
ANOVA-GP Modeling for High-Dimensional Bayesian Inverse Problems

Abstract
1. Introduction
2. Problem Setup
2.1. Bayesian Inverse Problem
| Algorithm 1 Classic Metropolis–Hastings (MH) algorithm |
Input: Number of samples N, forward model G, noise distribution , proposal distribution , prior distribution , and observation d. Output: Posterior samples .
|
2.2. Partial Differential Equations with Random Parameters
3. Methodology
3.1. ANOVA Decomposition
3.1.1. Anchored ANOVA Decomposition
3.1.2. Selection of the ANOVA Terms
3.2. Gaussian Process Regression
3.3. Principal Component Analysis
3.4. ANOVA-GP Modeling
| Algorithm 2 Construction of ANOVA-GP model |
Input: Sample set . Output: ANOVA-GP model .
|
3.5. Adaptive ANOVA-GP-MCMC
| Algorithm 3 Adaptive ANOVA-GP-MCMC algorithm |
Input: Number of MCMC samples N, number of samples to construct model , number of samples for updating model , noise distribution , proposal distribution , prior distribution , and observation d. Output: Posterior samples .
|
4. Numerical Study
4.1. Problem Setup
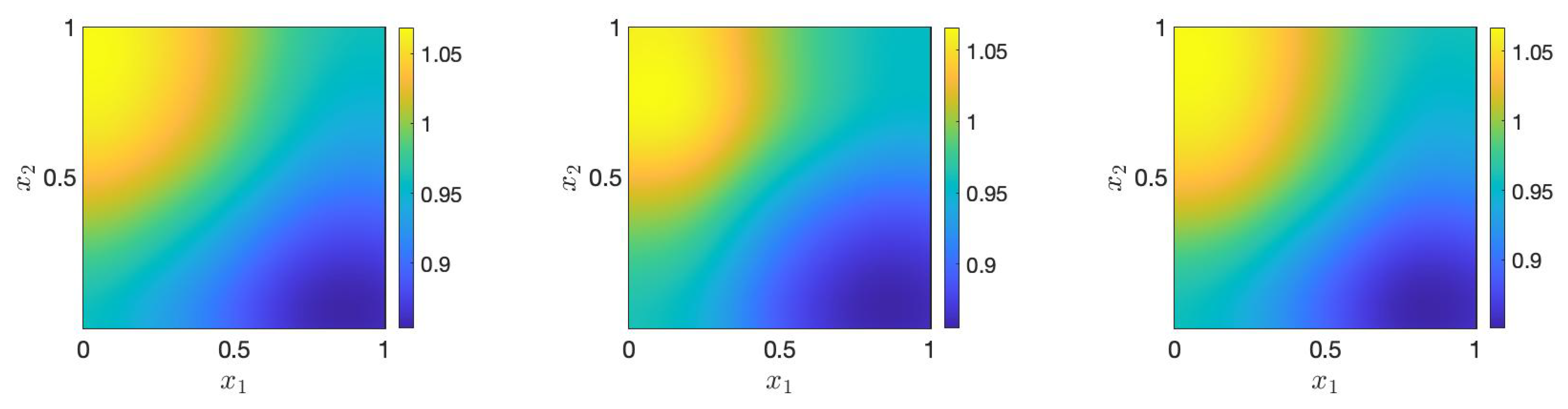
4.2. Performance in Forward Problem
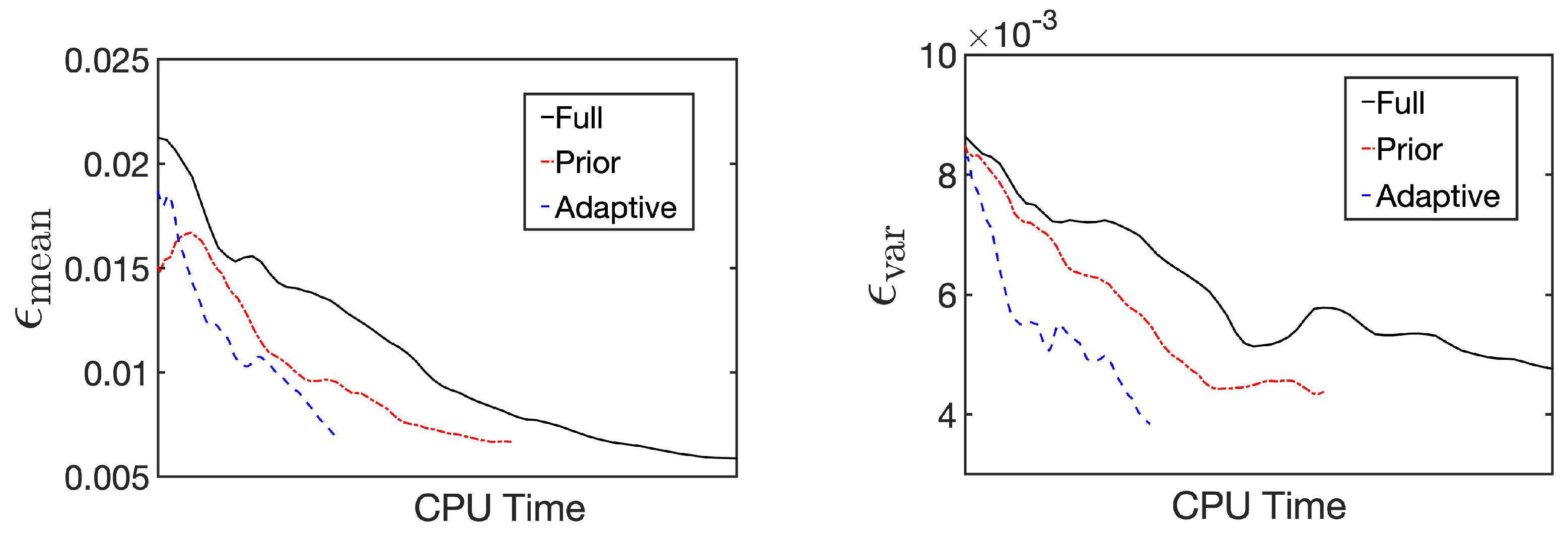
4.3. Performance in Inverse Problem
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| ANOVA | Analysis of variance |
| GP | Gaussian process |
| PCA | Principle component analysis |
| MCMC | Markov chain Monte Carlo |
References
- Tarantola, A. Inverse Problem Theory and Methods for Model Parameter Estimation; SIAM: Philadelphia, PA, USA, 2005. [Google Scholar]
- Keilis-Borok, V.; Yanovskaja, T. Inverse problems of seismology (structural review). Geophys. J. Int. 1967, 13, 223–234. [Google Scholar] [CrossRef]
- Beck, J.V. Nonlinear estimation applied to the nonlinear inverse heat conduction problem. Int. J. Heat Mass Transf. 1970, 13, 703–716. [Google Scholar] [CrossRef]
- Wang, J.; Zabaras, N. A Bayesian inference approach to the inverse heat conduction problem. Int. J. Heat Mass Transf. 2004, 47, 3927–3941. [Google Scholar] [CrossRef]
- Luo, C.; Shen, L.; Xu, A. Modelling and estimation of system reliability under dynamic operating environments and lifetime ordering constraints. Reliab. Eng. Syst. Saf. 2022, 218, 108136. [Google Scholar] [CrossRef]
- Wang, W.; Cui, Z.; Chen, R.; Wang, Y.; Zhao, X. Regression analysis of clustered panel count data with additive mean models. Stat. Pap. 2023, 1–22. [Google Scholar] [CrossRef]
- Tarantola, A. Popper, Bayes and the inverse problem. Nat. Phys. 2006, 2, 492–494. [Google Scholar] [CrossRef]
- Robert, C.P.; Casella, G.; Casella, G. Monte Carlo Statistical Methods; Springer: New York, NY, USA, 1999; Volume 2. [Google Scholar]
- Yeh, W.W.G. Review of parameter identification procedures in groundwater hydrology: The inverse problem. Water Resour. Res. 1986, 22, 95–108. [Google Scholar] [CrossRef]
- Virieux, J.; Operto, S. An overview of full-waveform inversion in exploration geophysics. Geophysics 2009, 74, WCC1–WCC26. [Google Scholar] [CrossRef]
- Marzouk, Y.M.; Najm, H.N.; Rahn, L.A. Stochastic spectral methods for efficient Bayesian solution of inverse problems. J. Comput. Phys. 2007, 224, 560–586. [Google Scholar] [CrossRef]
- Wang, H.; Li, J. Adaptive Gaussian process approximation for Bayesian inference with expensive likelihood functions. Neural Comput. 2018, 30, 3072–3094. [Google Scholar] [CrossRef]
- Chen, C.; Liao, Q. ANOVA Gaussian process modeling for high-dimensional stochastic computational models. J. Comput. Phys. 2020, 416, 109519. [Google Scholar] [CrossRef]
- Ma, X.; Zabaras, N. An efficient Bayesian inference approach to inverse problems based on an adaptive sparse grid collocation method. Inverse Probl. 2009, 25, 035013. [Google Scholar] [CrossRef]
- Galbally, D.; Fidkowski, K.; Willcox, K.; Ghattas, O. Non-linear model reduction for uncertainty quantification in large-scale inverse problems. Int. J. Numer. Methods Eng. 2010, 81, 1581–1608. [Google Scholar] [CrossRef]
- Lieberman, C.; Willcox, K.; Ghattas, O. Parameter and state model reduction for large-scale statistical inverse problems. SIAM J. Sci. Comput. 2010, 32, 2523–2542. [Google Scholar] [CrossRef]
- Frangos, M.; Marzouk, Y.; Willcox, K.; van Bloemen Waanders, B. Surrogate and reduced-order modeling: A comparison of approaches for large-scale statistical inverse problems. In Large-Scale Inverse Problems and Quantification of Uncertainty; John Wiley & Sons: Chichester, UK, 2010; pp. 123–149. [Google Scholar]
- Li, J. A note on the Karhunen–Loève expansions for infinite-dimensional Bayesian inverse problems. Stat. Probab. Lett. 2015, 106, 1–4. [Google Scholar] [CrossRef]
- Sobol’, I.M. Theorems and examples on high dimensional model representation. Reliab. Eng. Syst. Saf. 2003, 79, 187–193. [Google Scholar] [CrossRef]
- Gao, Z.; Hesthaven, J.S. On ANOVA expansions and strategies for choosing the anchor point. Appl. Math. Comput. 2010, 217, 3274–3285. [Google Scholar] [CrossRef]
- Elman, H.C.; Liao, Q. Reduced basis collocation methods for partial differential equations with random coefficients. SIAM/ASA J. Uncertain. Quantif. 2013, 1, 192–217. [Google Scholar] [CrossRef][Green Version]
- Liao, Q.; Li, J. An adaptive reduced basis ANOVA method for high-dimensional Bayesian inverse problems. J. Comput. Phys. 2019, 396, 364–380. [Google Scholar] [CrossRef]
- Ren, O.; Boussaidi, M.A.; Voytsekhovsky, D.; Ihara, M.; Manzhos, S. Random Sampling High Dimensional Model Representation Gaussian Process Regression (RS-HDMR-GPR) for representing multidimensional functions with machine-learned lower-dimensional terms allowing insight with a general method. Comput. Phys. Commun. 2022, 271, 108220. [Google Scholar] [CrossRef]
- Boussaidi, M.A.; Ren, O.; Voytsekhovsky, D.; Manzhos, S. Random sampling high dimensional model representation Gaussian process regression (RS-HDMR-GPR) for multivariate function representation: Application to molecular potential energy surfaces. J. Phys. Chem. A 2020, 124, 7598–7607. [Google Scholar] [CrossRef] [PubMed]
- Metropolis, N.; Rosenbluth, A.W.; Rosenbluth, M.N.; Teller, A.H.; Teller, E. Equation of state calculations by fast computing machines. J. Chem. Phys. 1953, 21, 1087–1092. [Google Scholar] [CrossRef]
- Hastings, W.K. Monte Carlo sampling methods using Markov chains and their applications. Biometrika 1970, 57, 97–109. [Google Scholar] [CrossRef]
- Rabitz, H.; Aliş, Ö.F. General foundations of high-dimensional model representations. J. Math. Chem. 1999, 25, 197–233. [Google Scholar] [CrossRef]
- Ma, X.; Zabaras, N. An adaptive high-dimensional stochastic model representation technique for the solution of stochastic partial differential equations. J. Comput. Phys. 2010, 229, 3884–3915. [Google Scholar] [CrossRef]
- Ki, W.C.; Rasmussen, C.E. Gaussian Processes for Machine Learning; MIT Press: Cambridge, MA, USA, 2006; Volume 14. [Google Scholar]
- Rasmussen, C.E. Gaussian processes in machine learning. In Summer School on Machine Learning; Springer: Berlin/Heidelberg, Germany, 2003; pp. 63–71. [Google Scholar]
- Schulz, E.; Speekenbrink, M.; Krause, A. A tutorial on Gaussian process regression: Modelling, exploring, and exploiting functions. J. Math. Psychol. 2018, 85, 1–16. [Google Scholar] [CrossRef]
- Williams, C.; Rasmussen, C. Gaussian processes for regression. Adv. Neural Inf. Process. Syst. 1995, 8, 514–520. [Google Scholar]
- Chen, Z.; Fan, J.; Wang, K. Remarks on multivariate Gaussian process. arXiv 2020, arXiv:2010.09830. [Google Scholar]
- Li, J.; Marzouk, Y.M. Adaptive construction of surrogates for the Bayesian solution of inverse problems. SIAM J. Sci. Comput. 2014, 36, A1163–A1186. [Google Scholar] [CrossRef]
- Elman, H.C.; Silvester, D.J.; Wathen, A.J. Finite Elements and Fast Iterative Solvers: With Applications in Incompressible Fluid Dynamics; Oxford University Press: Oxford, UK, 2014. [Google Scholar]
- Elman, H.C.; Ramage, A.; Silvester, D.J. IFISS: A computational laboratory for investigating incompressible flow problems. SIAM Rev. 2014, 56, 261–273. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Mean cost (s) | |||
| Mean relative error |
| 12 | 1 | 0 | 0 | 0 | 12 | |
| 12 | 3 | 3 | 0 | 0 | 15 | |
| 12 | 4 | 6 | 3 | 0 | 18 |
| Full | Prior | Adaptive | |
|---|---|---|---|
| Cost per sample (s) | |||
| Speedup | ∖ |
| Prior ANOVA-GP Model | Posterior ANOVA-GP Model | |
|---|---|---|
| Number of PCA modes | 47 | 29 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shi, X.; Zhang, H.; Wang, G. ANOVA-GP Modeling for High-Dimensional Bayesian Inverse Problems. Mathematics 2024, 12, 301. https://doi.org/10.3390/math12020301
Shi X, Zhang H, Wang G. ANOVA-GP Modeling for High-Dimensional Bayesian Inverse Problems. Mathematics. 2024; 12(2):301. https://doi.org/10.3390/math12020301
Chicago/Turabian StyleShi, Xiaoyu, Hanyu Zhang, and Guanjie Wang. 2024. "ANOVA-GP Modeling for High-Dimensional Bayesian Inverse Problems" Mathematics 12, no. 2: 301. https://doi.org/10.3390/math12020301
APA StyleShi, X., Zhang, H., & Wang, G. (2024). ANOVA-GP Modeling for High-Dimensional Bayesian Inverse Problems. Mathematics, 12(2), 301. https://doi.org/10.3390/math12020301