Abstract
Lattice enumeration is a linear-space algorithm for solving the shortest lattice vector problem (SVP). Extreme pruning is a practical technique for accelerating lattice enumeration, which has a mature theoretical analysis and practical implementation. However, these works have yet to be applied to discrete pruning. In this paper, we improve the discrete pruned enumeration (DP enumeration) and provide a solution to the problem proposed by Léo Ducas and Damien Stehlé regarding the cost estimation of discrete pruning. We first rectify the randomness assumption to more precisely describe the lattice point distribution of DP enumeration. Then, we propose a series of improvements, including a new polynomial-time binary search algorithm for cell enumeration radius, a refined cell-decoding algorithm and a rerandomization and reprocessing strategy, all aiming to lift the efficiency and build a more precise cost-estimation model for DP enumeration. Based on these theoretical and practical improvements, we build a precise cost-estimation model for DP enumeration by simulation, which has good accuracy in experiments. This DP simulator enables us to propose an optimization method of calculating the optimal parameters of DP enumeration to minimize the running time. The experimental results and asymptotic analysis both show that the discrete pruning method could outperform extreme pruning, which means that our optimized DP enumeration might become the most efficient polynomial-space SVP solver to date. An open-source implementation of DP enumeration with its simulator is also provided.
MSC:
94A60
1. Introduction
The shortest vector problem (SVP) and closest vector problem (CVP) are hard computing lattice problems, which have become central building blocks in lattice-based cryptanalysis. The security analysis of many lattice-based cryptographic primitives is usually reduced to solving the underlying mathematical problems, which are closely related to SVP and CVP. Some hard computing problems used in classical public-key cryptosystems can also be converted to a variant version of SVP or CVP, such as the knapsack problem [1,2,3], the hidden number problem [4] and the integer factoring problem [5].
Lattice enumeration is a general SVP solver with linear space complexity, which can be traced back to the early 1980s [6,7]. It outputs a lattice vector (or proves there is none) that is shorter than the given target length within superexponential time. Enumeration can also be used as the subroutine of the blockwise lattice basis reduction (BKZ) algorithm, and therefore plays an important role in the security analysis and parameter assessment of lattice-based cryptosystems [8,9,10].
Classical lattice enumeration can be traced back to the early 1980s. Kannan [6] proposed an algorithm to enumerate lattice points in a high-dimensional parallelepiped, which output the shortest vector, along with a well-reduced HKZ basis, at the cost of a huge time consumption. Fincke and Pohst [7,11] proposed using a lighter preprocessing method, such as LLL or BKZ algorithms, and spending more time on enumerating the lattice vector in a hyperellipsoid. Fincke–Pohst enumeration has a higher level of time complexity in theory, but it performs better than Kannan’s enumeration in practice.
Pruning is the most important technique to accelerate lattice enumeration. In the classical enumeration algorithm, all the coordinate vectors of lattice points are organized as an enumeration tree and are searched in a depth-first way. The pruning method cuts off the branch and stops searching in depth when the objective function value at the current node exceeds the bounding function. This might cut off the correct solution during searching; hence, enumeration becomes a probability algorithm. Gama, Nguyen and Regev [12] proposed the extreme pruning method, treating the bounding function as the solution to an optimization problem. The optimal bounding function can be regarded as an extreme point, which minimizes the expected total running time (with a given success probability). Therefore, the extreme pruning method is believed to be the most efficient pruning method for classical enumeration, which is also called GNR enumeration. The fplll library [13] provides an open-source implementation of GNR enumeration.
The classical pruned enumeration searches lattice vectors in a hypercylinder intersection, which is regarded as a continuous region in time analysis. Consequently, the computation of the expected running time of GNR enumeration is easy to handle, which implies that the upper bound on the cost of lattice enumeration is clear. Aono et al. also proved a lower bound on GNR enumeration [14].
The discrete pruning method is quite different. The discrete pruned enumeration (DP enumeration) originated from a heuristic “Sampling Reduction” algorithm [15], which iteratively samples lattice vectors under the restriction on their Gram–Schmidt coefficients and then rerandomizes the basis using lattice reduction. Ajtai, Buchmann and Ludwig [16,17] provided some analyses of the time complexity and success probability. Fukase and Kashiwabara [18] put forward a series of significant improvements, including the natural number representation (NNR) of lattice points, to make the sampling reduction method more practical and provided a heuristic analysis. Teruya et al. [19] designed a parallelized version of the Fukase–Kashiwabara sampling reduction algorithm and solved a 152-dimensional SVP challenge, which was the best record of that year. Other relevant studies include [20,21,22]. The Sampling Reduction algorithm shows good practicality but lacks sufficient theoretical support, especially regarding the parameter settings and estimation of running time. The conception of “discrete pruning” was formally put forward in EUROCRYPT’ 17 by Aono and Nguyen [23]. They proposed a novel conception named “lattice partition” to generalize the previous sampling methods, and they solved the problem of what kind of lattice points should be “sampled” using the classical enumeration technique. The success probability of discrete pruning can be described as the volume of “ball-box intersection”, and can be calculated efficiently using fast inverse Laplace transform(FILT). Aono et al. [24] made some modifications to DP enumeration and proposed a quantum variant. The theoretical foundation of DP enumeration was gradually developed, but some problems still remain.
- A precise cost estimation: There is a gap between theoretical time complexity and the actual cost. It has been proved that each subalgorithm of DP enumeration has a polynomial-time complexity, but the actual running time is not in proportion with the theoretical upper bound, since subalgorithms with different structures are analyzed using different arithmetic operations.
- The optimal parameter setting: The parameters of DP enumeration used to be set empirically, by hand. An important problem that [23,24] did not clearly explain is how many points should be enumerated in the iteration. The authors of [18,23] provided some examples of parameter selection, without further explanation. For a certain SVP instance, optimal parameter settings should exist to minimize the total running time. This is based on the solution to the first problem.
To solve the above problems, the whole work is carried out using two steps: First, we built a precise cost model for DP enumeration, called the “DP simulator”. During this procedure, some implementation details regarding DP enumeration are improved, and the cost model is based on these improvements. Second, we used the optimization method to find the optimal parameter of DP enumeration.
In the first step, to estimate the precise cost of DP enumeration, we studied and improved DP enumeration in terms of both mathematical theory and algorithm implementation. The main work was as follows:
- Rectification of the theoretical assumption: It is generally assumed that the lattice point in participating “cells” follows the uniform distribution, but Ludwig [25] (Section 2.4) pointed out that this randomness assumption does not strictly hold for Schnorr’s sampling method, i.e., Schnorr’s partition. This defect also exists in the randomness assumption of natural number partition and leads to a paradox, where two symmetric lattice vectors with the same length have a different moment value and success probability. This will lead to inaccuracies in cell enumeration and success probability analyses; hence, we provided a rectified assumption to describe lattice point distribution in cells more cautiously and accurately, and consequently eliminate the defect.
- Improvements in algorithm implementation: We propose a new polynomial-time binary search algorithm to find the cell enumeration radius, which guarantees a more precise output than [24] and is more conducive to building a precise cost model. We proposed using a lightweight rerandomization method and a truncated version of BKZ, “k-tours-BKZ”, as the reprocessing method when DP enumeration fails in one round and has to be repeated. This method takes both the basis of quality and controllable running time into consideration. We examined the stabilization of basis quality during repeated reprocessing and proposed a model to describe the relationship between orthogonal basis information and the parameters of DP enumeration.
- A cost simulator of DP enumeration: Based on the above improvements, we provided an open-source implementation of DP enumeration. To describe the actual running time of DP enumeration, it is necessary to define a unified “basic operation” for all subalgorithms of DP enumeration and fit the coefficients of polynomials. We calculated the fitted time cost formula in CPU-cycles for each subalgorithm of our implementation. We also modified the calculation procedures of success probability according to the rectified randomness assumption. Then, we built a cost model, the DP simulator, to estimate the exact cost of DP enumeration under any given parameters. In addition, for random lattices with GSA assumption holding, this works in a simple and efficient way, without computing any specific lattice basis.
In the second step, to predict the optimal parameter for DP enumeration, we proposed an optimization model. In this model, the DP enumeration parameter is regarded as the input of the DP simulator, and the output of the DP simulator is the estimated running time. We found that the Nelder–Mead method is suitable for solving the optimization problem, since the DP simulator has no explicit expression and has unknown derivatives. As the cost model is accurate, the parameter that minimizes the output of the DP simulator can also be considered the optimal parameter of the DP enumeration algorithm.
Contributions of this work: We propose a systematic solution to the open problem of DP enumeration by combining the improved implementation of DP enumeration, DP simulator and the optimization method used to find optimal parameters. The experiment confirms that DP enumeration outperforms the state-of-art enumeration with extreme pruning and provides concrete crossover points for algorithm performance. Furthermore, the experimental result is extrapolated to higher dimensions, and we provided the asymptotic expression of the cost of DP enumeration. These results provide valuable references for lattice-based cryptography. We released our implementation as an open source (https://github.com/LunaLuan9555/DP-ENUM, accessed on 30 December 2022) to promote the development of lattice-based cryptography.
Roadmap:Section 2 introduces the fundamental knowledge of lattices and provides an overview of pruning technologies for lattice enumeration. Section 3 first rectifies the basic randomness assumption of lattice partition, and then describes the details of three improvements in discrete pruning enumeration. Section 4 shows the details of our DP enumeration cost simulator, including the runtime estimation of every subalgorithm and the rectified success probability model. Section 5 describes how to find the optimal parameter setting for DP enumeration using our cost simulator. Section 6 provides experimental results to verify the accuracy of our cost simulator, and compares the efficiency of our implementation with the extreme pruned enumeration in fplll library. Finally, Section 7 provides the conclusion and discusses some further works.
2. Preliminaries
2.1. Lattice
Lattice: Let denote the m-dimensional Euclidean space. Given n linear independent vectors (), a lattice is defined by a set of points in : . The vector set is called a basis of lattice and can be written in the form of column matrix . The rank of matrix is n, which is also known as the dimension of lattice. From a computational perspective, we can only consider the case that for for convenience, since the real number is represented by a rational number in the computer, and a lattice with a rational basis can always be scaled to one with an integral basis. The lattice is full-rank when , which is a common case in lattice-based cryptanalysis. In the following, we only consider the case .
A lattice has many different bases. Given two bases of a lattice , there exists a unimodular matrix such that . A basis of the lattice corresponds to a fundamental parallelepiped . The shape of fundamental parallelepiped varies depending on the basis, but the volume of those fundamental parallelepipeds is an invariant of the lattice, which is denoted by . This is also called the determinant of a lattice, and we have .
Random lattice: The formal definition and generation algorithm of a random lattice can refer to Goldstein and Mayer’s work in [26]. The SVP challenge also adopts the Goldstein–Mayer lattice. The lattice of an n-dimensional SVP challenge instance has a volume of about .
Gaussian heuristic: For a lattice and a measurable set S in , we intuitively expect that the set contains fundamental parallelepipeds; therefore, there should be the same number of points in .
Assumption 1.
Gaussian heuristic. Let be a n-dimensional lattice in and S be a measurable set of . Then,
We note that the Gaussian heuristic should be used carefully, because in some “bad” cases, this assumption does not hold (see Section 2.1.2 in [27]). However, in random lattice, this assumption generally holds, especially for some “nice” set S; therefore, we can use the Gaussian heuristic to predict :
In fact, is exactly the radius of an n-dimensional ball with volume . It is widely believed that is a good estimation of when .
Shortest vector problem (SVP): For a lattice with basis , one can find a lattice vector with such that for any . The length of the shortest vector is denoted by .
It is of great interest to find the shortest nonzero vector of a lattice in the fields of complexity theory, computational algebra and cryptanalysis. However, a more common case in cryptanalysis is to find a lattice vector that is shorter than a given bound. In other words, researchers are more interested in finding an approximate solution to SVP. For example, the target of the SVP challenge [28] is to find a lattice vector such that .
Orthogonal projection: The Gram–Schmidt orthogonalization can be considered a direct decomposition of lattice and is frequently used in lattice problems.
Definition 1.
Gram–Schmidt orthogonalization. Let be a lattice basis, The Gram–Schmidt orthogonal basis is defined with , where the orthogonal coefficient .
Definition 2.
Orthogonal projection. Let be the i-th orthogonal projection. For , we define . Since any lattice vector can be represented by the orthogonal basis as , we also have .
For lattice and , we can define the -dimensional projected lattice . Note that the orthogonal basis of is exactly .
2.2. Discrete Pruning
In classical enumeration, we search for lattice points directly, according to their coordinates with respect to basis , such that . However, enumeration with discrete pruning behaves in a very different way.
Considering the representation , it is intuitive to search for a lattice vector with a small , especially for index j, corresponding to a very large . This idea is first applied in a heuristic vector sampling method proposed by Schnorr [15] and dramatically improved by Fukase and Kashiwabara [18]. These sampling strategies are summarized by Aono and Nguyen, and they defined lattice partition to generalize these sampling methods.
Definition 3.
(Lattice partition [23]). Let to be a full-rank lattice in . An -partition is a partition of such that:
- and . The index set T is a countable set.
- There is exactly one lattice point in each cell , and there is a polynomial time algorithm to convert a tag to the corresponding lattice vector .
A nontrivial partition is generally related to the orthogonal basis . Some examples are given in [23]. Here, we only introduce natural partition, which was first proposed by Fukase and Kashiwabara [18], since it has smaller moments than other lattice partitions such as Babai’s and Schnorr’s, implying that enumeration with natural partition tends to have more efficiency. In this paper, we only discuss discrete pruning based on natural partition, following the work of [18,23,24].
Definition 4.
Given a lattice with the basis , and a lattice vector , the natural number representation (NNR) of is a vector such that for all . Then, natural number representation leads to the natural partition by defining
The shape of is a union of hypercuboids (boxes), which are centrosymmetric and disjoint, where j is the number of nonzero coefficients in .
Given a certain cell, the lattice vector lying in it can be determined by the tag and lattice basis; however, if we randomly pick some cells, the position of the lattice vector in always shows a kind of randomness. We can naturally assume that the lattice point belonging to follows a random uniform distribution. The prototype of this assumption was first proposed by Schnorr [15] and generalized by Fukase and Kashiwabara [18]. Aono, Nguyen and Shen [23,24] also use this assumption by default.
Assumption 2.
(Randomness Assumption [18]). Given a lattice with orthogonal basis and a natural number vector , for the lattice vector contained in , the Gram–Schmidt coefficients () are uniformly distributed over and statistically independent with respect to j.
In such an ideal situation, by considering the GS coefficients of as random variables, one can compute the expectation and variance value of , since can also be considered a random variable. They are also defined as the first moment of cell [23]:
This means that, for a given tag , we can predict the length of the lattice vector immediately without converting to , which is precise but takes a rather long time. This leads to the core idea of the discrete pruning method: we first search for a batch of cells that are “most likely” to contain very short lattice vectors; then, we decode them to obtain the corresponding lattice vectors and check if there is a such that . The pruning set is . If the randomness assumption and Gaussian heuristic hold, the probability that P contains a lattice vector shorter than R can be easily described by the volume of the intersection .
The outline of discrete pruned enumeration is given in Algorithm 1.
| Algorithm 1 Discrete Pruned Enumeration |
|
3. Improvements in Discrete Pruning Method
3.1. Rectification of Randomness Assumption
Most of the studies on discrete pruning take randomness assumption as a foundation of their analyses; therefore, they can apply Equation (2) to predict vector length. However, we can easily point out a paradox if the following assumption holds: for two cells with tag and , if is odd; then, it is easy to verify that the corresponding lattice vectors of and are in opposite directions with the same length. However, the Equation (2) indicates . In fact, we also have , which means these two cells have different success probabilities, while the lattice vectors contained in them are essentially the same.
This paradox implies that the distribution of lattice points in cells is not completely uniform. As a matter of fact, for a tag , GS coefficient of the corresponding lattice vector, are fixed integers rather than uniformly distributed real numbers. The exact values of are given in Proposition 1.
Proposition 1.
Given a lattice with orthogonal basis and a tag , the corresponded lattice vector is denoted by , then
Proof.
We can verify the proposition through the procedures of decoding algorithm, and a brief theoretical proof is also provided. For lattice vector , where , the last nonzero coefficient of is if, and only if, is the last nonzero coefficient of , and . Then, according to Definition 4, we have for all ; is non-negative if, and only if, is odd; if and only if is even. For brevity, the tags with odd and even numbers in the last nonzero coefficient are called the “odd-ended tag” and “even-ended tag”, respectively. □
Based on Proposition 1, the rectified randomness assumption is given below, and the moments of natural partition are also modified.
Assumption 3.
(The Rectified Randomness Assumption). Let be an n-dimensional lattice with orthogonal basis . Given a tag with corresponding lattice vector , suppose the last nonzero coefficient of is ; then, for , we assume that is uniformly distributed over and independent with respect to j, for , can be directly given by proposition (3).
Then, the moments of lattice partition should also be modified, since the last several coefficients are not random variables after the rectification. For a tag , the expectation of the corresponding is
where is defined by Equation (3).
After the rectification, for two tags , which only differ by 1 in the last nonzero coefficient, we have , and the paradox mentioned in the beginning of this subsection is eliminated.
3.2. Binary Search and Cell Enumeration
A crucial step of Algorithm 1 is called cell enumeration (line 5), aiming to find the “best” M cells. We use the objective function to measure how good the cells are. (Equation (2)) is a tacit indicator for searching for the proper , since it is exactly the expected squared length of lattice vector . Aono and Gama [23] directly use as the objective function in cell enumeration, and Aono et al. [24] use a modified version of to guarantee its polynomial runtime. They require the function satisfying and for all i and , which means we have to drop the constants in , i.e., let . Based on their work and the rectification above, we propose a modified objective function. Given a tag vector as input, we first define
where is defined by Equation (3). Then, the objective function of cell enumeration is
The complete cell enumeration procedure is given below:
Remark 1.
Remark. Considering the symmetry of the lattice vector, we only search for even-ended tags (line 17 and line 31).
The time complexity of Algorithm 2 is similar to that of [24]: the number of times that Algorithm 2 enters the loop is, at most, , where M is the number of tags such that . For each loop iteration, the number of arithmetic operations performed is , and the number of calls to is exactly one. The proof is essentially the same as that of theorem 11 in [24]. (Note that, although we change the definition of , and therefore change the value calculated in line 3, this does not affect the total number of while loops in the asymptotic sense. Furthermore, the modification of does not change the key step in the proof: each partial assignment of a middle node can be expanded to a larger sum . )
In cell enumeration, a bound r should be determined as in the previous section, such that there are exactly M tags satisfying . Aono and Nugyen [23] first proposed the idea to use the binary search method to find a proper r. Aono et al. [24] gave a detailed binary search algorithm (Algorithm 5 in [24]), which was proved to have a polynomial running time . Their algorithm uses the input (radius r) precision to control the termination of the binary search, but a slight vibration of the radius r will cause a large disturbance to the number of valid tags, since the number of tags is , such that grows exponentially with r. Therefore, their binary search method could only guarantee an output of N tags with , which is a relatively large interval. Then, it would be intractable to estimate the precise cost of the subsequent tagwise calculation, such as in the decoding algorithm.
Since the current termination condition in the binary search of DP enumeration will bring uncertainty into the total cost-estimation model, we provide a more practical and stable polynomial-time binary search strategy to determine the parameter r for cell enumeration. The essential difference with ANS18 [24] is that we use the number of output tags as the bisection indicator of binary search. This method guarantees that cell enumeration algorithm (Algorithm 1, line 5) outputs about to tags , satisfying . When is small, the number of output tags can be approximately counted as M.
| Algorithm 2 CellENUM |
|
Remark 2.
In Algorithm 3,CellENUM in line 3 is actually a variant of the original Algorithm 2. It only needs to count the number of qualified tags and return early when , and it has no need to store the valid tags.
| Algorithm 3ComputeRadius |
|
Theorem 1 gives the asymptotic time complexity of Algorithm 3:
Theorem 1.
Given lattice , M, a relaxation factor ϵ, Algorithm 3 ends within loops and output the enumeration parameter r, such that . In each loop, subalgorithmcellENUM is called exactly once.
The approximate proof of Theorem 1 is given in Appendix A. In the following experiments, we set .
3.3. Lattice Decoding
The decoding algorithm converts a tag to a lattice vector . The complete algorithm is described both in [18,23]. However, in discrete pruned enumeration, almost all the tags we process do not correspond to the solution for SVP, and there is no need to recover the coordinates of those lattice vectors. Instead, inspired by classical enumeration, we use an intermediate result, the partial sum of the squared length of lattice vector (line 14 in Algorithm 4), as an early-abort indicator: when the projected squared length of lattice vector is larger than the target length of SVP, we stop the decoding, since it is not a short lattice vector. Therefore, we avoid a vector–matrix multiplication with time .
Algorithm 4 has loops and, in each loop, there are about arithmetic operations, which are mainly organized by line 7. Therefore, the time complexity of Algorithm 4 is . During experiments, we noticed that, for the SVP challenge, decoding terminates at index on average, which means that the early-abort technique works and saves decoding time.
Space complexity of DP enumeration. We note that Decode can be embedded into line 15 in CellENUM. In other words, the decoding procedure can be instantly determined when a candidate tag is found, and then we can decide whether to output the final solution to SVP or throw out the tag. This indicates that DP enumeration essentially has polynomial space complexity, since it has no need to store any tags.
| Algorithm 4Decode |
|
3.4. Lattice Reduction for Reprocessing
3.4.1. Rerandomization and Reduction
To solve an SVP instance, the DP enumeration should be repeatedly run on many different bases, which means that the lattice basis should be rerandomized when DP enumeration restarts; hence, it should be reprocessed to maintain good quality. A plain reduction method is to use the polynomial-time LLL reduction as the reprocessing method, which only guarantees some primary properties and is not as good as BKZ reduction. However, a complete BKZ reduction will take a long time, and the estimation of its runtime requires a sophisticated method. Additionally, the BKZ algorithm produces diminishing returns: after the first dozens of iterations, the quality of the basis, such as the root Hermite factor, changes slowly during iterations, as illustrated in [29,30].
A complete reduction is unnecessary, since our DP enumeration algorithm does not require that the lattice basis is strictly BKZ-reduced. The key point of reprocessing for DP enumeration is to achieve a compromise between time consumption and basis quality. An early-abort strategy called terminating BKZ [31] is a good attempt to decrease the number of iterations of BKZ reduction while maintaining some good properties. However, the runtime of BKZ is still hard to estimate, since the number of iterations is not fixed, and those properties mainly describe the shortness of , providing little help for our cost estimation.
Another idea is to use a BKZ algorithm with limited tours of reduction, which is convenient for runtime analysis and also efficiently produces a well-reduced basis. This is what we call the “k-tours-BKZ” algorithm (Algorithm 5), which restricts the total number of “tours” (lines 4–18 in Algorithm 5) of BKZ within k. Given BKZ blocksize and k, the time consumption of Algorithm 5 can be approximately estimated by multiplying and the cost of solving a single -dimensional SVP oracle. This is explained in Section 4.
| Algorithm 5 k-tours-BKZ |
|
The value of k is tightly related to the rerandomization; hence, the rerandomization method should also be cautiously discussed. The essence of this idea is to generate a unimodular matrix Q as the elementary column transformation performed on ; therefore, will become the new basis waiting to be reprocessed. A very “heavy” matrix Q means the basis is transformed with high intensity, which implies that the basis will lose many good properties after rerandomization, e.g., some very short basis vectors, which were achieved by the previous reduction, and the reprocessing procedure needs a long time to reach the well-reduced status. However, a very sparse Q may lead to insufficient randomness during transformation, which may not guarantee a very different basis. To balance the randomness and reprocessing cost, we heuristically require a Hamming distance between and an identity matrix satisfying
A practical way to generate such a is to randomly select n position with and let as a small integer, as well as let for all . This forms an upper-triangular unimodular matrix and immediately satisfies the above formula.
In practice, we find that this method can guarantee a new basis after reprocessing and will not destroy or reduce the basis quality too much; therefore, this can help the k-tours-BKZ to achieve a stable basis quality again in only few tours (see Figure 1, Figure 2 and Figure 3). The experiments in the next subsection suggest that we can set a very small k to save time in the reprocessing procedure. There is a broad consensus that “the most significant improvements of BKZ reduction only occurs in the first few rounds” [27], and this is proved in [31]. Some cryptanalyses also use an optimistically small constant c as the number of BKZ tours used to estimate the attack overhead (like in [32]). Considering the previous literature and the following experiments, we set for our k-tours-BKZ method.

Figure 1.
The Evolution of During reprocessing, , , .
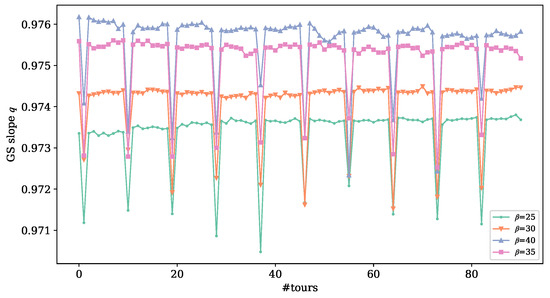
Figure 2.
The evolution of GS slope q during reprocessing, , , .

Figure 3.
The evolution of during reprocessing, , , .
3.4.2. Average Quality of Lattice Basis During Reprocessing
Even when using the same parameters, DP enumeration will have different runtimes and probabilities of success when used on different bases of a lattice. We expect the basis to have a stable quality that will remain largely unchanged by the reprocessing operation and can be easily simulated or predicted without conducting a real lattice reduction. The very first work aims to define the quality of the lattice basis and study how it changes during enumeration loops. We chose three indicators to describe the quality of the basis and observe their behavior during reprocessing.
Gram–Schmidt Sum.
For DP-enumeration, its success probability is tightly related to the lengths of the Gram–Schmidt basis vectors , and Fukase et al. [18] proposed using Gram–Schmidt Sum as a measurement of lattice basis quality and also gave an intuitive and approximate analysis of the strong negative correlation between and the efficiency of finding a short lattice vector: the larger the Gram–Schmidt Sum is, the smaller the success probability becomes. The Gram–Schmidt Sum is defined as
We generated an dimensional SVP challenge basis at random and showed how the k-tours-BKZ change the of the basis during reprocessing. They started to form a -reduced basis; then, the lattice basis was rerandomized and reprocessed by k-tours-BKZ for every tours with blocksize . As shown in Figure 1, the peak that comes up before every tours of BKZ reduction corresponds to the of the rerandomized basis without reprocessing. The peak indicates that the lattice basis is evidently disturbed by our rerandomization method and becomes worse, while, in the following k tours, the value of quickly returns to a similar state to the well-reduced initial state and hardly changes again. In general, when the lattice basis is iteratively reprocessed, the value of only shows mild fluctuations, which implies that the success probability when finding very short lattice vectors is quite stable.
Geometry Series Assumption and GS Slope.
For a well-reduced basis of a random lattice, such as the lattice of the SVP challenge, the Gram–Schmidt orthogonal basis generally has a regular pattern, which is called the Geometry Series Assumption (GSA). For an n-dimensional lattice with a -reduced basis , GSA means there is a , such that
If GSA holds, the points form a straight line with a slope of . In other words, q defines the “shape” of Gram–Schmidt sequence . In the following, we call the GS slope. In the real case of lattice reduction, the points do not strictly lie on a straight line, and the approximate value of q can be obtained by least square fitting. Generally, a q closer to 1 means that the basis is more reduced and vice versa. Figure 2 shows the evolution of fitted q in reprocessing. The value of q sharply decreases after each rerandomization and returns in the next few reprocessing tours, showing a stable trend during the iterative rerandomization and BKZ tours.
Root Hermite Factor.
In the studies of BKZ algorithm, the root Hermite factor is used to describe the “ability” of BKZ to find a short lattice vector, which is given as the first basis vector in the output basis:
Gama and Nguyen [8] pointed out the phenomenon that, for BKZ algorithm, when blocksize parameter , the root Hermite factor is only affected by the blocksize parameter but has no relationship with the lattice dimension. Additional observations of root Hermite factor are given by Table 2 of [29].
As in and GS slope q, Figure 3 shows the evolution of the root Hermite factor of the reprocessed basis. The peaks arising before reprocessing tours also indicate that the first basis vector is frequently changed by our rerandomization method, and in the following k tours, the value of quickly returns to a similar state to the well-reduced initial state and hardly changes again.
Based on the above observations, we believe that, during the reprocessing stage, only a few BKZ reduction tours can stabilize the properties of the lattice bases.
4. Precise Cost Estimation of DP-ENUM
The precise cost estimation of DP enumeration is a great concern and remains an open problem for cryptanalysis. However, there are several obstacles to building a good runtime model that is consistent with the experimental results of a viable dimension and can be extrapolated to a very high dimension.
First, DP enumeration contains many subalgorithms with different structures, such as binary search, cell enumeration, decoding and reprocessing. Although the asymptotic time complexity expression of each part is clearly discussed in Section 3, the real runtime of the DP enumeration still needs to be handled carefully. These subalgorithms involve a variety of arithmetic operations and logic operations, which make it hard to define a universal “basic operation” for all the DP enumeration procedures. To build a runtime model for DP enumeration, our key idea is to use CPU cycles as the basic operation unit, since this can avoid the differences caused by different types of operations and is also easy to count.
Second, the searching space of DP enumeration is a union of many discrete boxes irregularly distributed in . It is quite hard to compute the volume of the pruning set, which directly determines the probability for pruning success. Aono et al. proposed using FILT to compute the volume of its pruning set [23], but this calculation model should be modified to achieve better accuracy, according to the rectification of the original randomness assumption we made in Section 3.
According to Algorithm 1, the cost of each loop in DP enumeration can be divided into four parts:
- : Use binary search to determine cell enumeration parameter r (Algorithm 3)
- : Enumerate all the tags of candidate cells (Algorithm 2)
- : Decode a tag and check the length of the corresponding lattice vector (Algorithm 4)
- : If there is no valid solution to SVP, rerandomize the lattice basis and reprocess it by k-tours-BKZ algorithm (Algorithm 5)
Denote the success probability when finding a lattice vector shorter than R in a single loop of DP enumeration by and assume that is stable during rerandomizing; then, the expected number of loops is about according to geometric distribution, and the total runtime of DP enumeration can be estimated by
We assume that the preprocessing time for , which denotes the time for a full-tour reduction on the initial lattice basis, is far less than the time spent in the main iteration and can be ignored when . In this section, our aim is to determine the explicit expression of , , and , as well as provide an accurate estimation of .
For all the experiments in this paper, the computing platform is a server with Intel Xeon E5-2620 CPUs, with eight physical cores running at 2.10 GHz, and 64GB RAM. To obtain accurate CPU cycles for the DP enumeration algorithm, we fixed the CPU basic frequency and set the CPU affinity, and all the time data for fitting were obtained from our single-thread implementation.
4.1. Simulation of Lattice Basis
Some parts in the total time cost model Equation (10) are hugely dependent on the quality of the basis: more precisely, the vector lengths of Gram–Schmidt orthogonal basis . Based on the reprocessing method and the stability analysis in Section 3.4, we can reasonably assume the Gram–Schmidt sequence will not severely change in the loops of DP enumeration. Then, the issue is to simulate an “average” GS sequence for a -reduced basis.
BKZ simulator [29,30] is a universal method, especially when is quite large, since the Gaussian heuristic generally holds in -dimensional blocks where . In this case, the probabilistic BKZ simulator proposed by Bai et al. [30] is an appropriate model due to its reliable depiction of the “head concavity” phenomenon. Based on Algorithm 3 in [30], we provide this BKZ simulator in C++ as a component of our implementation.
However, the BKZ simulator does not work well for small- and medium-sized (), because the keystone of the BKZ simulator is to estimate the shortest vector length in a -dimensional sublattice (block) by computing , which will decrease in accuracy when . This is rarely the case with asymptotic cryptanalysis. However, this is a prevailing case in preprocessing and also needs investigation; hence, we have to propose a method that considers this case and fills the vacancy in GS sequence simulation.
Using Equation (11), we can approximately calculate the whole Gram–Schmidt sequence if GSA holds and one of or q is known. Here, we prefer to use the GS slope q rather than the value of , since it contains more information on the Gram–Schmidt orthogonal basis. Additionally, using to recover the Gram–Schmidt sequence might lead to an overly optimistic estimation, since the “head concavity” phenomenon [30] indicates that the might significantly deviate from the prediction given by GSA. Then, the feasible approach is to give an average estimation of q for a given lattice and BKZ parameter .
We find that the GS slope has similar properties to the root Hermite factor: when , the GS slope of a reduced basis is mostly related to its blocksize but not its lattice dimension. For each parameter set , we generate 50 random SVP challenge instances and apply on the n-dimensional lattice basis to verify this phenomenon. Then, we use the least square method to fit the of reduced bases. Figure 4 shows the relationship between q and lattice dimension n, indicating that q is hardly dependent on lattice dimension n and mostly varies with .
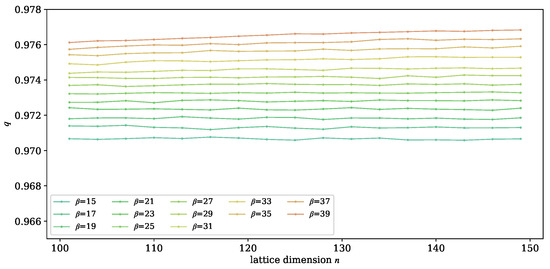
Figure 4.
The relation between q and lattice dimension n.
Figure 5 illustrates the positive correlation of q and , which is consistent with the idea that a larger blocksize makes the lattice basis better, and the GS slope is milder, which means that is closer to 1.

Figure 5.
The relation between q and BKZ blocksize .
Table 1 gives an estimated value of .

Table 1.
The estimated GS slope q of -reduced lattice basis.
By using the empirical data of , we can generate a virtual GS sequence to simulate the real behavior of the Gram–Schmidt orthogonal basis of a -reduced lattice basis by solving the following equations:
Remark 3.
All the explicit values of for are given in our open-source implementation. Note that the method proposed above only takes effect when , while we still give an extrapolation as an alternative reference. Since holds for all and is an increasing function of β, which implies a trend , we heuristically assume this function has a form of ; then, the fitting result of Table 1 is
The fitting curve is also illustrated in Figure 5.
4.2. Cost of Subalgorithms
Cost of Binary Search and Cell Enumeration.
For the cell enumeration algorithm (Algorithm 2), the asymptotic time complexity is . We take , and, for each parameter set , we generate 100 SVP lattices at random. The fitting result is
For the binary search algorithm (Algorithm 3), Theorem 1 indicates that the asymptotic time complexity has an asymptotic upperbound . To simplify the fitting function and retain accuracy, we only take the dominant term of the complete expansion, which is . For the SVP challenge lattice, we have . Then, the fitting function of is
Both fitting functions obtained by the least square method have a coefficient of determination (R-squared) larger than .
Cost of Decoding.
To decode one tag by running Algorithm 4, the number of times to enter the for loop is , and in each loop, this performs arithmetic operations. Therefore, can be regarded as a quadratic function of n. We take and fix , and we generate 100 SVP lattices at random for each n. The expected runtime of decoding algorithm is fitted by
Figure 6 shows that the fitting curve of is almost strictly consistent with the experimental data. The fitting function also has a coefficient of determination (R-squared) larger than .
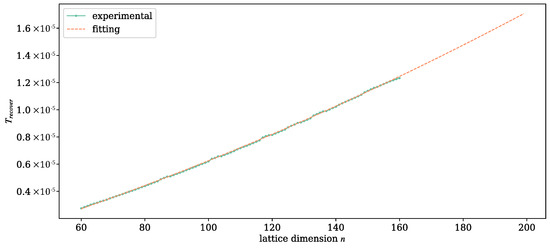
Figure 6.
The relation between and dimension n.
Cost of Reprocessing.
The cost of the k-tours-BKZ algorithm is a little complicated, since it iteratively calls an -dimensional SVP oracle. Our implementation of k-tours-BKZ is based on the BKZ 2.0 algorithm in fplll library [13]. In one tour of , the total runtime is composed of the processing time on blocks. For each block with and , the main steps are classical enumeration and LLL reduction for updating:
Then, the cost of k-tours-BKZ can be estimated by
In Equation (17), is the cost of updating basis (Algorithm 5, line 12). The asymptotic time complexity of this part is , which is mainly donated by LLL reduction [33], where for the SVP challenge lattice. When is small, the cost of updating cannot be ignored. For the cost of classical pruned enumeration, is the CPU cycles for processing a single node in the enumeration tree, which is said to be [34]; is the total amount of nodes that needs to be traversed to find a short vector on .
Let , and , we record the cost of each stage (including runtime and the number of nodes) of on 50 random lattices. The least squares fitting shows , and
The remaining part is , which is the number of nodes of enumeration on block . For a full enumeration of , the total number of nodes can easily be derived from the Gaussian heuristic, which can be considered a baseline enumeration cost:
where denotes the volume of a k-dimensional ball with radius R.
However, in our implementation of k-tours-BKZ, the SVP oracle uses extreme pruning and heuristic enumeration radius for acceleration. We assume that, for classical enumeration on a dimensional block , these methods offer a speedup ratio of in total, and is independent with the block index i and lattice dimension n. The key point is obtaining an explicit expression of . (An alternative (lowerbound) estimation of enumeration cost is provided by Chen and Nguyen [29]. The coefficients of their model are given in LWE estimator [35]. However, their model is more suitable for when is very high and is not very precise when the blocksize is small).
The value of can be calculated by Equation (20) with GS sequence , and the actual number of enumeration nodes is obtained from experiments. We recorded the number of enumeration nodes to calculate the speedup ratio data. To fit , we run on -reduced bases with and ; then, all the data of the same blocksize were gathered and averaged. It is well known that extreme pruning can offer an exponential speedup [12], and tightening the radius also leads to a superexponential speedup. We assume , and by fitting, we can obtain
Figure 7 shows the fitting results and the value of in experiments, reflecting that the assumptions we made are reasonable.
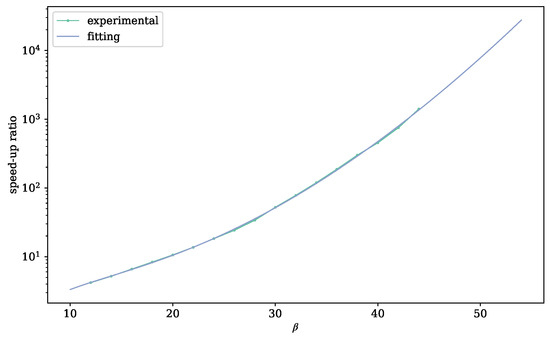
Figure 7.
Speedup ratio of extreme pruning.
To predict without any information on a specific lattice basis, the GS sequence contained Equation (21) should be replaced by the simulated values derived by equations set using the (12) or BKZ simulator.
Algorithm 6 gives the procedures of calculating , i.e., the cost of reprocessing.
| Algorithm 6 Calculating |
|
4.3. Success Probability
Under a Gaussian heuristic, the success probability of pruned enumeration can be directly reduced to computing the volume of the pruning set. For discrete pruning, the shape of the pruning set has always been considered a union of “ball-box intersections”, which is not easy to compute. Aono et al. [23] proposed an efficient numerical method based on fast inverse Laplace transform (FILT) to compute the volume of a single “ball-box intersection” and used stratified sampling to deduce the total volume of the union.
However, the imperfections in original randomness assumption (Assumption 2) lead to reduced accuracy of the success probability model for discrete pruning. For two cells with tag and , if is odd, i.e., is odd-ended and is the corresponding even-ended tags, they will have different success probabilities according to the model given by [23]. However, the lattice vectors contained in and have exactly the same length.
Figure 8 illustrates the gap at a larger scale. For the parameter settings , and , we used 30 -reduced n-dimensional lattice bases to compute the average value of theoretical success probability of M odd-ended cells enumerated by Algorithm 2, as well as compute of their corresponding even-ended cells, both using the method provided by [23]. Then, we ran a complete DP enumeration on each lattice basis using the same parameters and recorded the number of iteration rounds. Figure 8 shows that the actual number of rounds of DP enumeration is in the apparent gap between expectation value and , which were estimated using odd-ended and even-ended cells, respectively.
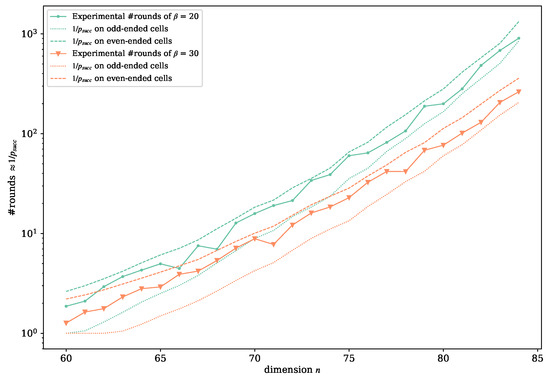
Figure 8.
The difference of estimated with odd-ended cells and even-ended cells.
This phenomenon calls for a proper rectification of the success probability model. As a matter of fact, in Section 3.1, Proposition 1 and the rectified Assumption 3 indicate that lattice point is actually randomly distributed in an hyperplane contained in , which can be described by the assumption below:
Assumption 4.
Given lattice basis and its orthogonal basis , for a tag vector , the lattice vector of can be considered to be uniformly distributed over , where
This assumption gives a more precise distribution of the lattice vector in the cell. In fact, is the union of a -dimensional “box”, which is formally denoted by
Based on Proposition 1 and the new assumption of lattice vector distribution, we redefine the success probability of DP enumeration on a single cell. For a with , denoting the lattice vector by , the probability that is defined by
Let , and ; then, the numerator part in Equation (24) can be written as
Then, the calculation of is reduced to computing the sum distribution of independent and identically distributed variables , which can be approximated by the FILT method combined with Euler transformation. The details of these methods are given in Appendix B.
For a set of tags , which is the output of cellENUM (Algorithm 2), the total success probability of finding a short lattice vector among is
To extrapolate the probability model to higher-dimensional SVP instances without performing any time-consuming computation of real lattice reduction, the concrete value of the GS sequence involved in the calculation of should be replaced by the simulated GS sequence .
Figure 9 verifies the accuracy of the rectified success probability model (Equations (24) and (26)). We take the SVP instances with and M = 50,000 as examples, and we run the DP enumeration algorithm to solve the SVP challenge on each SVP instance to record the total iteration rounds. The experiment was repeated 30 times on each parameter set to obtain the average value. The dashed line shows the expected iteration rounds calculated using the original of the real reduced basis, and the dotted line was only calculated with the simulated GS sequence . The results illustrate that the rectified model gives a more precise estimation of success probability than the original method provided in [23].
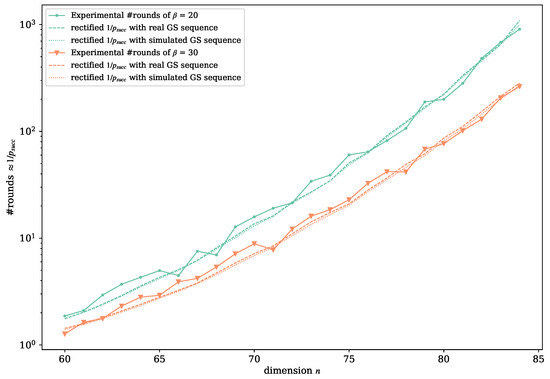
Figure 9.
Verification of the rectified success probability model.
4.4. Simulator for DP Enumeration
Based on all the works in this section, the runtime of DP enumeration can be estimated by Algorithm 7, shown below. This simulator only needs minimal information for a lattice .
| Algorithm 7 DP-simulator |
|
Remark 4.
The simulating method of GS sequence (line 1) only works for lattice bases that meet GSA. For those lattices that lack good “randomness” and do not satisfy GSA, one has to use a real reduction algorithm on several lattice bases and compute an averaged GS sequence as a good simulation of .
5. The Optimal Parameters for DP-ENUM
To solve a certain SVP instance, the parameters of DP enumeration that need to be manually determined are as follows: of BKZ reduction algorithm, k of preprocessing and M of cell enumeration.
It should be noted that k could be a fixed constant. There is no need to set a very large k because of the “diminishing returns” of lattice reduction, which means the improvement in basis quality would slow down with an increase in k. We heuristically set for SVP instances with , which is also roughly consistent with the observation of [32] (see Section 2.5 of [32] ). Then, only and M should be determined with restrictions and . The two parameters should minimize the total cost of DP enumeration, i.e., the expression value of (10). This value is calculated by Algorithm 7 and can barely be represented by a differentiable function. The Nelder–Mead simplex method is an effective method to solve this type of optimization problem. Since there are only two independent variables, it is reasonable to believe that the Nelder–Mead method can quickly converge to the optimal solution.
Algorithm 8 gives the optimal values of for a certain SVP instance based on the standard version of the Nelder–Mead method.
Table 2 gives some concrete values of optimal parameter sets for solving medium-size SVP challenges () and the corresponding estimation of running time. For the medium-size SVP challenges, the optimal parameter set basically follows and . Neither of them increase very rapidly with the growth of n.
| Algorithm 8 Finding optimal parameters for DP enumeration |
|
Table 2.
Optimal parameters of DP-ENUM for solving SVP challenge.
6. Experiments and Analysis
We compared the performance of our optimized DP enumeration with different SVP solvers, including the polynomial-space extreme pruned enumeration and exponential-space sieving. For each n, the experiments were repeated on 40 different SVP challenge instances. We ran our optimized DP enumeration with parameters given by Algorithm 8. The lattice dimension n ranged from 60 to 110, and the time cost predicted by DP simulator is also provided. The extreme pruned enumeration was implemented by fplll library [13] with the default pruning function up to . The data of sieving were implemented by G6K library [36] with the dimension-for-free method, i.e., G6K’s WorkOut from to 110. Figure 10 illustrates the prediction of the DP simulator, as well as the experimental results of our optimized DP enumeration, extreme pruning and G6K sieving.
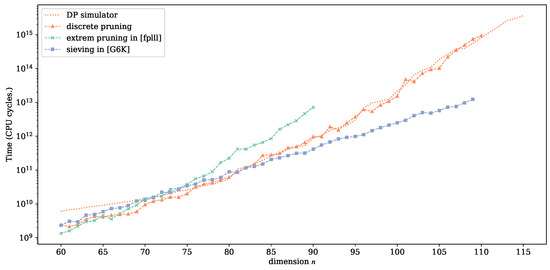
Figure 10.
The performance of optimized discrete pruning and other SVP solvers.
The experiments confirm the accuracy of our cost model proposed in Section 4. The prediction (orange dotted line) is quite consistent with the actual performance of DP enumeration (orange broken line). For , the DP enumeration algorithm sometimes finds a solution before the first round ends; therefore, the actual running time is slightly smaller than the simulated time. However, shows that our implementation of DP enumeration (with optimal parameter set) coincides with the DP simulator very well.
Compared with extreme pruning, Figure 10 shows that when , the optimized DP enumeration has a shorter runtime than the state-of-the-art extreme pruning enumeration. As for sieving, Albrecht et al. [37] has observed that the state-of-the-art sieving algorithm outperforms classical enumeration at dimension , which is also verified in our experiments. The experimental results reveal that the crossover point of DP enumeration and sieving is around , which is an update of the crossover dimension between enumeration and sieving.
In addition to the experimental performance, we also compared the asymptotic behavior of extreme pruned enumeration, G6K sieving and our implementation.
A commonly accepted cost model of extreme pruned enumeration originates from the work of Chen and Nguyen in ASIACRYPT’11 [29]. An explicit fitting function is given by LWE estimator estimator.BKZ.CheNgu12 [35]:
However, a more recent work [38] (denoted by [ABF+20] in Figure 11) suggests that the fitting formula should strictly follow the form , and their fitting result of [29] is
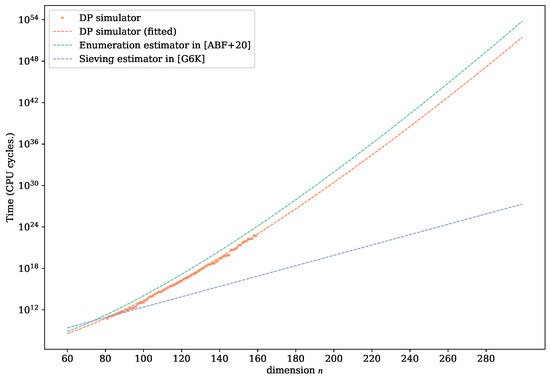
Figure 11.
The asymptotic behavior of DP enumeration and other SVP solvers.
The time complexity of sieving is believed to be [10], and G6K gives an even better result by fitting [37]:
Here, according to their implementation; thus, the metric of is unified to CPU cycles.
Since the cost model of (optimized) DP enumeration can accurately estimate the actual runtime in a high dimension, we used the DP simulator with an optimal parameter set to predict the runtime of discrete pruning during SVP challenge (from to ) and provide an asymptotic prediction. We required the fitting function to have a fixed form to be consistent with [38]. The fitting result is
Figure 11 shows the asymptotic behavior of extreme pruned enumeration (), sieved with the dimension-for-free technique (), and the fitting function of DP simulator (). Both the experimental and asymptotic comparison indicate that the discrete pruned enumeration might have more practical potential than the (classical) extreme pruning in solving high-dimensional SVP, and it might become the most efficient polynomial-space SVP solver known to date.
7. Conclusions
In this paper, the discrete pruned enumeration algorithm for solving SVP was thoroughly studied and improved. We refined the mathematical theory underlying DP enumeration and propose some improvements to the DP enumeration algorithm to make it more practical. The most valuable part is that our discrete pruning simulator combined theoretical analysis and many numerical techniques. The experimental results verify that the DP simulator can precisely predict the performance of DP enumeration. For a certain SVP instance, we can use the DP simulator to find optimal parameters to minimize the DP enumeration runtime. The explicit time and space consumption is also given by the simulator. Using simulation experiments, we believe that the time complexity of DP enumeration is still superexponential, and the space complexity is still linear, which does not change the conclusion of the enumeration algorithm.
When comparing the performance of our implementation and extreme pruned enumeration, we show that DP enumeration, under optimal parameter settings, could outperform extreme pruning when . By comparing this with the state-of-the-art exponential-space SVP algorithm, sieving with dimension for free [36,37], we report an updated crossover point of enumeration and sieving at , which is slightly higher than previously observed. Then, at a higher dimension (), we compared the asymptotic behavior of DP enumeration, extreme pruned enumeration and sieving, which also shows the advantage of the discrete pruning method compared with other polynomial-space SVP solvers.
We provide the analytical cost formula of DP enumeration as an asymptotic estimation for cryptanalysis reference, and we hope that the open-source implementation of this work could help cryptologists to further develop the algorithm.
There are several possible directions for improvement:
- Using a stronger reduction algorithm: As the results indicate, when , DP enumeration outperforms classical enumeration with extreme pruning, which means that the BKZ algorithm for preprocessing and reprocessing should use DP enumeration as an SVP oracle to achieve higher efficiency, and sieving is also an alternative SVP oracle. The structure of progressive BKZ algorithm [34] also shows high power, although it has a very complicated runtime estimator.
- Discussing the efficiency of many heuristic methods: Fukase and Kashiwabara [18] tried to improve the quality of the basis by inserting short lattice vectors into the basis, but this barely has theoretical proof. Since this method will influence the in every round, the success probability model of the FK algorithm should be modified.
- A parallelized implementation of DP enumeration, as well as an adaptive optimization model.
Author Contributions
Conceptualization and methodology, L.L.; writing—original draft preparation, L.L.; supervision, C.G.; writing—review and editing, Y.Z. and Y.S.; All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
Publicly available data was analyzed in this study. These data can be found here: http://www.latticechallenge.org/svp-challenge/, accessed on 30 December 2022.
Acknowledgments
The authors would like to thank Léo Ducas of CWI Amsterdam for his useful comments on this work. We also thank Hao Liang of IHEP (The Institute of High Energy Physics of the Chinese Academy of Sciences) for helping us improve the numerical calculation skills.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Proof of Theorem 1
Let be the original objective function proposed in [24]. We only prove Theorem 1 in the case that Algorithm 3 uses as objective function. When GSA holds, , and we assume the conclusion of is asymptotically the same with the case.
We note that the initial value guarantees that there are at least M tags, such that , which is a necessary condition of the correctness of Algorithm 3.
Proof.
Let , and denote an n-dimensional ellipsoid by
In Algorithm 3, for any , the inequality is equivalent to
i.e.,
The number of tags , such that satisfies the inequality above, is exactly the number of integer points in an n-dimensional ellipsoid centered on . To simplify the problem, we assume that a translation operation on the ellipsoid would not change the total number of integer points in it, and then we can focus on a centrosymmetric ellipsoid , where and . Then, we define
It is obvious that is a monotone undecreasing function of R. Assume that binary search Algorithm 3 terminates at the k-th iteration, and denote the upper bound and lower bound of radius by and , then we have , with being the input of Algorithm 3. The target of our proof is to find a such that holds for all possible terminating values of . Then, it is easy to prove that the binary search ends in rounds of iteration.
Now, assume satisfying . Then we have
Let ; we can investigate the asymptotic behavior of by estimating the value of .
There are some mature conclusions on the estimation of [39,40]. can be written as
where and can be written as , and is the volume of n-dimensional unit sphere:
Although is a discrete function of R, we can use the value of at as an approximation. In this case in an asymptotic sense, and then according to the Lagrange mean value theorem, for , there exists such that
Therefore, the total rounds of iterations of Algorithm 3 is at most
where . By further approximation and simplification, we can know that the algorithm ends in at most rounds. □
Appendix B. Calculating Success Probability by FILT and Euler Transformation
In this part, we introduce some detailed derivation of the numerical methods for computing success probability.
Let be uniformly distributed on , then the probability density function of is
Therefore, the p.d.f. of is
where “*” denotes the convolution operation .
To estimate the success probability of DP enumeration, our goal is to calculate .
Step 1. Fast inverse Laplace transform
Theorem A1.
If the random variable X is non-negative and has p.d.f. , then the c.d.f of X is
Here, the symbol specially refers to the Laplace transform, which satisfies
Then, our goal is to calculate the value
Note that , since Laplace inverse transform is an integral in a complex field with an integral path perpendicular to the x-axis.
To calculate in Equation (A6), we first perform the Laplace transform
and then apply inverse Laplace transform
Step 2. Approximate integral calculation with series
Put the approximation of in complex field
into Equation (A7), (here, the value of a should guarantee the convergence of series. For example, Hosono [41] claimed that the error is very small when , and Aono and Nugyen [23] recommended to use ); now, notice that the integral has singularity points (in Equation (A7), the integral path should be to the right of all singularities, i.e., . Additionally, for the in , since s is a complex variable, the argument of should satisfy to be consistent with the integration path).
According to the residue theorem and Jordan theorem, Equation (A7) can be approximated by
Step 3. Using Euler transformation to accelerate the convergence of series
Since the series in Equation (A8) converges slowly, the Euler transformation is a practical method to accelerate the convergence. Therefore, we can use fewer terms to approximate the infinite series.
Let , then the value of Equation (A8) can be calculated by finite terms:
where is the “forward difference” that can be iteratively computed by van Wijingaarden transformation. In our implementation, we set , by default.
Remark A1.
Remarks. The computation of at is a time-consuming procedure. It involves the computation of over complex field , which also needs to be approximated by series expansion. In the original computation model, since and only have a few fixed values only related with the GS sequence, we can accelerate the computation by building an “erf table” to record some values of and that would be repeatedly used in the calculation. However, for the rectified success probability model, the values of and are also connected with the explicit value of cell tag , which makes the “erf table” invalid, and the running time could be very long. Fortunately, we still find that the original computation model could help us to estimate the rectified success probability. In our implementation of DP enumeration, in addition to the step-by-step computation, we also provide a heuristic method using the harmonic average of and , which can be calculated efficiently, to roughly estimate the actual success probability.
[custom]
References
- Coster, M.; Joux, A.; Lamacchia, B.; Odlyzko, A.; Schnorr, C.; Stern, J. Improved Low-Density Subset Sum Algorithms. Comput. Complex. 1999, 2, 111–128. [Google Scholar] [CrossRef]
- Schnorr, C.P.; Euchner, M. Lattice Basis Reduction: Improved Practical Algorithms and Solving Subset Sum Problems. Math. Program. 1994, 66, 181–199. [Google Scholar] [CrossRef]
- Nguyen, P.Q.; Stern, J. Adapting Density Attacks to Low-Weight Knapsacks. In Advances in Cryptology—ASIACRYPT 2005; Springer: Berlin/Heidelberg, Germany, 2005; pp. 41–58. [Google Scholar] [CrossRef]
- Li, S.; Fan, S.; Lu, X. Attacking ECDSA Leaking Discrete Bits with a More Efficient Lattice. In Proceedings of the Inscrypt 2021; Springer: Cham, Switzerland, 2021. [Google Scholar]
- Schnorr, C.P. Fast Factoring Integers by SVP Algorithms, Corrected. Cryptology ePrint Archive, Report 2021/933. 2021. Available online: https://ia.cr/2021/933 (accessed on 30 December 2022).
- Kannan, R. Improved Algorithms for Integer Programming and Related Lattice Problems. In Proceedings of the Fifteenth Annual ACM Symposium on Theory of Computing; Association for Computing Machinery: New York, NY, USA, 1983; pp. 193–206. [Google Scholar] [CrossRef]
- Fincke, U.; Pohst, M. Improved methods for calculating vectors of short length in a lattice, including a complexity analysis. Math. Comput. 1985, 44, 463–471. [Google Scholar] [CrossRef]
- Gama, N.; Nguyen, P.Q. Predicting Lattice Reduction. In Proceedings of the Advances in Cryptology—EUROCRYPT 2008; Smart, N., Ed.; Springer: Berlin/Heidelberg, Germany, 2008; Volume 4965, pp. 31–51. [Google Scholar] [CrossRef]
- Lindner, R.; Peikert, C. Better Key Sizes (and Attacks) for LWE-Based Encryption. In Topics in Cryptology—CT-RSA 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 319–339. [Google Scholar] [CrossRef]
- Alkim, E.; Ducas, L.; Pöppelmann, T.; Schwabe, P. Post-quantum Key Exchange—A New Hope. In Proceedings of the 25th USENIX Security Symposium (USENIX Security 16), Austin, TX, USA, 10–12 August 2016; USENIX Association: Austin, TX, USA, 2016; pp. 327–343. [Google Scholar]
- Pohst, M. On the Computation of Lattice Vectors of Minimal Length, Successive Minima and Reduced Bases with Applications. SIGSAM Bull. 1981, 15, 37–44. [Google Scholar] [CrossRef]
- Gama, N.; Nguyen, P.Q.; Regev, O. Lattice Enumeration Using Extreme Pruning. In Proceedings of the Advances in Cryptology—EUROCRYPT 2010; Gilbert, H., Ed.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 257–278. [Google Scholar]
- Lattice Algorithms Using Floating-Point Arithmetic(fplll). Available online: https://github.com/fplll/fplll (accessed on 30 December 2022).
- Aono, Y.; Nguyen, P.Q.; Seito, T.; Shikata, J. Lower Bounds on Lattice Enumeration with Extreme Pruning. In Proceedings of the Advances in Cryptology—CRYPTO 2018; Shacham, H., Boldyreva, A., Eds.; Springer International Publishing: Berlin/Heidelberg, Germany, 2018; pp. 608–637. [Google Scholar]
- Schnorr, C.P. Lattice Reduction by Random Sampling and Birthday Methods. In Proceedings of the Annual Symposium on Theoretical Aspects of Computer Science (STACS 2003); Alt, H., Habib, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2003; pp. 145–156. [Google Scholar]
- Ajtai, M. The Worst-Case Behavior of Schnorr’s Algorithm Approximating the Shortest Nonzero Vector in a Lattice. In Proceedings of the Thirty-Fifth Annual ACM Symposium on Theory of Computing, San Diego, CA, USA, 9–10 June 2003; Association for Computing Machinery: New York, NY, USA, 2003; pp. 396–406. [Google Scholar] [CrossRef]
- Buchmann, J.; Ludwig, C. Practical Lattice Basis Sampling Reduction. In Proceedings of the Algorithmic Number Theory; Hess, F., Pauli, S., Pohst, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2006; pp. 222–237. [Google Scholar]
- Fukase, M.; Kashiwabara, K. An accelerated algorithm for solving SVP based on statistical analysis. J. Inf. Process. 2015, 23, 67–80. [Google Scholar] [CrossRef]
- Teruya, T.; Kashiwabara, K.; Hanaoka, G. Fast Lattice Basis Reduction Suitable for Massive Parallelization and Its Application to the Shortest Vector Problem. In Proceedings of the Public-Key Cryptography—PKC 2018; Abdalla, M., Dahab, R., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 437–460. [Google Scholar]
- Fukase, M.; Yamaguchi, K. Analysis of the Extended Search Space for the Shortest Vector in Lattice. In Proceedings of the IMETI 2010—3rd International Multi-Conference on Engineering and Technological Innovation, Proceedings, Orlando, FL, USA, 29 June–2 July 2010; Volume 2. [Google Scholar]
- Fukase, M.; Yamaguchi, K. Finding a Very Short Lattice Vector in the Extended Search Space. Trans. Inf. Process. Soc. Jpn. 2012, 53, 11. [Google Scholar] [CrossRef]
- Ding, D.; Zhu, G. A Random Sampling Algorithm for SVP Challenge based on y-Sparse Representations of Short Lattice Vectors. In Proceedings of the 2014 Tenth International Conference on Computational Intelligence and Security, Kunming, China, 15–16 November 2014. [Google Scholar] [CrossRef]
- Aono, Y.; Nguyen, P.Q. Random Sampling Revisited: Lattice Enumeration with Discrete Pruning. In Proceedings of the Advances in Cryptology—EUROCRYPT 2017; Coron, J.S., Nielsen, J.B., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 65–102. [Google Scholar]
- Aono, Y.; Nguyen, P.Q.; Shen, Y. Quantum Lattice Enumeration and Tweaking Discrete Pruning. In Proceedings of the Advances in Cryptology—ASIACRYPT 2018; Peyrin, T., Galbraith, S., Eds.; Springer International Publishing: Berlin/Heidelberg, Germany, 2018; pp. 405–434. [Google Scholar]
- Ludwig, C. Practical Lattice Basis Sampling Reduction. Ph.D. Thesis, der Technischen Universität Darmstadt, Darmstadt, Germany, 2005. [Google Scholar]
- Goldstein, D.; Mayer, A. On the equidistribution of Hecke points. Forum Math. 2003, 15, 165–189. [Google Scholar] [CrossRef]
- Chen, Y. Réduction de Réseau et Sécurité Concrète du Chiffrement Complètement Homomorphe. Ph.D. Thesis, Université Paris Diderot (Paris 7), Paris, France, 2013. [Google Scholar]
- TU Darmstadt, SVP Challenge. Available online: https://www.latticechallenge.org/svp-challenge/ (accessed on 30 December 2022).
- Chen, Y.; Nguyen, P.Q. BKZ 2.0: Better Lattice Security Estimates. In Advances in Cryptology—ASIACRYPT 2011; Springer: Berlin/Heidelberg, Germany, 2011; Volume 7073, pp. 1–20. [Google Scholar] [CrossRef]
- Bai, S.; Stehlé, D.; Wen, W. Measuring, Simulating and Exploiting the Head Concavity Phenomenon in BKZ. In Proceedings of the Advances in Cryptology—ASIACRYPT 2018; Peyrin, T., Galbraith, S., Eds.; Springer International Publishing: Berlin/Heidelberg, Germany, 2018; pp. 369–404. [Google Scholar]
- Hanrot, G.; Pujol, X.; Stehlé, D. Analyzing Blockwise Lattice Algorithms Using Dynamical Systems. In Proceedings of the Advances in Cryptology—CRYPTO 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 447–464. [Google Scholar]
- Albrecht, M.R. On Dual Lattice Attacks Against Small-Secret LWE and Parameter Choices in HElib and SEAL. In Advances in Cryptology—EUROCRYPT 2017; Springer International Publishing: Berlin/Heidelberg, Germany, 2017; pp. 103–129. [Google Scholar]
- Stehlé, D. Floating-Point LLL: Theoretical and Practical Aspects. In The LLL Algorithm: Survey and Applications; Nguyen, P.Q., Vallée, B., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 179–213. [Google Scholar] [CrossRef]
- Aono, Y.; Wang, Y.; Hayashi, T.; Takagi, T. Improved Progressive BKZ Algorithms and Their Precise Cost Estimation by Sharp Simulator. In Proceedings of the Advances in Cryptology—EUROCRYPT 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 789–819. [Google Scholar] [CrossRef]
- Albrecht, M.; Göpfert, F.; Lefebvre, C.; Owen, J.; Player, R. LWE Estimator’s Documentation. Online. Available online: https://lwe-estimator.readthedocs.io/en/latest/index.html (accessed on 25 December 2022).
- The General Sieve Kernel. Available online: https://github.com/fplll/g6k (accessed on 25 December 2022).
- Albrecht, M.R.; Ducas, L.; Herold, G.; Kirshanova, E.; Postlethwaite, E.W.; Stevens, M. The General Sieve Kernel and New Records in Lattice Reduction. In Proceedings of the Advances in Cryptology—EUROCRYPT 2019, Kobe, Japan, 8–12 December 2019; pp. 717–746. [Google Scholar]
- Albrecht, M.R.; Bai, S.; Fouque, P.A.; Kirchner, P.; Stehlé, D.; Wen, W. Faster Enumeration-Based Lattice Reduction: Root Hermite Factor k1/(2k) Time kk/8+o(k). In Proceedings of the Advances in Cryptology—CRYPTO 2020, Santa Barbara, CA, USA, 17–21 August 2020; pp. 186–212. [Google Scholar]
- Müller, W. Lattice Points in Large Convex Bodies. Monatshefte Math. 1999, 128, 315–330. [Google Scholar] [CrossRef]
- Krätzel, E. A sum formula related to ellipsoids with applications to lattice point theory. Abh. Aus Dem Math. Semin. Der Univ. Hambg. 2001, 71, 143–159. [Google Scholar] [CrossRef]
- Hosono, T. Numerical inversion of Laplace transform and some applications to wave optics. Radio Sci. 1981, 16, 1015–1019. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).