1. Introduction
Every day, a newsvendor needs to buy journals based on an uncertain demand. Assuming that each journal has a fixed cost and selling price, if she/he asks for too many journals and the demand is insufficient, there is a reduction in the profit. On the other hand, if the demand is higher than the number of journals ordered, potential sales do not occur, resulting in “lost profits” [
1]. This dilemma of buying more or less newspapers, which is known as the
newsvendor problem, can be applied to any problem that deals with perishable goods, such as newspapers, magazines, fresh food, or holiday decorations, e.g., Christmas trees. This type of problem has one planning cycle of useful life with uncertain demand and can be modeled as an inventory management problem. Further, the framework of the newsvendor problem can also be applied to capacity investment problems, which can solve relevant societal challenges, such as medical capacity investments. One example is the establishment of epidemic diffusion models to characterize how transmission evolves with (and without) vaccination [
2].
Several solutions can be found for solving various inventory management problems [
1,
3,
4]. When multi-items are considered for perishable goods, one deals with a multi-item newsvendor problem (MINP). In this problem, it is important to consider the number of constraints and their type (cost, service level, etc.), the decision-making policies (e.g., optimizing expected profit, service level, etc.). Often, solutions are found using risk-averse techniques. Further, very often MINPs use probability density functions to model the uncertain demand [
5,
6,
7,
8].
However, the demanded probabilistic density functions are difficult to derive in real scenarios, especially for innovative and disruptive products, where there are not sufficient data to accurately predict the demand probability distribution. It is possible to mitigate these limitations by including additional information from human expertise using, e.g., fuzzy systems [
9]. Fuzzy logic is a suitable tool for incorporating uncertain demands with a proven effectiveness in solving MINPs [
9,
10,
11]. A fuzzy environment can use few data points to describe uncertainty through meaningful membership functions. Furthermore, fuzzy logic offers an ideal environment for describing the vagueness of human thinking through mathematical operations, defining linguistic terms such as “the demand of a product is around 2000” [
12].
The first fuzzy solution to the newsvendor problem and inventory management with perishable goods dates back to 1996 [
9]. Analytical analyses in a fuzzy environment are useful for specific cases, where it is possible to study a limited number of items in a well-isolated economic environment [
13,
14,
15,
16]. Problems arise when the number of items and their relations increase, leading to highly nonlinear problems, making analytical approaches hard to implement [
17]. Most of the recent fuzzy [
18,
19,
20] and non-fuzzy [
21,
22,
23,
24,
25] solutions have focused on solving highly complex single-item problems, lacking generalization to multi-item problems.
Fuzzy MINP problems are usually solved using metaheuristic algorithms [
10,
11]. Inspired by real-world phenomena, metaheuristics use computational power to find solutions when the classical methods cannot, due to time and complexity. However, metaheuristics do not always guarantee that the solutions found are optimal. However, they can, at least, provide good results for highly complex optimization problems [
26]. Shao proposed a genetic algorithm to solve the newsvendor problem with a fuzzy environment [
10]. This paper extended the fuzzy objective functions proposed in [
9], with the adoption of credibility theory concepts [
27,
28], namely using the concepts of possibility, necessity, and credibility of a fuzzy event, as well as the excepted value of a fuzzy variable [
29] to derive objective functions for different decision-making policies. Further, in 2011, Taleizadeh [
11] studied a variety of metaheuristic algorithms to solve a fuzzy single-period newsvendor problem and also proved the suitability of genetic algorithms for this problem.
This paper proposes the following contributions to the fuzzy multi-item newsvendor problem:
A new credibility estimation is proposed to explore the neighborhood around the most impactful demand scenarios.
A simulation procedure is designed for different demand scenarios, allowing the comparison of the different fuzzy MINP approaches.
The genetic algorithm in [
11] is modified to solve the fuzzy multi-item newsvendor problem, enhancing the work of [
10] in both the generation and evaluation of solutions.
This paper is organized as follows.
Section 2 describes classical and fuzzy multi-item newsvendor problems. The proposed hybrid algorithm used to solve fuzzy multi-item newsvendor problems is presented in
Section 3. This section first describes a simulation procedure to generate the demand vectors. Then, the proposed credibility estimation is presented. Finally, the optimization architecture using a modified genetic algorithm with three novel mechanisms is described. Benchmark case studies are described in
Section 4.
Section 5 presents the obtained results, and the conclusions and future work are presented in
Section 6.
3. Proposed Hybrid Algorithm
In order to solve the fuzzy multi-item newsvendor problem, it is necessary to define a simulation procedure that generates the demand vectors. The simulation procedure proposed to simulate the demand is presented in
Section 3.1. A critical issue in the simulation procedure is to estimate the credibility, which is presented in
Section 3.2. Afterwards, the proposed optimization architecture using a modified genetic algorithm is presented in
Section 3.3.
3.1. Demand Simulation Procedure
This section presents a general simulation procedure for addressing fuzzy multi-item newsvendor problems. Let be the vector of fuzzy demands, for all n items. Let be the membership function of , and be the membership function of , for .
The simulation must generate a sufficiently large positive number for N demand vectors , with , and . This procedure simulates real scenarios by using a diverse range of demand vectors , with a greater emphasis on probable vectors, while still accounting for less likely ones. By computing the profit for each demand vector with a given solution, the average profit and profit standard deviation across all vectors can be determined.
Let one assume that
is a demand vector of
n items. The estimated membership grade of the demand vector is given by
where
is the estimated membership grade, and
is the membership grade associated with each order quantity of an item
i, with
.
The possibility and necessity estimations of multi-item solutions from the demand vectors
can now be estimated, respectively, in the following way:
where
is the profit function,
N is the total number of random demand vectors, and
is a profit target. The estimation of the credibility is based on the previous estimations of possibility and necessity, as follows:
This estimation is generic for a solution x and for the kth iteration. It is necessary to estimate the credibility for the complete simulation. The estimation proposed in this paper is described next.
3.2. Proposed Credibility Estimation
The proposed credibility estimation is presented in Algorithm 1. The main objective of this approach is to estimate the credibility of a solution x generating a profit higher than a profit target . It repeats the estimation K times until it finds it. Estimations for different profit targets are further used to estimate the expected profit of the solution x.
The demand vector is randomly generated and considers quantities that have a membership grade higher than a
, which are defined by 10% quantiles, and as so can have the following values:
Further, the
is always equal or greater than the minimum value between the highest membership grades found for both possibility and necessity. The
progressively increases the minimal membership grade of the randomly generated demand vectors. This is useful because the possibility estimation requires finding the demand vector with the highest membership grade that generates a profit higher than the profit target
, as defined in (
13). In addition, the necessity estimation requires finding the demand vector with the highest membership grade that generates a profit lower than the profit target
, as defined in (
14).
Note also that sometimes, due to the random generation, for low credibility solutions, the necessity estimation can be higher than the possibility estimation. These results are impossible, due to the nature of the problem, and therefore are automatically rejected by the algorithm.
The credibility is mandatory to estimate the expected profit of a solution
x, with
). To focus resources on plausible values, the profit targets are extracted from the interval defined by
On the one hand, the interval lower limit corresponds to the scenario where no sales are made. On the other hand, the upper limit corresponds to the scenario where all purchased items are sold.
Assuming that the total number of profit targets is given by
S, the profit targets are equally distributed and the set of profit targets are defined by
, where
. Equations (
18)–(
20) describe the necessary steps for estimating the expected profit
E of a solution
x:
The number of credibility samples
S is a crucial variable in this estimation. This variable must be studied to obtain the best possible trade-off between computational time and accuracy.
| Algorithm 1 Credibility Estimation |
Require: x; ; ; ; K; ; ; while
do Compute random with Compute using ( 12) ====== Possibility and Necessity Update ====== if and then else if and then ===========Threshold Update ========== if then (soft threshold update) else if and then (finish execution) else if then ) (hard threshold update) else =========== Finish Execution ========== if
then Compute using ( 15) else (solution rejected)
|
3.3. Proposed Optimization Architecture
The formulation of the fuzzy newsvendor problem allows its application to inventory problems. This is accomplished with an optimization architecture that combines a modified genetic algorithm (GA) and the expected profit estimation. Along with the common mechanisms of a genetic algorithm, crossover, mutation, and selection [
32], novel problem-specific genetic mechanisms are introduced.
The proposed optimization architecture finds the solution
with the highest expected profit, according to the fundamentals previously introduced in
Section 2. Algorithm 2 details the proposed genetic algorithm for maximizing the expected profit. This algorithm needs to estimate the credibility
, as proposed in
Section 3.2 and Algorithm 1. The genetic algorithm used is the one in [
10], using classic selection, crossover, and mutation operators. Further, the genetic algorithm also uses the novel problem-specific genetic mechanisms described in the next section.
| Algorithm 2 Proposed Genetic Algorithm |
Require: G; - 1:
while
do - 2:
for each individual of generation i do - 3:
Compute profit interval using ( 17) - 4:
Compute all profit targets by equally sample profit interval - 5:
Compute the credibility for all j using Algorithm 1 - 6:
Compute expected profit using ( 18)–( 20) - 7:
Compute next population using novel GA mechanisms in Section 3.4- 8:
- 9:
Select the individual x with the highest expected profit E.
|
3.4. Novel Problem-Specific Genetic Mechanisms
This section describes problem-specific mechanisms, which are implemented in the architecture proposed in Algorithm 2. These methods enhance the set of solutions by (1) discarding items in the initial population, (2) scaling chromosomes according to the available budget, and (3) introducing a problem-specific context to the crossover operator. This section thus proposes chromosome initialization, solution resizing, and chromosome normalization, which are described next.
3.4.1. Initialization with Zero Quantities
The initialization with zero quantities initializes chromosomes with a single non-zero ordering quantity
. After selecting a random item
i for the non-zero ordering quantity, the chromosome is resized as explained in
Section 3.4.2 to scale
to reach the available budget. If
i is a profitable item, the chromosome is selected, because the expected profit is higher than chromosomes containing less profitable items. This mechanism aims to select (and further combine) only the most profitable items.
3.4.2. Solution Resizing
The solution resizing mechanism scales the chromosome ordering quantities
to use all the available budget. It scales the quantities up or down without changing the relative proportions between them. On the one hand, this mechanism can transform over-budget solutions into feasible solutions by scaling them down. On the other hand, it can scale up under-budget solutions to use all the available budget. To apply this mechanism, the ordering quantities
are resized to quantities
by multiplying them by a resizing ratio, as follows:
3.4.3. Chromosome Normalization
This normalization makes the crossover independent of the absolute values in
x, by normalizing them according to the items with the highest expected demand value. In this paper, the highest expected demand value comes from the item with the probabilistic density function
, but it could also be the fuzzy value with the highest grade. To apply the chromosome normalization, first, the ordering quantities
must be normalized by applying the transformation:
where
is the ordering quantity of item
i,
is the expected demand value of the probabilistic distribution of item
i, and
is the normalized ordering quantity of item
i. After the crossover has been applied, all normalized ordering quantities
must be de-normalized by multiplying them by
.
6. Conclusions
A novel approach to the fuzzy newsvendor problem for inventory management applications was proposed in this paper. A hybrid algorithm was proposed to solve fuzzy multi-item newsvendor problems by introducing a simulation procedure to generate the demand vectors. One of the main contributions of this work was the redesigning of a mandatory variable in the simulation procedure, the credibility estimation, which introduced a dynamic adjustment of an threshold to generate meaningful demand vectors, instead of using a purely random vector generation. Further, a modified genetic algorithm that discards some products in the initial population, scales the chromosomes according to the available budget, and makes the crossover operator independent of the absolute values of the solutions.
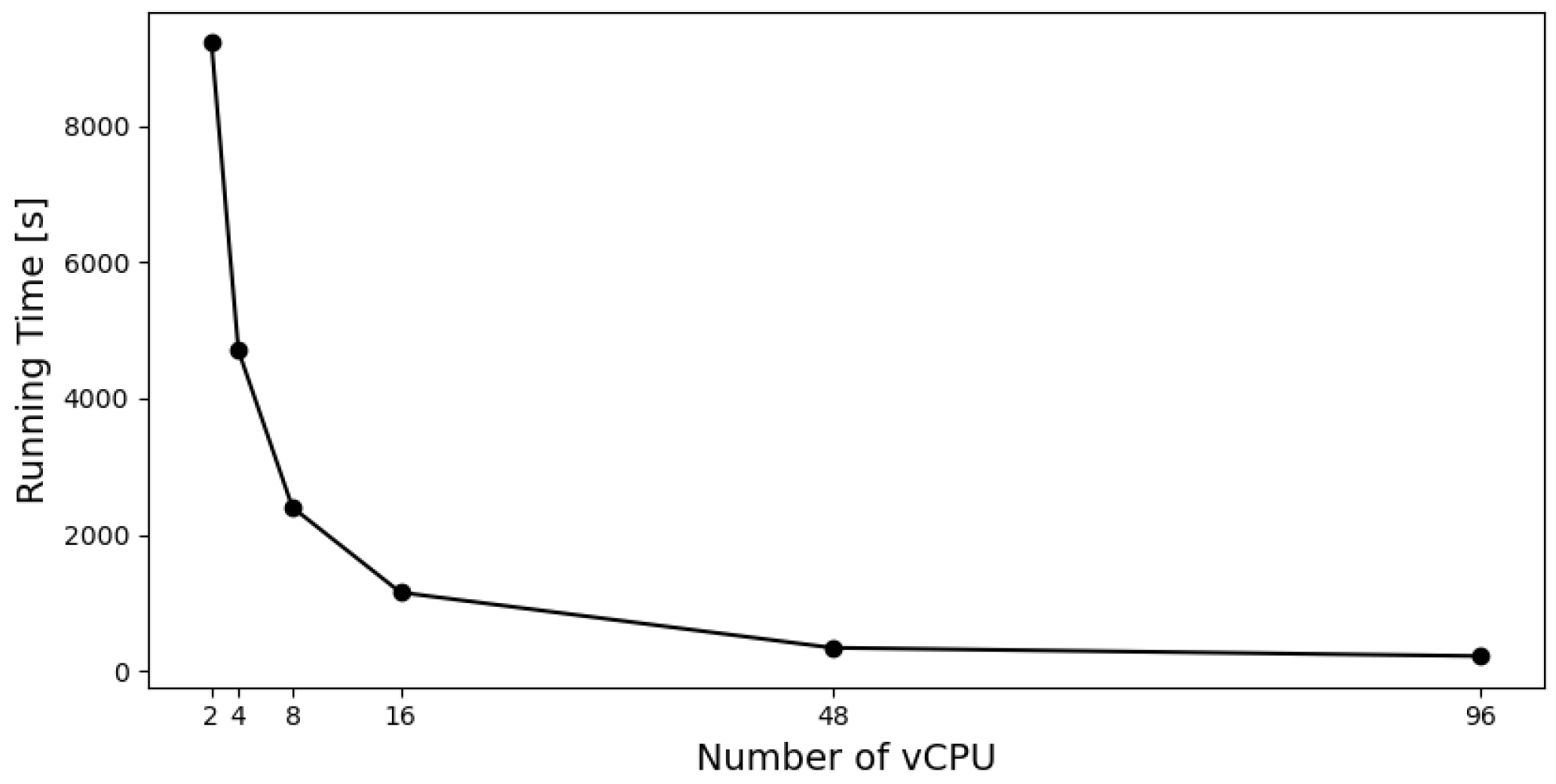
The proposed hybrid algorithm was compared to other classical and fuzzy approaches in two benchmark case studies, and it slightly outperformed the classical approach. However, it clearly outperformed the previous fuzzy approach. In the most complex case, Case Study 2, it improved the profit by 55%. This performance increase was the result of introducing a new initialization with null values, which proved to be a valuable mechanism in low-budget scenarios, where there is the need for rejecting less profitable items. Please note that Case Study 2 already has a high dimension and it is similar to a large number of real-world problems in inventory management. The main limitation of the proposed approach was the computational effort of the algorithm. Using a cloud environment and parallel computing led to low computational times (about 8 min), which is very acceptable. However, these resources can be expensive.
The proposed hybrid algorithm is very flexible. Despite using fixed costs to prove its effectiveness against analytical approaches, this solution can work with nonlinear pricing models. To perform this, one only needs to integrate the pricing information when calculating profits in the credibility estimation. This is suggested for future work. Moreover, there is the possibility of changing performance measures. Profit was used to prove the effectiveness against analytical approaches, but the algorithm could prioritize the solutions that most satisfied possible customer demand, by replacing the profit calculation with a service-level calculation, for instance. We used perhaps the most usual version of a fuzzy number. However, other fuzzy numbers such as Z–numbers [
37], G–numbers [
38], or R–numbers [
39] could be used. This is another avenue of future research. Last but not the least, in the near future, we are going to implement the fuzzy MINP in a model of medical capacity investment, to evaluate the impact of health public policies in terms of infant mortality rates.








{kind=link}
{kind=link}