1. Introduction
With the rapid development of artificial intelligence [
1] and IoT (Internet of Things) technology, an increasing number of data are dispersed across various terminal devices and edge servers. Therefore, data silos and data privacy protection are the two primary challenges in artificial intelligence technology [
2]. In 2016, Google first introduced the concept of federated learning in a paper published on arXiv [
3], which allows users to protect their dataset privacy while jointly training and sharing models. As an emerging distributed machine learning approach, federated learning has emerged as a solution to effectively address privacy preservation and data security issues [
4] by conducting model training locally on devices, avoiding centralized data collection and storage.
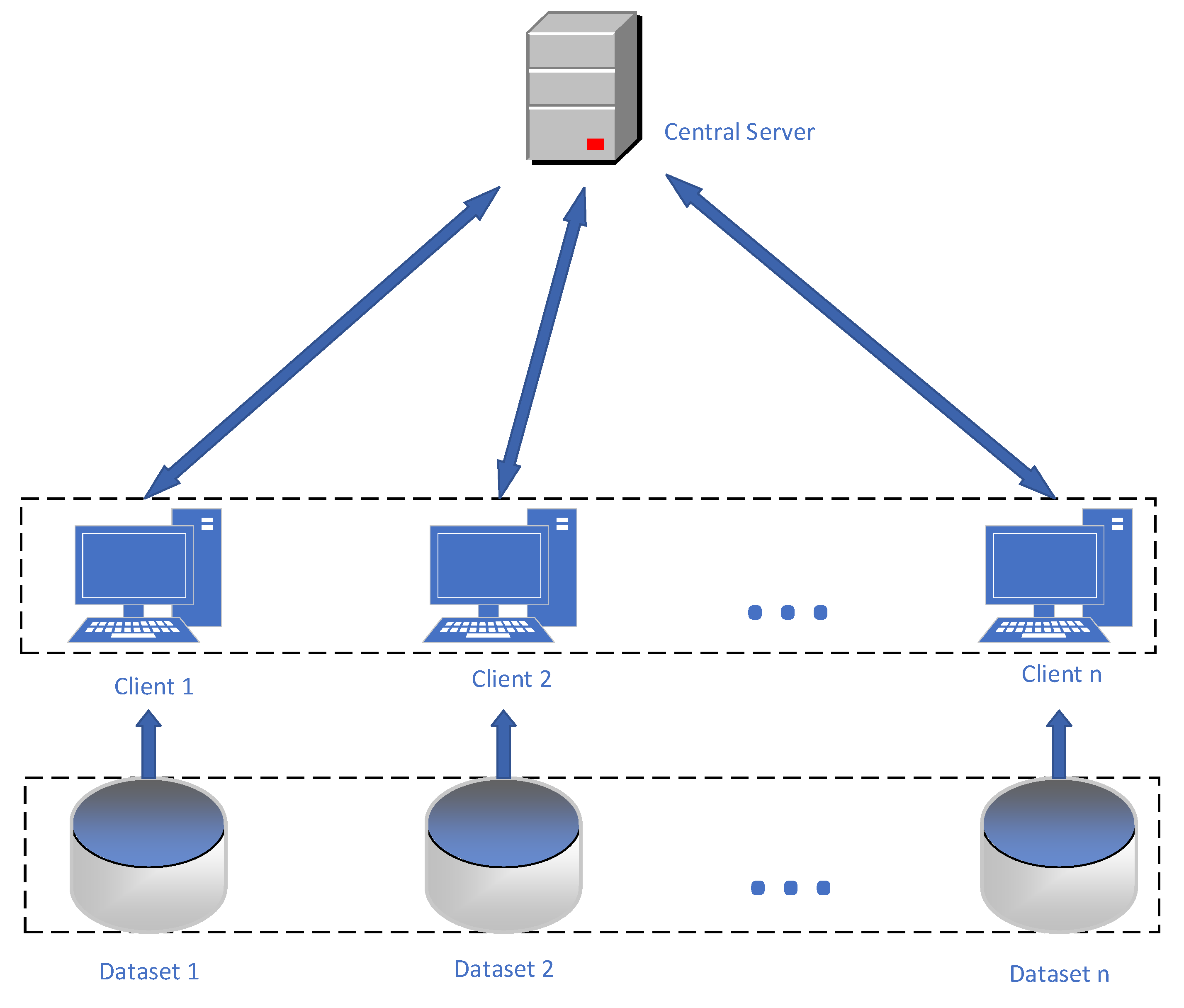
However, federated learning faces several challenges, including significant resource consumption and low aggregation efficiency when aggregating client model parameters during the training process. In traditional federated learning, all clients typically use the same fixed learning rate for local model training, as shown in
Figure 1. Nevertheless, due to variations in client performance and data heterogeneity, using a fixed learning rate may result in slow convergence or performance degradation of the global model. For instance, on mobile devices, certain clients may have limited computational resources and higher energy consumption, leading to slower processing speeds, while other high-performance servers can complete model training more quickly. Consequently, there is a need to introduce a learning rate adjustment strategy into the federated learning framework to dynamically adjust the learning rate, personalized to adapt to the characteristics of different clients, and enhance the algorithm’s performance and convergence speed.
Another challenge is to select the participating clients carefully during the aggregation process in federated learning. Traditional federated averaging algorithms often employ random selection or follow certain rules to choose clients. However, such selection methods may overlook the contributions of certain clients or lead to excessive participation, thereby affecting the accuracy and stability of the aggregation results. For example, some clients may have a high accuracy in model aggregation but may not be able to participate in a timely manner, resulting in delayed model updates. To address this issue, a multi-client selection scheme is needed, which takes into account factors such as client accuracy and data scale to make a rational choice of participating clients and better balance their contributions.
To address the above challenges, this paper proposes a federated learning aggregation algorithm with improved efficiency. In this method, we introduce cyclic adaptive learning rate adjustment to adjust the learning rate of local clients dynamically, based on the progress and performance of their local training, to accelerate the convergence speed of the model. Simultaneously, we design a client-weighted sampling algorithm, considering the sampling frequency of clients, to avoid the drawbacks of multiple sampling for some clients and nonsampling for others, and assign different weights to clients to enhance the accuracy and stability of the aggregation process.
The following sections will provide a detailed description of our algorithm design and experimental results to validate the effectiveness and performance advantages of the proposed improvements. Through experimental evaluations comparing different learning rate schemes and real-world application scenarios, we will demonstrate the superiority of cyclic adaptive learning rate and client-weighted sampling algorithms in federated learning aggregation models. We will also explore their potential in improving model convergence speed, accuracy, and stability. This research will provide new insights and solutions for the development of federated learning, promoting its widespread application in practical scenarios and further research.
The main contributions of this paper are as follows:
Traditional learning rate strategies lack adaptability and cannot adjust the learning rate based on dynamic changes during the training process. The proposed cyclic adaptive learning rate adjustment algorithm replaces the traditional approach of fixed learning rates for clients. Experimental results on various datasets show that it improves the training effectiveness of local models and enhances the performance of the global model;
Addressing the issue of slow aggregation caused by traditional random sampling of clients, this paper introduces a client sampling strategy to balance the frequency of client sampling and their contributions, effectively enhancing the efficiency of model training in federated learning. The proposed federated learning client-weighted sampling method eliminates the impact of a single randomly selected client on global weights, addressing existing issues in client sampling algorithms;
This paper conducts experimental evaluations on two representative datasets. The experimental results on these datasets demonstrate that, compared to baseline algorithms, the enhanced algorithm achieves the same test accuracy with an average reduction of 27.65% in training rounds on the MNIST dataset and an average reduction of 27.75% in training rounds on the CIFAR-10 dataset.
2. Related Work
Federated learning is a machine learning framework that protects user data privacy, allowing multiple participants to locally train models without sharing raw data [
5]. Many researchers have combined federated learning with technologies such as secret sharing [
6], differential privacy [
7], secure multi-party computation [
8], and homomorphic encryption [
9,
10] to achieve secure and efficient federated learning solutions. In recent years, the field of federated learning has seen a surge in new algorithms and optimization techniques to address challenges related to communication efficiency, model security, and convergence speed.
One of the most commonly used algorithms in federated learning is the FedAvg [
3] algorithm. In the federated learning research, Briggs et al. [
11] introduced hierarchical clustering based on FedAvg. They clustered and separated clients according to the similarity between the local updates of clients and the global model, thereby improving aggregation efficiency. Karimireddy et al. [
12] corrected the direction of client local updates by estimating the difference between the server and client update directions, successfully overcoming the problem of non-uniform data distribution. This correction strategy enables faster model convergence within fewer communication rounds, accelerating the federated learning training process.
Ye et al. [
13] introduced the FedCNM algorithm, which employs global momentum to mitigate “client drift”, leading to a significant improvement in test accuracy, with an enhancement ranging from 1.46% to 11.12%. Additionally, the use of local optimizers, SGD + M and NAG, further improved test accuracy by 10.53% and 10.44%, respectively. Ref. [
14] presented the Client-Level Federated Learning (CL-FL) method, primarily addressing client contribution protection in federated learning. This method adds Gaussian noise to each participant’s contributions through a central server to hide their contributions and designs a dynamic differential privacy adjustment method to improve training efficiency. Chen et al. [
15] divided the neural network in federated learning into shallow and deep layers and observed that the update frequency of deep layers was lower than that of shallow layers. Based on this observation, they proposed an asynchronous update strategy, effectively reducing the number of parameters transmitted in each round by reducing the transmission of deep-layer parameters during the communication process.
Haddadpour et al. [
16] reduced communication overhead in federated learning by employing gradient compression and local computation on top of FedAvg, thereby improving the algorithm’s efficiency. Specifically, the algorithm computes gradients locally, compresses them, and then uploads them to the server, reducing the amount of communication. Zhang et al. [
17] designed a federated learning method for mechanical fault diagnosis and proposed a dynamic verification scheme based on the federated learning framework to adaptively adjust the model aggregation process. They also introduced a self-supervised learning scheme to learn structural information from limited training data. Meng et al. [
18], in the context of differentially private federated learning, addressed the problem of gradient explosion caused by a learning rate that is too large or too small during the neural network training process. They proposed the CAdabelief algorithm and integrated it into the framework of differentially private federated learning, conducting federated learning differential privacy experiments with the MNIST dataset. The experimental results demonstrated that under the same privacy budget, the CAdabelief algorithm outperformed three comparative algorithms: SGD [
19], Adam [
20], and Adabelief [
21]. In this paper, we improve the federated learning algorithm by changing the learning rate allocation scheme and client sampling scheme, aiming to accelerate model training speed, reduce loss, and minimize communication rounds.
4. High-Performance Aggregation Mechanism
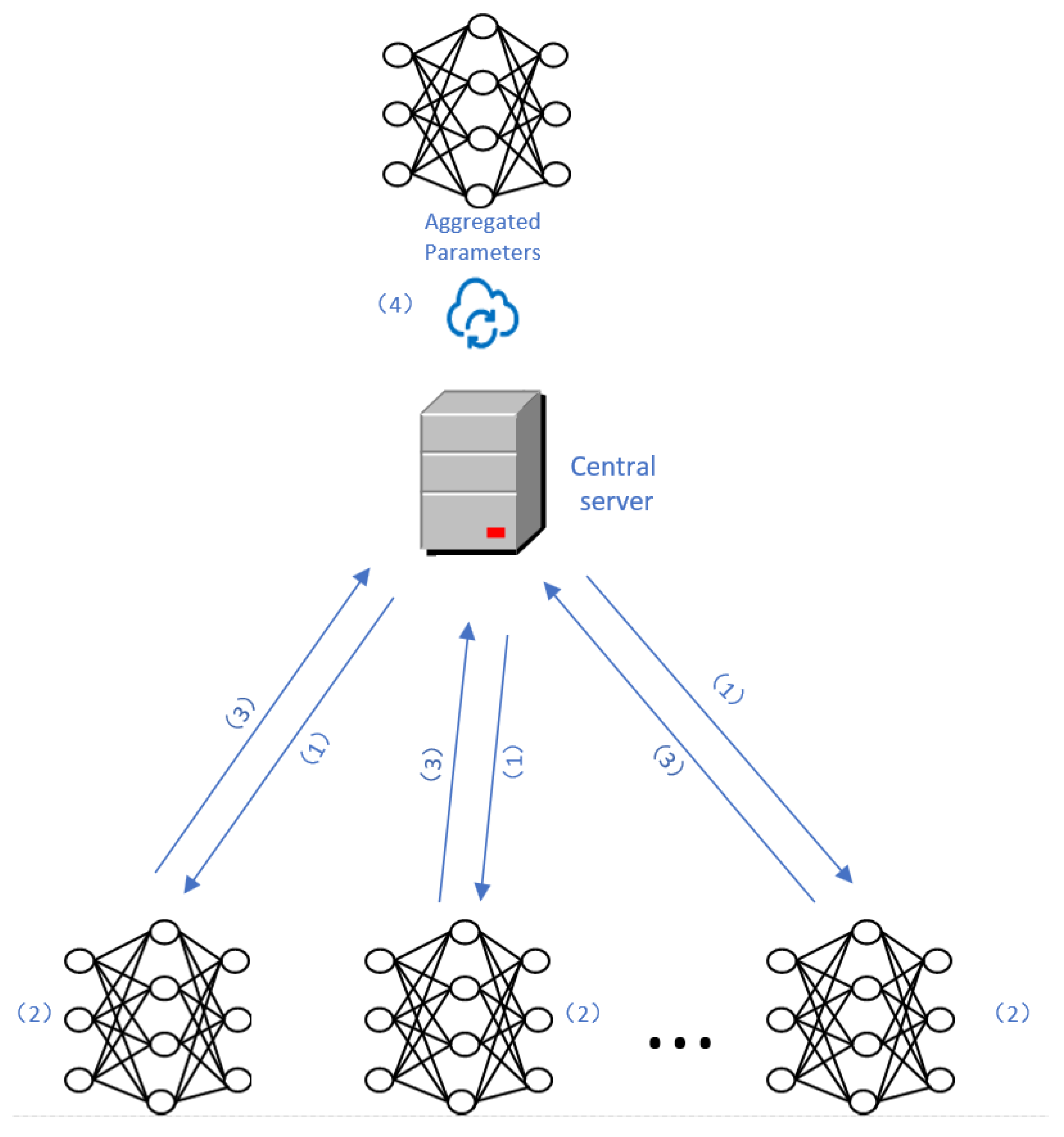
By introducing the improved approach of cyclic adaptive learning rate adjustment and weighted random client sampling, we can effectively enhance the aggregation performance of the federated learning aggregation algorithm, reducing communication overhead and accelerating the convergence speed of the model. The cyclic adaptive learning rate adjustment strategy enables clients to automatically adjust the learning rate based on their local model’s performance and loss, allowing them to better adapt to their training progress. The weighted random client sampling strategy takes into account the historical sampling frequency of clients, assigning different sampling weights to clients to reduce the sampling weight of clients that are frequently sampled randomly. This balances the contributions of each client and increases the diversity of the aggregated model. Through these improvement measures, we can significantly reduce unnecessary communication overhead, improve the efficiency of federated learning, and accelerate the convergence speed of the global model, thereby providing better performance and scalability for practical applications of federated learning.
4.1. Cyclic Adaptive Learning Rate Strategy
In this work, we address the learning rate issue in the Federated Averaging (FedAvg) aggregation algorithm used in federated learning. We propose a cyclic adaptive learning rate (CALR) adjustment strategy based on the change in loss. This strategy replaces the traditional fixed learning rate used in FedAvg, as a fixed learning rate can result in slow or unstable convergence during model training. The content of Adaptive Learning Rate Adjustment Algorithm 1 is as follows:
| Algorithm 1 Learning Rate Adjustment. |
| function ADJUST_LEARNING_RATE(Passing values: communication round number , current loss , historical loss , and loss ratio threshold threshold) |
| Calculate loss ratio: |
|
|
| Calculate rate of change: |
|
|
| if then |
|
| end if |
| Calculate learning rate adjustment factor: |
|
| if then |
| Set new learning rate: |
|
| else if and then Calculate : |
|
| else if and then Calculate : |
|
| else |
| Set new learning rate: |
|
| Unchanged |
| end if |
The cyclic adaptive learning rate algorithm takes into account the model aggregation rounds
and the loss change rate
, and it constrains the range of learning rate variations. The algorithm sets the maximum value
and the minimum value
for the learning rate, enabling it to cycle within a certain range. The learning rate variation range is determined through practical measurements, and, within each cycle, the learning rate
adapts dynamically based on specific factors. The formula for the learning rate in the
ith round is as follows:
The adaptive learning rate variation depends on the magnitude of the change in loss between two consecutive training iterations. Therefore, the first step is to calculate the rate of change in loss between these iterations:
The specific learning rate variation coefficient is related to the rate of change in loss
and the communication round
. The learning rate variation coefficient
is calculated as follows:
The relationship between
and
can be expressed as follows:
: Learning rate. is the learning rate for the ith (i > 0) round, and the initial learning rate is set to 0.001.
: is the number of iterations between the client and the central server.
: is the change rate of the learning rate with respect to the historical learning rates, based on which the decay coefficient is generated.
: The learning rate change coefficient represents how fast the learning rate changes, with a larger leading to faster learning rate variations.
: The client model training initialization parameters represent the initial model parameters for client training. After the learning rate changes, the model parameters are updated, allowing the client to use the new learning rate for training in the next round.
In this paper, the improved algorithm monitors the loss variation of each client in every round and adjusts the learning rate based on the training iterations. If a client’s loss decreases slowly in a particular round, it indicates that its training process may be challenging and requires a smaller learning rate for finer adjustments. Conversely, if a client’s loss decreases rapidly, it suggests that its training process is smooth, and a larger learning rate can be used to accelerate the convergence speed. By dynamically adapting the learning rate based on the loss variation and training rounds, the algorithm aims to achieve faster and more stable convergence during the federated learning process.
When the model’s loss function exhibits oscillations or instability during the training process, the learning rate is reduced:
When the training process reveals slow convergence or a gradual decrease in the loss function, the learning rate is increased:
4.2. Weighted Random Sampling Strategy
In each round of federated learning communication, the server selects a subset of available clients to participate in training. The server’s operations include client sampling and assigning weights to the sampled clients. Common methods for client sampling are random selection and weighted averaging. In random selection, a portion of clients is randomly chosen to participate in training, and each client is assigned the same weight. The server then calculates the weighted average of the model parameters from the sampled clients and sends it back to the clients as the new version of the global model for the next round of training.
However, random selection may lead to some clients having low participation rates, especially when there are differences in computational power, data size, and other factors among clients. The contributions of clients with different data distributions may be underestimated, which can result in some clients’ data not being fully utilized during training, leading to a decrease in the performance of the global model on those data distributions and, subsequently, affecting the overall model’s performance.
To address this issue, this paper introduces the innovative weighted random sampling (WRS) strategy for clients. WRS balances the relationship between the client sampling frequency and the random sampling weights. Initially, all clients have zero sampling frequency and equal sampling weights. However, after each round of communication and aggregation, the client sampling frequency is updated, and the sampling weights are adjusted accordingly. For example, if a client is repeatedly selected in multiple rounds, its sampling weight may be reduced. By dynamically adjusting the sampling weights, WRS ensures a balanced client selection and avoids extreme selection results.
The detailed steps of the client-weighted random sampling strategy are as follows:
Initialization: For each client, its sampling weight is determined based on the number of times it has been sampled. Therefore, a global list is defined to record the sampling count for each client. The sampling count for all clients in the list is initially set to 0;
Initial Weight Assignment: represents the weight of random sampling for each client. The initial sampling weights for each client are defined as equal, with the initial unnormalized value for each client being ;
Sampling Round Update: The sampling count in the list is increased by 1 for the selected clients in each sampling round. represents the weight of the client during the ith interaction between the client and the central server;
Weight Adjustment: Based on the number of times each client has been sampled, the client’s sampling weight is adjusted. Typically, clients with more sampling will receive lower weights to balance the sampling results. The client weight adjustment formula is as follows:
Weight Normalization: To ensure that the total sum of sampling weights for all clients is equal to 1, the client’s sampling weights are normalized. The weight normalization formula is as follows:
Random Sampling: Based on the sampling ratio and the client’s sampling weights , random sampling is performed. The sampling ratio determines the probability of selecting each client;
Updating Sampling Counts: The sampling count for the selected clients is increased by 1 to reflect their participation;
Returning Sampling Results: The finally selected clients are assembled into a list and returned to the aggregation algorithm for further parameter aggregation.
Below is the pseudo code for Algorithm 2, which is a weighted random client sampling strategy. This strategy selects clients and passes their parameters to the federated learning aggregation algorithm for parameter aggregation.The server then returns the aggregated parameters to the clients for the next round of training.
| Algorithm 2 Sample Clients. |
| function Sample_Clients(Passing values: sample ratio ) |
| if sampler=None then |
| Sampler <- RandomSampler() |
| end if |
| Define :this list records the number of times each client has been sampled. |
| When a client is selected multiple times, update the sampling count for each client in the : |
|
| After that, normalize the weights of each client: |
|
| Perform weighted random sampling with the given total number of clients , individual client weights , and sampling ratio : |
| Sampled <- random.choices(range(), , ) |
| for in Sampled do |
|
| end for |
| assert |
| return
|
| end function |
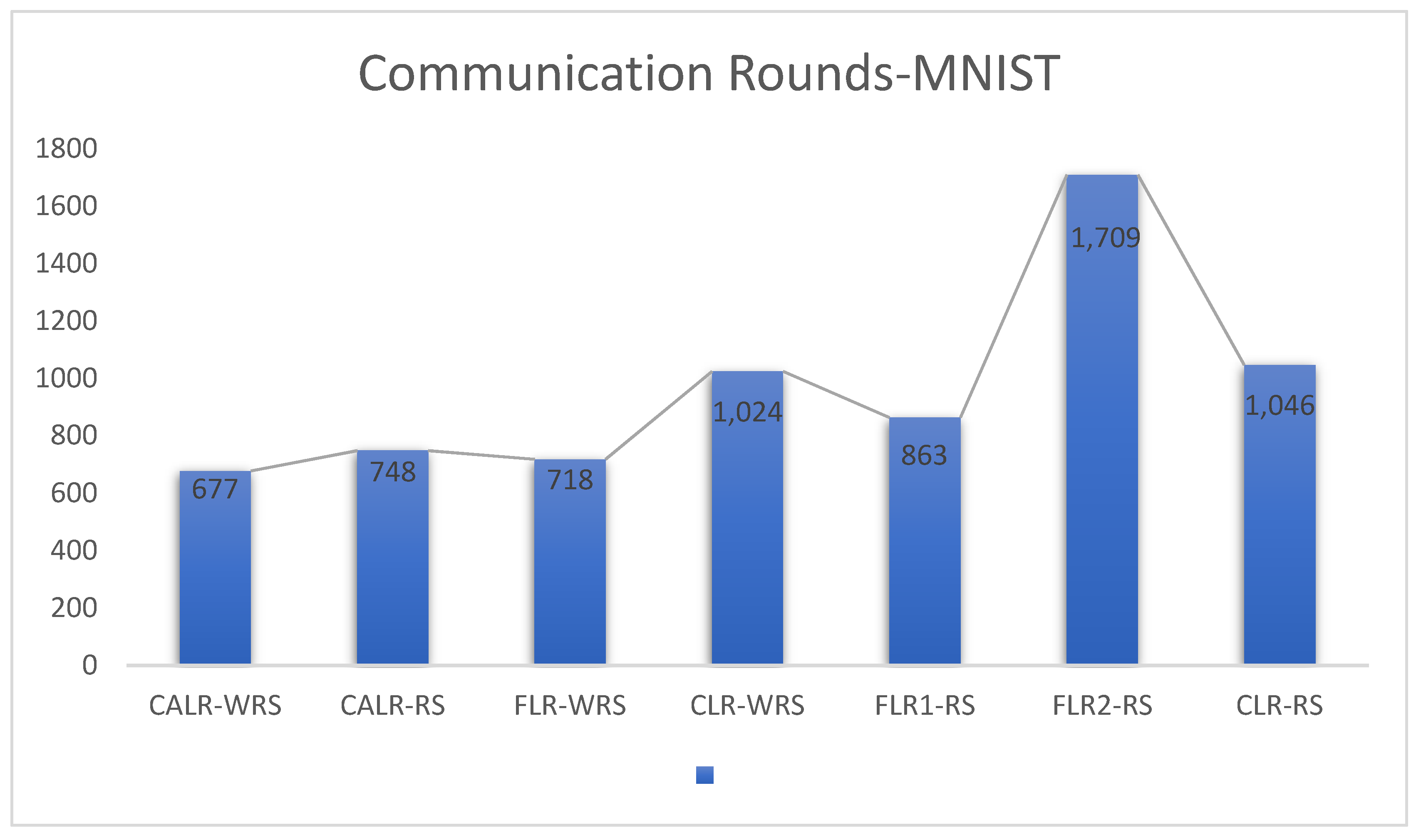
4.3. Complexity Analysis of CALR-WRS Algorithm
A total of clients is assumed, each with a local dataset size of , model parameter size of , and clients participating in model aggregation in each round, with each client conducting local iterations.
The computational complexity of each client’s local updates typically depends on the number of samples updated in each round and the number of communication rounds. Therefore, the time complexity of local updates on each client is .
Parameter Aggregation: The server’s aggregation complexity is generally related to the number of clients participating in aggregation () and the dimension of the global model parameters (). Hence, the time complexity of aggregating parameters on the server can be represented as .
Weight Update: On the server side, the weights of clients are recalculated based on the sampling counts of all clients, and since there are clients in total, its time complexity can be expressed as .
Communication costs include two parts: transmitting local model parameters from clients to the central server and returning the aggregated parameters from the central server to clients. In the first part, only the clients participating in aggregation need to transmit model parameters, resulting in a complexity of . In the second part, the central server needs to return updated model parameters to all clients, resulting in a complexity of . Therefore, the communication cost can be expressed as .
The comparison of complexity between the proposed improved algorithm and FedAvg and FedProx algorithms is shown in
Table 2. Our algorithm achieves improved communication efficiency while maintaining lower complexity.
5. Experiment and Performance Evaluation
The experiments in this paper were conducted using Python programming language version 3.7. The federated learning framework used was FedLab version 1.3.0. The total number of clients in the federated learning experiment was set to 100, and the maximum number of training rounds was set to 10,000. The client sampling ratio was set to 0.2, with each client performing five epochs and a batch size of 600. The hardware and software used for the experiments are summarized in
Table 3.
The experiments in this paper were conducted to evaluate the algorithm’s performance on two image recognition tasks using the MNIST [
28] and CIFAR-10 [
29] datasets. The MNIST dataset consists of 70,000 grayscale images of handwritten digits (0–9), with each image having a size of 28 × 28 pixels. The dataset is divided into 10 classes, each representing a digit from 0 to 9. There are 7000 images in each class, with 60,000 images used for training and 10,000 images used for testing.
The CIFAR-10 dataset consists of 60,000 color images with a size of 32 × 32 pixels. It is also divided into 10 classes representing different objects: airplane, automobile, bird, cat, deer, dog, frog, horse, ship, and truck. Each class contains 6000 images, with 50,000 images used for training and 10,000 images used for testing. Each sample in the dataset is associated with a label that indicates its corresponding class. The experiments were designed to assess the performance of the proposed algorithm on these two datasets, and the results will be used to demonstrate the effectiveness and efficiency of the improvements made to the federated learning process.
In our federated learning aggregation experiments, we trained the MNIST dataset using MLP networks with termination conditions set at either 10,000 communication rounds or an accuracy of 0.97. Key metrics of interest included communication rounds at the experiment’s end, accuracy changes, and loss changes. For the CIFAR-10 dataset, ResNet networks were employed under similar termination criteria: 10,000 communication rounds or an accuracy of 0.75. We also focused on metrics such as communication rounds, accuracy changes, and loss changes. These metrics are standard in the machine learning field.
In addition, we conducted training on various datasets and deep learning network architectures. The Adam algorithm is commonly best practice in optimization, and, in line with best practices, this study initialized parameters using the Adam optimization algorithm in experiments. Additionally, experiments were compared against various traditional baseline methods, including fixed learning rates, cyclic learning rates, and random client sampling. By contrasting these widely used traditional methods and evaluating model performance with standard metrics, we have drawn robust experimental conclusions.
5.1. Cyclic Adaptive Learning Rate Algorithm
In this section, we present the cyclic adaptive learning rate (CALR) algorithm and compare its performance with several other non-CALR algorithms on different datasets. We evaluate the test accuracy and loss variation during the training process. The experimental results demonstrate that the proposed algorithm significantly improves the convergence speed and reduces the loss in the federated learning aggregation process.
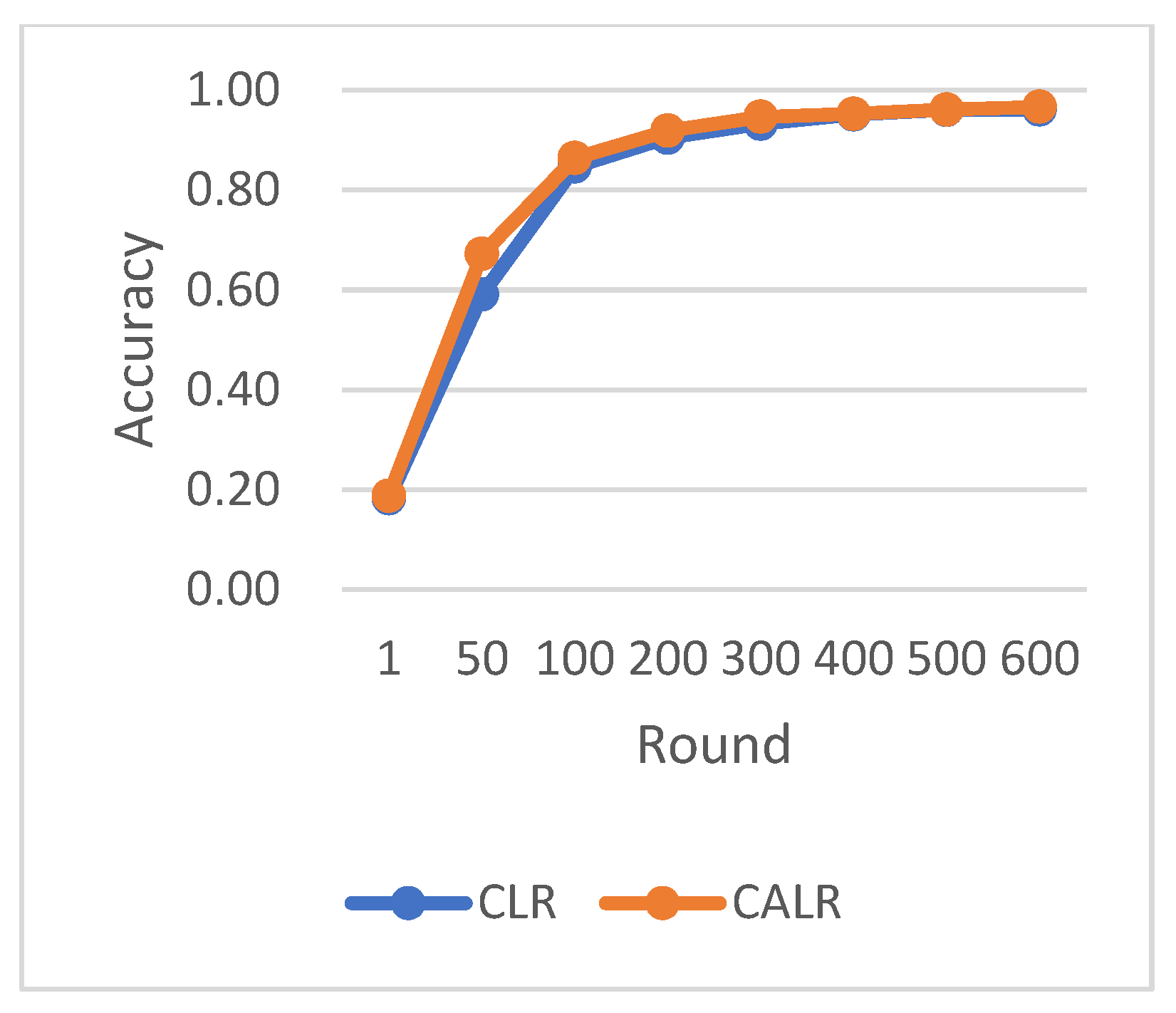
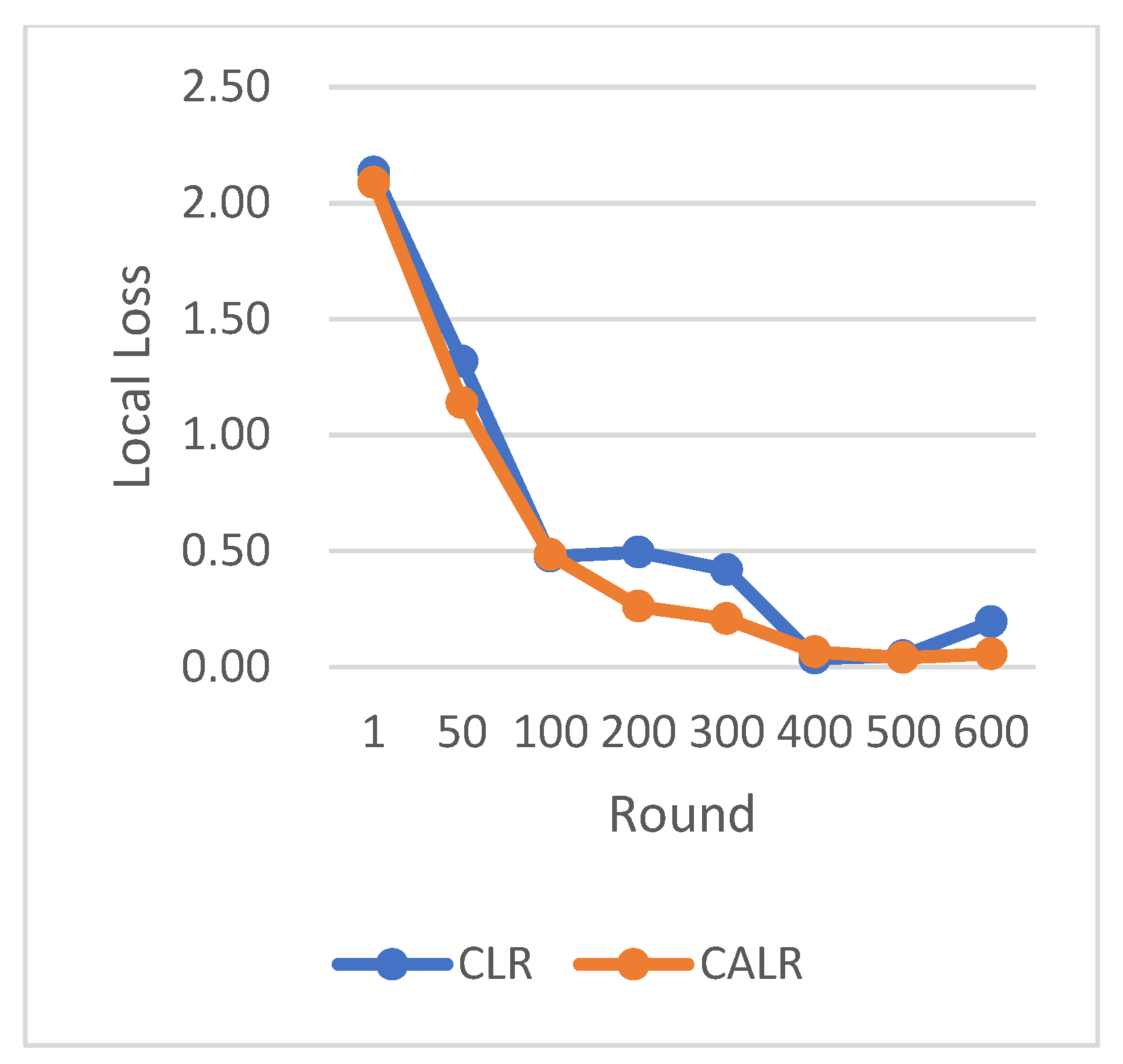
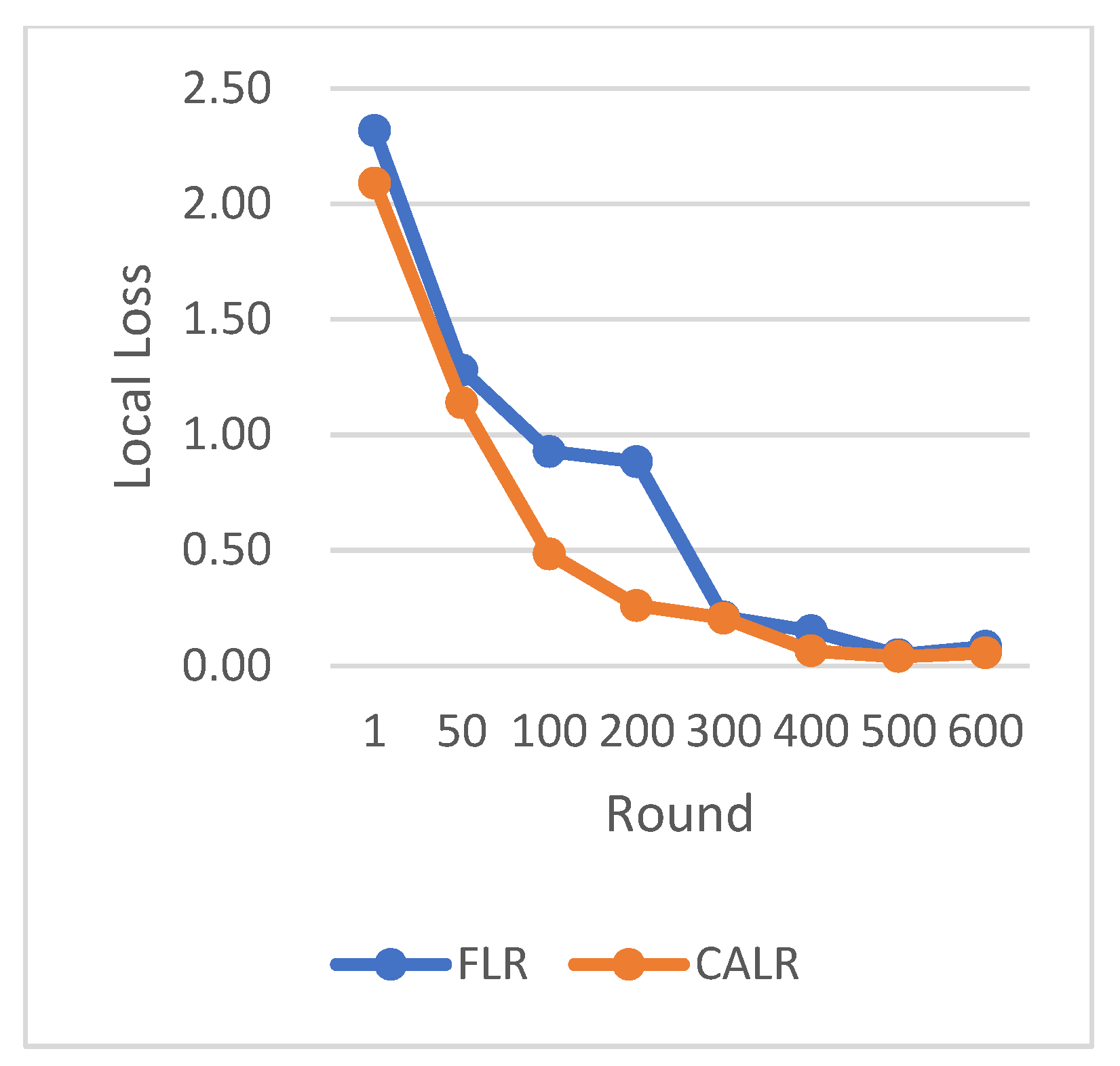
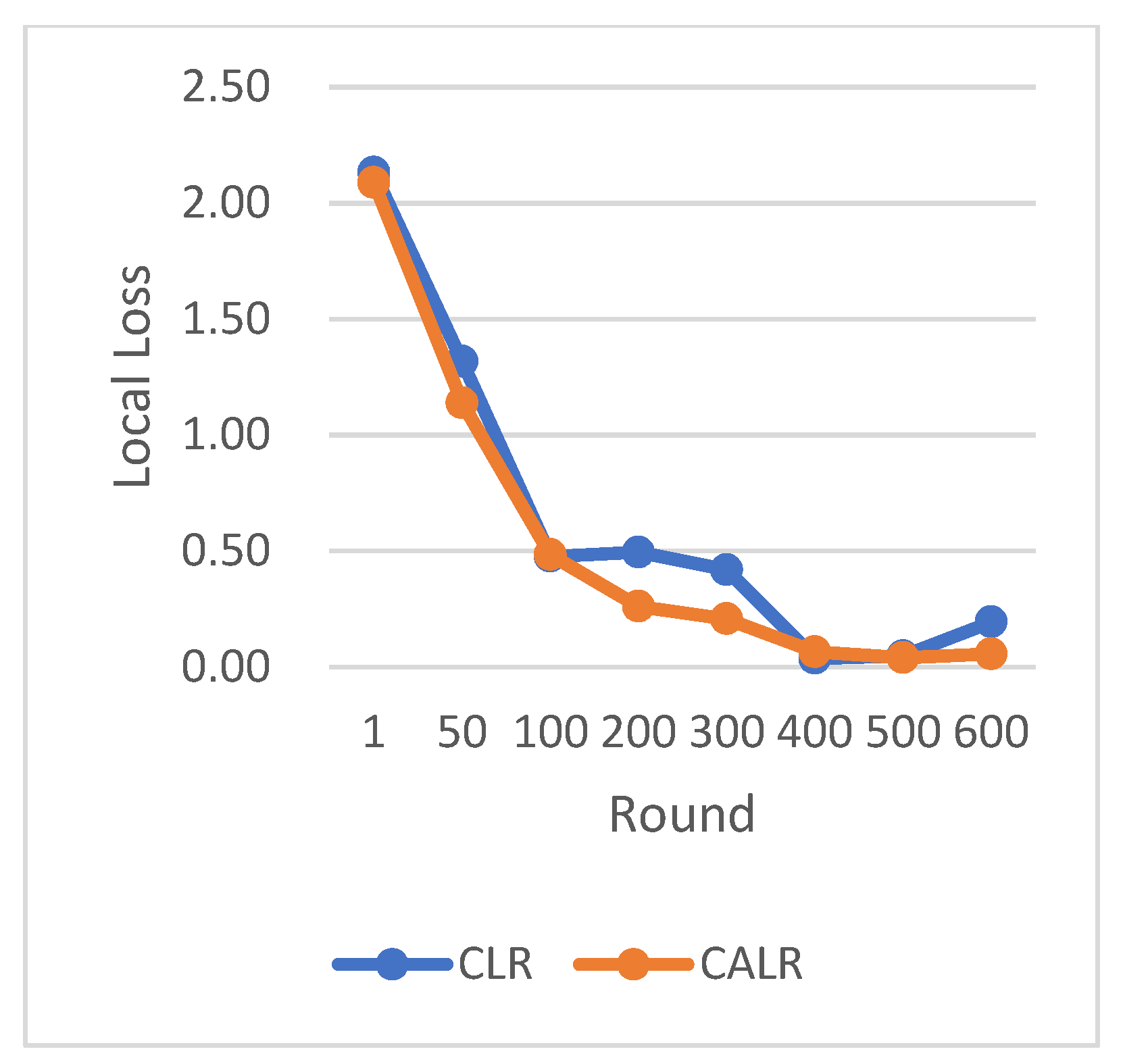
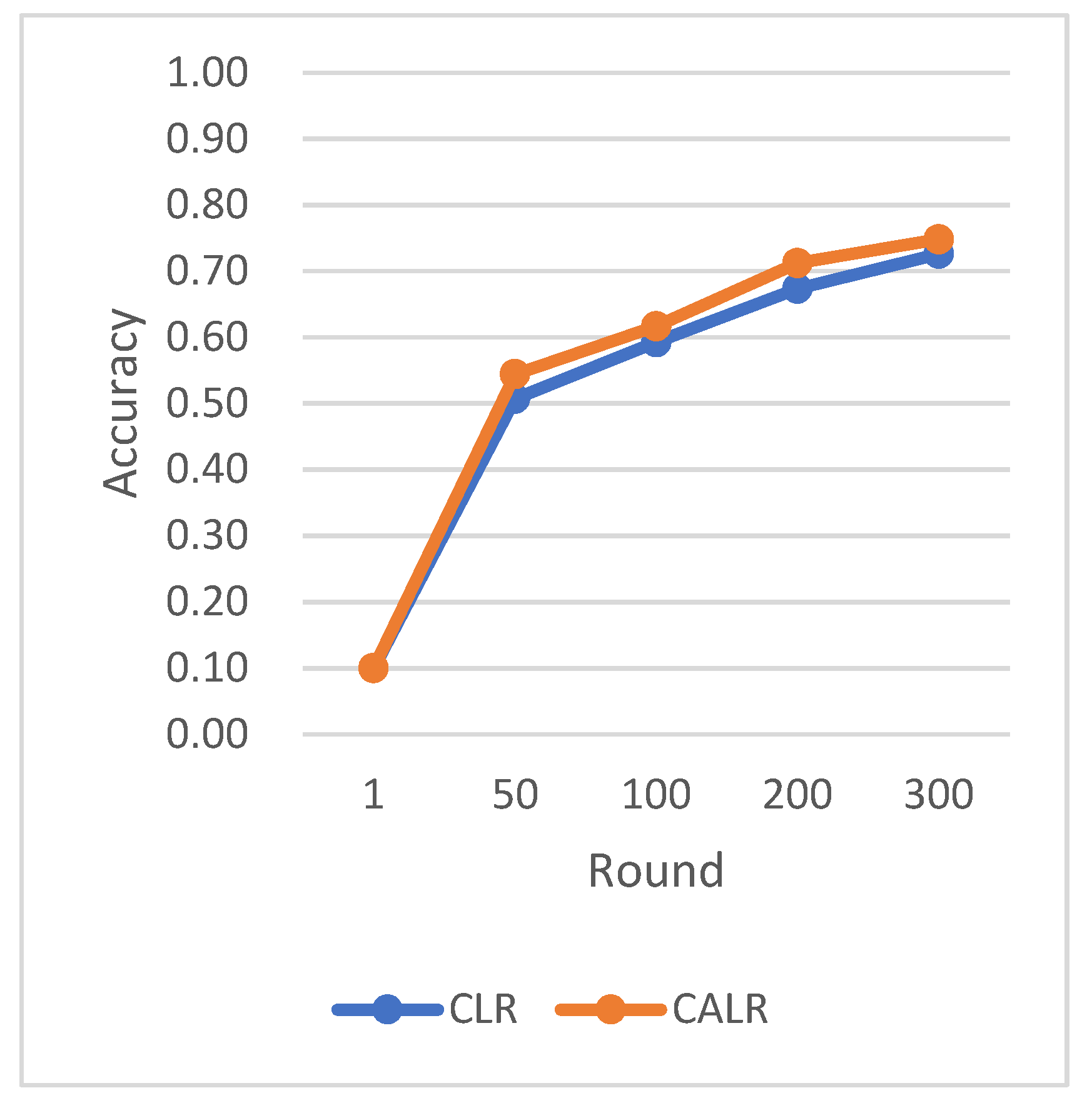
CLR refers to the traditional cyclic learning rate strategy, FLR represents the fixed learning rate strategy, and CALR denotes the cyclic adaptive learning rate adjustment strategy proposed in this paper. From the graphs, it is evident that the CALR strategy proposed in this paper exhibits a more stable and efficient improvement in accuracy compared to both the traditional fixed learning rate strategy and the CLR cyclic learning rate strategy. Since the CALR strategy in this paper adjusts the current learning rate based on the client’s loss and training epochs in federated learning, the changes in loss are more stable and persistent.
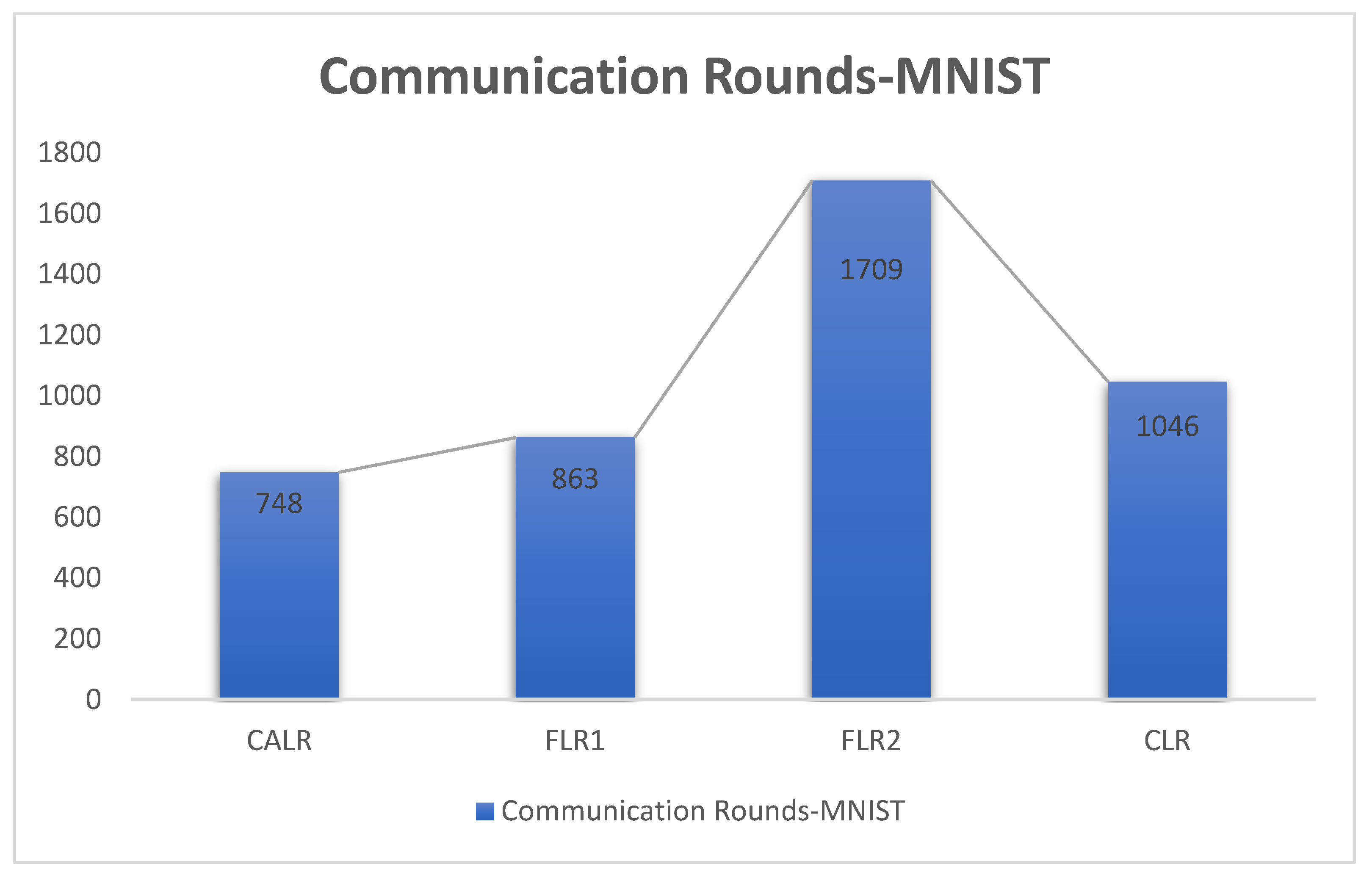
CALR represents the cyclic adaptive learning rate adjustment strategy proposed in
Figure 8, FLR1 corresponds to a fixed learning rate of 0.0005, FLR2 corresponds to a fixed learning rate of 0.003, and CLR denotes the traditional cyclic learning rate strategy. In this experiment, training is stopped when the test accuracy reaches 97%. By comparing the training epochs under various learning rate strategies for federated learning aggregation algorithms, it is observed that the CALR strategy improves the worst-performing strategy by 56.2% and the best strategy by 13.3%. This indicates that the training epochs in this paper are minimized, leading to faster achievement of the aggregated model accuracy.
Based on the CIFAR-10 dataset and using the ResNet neural network model, the comparison of multiple algorithm strategies is shown below in
Figure 9,
Figure 10,
Figure 11 and
Figure 12.
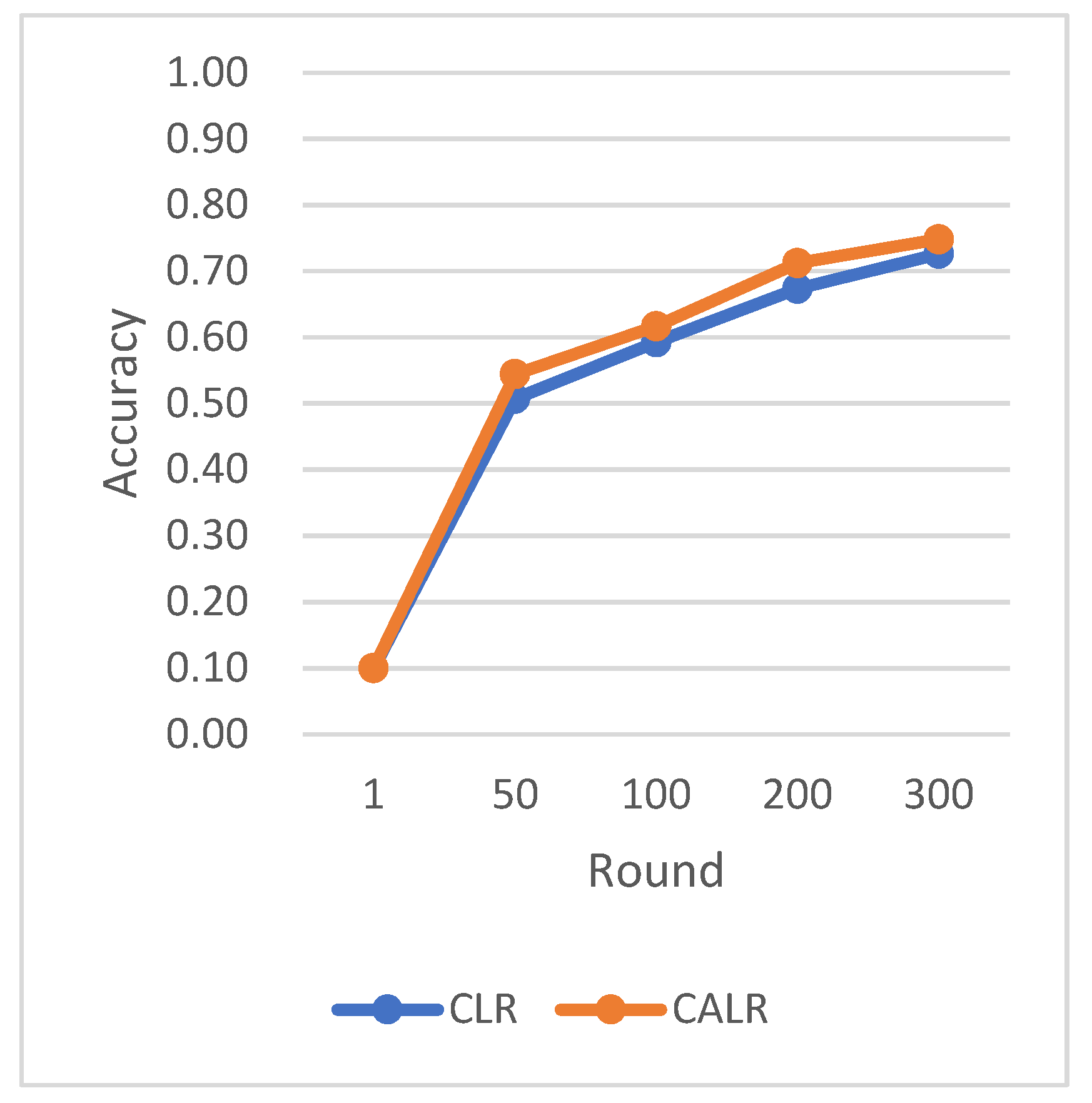
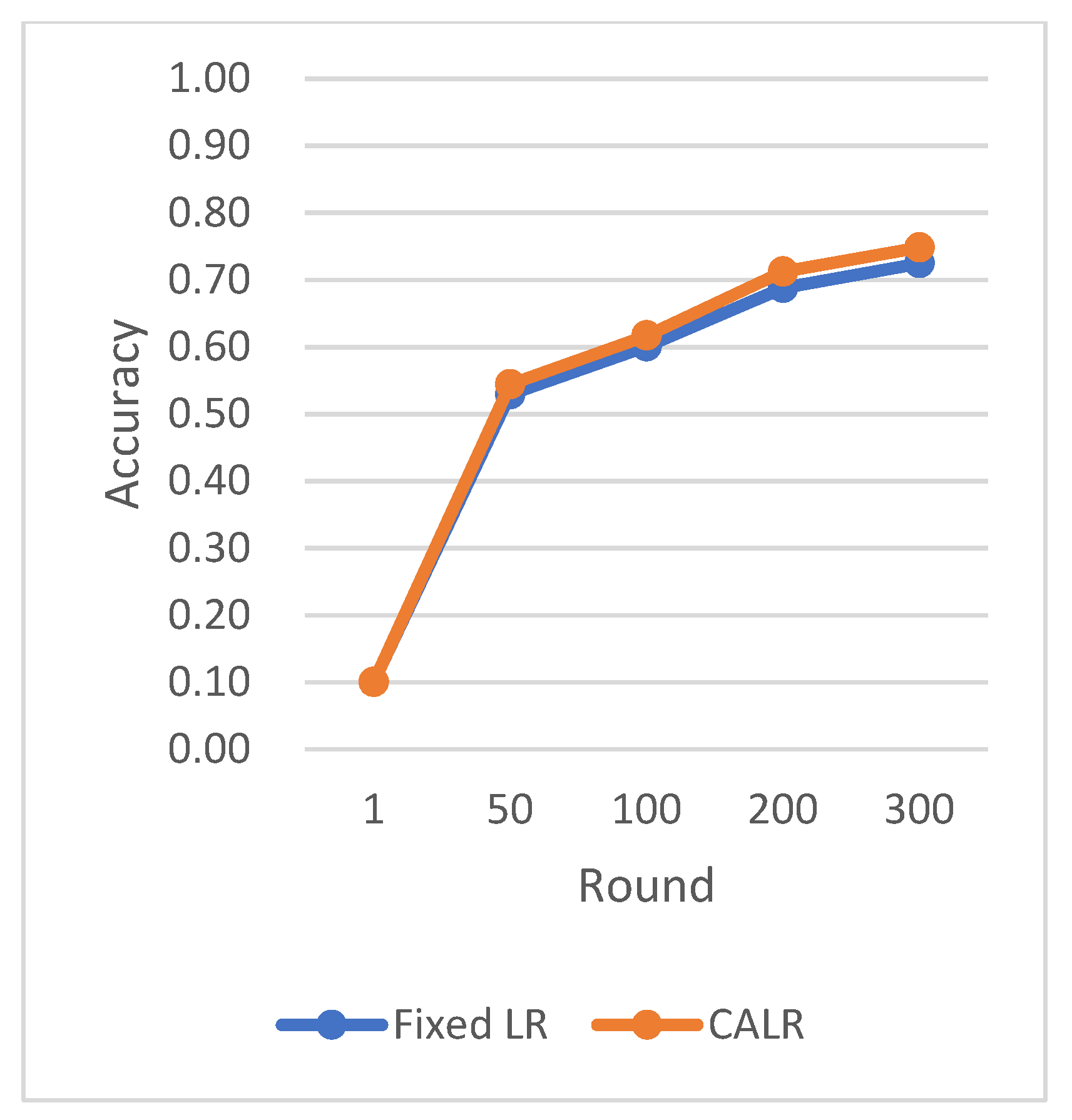
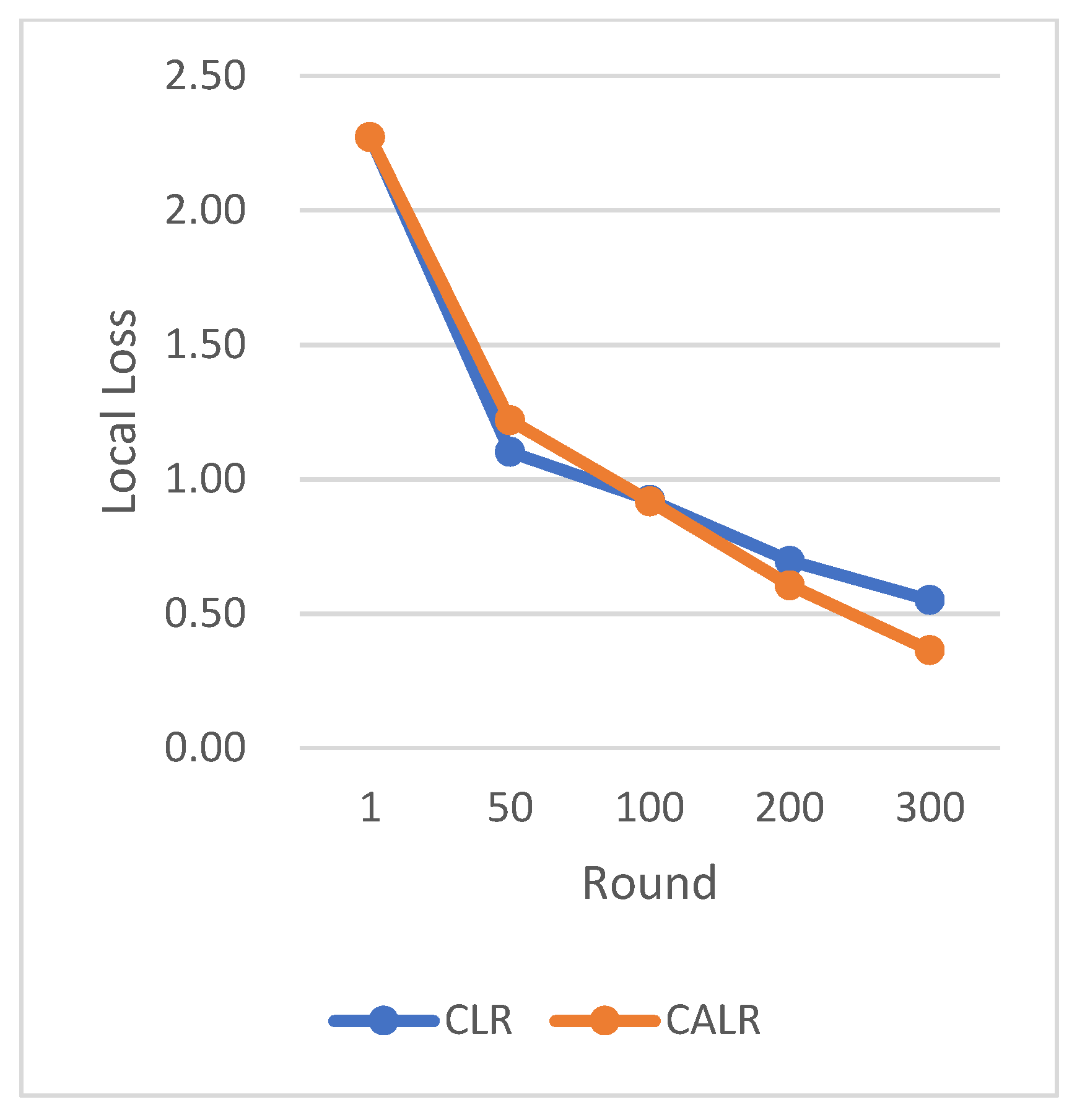
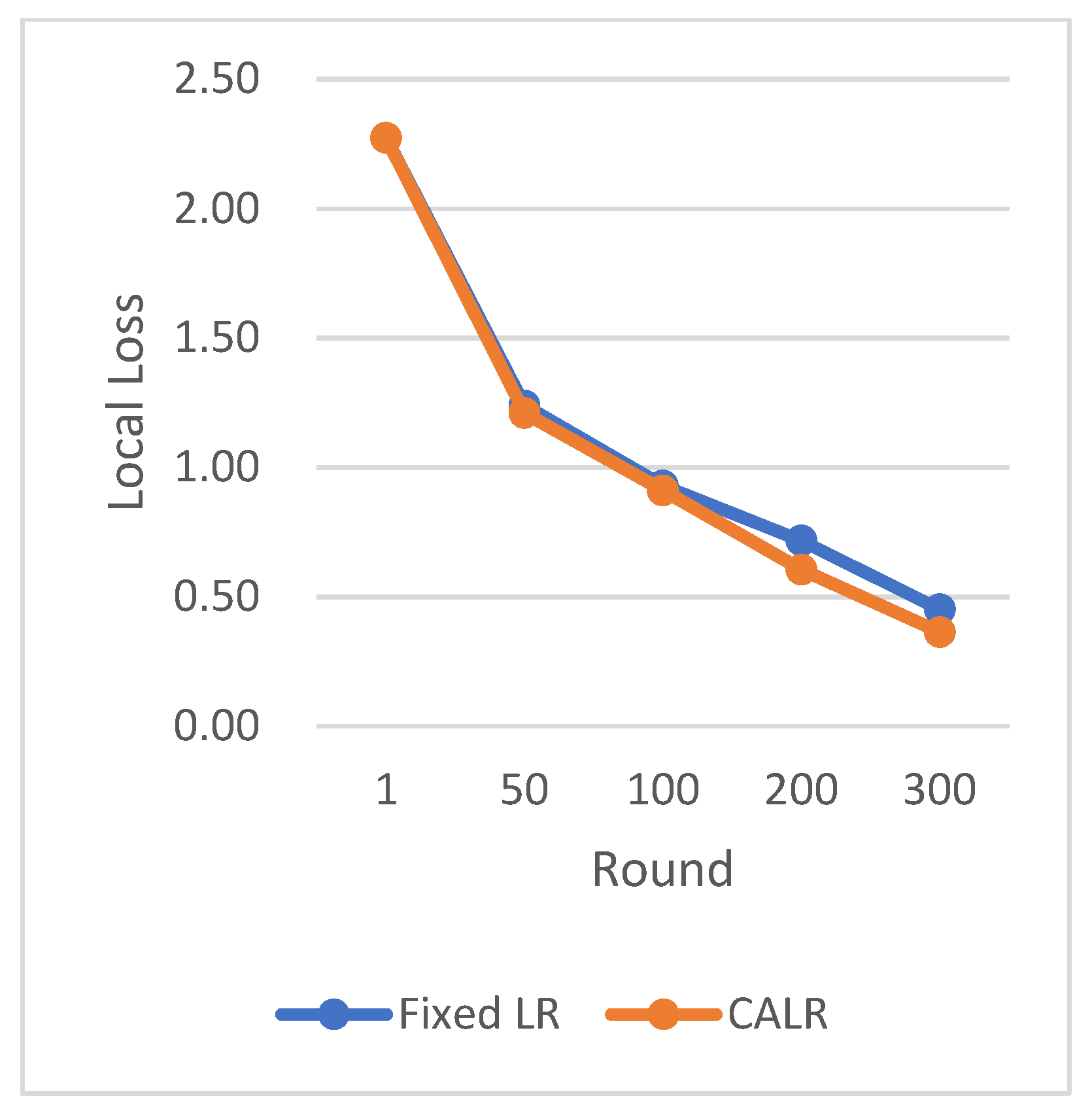
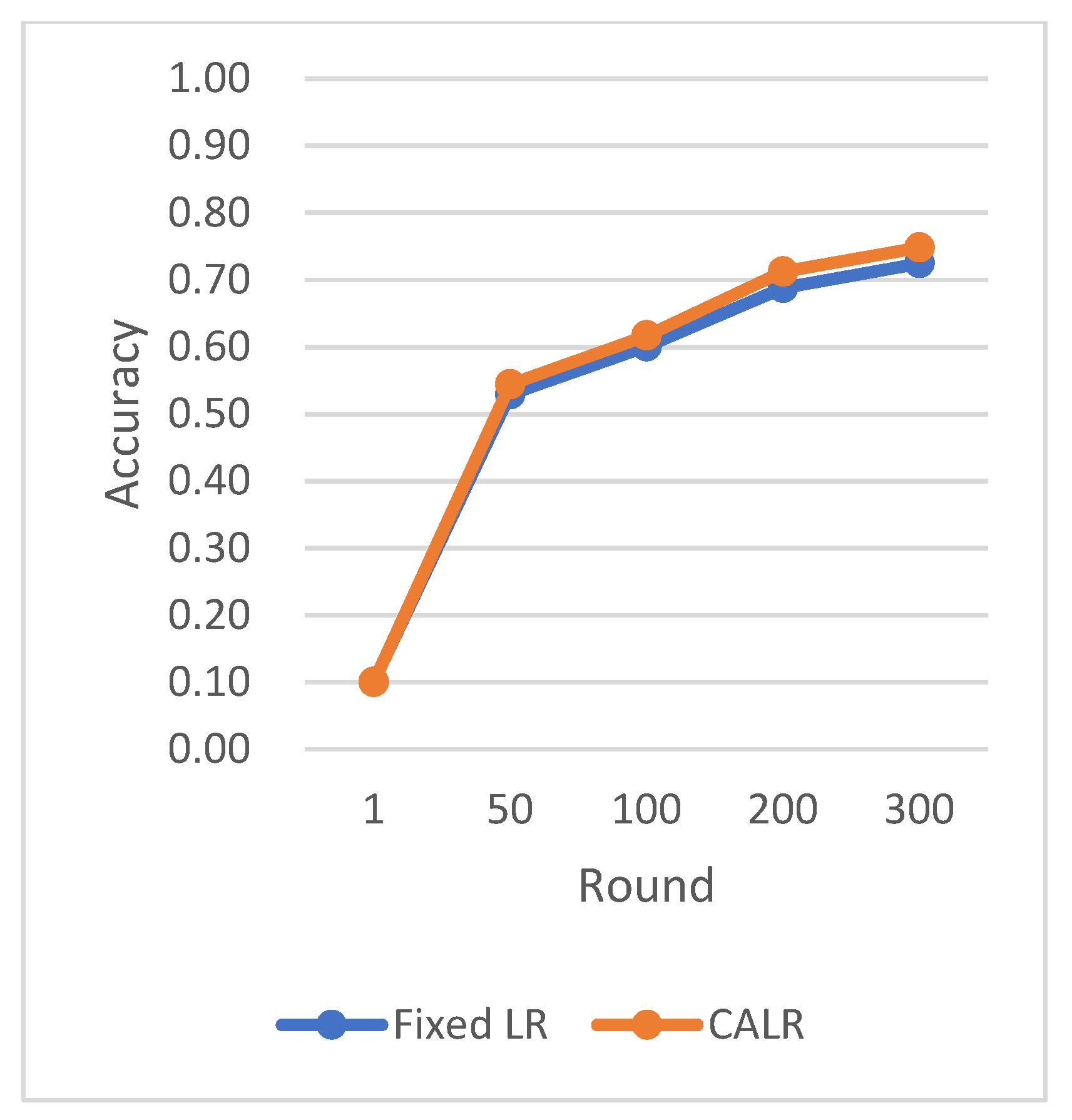
The CLR adopts the traditional cyclic learning rate strategy, Fixed LR represents the fixed learning rate strategy, and CALR denotes the cyclic adaptive learning rate adjustment strategy designed in this paper.
The chart results clearly demonstrate the excellent performance of our proposed cyclic adaptive learning rate adjustment strategy on the CIFAR-10 dataset. Compared to the traditional fixed learning rate strategy and the traditional cyclic learning rate strategy (CLR), our method shows slightly more stable and efficient accuracy improvement. Additionally, our approach exhibits a persistent and stable advantage in reducing losses, demonstrating its effectiveness in optimizing the learning process.
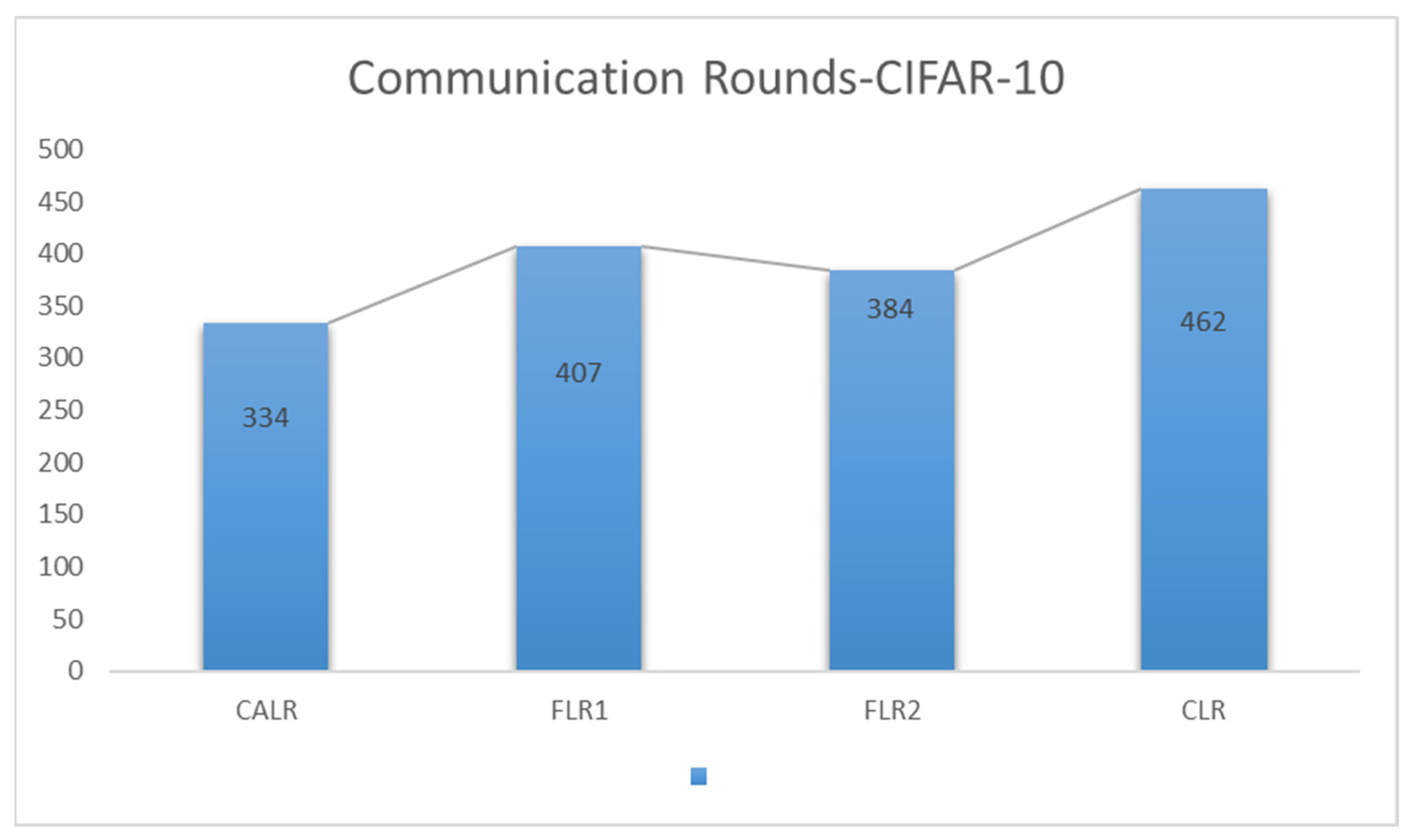
In this experiment, User represents the cyclic adaptive learning rate adjustment strategy proposed in this paper, FLR1 corresponds to a fixed learning rate of 0.001, FLR2 corresponds to a fixed learning rate of 0.0005, and CLR denotes the traditional cyclic learning rate strategy. The training is stopped when the test accuracy reaches 75%. By comparing the training epochs under various learning rate strategies for federated learning aggregation algorithms, it is observed that our proposed strategy requires the fewest training epochs, effectively accelerating the model convergence speed. In
Figure 13, it can be seen that our approach has improved by 27.7% compared to the worst-performing strategy and achieved a 13% improvement compared to the best strategy. From the test accuracy comparison experiment, it can be seen that both our proposed algorithm and the comparison algorithms show similar convergence speeds in the early stages of model training. However, in the later stages of model convergence, our algorithm, which adjusts the learning rate based on the loss, significantly accelerates the model convergence speed, effectively improving algorithm performance.
5.2. Weighted Random Sampling Based on Sampling Times
In this section, we conducted experiments comparing the weighted random sampling (WRS) algorithm, based on the number of samples, with the traditional random sampling strategy under different datasets and learning rates. During the experimental process, we observed that the proposed improvement algorithm strategy achieved positive effects in both the test accuracy during the federated learning aggregation process and the loss during the training process.
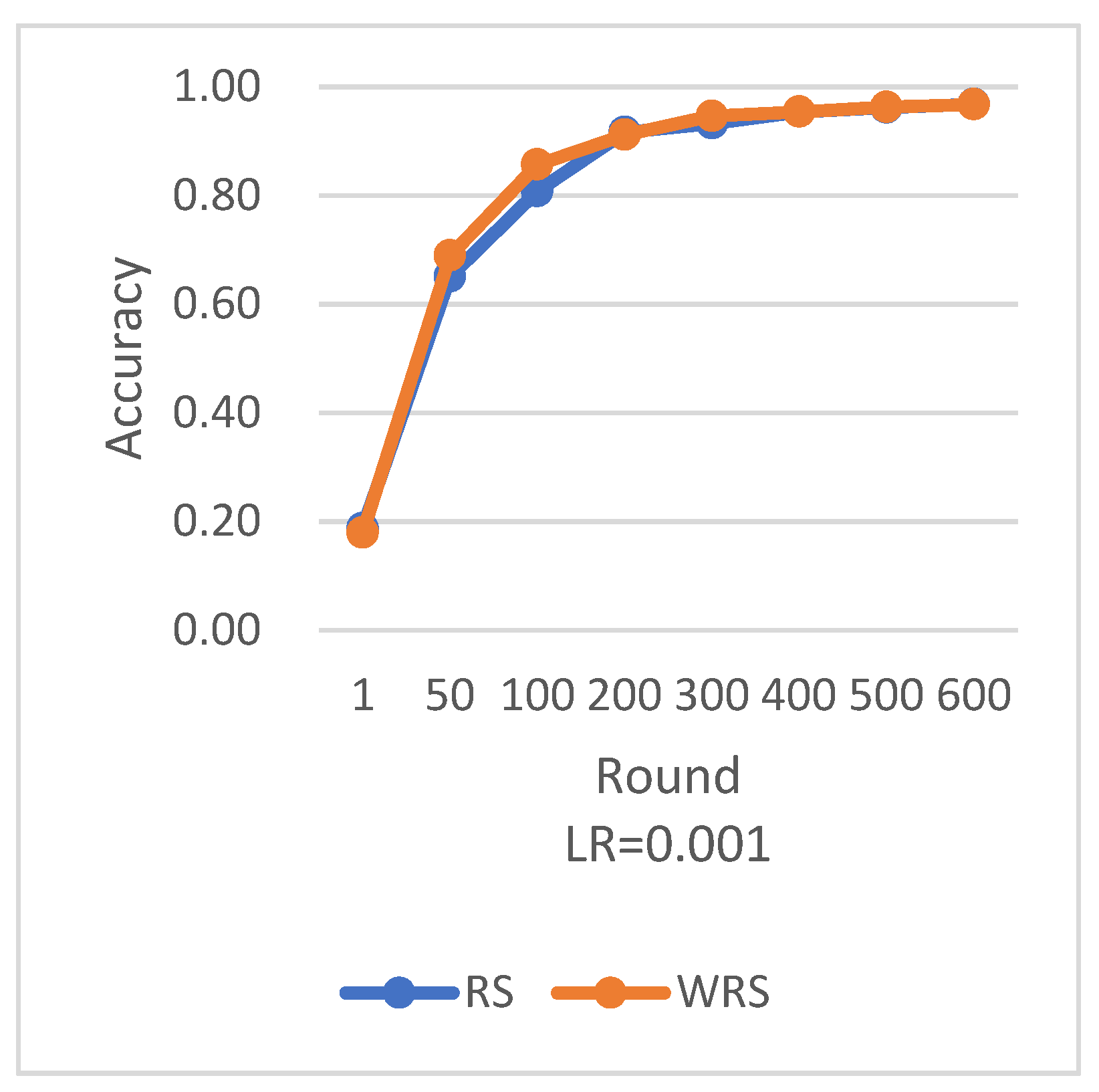
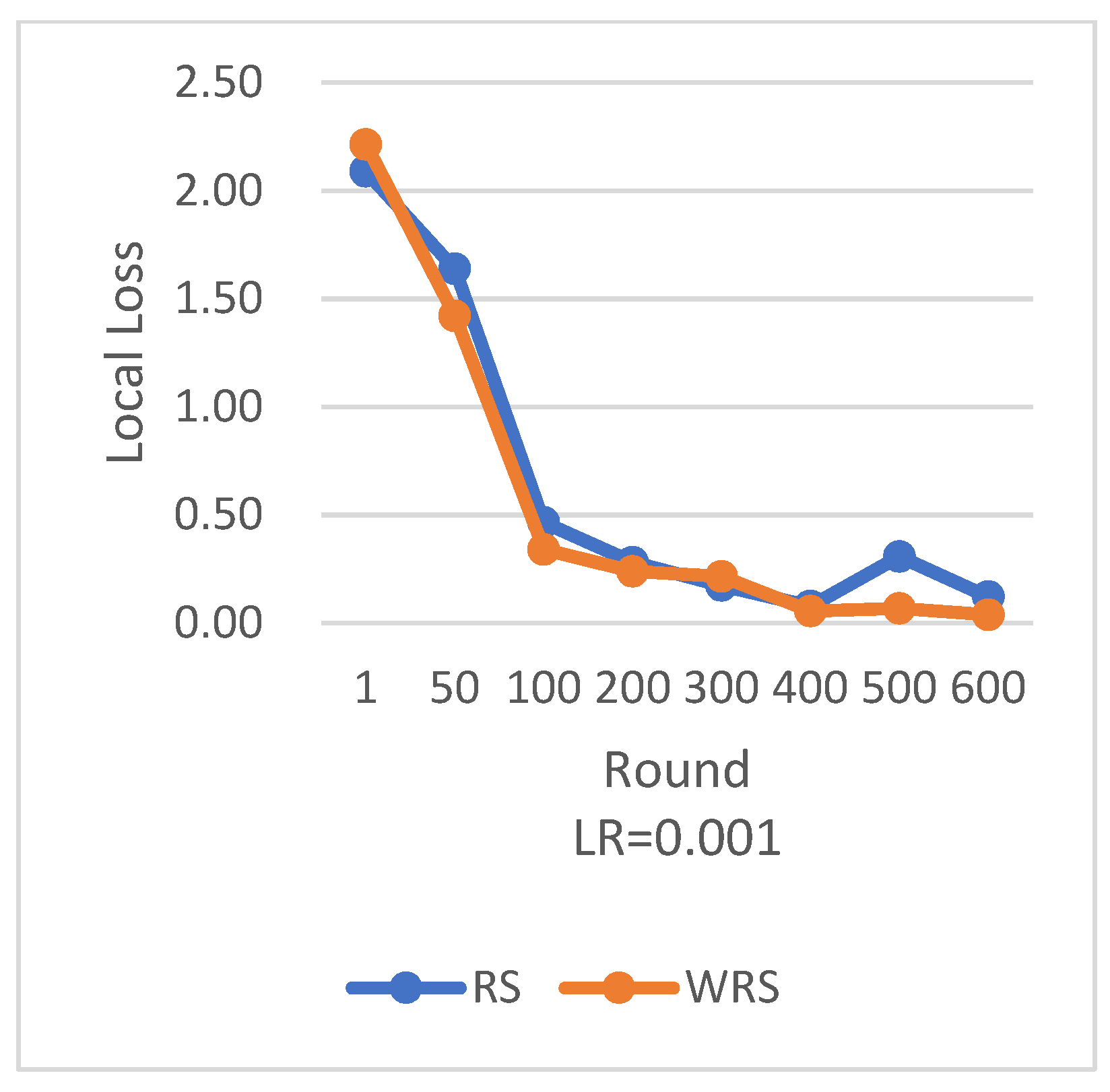
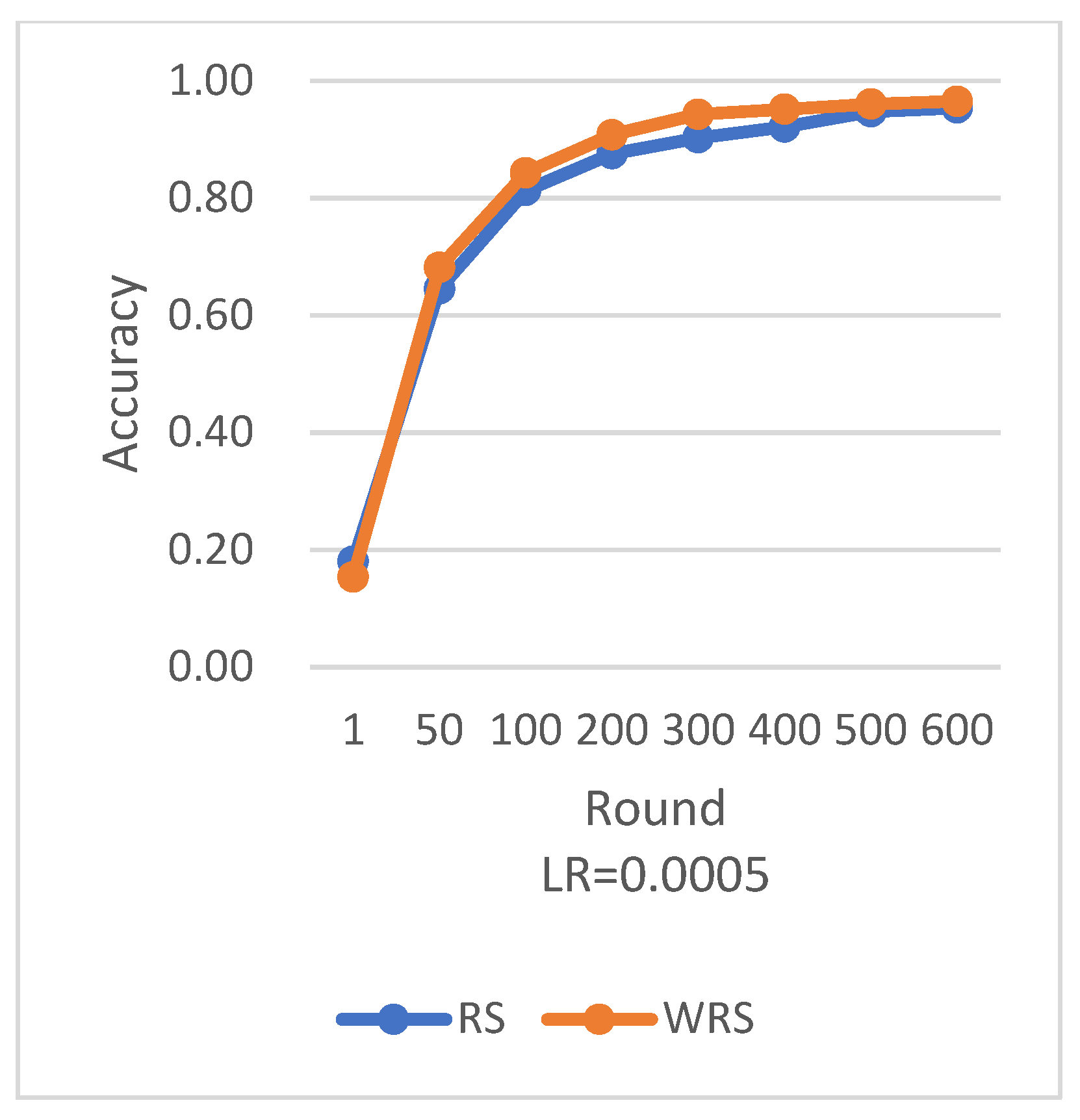
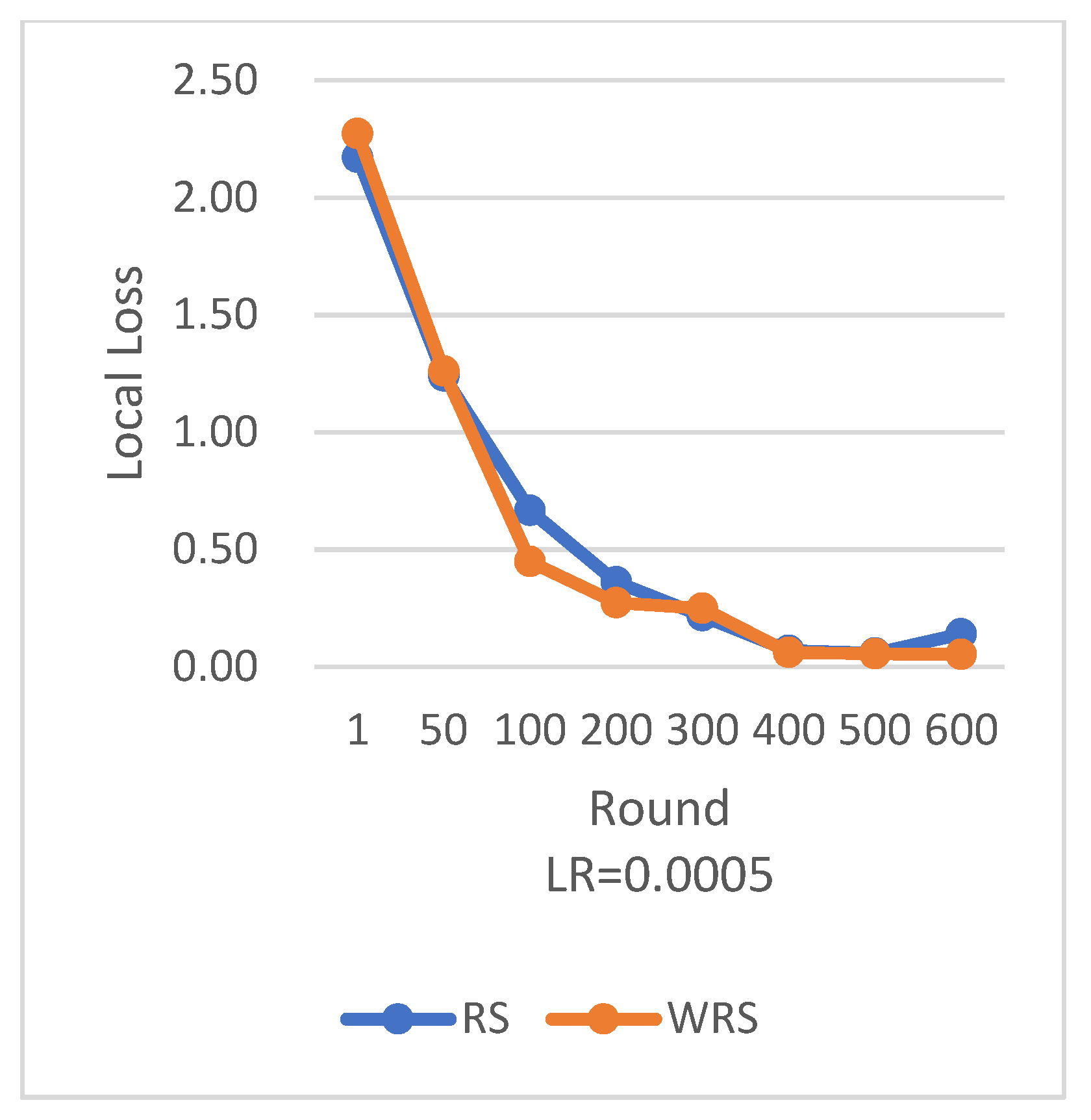
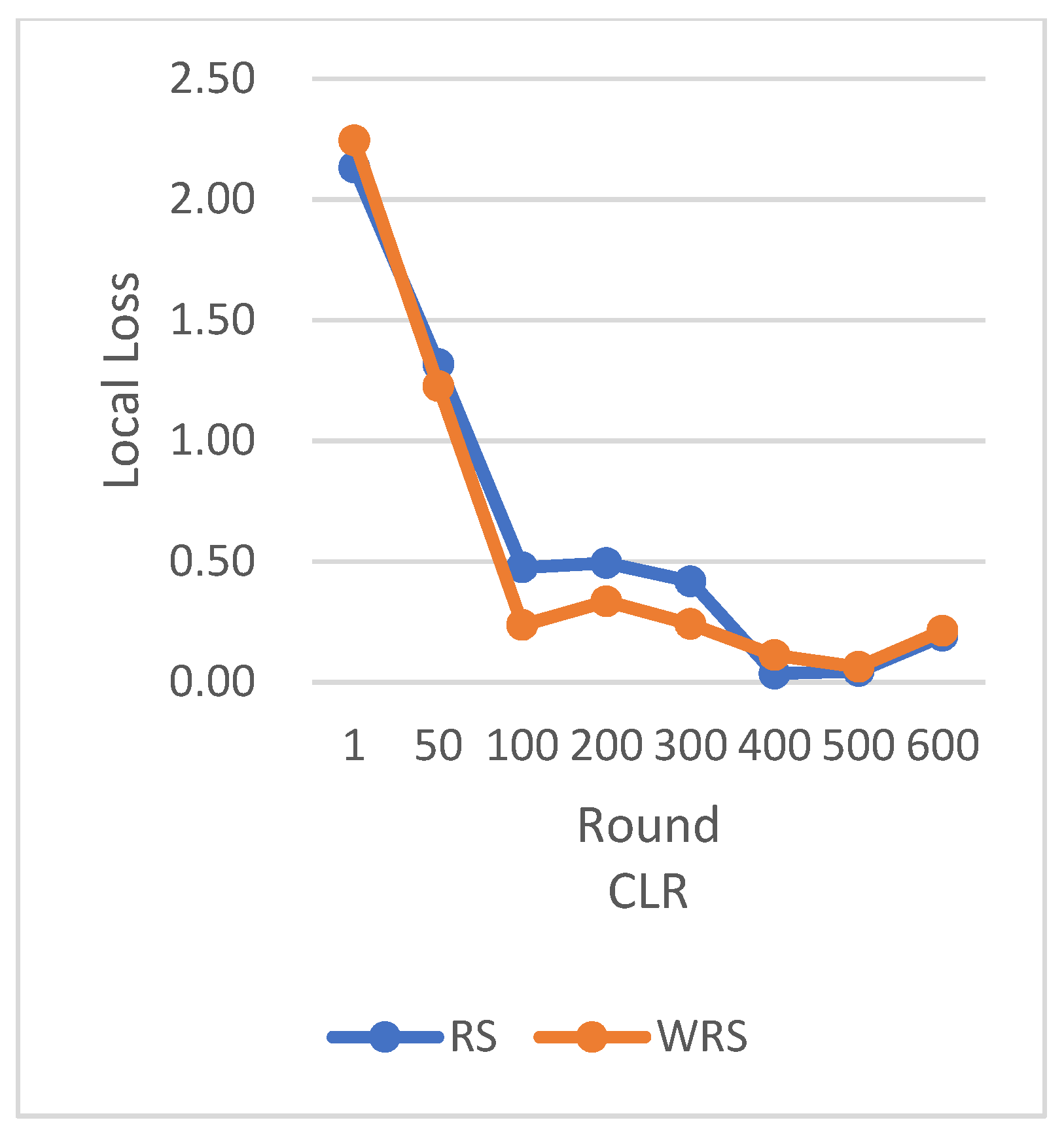
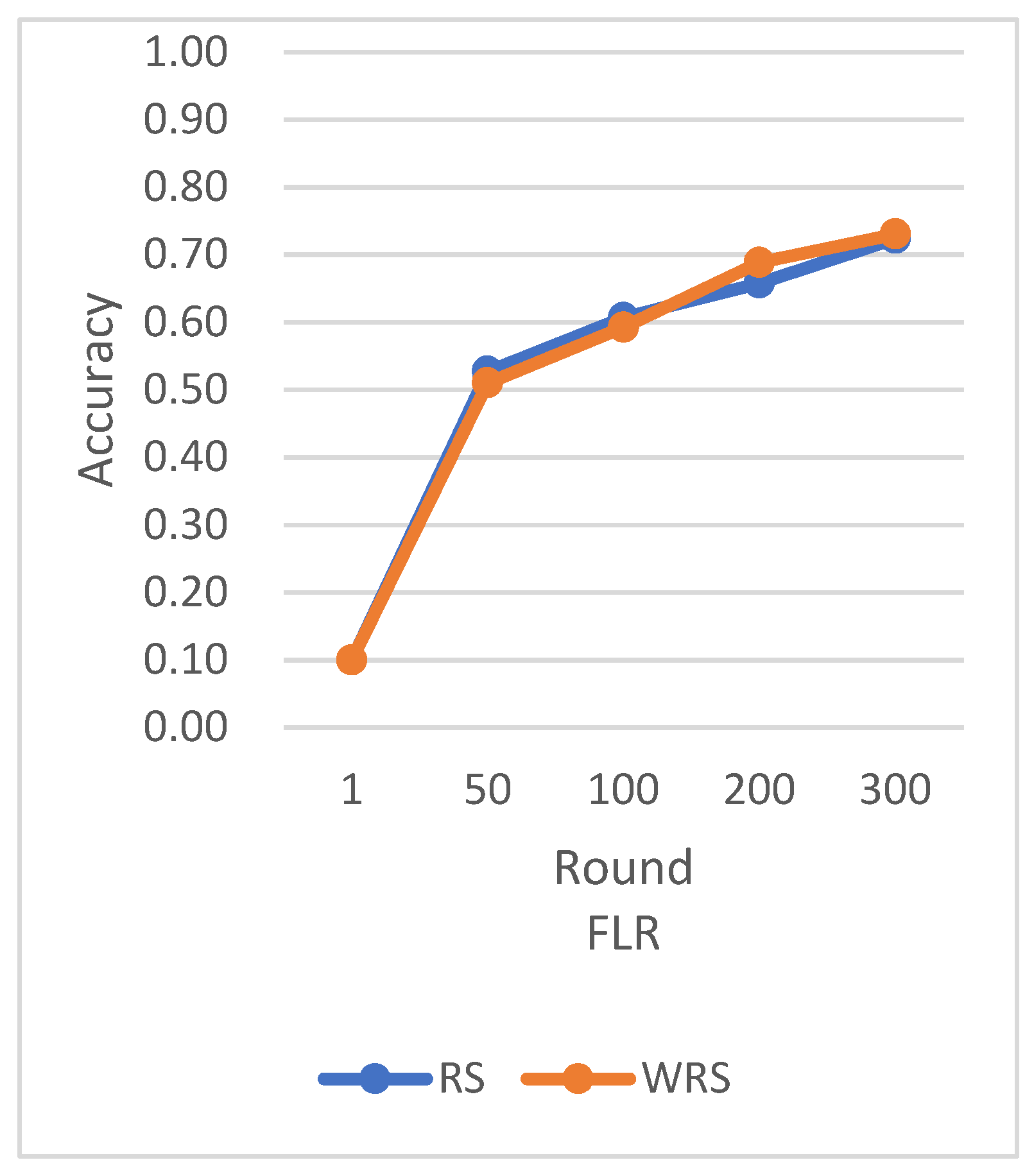
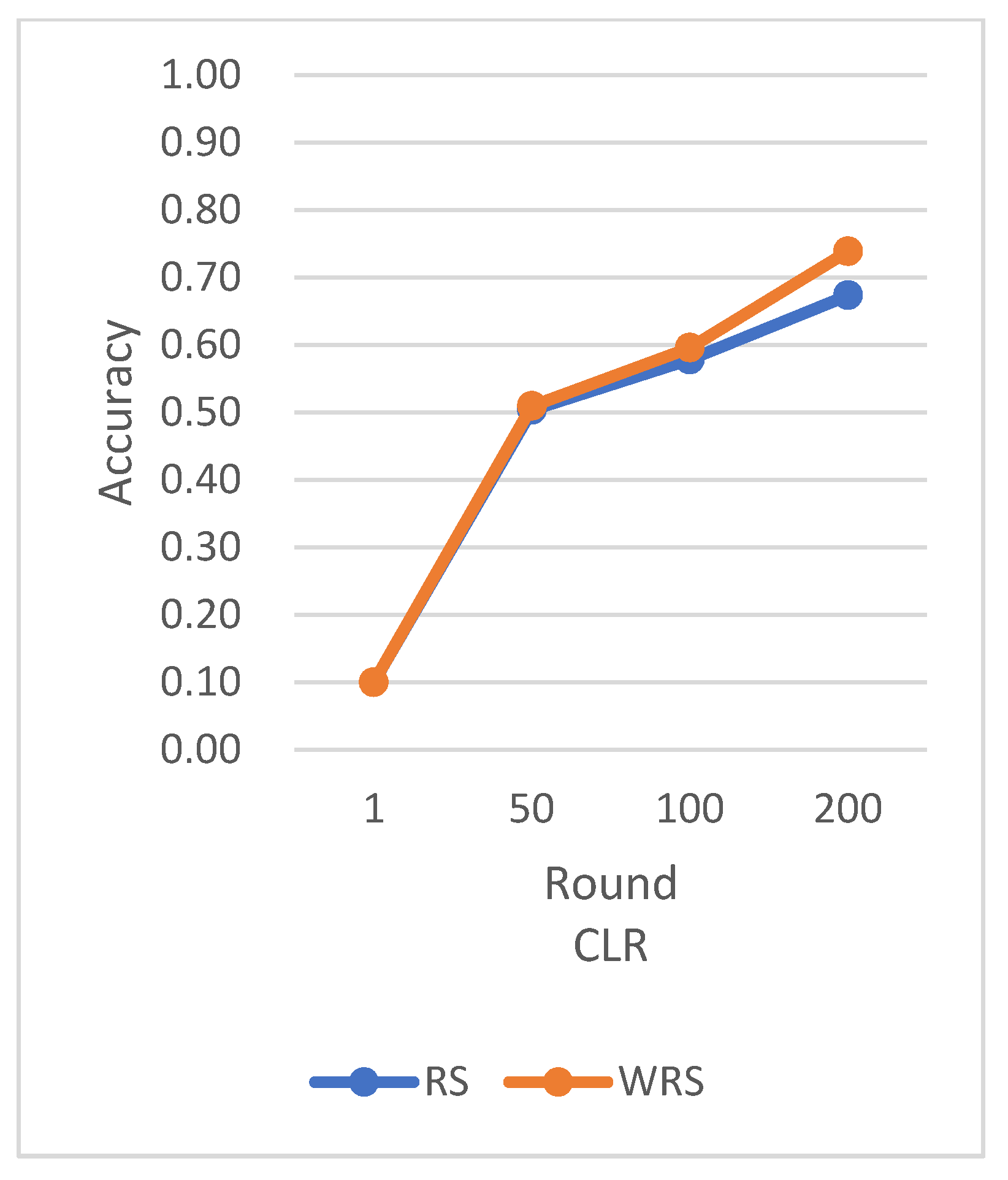
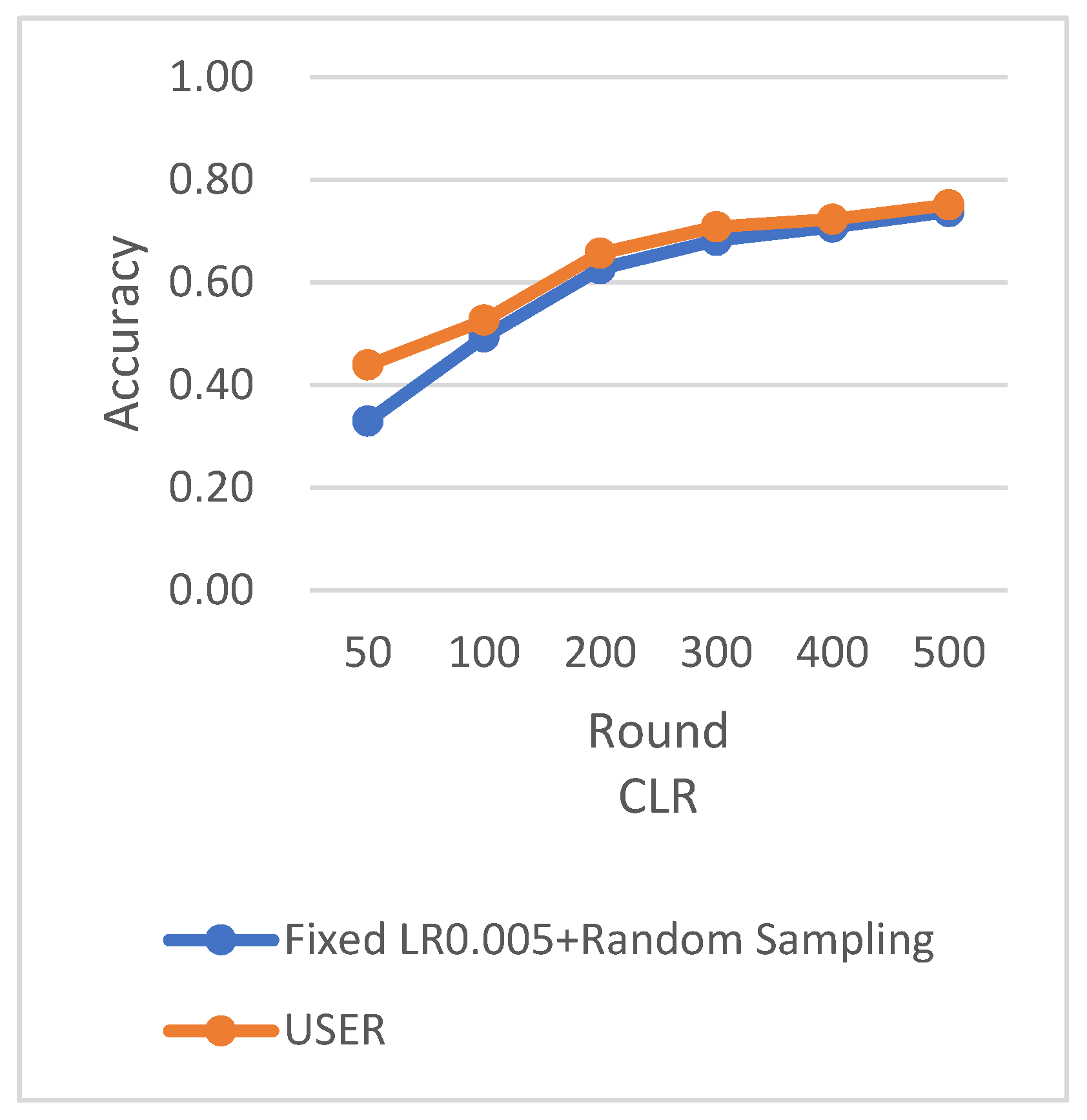
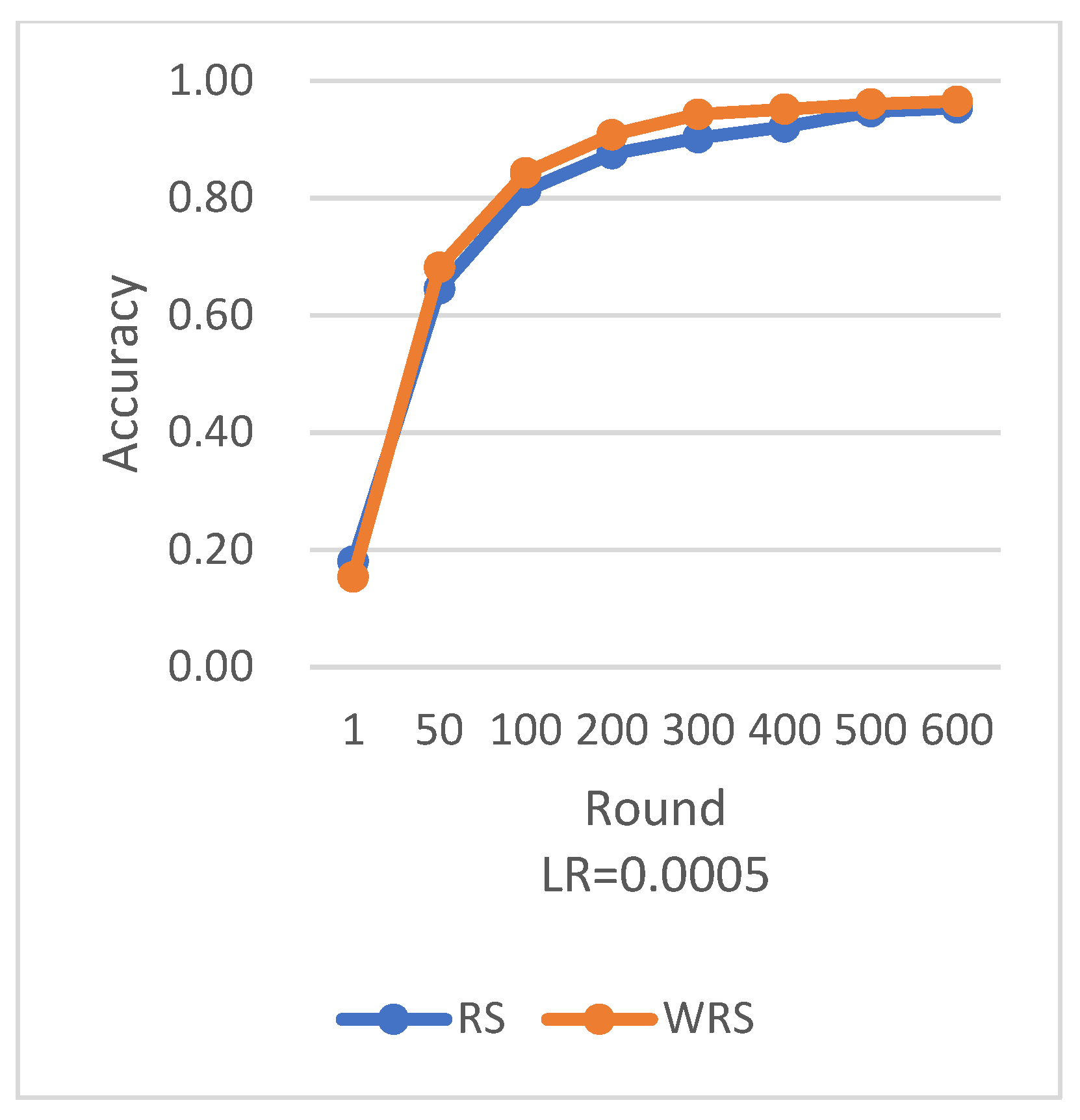
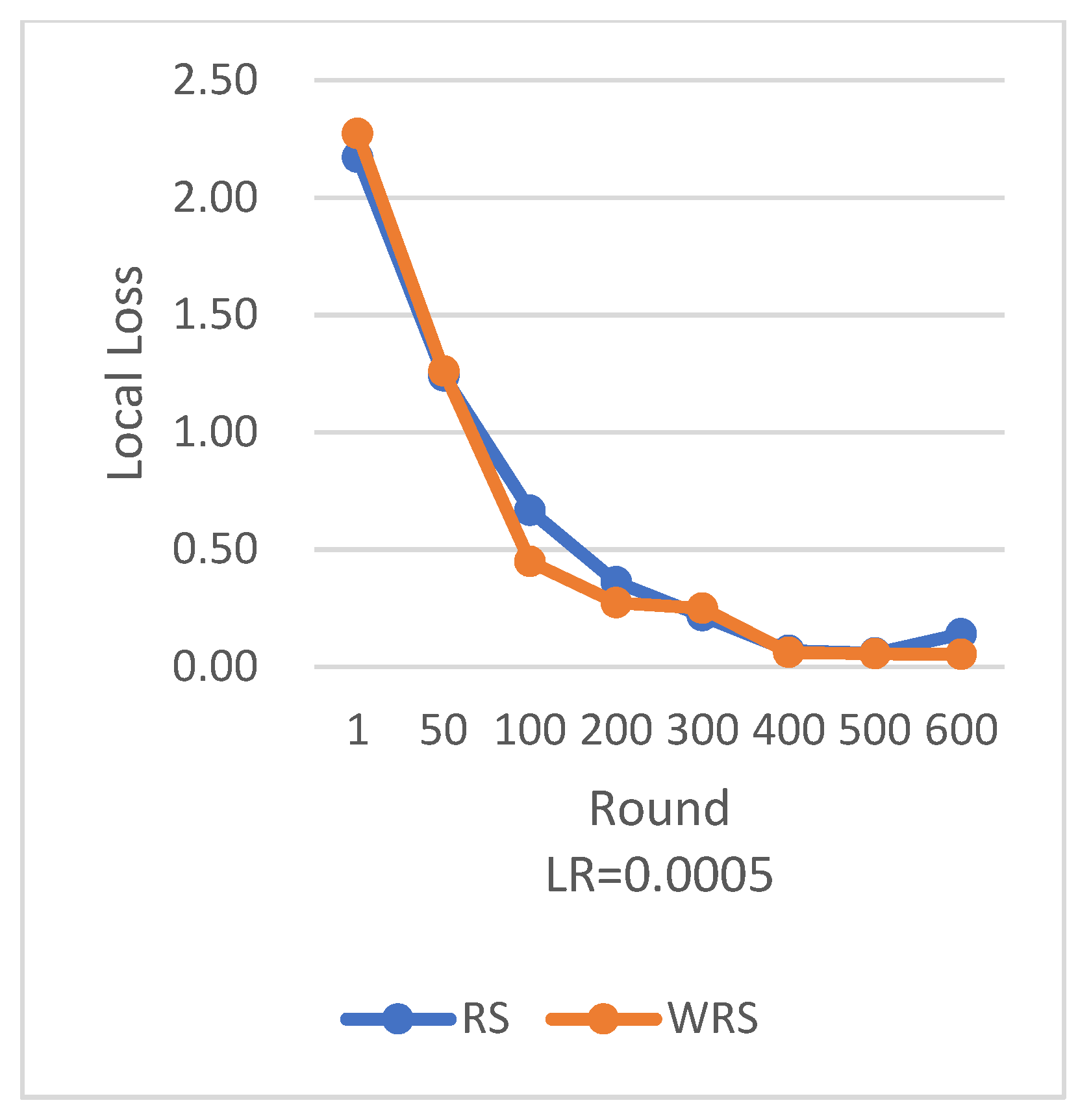
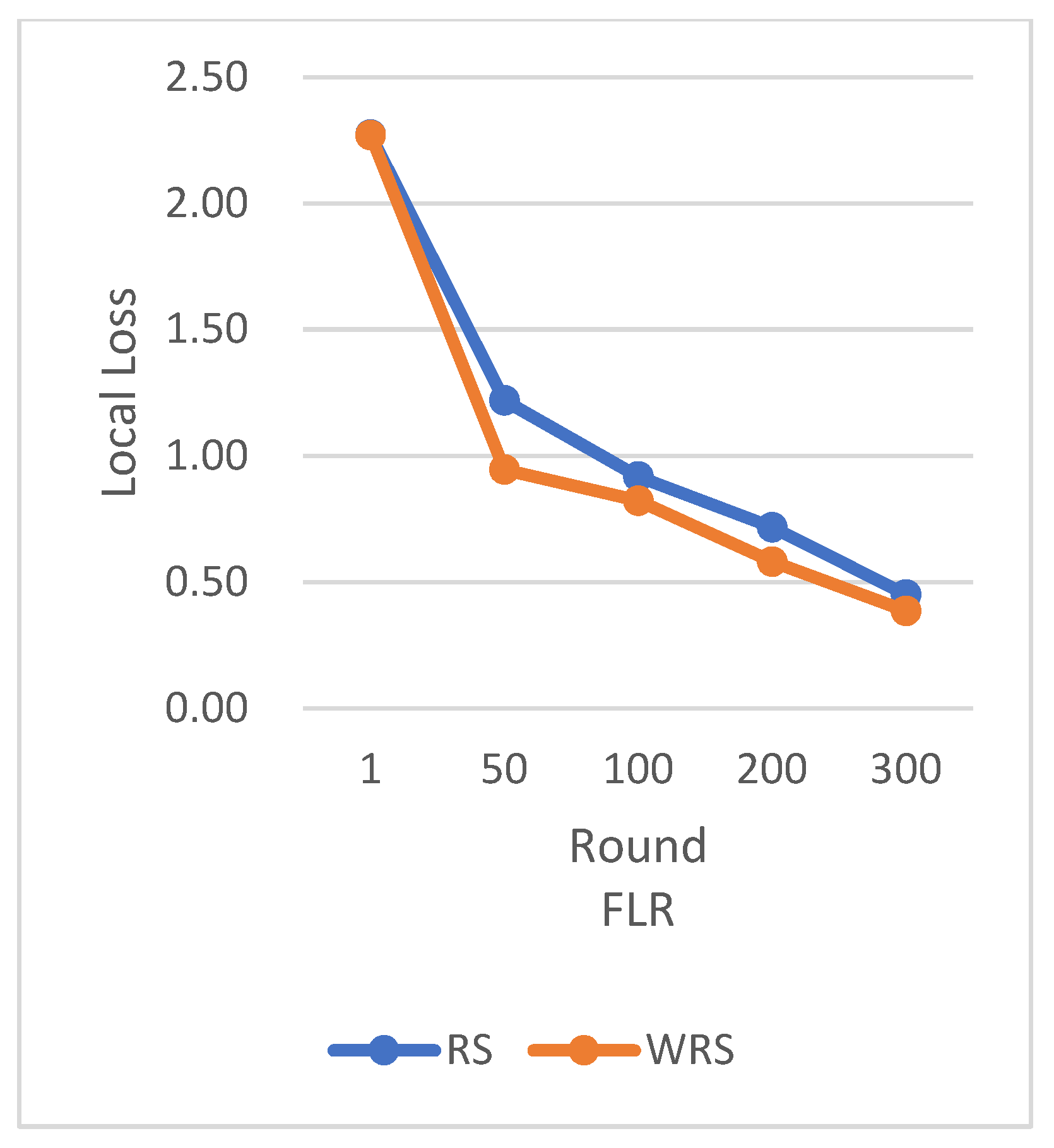
RS employs the traditional random sampling strategy, while WRS is the weighted random sampling strategy designed in this paper based on the number of samples.
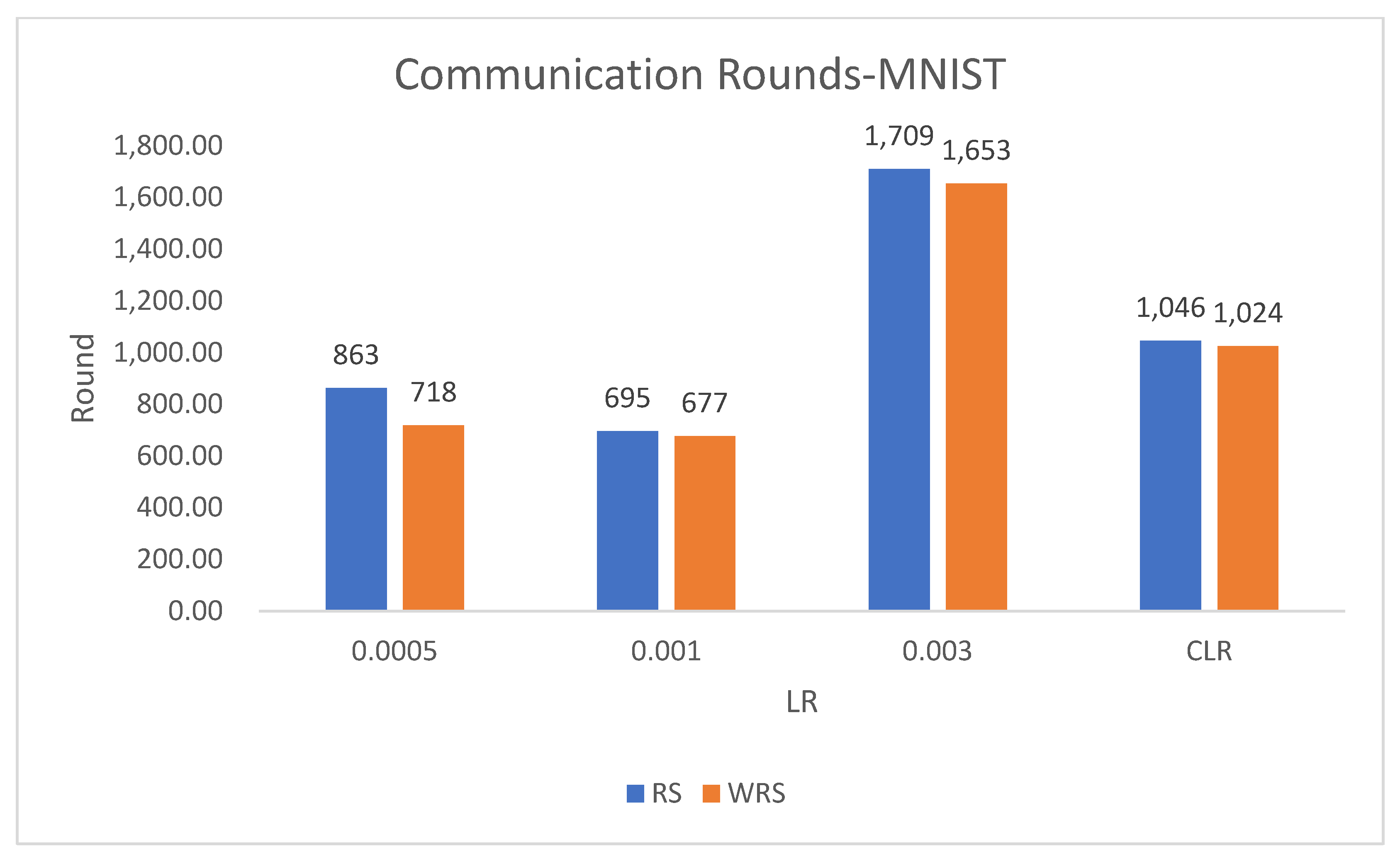
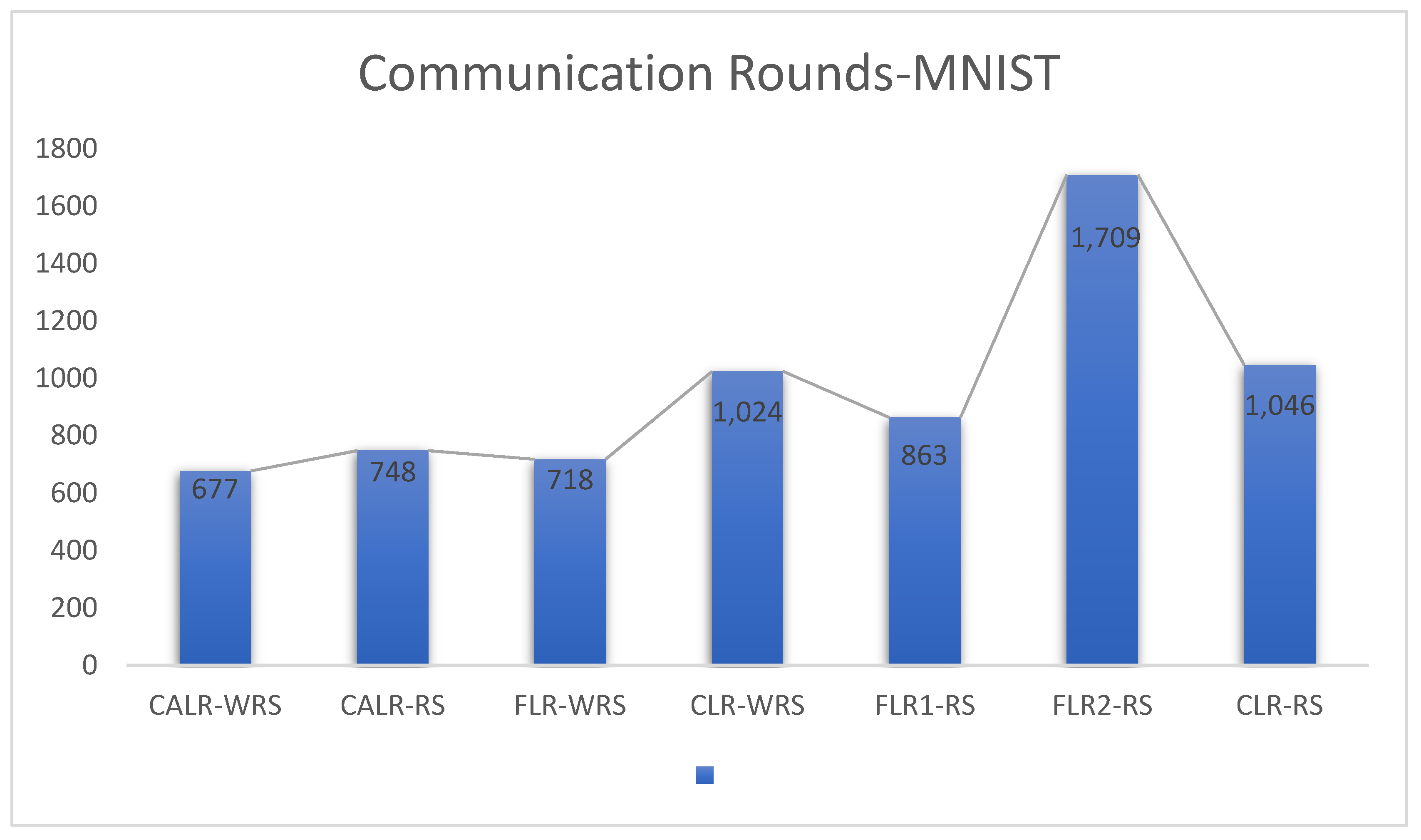
Under different learning rates, random sampling employs the traditional random sampling strategy, while WRS is the weighted random sampling strategy designed in this paper based on the number of samples. In this experiment conducted on the MNIST dataset, the training process is stopped when the test accuracy reaches 97%. By comparing the training iterations of the federated learning aggregation algorithm with traditional random sampling, it can be observed that, regardless of the learning rate, the training iterations in this paper are fewer than random sampling. In
Figure 20, it is evident that when the learning rate is set to 0.0005, the maximum improvement in convergence iterations is 16.8%, while with a learning rate of 0.001, the minimum improvement in convergence iterations is 2.5%.
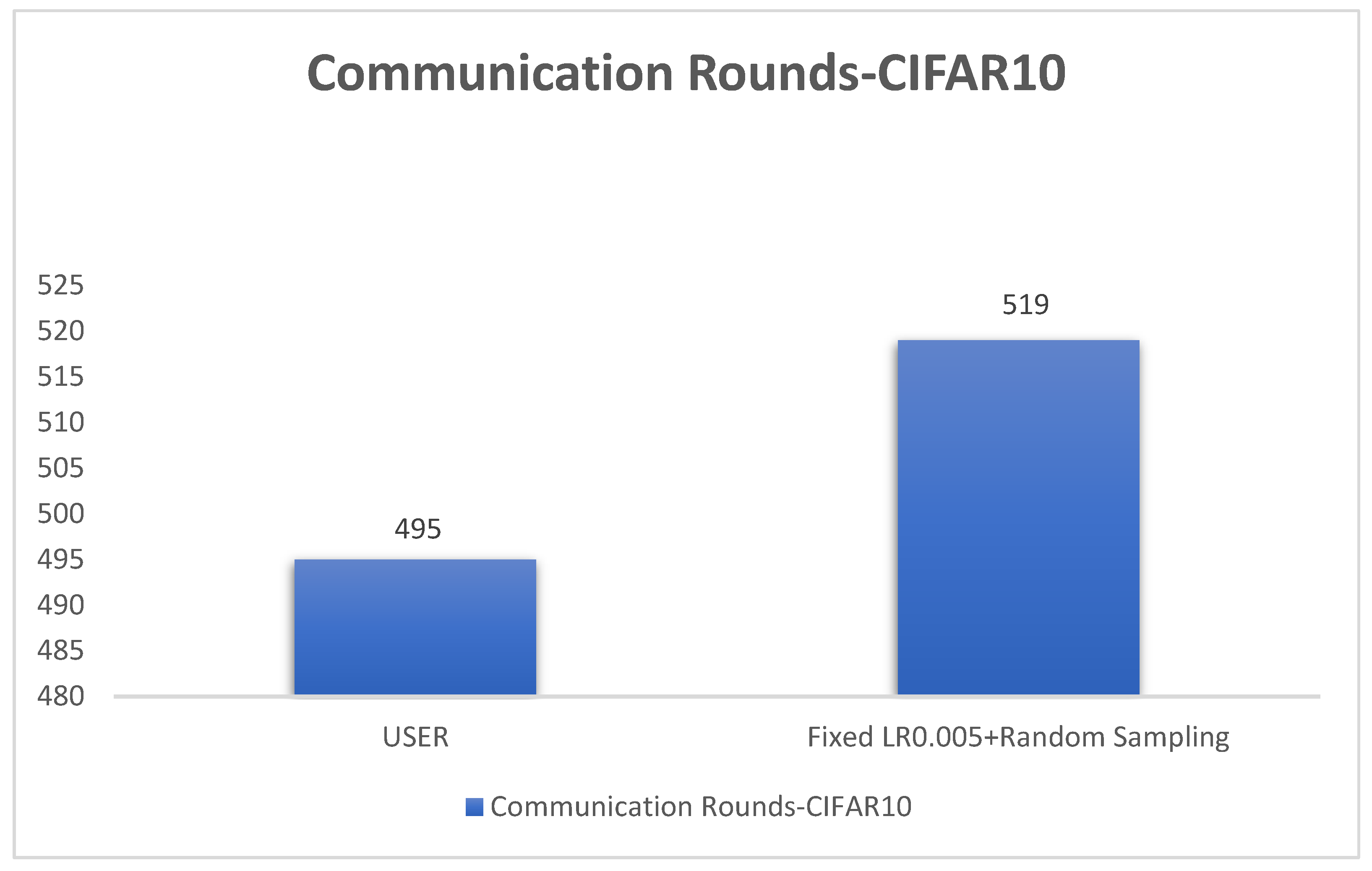
Under the scenario of using the CIFAR-10 dataset and the ResNet neural network model, the comparison of various algorithm strategies is as follows in
Figure 21,
Figure 22,
Figure 23 and
Figure 24.
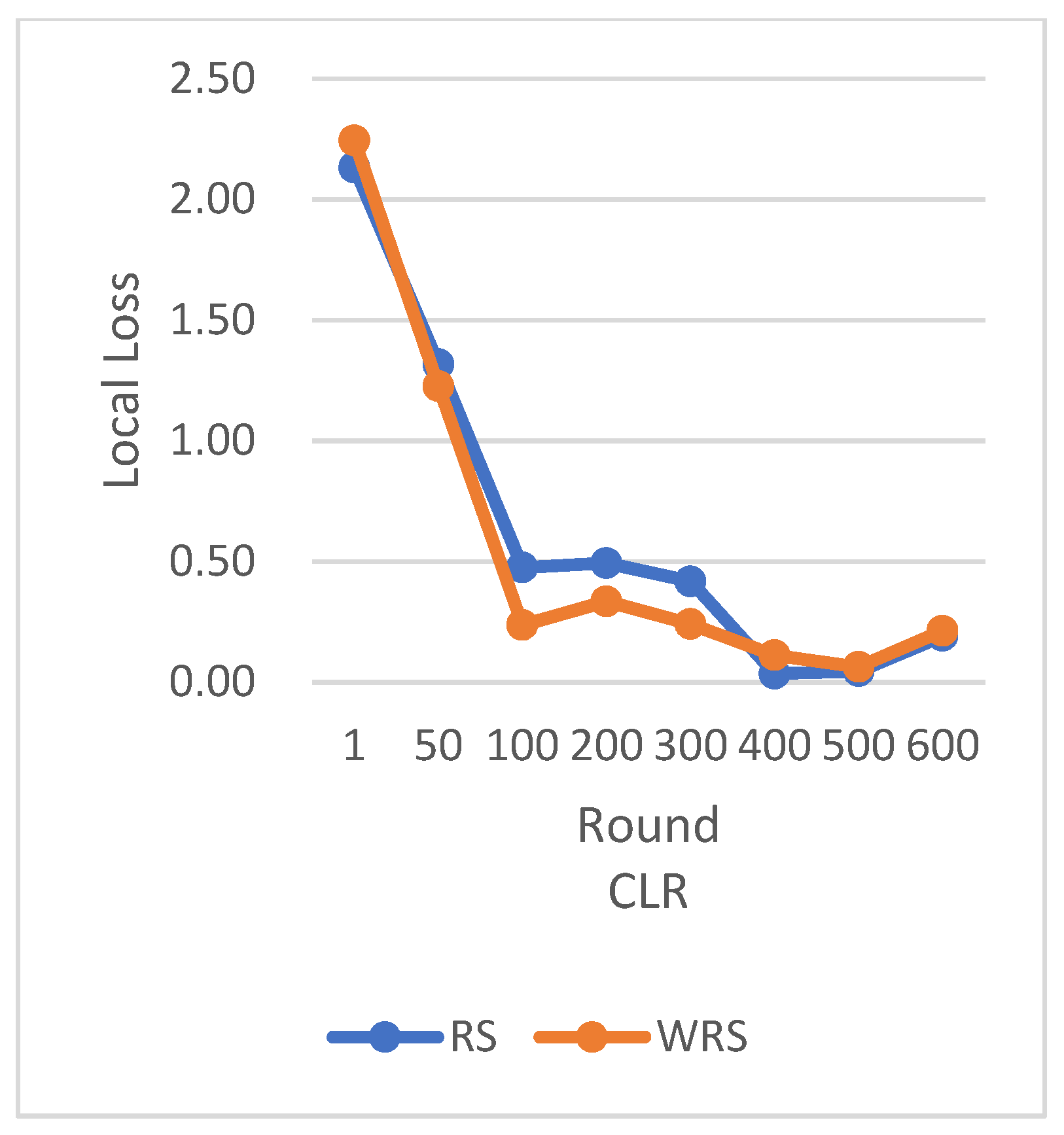
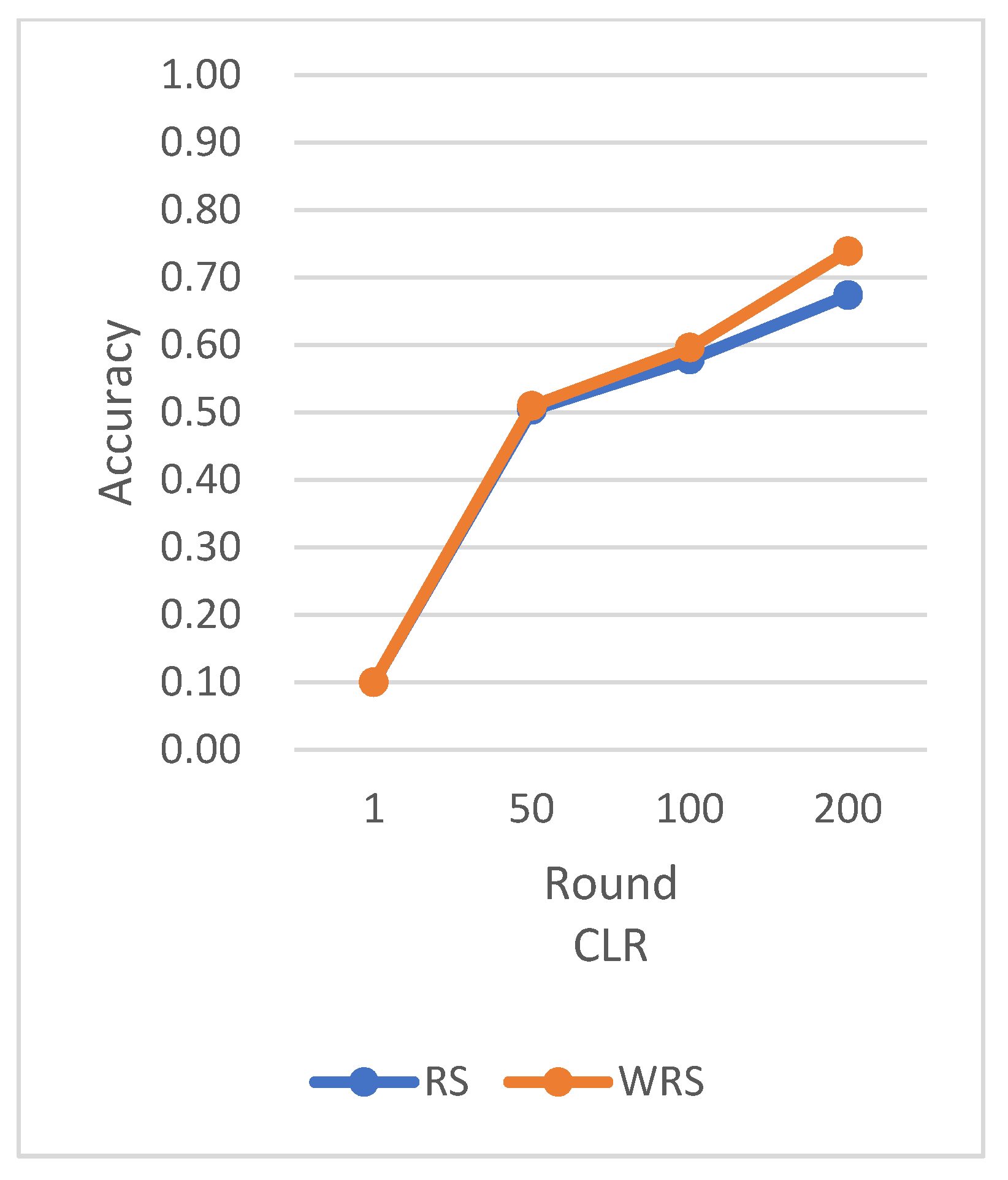
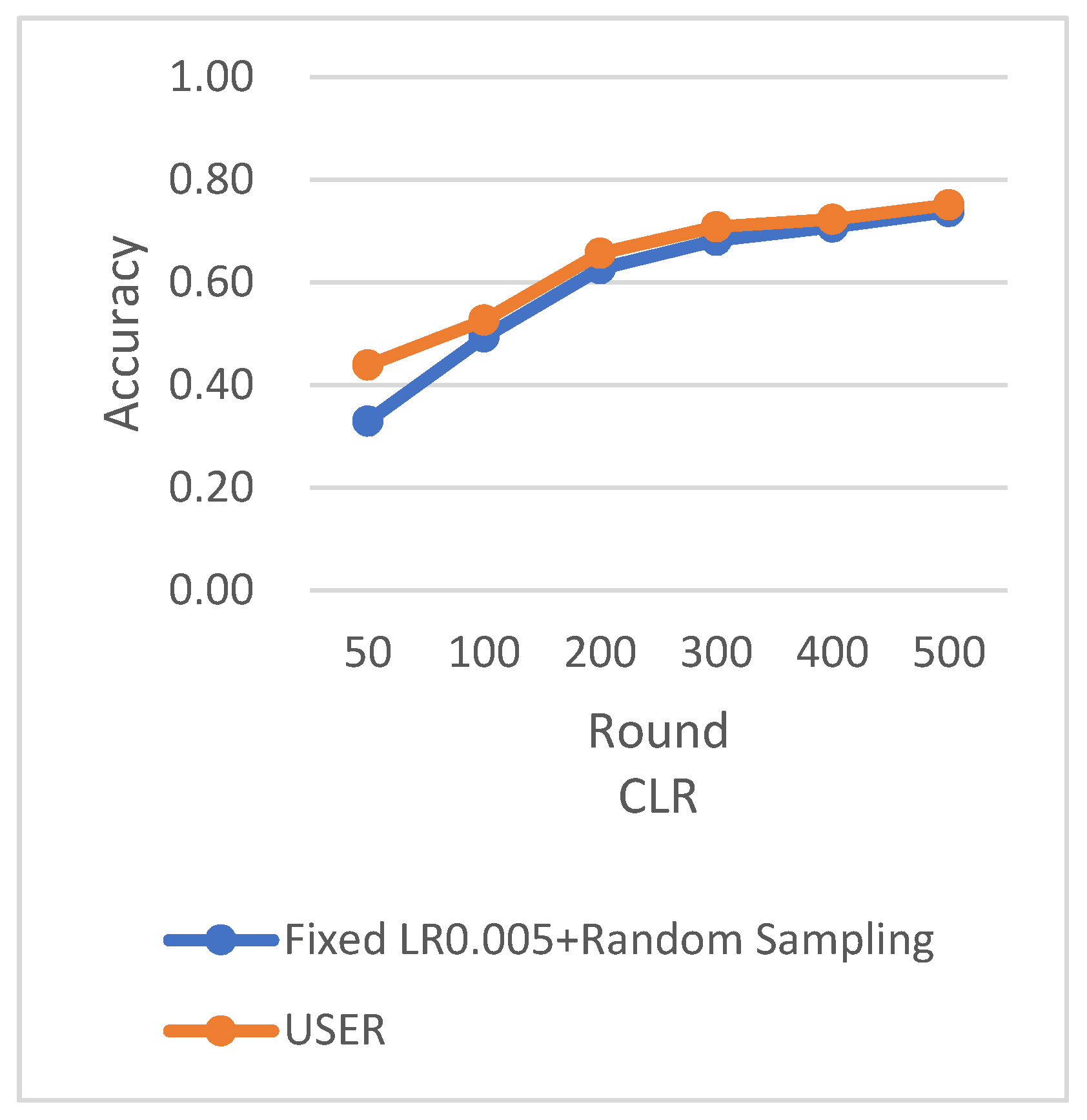
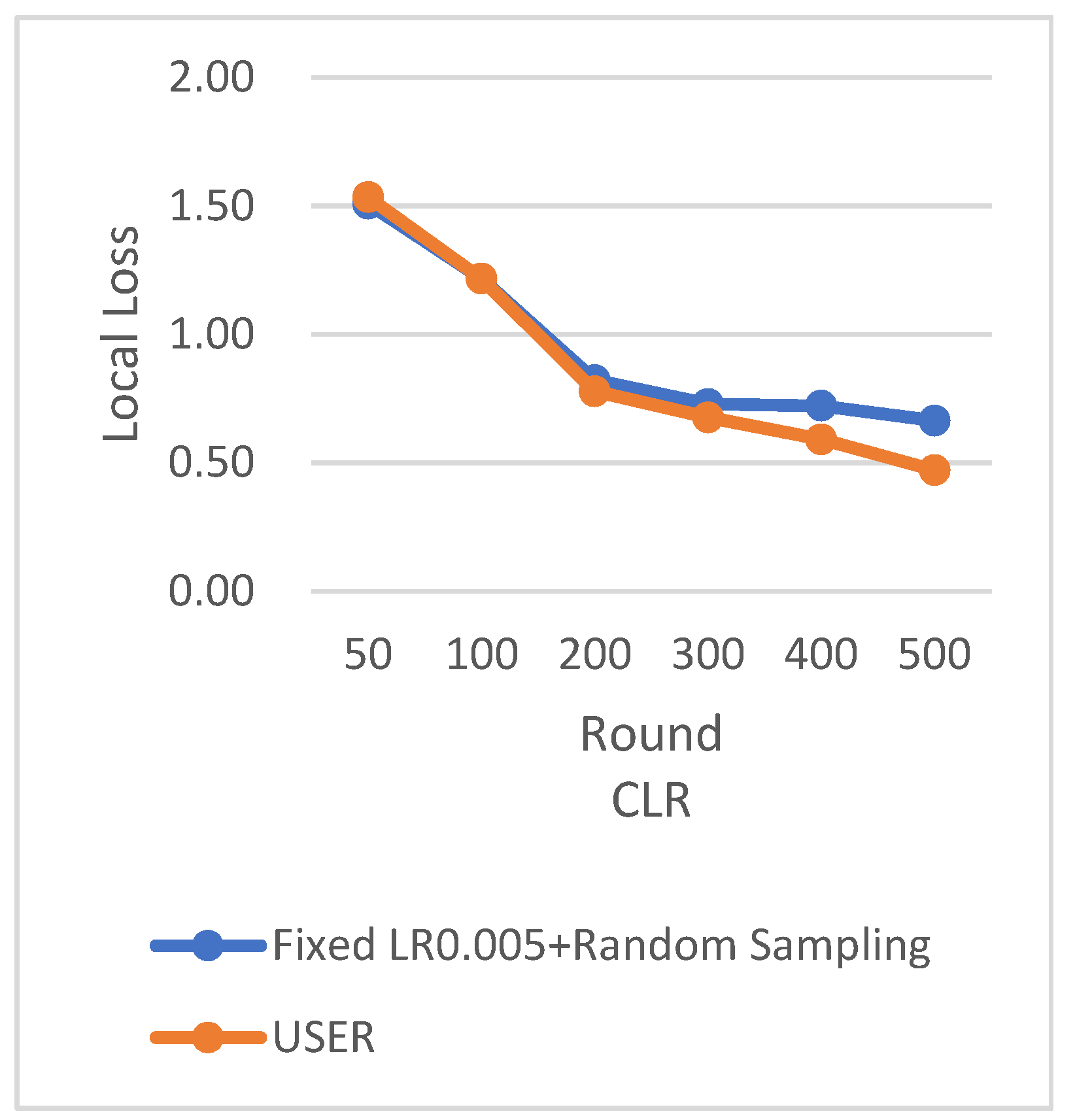
RS uses the traditional random sampling strategy and USER based on the number of samples designed in this paper.
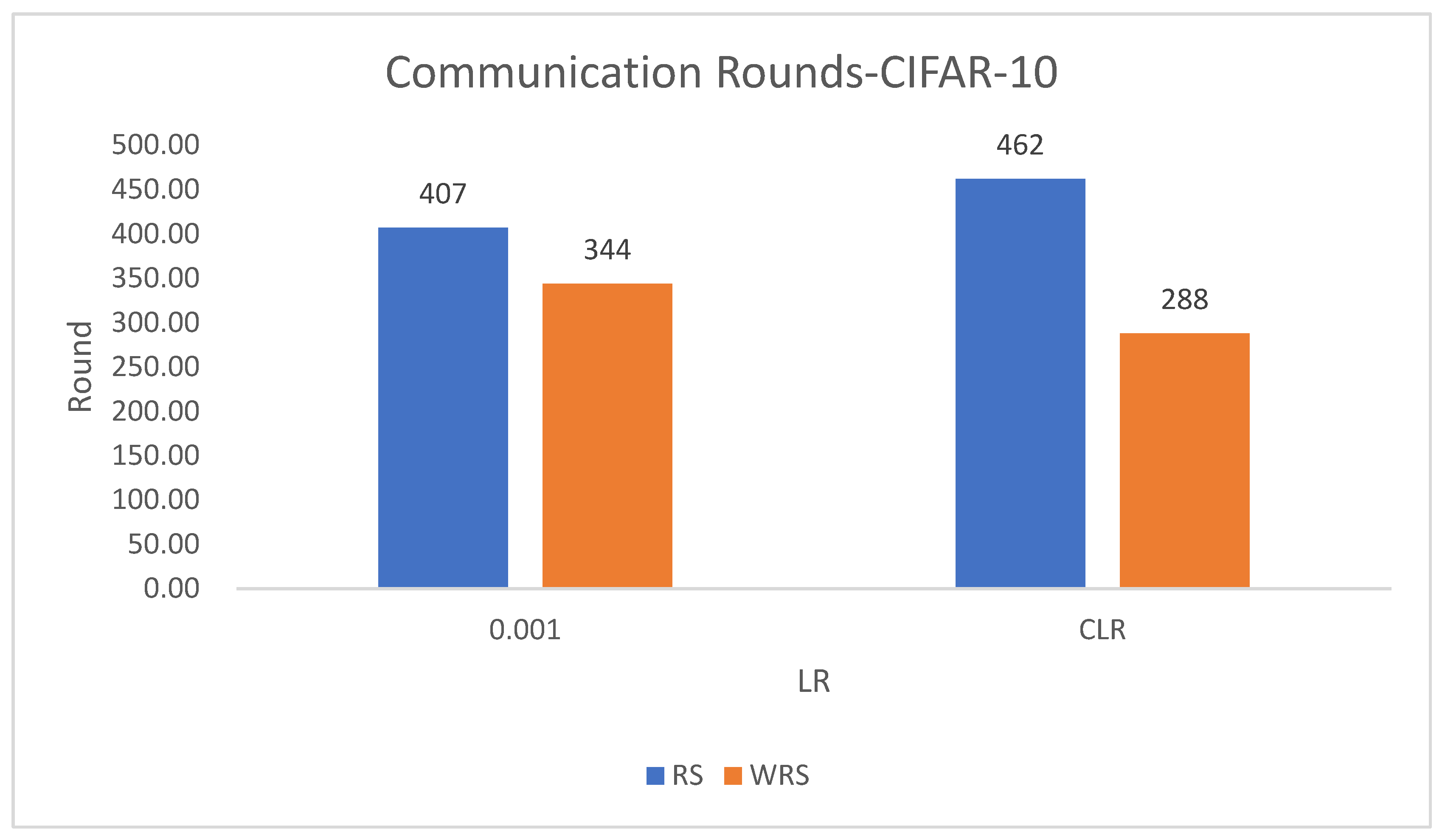
In this experiment using the CIFAR-10 dataset, the training is stopped when the test accuracy reaches 75%. By comparing the training rounds of the traditional random sampling strategy (RS) and our weighted random sampling strategy based on the number of samples (USER), it can be observed that our algorithm consistently requires fewer training rounds regardless of the learning rate used. At a learning rate of 0.001, the convergence speed is improved by 15.4%, and with the traditional CLR learning rate, the convergence speed is improved by 37.6%.
The results from
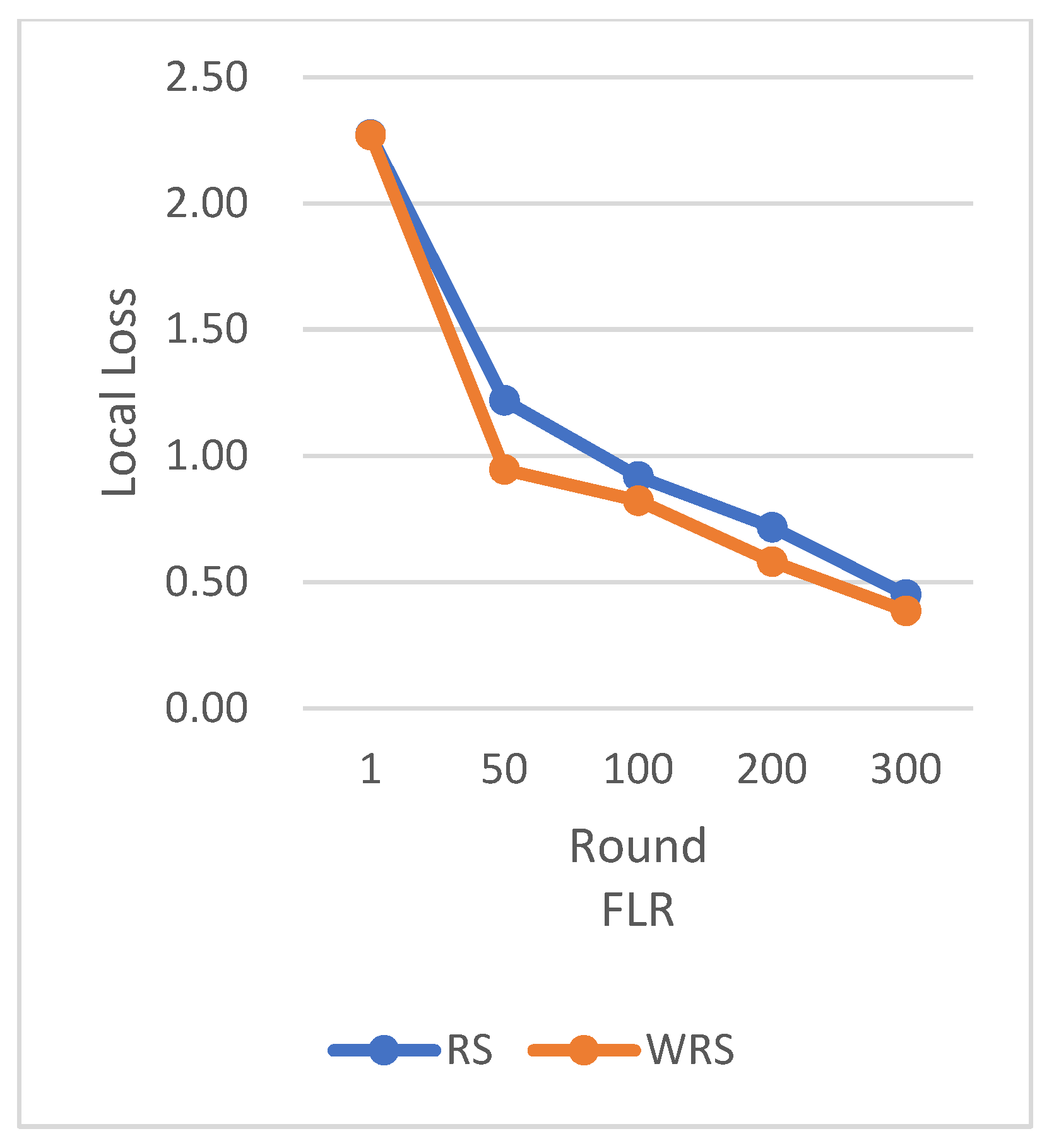
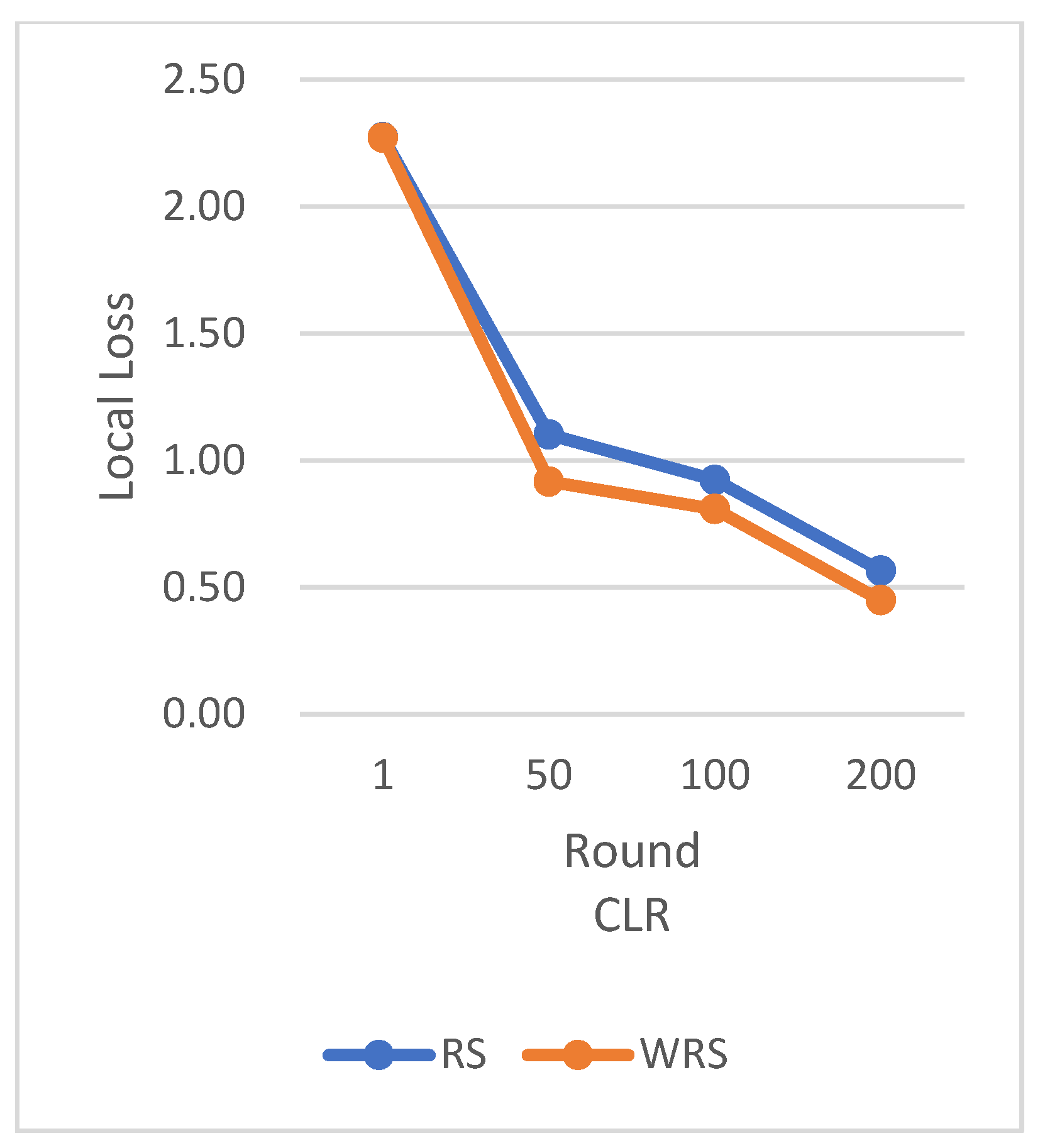
Figure 25 clearly demonstrate that our weighted random sampling algorithm based on the number of samples outperforms the traditional random sampling strategy in terms of test accuracy on both the MNIST and CIFAR-10 datasets. This indicates that our algorithm can better utilize the importance weights of each sample, resulting in improved classification accuracy on the test set.
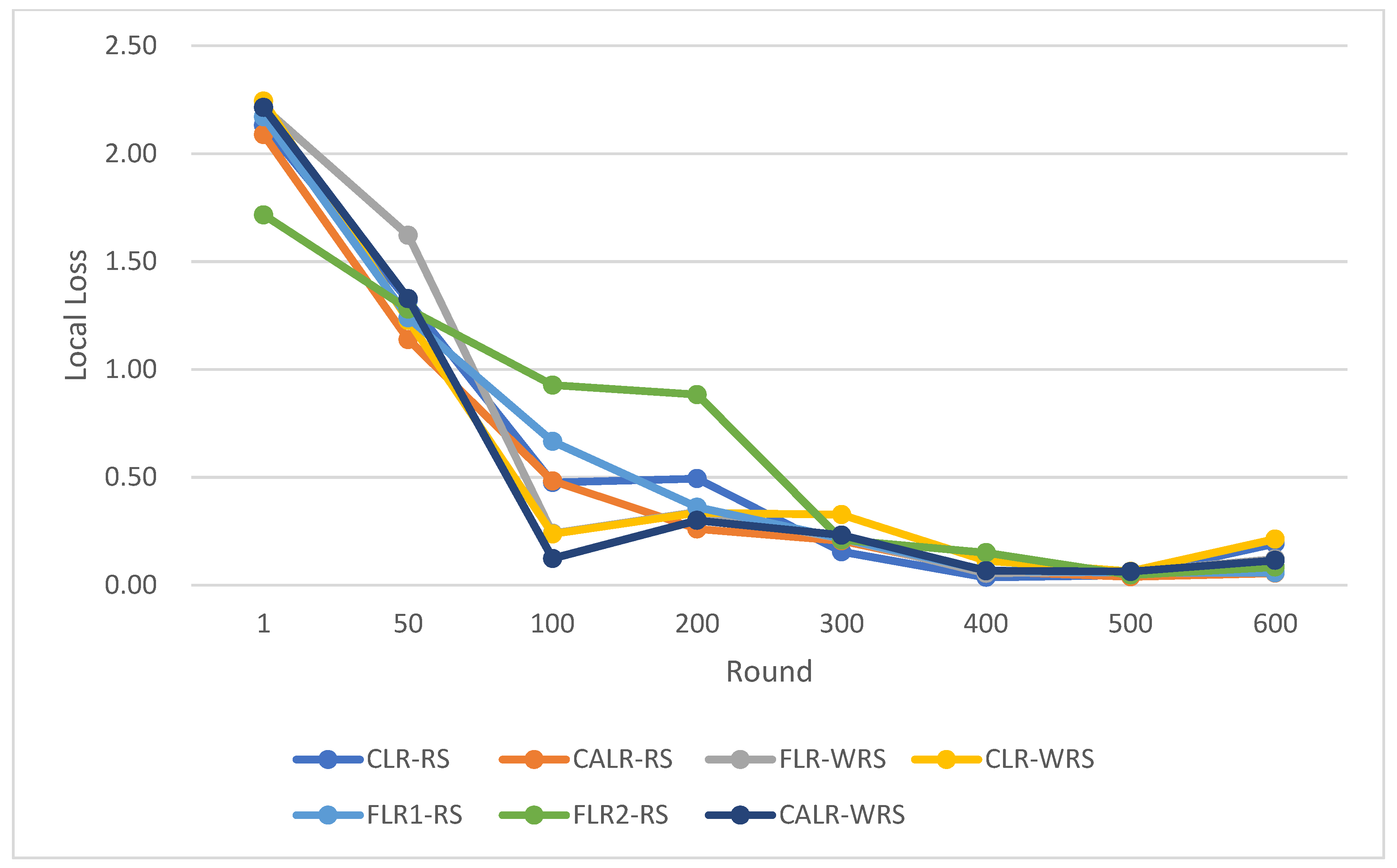
In terms of loss function reduction, our algorithm exhibits more stable and persistent behavior. By observing the loss function, it is evident that the weighted random sampling algorithm based on the number of samples can better control the loss reduction during training, avoiding significant fluctuations and oscillations. This indicates that our algorithm can more stably guide the model to learn data features and patterns, leading to improved training effectiveness. The convergence round data of the algorithm under different datasets and learning rates show that our algorithm can effectively accelerate the model convergence speed in federated learning, thereby enhancing model performance.
5.3. High-Performance Federated Learning Aggregation Algorithm
In this section, we achieved significant improvements in federated learning by combining the cyclic adaptive learning rate adjustment algorithm with the weighted random sampling strategy. We compared various strategies based on the convergence speed and loss function changes of the federated learning model.
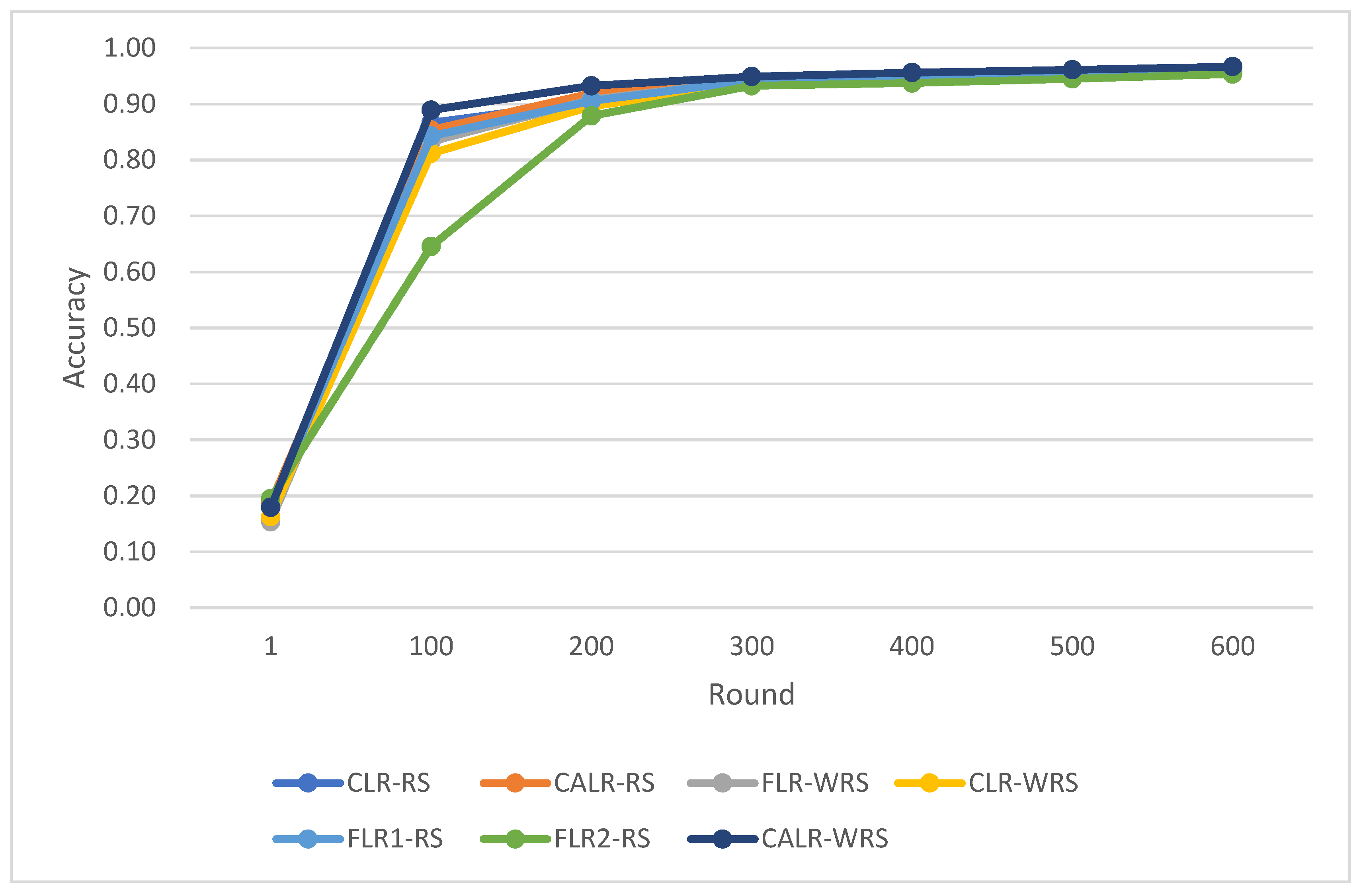
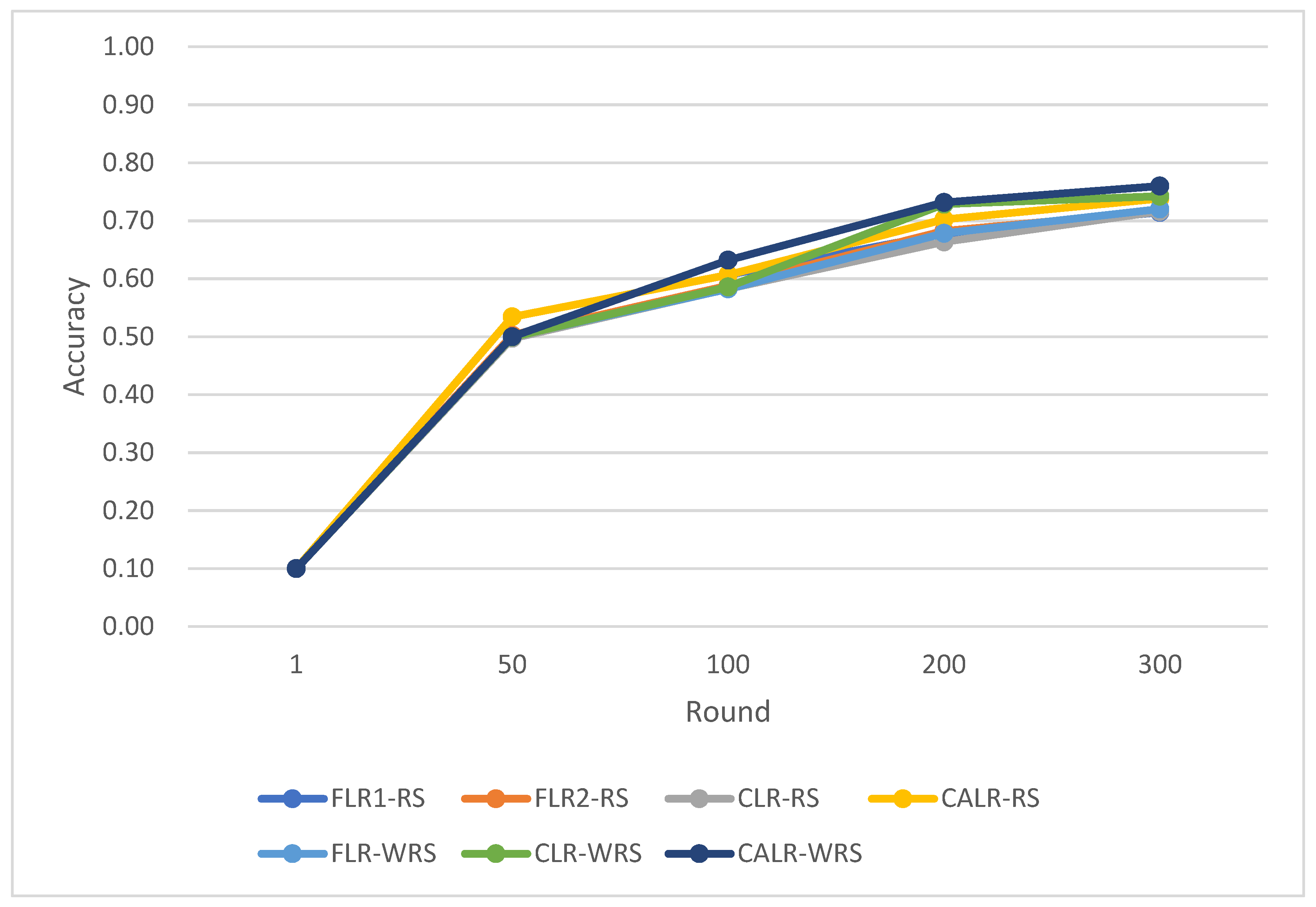
The comparison of multiple algorithm strategies based on the MNIST dataset and using the MLP neural network model is as follows in
Figure 26,
Figure 27 and
Figure 28:
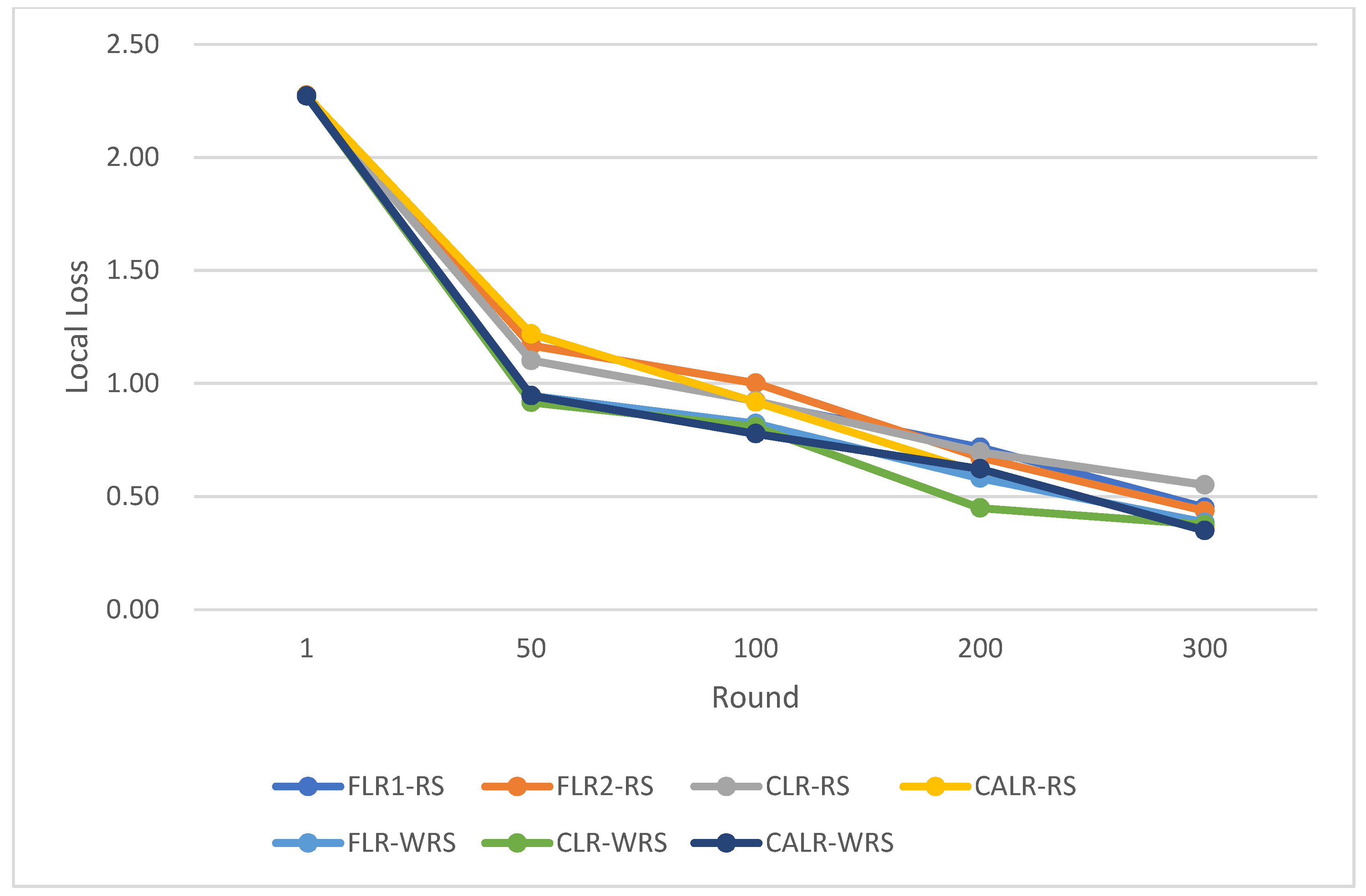
CLR-RS: cyclic learning rate—random sampling strategy;
FLR-WRS: fixed learning rate—weighted random sampling strategy;
FLR1-RS: fixed learning rate 0.0005—random sampling strategy;
FLR2-RS: fixed learning rate 0.003—random sampling strategy;
CALR-RS: cyclic adaptive learning rate—random sampling strategy;
CLR-WRS: cyclic learning rate—weighted random sampling strategy;
CALR-WRS: cyclic adaptive learning rate—weighted random sampling strategy.
The above data demonstrate that the CALR-WRS algorithm exhibits superior convergence performance on the MNIST dataset compared to other algorithms, showing significant improvements.
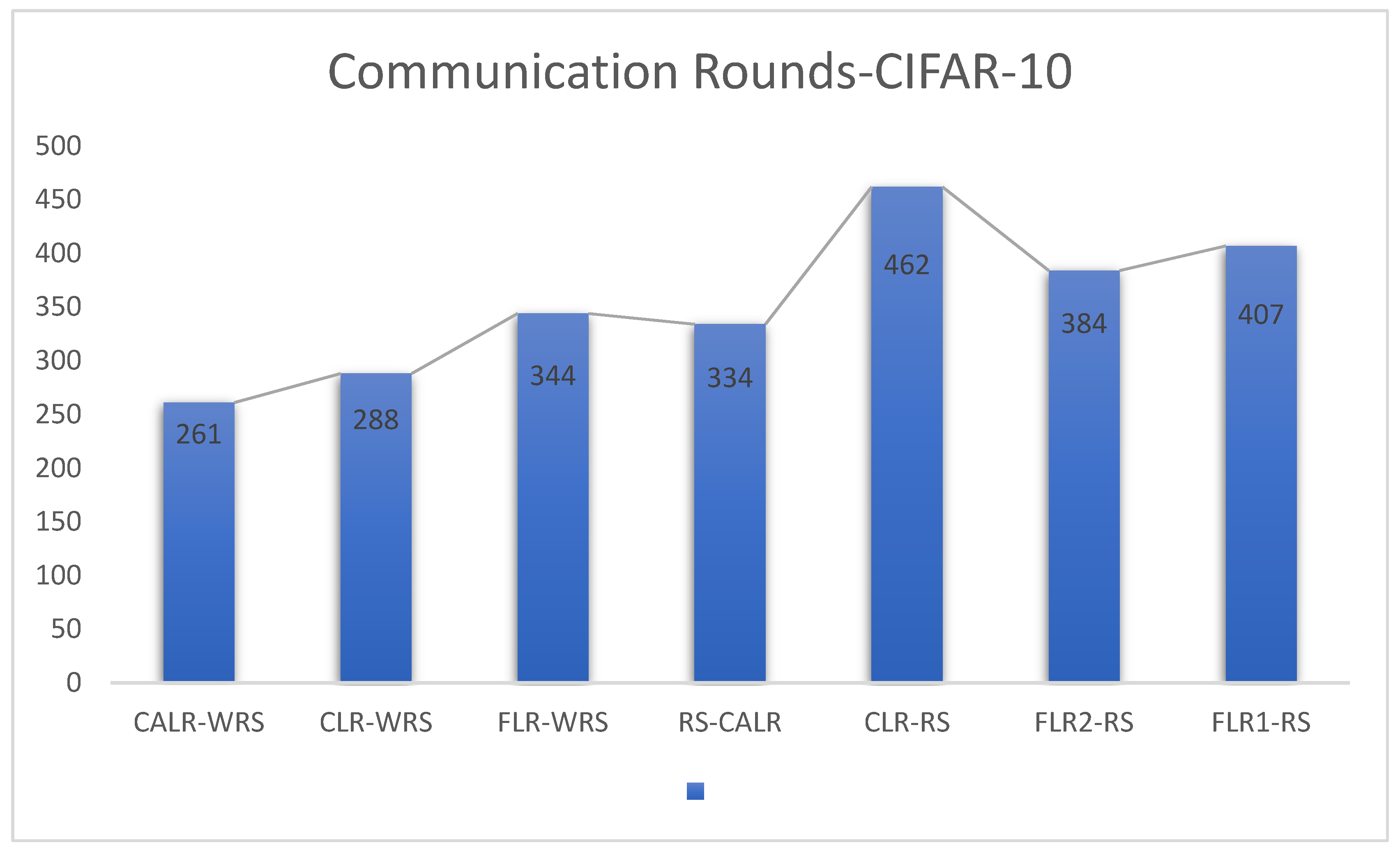
The comparison of various algorithmic strategies based on the CIFAR-10 dataset and using the ResNet neural network model is as follows in
Figure 29,
Figure 30 and
Figure 31:
CLR-RS: cyclic learning rate—random sampling strategy;
FLR-WRS: fixed learning rate—weighted random sampling strategy;
FLR1-RS: fixed learning rate 0.005—random sampling strategy;
FLR2-RS: fixed learning rate 0.001—random sampling strategy;
CALR-RS: cyclic adaptive learning rate—random sampling strategy;
CLR-WRS: cyclic learning rate—weighted random sampling strategy;
CALR-WRS: cyclic adaptive learning rate—weighted random sampling strategy.
In this study, we also conducted comparisons between the improved algorithm and baseline algorithms to assess their convergence performance under uneven client sample distributions. Specifically, we examined the performance of different algorithmic strategies using the CIFAR-10 dataset and the ResNet neural network model in scenarios where client sample distributions were uneven. Below are the comparative results of our analysis.
Based on the above
Figure 32,
Figure 33 and
Figure 34, it is evident that even in the case of non-uniform distribution of client dataset sizes, our algorithm can achieve convergence more rapidly. Furthermore, our algorrithm exhibits faster accuracy improvement, smoother loss changes, and an increase in training rounds of 4.84%, further saving communication time costs.
In this study, we compared various learning rate adjustment and client sampling strategies in the federated learning aggregation process. Experimental results demonstrate that the CALR-WRS strategy has achieved significant performance improvements on the MNIST and CIFAR-10 datasets. As shown in
Figure 26,
Figure 27 and
Figure 28, the CALR-WRS algorithm, on average across training rounds, increased performance by 27.65% compared to the baseline algorithm, achieving similar test accuracy on the MNIST dataset. In
Figure 29,
Figure 30 and
Figure 31, it is evident that on the CIFAR-10 dataset, there was an average improvement of 27.75%. In terms of accuracy improvement rate, CALR-WRS demonstrated greater stability and efficiency compared to traditional fixed learning rate and other cyclic learning rate strategies. Moreover, CALR-WRS showed more stable and persistent loss reduction.
The CALR-WRS strategy exhibited clear superiority in the aggregation process of federated learning, and it is of great significance for improving the performance and efficiency of federated learning. The algorithm design presented in this study provides new insights and solutions for the development of federated learning, and it is expected to promote its wide application and further research in practical scenarios.
6. Discussion
In this paper, we propose a novel approach to improve the performance and efficiency of federated learning aggregation. We address two key challenges in the federated learning process: selecting appropriate learning rates for client and designing a weighted random client sampling strategy for client aggregation.
Combining CALR and WRS, we propose the CALR-WRS strategy, a comprehensive improvement for the federated learning aggregation process. By dynamically adjusting the learning rate and using weighted random sampling, CALR-WRS effectively addresses the challenges of client selection and convergence speed. This research provides new insights and solutions for federated learning, promoting its widespread application and further research in practical scenarios. However, although the CALR-WRS strategy demonstrates good performance in the aggregation process, it may still have some limitations in specific scenarios. For example, in cases of highly imbalanced data distribution, the contributions of certain clients may still be neglected. Hence, future research could explore more complex client selection strategies to further enhance the efficiency and accuracy of the aggregation process.
Finally, this study focuses on improving the aggregation process of federated learning, while research on other aspects of federated learning, such as privacy protection and security, is relatively limited. Future exploration can investigate the broader application of federated learning in various scenarios, incorporating more optimization techniques and privacy protection mechanisms to build a more comprehensive and efficient federated learning system.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}