

Adaptive Regression Analysis of Heterogeneous Data Streams via Models with Dynamic Effects

Abstract
:1. Introduction
2. The Model Setup
3. Proposed Methodology
3.1. Online Estimation of Dynamic Coefficients
3.2. Motivation and Derivation of the Proposed Estimator
3.3. Tuning Parameter Selection and Implentation Algorithm
- Step 1.
- Sequentially input arriving datasets from model (1).
- Step 2.
- Compute and using initial dataset .
- Step 3.
- For each :
- Read in dataset .
- Calculate using only and set .
- For in a sequence tuning parameter , obtain and by optimizing the objective function (6).
- Choose optimal via the online BIC criterion shown in (12).
- Set and , and update .
- Save the newest set of summary statistics as defined in (7).
- Release dataset from the memory
- Step 4.
- Output the parameters of interest and for each .
4. Numerical Studies
4.1. Mathematical Formulation for a Special Case: The Logistic Model
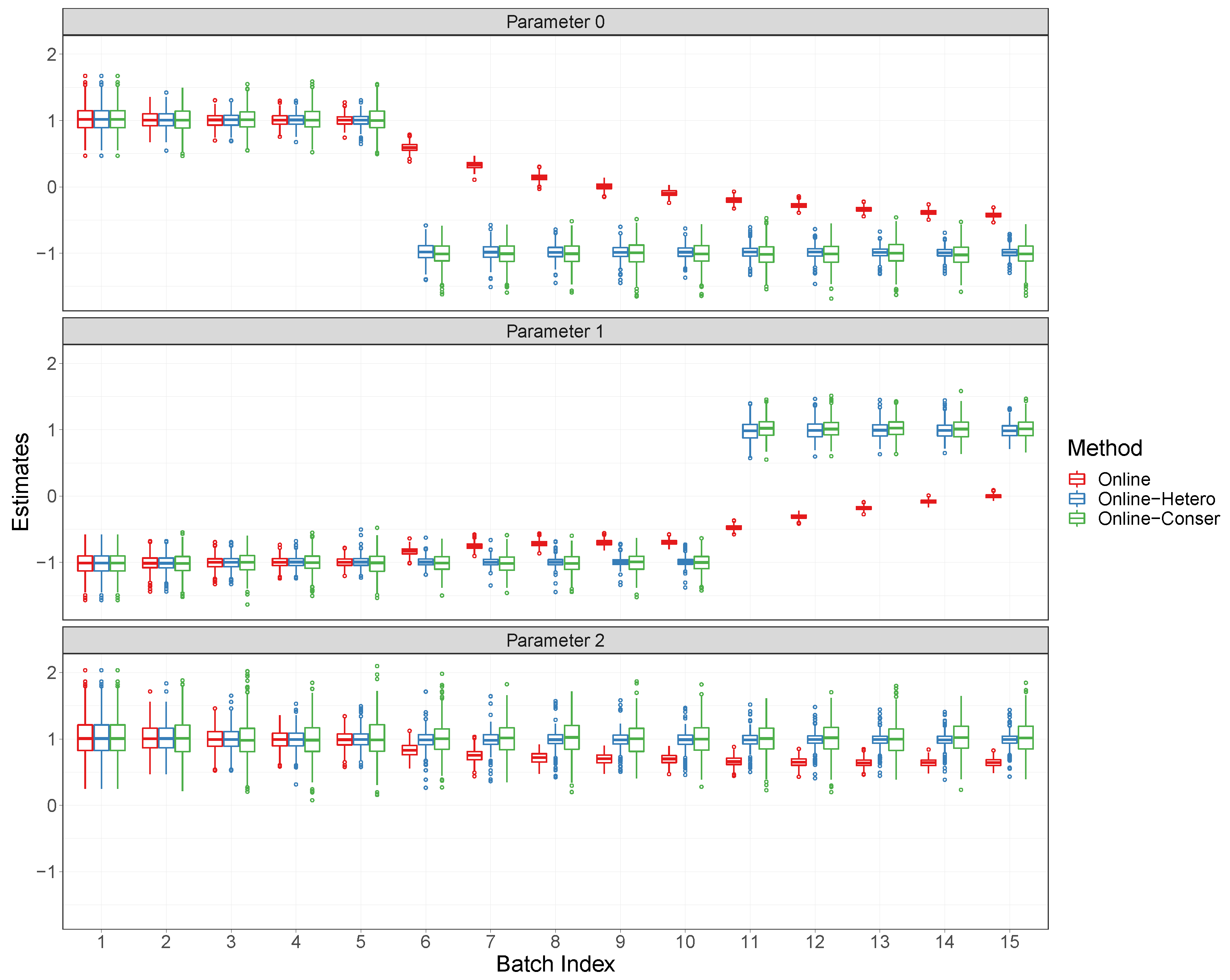
4.2. Simulation Experiments
- Case 1.
- , , and .
- Case 2.
- , , and .
- Case 3.
- , , , .
- Case 4.
- , , , .
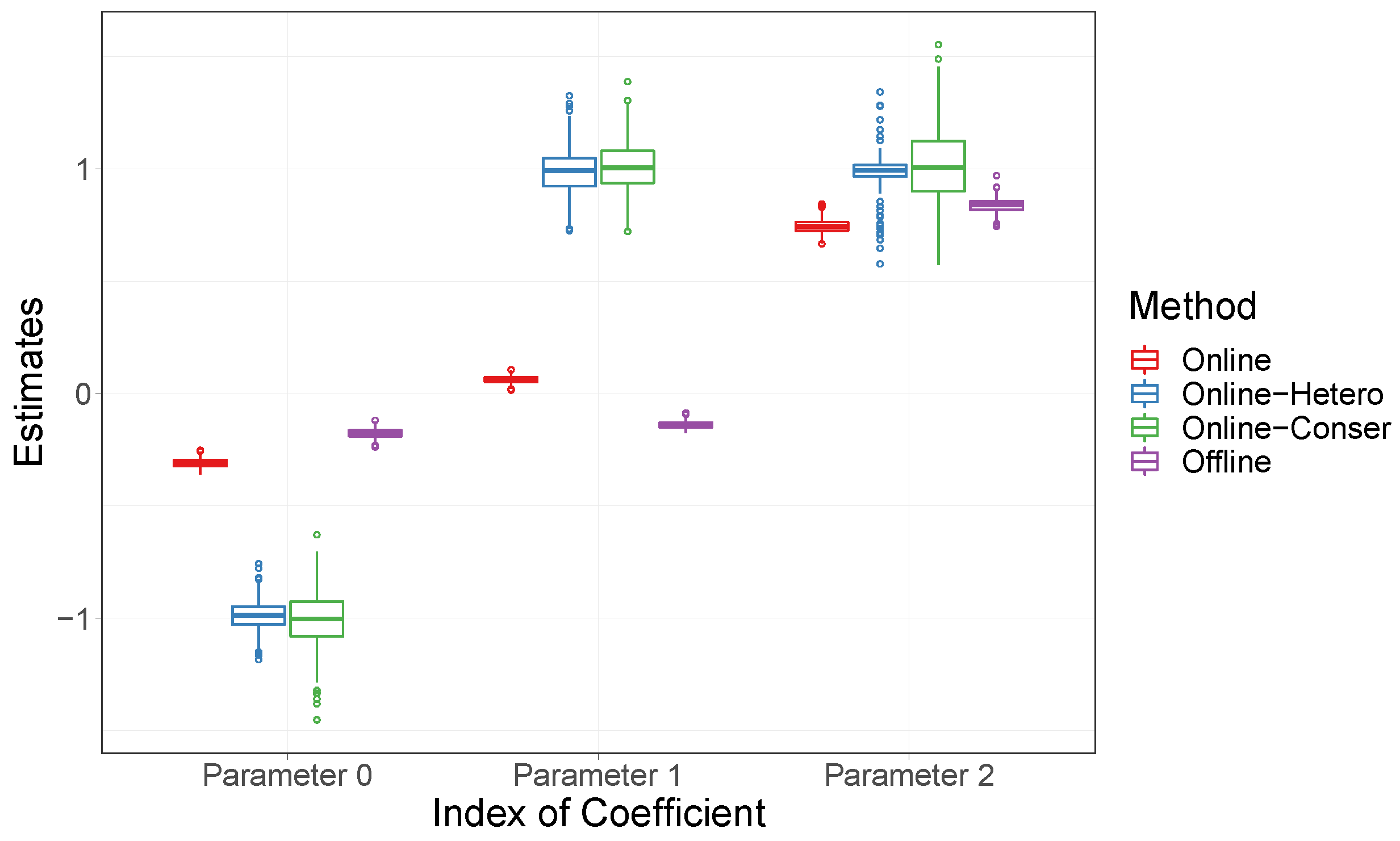
4.3. Real Data Analysis
4.3.1. Presentation of the Streaming Airline Data
4.3.2. Fitting in an Online Manner Using Various Approaches
5. Discussion
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| GLM | Generalized linear model |
Appendix A. Supplementary Numerical Results




References
- Wang, C.; Chen, M.H.; Schifano, E.; Wu, J.; Yan, J. Statistical methods and computing for big data. Stat. Its Interface 2016, 9, 399–414. [Google Scholar] [CrossRef]
- Luo, L.; Song, P.X.K. Renewable estimation and incremental inference in generalized linear models with streaming data sets. J. R. Stat. Soc. Ser. (Stat. Methodol.) 2020, 82, 69–97. [Google Scholar] [CrossRef]
- McCullagh, P.; Nelder, J.A. Generalized Linear Models; Routledge: New York, NY, USA, 2019. [Google Scholar]
- Robbins, H.; Monro, S. A Stochastic Approximation Method. Ann. Math. Stat. 1951, 22, 400–407. [Google Scholar] [CrossRef]
- Toulis, P.; Airoldi, E.M. Scalable estimation strategies based on stochastic approximations: Classical results and new insights. Stat. Comput. 2015, 25, 781–795. [Google Scholar] [CrossRef] [PubMed]
- Toulis, P.; Airoldi, E.M. Asymptotic and finite-sample properties of estimators based on stochastic gradients. Ann. Stat. 2017, 45, 1694–1727. [Google Scholar] [CrossRef]
- Fang, Y. Scalable statistical inference for averaged implicit stochastic gradient descent. Scand. J. Stat. 2019, 46, 987–1002. [Google Scholar] [CrossRef]
- Schifano, E.D.; Wu, J.; Wang, C.; Yan, J.; Chen, M.H. Online updating of statistical inference in the big data setting. Technometrics 2016, 58, 393–403. [Google Scholar] [CrossRef]
- Luo, L.; Zhou, L.; Song, P.X.K. Real-time regression analysis of streaming clustered data with possible abnormal data batches. J. Am. Stat. Assoc. 2022, 543, 2029–2044. [Google Scholar] [CrossRef]
- Wang, K.; Wang, H.; Li, S. Renewable quantile regression for streaming datasets. Knowl. Based Syst. 2022, 235, 107675. [Google Scholar] [CrossRef]
- Jiang, R.; Yu, K. Renewable quantile regression for streaming data sets. Neurocomputing 2022, 508, 208–224. [Google Scholar] [CrossRef]
- Sun, X.; Wang, H.; Cai, C.; Yao, M.; Wang, K. Online renewable smooth quantile regression. Comput. Stat. Data Anal. 2023, 185, 107781. [Google Scholar] [CrossRef]
- Wang, T.; Zhang, H.; Sun, L. Renewable learning for multiplicative regression with streaming datasets. Comput. Stat. 2023, 1–28. [Google Scholar] [CrossRef]
- Ma, X.; Lin, L.; Gai, Y. A general framework of online updating variable selection for generalized linear models with streaming datasets. J. Stat. Comput. Simul. 2023, 93, 325–340. [Google Scholar] [CrossRef]
- Hector, E.C.; Luo, L.; Song, P.X.K. Parallel-and-stream accelerator for computationally fast supervised learning. Comput. Stat. Data Anal. 2023, 177, 107587. [Google Scholar] [CrossRef]
- Han, R.; Luo, L.; Lin, Y.; Huang, J. Online inference with debiased stochastic gradient descent. Biometrika 2023, asad046. [Google Scholar] [CrossRef]
- Luo, L.; Wang, J.; Hector, E.C. Statistical inference for streamed longitudinal data. arXiv 2022, arXiv:2208.02890. [Google Scholar] [CrossRef]
- Luo, L.; Song, P.X.K. Multivariate online regression analysis with heterogeneous streaming data. Can. J. Stat. 2023, 51, 111–133. [Google Scholar] [CrossRef]
- Klein, L. A Textbook of Econometrics; Prentice-Hall: Upper Saddle River, NJ, USA, 1953. [Google Scholar]
- Hsiao, C. Analysis of Panel Data; Cambridge University Press: New York, NY, USA, 1986. [Google Scholar]
- Hamilton, J.D. Time Series Analysis; Princeton University Press: Princeton, NJ, USA, 1994. [Google Scholar]
- Zou, H. The adaptive lasso and its oracle properties. J. Am. Stat. Assoc. 2006, 101, 1418–1429. [Google Scholar] [CrossRef]
- Fan, J.; Li, R. Variable Selection via Nonconcave Penalized Likelihood and its Oracle Properties. J. Am. Stat. Assoc. 2001, 96, 1348–1360. [Google Scholar] [CrossRef]
- Zhang, C.H. Nearly unbiased variable selection under minimax concave penalty. Ann. Stat. 2010, 38, 894–942. [Google Scholar] [CrossRef]
- Wang, H.; Leng, C. Unified LASSO estimation by least squares approximation. J. Am. Stat. Assoc. 2007, 102, 1039–1048. [Google Scholar] [CrossRef]
- Wang, H.; Li, B.; Leng, C. Shrinkage tuning parameter selection with a diverging number of parameters. J. R. Stat. Soc. Ser. (Stat. Methodol.) 2009, 71, 671–683. [Google Scholar] [CrossRef]
- Akaike, H. A new look at the statistical model identification. IEEE Trans. Autom. Control 1974, 19, 716–723. [Google Scholar] [CrossRef]
- Schwarz, G. Estimating the dimension of a model. Ann. Stat. 1978, 6, 461–464. [Google Scholar] [CrossRef]
- Tibshirani, R. Regression shrinkage and selection via the lasso. J. R. Stat. Soc. Ser. (Stat. Methodol.) 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Zhang, H.H.; Lu, W. Adaptive Lasso for Cox’s proportional hazards model. Biometrika 2007, 94, 691–703. [Google Scholar] [CrossRef]
- Friedman, J.; Hastie, T.; Tibshirani, R. Regularization Paths for Generalized Linear Models via Coordinate Descent. J. Stat. Softw. 2010, 33, 1–22. [Google Scholar] [CrossRef] [PubMed]
- Cox, D.R. Regression models and life tables (with discussion). J. R. Stat. Soc. Ser. (Stat. Methodol.) 1972, 34, 187–202. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Frequency | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Batch | MSE | U% | O% | E% | MSE | U% | O% | E% | ||||||
| 2 | 0.008 | 0.0 | 1.6 | 98.4 | 0.005 | 0.0 | 2.0 | 98.0 | 2 | 4 | 3 | 1 | 3 | 6 |
| 3 | 0.005 | 0.0 | 1.8 | 98.2 | 0.001 | 0.0 | 0.8 | 99.2 | 4 | 2 | 3 | 0 | 2 | 2 |
| 4 | 0.004 | 0.0 | 1.8 | 98.2 | 0.002 | 0.0 | 1.4 | 98.6 | 2 | 6 | 1 | 1 | 2 | 4 |
| 5 | 0.004 | 0.0 | 1.8 | 98.2 | 0.003 | 0.0 | 1.2 | 98.8 | 2 | 5 | 2 | 1 | 0 | 6 |
| 6 | 0.022 | 0.0 | 1.2 | 98.8 | 0.014 | 0.0 | 1.4 | 98.6 | 500 | 4 | 2 | 500 | 1 | 6 |
| 7 | 0.006 | 0.0 | 3.2 | 96.8 | 0.006 | 0.0 | 3.6 | 96.4 | 10 | 3 | 3 | 10 | 2 | 7 |
| 8 | 0.001 | 0.0 | 0.6 | 99.4 | 0.003 | 0.0 | 3.0 | 97.0 | 2 | 1 | 1 | 10 | 2 | 4 |
| 9 | 0.005 | 0.0 | 2.0 | 98.0 | 0.001 | 0.0 | 1.8 | 98.2 | 7 | 3 | 1 | 7 | 2 | 1 |
| 10 | 0.007 | 0.0 | 1.8 | 98.2 | 0.002 | 0.0 | 1.6 | 98.4 | 5 2 | 5 | 3 | 3 | 3 | |
| 11 | 0.032 | 0.0 | 2.0 | 98.0 | 0.013 | 0.0 | 1.4 | 98.6 | 5 | 500 | 6 | 6 | 500 | 1 |
| 12 | 0.009 | 0.0 | 4.4 | 95.6 | 0.003 | 0.0 | 3.8 | 96.2 | 4 | 15 | 3 | 1 | 16 | 2 |
| 13 | 0.005 | 0.0 | 3.0 | 97.0 | 0.002 | 0.0 | 1.6 | 98.4 | 6 | 8 | 1 | 3 | 3 | 2 |
| 14 | 0.006 | 0.0 | 3.0 | 97.0 | 0.003 | 0.0 | 2.8 | 97.2 | 5 | 6 | 5 | 3 | 9 | 2 |
| 15 | 0.006 | 0.0 | 2.6 | 97.4 | 0.000 | 0.0 | 0.2 | 99.8 | 4 | 4 | 6 | 0 | 1 | 0 |
| Frequency | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Batch | MSE | U% | O% | E% | MSE | U% | O% | E% | ||||||
| 2 | 0.010 | 0.0 | 3.2 | 96.8 | 0.001 | 0.0 | 0.8 | 99.2 | 8 | 3 | 5 | 3 | 0 | 1 |
| 3 | 0.005 | 0.0 | 1.6 | 98.4 | 0.001 | 0.0 | 1.2 | 98.8 | 3 | 2 | 3 | 4 | 1 | 1 |
| 4 | 0.006 | 0.0 | 2.2 | 97.8 | 0.001 | 0.0 | 0.8 | 99.2 | 2 | 4 | 5 | 4 | 0 | 1 |
| 5 | 0.002 | 0.0 | 1.0 | 99.0 | 0.002 | 0.0 | 1.4 | 98.6 | 2 | 1 | 2 | 2 | 3 | 3 |
| 6 | 0.040 | 0.0 | 4.8 | 95.2 | 0.012 | 0.0 | 1.8 | 98.2 | 500 | 6 | 18 | 500 | 4 | 5 |
| 7 | 0.011 | 0.0 | 6.2 | 93.8 | 0.002 | 0.0 | 2.2 | 97.8 | 19 | 6 | 9 | 7 | 2 | 2 |
| 8 | 0.005 | 0.0 | 2.8 | 97.2 | 0.002 | 0.0 | 1.6 | 98.4 | 10 | 4 | 1 | 3 | 2 | 3 |
| 9 | 0.005 | 0.0 | 2.8 | 97.2 | 0.003 | 0.0 | 2.4 | 97.6 | 4 | 5 | 6 | 7 | 0 | 5 |
| 10 | 0.005 | 0.0 | 2.6 | 97.4 | 0.002 | 0.0 | 2.2 | 97.8 | 8 | 4 | 3 | 2 | 4 | 5 |
| 11 | 0.026 | 0.0 | 3.8 | 96.2 | 0.009 | 0.0 | 1.2 | 98.8 | 10 | 500 | 9 | 3 | 500 | 3 |
| 12 | 0.007 | 0.0 | 5.4 | 94.6 | 0.003 | 0.0 | 2.8 | 97.2 | 2 | 22 | 4 | 3 | 8 | 4 |
| 13 | 0.004 | 0.0 | 2.6 | 97.4 | 0.002 | 0.0 | 2.6 | 97.4 | 4 | 10 | 2 | 3 | 7 | 4 |
| 14 | 0.003 | 0.0 | 2.0 | 98.0 | 0.001 | 0.0 | 1.2 | 98.8 | 1 | 4 | 5 | 1 | 5 | 0 |
| 15 | 0.003 | 0.0 | 2.0 | 98.0 | 0.001 | 0.0 | 1.4 | 98.6 | 3 | 4 | 3 | 0 | 5 | 2 |
| Frequency | |||||||
|---|---|---|---|---|---|---|---|
| Batch | MSE | U% | O% | E% | |||
| Results for Case 3 | |||||||
| 6 | 0.013 | 0.0 | 1.2 | 98.8 | 500 | 2 | 4 |
| 7 | 0.004 | 0.0 | 4.0 | 96.0 | 10 | 5 | 5 |
| 11 | 0.010 | 0.0 | 1.8 | 98.2 | 6 | 500 | 3 |
| 12 | 0.002 | 0.0 | 3.0 | 97.0 | 4 | 9 | 2 |
| 16 | 0.010 | 0.0 | 2.4 | 97.6 | 500 | 9 | 3 |
| 17 | 0.003 | 0.0 | 3.6 | 96.4 | 14 | 2 | 2 |
| 21 | 0.015 | 0.0 | 1.4 | 98.6 | 5 | 500 | 2 |
| 22 | 0.005 | 0.0 | 5.0 | 95.0 | 5 | 19 | 2 |
| Results for Case 4 | |||||||
| 11 | 0.012 | 0.0 | 1.4 | 98.6 | 500 | 1 | 6 |
| 12 | 0.005 | 0.0 | 4.4 | 95.6 | 9 | 4 | 9 |
| 21 | 0.009 | 0.0 | 1.4 | 98.6 | 3 | 500 | 5 |
| 22 | 0.002 | 0.0 | 2.6 | 97.4 | 4 | 7 | 2 |
| 31 | 0.009 | 0.0 | 1.0 | 99.0 | 500 | 4 | 1 |
| 32 | 0.003 | 0.0 | 3.4 | 96.6 | 8 | 4 | 5 |
| 41 | 0.016 | 0.0 | 2.0 | 98.0 | 6 | 500 | 5 |
| 42 | 0.005 | 0.0 | 3.8 | 96.2 | 3 | 11 | 5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wei, J.; Yang, J.; Cheng, X.; Ding, J.; Li, S. Adaptive Regression Analysis of Heterogeneous Data Streams via Models with Dynamic Effects. Mathematics 2023, 11, 4899. https://doi.org/10.3390/math11244899
Wei J, Yang J, Cheng X, Ding J, Li S. Adaptive Regression Analysis of Heterogeneous Data Streams via Models with Dynamic Effects. Mathematics. 2023; 11(24):4899. https://doi.org/10.3390/math11244899
Chicago/Turabian StyleWei, Jianfeng, Jian Yang, Xuewen Cheng, Jie Ding, and Shengquan Li. 2023. "Adaptive Regression Analysis of Heterogeneous Data Streams via Models with Dynamic Effects" Mathematics 11, no. 24: 4899. https://doi.org/10.3390/math11244899
APA StyleWei, J., Yang, J., Cheng, X., Ding, J., & Li, S. (2023). Adaptive Regression Analysis of Heterogeneous Data Streams via Models with Dynamic Effects. Mathematics, 11(24), 4899. https://doi.org/10.3390/math11244899