

A Cloud-Based Software Defect Prediction System Using Data and Decision-Level Machine Learning Fusion
 ,
,  , , and
, , and 
Abstract
1. Introduction
2. Literature Review
- Data fusion was performed, through which the developed classification models were rendered more robust and effective for the test datasets. The proposed system was implemented on a fused dataset, which was generated by fusing publicly available defect prediction datasets from NASA’s repository, including CM1, MW1, PC1, PC3, and PC4.
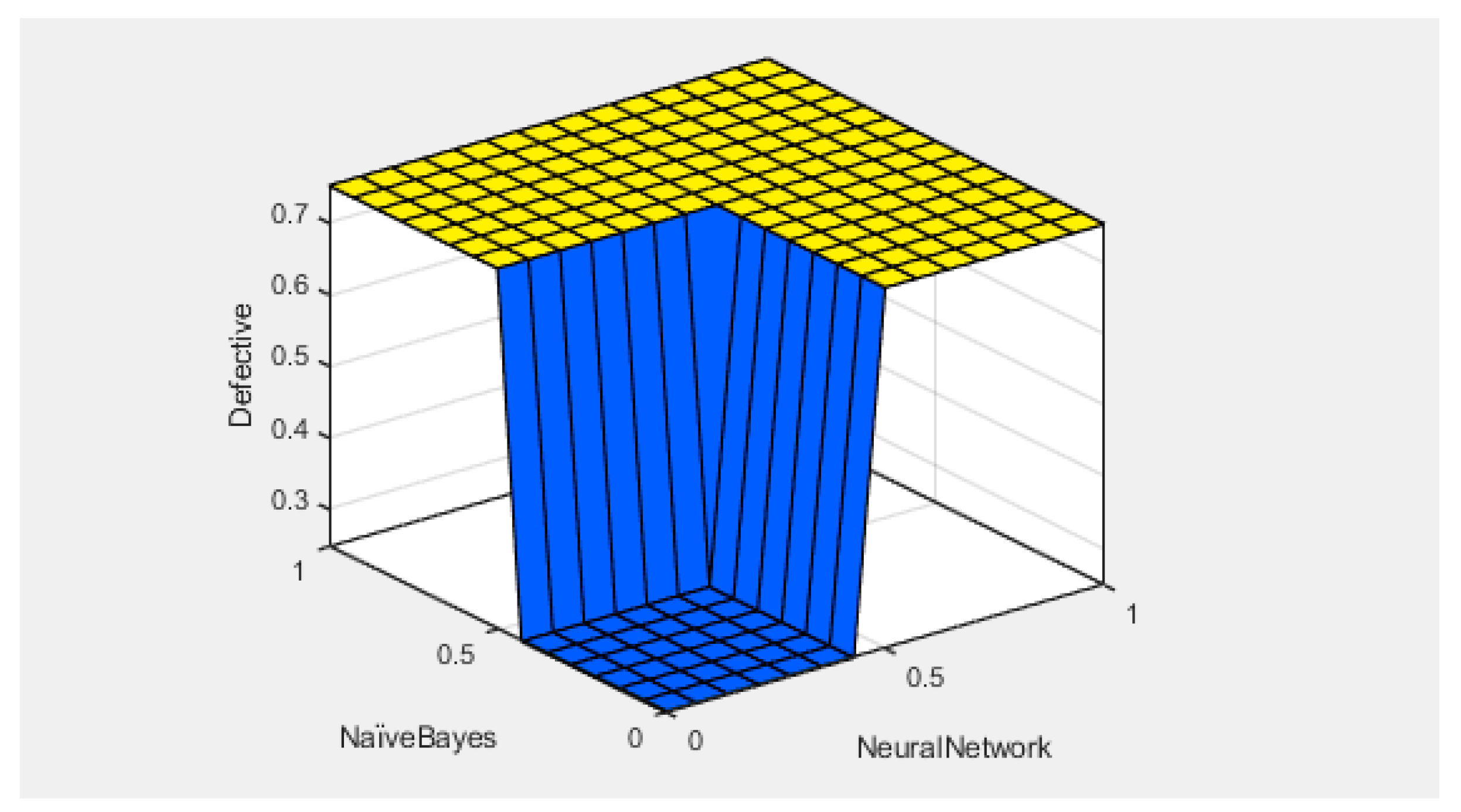
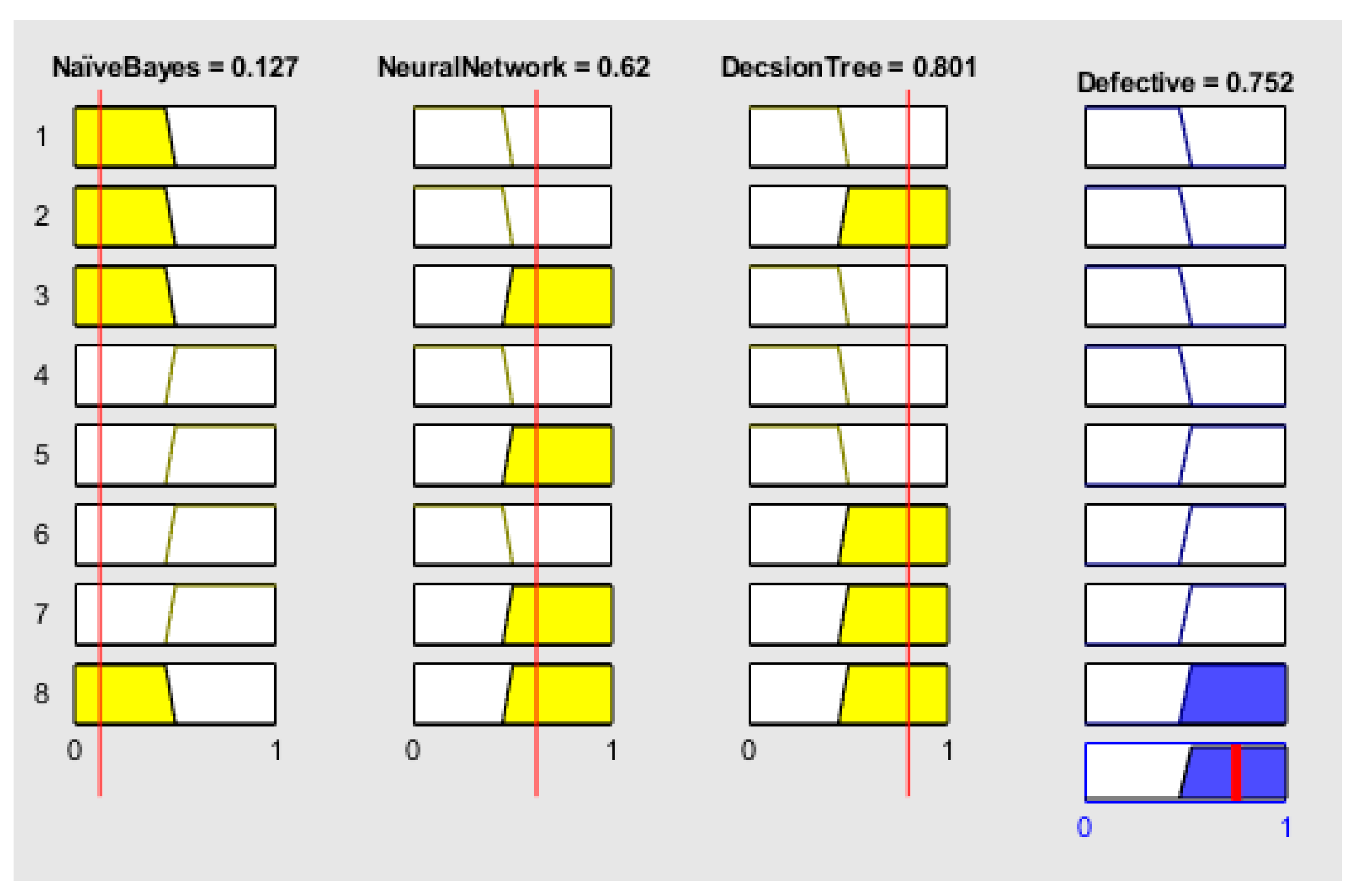
- The prediction accuracy of three classifiers, including NB, ANN, and DT, was integrated using a fuzzy logic technique. The proposed framework used eight fuzzy logic-based if–then rules for decision-level accuracy fusion.
- The performance of the proposed fusion-based intelligent system was compared with that of other state-of-the-art defect prediction systems, and it was observed that the proposed system outperformed the other methods and achieved a 91.05% accuracy for the fused dataset.
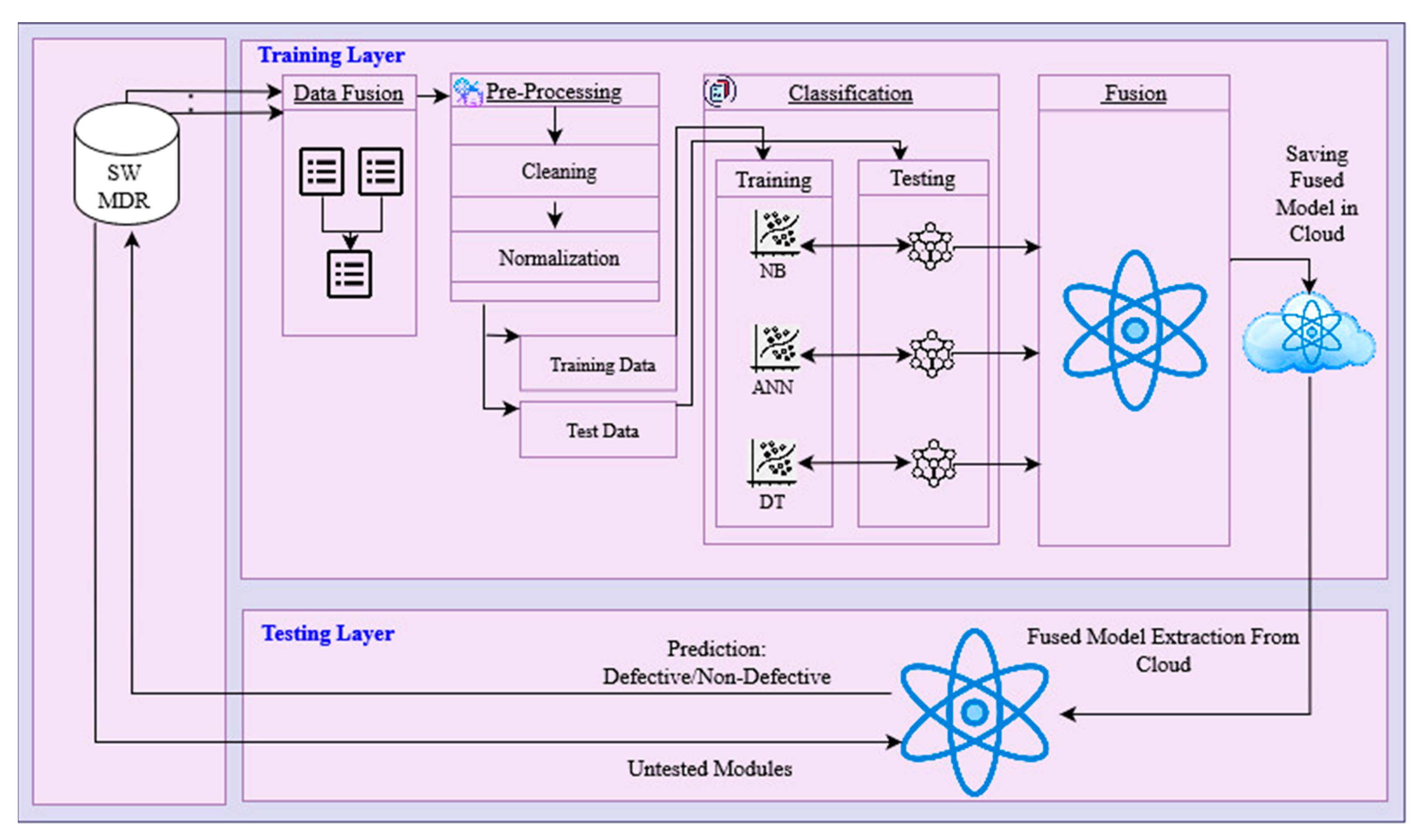
3. Materials and Methods
4. Results and Discussion
5. Threat to Validity
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Suresh Kumar, P.; Behera, H.S.; Nayak, J.; Naik, B. Bootstrap aggregation ensemble learning-based reliable approach for software defect prediction by using characterized code feature. Innov. Syst. Softw. Eng. 2021, 17, 355–379. [Google Scholar] [CrossRef]
- Balogun, A.O.; Basri, S.; Abdulkadir, S.J.; Hashim, A.S. Performance analysis of feature selection methods in software defect prediction: A search method approach. Appl. Sci. 2019, 9, 2764. [Google Scholar] [CrossRef]
- Balogun, A.O.; Basri, S.; Mahamad, S.; Abdulkadir, S.J.; Capretz, L.F.; Imam, A.A.; Almomani, M.A.; Adeyemo, V.E.; Kumar, G. Empirical analysis of rank aggregation-based multi-filter feature selection methods in software defect prediction. Electronics 2021, 10, 179. [Google Scholar] [CrossRef]
- Huda, S.; Alyahya, S.; Ali, M.M.; Ahmad, S.; Abawajy, J.; Al-Dossari, H.; Yearwood, J. A framework for software defect prediction and metric selection. IEEE Access 2017, 6, 2844–2858. [Google Scholar] [CrossRef]
- Song, Q.; Jia, Z.; Shepperd, M.; Ying, S.; Liu, J. A general software defect-proneness prediction framework. IEEE Trans. Softw. Eng. 2010, 37, 356–370. [Google Scholar] [CrossRef]
- Zhang, Q.; Ren, J. Software-defect prediction within and across projects based on improved self-organizing data mining. J. Supercomput. 2021, 78, 6147–6173. [Google Scholar] [CrossRef]
- Ibrahim, D.R.; Ghnemat, R.; Hudaib, A. Software defect prediction using feature selection and random forest algorithm. In Proceedings of the International Conference on New Trends in Computer Science, Amman, Jordan, 11–13 October 2017; pp. 252–257. [Google Scholar]
- Mahajan, R.; Gupta, S.; Bedi, R.K. Design of software fault prediction model using br technique. Procedia Comput. Sci. 2015, 46, 849–858. [Google Scholar] [CrossRef]
- Goyal, S.; Bhatia, P.K. Heterogeneous stacked ensemble classifier for software defect prediction. Multimed. Tools Appl. 2021, 81, 37033–37055. [Google Scholar] [CrossRef]
- Mehta, S.; Patnaik, K.S. Stacking based ensemble learning for improved software defect prediction. In Proceeding of Fifth International Conference on Microelectronics, Computing and Communication Systems; Springer: Singapore, 2021; pp. 167–178. [Google Scholar]
- Daoud, M.S.; Aftab, S.; Ahmad, M.; Khan, M.A.; Iqbal, A.; Abbas, S.; Ihnaini, B. machine learning empowered software defect prediction system. Intell. Autom. Soft Comput. 2022, 31, 1287–1300. [Google Scholar] [CrossRef]
- Ali, U.; Aftab, S.; Iqbal, A.; Nawaz, Z.; Bashir, M.S.; Saeed, M.A. Software defect prediction using variant based ensemble learning and feature selection techniques. Int. J. Mod. Educ. Comput. Sci. 2020, 12, 29–40. [Google Scholar] [CrossRef]
- Iqbal, A.; Aftab, S. Prediction of defect prone software modules using MLP based ensemble techniques. Int. J. Inf. Technol. Comput. Sci. 2020, 12, 26–31. [Google Scholar] [CrossRef]
- Iqbal, A.; Aftab, S. A classification framework for software defect prediction using multi-filter feature selection technique and MLP. Int. J. Mod. Educ. Comput. Sci. 2020, 12, 42–55. [Google Scholar] [CrossRef]
- Arasteh, B. Software fault-prediction using combination of neural network and Naive Bayes algorithm. J. Netw. Technol. 2018, 9, 95. [Google Scholar] [CrossRef]
- Alsaeedi, A.; Khan, M.Z. Software defect prediction using supervised machine learning and ensemble techniques: A comparative study. J. Softw. Eng. Appl. 2019, 12, 85–100. [Google Scholar] [CrossRef]
- Balogun, A.O.; Basri, S.; Capretz, L.F.; Mahamad, S.; Imam, A.A.; Almomani, M.A.; Kumar, G. software defect prediction using wrapper feature selection based on dynamic re-ranking strategy. Symmetry 2021, 13, 2166. [Google Scholar] [CrossRef]
- Alsawalqah, H.; Hijazi, N.; Eshtay, M.; Faris, H.; Radaideh, A.A.; Aljarah, I.; Alshamaileh, Y. Software defect prediction using heterogeneous ensemble classification based on segmented patterns. Appl. Sci. 2020, 10, 1745. [Google Scholar] [CrossRef]
- Bi, J.; Yuan, H.; Zhou, M. Temporal prediction of multiapplication consolidated workloads in distributed clouds. IEEE Trans. Autom. Sci. Eng. 2019, 16, 1763–1773. [Google Scholar] [CrossRef]
- Shepperd, M.; Song, Q.; Sun, Z.; Mair, C. Data quality: Some comments on the NASA software defect datasets. IEEE Trans. Softw. Eng. 2013, 39, 1208–1215. [Google Scholar] [CrossRef]
- NASA Defect Dataset. Available online: https://github.com/klainfo/NASADefectDataset (accessed on 17 September 2022).
- Ahmed, U.; Issa, G.F.; Khan, M.A.; Aftab, S.; Khan, M.F.; Said, R.A.; Ghazal, T.M.; Ahmad, M. Prediction of diabetes empowered with fused machine learning. IEEE Access 2022, 10, 8529–8538. [Google Scholar] [CrossRef]
- Rahman, A.U.; Abbas, S.; Gollapalli, M.; Ahmed, R.; Aftab, S.; Ahmad, M.; Khan, M.A.; Mosavi, A. Rainfall prediction system using machine learning fusion for smart cities. Sensors 2022, 22, 3504. [Google Scholar] [CrossRef]
- Naeem, Z.; Farzan, M.; Naeem, F. Predicting the performance of governance factor using fuzzy inference system. Int. J. Comput. Innov. Sci. 2022, 1, 35–50. [Google Scholar]
- Goyal, S.; Bhatia, P.K. Comparison of machine learning techniques for software quality prediction. Int. J. Knowl. Syst. Sci. 2020, 11, 20–40. [Google Scholar] [CrossRef]
- Balogun, A.O.; Lafenwa-Balogun, F.B.; Mojeed, H.A.; Adeyemo, V.E.; Akande, O.N.; Akintola, A.G.; Bajeh, A.O.; Usman-Hamza, F.E. SMOTE-based homogeneous ensemble methods for software defect prediction. In International Conference on Computational Science and Its Applications; Springer: Cham, Switzerland, 2020; pp. 615–631. [Google Scholar]
- Khuat, T.T.; Le, M.H. Evaluation of sampling-based ensembles of classifiers on imbalanced data for software defect prediction problems. SN Comput. Sci. 2020, 1, 108. [Google Scholar] [CrossRef]
- Kumudha, P.; Venkatesan, R. Cost-sensitive radial basis function neural network classifier for software defect prediction. Sci. World J. 2016, 11, 126–134. [Google Scholar] [CrossRef] [PubMed]
- Abdou, A.S.; Darwish, N.R. Early prediction of software defect using ensemble learning: A comparative study. Int. J. Comput. Appl. 2018, 179, 29–40. [Google Scholar]
- Wohlin, C.; Runeson, P.; Höst, M.; Ohlsson, M.C.; Regnell, B.; Wesslén, A. Experimentation in Software Engineering; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Gao, K.; Khoshgoftaar, T.M.; Seliya, N. Predicting high-risk program modules by selecting the right software measurements. Softw. Qual. J. 2012, 20, 3–42. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Prediction Technique | Dataset Repository | Datasets | Performance Measures |
|---|---|---|---|---|
| Daoud, M. S. et al. [11] | Four training functions of back propagation in ANN are used for SDP. The fuzzy logic-based technique is proposed for the identification of the best training function. | NASA | CM1, JM1, KC1, KC3, MC1, MC2, MW1, PC1, PC2, PC3, PC4, PC5 | Specificity, precision, F-measure, recall, accuracy, AUC, R2, MSE |
| Ali, U. et al. [12] | A metric selection-based variant ensemble machine learning technique is proposed for software defect prediction. | NASA | JM1, KC1, PC4, PC5 | F-measure, accuracy, MCC |
| Iqbal, A. et al. [13] | An ANN-based ensemble machine learning technique is proposed for SDP. | NASA | KC1, MW1, PC4, PC5 | F-measure, accuracy, AUC, MCC |
| Iqbal, A. et al. [14] | A multi-filter feature selection technique is used with ANN for SDP. | NASA | CM1, JM1, KC1, KC3, MC1, MC2, MW1, PC1, PC2, PC3, PC4, PC5 | F-measure, accuracy, AUC, MCC |
| Arasteh, B. et al. [15] | Proposes a technique by integrating the ANN and NB for SDP. | PROMISE | KC1, KC2, CM1, PC1, JM1 | Accuracy, precision |
| Alsaeedi, A. et al. [16] | Various supervised classification techniques are used for SDP, including: SVM, DT, RF, bagging, and boosting. The SMOTE technique is used to tackle the issue of class imbalance. | NASA | PC1, PC2, PC3, PC4, PC5, MC1, MC2, JM1, MW1, KC3 | Accuracy, precision, F-measure, recall, true-positive rate, false-positive rate, probability of false alarm, specificity, G-measure |
| Balogun, A. O. et al. [17] | An enhanced wrapper feature selection technique is proposed. The proposed technique is used with NB and DT. | PROMISE, NASA, AEEEM, | EQ, JDT, ML PDE, CM1, KC1, KC2, KC3, MW1, PC1, PC3, PC4, PC5, ANT, CAMEL, JEDIT, REDKITOR, TOMCAT, VELOCITY, XALAN, SAFE, ZXING, APACHE, ECLIPSE, SWT | Accuracy, F-measure, AUC |
| Alsawalqah, H. et al. [18] | Heterogeneous ensemble classifiers are used for SDP. | PROMISE, NASA, | PC1, PC2, PC3, PC4, PC5, KC1, KC3, CM1, JM1, MC1, MW1, ant-1.7, camel-1.6, ivy-2.0, jedit-4.3, log4j-1.2, ucene-2.4, poi-3.0, tomcat-6, xalan-2.6, xerces-1.4 | Precision, recall, G-mean |
| Membership Functions | Graphical Representation |
|---|---|
| 𝛄𝓑 (𝓃𝒷)= |  |
| 𝛄𝓑 (𝓃𝒷)= |  |
| 𝛄 (𝓃𝓃)= |  |
| 𝛄 (𝓃𝓃)= |  |
| 𝛄 (𝒹𝓉) = |  |
| 𝛄 (𝒹𝓉)= |  |
| 𝛄 (₫)= |  |
| 𝛄 (₫)= |  |
| N = 2506 (No. of Records) | Predicted Result OR0, OR1 | ||
|---|---|---|---|
| INPUT | Expected output result (OR0, OR1) | OR0 (Non-defective -0) | OR1 (Defective -1) |
| OR0 = 2206 (Non-defective -0) | 1948 | 258 | |
| OR1 = 300 (Defective -1) | 193 | 107 | |
| N = 1073 (No. of Records) | Predicted Result OR0, OR1 | ||
|---|---|---|---|
| INPUT | Expected output result (OR0, OR1) | OR0 (Non-defective -0) | OR1 (Defective -1) |
| OR0 = 945 (Non-defective -0) | 872 | 73 | |
| OR1 = 128 (Defective -1) | 106 | 22 | |
| N = 2506 (No. of Records) | Predicted Result OR0, OR1 | ||
|---|---|---|---|
| INPUT | Expected output result (OR0, OR1) | OR0 (Non-defective -0) | OR1 (Defective -1) |
| OR0 = 2206 (Non-defective -0) | 2100 | 106 | |
| OR1 = 300 (Defective -1) | 244 | 56 | |
| N = 1073 (No. of Records) | Predicted Result OR0, OR1 | ||
|---|---|---|---|
| INPUT | Expected output result (OR0, OR1) | OR0 (Non-defective -0) | OR1 (Defective -1) |
| OR0 = 945 (Non-defective -0) | 905 | 40 | |
| OR1 = 128 (Defective -1) | 112 | 16 | |
| N = 2506 (No. of Records) | Predicted Result OR0, OR1 | ||
|---|---|---|---|
| INPUT | Expected output result (OR0, OR1) | OR0 (Non-defective -0) | OR1 (Defective -1) |
| OR0 = 2206 (Non-defective -0) | 2073 | 133 | |
| OR1 = 300 (Defective -1) | 101 | 199 | |
| N = 1073 (No. of Records) | Predicted Result OR0, OR1 | ||
|---|---|---|---|
| INPUT | Expected output result (OR0, OR1) | OR0 (Non-defective -0) | OR1 (Defective -1) |
| OR0 = 945 (Non-defective -0) | 887 | 58 | |
| OR1 = 128 (Defective -1) | 102 | 26 | |
| N = 1073 (No. of Records) | Predicted Result OR0, OR1 | ||
|---|---|---|---|
| INPUT | Expected output result (OR0, OR1) | OR0 (Non-defective -0) | OR1 (Defective -1) |
| OR0 = 945 (Non-defective -0) | 935 | 10 | |
| OR1 = 128 (Defective -1) | 86 | 42 | |
| ML Algorithm | Dataset | Accuracy | Specificity | Sensitivity | Positive Prediction Value | Negative Prediction Value | False Positive Value | False Negative Value | Likelihood Ratio Positive | Likelihood Ratio Negative |
|---|---|---|---|---|---|---|---|---|---|---|
| Naïve Bayes | Training | 0.8200 | 0.8830 | 0.3567 | 0.2932 | 0.9099 | 0.1170 | 0.6433 | 3.049 | 0.8200 |
| Testing | 0.8332 | 0.9228 | 0.1719 | 0.2316 | 0.8916 | 0.0772 | 0.8281 | 2.225 | 0.8332 | |
| Artificial neural network | Training | 0.8603 | 0.9519 | 0.1867 | 0.3456 | 0.8959 | 0.0481 | 0.8133 | 3.885 | 0.8603 |
| Testing | 0.8583 | 0.9577 | 0.125 | 0.2857 | 0.8899 | 0.0423 | 0.875 | 2.953 | 0.8583 | |
| Decision tree | Training | 0.9066 | 0.9397 | 0.6633 | 0.5994 | 0.9535 | 0.0603 | 0.3367 | 11.00 | 0.9066 |
| Testing | 0.8509 | 0.9386 | 0.2031 | 0.3095 | 0.8969 | 0.0614 | 0.7969 | 3.310 | 0.8509 | |
| Fused/proposed method | Testing | 0.9105 | 0.9894 | 0.3281 | 0.8077 | 0.9158 | 0.0106 | 0.6719 | 31.01 | 0.9087 |
| Prediction Technique | Accuracy (%) |
|---|---|
| Stacked ensemble [9] | 89.10 |
| Fused-ANN-BR [11] | 85.45 |
| FS-VEML [12] | 84.97 |
| Boosting-OPT-MLP [13] | 79.08 |
| MLP-FS [14] | 85.13 |
| NB [18] | 82.65 |
| ANN [25] | 89.96 |
| Tree [25] | 84.94 |
| Bagging [26] | 80.20 |
| Boosting [26] | 81.30 |
| Heterogeneous [27] | 89.20 |
| ADBBO-RBFNN [28] | 88.65 |
| Bagging LWL [29] | 90.10 |
| Proposed FSDPS | 91.05 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aftab, S.; Abbas, S.; Ghazal, T.M.; Ahmad, M.; Hamadi, H.A.; Yeun, C.Y.; Khan, M.A. A Cloud-Based Software Defect Prediction System Using Data and Decision-Level Machine Learning Fusion. Mathematics 2023, 11, 632. https://doi.org/10.3390/math11030632
Aftab S, Abbas S, Ghazal TM, Ahmad M, Hamadi HA, Yeun CY, Khan MA. A Cloud-Based Software Defect Prediction System Using Data and Decision-Level Machine Learning Fusion. Mathematics. 2023; 11(3):632. https://doi.org/10.3390/math11030632
Chicago/Turabian StyleAftab, Shabib, Sagheer Abbas, Taher M. Ghazal, Munir Ahmad, Hussam Al Hamadi, Chan Yeob Yeun, and Muhammad Adnan Khan. 2023. "A Cloud-Based Software Defect Prediction System Using Data and Decision-Level Machine Learning Fusion" Mathematics 11, no. 3: 632. https://doi.org/10.3390/math11030632
APA StyleAftab, S., Abbas, S., Ghazal, T. M., Ahmad, M., Hamadi, H. A., Yeun, C. Y., & Khan, M. A. (2023). A Cloud-Based Software Defect Prediction System Using Data and Decision-Level Machine Learning Fusion. Mathematics, 11(3), 632. https://doi.org/10.3390/math11030632