

PIDFusion: Fusing Dense LiDAR Points and Camera Images at Pixel-Instance Level for 3D Object Detection

Abstract
:1. Introduction
2. Related Works
2.1. 3D Object Detection Method Based on Single-Model
2.2. 3D Object Detection Method Based on Multi-Modal
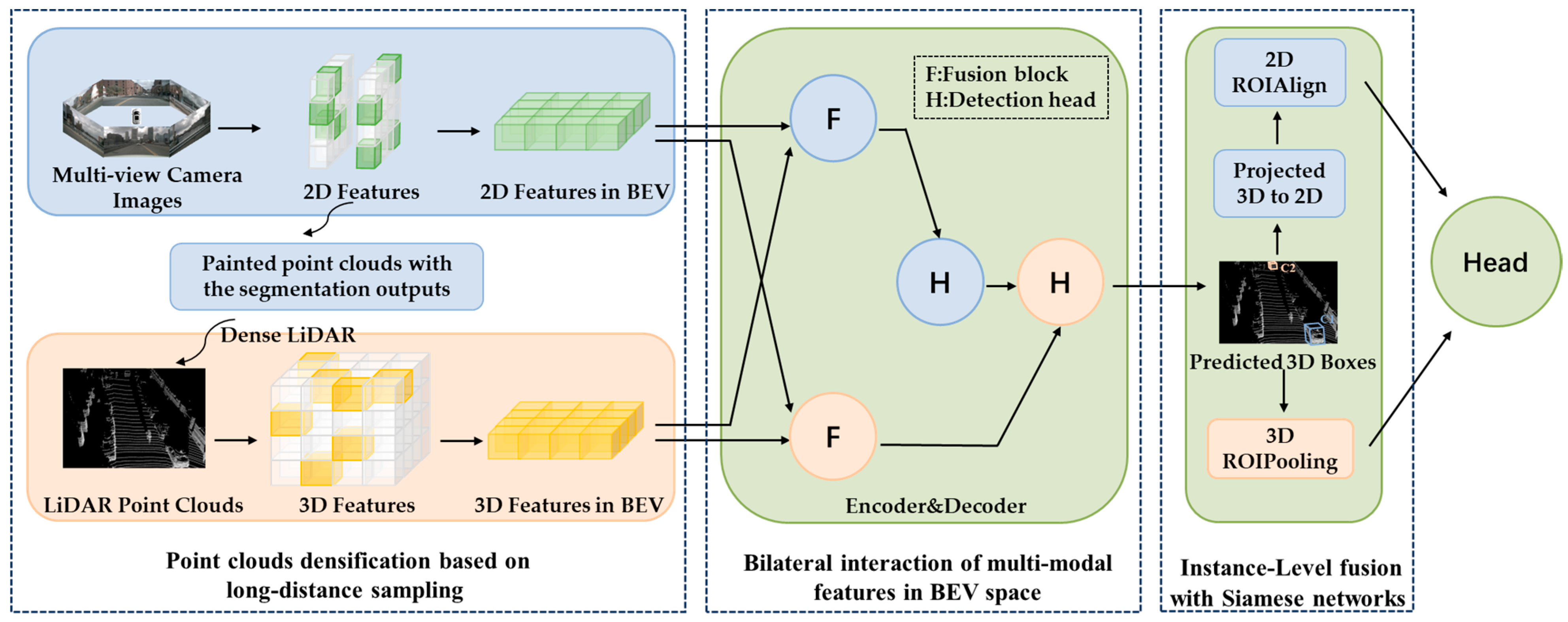
3. Method
3.1. Point Clouds Densification Based on Long-Distance Sampling
3.2. Bilateral Interaction of Multi-Modal Features in BEV Space
3.2.1. Feature Interaction between Multimodalities
- 1.
- The image coordinate system C and the point clouds coordinate system P are constructed, respectively. and represent the image representation and LiDAR representation from the perspective of BEV, respectively. Establish the alignment from IMAGE BEV to LiDAR BEV coordinate system: →. Given a coordinate (, ) in IMAGE BEV, use LSS [28] to find the pixel coordinates in the corresponding image. Then, according to the camera and LiDAR’s internal and external reference matrices, the corresponding relationship between the pixel coordinate system and the LiDAR coordinate system is found. The Z-axis compressed by the LiDAR coordinate system is the LiDAR BEV coordinate system. Then, find in LiDAR BEV to complete the mapping between the IMAGE BEV representation and the LiDAR BEV representation and the corresponding relationship . Similarly, from LiDAR BEV to Ithe MAGE BEV coordinate system , a coordinate in LiDAR BEV is given, and the pixel coordinates of the corresponding position in the point clouds are found. The pixel coordinates in the picture are obtained by the coordinate matrix and then projected to IMAGE BEV. The corresponding relationship is .
- 2.
- The interaction process from camera images to point clouds: A feature point of IMAGE BEV is used as , and the cross-modal feature is used as K and V for cross-attention learning; denotes indexing the element at location on the 2D representation g. This is image-to-LiDAR representational interaction.
3.2.2. Feature Interaction within a Single Modality
3.2.3. Feature integration
3.3. Instance-Level Fusion with Siamese Networks
4. Experiment
4.1. Dataset Introduction
4.2. Implementation Details
4.3. Evaluation Metrics
4.4. Experimental Results on nuScenes Dataset
4.5. Ablation Experiment
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chen, Z.; Li, Z.; Zhang, S.; Fang, L.; Jiang, Q.; Zhao, F.; Zhou, B.; Zhao, H.J. Autoalign: Pixel-instance feature aggregation for multi-modal 3d object detection. In Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence (IJCAI-22), Vienna, Austria, 23–29 July 2022. [Google Scholar]
- Li, Y.; Qi, X.; Chen, Y.; Wang, L.; Li, Z.; Sun, J.; Jia, J. Voxel field fusion for 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 1120–1129.
- Zhou, Y.; Tuzel, O. Voxelnet: End-to-end learning for point cloud based 3d object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4490–4499. [Google Scholar]
- Vora, S.; Lang, A.H.; Helou, B.; Beijbom, O. Pointpainting: Sequential fusion for 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 4604–4612. [Google Scholar]
- Wang, C.; Ma, C.; Zhu, M.; Yang, X. Pointaugmenting: Cross-modal augmentation for 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 11794–11803. [Google Scholar]
- Xu, S.; Zhou, D.; Fang, J.; Yin, J.; Bin, Z.; Zhang, L. Fusionpainting: Multimodal fusion with adaptive attention for 3d object detection. In Proceedings of the 2021 IEEE International Intelligent Transportation Systems Conference (ITSC), Indianapolis, IN, USA, 19–22 September 2021; pp. 3047–3054. [Google Scholar]
- Yin, T.; Zhou, X.; Krähenbühl, P. Multimodal virtual point 3d detection. Adv. Neural Inf. Process. Syst. 2021, 34, 16494–16507. [Google Scholar]
- Li, Y.; Yu, A.W.; Meng, T.; Caine, B.; Ngiam, J.; Peng, D.; Shen, J.; Lu, Y.; Zhou, D.; Le, Q.V. Deepfusion: Lidar-camera deep fusion for multi-modal 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 17182–17191. [Google Scholar]
- Fan, L.; Pang, Z.; Zhang, T.; Wang, Y.-X.; Zhao, H.; Wang, F.; Wang, N.; Zhang, Z. Embracing single stride 3d object detector with sparse transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 8458–8468. [Google Scholar]
- Wang, Y.; Chao, W.-L.; Garg, D.; Hariharan, B.; Campbell, M.; Weinberger, K.Q. Pseudo-lidar from visual depth estimation: Bridging the gap in 3d object detection for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 8445–8453. [Google Scholar]
- Lu, J.; Zhou, Z.; Zhu, X.; Xu, H.; Zhang, L. Learning ego 3d representation as ray tracing. In Proceedings of the Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; Proceedings, Part XXVI. pp. 129–144. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Chen, Y.; Liu, G.; Xu, Y.; Pan, P.; Xing, Y. PointNet++ network architecture with individual point level and global features on centroid for ALS point cloud classification. Remote Sens. 2021, 13, 472. [Google Scholar] [CrossRef]
- Mao, J.; Xue, Y.; Niu, M.; Bai, H.; Feng, J.; Liang, X.; Xu, H.; Xu, C. Voxel transformer for 3d object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 3164–3173. [Google Scholar]
- Lang, A.H.; Vora, S.; Caesar, H.; Zhou, L.; Yang, J.; Beijbom, O. Pointpillars: Fast encoders for object detection from point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 12697–12705. [Google Scholar]
- Yan, Y.; Mao, Y.; Li, B. Second: Sparsely embedded convolutional detection. Sensors 2018, 18, 3337. [Google Scholar] [CrossRef] [PubMed]
- Chen, X.; Kundu, K.; Zhang, Z.; Ma, H.; Fidler, S.; Urtasun, R. Monocular 3d object detection for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2147–2156. [Google Scholar]
- Brazil, G.; Liu, X. M3d-rpn: Monocular 3d region proposal network for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9287–9296. [Google Scholar]
- Simonelli, A.; Bulo, S.R.; Porzi, L.; López-Antequera, M.; Kontschieder, P. Disentangling monocular 3d object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1991–1999. [Google Scholar]
- Wang, T.; Zhu, X.; Pang, J.; Lin, D. Fcos3d: Fully convolutional one-stage monocular 3d object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 913–922. [Google Scholar]
- You, Y.; Wang, Y.; Chao, W.-L.; Garg, D.; Pleiss, G.; Hariharan, B.; Campbell, M.; Weinberger, K.Q. Pseudo-lidar++: Accurate depth for 3d object detection in autonomous driving. In Proceedings of the Eighth International Conference on Learning Representations (ICLR 2020), Virtual, 26 April–1 May 2019. [Google Scholar]
- Reading, C.; Harakeh, A.; Chae, J.; Waslander, S.L. Categorical depth distribution network for monocular 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 8555–8564. [Google Scholar]
- Liang, T.; Xie, H.; Yu, K.; Xia, Z.; Lin, Z.; Wang, Y.; Tang, T.; Wang, B.; Tang, Z. Bevfusion: A simple and robust lidar-camera fusion framework. Adv. Neural Inf. Process. Syst. 2022, 35, 10421–10434. [Google Scholar]
- Rubino, C.; Crocco, M.; Del Bue, A. 3d object localisation from multi-view image detections. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 1281–1294. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Guizilini, V.C.; Zhang, T.; Wang, Y.; Zhao, H.; Solomon, J. Detr3d: 3d object detection from multi-view images via 3d-to-2d queries. In Proceedings of the Conference on Robot Learning, Auckland, New Zealand, 14–18 December 2022; pp. 180–191. [Google Scholar]
- Yoo, J.H.; Kim, Y.; Kim, J.; Choi, J.W. 3d-cvf: Generating joint camera and lidar features using cross-view spatial feature fusion for 3d object detection. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XXVII 16. pp. 720–736. [Google Scholar]
- Liu, Z.; Tang, H.; Amini, A.; Yang, X.; Mao, H.; Rus, D.; Han, S. BEVFusion: Multi-Task Multi-Sensor Fusion with Unified Bird’s-Eye View Representation. In Proceedings of the 2023 IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May–2 June 2023. [Google Scholar]
- Philion, J.; Fidler, S. Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XIV 16. pp. 194–210. [Google Scholar]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Bai, X.; Hu, Z.; Zhu, X.; Huang, Q.; Chen, Y.; Fu, H.; Tai, C.-L. Transfusion: Robust lidar-camera fusion for 3d object detection with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 1090–1099. [Google Scholar]
- Yang, Z.; Chen, J.; Miao, Z.; Li, W.; Zhu, X.; Zhang, L. Deepinteraction: 3d object detection via modality interaction. Adv. Neural Inf. Process. Syst. 2022, 35, 1992–2005. [Google Scholar]
- Chen, X.; Ma, H.; Wan, J.; Li, B.; Xia, T. Multi-view 3d object detection network for autonomous driving. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1907–1915. [Google Scholar]
- Piergiovanni, A.; Casser, V.; Ryoo, M.S.; Angelova, A. 4d-net for learned multi-modal alignment. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 15435–15445. [Google Scholar]
- Lin, Z.; Shen, Y.; Zhou, S.; Chen, S.; Zheng, N. MLF-DET: Multi-Level Fusion for Cross-Modal 3D Object Detection. In Artificial Neural Networks and Machine Learning—ICANN; Springer Nature: Cham, Switzerland, 2023. [Google Scholar]
- Liu, Z.; Ye, X.; Zou, Z.; He, X.; Tan, X.; Ding, E.; Wang, J.; Bai, X. Multi-Modal 3D Object Detection by Box Matching. arXiv 2023, arXiv:2305.07713. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable detr: Deformable transformers for end-to-end object detection. In Proceedings of the Ninth International Conference on Learning Representations, Virtual, 3–7 May 2020. [Google Scholar]
- Mills-Tettey, G.A.; Stentz, A.; Dias, M.B. The Dynamic Hungarian Algorithm for the Assignment Problem with Changing Costs; Tech. Rep. CMU-RI-TR-07-27; Robotics Institute: Pittsburgh, PA, USA, 2007. [Google Scholar]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. nuscenes: A multimodal dataset for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 11621–11631. [Google Scholar]
- Graham, B.; Engelcke, M.; Van Der Maaten, L. 3d semantic segmentation with submanifold sparse convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 9224–9232. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the 28th International Conference on Neural Information Processing Systems (NIPS 2015), Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Zhu, B.; Jiang, Z.; Zhou, X.; Li, Z.; Yu, G. Class-balanced grouping and sampling for point cloud 3d object detection. arXiv 2019, arXiv:1908.09492. [Google Scholar]
- Chen, X.; Zhang, T.; Wang, Y.; Wang, Y.; Zhao, H. Futr3d: A unified sensor fusion framework for 3d detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Vancouver, BC, Canada, 18–22 June 2023. [Google Scholar]
- Jiao, Y.; Jie, Z.; Chen, S.; Chen, J.; Wei, X.; Ma, L.; Jiang, Y.-G. MSMDFusion: Fusing LiDAR and Camera at Multiple Scales with Multi-Depth Seeds for 3D Object Detection. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Yin, T.; Zhou, X.; Krahenbuhl, P. Center-based 3d object detection and tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 11784–11793. [Google Scholar]
- Yu, K.; Tao, T.; Xie, H.; Lin, Z.; Wu, Z.; Xia, Z.; Liang, T.; Sun, H.; Deng, J.; Hao, D. Benchmarking the Robustness of LiDAR-Camera Fusion for 3D Object Detection. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Vancouver, BC, Canada, 17–24 June 2023. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Modality | mAP | NDS | Car | Truck | C.V. | Bus | Trailer | Barrier | Motor. | Bike | Ped. | T.C. |
| FUTR [44] | LC | 64.2 | 68.0 | 86.3 | 61.5 | 26.0 | 71.9 | 42.1 | 64.4 | 73.6 | 63.3 | 82.6 | 70.1 |
| TransFusion [31] | LC | 67.3 | 71.2 | 87.6 | 62.0 | 27.4 | 75.7 | 42.8 | 73.9 | 75.4 | 63.1 | 87.8 | 77.0 |
| BEVFusion [23] | LC | 67.9 | 71.0 | 88.6 | 65.0 | 28.1 | 75.4 | 41.4 | 72.2 | 76.7 | 65.8 | 88.7 | 76.9 |
| MSMDFusion [45] | LC | 69.1 | 71.8 | 88.5 | 64.0 | 29.2 | 76.2 | 44.7 | 70.4 | 79.1 | 68.6 | 89.7 | 80.1 |
| DeepInteraction [32] | LC | 69.9 | 72.6 | 87.1 | 60.0 | 33.1 | 68.3 | 60.8 | 78.1 | 73.6 | 52.9 | 88.4 | 86.7 |
| PIDFusion | LC | 70.2 | 73.5 | 87.8 | 65.8 | 30.0 | 75.8 | 59.6 | 79.5 | 77.6 | 69.0 | 90.3 | 86.2 |
| Method | Modality | mAP | NDS | Car | Truck | C.V. | Bus | Trailer | Barrier | Motor. | Bike | Ped. | T.C. |
| PointPillars [15] | L | 40.1 | 55.0 | 76.0 | 31.0 | 11.3 | 32.1 | 36.6 | 56.4 | 34.2 | 14.0 | 64.0 | 45.6 |
| CenterPoint [46] | L | 60.3 | 67.3 | 85.2 | 53.5 | 20.0 | 63.6 | 56.0 | 71.1 | 59.5 | 30.7 | 84.6 | 78.4 |
| TransFusion-L [31] | L | 65.5 | 70.2 | 86.2 | 56.7 | 28.2 | 66.3 | 58.8 | 78.2 | 68.3 | 44.2 | 86.1 | 82.0 |
| PointPainting [4] | LC | 46.4 | 58.1 | 77.9 | 35.8 | 15.8 | 36.2 | 37.3 | 60.2 | 41.5 | 24.1 | 73.3 | 62.4 |
| 3D-CVF [26] | LC | 52.7 | 62.3 | 83.0 | 45.0 | 15.9 | 48.8 | 49.6 | 65.9 | 51.2 | 30.4 | 74.2 | 62.9 |
| TransFusion [31] | LC | 68.9 | 71.7 | 87.1 | 60.0 | 33.1 | 68.3 | 60.8 | 78.1 | 73.6 | 52.9 | 88.4 | 86.7 |
| BEVFusion [27] | LC | 70.2 | 72.9 | 88.6 | 60.1 | 39.3 | 69.8 | 63.8 | 80.0 | 74.1 | 51.0 | 89.2 | 86.5 |
| MSMDFusion [45] | LC | 70.8 | 73.2 | 87.9 | 61.6 | 38.1 | 70.0 | 64.4 | 79.0 | 73.9 | 56.6 | 89.7 | 87.1 |
| DeepInteraction [32] | LC | 70.8 | 73.4 | 87.9 | 60.2 | 37.5 | 70.8 | 63.8 | 80.4 | 75.4 | 54.5 | 91.7 | 87.2 |
| PIDFusion | LC | 71.5 | 74.2 | 88.1 | 61.3 | 39.6 | 71.2 | 64.1 | 81.2 | 74.8 | 57.1 | 92.9 | 87.6 |
| Point Cloud Densification | Bilateral Interaction | Instance-Level Fusion | mAP | NDS |
|---|---|---|---|---|
| 67.3 | 71.2 | |||
| √ | 68.3 | 71.6 | ||
| √ | √ | 69.7 | 72.9 | |
| √ | √ | √ | 71.5 | 74.2 |
| Method | NVPF3 | mAP | NDS |
|---|---|---|---|
| BEVFusion [23] | 5M | 69.2 | 71.8 |
| BEVFusion [27] | 2M | 70.2 | 72.9 |
| MSMDFusion [45] | 16K | 70.8 | 73.2 |
| PIDFusion | 10K | 71.5 | 74.2 |
| (a) Comparison between PointPillars-Based Methods | |||
| Methods | Modility | mAP | NDS |
| PointPillars [15] | L | 46.2 | 59.1 |
| Transfusion-L [31] | L | 54.5 | 62.7 |
| Transfusion [31] | L+C | 58.3 | 64.5 |
| PIDFusion | L+C | 61.5 | 66.3 |
| (b) Comparison between SECOND-Based Methods | |||
| Methods | Modility | mAP | NDS |
| SECOND [16] | L | 52.6 | 63.0 |
| Transfusion-L [31] | L | 65.1 | 70.1 |
| Transfusion [31] | L+C | 67.5 | 71.3 |
| PIDFusion | L+C | 71.5 | 74.2 |
| Methods | LiDAR-FOV | LiDAR-Object | Camera-Missing |
|---|---|---|---|
| BEVFusion [27] | 51.3 | 54.7 | 69.2 |
| PIDFusion | 55.6 | 59.3 | 70.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Z.; Xu, R.; Tian, Q. PIDFusion: Fusing Dense LiDAR Points and Camera Images at Pixel-Instance Level for 3D Object Detection. Mathematics 2023, 11, 4277. https://doi.org/10.3390/math11204277
Zhang Z, Xu R, Tian Q. PIDFusion: Fusing Dense LiDAR Points and Camera Images at Pixel-Instance Level for 3D Object Detection. Mathematics. 2023; 11(20):4277. https://doi.org/10.3390/math11204277
Chicago/Turabian StyleZhang, Zheng, Ruyu Xu, and Qing Tian. 2023. "PIDFusion: Fusing Dense LiDAR Points and Camera Images at Pixel-Instance Level for 3D Object Detection" Mathematics 11, no. 20: 4277. https://doi.org/10.3390/math11204277
APA StyleZhang, Z., Xu, R., & Tian, Q. (2023). PIDFusion: Fusing Dense LiDAR Points and Camera Images at Pixel-Instance Level for 3D Object Detection. Mathematics, 11(20), 4277. https://doi.org/10.3390/math11204277