1. Introduction
1.1. Motivation
The rapid advancement of Internet and Artificial Intelligence (AI) technologies has profoundly influenced various aspects of our lives, including smart city development [
1,
2,
3,
4], energy management [
5,
6], and financial services [
7]. Particularly notable is its impact in the field of education, especially in the realm of Massive Open Online Courses (MOOCs). As an emerging form of online education, MOOCs are undergoing continuous transformation and innovation through the application of AI and Internet technologies.
The phenomenon of student dropout in MOOCs represents a critical challenge in online education, attracting extensive research and investigation. High dropout rates, prevalent in certain courses and programs, adversely affect student success and institutional reputations. To combat this, various dropout prediction models have been developed, employing machine learning algorithms and deep learning models [
8,
9,
10,
11]. These models aim to identify at-risk students early, enabling timely interventions to bolster retention rates. Computational approaches, including advanced algorithms and mathematical models, have been instrumental in enhancing the accuracy and efficiency of these predictions. Notably, the integration of parallel and distributed computing techniques, including federated learning approaches, has begun to transform dropout prediction in MOOCs. By leveraging distributed data while maintaining privacy and reducing computational burdens, federated learning offers a promising avenue for developing more robust, scalable, and efficient dropout prediction systems. Such advancements hold the potential not only to refine intervention strategies but also to significantly improve student engagement and retention outcomes in online educational platforms.
Extensive research has been conducted to unravel the factors influencing student dropout in various educational contexts, with a significant focus on Massive Open Online Courses (MOOCs). Studies such as Feng et al.’s analysis of XuetangX, China’s largest MOOC platform, shed light on distinct studying behaviors and their linkage to dropout motivations [
12]. These investigations reveal correlations between dropout rates and various factors, including peer influence, engagement levels, course difficulty, workload, and content relevance [
9,
13,
14]. Jin et al.’s definition of dropout as a sustained absence of learning behavior further underscores the need for sophisticated data analysis techniques in these large-scale educational datasets [
14]. These insights form a crucial foundation for the development of advanced dropout prediction models, driving the need for more nuanced analytical approaches that can process complex data patterns and address data privacy considerations.
In addition to the factors mentioned earlier, the significance of learning patterns in predicting student dropout is paramount. Learning patterns, defined as a coherent set of learning activities that learners engage in over a specific time period [
15], provide profound insights into student behavior and motivations. These patterns are critical in assessing the likelihood of students dropping out. Research indicates that students who share similar beliefs about learning and motivation tend to exhibit similar learning patterns [
16]. However, the variability of these patterns across different courses, shaped by unique educational contexts and motivations [
17,
18], presents a complex challenge in accurately predicting dropout.
1.2. Significance
Addressing this challenge necessitates the adoption of advanced computational approaches. The application of particularly parallel and distributed processing techniques becomes crucial here. These techniques facilitate effective handling and analysis of diverse learning patterns, adapting to the dynamic nature of educational data. Moreover, integrating mathematical models and federated learning approaches into this framework not only enhances the accuracy of predictions but also aligns with the decentralized nature of MOOC data. By focusing on these unique learning patterns through sophisticated analytical models, our approach aims to refine dropout prediction methods in MOOCs, tailoring them to the intricacies of different courses and student behaviors.
Our study undertook a comprehensive analysis of existing dropout prediction models. Utilizing the t-SNE dimensionality reduction technique [
19], we visualized the models’ representations to assess their effectiveness. This analysis uncovered two key limitations. First, we observed that mainstream models often fall short in adequately capturing the distinct learning patterns of students. Such inadequacy hinders their predictive accuracy, limiting their utility in identifying potential dropouts based on these patterns. Second, these models typically fail to represent personalized learning patterns that vary across different courses. This lack of customization in model representations leads to ineffective predictions of student dropout behavior in varied educational settings. These findings underscore the necessity for more sophisticated computational approaches. By leveraging such advanced methods, we aim to develop enhanced models that can more accurately capture and analyze the intricate and varied learning patterns of students, thereby significantly improving the precision of dropout predictions in MOOC environments.
1.3. Objectives
To effectively overcome the limitations of traditional dropout prediction models, we have developed the Federated Learning Pattern Aware Dropout Prediction Model (FLPADPM), an approach that maintains the original model architecture while integrating the principles of federated learning. In our federated learning setup, each client (e.g., different educational institutions or MOOC platforms) independently trains a local instance of FLPADPM on their own dataset. This local training process utilizes the one-dimensional convolutional neural network (CNN) and bidirectional long short-term memory (LSTM) layer, ensuring consistency in feature extraction and analysis of temporal relationships in student learning patterns.
During the local training phase, each client’s model learns to identify and understand the unique learning behaviors and patterns prevalent in their respective datasets. The course-specific learnable matrices, and , within each local model, adapt to the distinct educational contexts of their data, offering personalized insights into student learning patterns. The attention mechanism, deployed at each client, tailors the dropout prediction to individual students by focusing on the most relevant learning patterns, as determined by the local data.
Once the local models complete their training, the key step in our federated learning approach comes into play: the aggregation of learned parameters on a central server. Here, the parameters from all clients are aggregated to update the global FLPADPM model. This aggregation process ensures that the global model benefits from the diverse and comprehensive learning insights gathered across all participating clients, enhancing its overall predictive accuracy.
1.4. Contributions
In this study, we present three key contributions to the field of dropout prediction in MOOCs. First, we identify and articulate the limitations of mainstream dropout prediction models, particularly their inability to effectively uncover and interpret the distinct learning patterns exhibited by students. We observe that these conventional models often overlook the personalized variations in learning patterns across different courses, leading to a shortfall in their predictive accuracy for student dropout behavior.
Second, in response to these challenges, we propose the Federated Learning Pattern Aware Dropout Prediction Model (FLPADPM), an innovative approach that integrates the original architecture of the Learning Pattern Aware Dropout Prediction Model (LPADPM) with the principles of federated learning. FLPADPM leverages a one-dimensional convolutional neural network (CNN) and a bidirectional long short-term memory (LSTM) layer to deeply analyze relationships, patterns, and the temporal dynamics of student data. Furthermore, we incorporate learnable matrices to model and understand the variations in learning patterns specific to different courses. This aspect of the model is crucial in capturing the unique educational contexts and thereby enhancing the accuracy of dropout predictions.
Third, through extensive empirical evaluation, we demonstrate that FLPADPM significantly outperforms existing state-of-the-art models in accurately predicting student dropout behavior. This superior performance is attributed to our model’s ability to effectively integrate and analyze personalized learning patterns within a federated learning framework. Our study underscores the importance of considering distinct learning patterns in dropout prediction and showcases the effectiveness of our novel model in capturing these patterns. By incorporating these nuanced insights into student behavior, FLPADPM enables the design of targeted interventions and support systems, ultimately aiming to bolster student engagement and improve retention rates in MOOC environments.
2. Related Work
2.1. Dropout Prediction Task
Several studies have been conducted to understand the factors influencing student dropout in Massive Open Online Courses (MOOCs). These studies have explored various aspects such as learning behaviors, course design, social interactions, and demographic factors. In this section, we review the relevant literature and discuss the findings of these studies.
One important factor that has been investigated is the relationship between learning behaviors and dropout rates. Wang et al. [
20] analyzed MOOC data and found that users’ learning behaviors are relative for several consecutive days. They highlighted the need to consider factors that may affect dropout and incorporate them into dropout prediction models. Similarly, Wen et al. [
21] studied the local correlation between learning behaviors and its impact on dropout prediction. They found that the time interval of the learning behavior has a significant influence on future user states.
Another aspect that has been explored is the influence of course design on dropout rates. Feng et al. [
12] conducted a clustering analysis of users’ learning activity data and found that studying behavior can be grouped into distinct categories. They also observed a high correlation between dropout rates in similar courses and the strong influence of friends’ dropout behaviors on each other. In addition to learning behaviors and course design, demographic factors have also been studied. For example, Aldowah et al. [
13] investigated the impact of academic skills, prior experience, and social support on dropout rates. They found that these factors play a significant role in predicting dropout behavior.
Furthermore, the use of machine learning algorithms [
22] and deep learning models [
23,
24] has been explored for dropout prediction in MOOCs. Mrhar et al. [
25] used a data mining method to analyze learners’ learning behavior and identify characteristics of learners who tend to drop out. They found that features such as number of threads viewed and number of forum posts can be used to predict learner attrition. Similarly, Liu et al. [
26] proposed a learning behavior feature fused deep learning network model for dropout prediction, which considers temporal features among individual videos and incorporates general information such as student and course features. Other studies have focused on the analysis of clickstream data and the use of time series models for dropout prediction. Tang et al. [
27] applied recurrent neural networks with long short-term memory cells to predict course dropout based on learners’ daily activities. They found that the time series model outperformed other contrast models in terms of prediction accuracy. Recently, advancements in deep learning for dropout prediction have been notable. Kumar et al. [
28] introduced an Ensemble Deep Learning Network model that leverages ResNet-50 and Faster RCNN with an attention mechanism for improved dropout prediction accuracy. Additionally, Li et al. [
29] explored the use of a deep learning model with an attention mechanism in a flipped classroom setting, aiming to enhance the prediction of students’ performance and the identification of critical learning stages.
While these studies have provided valuable insights into the predictors of dropout rates, there is a gap in the research when it comes to understanding the correlation between distinct learning patterns and dropout rates. This gap highlights the need for further investigation into the relationship between learning patterns and dropout rates in order to develop more accurate prediction models. In our study, we aim to address this gap by analyzing the impact of learning patterns on dropout rates in MOOCs.
2.2. Federated Learning
At present, federated learning is gaining increasing attention for its ability to train distributed models while preserving clients’ privacy. In the federated learning setting, multiple clients perform the machine learning tasks collaboratively under the coordination of the server without sharing their local data [
30,
31]. Many algorithms were proposed to learn a single global model which can perform well for all clients. For example, FedProx [
32] utilized the regularization for global model to alleviate the distribution drift between local models and a global model; SCAFFOLD [
33] aimed to correct local drift using control variates. To improve the global model learning with non-independent and identically distributed (non-IID) data, both Zhao et al. [
34] and Yoon et al. [
35] introduced a data sharing method and data augmentation technique among clients to mitigate statistical heterogeneity issues.
Differing from learning a single global model for all clients, personalized federated learning was proposed by designing a tailored model for each client under a traditional federated learning information communication setting. Per-FedAvg [
36] and pFedMe [
37] attempted to learn a shared meta-model for each client through a Model-Agnostic Meta-Learning Approach and Moreau Envelopes, separately. Moreover, Fedsteg [
38] and Fedhealth [
39] learn the shared knowledge among the related clients via transfer learning to improve the local model’s performance. Recently, various DNN-based personalized federated learning approaches were proposed for learning a common representation and personalized classifier by decoupling the neural network into the representation layers and decision layer [
40,
41]. FedPer [
42] and FedRep [
43] learn the entire neural network jointly over the local updating and only send the representation layers for aggregation; the difference between these two methods lies in the local updating. FedPer simultaneously updates both the representation layers and the decision layer, whereas FedRep alternately updates the two parts. FedPop [
44] is a Bayesian federated learning framework which aims to learn a common deterministic representation layer and a personalized stochastic decision layer for capturing the uncertainty over the model parameters. Unfortunately, existing federated learning methods have not taken into consideration the application in dropout prediction.
3. Methodology
3.1. Problem Definition
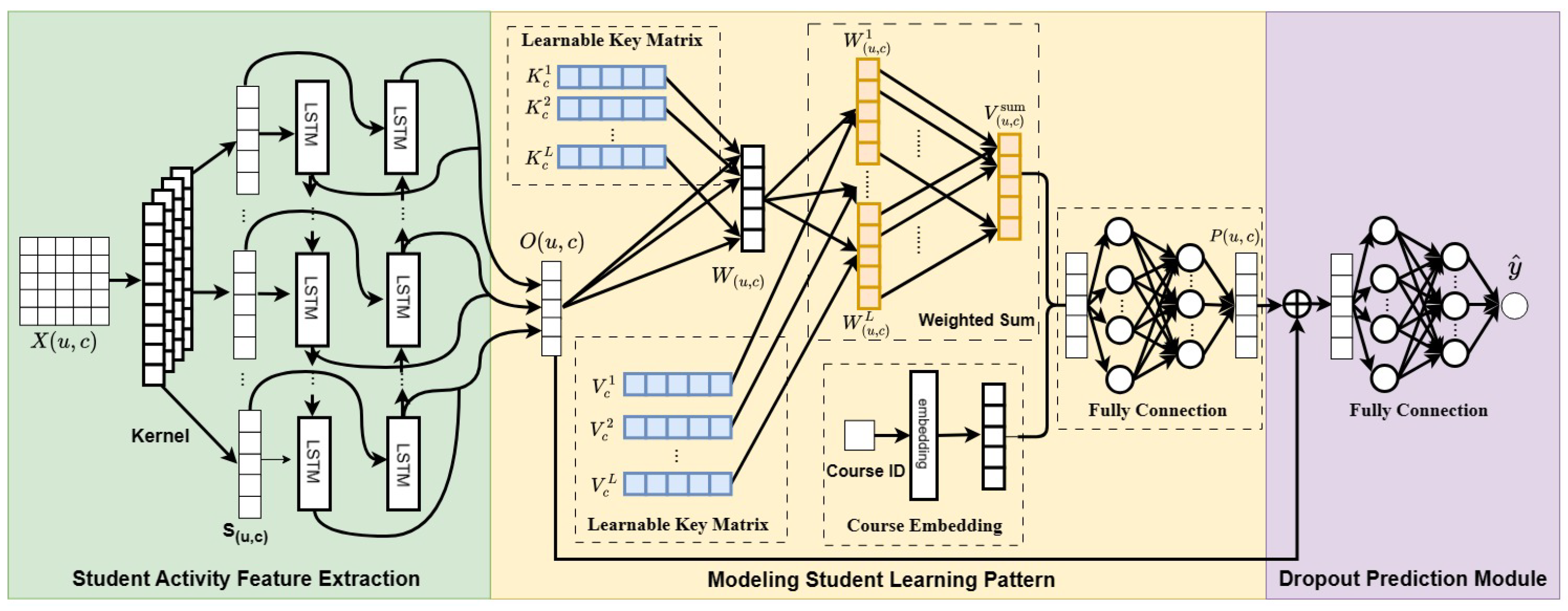
The objective of this study is to predict student dropout rates in MOOCs within a federated learning framework, as shown in
Figure 1. Formally, let
C denote the set of courses,
U the set of users, and
I the set of institutions or MOOC platforms, each acting as a client in the federated learning system. The set of all enrollments is denoted as
E, with each enrollment represented as a tuple
, indicating that user
u has enrolled in course
c offered by institution
i. Our goal is to predict the dropout likelihood, denoted by a binary variable
, where 1 indicates dropout and 0 indicates continuation. The prediction is based on user activity data, represented by a matrix
of dimensions
, where
m and
n represent the number of days and types of learning activities, respectively. Each client (institution) trains a local model on its dataset, and these local models are aggregated to enhance the global prediction model.
3.2. Student Activity Feature Extraction
Students often exhibit numerous behaviors within online education systems, where the temporal combination of different learning behaviors often constitutes their unique learning methods and styles. Therefore, to unearth these distinctive learning styles, it is essential to explore the complex coupling relationships between various learning behaviors, as well as the temporal dependencies between these behaviors, in order to discern each student’s unique learning pattern.
Inspired by existing models [
45,
46], we utilize a one-dimensional CNN to capture the relationships between different activity features and obtain the resulting feature matrix
, where
m represents the number of historical active days,
denotes the number of CNN channels, and
n represents the number of student activity features.
The input to the CNN is the course identifier
c and the activity information
. The CNN is applied to learn the relationships between different activity features and generate the feature matrix
. The CNN operation is defined as follows:
where
represents the one-dimensional Convolutional Neural Network.
Next, we utilize a Bi-LSTM layer to capture the temporal relationships between different days. The input to the Bi-LSTM layer is the feature matrix
, and the output is the hidden state matrix
, where
represents the number of hidden units in the Bi-LSTM layer. The Bi-LSTM capturing both forward and backward dependencies in student activity patterns. This dual-direction processing is critical for understanding the context of student interactions over time, providing a robust feature set for dropout prediction. The Bi-LSTM layer is defined as follows:
where
represents the Bidirectional Long Short-Term Memory operation.
3.3. Modeling Distinct Learning Pattern
Due to factors such as class schedules and the nature of courses, different learning patterns often exist in different classes. Taking English and Mathematics classes as examples, varying class times may lead to different periodicities in learning English and Mathematics. Students often preview the material before class and review and complete assignments after class. Additionally, due to the distinct nature of English and Mathematics classes—the former being memory-oriented and the latter focusing on logical reasoning—the times of day students allocate for learning English and Mathematics tend to differ. Existing research indicates that memory tasks are more efficiently executed at night [
47,
48], while reasoning tasks are more effective during the day [
49].
We aim to capture different learning patterns in different courses by generating two learnable matrices, and , for each course. These matrices represent the keys and values of different learning patterns at different courses.
Firstly, we define the following variables: , the learnable matrices representing the keys of different learning patterns for different courses. Here, denotes the number of courses, denotes the number of learning patterns, m denotes the number of historical days, and denotes the dimension of the output of Bi-LSTM. are the learnable matrices representing the values of different learning patterns at different courses.
Given the course enrollment
c of user
u, we can index the corresponding keys and values to obtain
and
for that course. Next, we calculate the attention weights between the student’s activity embedding
and the keys
of different learning patterns using an attention mechanism. This allows us to measure the similarity between the student’s activities and the different learning patterns associated with each course. The attention weights are calculated as follows:
where
represents the index of the learning pattern and
is the number of learning patterns. After obtaining the attention weights, we multiply them with the values
, then combine it with course embedding
to obtain the student’s learning pattern
:
where ⊕ represents the concatenation operation.
3.4. Dropout Prediction
We concatenate the student’s activity, embedding
and the personal learning pattern
, and pass them through a multi-layer perceptron (MLP) to obtain the predicted dropout probability
:
Here,
denotes the sigmoid function and
is the rectified linear activation function.
3.5. Model Learning
In our learning setup, each participating institution or MOOC platform, denoted as a client, independently trains a local instance of the Learning Pattern Aware Dropout Prediction Model (LPADPM) on its dataset. The dataset for each client consists of user activity data and corresponding dropout indicators specific to the courses offered by that institution. We denote the model parameters from Student Activity Feature Extraction, Modeling Student Learning Pattern, and Dropout Prediction Module as , and ; C represents the participating clients in each communication round.
The local training involves feeding the user activity data into a one-dimensional convolutional neural network (CNN) and a bidirectional Bi-LSTM layer to capture the relationships and temporal patterns in student activities. It should be emphasized that the CNN and Bi-STM layer operates locally on each client’s dataset. Training occurs in parallel across institutions, with each client contributing to the construction of a shared global model without direct data exchange, thus preserving data sovereignty. Furthermore, each client employs learnable matrices
and
to model the distinct learning patterns of courses offered by them. An attention mechanism is used to determine the relevance of these patterns to individual students’ activities. The loss function in local training at
i-th client (institution) is shown as follows:
Our federated learning framework operates by distributing the model training process across multiple clients. Each client, representing a participating institution or MOOC platform, independently trains a local instance of the Bi-LSTM model on its own data. Once the local models complete their training, client
i only send the
to the server for model averaging while keeping the
and
locally. This process involves aggregating the weights and biases of the local models from participating clients to update the global model. The updated global model, which now reflects a broader understanding of student learning patterns across various institutions, is then distributed back to the clients. Algorithm 1 shows the entire federated training process.
| Algorithm 1 FLPADPM: Federated Learning Pattern Aware Dropout Prediction Model |
Input: T communication rounds, R local updating rounds, C random subset of all clients,
and initialization: , ,
Server executes:
for
do
Sample clients with size C uniformly at random
for each client in parallel do
Client Update()
end for
end for
Client Update():
, ,
for
do
Update , , with Stochastic Gradient Descent using Equation (6)
end for
Return
|
4. Experiment
4.1. Datasets Selection
We selected two widely used datasets, namely the KDD Cup 2015 dataset and the XuetangX dataset
http://moocdata.cn/data/user-activity (accessed on 15 December 2023), to study the factors influencing student dropout in MOOCs.The combination of these datasets allows us to analyze dropout patterns from different angles and validate the generalizability of our findings.
The KDD Cup 2015 dataset is a comprehensive dataset in the field of educational data mining. It was released as part of the KDD Cup 2015 competition, which aimed to predict student dropout in MOOCs. The dataset contains a large amount of information about student activities, including log data, forum posts, and course enrollment data. It covers a diverse range of courses from different domains and includes data from multiple MOOC platforms.
The XuetangX dataset is another valuable resource for studying student dropout rate in MOOCs. XuetangX is one of the largest MOOC platforms in China, hosting a wide variety of courses. The dataset provides detailed information about student interactions, including video watching, forum participation, and assignment submissions. It also includes demographic information and course-related features.
The experimental setting follows the KDD Cup 2015 and XueTangX with only 30 days of historical data. Objectively, there are trend changes in the dataset, but due to the short time limit of the existing dataset and the small time change, it is difficult to analyze the change, so the experimental results will not be affected by the peak or change of the data value trend.
4.2. Baseline Models
We analysis several baseline models that have been widely used in dropout rate prediction, which are as following:
CAL [
50] is a fusion deep dropout prediction model that utilizes a CNN to obtain local feature representations and a bidirectional LSTM network to obtain a time-series feature vector representation.
CLSA [
51] uses a CNN to extract local features and a LSTM to obtain a time-series incorporated vector representation. The model incorporates a static attention mechanism to obtain an attention weight on each dimension.
CNN [
21] considers the local correlation of learning behaviors and proposes a new feature matrix and a CNN model for dropout prediction.
DNN [
12] is a three-layer deep neural network.
CNNLS [
52] combines CNN and LSTM to automatically extract features from MOOC raw data.
CLMS [
53] is a deep neural network that combines CNN, LSTM, and SVM. It incorporates an effective feature extraction strategy and considers the impact of sequential relationships and class imbalance on dropout prediction.
CRM [
54] automatically extracts features from raw MOOC data using a combination of CNN and RNN.
CSEG [
55] is a hybrid deep neural network, which utilize a combination of a CNN, Squeeze-and-Excitation Networks (SE-Net), and GRU to predict the probabilistic of student dropout.
EDLN [
28] uses ResNet-50 to extract local features, uses Faster RCNN to obtain vector representation, and then applies a static attention mechanism to the vector to obtain the attention weight of each dimension.
These baseline models have been widely used in the field of dropout rate prediction in MOOCs and provide a benchmark for evaluating the performance and representation of the proposed model in this paper.
4.3. Experiment Setting
We implement local model data by adopting a specific federated learning algorithm, FedAvg. Each client periodically performs stochastic gradient descent on their local data batch and computes the model updates. These updates are then securely transmitted to the central server where they are aggregated to refine the global model parameters. For training our models within the federated framework, we adopted a dynamic learning rate approach. Initially set based on empirical studies, the learning rate is adjusted using a decay function to balance convergence speed and model stability across federated rounds. Additionally, regarding hyperparameter optimization, including learning rate selection, was conducted a grid search strategy. We evaluated various learning rates for their impact on convergence and predictive performance, selecting the rate that minimized cross-validation loss while ensuring consistent learning across clients.
We evaluated the performance of our proposed Federated Learning Pattern Aware Dropout Prediction Model (FLPADPM) compared to several baseline models with a FedAvg framework [
30] on the KDD Cup 2015 and XuetangX datasets. FedAvg is a popular federated learning framework. We used three evaluation metrics, namely area under the curve (AUC), root mean square error (RMSE), and mean absolute error (MAE), to assess the performance of the models. Each experiment is conducted with five random seeds, and the results are averaged for analysis. The experimental results presented in
Table 1 and
Table 2 demonstrate the superior performance of FLPADPM compared to existing prediction methods on both the KDD Cup 2015 and XuetangX datasets.
On the KDD Cup 2015 dataset, the FLPADPM achieves an impressive AUC of 0.9101 ± 0.0001, indicating its ability to accurately distinguish between dropout and non-dropout instances. The FLPADPM also achieves a low RMSE of and a low MAE of , indicating its high precision in predicting dropout rates. Similarly, on the XuetangX dataset, the FLPADPM achieves an outstanding AUC of , indicating its strong discriminatory power. The FLPADPM also achieves a low RMSE of and a low MAE of , further confirming its accuracy in predicting dropouts.
The superior performance of the FLPADPM can be attributed to its incorporation of learning patterns into the dropout prediction model. By modeling and extracting distinct learning patterns across students and different courses, the FLPADPM gains a comprehensive understanding of students’ learning behaviors and patterns. This enables the model to make more accurate predictions.
For each dataset, the conversations are divided into three sets: the training set, the test set, and the validation set. The training set consists of the first 60% of the conversations, the test set consists of the last 20%, and the remaining 20% is allocated to the validation set. This division ensures that the model is trained on a sufficient amount of data while also having separate sets for testing and validation.
To optimize the hyperparameters of the baseline models, a search is conducted for weight decay and learning rate. The weight decay is searched within the range of to , and the learning rate is searched within the range of 0.0001 to 0.01. Additionally, the optimal batch size is searched within the range of 16 to 64, while keeping other hyperparameters unchanged. This hyperparameter search helps to find the best combination of parameters for each model.
4.4. The Representation Analysis of Mainstream Dropout Prediction Model
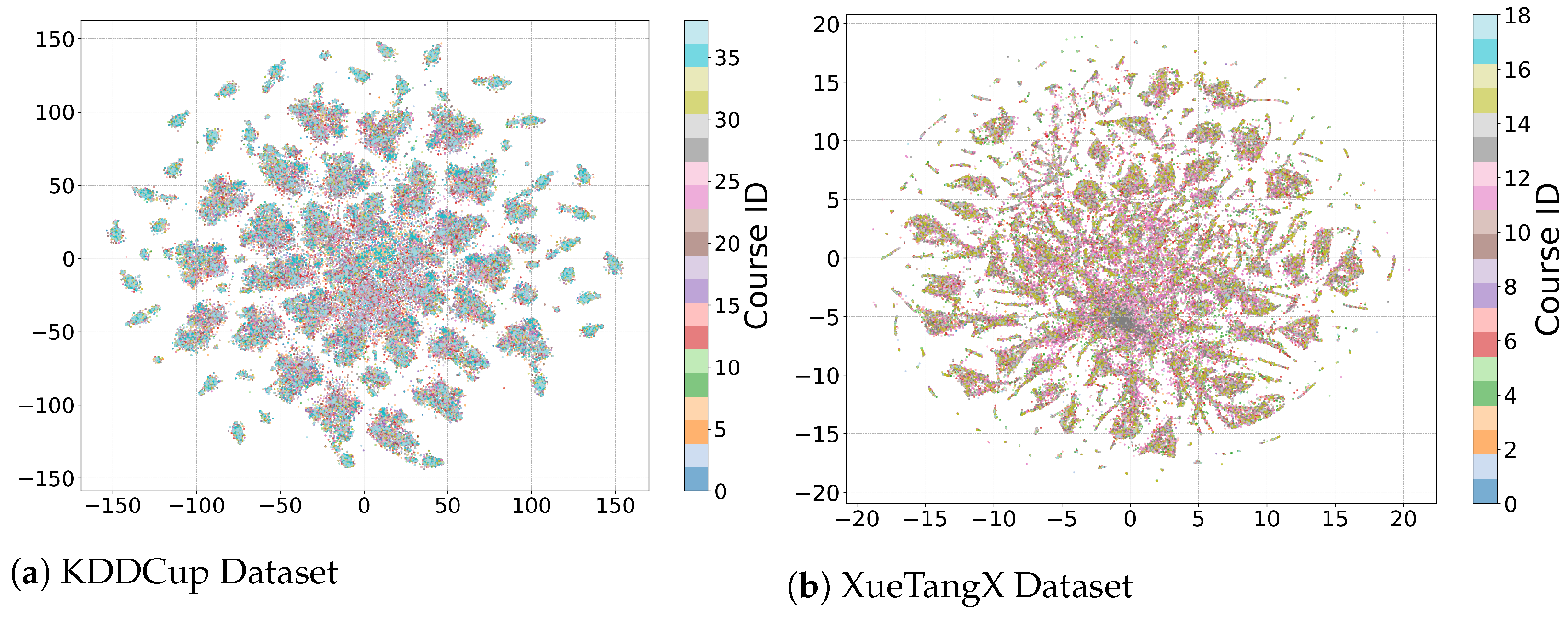
In this section, we perform a visualization of the distributed representations of the baseline models using the training dataset after hyperparameter optimization. These distributed representations serve as inputs to the classifiers. The representations are grouped based on the course ID or category ID of the courses. We employ the t-SNE dimensionality reduction technique to plot the distributed representations of all users for each course or category. The t-SNE function is used with the following hyperparameter settings: perplexity is set to 60, the number of iterations is set to 5000, the learning rate is set to 100, and the random state is set to 42. By reducing the distributed representations to a two-dimensional plane, we can observe the grouping of representations based on the course ID or category ID. Different colors are used to represent the distributed representations belonging to different courses.
As shown in
Figure 2 and
Figure 3, we present the analysis results of the mainstream dropout prediction models in terms of their ability to capture distinct learning patterns and variations across different courses. The analysis is based on the representation generated by these models on the KDD Cup 2015 and XuetangX datasets.
Firstly, we observe that all models exhibit a distinct cluster at the edge of the figure in both datasets. This suggests that the models are able to identify certain extreme cases of dropout, where students exhibit clear signs of disengagement from the learning process. However, at the center of the figure, all models show a large cluster, indicating that they struggle to differentiate between different learning patterns within this region. Interestingly, the size of the center cluster in the XueTangX dataset is larger than that in the KDD Cup 2015 dataset. This implies that the mainstream dropout prediction models perform even worse in capturing distinct learning patterns in the XueTangX dataset compared to the KDD Cup 2015 dataset. To further analyze the performance of the models, we examine the size of the center cluster in the KDD Cup 2015 dataset. We find that the models can be ranked in terms of the size of their center cluster from largest to smallest as follows: CAL ≥ CLSA > DNN > CSEG > CLMS ≥ CNN ≥ CNNLS ≥ CRM. This indicates that the CAL model has the largest center cluster, while the CNNLS model has the smallest. These findings suggest that the mainstream dropout prediction models fail to effectively mine the distinct learning patterns at the center of the figure, resulting in the mixing of different learning patterns within this region. This limitation hinders the models’ ability to accurately predict dropout for students who exhibit more subtle signs of disengagement.
Furthermore, we discover that the representations of all courses are mixed together by all models in both the KDD Cup 2015 and XuetangX datasets. This finding contradicts our prior knowledge that learning patterns can vary across different courses [
15,
17,
18]. The inability of the mainstream dropout prediction models to capture the variation of learning patterns across different courses suggests a significant limitation in their ability to provide accurate predictions for students in diverse educational contexts.
The analysis results demonstrate that the mainstream dropout prediction models are unable to effectively capture distinct learning patterns and variations across different courses. This limitation compromises their performance in accurately predicting dropout for students who exhibit subtle signs of disengagement.
4.5. Visualization of FLPADPM’s Representation
We analyze and compare the representation of students’ activity in the proposed model with the baseline model. This analysis helps to evaluate the effectiveness of the proposed model in capturing distinct learning patterns across students and different courses. We can combine the information from
Figure 4 and
Figure 5 to draw several conclusions.
Firstly, when comparing the representation of students’ activity between the proposed model and the baseline model, it is evident that our model’s representation of students’ activity is superior. This can be observed in
Figure 4a,b, where distinct clusters can be identified in the center of the figure for both the KDDCup and XueTangX datasets. This indicates that the activity feature extraction module in our model has a strong ability to mine and capture distinct learning patterns across students.
However, it is important to note that the embedding of students’ activity at different courses still tends to mix together. This suggests that solely relying on the activity feature extraction module is not sufficient. In order to effectively model the variation of students’ learning patterns across different courses, additional modules or mechanisms need to be incorporated.
As shown in
Figure 5a,b, the representation of our model successfully distinguishes learning patterns in different courses. Additionally, it is able to identify different learning patterns within a single course. This demonstrates the effectiveness of the learning pattern modeling module in our model, as it enables the model to capture and represent the variations in students’ learning patterns across different courses.
The visualization of the representation in our experiment provides strong evidence to support the claim that our proposed model outperforms the baseline model in capturing and representing distinct learning patterns across students and different courses. The combination of the activity feature extraction module and the learning pattern modeling module in our model enables a more comprehensive and accurate understanding of students’ learning patterns, leading to improved performance in dropout rate prediction.
5. Conclusions
In this study, we addressed the critical limitations inherent in existing mainstream dropout prediction models regarding their effectiveness in mining student learning patterns. Through a thorough analysis of the models’ representations, we identified two major shortcomings: their failure to capture distinct learning patterns and their lack of consideration for personalized variations across different courses. To address these gaps, we proposed the Learning Pattern Aware Dropout Prediction Model (LPADPM), which innovatively incorporates a one-dimensional convolutional neural network (CNN) and a bidirectional long short-term memory (LSTM) layer. This combination allows for an in-depth capture of relationships, patterns, and the temporal dynamics inherent in student data.
Furthermore, we introduced course-specific learnable matrices in LPADPM, enabling the model to adapt to variations in learning patterns across various courses. This addition significantly enhanced the model’s ability to tailor its predictions to the unique educational contexts of each course.
A key innovation in our approach was the integration of federated learning into the LPADPM framework. By adopting this decentralized learning structure, we enabled the model to train across multiple datasets from different institutions while preserving data privacy and autonomy. This federated learning approach not only improved the model’s predictive accuracy by leveraging diverse and comprehensive data but also maintained the confidentiality and security of individual datasets. At the same time, the application of federated learning in our study is critical for understanding the potential and challenges of privacy-preserving predictive analytics in educational settings. By analyzing the aggregation of local model updates, we can draw conclusions about the learning patterns without compromising student privacy or data security.
Our empirical evaluations using the KDD Cup 2015 and XuetangX datasets demonstrated that the FLPADPM outperforms state-of-the-art (SOTA) models with traditional federated learning framework in accurately predicting student dropout behavior. The visualizations of the representations generated by our model provided further evidence of its superior capability in effectively mining and interpreting learning patterns in various courses.
The successful implementation of LPADPM, enhanced with federated learning, marks a significant advancement in dropout prediction methodologies. It paves the way for more personalized, privacy-aware, and efficient predictive models in the realm of online education, particularly in MOOCs. This study not only contributes to the academic field of educational data mining but also offers practical insights for educators and platform administrators aiming to improve student retention and success in MOOCs.
6. Further Discussion
In this study, our deployment of the Federated Learning Pattern Aware Dropout Prediction Model (FLPADPM) has demonstrated notable advancements in predictive accuracy for student dropout rates within MOOCs. Moreover, the introduction of course-specific learnable matrices has innovatively enabled the customization of the model to the varied pedagogical methodologies across institutions. This bespoke approach sets a precedent for adaptive learning analytics, providing a pathway for educators to develop targeted interventions based on predictive insights.
However, the research encompasses certain limitations that must be acknowledged. The heterogeneity of data across different MOOC platforms presents a challenge to the federated learning approach, potentially impacting the model’s ability to generalize across diverse educational contexts. Additionally, the variability in student engagement within the datasets may introduce biases that could skew the predictive outcomes. These limitations highlight the need for extensive validation of the FLPADPM across a broader spectrum of educational settings and a more diverse student demographic to confirm its efficacy and scalability. It is also imperative to consider the computational overheads introduced by the federated learning process and the possible need for more efficient communication protocols to handle the increased data exchange.
Future research should focus on enhancing the FLPADPM by exploring alternative federated learning algorithms that can further optimize privacy and computational efficiency. Additionally, extending the model’s application to encompass a wider range of predictive tasks, such as course success and student engagement levels, could provide a more holistic tool for educational administrators. The potential for FLPADPM to inform real-time interventions and support personalized learning trajectories offers a promising horizon for the realm of online education, marking a step towards more responsive and student-centered learning environments.
Author Contributions
Author Contributions: Software, J.T.; Writing—original draft, H.L., Y.W. and H.C. Writing—review & editing, T.Z., H.L. and H.C.; Supervision, T.Z., M.Y. and G.Y.; Funding acquisition, T.Z. All authors have read and agreed to the published version of the manuscript.
Funding
National Natural Science Foundation of China: 62272093; National Natural Science Foundation of China: 62137001.
Data Availability Statement
Conflicts of Interest
The authors declare no conflict of interest.
References
- Li, T.; Chen, L.; Jensen, C.S.; Pedersen, T.B.; Gao, Y.; Hu, J. Evolutionary clustering of moving objects. In Proceedings of the 2022 IEEE 38th International Conference on Data Engineering (ICDE), Kuala Lumpur, Malaysia, 9–12 May 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 2399–2411. [Google Scholar]
- Li, T.; Huang, R.; Chen, L.; Jensen, C.S.; Pedersen, T.B. Compression of uncertain trajectories in road networks. Proc. VLDB Endow. 2020, 13, 1050–1063. [Google Scholar] [CrossRef]
- Li, T.; Chen, L.; Jensen, C.S.; Pedersen, T.B. TRACE: Real-time compression of streaming trajectories in road networks. Proc. VLDB Endow. 2021, 14, 1175–1187. [Google Scholar] [CrossRef]
- Zhu, R.; Wang, B.; Yang, X.; Zheng, B. Closest Pairs Search Over Data Stream. Proc. ACM Manag. Data 2023, 1, 1–26. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, H.; Liang, X.; Huang, B. Event-triggered-based distributed cooperative energy management for multienergy systems. IEEE Trans. Ind. Inform. 2018, 15, 2008–2022. [Google Scholar] [CrossRef]
- Li, Y.; Gao, D.W.; Gao, W.; Zhang, H.; Zhou, J. Double-mode energy management for multi-energy system via distributed dynamic event-triggered Newton-Raphson algorithm. IEEE Trans. Smart Grid 2020, 11, 5339–5356. [Google Scholar] [CrossRef]
- Wei, W.; Fan, X.; Li, J.; Cao, L. Model the complex dependence structures of financial variables by using canonical vine. In Proceedings of the 21st ACM International Conference on Information and Knowledge Management, Maui, HI, USA, 29 October–2 November 2012; pp. 1382–1391. [Google Scholar]
- Figueroa-Cañas, J.; Sancho-Vinuesa, T. Early Prediction of Dropout and Final Exam Performance in an Online Statistics Course. IEEE Rev. Iberoam. De Tecnol. Del Aprendiz. 2020, 15, 86–94. [Google Scholar] [CrossRef]
- Borrella, I.; Caballero-Caballero, S.; Ponce-Cueto, E. Taking action to reduce dropout in MOOCs: Tested interventions. Comput. Educ. 2022, 179, 104412. [Google Scholar] [CrossRef]
- Prenkaj, B.; Stilo, G.; Madeddu, L. Challenges and Solutions to the Student Dropout Prediction Problem in Online Courses. In Proceedings of the CIKM 2020 Proceedings of the 29th ACM International Conference on Information & Knowledge Management, Online, 19–23 October 2020; pp. 3513–3514. [Google Scholar] [CrossRef]
- Xu, C.; Zhu, G.; Ye, J.; Shu, J. Educational Data Mining: Dropout Prediction in XuetangX MOOCs. Neural Process. Lett. 2022, 54, 2885–2900. [Google Scholar] [CrossRef]
- Feng, W.; Tang, J.; Liu, T.X. Understanding dropouts in MOOCs. Proc. AAAI Conf. Artif. Intell. 2019, 33, 517–524. [Google Scholar] [CrossRef]
- Aldowah, H.; Samarraie, H.A.; Alzahrani, A.I.; Alalwan, N. Factors affecting student dropout in MOOCs: A cause and effect decision-making model. J. Comput. High. Educ. 2020, 32, 429–454. [Google Scholar] [CrossRef]
- Jin, C. Dropout prediction model in MOOC based on clickstream data and student sample weight. Soft Comput. 2021, 25, 8971–8988. [Google Scholar] [CrossRef]
- Vermunt, J.D.; Donche, V. A learning patterns perspective on student learning in higher education: State of the art and moving forward. Educ. Psychol. Rev. 2017, 29, 269–299. [Google Scholar] [CrossRef]
- Alamri, A.; Sun, Z.; Cristea, A.I.; Senthilnathan, G.; Shi, L.; Stewart, C. Is MOOC learning different for dropouts? A visually-driven, multi-granularity explanatory ML approach. In Proceedings of the Intelligent Tutoring Systems: 16th International Conference, ITS 2020, Athens, Greece, 8–12 June 2020; Proceedings 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 353–363. [Google Scholar]
- Moore, R.L.; Yen, C.J.; Powers, F.E. Exploring the relationship between clout and cognitive processing in MOOC discussion forums. Br. J. Educ. Technol. 2021, 52, 482–497. [Google Scholar] [CrossRef]
- Liu, S.; Liu, S.; Liu, Z.; Peng, X.; Yang, Z. Automated detection of emotional and cognitive engagement in MOOC discussions to predict learning achievement. Comput. Educ. 2022, 181, 104461. [Google Scholar] [CrossRef]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Wang, L.; Wang, H. Learning behavior analysis and dropout rate prediction based on MOOCs data. In Proceedings of the 2019 10th International Conference on Information Technology in Medicine and Education (ITME), Qingdao, China, 23–25 August 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 419–423. [Google Scholar]
- Wen, Y.; Tian, Y.; Wen, B.; Zhou, Q.; Cai, G.; Liu, S. Consideration of the local correlation of learning behaviors to predict dropouts from MOOCs. Tsinghua Sci. Technol. 2019, 25, 336–347. [Google Scholar] [CrossRef]
- Yao, D.; Hu, H.; Du, L.; Cong, G.; Han, S.; Bi, J. Trajgat: A graph-based long-term dependency modeling approach for trajectory similarity computation. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 14–18 August 2022; pp. 2275–2285. [Google Scholar]
- Guo, J.; Du, L.; Liu, H. GPT4Graph: Can Large Language Models Understand Graph Structured Data? An Empirical Evaluation and Benchmarking. arXiv 2023, arXiv:2305.15066. [Google Scholar]
- Du, L.; Chen, X.; Gao, F.; Fu, Q.; Xie, K.; Han, S.; Zhang, D. Understanding and Improvement of Adversarial Training for Network Embedding from an Optimization Perspective. In Proceedings of the Fifteenth ACM International Conference on Web Search and Data Mining, Tempe, AZ, USA, 21–25 February 2022; pp. 230–240. [Google Scholar]
- Mrhar, K.; Douimi, O.; Abik, M. A dropout predictor system in MOOCs based on neural networks. J. Autom. Mob. Robot. Intell. Syst. 2021, 14, 72–80. [Google Scholar] [CrossRef]
- Liu, H.; Chen, X.; Zhao, F. Learning behavior feature fused deep learning network model for MOOC dropout prediction. Educ. Inf. Technol. 2023, 1–22. [Google Scholar] [CrossRef]
- Tang, C.; Ouyang, Y.; Rong, W.; Zhang, J.; Xiong, Z. Time Series Model for Predicting Dropout in Massive Open Online Courses. In Proceedings of the Artificial Intelligence in Education. AIED 2018, London, UK, 27–30 June 2018; Volume 10948, pp. 353–357. [Google Scholar] [CrossRef]
- Kumar, G.; Singh, A.; Sharma, A. Ensemble Deep Learning Network Model for Dropout Prediction in MOOCs. Int. J. Electr. Comput. Eng. Syst. 2023, 14, 187–196. [Google Scholar] [CrossRef]
- Li, C.; Zhao, K.; Yan, M.; Zou, X.; Xiao, M.; Qian, Y. Research on the big data analysis of MOOCs in a flipped classroom based on attention mechanism in deep learning model. Comput. Appl. Eng. Educ. 2023, 31, 1867–1882. [Google Scholar] [CrossRef]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the Artificial intelligence and statistics. PMLR, Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- Cao, L.; Chen, H.; Fan, X.; Gama, J.; Ong, Y.S.; Kumar, V. Bayesian Federated Learning: A Survey. arXiv 2023, arXiv:2304.13267. [Google Scholar]
- Li, T.; Sahu, A.K.; Zaheer, M.; Sanjabi, M.; Talwalkar, A.; Smith, V. Federated optimization in heterogeneous networks. Proc. Mach. Learn. Syst. 2020, 2, 429–450. [Google Scholar]
- Karimireddy, S.P.; Jaggi, M.; Kale, S.; Mohri, M.; Reddi, S.J.; Stich, S.U.; Suresh, A.T. Mime: Mimicking centralized stochastic algorithms in federated learning. arXiv 2020, arXiv:2008.03606. [Google Scholar]
- Zhao, Y.; Li, M.; Lai, L.; Suda, N.; Civin, D.; Chandra, V. Federated learning with non-iid data. arXiv 2018, arXiv:1806.00582. [Google Scholar] [CrossRef]
- Yoon, T.; Shin, S.; Hwang, S.J.; Yang, E. Fedmix: Approximation of mixup under mean augmented federated learning. arXiv 2021, arXiv:2107.00233. [Google Scholar]
- Fallah, A.; Mokhtari, A.; Ozdaglar, A. Personalized federated learning with theoretical guarantees: A model-agnostic meta-learning approach. Adv. Neural Inf. Process. Syst. 2020, 33, 3557–3568. [Google Scholar]
- T Dinh, C.; Tran, N.; Nguyen, J. Personalized federated learning with moreau envelopes. Adv. Neural Inf. Process. Syst. 2020, 33, 21394–21405. [Google Scholar]
- Yang, H.; He, H.; Zhang, W.; Cao, X. FedSteg: A federated transfer learning framework for secure image steganalysis. IEEE Trans. Netw. Sci. Eng. 2020, 8, 1084–1094. [Google Scholar] [CrossRef]
- Chen, Y.; Qin, X.; Wang, J.; Yu, C.; Gao, W. Fedhealth: A federated transfer learning framework for wearable healthcare. IEEE Intell. Syst. 2020, 35, 83–93. [Google Scholar] [CrossRef]
- Oh, J.; Kim, S.; Yun, S.Y. Fedbabu: Towards enhanced representation for federated image classification. arXiv 2021, arXiv:2106.06042. [Google Scholar]
- Chen, H.; Liu, H.; Cao, L.; Zhang, T. Bayesian Personalized Federated Learning with Shared and Personalized Uncertainty Representations. arXiv 2023, arXiv:2309.15499. [Google Scholar]
- Arivazhagan, M.G.; Aggarwal, V.; Singh, A.K.; Choudhary, S. Federated learning with personalization layers. arXiv 2019, arXiv:1912.00818. [Google Scholar]
- Collins, L.; Hassani, H.; Mokhtari, A.; Shakkottai, S. Exploiting Shared Representations for Personalized Federated Learning. In Proceedings of the 38th International Conference on Machine Learning. PMLR, Virtual, 18–24 July 2021; pp. 2089–2099. [Google Scholar]
- Kotelevskii, N.; Vono, M.; Durmus, A.; Moulines, E. Fedpop: A bayesian approach for personalised federated learning. Adv. Neural Inf. Process. Syst. 2022, 35, 8687–8701. [Google Scholar]
- Wang, W.; Guo, L.; He, L.; Wu, Y.C.J. Effects of social-interactive engagement on the dropout ratio in online learning: Insights from MOOC. Behav. Inf. Technol. Behav. Inf. Technol. 2018, 38, 621–636. [Google Scholar] [CrossRef]
- Fu, C. Tracking user-role evolution via topic modeling in community question answering. Inf. Process. Manag. 2019, 56, 102075. [Google Scholar] [CrossRef]
- Cellini, N. Memory consolidation in sleep disorders. Sleep Med. Rev. 2017, 35, 101–112. [Google Scholar] [CrossRef]
- Hu, X.; Cheng, L.Y.; Chiu, M.H.; Paller, K.A. Promoting memory consolidation during sleep: A meta-analysis of targeted memory reactivation. Psychol. Bull. 2020, 146, 218. [Google Scholar] [CrossRef]
- Valdez, P.; Ramírez, C.; García, A. Circadian rhythms in cognitive performance: Implications for neuropsychological assessment. Chronophysiol. Ther. 2012, 2012, 81–92. [Google Scholar] [CrossRef]
- Zheng, Y.; Shao, Z.; Deng, M.; Gao, Z.; Fu, Q. MOOC dropout prediction using a fusion deep model based on behaviour features. Comput. Electr. Eng. 2022, 104, 108409. [Google Scholar] [CrossRef]
- Fu, Q.; Gao, Z.; Zhou, J.; Zheng, Y. CLSA: A novel deep learning model for MOOC dropout prediction. Comput. Electr. Eng. 2021, 94, 107315. [Google Scholar] [CrossRef]
- Mubarak, A.A.; Cao, H.; Hezam, I.M. Deep analytic model for student dropout prediction in massive open online courses. Comput. Electr. Eng. 2021, 93, 107271. [Google Scholar] [CrossRef]
- Wu, N.; Zhang, L.; Gao, Y.; Zhang, M.; Sun, X.; Feng, J. CLMS-Net: Dropout Prediction in MOOCs with Deep Learning. In ACM TURC ’19: Proceedings of the ACM Turing Celebration Conference—China, Chengdu, China, 17–19 May 2019; Association for Computing Machinery: New York, NY, USA, 2019. [Google Scholar] [CrossRef]
- Wang, W.; Yu, H.; Miao, C. Deep Model for Dropout Prediction in MOOCs. In ICCSE’17: Proceedings of the 2nd International Conference on Crowd Science and Engineering, Beijing, China, 6–9 July 2017; Association for Computing Machinery: New York, NY, USA, 2017; pp. 26–32. [Google Scholar] [CrossRef]
- Zhang, Y.; Chang, L.; Liu, T. MOOCs Dropout Prediction Based on Hybrid Deep Neural Network. In Proceedings of the 2020 International Conference on Cyber-Enabled Distributed Computing and Knowledge Discovery (CyberC), Chongqing, China, 29–30 October 2020; pp. 197–203. [Google Scholar] [CrossRef]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).


 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}