
Detect-Then-Resolve: Enhancing Knowledge Graph Conflict Resolution with Large Language Model


Abstract
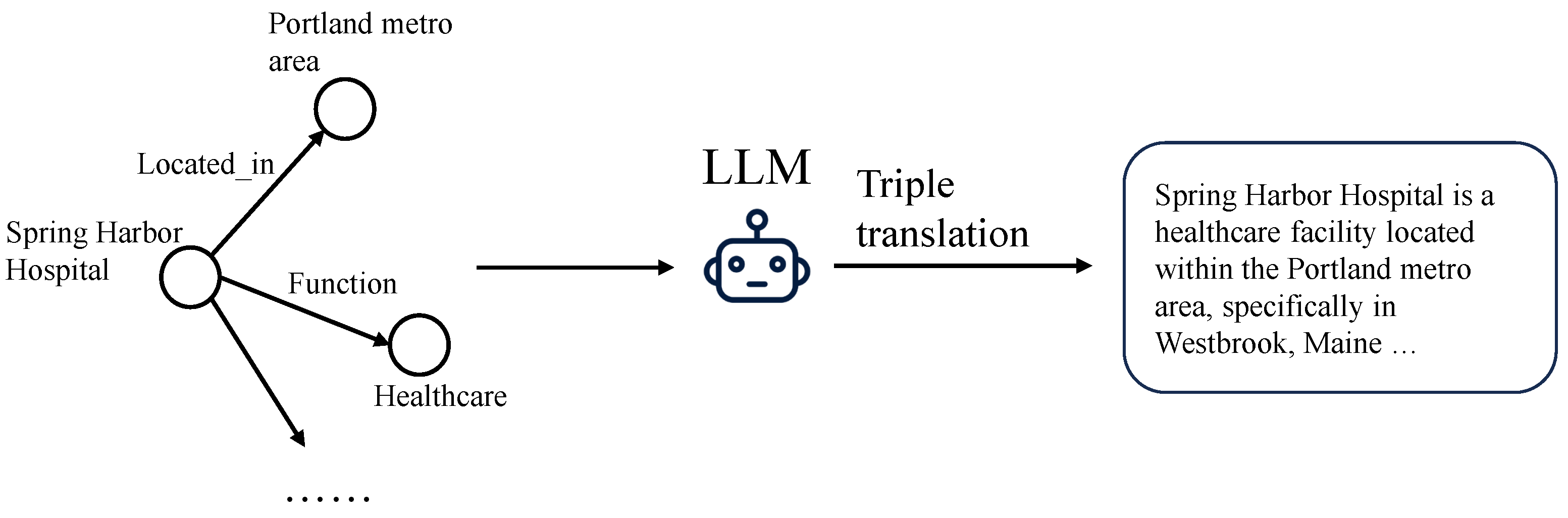
1. Introduction
- We propose CRDL, a conflict resolution framework that incorporates conflict detection and an LLM-based filter. This framework significantly improves the precision and recall in identifying the truths among external triples.
- We leverage the extensive knowledge embedded in LLMs to identify external triples. Specifically, we construct prompts using well-designed templates that contain insightful instructions to fully exploit the capabilities of LLMs.
- We employ conflict detection based on relation types to handle triples more precisely. By applying different strategies to 1-to-1 and non-1-to-1 relations, we achieve more accurate recognition.
2. Related Works
2.1. Conflict Resolution
2.2. Open Knowledge Graph Completion
2.3. Large Language Model
3. Methodology
3.1. Problem Formulation
- Notations: In this paper, we consider triples consist of relations and attributes. Formally, a knowledge graph is formulated as , where E, R, A, and V denote the set of entities, relations, attributes, and values, respectively. is set of relation triples, and is set of attribute triples. A fact is a triple from the knowledge graph, which is denoted as . Then the claims, namely triples extracted from open sources, are in the same form with facts but may contain unseen entities. Without losing generality, we consider the situation that the tails of claims are unseen. The set of claims is denoted as , where the head entity and the relation (or attribute) are contained by the KG, but the tail entity (or value) may not. The correct claims are called truths.
- Objective: Given a knowledge graph and set of claims C extracted from various sources, the target of conflict resolution is to identify truths .
3.2. Framework Overview
- (1)
- Represent all triples using KGE techniques.
- (2)
- Categorize all relations and attributes to facilitate subsequent conflict detection.
- (3)
- Detecting conflicts among claims based on their relations and attributes.
- (4)
- For claims involving 1-to-1 relations or attributes, select the claim with the lowest perplexity as the truth.
- (5)
- For claims involving non-1-to-1 relations or attributes, apply an initial filter and then use LLMs to determine the truth among the remaining claims.
3.3. KG Embedding
3.4. Conflict Detection
3.5. Conflict Resolution with LLMs
3.5.1. Task Declaration
3.5.2. Demonstrations
3.5.3. Input Claims
3.6. Overall Algorithm
| Algorithm 1: Algorithmic description of CRDL |
 |
4. Experiments
4.1. Experiment Settings
4.1.1. Dataset
4.1.2. Evaluation Metrics
4.1.3. Comparative Models
- TruthFinder [18], which estimates source reliability and finds truth based on Bayesian analysis for data fusion.
- Latent credibility analysis (LCA) [17], which constructs a strongly principled probabilistic model to capture the credibility of sources.
- Latent truth model (LTM) [47], which proposes a probabilistic graphical model that can automatically infer true records and source quality without supervision.
- Multi-truth Bayesian model (MBM) [48], which proposes an integrated Bayesian approach to multi-truth-finding problem.
- OKELE [15], which constructs a probabilistic graphical model to infer true facts of long-tail entities from open sources.
- Open world extension (OWE) [13], which presents an extension for embedding-based knowledge graph completion models, with the ability to perform open world link prediction.
- ConMask [33], which learns embeddings of the entity’s name and parts of its text description to connect unseen entities to the KG.
- KnowledgeVault [32], which employs supervised machine learning methods for fusing distinct information sources with prior knowledge derived from existing knowledge repositories.
- TKGC [14], which presents a trustworthy method that exploits facts of existing KG and infers truths from open sources.
4.1.4. Implement Details
4.2. Overall Performance
4.3. Ablation Study
4.3.1. LLM-Based Filter
4.3.2. Conflict Detection
4.4. K-Shot Demonstrations
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhang, Z.J. Graph Databases for Knowledge Management. IT Prof. 2017, 19, 26–32. [Google Scholar] [CrossRef]
- Zeng, W.; Zhao, X.; Tang, J.; Lin, X.; Groth, P. Reinforcement Learning-based Collective Entity Alignment with Adaptive Features. ACM Trans. Inf. Syst. 2021, 39, 1–31. [Google Scholar] [CrossRef]
- Ehrlinger, L.; Wöß, W. Towards a Definition of Knowledge Graphs. SEMANTiCS 2016, 48, 1–4. [Google Scholar]
- Chen, X.; Jia, S.; Xiang, Y. A review: Knowledge reasoning over knowledge graph. Expert Syst. Appl. 2020, 141, 112948. [Google Scholar] [CrossRef]
- Pujara, J.; Miao, H.; Getoor, L.; Cohen, W.W. Knowledge Graph Identification. In Semantic Web-ISWC 2013, Proceedings of the 12th International Semantic Web Conference, Sydney, Australia, 21–25 October 2013; Alani, H., Kagal, L., Fokoue, A., Groth, P., Biemann, C., Parreira, J.X., Aroyo, L., Noy, N.F., Welty, C., Janowicz, K., Eds.; Proceedings, Part I; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2013; Volume 8218, pp. 542–557. [Google Scholar] [CrossRef]
- Zeng, W.; Zhao, X.; Li, X.; Tang, J.; Wang, W. On entity alignment at scale. VLDB J. 2022, 31, 1009–1033. [Google Scholar] [CrossRef]
- Nguyen, H.L.; Vu, D.; Jung, J.J. Knowledge graph fusion for smart systems: A Survey. Inf. Fusion 2020, 61, 56–70. [Google Scholar] [CrossRef]
- Zhao, X.; Zeng, W.; Tang, J. Entity Alignment—Concepts, Recent Advances and Novel Approaches; Springer Nature: Singapore, 2023. [Google Scholar] [CrossRef]
- Zhao, X.; Jia, Y.; Li, A.; Jiang, R.; Song, Y. Multi-source knowledge fusion: A survey. World Wide Web 2020, 23, 2567–2592. [Google Scholar] [CrossRef]
- Hunter, A.; Summerton, R. Fusion Rules for Context-Dependent Aggregation of Structured News Reports. J. Appl.-Non-Class. Logics 2004, 14, 329–366. [Google Scholar] [CrossRef]
- Dong, X.L.; Berti-Équille, L.; Srivastava, D. Integrating Conflicting Data: The Role of Source Dependence. Proc. VLDB Endow. 2009, 2, 550–561. [Google Scholar] [CrossRef]
- Rekatsinas, T.; Joglekar, M.; Garcia-Molina, H.; Parameswaran, A.G.; Ré, C. SLiMFast: Guaranteed Results for Data Fusion and Source Reliability. In SIGMOD Conference 2017, Proceedings of the 2017 ACM International Conference on Management of Data, Chicago, IL, USA, 14–19 May 2017; Salihoglu, S., Zhou, W., Chirkova, R., Yang, J., Suciu, D., Eds.; ACM: New York, NY, USA, 2017; pp. 1399–1414. [Google Scholar] [CrossRef]
- Shah, H.; Villmow, J.; Ulges, A.; Schwanecke, U.; Shafait, F. An Open-World Extension to Knowledge Graph Completion Models. Proc. AAAI Conf. Artif. Intell. 2019, 33, 3044–3051. [Google Scholar] [CrossRef]
- Huang, J.; Zhao, Y.; Hu, W.; Ning, Z.; Chen, Q.; Qiu, X.; Huo, C.; Ren, W. Trustworthy Knowledge Graph Completion Based on Multi-sourced Noisy Data. In WWW’22, Proceedings of the ACM Web Conference 2022, Virtual Event, Lyon, France, 25–29 April 2022; Laforest, F., Troncy, R., Simperl, E., Agarwal, D., Gionis, A., Herman, I., Médini, L., Eds.; ACM: New York, NY, USA, 2022; pp. 956–965. [Google Scholar] [CrossRef]
- Cao, E.; Wang, D.; Huang, J.; Hu, W. Open Knowledge Enrichment for Long-tail Entities. In WWW’20, Proceedings of the Web Conference 2020, Taipei, Taiwan, 20–24 April 2020; Huang, Y., King, I., Liu, T., van Steen, M., Eds.; ACM: New York, NY, USA; IW3C2: Geneva, Switzerland, 2020; pp. 384–394. [Google Scholar] [CrossRef]
- Li, Y.; Gao, J.; Meng, C.; Li, Q.; Su, L.; Zhao, B.; Fan, W.; Han, J. A Survey on Truth Discovery. ACM Sigkdd Explor. Newsl. 2015, 17, 1–16. [Google Scholar] [CrossRef]
- Pasternack, J.; Roth, D. Knowing what to Believe (when you already know something). In COLING 2010, Proceedings of the 23rd International Conference on Computational Linguistics, Beijing, China, 23–27 August 2010; Huang, C., Jurafsky, D., Eds.; Tsinghua University Press: Beijing, China, 2010; pp. 877–885. [Google Scholar]
- Yin, X.; Han, J.; Yu, P.S. Truth Discovery with Multiple Conflicting Information Providers on the Web. IEEE Trans. Knowl. Data Eng. 2008, 20, 796–808. [Google Scholar] [CrossRef]
- Li, Q.; Li, Y.; Gao, J.; Zhao, B.; Fan, W.; Han, J. Resolving conflicts in heterogeneous data by truth discovery and source reliability estimation. In SIGMOD 2014, Proceedings of the International Conference on Management of Data, Snowbird, UT, USA, 22–27 June 2014; Dyreson, C.E., Li, F., Özsu, M.T., Eds.; ACM: New York, NY, USA, 2014; pp. 1187–1198. [Google Scholar] [CrossRef]
- Li, Y.; Li, Q.; Gao, J.; Su, L.; Zhao, B.; Fan, W.; Han, J. On the Discovery of Evolving Truth. In ACM SIGKDD, Proceedings of the 21th International Conference on Knowledge Discovery and Data Mining, Sydney, Australia, 10–13 August 2015; Cao, L., Zhang, C., Joachims, T., Webb, G.I., Margineantu, D.D., Williams, G., Eds.; ACM: New York, NY, USA, 2015; pp. 675–684. [Google Scholar] [CrossRef]
- Pochampally, R.; Sarma, A.D.; Dong, X.L.; Meliou, A.; Srivastava, D. Fusing data with correlations. In SIGMOD 2014, Proceedings of the International Conference on Management of Data, Snowbird, UT, USA, 22–27 June 2014; Dyreson, C.E., Li, F., Özsu, M.T., Eds.; ACM: New York, NY, USA, 2014; pp. 433–444. [Google Scholar] [CrossRef]
- Qi, G.; Aggarwal, C.C.; Han, J.; Huang, T.S. Mining collective intelligence in diverse groups. In WWW’13, Proceedings of the 22nd International World Wide Web Conference, Rio de Janeiro, Brazil, 13–17 May 2013; Schwabe, D., Almeida, V.A.F., Glaser, H., Baeza-Yates, R., Moon, S.B., Eds.; International World Wide Web Conferences Steering Committee: Geneva, Switzerland; ACM: New York, NY, USA, 2013; pp. 1041–1052. [Google Scholar] [CrossRef]
- Sarma, A.D.; Dong, X.L.; Halevy, A.Y. Data integration with dependent sources. In EDBT 2011, Proceedings of the 14th International Conference on Extending Database Technology, Uppsala, Sweden, 21–24 March 2011; Ailamaki, A., Amer-Yahia, S., Patel, J.M., Risch, T., Senellart, P., Stoyanovich, J., Eds.; ACM: New York, NY, USA, 2011; pp. 401–412. [Google Scholar] [CrossRef]
- Abboud, R.; Ceylan, I.; Lukasiewicz, T.; Salvatori, T. Boxe: A box embedding model for knowledge base completion. Adv. Neural Inf. Process. Syst. 2020, 33, 9649–9661. [Google Scholar]
- Bordes, A.; Usunier, N.; García-Durán, A.; Weston, J.; Yakhnenko, O. Translating Embeddings for Modeling Multi-relational Data. In Proceedings of the Advances in Neural Information Processing Systems 26: 27th Annual Conference on Neural Information Processing Systems 2013, Lake Tahoe, NV, USA, 5–8 December 2013; pp. 2787–2795. [Google Scholar]
- Cao, Z.; Xu, Q.; Yang, Z.; Cao, X.; Huang, Q. Dual Quaternion Knowledge Graph Embeddings. Proc. AAAI Conf. Artif. Intell. 2021, 35, 6894–6902. [Google Scholar] [CrossRef]
- Balazevic, I.; Allen, C.; Hospedales, T.M. TuckER: Tensor Factorization for Knowledge Graph Completion. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, EMNLP-IJCNLP 2019, Hong Kong, China, 3–7 November 2019; Inui, K., Jiang, J., Ng, V., Wan, X., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 5184–5193. [Google Scholar] [CrossRef]
- Yang, B.; Yih, W.; He, X.; Gao, J.; Deng, L. Embedding Entities and Relations for Learning and Inference in Knowledge Bases. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015; pp. 1–12. [Google Scholar]
- Nguyen, D.Q.; Vu, T.; Nguyen, T.D.; Nguyen, D.Q.; Phung, D.Q. A Capsule Network-based Embedding Model for Knowledge Graph Completion and Search Personalization. In NAACL-HLT 2019, Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Burstein, J., Doran, C., Solorio, T., Eds.; Volume 1 (Long and Short Papers); Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 2180–2189. [Google Scholar] [CrossRef]
- Wang, S.; Wei, X.; dos Santos, C.N.; Wang, Z.; Nallapati, R.; Arnold, A.O.; Xiang, B.; Yu, P.S.; Cruz, I.F. Mixed-Curvature Multi-Relational Graph Neural Network for Knowledge Graph Completion. In WWW’21, Proceedings of the Web Conference 2021, Virtual Event, Ljubljana, Slovenia, 19–23 April 2021; Leskovec, J., Grobelnik, M., Najork, M., Tang, J., Zia, L., Eds.; ACM: New York, NY, USA; IW3C2: Geneva, Switzerland, 2021; pp. 1761–1771. [Google Scholar] [CrossRef]
- Lin, Q.; Mao, R.; Liu, J.; Xu, F.; Cambria, E. Fusing topology contexts and logical rules in language models for knowledge graph completion. Inf. Fusion 2023, 90, 253–264. [Google Scholar] [CrossRef]
- Dong, X.; Gabrilovich, E.; Heitz, G.; Horn, W.; Lao, N.; Murphy, K.; Strohmann, T.; Sun, S.; Zhang, W. Knowledge vault: A web-scale approach to probabilistic knowledge fusion. In ACM SIGKDD, Proceedings of the 20th International Conference on Knowledge Discovery and Data Mining, KDD’14, New York, NY, USA, 24–27 August 2014; Macskassy, S.A., Perlich, C., Leskovec, J., Wang, W., Ghani, R., Eds.; ACM: New York, NY, USA, 2014; pp. 601–610. [Google Scholar] [CrossRef]
- Shi, B.; Weninger, T. Open-World Knowledge Graph Completion. Proc. AAAI Conf. Artif. Intell. 2018, 32, 1957–1964. [Google Scholar] [CrossRef]
- Niu, L.; Fu, C.; Yang, Q.; Li, Z.; Chen, Z.; Liu, Q.; Zheng, K. Open-world knowledge graph completion with multiple interaction attention. World Wide Web 2021, 24, 419–439. [Google Scholar] [CrossRef]
- OpenAI. GPT-4 Technical Report. arXiv 2023, arXiv:2303.08774. [Google Scholar]
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. LLaMA: Open and Efficient Foundation Language Models. arXiv 2023, arXiv:2302.13971. [Google Scholar]
- Zhao, W.X.; Zhou, K.; Li, J.; Tang, T.; Wang, X.; Hou, Y.; Min, Y.; Zhang, B.; Zhang, J.; Dong, Z.; et al. A Survey of Large Language Models. arXiv 2023, arXiv:2303.18223. [Google Scholar]
- Pan, S.; Luo, L.; Wang, Y.; Chen, C.; Wang, J.; Wu, X. Unifying Large Language Models and Knowledge Graphs: A Roadmap. IEEE Trans. Knowl. Data Eng. 2024, 36, 3580–3599. [Google Scholar] [CrossRef]
- Yao, L.; Mao, C.; Luo, Y. KG-BERT: BERT for Knowledge Graph Completion. arXiv 2019, arXiv:1909.03193. [Google Scholar]
- Zhu, Y.; Wang, X.; Chen, J.; Qiao, S.; Ou, Y.; Yao, Y.; Deng, S.; Chen, H.; Zhang, N. LLMs for Knowledge Graph Construction and Reasoning: Recent Capabilities and Future Opportunities. arXiv 2023, arXiv:2305.13168. [Google Scholar]
- Wei, Y.; Huang, Q.; Zhang, Y.; Kwok, J.T. KICGPT: Large Language Model with Knowledge in Context for Knowledge Graph Completion. In EMNLP 2023, Proceedings of the Findings of the Association for Computational Linguistics, Singapore, 6–10 December 2023; Bouamor, H., Pino, J., Bali, K., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2023; pp. 8667–8683. [Google Scholar] [CrossRef]
- Wu, Y.; Wang, Z. Knowledge Graph Embedding with Numeric Attributes of Entities. In Rep4NLP@ACL 2018, Proceedings of the Third Workshop on Representation Learning for NLP, Melbourne, Australia, 20 July 2018; Augenstein, I., Cao, K., He, H., Hill, F., Gella, S., Kiros, J., Mei, H., Misra, D., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; pp. 132–136. [Google Scholar] [CrossRef]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Zhao, Z.; Wallace, E.; Feng, S.; Klein, D.; Singh, S. Calibrate Before Use: Improving Few-shot Performance of Language Models. In Proceedings of the 38th International Conference on Machine Learning, ICML 2021, Virtual Event, 18–24 July 2021; Volume 139, pp. 12697–12706. [Google Scholar]
- Ye, J.; Wu, Z.; Feng, J.; Yu, T.; Kong, L. Compositional Exemplars for In-context Learning. Proc. Mach. Learn. Res. 2023, 202, 39818–39833. [Google Scholar]
- Bollacker, K.D.; Evans, C.; Paritosh, P.K.; Sturge, T.; Taylor, J. Freebase: A collaboratively created graph database for structuring human knowledge. In ACM SIGMOD, Proceedings of the International Conference on Management of Data, Vancouver, BC, Canada, 10–12 June 2008; Wang, J.T., Ed.; ACM: New York, NY, USA, 2008; pp. 1247–1250. [Google Scholar] [CrossRef]
- Zhao, B.; Rubinstein, B.I.P.; Gemmell, J.; Han, J. A Bayesian Approach to Discovering Truth from Conflicting Sources for Data Integration. Proc. VLDB Endow. 2012, 5, 550–561. [Google Scholar] [CrossRef]
- Wang, X.; Sheng, Q.Z.; Fang, X.S.; Yao, L.; Xu, X.; Li, X. An Integrated Bayesian Approach for Effective Multi-Truth Discovery. In CIKM 2015, Proceedings of the 24th International Conference on Information and Knowledge Management, Melbourne, VIC, Australia, 19–23 October 2015; Bailey, J., Moffat, A., Aggarwal, C.C., de Rijke, M., Kumar, R., Murdock, V., Sellis, T.K., Yu, J.X., Eds.; ACM: New York, NY, USA, 2015; pp. 493–502. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classes | Relation Triples | Attribute Triples |
|---|---|---|
| actor | 64,983 | 330 |
| album | 5897 | 155 |
| book | 10,766 | 499 |
| building | 2823 | 361 |
| drug | 26,432 | 1002 |
| film | 45,233 | 576 |
| food | 23,041 | 842 |
| mountain | 2720 | 623 |
| ship | 1805 | 852 |
| software | 2322 | 487 |
| Models | Precision | Recall | F1-Score |
|---|---|---|---|
| TruthFinder [18] | 0.279 | 0.374 | 0.320 |
| LCA [17] | 0.364 | 0.404 | 0.383 |
| LTM [47] | 0.262 | 0.394 | 0.315 |
| MBM [48] | 0.340 | 0.539 | 0.417 |
| OKELE [15] | 0.459 | 0.485 | 0.472 |
| OWE [13] | 0.351 | 0.421 | 0.383 |
| KnowledgeVault [32] | 0.385 | 0.455 | 0.417 |
| ConMask [33] | 0.376 | 0.443 | 0.407 |
| TKGC [14] | 0.524 | 0.491 | 0.507 |
| ChatGPT | 0.417 | 0.477 | 0.445 |
| CRDL | 0.959 | 0.768 | 0.853 |
| CRDL w/o LLM | 0.911 | 0.271 | 0.418 |
| CRDL w/o CD | 0.920 | 0.749 | 0.826 |
| k-Shot | Precision | Recall | F1-Score |
|---|---|---|---|
| 0-shot | 0.953 | 0.715 | 0.817 |
| 1-shot | 0.960 | 0.754 | 0.844 |
| 3-shot | 0.958 | 0.755 | 0.845 |
| 5-shot | 0.959 | 0.768 | 0.853 |
| 7-shot | 0.953 | 0.751 | 0.840 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Peng, H.; Zhang, P.; Tang, J.; Xu, H.; Zeng, W. Detect-Then-Resolve: Enhancing Knowledge Graph Conflict Resolution with Large Language Model. Mathematics 2024, 12, 2318. https://doi.org/10.3390/math12152318
Peng H, Zhang P, Tang J, Xu H, Zeng W. Detect-Then-Resolve: Enhancing Knowledge Graph Conflict Resolution with Large Language Model. Mathematics. 2024; 12(15):2318. https://doi.org/10.3390/math12152318
Chicago/Turabian StylePeng, Huang, Pengfei Zhang, Jiuyang Tang, Hao Xu, and Weixin Zeng. 2024. "Detect-Then-Resolve: Enhancing Knowledge Graph Conflict Resolution with Large Language Model" Mathematics 12, no. 15: 2318. https://doi.org/10.3390/math12152318
APA StylePeng, H., Zhang, P., Tang, J., Xu, H., & Zeng, W. (2024). Detect-Then-Resolve: Enhancing Knowledge Graph Conflict Resolution with Large Language Model. Mathematics, 12(15), 2318. https://doi.org/10.3390/math12152318