Abstract
Recognition of emotions and sentiment (affective states) from human audio–visual information is widely used in healthcare, education, entertainment, and other fields; therefore, it has become a highly active research area. The large variety of corpora with heterogeneous data available for the development of single-corpus approaches for recognition of affective states may lead to approaches trained on one corpus being less effective on another. In this article, we propose a multi-corpus learned audio–visual approach for emotion and sentiment recognition. It is based on the extraction of mid-level features at the segment level using two multi-corpus temporal models (a pretrained transformer with GRU layers for the audio modality and pre-trained 3D CNN with BiLSTM-Former for the video modality) and on predicting affective states using two single-corpus cross-modal gated self-attention fusion (CMGSAF) models. The proposed approach was tested on the RAMAS and CMU-MOSEI corpora. To date, our approach has outperformed state-of-the-art audio–visual approaches for emotion recognition by 18.2% (78.1% vs. 59.9%) for the CMU-MOSEI corpus in terms of the Weighted Accuracy and by 0.7% (82.8% vs. 82.1%) for the RAMAS corpus in terms of the Unweighted Average Recall.
Keywords:
audio–visual-based affective states recognition; emotion recognition; sentiment recognition; gated modality fusion; self-attention fusion; multi-corpus learning MSC:
68T45
1. Introduction
Emotions are important for people in that they shape their perceptions, behaviors, and interactions with each other. Similarly, emotions are important in human–computer interactions [1]. Understanding and recognition of emotions have long been fundamental aspects of human communication used for facilitating empathy, social bonding, and effective decision-making. In recent years, the field of affective computing has emerged to explore the automated recognition of emotions, particularly through the analysis of multimodal signals. The latter refers to the integration of various modalities, including facial expressions, vocal intonations, body gestures, and physiological responses, for a more comprehensive understanding of an individual’s emotional state. This holistic approach enables a more nuanced interpretation of emotions, surpassing the limitations of unimodal methods. The applications of multimodal emotion recognition span across diverse domains, including intelligent call centers [2], tutoring systems [3], healthcare [4], gaming [5], and virtual reality [6], to name only a few, where understanding and responding to emotions are crucial to effective communication and customer satisfaction. By leveraging multimodal emotion recognition techniques, such systems offer the potential to create more personalized and empathetic human–computer interactions. In recent years, the field of affective states recognition has experienced a significant shift towards studying emotions “in the wild”.
The emotions experienced “in the wild”, as well as their intensity, largely depend on the mood and sentiment of the human involved [7]. Emotion is an intense short-term affective state that a human is experiencing at a given moment [8]. On the other hand, sentiment is a more prolonged and more intense affective state that a human has relative to an object or a phenomenon [9]. If a person has a negative attitude towards something, they generally have negative emotions towards it regardless of their mood. Mood is the longest and the least intense affective state, and is not generally associated with a specific stimulus [10]. It is often influenced by physiological, social, and other factors. If a person experiences an unexpected emotion, such as fear, their mood may change.
The intensity of experienced emotions is known to depend on cultural [11], linguistic [12], and demographic [13] differences. For example, males tend to be more restrained in the expression of their emotions [14]. Low-intensity emotions are more typical of “easterners”, while high-intensity emotions are typical of “westerners” [11,15]. Emotions in different languages are conveyed through different variations in pitch, tone, and rhythm, resulting in a more or less explosive or intense speech style, word choice, facial expression, and body language. As a result, humans recognize emotions more accurately in people with similar languages than in those with vastly different languages [16]. Thus, to create a more effective emotion recognition system it is necessary to implement multimodal and multi-task approaches that can simultaneously recognize multiple affective states, as well as to have them optimized for speakers of different cultures and different languages.
There are several “in the wild” corpora available to the public that can enable the development of multimodal and multi-task approaches for recognition of human affective states, including Multimodal EmotionLines Dataset (MELD) [17], CMU Multimodal Opinion Sentiment and Emotion Intensity (CMU-MOSEI) [18], and Aff-Wild2 [19]. These corpora are most suitable for use in real-world applications. Nevertheless, although these corpora contain a wide range of speakers, they are limited to those speaking English; as a result, they may adhere to a number of locally accepted cultural norms of behavior. Thus, achieving more universal and objective results would require a combination of several corpora. This approach, known as Multi-Corpus Learning (MCL), enables the model to learn from a diverse set of data, thereby improving its generalization capabilities [20]. Not all corpora can be generalized to a single experimental setup, however, and it is a challenging task, especially in the perspective of multimodal and multitask affective states recognition. Nevertheless, this relatively novel approach is promising and has been gaining in popularity.
In this article, we present a new MCL approach for audio–visual emotion and sentiment recognition. The main contributions of this article are as follow:
- We propose a novel audio affective feature extractor based on a pretrained transformer model and two Gated Recurrent Units (GRU) layers. It is trained to recognize affective states at the segment level using the MCL approach.
- We propose a novel visual affective feature extractor based on a pretrained 3D Convolutional Neural Network (CNN) model and two Long Short-Term Memory (LSTM) layers with a self-attention mechanism. It is trained to recognize affective states at the segment level using the MCL approach.
- We propose a novel Cross-Modal Gated Self-Attention Fusion (CMGSAF) strategy at the feature level trained to recognize affective states at the instance level using the Single-Corpus Learning (SCL) approach. The proposed fusion strategy outperforms State-of-the-Art (SOTA) in emotion recognition.
- We conduct exhaustive experiments comparing SCL and MCL with and without a speech style recognition task, and evaluate the effects of the speech style recognition task on affective states recognition performance.
The rest of the article is organized as follows. In Section 2, we analyze the MCL and Multi-Task Learning (MTL) approaches for affective states recognition. Section 3 deals with the research corpora, while Section 4 provides a detailed description of the proposed approach. Our experimental results are presented in Section 5. Finally, in Section 6 we summarize the work and discuss directions for further research.
2. Related Work
In this section, we present an overview of SOTA approaches for affective states recognition. At the end of the section we present a classification of SOTA approaches (see Figure 1).
2.1. State-of-the-Art Approaches for Multi-Corpus Learning
Multi-corpus emotion recognition is predominantly performed using a single modality [20,21,22]. Research has focused on the use of the audio modality for the following reasons: (1) most of the existing corpora for emotion recognition consist only of audio; and (2) audio requires less computational effort compared to video, which greatly simplifies multi-corpus studies. Recent advances in multi-corpus studies are discussed below.
Gerczuk et al. [20] conducted a large-scale multi-corpus study on Speech Emotion Recognition (SER). The authors assembled 26 known corpora into a single one called EmoSet and proposed a model called EmoNet. EmoNet combines the deep ResNet architecture and residual adapters transferred from the field of multi-domain visual recognition. Compared to the model trained in the conventional way, the proposed model improves performance for 21 out of 26 corpora on EmoSet. To aggregate the 26 corpora annotated with different numbers of emotional labels, the authors grouped all labels into six classes according to principle of low arousal with three valence classes (neutral, positive, and negative) and high arousal with the same valence classes.
In contrast to the above approach, Alisamir et al. [21] conducted a multi-corpus study without changing their labeling schemes. The authors proposed an approach that relies on self-supervised representations, which can provide highly contextualized speech representations and MTL paradigms. The authors used four corpora, and their experimental results showed that the proposed emotion embeddings can effectively recognize the same emotions in different corpora.
Zhang et al. [22] proposed an effective approach for SER based on selective MTL considering the speech style attribute (acted or spontaneous). The authors collected a Japanese language corpus with spontaneous speech and used the Interactive Emotional Dyadic Motion Capture (IEMOCAP) [23] corpus with prepared speech. This model addresses two tasks, as it recognizes both emotions and speech styles. The results of the study showed that simultaneous recognition of emotion and speech style can increase the performance of the SER.
2.2. State-of-the-Art Approaches for Affective States Recognition
Zadeh et al. [18] proposed a novel multimodal fusion approach called Dynamic Fusion Graph (DFG) and Graph Memory Fusion Network (Graph-MFN). The authors conducted experiments to analyze how modalities interact with each other in human multimodal language. DFG was tested on two individual tasks, namely, sentiment and multi-label emotion recognition.
Sangwan et al. [24] presented the multi-task Gated Contextual Cross-Modal Attention (GCCMA) approach for sentiment and multi-label emotion recognition together. The authors developed a multi-task gated contextual cross-modal attention framework which considers more than one modality and multiple utterances for sentiment and emotion prediction together.
Akhtar et al. [25] presented the Multi-Task Multimodal Emotion and Sentiment (MTMM-ES) approach based on a context-level (pairwise) inter-modal attention mechanism. It can emphasize the contributing features by providing more attention to the respective utterance and neighboring utterances.
Chauhan et al. [26] proposed a temporal approach for two tasks: sentiment and multi-label emotion recognition. They used an auto-encoder mechanism to learn inter-modal interactions and Context-aware Attention Module (CAM) to capture the correspondence among neighboring utterances.
Mittal et al. [27] implemented the M3ER approach for multi-label emotion recognition. M3ER employs a data-driven multiplicative fusion to emphasize reliable cues and suppress others. M3ER uses the Canonical Correlational Analysis, and generates proxy features to replace ineffectual modalities.
Shenoy et al. [28] presented the Multilogue-Net approach to address two single tasks: sentiment and multi-label emotion recognition. Multilogue-Net models the affective state using several temporal models to track the conversation context and the emotional state. Multilogue-Net has a pairwise attention mechanism that uses important modalities and their respective combinations for affective prediction at each timestamp.
Tsai et al. [29] introduced a multimodal routing approach that dynamically adjusts weights between input modalities and output representations for each input sample. This approach identifies the relative importance of individual modalities and cross-modality features, and allows modality–prediction relationships to be interpreted both globally and locally for each single input sample.
Khare et al. [30] used multimodal self-supervised training for multi-label emotion recognition. The authors learned multimodal representations using a cross-modal transformer trained on the masked language modeling task with features obtained from different modalities. To increase temporal awareness, the authors used unimodal encoders to encode various modalities and one modality as the anchor.
Wen et al. [31] proposed the Cross-Modal Dynamic Convolution (CMDC) approach to solve the two single tasks of sentiment and multi-label emotion recognition. CMDC solves the sparsity of emotion-related clues by locally modeling the temporal dimension, thereby avoiding unrelated information overload, while CMDC is easy to stack and can model long-range cross-modal temporal interactions.
Franceschini et al. [32] implemented Modality-Pairwise Unsupervised Contrastive Loss (MPUCL) for multi-label emotion recognition. MPUCL analyzes raw data; this approach has several advantages. First, it uses unsupervised learning, which avoids the cost of labeling data. Second, it does not require spatial augmentation of the data, modality alignment, or large batch sizes. Third, it fuses data only during inference. Finally, it does not require backbones pre-trained on the emotion recognition task.
Le et al. [33] proposed a transformer-based fusion approach for multi-label emotion recognition that takes raw video frames, audio signals, and text subtitles as inputs and passes information from these multiple modalities through a unified transformer architecture to learn a joint multimodal representation.
Mamieva et al. [34] implemented multimodal emotion recognition using attention-based fusion of extracted facial and speech features. Their experimental results showed that the performance of this approach is significantly decreased when the attention mechanism fails to correctly identify and assign appropriate weights to relevant features.
Hsu et al. [35] introduced a bimodal transformer encoder for audio–visual emotion recognition. The emotional consistency scores (or the attention weights in the bimodal transformer encoder) of the audio and visual features were adjusted by a Neural Tensor Network (NTN) at the segment and signal levels.
Mai et al. [36] studied the correlation between audio, video, and text modalities using a new architecture based on a weak predictor, which they named Multimodal Correlation Learning. The authors researched the effectiveness of the correlation learning algorithm on both unsupervised and supervised learning strategies. Their approach is applicable to both classification and regression tasks in sentiment analysis and emotion recognition.
Wagner et al. [37] compared the performance of several deep models in SER: arousal, valence, dominance, and sentiment. Deep models have been evaluated for their downstream performance, with a focus on the impact of model size and pre-training data. The authors analyzed the generalization, robustness, fairness, and efficiency of these models.
Ryumina et al. [38] presented a partially-continuous single-label emotion recognition approach based on hand-crafted acoustic and deep visual features as well as a weighted fusion of probabilities. The authors analyzed the trade-off between annotation quality, sample size, and their influence on the performance of emotion recognition.
Savchenko et al. [39] proposed a novel approach with personalized acoustic and visual lightweight feed-forward neural network models. Their experimental results showed that the adaptation of user-independent classifiers significantly increased the performance on emotion recognition compared to universal speaker-independent models.
Ryumina et al. [40,41] presented a visual single-label emotion recognition approach based on hand-crafted and deep features. It was tested on several emotional corpora in a cross-corpus study. A backbone model for deep emotional feature extraction [41] is used in the current study.
Figure 1 shows the classification of the approaches discussed above. In this article, we develop our own approach following the trends highlighted in the above review.

Figure 1.
Classification of state-of-the-art approaches, including: Zadeh et al., 2018 [18]; Gerczuk et al., 2021 [20]; Alisamir et al., 2022 [21]; Zhang et al., 2022 [22]; Sangwan et al., 2019 [24]; Akhtar et al., 2019 [25]; Chauhan et al., 2019 [26]; Mittal et al., 2020 [27]; Shenoy et al., 2020 [28]; Tsai et al., 2020 [29]; Khare et al., 2021 [30]; Wen et al., 2021 [31]; Franceschini et al., 2022 [32]; Le et al., 2023 [33]; Mamieva et al., 2023 [34]; Hsu et al., 2023 [35]; Mai et al., 2023 [36]; Wagner et al., 2023 [37]; Ryumina et al., 2021 [38]; Savchenko et al., 2022 [39]; Ryumina et al., 2020 [40]; Ryumina et al., 2022 [41].

- The features used are classified as low-level features (hand-crafted, spectral, and non-specific deep features) and mid-level features (affective deep features). Deep features are predominantly extracted using CNNs and temporal models.
- Both types of features are mostly used for audio analysis. Exceptions are approaches using transfer learning [21,35,36,37] and approaches that simultaneously process raw signals from several modalities [26,29,34].
- To analyze visual signals, most of the proposed approaches use raw images (mostly face regions) and mid-level features extracted from them. Exceptions include approaches [18,32,40] using low-level (hand-crafted) features and their deep representations, with additional extraction of mid-level features from raw images.
- Modality fusion is mostly performed at the feature level using temporal models such as LSTM, GRU/Bidirectional GRU (BiGRU), and transformer. Exceptions are the two approaches in [38,39], in which modality fusion was performed at the probability level obtained from different modalities.
- The SOTA approaches considered above use (1) single-label [21,22,34,35,38,39,40,41] or multi-label [18,24,25,26,27,28,29,30,31,32,33] emotion recognition; (2) regression [37] or categorical [18,24,25,26,28,29,31,36] sentiment recognition; and (3) categorical [20] or regression [37] valence, activation, and dominance recognition. Fully Connected Layer (FCL) and various activation functions (Softmax, Sigmoid, ReLU) are used to obtain predictions.
- In [24,25], multi-task approaches were developed to simultaneously perform recognition of multiple affective states (i.e., emotion and sentiment). In [22], a multi-task approach for emotion and speech style recognition was implemented.
3. Research Corpora
Today, there are many corpora for recognition of affective states with a wide range of speakers and rich metadata. A detailed overview of existing corpora is presented in [42]. In this study, we use two corpora for modeling affective states: Russian Acted Multimodal Affective Set (RAMAS) and CMU-MOSEI. RAMAS is a unique audio–visual corpus of prepared Russian speech. CMU-MOSEI is a large-scale publicly available corpus that consists of “in the wild” recordings in English. Both corpora can enable the development of robust multimodal and multi-task approaches for recognition of human affective states in different conditions.
3.1. RAMAS Corpus
RAMAS [43] includes about 7 h of audio–visual recordings, motion capture data, and physiological signals from ten actors (five women and five men), aged 18–28 years, were recorded in different interactive dyadic scenarios with different topics (travel, work, health, and others). A total of six emotions are considered: Anger, Disgust, Happiness, Sadness, Fear, and Surprise. The corpus was labeled by a total of 21 annotators (fifteen women and six men) who assigned emotion tags to different time intervals of instances, resulting in overlapping emotion labels within the corpus. Therefore, multiple annotated intervals of varying lengths were obtained for each instance. An earlier study [38] indicated that an optimal level of annotation agreement was achieved when at least four annotators labeled an interval of a given instance with the same emotion. We used the fourth level of annotation agreement in our research as well. For sentiment analysis, the original emotion classes were grouped into Positive (Happiness, Surprise), Negative (Anger, Disgust, Sadness, Fear), and Neutral (Neutral) sentiment classes. Emotion and sentiment distributions are presented in Figure 2. The instances of the Neutral emotion class are completely zero vectors, i.e., none of the six emotions is present. The distribution of the emotion labels demonstrates that the number of instances is generally balanced, with the exception of Happiness. The sentiment distribution shows that the number of Neutral instances is significantly inferior compared to the other classes. Only one emotion/sentiment is provided for one instance, marked by at least four annotators out of the possible five.
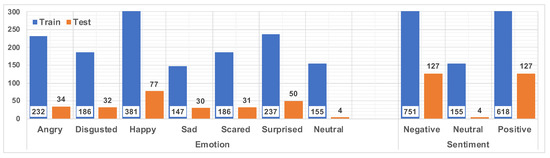
Figure 2.
The number of instances in each emotion and sentiment class in the training/testing subsets of the RAMAS corpus.
3.2. CMU-MOSEI Corpus
CMU-MOSEI [18] includes video monologues of 1000 speakers (430 women and 570 men) from YouTube. In total, there are approximately 66 h, 3228 videos, and 250 different topics, including reviews, debate, consulting, and others. The videos are segmented into around 23K sentences, and the corpus has been labeled by three crowdsourced annotators from the Amazon Mechanical Turk platform. Each utterance is annotated on a Likert scale into seven sentiment classes: highly negative, negative, weakly negative, neutral, weakly positive, positive, and highly positive. Emotions based on Ekman’s model (Anger, Disgust, Happiness, Sadness, Fear, Surprise) are presented with intensities on a Likert scale with a range of 0 (no evidence of emotion) to 3 (a high level of emotion). In our study, we combined the seven sentiment classes into the Negative, Neutral, and Positive classes. The emotion and sentiment distributions along with the number of annotated emotions per instance are shown in Figure 3. The top part of Figure 3 demonstrates that the CMU-MOSEI corpus has a strong class imbalance problem [44] for both emotion and sentiment distributions; 35% of labels belong to the Happiness class and 49% belong to the Positive sentiment class. The bottom part of Figure 3 shows that 15% of the instances have no emotional label, 49% of the instances have one emotional label, and 34% have two or three emotional labels. It should be noted that certain instances have opposite emotional and sentiment labels at the same time. The ambiguity of the labels can be attributed to the length of the instances. Considering the duration of the instances, individuals may experience several emotions which might contradict their overall sentiment [45].
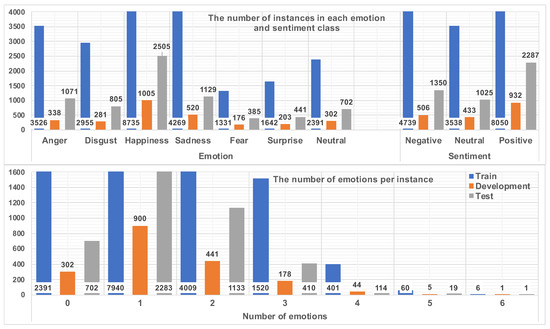
Figure 3.
Data distribution in the training/development/testing subsets of the CMU-MOSEI corpus.
4. Methodology
The pipeline of the proposed MCL approach for audio–visual emotion and sentiment recognition is presented in Figure 4. We trained multi-corpus temporal models for mid-level audio/video feature extraction at the segment level. Each audio–visual instance was divided into segments of 4 s with a step of 2 s. To predict affective states at the instance level, we trained single-corpus fusion models at the feature-level. In the following subsections, we describe the proposed approach for recognition of affective states based on audio, visual, and audio–visual data.
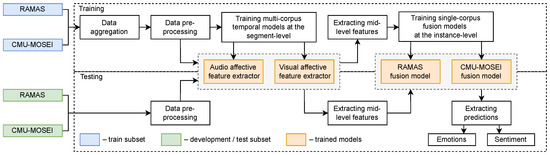
Figure 4.
Pipeline of the multi-corpus learning approach for audio–visual emotion and sentiment recognition.
4.1. Audio-Based Affective States Recognition
Inspired by previous studies on SER, we use several pre-trained transformer models as the backbone of our model:
- The pre-trained wav2vec (RW2V), HuBERT (RHuBERT), and WavLM (RWavLM) models proposed by https://github.com/Aniemore/Aniemore (accessed on 13 August 2023) were pre-trained using categorical emotions from the Russian Emotional Speech Dialogues (RESD) corpus. This corpus contains 4 h of audio dialogues in Russian recorded in studio quality, which is useful for training on the RAMAS corpus.
- The pre-trained wav2vec model (EW2V) proposed by [37] was pre-trained using the regression emotion dimensions (arousal, valence, and dominance) from the MSP-Podcast corpus [46]. This corpus consists of podcast recordings in English, which is useful for training on the CMU-MOSEI corpus.
The architecture of the proposed model is presented in Figure 5. This model predicts a binary vector for six emotions and a probability vector for three sentiments. The input data of the audio model is 4 s of raw signal (16,000 = 64,000). This vector is propagated through the backbone model, in our case the pre-trained transformer model. According to [37], freezing the CNN layers yields better results than full fine-tuning including the CNN-based feature encoder. In the operations to follow, we use the hidden states obtained from the final transformer layer with an output size of . On top of the model, we stack two GRU layers with 256 neurons and intermediate dropout with a probability of 0.5. The output size of the last GRU layer is . Recent research on SER has shown that combining an attention mechanism and recurrent layers can strengthen the transformer model and improve its performance [47,48]. After the last GRU layer, we apply FCL, with the number of neurons being 1. Thus, we aggregate the features along the time axis into a vector with size . We do this for sequence-to-sequence modeling. We squeeze this vector (i.e., remove dimensions of size one from a tensor) and add two more FCLs with six and three neurons for multi-class emotion and sentiment recognition, respectively. The output of the squeeze operation with size T is used as the feature vector of the audio modality for further fusion.
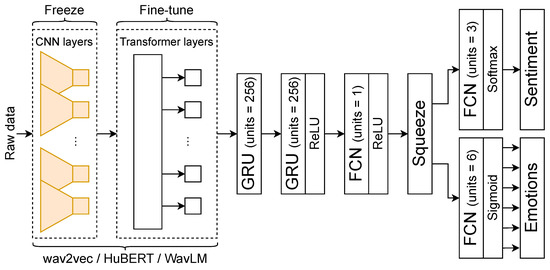
Figure 5.
The architecture of the proposed model for audio-based affective states recognition.
4.2. Visual-Based Affective States Recognition
In the current study, we compare several sets of facial features (see Figure 6):

Figure 6.
Visual features.
- Emotional Facial Features (EmoFF). Extracted using our EmoAffectNet model based on 2D ResNet-50 for frame-level static emotion recognition [41]. We converted 2D ResNet-50 to 3D ResNet-50 and froze the weights of four blocks (one convolutional and three residual blocks). The output size of the fifth block is (where T is the number of images in the sequence). We trained this block with a temporal model. Sequences of face region images were used as input data for 3D ResNet-50. The face regions were detected using the popular FaceMesh model [49] from the MediaPipe [50] open source library. We resized the face region images to 224 × 224 and applied channel normalization.
- Emotional Selfies Features (EmoSF). Extracted in the same way as EmoFF. By selfies, we mean the upper part of a human’s body down to the waist. Selfie regions were detected using the Selfie-Segmentation model from the MediaPipe library. The background in selfie images was filled in with black to prevent the model from focusing on non-human objects. The images were resized and normalized similarly to EmoFF.
- Histograms of Oriented Gradients (HOG). Extracted using the OpenFace [51] open source tool. HOG splits an image into small cells, then computes the directions and magnitudes of the changes in intensity values between the adjacent pixels. Thus, HOG represents information about the texture and edges of an image. The size of this feature set was .
- Head Pose, Eye Gaze and Action Units (PGAU). OpenFace can track head pose (translation and orientation) and eye gaze, and is able to detect Facial Action Units (FAUs). We combined these features into one vector. The size of this feature set was . FAUs are specific movements or muscle contractions of the face related to the expression of emotions. These movements are categorized and labeled according to a standardized coding system called the Facial Action Coding System (FACS).
To objectively compare all the considered feature sets, we implemented a multi-task temporal model based on Bidirectional LSTM (BiLSTM) with a self-attention mechanism. We refer to this model as BiLSTM-Former. BiLSTM models long-term dependencies in the input sequence in both the forward and backward directions, providing more comprehensive understanding of the input sequence. This recurrent model has demonstrated its advantage on facial expression recognition tasks [52]. The self-attention mechanism selects the most informative features and suppresses the less informative ones through corresponding different positions of the same input sequence [53]. BiLSTM-Former predicts a binary vector for six emotions and a probability vector for three sentiments. The architecture of the proposed model is presented in Figure 7.
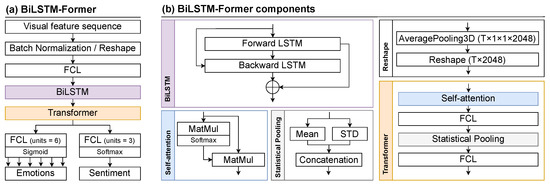
Figure 7.
Visual temporal model (BiLSTM-Former).
The input data for the BiLSTM-Former model consist of a sequence of features with size , where F represents the number of features. This number varies depending on the feature set used. Next, a Batch Normalization layer or Reshape block is applied. Batch Normalization allows the input data to be standardized to a mean value close to 0 and standard deviation close to 1. This layer is used with the HOG and PGAU feature sets, while a Reshape block is applied to EmoFF and EmoSF. The subsequent layers/blocks are the same for all feature sets. The BiLSTM block consists of two LSTM layers. The first layer receives a sequence of feature vectors as input in the forward direction, using as the input at each step t. The second layer receives the same sequence of feature vectors in the backward direction using as the input at each step t. This creates two new sequences of feature vectors and [54]. Then, the sequences of the feature vectors are added up as follows:
The transformer block has a dot-product attention layer [53], which is computed using the following formula:
Multi-task prediction is performed based on a single feature vector. The parameters of the temporal models are selected through grid search and depend on different feature sets, as described in Section 5.3.
4.3. Audio–Visual-Based Affective States Recognition
In this paper, we consider several strategies for modality fusion. The Probability Weighted Fusion (PWF) and Probability Concatenation Fusion (PCF) strategies involve late modality fusion, and are based on the predictions received from each modality, while the Feature Concatenation Fusion (FCF) and CMGSAF strategies involve early modality fusion and are based on the audio and visual mid-level features.
- PWF. To fuse the predictions of the two models, which provide probabilities for three sentiment and six binary emotion classes, we generate two weight vectors (where C is the number of classes) of sizes 2 × 3 and 2 × 6. These weight vectors are generated randomly using the Dirichlet distribution. The final prediction vector for emotion/sentiment recognition is calculated as follows:where and are prediction vectors obtained by the audio and visual modalities, respectively. This strategy has been successfully applied in [38,55,56]. Before performing PWF, we calculate the average value of the prediction vectors for each segment.
- PCF. In the research corpora, the duration of instances varies from less than one second to more than 100 s. For this reason, the number of prediction/feature vectors is different for each instance. To address this problem, we extract statistical functionals such as the mean and standard deviation from the four prediction matrices. This allows a single prediction vector to be created for each instance, for each modality, and for each recognition task. We then concatenate these audio and video statistical functionals of predictions for emotions and sentiment and use them as input to classifiers based on one FCL.
- FCF. Unlike the previous strategies, this approach is based on the mid-level features obtained by audio and video models at the segment level. Similar to the PCF strategy, we compute statistical functionals, except this time only for two feature matrices. This allows a single feature vector to be created for each instance and each modality. We then use two FCLs for emotion and sentiment recognition.
- CMGSAF. Unlike previous strategies, this one (see Figure 8) requires large computational resources, as it uses deep machine learning. To fuse modalities, we transform the statistical functionals of both feature vectors into four feature sets (two for each modality) using FCLs. Feature sets are used as input data for two successive attention layers: (1) gated fusion [57], which is responsible for feature fusion of different modalities and (2) self-attention (similar to the BiLSTM-Former model) to enhance the most informative features. CMGSAF uses four feature sets F and a number of units U as inputs, which together determine the size of the weight matrix .
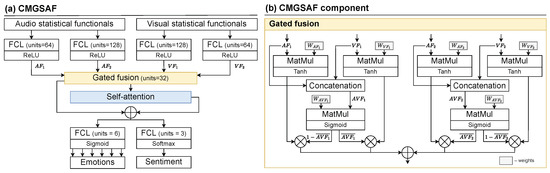 Figure 8. CMGSAF strategy. and refer to audio feature sets. and to visual feature sets, and to audio–visual feature sets, and to modified audio–visual feature sets, and W to weights optimized during training.
Figure 8. CMGSAF strategy. and refer to audio feature sets. and to visual feature sets, and to audio–visual feature sets, and to modified audio–visual feature sets, and W to weights optimized during training.
In addition, to increase the performance of emotion and sentiment recognition we applied a simple logarithmic weighting of the classes proposed in [58]. The weights for the classes were determined using the following formula:
where means the natural logarithm, is an optimized parameter, M is the total number of instances for all classes, and is the number of instances per class i. The hyperparameter was set to a range of [0, 1] with a step of 0.1. The weights were then applied to the loss functions as follows:
where means the weighted categorical cross-entropy loss function used for sentiment recognition, is the weighted binary cross-entropy loss function used for multi-label emotion recognition, t is the ground truth vector, p is the prediction vector, is the sentiment weight vector (with a size of 3), is emotion weight matrix (with a size of 6 × 6), and , are the respective weight vectors for the no emotion and emotion classes.
5. Experimental Results
We conducted experiments involving audio/visual-based affective states recognition in several stages. In the first stage, we determined the best audio model/visual feature set for the single-corpus trained models for affective states recognition. In the second stage, we trained multi-corpus models with and without the speech style recognition task using this audio model/feature set. In the third stage, we used the best multi-corpus trained models, froze all of the weights except those of the last FCL layers, and trained two single-corpus models for the RAMAS and CMU-MOSEI corpora. These experiments were conducted at the segment level of instances.
Finally, we extracted audio and visual mid-level features at the segment level using the multi-corpus trained models, computed statistical functionals at the instance level, and trained single-corpus and multi-corpus fusion models at the feature level.
In our experiments, we used the training subsets of the RAMAS and CMU-MOSEI corpora to train our models, the testing/development subset of the RAMAS/CMU-MOSEI corpora to tune the hyperparameters of our models, and the testing subsets of the RAMAS and CMU-MOSEI corpora to evaluate the models.
5.1. Performance Measures
We used several performance measures to evaluate the proposed approach. Weighted Accuracy (WA) and the Weighted F1-score (WF1) were used to estimate multi-label emotion recognition. These measures were calculated as follows:
where and are true positive and negative predictions, respectively, P and N are the total number of positive and negative instances, respectively, C is the number of classes, is the total number of instances per class i, and M is the total number of instances for all classes. To estimate proposed models for multi-label emotion recognition, we averaged the and values between the six classes. To evaluate sentiment classification models, we used and accuracy A:
These performance measures are the baseline for the CMU-MOSEI corpus [18]. To compare the proposed approach with the SOTA approaches [38,39] for the RAMAS [43] corpus, we used the Unweighted Average Recall (UAR):
Because we split the instances into segments of 4 s with a step of 2 s, we obtained several predictions for each segment. To obtain the final predictions for a whole instance, we used two strategies. In multi-label emotion recognition, our models predicted a vector , where , D is the number of instance segments, with six values in the range for the six emotions. First, we transformed predicted vectors into binary vectors as follows:
where i is the emotion class number.
Then, we summed () all the binary vectors of the segments of the whole instance and converted this vector into the final prediction vector using the following formula.
For sentiment prediction, we used a segment–instance voting strategy:
where is the class number that occurs most often between the predictions of instance segments and determines the class that has the maximum probability. Both strategies were applied to unimodal approaches. For all modality fusion strategies, we normalized only the predicted emotion vectors in the same way as in Formula (13). After that, we calculated the performance.
5.2. Audio-Based Affective States Recognition
Before training, we performed several data preprocessing steps on the research corpora. First, we processed the audio data by selecting the voice using the Spleeter source separation library [59]. Second, we applied Voice Activity Detector (VAD) https://github.com/snakers4/silero-vad (accessed on 13 August 2023) to the resulting data. Finally, the data were chunked and used for training.
In the training phase, we froze the weights of the CNN layers of the backbone models and fine-tuned the transformer layers. This partial tuning provides superior results compared to full tuning incorporating the feature extractor based on the CNN [60]. We trained all audio models using the Stochastic Gradient Descent (SGD) optimizer with the Cosine Annealing Warm Restarts [61] scheduler for 100 epochs. The learning rate varied from 0.001 to 0.0001.
The results of the experiments obtained for the audio modality are presented in Table 1. The table shows almost the same performance for all the models pre-trained on the RESD corpus. RWavLM models slightly outperform RW2V and RHuBERT. Overall, the English-based models outperform the Russian-based models. The and A performance measures for emotion and sentiment recognition of the best model decreases by 0.6% (73.3% vs. 72.7%) and 2.3% (55.4% vs. 53.1%.), respectively, on the RAMAS corpus. The best performance is shown by the EW2V model pre-trained on the MSP-Podcast corpus. This again confirms the importance of the amount of training data; the MSP-Podcast corpus is much larger than the RESD corpus (238 h vs. 4 h), which initially increases the generalizability of the model. The performance measure of the EW2V model for emotion recognition increases by 10.2% (47.0% vs. 57.2%) on the RAMAS corpus and by 10.7% (45.0% vs. 55.7%) on the CMU-MOSEI corpus.

Table 1.
Experimental results obtained for the audio modality. Performance measure superscript shows the number of classes.
Training the EW2V model on both corpora improves the performance of affective states recognition by 3.2% (62.1% vs. 58.9%); however, including the speech style recognition task in the multi-corpus trained model decreases the overall performance. Thus, the distinction between prepared and spontaneous speech does not contribute to better performance on any of corpora.
Table 1 shows that pre-training of the multi-corpus model and its further fine-tuning on each corpus improves the performance measures by an average of 4.6% (58.9% vs. 63.5%) for recognition of affective states. Overall, we achieve an absolute performance increase of 8.1% (63.5% vs. 55.4%).
5.3. Visual-Based Affective States Recognition
The CMU-MOSEI corpus contains videos with multiple people in the frames. When using face detectors “in the wild”, confusion between people’s faces can occur due to factors such as facial occlusions and changing camera angles. To address this issue, it is necessary to use face identification approaches.
In this article, we employed the VGGFace model [62] to extract embeddings of faces from the current and previous frames. Then, we utilized cosine similarity to compare these embeddings. If the cosine similarity between the two facial embeddings exceeded 0.5, the faces were considered equivalent.
We trained the BiLSTM-Former models using the Adam optimizer with a learning rate of 0.0001 for 100 epochs. Training was interrupted if the performance measure did not increase for six epochs on the testing/development subset of the RAMAS/CMU-MOSEI corpus. The best parameters of the BiLSTM-Former model are presented in Table 2.
Table 2.
Optimal parameters of the BiLSTM-Former model depending on the different feature sets.
The results of the experiments obtained for the video modality are presented in Table 3. The feature sets are arranged in ascending order of their performance. The experimental results show that EmoFF were the most informative features for affective states recognition. In addition, the HOG feature set shows higher performance. Both feature sets reflect textural information about the face. On the other hand, the PGAU feature set reflects geometric information about the face, and shows the lowest results. Textural scene features (EmoSF) are less informative for affective states recognition. Based on these results, we can conclude that textural information about the face is better suited for describing affective changes.
Table 3.
Experimental results obtained for the video modality. Performance measure superscript shows the number of classes.
Table 3 shows that training the model on both corpora improves the performance of affective states recognition. The performance measure for emotion recognition increased by 3.1% (81.7% vs. 78.6%) for the RAMAS corpus and by 2.9% (65.4% vs. 62.5%) for the CMU-MOSEI corpus. However, the A performance measure for sentiment recognition decreased by 3.1% (91.1% vs. 94.2%) for the RAMAS corpus and increased by 0.6% (49.5% vs. 48.9%) for the CMU-MOSEI corpus. This is probably due to significant differences in sentiment annotation between the RAMAS and CMU-MOSEI corpora.
Including the speech style recognition task in the multi-corpus trained model improves sentiment recognition. Thus, the models learned to distinguish between acted and spontaneous sentiment. However, we observed lower performance when applying the model to the RAMAS corpus compared to the single-corpus trained model for both affective recognition tasks. In contrast, the model performance increased on the CMU-MOSEI corpus. Thus, model training, whether with or without the speech style recognition task for the two corpora, has a positive impact on performance for the CMU-MOSEI corpus.
To perform the final stage, we used the multi-corpus model trained without speech style recognition. The experimental results show that pre-training of the multi-corpus model and its further fine-tuning for each corpus improved the performance by an average of 1.2% (75.1% vs. 73.9%) for recognition of affective states. Overall, we achieved an absolute performance increase of 5.9% (75.1% vs. 69.2%), depending on the features used and the training strategy (multi-corpus or single-corpus).
5.4. Audio–Visual-Based Affective States Recognition
Table 4 shows the results of affective states recognition obtained using the proposed modality fusion strategies. The interaction of modalities in the PWF strategy is regulated by a single generated weights matrix using the Dirichlet distribution depending on the task. The PCF and FCF strategies generate two weight matrices using a single-layer FCL by analyzing the audio–visual statistical functionals of predictions and features, respectively. The CMGSAF strategy has more complex components. It consists of several FCL, gated fusion, and a self-attention mechanism. The number of weights in this strategy is much larger, allowing a controlled degree of interaction between the two modalities to be modeled more accurately. The experimental results show that regardless of the learning strategy (single-corpus or multi-corpus), the CMGSAF outperforms the other strategies. The two simple fusion strategies (late PCF and early FCF) show approximately the same average performance, and underperform the CMGSAF strategy by 2% (77.4%/77.2% vs. 79.4%). Comparison of these learning approaches shows that the average performance of MCL approach is 1% lower compared to SCL (78.4% vs. 79.4%). Overall, the average values of the performance measures increased by 5% (79.4% vs. 74.4%) when combining the two modalities.
Table 4.
Experimental results obtained using audio–visual fusion strategies. Performance measure superscript shows the number of classes.
It should be noted that in terms of modalities the CMGSAF strategy showed different performance depending on the corpus used. Thus, when predicting affective states of instances in the RAMAS corpus the visual modality (CMGSAF without audio) outperforms the acoustic modality (CMGSAF without video), and vice versa for the CMU-MOSEI corpus. This is because in each instance of the RAMAS corpus the video modality consists of recordings of one actor, while the audio modality may contain the speech of several actors. In the CMU-MOSEI corpus the video modality can contain several persons, while the audio modality is represented by one speaker in each instance. In general, the use of both modalities compensates for the weaknesses of each.
Experiments conducted with the same parameter for the two logarithmic weighting research tasks showed that the optimal performance was achieved at . Class weighting improved performance on the RAMAS corpus in the case of SCL. However, for the CMU-MOSEI corpus SCL performance gains were only achieved for sentiment recognition. These results show that data balancing using logarithmic weighting has a positive effect on performance.
A performance comparison between the proposed approach and SOTA approaches on the CMU-MOSEI corpus is presented in Table 5. To compare our approach with the others, we combined two classes of sentiment (Neutral and Negative) as proposed in previous studies [24,25,26,28,32]. On the sentiment recognition task, our approach underperforms the SOTA approaches by an average value of 8.7% in both performance measures. However, on the emotion recognition task the proposed approach significantly outperforms the SOTA approaches, by 1.6% in terms of the and by 18.2% in terms of the . It can be observed that although data balancing had a positive effect on the ability to recognize the three sentiment classes, the performance decreased for recognition of only two sentiment classes.
Table 5.
Comparison with SOTA audio–visual approaches on the CMU-MOSEI corpus. Performance measure superscript shows the number of classes.
To compare the results on the RAMAS corpus, we used the UAR. The proposed approach outperforms the SOTA [39] by 0.5% (82.6% vs. 82.1%). The use of data balancing in the proposed approach improves performance, and it outperforms the SOTA [39] by 0.7% (82.8% vs. 82.1%) in terms of the UAR. Thus, our approach outperforms the SOTA for both corpora, which appears to indicate its effectiveness.
6. Conclusions
In this article, we compared two learning approaches (single-corpus and multi-corpus) for audio–visual emotion and sentiment recognition. We used the RAMAS and CMU-MOSEI corpora, and proposed two multi-corpus temporal models for recognition of affective states in order to extract mid-level features at the segment level of both the audio and video modalities. The audio model was built on the basis of a pre-trained transformer model with additional GRU layers, while the video model was based on a pre-trained 3D CNN model with an additional BiLSTM layer and self-attention mechanism. We proposed a fusion strategy based on gated fusion and self-attention, the CMGSAF, to combine the mid-level features of the two modalities. Our experiments included several stages, from SCL to MCL; we compared multiple audio models and visual feature sets. Our results show that MCL outperforms SCL at the segment level of both the audio and video approaches, while the opposite is the case for the audio–visual approach at the instance level. In general, however, the use of both modalities compensates for the weaknesses of each.
In addition, we applied logarithmic weighting to highlight the classes least represented in the training data as a means of improving model performance. Our results show that data balancing improved all four performance measures on the RAMAS corpus; although this method was less effective on the CMU-MOSEI corpus, it had a positive impact on sentiment recognition performance.
Finally, we compared the performance measures of our approach with SOTA approaches on both the RAMAS and CMU-MOSEI corpora. Our results show that the proposed approach outperforms SOTA approaches in multi-label emotion recognition by 18.2% in terms of the WA, though it is was weaker in sentiment recognition on the CMU-MOSEI corpus. For the RAMAS corpus, the proposed CMGSAF outperforms the SOTA approaches by 0.7% in terms of the UAR.
In our future research, we plan to use the text modality to further improve the performance of our approach, and to use other corpora to improve its robustness with new unknown data. Moreover, we plan to investigate different data balancing methods in order to improve the emotion and sentiment recognition performance.
Author Contributions
Conceptualization, E.R.; methodology, E.R. and M.M.; validation, E.R. and M.M.; formal analysis, A.K.; investigation, E.R. and M.M.; resources, A.K.; writing—original draft preparation, E.R. and M.M.; writing—review and editing, M.M. and A.K.; visualization, E.R. and M.M.; supervision, A.K.; project administration, E.R.; funding acquisition, A.K. All authors have read and agreed to the published version of the manuscript.
Funding
This study was supported by the Russian Science Foundation (project No. 22-11-00321).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
This work uses the following large-scale publicly available dataset: CMU-MOSEI—http://multicomp.cs.cmu.edu/resources/cmu-mosei-dataset/, accessed on 6 June 2023.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| SOTA | State-of-the-Art |
| MTL | Multi-Task Learning |
| SCL | Single-Corpus Learning |
| MCL | Multi-Corpus Learning |
| DFG | Dynamic Fusion Graph |
| Graph-MFN | Graph Memory Fusion Network |
| MTMM-ES | Multi-Task Multimodal Emotion and Sentiment |
| CAM | Context-aware Attention Module |
| CMDC | Cross-Modal Dynamic Convolution |
| MPUCL | Modality-Pairwise Unsupervised Contrastive Loss |
| CNN | Convolutional Neural Network |
| GRU | Gated Recurrent Units |
| BiLSTM | Bidirectional LSTM |
| BiGRU | Bidirectional GRU |
| FCL | Fully Connected Layer |
| RAMAS | Russian Acted Multimodal Affective Set |
| CMU-MOSEI | CMU Multimodal Opinion Sentiment and Emotion Intensity |
| EmoFF | Emotional Facial Features |
| EmoSF | Emotional Selfies Features |
| HOG | Histograms of Oriented Gradients |
| LSTM | Long Short-Term Memory |
| MELD | Multimodal EmotionLines Dataset |
| GCCMA | Gated Contextual Cross-Modal Attention |
| PGAU | Head Pose, Eye Gaze, and Action Units |
| FAUs | Facial Action Units |
| FACS | Facial Action Coding System |
| PWF | Probability-Weighted Fusion |
| CMGSAF | Cross-Modal Gated Self-Attention Fusion |
| UAR | Unweighted Average Recall |
| WA | Weighted Accuracy |
| WF1 | Weighted F1-score |
| SER | Speech Emotion Recognition |
| IEMOCAP | Interactive Emotional Dyadic Motion Capture |
| SGD | Stochastic Gradient Descent |
| RESD | Russian Emotional Speech Dialogues |
| VAD | Voice Activity Detector |
| PCF | Probability Concatenation Fusion |
| FCF | Feature Concatenation Fusion |
| MCM | Multitask learning and Contrastive learning for Multimodal sentiment analysis |
| NTN | Neural Tensor Network |
References
- Picard, R.W. Affective Computing; MIT Press: Cambridge, MA, USA, 2000. [Google Scholar]
- Bojanić, M.; Delić, V.; Karpov, A. Call redistribution for a call center based on speech emotion recognition. Appl. Sci. 2020, 10, 4653. [Google Scholar] [CrossRef]
- van der Haar, D. Student Emotion Recognition Using Computer Vision as an Assistive Technology for Education. Inf. Sci. Appl. 2020, 621, 183–192. [Google Scholar] [CrossRef]
- Tripathi, U.; Chamola, V.; Jolfaei, A.; Chintanpalli, A. Advancing remote healthcare using humanoid and affective systems. IEEE Sens. J. 2021, 22, 17606–17614. [Google Scholar] [CrossRef]
- Blom, P.M.; Bakkes, S.; Tan, C.; Whiteson, S.; Roijers, D.; Valenti, R.; Gevers, T. Towards personalised gaming via facial expression recognition. In Proceedings of the AAAI Conference on Artificial Intelligence and Interactive Digital Entertainment, Raleigh, NC, USA, 3–7 October 2014; Volume 10, pp. 30–36. [Google Scholar] [CrossRef]
- Marín-Morales, J.; Higuera-Trujillo, J.L.; Greco, A.; Guixeres, J.; Llinares, C.; Scilingo, E.P.; Alcañiz, M.; Valenza, G. Affective computing in virtual reality: Emotion recognition from brain and heartbeat dynamics using wearable sensors. Sci. Rep. 2018, 8, 13657. [Google Scholar] [CrossRef] [PubMed]
- Beedie, C.; Terry, P.; Lane, A. Distinctions between emotion and mood. Cogn. Emot. 2005, 19, 847–878. [Google Scholar] [CrossRef]
- Quoidbach, J.; Mikolajczak, M.; Gross, J.J. Positive interventions: An emotion regulation perspective. Psychol. Bull. 2015, 141, 655. [Google Scholar] [CrossRef] [PubMed]
- Verkholyak, O.; Dvoynikova, A.; Karpov, A. A Bimodal Approach for Speech Emotion Recognition using Audio and Text. J. Internet Serv. Inf. Secur. 2021, 11, 80–96. [Google Scholar] [CrossRef]
- Gebhard, P. ALMA: A layered model of affect. In Proceedings of the 4th International Joint Conference on Autonomous Agents and Multiagent Systems, Utrecht, The Netherlands, 25–29 July 2005; pp. 29–36. [Google Scholar] [CrossRef]
- Lim, N. Cultural differences in emotion: Differences in emotional arousal level between the East and the West. Integr. Med. Res. 2016, 5, 105–109. [Google Scholar] [CrossRef]
- Perlovsky, L. Language and emotions: Emotional Sapir–Whorf hypothesis. Neural Netw. 2009, 22, 518–526. [Google Scholar] [CrossRef]
- Mankus, A.M.; Boden, M.T.; Thompson, R.J. Sources of variation in emotional awareness: Age, gender, and socioeconomic status. Personal Individ. Differ. 2016, 89, 28–33. [Google Scholar] [CrossRef]
- Samulowitz, A.; Gremyr, I.; Eriksson, E.; Hensing, G. “Brave men” and “emotional women”: A theory-guided literature review on gender bias in health care and gendered norms towards patients with chronic pain. Pain Res. Manag. 2018, 2018, 6358624. [Google Scholar] [CrossRef] [PubMed]
- Fang, X.; van Kleef, G.A.; Kawakami, K.; Sauter, D.A. Cultural differences in perceiving transitions in emotional facial expressions: Easterners show greater contrast effects than westerners. J. Exp. Soc. Psychol. 2021, 95, 104143. [Google Scholar] [CrossRef]
- Pell, M.D.; Monetta, L.; Paulmann, S.; Kotz, S.A. Recognizing emotions in a foreign language. J. Nonverbal Behav. 2009, 33, 107–120. [Google Scholar] [CrossRef]
- Poria, S.; Hazarika, D.; Majumder, N.; Naik, G.; Cambria, E.; Mihalcea, R. MELD: A Multimodal Multi-Party Dataset for Emotion Recognition in Conversations. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 527–536. [Google Scholar] [CrossRef]
- Zadeh, A.B.; Liang, P.P.; Poria, S.; Cambria, E.; Morency, L.P. Multimodal language analysis in the wild: Cmu-mosei dataset and interpretable dynamic fusion graph. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Melbourne, Australia, 15–20 July 2018; pp. 2236–2246. [Google Scholar] [CrossRef]
- Kollias, D.; Zafeiriou, S. Aff-wild2: Extending the aff-wild database for affect recognition. arXiv 2018, arXiv:1811.07770. [Google Scholar] [CrossRef]
- Gerczuk, M.; Amiriparian, S.; Ottl, S.; Schuller, B.W. Emonet: A transfer learning framework for multi-corpus speech emotion recognition. IEEE Trans. Affect. Comput. 2021, 33, 1472–1487. [Google Scholar] [CrossRef]
- Alisamir, S.; Ringeval, F.; Portet, F. Multi-Corpus Affect Recognition with Emotion Embeddings and Self-Supervised Representations of Speech. In Proceedings of the 10th International Conference on Affective Computing and Intelligent Interaction (ACII), Nara, Japan, 18–21 October 2022; pp. 1–8. [Google Scholar] [CrossRef]
- Zhang, H.; Mimura, M.; Kawahara, T.; Ishizuka, K. Selective Multi-Task Learning For Speech Emotion Recognition Using Corpora Of Different Styles. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; pp. 7707–7711. [Google Scholar] [CrossRef]
- Busso, C.; Bulut, M.; Lee, C.C.; Kazemzadeh, A.; Mower, E.; Kim, S.; Chang, J.N.; Lee, S.; Narayanan, S.S. IEMOCAP: Interactive emotional dyadic motion capture database. Lang. Resour. Eval. 2008, 42, 335–359. [Google Scholar] [CrossRef]
- Sangwan, S.; Chauhan, D.S.; Akhtar, M.S.; Ekbal, A.; Bhattacharyya, P. Multi-task gated contextual cross-modal attention framework for sentiment and emotion analysis. In Proceedings of the ICONIP, Sydney, NSW, Australia, 12–15 December 2019; pp. 662–669. [Google Scholar] [CrossRef]
- Akhtar, M.S.; Chauhan, D.; Ghosal, D.; Poria, S.; Ekbal, A.; Bhattacharyya, P. Multi-task Learning for Multi-modal Emotion Recognition and Sentiment Analysis. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 370–379. [Google Scholar] [CrossRef]
- Chauhan, D.S.; Akhtar, M.S.; Ekbal, A.; Bhattacharyya, P. Context-aware interactive attention for multi-modal sentiment and emotion analysis. In Proceedings of the Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 5647–5657. [Google Scholar] [CrossRef]
- Mittal, T.; Bhattacharya, U.; Chandra, R.; Bera, A.; Manocha, D. M3er: Multiplicative multimodal emotion recognition using facial, textual, and speech cues. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 1359–1367. [Google Scholar] [CrossRef]
- Shenoy, A.; Sardana, A.; Graphics, N. Multilogue-Net: A Context Aware RNN for Multi-modal Emotion Detection and Sentiment Analysis in Conversation. In Proceedings of the Annual Meeting of the Association for Computational Linguistics, Seattle, WA, USA, 5–10 July 2020; pp. 19–28. [Google Scholar] [CrossRef]
- Tsai, Y.H.H.; Ma, M.Q.; Yang, M.; Salakhutdinov, R.; Morency, L.P. Multimodal routing: Improving local and global interpretability of multimodal language analysis. In Proceedings of the Conference on Empirical Methods in Natural Language Processing. Conference on Empirical Methods in Natural Language Processing, Online, 16–20 November 2020; pp. 1823–1833. [Google Scholar] [CrossRef]
- Khare, A.; Parthasarathy, S.; Sundaram, S. Self-supervised learning with cross-modal transformers for emotion recognition. In Proceedings of the IEEE Spoken Language Technology Workshop (SLT), Shenzhen, China, 19–22 January 2021; pp. 381–388. [Google Scholar] [CrossRef]
- Wen, H.; You, S.; Fu, Y. Cross-modal dynamic convolution for multi-modal emotion recognition. J. Visual Commun. Image Represent. 2021, 78, 103178. [Google Scholar] [CrossRef]
- Franceschini, R.; Fini, E.; Beyan, C.; Conti, A.; Arrigoni, F.; Ricci, E. Multimodal Emotion Recognition with Modality-Pairwise Unsupervised Contrastive Loss. In Proceedings of the International Conference on Pattern Recognition (ICPR), Montreal, QC, Canada, 21–25 August 2022; pp. 2589–2596. [Google Scholar] [CrossRef]
- Le, H.D.; Lee, G.S.; Kim, S.H.; Kim, S.; Yang, H.J. Multi-Label Multimodal Emotion Recognition With Transformer-Based Fusion and Emotion-Level Representation Learning. IEEE Access 2023, 11, 14742–14751. [Google Scholar] [CrossRef]
- Mamieva, D.; Abdusalomov, A.B.; Kutlimuratov, A.; Muminov, B.; Whangbo, T.K. Multimodal Emotion Detection via Attention-Based Fusion of Extracted Facial and Speech Features. Sensors 2023, 23, 5475. [Google Scholar] [CrossRef]
- Hsu, J.H.; Wu, C.H. Applying Segment-Level Attention on Bi-modal Transformer Encoder for Audio-Visual Emotion Recognition. IEEE Trans. Affect. Comput. 2023, 1–13. [Google Scholar] [CrossRef]
- Mai, S.; Sun, Y.; Zeng, Y.; Hu, H. Excavating multimodal correlation for representation learning. Inf. Fusion 2023, 91, 542–555. [Google Scholar] [CrossRef]
- Wagner, J.; Triantafyllopoulos, A.; Wierstorf, H.; Schmitt, M.; Burkhardt, F.; Eyben, F.; Schuller, B.W. Dawn of the transformer era in speech emotion recognition: Closing the valence gap. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 10745–10759. [Google Scholar] [CrossRef] [PubMed]
- Ryumina, E.; Verkholyak, O.; Karpov, A. Annotation confidence vs. training sample size: Trade-off solution for partially-continuous categorical emotion recognition. In Proceedings of the Interspeech, Brno, Czechia, 30 August–3 September 2021; pp. 3690–3694. [Google Scholar] [CrossRef]
- Savchenko, A.; Savchenko, L. Audio-Visual Continuous Recognition of Emotional State in a Multi-User System Based on Personalized Representation of Facial Expressions and Voice. Pattern Recognit. Image Anal. 2022, 32, 665–671. [Google Scholar] [CrossRef]
- Ryumina, E.; Karpov, A. Facial expression recognition using distance importance scores between facial landmarks. In Proceedings of the CEUR Workshop Proceedings, St. Petersburg, Russia, 22–25 September 2020; Volume 2744, pp. 1–10. [Google Scholar] [CrossRef]
- Ryumina, E.; Dresvyanskiy, D.; Karpov, A. In search of a robust facial expressions recognition model: A large-scale visual cross-corpus study. Neurocomputing 2022, 514, 435–450. [Google Scholar] [CrossRef]
- Dvoynikova, A.; Markitantov, M.; Ryumina, E.; Uzdiaev, M.; Velichko, A.; Ryumin, D.; Lyakso, E.; Karpov, A. Analysis of infoware and software for human affective states recognition. Inform. Autom. 2022, 21, 1097–1144. [Google Scholar] [CrossRef]
- Perepelkina, O.; Kazimirova, E.; Konstantinova, M. RAMAS: Russian multimodal corpus of dyadic interaction for affective computing. In Proceedings of the International Conference on Speech and Computer, Leipzig, Germany, 18–22 September 2018; pp. 501–510. [Google Scholar] [CrossRef]
- Ryumina, E.; Karpov, A. Comparative analysis of methods for imbalance elimination of emotion classes in video data of facial expressions. Sci. Tech. J. Inf. Technol. Mech. Opt. 2020, 20, 683–691. [Google Scholar] [CrossRef]
- Dvoynikova, A.; Karpov, A. Bimodal sentiment and emotion classification with multi-head attention fusion of acoustic and linguistic information. In Proceedings of the International Conference “Dialogue 2023”, Online, 14–16 June 2023; pp. 51–61. [Google Scholar]
- Lotfian, R.; Busso, C. Building naturalistic emotionally balanced speech corpus by retrieving emotional speech from existing podcast recordings. IEEE Trans. Affect. Comput. 2017, 10, 471–483. [Google Scholar] [CrossRef]
- Andayani, F.; Theng, L.B.; Tsun, M.T.; Chua, C. Hybrid LSTM-transformer model for emotion recognition from speech audio files. IEEE Access 2022, 10, 36018–36027. [Google Scholar] [CrossRef]
- Huang, J.; Tao, J.; Liu, B.; Lian, Z.; Niu, M. Multimodal transformer fusion for continuous emotion recognition. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 3507–3511. [Google Scholar] [CrossRef]
- Ivanko, D.; Ryumin, D.; Karpov, A. A Review of Recent Advances on Deep Learning Methods for Audio-Visual Speech Recognition. Mathematics 2023, 11, 2665. [Google Scholar] [CrossRef]
- Lugaresi, C.; Tang, J.; Nash, H.; McClanahan, C.; Uboweja, E.; Hays, M.; Zhang, F.; Chang, C.L.; Yong, M.G.; Lee, J.; et al. Mediapipe: A framework for building perception pipelines. arXiv 2019, arXiv:1906.08172. [Google Scholar]
- Baltrusaitis, T.; Zadeh, A.; Lim, Y.C.; Morency, L.P. Openface 2.0: Facial behavior analysis toolkit. In Proceedings of the 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG), Xi’an, China, 15–19 May 2018; pp. 59–66. [Google Scholar] [CrossRef]
- Febrian, R.; Halim, B.M.; Christina, M.; Ramdhan, D.; Chowanda, A. Facial expression recognition using bidirectional LSTM-CNN. Procedia Comput. Sci. 2023, 216, 39–47. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 1–11. [Google Scholar] [CrossRef]
- Clark, K.; Luong, M.T.; Manning, C.D.; Le, Q.V. Semi-Supervised Sequence Modeling with Cross-View Training. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 1914–1925. [Google Scholar]
- Markitantov, M.; Ryumina, E.; Ryumin, D.; Karpov, A. Biometric Russian Audio-Visual Extended MASKS (BRAVE-MASKS) Corpus: Multimodal Mask Type Recognition Task. In Proceedings of the Interspeech, Incheon, Korea, 18–22 September 2022; pp. 1756–1760. [Google Scholar] [CrossRef]
- Ryumin, D.; Ivanko, D.; Ryumina, E.V. Audio-Visual Speech and Gesture Recognition by Sensors of Mobile Devices. Sensors 2023, 23, 2284. [Google Scholar] [CrossRef]
- Liu, P.; Li, K.; Meng, H. Group Gated Fusion on Attention-Based Bidirectional Alignment for Multimodal Emotion Recognition. In Proceedings of the Interspeech, Shanghai, China, 25–29 October 2020; pp. 379–383. [Google Scholar] [CrossRef]
- Dresvyanskiy, D.; Ryumina, E.; Kaya, H.; Markitantov, M.; Karpov, A.; Minker, W. End-to-End Modeling and Transfer Learning for Audiovisual Emotion Recognition in-the-Wild. Multimodal Technol. Interact. 2022, 6, 11. [Google Scholar] [CrossRef]
- Hennequin, R.; Khlif, A.; Voituret, F.; Moussallam, M. Spleeter: A fast and efficient music source separation tool with pre-trained models. J. Open Source Softw. 2020, 5, 2154. [Google Scholar] [CrossRef]
- Wang, Y.; Boumadane, A.; Heba, A. A fine-tuned wav2vec 2.0/hubert benchmark for speech emotion recognition, speaker verification and spoken language understanding. arXiv 2021, arXiv:2111.02735. [Google Scholar]
- Loshchilov, I.; Hutter, F. Sgdr: Stochastic gradient descent with warm restarts. arXiv 2016, arXiv:1608.03983. [Google Scholar]
- Cao, Q.; Shen, L.; Xie, W.; Parkhi, O.M.; Zisserman, A. Vggface2: A dataset for recognising faces across pose and age. In Proceedings of the 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG), Xi’an, China, 15–19 May 2018; pp. 67–74. [Google Scholar] [CrossRef]







Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).