When Fairness Meets Consistency in AHP Pairwise Comparisons




Abstract
1. Introduction
2. Materials and Methods
2.1. Insight into Related Literature
- There are 35,430 articles published in the period 1980–2021 (from which 15,000 articles are from 2017–2021), according to Madzík and Falát [33] and based on Scopus;
- There are 8441 articles published in the period 1979–2017 (more specifically, there are 86 articles from 1979–1990, 716 articles from 1991–2001, and 7639 articles from 2002–2017), according to Emrouznejad and Marra [34] and based on ISI Web of Science;
- There are 9859 harvested articles published in the period 1982–2018, according to Yu et al. [35] and based on ISI Web of Science. This review also includes an improved Saaty’s version of the AHP, i.e., the analytic network process (ANP) that considers interaction and dependence among hierarchically structured elements.
- Up-down decomposition of decision problem in hierarchy levels, starting from the goal on the top, followed by criteria in the middle, sub-criteria if necessary, in the next/lower level(s), and finally, decision alternatives/options at the bottom of the elaborated hierarchy;
- Comparative judgments, i.e., comparisons of the decomposed elements from the same level in pairs (within PCMs) regarding the above-level goal or criteria (according to the nine-degree scale defined in [10]), to derive principal eigenvectors, i.e., relative priorities;
- Synthesis of the priorities, from local to the global plane, for overall alternatives’ ranking corresponding to the goal.
2.1.1. Common-Mentioned Shortcomings of AHP Pairwise Comparisons
2.1.2. Fairness Notes on AHP Pairwise Comparisons
- Concerning DMs–it is applicable in group decision-making when decision systems should fairly include DMs’ opinions. For example, a decision support system for group MCDM can mitigate or eliminate biased DMs’ opinions [62] or follow a democratic approach in conflict situations by choosing a consensual value for parameter v (related to the VIKOR method, it equals 0.5) [63].
- Concerning decision criteria–criterion weights are essential for two levels of fairness: among criteria and alternatives [64]; while it is generally possible to introduce discrimination based on a single property (e.g., racial discrimination–[65], gender discrimination–[66], age discrimination–[67], etc.), several separate properties (i.e., multiple discrimination–[68]), or one joint property (i.e., intersectional discrimination–[69]). In MCDM, opposite to wash criteria about which alternatives are equally preferred [70], DMs can define criteria (or their weights) that favor/damage some alternatives or groups (the favored group is privileged, and the damaged group is unprivileged).
- Concerning the used algorithms–it can imply the absence of unintentional (coincidentally made) discrimination toward vulnerable groups in society that algorithmic decision-making techniques may amplify. The harmful practice is possible because of, for example, data that reflect historically widespread biases and contain the prejudices of prior DMs [71] or impose discriminatory inferences towards underrepresented groups [23].
2.2. Toward Consistent and Fair AHP Pairwise Methodology
2.2.1. Discrete Optimization Problem
2.3. Synthetic Experiment
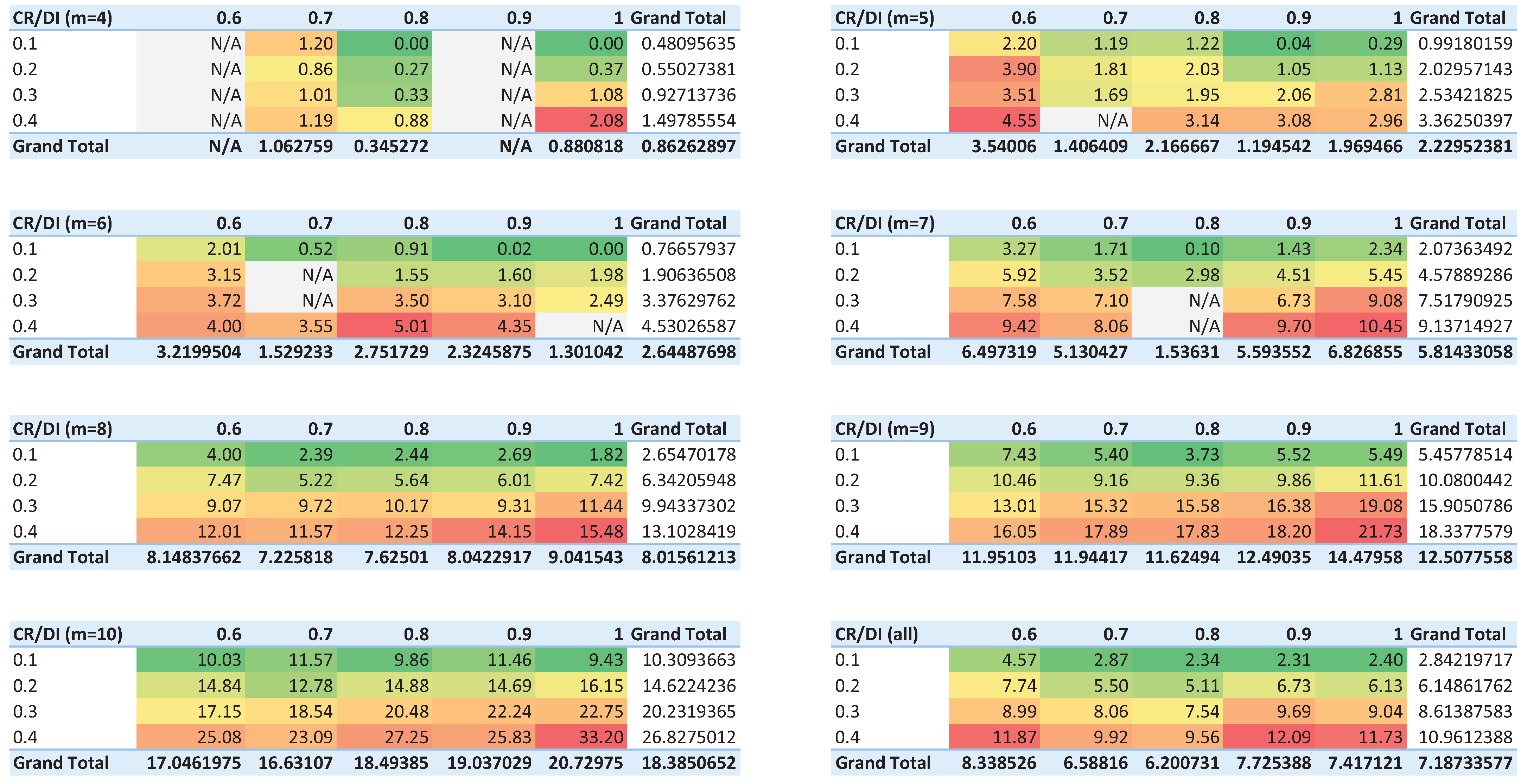
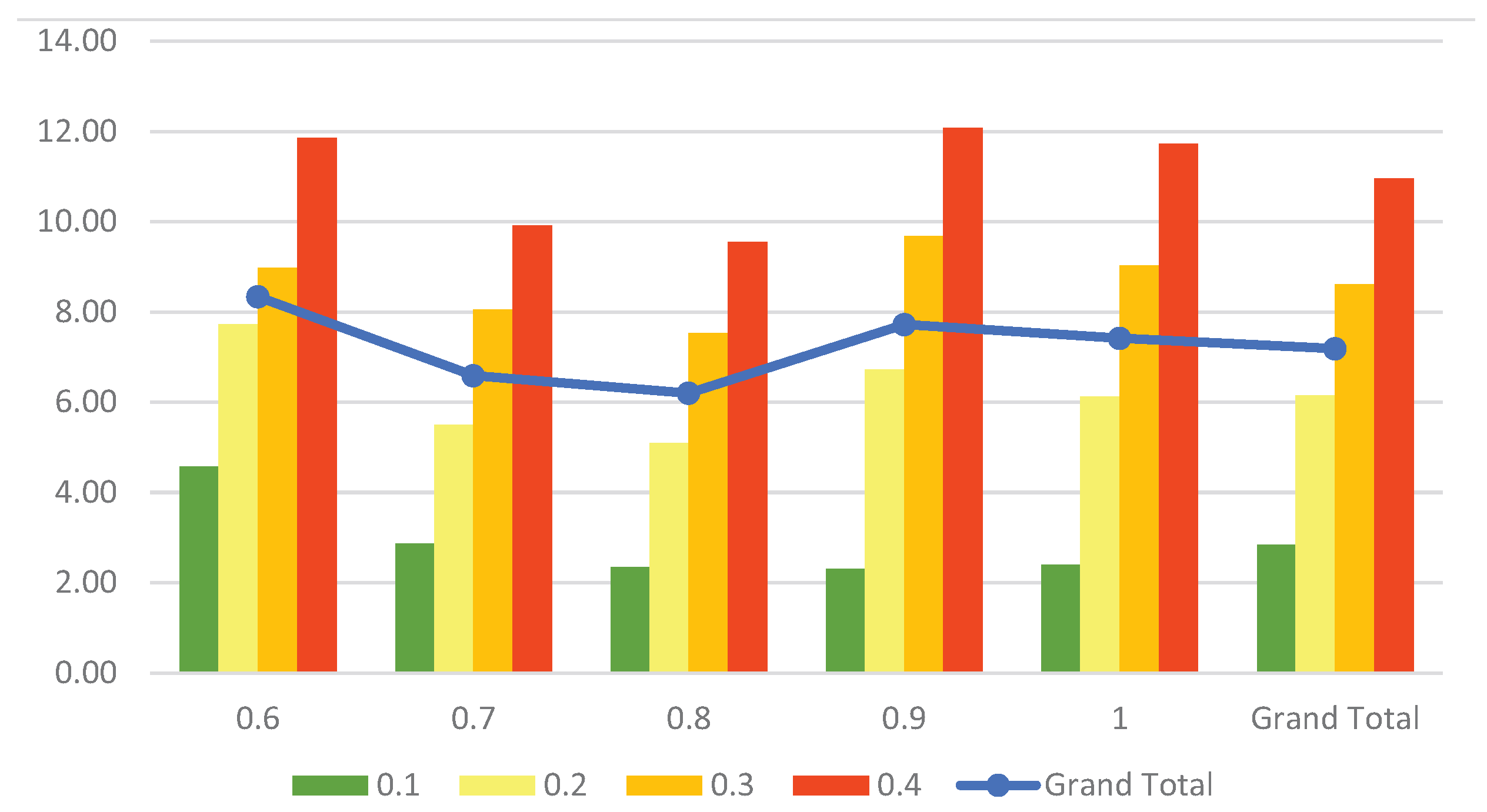
3. Results
4. Discussion
5. Conclusions
- Expanding and applying the methodology to the whole AHP hierarchy structure;
- Fixing some judgments that DMs do not want to change;
- Setting multiobjective discrete optimizations (such as in [87]) to achieve additional goals (regarding AHP hierarchy structure or the used accuracy/fairness metrics).
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AHP | Analytic hierarchy process |
| AI | Artificial intelligence |
| CR | Consistency ratio |
| DI | Disparate impact |
| DM(s) | Decision-maker(s) |
| GA | Genetic algorithm |
| MCDM | Multi-criteria decision-making |
| ML | Machine learning |
| MM | Mathematical model |
| MP | Mathematical programming |
| OM | Operation management |
| PCM(s) | Pairwise comparison matrice(s) |
| RQ | Rayleigh quotient |
| UT(s) | Upper triangle(s) |
References
- Saaty, R.W. The analytic hierarchy process—What it is and how it is used. Math. Model. 1987, 9, 161–176. [Google Scholar] [CrossRef]
- de FSM Russo, R.; Camanho, R. Criteria in AHP: A systematic review of literature. Procedia Comput. Sci. 2015, 55, 1123–1132. [Google Scholar] [CrossRef]
- Cabała, P. Using the analytic hierarchy process in evaluating decision alternatives. Oper. Res. Decis. 2010, 20, 5–23. [Google Scholar]
- Vaidya, O.S.; Kumar, S. Analytic hierarchy process: An overview of applications. Eur. J. Oper. Res. 2006, 169, 1–29. [Google Scholar] [CrossRef]
- Darko, A.; Chan, A.P.C.; Ameyaw, E.E.; Owusu, E.K.; Parn, E.; Edwards, D.J. Review of application of analytic hierarchy process (AHP) in construction. Int. J. Constr. Manag. 2019, 19, 436–452. [Google Scholar] [CrossRef]
- Al-Harbi, K.M.A.S. Application of the AHP in project management. Int. J. Proj. Manag. 2001, 19, 19–27. [Google Scholar] [CrossRef]
- Subramanian, N.; Ramanathan, R. A review of applications of Analytic Hierarchy Process in operations management. Int. J. Prod. Econ. 2012, 138, 215–241. [Google Scholar] [CrossRef]
- Liberatore, M.J.; Nydick, R.L. The analytic hierarchy process in medical and health care decision making: A literature review. Eur. J. Oper. Res. 2008, 189, 194–207. [Google Scholar] [CrossRef]
- Ruiz Bargueño, D.; Salomon, V.A.P.; Marins, F.A.S.; Palominos, P.; Marrone, L.A. State of the art review on the analytic hierarchy process and urban mobility. Mathematics 2021, 9, 3179. [Google Scholar] [CrossRef]
- Saaty, T.L. A scaling method for priorities in hierarchical structures. J. Math. Psychol. 1977, 15, 234–281. [Google Scholar] [CrossRef]
- Munier, N.; Hontoria, E. Uses and Limitations of the AHP Method; Springer: Cham, Switzerland, 2021. [Google Scholar]
- Kwiesielewicz, M.; Van Uden, E. Inconsistent and contradictory judgements in pairwise comparison method in the AHP. Comput. Oper. Res. 2004, 31, 713–719. [Google Scholar] [CrossRef]
- Bozóki, S.; Fulop, J.; Poesz, A. On reducing inconsistency of pairwise comparison matrices below an acceptance threshold. Cent. Eur. J. Oper. Res. 2015, 23, 849–866. [Google Scholar] [CrossRef]
- Pereira, V.; Costa, H.G. Nonlinear programming applied to the reduction of inconsistency in the AHP method. Ann. Oper. Res. 2015, 229, 635–655. [Google Scholar] [CrossRef]
- Zhang, Y.; Bellamy, R.; Varshney, K. Joint optimization of AI fairness and utility: A human-centered approach. In Proceedings of the Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society, New York, NY, USA, 7–9 February 2020; pp. 400–406. [Google Scholar] [CrossRef]
- Dodevska, Z.; Petrović, A.; Radovanović, S.; Delibašić, B. Changing criteria weights to achieve fair VIKOR ranking: A postprocessing reranking approach. Auton. Agents Multi-Agent Syst. 2023, 37, 1–44. [Google Scholar] [CrossRef]
- Chen, C.; Cook, W.D.; Imanirad, R.; Zhu, J. Balancing Fairness and Efficiency: Performance Evaluation with Disadvantaged Units in Non-homogeneous Environments. Eur. J. Oper. Res. 2020, 287, 1003–1013. [Google Scholar] [CrossRef]
- Radovanović, S.; Petrović, A.; Delibašić, B.; Suknović, M. Eliminating Disparate Impact in MCDM: The case of TOPSIS. In Proceedings of the Central European Conference on Information and Intelligent Systems, Varaždin, Croatia, 13–15 October 2021; pp. 275–282. [Google Scholar]
- Çakır, O.; Gurler, İ.; Gunduzyeli, B. Analysis of a Non-Discriminating Criterion in Simple Additive Weighting Deep Hierarchy. Mathematics 2022, 10, 3192. [Google Scholar] [CrossRef]
- Askarisichani, O.; Bullo, F.; Friedkin, N.E.; Singh, A.K. Predictive models for human–AI nexus in group decision making. Ann. N. Y. Acad. Sci. 2022, 1514, 70–81. [Google Scholar] [CrossRef]
- Bastani, H.; Bastani, O.; Sinchaisri, W.P. Improving human decision-making with machine learning. arXiv 2021, arXiv:2108.08454. [Google Scholar] [CrossRef]
- Jago, A.S.; Laurin, K. Assumptions about algorithms’ capacity for discrimination. Personal. Soc. Psychol. Bull. 2022, 48, 582–595. [Google Scholar] [CrossRef]
- Pessach, D.; Shmueli, E. Improving fairness of artificial intelligence algorithms in Privileged-Group Selection Bias data settings. Expert Syst. Appl. 2021, 185, 115667. [Google Scholar] [CrossRef]
- Kordzadeh, N.; Ghasemaghaei, M. Algorithmic bias: Review, synthesis, and future research directions. Eur. J. Inf. Syst. 2022, 31, 388–409. [Google Scholar] [CrossRef]
- Rambachan, A.; Roth, J. Bias in, bias out? Evaluating the folk wisdom. arXiv 2019, arXiv:1909.08518. [Google Scholar]
- Cecere, G.; Corrocher, N.; Jean, C. Fair or Unbiased Algorithmic Decision-Making? A Review of the Literature on Digital Economics. In A Review of the Literature on Digital Economics (October 15, 2021); SSRN: Rochester, NY, USA, 2021. [Google Scholar] [CrossRef]
- Tolan, S. Fair and unbiased algorithmic decision making: Current state and future challenges. arXiv preprint 2019, arXiv:1901.04730. [Google Scholar]
- Hakli, H.; Uguz, H.; Ortacay, Z. Comparing the performances of six nature-inspired algorithms on a real-world discrete optimization problem. Soft Comput. 2022, 26, 11645–11667. [Google Scholar] [CrossRef]
- Hajian, S.; Domingo-Ferrer, J. A methodology for direct and indirect discrimination prevention in data mining. IEEE Trans. Knowl. Data Eng. 2012, 25, 1445–1459. [Google Scholar] [CrossRef]
- Zliobaite, I. A survey on measuring indirect discrimination in machine learning. arXiv 2015, arXiv:1511.00148. [Google Scholar]
- Bennett, C.; Keyes, O. What is the point of fairness? Interactions 2020, 27, 35–39. [Google Scholar] [CrossRef]
- Hacker, P. Teaching fairness to artificial intelligence: Existing and novel strategies against algorithmic discrimination under EU law. Common Mark. Law Rev. 2018, 55, 1143–1185. [Google Scholar] [CrossRef]
- Madzík, P.; Falát, L. State-of-the-art on analytic hierarchy process in the last 40 years: Literature review based on Latent Dirichlet Allocation topic modelling. PLoS ONE 2022, 17, e0268777. [Google Scholar] [CrossRef]
- Emrouznejad, A.; Marra, M. The state of the art development of AHP (1979–2017): A literature review with a social network analysis. Int. J. Prod. Res. 2017, 55, 6653–6675. [Google Scholar] [CrossRef]
- Yu, D.; Kou, G.; Xu, Z.; Shi, S. Analysis of collaboration evolution in AHP research: 1982–2018. Int. J. Inf. Technol. Decis. Mak. 2021, 20, 7–36. [Google Scholar] [CrossRef]
- Kong, F.; Liu, H. An improvement on Saaty’s AHP. In Proceedings of the IFIP International Conference on Artificial Intelligence Applications and Innovations, Beijing, China, 7–9 September 2005; pp. 301–312. [Google Scholar] [CrossRef]
- Lootsma, F.A. The Additive and the Multiplicative AHP. In Fuzzy Logic for Planning and Decision Making; Springer: New York, NY, USA, 1997; pp. 109–147. [Google Scholar] [CrossRef]
- Maleki, H.; Zahir, S. A comprehensive literature review of the rank reversal phenomenon in the analytic hierarchy process. J. Multi-Criteria Decis. Anal. 2013, 20, 141–155. [Google Scholar] [CrossRef]
- Munier, N.; Hontoria, E. Shortcomings of the AHP Method. In Uses and limitations of the AHP Method; Springer: Cham, Switzerland, 2021; pp. 41–90. [Google Scholar] [CrossRef]
- Pant, S.; Kumar, A.; Ram, M.; Klochkov, Y.; Sharma, H.K. Consistency Indices in Analytic Hierarchy Process: A Review. Mathematics 2022, 10, 1206. [Google Scholar] [CrossRef]
- Mardani, A.; Zavadskas, E.K.; Govindan, K.; Amat Senin, A.; Jusoh, A. VIKOR technique: A systematic review of the state of the art literature on methodologies and applications. Sustainability 2016, 8, 37. [Google Scholar] [CrossRef]
- Sangiorgio, V.; Uva, G.; Fatiguso, F. Optimized AHP to overcome limits in weight calculation: Building performance application. J. Constr. Eng. Manag. 2018, 144, 04017101. [Google Scholar] [CrossRef]
- Ishizaka, A.; Pearman, C.; Nemery, P. AHPSort: An AHP-based method for sorting problems. Int. J. Prod. Res. 2012, 50, 4767–4784. [Google Scholar] [CrossRef]
- Ishizaka, A.; López, C. Cost-benefit AHPSort for performance analysis of offshore providers. Int. J. Prod. Res. 2019, 57, 4261–4277. [Google Scholar] [CrossRef]
- Li, F.; Phoon, K.K.; Du, X.; Zhang, M. Improved AHP method and its application in risk identification. J. Constr. Eng. Manag. 2013, 139, 312–320. [Google Scholar] [CrossRef]
- Lin, C.C.; Wang, W.C.; Yu, W.D. Improving AHP for construction with an adaptive AHP approach (A3). Autom. Constr. 2008, 17, 180–187. [Google Scholar] [CrossRef]
- Xiulin, S.; Dawei, L. An improvement analytic hierarchy process and its application in teacher evaluation. In Proceedings of the 2014 Fifth International Conference on Intelligent Systems Design and Engineering Applications, Zhangjiajie, China, 15–16 June 2014; pp. 169–172. [Google Scholar] [CrossRef]
- Leal, J.E. AHP-express: A simplified version of the analytical hierarchy process method. MethodsX 2020, 7, 100748. [Google Scholar] [CrossRef]
- Chen, T. A diversified AHP-tree approach for multiple-criteria supplier selection. Comput. Manag. Sci. 2021, 18, 431–453. [Google Scholar] [CrossRef]
- Abastante, F.; Corrente, S.; Greco, S.; Ishizaka, A.; Lami, I.M. A new parsimonious AHP methodology: Assigning priorities to many objects by comparing pairwise few reference objects. Expert Syst. Appl. 2019, 127, 109–120. [Google Scholar] [CrossRef]
- Nefeslioglu, H.A.; Sezer, E.A.; Gokceoglu, C.; Ayas, Z. A modified analytical hierarchy process (M-AHP) approach for decision support systems in natural hazard assessments. Comput. Geosci. 2013, 59, 1–8. [Google Scholar] [CrossRef]
- Tesfamariam, S.; Sadiq, R. Risk-based environmental decision-making using fuzzy analytic hierarchy process (F-AHP). Stoch. Environ. Res. Risk Assess. 2006, 21, 35–50. [Google Scholar] [CrossRef]
- Bañuelas, R.; Antony, J. Modified analytic hierarchy process to incorporate uncertainty and managerial aspects. Int. J. Prod. Res. 2004, 42, 3851–3872. [Google Scholar] [CrossRef]
- Xu, S.; Xu, D.; Liu, L. Construction of regional informatization ecological environment based on the entropy weight modified AHP hierarchy model. Sustain. Comput. Informatics Syst. 2019, 22, 26–31. [Google Scholar] [CrossRef]
- Sadiq, R.; Tesfamariam, S. Environmental decision-making under uncertainty using intuitionistic fuzzy analytic hierarchy process (IF-AHP). Stoch. Environ. Res. Risk Assess. 2009, 23, 75–91. [Google Scholar] [CrossRef]
- Lin, K.; Chen, H.; Xu, C.Y.; Yan, P.; Lan, T.; Liu, Z.; Dong, C. Assessment of flash flood risk based on improved analytic hierarchy process method and integrated maximum likelihood clustering algorithm. J. Hydrol. 2020, 584, 124696. [Google Scholar] [CrossRef]
- Deng, X.; Hu, Y.; Deng, Y.; Mahadevan, S. Supplier selection using AHP methodology extended by D numbers. Expert Syst. Appl. 2014, 41, 156–167. [Google Scholar] [CrossRef]
- Gao, R.; Shah, C. Toward creating a fairer ranking in search engine results. Inf. Process. Manag. 2020, 57, 102138. [Google Scholar] [CrossRef]
- Mehrabi, N.; Morstatter, F.; Saxena, N.; Lerman, K.; Galstyan, A. A survey on bias and fairness in machine learning. ACM Comput. Surv. (CSUR) 2021, 54, 1–35. [Google Scholar] [CrossRef]
- Verma, S.; Rubin, J. Fairness definitions explained. In Proceedings of the 2018 IEEE/ACM International Workshop on Software Fairness (Fairware), Gothenburg, Sweden, 29 May 2018; pp. 1–7. [Google Scholar] [CrossRef]
- Narayanan, A. Translation tutorial: 21 fairness definitions and their politics. In Proceedings of the Conference Fairness Accountability, and Transparency New York, NY, USA, 23–24 February 2018; Volume 1170, p. 3. [Google Scholar]
- Rabiee, M.; Aslani, B.; Rezaei, J. A decision support system for detecting and handling biased decision-makers in multi criteria group decision-making problems. Expert Syst. Appl. 2021, 171, 114597. [Google Scholar] [CrossRef]
- Opricovic, S. A compromise solution in water resources planning. Water Resour. Manag. 2009, 23, 1549–1561. [Google Scholar] [CrossRef]
- Fu, C.; Zhou, K.; Xue, M. Fair framework for multiple criteria decision making. Comput. Ind. Eng. 2018, 124, 379–392. [Google Scholar] [CrossRef]
- Pager, D.; Shepherd, H. The sociology of discrimination: Racial discrimination in employment, housing, credit, and consumer markets. Annu. Rev. Sociol. 2008, 34, 181. [Google Scholar] [CrossRef]
- Nuseir, M.T.; Al Kurdi, B.H.; Alshurideh, M.T.; Alzoubi, H.M. Gender discrimination at workplace: Do Artificial Intelligence (AI) and Machine Learning (ML) have opinions about it. In Proceedings of the The International Conference on Artificial Intelligence and Computer Vision, Settat, Morocco, 28–30 June 2021; pp. 301–316. [Google Scholar] [CrossRef]
- Macnicol, J. Age Discrimination: An Historical and Contemporary Analysis; Cambridge University Press: Cambridge, UK, 2006. [Google Scholar]
- Uccellari, P. Multiple discrimination: How law can reflect reality. Equal. Rights Rev. 2008, 1, 24–49. [Google Scholar]
- Ghosh, A.; Dutt, R.; Wilson, C. When fair ranking meets uncertain inference. In Proceedings of the Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, 11–15 July 2021; pp. 1033–1043. [Google Scholar] [CrossRef]
- Liberatore, M.J.; Nydick, R.L. Wash criteria and the analytic hierarchy process. Comput. Oper. Res. 2004, 31, 889–892. [Google Scholar] [CrossRef]
- Barocas, S.; Selbst, A.D. Big data’s disparate impact. Calif. Law Rev. 2016, 104, 671. [Google Scholar] [CrossRef]
- Besse, P.; del Barrio, E.; Gordaliza, P.; Loubes, J.M.; Risser, L. A survey of bias in machine learning through the prism of statistical parity. Am. Stat. 2022, 76, 188–198. [Google Scholar] [CrossRef]
- Feldman, M.; Friedler, S.A.; Moeller, J.; Scheidegger, C.; Venkatasubramanian, S. Certifying and removing disparate impact. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, Australia, 10–13 August 2015; pp. 259–268. [Google Scholar] [CrossRef]
- Katoch, S.; Chauhan, S.S.; Kumar, V. A review on genetic algorithm: Past, present, and future. Multimed. Tools Appl. 2021, 80, 8091–8126. [Google Scholar] [CrossRef]
- Mirjalili, S. Genetic algorithm. In Evolutionary Algorithms and Neural Networks; Springer: Cham, Switzerland, 2019; pp. 43–55. [Google Scholar] [CrossRef]
- Lee, C.K.H. A review of applications of genetic algorithms in operations management. Eng. Appl. Artif. Intell. 2018, 76, 1–12. [Google Scholar] [CrossRef]
- Slowik, A.; Kwasnicka, H. Evolutionary algorithms and their applications to engineering problems. Neural Comput. Appl. 2020, 32, 12363–12379. [Google Scholar] [CrossRef]
- Solgi, R.M. MIT License Geneticalgorithm 1.0.2. Available online: https://pypi.org/project/geneticalgorithm/ (accessed on 27 November 2022).
- Zhang, J.; Kou, G.; Peng, Y.; Zhang, Y. Estimating priorities from relative deviations in pairwise comparison matrices. Inf. Sci. 2021, 552, 310–327. [Google Scholar] [CrossRef]
- Benítez, J.; Delgado-Galván, X.; Gutiérrez, J.A.; Izquierdo, J. Balancing consistency and expert judgment in AHP. Math. Comput. Model. 2011, 54, 1785–1790. [Google Scholar] [CrossRef]
- Kułakowski, K. Inconsistency in the ordinal pairwise comparisons method with and without ties. Eur. J. Oper. Res. 2018, 270, 314–327. [Google Scholar] [CrossRef]
- Ishizaka, A.; Nemery, P. Multi-Criteria Decision Analysis: Methods and Software; John Wiley & Sons: Hoboken, NJ, USA, 2013. [Google Scholar]
- Crawford, G.; Williams, C. A note on the analysis of subjective judgment matrices. J. Math. Psychol. 1985, 29, 387–405. [Google Scholar] [CrossRef]
- Li, B.; Liang, H.; He, Q. Multiple and generic bifurcation analysis of a discrete Hindmarsh-Rose model. Chaos Solitons Fractals 2021, 146, 110856. [Google Scholar] [CrossRef]
- Eskandari, Z.; Avazzadeh, Z.; Khoshsiar Ghaziani, R.; Li, B. Dynamics and bifurcations of a discrete-time Lotka–Volterra model using nonstandard finite difference discretization method. Math. Methods Appl. Sci. 2022. [Google Scholar] [CrossRef]
- Li, B.; Liang, H.; Shi, L.; He, Q. Complex dynamics of Kopel model with nonsymmetric response between oligopolists. Chaos Solitons Fractals 2022, 156, 111860. [Google Scholar] [CrossRef]
- Liu, Q.; Li, X.; Liu, H.; Guo, Z. Multi-objective metaheuristics for discrete optimization problems: A review of the state-of-the-art. Appl. Soft Comput. 2020, 93, 106382. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| m | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|
| 0.58 | 0.9 | 1.12 | 1.24 | 1.32 | 1.41 | 1.45 | 1.49 |
| Author(s) | Name | Purpose of Transformation | The Used Method | Field of Application |
|---|---|---|---|---|
| Sangiorgio et al. [42] | Optimized-AHP (O-AHP) | It successfully overcomes the following drawbacks of classical AHP, common in situations when the number of criteria or alternatives is greater than nine:
| The weights evaluation procedure based on mathematical programming (MP) redefines the process of forming a judgment matrix in the following ways:
| Construction |
| Ishizaka et al. [43] | AHPSort | It reduces the number of required comparisons and facilitates decision-making. | A new variant sorts alternatives into ordered predefined categories according to DMs’ preferences. | Supplier selection |
| Ishizaka and López [44] | Cost-Benefit AHPSort | It provides better and easier comparisons and benchmarks for evaluating alternatives. | A modification of the AHPSort treats cost and benefit criteria separately, i.e., into two distinct hierarchies. | Performance analysis of offshore providers in the aerospace industry |
| Li et al. [45] | Improved AHP (IAHP) | It improves consistency in PCMs when the number of elements equals five or more. | The improvement uses the sorting technique (instead of quantification on Saaty’s 9-point scale) to judge between two elements in pairwise comparisons. | Risk identification in construction |
| Lin et al. [46] | Adaptive AHP approach () | It helps to improve consistency in pairwise comparisons, reduce costs and timeliness, and improve decision-making quality. | The approach uses a soft computing technique (i.e., a GA) to improve consistency automatically. | Construction |
| Xiulin and Dawei [47] | Improved AHP | It overcomes the difficulties of making judgments according to the traditional nine-scaling method and blindness in checking consistency. It is helpful in the determination of target weights. | The improvement uses a 3-scale point method: 1/0.5/0 indicates that the alternative is more/equally/less important than the alternative. | Teacher evaluation |
| Leal [48] | AHP-express | The simplified version helps make decisions in constrained times. It reduces the number of required comparisons and facilitates calculations. | The simplification requires only comparisons (n–number of alternatives) for each criterion, unlike required comparisons in traditional AHP. | Business application |
| Chen [49] | Diversified AHP-tree approach | It allows diverse viewpoints of DMs regarding criteria relative importance. | The approach decomposes an inconsistent judgment matrix into several sub-judgment matrices. It uses the GA for solving nonlinear programming models to maximize the sum of distances between any two sub-judgment matrices. | Supplier selection |
| Abastante et al. [50] | New parsimonious AHP methodology | It reduces the number of comparisons and inconsistencies and avoids rank reversal problems compared to the original AHP. | A newly developed proposal implies using reference objects for pairwise comparisons. It avoids comparisons of more relevant objects with less relevant ones. | General application |
| Author(s) | Name | Purpose of Transformation | The Used Method | Field of Application |
|---|---|---|---|---|
| Nefeslioglu et al. [51] | Modified AHP (M-AHP) | It compensates for expert subjectivism in pairwise comparisons due to a lack of knowledge or data for the relevant problem. | A computer code is postulated on factors and the decision points, whereby the role of experts in preparing the comparison matrix is limited to defining the maximum scores for factors in the system. | Natural hazards |
| Tesfamariam and Sadiq [52] | Fuzzy AHP (F-AHP) | It allows DMs to account for uncertainty (vagueness). | The fuzzy-based technique used fuzzy arithmetic operations. It aggregates the fuzzy global preference weights concerning each alternative. | Environmental risk management |
| Banuelas and Antony [53] | Modified AHP (MAHP) | It includes uncertainty and managerial aspects (‘soft’ issues) in judgment comparisons and, therefore, a better understanding of the context of the applied technique. | The method incorporates uncertainty by using probabilistic distributions. It tests the results for statistical significance and analyses rank reversal using ANOVA. | Application in organizations |
| Xu et al. [54] | Entropy weight modified AHP hierarchy model (EWMAHPHM) | It improves decision-making efficiency in changing environments where regional information is insufficient. | The method includes the entropy weight method in AHP. The construction of the distributed model precedes the entropy weight correction. | Information-based ecological environment construction |
| Sadiq and Tesfamariam [55] | Intuitionistic fuzzy AHP (IF-AHP) | It handles both uncertainty categories–vagueness and ambiguity in human subjective evaluation. | The methodology uses intuitionistic fuzzy sets. | Environmental decision-making |
| Lin et al. [56] | Improved AHP (IAHP) | It comprehensively determines the weights of risk indices. | The improvement uses the entropy weight method and integrates objective data variability with subjective judgments. | Flash flood risk assessment |
| Deng et al. [57] | D-AHP | It provides a new, effective, and feasible expression of uncertain information. | The method extends the fuzzy preference relation approach by using the so-called D numbers, resulting from the Dempster–Shafer theory extension. | Supplier selection |
| PCM Size (m) | Percentage |
|---|---|
| 4 | 100.00% |
| 5 | 100.00% |
| 6 | 100.00% |
| 7 | 99.5% |
| 8 | 99.25% |
| 9 | 98.25% |
| 10 | 99.5% |
| Total | 99.5% |
| Approach | Successful Optimizations (in%) | |||
|---|---|---|---|---|
| Iterative–eigenvector | 99.00% | 13.6658 | 0.0939 | 0.8476 |
| Approximate–RQ | 86.00% | 12.4885 | 0.0943 | 0.8499 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dodevska, Z.; Radovanović, S.; Petrović, A.; Delibašić, B. When Fairness Meets Consistency in AHP Pairwise Comparisons. Mathematics 2023, 11, 604. https://doi.org/10.3390/math11030604
Dodevska Z, Radovanović S, Petrović A, Delibašić B. When Fairness Meets Consistency in AHP Pairwise Comparisons. Mathematics. 2023; 11(3):604. https://doi.org/10.3390/math11030604
Chicago/Turabian StyleDodevska, Zorica, Sandro Radovanović, Andrija Petrović, and Boris Delibašić. 2023. "When Fairness Meets Consistency in AHP Pairwise Comparisons" Mathematics 11, no. 3: 604. https://doi.org/10.3390/math11030604
APA StyleDodevska, Z., Radovanović, S., Petrović, A., & Delibašić, B. (2023). When Fairness Meets Consistency in AHP Pairwise Comparisons. Mathematics, 11(3), 604. https://doi.org/10.3390/math11030604