1. Introduction
Research on inventory systems subject to multiple customer classes is based on the fact that, for the same product, demand may arise from different customer groups with varying requirements for delivery times or service levels regarding product availability. Although these inventory systems have been extensively studied, less attention has been focused on the single-period problem under stochastic demand and individual service-level requirements from multiple customer classes. This scenario is not unusual; we are talking about a relatively common situation, e.g., wholesalers supplying products to different customers in a retail market, and where the attention priority of each customer, as well as their demand, is different.
In these scenarios, a key challenge is to minimize the amount of products the wholesaler needs to meet customer demand, all while ensuring a specified service level. This is especially important in shortage situations. A common practice is to group customers into two or three customer classes, using Pareto or ABC classifications, respectively, where A-class represents priority customers who can demand high service levels. However, to the best of our knowledge, there is no evidence that grouping customers into two or three classes achieves inventory level minimization in a single-period inventory system with multiple customer classes. The complexity of this problem, arising when customers are grouped into more than three classes, has hindered research on the effect of the number of customer classes on inventory level in this type of inventory system.
In this paper, we consider a seasonal product wholesaler who serves several customer classes with different service level requirements in terms of product availability; the wholesaler is likely to face shortages because the purchase order is made before knowing the real demand of its different customer classes. Given this situation, the wholesaler has to make two decisions. The first one is the amount of products to purchase and the second decision involves determining how to allocate the available inventory when the purchased quantity is less than the total demand. Two types of priority policies can be identified in the case of shortage, (i) responsive priority policies, where the order in which customer classes are going to be served (priority list) is defined using the realized demand information, and (ii) anticipative priority policies, where a priority list is defined before demand realization. The simplest responsive policy is the greedy allocation priority policy (GP policy), where customers are served in ascending order according to the demand realization, while the simplest anticipative policy is the fixed-list allocation priority policy (FLP policy), where customers are served in descending order based on the preset service level of each customer class.
The objective of this paper is to determine the effect of the number of customer classes on the inventory level of a single-period inventory system with stochastic demand and individual service level requirements from multiple customer classes. The research questions we consider in this paper are as follows: (i) How does the number of customer classes affect the inventory level under different priority policies? (ii) What is the optimal number of customer classes under different demand configurations? and (iii) What priority policy performs better under different demand configurations?
To address this issue, both priority policies mentioned above, GP and FLP, are used, and the service level, considered to ensure product availability for each customer class, is measured by the probability of satisfying the entire demand for each class, namely, the service-level. For each priority policy, we formulate a multi-customer class service-level constraint (SLC) problem under the service level as a chance-constrained stochastic programming model. These -SLC problems are difficult to solve since they imply leading with convolutions and multiple integrals when customers are grouped into more than three classes, which limits the study of how the number of classes affects the inventory level. An efficient way to deal with chance constraints is to utilize the Sample Average Approximation (SAA) approach. The basic idea of SAA in problems where chance constraints are involved is to replace the theoretical distribution function by the empirical distribution obtained from random sampling. Thus, we show how to formulate the multi-customer class SLC models with chance constraints as mixed integer linear problems (MIPs) using a sample-based approach (SAA models), and taking advantage of the SAA method, we obtain a feasible solution with guaranteed quality in terms of its optimality gap. Then, assuming knowledge of the number of initial classes () and using a round-up aggregation scheme to reduce the customer classes, we study how the number of classes affects the inventory level under GP and FLP policies. Based on the SAA models, structural insights into the number of classes when a round-up aggregation scheme is used are derived. Under this aggregation scheme, which does not harm the service level of the aggregated classes, the variation in the inventory level is caused by the free-rider classes (free-rider effect) and by the aggregation scheme (cluster effect). We isolated and separately measured the effect induced by the free riders and the aggregation scheme on the order quantity. We show in this paper that the order quantities under the GP and FLP policies have different behaviors regarding the number of classes. The order quantity under the GP policy is not monotonous with respect to the number of classes, while the quantity ordered under a FLP policy is.
The main contributions of this study are summarized as follows: (1) To the best of our knowledge, this is the first time that the effect of the number of customer classes on the inventory level has been studied. (2) We show how to reformulate the multi-class -SLC problem under GP and FLP policies as MIPs using a sample-based approach. (3) An efficient mechanism for grouping customer classes (round-up aggregation scheme) is presented. (4) Novel propositions to analytically characterize the optimal inventory level under GP and FLP policies are provided. (5) To the best of our knowledge, this is the first time that the effect of free-riders and the customer class aggregation scheme on the inventory level under GP and FLP policies, respectively, has been explored.
The remainder of this paper is structured as follows. A review of related work is discussed in
Section 2.
Section 3 presents the multi-class
-SLC problems under the GP and FLP policies, respectively. In
Section 4, we show how to reformulate the
-SLC problems as MIPs using a sample-based approach.
Section 5 presents the SAA method to obtain
-SLC model bounds under GP and FLP policies and measure the solution quality in terms of the optimality gap.
Section 6 presents the customer class aggregation scheme and addresses the relationship between inventory level and the number of customer classes under GP and FLP policies. Computational results are reported in
Section 7. Finally, we conclude with managerial insights and future extensions to this work in
Section 8.
2. Literature Review
Inventory systems with several customer classes have been extensively studied in various contexts, in which four dimensions are distinguished according to Schulte and Pibernik [
1]: (i) the frequency with which rationing decisions are made (static or dynamic), (ii) the number of customer classes (two or an arbitrary number), (iii) the number of periods (single or multi-period, with different ordering inventory policies in the latter case), and (iv) the shortage approach (backorders or lost sales). A comprehensive review of multi-class inventory systems can be found in Kleijn and Dekker [
2], and the details of classification are well documented in Teunter and Haneveld [
3].
Several priority policies have been studied under a single-period inventory system with multiple customer classes. Lagodimos [
4] proposed two priority policies when faced with inventory shortages, namely
fair share rationing and
priority rationing. Fair share rationing consists of rationing the available inventory among different customers to achieve the same stockout probabilities, while priority rationing satisfies customer demands in the sequence defined by a priority list. Two rules for building priority lists are proposed. The first one is the GP policy, and the second one is to assign random priorities (
randomized list policy). Lagodimos [
4] also introduced the
availability assumption, which states that the demand of only one customer is not completely satisfied in the case of a shortage. More precisely, given a rationing policy, the last customer on the list will not be fully served. Alptekinoğlu et al. [
5] classifies the priority rules according to whether they make use of actual demand information or not, i.e., responsive and anticipative priority policies, respectively. According to Alptekinoğlu et al. [
5], a GP policy is responsive, while the FLP and randomized-list policies are anticipative priority policies. Chen and Thomas [
6] analyzed four responsive priority policies: the GP policy; the
proportional priority policy, which gives each customer the same fraction of his order; the
linear priority policy, which satisfies each customer minus a common amount corresponding to the difference between total orders and capacity divided by the number of customers; and the
uniform priority policy, which allocates an equal inventory quantity for every customer and evenly redistributes any excess inventory to customers whose demands are not yet fully satisfied.
In this paper, we consider a single-period inventory problem under stochastic demand and individual service-level constraints from multiple customer classes, where given a priority policy in the case of shortage, it is required to determine the minimum order quantity such that the preset service levels of each customer class are met. In
Table 1, we classify these works according to (i) the priority policy (responsive or anticipative), (ii) the service level (
or
), (iii) the stochastic programming model approach, (iv) the solution approach, and (v) the number of customer classes reported in the numerical results.
Swaminathan and Srinivasan [
7] studied the single-period problem with individual
service levels. They formulated a service-level problem with chance constraints under a responsive priority policy. To solve this problem, the authors partitioned the demand space into mutually excluded regions, where each region has a unique combination of service customers and an occurrence probability. They proposed an algorithm that defines the regions and obtains an upper bound for the optimal order quantity. A binary search is performed within the pre-established regions to find the optimum value of the order quantity. The combinatorial complexity of the problem and hence the difficulty of obtaining a solution are evident from their work.
Zhang [
8] analyzed the single-period problem with individual
service levels under a randomized priority policy. Firstly, he formulated a service-level model with chance constraints for two customers, where the service level constraints are based on the probability of using one of the two feasible lists, which is equivalent to the probability that one customer is in the first or second place on the list. The author concludes that it is difficult to extend his results to
n-customers because this involves determining the probabilities for all
possible priority lists. To formulate the problem for multiple customers, this author employed the availability assumption of Lagodimos [
4] and defined an approximation for the service level of each customer based on the probability that the customer is the last one on the list. Consequently, he developed a stochastic programming model to determine the minimum order quantity such that the service level provided to a customer should be higher than his/her preset service level. Finally, Zhang [
8] determined the optimum probability of a customer being in the last place on the list to make a minimum purchase.
Alptekinoğlu et al. [
5] proposed a single-period model with individual
service levels from multiple customers as a service level problem with chance constraints. The objective is to minimize the order quantity and to determine an optimal priority policy that satisfies the service levels of each customer. They obtain complete solutions for the anticipative priority policy and partial solutions for the responsive priority policy in the form of bounds. The numerical experiments shown by Alptekinoğlu et al. [
5] are up to three customer classes. Zhong et al. [
9] studied the single period problem with individual fill-rate (
) service levels under an anticipative priority policy called the
largest-debt-first policy. The problem is formulated as a semi-infinite linear model. The solution approach is a sample-based heuristic, where the priority policy of the
tth scenario is built in descending order to the average debt for the first
samples. Zhong et al. [
9] showed results for only three customers since the solution of a larger number is computationally prohibitive due to the exponential number of constraints involved. Lyu et al. [
10] studied the same problem as Zhong et al. [
9] but solved it using SAA. They show results in up to four customer classes.
Lyu et al. [
11] study a single-period multi-customer inventory system under
and
service levels and responsive priority policy. The responsive priority policy problem is formulated in two stages, where in the first stage, the optimal order quantity is determined using the bisection method, and in the second stage, the optimal allocation rule is determined by solving a knapsack problem. They, using their two-stage formulation, determine bounds for the order quantity based on an anticipative policy with respect to the responsive policy. They show results for up to six customer classes.
Jiang et al. [
12] present a framework to study a single-period multi-customer inventory system under the
and
service levels and responsive priority policy. The problem is formulated as a two-stage stochastic problem with chance constraints (service-level constraints). In the first stage, they assume a feasible order quantity and solve the dual problem using the stochastic gradient descent (SGD) algorithm. Thus, they obtain the optimal responsive priority policy, denoted as
max-weighted-service policy, where the weights are the Lagrangian multipliers of each service level constraint. In the second stage, given the optimal priority policy, they determine the optimal order quantity using a min-max stochastic programming formulation of the original problem, which is solved using the descent stochastic approximation (SA) algorithm of Juditsky and Nemirovski [
13]. They show results for up to ten customer classes.
In summary, only a few papers have considered single-period inventory systems with individual service-level requirements from multiple customers under priority policies in the case of shortage. Furthermore, given its combinatorial complexity or its multidimensional integration requirements, the single-period problem under priority policies is difficult to solve. This has limited the study of the effect of the number of customer classes on the inventory level. Unlike previous works, we study the effect of the number of customer classes on the inventory level under responsive and anticipative policies.
An efficient way to deal with chance constraints is to utilize the
Sample Average Approximation (SAA) approach. The basic idea of SAA in problems where chance constraints are involved is to replace the theoretical distribution function with the empirical distribution obtained from random sampling. In this sense Calafiore and Campi [
14] studied an alternative ‘randomized’ or ‘scenario’ approach for dealing with uncertainty in optimization based on constraint sampling. They show that a convex optimization problem in which constraints are imprecisely known can be efficiently solved in the
sense using a randomized algorithm, i.e., the probability that a candidate solution violates the constraint of the problem is at most
. Calafiore and Campi [
15] extended their work by focusing on the robust control and showing the usefulness of probabilistic optimization in this context. Ahmed and Shapiro [
16], in addressing a chance-constrained problem with a discrete distribution that can be quite difficult to solve, presented several approaches based on integer programming for solving the SAA problem. In contrast, Luedtke and Ahmed [
17] studied the utilization of sample approximation to generate feasible solutions and optimality bounds for general chance-constrained problems. They show an approach to choosing the number of replications that is independent of the size of the sample and the risk level and showed how the sample approximation scheme can be used to obtain lower bounds that are valid with high confidence. Finally, Pagnoncelli et al. [
18] applied SAA in a chance-constrained portfolio selection problem and obtained the upper bounds as well as candidate solutions to the problem. Furthermore, they presented a way to choose the size of the sample such that the optimal solution of the SAA problem is feasible for the corresponding true problem with high confidence.
3. Problem Description and Formulation
Consider a wholesaler who supplies a single product to several customers, including large retail chains that request high service level in terms of product availability, from a centralized inventory pool in a single period. The inventory can also be viewed as various capacities in manufacturing or service systems.
The wholesaler classifies its consumers in I () customer classes, where each class is a group of customers with the same preset service level in terms of product availability. Let class 1 () be the high-priority class, which corresponds to large retail chains, and let class n () be the lowest-priority class, which represents retailers who have to settle for the lowest service level. Let be the demand of class i with non-negative continuous distribution function and density function , and let be the realization of customer class i. Throughout the paper, we use boldface letters to denote vectors; for example, the demand vector is denoted as .
At the beginning of a period, the wholesaler orders a lot of sizes , without knowing the actual demand of the customer classes. Next, the demand is realized for each customer, who then orders from the wholesaler. After learning the demand of each customer class, two mutually exclusive events could happen: (i) no rationing is required, because , or (ii) rationing occurs, because , and the wholesaler must allocate S according to an explicit priority policy.
The objective of the wholesaler is to determine the minimum order quantity
S under an explicit priority policy that meets the preset service level of each customer class. In this paper, we consider the
service level defined as the probability of no stockout [
19]. In the case of several customer classes, we interpret the
service level of class
i, with
, as the probability of satisfying the entire demand of class
i. Let
and
be the provided and preset
service-levels for class
i, respectively, with
.
Using the
service-level definitions described above and the priority list approach of Alptekinoğlu et al. [
5] to model the GP and FLP policies, we present two multi-customer class SLC problems, which are denoted as
, with
specifying the GP and FLP policies, respectively.
3.1. Multi-Class SLC Problem under the Service Level and a GP Policy
A priority list under a GP policy is constructed using a smaller-demand-filled-first rule; i.e., this list serves the customer classes in ascending order of demand realizations. Let be the customer class in the kth position of the priority list and be the priority list under a GP policy.
The conditions required to fully meet the demand of class
i under a non-negative demand and a GP policy are as follows: (i) there does not exist rationing, i.e.,
, or (ii) rationing occurs and all demands for classes before
i in the priority list are less than or equal to
S, including customer class
i, i.e.,
and
,
, for any
. Therefore, the
service level provided to the class
i under a GP policy is
. Using the total probability law, we have
Using (
1), we formulate a multi-customer class SLC problem under a GP policy and
service level as the following NLP problem.
The objective is to determine the minimum order quantity S that satisfies the preset service level for each customer class. Constraint (3) ensures that the service level provided to class i, under the GP policy, is greater than or equal to its preset service level, and constraint (4) is the non-negativity constraint.
The
model is difficult to solve because the events that describe the position of class
i in the priority list increase with the number of classes, which induces
terms in (
1) for any
. Furthermore, (
1) must be conditioned in
n random variables, which induces expressions with multiple integrals when
. A simple illustrative example with two customer classes is provided in
Appendix A.
3.2. Multi-Class SLC Problem under Service-Level and FLP Policy
A priority list under an FLP policy is constructed using a high-service-level-first rule; i.e., this list serves customer classes in decreasing order according to the preset service level of each customer class. Thus, under an FLP policy, for any .
The conditions to fully meet the demand of class
i, under non-negative demand and FLP policy, are as follows: (i) rationing does not exist, i.e.,
, or (ii) rationing occurs, and all demands for classes before
i in the priority list are less than or equal to
S, including the customer class
i, i.e.,
and
. Therefore, the
service level provided to the class
i under a FLP policy is
. Using the total probability law, we have:
It should be noted that
is independent of
n for any
because the position of class
i in the priority list is fixed. Then, using (
5), we formulate a multi-customer class SLC problem under an FLP policy and an
service level as the following NLP problem.
Constraint (
6) ensures that the
service-level provided to class
i, under the FLP policy, is greater than or equal to its preset service level.
Alptekinoğlu et al. [
5] shows that the optimal solution to the
problem is
, where
is the distribution function of
for
. This solution is difficult to compute when
have different distribution functions, which implies leading with convolutions.
4. A Sample-Based Formulation of Multi-Class SLC Problems
The models, with , are difficult to solve for more than three customer classes since they require multidimensional integration. In this section, we present a sample-based reformulation of and , respectively, using the SAA approach.
Consider a sample with
N scenarios (
) of the random vector
. Let
J (
) be the set of scenarios and let
be the demand realization for the customer class
i in the
jth scenario. Let
be equal to 1 if the class
i is fully satisfied in the
jth scenario, and 0 otherwise. Under a sampling-based approach, the
service level provided to the class
i is defined as
i.e., the number of times the demand for class
i is fully satisfied over the total number of scenarios sampled.
The GP policy under a sample-based approach is modeled for class
i using the indexed set
, defined as the set of customer classes that must be satisfied completely before customer class
i in the
jth scenario, i.e.,
, for any
. Thus, the sampled version of
can be formulated as the following MIP:
Constraint (8) ensures that the sampled service level provided to the class i is greater than or equal to its preset service level. Constraint (9) prevents the total satisfied demand in the jth realization from exceeding the order quantity S. Constraint (10) satisfies the demands of the customer classes according to the GP policy. Constraint (11) is an integrality constraint.
In the same way, the sampled version of
can be formulated as the following MIP:
where constraint (
12) ensures that customer classes are satisfied according to an FLP policy (high-service-level-first rule).
5. The SAA Method and Validation Procedure
Let and be the optimal solutions of and , respectively, with . In the SAA approach, M independent batches are generated, each of which has N scenarios, and the SAA problem is solved M times. Therefore, M optimal solutions are obtained, one for each batch .
According to Pagnoncelli et al. [
18], the value
converges to optimality as
N tends towards infinity. Since the determination of the true optimal value
of the optimal solution is impossible due to the extremely large number of scenarios required, we statistically estimated the lower and upper bounds. In this sense, Luedtke and Ahmed [
17] shows that the minimum of the objective function values from these
M replications provides a statistical estimation of a lower bound of the true optimum. In contrast, Ahmed and Shapiro [
16] took any optimal solution by solving the SAA problem
and validated the result according to a given confidence level
, as a feasible solution of the true problem by obtaining an upper bound for the optimal value
. These statistical estimates of the upper and lower bounds allow us to compute an estimation of the optimality gap and the construction of confidence intervals.
The SAA procedure to determine estimates of the bounds for the models, with , can be stated as follows:
SAA Procedure:
Initialize: Generate M independent replications, each with N random samples of , given by for , and . For each r, solve the model. Let be the corresponding optimal solutions. Also, independently generate a large enough sample of scenarios where .
Step 1: To estimate a lower bound, rearrange the calculated optimal solutions in increasing order as follows:
. Then, with a probability of at least
, the random quantity
,
, gives a lower bound for the true optimal solution
. Following Luedtke and Ahmed [
17], use the minimum of the optimal solutions from these
M replications. Thus, the lower bound is expressed as
.
Step 2: To estimate an upper bound, first verify the feasibility of the candidate solution in the true problem . In this sense, there are different criteria for choosing candidate solutions that verify their feasibility, e.g., the feasibility of all the optimal solutions of the SAA problem can be verified , and the lowest feasible solution is determined. Another approach may be to select the greatest value of the optimal solution .
Based on Ahmed and Shapiro [
16], estimate the probability for the greedy and fixed-list service level problems such that constraint (3) and (
6) are violated for the customer class
i. Let
be the estimation of the probability of violating the constraint, where
is the number of times the constraint is violated for the customer class
i in
samples. Note that it is not necessary to solve any optimization problems in this case. This leads to the following approximation
-confidence for the upper bound of this probability for each customer class
i:
where
is the inverse standard normal distribution for a confidence level
. If the bound results in
for each
, it is possible to ensure ‘up to a probability of bad sampling
’, that
is feasible in the true problem and that it is an upper bound for the true optimal value
.
Step 3: Compute an estimation of the optimality gap of the solution
, using the lower bound estimate in Step 1 and the upper bound estimated in Step 2, as follows:
6. Relationship between the Number of Customer Classes and Order Quantity
In this section, we derive several properties of the ordered quantity resulting from solving models, with . These properties allow us to establish how the number of classes affects the order quantity under GP and FLP policies.
To modify the number of customer classes, we consider a round-up aggregation scheme. This policy adds the demand of class i to the demand of class , for any , and maintains the preset service level of class . As a result, customers are grouped into classes. This procedure could continue until the customer classes are grouped into a single class.
The round-up aggregation scheme does not negatively affect the service level of the aggregate classes, because it is ensured that they receive a higher service level than their original preset service level. This implies that the customer classes added under a round-up aggregation scheme are free-riders, i.e., classes that receive a higher service level than required.
It should be noted that there are several rules for adding demand under the round-up scheme, e.g., (i) the low-service-level-first-rule, which always adds the demand of the class n to the demand of the class ; (ii) the high-service-level-first-rule, which always adds the demand of class 2 to the demand of class 1; and (iii) the random rule, which randomly chooses the class i whose demand is added to the demand of class .
Let be the number of classes added under any aggregation rule of the round-up scheme, for any . In this case, the customers are grouped into () classes. Let and be the demand and preset service levels for the new set of customer classes. To determine the minimum order quantity S such that the preset service level of each customer class is satisfied, under a GP or FLP policy, we solve the model with and . We denote this problem as and as its optimal solution. Under the low-service-level-first-rule round-up aggregation scheme, for any , for any , and . The following propositions establish an ordering of the optimal order quantity when the number of customer classes varies according to the low-service-level-first-rule round-up aggregation scheme.
Proposition 1. for any , where and are the optimal solutions of , with , and , respectively.
The main consequence of Proposition 1 is that grouping all classes in a single class with the highest preset service level (full-round up) induces the largest optimal order quantity. In other words, grouping customers into classes is better than grouping them into a single class. Proposition 1 is independent of the preset service levels; i.e., it is valid when for any . Thus, we conclude that the reduction in the order quantity by grouping customers in classes is not only caused by free-rider customer classes.
Proposition 2. for any , where and are the optimal solution of and , respectively.
The main consequence that we observe in Proposition 2 is that the order quantity induced by the FLP policy is non-increasing with the number of customer classes.
Proposition 3. , where is the optimal solution of model with preset service levels , and is the optimal solution of with preset service levels for any and for any .
The main consequence that we observe in Proposition 3 is that the order quantity induced by the GP and FLP policies is non-decreasing with the number of free-rider classes.
7. Computational Study
In this section, we present our numerical study and its results. The main objectives of the computational study are as follows: (i) to quantify Proposition 1, which establishes that the order quantity induced by the GP policy when customer classes are grouped in more than one class is less than or equal to the order quantity induced when customer classes are grouped into a single class; (ii) to quantify Proposition 2, which establishes that the order quantity induced by the FLP policy is non-increasing in the number of customer classes; (iii) to quantify separately the effect of the free-rider customer classes and the effect of the aggregation rule on the order quantity; and (iv) to evaluate the performance of the SAA approach in terms of quality solution (optimality gap).
To illustrate the performance of GP and FLP policies under the service level, we generated several instances under different demand configurations. Each instance started with eight customer classes, i.e., , which were then gradually merged according to the low-service-level-first-rule round-up aggregation scheme until all classes were grouped into a single class, solving models, with , for any . Thus, it is possible to compute the effect of the number of customer classes on the order quantity.
We analyze four different configurations in terms of demand. What changes in each configuration is the set of classes that dominate in terms of demand in each initial instance. We generated 200 random instances. To illustrate the concept of dominance demand, consider any configuration where the dominant classes belong to the set
, where
is the set of classes that dominate in terms of demand in the configuration
. We say that the classes that belong to
dominate in terms of demand if
.
Table 2 shows the four configurations.
As shown in
Table 2, the first configuration considers that the demand is concentrated on the first three classes; i.e., the high-priority classes dominate demand. The second configuration considers that the last three classes concentrate the demand; i.e., the low-priority classes dominate demand. The third configuration considers that the two middle classes concentrate the demand. Finally, in the fourth configuration, there are no demand dominant classes; i.e., all customer classes have similar demands.
Each initial instance with eight customer classes uses the following common criteria and parameters: service level requirements
and
with
, and normal demand distributions with a coefficient of variation
for any
. In
Appendix E, we show how each configuration is built. Once the instances for each configuration are built, we solve the
models for any
for each instance using a number of replications and scenarios according to Luedtke and Ahmed [
17] and Pagnoncelli et al. [
18], respectively. Consequently, we use
and
. Furthermore, we determine the number of sufficiently large samples
to obtain the upper bound. The bounds are determined with a confidence level of 99.9%, i.e.,
.
The models, with are solved using CPLEX 20.1 for any . For each instance, the stopping criterion is optimality gap. All tests were performed on a MacBook Pro with an Intel Core i7 2.3 GHz processor and 16 GB RAM, designed by Apple in Cupertino, CA, USA, and assembled in China.
We determined for each instance the CPU time of for any . The average and maximum CPU times for each instance under the GP policy were 3798 and 29,363 s, respectively, and under the FLP policy, they were 9618 and 19,253 s, respectively.
7.1. Number of Customer Classes Versus Order Quantity
From Propositions 1 and 2, we conclude that grouping customer classes into several classes has a positive effect on the order quantity. To quantify this effect, we computed the benefit of grouping customer classes into different numbers of classes versus a single class under GP and FLP policies. This benefit is measured for each instance as follows:
where
is the order quantity obtained by solving the
rth replication of
with
, and
is the order quantity obtained by solving the
rth replication of
with
.
The benefit is interpreted as the percentage for which the order quantity of a single class is reduced. Note that the benefit of considering a single-class, i.e.,
, will always be zero, and
for any
and
, allowing a comparison to the priority policy that yields the greater benefit.
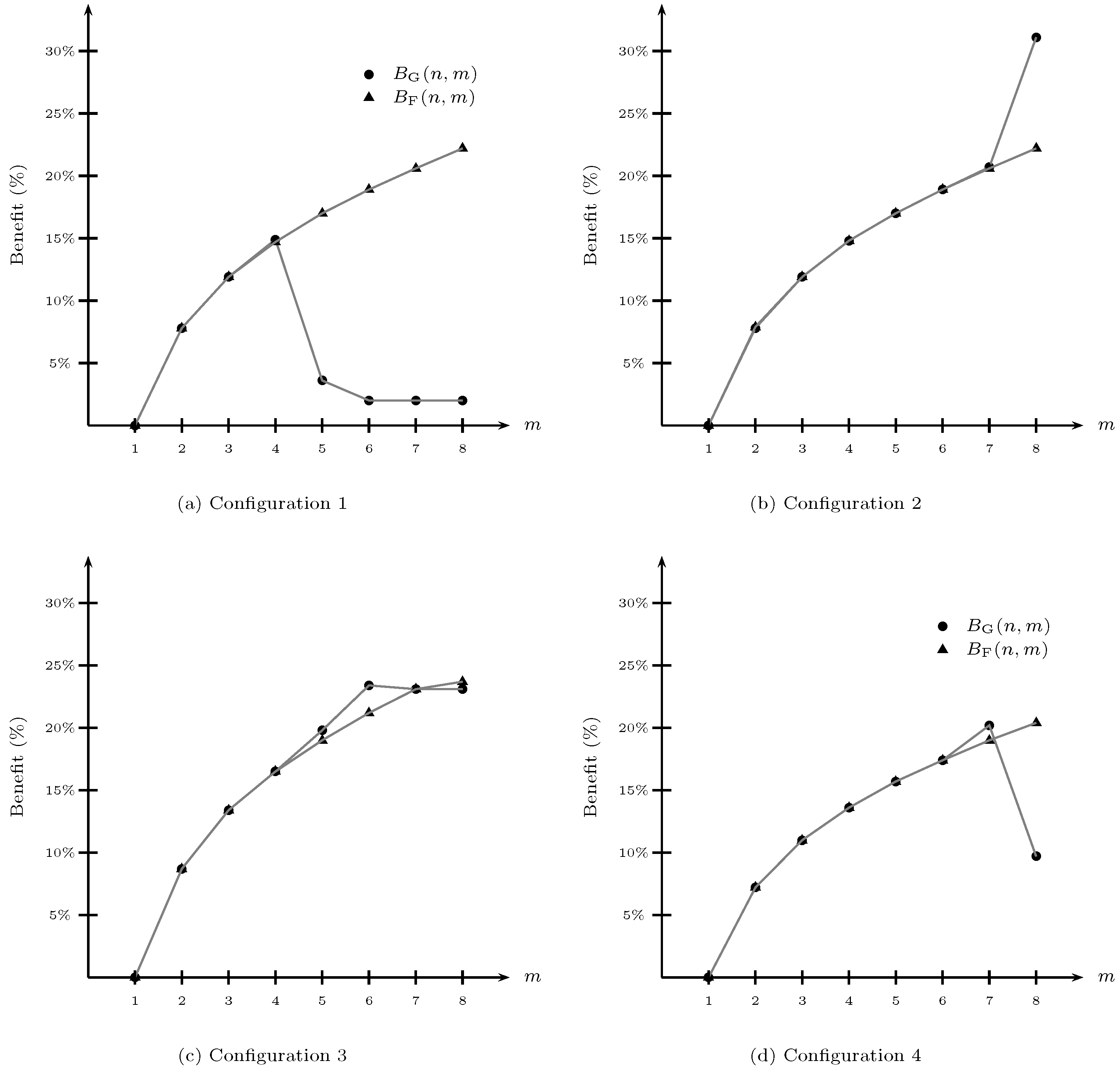
Figure 1 shows, for each demand configuration, the average benefits of grouping customer classes into different numbers of classes according to (
14).
As we expected,
Figure 1 shows that under GP and FLP policies, grouping all customer classes into more than a single class has a positive benefit on the order quantity (Proposition 1). The benefit is on average 22.4% and 22.1% for GP and FLP policies, respectively (
Appendix F contains the details of the average and maximum benefit). In particular, under the FLP policy, the benefit monotonically increases with the number of customer classes (Proposition 2), increasing on average by 3.3% for each increase in the number of customer classes.
From
Figure 1, we observe that the allocation under the GP policy is not always better than under the FLP policy. For example, when the high-priority classes dominate in terms of demand (configuration 1) and the customer classes are strictly grouped into more than four classes, the FLP policy performs better than the GP policy because
for any
. Under configurations 3 and 4,
. Unlike the case when low-priority classes dominate in terms of demand (configuration 2), the GP policy always performs better than the FLP policy, i.e.,
for any
.
We also observe that for each configuration under the GP policy, there is an optimal number of customer classes
such that the benefit obtained is always greater than or equal to the benefit obtained under the FLP policy. All grouping of customer classes into a number of customer classes that exceed the optimum
will have a benefit under the FLP policy that is greater than that if the allocation is performed under the GP policy. Therefore, the optimal number of customer classes for configurations 1, 2, 3, and 4 under the GP policy are
= 4, 8, 6, and 7 classes, respectively. In contrast,
Figure 1 shows that the optimal number of customer classes under the FLP policy is to group the classes into eight customer classes for all demand configurations. This result is aligned with Proposition 2.
In particular, under the GP policy,
Figure 1 shows that the maximum average benefit is achieved when the low-priority classes dominate demand (configuration 2) and the customer classes are grouped into eight classes. Its benefit has a value in excess of 30%. This occurs because the customer classes with high demand require a lower service level by increasing the number of customer classes, thus reducing the order quantity. Furthermore, under the FLP policy,
Figure 1 shows that the maximum average benefit is achieved when the middle priority classes dominate demand (configuration 3) and the customer classes are grouped into eight classes. Its benefit has a value of 23.7%. Note that the benefit does not vary greatly according to the demand configuration. This is because the priority list is not built based on the demand realization;i.e., the allocation order in a shortage is defined previously.
The variation of the order quantity when grouping the customer classes into different numbers of classes is caused by the free riders and by the aggregation rule. In what follows, we quantify the effect induced by the free riders and the aggregation rule on the order quantity. We denote these effects as the free-rider effect and the cluster effect, respectively.
7.2. Free-Rider and Cluster Effects
Free-rider classes are customer classes that receive a higher service level than required. To isolate and measure the free-rider effect, we determine the variation in
S by increasing the preset service level of
customer classes to
for any
. Consequently, under Sample Average Approximation, the variation of
S induced by the free-rider effect is defined as:
where
is the order quantity obtained by solving the
rth replication of the
model, and
is the order quantity obtained by solving the
rth replication of the
model with
for any
and
for any
. The variation of the order quantity induced by the free-rider effect is the percentage at which the order quantity is only modified by providing a higher service level than that required, without modifying the number of customer classes. Under GP and FLP policies, the free-rider effect is always negative or zero, i.e.,
, because
for any
and
(Proposition 3).
Table 3 shows the average and maximum variation of the order quantity induced by the free-rider effect for all configurations according to (
15).
As we expected,
Table 3 shows that the free-rider effect is negative or zero for all configurations. We also noticed that the free-rider effect is non-increasing for the number of classes that are free-rider, i.e.,
for any
. In particular, under the FLP policy, the free-rider effect is strictly decreasing in the number of free-rider classes, i.e.,
for any
.
From
Table 3, we observe that when high-priority classes dominate demand (configuration 1), the GP policy is absolutely robust in terms of the number of free-rider classes because the order quantity does not change even when providing the highest service level for all customer classes, i.e.,
for any
. This occurs because when building the priority list under a GP policy, the customer classes with the highest demand and required service level will be located at the end of this list. Therefore, to meet their required service level, the rest of the customer classes located earlier in the priority list will receive the highest service level. In contrast, when the low-priority classes dominate demand (configuration 2), the GP policy does not accept any free-rider classes without modifying the order quantity.
Table 3 also shows that the FLP policy is not robust in the number of free-rider classes because the order quantity is increasing in the number of free-rider classes. This occurs because the allocation will always follow the order of the same priority list; therefore, when attending the last customer class, which requires a greater service level as a result of being a free-rider class, the order quantity will increase.
The variation in the order quantity when grouping the customer classes into different numbers of classes is also caused by the aggregation rule that we referred to as the
cluster effect. To isolate and measure the cluster effect under the low-service-level-first round-up aggregation scheme, we compute the variation induced in
S by grouping
customer classes, each of them with preset service level
for any
, in a single class with preset service level
. Consequently, under Sample Average Approximation, the variation in
S induced by the cluster effect is
where
is the order quantity resulting from solving the
rth replication of the
model with
for any
and
for any
;
is the order quantity resulting from solving the
rth replication of the
; and
is the order quantity resulting from solving the
rth replication of the
model. If this variation is positive, i.e.,
with
and
, this means that grouping customer classes in
m classes reduces the order quantity.
Table 4 shows the average and maximum variation n the order quantity induced by the cluster effect for all configurations according to (
16).
From
Table 4, we observe that under the GP policy, there is a number of customer classes
that have the maximum positive variation in the order quantity. Therefore, any grouping of customer classes in a number of classes other than
yields a lower variation on the order quantity, i.e.,
for any
. Note that the optimal number of customer classes
that we observe in
Table A1 matches the number of classes that have maximum positive variation, i.e.,
. In contrast, under the FLP policy,
Table 4 shows that there is no variation in the order quantity for the grouping of customer classes into fewer classes providing the same service level. This occurs because the priority list built under an FLP policy is the same for both problems. Therefore, the order quantity will not change if there are no modifications in the service level required by any customer class.
The total variation in the order quantity produced by grouping customer classes according to the low-service-level-first-rule round-up aggregation scheme in
m classes, instead of grouping them in
n classes, is the sum of the free-rider (
15) and cluster effects (
16), i.e.,
From
Table 3 and
Table 4, we observe that when high-priority classes dominate demand (configuration 1), the total variation in the order quantity
S under the GP policy is totally caused by the cluster effect, while for configurations 2, 3, and 4, the total variation of the order quantity
S is caused by both effects. Note that the total variation in the order quantity under the GP policy by grouping customer classes in
instead of
n classes is only caused by the cluster effect, given that under the same number of customer classes
, the free-rider effect is null under the GP policy. In contrast, from
Table 3 and
Table 4, we observe that the total variation in the order quantity
S under the FLP policy, for all configurations, is only caused by the free-rider effect because the cluster effect is null under the FLP policy.
7.3. Performance of Sample Average Approximation
To measure the quality solutions resulting from solving the SAA problems, the optimality gap is determined according to (
13) using the minimum value of the
M replicates as a lower bound and verifying the feasibility of the highest value of these replicates. In the case of non-feasibility, this value is increased by
until it meets the established condition and is considered a feasible solution and the upper bound. The values are, at least with
probability, the lower and upper bounds of the problem.
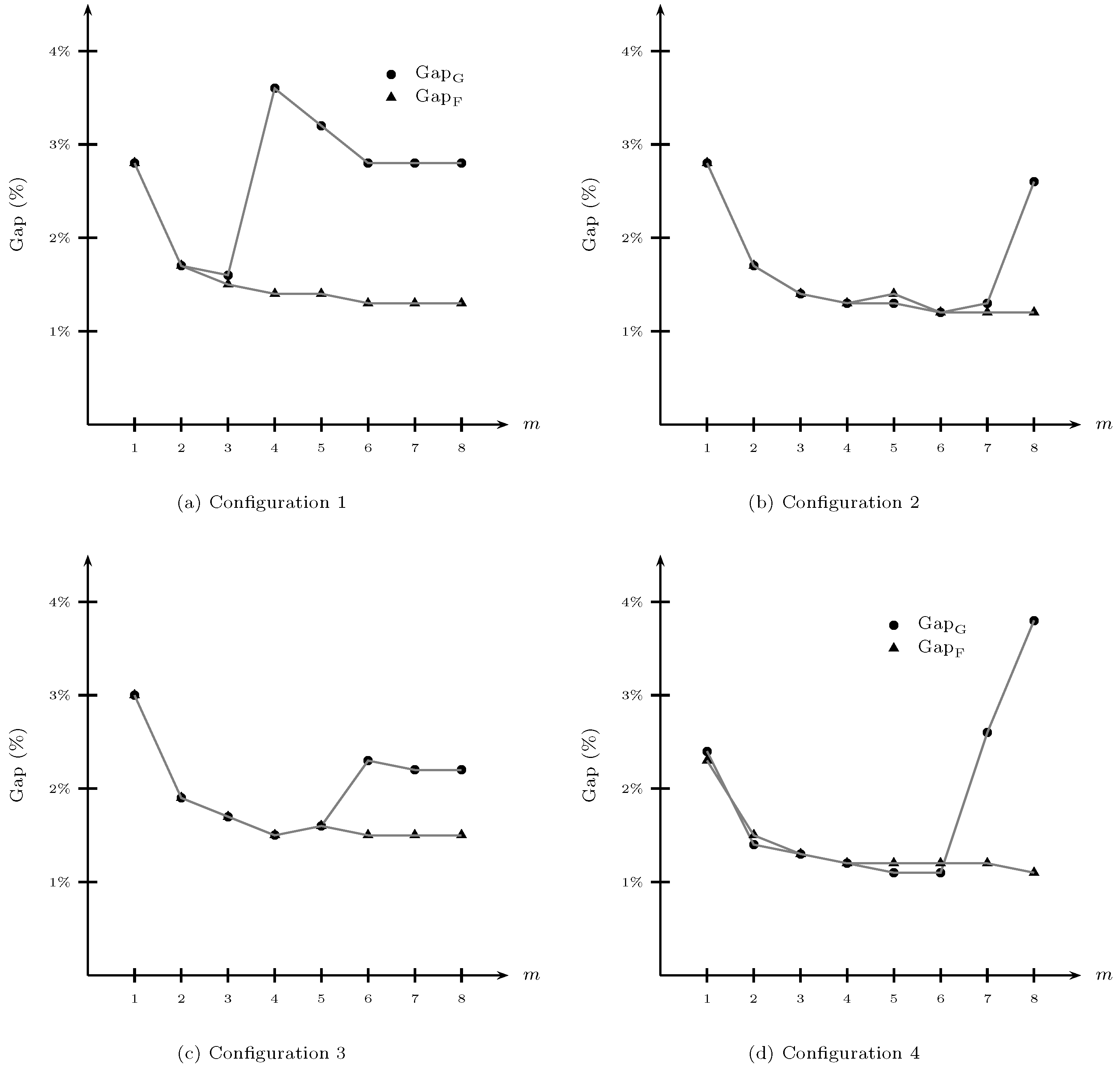
Figure 2 shows, for each demand configuration, the average relative optimality gap of the feasible solution,
, resulting from the SAA method and using the
model with
, under the GP and FLP policies.
From
Figure 2, we observe that the average optimality gap of the feasible solution
is decreasing with
m under a GP policy. Furthermore, the magnitude of the average optimality gap under the GP policy does not vary with the demand configurations. On the other hand, the average optimality gap under the FLP policy decreasesand then increases with
m. The inflection coincides, for each demand configuration, with the inflection of the benefit of grouping customer classes into different numbers of classes (
Figure 1).
We observe that the SAA method has a good performance in terms of solving the greedy and fixed-list service level problems because the maximum optimality gap is
and
under GP and FLP policies, respectively.
Table A2 in
Appendix G contains the average and maximum optimality gap for each demand configuration and priority policy.
8. Conclusions
This paper studies the effect that the number of customer classes has on the order quantity under a single-period inventory system with stochastic demand and individual service-level requirements from multiple customer classes. We formulated multi-customer class service-level problems under greedy and fixed-list priority policies as nonlinear problems with chance constraints. These problems are difficult to solve for more than three customer classes. Consequently, we have proposed a reformulation of models as MIP using a Sample Average Approximation approach, which allowed us to obtain results for up to eight customer classes in reasonable computational times. The computational results show that the Sample Average Approximation method is able to identify good-quality solutions because, for the tested instances, the maximum optimality gap was 4.8%, which is a very good solution.
To determine the effect of the number of customer classes on the inventory level under greedy and fixed-list priority policies, we considered a round-up aggregation scheme that does not harm the service level of the aggregated classes. Under such a policy, the variation in the order quantity when grouping the customers into different numbers of customer classes is caused by the free-rider classes (free-rider effect) and by the aggregation rule (cluster effect).
Under a low-service-level-first-rule round-up aggregation scheme, several properties of the models were proven, from which we obtained the following managerial insights.
Under greedy and fixed-list priority policies, grouping all customer classes in a single class with the highest preset service level induces the largest optimal order quantity. Therefore, grouping customers into more than one class has a positive effect on the order quantity.
The order quantity induced by the fixed-list priority policy is non-increasing with the number of customer classes.
The order quantity induced by the greedy and fixed-list priority policies is non-decreasing with the number of free-rider classes.
We conducted several test problems under low-service-level-first-rule round-up aggregation scheme and different demand configurations of customer classes, from which we observed the following managerial insights.
When the high-priority classes dominate demand and customers are grouped into strictly more than four classes, the fixed-list priority policy performs better than the greedy priority policy; i.e., allocating resources under greedy priority policy is not always better than that of the fixed-list priority policy.
When the low-priority classes dominate demand, the greedy priority policy always performs better than the fixed-list priority policy.
Under greedy and fixed-list priority policies, the optimal number of customer classes is greater than or equal to four classes. Therefore, for the instances we tested, it was not optimal to group the customers into two or three customer classes using, for example, Pareto or ABC classification.
When high-priority classes dominate demand, the total variation of the order quantity, when grouping customers into different numbers of customer classes under greedy priority policy is totally caused by the cluster effect. For other demand configurations, the total variation in the order quantity is caused by cluster and free-rider effects.
Under greedy priority policy, the total variation of the order quantity when grouping customers into the optimal number of customer classes is totally caused by the cluster effect because, under the same number of customer classes, the free-rider effect is null.
Under the fixed-list priority policy, the total variation of the order quantity when grouping customers into different numbers of customer classes is totally caused by the free-rider effect because the cluster effect is null under fixed-list policy.
When the high-priority classes dominate demand, greedy priority policy is absolutely robust in the number of free-rider classes because there is no variation in the order quantity by increasing the number of free-rider classes.
In this way, we have answered the research questions posed at the beginning of this document. A brief response for each research question is the following. (i) How does the number of customer classes affect the inventory level under different priority policies? From
Figure 1, we can see that under the greedy priority policy, the inventory level depends on the demand configuration, having in all configurations a number of classes that minimizes the inventory level. Here there is no monoticity. Under a fixed-list priority policy, the inventory level is non-increasing in the number of classes for all the configurations. (ii) What is the optimal number of customer classes under different demand configurations? According to
Figure 1, for the greedy priority policy, the optimal number depends on the configuration of the demand, but we can observe that when the demand is dominated by the high-priority classes (configuration 1), the optimal number of classes is smaller than when the demand is dominated by the low-priority classes (configuration 2). For the fixed-list priority approach, the optimal number is always the maximum number of classes that can be had. (iii) What priority policy performs better under different demand configurations? When the high-priority classes dominate in terms of demand (configuration 1) and the customer classes are strictly grouped into more than four classes, the fixed-list priority policy performs better than the greedy priority policy. When the low-priority classes dominate in terms of demand (configuration 2), the greedy priority policy always performs better than the fixed-list priority policy.
There are two main questions left for future research. The first one is to determine the best aggregation rule under a round-up scheme because the low-service-level-first-rule is not the only aggregation rule under a round-up scheme. Other aggregation rules include the high-service-level-first-rule and the random-rule. The second issue is to determine how different priority policies, such as the
largest-debt-first policy of Zhong et al. [
9] or the
max-weighted-service policy of Jiang et al. [
12], affect the number of customer classes in a single-period inventory system. A final issue is to address the risk of using responsive priority policies because, under these types of policies, the priority list in case a shortage is not previously known by customers or offers.
Finally, this contribution is intended to be useful for managers seeking guidelines for grouping their customers, as well as for academics seeking to investigate the performance of different configurations of customer service policies.


 ,
, 
{kind=link}
{kind=link}