
A Multimodal Graph Recommendation Method Based on Cross-Attention Fusion


Abstract
1. Introduction
- We introduce a multimodal information purification and denoising approach based on item and user interaction ID features, aimed at exploring more effective ways to enhance multimodal information.
- We utilize a multimodal feature fusion module based on a cross-attention mechanism, allowing for more comprehensive and efficient processing and fusion of multimodal information.
- Our model’s performance was compared against baseline methods in the field of multimodal recommendation on three public benchmark datasets, demonstrating superior performance over existing baseline models.
2. Related Work
2.1. Multimodal Graph Recommendation
2.2. Multimodal Information Denoising
2.3. Cross-Attention-Based Fusion Methods
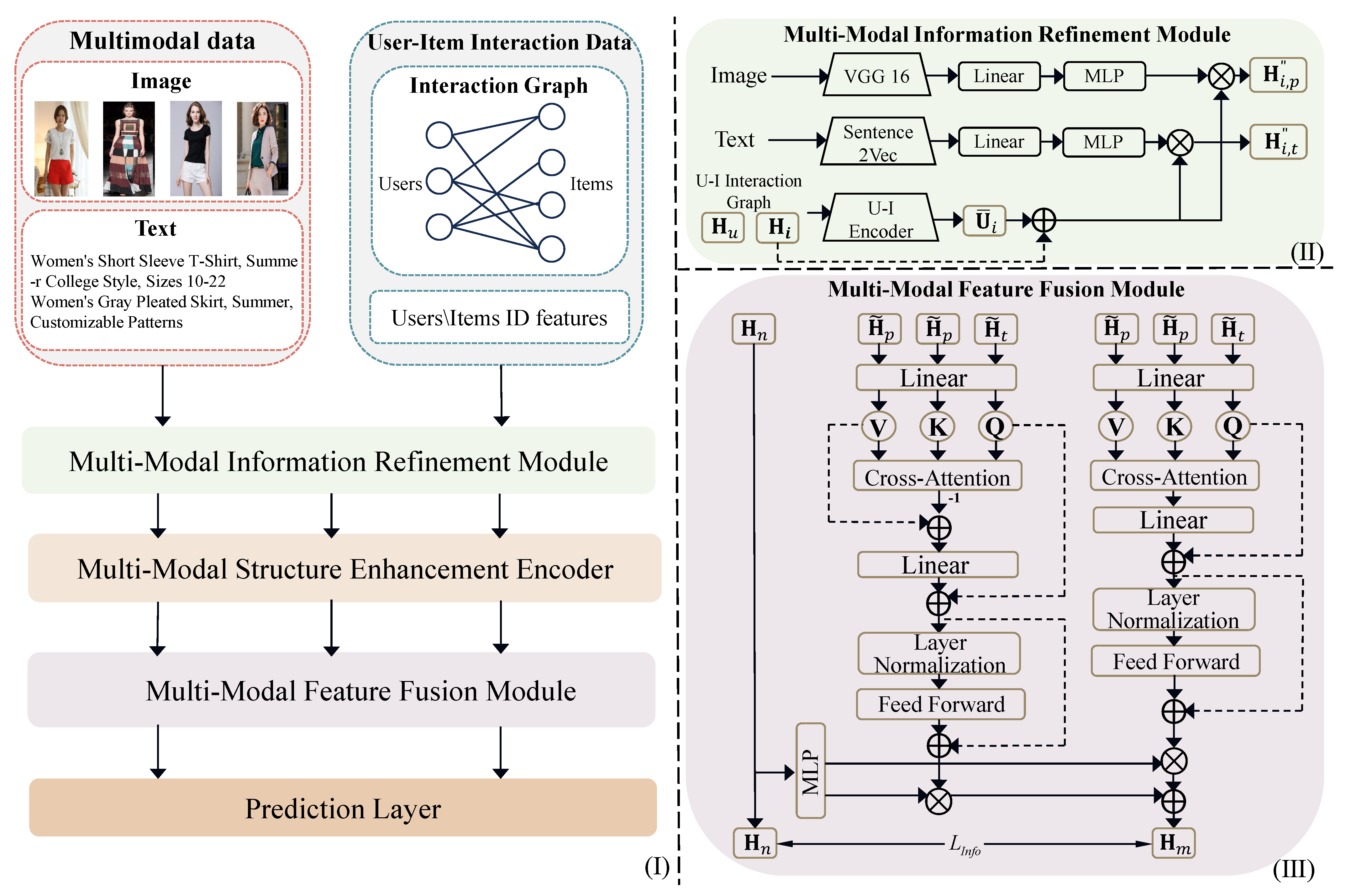
3. Formulation of CAmgr
3.1. Problem Definition
3.2. Multimodal Information Refinement Method Enhanced by Item and Interaction User ID Features
3.3. Multimodal Structure Enhanced Encoder
3.4. The Multimodal Feature Fusion Module Based on Cross-Attention Mechanism
3.5. Prediction Layer
3.6. Loss Function
4. Experiment
4.1. Research Question
4.2. Datasets
- Baby: This dataset contains e-commerce interaction data for baby products, including multimodal data such as images and reviews.
- Sports: This dataset includes interaction data for sports products, with data spanning recent years.
- Clothing: This dataset comprises a bipartite interaction graph for various clothing items, along with reviews and interaction records from recent years.
4.3. Model Summary
- MF [36]: A widely used collaborative filtering model in recommendation systems, employing matrix factorization to learn user and item representations.
- LightGCN [37]: Combines GCN with collaborative filtering, simplifying the GCN model to better suit recommendation tasks.
- VBPR [8]: Introduces visual modality information by extracting image features via CNN and integrating them with item ID embeddings for recommendations.
- MMGCN [38]: Effectively utilizes multimodal information to assist in solving ERC tasks by constructing dependencies within and across modalities.
- GRCN [39]: Investigates the impact of implicit feedback in GCN-based recommendation models and improves the user–item interaction graph structure using GAT.
- SLMRec [40]: Incorporates self-supervised learning in multimedia recommendation to capture the inherent multimodal patterns in data.
- BM3 [41]: Eliminates negative sampling in self-supervised learning to avoid introducing noisy supervision during training.
- MICRO [42]: Designs a contrastive method to fuse multimodal features, using the obtained multimodal item representations directly in collaborative filtering, for more accurate recommendations.
- MGCN [35]: Proposes using item behavior information to purify modality information and models user preferences comprehensively through a behavior-aware fusion mechanism.
4.4. Experimental Setup and Evaluation Metrics
5. Results and Discussion
5.1. Overall Performance
5.2. Ablation Studies
5.3. Hyperparameter Study
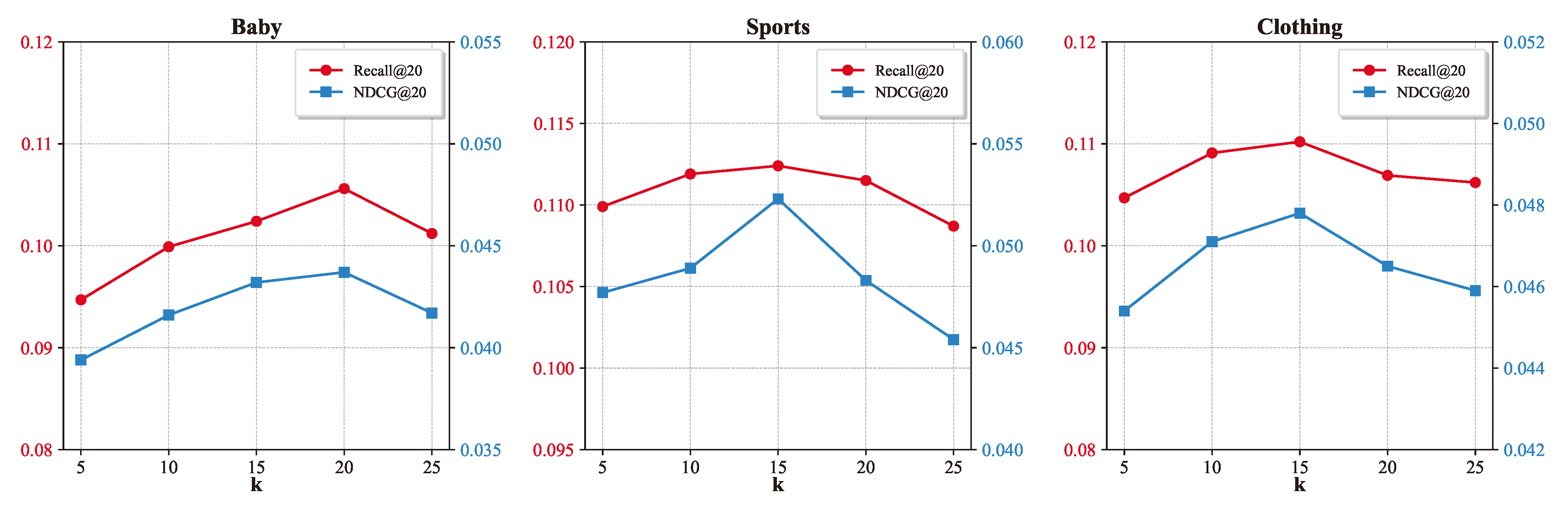
5.3.1. Impact of the Number of Multimodal Semantic Neighbors k
5.3.2. Impact of the Weight of Self-Supervised Learning Loss
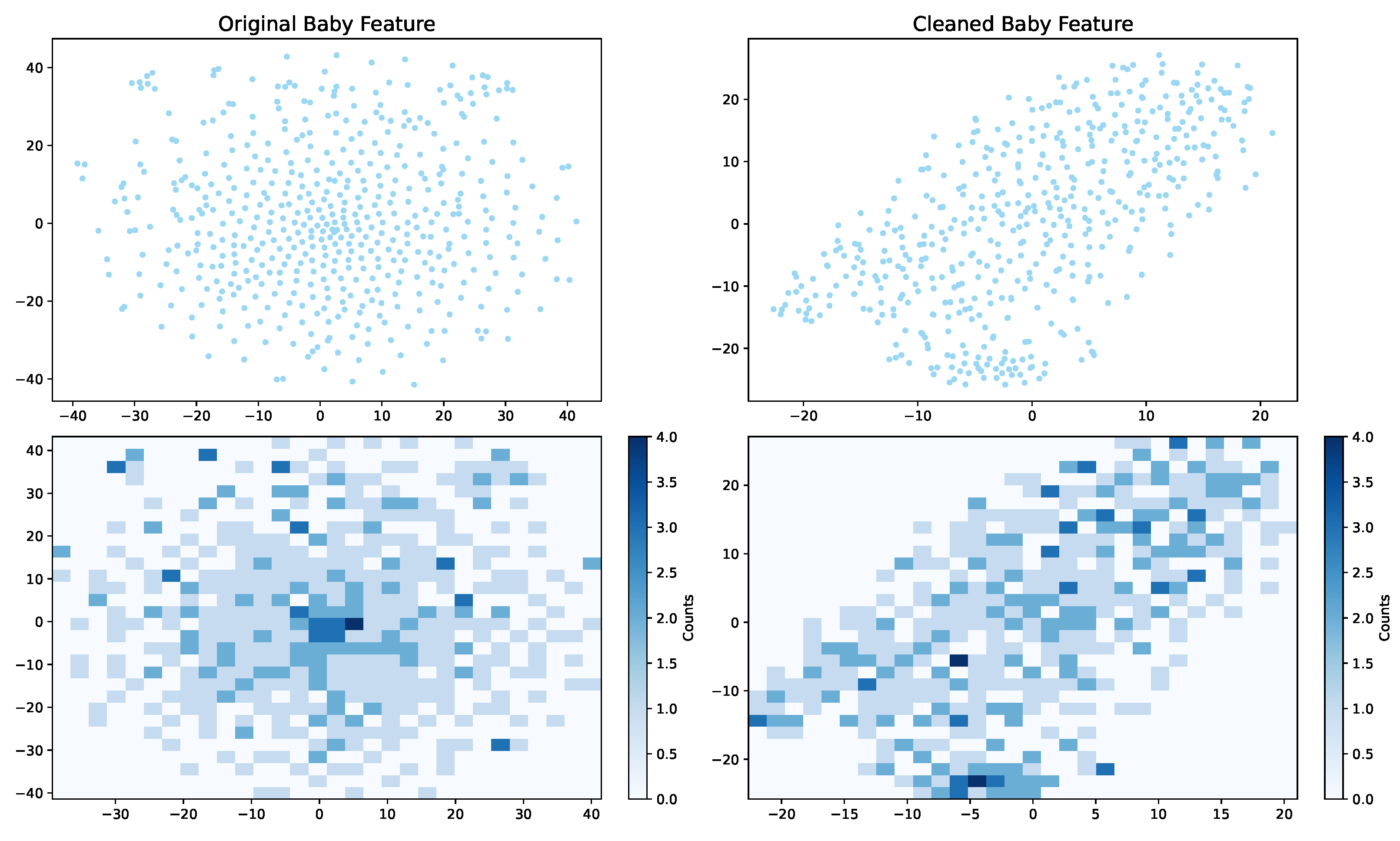
5.4. Visual Analysis
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Cinar, Y.G.; Renders, J. Adaptive Pointwise-Pairwise Learning-to-Rank for Content-based Personalized Recommendation. In Proceedings of the RecSys, Rio de Janeiro, Brazil, 25 September 2020; pp. 414–419. [Google Scholar]
- Lei, F.; Cao, Z.; Yang, Y.; Ding, Y.; Zhang, C. Learning the User’s Deeper Preferences for Multi-modal Recommendation Systems. ACM Trans. Multim. Comput. Commun. Appl. 2023, 19, 138:1–138:18. [Google Scholar] [CrossRef]
- Serra, F.D.; Jacenków, G.; Deligianni, F.; Dalton, J.; O’Neil, A.Q. Improving Image Representations via MoCo Pre-training for Multimodal CXR Classification. In Lecture Notes in Computer Science, Proceedings of the Medical Image Understanding and Analysis, Cambridge, UK, 27–29 July 2022; Springer: Berlin/Heidelberg, Germany, 2022; Volume 13413, pp. 623–635. [Google Scholar]
- Yi, J.; Chen, Z. Multi-Modal Variational Graph Auto-Encoder for Recommendation Systems. IEEE Trans. Multim. 2022, 24, 1067–1079. [Google Scholar] [CrossRef]
- Chen, X.; Chen, H.; Xu, H.; Zhang, Y.; Cao, Y.; Qin, Z.; Zha, H. Personalized Fashion Recommendation with Visual Explanations based on Multimodal Attention Network: Towards Visually Explainable Recommendation. In Proceedings of the SIGIR, Paris, France, 21–25 July 2019; pp. 765–774. [Google Scholar]
- Zhang, F.; Yuan, N.J.; Lian, D.; Xie, X.; Ma, W. Collaborative Knowledge Base Embedding for Recommender Systems. In Proceedings of the SIGKDD, San Francisco, CA, USA, 13–17 August 2016; pp. 353–362. [Google Scholar]
- Hu, H.; Guo, W.; Liu, Y.; Kan, M. Adaptive Multi-Modalities Fusion in Sequential Recommendation Systems. In Proceedings of the CIKM, Birmingham, UK, 21–25 October 2023; pp. 843–853. [Google Scholar]
- He, R.; McAuley, J.J. VBPR: Visual Bayesian Personalized Ranking from Implicit Feedback. In Proceedings of the AAAI, Phoenix, AZ, USA, 12–17 February 2016; pp. 144–150. [Google Scholar]
- Tang, J.; Du, X.; He, X.; Yuan, F.; Tian, Q.; Chua, T. Adversarial Training Towards Robust Multimedia Recommender System. IEEE Trans. Knowl. Data Eng. 2020, 32, 855–867. [Google Scholar] [CrossRef]
- Liu, Y.; Yang, S.; Lei, C.; Wang, G.; Tang, H.; Zhang, J.; Sun, A.; Miao, C. Pre-training Graph Transformer with Multimodal Side Information for Recommendation. In Proceedings of the MM, Virtual, 20–24 October 2021; pp. 2853–2861. [Google Scholar]
- Sun, R.; Cao, X.; Zhao, Y.; Wan, J.; Zhou, K.; Zhang, F.; Wang, Z.; Zheng, K. Multi-modal Knowledge Graphs for Recommender Systems. In Proceedings of the CIKM, Virtual, 19–23 October 2020; pp. 1405–1414. [Google Scholar]
- Rajalingam, B.; Al-Turjman, F.M.; Santhoshkumar, R.; Rajesh, M. Intelligent multimodal medical image fusion with deep guided filtering. Multim. Syst. 2022, 28, 1449–1463. [Google Scholar] [CrossRef]
- Xue, Z.; Marculescu, R. Dynamic Multimodal Fusion. In Proceedings of the CVPR, Vancouver, BC, Canada, 18–22 June 2023; pp. 2575–2584. [Google Scholar]
- Wang, W.; Shui, P.; Feng, X. Variational Models for Fusion and Denoising of Multifocus Images. IEEE Signal Process. Lett. 2008, 15, 65–68. [Google Scholar] [CrossRef]
- Quan, Y.; Tong, Y.; Feng, W.; Dauphin, G.; Huang, W.; Zhu, W.; Xing, M. Relative Total Variation Structure Analysis-Based Fusion Method for Hyperspectral and LiDAR Data Classification. Remote. Sens. 2021, 13, 1143. [Google Scholar] [CrossRef]
- Radenovic, F.; Dubey, A.; Kadian, A.; Mihaylov, T.; Vandenhende, S.; Patel, Y.; Wen, Y.; Ramanathan, V.; Mahajan, D. Filtering, Distillation, and Hard Negatives for Vision-Language Pre-Training. In Proceedings of the CVPR, Vancouver, BC, Canada, 17–24 June 2023; pp. 6967–6977. [Google Scholar]
- Li, J.; Li, D.; Xiong, C.; Hoi, S.C.H. BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language understanding and Generation. In International Conference on Machine Learning, Proceedings of the ICML, Baltimore, MD, USA, 17–23 July 2022; Microtome Publishing: Brookline, MA, USA, 2022; Volume 162, pp. 12888–12900. [Google Scholar]
- Huang, R.; Long, Y.; Han, J.; Xu, H.; Liang, X.; Xu, C.; Liang, X. NLIP: Noise-Robust Language-Image Pre-training. In Proceedings of the AAAI, Vancouver, BC, Canada, 20–27 February 2023; pp. 926–934. [Google Scholar]
- Ma, J.; Zhao, J.; Jiang, J.; Zhou, H.; Guo, X. Locality Preserving Matching. Int. J. Comput. Vis. 2019, 127, 512–531. [Google Scholar] [CrossRef]
- Zhu, H.; Ke, W.; Li, D.; Liu, J.; Tian, L.; Shan, Y. Dual Cross-Attention Learning for Fine-Grained Visual Categorization and Object Re-Identification. In Proceedings of the CVPR, New Orleans, LA, USA, 18–24 June 2022; pp. 4682–4692. [Google Scholar]
- Praveen, R.G.; de Melo, W.C.; Ullah, N.; Aslam, H.; Zeeshan, O.; Denorme, T.; Pedersoli, M.; Koerich, A.L.; Bacon, S.; Cardinal, P.; et al. A Joint Cross-Attention Model for Audio-Visual Fusion in Dimensional Emotion Recognition. In Proceedings of the CVPR, New Orleans, LA, USA, 18–24 June 2022; pp. 2485–2494. [Google Scholar]
- Kim, B.; Jung, H.; Sohn, K. Multi-Exposure Image Fusion Using Cross-Attention Mechanism. In Proceedings of the IEEE, Padua, Italy, 18–23 July 2022; pp. 1–6. [Google Scholar]
- Tang, L.; Deng, Y.; Ma, Y.; Huang, J.; Ma, J. SuperFusion: A Versatile Image Registration and Fusion Network with Semantic Awareness. IEEE CAA J. Autom. Sinica 2022, 9, 2121–2137. [Google Scholar] [CrossRef]
- Xie, H.; Zhang, Y.; Qiu, J.; Zhai, X.; Liu, X.; Yang, Y.; Zhao, S.; Luo, Y.; Zhong, J. Semantics lead all: Towards unified image registration and fusion from a semantic perspective. Inf. Fusion 2023, 98, 101835. [Google Scholar] [CrossRef]
- Ma, J.; Tang, L.; Fan, F.; Huang, J.; Mei, X.; Ma, Y. SwinFusion: Cross-domain Long-range Learning for General Image Fusion via Swin Transformer. IEEE CAA J. Autom. Sinica 2022, 9, 1200–1217. [Google Scholar] [CrossRef]
- Jha, A.; Bose, S.; Banerjee, B. GAF-Net: Improving the Performance of Remote Sensing Image Fusion using Novel Global Self and Cross Attention Learning. In Proceedings of the WACV, Waikoloa, HI, USA, 2–7 January 2023; pp. 6343–6352. [Google Scholar]
- Wei, W.; Ren, X.; Tang, J.; Wang, Q.; Su, L.; Cheng, S.; Wang, J.; Yin, D.; Huang, C. LLMRec: Large Language Models with Graph Augmentation for Recommendation. In Proceedings of the WSDM, Merida, Mexico, 4–8 March 2024; pp. 806–815. [Google Scholar]
- Wu, S.; Sun, F.; Zhang, W.; Xie, X.; Cui, B. Graph Neural Networks in Recommender Systems: A Survey. ACM Comput. Surv. 2023, 55, 97:1–97:37. [Google Scholar] [CrossRef]
- Deldjoo, Y.; He, Z.; McAuley, J.J.; Korikov, A.; Sanner, S.; Ramisa, A.; Vidal, R.; Sathiamoorthy, M.; Kasirzadeh, A.; Milano, S. A Review of Modern Recommender Systems Using Generative Models (Gen-RecSys). arXiv 2024, arXiv:2404.00579v1. [Google Scholar]
- Zong, Y.; Aodha, O.M.; Hospedales, T.M. Self-Supervised Multimodal Learning: A Survey. arXiv 2023, arXiv:2304.01008. [Google Scholar]
- Korbar, B.; Tran, D.; Torresani, L. Cooperative Learning of Audio and Video Models from Self-Supervised Synchronization. In Proceedings of the NeurIPS, Montréal, QC, Canada, 3–8 December 2018; pp. 7774–7785. [Google Scholar]
- Alayrac, J.; Recasens, A.; Schneider, R.; Arandjelovic, R.; Ramapuram, J.; Fauw, J.D.; Smaira, L.; Dieleman, S.; Zisserman, A. Self-Supervised MultiModal Versatile Networks. In Proceedings of the NeurIPS, Virtual, 6–12 December 2020. [Google Scholar]
- Akbari, H.; Yuan, L.; Qian, R.; Chuang, W.; Chang, S.; Cui, Y.; Gong, B. VATT: Transformers for Multimodal Self-Supervised Learning from Raw Video, Audio and Text. In Proceedings of the NeurIPS, Virtual, 6–14 December 2021; pp. 24206–24221. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R.B. Momentum Contrast for Unsupervised Visual Representation Learning. In Proceedings of the Computer Vision Foundation, (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 9726–9735. [Google Scholar]
- Yu, P.; Tan, Z.; Lu, G.; Bao, B. Multi-View Graph Convolutional Network for Multimedia Recommendation. In Proceedings of the MM, Ottawa, ON, Canada, 29 October–3 November 2023; pp. 6576–6585. [Google Scholar]
- Koren, Y.; Bell, R.M.; Volinsky, C. Matrix Factorization Techniques for Recommender Systems. Computer 2009, 42, 30–37. [Google Scholar] [CrossRef]
- He, X.; Deng, K.; Wang, X.; Li, Y.; Zhang, Y.; Wang, M. LightGCN: Simplifying and Powering Graph Convolution Network for Recommendation. In Proceedings of the SIGIR, Virtual, 25–30 July 2020; pp. 639–648. [Google Scholar]
- Wei, Y.; Wang, X.; Nie, L.; He, X.; Hong, R.; Chua, T. MMGCN: Multi-modal Graph Convolution Network for Personalized Recommendation of Micro-video. In Proceedings of the MM, Nice, France, 21–25 October 2019; pp. 1437–1445. [Google Scholar]
- Wei, Y.; Wang, X.; Nie, L.; He, X.; Chua, T. Graph-Refined Convolutional Network for Multimedia Recommendation with Implicit Feedback. In Proceedings of the MM, Seattle, DC, USA, 12–16 October 2020; pp. 3541–3549. [Google Scholar]
- Tao, Z.; Liu, X.; Xia, Y.; Wang, X.; Yang, L.; Huang, X.; Chua, T. Self-Supervised Learning for Multimedia Recommendation. IEEE Trans. Multim. 2023, 25, 5107–5116. [Google Scholar] [CrossRef]
- Zhou, X.; Zhou, H.; Liu, Y.; Zeng, Z.; Miao, C.; Wang, P.; You, Y.; Jiang, F. Bootstrap Latent Representations for Multi-modal Recommendation. In Proceedings of the WWW, Melbourne, Australia, 14–20 May 2023; pp. 845–854. [Google Scholar]
- Zhang, J.; Zhu, Y.; Liu, Q.; Zhang, M.; Wu, S.; Wang, L. Latent Structure Mining with Contrastive Modality Fusion for Multimedia Recommendation. IEEE Trans. Knowl. Data Eng. 2023, 35, 9154–9167. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Users | Items | Ratings | Density | Rating Scale |
|---|---|---|---|---|---|
| Baby | 19,445 | 7050 | 160,792 | 0.117% | [1–5] |
| Sports | 35,598 | 18,357 | 296,337 | 0.045% | [1–5] |
| Clothing | 39,387 | 23,033 | 278,677 | 0.031% | [1–5] |
| Datasets | Metrics | MF | LightGCN | VBPR | MMGCN | GRCN | SLMRec | BM3 | MICRO | MGCN | CAmgr |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Baby | Recall@10 | 0.0357 | 0.0479 | 0.0423 | 0.0378 | 0.0532 | 0.0540 | 0.0564 | 0.0584 | 0.0620 | 0.0640 |
| Recall@20 | 0.0575 | 0.0754 | 0.0663 | 0.0615 | 0.0824 | 0.0810 | 0.0883 | 0.0929 | 0.0964 | 0.1056 | |
| NDCG@10 | 0.0192 | 0.0257 | 0.0223 | 0.0200 | 0.0282 | 0.0285 | 0.0301 | 0.0318 | 0.0339 | 0.0382 | |
| NDCG@20 | 0.0249 | 0.0328 | 0.0284 | 0.0261 | 0.0358 | 0.0357 | 0.0383 | 0.0407 | 0.0427 | 0.0437 | |
| Sports | Recall@10 | 0.0432 | 0.0569 | 0.0558 | 0.0370 | 0.0559 | 0.0676 | 0.0656 | 0.0679 | 0.0729 | 0.0751 |
| Recall@20 | 0.0653 | 0.0864 | 0.0856 | 0.0605 | 0.0877 | 0.1017 | 0.0980 | 0.1050 | 0.1106 | 0.1124 | |
| NDCG@10 | 0.0241 | 0.0311 | 0.0307 | 0.0193 | 0.0306 | 0.0374 | 0.0355 | 0.0367 | 0.0397 | 0.0429 | |
| NDCG@20 | 0.0298 | 0.0387 | 0.0384 | 0.0254 | 0.0389 | 0.0462 | 0.0438 | 0.0463 | 0.0496 | 0.0523 | |
| Clothing | Recall@10 | 0.0187 | 0.0340 | 0.0280 | 0.0197 | 0.0424 | 0.0452 | 0.0421 | 0.0521 | 0.0641 | 0.0695 |
| Recall@20 | 0.0279 | 0.0526 | 0.0414 | 0.0328 | 0.0650 | 0.0675 | 0.0625 | 0.0772 | 0.0945 | 0.1102 | |
| NDCG@10 | 0.0103 | 0.0188 | 0.0159 | 0.0101 | 0.0225 | 0.0247 | 0.0228 | 0.0283 | 0.0347 | 0.0386 | |
| NDCG@20 | 0.0126 | 0.0236 | 0.0193 | 0.0135 | 0.0283 | 0.0303 | 0.0280 | 0.0347 | 0.0428 | 0.0478 |
| Datasets | Modules | Recall@20 | NDCG@20 |
|---|---|---|---|
| Baby | CAmgr | 0.1056 | 0.0437 |
| w/o IUD | 0.0563 | 0.0188 | |
| w/o CAFF | 0.0847 | 0.0386 | |
| Sports | CAmgr | 0.1124 | 0.0523 |
| w/o IUD | 0.0612 | 0.0259 | |
| w/o CAFF | 0.0905 | 0.0341 | |
| Clothing | CAmgr | 0.1102 | 0.0478 |
| w/o IUD | 0.0584 | 0.0216 | |
| w/o CAFF | 0.0862 | 0.0254 |
| Datasets | = 0.001 | = 0.005 | = 0.01 | = 0.05 | = 0.1 | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Recall@20 | NDCG@20 | Recall@20 | NDCG@20 | Recall@20 | NDCG@20 | Recall@20 | NDCG@20 | Recall@20 | NDCG@20 | |
| Baby | 0.0592 | 0.0395 | 0.1035 | 0.0428 | 0.1056 | 0.0437 | 0.1010 | 0.0421 | 0.0479 | 0.0194 |
| Sports | 0.1006 | 0.0493 | 0.1087 | 0.0501 | 0.1124 | 0.0523 | 0.1093 | 0.0507 | 0.0373 | 0.0188 |
| Clothing | 0.1039 | 0.0447 | 0.1075 | 0.0461 | 0.1102 | 0.0478 | 0.0580 | 0.0269 | 0.0584 | 0.0263 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, K.; Xu, L.; Zhu, C.; Zhang, K. A Multimodal Graph Recommendation Method Based on Cross-Attention Fusion. Mathematics 2024, 12, 2353. https://doi.org/10.3390/math12152353
Li K, Xu L, Zhu C, Zhang K. A Multimodal Graph Recommendation Method Based on Cross-Attention Fusion. Mathematics. 2024; 12(15):2353. https://doi.org/10.3390/math12152353
Chicago/Turabian StyleLi, Kai, Long Xu, Cheng Zhu, and Kunlun Zhang. 2024. "A Multimodal Graph Recommendation Method Based on Cross-Attention Fusion" Mathematics 12, no. 15: 2353. https://doi.org/10.3390/math12152353
APA StyleLi, K., Xu, L., Zhu, C., & Zhang, K. (2024). A Multimodal Graph Recommendation Method Based on Cross-Attention Fusion. Mathematics, 12(15), 2353. https://doi.org/10.3390/math12152353