genuine target example), substitute target model , fooling rate , norm restriction of perturbation , fixed filters and decision threshold t, learning rate . Output: Universal adversarial perturbations and learnable filters - 1:
Initialize - 2:
while do - 3:
for a batch of examples in do - 4:
Perform DCT transformation to obtain ; use to obtain - 5:
Perform DCT transformation to obtain ; use to obtain - 6:
Perform IDCT transformation to obtain - 7:
if average or average then - 8:
- 9:
Update the learnable filters - 10:
Update the perturbation - 11:
Clip to satisfy the norm restriction - 12:
Update , , - 13:
end if - 14:
end for - 15:
end while - 16:
return and
|
We abstract seven computation units and summarize the overall and dominant time required for FaUAP-FBF by using the seven computation units and parameters of the training set and the hyper-parameters of the learning algorithm. These are listed in
Table 2. Specifically, there are two phases of forward and backward computation. In forward computation, there are five computation units, including DCT, IDCT, filtering, and feature extraction from VGG and from the substitute target model, in which the consumed time of the five computation units are denoted as
and
, respectively. In backward computation, there are two computation units, including filter gradient computation and perturbation gradient computation, in which the times consumed for the two computation units are denoted as
and
, respectively. Here,
and
denote the width and height of UAP.
and
denote the number of training examples and the number of blocks in size
.
and
are the learning iteration number and batch size. Notice that in forward computation, the legitimate image set computation only needs one time and is completed before iteration for learning the UAP and filters.
3.2. Non-Target Attack via Customizing a Target Example
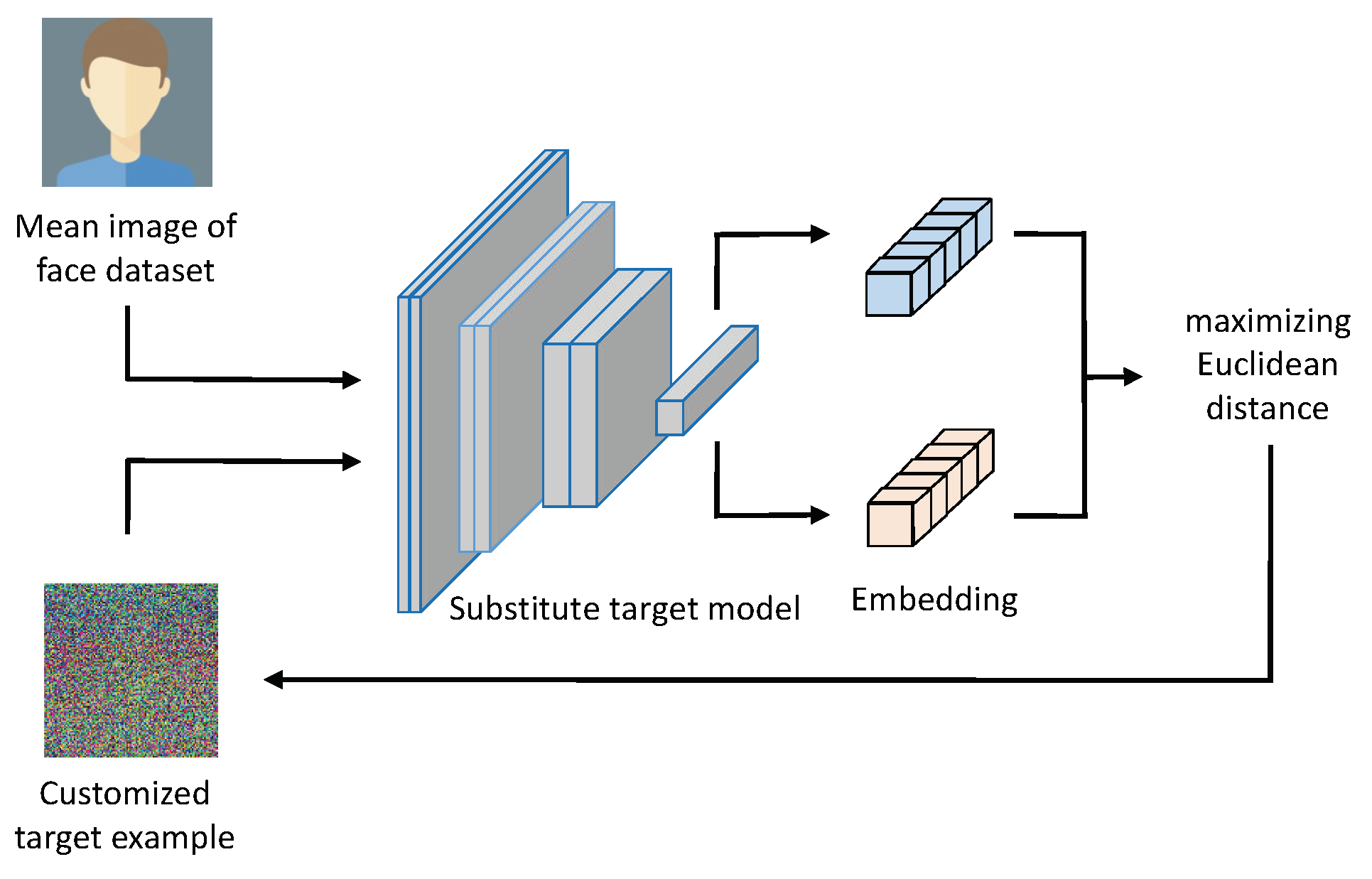
Unlike the conventional non-target attack that forces the adversarial example to be away from an image of the specified person, we convert the non-target attack to be specific to varying victims to a unique target attack by customizing an example that is utilized as the target. Specifically, a customized target example
is sought by maximizing its distance from the overall distribution of the legitimate dataset. The flowchart is shown in
Figure 4.
First, an image subset
is selected from legitimate dataset
, which contains one facial image for each identity, and their average yields a mean image
associated with the face dataset:
Subsequently,
is initialized by Gaussian noise and iteratively updated by progressively increasing the Euclidean distance between the embedding of
and
, in which the embeddings
and
are extracted from the substitute target model (Arcface model). The procedure leads to
, which significantly deviates from the distribution of the legitimate dataset, serving as our customized target example. It can be formulated as follows:
where
refers to the substitute target model and
denotes the embedding of the input image.
Since has a significant distinction from the average of the legitimate dataset, decreasing the distance between the adversarial example and is consistent with increasing the distance between the adversarial example and the image of an uncertain victim, thus achieving the desired effect of a non-target attack immune to specific non-target victims. Under a genuine target attack, the only necessary alteration is to replace the customized target example with the image of the desired victim, thereby unifying the non-target and target attack into a uniform target attack.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}