1. Introduction
Cloud computing remains a prominent framework for managing extensive distributed workflow module applications due to its adaptability, consistent performance, and robust oversight [
1,
2,
3]. Through virtualization techniques, users can conduct multiple application tasks globally and concurrently. These applications vary in complexity, ranging from straightforward linear pipelines to intricate Directed Acyclic Graphs (DAGs). Effectively dispatching these workflow applications to achieve optimal network performance has garnered research attention, leading to numerous natural network deployment experiments in the grid and cloud infrastructures [
4].
Over the past few years, numerous approaches to workflow scheduling have emerged to address the challenge of reducing End-to-End Delay (EED) constraints—the time required to complete a workflow from start to finish. This is a complex problem classified as Nondeterministic Polynomial (NP) [
5], which can be tackled using metaheuristic optimization techniques. Yet, the reliability of workflow applications has received a relatively opinionated focus [
6]. Given the across-the-board adoption of cloud systems, the reliability of workflow application systems has become an increasingly crucial performance metric alongside EED [
7,
8]. Inevitable failures in processing servers and network links underscore the need to carefully select operational nodes and transfer links to minimize their detrimental effects. Accessible resources might unexpectedly become deficient, behave unpredictably, or exhibit malicious behavior. Subsidizing scientific workflows in unstable and ever-changing network environments is absolutely critical. It is imperative that we ensure precise end-to-end execution times to achieve successful mission-sensitive task execution. Accurate and prompt handling of data is an absolute necessity, not just a preference, as seen in applications like climate systems and data analysis using advanced scientific mechanisms.
To enhance the reliability of execution, duplicating tasks and restarting from checkpoints is imperative to diminish the likelihood of failure by implementing redundancy. However, this approach increases network traffic and computational requirements. An alternative solution entails the recording of checkpoints and the subsequent restart of the application in the event of a failure, albeit with added overhead and potential delays due to repeated computations and communications. Hence, it is imperative to decrease the likelihood of initial failure even prior to mapping the application onto the network. Simultaneously achieving the objectives of minimizing EED and maximizing reliability is impossible due to the inherent conflict between the two. The optimization of a single objective or weighted cost function with subjective weight values is the primary focus of traditional mapping and scheduling algorithms.
1.1. Research Motivation
Centralized scheduling schemes have been the primary focus of past research. These schemes necessitate a central server to collect network conditions and establish mapping strategies. However, this approach exhibits certain limitations, including the peril of a sole failure point, the requirement for storage and transfer, and an extra computational load. A distributed system that shares network conditions and decisions among various nodes is essential to ensure scalability in workflow mapping within extensive networks. This is necessary due to potential delays in executing the mapping algorithm on the central server before dynamic network status updates occur. It is highly desirable to achieve both optimization objectives in this context.
Utilizing multiple meta-heuristic computations proves more advantageous as compared to relying solely on individual meta-heuristic analyses, which tend to encounter premature convergence. Consequently, the incorporation of population-based meta-heuristics becomes crucial for achieving optimal arrangements of task–server combinations. An instance of an artificial intelligence-driven technique is the wild horse optimization (WHO) algorithm. The amalgamation of this optimization algorithm with the levy flight algorithm has been empirically validated as a potent solution. This combined approach not only addresses network contention effectively but also plays a pivotal role in optimizing both scheduling reliability and End-to-End Delay (EED) to align with user expectations. By harnessing the synergy between thin–thick clients and the cloud network, this approach enhances task scheduling within the processing system, tackling prevalent issues and thereby elevating Quality of Service (QoS), user satisfaction, and system dependability.
1.2. Research Novelty
Recent studies have predominantly adopted a centralized mapping strategy, wherein the global network condition is aggregated to make mapping decisions. However, this approach carries a notable risk of encountering a single point of failure, consequently impairing both storage and computational efficiency. Moreover, this vulnerability can potentially trigger network failures due to dynamic changes in the network state that might surpass the central server’s ability to execute the mapping algorithm promptly. Given these constraints, our proposed workflow scheduling hybrid optimization (WSHO) algorithm breaks free from the reliance on a central server during the mapping phase. Instead, it employs a decentralized approach by broadcasting network decisions among processing servers. This enables the dissemination of messages across the network, precluding failure issues before application scheduling takes place. The most unfavorable situation emerges when a server overlooks its failure, prompting the system to employ downstream servers to detect the failure via timeouts. Upon failure detection, our model reassigns only the pending applications within and after the layer containing the failed application.
1.3. Research Contribution
The key discoveries of this investigation are as follows:
A distributed workflow scheduling algorithm using meta-heuristic techniques is introduced to enhance application placement reliability goals while strictly adhering to the limitations imposed by the EED objective (
Section 1).
The integration of the levy flight model enriches the WHO paradigm by achieving a balance between exploring globally and exploiting locally. This also involves efficiently utilizing the search space and reducing the preference for resources prone to high failure rates (
Section 3).
The study suggests a workflow scheduling approach that incorporates critical path analysis, topological sorting, layer prioritization, and sorting techniques. This method aims to enhance the resilience and reduce the energy consumption of applications in each cycle. The process will persist until convergence is achieved (
Section 5).
The proposed algorithm simultaneously investigates the demonstration of opposing goals: achieving the lowest EED and the highest reliability (
Section 6).
1.4. Research Outline
The subsequent parts are structured as follows:
Section 2 delves into an extensive examination of existing research efforts.
Section 3 outlines the primary structure of the proposed system framework.
Section 4 presents the issue’s formulation, demonstrating the incompatibility of EED and reliability goals. The algorithms’ development process is discussed in
Section 5, while
Section 6 encompasses the results from experimental trials of the suggested algorithm.
Section 7 offers the concluding remarks.
2. Related Works
The hybrid workflow scheduling approach proposed has the potential to enhance the dependability of allocating workflow module applications across cloud resources, while concurrently decreasing their execution duration. Additionally, this algorithm can more effectively utilize the computing resources available in a diverse device environment. Various task scheduling methods, like the ACO, PSO, and GA, have been explored in the existing literature. However, the majority of these methods possess limitations as they disregard the simultaneous optimization of both reliability and EED during task–resource allocation. In comparison, our solution surpasses conventional task scheduling algorithms, achieving a 42% increase in placement reliability and a 67% reduction in mean execution time.
The publication referenced as [
9] introduced a multi-dimensional challenge of assigning workflows within multi-cloud systems. Their approach to multi-objective workflow management encompasses factors like task completion time, operational expenses, and system reliability. To enhance reliability, they incorporated a backup technique. They outlined two distinctive strategies. The first, referred to as a diversification strategy, incorporates problem-specific genetic operators to generate diverse offspring entities. Conversely, the intensification strategy leverages four distinct neighborhood operators, tailored to critical path and resource usage, to enhance the quality of entities stored in the archive set. The suggested approach considers particular limitations, such as the duration of tasks, operational expenditures, and system reliability, but does not give equal attention to other goals, like minimizing energy usage or maximizing service provider profits. Our method distinguishes itself from their model by incorporating an enhanced iteration of the wild horse optimization method in conjunction with a levy flight strategy.
The publication referenced as [
10] introduced a dual-objective optimization scenario that focuses on both makespan and enhancing reliability. The authors tackled the challenge of scheduling scientific workflows across cloud resources. They introduced a centralized log, functioning as a repository, to record various system failures. Additionally, they introduced a novel scheduling failure factor (SFF) inversely correlated with system reliability. Consequently, the previously mentioned model was cast into a dual-objective optimization problem, aiming to minimize both makespan and SFF—a task known to be NP-Hard. To solve this combinatorial issue and strike a balance between exploration and exploitation in optimization, they employed a discrete cuckoo search approach alongside levy flight operators. While their approach represents a pioneering solution for deploying applications on functional hosts, it lacks consideration for specific Quality of Service (QoS) aspects related to computing servers. In contrast, our model distinguishes itself from their methods by effectively overseeing the allocation of time slots for virtual machines to prevent any overlap.
The publication referred to as [
11] delved into the scheduling of directed acyclic graph (DAG) module applications across cloud resources. They transformed their DAG task placement challenge into an integer programming problem with binary values (zero and one), aiming to minimize makespan and ensure a high rate of successful executions. To address this issue, they introduced a dynamic downward ranking approach that organizes the scheduling priorities of various subtasks. This approach takes into explicit consideration the sequential execution nature of the DAG structure. Moreover, they introduced a mechanism that relies on degree-based weighting and earliest finish time calculation. This mechanism assigns the subtask with the highest scheduling priority to available resources, thereby facilitating swift task execution and dependable communication links. The problem of dispatching applications onto available resources without reusing the allocated virtual machines leads to higher latency overhead and increased computational costs as the volume of requests grows. Our approach sets itself apart from their methods by taking into account more complex system attributes.
The publication referenced as [
12] introduced a heuristic framework with the goal of reducing the operational expenses associated with microservice-oriented workflow modules. This framework also ensures adherence to predefined deadlines and reliability thresholds. To achieve this, the authors implemented a greedy approach to placing application replicas, which considers fault tolerance. This method aims to locate suitable resources that meet the deadlines and minimize costs while ensuring reliability. Additionally, they introduced a resource optimization process to enhance the utilization of available resources. The extensive mapping of applications onto cloud resources results in amplified transmission delays, particularly when users are distant from data sources. Our algorithm distinguishes itself from their methods by actively addressing and alleviating the cloud computing bottleneck.
The paper [
13] introduced an innovative method for arranging tasks on cloud resources through a unique scheduling technique based on the reliability of critical parent tasks. The objective was to enhance the reliability of the scheduling process while upholding restrictions such as deadlines and operational expenses. The authors also factored in potential failures in processors and communication links within their system design. Their suggested solution demonstrated superior performance compared to rival algorithms, as evidenced by evaluations on benchmark workflow systems like Cybershake, Sipht, and Montage. Their approach falls short when it comes to articulating the intricacies of the workload balancing challenge and relies on basic system characteristics. In contrast, our model stands apart from their strategies because our technique arrives at a dependable decision by reducing the workload, a crucial aspect that becomes inadequate when virtual machines migrate away from overloaded server machines.
The paper [
14] tackled the challenge posed by resource-intensive scientific workflows with diverse requirements. The authors pointed out that relying solely on cloud solutions is not always sufficient to meet the escalating demands of these intensive applications. Given these constraints, they introduced a multi-cloud approach centered around robust workflow placement systems. Their primary objectives were to enhance the dependability of workflow execution and to minimize the associated costs. They achieved this by applying the Weibull distribution to analyze the reliability and hazard rate of module application execution. Additionally, they harnessed the billing strategies of multiple cloud service providers to enhance overall system efficiency. The article also introduces a cost-effective layer for DAG-structured workflows, integrating a fault-tolerant and cost-efficient scheduling model. This integration aims to reduce both the operational costs and time of task execution, all while ensuring their reliability. Nonetheless, the authors do not prioritize the service provider’s profitability as one of the top objectives in their assessed metrics. Therefore, our approach addresses this concern by incorporating cloud service providers into the system design and formulating strategies to enhance their profits.
The paper [
15] introduced an innovative approach to mapping workflow module applications, utilizing fuzzy resource utilization and incorporating the PSO model. The primary goal of this approach is to reduce both operational costs and the time required for completion, while still adhering to reliability constraints. The proposed system takes into account factors such as the origin of the data and the sequence of conveyance. While their algorithm has indeed demonstrated superior system performance, the proposed solution focuses exclusively on three evaluated metrics: makespan, operational costs, and reliability. It falls short in terms of optimizing power costs and resource utilization rates effectively.
The article [
16] presented a dependable system using a distributed scientific workflow scheduling method to allocate module applications within a diverse distributed computing setup, in which failures in processing hosts and communication networks are inevitable. The proposed algorithm aims to improve the reliability of task execution while adhering to an unavoidable end-to-end delay (EED) limit. The algorithm operates through sequential phases. Initially, it gives priority to, arranges, and organizes workflow tasks on the critical path (CP). These tasks are then assigned to dependable and time-conscious resources, using techniques such as iterative CP exploration and layer priority definition. In the subsequent phase, the algorithm assigns tasks on the non-critical path to cloud resources for enhanced execution dependability.
The article [
17] proposed a new placement model to adjust the makespan and operational costs for scheduled tasks while security and reliability metrics are optimized. The proposed paradigm works in two phases. In the first phase, the optimal task–server pairing is detected, guaranteeing system performance, security, and reliability. In contrast, the second phase of the reallocating procedure is repeated iteratively to modify the execution process and operational expenses by lowering the variance of the gauged makespan. Their proposed system outperforms other state-of-the-art algorithms in terms of completion time, operating costs, efficient resource utilization rates, and more acceptable time and economic expenditure trade-offs. The existing paradigm has not incorporated specific objectives like service provider profits and virtual machine time slots, whereas our approach takes these objectives into account.
The paper [
18] introduced a mixed reliability-conscious solution designed for executable resources, with the goal of enhancing users’ quality of service. The dependability of a resource can significantly influence the efficiency of workload distribution. The arrangement of workloads is structured as a sophisticated scientific workflow. Within the suggested framework, strategies for dividing deadlines and budgets are explored to differentiate between resource instances and module applications. The sequence of users is established through a user sequencing method. Moreover, the allocation strategy for applications is examined, focusing on the arrangement of tasks that are prepared for assignment onto appropriate and available resources. While their approach effectively achieves load balancing among virtual machines, it does not take into account the potential energy savings that can be realized through application placement. Conversely, our method calculates energy consumption by considering the allocated power costs.
As the demand for workflow applications continues to grow, the task of locating the best pair of task servers is becoming increasingly challenging. This challenge is exacerbated by the rising number of workflow applications, resulting in higher system latency. Additionally, incorporating meta-heuristic methods to strike a balance between exploration and exploitation in the search process poses another obstacle, often leading to longer processing times and latency-related delays. These represent the primary constraints of the suggested algorithm that require substantial consideration.
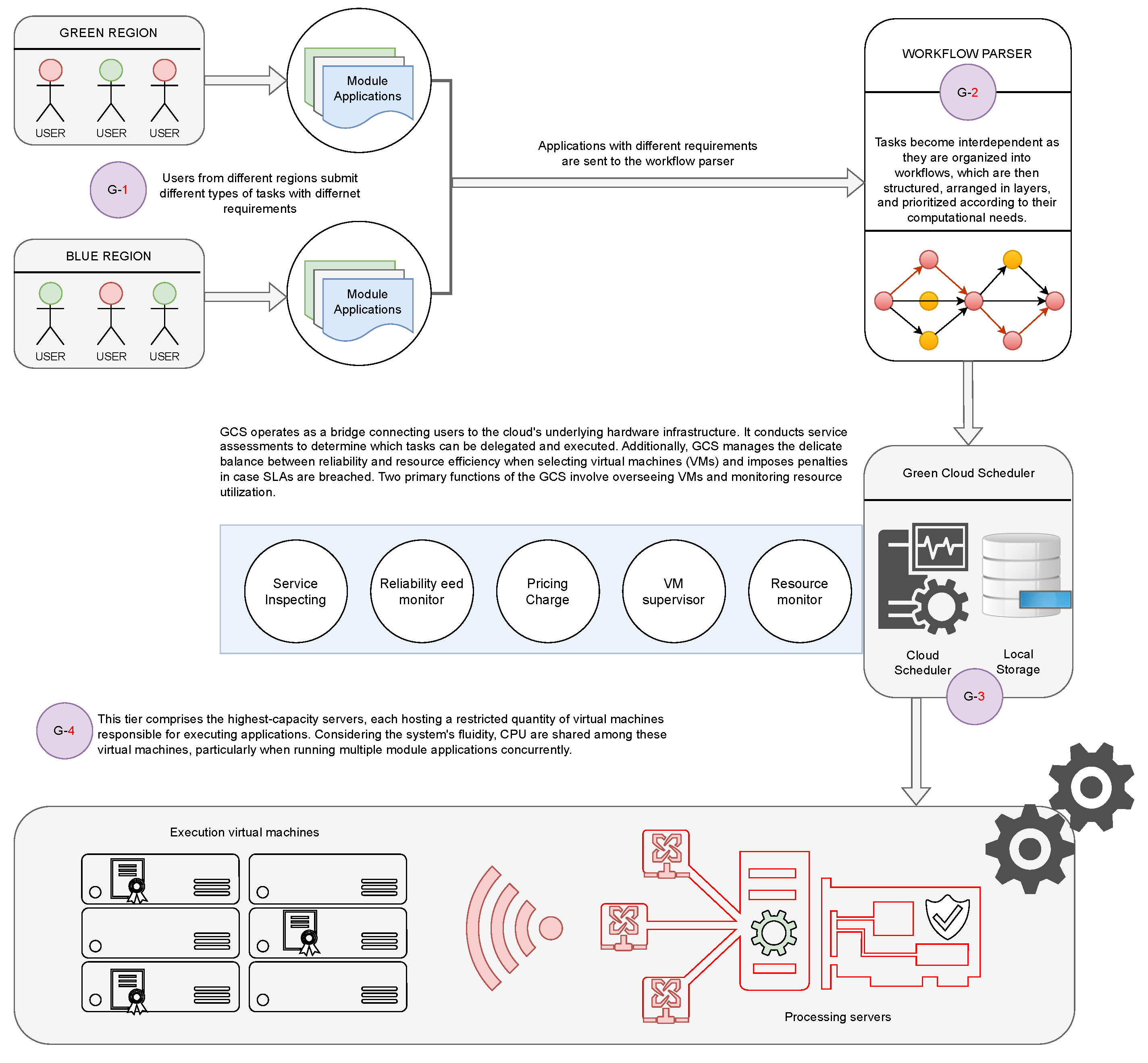
5. Algorithm Formulation
This section seeks to clarify the method we propose to augment the efficiency of the suggested WSHO algorithm within cloud systems by integrating hybridized metaheuristic approaches. The paired procedural methods of the suggested WSHO algorithm are elucidated in Algorithm 1.
The initial method integrates an iterative exploration of the critical path and prioritization techniques based on layer structure. This approach is employed to identify the critical path for designated workflows, divide applications into distinct layers, and arrange the applications within each layer according to their computational and communicative needs. This phase differentiates between module applications as sensitive or non-sensitive tasks, harnessing the EED minimization function.
In the second phase, the analysis accounts for the likelihood of server failures and aims to avoid servers with elevated probabilities of experiencing failures. During this stage, we have implemented a wild horse optimization algorithm incorporating a levy flight model. This choice strengthens the objective of enhancing reliability by strategically assigning module applications to appropriate server resources.
| Algorithm 1: Workflow scheduling horse optimization (WSHO) |
Input: Module Applications Graph (), Network Placement Graph
(), and Network Dependency Edges in the Graph
(), Deadline for moudle applications in the workflow
Output: Scheduling module applications on the most reliable and EED optimized processing servers in the Graph
![Mathematics 11 04334 i001]() |
5.1. Module Application Scheduling
This algorithm operates within the architecture of a workflow parser system to identify a mapping solution while considering resource sharing for all module applications present in the directed acyclic graph (DAG). By analyzing the architecture and requirements of each application, the algorithm organizes tasks and creates various types of workflows. It calculates the time costs for both computation and data transfer of the applications and then utilizes a linear-time, layer-based sorting model to group the applications into different layers. Applications within the same layer can be executed concurrently, with at most one application from the critical path included in the same layer.
Subsequently, the algorithm prioritizes applications within the same layer based on their respective computation and transfer time costs. Applications with higher costs are given greater priority and are assigned first. The algorithm establishes the initial critical path for each workflow, starting from the first application and proceeding through to the final application, using the polynomial-time technique of determining the longest path. Identifying the critical path is crucial as it highlights the longest route, and any application within this path is recognized as consuming the most time and therefore must be executed sequentially.
The algorithm also incorporates a consideration of failure rates to enhance task security during the execution process. It calculates both the initial and overall reliability-enhanced execution time for the critical path, along with the initial and real reliability-enhanced data transfer time for that path. The newly adjusted critical path is computed based on the existing mapping solution, resulting in the regeneration of reliability-enhanced execution and transfer times. The comprehensive description of the algorithm is provided in Algorithm 2.
| Algorithm 2: Application Scheduling Algorithm (ASA) |
Input: , , and Output: Improved Reliability–EED provisional and ultimate mapping arrangement |
5.2. Module Application Placement
The Algorithm 3 initially enhances the reliability of data execution and transmission durations as outlined in Equations (
23) and (
24). These factors have a direct impact on the operational timeframe of module applications and the occurrence of network link failures.
The equation above indicates that the improvement in data execution efficiency is inversely proportional to the success rate of the assigned processing server.
The equation above suggests that the enhancement of data transmission efficiency is inverse to the success rate of the designated bandwidth connection.
The algorithm transmits historical data from module applications to the underlying cloud hardware and obtains details about processing servers, encompassing their connections and assigned virtual machines. These data aid the algorithm in creating a query for precursor and successor servers, streamlining the assignment of dependent modules. Applications are received by the algorithm in a sequential manner, prioritized based on their importance, commencing from the initial layer and continuing until completion. After mapping all applications in the first layer, the algorithm enters a brief waiting period prior to commencing the mapping of applications in the subsequent layer. This encompasses a check to ascertain whether all module applications in the first layer have been situated on servers that are conscious of the trade-off between reliability and EED. In the aftermath of this process, each server exchanges information about its neighboring connections with other processing servers. Consequently, three potential scenarios come into play.
| Algorithm 3: Application placement algorithm (APA) |
Input: , , ,
, , , , and
Output: Final module application mapping scheme with reliability and EED improvement
![Mathematics 11 04334 i003]() |
The processing server holds all preceding module applications leading up to the current preprocessing , which could render it a viable option for selecting the server destination.
The processing server has the task of hosting a module application that comes before in sequence. We check if is connected to any servers holding module applications before . If such connections are established, then becomes a possible choice for assigning the mapping; otherwise, it is not considered suitable.
The processing server cannot host any module applications before in sequence. In this case, we investigate the connections of the server with others. If it connects with a server that houses module applications preceding , then becomes a viable choice for mapping; otherwise, it is deemed unsuitable.
The primary aim of these situations is to determine the server that can provide the most favorable balance between reliability and time. To achieve a portion of this improvement, the process involves computing the partial end-to-end delay of the mapping procedure. This calculation aids in selecting the mapping approach that results in the lowest partial EED for the mapping process.
Once the mapping of highly sensitive module applications is completed, the algorithm proceeds to map applications that are not part of the critical path. Similar to the initial mapping phase, it is necessary to balance between reliability and EED. In this regard, the algorithm begins with applications that have a new completion time that is earlier than their latest recorded finish time. Just as in the previous mapping procedure, processing servers that have direct connections to servers containing previously assigned module applications are taken into account for this round of mapping.
6. Experimental Findings and Discussions
This section primarily concentrates on the examination of three key phases. Initially, we delve into the configuration of the simulation. Subsequently, we elucidate the approach based on scenarios employed in this study. Lastly, we assess the results derived from the simulation.
6.1. Software Setup
We implemented the suggested WSHO algorithm using the CloudSim toolkit [
25] on the Windows 11 operating system. The system utilized an Intel Core i5 CPU from the 12th generation, clocked at 1.3 GHz, along with 8.0 GB of memory. The specifics of the simulation configuration, processing servers, and virtual machines can be found in
Table 1.
6.2. Scenario-Based Study
To verify the experimental simulation results concerning time efficiency and reliability, we executed two distinct scenarios. The initial scenario encompassed applications with modest to moderate resource requirements, while the subsequent scenario entailed applications spanning from moderate to substantial data sizes. Both scenarios incorporated factors such as server processing capacity, server failure likelihood, communication link reliability, bandwidth failure probability, and minimal link latency.
Furthermore, for the purpose of performing comparative assessments, we employed three effective algorithms:
Reliability-Aware Multi-Objective Memetic Algorithm (RA-MOMA) [
9]: This represents a versatile algorithm that harmonizes task completion speed, operational costs, and system dependability through a diversified approach to generating various offspring entities. It takes into account specific constraints, including task duration, operational expenses, and system reliability.
Critical Parent Reliability-based Scheduling (CPRS) [
13]: The authors of this research brought forth a novel approach to organizing tasks on cloud resources by employing an exclusive scheduling method that hinges on the dependability of crucial parent tasks. Its objective is to boost the dependability of the scheduling procedure while adhering to constraints like deadlines and operational costs. Additionally, the algorithm takes into account processor failures and communication links as integral elements of their system design.
Distributed Reliability Maximization workflow mapping algorithm under End-to-end Delay constraint (dis-DRMED) [
16]: This study introduced a reliable system that utilizes a distributed scientific workflow scheduling technique to allocate module applications in a varied distributed computing environment, recognizing the inevitability of failures in processing hosts and communication networks. The primary goal is to enhance the dependability of task execution while respecting an unavoidable end-to-end delay (EED) constraint.
6.3. WSHO Complexity Analysis
The computational intricacy of the WSHO model is characterized by a complexity of , with representing the count of processing servers, indicating the quantity of applications, and standing for the iterations. The highest level of complexity emerges when the network is fully connected, leading to every server potentially serving as a candidate mapping destination for all module applications.
6.4. Simulation-Based Result Analysis
This section elucidates the primary elements that directly influence the results of the experiments. This encompasses their effects on completion time, reliability, energy usage, and provider throughput across a spectrum of application sizes, ranging from small to medium and up to large datasets.
6.4.1. Impact of Application Sizes on the EED
Figure 2a depicts the time analysis of the suggested WSHO approach and the existing dis-DRMED, RA-MOMA, and CPRS methods, concerning workloads ranging from small to moderate sizes. With an increase in the number of module applications, there is a corresponding rise in the time rate. This occurrence is attributed to the submission of more applications by users from various locations, each carrying distinct weights. Nevertheless, the proposed WSHO algorithm outperforms its competitors. For instance, when the applications reach a count of 100, the time value for WSHO stands at 5.75, compared to 6.38 for dis-DRMED, 7.0 for RA-MOMA and 7.80 for CPRS. Moreover, as the number of applications surges to 500, the EED values for WSHO, dis-DRMED, RA-MOMA, and CPRS are 19.12, 21.88, 25.12, and 29.34, respectively.
In
Figure 2b, the same evaluation is conducted for the proposed WSHO approach and current algorithms, namely dis-DRMED, RA-MOMA, and CPRS. However, this time, the weights of the workload are adjusted to encompass tasks of moderate to extensive sizes. Initially, all approaches exhibit similar trends, but as the number of applications increases, differences between the algorithms become more pronounced. For instance, when the application count reaches 100, the EED values for WSHO, dis-DRMED, RA-MOMA, and CPRS are 17.15, 18.10, 19.30, and 21.13, respectively. Yet, with 500 applications, these values escalate to 27.45, 28.52, 32.80, and 35.14 for all algorithms.
The aforementioned data analysis underscores that extensive applications demanding high computational power and complexity tend to result in longer finish time due to heightened application transfer latency. As evident from the comparison figures, the time values for WSHO are significantly lower than the other three algorithms. This performance gap becomes especially conspicuous as the module application data transfer size expands. Overall, the proposed WSHO consistently maintains a lower finish time across all scenarios. This accomplishment is attributed to the distinctive manner in which our model distributes the mapping schedule, enabling superior scalability as the network environment scales up.
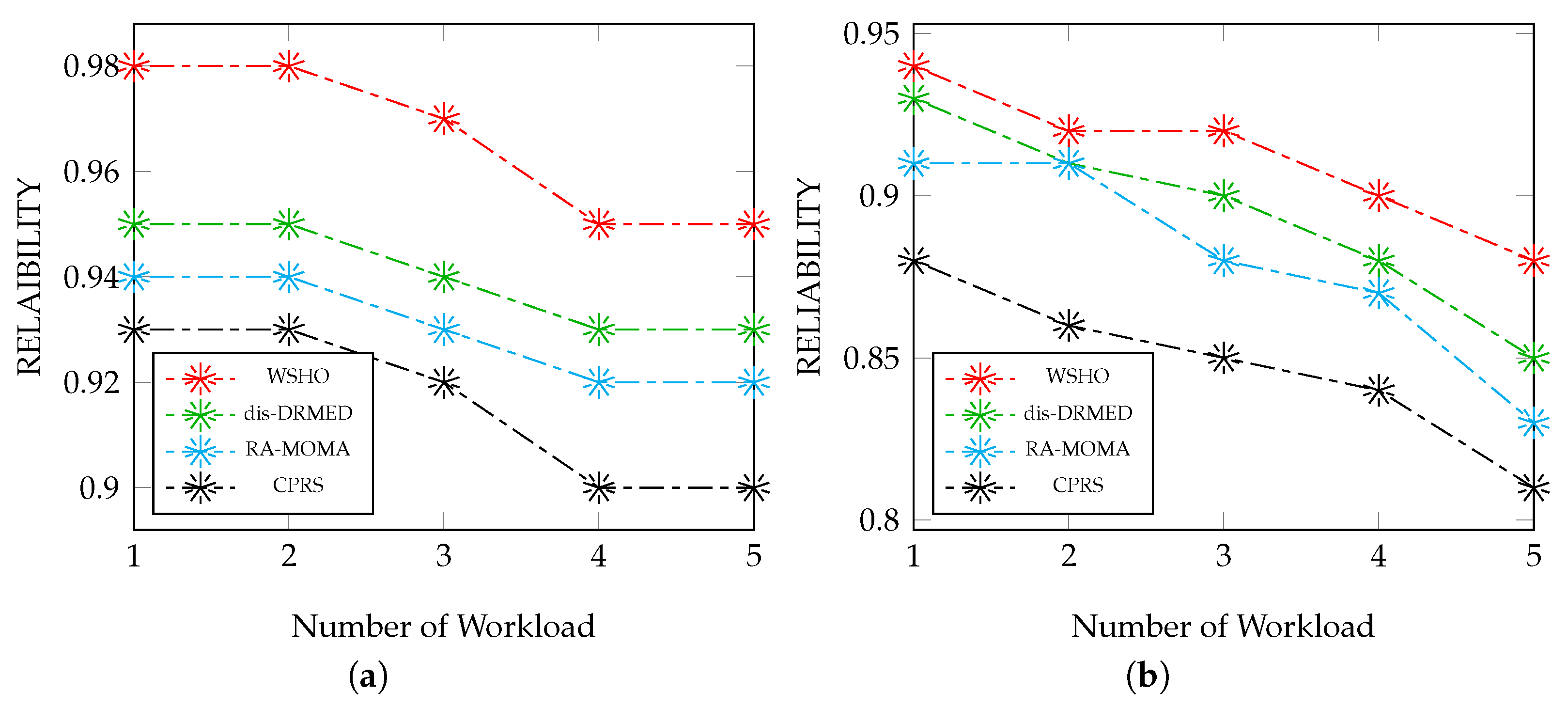
6.4.2. Impact of Application Sizes on the Reliability
Figure 3a illustrates the evaluation of the reliability of the suggested WSHO algorithm in comparison to existing methods, dis-DRMED, RA-MOMA, and CPRS, concerning data sizes ranging from small to moderate. The effectiveness of the system is directly impacted by the accurate placement of module applications on dependable destinations. Therefore, enhancing this percentage rate holds crucial importance. The proposed WSHO algorithm outperforms alternative methods by a substantial margin. For instance, when the count of applications reaches 100, the proposed WSHO algorithm achieves a reliability rate of 0.98, whereas the competing algorithms, dis-DRMED, RA-MOMA, and CPRS, attain rates of 0.95, 0.94, and 0.93, respectively. Moreover, as the count of module applications reaches 500, WSHO achieves a reliability improvement of 0.95. In contrast, dis-DRMED, RA-MOMA, and CPRS experience enhancements of 0.93, 0.92, and 0.90, respectively.
Figure 3b presents a comparison between the proposed WSHO algorithm and alternative approaches like dis-DRMED, RA-MOMA, and CPRS, focusing on varying numbers of workloads, spanning from moderate to intense. Across all scenarios, as the sizes of applications increase, there is a gradual decline in reliability, leading to a degradation of the system’s performance. However, the suggested WSHO algorithm maintains a satisfactory level of reliability. To illustrate, when the module count reaches 100, the proposed WSHO algorithm achieves a reliability value of 0.94, in contrast to dis-DRMED, RA-MOMA, and CPRS, which achieve reliabilities of 0.93, 0.91, and 0.88, respectively. This enhancement is also evident with a workload size of 500. The proposed WSHO algorithm achieves a reliability of 0.88, while the competing algorithms, dis-DRMED, RA-MOMA, and CPRS, record reliabilities of 0.85, 0.83, and 0.81, respectively.
The data assessments clearly indicate that the proposed WSHO algorithm exhibits considerably superior reliability rates compared to the other algorithms, dis-DRMED, RA-MOMA, and CPRS. This decline in performance becomes notably conspicuous as both the module application sizes and network connection links expand. Additionally, it is evident that reliability experiences a reduction as the problem size grows due to increased computing and application transfer activities within the system. However, the improvement in reliability achieved using the proposed WSHO algorithm remains noteworthy when compared to alternative methods of similar nature. Our approach distinguishes itself from other algorithms by factoring in potential failures of processing servers and network links, thereby achieving enhanced scalability as the network environment expands.
6.4.3. Impact of Application Sizes on the Energy
Energy usage poses a significant concern when deploying applications on cloud resources. This factor can have negative impacts on other performance metrics. To demonstrate the effectiveness of the proposed WSHO algorithm,
Figure 4a provides a comparison between the algorithm and dis-DRMED, RA-MOMA, and CPRS in terms of energy consumption. The data analysis reveals that the suggested WSHO algorithm outperforms its competitors in scenarios involving small to moderate workloads. As the packet sizes increased to 500, all algorithms experienced a sharp rise in energy consumption, with the WSHO algorithm exhibiting superior efficiency in conservation. Conversely, the dis-DRMED, RA-MOMA, and CPRS algorithms consumed around 13.05, 22.11, and 24.65, respectively. In scenarios involving 100 workloads, the energy consumption was approximately 3.45 for the WSHO algorithm, 3.88 for dis-DRMED, 4.65 for RA-MOMA, and 5.64 for CPRS.
To affirm the efficacy of the introduced WSHO algorithm, we subjected it to an assessment under conditions of moderate to high workloads. Upon initial observation, the proposed WSHO algorithm demonstrates a greater capacity for energy preservation compared to alternative algorithms, specifically when the application count is set at 100. In this scenario, its consumption stands at a mere 7.65 units, while competing models, namely dis-DRMED, RA-MOMA, and CPRS, register consumption levels of approximately 9.45, 11.23, and 13.14 correspondingly. As the number of applications increases, consumption values also rise accordingly. For instance, at an application count of 500, the consumption rates are measured at 23.74 for the WSHO algorithm, 25.09 for dis-DRMED, 28.27 for RA-MOMA, and 31.21 for CPRS, reaffirming the superior performance of the proposed WSHO algorithm.
As indicated by the conclusions drawn from both figures, the suggested WSHO framework demonstrates proficient energy conservation in contrast to alternative strategies, specifically dis-DRMED, RA-MOMA, and CPRS. This superiority is attributed to how the proposed WSHO algorithm efficiently redistributes virtual machines, thus averting the introduction of unnecessary overheads that arise when adjacent virtual machines are tasked with handling applications. A notable advantage of the proposed WSHO algorithm lies in its adept handling of application allocation across servers. This approach not only mitigates latency and addresses server and network failures, but also encompasses considerations for optimizing processing resource utilization during application execution.
6.4.4. Impact of Application Sizes on the Service Throughput
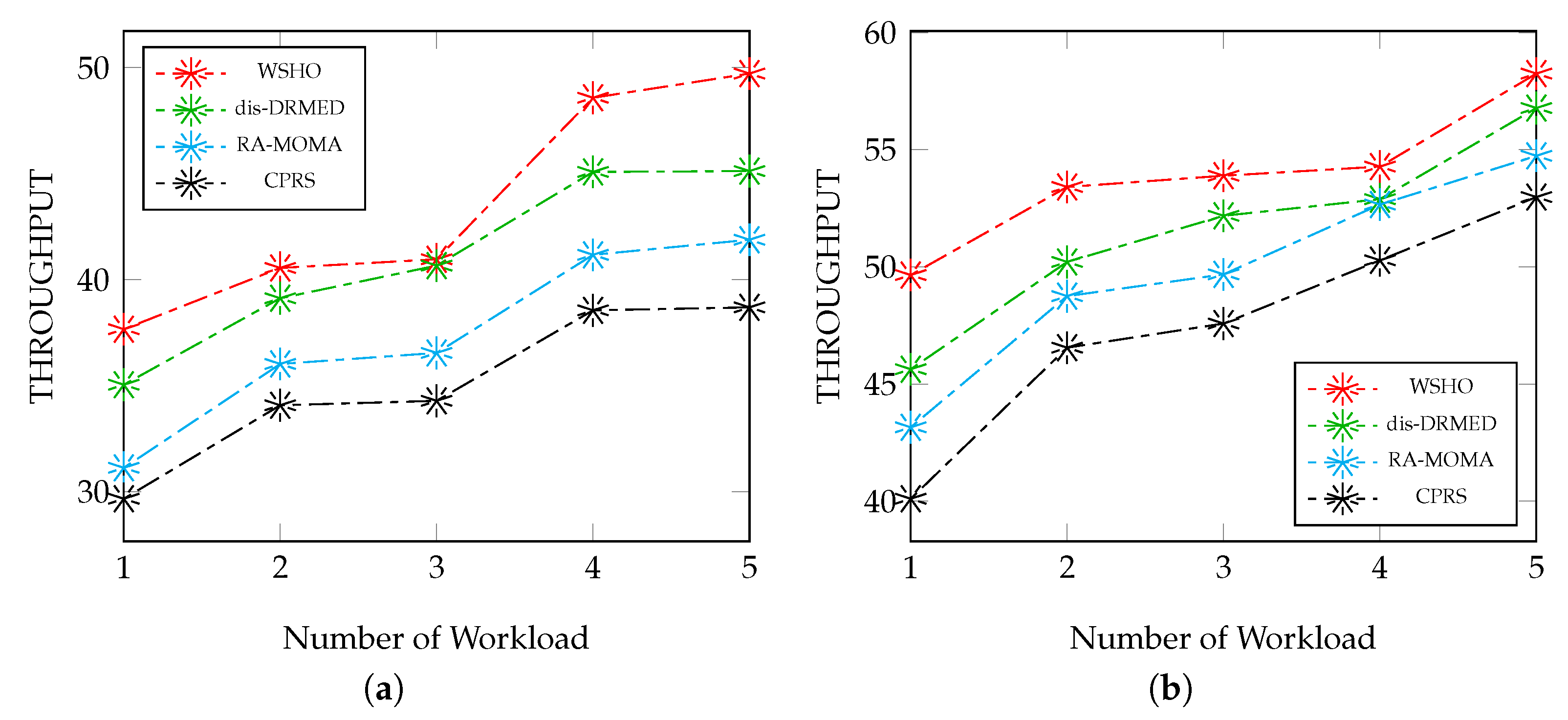
Cloud service providers continuously strive to enhance the rate of this evaluation parameter, as it plays a pivotal role in augmenting the providers’ returns. Illustrated in
Figure 5a, we conducted a comparative analysis using small to moderate dataset to juxtapose our novel WSHO algorithm against dis-DRMED, RA-MOMA, and CPRS, gauging the provider profit percentages. The numerical results underscore the substantial profit gains achieved by the proposed WSHO algorithm compared to the other algorithms, dis-DRMED, RA-MOMA, and CPRS. Particularly, the least favorable outcome is observed with CPRS, which exhibits the lowest values.
We executed two distinct experimental scenarios. Initially, we evaluated the algorithms’ performance across a range of workloads, spanning from light to moderate. Subsequently, we assessed their performance within the realm of moderate to heavy workload sizes. In the initial scenario, with 100 applications in play, the proposed WSHO algorithm achieved a rate of 37.66, while the alternative methodologies, dis-DRMED, RA-MOMA, and CPRS, registered rates of 35.84, 31.12, and 29.66, correspondingly. Even as the workload count escalated to 500, the proposed WSHO algorithm maintained its superiority, achieving a rate of 49.72. In comparison, dis-DRMED secured a rate of 45.12, while RA-MOMA, and CPRS achieved rates of 41.88 and 38.69.
In the second scenario, we opted to evaluate the algorithms’ effectiveness concerning provider outcomes under conditions ranging from moderate to intense workloads. Once again, the proposed WSHO algorithm consistently outperformed the other alternatives, namely dis-DRMED, RA-MOMA, and CPRS, in terms of throughput percentage. When the data size stood at 100, the proposed WSHO algorithm achieved a throughput of 49.65, while dis-DRMED achieved 45.63, RA-MOMA gained 43.15, and CPRS reached 40.10. Moreover, even as the workload count escalated to 500, the proposed WSHO model continued to exhibit superior performance compared to the other three methods. Specifically, the throughput efficiency for the WSHO algorithm measured 58.25, while for dis-DRMED it was 66.78, for RA-MOMA it was 54.74, and for CPRS it reached 52.98.
With the augmentation in the quantity of packet weights related to module applications, there is a corresponding gradual rise in the service profits for the providers. This progression contributes to an enhanced framework profitability. Notably, the suggested WSHO algorithm demonstrates superior performance across all scenarios when compared to the alternative models, dis-DRMED, RA-MOMA, and CPRS. The achievement of this heightened provider interest is primarily attributed to the proposed WSHO algorithm’s adept management of overhead latency, energy consumption, completion time, scheduling reliability, and efficient application placement. These factors collectively contribute to attaining the highest level of provider interest.
6.5. Real-Time-Based Result Analysis
Reliability and time constraints are considered two of the most effective evaluation metrics for resource placement algorithms. Users desire to place their applications on reliable resources and finish them before their deadlines. For this evaluation test, we compare our proposed paradigm with other comparable algorithms with respect to two different real scientific workflows, LiGO and SIPHT, for different workload sizes.
6.5.1. Real-Time Evaluation Based on Application Finish Time
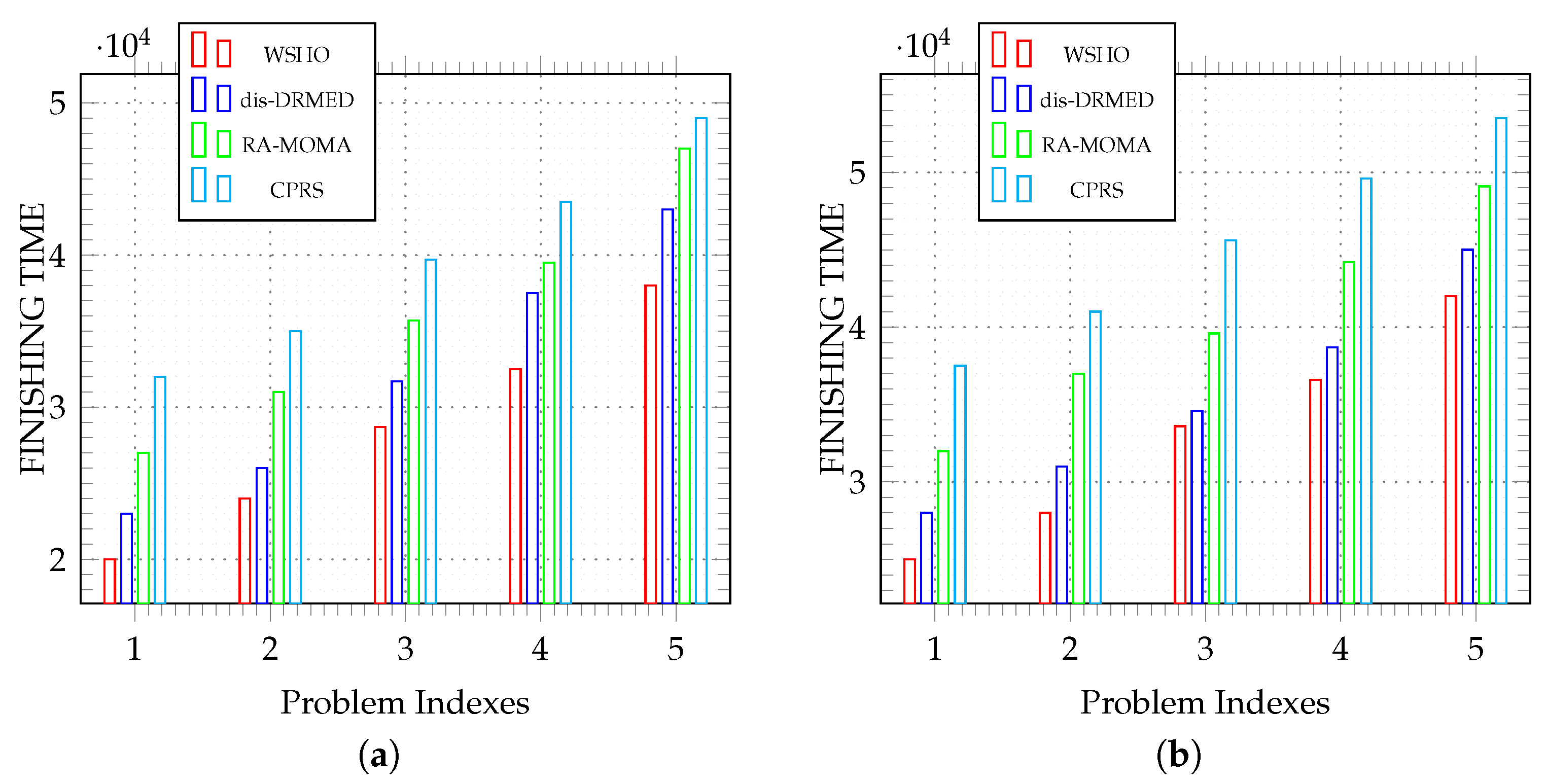
Figure 6 illustrates a comparison between our WSHO algorithm and alternative algorithms, including dis-DRMED, RA-MOMA, and CPRS, concerning scientific workflow applications like LIGO and SIPHT. For smaller application sizes, such as indexes 1, 2, and 3, the distinctions between the algorithms are minimal. However, as the dimensions increase in indexes 4 and 5, the disparities between them become more pronounced.
Figure 6a demonstrates that, when analyzing LIGO scientific workflow applications, our proposed WSHO algorithm achieves faster application execution times compared to the other three algorithms. Initially, the performance trends for all algorithms appear to be similar. However, as application sizes increase, the distinctions among them become more pronounced. This discrepancy arises because applications in indexes 1, 2, and 3 demand lower computational resources and exhibit lower complexity. Conversely, applications in indexes 4 and 5 necessitate substantial computational power and intricate processing, resulting in longer execution times.
Figure 6b illustrates that, in the evaluation of SIPHT scientific workflow applications, our proposed WSHO algorithm completes the assigned tasks more quickly than the dis-DRMED, RA-MOMA, and CPRS algorithms. The difference becomes particularly significant as the size of the workflow applications increases, notably in indexes 4 and 5. These algorithms demand more executable resources to process the incoming large-scale applications. In certain cases, particularly with the RA-MOMA and CPRS algorithms, applications are placed in waiting queues and experience longer wait times due to limited resource availability and challenges related to virtual machine window matrices. This results in extended execution times, leading to missed deadlines. The overall improvement in performance, as measured by finish time, is remarkable when using the WSHO algorithm compared to the dis-DRMED, RA-MOMA, and CPRS algorithms. This improvement is attributed to the dynamic resource executable management and avoidance of virtual machine overlapping offered by the former algorithm.
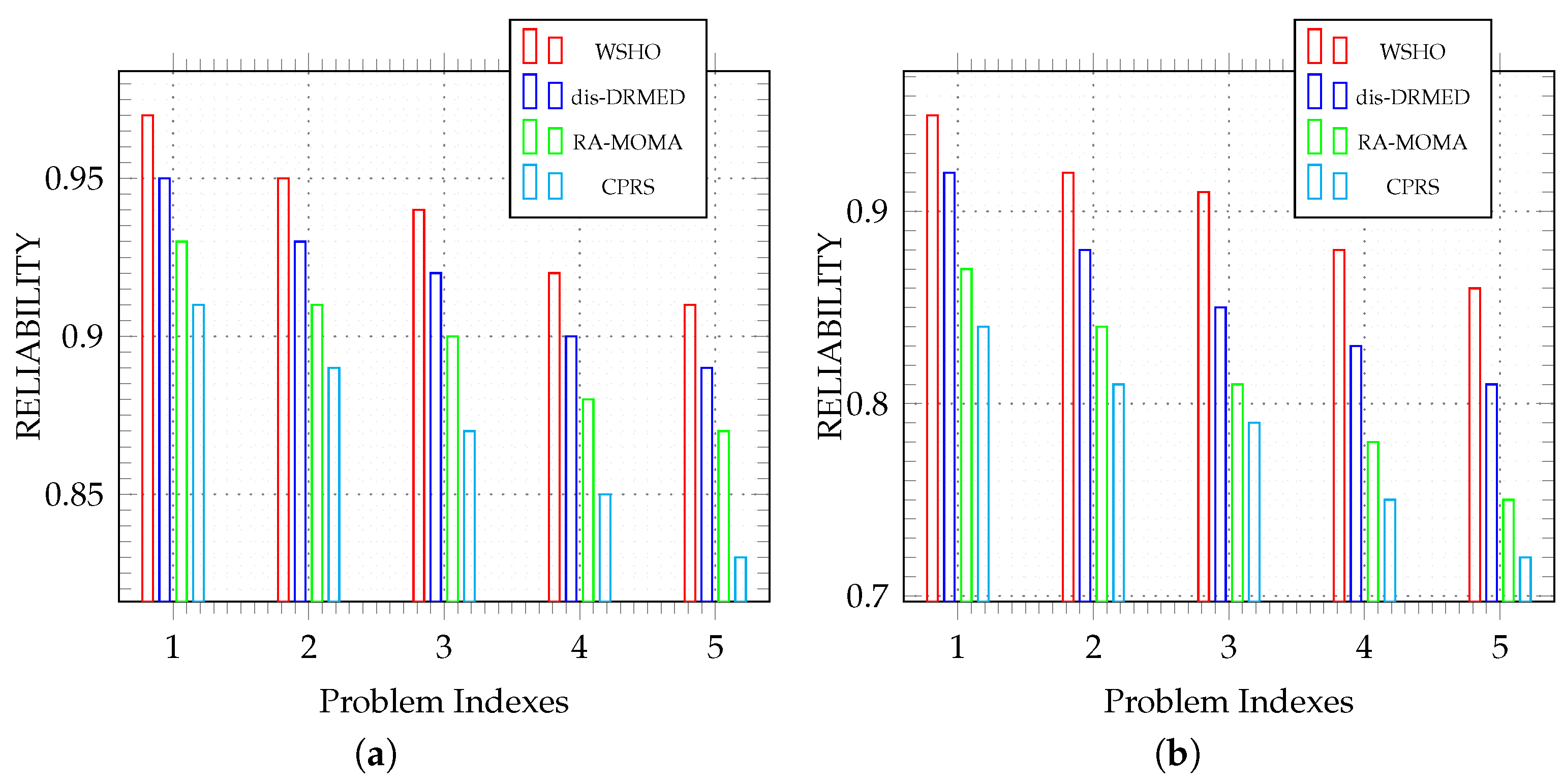
6.5.2. Real-Time Evaluation Based on Execution Reliability
Figure 7 presents a comparison between our WSHO model and three other algorithms, dis-DRMED, RA-MOMA, and CPRS, in the context of scientific workflow applications such as LIGO and SIPHT. As application sizes increase, ensuring their execution reliability becomes increasingly challenging. This is primarily due to the inclusion of more computationally intensive applications that demand greater attention to reliability.
Figure 7a assesses the reliability of LIGO workflow module applications, where an effective algorithm can reduce resource and communication fault rates. To comprehensively evaluate our proposed WSHO algorithm against its competitors, we conducted an analysis of execution reliability across various index problem sizes. The results depicted in
Figure 7a indicate that the WSHO algorithm adeptly manages server and communication link failures during application placement, leading to superior reliability outcomes. For problem sizes 1, 2, and 3, the algorithms exhibit similar performances, but as the workload increases in indexes 4 and 5, WSHO outperforms the other algorithms. Based on the findings from
Figure 7a, it is evident that the WSHO algorithm excels in identifying and utilizing the most reliable resources for accommodating LIGO workflow applications.
Figure 7b provides a comparison of algorithm reliability and efficiency concerning various sizes of SIPHT workflow applications. The results depicted in
Figure 7b confirm that our proposed WSHO algorithm consistently achieves higher execution reliability compared to dis-DRMED, RA-MOMA, and CPRS across all workflow sizes. As is evident from
Figure 7b, as the size of workflow applications increases, the reliability of all algorithms decreases significantly due to the inclusion of more computationally demanding applications. Nevertheless, the WSHO algorithm outperforms the other models. Notably, the WSHO and dis-DRMED algorithms exhibit closely aligned performances because they both prioritize server and communication link reliability during application placement.
7. Conclusions and Future Work
This study introduces an innovative method for arranging and situating workflow module applications on appropriate cloud resources. The objective is to strike a balance between scheduling reliability and end-to-end application delay, reaching a point that maximizes provider benefits. Achieving optimization for both these conflicting goals concurrently poses a formidable challenge. To address this, we have integrated artificial intelligence-driven techniques, utilizing an enhanced version of wild horse optimization (WSHO) that blends with the levy flight strategy to efficiently explore novel avenues.
Our sophisticated hybrid approach facilitates the exchange of mapping decisions and routing information among processing servers. This not only highlights processing server and communication link failures to prevent system crashes and network congestion, but also imbues the model with local search capabilities and safeguards against premature convergence. To validate the efficacy of the proposed WSHO algorithm, we conducted two scenarios varying in application sizes. The first scenario covers applications with light to moderate complexity, while the second encompasses applications with moderate to heavy complexity. The central aim of this research is to identify resource placements that achieve a harmonious blend of exploring globally and exploiting locally. This involves efficiently utilizing the search space while mitigating the preference for resources prone to frequent failures.
Moreover, we subjected the simulation to four key evaluation metrics. In all case scenarios, our proposed WSHO algorithm outperforms the dis-DRMED, RA-MOMA, and CPRS methods, demonstrating its superiority. In the upcoming period, our focus will be on creating a real-time environment where we can assess the effectiveness of our proposed algorithm and examine how it compares to similar algorithms.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}