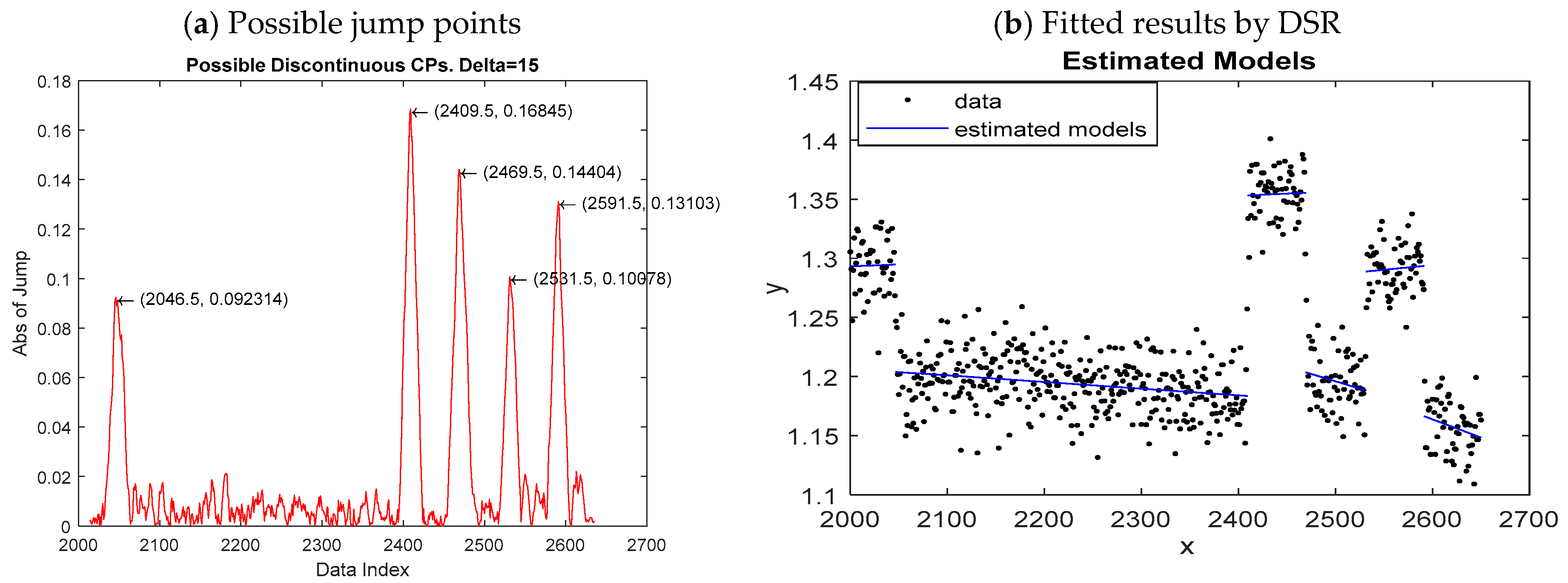
4.1. Simulation Study
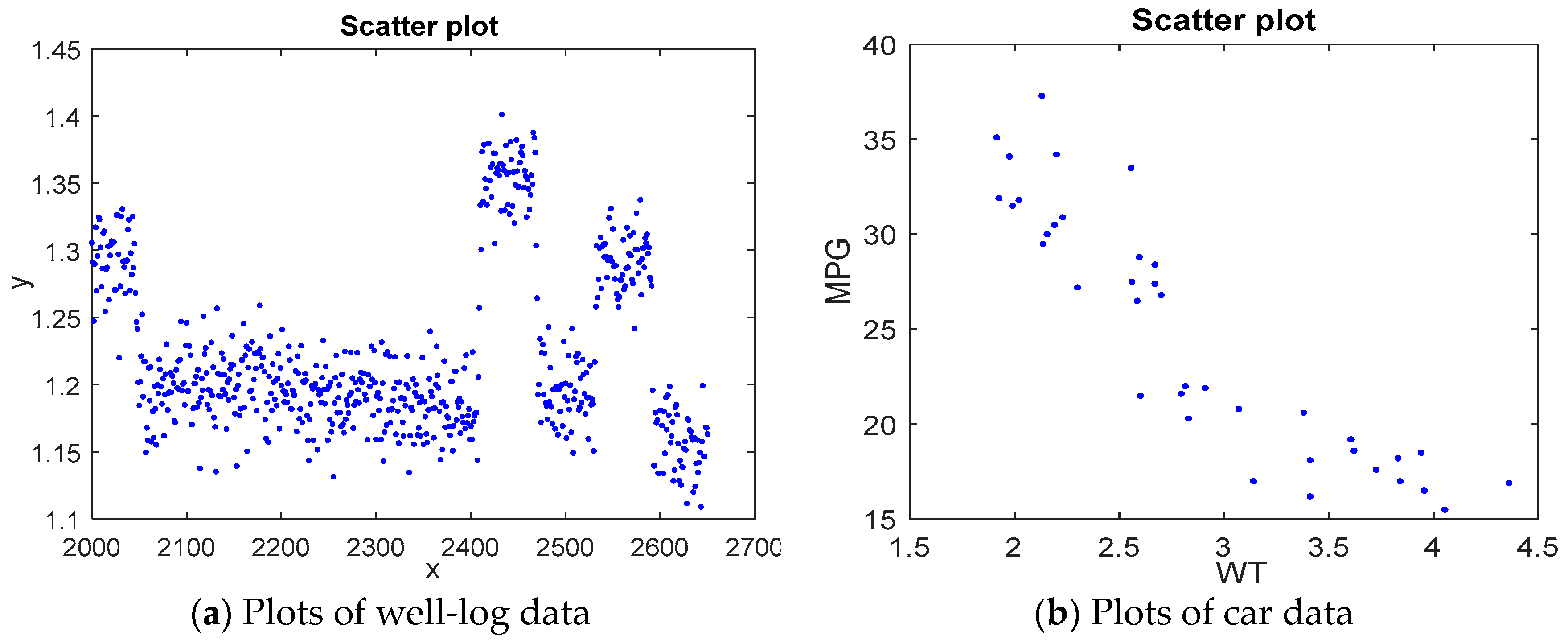
We demonstrate the efficacy and superiority of the proposed method through a simulation study. We consider both continuous and dis-continuous models with single and multiple change-points, respectively. The scheme for generating data is as follows. First, n uniformly distributed values over the interval [0,10] were chosen as the values of the partition variable x. Then, the values of the response y were computed according to the settings of the model, where the regression noises follow a normal distribution In following simulations, we set , m = 4, and let be the stop criterion.
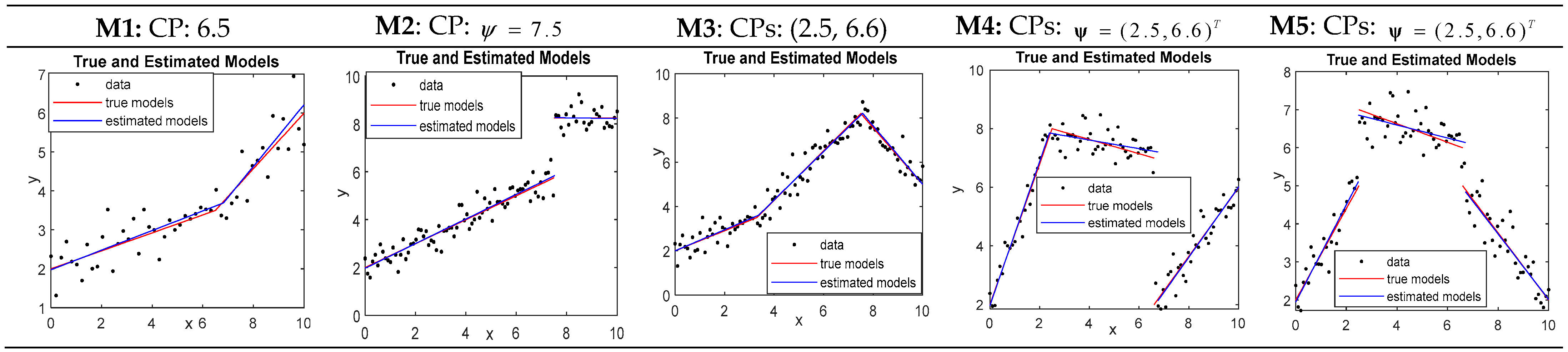
The performance of DSR is first examined based on continuous and discontinuous frames with five different types of models described in
Table 2. For all models in
Table 2,
,
, and
are independent and normally distributed
. For illustrative purposes, plots of one simulated sample with the estimated model associated with each individual model in
Table 2 are shown in
Figure 6.
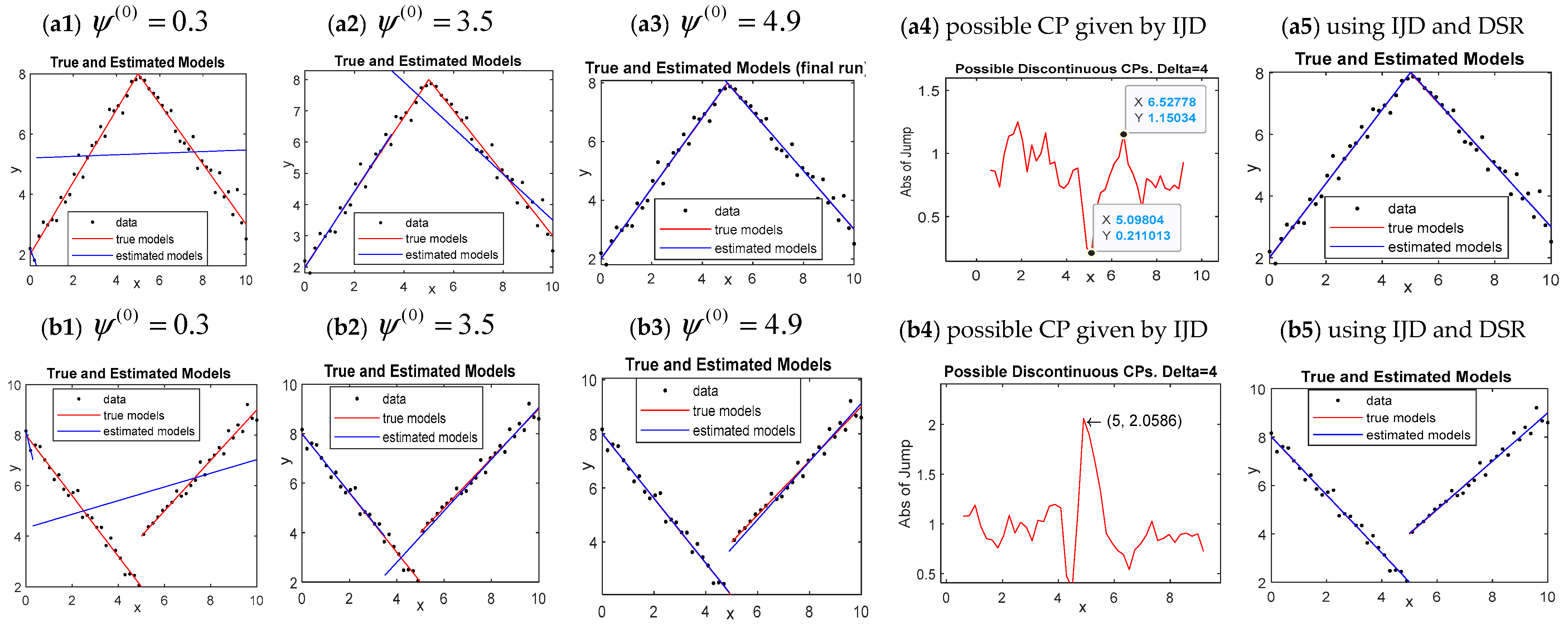
We first evaluate the performance of DSR using Model 4 with simulations carried out under different scenarios: different sample sizes (
n), different change-point locations (
), different standard deviations (
). The behavior of change-point estimators is observed on the basis of 1000 replicates through the mean (CPhat) and the standard deviation (stdCP). The IJD was used with the values of
(see
Section 3.2.1) chosen as 4, 8, and 15 for the sample sizes
n = 150, 300, and 600, respectively. The performance of the parameter estimator was accessed by means of 1000 replicates for each model through several measures, defined as follows:
- (1)
, is the estimator of , in the rth replication;
- (2)
;
- (3)
, , is the estimator of in the rth replication;
- (4)
RSS and the time (in seconds) consumed by DSR over 1000 replications.
Moreover, the goodness of fit of the fitted model is accessed through a criterion using the concept of statistical tests. Since the considered models are assumed to be normally distributed, the estimator of regression coefficients
follows a multivariate normal distribution
(c.f. [
46]), where
is a matrix in
, with
as its
jth row,
given
,
,
(
K is the number of change-points), and
is the number of data in the
ith segment. Thus, based on the properties of multivariate normal distributions, the random variable
follows a
distribution (c.f. [
46]). Utilizing the concept of statistical tests, we think
is acceptable if
. Let
. Then, a fitted model can be viewed as acceptable only if
, which is quite strict.
Table 3 reports the simulation results.
As expected, the estimations generally get better when
n increases. For instance, under the case
, the change point estimators with
n = 300 are much less varied than those with
n = 150, for less stdCP1 (0.043 < 0.115) and stdCP2 (0.078 < 0.248), resulting in a much better fitted model with
n = 300, for less SSEC (1.365 < 4.828). Moreover, as
increases to 0.8, the impact of large deviation on the estimators can be alleviated by a larger sample size. For instance, the estimations with
n = 600 and
are almost as good as those with
n = 150 and
in the case of
. The locations of change-points also affect the estimations. Based on many simulations, we found that, if the true change-points were at
, the estimates of change-points and regression coefficients were inferior to those with the true change-points different from
. For example, the estimations with the true change-points at
are better than those with
in all considered cases (see
Table 3). Furthermore, in all cases with
, the acceptable proportions of the estimates for regression coefficients are above 85%, which is much higher than those in cases of
(see
Table 3). Note that the case
means two change-points evenly divide the whole range of independent variable
x,
, i.e., the lengths of three sub-segments are equal. It seems reasonable that change-point detection is harder when the length of each sub-segment is the same than when the length of each sub-segment is different. Additionally, the time taken by DSR over 1000 replications with the sample size equal to 600 is very short, and the time increases mildly as
n increases (the computational complexity will be discussed later). Therefore, DSR could be applicable to most real data sets effortlessly. Specifically, Seber [
1] commented that piecewise regression models are intended for circumstances where the number of regimes is small and there are fairly sharp changes between sub-segments. Muggeo [
4] also mentioned that a few change-points might be enough for dealing with practical situations, and the significance of change-points may become disputable as the number of change-points gets large. Thus, DSR could be a very practical technique for solving change-point regression problems.
Next, we compare the proposed DSR with the following four methods: the segmented method (SEG) [
4], the EM-BP algorithm [
12], the FCP algorithm [
47], and the FCM-BP method (FCM) [
12]. The estimations for change-points and regression coefficients are observed on the basis of 1000 and 200 replicates with the sample of size equal to 50 and 100 for models of one and multiple change-points, respectively. Note that the sample sizes utilized in the comparisons are small because the existing methods are very time-consuming due to their high computational cost. The measures used for making comparisons are the same as those used earlier for evaluating DSR.
Table 4 and
Table 5 report the estimations for the five models given in
Table 2 by using the five methods, respectively.
Table 4 shows that SEG performs best in the estimations for model M1 because SEG produced a change-point estimator with very small biases and variations (note that the stdCP obtained by SEG equal to 0.315 is the least small among the five methods). Furthermore, SEG results in the best fitted model with the least SSEC (0.208) and the highest acceptance rate (0.837). However, SEG is totally unworkable for the discontinuous model M2. On the other hand, the other four methods also perform well in all cases reported in
Table 4. They are competitive in the estimations for models M1 and M2 regarding the precision and variation of the change-point estimators and the adequacy of the estimated model.
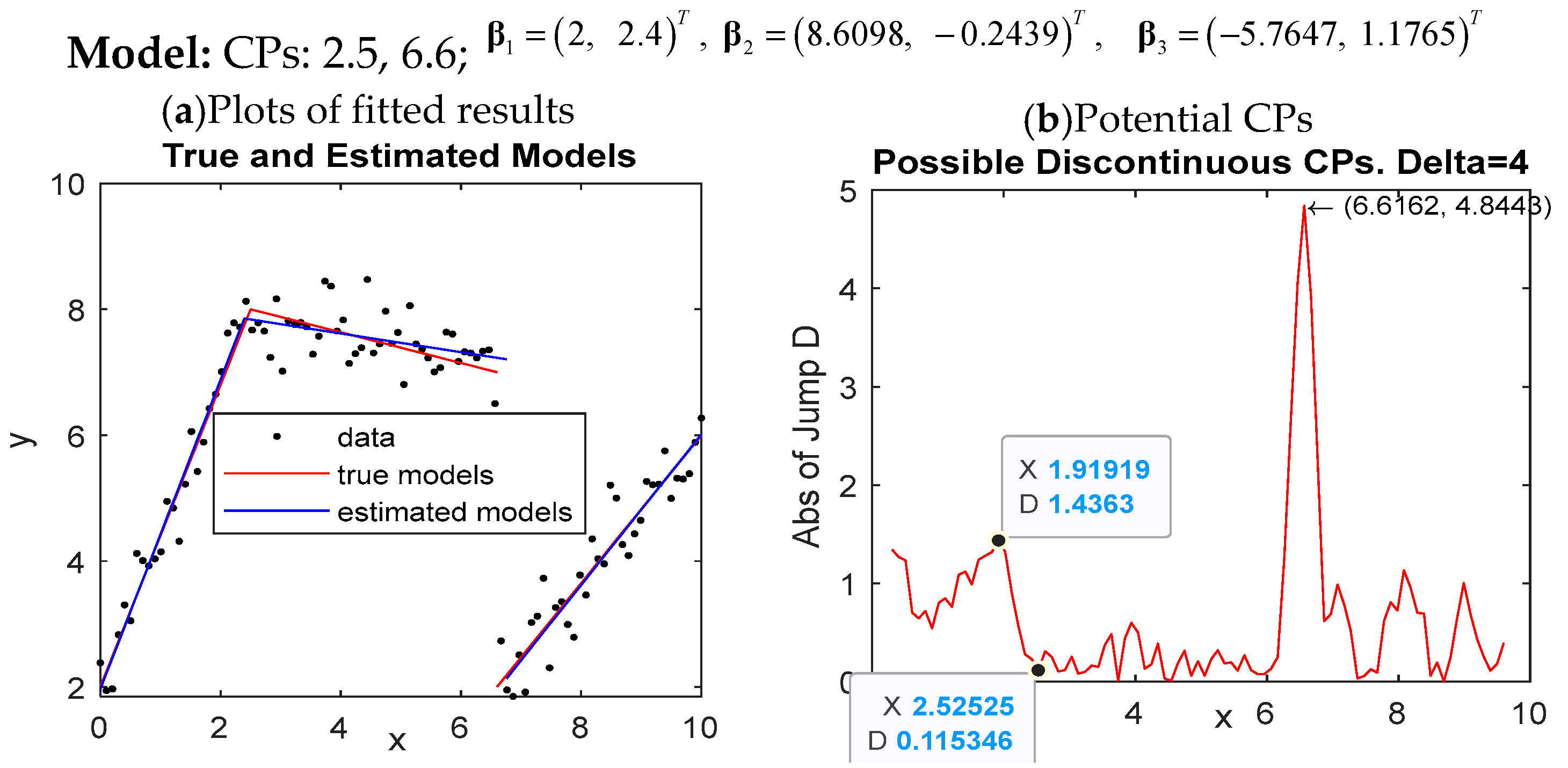
For the estimations of multiple change-point models M3-M5 shown in
Table 5, DSR generally outperforms the other four methods for producing highly accurate estimates of change-points and regression coefficients in a very short time. In particular, DSR is much more economical in terms of time-consumption than the EM-BP, FCP, and FCM. In particular, the time consumed by EM-BP is extremely high. Even worse, EM-BP could not produce adequate estimates for model M5 due to a very large bias with the estimate of
(bias = 6.6 − 3.741 = 2.859) and the poor fit of the estimated model with a large SSEC (5.836) and a very low acceptance rate (0.04). Although the estimations made by FCP and FCM for M3-M5 are satisfactory, they are also much more computationally expensive than DSR. Notice that the time taken by FCP and FCM looks tolerable because of the small sample size,
n, and the small number of change-points, K. In fact, their computational complexity increases drastically with
n and
k, and the computational time would increase drastically even if
n or
K increased slightly. This evidence can be understood through the computational complexity analysis below.
We noted from the above comparisons that the superiority of DSR over EM-BP, FCP, and FCM is particularly significant in view of time consumption. This fact can be attributed to the incorporation of IJD with DSR and the much less complexity of DSR. IJD helps DSR converge faster by producing suitable initial values to be used (see the illustrations of IJD in
Section 3.2). But the computational complexity may account for the preference of DSR mostly. The computational complexity of DSR is
where
n is the data size,
K is the number of regimes,
d is the data dimension, and
i is the number of iterations. For EM-BP, FCP, and FCM, the computations for estimated parameters must be performed for each possible collection of change-points which include
combinations. Thus, the computational complexity of EM-BP, FCP, and FCM is
. That may be the reason why the time consumed by DSR is much less than that of the other three methods as the number of change-points increases.
Table 6 summaries the time consumed by DSR, EM-BP, FCP, and FCM in the cases used for comparisons previously. Note the simulation results shown in
Table 4 and
Table 5 are based on 1000 and 200 replications for one and multiple change-points in the models, respectively. The results in
Table 6 indicate that the time taken by DSR increases slowly with the number of change-points,
K. But the time taken by the other three methods increases sharply as
K increases, especially for EM-BP. Notice that the time consumed by DSR in case M2 is much higher due to the detection of jumps.
To sum up, the comparison results obtained with the models in
Table 2 reveal that DSR can work well in all cases of continuous and discontinuous models. More importantly, DSR produces better estimates for change-points and regression coefficients in virtue of smaller biases and variations of change-point estimators, as well as the small mean squared errors of estimated regression coefficients in almost all cases of continuous and discontinuous models. Moreover, DSR is much more economic in terms of the time consumed than EM-BP, FCP, and FCM, especially in cases involving multiple change-points. By contrast, SEG performs well for continuous models but is totally unworkable for discontinuous models. Simulation results show that the time consumed by DSR over 1000 replications increases slowly with
K. This fact indicates that the computational effort of DSR increases mildly with the complexity of the model. As remarked by Muggeo [
4] and Seber [
1], piecewise regression models with a few change-points are sufficient for handling many practical situations because the meaning of change-points may become questionable as the number of regimes increases. Thus, the proposed DSR is feasible for most practical problems.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}