

Constrained Self-Adaptive Physics-Informed Neural Networks with ResNet Block-Enhanced Network Architecture


Abstract
1. Introduction
- We develop a constrained self-adaptive physics-informed neural network (cSPINN), which had better accuracy in numerical results. Meanwhile, the dynamics of residual weights changed more steadily during the training process.
- To better capture the solution with sharp transitions in the physical domain, we develop a ResNet block-enhanced modified MLP architecture, which also has the ability to tackle the vanishing gradient problem using identity mapping, even for deep architectures.
2. Related Works
2.1. Model Problem
2.2. PINNs Formulation
3. Formulation of Constrained Self-Adaptive PINNs (cSPINNs)
3.1. Constrained Self-Adaptive Weighting Scheme
3.2. ResNet Block-Enhanced Modified Network
4. Numerical Experiments
4.1. 1D Allen–Cahn Equation
- The constrained self adaptive loss for the residual of the governing equation
- Mean squared loss on the initial condition
- Mean squared loss on the boundary conditionwhere is the prediction of neural network and we sampled = 25,600 residual points, boundary points and points on the initial condition. Here, we used the Adam optimizer with 10,000 epochs and L-BFGS optimizer with 1000 epochs to optimize the network architecture. During the training process, we set the boundary weight and the initial weight , which could help expedite the convergence. Figure 4 shows the numerical results of constrained self-adaptive PINNs(cSPINNs) compared with the reference solution obtained through the Chebfun method [29] and the training loss history. The relative error was 1.472 × 10, which was better than the time-adaptive approach in [7] and the original PINNs [1].
4.2. 1D Viscous Burgers’ Equation
- The constrained self adaptive loss for the residual of the governing equation
- Mean squared loss on the initial condition
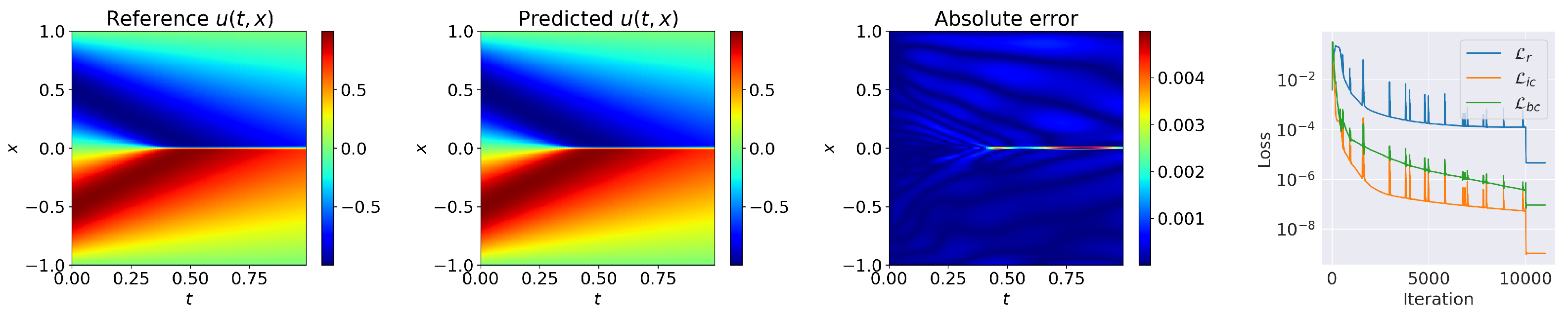
- Mean squared loss on the boundary conditionsHere, we trained the network with a constrained self-adaptive scheme and was the prediction of neural network. In this case, we sampled = 25,600 residual points, boundary points and points on the initial condition. We set the weights of initial condition and boundary condition as . Training was performed using 10,000 Adam iterations and 1000 L-BFGS epochs. The predicted solution of cSPINNs, and loss history are shown in Figure 5. Despite a sharp transition in the center of the domain, the solution of cSPINNs was still accurate in the whole domain, yielding a relative error of 4.796 × 10.
4.3. 2D Helmholtz Equation
- The constrained self adaptive loss for the residual of the governing equation
- Mean squared loss on the boundary conditions
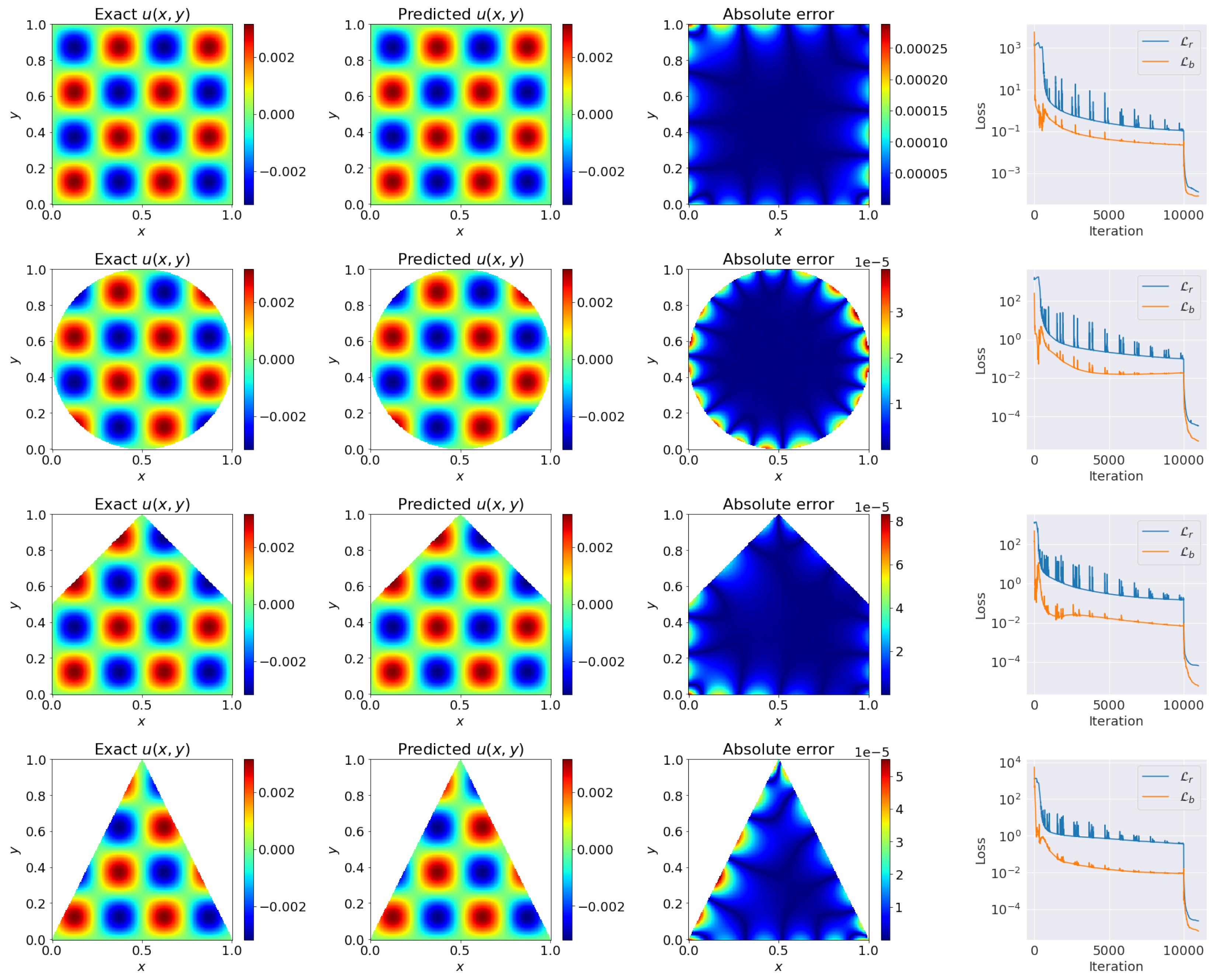
4.4. 2D Poisson Equation on Different Geometries
- The constrained self adaptive loss for the residual of the governing equation:
- Mean squared loss on the boundary conditions (Taking the rectangular area as example):
- The constrained self adaptive loss for the residual of the governing equation
- Mean squared loss on the boundary condition
4.5. High Dimensional Poisson Equation
- The constrained self adaptive loss for the residual of the governing equation:
- Mean squared loss on the boundary condition:
5. Conclusions and Future
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Raissi, M.; Perdikaris, P.; Karniadakis, G. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. J. Comput. Phys. 2019, 378, 686–707. [Google Scholar] [CrossRef]
- Raissi, M.; Perdikaris, P.; Karniadakis, G.E. Physics Informed Deep Learning (Part II): Data-driven Discovery of Nonlinear Partial Differential Equations. arXiv 2017, arXiv:1711.10566. [Google Scholar]
- Song, C.; Alkhalifah, T.; Waheed, U.B. Solving the frequency-domain acoustic VTI wave equation using physics-informed neural networks. Geophys. J. Int. 2021, 225, 846–859. [Google Scholar] [CrossRef]
- Zheng, X.; Yazdani, A.; Li, H.; Humphrey, J.D.; Karniadakis, G.E. A three-dimensional phase-field model for multiscale modeling of thrombus biomechanics in blood vessels. PLoS Comput. Biol. 2020, 16, e1007709. [Google Scholar] [CrossRef] [PubMed]
- Yin, M.; Zheng, X.; Humphrey, J.D.; Karniadakis, G.E. Non-invasive inference of thrombus material properties with physics-informed neural networks. Comput. Methods Appl. Mech. Eng. 2021, 375, 113603. [Google Scholar] [CrossRef]
- Sahli Costabal, F.; Yang, Y.; Perdikaris, P.; Hurtado, D.E.; Kuhl, E. Physics-informed neural networks for cardiac activation mapping. Front. Phys. 2020, 8, 42. [Google Scholar] [CrossRef]
- Colby, L.; Wight, J.Z. Solving Allen-Cahn and Cahn-Hilliard Equations using the Adaptive Physics Informed Neural Networks. arXiv 2020, arXiv:2007.04542. [Google Scholar]
- Nabian, M.A.; Gladstone, R.; Meidani, H. Efficient training of physics-informed neural networks via importance sampling. arXiv 2021, arXiv:2104.12325. [Google Scholar] [CrossRef]
- Wang, S.; Teng, Y.; Perdikaris, P. Understanding and Mitigating Gradient Flow Pathologies in Physics-Informed Neural Networks. SIAM J. Sci. Comput. 2021, 43, A3055–A3081. [Google Scholar] [CrossRef]
- Wang, S.; Sankaran, S.; Perdikaris, P. Respecting causality is all you need for training physics-informed neural networks. arXiv 2022, arXiv:2203.07404. [Google Scholar]
- Cheng, C.; Zhang, G.T. Deep Learning Method Based on Physics Informed Neural Network with Resnet Block for Solving Fluid Flow Problems. Water 2021, 13, 423. [Google Scholar] [CrossRef]
- McClenny, L.; Braga-Neto, U. Self-adaptive physics-informed neural networks using a soft attention mechanism. arXiv 2020, arXiv:2009.04544. [Google Scholar]
- Wang, C.; Li, S.; He, D.; Wang, L. Is L2 Physics-Informed Loss Always Suitable for Training Physics-Informed Neural Network? arXiv 2022, arXiv:2206.02016. [Google Scholar]
- Yu, J.; Lu, L.; Meng, X.; Karniadakis, G.E. Gradient-enhanced physics-informed neural networks for forward and inverse PDE problems. Comput. Methods Appl. Mech. Eng. 2022, 393, 114823. [Google Scholar] [CrossRef]
- Cai, W.; Li, X.; Liu, L. A Phase Shift Deep Neural Network for High Frequency Approximation and Wave Problems. SIAM J. Sci. Comput. 2020, 42, A3285–A3312. [Google Scholar] [CrossRef]
- Wang, Y.; Han, X.; Chang, C.Y.; Zha, D.; Braga-Neto, U.; Hu, X. Auto-PINN: Understanding and Optimizing Physics-Informed Neural Architecture. arXiv 2022, arXiv:2205.13748. [Google Scholar]
- Wang, S.; Wang, H.; Perdikaris, P. On the eigenvector bias of Fourier feature networks: From regression to solving multi-scale PDEs with physics-informed neural networks. Comput. Methods Appl. Mech. Eng. 2021, 384, 113938. [Google Scholar] [CrossRef]
- Dong, S.; Ni, N. A method for representing periodic functions and enforcing exactly periodic boundary conditions with deep neural networks. J. Comput. Phys. 2021, 435, 110242. [Google Scholar] [CrossRef]
- Gao, H.; Sun, L.; Wang, J.X. PhyGeoNet: Physics-informed geometry-adaptive convolutional neural networks for solving parameterized steady-state PDEs on irregular domain. J. Comput. Phys. 2021, 428, 110079. [Google Scholar] [CrossRef]
- Wandel, N.; Weinmann, M.; Klein, R. Learning Incompressible Fluid Dynamics from Scratch - Towards Fast, Differentiable Fluid Models that Generalize. arXiv 2021, arXiv:2006.08762. [Google Scholar]
- Yang, L.; Meng, X.; Karniadakis, G.E. B-PINNs: Bayesian physics-informed neural networks for forward and inverse PDE problems with noisy data. J. Comput. Phys. 2021, 425, 109913. [Google Scholar] [CrossRef]
- Yang, L.; Zhang, D.; Karniadakis, G.E. Physics-Informed Generative Adversarial Networks for Stochastic Differential Equations. SIAM J. Sci. Comput. 2020, 42, A292–A317. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Tan, M.; Le, Q. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019. [Google Scholar]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Su, Y.; Zhao, Y.; Niu, C.; Liu, R.; Sun, W.; Pei, D. Robust anomaly detection for multivariate time series through stochastic recurrent neural network. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019. [Google Scholar]
- Berland, H.; Skaflestad, B.; Wright, W.M. EXPINT—A MATLAB package for exponential integrators. ACM Trans. Math. Softw. 2007, 33, 4-es. [Google Scholar] [CrossRef]
- Lu, L.; Meng, X.; Mao, Z.; Karniadakis, G.E. DeepXDE: A deep learning library for solving differential equations. SIAM Rev. 2021, 63, 208–228. [Google Scholar] [CrossRef]
- Kharazmi, E.; Zhang, Z.; Karniadakis, G.E. hp-VPINNs: Variational physics-informed neural networks with domain decomposition. Comput. Methods Appl. Mech. Eng. 2021, 374, 113547. [Google Scholar] [CrossRef]
- Weinan, E.; Yu, B. The Deep Ritz Method: A Deep Learning-Based Numerical Algorithm for Solving Variational Problems. Commun. Math. Stat. 2018, 6, 1–12. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| The 2D Poisson Equation | Relative Error (Inner) | Relative Error (Boundary) |
|---|---|---|
| Rectangular area | 4.844 × 10 | NaN |
| Circular area | 4.349 × 10 | 2.258 × 10 |
| Triangle area | 3.375 × 10 | 8.735 × 10 |
| Pentagon area | 4.304 × 10 | 1.527 × 10 |
| The 2D Poisson Equation | Relative Error (Inner) | Relative Error (Boundary) |
|---|---|---|
| Rectangular | 2.522 × 10 | NaN |
| Circular | 1.748 × 10 | 1.077 × 10 |
| Triangular | 4.154 × 10 | 1.418 × 10 |
| Pentagonal | 2.329 × 10 | 6.309 × 10 |
| Equation | PINNs | cSPINNs |
|---|---|---|
| 1D Allen-Cahn | 1.000 | 2.123 |
| 1D Burgers | 1.000 | 2.346 |
| 2D Helmholtz | 1.000 | 2.121 |
| 2D Poisson | 1.000 | 2.101 |
| HD Poisson | 1.000 | 2.709 |
| Equation | L2 loss+MLP | L2 loss+ResMNet | cSA+MMLP | cSA+ResMNet |
|---|---|---|---|---|
| 1D Allen-Cahn | 9.63 × 10 | 2.38 × 10 | 1.61 × 10 | 1.16 × 10 |
| 1D Burgers | 6.70 × 10 | 4.68 × 10 | 3.80 × 10 | 2.70 × 10 |
| 2D Helmholtz | 4.69 × 10 | 3.61 × 10 | 1.01 × 10 | 9.50 × 10 |
| 2D Poisson (Rectangular) | 3.58 × 10 | 1.64 × 10 | 1.12 × 10 | 1.94 × 10 |
| 2D Poisson (L-shaped) | 5.65 × 10 | 4.82 × 10 | 4.26 × 10 | 3.78 × 10 |
| HD Poisson (d = 10) | 1.33 × 10 | 1.01 × 10 | 1.25 × 10 | 8.62 × 10 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, G.; Yang, H.; Pan, G.; Duan, Y.; Zhu, F.; Chen, Y. Constrained Self-Adaptive Physics-Informed Neural Networks with ResNet Block-Enhanced Network Architecture. Mathematics 2023, 11, 1109. https://doi.org/10.3390/math11051109
Zhang G, Yang H, Pan G, Duan Y, Zhu F, Chen Y. Constrained Self-Adaptive Physics-Informed Neural Networks with ResNet Block-Enhanced Network Architecture. Mathematics. 2023; 11(5):1109. https://doi.org/10.3390/math11051109
Chicago/Turabian StyleZhang, Guangtao, Huiyu Yang, Guanyu Pan, Yiting Duan, Fang Zhu, and Yang Chen. 2023. "Constrained Self-Adaptive Physics-Informed Neural Networks with ResNet Block-Enhanced Network Architecture" Mathematics 11, no. 5: 1109. https://doi.org/10.3390/math11051109
APA StyleZhang, G., Yang, H., Pan, G., Duan, Y., Zhu, F., & Chen, Y. (2023). Constrained Self-Adaptive Physics-Informed Neural Networks with ResNet Block-Enhanced Network Architecture. Mathematics, 11(5), 1109. https://doi.org/10.3390/math11051109