
Inverse Probability-Weighted Estimation for Dynamic Structural Equation Model with Missing Data

Abstract
1. Introduction
2. Review of Dynamic Structural Equation Models and Estimation Methods
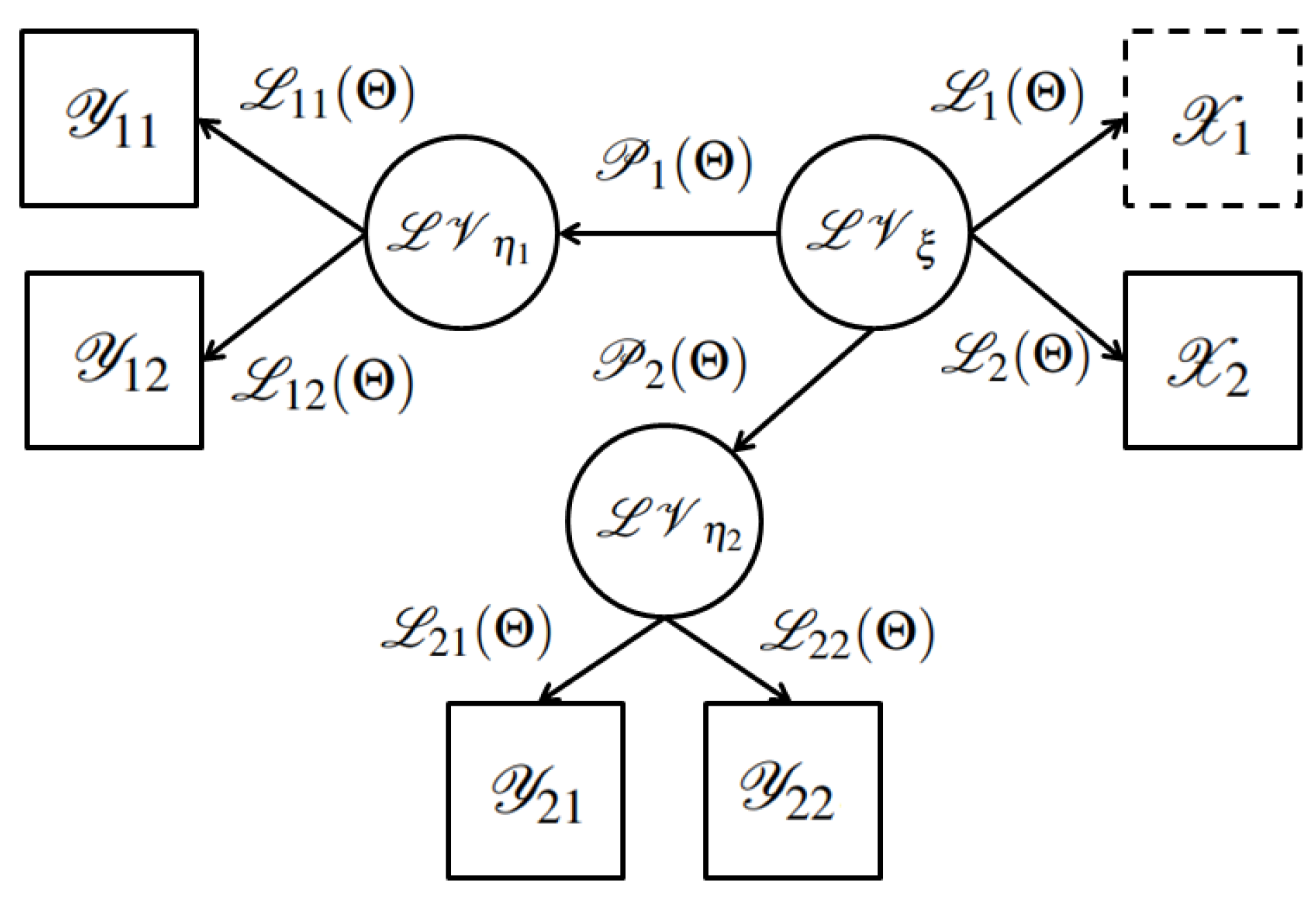
2.1. Dynamic Structural Equation Models with Varying Coefficients
2.2. The Local Polynomial PLS Estimation for Dynamic Structural Equation Models
3. The Proposed IPW Estimation Algorithms
3.1. The Proposed Parametric IPW Estimation Algorithms
| Algorithm 1 The proposed IPW estimation algorithm in the dynamic structural equation model |
Step 0: Assume the initial values of outer weights. Step 1: External estimation. Use complete cases of observed variables to calculate estimation of latent variables for the Ith iteration. Step 2: Internal estimation. Choose centroid scheme, calculate internal weights, and use the product of internal weights and the external estimation of latent variables to obtain internal estimations for the Ith iteration. Step 3: Update the external weights. Step 3-1: Estimate the external weights between latent and observed variables using . Step 3-2: Calculate the differences of estimated external weights between two consecutive iterations Ith and th. Step 4: Iterate repeatedly from Step 1 to Step 3. Step 4-1: Iterate repeatedly until the results meet the stop criterion. Step 4-2: Obtain the final estimated external weights. Step 5: Estimate the final varying path coefficients using . |
3.2. The Proposed Nonparametric IPW Estimation Algorithms
3.2.1. The Determination of the Nonparametric IPW Equation
3.2.2. The Choice of Kernel Function
3.2.3. Determining the Order of Kernel Function
3.2.4. Determining the Dimension of W, d
3.2.5. Selecting Bandwidth Smoothing Parameter h
3.2.6. NIPW Estimation Algorithms
3.3. Modified IPW and NIPW Estimation Algorithms
4. Simulation Investigations
4.1. Notations
4.2. Models
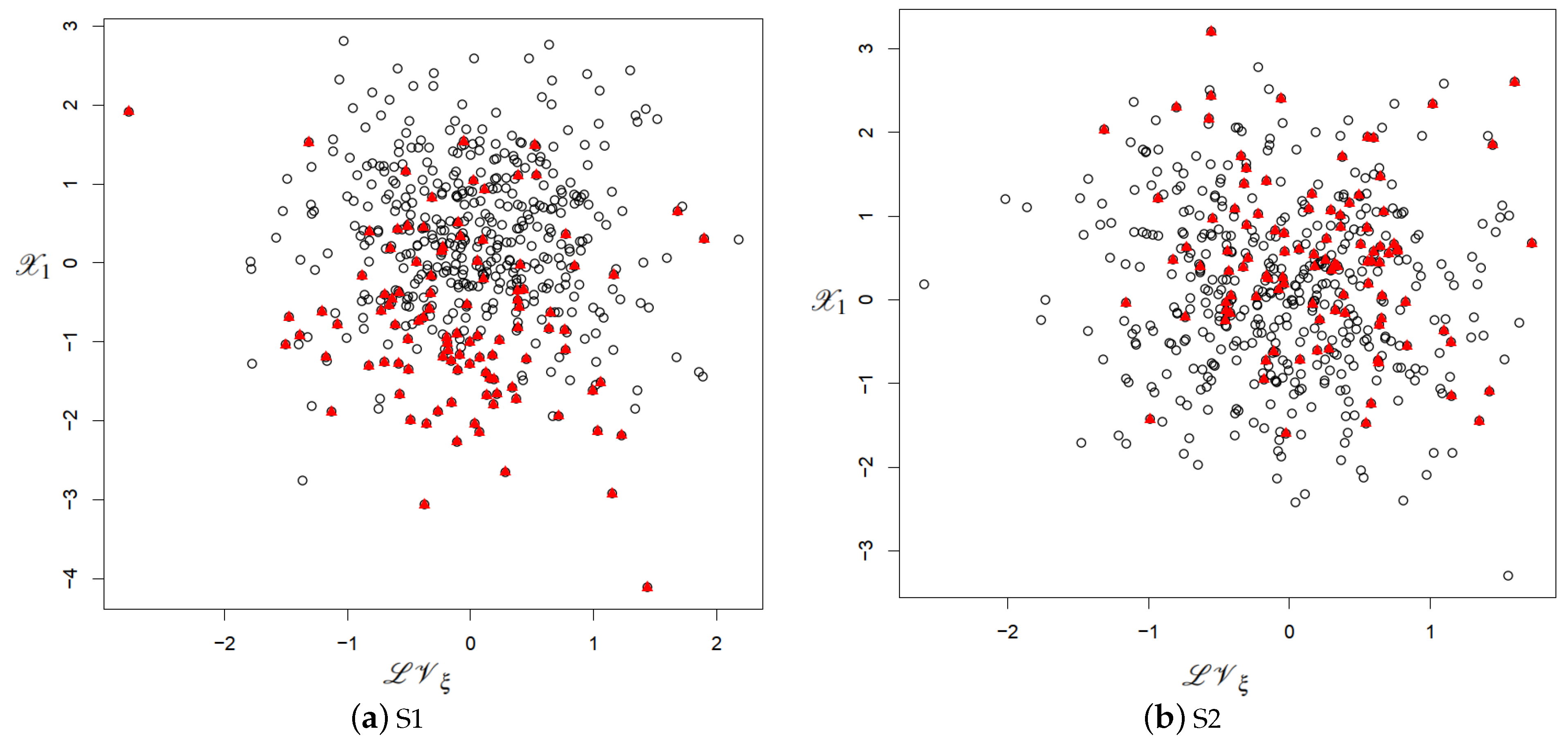
4.3. Simulation Data Generation Mechanism
4.4. Evaluation Indexes
4.5. Results
4.5.1. Comparisons of Estimation Accuracy and Efficiency in Setting S1
4.5.2. Comparisons of Estimation Accuracy and Efficiency in Setting S2
4.5.3. Comparison of Computing Time
5. Empirical Study
6. Discussion
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Seaman, S.R.; White, I.R.; Copas, A.J.; Li, L. Combining multiple imputation and inverse-probability weighting. Biometrics 2012, 68, 129–137. [Google Scholar] [CrossRef] [PubMed]
- Jöreskog, K.G.; Sörbom, D. LISREL V: Analysis of Linear Structural Relationships by the Method of Maximum Likelihood. In National Educational Resources; Scientific Software: Chapel Hill, NC, USA, 1981. [Google Scholar]
- Jöreskog, K.G.; Sörbom, D. Recent developments in structural equation modeling. J. Mark. Res. 1982, 19, 404–416. [Google Scholar]
- Bollen, K.A. Structural Equations with Latent Variables; Wiley: New York, NY, USA, 1989. [Google Scholar]
- Lohmöller, J.B. Latent Variable Path Modeling with Partial Least Squares; Physica-Verlag: Heidelberg, Germany, 1989. [Google Scholar]
- Sammel, M.D.; Ryan, L.M. Latent variable models with fixed effects. Biometrics 1996, 52, 650–663. [Google Scholar] [CrossRef] [PubMed]
- Ciavolino, E.; Nitti, M. Simulation study for PLS path modeling with high-order construct: A job satisfaction model evidence. In Advanced Dynamic Modeling of Economic and Social Systems; Springer: Berlin/Heidelberg, Germany, 2013; pp. 185–207. [Google Scholar]
- Ciavolino, E.; Nitti, M. Using the hybrid two-step estimation approach for the identification of second-order latent variable models. J. Appl. Stat. 2013, 40, 508–526. [Google Scholar] [CrossRef]
- Hair, J.F.; Hult, G.T.M.; Ringle, C.M.; Sarstedt, M. A Primer on Partial Least Squares Structural Equation Modeling (PLS-SEM), 2nd ed.; SAGE Publications: Thousand Oaks, CA, USA, 2017. [Google Scholar]
- Tenenhaus, M.; Esposito, V.V.; Chatelin, Y.M.; Lauro, C. PLS path modeling. Comput. Stat. Data Anal. 2005, 48, 159–205. [Google Scholar] [CrossRef]
- Davino, C.; Esposito, V.V. Quantile composite-based path modelling. Adv. Data Anal. Classif. 2016, 10, 491–520. [Google Scholar] [CrossRef]
- Davino, C.; Esposito, V.V.; Dolce, P. Assessment and validation in quantile composite-based path modeling. In The Multiple Facets of Partial Least Squares and Related Methods; Springer Proceedings in Mathematics and Statistics; Springer: New York, NY, USA, 2016; pp. 169–185. [Google Scholar]
- Davino, C.; Dolce, P.; Taralli, S. Quantile composite-based model: A recent advance in PLS-PM. In Partial Least Squares Path Modeling; Basic Concepts, Methodological Issues and Applications; Springer International Publishing AG: Berlin/Heidelberg, Germany, 2017; pp. 81–108. [Google Scholar]
- Davino, C.; Dolce, P.; Taralli, S. A quantile composite-indicator approach for the measurement of equitable and sustainable well-Being: A case study of the Italian provinces. Soc. Indic. Res. 2018, 136, 999–1029. [Google Scholar] [CrossRef]
- Dolce, P.; Davino, C.; Vistocco, D. Quantile Composite-Based Path Modeling: Algorithms, Properties and Applications; Springer: Berlin/Heidelberg, Germany, 2021. [Google Scholar]
- Allison, P.D. Missing data techniques for structural equation modeling. J. Abnorm. Psychol. 2003, 112, 545. [Google Scholar] [CrossRef]
- Fang, Y.; Wang, L. Dynamic structural equation models with missing data: Data requirements on N and T. Struct. Equ. Model. Multidiscip. J. 2024, 31, 891–908. [Google Scholar] [CrossRef]
- Cai, Z.; Fan, J.; Li, R. Efficient estimation and inferences for varying-coefficient models. J. Am. Stat. Assoc. 2001, 95, 888–902. [Google Scholar] [CrossRef]
- Cheng, H. A class of new partial least square algorithms for first and higher order models. Commun. Stat. Simul. Comput. 2020, 51, 4349–4371. [Google Scholar] [CrossRef]
- Cheng, H.; Pei, R.M. Visualization analysis of functional dynamic effects of globalization talent flow on international cooperation. J. Stat. Inf. 2022, 37, 107–116. [Google Scholar]
- Ji, L.; Chow, S.M.; Schermerhorn, A.C.; Jacobson, N.C.; Cummings, E.M. Handling Missing Data in the Modeling of Intensive Longitudinal Data. Struct. Equ. Model. A Multidiscip. J. 2018, 25, 715–736. [Google Scholar] [CrossRef]
- Fan, J.; Zhang, J.T. Statistical estimation in varying coefficient models. Ann Stat 1999, 27, 1491–1518. [Google Scholar] [CrossRef]
- Fan, J.; Zhang, J.T. Functional linear models for longitudinal data. J. R. Stat. Soc. B 2000, 62, 303–322. [Google Scholar] [CrossRef]
- Assuno, R.M. Space varying coefficient models for small area data. Environmetrics 2003, 14, 453–473. [Google Scholar] [CrossRef]
- Fan, J.; Zhang, W. Statistical methods with varying coefficient models. Stat. Interface 2008, 1, 179. [Google Scholar] [CrossRef]
- Zhang, W.Y.; Lee, S.Y. Nonlinear dynamical structural equation models. Quant. Financ. 2009, 9, 305–314. [Google Scholar] [CrossRef]
- Asparouhov, T.; Hamaker, E.L.; Muthen, B. Dynamic latent class analysis. Struct. Equ. Model. A Multidiscip. J. 2017, 24, 257–269. [Google Scholar] [CrossRef]
- Asparouhov, T.; Hamaker, E.L.; Muthen, B. Dynamic structural equation models. Struct. Equ. Model. Multidiscip. J. 2017, 25, 359–388. [Google Scholar] [CrossRef]
- Wei, C.H.; Wang, S.J.; Su, Y.N. Local GMM estimation in spatial varying coefficient geographocally weighted autoregressive model. J. Stat. Inf. 2022, 37, 3–13. [Google Scholar]
- Cheng, H. New latent variable models with varying-coefficients. Commun. Stat. Theory Methods 2024, 1–18. [Google Scholar] [CrossRef]
- Cheng, H. Quantile Varying-coefficient Structural Equation Models. Stat. Methods Appl. 2023, 32, 1439–1475. [Google Scholar] [CrossRef]
- Koenker, R.; Bassett, G.J. Regression quantiles. Econometrica 1978, 46, 33–50. [Google Scholar] [CrossRef]
- Koenker, R. Quantile Regression; Cambridge University Press: Cambridge, UK, 2005. [Google Scholar]
- Fan, J.; Gijbels, I. Local Polynomial Modeling and Its Applications; Chapman & Hall: London, UK, 1996. [Google Scholar]
- Chen, X.R.; Wan, A.T.K.; Zhou, Y. Efficient Quantile Regression Analysis With Missing Observations. J. Am. Stat. Assoc. 2015, 110, 723–741. [Google Scholar] [CrossRef]
- Chatelin, Y.M.; Esposito, V.V.; Tenenhaus, M. State-of-Art on PLS Path Modeling through the Available Software; HEC: Paris, France, 2002. [Google Scholar]
- Ringle, C.M.; Wende, S.; Becker, J.M. SmartPLS 3; SmartPLS GmbH: Boenningstedt, Germany, 2015. [Google Scholar]
- Wang, C.Y.; Wang, S.J.; Zhao, L.; Ou, S.T. Weighted semiparametric estimation in regression analysis with missing covariate data. J. Am. Stat. Assoc. 1997, 92, 512–525. [Google Scholar] [CrossRef]
- Cheng, H. Research on Nonparametric Inverse Probability Weighting Quantile Regression with Its Application in CHARLS Data. J. Appl. Stat. Manag. 2023, 42, 403–415. [Google Scholar]
- Eubank, R.L. Smoothing Spline and Nonparametric Regression; Marcel Dekker: New York, NY, USA, 1988. [Google Scholar]
- Zhou, Y.; Wan, A.T.K.; Wang, X. Estimating Equation Inference with Missing Data. J. Am. Stat. Assoc. 2008, 103, 1187–1199. [Google Scholar] [CrossRef]
- Sepanski, J.H.; Knickerbocker, R.; Carroll, R.J. A semiparametric correction for attenuation. J. Am. Stat. Assoc. 1994, 89, 1366–1373. [Google Scholar] [CrossRef]
- Carroll, R.J.; Wand, M.P. Semiparametric estimation in logistic measurement error models. J. R. Stat. Soc. 1991, 53, 573–585. [Google Scholar] [CrossRef]
- Silverman, B.W. Density Estimation; Chapman and Hall: London, UK, 1986. [Google Scholar]
- Chin, W.W.; Marcolin, B.L.; Newsted, P.R. A partial least squares latent variable modeling approach for measuring interaction effects: Results from a Monte Carlo simulation study and an electronic-mail emotion/adoption study. Inf. Syst. Res. 2003, 14, 189–217. [Google Scholar] [CrossRef]
- Reinartz, B.; Ballmann, J. Shock Waves; Springer: Berlin/Heidelberg, Germany, 2009; pp. 1099–1104. [Google Scholar]
- Henseler, J.; Chin, W.W. A comparison of approaches for the analysis of interaction effects between latent variables using partial least squares path modeling. Struct. Equ. Model. 2010, 17, 82–109. [Google Scholar] [CrossRef]
- Becker, J.M.; Klein, K.; Wetzels, M. Formative hierarchical latent variable models in PLS-SEM: Recommendations and guidelines. Long Range Plan. 2012, 45, 359–394. [Google Scholar] [CrossRef]
- Hahn, J. Bootstrapping quantile regression estimators. Econom. Theory 1995, 11, 105–121. [Google Scholar] [CrossRef]
- Lu, J.; Guo, Z.A. New quality productivity research in urban areas contains horizontal measurement, spatiotemporal evolution and influencing factors based on panel data from 277 cities across China from 2012 to 2021. Soc. Sci. J. 2024, 4, 124–133. [Google Scholar]

{kind=link}
{kind=link}
| 0.10 | CC | 1.003 | 0.461 | 0.418 | 1.102 | 0.425 | 1.017 | 1.031 | 1.029 |
| IPW | 1.022 | 0.494 | 0.323 | 0.609 | 0.453 | 1.030 | 1.015 | 1.017 | |
| IPWM | 1.008 | 0.427 | 0.317 | 0.607 | 0.399 | 1.027 | 1.024 | 1.023 | |
| NIPW | 1.003 | 0.420 | 0.316 | 0.562 | 0.385 | 1.025 | 1.024 | 1.020 | |
| NIPWM | 1.008 | 0.427 | 0.317 | 0.561 | 0.401 | 1.028 | 1.028 | 1.026 | |
| 0.50 | CC | 0.966 | 0.296 | 0.362 | 0.998 | 0.303 | 1.000 | 1.032 | 1.032 |
| IPW | 0.968 | 0.298 | 0.354 | 0.988 | 0.304 | 1.008 | 1.027 | 1.024 | |
| IPWM | 0.975 | 0.290 | 0.348 | 0.984 | 0.298 | 1.004 | 1.030 | 1.029 | |
| NIPW | 0.977 | 0.295 | 0.356 | 0.994 | 0.297 | 1.006 | 1.030 | 1.030 | |
| NIPWM | 0.975 | 0.292 | 0.360 | 0.996 | 0.299 | 1.002 | 1.028 | 1.029 | |
| 0.90 | CC | 1.013 | 0.471 | 0.356 | 0.940 | 0.418 | 1.050 | 1.022 | 1.024 |
| IPW | 1.030 | 0.480 | 0.578 | 1.462 | 0.418 | 1.056 | 1.025 | 1.023 | |
| IPWM | 1.033 | 0.455 | 0.570 | 1.453 | 0.404 | 1.062 | 1.022 | 1.021 | |
| NIPW | 1.033 | 0.525 | 0.589 | 1.561 | 0.451 | 1.062 | 1.034 | 1.032 | |
| NIPWM | 1.032 | 0.457 | 0.575 | 1.549 | 0.404 | 1.062 | 1.022 | 1.022 |
| 0.10 | CC | 1.245 | 0.316 | 0.259 | 1.337 | 0.275 | 1.221 | 1.403 | 1.394 |
| IPW | 1.325 | 0.370 | 0.180 | 0.513 | 0.315 | 1.279 | 1.364 | 1.362 | |
| IPWM | 1.214 | 0.273 | 0.173 | 0.508 | 0.244 | 1.217 | 1.389 | 1.382 | |
| NIPW | 1.190 | 0.269 | 0.167 | 0.442 | 0.229 | 1.198 | 1.386 | 1.370 | |
| NIPWM | 1.214 | 0.273 | 0.170 | 0.440 | 0.246 | 1.219 | 1.396 | 1.389 | |
| 0.50 | CC | 0.971 | 0.118 | 0.194 | 1.088 | 0.124 | 1.039 | 1.408 | 1.407 |
| IPW | 0.982 | 0.124 | 0.190 | 1.091 | 0.126 | 1.061 | 1.394 | 1.387 | |
| IPWM | 0.983 | 0.110 | 0.178 | 1.081 | 0.116 | 1.044 | 1.403 | 1.399 | |
| NIPW | 0.993 | 0.117 | 0.185 | 1.096 | 0.119 | 1.053 | 1.404 | 1.401 | |
| NIPWM | 0.982 | 0.111 | 0.194 | 1.098 | 0.117 | 1.041 | 1.400 | 1.400 | |
| 0.90 | CC | 1.233 | 0.332 | 0.224 | 1.028 | 0.263 | 1.264 | 1.386 | 1.387 |
| IPW | 1.281 | 0.346 | 0.470 | 2.378 | 0.262 | 1.291 | 1.390 | 1.383 | |
| IPWM | 1.265 | 0.312 | 0.459 | 2.352 | 0.244 | 1.287 | 1.387 | 1.381 | |
| NIPW | 1.331 | 0.408 | 0.479 | 2.664 | 0.304 | 1.339 | 1.410 | 1.402 | |
| NIPWM | 1.262 | 0.314 | 0.456 | 2.627 | 0.245 | 1.286 | 1.386 | 1.383 |
| CC | 0.10 | 0.998 | 0.523 | 0.487 | 1.198 | 0.460 | 0.997 | 1.017 | 1.016 |
| 0.50 | 0.998 | 0.309 | 0.354 | 1.028 | 0.287 | 0.980 | 1.018 | 1.018 | |
| 0.90 | 1.015 | 0.493 | 0.328 | 0.881 | 0.437 | 1.012 | 1.017 | 1.016 | |
| IPW | 0.10 | 1.006 | 0.555 | 0.339 | 0.569 | 0.489 | 1.004 | 1.013 | 1.012 |
| 0.50 | 1.001 | 0.309 | 0.341 | 1.016 | 0.283 | 0.979 | 1.015 | 1.015 | |
| 0.90 | 1.020 | 0.512 | 0.691 | 1.630 | 0.448 | 1.016 | 1.015 | 1.015 | |
| IPWM | 0.10 | 1.002 | 0.502 | 0.342 | 0.567 | 0.440 | 0.998 | 1.016 | 1.015 |
| 0.50 | 1.003 | 0.305 | 0.337 | 1.014 | 0.283 | 0.981 | 1.017 | 1.016 | |
| 0.90 | 1.020 | 0.496 | 0.695 | 1.635 | 0.432 | 1.013 | 1.014 | 1.013 | |
| NIPW | 0.10 | 0.998 | 0.456 | 0.334 | 0.518 | 0.405 | 1.001 | 1.013 | 1.011 |
| 0.50 | 1.002 | 0.306 | 0.350 | 1.023 | 0.284 | 0.982 | 1.016 | 1.016 | |
| 0.90 | 1.026 | 0.566 | 0.705 | 1.729 | 0.488 | 1.020 | 1.019 | 1.019 | |
| NIPWM | 0.10 | 1.003 | 0.502 | 0.336 | 0.516 | 0.440 | 0.998 | 1.017 | 1.015 |
| 0.50 | 1.002 | 0.304 | 0.347 | 1.021 | 0.283 | 0.982 | 1.017 | 1.017 | |
| 0.90 | 1.019 | 0.495 | 0.707 | 1.735 | 0.432 | 1.013 | 1.015 | 1.014 |
| CC | 0.10 | 1.311 | 0.382 | 0.355 | 1.555 | 0.302 | 1.229 | 1.355 | 1.353 |
| 0.50 | 1.033 | 0.127 | 0.183 | 1.116 | 0.104 | 0.987 | 1.357 | 1.357 | |
| 0.90 | 1.306 | 0.347 | 0.178 | 0.892 | 0.286 | 1.227 | 1.355 | 1.353 | |
| IPW | 0.10 | 1.364 | 0.429 | 0.206 | 0.445 | 0.338 | 1.275 | 1.347 | 1.341 |
| 0.50 | 1.044 | 0.128 | 0.170 | 1.103 | 0.105 | 0.989 | 1.350 | 1.351 | |
| 0.90 | 1.341 | 0.366 | 0.653 | 2.923 | 0.295 | 1.252 | 1.349 | 1.347 | |
| IPWM | 0.10 | 1.286 | 0.352 | 0.209 | 0.444 | 0.276 | 1.200 | 1.353 | 1.351 |
| 0.50 | 1.040 | 0.122 | 0.167 | 1.098 | 0.100 | 0.988 | 1.354 | 1.353 | |
| 0.90 | 1.320 | 0.344 | 0.658 | 2.939 | 0.275 | 1.227 | 1.348 | 1.344 | |
| NIPW | 0.10 | 1.237 | 0.299 | 0.198 | 0.377 | 0.240 | 1.178 | 1.345 | 1.340 |
| 0.50 | 1.042 | 0.125 | 0.175 | 1.116 | 0.103 | 0.992 | 1.354 | 1.352 | |
| 0.90 | 1.415 | 0.439 | 0.657 | 3.238 | 0.345 | 1.309 | 1.359 | 1.358 | |
| NIPWM | 0.10 | 1.287 | 0.351 | 0.201 | 0.374 | 0.276 | 1.200 | 1.355 | 1.352 |
| 0.50 | 1.040 | 0.122 | 0.173 | 1.110 | 0.100 | 0.988 | 1.355 | 1.354 | |
| 0.90 | 1.318 | 0.344 | 0.659 | 3.254 | 0.275 | 1.227 | 1.351 | 1.348 |
| 0.10 | CC | 0.975 | 0.439 | 0.386 | 0.999 | 0.408 | 1.001 | 1.018 | 1.019 |
| IPW | 0.999 | 0.464 | 0.574 | 1.280 | 0.429 | 1.023 | 1.022 | 1.021 | |
| IPWM | 1.013 | 0.422 | 0.577 | 1.284 | 0.396 | 1.025 | 1.018 | 1.016 | |
| NIPW | 1.003 | 0.472 | 0.614 | 1.349 | 0.438 | 1.027 | 1.019 | 1.016 | |
| NIPWM | 1.014 | 0.422 | 0.607 | 1.348 | 0.395 | 1.026 | 1.019 | 1.019 | |
| 0.50 | CC | 0.963 | 0.298 | 0.372 | 0.998 | 0.300 | 0.989 | 1.025 | 1.024 |
| IPW | 0.972 | 0.300 | 0.358 | 0.981 | 0.298 | 0.997 | 1.023 | 1.022 | |
| IPWM | 0.971 | 0.289 | 0.356 | 0.982 | 0.297 | 1.000 | 1.024 | 1.023 | |
| NIPW | 0.967 | 0.298 | 0.370 | 0.998 | 0.299 | 0.994 | 1.025 | 1.024 | |
| NIPWM | 0.970 | 0.288 | 0.368 | 0.999 | 0.298 | 1.001 | 1.025 | 1.025 | |
| 0.90 | CC | 1.023 | 0.471 | 0.391 | 1.030 | 0.428 | 1.061 | 1.020 | 1.021 |
| IPW | 1.022 | 0.487 | 0.322 | 0.755 | 0.435 | 1.052 | 1.015 | 1.015 | |
| IPWM | 1.016 | 0.441 | 0.321 | 0.754 | 0.395 | 1.055 | 1.019 | 1.018 | |
| NIPW | 1.014 | 0.468 | 0.318 | 0.722 | 0.420 | 1.051 | 1.014 | 1.016 | |
| NIPWM | 1.015 | 0.441 | 0.332 | 0.729 | 0.395 | 1.055 | 1.012 | 1.012 |
| 0.10 | CC | 1.166 | 0.290 | 0.240 | 1.146 | 0.261 | 1.173 | 1.371 | 1.373 |
| IPW | 1.237 | 0.323 | 0.463 | 1.856 | 0.284 | 1.234 | 1.379 | 1.373 | |
| IPWM | 1.223 | 0.268 | 0.467 | 1.872 | 0.242 | 1.208 | 1.373 | 1.368 | |
| NIPW | 1.259 | 0.332 | 0.517 | 2.022 | 0.297 | 1.250 | 1.375 | 1.368 | |
| NIPWM | 1.223 | 0.269 | 0.495 | 2.014 | 0.241 | 1.210 | 1.376 | 1.375 | |
| 0.50 | CC | 0.966 | 0.118 | 0.210 | 1.106 | 0.122 | 1.019 | 1.388 | 1.385 |
| IPW | 0.987 | 0.122 | 0.192 | 1.080 | 0.124 | 1.038 | 1.382 | 1.379 | |
| IPWM | 0.974 | 0.108 | 0.188 | 1.078 | 0.115 | 1.036 | 1.384 | 1.384 | |
| NIPW | 0.977 | 0.120 | 0.198 | 1.105 | 0.123 | 1.031 | 1.388 | 1.386 | |
| NIPWM | 0.973 | 0.108 | 0.196 | 1.104 | 0.116 | 1.038 | 1.388 | 1.389 | |
| 0.90 | CC | 1.256 | 0.336 | 0.240 | 1.214 | 0.277 | 1.299 | 1.380 | 1.378 |
| IPW | 1.281 | 0.357 | 0.174 | 0.730 | 0.284 | 1.297 | 1.369 | 1.360 | |
| IPWM | 1.220 | 0.295 | 0.175 | 0.728 | 0.235 | 1.266 | 1.376 | 1.370 | |
| NIPW | 1.241 | 0.331 | 0.165 | 0.679 | 0.267 | 1.282 | 1.366 | 1.365 | |
| NIPWM | 1.218 | 0.294 | 0.193 | 0.691 | 0.235 | 1.266 | 1.365 | 1.360 |
| CC | 0.10 | 0.970 | 0.493 | 0.354 | 0.984 | 0.433 | 0.966 | 1.018 | 1.016 |
| 0.50 | 0.992 | 0.308 | 0.355 | 1.015 | 0.290 | 0.969 | 1.019 | 1.019 | |
| 0.90 | 1.026 | 0.510 | 0.414 | 1.103 | 0.455 | 1.020 | 1.014 | 1.016 | |
| IPW | 0.10 | 1.004 | 0.523 | 0.685 | 1.420 | 0.460 | 0.998 | 1.016 | 1.013 |
| 0.50 | 1.000 | 0.306 | 0.345 | 1.008 | 0.286 | 0.975 | 1.017 | 1.017 | |
| 0.90 | 1.017 | 0.528 | 0.340 | 0.708 | 0.470 | 1.008 | 1.014 | 1.013 | |
| IPWM | 0.10 | 1.007 | 0.492 | 0.683 | 1.420 | 0.426 | 1.003 | 1.016 | 1.012 |
| 0.50 | 0.997 | 0.305 | 0.344 | 1.006 | 0.285 | 0.977 | 1.018 | 1.018 | |
| 0.90 | 1.005 | 0.484 | 0.336 | 0.706 | 0.422 | 1.003 | 1.016 | 1.017 | |
| NIPW | 0.10 | 1.009 | 0.534 | 0.704 | 1.468 | 0.471 | 1.003 | 1.019 | 1.017 |
| 0.50 | 0.998 | 0.304 | 0.365 | 1.016 | 0.285 | 0.973 | 1.018 | 1.018 | |
| 0.90 | 1.008 | 0.505 | 0.338 | 0.680 | 0.450 | 1.005 | 1.015 | 1.015 | |
| NIPWM | 0.10 | 1.007 | 0.492 | 0.709 | 1.472 | 0.426 | 1.002 | 1.016 | 1.013 |
| 0.50 | 0.997 | 0.305 | 0.364 | 1.015 | 0.285 | 0.978 | 1.019 | 1.019 | |
| 0.90 | 1.005 | 0.484 | 0.340 | 0.685 | 0.422 | 1.004 | 1.017 | 1.017 |
| CC | 0.10 | 1.215 | 0.340 | 0.196 | 1.083 | 0.271 | 1.138 | 1.370 | 1.364 |
| 0.50 | 1.022 | 0.126 | 0.187 | 1.098 | 0.107 | 0.967 | 1.373 | 1.371 | |
| 0.90 | 1.346 | 0.367 | 0.267 | 1.329 | 0.304 | 1.253 | 1.362 | 1.363 | |
| IPW | 0.10 | 1.314 | 0.382 | 0.651 | 2.266 | 0.304 | 1.224 | 1.364 | 1.358 |
| 0.50 | 1.040 | 0.126 | 0.177 | 1.084 | 0.106 | 0.979 | 1.368 | 1.368 | |
| 0.90 | 1.357 | 0.387 | 0.215 | 0.647 | 0.319 | 1.255 | 1.360 | 1.359 | |
| IPWM | 0.10 | 1.281 | 0.342 | 0.649 | 2.264 | 0.264 | 1.196 | 1.366 | 1.360 |
| 0.50 | 1.030 | 0.122 | 0.176 | 1.082 | 0.101 | 0.980 | 1.371 | 1.371 | |
| 0.90 | 1.272 | 0.328 | 0.206 | 0.642 | 0.262 | 1.197 | 1.367 | 1.366 | |
| NIPW | 0.10 | 1.338 | 0.397 | 0.663 | 2.385 | 0.317 | 1.245 | 1.371 | 1.364 |
| 0.50 | 1.037 | 0.125 | 0.191 | 1.100 | 0.105 | 0.977 | 1.371 | 1.370 | |
| 0.90 | 1.315 | 0.357 | 0.205 | 0.600 | 0.294 | 1.227 | 1.364 | 1.363 | |
| NIPWM | 0.10 | 1.280 | 0.342 | 0.673 | 2.392 | 0.264 | 1.196 | 1.367 | 1.361 |
| 0.50 | 1.028 | 0.122 | 0.190 | 1.098 | 0.101 | 0.981 | 1.372 | 1.372 | |
| 0.90 | 1.272 | 0.327 | 0.205 | 0.609 | 0.262 | 1.198 | 1.367 | 1.366 |
| S1 | S2 | |||||
|---|---|---|---|---|---|---|
| 0.10 | 0.50 | 0.90 | 0.10 | 0.50 | 0.90 | |
| CC (seconds) | 8.612 | 14.640 | 13.926 | 3.977 | 10.594 | 6.287 |
| IPW (seconds) | 32.102 | 30.569 | 31.730 | 11.859 | 28.559 | 21.939 |
| IPWM (seconds) | 18.020 | 23.176 | 19.804 | 7.530 | 15.204 | 12.718 |
| NIPW (seconds) | 96.025 | 88.768 | 83.741 | 33.693 | 45.456 | 87.876 |
| NIPWM (seconds) | 29.316 | 24.669 | 17.760 | 10.639 | 12.214 | 27.657 |
| IPWM/IPW (%) | 56.134 | 75.817 | 62.413 | 63.500 | 53.237 | 57.970 |
| NIPWM/NIPW (%) | 30.529 | 27.791 | 21.209 | 31.577 | 26.871 | 31.473 |
| Dimensions | Observed Variables |
|---|---|
| science and technology investment | : number of employees in scientific research, |
| technical services and | |
| geological exploration industry | |
| : financial expenditure on science and education | |
| environment condition | : industrial sulfur dioxide emissions/GDP |
| : industrial waste water generation/GDP | |
| digital infrastructure | : total telecommunications business volume |
| : number of Internet broadband access ports |
| MAE0.1 | CC | 0.428 | 0.324 | 1.993 | 2.116 | 1.057 | 0.455 | 0.256 | 0.120 |
| IPW | 0.424 | 0.310 | 0.831 | 0.795 | 0.966 | 0.449 | 0.061 | 0.100 | |
| IPWM | 0.421 | 0.317 | 0.833 | 0.814 | 1.006 | 0.435 | 0.098 | 0.138 | |
| NIPW | 0.440 | 0.307 | 0.893 | 0.802 | 1.006 | 0.451 | 0.069 | 0.095 | |
| NIPWM | 0.417 | 0.311 | 0.895 | 0.827 | 1.017 | 0.427 | 0.100 | 0.114 | |
| MAE0.5 | CC | 0.120 | 0.096 | 0.489 | 0.809 | 0.565 | 0.281 | 0.043 | 0.038 |
| IPW | 0.120 | 0.104 | 0.273 | 0.281 | 0.514 | 0.291 | 0.025 | 0.032 | |
| IPWM | 0.109 | 0.094 | 0.271 | 0.282 | 0.558 | 0.271 | 0.028 | 0.033 | |
| NIPW | 0.115 | 0.112 | 0.272 | 0.274 | 0.561 | 0.274 | 0.032 | 0.033 | |
| NIPWM | 0.108 | 0.092 | 0.268 | 0.273 | 0.557 | 0.266 | 0.031 | 0.034 | |
| MAE0.9 | CC | 0.591 | 0.562 | 5.946 | 7.745 | 1.148 | 0.431 | 0.106 | 1.904 |
| IPW | 0.621 | 0.439 | 1.022 | 1.067 | 0.709 | 0.440 | 0.142 | 0.165 | |
| IPWM | 0.607 | 0.418 | 1.027 | 1.051 | 0.674 | 0.485 | 0.177 | 0.185 | |
| NIPW | 0.661 | 0.356 | 0.839 | 0.802 | 0.630 | 0.491 | 0.161 | 0.143 | |
| NIPWM | 0.737 | 0.362 | 0.871 | 0.818 | 0.536 | 0.496 | 0.218 | 0.169 | |
| MSE0.1 | CC | 0.286 | 0.199 | 5.216 | 4.902 | 2.186 | 0.356 | 0.102 | 0.071 |
| IPW | 0.271 | 0.190 | 1.413 | 1.222 | 1.973 | 0.348 | 0.043 | 0.072 | |
| IPWM | 0.274 | 0.210 | 1.411 | 1.261 | 2.114 | 0.337 | 0.079 | 0.177 | |
| NIPW | 0.289 | 0.179 | 1.554 | 1.193 | 2.073 | 0.346 | 0.046 | 0.073 | |
| NIPWM | 0.270 | 0.203 | 1.584 | 1.267 | 2.096 | 0.313 | 0.073 | 0.127 | |
| MSE0.5 | CC | 0.025 | 0.022 | 0.416 | 0.784 | 0.814 | 0.126 | 0.012 | 0.005 |
| IPW | 0.026 | 0.023 | 0.147 | 0.146 | 0.669 | 0.134 | 0.003 | 0.002 | |
| IPWM | 0.023 | 0.022 | 0.152 | 0.150 | 0.817 | 0.118 | 0.004 | 0.002 | |
| NIPW | 0.025 | 0.025 | 0.150 | 0.139 | 0.772 | 0.121 | 0.004 | 0.002 | |
| NIPWM | 0.023 | 0.021 | 0.148 | 0.143 | 0.801 | 0.113 | 0.005 | 0.002 | |
| MSE0.9 | CC | 0.608 | 0.445 | 36.722 | 60.798 | 1.677 | 0.275 | 0.130 | 3.677 |
| IPW | 0.550 | 0.229 | 1.674 | 1.752 | 1.289 | 0.283 | 0.216 | 0.074 | |
| IPWM | 0.532 | 0.208 | 1.685 | 1.702 | 0.992 | 0.316 | 0.301 | 0.183 | |
| NIPW | 0.697 | 0.258 | 1.203 | 1.097 | 1.149 | 0.437 | 0.165 | 0.067 | |
| NIPWM | 0.838 | 0.265 | 1.271 | 1.124 | 0.786 | 0.436 | 0.266 | 0.126 |
| 0.10 | 0.50 | 0.90 | |
|---|---|---|---|
| CC | 0.061 | 0.064 | 0.062 |
| IPW | 0.208 | 0.197 | 0.196 |
| IPWM | 0.099 | 0.094 | 0.093 |
| NIPW | 2.114 | 1.817 | 2.000 |
| NIPWM | 0.590 | 0.788 | 0.502 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheng, H. Inverse Probability-Weighted Estimation for Dynamic Structural Equation Model with Missing Data. Mathematics 2024, 12, 3010. https://doi.org/10.3390/math12193010
Cheng H. Inverse Probability-Weighted Estimation for Dynamic Structural Equation Model with Missing Data. Mathematics. 2024; 12(19):3010. https://doi.org/10.3390/math12193010
Chicago/Turabian StyleCheng, Hao. 2024. "Inverse Probability-Weighted Estimation for Dynamic Structural Equation Model with Missing Data" Mathematics 12, no. 19: 3010. https://doi.org/10.3390/math12193010
APA StyleCheng, H. (2024). Inverse Probability-Weighted Estimation for Dynamic Structural Equation Model with Missing Data. Mathematics, 12(19), 3010. https://doi.org/10.3390/math12193010