Abstract
The unit log-logistic distribution is a suitable choice for modeling data enclosed within the unit interval. In this paper, estimating the parameters of the unit-log-logistic distribution is performed through a Bayesian approach with non-informative priors. Specifically, we use Jeffreys, reference, and matching priors, with the latter depending on the interest parameter. We derive the corresponding posterior distributions and validate their propriety. The Bayes estimators are then computed using Markov Chain Monte Carlo techniques. To assess the finite sample performance of these Bayes estimators, we conduct Monte Carlo simulations, evaluating their mean squared errors and their coverage probabilities of the highest posterior density credible intervals. Finally, we use these priors to obtain estimations and credible sets for the parameters in an example of a real data set for illustrative purposes.
Keywords:
unit log-logistic distribution; Jeffreys prior; reference priors; probability matching priors; predictive p-value MSC:
62F15; 62J05
1. Introduction
Data sets in various fields, including environmental science, biology, epidemiology, and finance, often exhibit values within a specific range, frequently falling within the bounded unit interval . Examples of such data include proportions in environmental studies, infection rates in epidemiology, and profit margins in finance. To model this type of data, traditional continuous probability distributions like the unit uniform, beta, Johnson SB [1], and Kumaraswamy [2] distributions can be applied in theory. However, it is important to recognize that these conventional distributions may prove ineffective in modeling such data, often due to skewness or extreme events. Consequently, this challenge has stimulated numerous researchers to explore new, more flexible unit distributions that do not require the introduction of additional parameters. More specifically, let be a random variable with a probability density function (pdf) denoted as . It can be shown that follows a probability distribution denoted as , with y lying within the interval . This method of transformation has been widely employed in the introduction of various unit distributions by numerous authors. Some noteworthy recent examples include the work of Ghitany et al. [3], who introduced the unit-inverse Gaussian distribution, Mazucheli et al. [4], who proposed the unit-Gompertz distribution, Mazucheli et al. [5], who investigated the unit-Weibull distribution, Ribeiro–Reis [6], who studied the unit log-logistic distribution, Korkmaz and Chesneau [7], who conducted research into the unit Burr-XII distribution, Korkmaz and Korkmaz [8], who proposed the log-log distribution, and finally Najwan et al. [9], who investigated the inverse unit Teissier distribution, among other distributions.
The two-parameter unit log-logistic (ULL) distribution with parameters, , and is defined through the following probability density function
where are unknown parameters. Notice that the parameter is no longer considered a scale parameter, in contrast to the ULL distribution in Ribeiro–Reis [6], where serves as a scale parameter.
Estimating the parameters of the ULL distribution is typically achieved through a maximum likelihood (ML) estimation approach. It is worth noting that there has been limited exploration of Bayesian estimation techniques for unit distributions, and, in particular, no prior work has addressed Bayesian analysis for ULL distribution parameters.
In this paper, we introduce a non-informative Bayesian analysis method for these parameters. Notably, among non-informative priors, the Jeffreys prior stands out due to its many appealing properties, such as invariance under one-to-one transformations and computational simplicity. However, this prior may lack robustness when dealing with high-dimensional distributions. On the other hand, there exist two alternative approaches for deriving non-informative priors. One is the reference prior that is originally proposed in [10,11], and formally defined in [12] for one block of parameters. It should be noted that the reference prior separates the parameters into different ordering groups of interest. The other approach considers the concept of probability matching priors for the parameters of interest first introduced by [13]. Notably, these prior distributions are designed in a way that the posterior probabilities within specified intervals match with their corresponding coverage probabilities; see, for example, [14].
The motivation for choosing non-informative priors lies in their capacity to avoid incorporating much information about the model parameters. Additionally, these priors are constructed based on sound scientific principles. In contrast, subjective priors, while reasonable when historical or reliable data are available for eliciting the accompanying hyperparameters to these priors, may be impractical in situations where such data are unavailable.
The remainder of the paper is organized as follows. In Section 2, we provide some specific preparation steps for formulating noninformative priors. Objective priors for the parameter of interest are given in Section 3. In Section 4, we introduce objective priors when the parameter of interest is The Posterior predictive assessment of the model is given in Section 5. In Section 6, a simulation study is carried out to assess the finite properties of Bayesian estimators using the noninformative priors. The suggested Bayesian approach is employed to analyze a real data set given in Section 7. In Section 8, we present some conclusions.
2. Formulating Noninformative Priors: Preparation Steps
In this section, our focus is on introducing non-informative priors for the parameters of the unit log-logistic distribution using principle rules. Specifically, we derive Jeffreys’s prior, reference priors, and probability matching priors. It is important to see that the development of these priors is significantly dependent on the Fisher information matrix. So, we report here the Fisher information matrix for the unit log-logistic distribution.
2.1. Jeffreys-Rule Prior
Jeffreys’ prior is a common choice for non-informative priors in Bayesian statistics due to its fascinating properties. One important feature is its ability to yield a prior distribution that remains invariant under reparameterization, thus ensuring consistency across various parameterizations. The Jeffreys prior for the parameters is defined as proportional to the square root of the determinant of the Fisher information matrix.
Theorem 1.
The Jeffreys prior for the parameters of the ULL() (2) has the following form
2.2. Useful Results in Establishing Reference and Matching Priors
Here, we present some results about the reference and matching priors. These results may facilitate in obtaining such priors.
Theorem 2.
Consider a probability density function, with and Fix i, let be the parameter of interest and be the vector of nuisance parameters of length Assume that the Fisher information matrix per unit observation is
where for is a positive function of and is a positive function of Then, for any preferred parameter of interest and any ordering of the nuisance parameters, the one-at-a-time reference prior has the following form
Proof.
See Datta and Ghosh [15]. □
Theorem 3.
Consider the assumptions of Theorem 2. Suppose that the Fisher information matrix per unit of observation is diagonal, but not necessarily that the components of the matrix can be factorized, i.e.,
where is the th-element of Then, the matching prior for the parameter of interest is
Proof.
See Tibshirani [16]. □
3. Objective Priors for the Parameter
In this Section, we develop reference and matching priors for the parameter of interest, Note that the Fisher information is not a diagonal matrix, implying that the parameters are not orthogonal. So, our task now is to find a 1-1 transformation from onto so that the new Fisher information matrix is a diagonal matrix. The following lemma reports the required transformation.
Lemma 1.
Proof.
The Jacobian of transformation, , matrix is
So, the new Fisher information matrix in terms of and is obtained via . □
3.1. Reference Prior
Following the preparation steps outlined along with the results presented in Section 3, we are now in a position to derive the reference prior for the parameter of interest;
Theorem 4.
For the ordering group , the reference prior is given by
Proof.
The Fisher information presented in Lemma 1 exhibits a diagonal matrix structure. Observe that with
and On applying Theorem 2, the reference prior associated with the parameters can be expressed as:
Upon a transformation back to the original parameters and taking into consideration the Jacobian of the transformation from to , which is given by , it is evident that the reference prior follows the form specified in (4). □
3.2. Probability Matching Priors
Let be a random sample from the unit log-logistic distribution in (1). Given a prior , denote as the th quantile of the marginal posterior of , i.e.,
where is the nuisance parameter and is the posterior probability measure. We seek for priors such that the following equation holds for all
where is the probability distribution measure of indexed by the parameter A prior that satisfies Equations (6) and (7) is referred as a second-order probability matching when the parameter of interest is The following theorem establishes the required prior.
Theorem 5.
For the parameter of interest λ and the nuisance parameter the second-order probability matching has the following form
where represents an arbitrary positive function.
Proof.
We have that
Upon application of Theorem 3, the form of the matching prior should take the following form
□
Theorem 6.
The Jeffreys prior is not a second-order probability matching prior.
Proof.
Theorem 7.
The reference prior in (4) is a second-matching prior.
3.3. Propriety of Posterior Distributions
It is evident that the priors derived in Section 2 are all improper. Therefore, it becomes necessary to assess the propriety of the resulting posterior distributions that arise from these priors. Here, we consider a general class of priors
where
Theorem 8.
The posterior distribution under the general prior in (9) is proper whenever .
Proof.
The joint posterior distribution of and under the prior (9) given is given by
Let for and
where and For we have that Therefore, there exists positive constants, such that
Putting it then follows that
Observe that the function
attains its maximum at It then follows that So, the joint posterior distribution in (11) can be displayed as follows
where Thus,
Let , it then follows that
where Clearly, the integral in the above inequality is finite provided that yielding that is proper. □
Theorem 9.
The posterior distributions under and all exhibit finiteness. Furthermore, the means under the corresponding posterior distributions are also finite.
Proof.
The proof can be analogously established to the proof of Theorem 8. □
4. Objective Priors for the Parameter
In this section, we define the reference and matching priors for the parameter of interest, denoted as . To achieve this, we first reorganize the components of the Fisher information matrix as follows:
Given the unattainable 1-1 orthogonal transformation, it is necessary to utilize the generic algorithm provided by [17] for deriving a reference prior when dealing with the parameter of interest, , and the nuisance parameter, . Notably, when is independent of the nuisance parameter space, the application of this algorithm becomes particularly appealing, as highlighted in the subsequent proposition.
Proposition 1
(Bernardo and Smith [17] (2000, p. 328)). Assuming that the conditions of the algorithm by Bernardo and Smith [17] are satisfied, and under the assumption that the parameter of interest β demonstrates independence from the nuisance parameter space , with the functions and factorizing as provided below:
then the reference prior with respect to the ordered group is
Similarly, it is not feasible to obtain a matching prior for the parameter of interest, , using Theorem 3, due to the unattainable 1-1 orthogonal transformation. Consequently, we must turn to the approach outlined by Peer and Welch [13], who have provided a general formula for deriving a probability matching prior when dealing with a two-parameter distribution. To elaborate, considering as the parameter of interest, any prior for both and -denoted as -should satisfy the following partial differential equation:
Here, provides a second-order probability matching prior.
4.1. Reference Prior
Following the preparation steps outlined above, we are now in a position to derive the reference prior for the parameter of interest;
Theorem 10.
For the ordering group , the reference prior is given by
Proof.
On using the Fisher information presented in (12), we have that where and Next where and In view of Proposition 1, it follows that the reference prior for the ordered group is . □
Remark 1.
Observe that when the parameter of interest is β, the reference prior is equivalent to .
4.2. Probability Matching Priors
Theorem 11.
The general form of the second-order probability matching prior, for the parameter of interest β and the nuisance parameter is
where is any positive function.
Proof.
Since the parameter of interest is , direct calculations yield the following:
Substituting these quantities into the partial differential equation in (13), we find that the required second-order probability matching prior should satisfy the following partial differential equation.
It is not difficult to see that the above partial differential equation reduces to
The general solution of the mentioned partial differential equation can be readily obtained and is equivalent to the one presented in (15). □
Theorem 12.
Considering the general form of the second-order probability matching prior in (15), the following
are matching priors.
Proof.
By taking and , respectively, then we obtain the second-order probability matching priors given in (16) and (17). □
4.3. Propriety of Posterior Distributions
In this subsection, we investigate the finiteness of the posterior distributions under the developed priors when the parameter of interest is . It is of interest to note that the reference prior for this case is precisely equivalent to , ensuring a finite posterior distribution, as guaranteed by Theorem 8. Additionally, the matching prior given via (16) yields a proper posterior distribution, as affirmed by Theorem 8 as well. It remains to check the appropriateness of the posterior distributions under the matching given in (17).
Theorem 13.
The posterior distribution under the matching prior (17) is improper.
Proof.
The joint posterior distribution under the matching prior in (17) is
Now, we have that
It is not difficult to see that
where Clearly, the integral above diverges for , which completes the proof. □
Remark 2.
Notice that which is equivalent to the reference prior is not a second-order matching prior.
5. Posterior Predictive Assessment of the Model
After establishing posterior propriety using the developed priors for the parameter of interest, the next step involves evaluating the model’s goodness-of-fit to real data. Among the various Bayesian validation techniques available, one particularly powerful method is the use of posterior predictive checks. These checks involve generating new observations (predictive samples) from the model by sampling from the posterior distribution of the parameters and subsequently comparing these replicates to the observed data via graphical tools. Furthermore, we employ the posterior predictive p-value, originally introduced by [18] and formally defined by [19], as an additional tool for model evaluation. It is important to emphasize that this method involves utilizing a discrepancy measure that does not depend on the unknown parameters. An extension of this approach, which permits the discrepancy measure to depend on the unknown parameters, has been proposed by Gelman et al. [20]. We use the following discrepancy measure which is defined as Bayesian Chi-square residuals and given by
where To compute the posterior predictive p-value, we define, the algorithm
- Input observed data .
- Sample from the posterior distribution, considering a specified prior and observed data under the specified prior, to obtain a posterior sample.
- For each generate new observations of the same size of the observed data using the UUL distribution; . This represents a predictive sample.
- Compute the discrepancy measures using the predictive and observed data, respectively and .
- Repeat steps 2–4 sufficiently large number of times K.
The posterior predictive p-value is then approximated by
It is of interest to see that one can produce a scatter plot of against for visualization purposes.
6. Simulation Study
The Bayesian estimators of and under the various non-informative priors presented in this paper cannot be expressed in a closed-form analytical expression. Furthermore, the marginal posterior densities of and do not appear to yield well-known probability distributions, and this complicates sampling from the joint posterior distribution of and .
Alternatively, we evaluate the finite sample behavior of the Bayesian estimators for the parameters and , considering the noninformative priors , , and discussed in Section 3 and Section 4 by conducting a simulation study using Markov Chain Monte Carlo (MCMC). The study involves generating samples from the ULL distribution (1) using different true parameter values and samples of size . Subsequently, posterior samples are drawn from the joint posterior distribution of using the random-walk Metropolis algorithm, as detailed in [21]. Each chain within the process consisted of 5500 samples after discarding the initial 500 burn-in samples. The entire process is replicated 1000 times. Consequently, we can compute the estimated mean squared error (MSE) and the coverage probability (CP) of credible intervals for the parameters and . The empirical findings concerning the MSEs and CPs for 95% credible intervals are available in Table 1 and Table 2, respectively. Several findings from the study conform to our expectations and are evident, as illustrated in both the tables and Figure 1, Figure 2, Figure 3 and Figure 4.

Table 1.
Empirical average MSEs and CPs (within parentheses) of Bayesian estimators for the parameter under different true of and .
Table 2.
Empirical average MSEs and CPs (within parentheses) of Bayesian estimators for the parameter under different true of and .
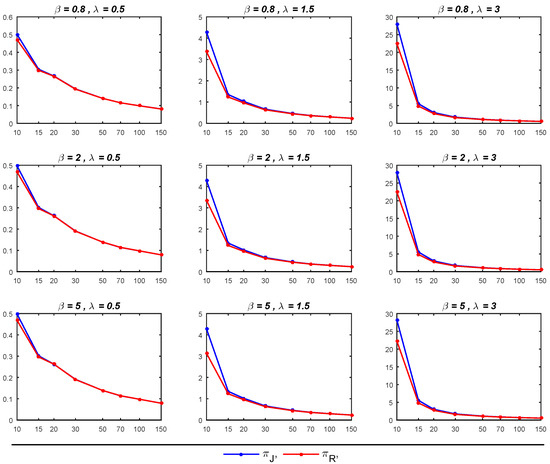
Figure 1.
MSEs of Bayesian Estimates of under and with different parameters of and .
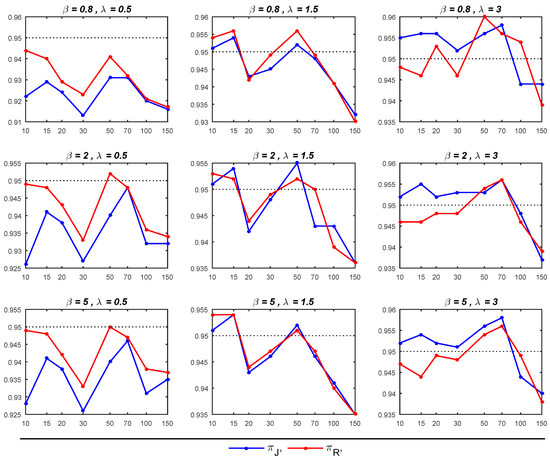
Figure 2.
CPs of 95% credible intervals for based on and priors with different parameters of and .
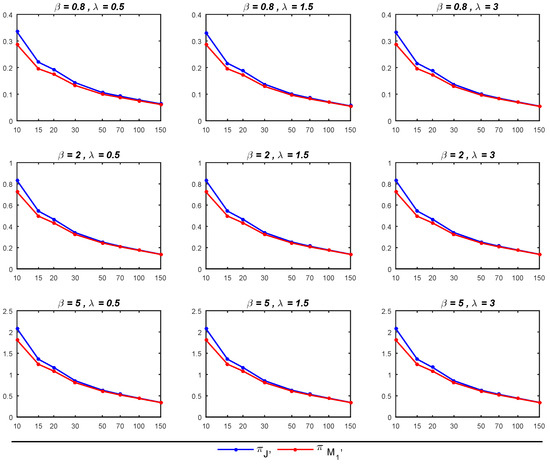
Figure 3.
MSEs of the Bayesian estimates of using and across different parameter values of and .
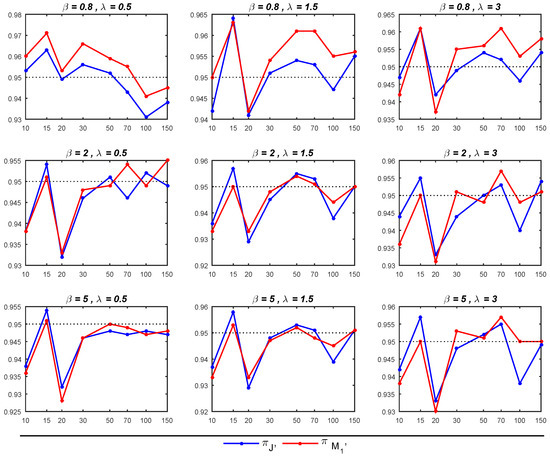
Figure 4.
CPs of 95% of credible intervals for based on and across different parameter values of and .
- As expected, it is noticed that as the sample size increased, the performance of all estimators for and improved, leading to a reduction in MSEs.
- The Bayesian estimators for the parameter of interest, , under the prior tends to outperform its counterpart under the prior , particularly in terms of exhibiting smaller MSEs, especially for small sample sizes (when ). Moreover, in most cases with sample sizes up to 70, the 95% credible intervals under are close to the nominal level of 0.95, surpassing the corresponding intervals under . Nevertheless, when dealing with sample sizes exceeding 70, the 95% credible intervals for both priors tend to deviate from the nominal level of 0.95, though they generally remain above the 0.90 nominal level.
- The Bayesian estimator of exhibits better performance under , particularly when compared to , as it yields smaller MSEs. When both and are greater than 1, the 95% credible intervals derived from closely approximate the nominal level of 0.95, outperforming the corresponding intervals under . In other cases, the 95% credible intervals behave similarly for both priors. Moreover, for sample sizes exceeding 30, the 95% credible intervals not only approach the nominal level but also demonstrate greater stability.
7. Real Data Analysis
In this section, we employ the proposed noninformative priors and illustrate their application using actual data obtained from a sample of 38 households, specifically relating to their food expenditures. These data can be accessed through the betareg package in R software, and they incorporate various covariates. For our analysis, we specifically focus on the variable representing food expenditures as a proportion of income. These data are: 0.2561, 0.2023, 0.2911, 0.1898, 0.1619, 0.3683, 0.2800, 0.2068, 0.1605, 0.2281, 0.1921, 0.2542, 0.3016, 0.2570, 0.2914, 0.3625, 0.2266, 0.3086, 0.3705, 0.1075, 0.3306, 0.2591, 0.2502, 0.2388, 0.4144, 0.1783, 0.2251, 0.2631, 0.3652, 0.5612, 0.2424, 0.3419, 0.3486, 0.3285, 0.3509, 0.2354, 0.5140, 0.5430.
The initial step in our analysis is to assess the suitability of the ULL distribution for fitting this data set. Upon conducting the Kolmogorov–Smirnov (KS) test on the data, the results indicate a KS statistic of 0.098 and a p-value of 0.82. This suggests that the ULL distribution is indeed a suitable fit for this data set.
Following this, we proceed with a posterior predictive assessment to gauge the alignment of the Bayesian model with the observed data. We initially drew 30 samples of () from the joint posterior distribution. For each draw of (), we generate a random sample of the same length as the observed data, which is 38 in this case, from the ULL distribution. This sample represents a single posterior predictive sample. Subsequently, for each posterior predictive sample, we calculate the cumulative distribution of the ULL distribution. The empirical distribution of the observed data and the predictive distribution functions are depicted in Figure 5.
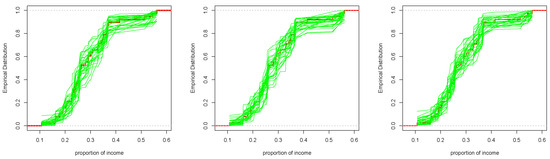
Figure 5.
Empirical distribution of the observed data (solid red line) and predictive simulated data sets under the proposed non-informative priors; (left): , (middle): , (right): .
Figure 5 reveals that the empirical cumulative distribution of income proportions for 38 households closely aligns with the cumulative distribution of the 30 predictive samples. For further assessment, we compute approximate described in Section 5. It is worth mentioning that the calculation of D requires the computation of the expected value and the variance for the ULL distribution. Unfortunately, their values can not be obtained in a closed form, and hence we use numerical computations to approximate these quantities. We generate 1000 samples of from the joint posterior distribution of given the observed data. For each we generate a random sample say of the same size of the observed data from the ULL distribution. When we utilize the discrepancy measure defined in Equation (18), we obtain a set of pairs of discrepancy measures for observed and replicated data sets as follows:
Figure 6 shows a scatterplot of the observed discrepancy; and the predictive discrepancy; using the priors , , and . The approximate can be computed as the proportions of points above the line in each panel in the figure. The values are, respectively, 0.35, 0.38, and 0.40. These high values indicate that the Bayesian model demonstrates compatibility with the current data.
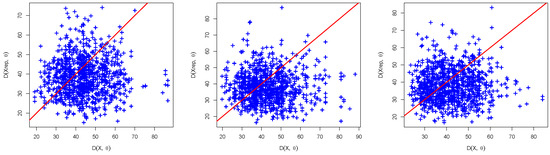
Figure 6.
Scatterplot of predictive discrepancy versus observed discrepancy for the proportion of income data, using the joint posterior distribution under the proposed non-informative priors; (left): , (middle): , (right): . The p-value is estimated by considering the proportion of points located above the line.
The Bayesian analysis of the current data set is conducted using , , and priors, chosen due to their demonstrated compatibility with the Bayesian model and the data. We compute Bayesian estimates employing the squared error loss function. To derive the Bayesian estimates for and , we generate 5500 MCMC samples from the joint posterior distribution of and using the random-walk Metropolis–Hastings (MH) algorithm, with a burn-in of 500 iterations. To assess the convergence of the random-walk MH algorithm, we employ graphical diagnostic tools, including trace and autocorrelation function (ACF) plots. The trace and ACF plots for are presented in Figure 7 under the specified priors. Similarly, Figure 8 illustrates the trace and ACF plots for under the introduced priors. Notably, the trace graphs depict scattered paths around the mean values represented by solid lines for the simulated values of and . Additionally, the ACF plots demonstrate minimal auto-correlation, with ACFs approaching zero. These plots signify the fast convergence of the random-walk MH algorithm using a proposal bivariate normal distribution. Furthermore, Figure 7 and Figure 8 reveal that the marginal posterior distributions of and closely resemble Gaussian distributions, indicating the appropriateness of the bivariate normal proposal distribution.
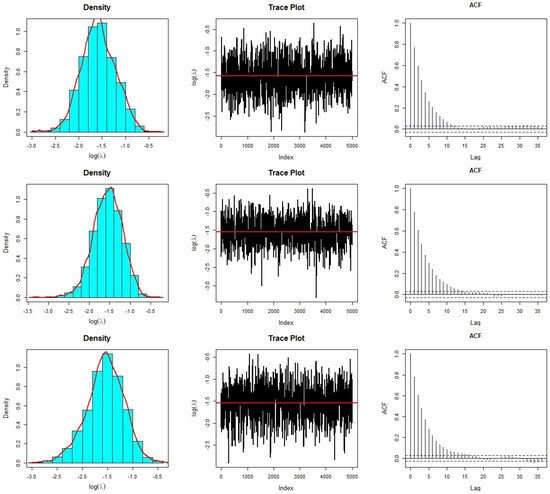
Figure 7.
Diagnostic plots of the random–walk MH algorithm for under (first row); (second row); and (bottom row).
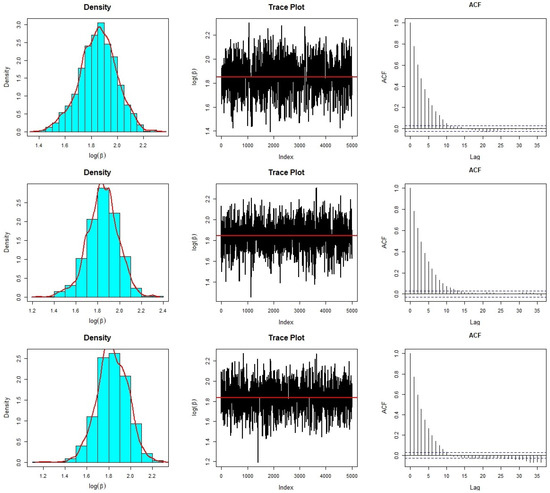
Figure 8.
Diagnostic plots of the random–walk MH algorithm for under (first row); (second row); and (bottom row).
Table 3 presents the ML and Bayesian estimates obtained under three different priors: , , and for both and , along with their respective standard errors (SDs) and 95% asymptotic confidence and credible intervals. The point estimates for using all methods are relatively close to each other. However, the SDs of the Bayesian estimates of under and exhibit slightly smaller SDs compared to the Bayes estimate under and the ML estimate for , with the smallest SD observed under the prior. Additionally, the widths of the 95% confidence intervals for using ML, , , and are and , respectively. This indicates that the 95% credible interval of the under is relatively shorter than the other confidence intervals. Similarly, the point estimates and their corresponding SDs for are close to each other, with the smallest SD for the Bayes estimate for occurring under the prior. Moreover, the widths of the 95% confidence intervals for are and , respectively. These results reveal that the lengths of all intervals are close to each other with a slightly shorter interval, corresponding to prior.
Table 3.
ML and Bayes estimates, SD, and the 95% confidence/credible intervals of and .
8. Concluding Remarks
In this paper, we develop Bayesian estimators for the parameters of the unit log-logistic distribution with parameters and under non-informative priors. More precisely, we derive Jeffreys, reference, and matching priors for these parameters. Surprisingly, when is the parameter of interest, the Jeffreys prior is equivalent to the reference prior, but it is not a matching prior. When is the parameter of interest, we show that the reference prior is a second-order matching prior. Additionally, our numerical results from a simulation study demonstrate that the Bayes estimates with reference and matching priors outperform the Jeffreys prior, exhibiting smaller standard deviations and possessing good coverage property.
Author Contributions
Conceptualization, M.K.S.; methodology, M.K.S.; writing—original draft preparation, M.K.S.; writing—review and editing; M.K.S. and M.A.A.; software, M.A.A.; validation, M.A.A.; formal analysis, M.K.S. and M.A.A. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
Data is contained within the article.
Acknowledgments
The authors express their sincere gratitude to the Editor, Associate Editor, and anonymous reviewers for their invaluable comments and constructive suggestions that led to improvements in the paper.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Johnson, N.L. Systems of frequency curves generated by methods of translation. Biometrika 1949, 36, 149–176. [Google Scholar] [CrossRef] [PubMed]
- Kumaraswamy, P. A generalized probability density function for double-bounded random processes. J. Hydrol. 1980, 46, 79–88. [Google Scholar] [CrossRef]
- Ghitany, M.E.; Mazucheli, J.; Menezes, A.F.B.; Alqallaf, F. The unit-inverse Gaussian distribution: A new alternative to two-parameter distributions on the unit interval. Commun. Stat. Theory Methods 2019, 48, 3423–3438. [Google Scholar] [CrossRef]
- Mazucheli, J.; Menezes, A.F.; Dey, S. Unit-Gompertz distribution with applications. Statistica 2019, 79, 25–43. [Google Scholar]
- Mazucheli, J.; Menezes, A.F.B.; Fernandes, L.B.; de Oliveira, R.P.; Ghitany, M.E. The unit-Weibull distribution as an alternative to the Kumaraswamy distribution for the modeling of quantiles conditional on covariates. J. Appl. Stat. 2020, 47, 954–974. [Google Scholar] [CrossRef] [PubMed]
- Ribeiro-Reis, L.D. Unit log-logistic distribution and unit log-logistic regression model. J. Indian Soc. Probab. Stat. 2021, 22, 375–388. [Google Scholar] [CrossRef]
- Korkmaz, M.; Chesneau, C. On the unit Burr-XII distribution with the quantile regression modeling and applications. Comput. Appl. Math. 2021, 40, 29. [Google Scholar] [CrossRef]
- Korkmaz, M.C.; Korkmaz, Z.S. The unit log-log distribution: A new unit distribution with alternative quantile regression modeling and educational measurements applications. J. Appl. Stat. 2023, 50, 889–908. [Google Scholar] [CrossRef] [PubMed]
- Najwan Alsadat, N.; Elgarhy, M.; Karakaya, K.; Gemeay, A.M.; Chesneau, C.; Abd El-Raouf, M.M. Inverse Unit Teissier Distribution: Theory and Practical Examples. Axioms 2023, 12, 502. [Google Scholar] [CrossRef]
- Bernardo, J.M. Reference posterior distributions for Bayesian inference (C/R p128-147). J. R. Stat. Soc. Ser. 1979, 41, 113–128. [Google Scholar]
- Berger, J.O.; Bernardo, J.M. Ordered group reference priors with application to the multinomial problem. Biometrika 1992, 79, 25–37. [Google Scholar] [CrossRef]
- Berger, J.O.; Bernardo, J.M.; Sun, D.C. The formal definition of reference priors. Ann. Stat. 2009, 37, 905–938. [Google Scholar] [CrossRef]
- Welch, B.L.; Peers, H.W. On formulae for confidence points Based on integrals of weighted likelihoods. J. R. Stat. Soc. Ser. 1963, 25, 318–329. [Google Scholar] [CrossRef]
- Datta, G.S.; Sweeting, T.J. Probability matching priors. In Handbook of Statistics Vol. 25: Bayesian Thinking: Modeling and Computation; Dey, D.K., Rao, C.R., Eds.; Elsevier: Amsterdam, The Netherlands, 2005; pp. 91–114. [Google Scholar]
- Datta, G.K.; Ghosh, M. On the invariance of noninformative priors. Ann. Stat. 1996, 24, 141–159. [Google Scholar] [CrossRef]
- Tibshirani, R. Noninformative priors for one parameter of many. Biometrika 1989, 76, 604–608. [Google Scholar] [CrossRef]
- Bernardo, J.M.; Smith, A.F.M. Bayesian Theory; John Wiley & Sons: New York, NY, USA, 2000. [Google Scholar]
- Guttman, J. The use of the concept of a future observation in goodness-of-fit problems. J. R. Stat. Soc. B 1967, 29, 83–100. [Google Scholar] [CrossRef]
- Meng, X.L. Posterior predictive p-values. Ann. Stat. 1994, 22, 1142–1160. [Google Scholar] [CrossRef]
- Gelman, A.; Meng, X.L.; Stern, H. Posterior Predictive Assessment of Model Fitness via Realized Discrepancies. Stat. Sin. 1996, 6, 733–760. [Google Scholar]
- Roberts, G.O.; Gelman, A.; Gilks, W.R. Weak convergence and optimal scaling of random walk Metropolis algorithms. Ann. Appl. Probab. 1997, 7, 110–120. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).