
Adaptive Bi-Encoder Model Selection and Ensemble for Text Classification


Abstract
1. Introduction
- We introduce a foundational version of the proposed approaches, utilizing k-NN text classification with a bi-encoder model (Section 2).
- We present novel adaptive selection and ensemble techniques, which significantly improve the performance of the basic approaches introduced in the previous section (Section 3).
- We present experimental results from datasets of various sizes (Section 4.1 and Section 4.2), followed by a comprehensive analysis of the proposed approaches (Section 4.3).
2. k-NN Text Classification Using a Bi-Encoder Model
2.1. Text Classification with a Bi-Encoder Model
- Training Phase: We employ a pre-trained Sentence BERT (SBERT) bi-encoder to convert each sentence in into an embedding vector . The training set is then updated to .
- Inference Phase: For each sentence in , we generate its corresponding embedding vector using the same SBERT bi-encoder. The test set is then updated to . To predict the label for each sentence , we compute the cosine similarity between and the embedding vectors of all sentences in the training set . The predicted label is assigned as follows:Here, is the index of the sentence in whose embedding has the highest cosine similarity with the embedding .
2.2. Enhanced k-NN Classification Techniques
- Majority Voting: For each sentence embedding in , we identify the k most similar embeddings from the set of sentence embeddings in based on cosine similarity. The predicted label for the sentence in is then determined by majority voting among the labels corresponding to these k most similar sentences:Here, represents the indices corresponding to the k most similar embeddings to in , and is an indicator function that equals 1 if the label is equal to , and 0 otherwise.
- Weighted Voting: For each sentence embedding in , we identify the k-most similar embeddings in by comparing their cosine similarity scores. Instead of simply counting label occurrences, we sum the similarity scores for each label. The predicted label for is the label with the highest sum of cosine similarity scores:where refers to the cosine similarity between and , and denotes the set of indices for the k-most similar sentence embeddings to in . The indicator function returns 1 if , and 0 otherwise.
- Fair Weighted Voting: To prevent bias towards labels that are more frequent in the training set, we introduce a “fair weighted voting” strategy. For each sentence embedding in , we perform the following steps: For each possible label , we select the top m nearest neighbors from the sentence embeddings in that have the label , based on their cosine similarity to . The value of m is defined as follows:where k is a predefined constant, and represents the number of training examples with label . Once the top m nearest neighbors for each label are identified, we proceed similarly to the weighted voting method. We calculate the total similarity score for these neighbors and predict the label for the sentence in as the label with the highest cumulative score:Here, represents the indices of the top m nearest embeddings with label in that are most similar to the sentence embedding .
3. Adaptive Selection and Ensemble Techniques
3.1. Adaptive Selection of Bi-Encoders
- Divide the training set into F equal-sized folds , where each fold serves as a validation set once, and the remaining folds form the training subset.
- For each bi-encoder and for each fold f, train on the corresponding training subset and evaluate it on the corresponding validation fold .
- Define the cross-validated accuracy for bi-encoder as follows:where represents the accuracy of bi-encoder on the f-th validation fold.
- Select the bi-encoder that maximizes the cross-validated accuracy:
3.2. Ensemble of Bi-Encoders
- Perform the F-fold cross-validation process as described in Section 3.1 for each bi-encoder , and compute their respective cross-validated accuracies .
- Select the top H bi-encoders with the highest cross-validated accuracies:Here, is the bi-encoder with the highest cross-validated accuracy, is the bi-encoder with the second-highest accuracy, and so on until the H-th best model, .
- For each sentence in , generate H embedding vectors using the selected H models. This results in H vectors for each sentence .
- Similarly, transform each sentence in into H embedding vectors using the same H models.
- Compute the “ensemble similarity” between a sentence in and a sentence in as the average of the cosine similarities between their corresponding vectors from all H models. This can be expressed as follows:
- Use the computed during the inference phase for the process of finding the nearest neighbors as described in Section 2.
3.3. Adaptive Selection of Existing and Proposed Approaches
- Fine-tune the BERT model on 90% of the training set , while reserving 10% as a validation set .
- Calculate the validation accuracy .
- If exceeds a threshold , use for inference on the test set . Otherwise, use our model for inference on .
4. Experiments
4.1. Experimental Setup
4.1.1. Datasets
4.1.2. Existing Models
4.1.3. Proposed Models
- Approaches Without Pre-trained Transformers: These models perform text classification based on the training and inference phases described in Section 2, without using transformer models. The “GloVe.6B.300d” model generates embedding vectors with the GloVe model [20] and classifies text by finding the most similar instances. The “Jaccard+Word1Gram” and “Jaccard+Char3Gram” models skip embedding generation, directly finding the most similar instances using Jaccard similarity based on word-level 1-grams and character-level 3-grams, respectively. Similarly, the “Cosine+TFIDF” model finds the most similar instances using cosine similarity applied to tf-idf values. These tf-idf values are calculated from the training data using the TfidfVectorizer class from the scikit-learn library [21].
- Bi-Encoder-Based Approaches: These approaches use Sentence BERT (SBERT) bi-encoder models. “Model NN” employs the default bi-encoder, following the training and inference phases described in Section 2, which finds the most similar embeddings. “Model MV” extends this by incorporating the majority voting technique. “Model WV” is similar to “Model MV” but uses weighted voting. Finally, “Model FW” builds on “Model WV” by employing our fair weighted voting technique.
- Bi-Encoder + Adaptive Selection: This approach “Model FW-AS” incorporates the proposed adaptive selection technique described in Section 3.1, along with our fair weighted voting method described in Section 2.
- Bi-Encoder + Adaptive Selection + Ensemble: These approaches use the techniques proposed in Section 2, Section 3.1, and Section 3.2. “Model FW-AS-2BI” extends “Model FW-AS” by applying the ensemble technique from Section 3.2, with H set to 2. “Model FW-AS-3BI” is similar to “Model FW-AS-2BI,” but with H set to 3.
- Bi-Encoder + Adaptive Selection + Ensemble + Existing Approach: This approach “Model FW-AS-2BI-BT” extends “Model FW-AS-2BI” by incorporating the RoBERTa-10 model, following the technique described in Section 3.3.
4.2. Experimental Results
4.3. Analysis of Results
5. Related Work
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T. DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter. arXiv 2019, arXiv:1910.01108. [Google Scholar]
- Lan, Z.; Chen, M.; Goodman, S.; Gimpel, K.; Sharma, P.; Soricut, R. Albert: A lite BERT for self-supervised learning of language representations. arXiv 2019, arXiv:1909.11942. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding with Unsupervised Learning. Technical Report. OpenAI. 2018. Available online: https://openai.com/index/language-unsupervised/ (accessed on 30 September 2024).
- OpenAI. GPT-4 Technical Report. arXiv 2023, arXiv:2303.08774. [Google Scholar]
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. Llama: Open and efficient foundation language models. arXiv 2023, arXiv:2302.13971. [Google Scholar]
- Li, Z.; Li, X.; Liu, Y.; Xie, H.; Li, J.; Wang, F.-L.; Li, Q.; Zhong, X. Label supervised llama finetuning. arXiv 2023, arXiv:2310.01208. [Google Scholar]
- Park, Y.; Shin, Y. A block-based interactive programming environment for large-scale machine learning education. Appl. Sci. 2022, 12, 13008. [Google Scholar] [CrossRef]
- Jiao, X.; Yin, Y.; Shang, L.; Jiang, X.; Chen, X.; Li, L.; Wang, F.; Liu, Q. TinyBERT: Distilling BERT for natural language understanding. arXiv 2019, arXiv:1909.10351. [Google Scholar]
- Reimers, N.; Gurevych, I. Sentence-BERT: Sentence embeddings using siamese BERT-networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing, Hong Kong, China, 3–7 November 2019. [Google Scholar]
- Reimers, N.; Gurevych, I. Making monolingual sentence embeddings multilingual using knowledge distillation. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, Online, 16–20 November 2020. [Google Scholar]
- Schopf, T.; Braun, D.; Matthes, F. Evaluating unsupervised text classification: Zero-shot and similarity-based approaches. In Proceedings of the 2022 6th International Conference on Natural Language Processing and Information Retrieval, Sanya, China, 16–18 December 2022; pp. 6–15. [Google Scholar]
- Park, Y.; Shin, Y. Tooee: A novel scratch extension for K-12 big data and artificial intelligence education using text-based visual blocks. IEEE Access 2021, 9, 149630–149646. [Google Scholar] [CrossRef]
- Socher, R.; Perelygin, A.; Wu, J.; Chuang, J.; Manning, C.D.; Ng, A.; Potts, C. Recursive deep models for semantic compositionality over a sentiment treebank. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, WA, USA, 18–21 October 2013; pp. 1631–1642. [Google Scholar]
- Wang, A.; Singh, A.; Michael, J.; Hill, F.; Levy, O.; Bowman, S.R. GLUE: A multi-task benchmark and analysis platform for natural language understanding. arXiv 2018, arXiv:1804.07461. [Google Scholar]
- Del Corso, G.M.; Gulli, A.; Romani, F. Ranking a stream of news. In Proceedings of the 14th International Conference on World Wide Web, Chiba, Japan, 10–14 May 2005; pp. 97–106. [Google Scholar]
- Almeida, T.A.; Hidalgo, J.M.G.; Yamakami, A. Contributions to the study of SMS spam filtering: New collection and results. In Proceedings of the 11th ACM Symposium on Document Engineering, Mountain View, CA, USA, 19–22 September 2011; pp. 259–262. [Google Scholar]
- Li, X.; Roth, D. Learning question classifiers. In Proceedings of the 19th International Conference on Computational Linguistics, Taipei, Taiwan, 24 August–1 September 2002. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why Should I Trust You?” Explaining the Predictions of Any Classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Bekamiri, H.; Hain, D.S.; Jurowetzki, R. PatentsBERTA: A deep NLP-based hybrid model for patent distance and classification using augmented SBERT. Technol. Forecast. Soc. Chang. 2024, 206, 123536. [Google Scholar] [CrossRef]
- Thakur, N.; Reimers, N.; Daxenberger, J.; Gurevych, I. Augmented SBERT: Data augmentation method for improving bi-encoders for pairwise sentence scoring tasks. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; pp. 296–310. [Google Scholar]
- Piao, G. Scholarly text classification with sentence BERT and entity embeddings. In Proceedings of the Trends and Applications in Knowledge Discovery and Data Mining: PAKDD 2021 Workshops, Delhi, India, 11 May 2021; Springer International Publishing: Cham, Switzerland, 2021; pp. 79–87. [Google Scholar]
- Stammbach, D.; Ash, E. Docscan: Unsupervised text classification via learning from neighbors. arXiv 2021, arXiv:2105.04024. [Google Scholar]
- Petrovic, A.; Jovanovic, L.; Bacanin, N.; Antonijevic, M.; Savanovic, N.; Zivkovic, M.; Milovanovic, M.; Gajic, V. Exploring Metaheuristic Optimized Machine Learning for Software Defect Detection on Natural Language and Classical Datasets. Mathematics 2024, 12, 2918. [Google Scholar] [CrossRef]
- Sung, Y.W.; Park, D.S.; Kim, C.G. A Study of BERT-Based Classification Performance of Text-Based Health Counseling Data. CMES-Comput. Model. Eng. Sci. 2023, 135, 1–20. [Google Scholar]
- Veisi, H.; Awlla, K.M.; Abdullah, A.A. KuBERT: Central Kurdish BERT Model and Its Application for Sentiment Analysis. Res. Sq. 2024. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
| Training Dataset | # of Classes | # of Samples | Average Class Sample Size | Minimum Class Sample Size | Maximum Class Sample Size |
|---|---|---|---|---|---|
| SST 100% | 2 | 67,349 | 33,675 | 29,780 | 37,569 |
| SST 10% | 2 | 6734 | 3367 | 2932 | 3802 |
| SST 1% | 2 | 673 | 337 | 291 | 382 |
| SST 0.1% | 2 | 67 | 34 | 31 | 36 |
| AGNEWS 100% | 4 | 120,000 | 30,000 | 30,000 | 30,000 |
| AGNEWS 10% | 4 | 12,000 | 3000 | 2964 | 3019 |
| AGNEWS 1% | 4 | 1200 | 300 | 269 | 320 |
| AGNEWS 0.1% | 4 | 120 | 30 | 22 | 42 |
| SMSSpam 100% | 2 | 5074 | 2537 | 686 | 4388 |
| SMSSpam 10% | 2 | 507 | 254 | 55 | 452 |
| SMSSpam 1% | 2 | 50 | 25 | 8 | 42 |
| TREC 100% | 6 | 5452 | 909 | 86 | 1250 |
| TREC 10% | 6 | 545 | 91 | 6 | 125 |
| Test Dataset | # of Classes | # of Samples | Average Class Sample Size | Minimum Class Sample Size | Maximum Class Sample Size |
|---|---|---|---|---|---|
| SST | 2 | 872 | 436 | 428 | 444 |
| AGNEWS | 4 | 7600 | 1900 | 1900 | 1900 |
| SMSSpam | 2 | 500 | 250 | 61 | 439 |
| TREC | 6 | 500 | 83 | 9 | 138 |
| Bi-Encoder ID | Model Name | # of Embedding Dimensions | # of Parameters |
|---|---|---|---|
| Bi-encoder 1 | all-mpnet-base-v2 | 768 | 109,486,464 |
| Bi-encoder 2 | multi-qa-mpnet-base-dot-v1 | 768 | 109,486,464 |
| Bi-encoder 3 | all-distilroberta-v1 | 768 | 82,118,400 |
| Bi-encoder 4 | all-MiniLM-L12-v2 | 384 | 33,360,000 |
| Bi-encoder 5 | multi-qa-distilbert-cos-v1 | 768 | 66,362,880 |
| Bi-encoder 6 | all-MiniLM-L6-v2 | 384 | 22,713,216 |
| Bi-encoder 7 | multi-qa-MiniLM-L6-cos-v1 | 384 | 22,713,216 |
| Bi-encoder 8 | paraphrase-multilingual-mpnet-base-v2 | 768 | 278,043,648 |
| Bi-encoder 9 | paraphrase-albert-small-v2 | 768 | 11,683,584 |
| Bi-encoder 10 | paraphrase-multilingual-MiniLM-L12-v2 | 384 | 117,653,760 |
| Bi-encoder 11 | paraphrase-MiniLM-L3-v2 | 384 | 17,389,824 |
| Bi-encoder 12 | distiluse-base-multilingual-cased-v1 | 512 | 135,127,808 |
| Bi-encoder 13 | distiluse-base-multilingual-cased-v2 | 512 | 135,127,808 |
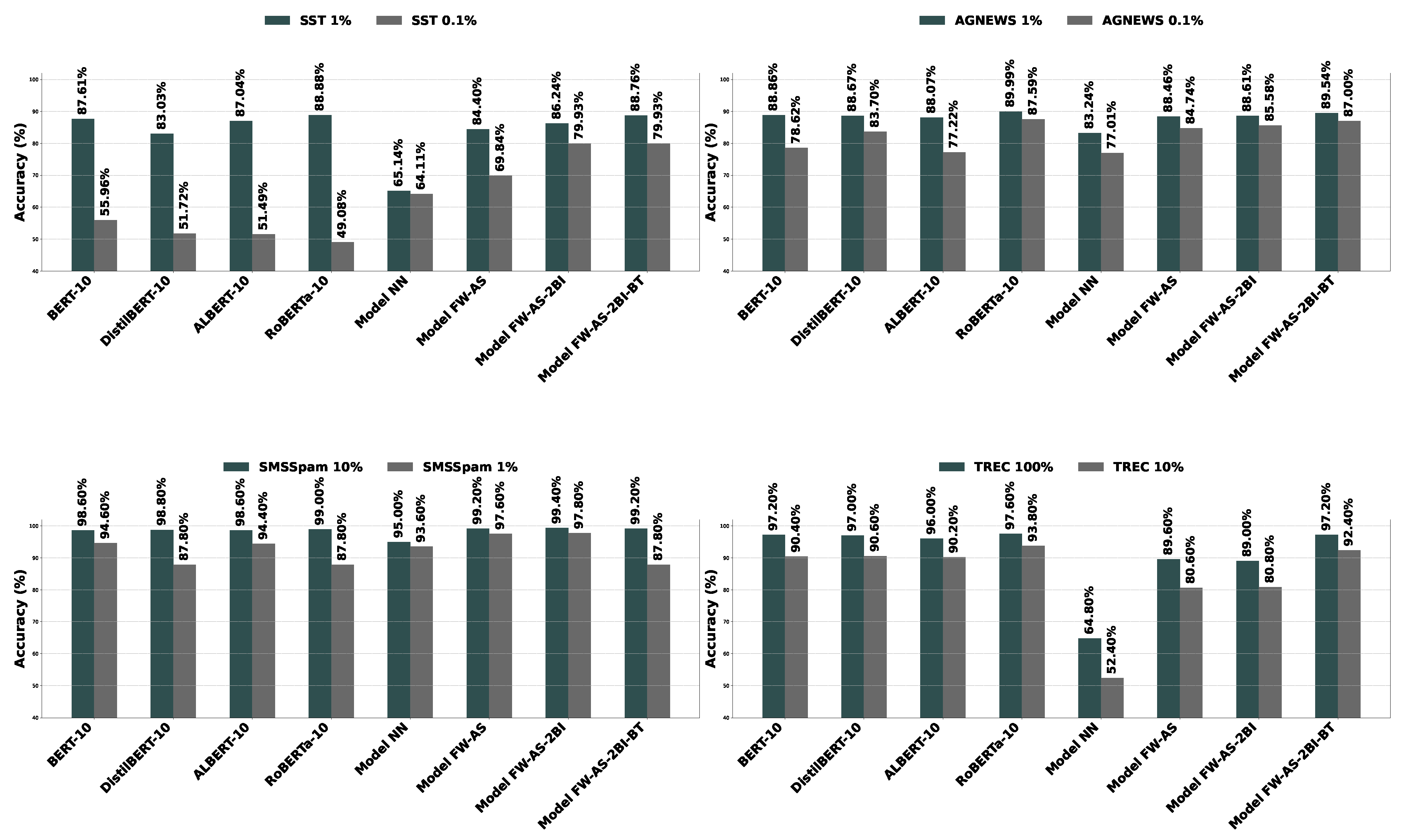
| Model Name | SST | AGNEWS | SMSSpam | TREC | Total | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 100% | 10% | 1% | 0.1% | Avg. | 100% | 10% | 1% | 0.1% | Avg. | 100% | 10% | 1% | Avg. | 100% | 10% | Avg. | Avg. | |
| Existing Approaches | ||||||||||||||||||
| BERT | 90.83 | 89.45 | 87.96 | 50.46 | 79.68 | 94.50 | 92.32 | 89.57 | 74.67 | 87.77 | 98.80 | 98.60 | 96.20 | 97.87 | 96.60 | 90.60 | 93.60 | 88.50 |
| BERT-10 | 91.74 | 90.60 | 87.61 | 55.96 | 81.48 | 94.22 | 92.17 | 88.86 | 78.62 | 88.47 | 99.40 | 98.60 | 94.60 | 97.53 | 97.20 | 90.40 | 93.80 | 89.23 |
| DistilBERT | 91.17 | 85.78 | 84.29 | 49.08 | 77.58 | 94.21 | 91.71 | 89.29 | 83.01 | 89.56 | 99.40 | 98.00 | 87.80 | 95.07 | 97.00 | 88.80 | 92.90 | 87.66 |
| DistilBERT-10 | 89.79 | 89.45 | 83.03 | 51.72 | 78.50 | 94.37 | 91.25 | 88.67 | 83.70 | 89.50 | 99.20 | 98.80 | 87.80 | 95.27 | 97.00 | 90.60 | 93.80 | 88.11 |
| ALBERT | 89.11 | 84.06 | 80.73 | 50.00 | 75.98 | 93.67 | 91.17 | 88.53 | 73.83 | 86.80 | 98.60 | 96.60 | 96.40 | 97.20 | 94.20 | 88.80 | 91.50 | 86.59 |
| ALBERT-10 | 91.28 | 88.88 | 87.04 | 51.49 | 79.67 | 94.04 | 91.53 | 88.07 | 77.22 | 87.72 | 99.20 | 98.60 | 94.40 | 97.40 | 96.00 | 90.20 | 93.10 | 88.30 |
| RoBERTa | 93.81 | 92.20 | 88.42 | 49.08 | 80.88 | 95.13 | 92.71 | 90.33 | 25.00 | 75.80 | 99.60 | 99.40 | 87.80 | 95.60 | 97.40 | 85.40 | 91.40 | 84.33 |
| RoBERTa-10 | 94.04 | 92.89 | 88.88 | 49.08 | 81.22 | 94.45 | 92.38 | 89.99 | 87.59 | 91.10 | 99.60 | 99.00 | 87.80 | 95.47 | 97.60 | 93.80 | 95.70 | 89.78 |
| Proposed Approaches | ||||||||||||||||||
| Approaches Without Pretrained Transformers | ||||||||||||||||||
| GloVe.6B.300d | 64.68 | 63.19 | 59.52 | 55.16 | 60.64 | 88.95 | 85.50 | 83.57 | 78.03 | 84.01 | 96.40 | 94.40 | 89.60 | 93.47 | 51.80 | 41.60 | 46.70 | 73.26 |
| Jaccard+Word1Gram | 60.67 | 61.24 | 53.44 | 52.41 | 56.94 | 84.13 | 74.04 | 60.96 | 42.41 | 65.39 | 98.00 | 94.60 | 89.00 | 93.87 | 81.20 | 54.60 | 67.90 | 69.75 |
| Jaccard+Char3Gram | 66.17 | 62.16 | 58.14 | 51.26 | 59.43 | 88.33 | 82.03 | 70.43 | 54.09 | 73.72 | 98.80 | 96.00 | 93.20 | 96.00 | 79.60 | 61.00 | 70.30 | 73.94 |
| Cosine+TFIDF | 70.07 | 66.74 | 59.98 | 53.90 | 62.67 | 88.26 | 83.70 | 74.79 | 57.03 | 75.95 | 98.40 | 96.00 | 93.00 | 95.80 | 64.00 | 65.60 | 64.80 | 74.73 |
| Bi-Encoder-Based Approaches | ||||||||||||||||||
| Model NN | 74.43 | 66.06 | 65.14 | 64.11 | 67.44 | 90.00 | 87.49 | 83.24 | 77.01 | 84.44 | 98.60 | 95.00 | 93.60 | 95.73 | 64.80 | 52.40 | 58.60 | 77.84 |
| Model MV | 73.74 | 72.48 | 71.79 | 66.06 | 71.02 | 92.11 | 90.26 | 87.05 | 82.75 | 88.04 | 98.60 | 95.40 | 95.60 | 96.53 | 76.60 | 64.80 | 70.70 | 82.10 |
| Model WV | 74.66 | 72.71 | 71.90 | 65.94 | 71.30 | 92.13 | 90.21 | 87.18 | 83.08 | 88.15 | 98.60 | 95.40 | 95.40 | 96.47 | 76.40 | 64.80 | 70.60 | 82.19 |
| Model FW | 74.89 | 72.59 | 70.87 | 67.09 | 71.36 | 92.49 | 90.45 | 87.62 | 84.14 | 88.68 | 99.00 | 95.60 | 96.00 | 96.87 | 78.60 | 63.40 | 71.00 | 82.52 |
| Bi-Encoder + Adaptive Selection | ||||||||||||||||||
| Model FW-AS | 83.49 | 83.94 | 84.40 | 69.84 | 80.42 | 92.49 | 91.04 | 88.46 | 84.74 | 89.18 | 99.40 | 99.20 | 97.60 | 98.73 | 89.60 | 80.60 | 85.10 | 88.06 |
| Bi-Encoder + Adaptive Selection + Ensemble | ||||||||||||||||||
| Model FW-AS-2BI | 86.01 | 86.47 | 86.24 | 79.93 | 84.66 | 92.88 | 91.04 | 88.61 | 85.58 | 89.53 | 99.60 | 99.40 | 97.80 | 98.93 | 89.00 | 80.80 | 84.90 | 89.49 |
| Model FW-AS-3BI | 85.09 | 85.78 | 85.67 | 79.70 | 84.06 | 92.88 | 91.18 | 88.66 | 85.96 | 89.67 | 99.60 | 99.20 | 97.80 | 98.87 | 89.40 | 80.40 | 84.90 | 89.33 |
| Bi-Encoder + Adaptive Selection + Ensemble + Existing Approach | ||||||||||||||||||
| Model FW-AS-2BI-BT | 94.04 | 93.35 | 88.76 | 79.93 | 89.02 | 94.75 | 92.05 | 89.54 | 87.00 | 90.84 | 99.40 | 99.20 | 87.80 | 95.47 | 97.20 | 92.40 | 94.80 | 91.96 |
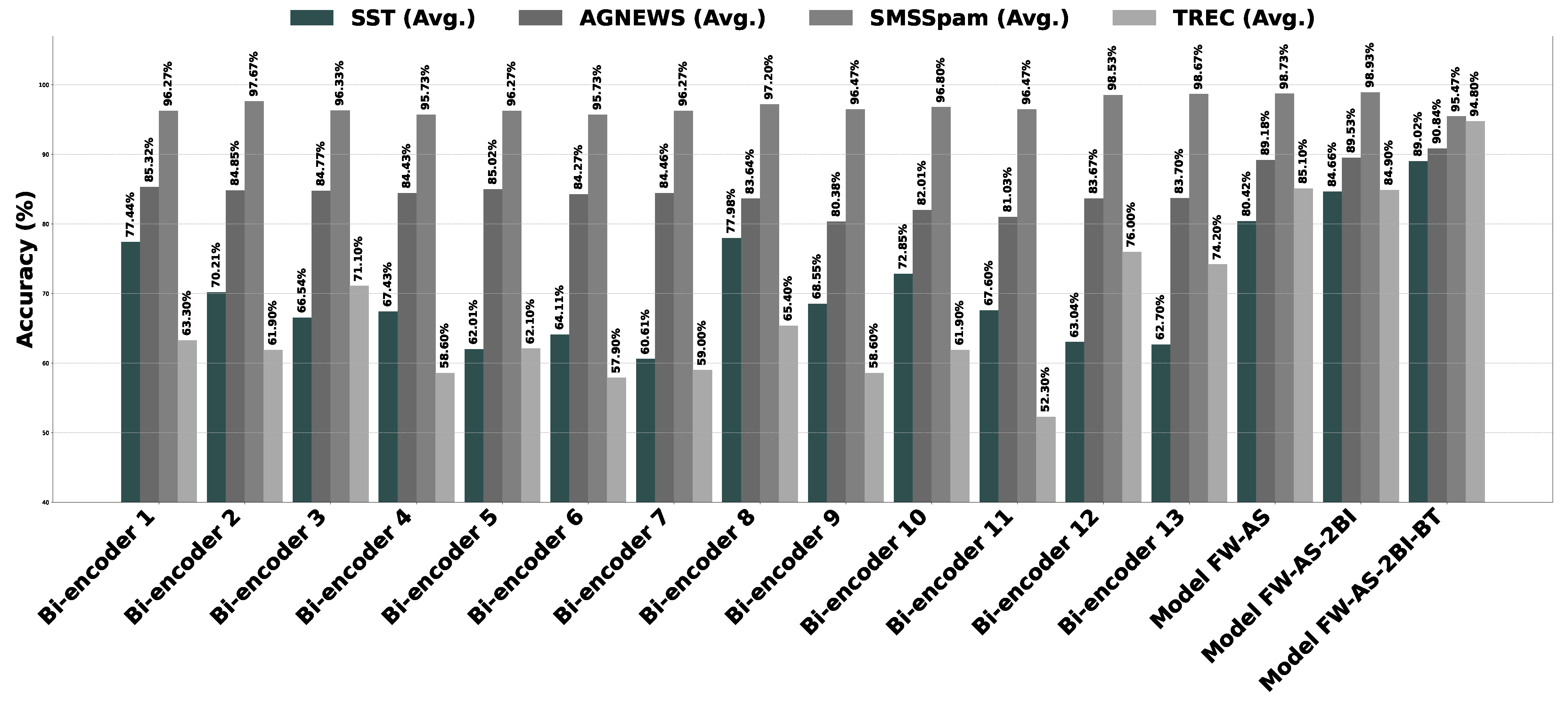
| Bi-Encoder ID | SST | AGNEWS | SMSSpam | TREC | Total | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 100% | 10% | 1% | 0.1% | Avg. | 100% | 10% | 1% | 0.1% | Avg. | 100% | 10% | 1% | Avg. | 100% | 10% | Avg. | Avg. | |
| Bi-encoder 1 | 81.31 | 76.03 | 75.46 | 76.95 | 77.44 | 90.32 | 87.57 | 84.37 | 79.04 | 85.32 | 98.20 | 96.00 | 94.60 | 96.27 | 70.00 | 56.60 | 63.30 | 82.03 |
| Bi-encoder 2 | 76.15 | 73.28 | 63.53 | 67.89 | 70.21 | 90.20 | 87.75 | 83.99 | 77.45 | 84.85 | 98.80 | 98.40 | 95.80 | 97.67 | 65.80 | 58.00 | 61.90 | 79.77 |
| Bi-encoder 3 | 72.94 | 69.04 | 64.11 | 60.09 | 66.54 | 90.05 | 87.00 | 83.92 | 78.11 | 84.77 | 99.20 | 96.40 | 93.40 | 96.33 | 73.80 | 68.40 | 71.10 | 79.73 |
| Bi-encoder 4 | 74.43 | 66.06 | 65.14 | 64.11 | 67.43 | 90.00 | 87.49 | 83.24 | 77.01 | 84.43 | 98.60 | 95.00 | 93.60 | 95.73 | 64.80 | 52.40 | 58.60 | 77.84 |
| Bi-encoder 5 | 68.23 | 64.33 | 57.45 | 58.03 | 62.01 | 90.92 | 87.61 | 83.55 | 78.01 | 85.02 | 98.40 | 95.80 | 94.60 | 96.27 | 67.00 | 57.20 | 62.10 | 77.01 |
| Bi-encoder 6 | 68.23 | 63.76 | 61.58 | 62.84 | 64.11 | 90.32 | 87.42 | 83.08 | 76.25 | 84.27 | 97.60 | 96.20 | 93.40 | 95.73 | 62.60 | 53.20 | 57.90 | 76.65 |
| Bi-encoder 7 | 65.14 | 62.96 | 57.91 | 56.42 | 60.61 | 90.25 | 87.34 | 82.42 | 77.83 | 84.46 | 98.80 | 95.00 | 95.00 | 96.27 | 62.60 | 55.40 | 59.00 | 75.93 |
| Bi-encoder 8 | 79.47 | 78.90 | 78.21 | 75.34 | 77.98 | 89.99 | 86.37 | 82.41 | 75.82 | 83.64 | 99.20 | 97.40 | 95.00 | 97.20 | 70.00 | 60.80 | 65.40 | 82.22 |
| Bi-encoder 9 | 72.25 | 69.84 | 66.74 | 65.37 | 68.55 | 88.54 | 84.67 | 79.88 | 68.41 | 80.38 | 98.80 | 95.60 | 95.00 | 96.47 | 63.20 | 54.00 | 58.60 | 77.10 |
| Bi-encoder 10 | 75.46 | 73.97 | 71.79 | 70.18 | 72.85 | 89.70 | 85.42 | 80.34 | 72.58 | 82.01 | 97.40 | 97.00 | 96.00 | 96.80 | 66.60 | 57.20 | 61.90 | 79.51 |
| Bi-encoder 11 | 71.33 | 68.58 | 65.48 | 65.02 | 67.60 | 89.28 | 85.29 | 80.00 | 69.57 | 81.03 | 99.20 | 96.60 | 93.60 | 96.47 | 57.60 | 47.00 | 52.30 | 76.04 |
| Bi-encoder 12 | 66.86 | 64.91 | 60.67 | 59.75 | 63.04 | 90.14 | 86.53 | 83.01 | 75.01 | 83.67 | 99.40 | 98.80 | 97.40 | 98.53 | 79.40 | 72.60 | 76.00 | 79.58 |
| Bi-encoder 13 | 67.89 | 64.56 | 60.21 | 58.14 | 62.70 | 90.16 | 86.80 | 82.74 | 75.09 | 83.70 | 99.60 | 98.80 | 97.60 | 98.67 | 76.80 | 71.60 | 74.20 | 79.23 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, Y.; Shin, Y. Adaptive Bi-Encoder Model Selection and Ensemble for Text Classification. Mathematics 2024, 12, 3090. https://doi.org/10.3390/math12193090
Park Y, Shin Y. Adaptive Bi-Encoder Model Selection and Ensemble for Text Classification. Mathematics. 2024; 12(19):3090. https://doi.org/10.3390/math12193090
Chicago/Turabian StylePark, Youngki, and Youhyun Shin. 2024. "Adaptive Bi-Encoder Model Selection and Ensemble for Text Classification" Mathematics 12, no. 19: 3090. https://doi.org/10.3390/math12193090
APA StylePark, Y., & Shin, Y. (2024). Adaptive Bi-Encoder Model Selection and Ensemble for Text Classification. Mathematics, 12(19), 3090. https://doi.org/10.3390/math12193090