Correction: Demidova, L.A. A Novel Approach to Decision-Making on Diagnosing Oncological Diseases Using Machine Learning Classifiers Based on Datasets Combining Known and/or New Generated Features of a Different Nature. Mathematics 2023, 11, 792


{kind=link}
{kind=link}
{kind=link}

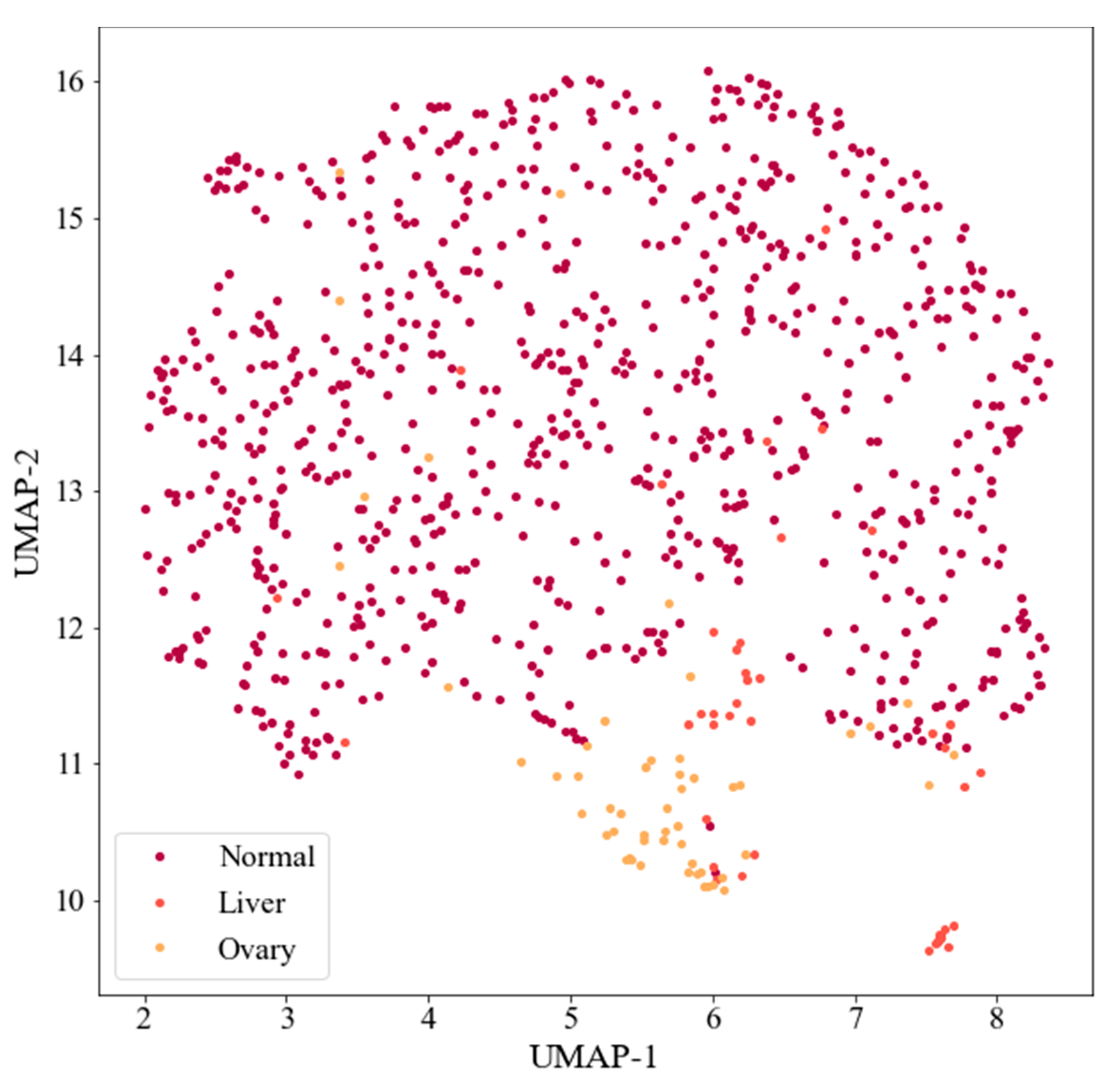
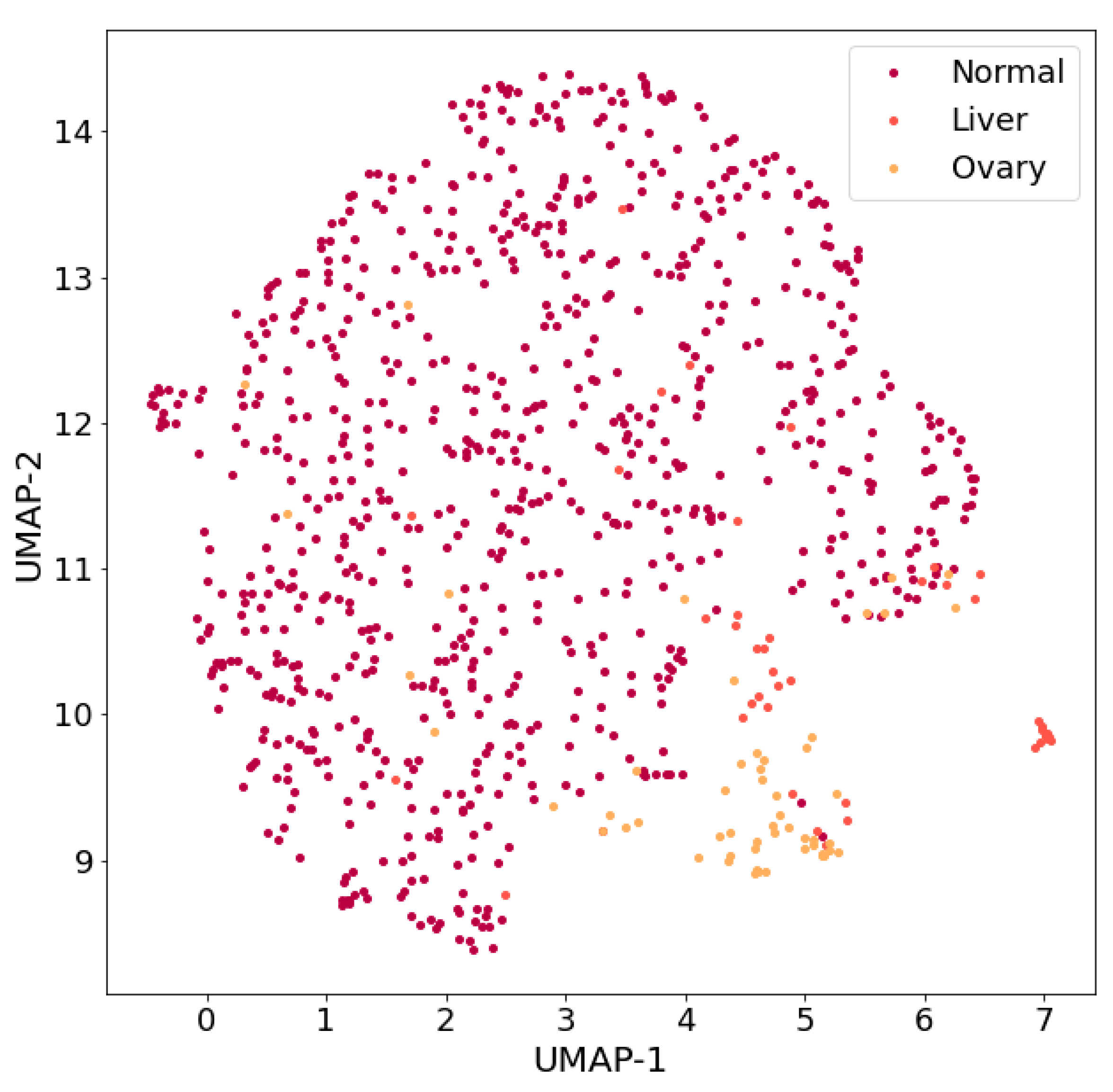
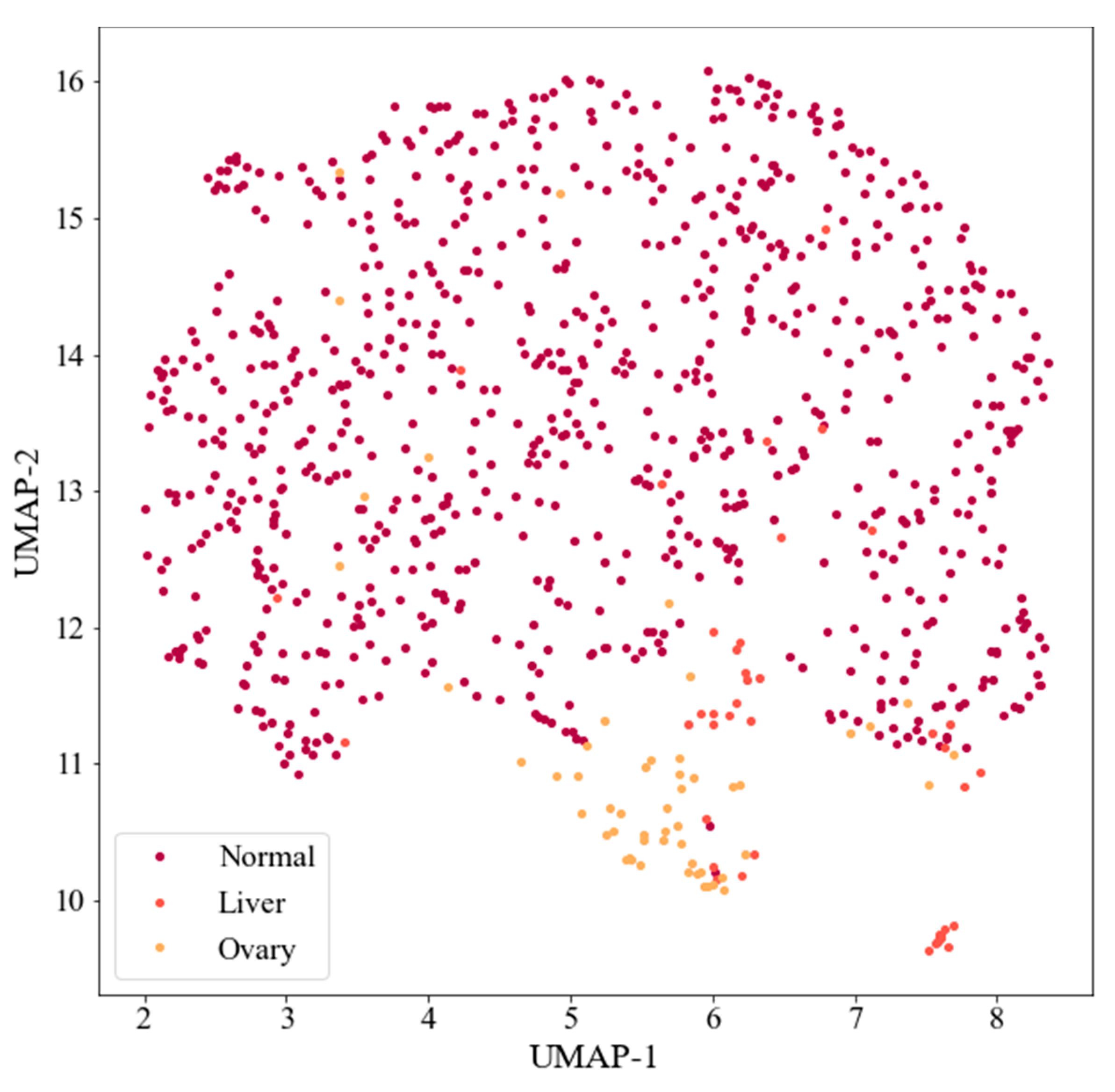
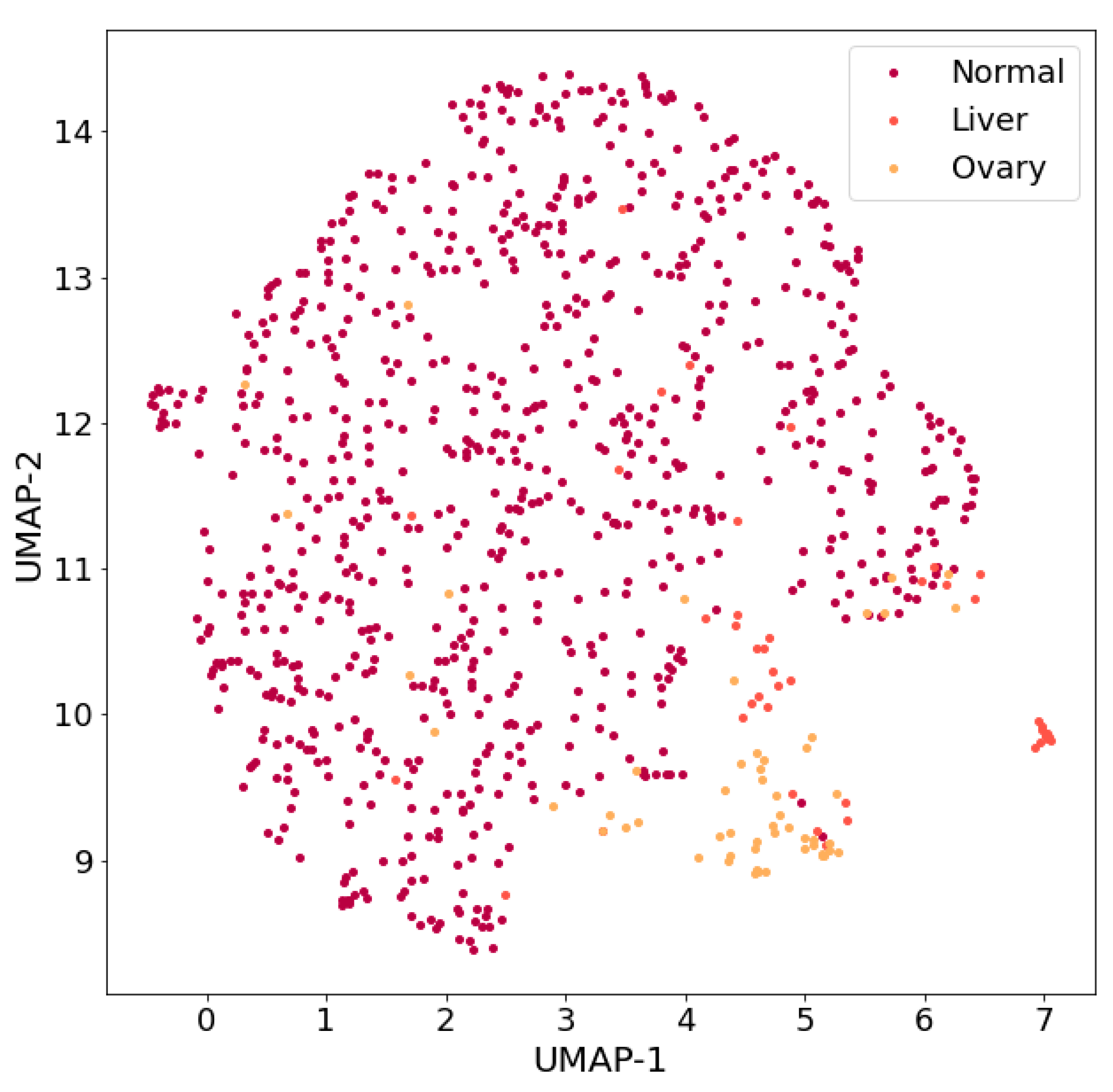
- “Approaches using various class balancing algorithms that implement oversampling technologies (for example, SMOTE algorithm (Synthetic Minority Oversampling Technique) [21–23], ADASYN algorithm (Adaptive Synthetic Sampling Approach) [24], undersampling (for example, Tomek Links algorithm) [23,25]) and their combinations;”
- “Approaches using various class balancing algorithms that implement oversampling technologies (for example, SMOTE algorithm (Synthetic Minority Oversampling Technique) [21–23], ADASYN algorithm (Adaptive Synthetic Sampling Approach) [24]), undersampling technologies (for example, Tomek Links algorithm) [23,25] and their combinations;”
Reference
- Demidova, L.A. A Novel Approach to Decision-Making on Diagnosing Oncological Diseases Using Machine Learning Classifiers based on Datasets Combining Known and/or New Generated Features of a Different Nature. Mathematics 2023, 11, 792. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Demidova, L.A. Correction: Demidova, L.A. A Novel Approach to Decision-Making on Diagnosing Oncological Diseases Using Machine Learning Classifiers Based on Datasets Combining Known and/or New Generated Features of a Different Nature. Mathematics 2023, 11, 792. Mathematics 2023, 11, 2150. https://doi.org/10.3390/math11092150
Demidova LA. Correction: Demidova, L.A. A Novel Approach to Decision-Making on Diagnosing Oncological Diseases Using Machine Learning Classifiers Based on Datasets Combining Known and/or New Generated Features of a Different Nature. Mathematics 2023, 11, 792. Mathematics. 2023; 11(9):2150. https://doi.org/10.3390/math11092150
Chicago/Turabian StyleDemidova, Liliya A. 2023. "Correction: Demidova, L.A. A Novel Approach to Decision-Making on Diagnosing Oncological Diseases Using Machine Learning Classifiers Based on Datasets Combining Known and/or New Generated Features of a Different Nature. Mathematics 2023, 11, 792" Mathematics 11, no. 9: 2150. https://doi.org/10.3390/math11092150
APA StyleDemidova, L. A. (2023). Correction: Demidova, L.A. A Novel Approach to Decision-Making on Diagnosing Oncological Diseases Using Machine Learning Classifiers Based on Datasets Combining Known and/or New Generated Features of a Different Nature. Mathematics 2023, 11, 792. Mathematics, 11(9), 2150. https://doi.org/10.3390/math11092150