1. Introduction
Tensors are high-dimensional arrays that have many applications in science and engineering, including in image, video and signal processing, computer vision, and network analysis [
1,
2,
3,
4,
5,
6,
7,
8]. A new t-product based on third-order tensors was proposed by Kilmer et al. [
9,
10]. When using high-dimensional data, t-product shows a greater potential value than matricization; see [
1,
2,
10,
11,
12,
13,
14,
15,
16]. Compared to other products, the t-product preserves the inherent natural order and higher correlation embedded in the data, avoiding the loss of intrinsic information during the flattening process of the tensor; see [
10]. The t-product has been found to have special value in many application fields, including image deblurring problems [
1,
2,
9,
11], image and video compression [
8], facial recognition problems [
10], etc.
The t-product is widely used in image and video restoration problems; see, e.g., [
1,
2,
9]. In this paper, we consider the solution of large minimization problems of the form
Tensor
has a tubal rank that is difficult to determine, and many of its singular tubes are non-zero and have tiny Frobenius norms of different orders of magnitude. As the exponent increases, the Frobenius norms of these singular tubes rapidly decay to zero. Then, Problems (
1) are called the tensor discrete linear ill-posed problems.
We assume that
is derived from an unknown and unavailable tensor
polluted by noise
,
We have
represent a clear solution to Problem (
1) to be found and obtain
through
. We assume that the upper bound of the Frobenius norm of
is known,
A straightforward solution of (
1) is usually meanless to obtain an approximation of
because of the illposeness of
and because error
is amplified severely. The Tikhonov regularization method is a mathematical approach proposed by Tikhonov [
17] to address ill-posed problems. This method introduces a regularization term into the objective function, modeling the properties of the solution based on prior information. This serves to constrain the solution space, enhancing the stability of the problem. Therefore, we consider the application of the Tikhonov regularization method to address Problems (
1) and subsequently proceed to solve the problems formulated in the manner of
where
is a regularization parameter. We refer to (
4) as the tensor penalty least-squares problems. We assume that
where
denotes the null space of
,
is the identity tensor and
is a lateral slice whose elements are all zero. The normal equation of (
4) is represented by
and under the condition given in (
5), it admits a unique solution
There are many techniques to determine regularization parameter
, such as the L-curve criterion, generalized cross-validation (GCV), and the discrepancy principle. We refer to [
18,
19,
20,
21,
22] for more details. In this paper, the discrepancy principle is extended to tensors based on t-product and is employed to determine a suitable
in (
4). The solution
of (
4) satisfies
where
is usually a user-specified constant and is independent of
in (
3). When
is small enough, and
approaches 0, it results in
. For more details regarding the discrepancy principle, please refer to [
23].
In this paper, we additionally explore the extension of the minimization problems represented by (
1), where the formulation takes the form
where
,
.
In recent literature addressing discrete ill-posed Problems (
1), the prevailing methodologies predominantly feature the application of Tikhonov regularization and truncated singular value methods. Reichel et al. confronted Problems (
4) through the application of a subspace construction technique, thereby mitigating the inherent challenges of large-scale regularization problems by effecting a transformation into a more tractable smaller-scale formulation. As a result, they introduced the tensor Arnoldi–Tikhonov (tAT), GMRES-type methods (tGMRES) [
2] and the tensor Golub–Kahan–Tikhonov method (tGKT) [
1]. The truncated tensor singular value decomposition (T-tSVD) was introduced by Kilmer et al. and colleagues in [
9]. Zhang et al. introduced the method of randomized tensor singular value decomposition (rt-SVD) in their work [
24]. This method exhibits notable advantages in handling large-scale datasets and holds significant potential for applications in image data compression and analysis. Ugwu and Reichel [
25] proposed a new random tensor singular value decomposition (R-tSVD), which improves T-tSVD.
The conjugate gradient method (CG), initially proposed in [
26], is well-suited for addressing large-scale problems, particularly in scenarios requiring multiple iterations. Compared to alternative methods, it demonstrates a relatively faster convergence rate. The method’s favorable characteristic of low memory requirements renders it suitable for efficiently handling extensive datasets or high-dimensional problems. Detailed discussions on this approach can be found in the literature, as referenced in [
26,
27,
28,
29,
30]. Song et al. [
31] proposed a tensor conjugate gradient method for automatic parameterization in the Fourier domain (A-tCG-FFT). The A-tCG-FFT method projects Problems (
1) into the Fourier domain and uses the CG method that preserves the matrix structure for computation. The solution obtained by the A-tCG-FFT method is of higher quality than the solution obtained by directly matrix or vectorizing the data. The tensor Conjugate Gradient (t-CG) method proposed by Kilmer et al. [
10] is employed to address Problem (
4), where the regularization parameter is user specified. In this article, we extend our work on the tCG method from [
10] and utilize the discrepancy principle for automatic parameter estimation. The proposed method is called the tCG method with automatical determination of regularization parameters (auto-tCG). We also present a truncated auto-tCG method (auto-ttCG) to improve the auto-tCG method by reducing the computation. At last, a preprocessed version of the auto-ttCG method is proposed, which is abbreviated as auto-ttpCG. We remark that the auto-tCG, auto-ttCG, and auto-ttpCG methods are quite different from the methods in [
31] because the former do not need to project the problems (
1) into the Fourier domain and could maintain the t-product structure of tensors during the iteration process.
The remainder of this manuscript is structured as follows:
Section 2 provides an introduction to relevant symbols and foundational concepts essential for the ensuing discussion. In
Section 3, we expound upon the auto-tCG, auto-ttCG, and auto-ttpCG methodologies designed to address minimization Problems (
4) and (
9). Subsequently,
Section 4 illustrates various examples pertaining to image and video restoration, while
Section 5 encapsulates concluding remarks.
2. Preliminaries
This section provides notations and definitions, offering a concise overview of relevant results that are subsequently applied in the ensuing discourse.
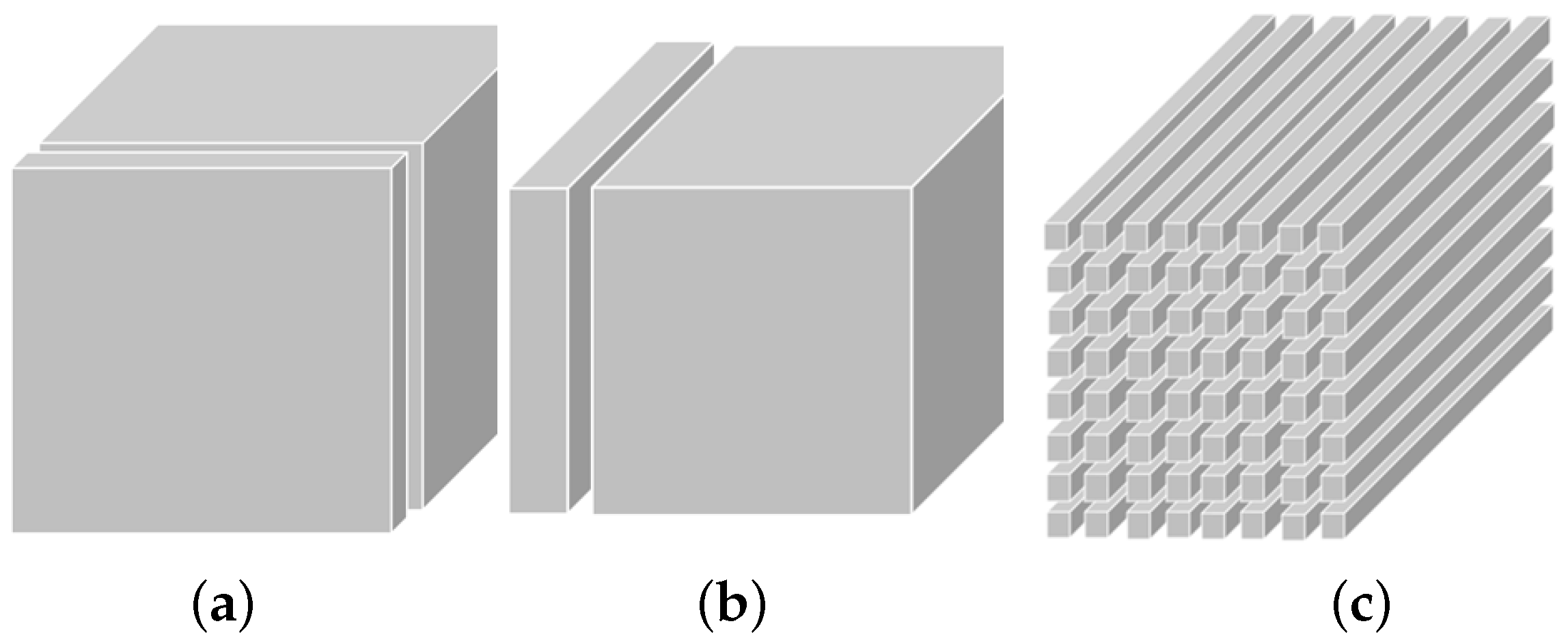
Figure 1 illustrates the frontal slices (
), lateral slices (
), and tube fibers (
).
In this manuscript, we employ two operators,
and
. The operator
unfolds the tensor into a matrix of dimensions
, while
serves as the inverse of
folding the matrix back into its original three-order tensor form. For clarity of exposition, we denote matrix
specifically as the
kth frontal slice of third-order tensor
, i.e.,
. We have
The forthcoming definitions and remarks, introduced herein, are utilized in the subsequent theoretical proofs.
Definition 1. Assuming is a third-order tensor, the block-circulant matrix is defined as follows: Definition 2 ([
9])
. Given two tensors and , the t-product is defined aswhere . Remark 1 ([
32])
. For any two tensors and for which the t-product is defined, they satisfy(1). .
(2). .
(3). .
We define tensor
obtained by applying the Fast Fourier Transform (FFT) along each tube of
, i.e.,
where ⊗ is the Kronecker product, and matrix
represents the conjugate transpose of the n-by-n unitary discrete Fourier transform matrix
. The structure of
is defined as follows:
where
. Thus the t-product in (
10) can be represented as
and (
10) is reformulated as
It is easy to calculate (
12) in MATLAB.
For a non-zero tensor
, we can decompose it in the form
where
is a normalized tensor; see, e.g., ref. [
11], and
is a tube scalar. Algorithm 1 summarizes the decomposition in (
14).
| Algorithm 1 Normalization |
Input: is a nonzero tensor Output:, with , fft(,[ ],3) for
do ( is a vector) if then else ; ; ; end if end for ifft(,[ ],3); ifft(,[ ],3)
|
Given tensor
, the singular value decomposition (tSVD) of
is expressed as
where
and
are orthogonal under the t-product;
is an upper triangular tensor with the singular tubes
satisfying
Algorithm 2 introduces the tensor Conjugate Gradient (t-CG) method, presented in [
11], for solving the least squares solution of the tensor linear systems (
1).
| Algorithm 2 The tCG method for sloving (4). |
Input: , . Output: Approximate solution of Problem ( 4). . Normalize; . for until do . . . . end for
|
The operators
and
[
11] are expressed by
Figure 2 illustrates the transformation between a matrix and a tensor column by using
and
. Generally, operators
and
are defined for a third-order tensor to make it squeezed or twisted. For tensor
with
,
means that all side slices of
are squeezed and stacked as front slices of
, the operator
is the reverse operation of
. Thus,
. We refer to
Table 1 for more notations and definitions.
4. Numerical Examples
This section presents three illustrative examples showcasing the application of Algorithms 3, 4 and 6 in the context of image and video restoration. All computations are executed using MATLAB R2018a on computing platforms equipped with Intel Core i7 processors and 16 GB of RAM.
We suppose
is the
kth approximate solution to Minimization problem (
9). The quality of the approximate solution
is defined by the relative error
and the signal-to-noise ratio (SNR)
where
represents the uncontaminated data tensor and
is the average gray-level of
. The observed data,
, in (
9) is contaminated by a “noise” tensor
, i.e.,
.
is determined as follows. We let
be the
jth transverse slice of
, whose entries are scaled and normally distributed with a mean of zero, i.e.,
where the data of
is generated according to N(0, 1).
Example 1 (Gray image)
. This illustration concerns the restoration of the blurred and noisy image of the cameraman
with a size of . For operator , its front slices are generated by using the MATLAB function blur
, i.e., with , and . The condition numbers of are , while he condition numbers of the remaining slices are infinite. We let denote the original undaminated cameraman
image. The operator converts into tensor column for storage. The noised tensor is generated by (36) with different noise level . The images characterized by blurring and noise are generated through the mathematical expression . The auto-tCG, auto-ttCG and auto-ttpCG methods are used to solve tensor discrete linear ill-posed Problems (
1). The discrepancy principle is utilized to ascertain an appropriate regularization parameter and set
,
,
. We set
in (
8).
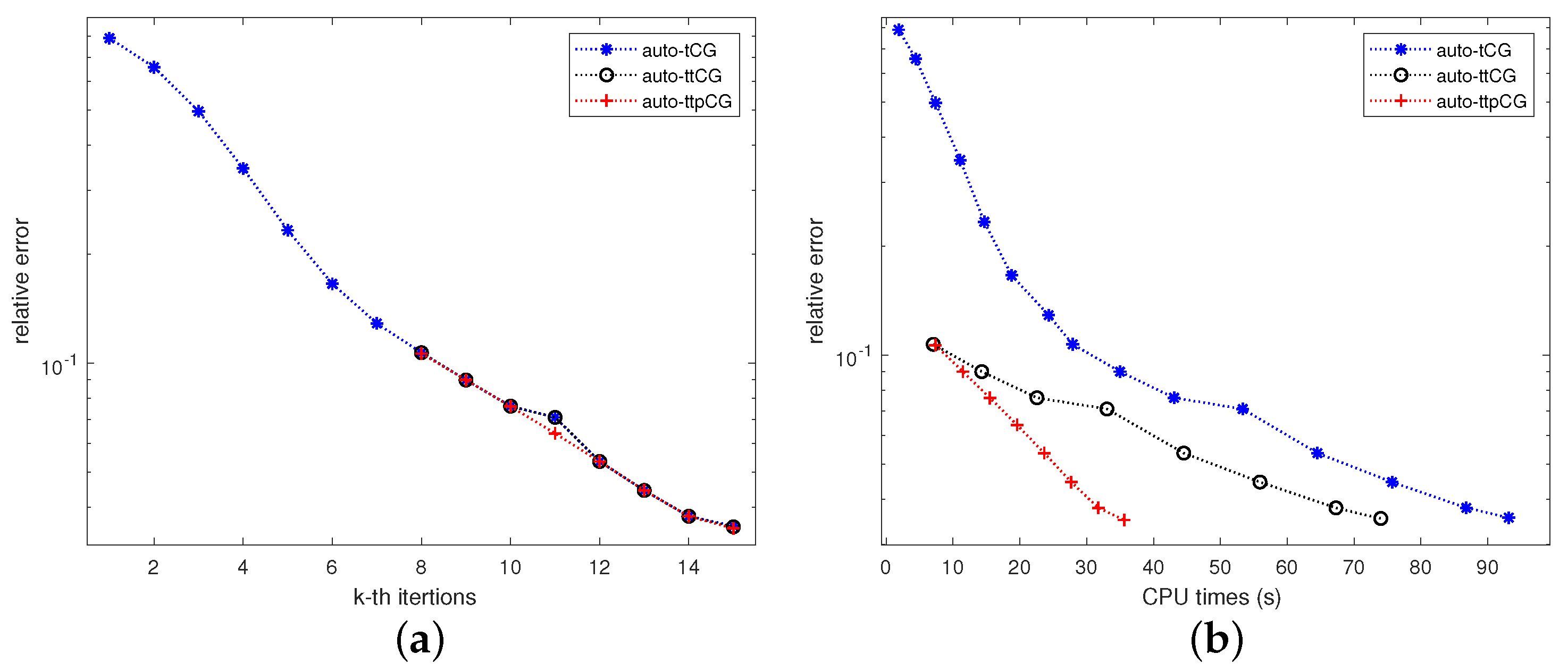
Figure 3 shows the convergence of relative errors verus (a) the iteration number
k and (b) the CPU time for the tCG, auto-tCG, auto-ttCG and auto-ttpCG methods with the noise level
corresponding in
Table 2. The iteration process is terminated when the discrepancy principle is satisfied. From
Figure 3a, we can see that the auto-ttCG and auto-ttpCG methods do not need to solve the normal equation for all
. This shows that the auto-ttCG and auto-ttpCG methods improve the auto-tCG method by Condition (
24).
Figure 3b shows that the auto-ttpCG method converges fastest among three methods.
Table 2 lists the regularization parameter, the iteration number, the relative error, SNR and the CPU time of the optimal solution obtained by using the tCG, A-tCG-FFT, A-CGLS-FFT, A-tpCG-FFT, auto-tCG, auto-ttCG and auto-ttpCG methods with different noise levels
. The determination of the regularization parameter for the tCG method involved conducting several experiments to obtain a more appropriate value. The CPU time represents only the usage in a single CG process.
The image restoration experiment of Example 1, the A-tCG-FFT, A-CGLS-FFT, and A-tpCG-FFT methods proposed by Song et al. [
31] project the t-product into the Fourier domain and solve 256 ill-posed problems in matrix form, respectively. In Song et al.’s setting, when the frontal slice is small, the time required is very small. In the setting of our article, the number of frontal slices is related to the size of the image. As the number of frontal slices increases, the time cost increases. The calculation process of auto-tCG, auto-ttCG and auto-ttpCG methods always maintains the tensor t-product structure, resulting in higher quality image restoration in the end. The quality of the regularization solution obtained by the auto-tCG surpasses that of the solution obtained by the tCG method. It can be seen from
Table 2 that the auto-ttpCG method has the lowest relative error, highest SNR and the least CPU time for different noise level.
Figure 4 shows the reconstructed images obtained by using the tCG, A-tCG-FFT, A-CGLS-FFT, auto-tCG, auto-ttCG and auto-ttpCG methods on the blurred and noised image with the noise level
in
Table 2. From
Figure 4, we can see that the restored image by the auto-ttpCG method looks a bit better than others but with the least CPU time. The image restoration performance of the tCG method is inferior to three conjugate gradient methods with automatically determined parameters.
Example 2 (Color image)
. This example illustrates the restoration of a blurred color image using Algorithms 3, 4 and 6. The original image is stored as a tensor through the MATLAB function . We set and band = 12, and obtain byThen, , and the condition number of other tensor slices of is infinite. The noise tensor is defined by (36). The blurred and noised tensor is derived by , which is shown in Figure 5b. We set color image
to be divided into multiple lateral slices and independently process each slice through (
1) by using the tCG, auto-tCG, auto-ttCG and auto-ttpCG methods.
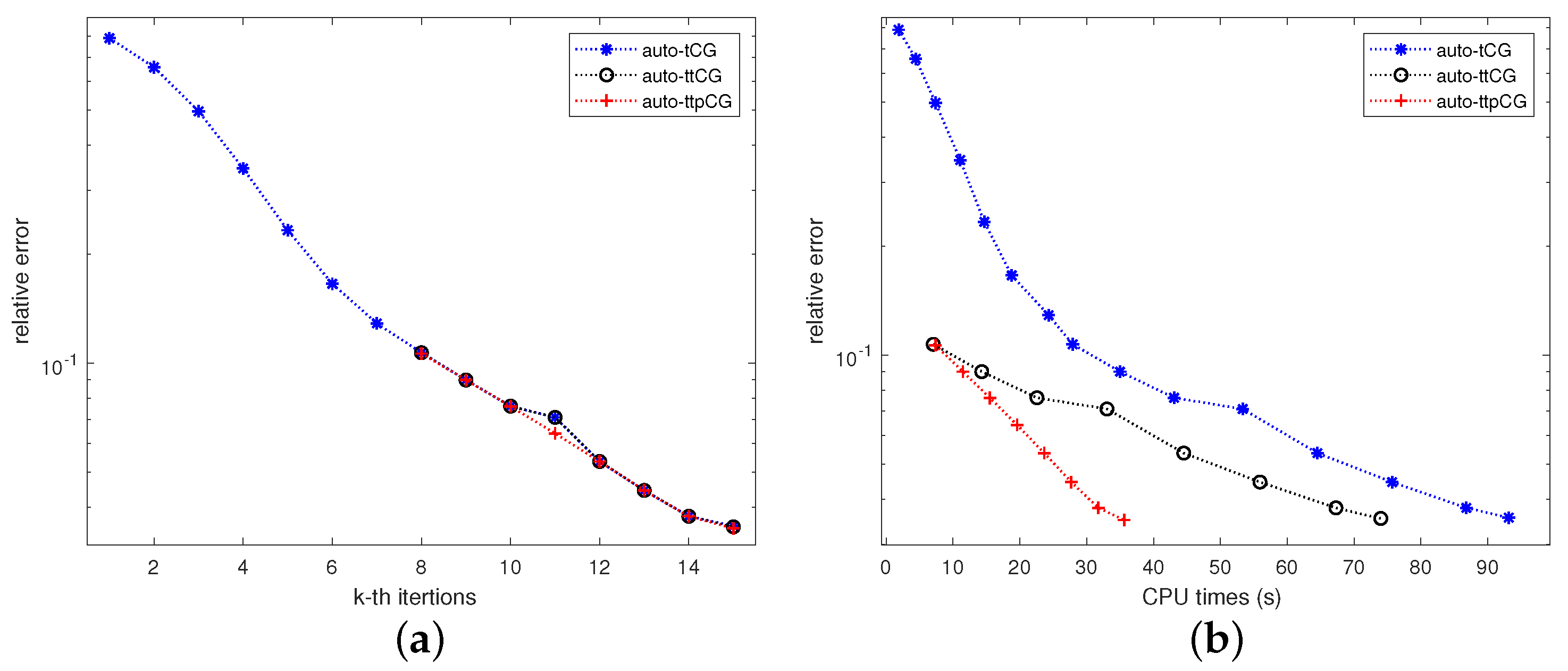
Figure 6 shows the convergence of relative errors verus (a) the iteration number
k and (b) the CPU time for the auto-tCG, auto-ttCG and auto-ttpCG methods when dealing with the first tensor lateral slice
of
with
. Similar results can be derived as that in Example 1 from
Figure 6. We can see that the auto-ttCG and auto-ttpCG methods need less iterations than the auto-tCG method from
Figure 6a and the auto-ttpCG method converges fastest among all methods from
Figure 6b.
Table 3 lists the relative error, SNR and the CPU time of the optimal solution obtained by using the tCG, A-tCG-FFT, A-CGLS-FFT, A-tpCG-FFT, auto-tCG, auto-ttCG and auto-ttpCG methods with different noise levels
. The results are very similar to that in
Table 2 for different noise levels. In the application of the tCG method, we define distinct regularization parameters, specifically setting
when
, and
when
. The regularization parameter set for the tCG method has been determined through multiple iterations, yielding a reasonably suitable value. However, when applying tCG to solve Problem (
9) corresponding to other regularization parameters attempted during this process, divergence or excessively large relative errors are commonly observed. When the condition number for frontal slicing is larger, the condition number for the matrix projected into the Fourier domain also increases, which leads to increased ill-posedness and results in more CPU time for the A-tCG-FFT, A-CGLS-FFT and A-tpCG-FFT methods to obtain regularization parameters. The quality of the solutions obtained by the tCG method is inferior to that of the other three versions with automatic parameter tuning. However, the CPU time used by the tCG method is shorter than the other three methods. This is because it only represents the time spent solving a regularized equation, whereas the process of manually selecting regularization parameters would consume more time.
Table 3 also reflects the advantages of both truncation parameters and preprocessing operations.
Figure 5 shows the recovered images by the tCG, A-tCG-FFT, A-CGLS-FFT, auto-tCG, auto-ttCG and auto-ttpCG methods corresponding to the results with noise level
. The results are very similar to that in
Figure 5.
Example 3 (Video)
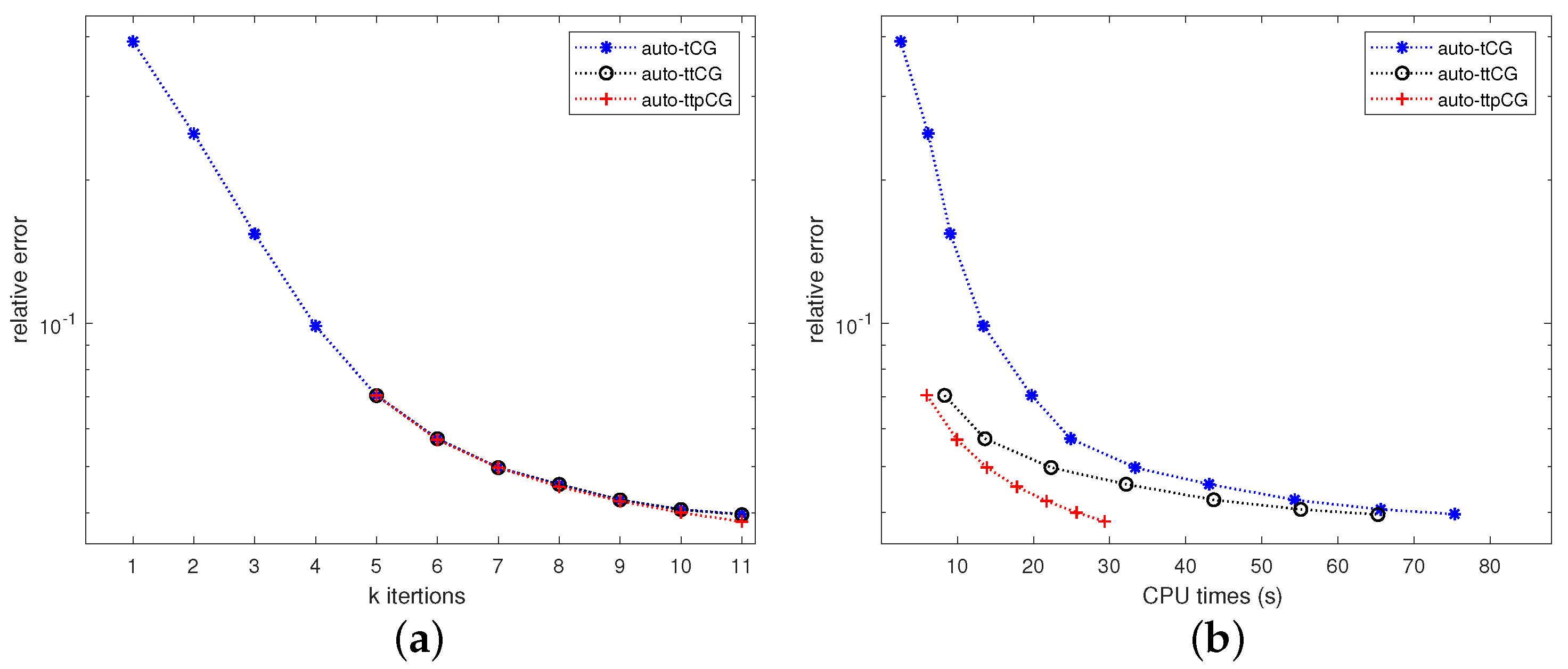
. In this example, we employ three distinct reconstruction methods on MATLAB to recover the initial 10 consecutive frames of the blurred and noisy video, with each frame containing pixels. We store ten frames devoid of pollution and noise from the original video in the tensor . We let z be defined by (37) with , and . The coefficient tensor is defined as follows:The condition number of the frontal slices of is , and the condition number of the remaining frontal sections of is infinite. The suitable regularization parameter is determined by using the discrepancy principle with . The blurred and noised tensor is generated by with being defined by (36). Figure 7 shows the convergence of relative errors verus the iteration number
k and relative errors verus the CPU time for the auto-tCG, auto-ttCG and auto-ttpCG methods when the second frame of the video with
is restored. Very similar results can be derived from
Figure 7 to that in Example 1.
Table 4 displays the relative error, SNR and the CPU time of the optimal solution obtained by using the tCG, the A-tCG-FFT, A-CGLS-FFT, A-tpCG-FFT, auto-tCG, auto-ttCG and auto-ttpCG methods for the second frame with different noise levels
,
. In video restoration experiments with continuous frames, using the A-tCG-FFT, A-CGLS-FFT, A-tpCG-FFT methods to perform matrix calculations in the Fourier domain may cause a certain degree of damage to the spatial structure that may exist between consecutive frames, resulting in a decrease in restoration quality. When employing the tCG method, we configured distinct regularization parameters, specifically, when
,
; and when
,
. With the increase in data volume, the auto-tCG method demonstrates better solution quality compared to the tCG method. Additionally, the truncation parameter operation and preprocessing strategy exhibit superior solution quality and time advantages over auto-tCG. We can see that the auto-ttpCG method has the largest SNR and the lowest CPU time for different noise level
.
Figure 8 shows the original video, blurred and noised video, and the recovered video of the second frame of the video for the tCG, A-tCG-FFT, A-CGLS-FFT, A-tCG-FFT, A-CGLS-FFT, auto-tCG, auto-ttCG and the auto-ttpCG methods with noise level
corresponding to the results in
Table 4. The recovered frame by the auto-ttpCG method looks best among all recovered frames.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}