
Hyperparameter Optimization for 1D-CNN-Based Network Intrusion Detection Using GA and PSO

Abstract
:1. Introduction
1.1. Research Context and Motivation
1.2. Research Aims and Contributions
- Hyperparameter optimization exploration: To comprehensively investigate the application of evolutionary computation techniques, particularly GA and PSO, for hyperparameter optimization in 1D-CNNs tailored for NIDSs.
- Benchmarking and validation: To empirically assess and validate the performance of 1D-CNN models that have been optimized using GA and PSO against standard, non-optimized models. This aim seeks to establish the merits of using these evolutionary algorithms in a practical, real-world setting.
- Fine-tuning and adaptation: Given the unique demands of intrusion detection, we aim to refine and adapt the GA and PSO algorithms, ensuring they are tailored specifically for this domain. This involves adjusting parameters and processes within these algorithms to achieve a harmonious balance between the exploration of new solution spaces and the exploitation of known, effective solutions.
- Future-readiness: Given the constantly evolving nature of cyber threats, we aim to ensure that the methodologies and findings of this research not only address current challenges but also offer insights and frameworks that can be adaptable to future threats and technologies.
- Novel GA and PSO application in NIDSs: This study is among the first to investigate the application of GA and PSO for hyperparameter optimization in 1D-CNN-based NIDSs. We demonstrate that these optimization techniques can effectively explore the search space and identify optimal configurations to achieve improved intrusion-detection performance.
- Comparative analysis: We comprehensively compare the GA and PSO, highlighting their strengths and weaknesses in the context of hyperparameter optimization in 1D-CNN-based NIDSs. This analysis can help practitioners and researchers make informed decisions when selecting an optimization technique for a specific NIDS application.
- Performance improvement: The experimental results reveal that the application of GA and PSO can produce significant performance improvement in terms of accuracy, precision, recall, and F1-score, compared to that of models with manually tuned hyperparameters. This demonstrates that the GA and PSO techniques can be instrumental in enhancing the effectiveness of NIDSs, ultimately contributing to more robust and secure network systems.
- Methodological framework: The systematic approach proposed in this study can be adapted and extended to other ML and DL models, offering a valuable resource for future research in network intrusion detection.
- Practical implications: The findings of this study have practical implications for network-security practitioners tasked with designing and deploying effective NIDSs. Practitioners can achieve improved performances and reduce the time and effort required for manual hyperparameter tuning, thereby improving the overall efficiency of their network-security infrastructure.
1.3. Structure of the Paper
2. Related Works
3. Optimization of 1D-CNN Hyperparameters
3.1. Hyperparameters of 1D-CNNs
3.2. Optimization Methods
3.3. GA and PSO Algorithms
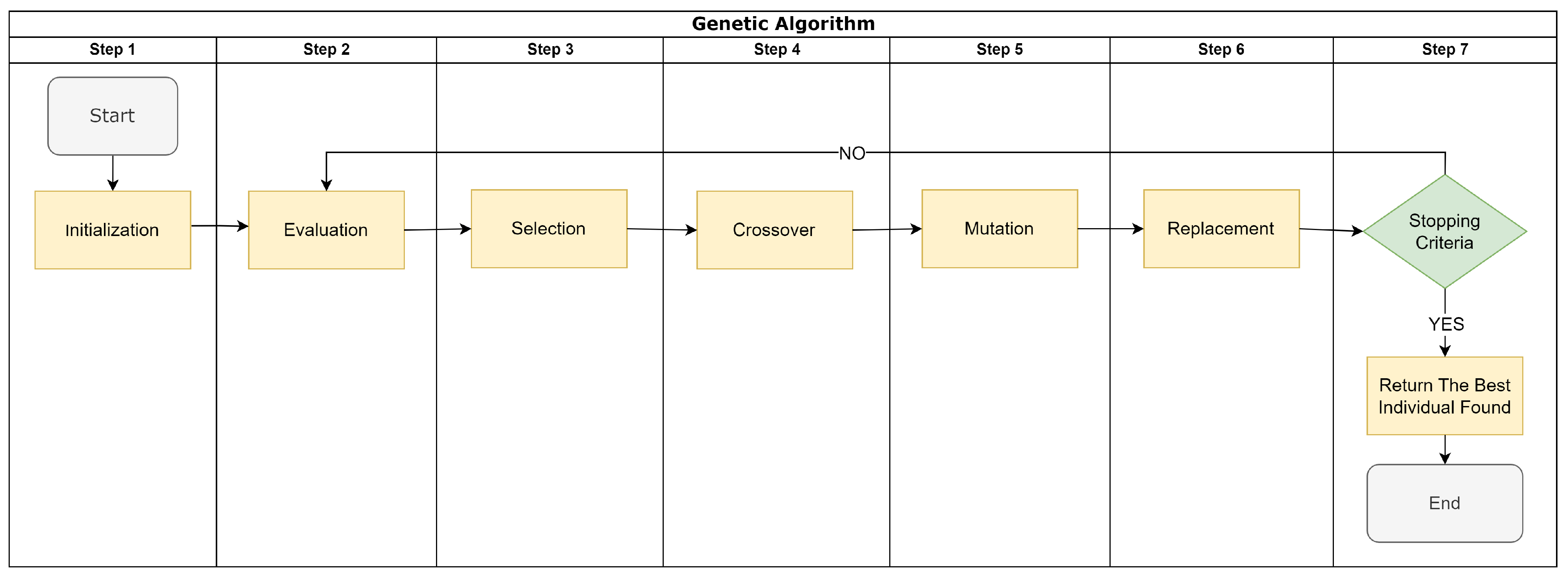
3.3.1. Genetic Algorithm (GA)
- Step 1. Initialization: Generate a population of random solutions.
- Step 2. Fitness evaluation: For each individual in the population, its fitness is validated, e.g., accuracy of the trained model.
- Step 3. Selection: Select pairs of individuals from the population to be parents based on their fitness scores. Individuals with higher fitness have a higher chance of being selected.
- Step 4. Crossover: For each pair of parents, create a child individual by randomly choosing from one of the two parents.
- Step 5. Mutation: For each child individual, it has a small chance of being replaced by a randomly generated value.
- Step 6. Replacement: Replace the least fit individuals in the population with the child individuals.
- Step 7. Termination check: If the stopping criterion (e.g., reaching the maximum number of generations) is met, stop the algorithm and return the most fit individual in the population as the best set. Otherwise, go back to step 2.
3.3.2. Particle Swarm Optimization (PSO)
- Proximity: This principle underlines the algorithm’s capability to perform basic time and space computations.
- Stability: The swarm retains its behavioral characteristics regardless of alterations in the environment.
- Quality: It exhibits a keen sensitivity to changes in environmental quality, and adjusts its response accordingly.
- Diverse response: It embodies the algorithm’s unrestricted adaptability in response to environmental shifts.
- Adaptability: The algorithm can discern whether changes in the environment warrant a behavioral shift.
- Step 1. Initialization: The PSO algorithm starts by initializing a swarm of particles. Each particle represents a potential solution. The position of a particle in the search space corresponds to the specific values, and the velocity determines how much they change in each iteration.
- Step 2. Fitness evaluation: Next, the fitness of each particle is evaluated. The fitness of the particle can be the validation accuracy, or 1-validation accuracy if you want a minimization problem.
- Step 3. Update personal best: If the new fitness score of a particle is better than its personal best fitness score, the personal best is updated to the new fitness score.
- Step 4. Update global best: The particle with the best fitness score in the entire swarm is identified, and its fitness score and particle values are stored as the global best.
- Step 5. Update velocities and positions: The velocities and positions of the particles are updated based on a combination of their current velocities, the distance from their personal best positions, and the distance from the global best position. This involves some randomization to maintain diversity in the swarm, and certain parameters (the cognitive and social parameters) to control the influence of the personal best and global best on the new velocity.
- Step 6. Termination check: If a termination criterion is met (such as reaching a maximum number of iterations, or achieving a sufficiently good fitness score), the algorithm stops, and the global best fitness score is returned. If the termination criterion is not met, the algorithm goes back to step 2.
4. Proposed 1D-CNN-Based Network Intrusion-Detection Model
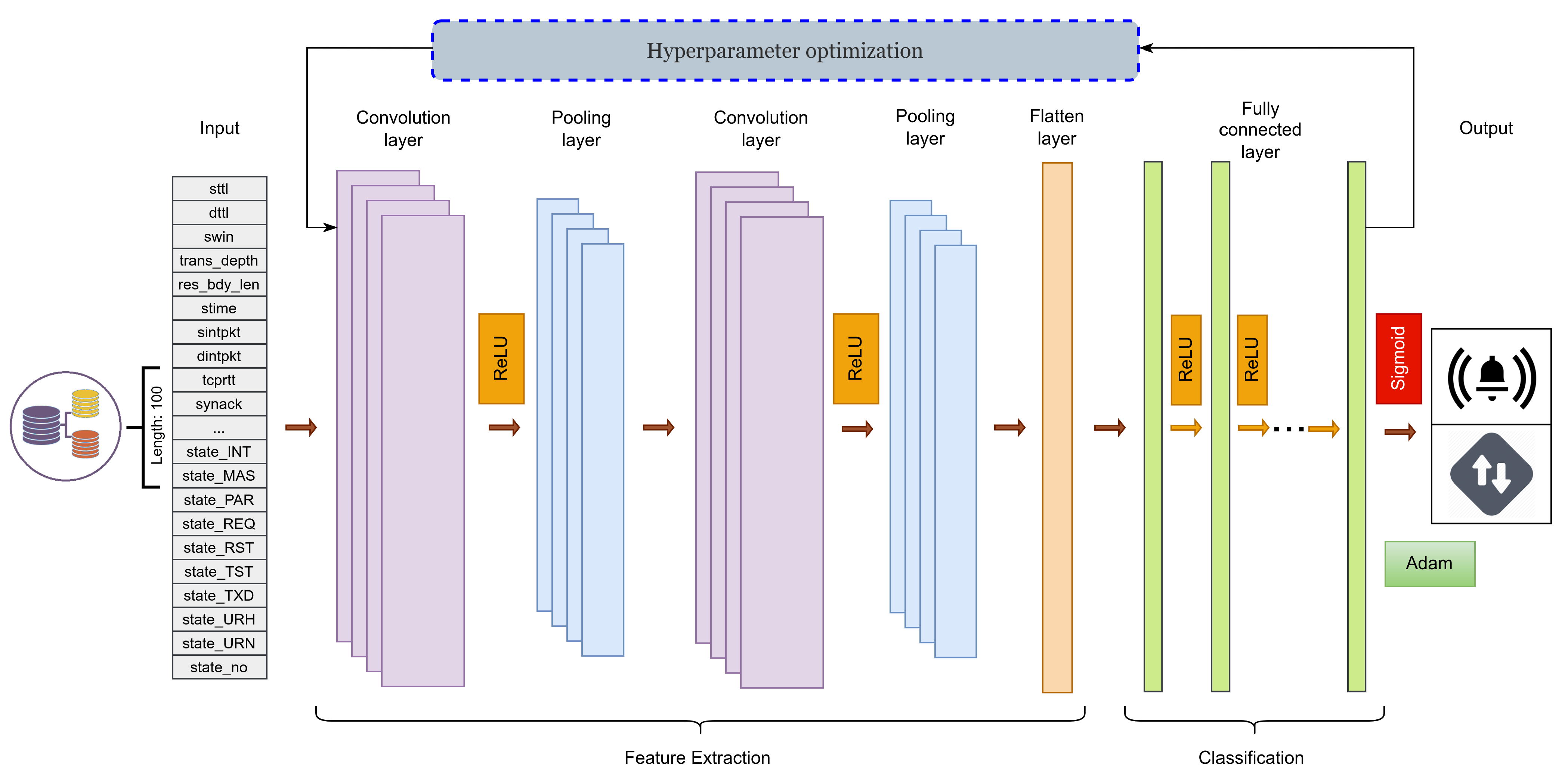
4.1. Overview of 1D-CNN Architecture
4.2. Hyperparameter Optimization Problem of the 1D-CNN Model Training
4.2.1. GA Algorithm for Hyperparameter Optimization
- Initialization: Generate an initial population of size with random solutions within the constraints.
- Evaluation: For each individual in the population P, compute its fitness by training and validating the 1D-CNN model using the hyperparameters .
- Selection: Select individuals from P to be parents based on their fitness scores. Methods include roulette wheel selection, tournament selection, etc.
- Crossover: Perform crossover on pairs of parents to produce offspring. This involves mixing the hyperparameters from two parents to produce one or more offspring.
- Mutation: Apply mutation on offspring with a certain probability. This involves randomly changing some hyperparameters within their allowable range.
- Replacement: Update the population by replacing less fit individuals with the offspring.
- Termination: If a stopping criterion (such as reaching G generations or achieving a desired fitness) is met, return the individual with the highest fitness. Otherwise, go back to the Evaluation step.
- Defining the appropriate initialization method to ensure diverse solutions in the initial population.
- Deciding on the selection strategy (e.g., roulette wheel, tournament).
- Choosing and implementing a crossover method (e.g., single-point, uniform).
- Setting the mutation probability and method.
- Ensuring hyperparameter constraints are always maintained.
- Handling convergence criteria and early stopping, if desired.
| Algorithm 1: Optimizing 1D CNN hyperparameters for IDS using GA. |
 |
4.2.2. PSO Algorithm for Hyperparameter Optimization
- Initialization: Randomly initialize each particle’s position and velocity within the bounds of the hyperparameter space.
- Evaluation: For each particle in the swarm S, compute its fitness by training and validating the 1D-CNN model using the hyperparameters represented by its position .
- Update Personal Best: If the current position of a particle has a better fitness than its personal best position , update with the current position.
- Update Global Best: If any particle’s personal best position has a better fitness than the current global best position , update with .
- Update Velocities and Positions: For each particle:
- Update its velocity using its current velocity, the difference between its personal best position and its current position, and the difference between the global best position and its current position.
- Update its position based on the updated velocity .
- Termination: If a stopping criterion (e.g., reaching a maximum number of iterations or achieving a desired fitness) is met, return the global best position as the best set of hyperparameters. Otherwise, go back to the Evaluation step.
- The function evaluate_fitness() would involve training the 1D CNN model on the training set with the given hyperparameters and evaluating its performance on the validation set.
- The procedure’s logic focuses on maximizing the fitness value (i.e., performance metric such as accuracy or F1-score). Adjustments would be needed if a different optimization direction is required.
- Specifics such as the initialization ranges, inertia weight adjustments, and other hyperparameters would need fine-tuning for a real-world application.
| Algorithm 2: PSO for Hyperparameter Optimization. |
 |
4.2.3. Time and Space Complexity Analysis
- Initialization: For both GA and PSO, the initial setup involves generating a collection of entities.
- −
- For GA, it is about establishing a set of chromosomes.
- −
- For PSO, it means setting initial positions and velocities for particles.
Complexity: where P denotes population (or swarm) size, and D represents the dimensionality (or chromosome length). - Evaluation: The process of evaluating the quality of each entity in the population:
- −
- In GA, it is the fitness evaluation for each chromosome.
- −
- In PSO, it is assessing the objective function for particle positions.
Complexity: where T symbolizes the individual evaluation complexity. - Update Mechanisms: The processes of evolution or movement:
- −
- In GA, this captures selection, crossover, and mutation operations.
- −
- In PSO, it is about updating particle positions and velocities based on personal and global bests.
Complexity: for both.
- In GA, this relates to the chromosomes’ information.
- In PSO, it is about particle positions, velocities, and personal bests.
4.3. Dataset Description
4.4. Data Preprocessing
5. Experiments and Results
5.1. Evaluation Metrics
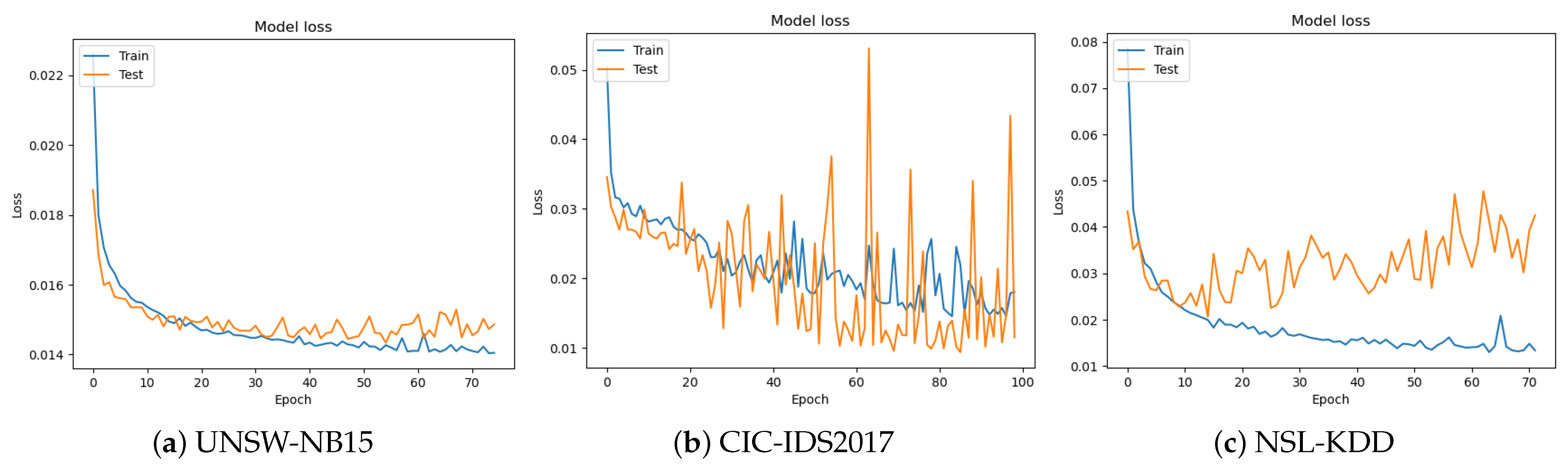
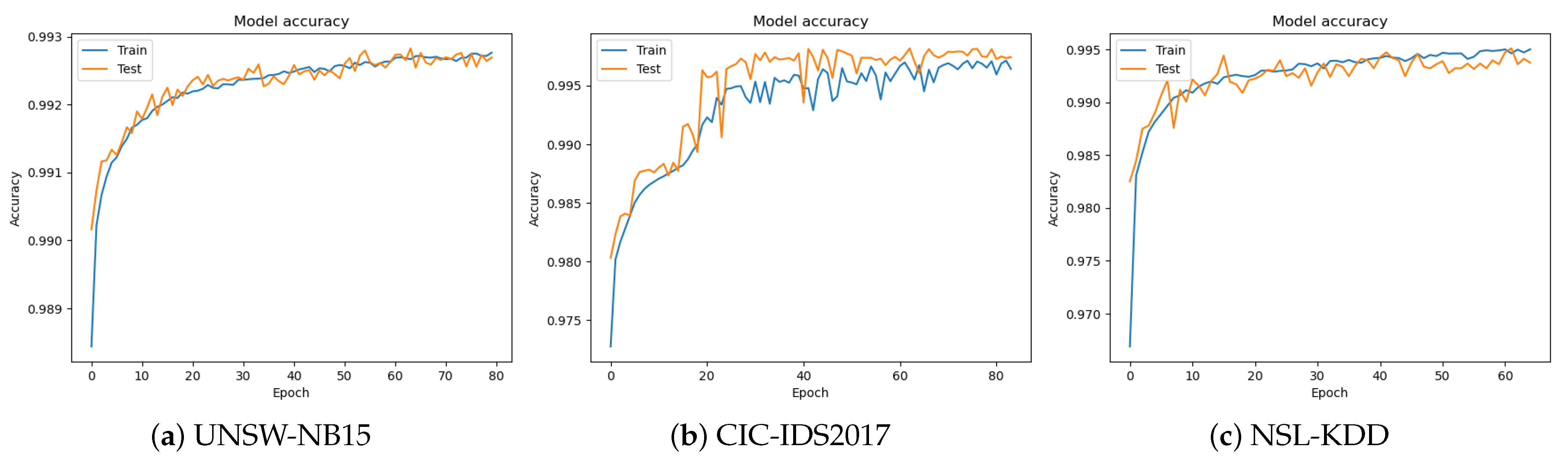
5.2. Optimizing Hyperparameters Using GA
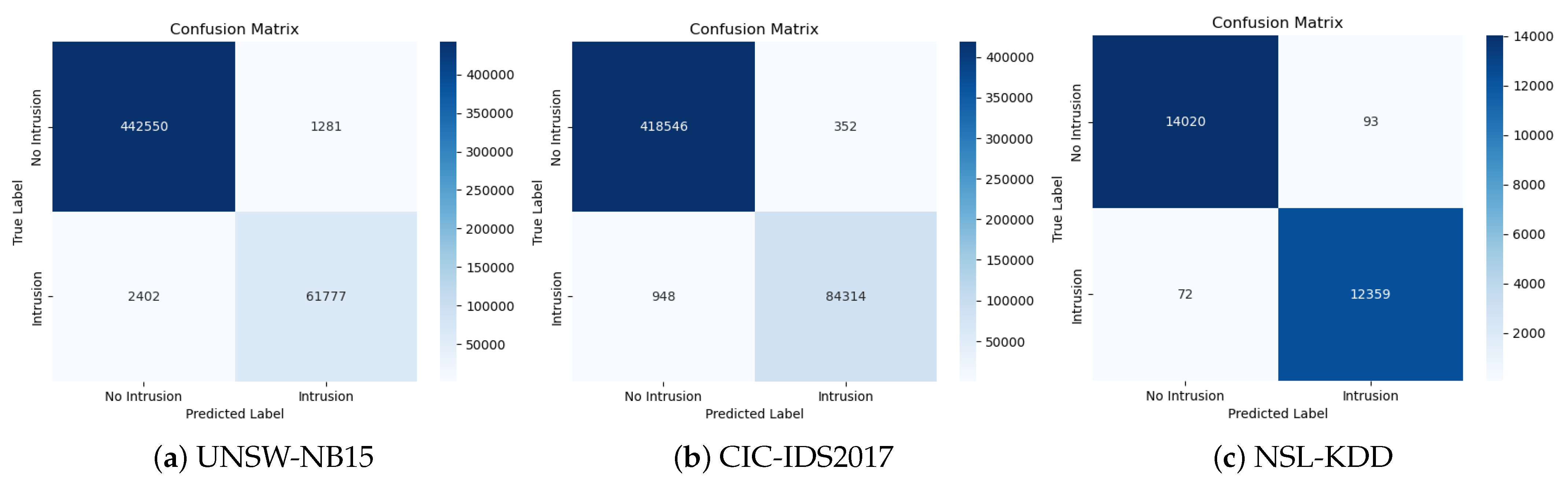
- On the UNSW-NB15 dataset, the model achieves an accuracy of 99.31% with a loss of 1.44.
- On the CIC-IDS2017 dataset, the model achieves a higher accuracy of 99.71% with a lower loss of 1.15.
- On the NSL-KDD dataset, the model achieves an accuracy of 99.63% with a loss of 1.78.
5.3. Hyperparameter Optimization Using PSO
- On the UNSW-NB15 dataset, the model achieves a loss of 1.47 and accuracy of 99.28%.
- On the CIC-IDS2017 dataset, the model achieves a lower loss of 0.88 and higher accuracy of 99.74%.
- On the NSL-KDD dataset, the model achieves a loss of 1.75 and accuracy of 99.52%.
6. Discussion
6.1. Analysis of the Results of Models Based on GA and PSO
6.2. Comparison with Existing Methods
6.3. Strengths and Limitations
- Superior accuracy: The GA-1D-CNN and PSO-1D-CNN models demonstrated consistently high accuracy across all three datasets—UNSW-NB15, CIC-IDS2017, and NSL-KDD. Their accuracy surpassed existing models by a substantial margin, affirming the efficacy of GA and PSO in fine-tuning the models’ parameters to achieve more accurate predictions.
- Enhanced precision and recall: Our models exhibited elevated precision and recall rates, indicating their proficiency in minimizing false positives while effectively identifying true intrusions. This ability is crucial in real-world applications, where precision and recall directly impact the effectiveness of an IDS.
- Optimized hyperparameters: The key to our model’s success lies in the utilization of GA and PSO for hyperparameter optimization. This allows our models to fine-tune their configurations to extract the most salient features from the data, enhancing their discriminative power.
- Robust generalization: The models showcased remarkable generalization across datasets, suggesting their ability to adapt to diverse network environments and handle varying intrusion patterns effectively.
- Computational complexity: The incorporation of GA or PSO does introduce some level of computational complexity, especially during hyperparameter optimization. While the models’ results justify the trade-off, it is essential to consider computational resources in practical deployment scenarios.
- Domain dependency: Like most ML models, the performance of our models may depend on the specific characteristics of the datasets they are trained on. While our models demonstrated excellent results on the chosen datasets, further evaluations on different datasets may be necessary to establish their general applicability.
- Data imbalance: Intrusion-detection datasets often suffer from class imbalance, where the number of intrusion instances is significantly lower than normal instances. While our models show resilience to this challenge, further investigations and potential techniques to address data imbalance could enhance their performance even further.
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ahmad, I.; Ul Haq, Q.E.; Imran, M.; Alassafi, M.O.; AlGhamdi, R.A. An Efficient Network Intrusion Detection and Classification System. Mathematics 2022, 10, 530. [Google Scholar] [CrossRef]
- Mohammadpour, L.; Ling, T.C.; Liew, C.S.; Aryanfar, A. A Survey of CNN-Based Network Intrusion Detection. Appl. Sci. 2022, 12, 8162. [Google Scholar] [CrossRef]
- Desta, A.K.; Ohira, S.; Arai, I.; Fujikawa, K. Rec-CNN: In-vehicle networks intrusion detection using convolutional neural networks trained on recurrence plots. Veh. Commun. 2022, 35, 100470. [Google Scholar] [CrossRef]
- Sheraz, N.; Yasir, S. Enhanced Network Intrusion Detection using Deep Convolutional Neural Networks. KSII Trans. Internet Inf. Syst. 2018, 12, 5159–5178. [Google Scholar] [CrossRef]
- Selvarajan, P.; Salman, R.; Ahamed, S.; Jayasuriya, P. Networks Intrusion Detection Using Optimized Hybrid Network. In Proceedings of the 2023 International Conference on Smart Computing and Application (ICSCA), Hail, Saudi Arabia, 5–6 February 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Kanna, R.P.; Santhi, P. Unified Deep Learning approach for Efficient Intrusion Detection System using Integrated Spatial–Temporal Features. Knowl.-Based Syst. 2021, 226, 107132. [Google Scholar] [CrossRef]
- Zhao, X.; Su, H.; Sun, Z. An Intrusion Detection System Based on Genetic Algorithm for Software-Defined Networks. Mathematics 2022, 10, 3941. [Google Scholar] [CrossRef]
- Yang, L.; Shami, A. A Transfer Learning and Optimized CNN Based Intrusion Detection System for Internet of Vehicles. In Proceedings of the ICC 2022—IEEE International Conference on Communications, Foshan, China, 11–13 August 2022; pp. 2774–2779. [Google Scholar] [CrossRef]
- Chen, Y.; Lin, Q.; Wei, W.; Ji, J.; Wong, K.C.; Coello, C.A. Intrusion detection using multi-objective evolutionary convolutional neural network for Internet of Things in Fog computing. Knowl.-Based Syst. 2022, 244, 108505. [Google Scholar] [CrossRef]
- Ragab, M.; Sabir, F. Outlier detection with optimal hybrid deep learning enabled intrusion detection system for ubiquitous and smart environment. Sustain. Energy Technol. Assess. 2022, 52, 102311. [Google Scholar] [CrossRef]
- Yan, F.; Zhang, G.; Zhang, D.; Sun, X.; Hou, B.; Yu, N. TL-CNN-IDS: Transfer learning-based intrusion detection system using convolutional neural network. J. Supercomput. 2023, 242. [Google Scholar] [CrossRef]
- Okey, O.D.; Melgarejo, D.C.; Saadi, M.; Rosa, R.L.; Kleinschmidt, J.H.; Rodríguez, D.Z. Transfer Learning Approach to IDS on Cloud IoT Devices Using Optimized CNN. IEEE Access 2023, 11, 1023–1038. [Google Scholar] [CrossRef]
- El-Ghamry, A.; Darwish, A.; Hassanien, A.E. An optimized CNN-based intrusion detection system for reducing risks in smart farming. Internet Things 2023, 22, 100709. [Google Scholar] [CrossRef]
- Rosay, A.; Riou, K.; Carlier, F.; Leroux, P. Multi-layer perceptron for network intrusion detection: From a study on two recent data sets to deployment on automotive processor. Ann. Telecommun. 2022, 77, 371–394. [Google Scholar] [CrossRef]
- Obeidat, A.; Yaqbeh, R. Smart Approach for Botnet Detection Based on Network Traffic Analysis. J. Electr. Comput. Eng. 2022, 2022, 3073932. [Google Scholar] [CrossRef]
- Zhang, X.; Zou, D.; Shen, X. A Novel Simple Particle Swarm Optimization Algorithm for Global Optimization. Mathematics 2018, 6, 287. [Google Scholar] [CrossRef]
- Moustafa, N.; Slay, J. UNSW-NB15: A comprehensive data set for network intrusion detection systems (UNSW-NB15 network data set). In Proceedings of the 2015 Military Communications and Information Systems Conference (MilCIS), Canberra, Australia, 10–12 November 2015; pp. 1–6. [Google Scholar] [CrossRef]
- Sharafaldin, I.; Habibi Lashkari, A.; Ghorbani, A.A. Toward Generating a New Intrusion Detection Dataset and Intrusion Traffic Characterization. In Proceedings of the 4th International Conference on Information Systems Security and Privacy—ICISSP, Funchal, Portugal, 22–24 January 2018; pp. 108–116. [Google Scholar] [CrossRef]
- Tavallaee, M.; Bagheri, E.; Lu, W.; Ghorbani, A.A. A detailed analysis of the KDD CUP 99 data set. In Proceedings of the 2009 IEEE Symposium on Computational Intelligence for Security and Defense Applications, Ottawa, ON, Canada, 8–10 July 2009; pp. 1–6. [Google Scholar] [CrossRef]
- Gautam, S.; Henry, A.; Zuhair, M.; Rashid, M.; Javed, A.R.; Maddikunta, P.K.R. A Composite Approach of Intrusion Detection Systems: Hybrid RNN and Correlation-Based Feature Optimization. Electronics 2022, 11, 3529. [Google Scholar] [CrossRef]
- Preuveneers, D.; Rimmer, V.; Tsingenopoulos, I.; Spooren, J.; Joosen, W.; Ilie-Zudor, E. Chained Anomaly Detection Models for Federated Learning: An Intrusion Detection Case Study. Appl. Sci. 2018, 8, 2663. [Google Scholar] [CrossRef]
- Potluri, S.; Ahmed, S.; Diedrich, C. Convolutional Neural Networks for Multi-class Intrusion Detection System. In Proceedings of the Mining Intelligence and Knowledge Exploration, Cluj-Napoca, Romania, 20–22 December 2018; Groza, A., Prasath, R., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 225–238. [Google Scholar] [CrossRef]
- Azizjon, M.; Jumabek, A.; Kim, W. 1D CNN based network intrusion detection with normalization on imbalanced data. In Proceedings of the 2020 International Conference on Artificial Intelligence in Information and Communication (ICAIIC), Fukuoka, Japan, 19–21 February 2020; pp. 218–224. [Google Scholar] [CrossRef]
- Gamal, M.; Abbas, H.M.; Moustafa, N.; Sitnikova, E.; Sadek, R.A. Few-Shot Learning for Discovering Anomalous Behaviors in Edge Networks. Comput. Mater. Contin. 2021, 69, 1823–1837. [Google Scholar] [CrossRef]
- Al-Turaiki, I.; Altwaijry, N. A Convolutional Neural Network for Improved Anomaly-Based Network Intrusion Detection. Big Data 2021, 9, 233–252. [Google Scholar] [CrossRef]
- Mohammadpour, L.; Ling, T.C.; Liew, C.S.; Aryanfar, A. A mean convolutional layer for intrusion detection system. Secur. Commun. Netw. 2020, 2020, 8891185. [Google Scholar] [CrossRef]
- Aldarwbi, M.Y.; Lashkari, A.H.; Ghorbani, A.A. The sound of intrusion: A novel network intrusion detection system. Comput. Electr. Eng. 2022, 104, 108455. [Google Scholar] [CrossRef]
- Qazi, E.U.H.; Almorjan, A.; Zia, T. A One-Dimensional Convolutional Neural Network (1D-CNN) Based Deep Learning System for Network Intrusion Detection. Appl. Sci. 2022, 12, 7986. [Google Scholar] [CrossRef]
- Ding, Y.; Zhai, Y. Intrusion detection system for NSL-KDD dataset using convolutional neural networks. In Proceedings of the 2018 2nd International Conference on Computer Science and Artificial Intelligence, Shenzhen, China, 8–10 December 2018; pp. 81–85. [Google Scholar] [CrossRef]
- Zhang, X.; Ran, J.; Mi, J. An Intrusion Detection System Based on Convolutional Neural Network for Imbalanced Network Traffic. In Proceedings of the 2019 IEEE 7th International Conference on Computer Science and Network Technology (ICCSNT), Dalian, China, 19–20 October 2019; pp. 456–460. [Google Scholar] [CrossRef]
- Verma, A.K.; Kaushik, P.; Shrivastava, G. A Network Intrusion Detection Approach Using Variant of Convolution Neural Network. In Proceedings of the 2019 International Conference on Communication and Electronics Systems (ICCES), Coimbatore, India, 17–19 July 2019; pp. 409–416. [Google Scholar] [CrossRef]
- Li, Y.; Xu, Y.; Liu, Z.; Hou, H.; Zheng, Y.; Xin, Y.; Zhao, Y.; Cui, L. Robust detection for network intrusion of industrial IoT based on multi-CNN fusion. Measurement 2020, 154, 107450. [Google Scholar] [CrossRef]
- Yang, H.; Wang, F. Wireless Network Intrusion Detection Based on Improved Convolutional Neural Network. IEEE Access 2019, 7, 64366–64374. [Google Scholar] [CrossRef]
- Khan, R.U.; Zhang, X.; Alazab, M.; Kumar, R. An Improved Convolutional Neural Network Model for Intrusion Detection in Networks. In Proceedings of the 2019 Cybersecurity and Cyberforensics Conference (CCC), Melbourne, Australia, 8–9 May 2019; pp. 74–77. [Google Scholar] [CrossRef]
- Wang, H.; Cao, Z.; Hong, B. A network intrusion detection system based on convolutional neural network. J. Intell. Fuzzy Syst. 2020, 38, 7623–7637. [Google Scholar] [CrossRef]
- Wang, X.; Yin, S.; Li, H.; Wang, J.; Teng, L. A network intrusion detection method based on deep multi-scale convolutional neural network. Int. J. Wirel. Inf. Netw. 2020, 27, 503–517. [Google Scholar] [CrossRef]
- Jo, W.; Kim, S.; Lee, C.; Shon, T. Packet Preprocessing in CNN-Based Network Intrusion Detection System. Electronics 2020, 9, 1151. [Google Scholar] [CrossRef]
- Hu, Z.; Wang, L.; Qi, L.; Li, Y.; Yang, W. A Novel Wireless Network Intrusion Detection Method Based on Adaptive Synthetic Sampling and an Improved Convolutional Neural Network. IEEE Access 2020, 8, 195741–195751. [Google Scholar] [CrossRef]
- Akhtar, M.S.; Feng, T. Deep learning-based framework for the detection of cyberattack using feature engineering. Secur. Commun. Netw. 2021, 2021, 6129210. [Google Scholar] [CrossRef]
- Zhang, H.; Huang, L.; Wu, C.Q.; Li, Z. An effective convolutional neural network based on SMOTE and Gaussian mixture model for intrusion detection in imbalanced dataset. Comput. Netw. 2020, 177, 107315. [Google Scholar] [CrossRef]
- Meliboev, A.; Alikhanov, J.; Kim, W. Performance Evaluation of Deep Learning Based Network Intrusion Detection System across Multiple Balanced and Imbalanced Datasets. Electronics 2022, 11, 515. [Google Scholar] [CrossRef]
- Altunay, H.C.; Albayrak, Z. A hybrid CNN+LSTM-based intrusion detection system for industrial IoT networks. Eng. Sci. Technol. Int. J. 2023, 38, 101322. [Google Scholar] [CrossRef]
- Thilagam, T.; Aruna, R. LM-GA: A Novel IDS with AES and Machine Learning Architecture for Enhanced Cloud Storage Security. J. Mach. Comput. 2023, 3, 69–79. [Google Scholar] [CrossRef]
- Karthic, S.; Kumar, S.M. Hybrid Optimized Deep Neural Network with Enhanced Conditional Random Field Based Intrusion Detection on Wireless Sensor Network. Neural Process. Lett. 2023, 55, 459–479. [Google Scholar] [CrossRef]
- Khan, A.S.; Ahmad, Z.; Abdullah, J.; Ahmad, F. A Spectrogram Image-Based Network Anomaly Detection System Using Deep Convolutional Neural Network. IEEE Access 2021, 9, 87079–87093. [Google Scholar] [CrossRef]
- Mendonça, R.V.; Teodoro, A.A.M.; Rosa, R.L.; Saadi, M.; Melgarejo, D.C.; Nardelli, P.H.J.; Rodríguez, D.Z. Intrusion Detection System Based on Fast Hierarchical Deep Convolutional Neural Network. IEEE Access 2021, 9, 61024–61034. [Google Scholar] [CrossRef]
- Bowen, B.; Chennamaneni, A.; Goulart, A.; Lin, D. BLoCNet: A hybrid, dataset-independent intrusion detection system using deep learning. Int. J. Inf. Secur. 2023, 22, 893–917. [Google Scholar] [CrossRef]
- Li, S.; Li, Q.; Li, M. A Method for Network Intrusion Detection Based on GAN-CNN-BiLSTM. Int. J. Adv. Comput. Sci. Appl. 2023, 14, 507–515. [Google Scholar] [CrossRef]
- Nguyen, M.T.; Kim, K. Genetic convolutional neural network for intrusion detection systems. Future Gener. Comput. Syst. 2020, 113, 418–427. [Google Scholar] [CrossRef]
- Bhuvaneshwari, K.S.; Venkatachalam, K.; Hubálovský, S.; Trojovský, P.; Prabu, P. Improved Dragonfly Optimizer for Intrusion Detection Using Deep Clustering CNN-PSO Classifier. Comput. Mater. Contin. 2022, 70, 5949–5965. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Authors | Model | Optimized Hyperparameters | Optimization Techniques | |
|---|---|---|---|---|
| Selvarajan et al. [5] | LSTM-CNN 2023 | 6 | Batch size | Manual tuning |
| Decay rate | ||||
| Learning rate | ||||
| Momentum | ||||
| Number of epochs | ||||
| Optimizer | ||||
| Sheraz et al. [4] | DCNN 2018 | 4 | Activation | Randomized search |
| Kernel initialization | ||||
| Loss function | ||||
| Optimizer | ||||
| Desta et al. [3] | Rec-CNN 2022 | 8 | Batch size | Hyperband |
| Decay rate | ||||
| Decay steps | ||||
| Dropout rate | ||||
| Learning rate | ||||
| Number of filters | ||||
| Number of neurons in dense layers | ||||
| Optimizer | ||||
| Kanna et al. [6] | OCNN-HMLSTM 2021 | 5 | Convolutional layer | Lion Swarm Optimization |
| Fully connected layer | ||||
| Hidden units/layer | ||||
| Pooling layer | ||||
| Pooling size | ||||
| Chen et al. [9] | MECNN 2022 | 3 | Batch size | Multiobjective evolutionary algorithm |
| Learning rate | ||||
| Learning rule | ||||
| Mahmoud et al. [10] | CNN-ALSTM 2022 | - | - | Poor and rich optimization algorithm |
| Yan et al. [11] | TL-CNN-IDS 2023 | 5 | Dropout rate | Tree-Structured Parzen Estimator algorithm |
| Early-stop patience | ||||
| Frozen layers | ||||
| Learning rate | ||||
| Number of epochs | ||||
| Okey et al. [12] | CNN 2023 | 6 | Batch size | Bayesian Optimization— Tree Parzen Estimator |
| Dropout rate | ||||
| Early-stop patience | ||||
| Frozen layers | ||||
| Learning rate | ||||
| Number of epochs | ||||
| Yang et al. [8] | CNN 2023 | 6 | Batch size | Particle Swarm Optimization |
| Dropout rate | ||||
| Early-stop patience | ||||
| Frozen layers | ||||
| Learning rate | ||||
| Number of epochs | ||||
| Amir et al. [13] | CNN 2023 | 5 | Dropout rate | Random search |
| Early-stop patience | ||||
| Frozen layers | ||||
| Learning rate | ||||
| Number of epochs | ||||
| 5 | Dropout rate | Particle Swarm Optimization | ||
| Early-stop patience | ||||
| Frozen layers | ||||
| Learning rate | ||||
| Number of epochs | ||||
| Proposed optimization method | 1D-CNN 2023 | 9 | Batch size | Genetic Algorithm |
| Dropout rate | ||||
| Kernel size | ||||
| Learning rate | ||||
| Number of dense layers | ||||
| Number of epochs | ||||
| Number of filters | ||||
| Number of neurons in dense layers | ||||
| Pooling size | ||||
| 9 | Batch size | Particle Swarm Optimization | ||
| Dropout rate | ||||
| Kernel size | ||||
| Learning rate | ||||
| Number of dense layers | ||||
| Number of epochs | ||||
| Number of filters | ||||
| Number of neurons in dense layers | ||||
| Pooling size |
| Criteria | Hyperparameter | Description |
|---|---|---|
| Network structure | Number of layers | Depth of the neural network. More layers can model more complex features, but can lead to overfitting. |
| Number of units per layer | Breadth of each layer. More units can capture more complex features, but increase the risk of overfitting. | |
| Number of filters | Number of filters in a convolution layer. More filters allow the model to learn more complex patterns but increase the computational requirements. | |
| Filter size | Size of filters in a convolution layer. Small filters capture local patterns and large filters capture more global patterns. | |
| Stride size | Amount of movement over the input data. A larger stride results in a smaller output dimensionality. | |
| Padding | Helps maintain the spatial dimensions of the input, allowing the network to learn from the edge and corner information. | |
| Kernel size | Determines how many input data points each filter handles at a time. | |
| Pooling size | Size of the pooling operation, affecting the amount of downsampling in the network. | |
| Number of dense layers | Number of fully connected (dense) layers in a network. More layers can model complex patterns, but increase the risk of overfitting. | |
| Number of neurons in dense layers | Number of units in fully connected (dense) layers. More neurons can capture complex patterns, but increase the computational requirements and risk of overfitting. | |
| Dilation rate | In dilated convolutions, the filter is applied to inputs with gaps; it is useful for capturing information across a wide range of inputs. | |
| Learning and optimization | Learning rate | Determines how much the weights are adjusted during each update. |
| Momentum | Helps prevent the optimization from falling into local minima by adding a fraction of the previous weight update to the current weight. | |
| Batch size | Affects how often the weights in the network are updated. | |
| Optimizer | Different optimization algorithms (such as SGD, Adam, and RMSprop) have different behaviors and may influence how quickly and effectively the model learns. | |
| Number of epochs | Number of times the learning algorithm works through the entire training dataset. | |
| Learning rate Decay/Scheduler | Controls the change in learning rate over time or epoch. This can help the optimizer converge more effectively. | |
| Regularization effect | Dropout rate | Probability that a given neuron will be turned off during training. Dropout is a regularization technique to prevent overfitting. |
| Weight decay (L2 regularization) | Adds a penalty to the loss function based on the sizes of the weights. This helps prevent the weights from becoming too large and overfitting to the training data. | |
| Early stopping | The training process is stopped when the performance on a validation set stops improving. This helps prevent overfitting. | |
| L1 regularization | Adds a penalty to the loss function based on the absolute values of the weights. It encourages the weights to be small and can lead to sparse weights, effectively achieving feature selection. |
| Algorithm | Nature | Search Strategy | Applicability | Strengths in Hyperparameter Optimization |
|---|---|---|---|---|
| Genetic Algorithms | Inspired by natural evolution | Mutation, crossover, and selection | Both continuous and discrete | Maintains diverse population; balances exploration and exploitation |
| Particle Swarm Optimization | Inspired by bird/fish social behavior | Velocity and position updates based on best solutions | Primarily continuous, can be adapted | Rapid convergence to good solutions; excellent fine-tuning |
| Manual Tuning | Human-guided iterative adjustment | Relies on human intuition | All types of problems | Simple; no overhead, but relies heavily on human expertise |
| Randomized Search | Purely random exploration | Random sampling of hyperparameters | High-dimensional spaces | Baseline method; can sometimes find good solutions quickly |
| Hyperband | Bandit-based approach | Allocates resources to different configurations | Deep learning models | Efficiently handles large search spaces with limited budget |
| TPE and Bayesian Optimization | Probabilistic modeling | Sequential sampling to maximize acquisition function | Expensive evaluations, e.g., deep learning | Systematic; builds on prior evaluations; can be very precise |
| Gradient Descent | Iterative based on gradient | Moves opposite to the gradient | Differentiable functions | Direct; efficient for specific problems but requires gradient |
| Simulated Annealing | Metallurgy-inspired probabilistic method | Occasional uphill moves to escape local optima | Both continuous and discrete problems | Ability to escape local minima; probabilistic balance between search areas |
| Other Swarm Methods (e.g., Lion Swarm Optimization) | Various inspirations (e.g., lions) | Various (e.g., hunting, mating tactics) | Continuous optimization problems | Specialized tactics; often problem-specific benefits |
| Tabu Search | Iterative with memory structures | Uses memory to avoid revisiting solutions | Combinatorial optimization | Efficient for combinatorial tasks with its memory use |
| Tool | Description |
|---|---|
| Python | The code was written in Python, a popular language for data science and ML. |
| TensorFlow | TensorFlow was used as the backend for Keras. |
| Keras | Keras is a high-level neural network API, written in Python and capable of running on top of TensorFlow, CNTK, and Theano. |
| NumPy | NumPy is a library for the Python programming language, which provides support for large, multidimensional arrays and matrices along with a large collection of high-level mathematical functions to operate on these arrays. |
| Hyperparameter | Range | UNSW-NB15 | CIC-IDS2017 | NSL-KDD |
|---|---|---|---|---|
| Number of filters | [16, 32, 64, 128, 256] | 64, 128 | 64, 128 | 32, 64 |
| Kernel size | [3, 5, 7, 9, 11] | 5 | 9 | 9 |
| Pooling size | (2, 6) | 3 | 5 | 5 |
| Number of dense layers | (1, 5) | 2 | 2 | 1 |
| Number of neurons in dense layers | [16, 32, 64, 128, 256] | 128 | 256 | 128 |
| Dropout rate | (0.1, 0.5) | 0.277205 | 0.113585 | 0.253378 |
| Learning rate | (1 × 10, 1 × 10) | 0.003488 | 0.001193 | 0.000471 |
| Batch size | [16, 32, 64, 128, 256] | 256 | 64 | 32 |
| Number of epochs | (10, 100) | 75 | 99 | 72 |
| Dataset | UNSW-NB15 | CIC-IDS2017 | NSL-KDD |
|---|---|---|---|
| Loss | 1.44 | 1.15 | 1.78 |
| Accuracy | 99.31% | 99.71% | 99.63% |
| Hyperparameter | Range | UNSW-NB15 | CIC-IDS2017 | NSL-KDD |
|---|---|---|---|---|
| Number of filters | [16, 32, 64, 128, 256] | 128, 256 | 128, 256 | 128, 256 |
| Kernel size | [3, 5, 7, 9, 11] | 7 | 11 | 11 |
| Pooling size | (2, 6) | 3 | 5 | 4 |
| Number of dense layers | (1, 5) | 3 | 3 | 5 |
| Number of neurons in dense layers | [16, 32, 64, 128, 256] | 128 | 256 | 256 |
| Dropout rate | (0.1, 0.5) | 0.161583 | 0.368390 | 0.053669 |
| Learning rate | (1 × 10, 1 × 10) | 0.000841 | 0.000782 | 0.001330 |
| Batch size | [16, 32, 64, 128, 256] | 16 | 64 | 64 |
| Number of epochs | (10, 100) | 80 | 84 | 65 |
| Dataset | UNSW-NB15 | CIC-IDS2017 | NSL-KDD |
|---|---|---|---|
| Loss | 1.47 | 0.88 | 1.75 |
| Accuracy | 99.28% | 99.74% | 99.52% |
| Dataset | Metric | Algorithm | |
|---|---|---|---|
| GA | PSO | ||
| UNSW-NB15 | Loss | 1.44 | 1.47 |
| Accuracy | 99.31% | 99.28% | |
| Precision | 99% | 99% | |
| Recall | 98% | 98% | |
| F1-score | 98% | 98% | |
| CIC-IDS2017 | Loss | 1.15 | 0.88 |
| Accuracy | 99.71% | 99.74% | |
| Precision | 100% | 100% | |
| Recall | 99% | 99% | |
| F1-score | 99% | 100% | |
| NSL-KDD | Loss | 1.78 | 1.75 |
| Accuracy | 99.63% | 99.52% | |
| Precision | 99% | 99% | |
| Recall | 99% | 99% | |
| F1-score | 99% | 99% | |
| Dataset | Model | Year | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|---|---|
| UNSW-NB15 | CNN [22] | 2018 | 94.9 | - | - | - |
| 1D-CNN [23] | 2019 | 91.2 | 87.53 | 96.17 | 91.59 | |
| CNN-IDS [24] | 2021 | 91 | - | - | - | |
| BCNN [25] | 2021 | 90.25 | 91 | 90 | 90.45 | |
| GA-1D-CNN | 2023 | 99.31 | 99 | 98 | 98 | |
| PSO-1D-CNN | 2023 | 99.28 | 99 | 98 | 98 | |
| CIC-IDS2017 | CNN-MCL [26] | 2020 | 99.46 | 99.76 | 99.15 | 99.46 |
| CNN [27] | 2022 | 99.41 | - | - | - | |
| 1D-CNN [28] | 2022 | 98.68 | 99.2 | 98.94 | 98.96 | |
| GA-1D-CNN | 2023 | 99.71 | 100 | 99 | 99 | |
| PSO-1D-CNN | 2023 | 99.74 | 100 | 99 | 100 | |
| NSL-KDD | CNN [29] | 2018 | 80.13 | - | - | - |
| SMOTE-ENN [30] | 2019 | 83.31 | 96.97 | - | - | |
| CNN-1D [31] | 2019 | 84.29 | 74.62 | - | - | |
| Multi-CNN [32] | 2019 | 86.95 | 89.56 | 87.25 | 88.41 | |
| IBWNIDM [33] | 2019 | 95.36 | 95.55 | - | - | |
| Improved CNN [34] | 2019 | 99.23 | - | - | - | |
| IDS-CNN [35] | 2020 | 97.7 | - | - | - | |
| DMCNN [36] | 2020 | 94.65 | 96.66 | - | - | |
| CNN(AVG) [37] | 2020 | 88.82 | - | - | 90.67 | |
| AS-CNN [38] | 2020 | 84.08 | 80 | - | - | |
| BCNN-DFS [25] | 2021 | 90.14 | 90 | 90 | 90 | |
| CNN [39] | 2021 | 99 | 98 | 97 | 97 | |
| CNN-B [27] | 2022 | 84.82 | 85.74 | 87.96 | - | |
| GA-1D-CNN | 2023 | 99.63 | 99 | 99 | 99 | |
| PSO-1D-CNN | 2023 | 99.52 | 99 | 99 | 99 |
| Dataset | Model | Year | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|---|---|
| UNSW-NB15 | SGM-CNN [40] | 2020 | 98.82 | 99.74 | - | 95.53 |
| OCNN-HMLSTM [6] | 2021 | 96.33 | 100 | 95.87 | 98.13 | |
| CNN + LSTM [41] | 2022 | 87.6 | 85.5 | 90.6 | 88 | |
| ODODL-IDS [10] | 2022 | 92.87 | 97.33 | 77.53 | 72.53 | |
| CNN + LSTM [42] | 2023 | 93.21 | - | - | - | |
| CNN-LSTM [43] | 2023 | 96.99 | 95.45 | - | - | |
| OHDNN + ECRF [44] | 2023 | 98.3 | 97.5 | 96.7 | 97.1 | |
| GA-1D-CNN | 2023 | 99.31 | 99 | 98 | 98 | |
| PSO-1D-CNN | 2023 | 99.28 | 99 | 98 | 98 | |
| CIC-IDS2017 | SDCNN [45] | 2021 | 99.35 | - | - | - |
| Tree-CNN [46] | 2021 | 98 | - | - | 98 | |
| ODODL-IDS [10] | 2022 | 97.62 | 97.26 | 97.25 | 99 | |
| CNN 1D + BLSTM [47] | 2023 | 98 | 86 | 84 | 81 | |
| GAN-CNN-BiLSTM [48] | 2023 | 96.32 | 96.55 | 95.38 | 96.04 | |
| GA-1D-CNN | 2023 | 99.71 | 100 | 99 | 99 | |
| PSO-1D-CNN | 2023 | 99.74 | 100 | 99 | 100 | |
| NSL-KDD | DCNN [4] | 2018 | 85.22 | 97 | - | - |
| IFS-CNN-BG [49] | 2020 | 98.24 | 95.44 | - | - | |
| PSO-CCNN [50] | 2021 | 98.71 | - | - | - | |
| OCNN-HMLSTM [6] | 2021 | 90.67 | 86.71 | 95.19 | 91.46 | |
| CNN + LSTM [41] | 2022 | 95.2 | 99.5 | 90.8 | 94.9 | |
| ODODL-IDS [10] | 2022 | 89.09 | 95.38 | 99.65 | 78.44 | |
| CNN-LSTM [43] | 2023 | 97.23 | 96.45 | - | - | |
| OHDNN [44] | 2023 | 97.17 | 97.32 | 97.02 | 95.92 | |
| TL-CNN-IDS [11] | 2023 | 99.53 | 97.63 | 96.77 | 97.13 | |
| LSTM-CNN [5] | 2023 | 97.8 | 93.71 | 96.19 | 95.46 | |
| GA-1D-CNN | 2023 | 99.63 | 99 | 99 | 99 | |
| PSO-1D-CNN | 2023 | 99.52 | 99 | 99 | 99 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kilichev, D.; Kim, W. Hyperparameter Optimization for 1D-CNN-Based Network Intrusion Detection Using GA and PSO. Mathematics 2023, 11, 3724. https://doi.org/10.3390/math11173724
Kilichev D, Kim W. Hyperparameter Optimization for 1D-CNN-Based Network Intrusion Detection Using GA and PSO. Mathematics. 2023; 11(17):3724. https://doi.org/10.3390/math11173724
Chicago/Turabian StyleKilichev, Dusmurod, and Wooseong Kim. 2023. "Hyperparameter Optimization for 1D-CNN-Based Network Intrusion Detection Using GA and PSO" Mathematics 11, no. 17: 3724. https://doi.org/10.3390/math11173724
APA StyleKilichev, D., & Kim, W. (2023). Hyperparameter Optimization for 1D-CNN-Based Network Intrusion Detection Using GA and PSO. Mathematics, 11(17), 3724. https://doi.org/10.3390/math11173724